Abstract
In the medical field, blood analysis is a key method used to evaluate the health status of the human body. The types and number of blood cells serve as important criteria for doctors to diagnose and treat diseases. In view of the problems regarding difficult classification and low efficiency in blood cell detection, this paper proposes an improved YOLOv5-BS blood cell target detection algorithm. The purpose of the improvement is to enhance the real-time performance and accuracy of blood cell type recognition. The algorithm is based on YOLOv5s as the basic network, incorporating the advantages of both CNN and Transformer architectures. First, the BotNet backbone network is incorporated. Then the YOLOv5 head architecture is replaced with the Decoupled Head structure. Finally, a new loss function SIoU is used to improve the accuracy and efficiency of the model. To detect the feasibility of the algorithm, a comparative experiment was conducted. The experiment shows that the improved algorithm has an accuracy of 92.8% on the test set, an average precision of 83.3%, and a recall rate of 99%. Compared with YOLOv8s and PP-YOLO, the average precision is increased by 3.9% and 1%, and the recall rate is increased by 3% and 2%. This algorithm effectively improves the efficiency and accuracy of blood cell detection and effectively improves the problem of blood cell detection.
1. Introduction
In the medical field, blood cell image analysis plays a vital role in clinical laboratories and serves as the foundation for diagnosing and monitoring numerous diseases [1]. The type and quantity of blood cells are critical indicators for doctors when diagnosing and treating various conditions. Currently, most tests rely on manual microscopy and instrument-based counting methods. However, these approaches are often inefficient and fail to provide image information during testing. Manual microscopy is not only time-consuming and labor-intensive but is also prone to the subjective judgment of medical staff, which can compromise the accuracy of the results [2]. By contrast, employing computers and digital processing technologies for blood cell detection and classification enables objective and precise analysis of microscopic images, significantly reducing analysis time. As such, the adoption of computer vision technology to replace manual detection has become a key trend in modern medical diagnostics.
Detection methods based on deep learning have more efficient image feature extraction capabilities than traditional machine vision methods. Liang [3] proposed a multi-task learning framework (MTLA) based on convolutional neural networks to address the problem of image target recognition and positioning. The model accuracy reached 81.5%; Byahatti R [4] proposed the design ideas and implementation details of the Decoupled Head module. The Decoupled Head module separates the feature fusion layer and the convolution layer to make the model more flexible and able to detect targets of different sizes on feature maps of different sizes, thereby improving the accuracy of target detection. Mahto [5] designed the refined YOLOv4 model and improved three aspects: anchor box, post-processing algorithm, and attention mechanism, to improve the accuracy of small target detection. Wang Pengfei [6] added a shallow detection layer based on YOLOv5 and improved the loss function to Quality Focal Loss to improve the detection capability of dense targets. Chen [7] introduced the Content-Aware ReAssembly of Features (CARAFE) module to perceive effective features. The Wise–IoU loss function with a dynamic focusing mechanism was used to replace the original loss function in YOLOv7 to improve the generalization ability and detection accuracy of the model. Han [8] improved the design of the STC-YOLOv5 model to address the difficulty in identifying small wood targets and dense defects. Compared with the original YOLOv5, the accuracy rate was improved by 3.1%.
There are usually two types of commonly used algorithms [9]. One is the single-stage detection algorithm, including SSD [10], MultiGrasp [11], and YOLO [12,13,14] series algorithms. The other is the two-stage detection algorithm, with representative examples being R-CNN [15], SPP-Net [16], and Faster-RCNN [17]. However, the above algorithms still have many problems in blood cell detection, such as insufficient feature extraction capabilities for different types of blood cells and low detection accuracy [18]. YOLO is a typical single-stage target detection algorithm. Its main idea is to use the entire image as input to the model and use CNN to directly regress the target coordinates and classification probability. Although the YOLO series has higher versions such as YOLOv7 [19], YOLOv8 [20], and YOLOX [21], the YOLOv5 algorithm has a smaller model, less computational effort, and considerable speed. It is also particularly suitable for real-time target detection tasks. It has a high cost-effectiveness without considering whether a GPU exists, especially when the CPU usage on the PC is low. Compared with YOLOv7 and YOLOv8, YOLOv5 is more suitable for running on mobile devices and is more suitable for detecting small objects [22], requiring less equipment cost. YOLOv5 mainly consists of four components: Input, Backbone, Neck, and Head. It can be used in the following architectures: YOLOv5n, YOLOv5s [23], YOLOv5m, YOLOv5l, and YOLOv5x. These architectures differ in network depth and feature map width. YOLOv5s can be divided into three parts: Backbone [24], Neck, and Head. Backbone is the backbone network, which mostly refers to the network for extracting features. The role of the Neck is to better integrate the features given by the Backbone, thereby enhancing the target positioning information capability. The Head uses the previously extracted features to make predictions.
The following is an introduction to the work completed in this paper. Section 2 summarizes the improvement principle of the algorithm. Section 3 is the experimental results and analysis. This chapter first introduces the process of establishing a blood cell target detection dataset. It then explains how four groups of ablation experiments were performed, comparative experiments were conducted, and the experimental process and test results are explained. The classification ability of the improved algorithm is demonstrated through the parameter indicators of the model, the evaluation indicators of the test set, the prediction result graph, and the performance curve.
2. Materials and Methods
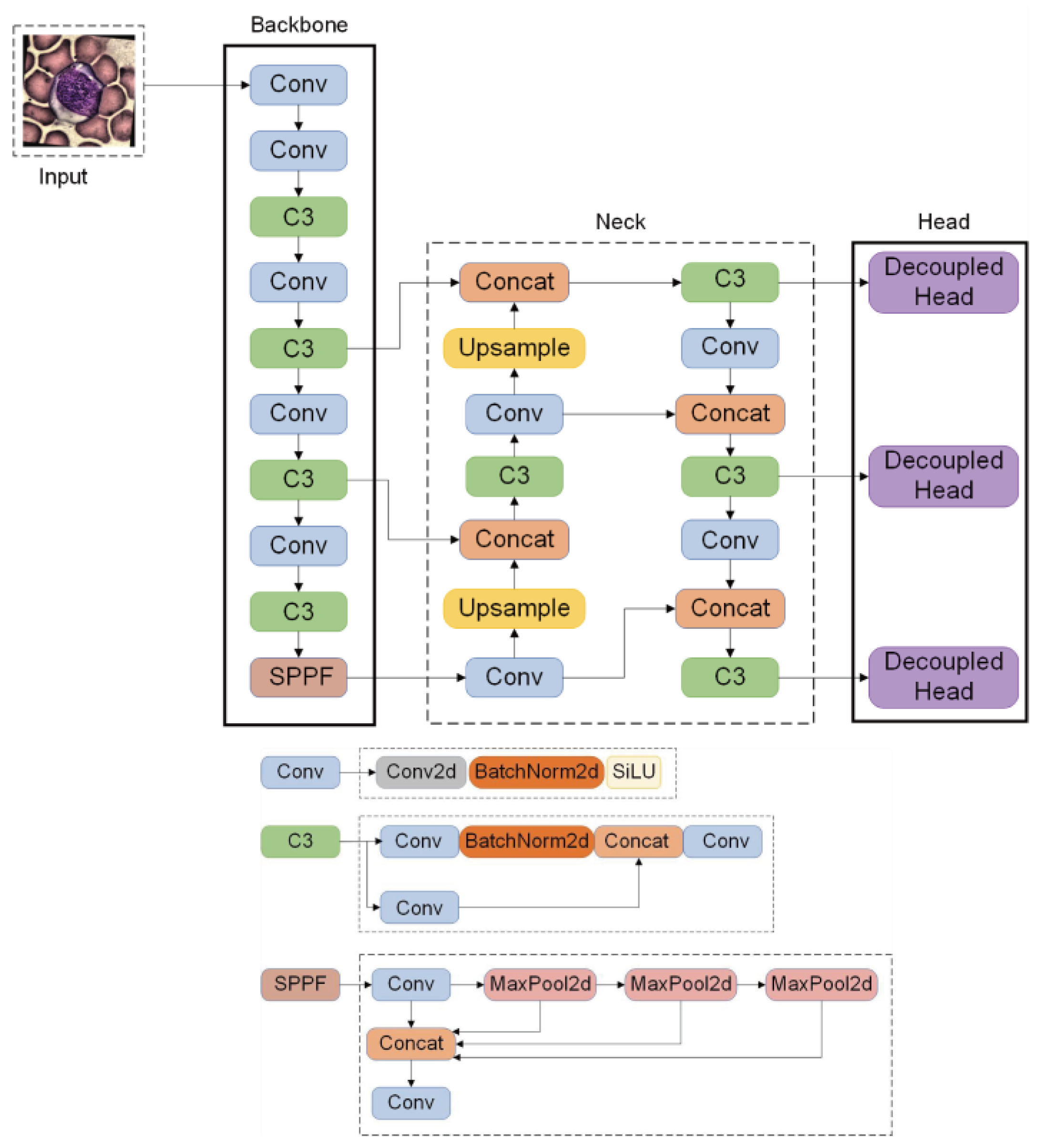
YOLOv5s is the network with the smallest depth and the smallest feature map width in the YOLOv5 series. Its model size is small, which is convenient for subsequent expansion and application. In order to meet the actual needs of target detection algorithms, real-time detection, and simple deployment, this paper selects the YOLOv5s network as the baseline network for blood cell recognition. This network can provide higher detection accuracy, a faster processing speed, and provides a reliable foundation for the accuracy of the blood cell detection system. The improved YOLOv5s structure diagram is shown in Figure 1. The Backbone and Head marked with solid lines are the improved parts.
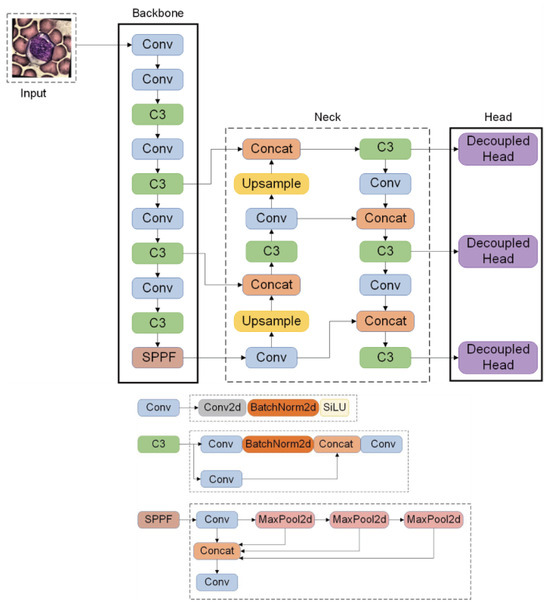
Figure 1.
Improved YOLOv5s network structure and details.
2.1. Backbone Network Module
As the number of network layers increases, the extracted feature information may gradually be lost. Therefore, to improve the detection performance of the network model, the multi-scale feature fusion method is often widely used in the target detection network. Multi-scale feature fusion improves the performance of the target detection algorithm by fusing feature maps from different levels. This method helps to reduce information loss and improve the generalization ability of the algorithm. It enables the algorithm to better detect targets in a variety of situations, including when there are too many cells in the blood cell image and their shapes are different. Complex features cannot be fully extracted by the original YOLOv5, therefore the BotNet module is introduced into YOLOv5. BotNet can enhance low-level feature extraction, combine multi-scale feature information, and improve the structure of the network calculation graph. Especially in the input layer and shallow convolutional layer, the network can reduce the ambiguity of the object during positioning. For the detection of small objects, it can better capture the details of small objects and improve the recognition ability of small objects [25]. Furthermore, it enhances the feature fusion ability of the network so that it can fully extract cell features.
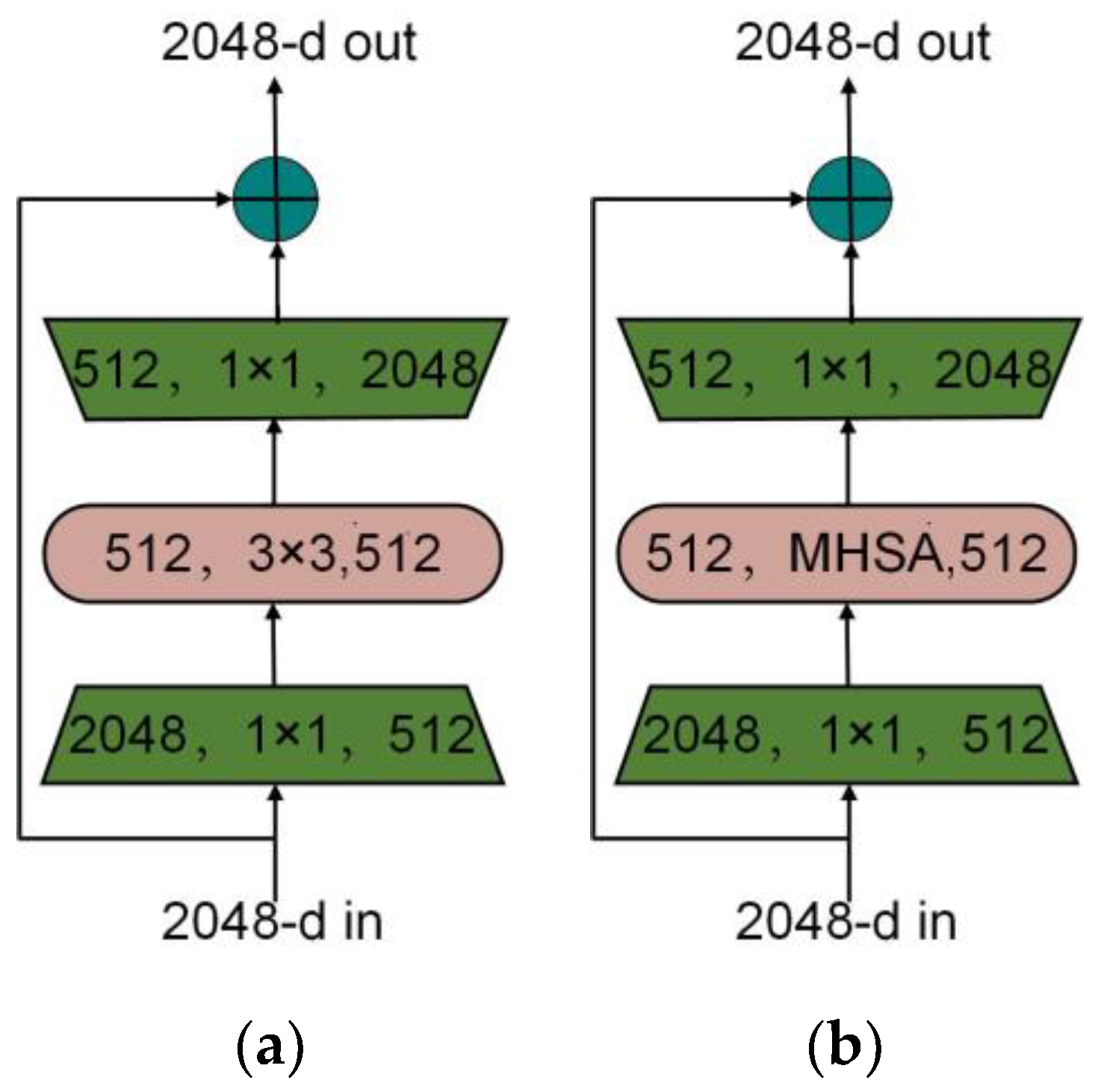
Microsoft Research Asia proposed combining the BotNet module with the original backbone network. BotNet is a convolutional neural network architecture based on Transformer [26]. BotNet replaces the bottleneck in the fourth block of ResNet with the MHSA (Multi-Head Self-Attention) module to form a new module. This structure can associate each pixel in the input feature map with each other, thereby extracting more detailed features. It also reduces the overall parameters and reduces latency overhead. The difference between BotNet and ResNet is that BotNet uses multi-head self-attention MHSA (Multi-Head Self-Attention) to replace the spatial 3 × 3 convolution, thereby improving the detection effect. The structure is shown in Figure 2.
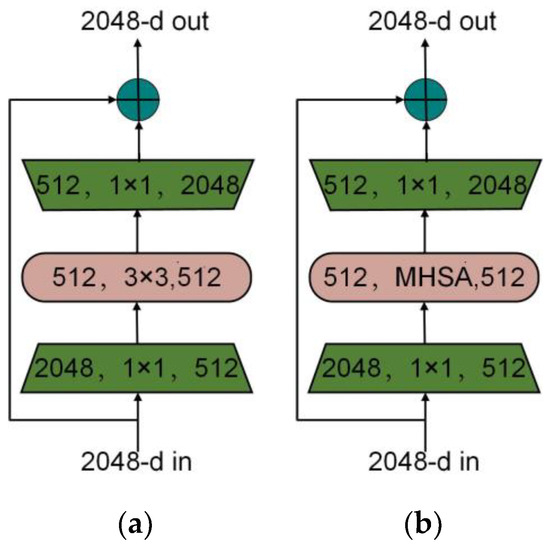
Figure 2.
BotNet structure diagram. (a) The original 3 × 3 convolution; (b) The replacement MHSA.
2.2. Decoupled Head Module
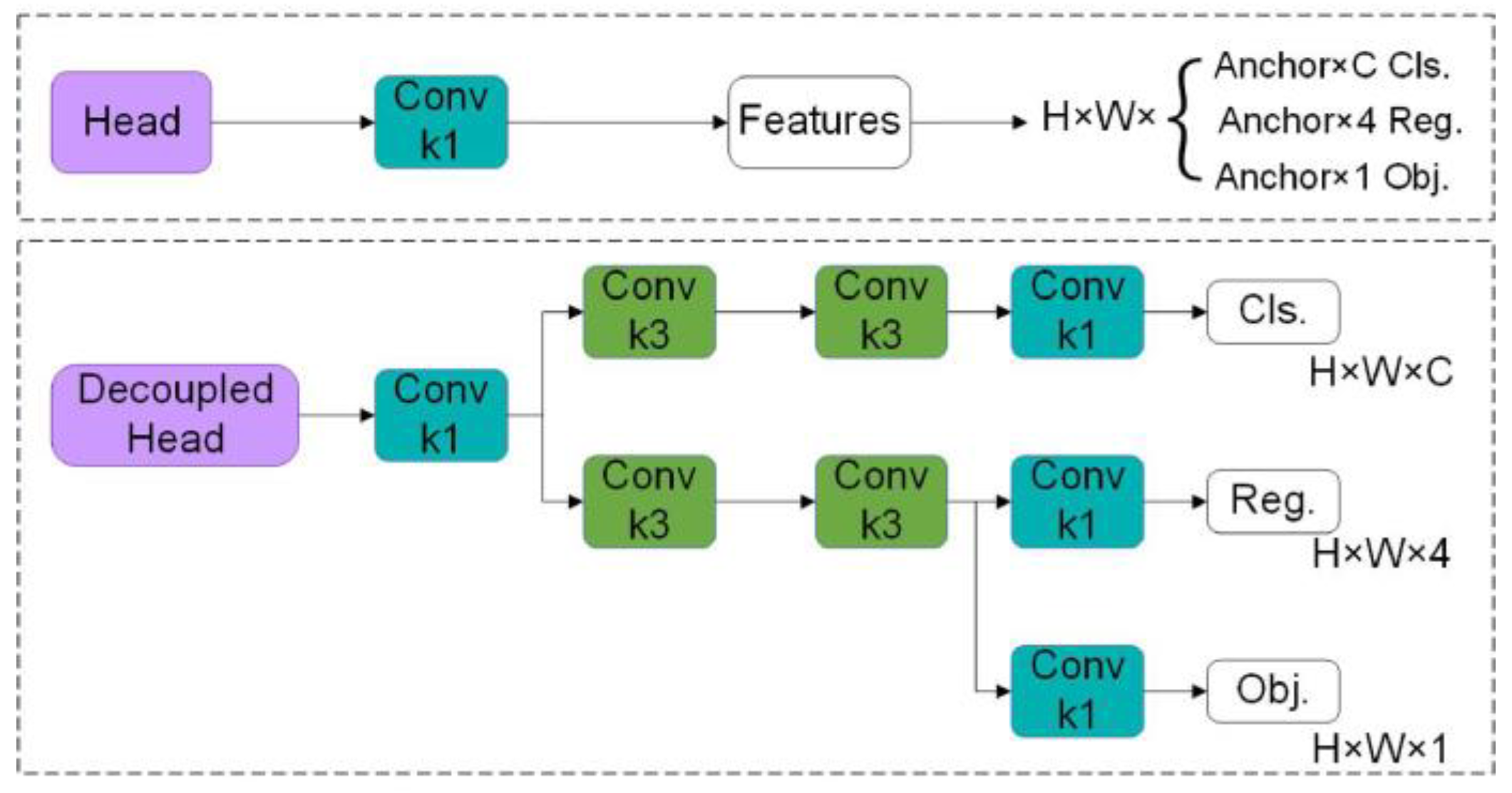
Ideally, the target detection algorithm, the detection problem, and the classification problem should be independent of each other. However, in the YOLO network, the head module in the prediction stage couples the detection and classification problems. This method reduces the performance of the algorithm to a certain extent. This paper improves the head structure to address the above problems. In 2020, Byahatti R proposed the design ideas and implementation details of the Decoupled Head module. The Decoupled Head module is a model framework of YOLO. In the traditional YOLO structure, the classification and regression tasks share the same part of the network resources, which may cause the performance of the two to affect each other. As small objects often occupy less space, traditional methods may cause information loss or deviation due to the simultaneous processing of classification and regression tasks at the same network level. The Decoupled Head can split the tasks and optimize them separately [21] so that the network can optimize classification and regression independently and can more accurately handle the positioning and classification of small objects. Subsequently, this avoids the mutual interference between classification and regression tasks, thereby improving the processing ability of small objects. This paper improves the head structure and introduces the Decoupled Head. The structure diagram is shown in Figure 3. This method enables the detection of different types of blood cells at different feature layers and improves the detection accuracy of the model.
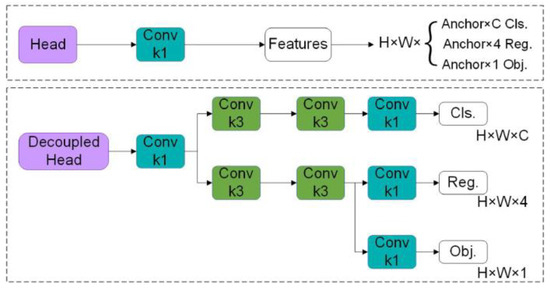
Figure 3.
Decoupled Head.
In YOLOv5, the prediction element is called SPP-YOLO [27] (Spatial Pyramid Pooling YOLO). In SPP-YOLO, the input image is scaled down to multiple feature maps of different sizes, and then object detection is performed on the feature maps. However, this method has some problems. For example, detecting large objects on smaller feature maps may result in decreased accuracy, and detecting small objects on larger feature maps may result in too low detection accuracy. The Decoupled Head scales down the input image to multiple feature maps of different sizes and then performs object detection on these feature maps separately. This method can detect large objects on larger feature maps and small objects on smaller feature maps. It avoids the above problems at the same time. The advantage of the Decoupled Head structure is that it can adjust the balance between accuracy and efficiency by adjusting the size of each feature map. For example, a larger feature map can be used to improve accuracy and a smaller feature map can be used to improve efficiency. In general, the Decoupled Head structure can improve the accuracy and efficiency of YOLOv5 by using multiple feature maps of different sizes.
2.3. SIoU_LOSS
In order to speed up the network convergence, improve the detection accuracy, and reduce the false detection in blood cell detection, an updated loss function SIoU (Soft Intersection Over Union) [28] is used in YOLOv5 instead of the standard CIoU (Complete Intersection Over Union) [29]. The only dimensions that CIoU can consider are the overlapping area, centroid distance, and aspect ratio of the real frame and the predicted frame. There are four common intersection over union loss functions: IoU, GIoU (Generalized Intersection Over Union), DIoU, and CIoU. IoU is one of the most commonly used position loss functions. The larger the IoU, the more overlap the two bounding boxes have, and the less loss there will be. However, when the intersection between the predicted box and the real box is zero, it may lead to slower convergence. DIoU is another improved version of the position loss function. It evaluates the overlap of the two bounding boxes by calculating the distance between their center points. However, the aspect ratio of the predicted box regression is not added, resulting in its convergence speed still not being fast enough. We chose SIoU because it can better reflect the changes in width, height, and confidence level, for more accurate target box positioning.
Gevorgyan proposed the SIoU function. This function adds the vector angle between the predicted box and the true box when defining the loss index. SIoU takes into account the vector angle between the predicted box and the true box and uses positioning information to redefine the loss item. It reduces the probability of free transformation of the prediction box and guides the detection box to approach the target box in a more reasonable way, to improve the regression accuracy. SIoU is an area-based loss function, and its value is not affected by the change of the bounding box but is only related to the area of the target box, which makes the training process more stable. The SIoU loss function does not involve complex distance metrics and division operations, and the calculation is simpler. At the same time, the matching direction can help the prediction box move quickly to the nearest axis, thereby increasing the speed of training. SIoU consists of 4 parts: angle loss, distance loss, shape loss, and IoU loss. The total loss function is expressed as shown in Formula (1):
where Lcls is the cross-entropy loss (Focal loss); Wbox and Wcls are the prediction box and classification loss weights, respectively.
SIoU Loss adds a weight factor for category information. Using the SIoU loss function, the model tends to prioritize the position of the bounding box during training by aligning it with the nearest coordinate axis and then further adjusting it on the corresponding coordinate axis. In short, the addition of the angle penalty cost effectively reduces the total degrees of freedom. It helps to improve the stability and speed of training and reduces the errors generated during training, to improve the final object detection model.
2.4. Model Evaluation Index
In target detection research, commonly used evaluation indicators include precision, recall, average precision (AP), and multi-category average precision (mAP).
Precision is the ratio of the number of actual positive samples to all samples detected as positive. The calculation formula is shown in Formula (2):
where P represents the accuracy rate, TP represents the number of positive samples predicted as a positive class, and FP represents the number of negative samples predicted as a positive class.
Recall rate, also known as recall rate, refers to the proportion of positive samples detected as positive in all actual positive samples. The calculation formula is shown in Formula (3):
where R represents the recall rate and FN represents the number of positive samples predicted as a negative class.
The curve composed of the precision and recall of a certain category as variables is called the PR curve. In the PR curve, the area enclosed by the horizontal axis, the vertical axis, and the PR curve is the average precision of the category. The calculation formula is shown in Formula (4):
where P(R) represents the PR curve.
Multi-category average precision refers to the mean of the average precision of all categories. It is one of the most important evaluation indicators in the target detection algorithm and can be used to indicate the detection accuracy of the target detection model. The calculation formula of mAP is shown in Formula (5):
where N is the number of target categories.
F1-Score refers to the accuracy index of the model in the target detection task and is an evaluation index for classification problems. In the target detection task, it is often used to evaluate the model’s ability to detect the target. The calculation formula is shown in Formula (6):
3. Results
3.1. Experimental Process and Environment Configuration
In order to further verify the actual effect of the blood cell identification and counting system based on the QT interface this paper needed to conduct a series of experiments. Through the data import module, blood cell image data from different sources were loaded into the system. These data include static pictures, video files, and images captured by real-time cameras. The system flexibly loaded different types of data according to the user’s choice and displayed the corresponding test results in the image display module. In the image display module, users were able to easily browse and observe the test results of blood cells through the label control.
Platelets, RBCs, WBCs, and sickle cells were accurately marked in the image in the form of rectangular boxes. The algorithm demonstrated its ability to effectively identify different types of cells. First, the data set needed to be augmented and the cells labeled. Then the blood cell model was trained. In order to optimize the training effect of the model in this paper, 70% of the blood cell data set was used as the training set, 20% as the test set, and 10% as the validation set during the experiment. The image size of the training and validation process was 640 × 640, the number of training rounds was 150, the batch size was 16, and the initial learning rate was 0.001. The image size of the test process was 640 × 640, the batch size was 32, the confidence threshold was 0.001, the IOU threshold was 0.6, and the maximum number of targets detected in a single image was 300.
The training platform used was Windows 10 with the following configuration: Intel (R) Core (TM) i9-12900K processor, NVIDIA RTX A2000 discrete graphics card, deep learning framework was Pytorch1.11, Python was 3.8, and CUDA was 11.2.
3.2. Experimental Data
The experiment selected four common cell types with a total of 3153 images to construct the dataset, including platelets, RBC, WBC [30], and sickle cells. Platelets and RBC data came from the public blood cell dataset BCCD [31]. Sickle cell data came from the erythrocytesIDB dataset. The dataset contained a large number of red blood cells, while the number of white blood cells, platelets, and sickle cells was relatively small, which is consistent with the number of cells in a normal human body. However, this situation would have made the dataset unbalanced, resulting in model category imbalance, ignoring less common cell types and overfitting the majority class etc., which would affect the performance of the model. This paper improves the problem of category imbalance by performing random cropping, rotation scaling, translation, and other data augmentation techniques on a small number of cell categories.
This paper used the visual annotation tool Labelme to annotate the dataset. The annotation content was the type and location of the cell. Among them, the position annotation used a rectangular box. The requirement for the rectangular box was that it completely surrounded the cell and was not too large. For the type of annotation, the category label was required to match the actual cell category to avoid annotation errors. The training dataset obtained after the original dataset was accurately annotated is shown in Figure 4.

Figure 4.
Schematic diagram of blood cell classification.
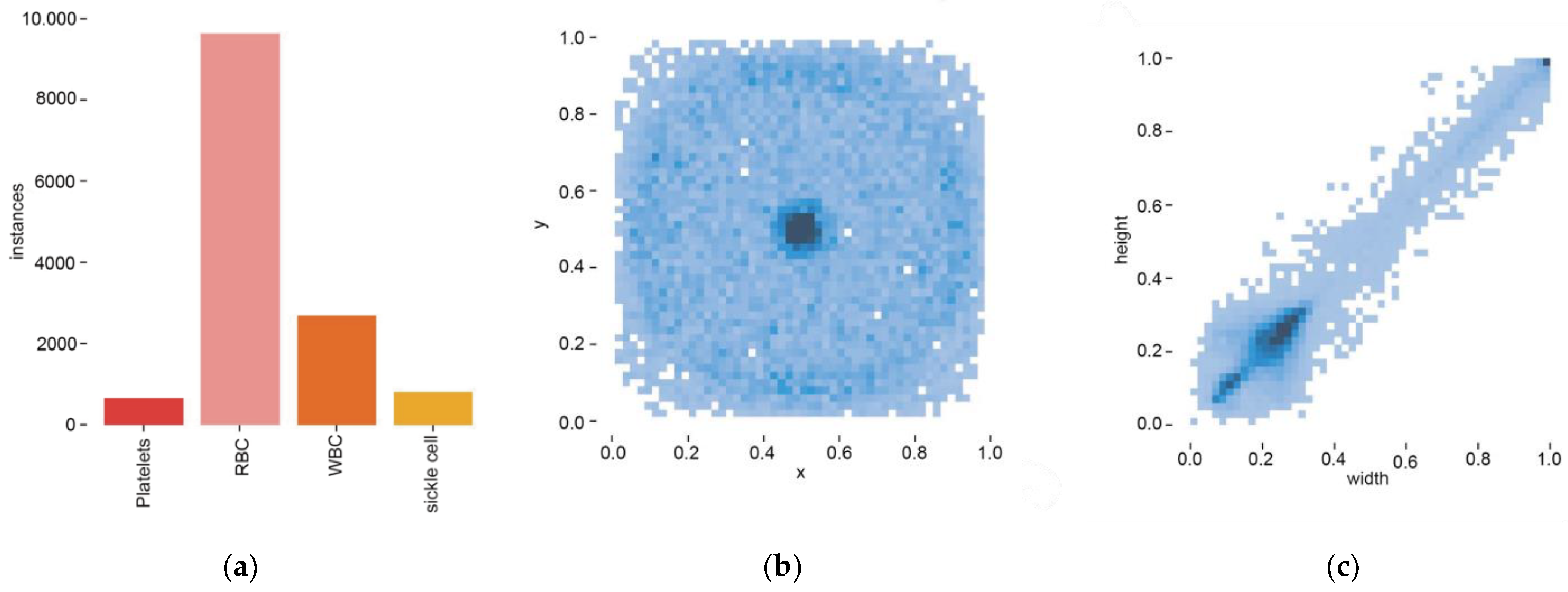
After labeling, the number of labels for each cell category and their position distribution on the image are shown in Figure 5. Each blood cell category is widely distributed in various positions of the image. This uniformity provides the algorithm with rich and comprehensive learning samples, enhancing the algorithm’s understanding of blood cell characteristics in different positions and scenarios. Strict data cleaning and verification ensure data quality and provide a reliable foundation for training blood cell recognition models. At the same time, it also improves the robustness of the algorithm, enabling it to better adapt to blood cell recognition tasks in real scenarios.
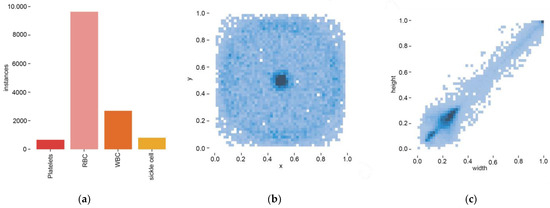
Figure 5.
Diagram of location distribution of blood cell labels. (a) Four blood cell counts; (b) Four blood cell location distribution; (c) Four blood cell sizes.
3.3. Ablation Experiment
In order to more intuitively demonstrate the performance of the model after the improved algorithm, an ablation experiment was conducted. The “√” symbol indicates that this improved method is added on the basis of the YOLOv5s network model. The experimental results are shown in Table 1.

Table 1.
Ablation results.
The experiment uses YOLOv5s as the baseline. The comparison of the first and second experimental results in Table 1 shows that after the network structure is changed to BoTNeT, the mAP increases from 83.2% to 83.3%. The results show that YOLOv5 integrates the BoTNeT module to effectively improve the detection accuracy. The mAP of the second group of experimental results is then compared with the third group of experiments. The Decoupled Head is added to the network, and the mAP decreases from 83.3% to 83.2%. The results show that the detection head in YOLOv5s changes from coupled to Decoupled Head, which reduces the prediction ability and accuracy of model classification and regression. This decline is the result of a combination of reasons. These reasons include that the Decoupled Head adds additional parameters and computational complexity to independently handle classification and regression tasks, that the Decoupled Head model needs to optimize two loss functions separately, which increases the complexity of the optimization objective, and the impact of additional computing modules on the model’s capacity. These factors and the imbalanced data set lead to excessive parameters and computational burdens, making the model unstable during training and overfitting the training data, which leads to a decrease in mAP. The extent to which these reasons affect the results is not the focus of the study, so they will not be discussed in more depth in this paper. The comparison of the third and fourth groups of experimental results shows that the mAP increases from 83.2% to 83.8% by replacing the loss function in the network. The results show that the loss function SIoU in the network improves the detection accuracy of the algorithm. The comparison of the experimental results of the first and fourth groups shows that in the YOLOv5s network, after the network structure fusion, Decoupling Head, and loss function improvement, the mAP increased by 0.6% and the precision increased by 1.7%. The FPS of the improved model is 76.8 and the model size is 13.8 MB.
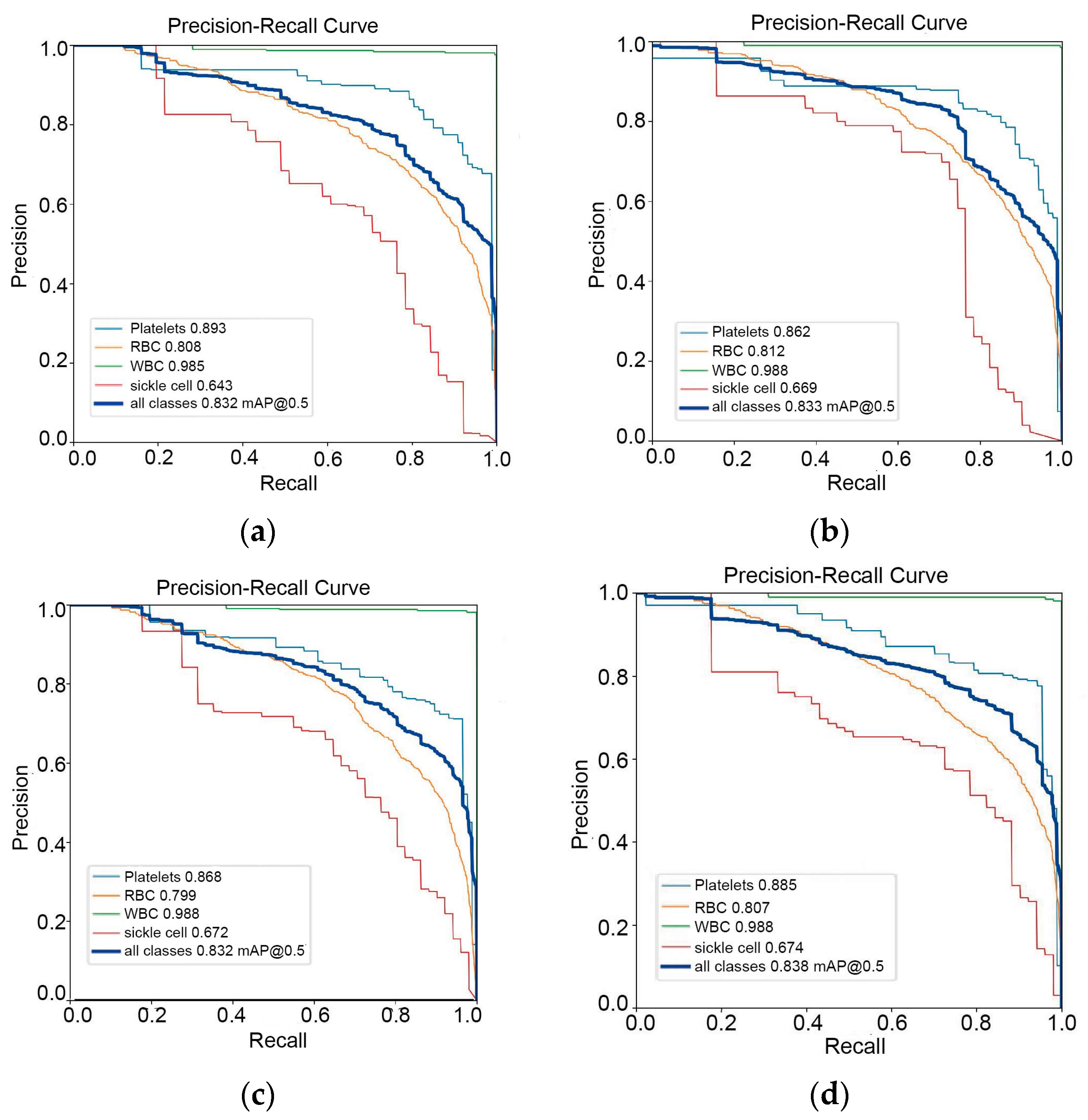
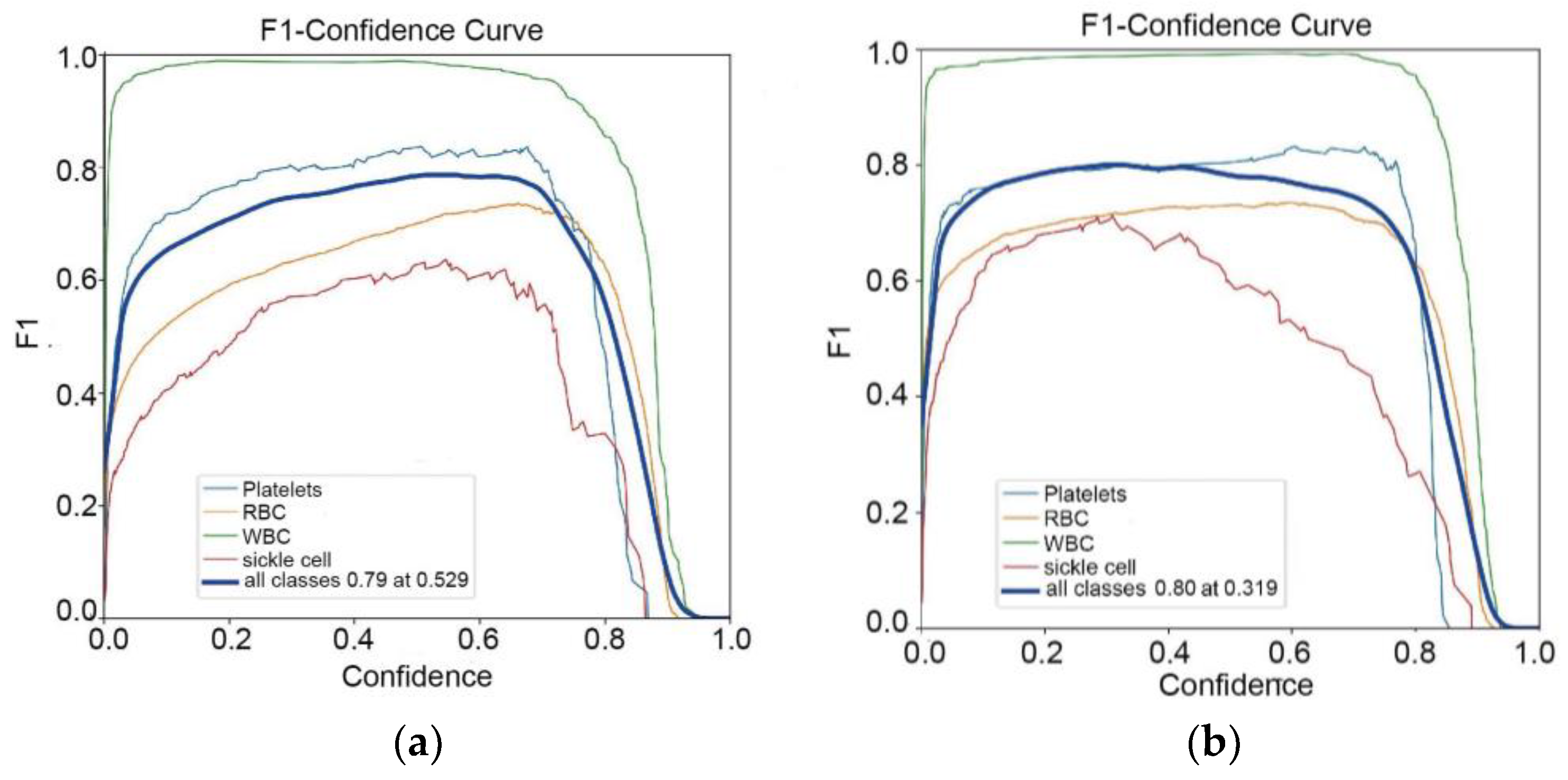
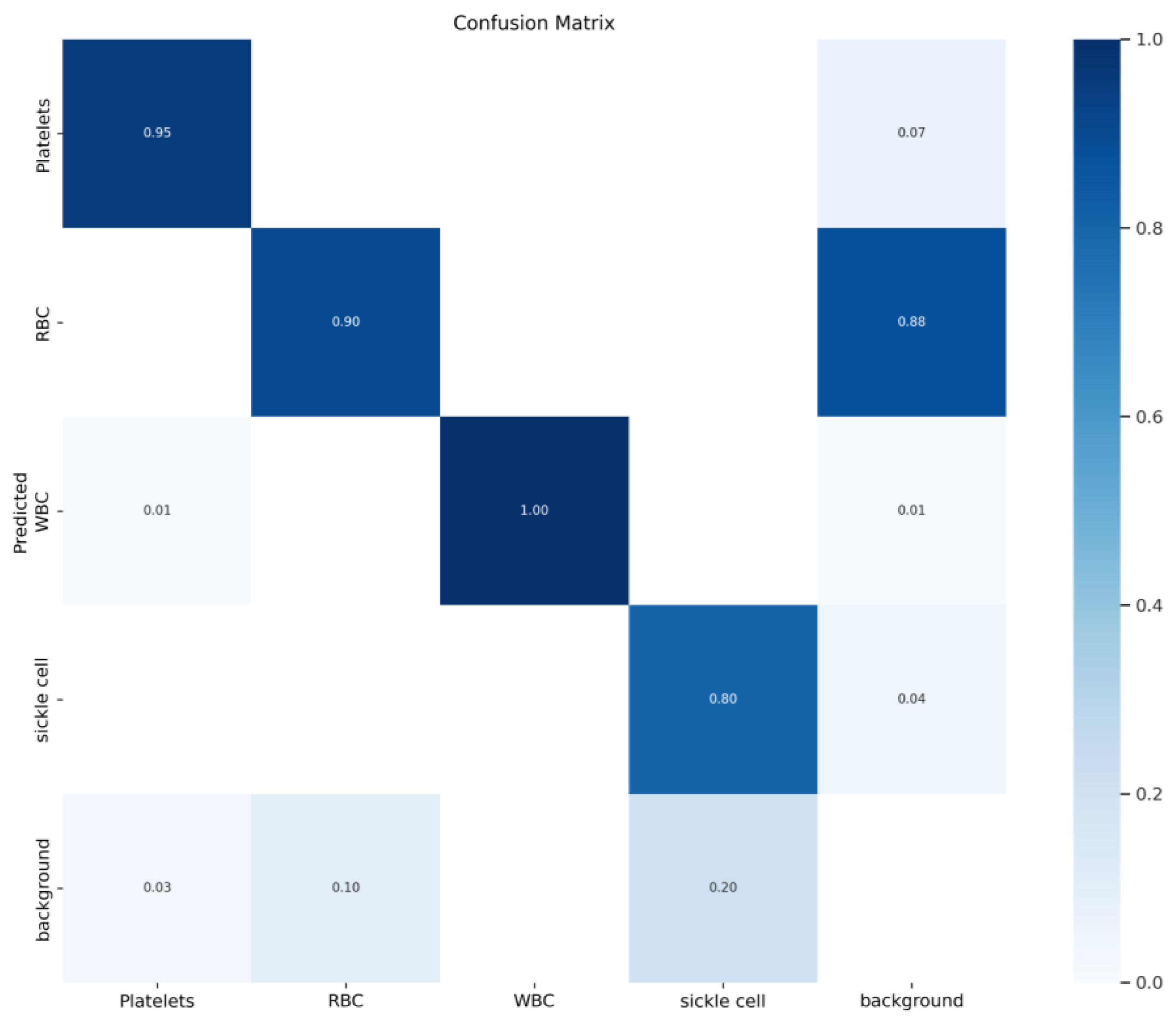
In the PR curve shown in Figure 6, the shape of the PR curve reflects the performance of the classifier. If the precision and recall rate of the classifier are both high, the PR curve will be close to the upper right corner, that is, the larger the area between the curve and the x-axis. This indicates better performance. By comparison, it is found that the improved algorithm result is the best. Figure 7 shows the F1 curve. It takes into account the precision and recall rate. The larger the F1 value, the better the model detection performance. Figure 8 shows the confusion matrix of the improved YOLOv5-BS model. Through it, the classification performance of the model can be intuitively evaluated. The data shows that the model has a low false detection rate and missed detection rate for each category, and the accuracy rate is as high as 80%, showing good classification ability and highlighting the model’s efficient recognition ability for these cell types.
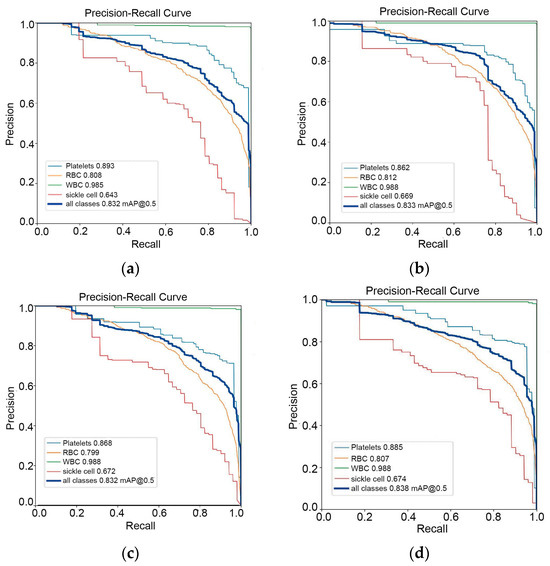
Figure 6.
PR curves of 4 models. (a) PR curve of YOLOv5s model; (b) PR curve of BoTNeT model; (c) BoTNeT + Decoupled Head model PR curve; (d) BoTNeT + Decoupled Head + SIoU model PR curve graph.
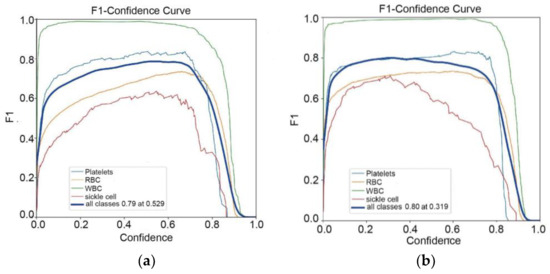
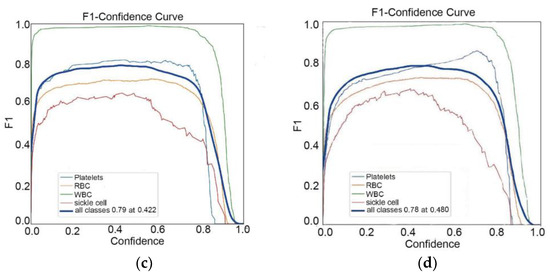
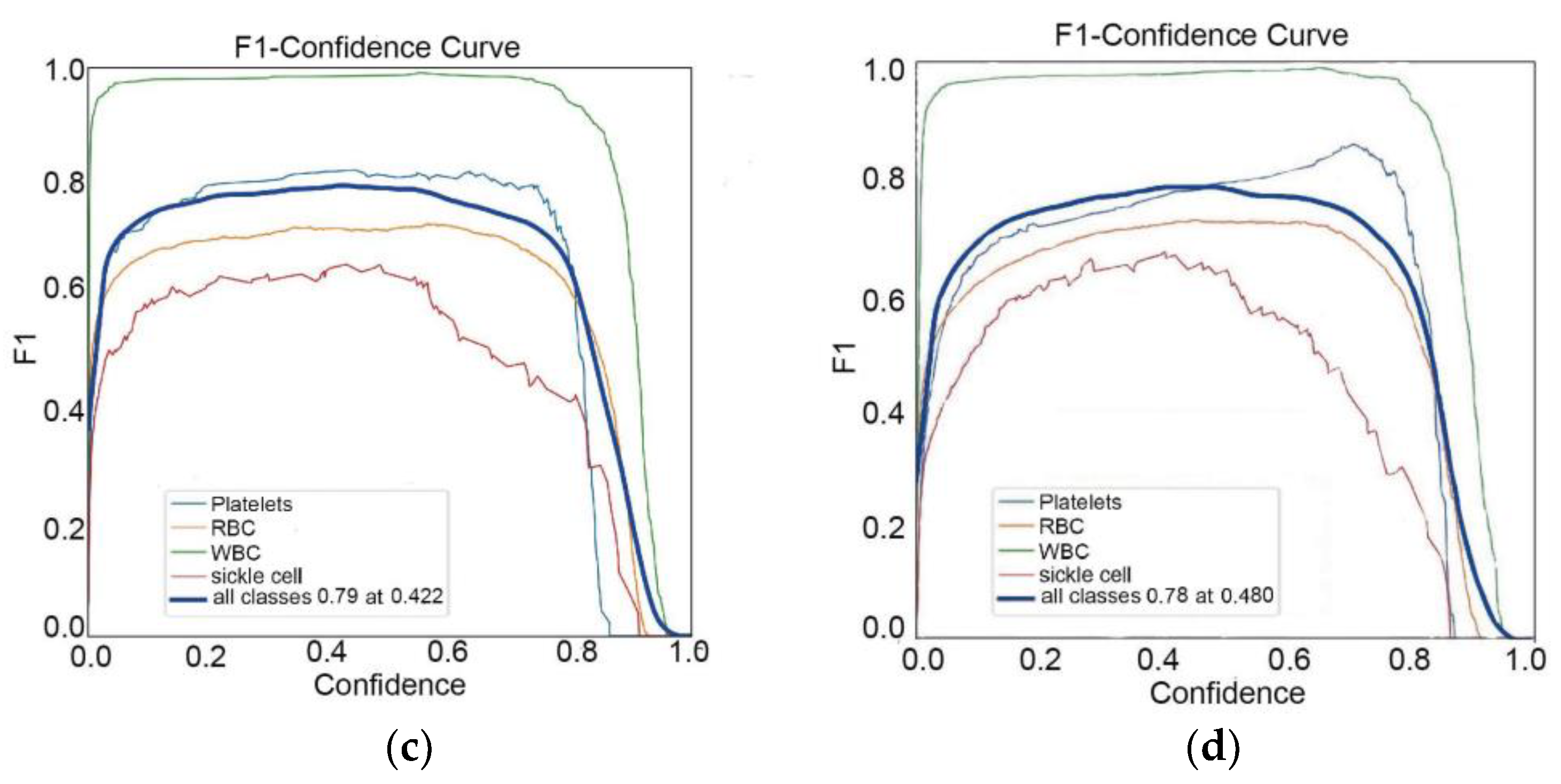
Figure 7.
F1 curves for 4 models. (a) F1 curve of YOLOv5s model; (b) F1 curve of BoTNeT model; (c) Botnets + Decoupled F1 curve of the Head model; (d) BotNet + Decoupled Head + F1 curve of the SIoU model.
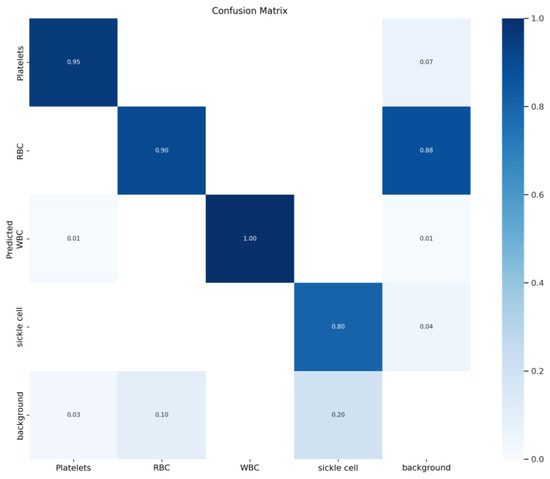
Figure 8.
Improved confusion matrix.
3.4. Contrast Experiment
In order to test the performance of the improved algorithm, a comparative experiment was conducted. It was tested on the data set with YOLOv8s and PP-YOLO, and the specific results are shown in Table 2. Table 2 is a comparison of the results of the three experimental models.
Table 2.
Comparative experimental results.
Experimental results show that YOLOv5-BS outperforms other algorithms in terms of mAP and recall rate, and the model size is smaller. Figure 9 shows the comparison of the detection results of the improved YOLOv5-BS model in this paper with the models YOLOv8s and PP-YOLO on the test set.
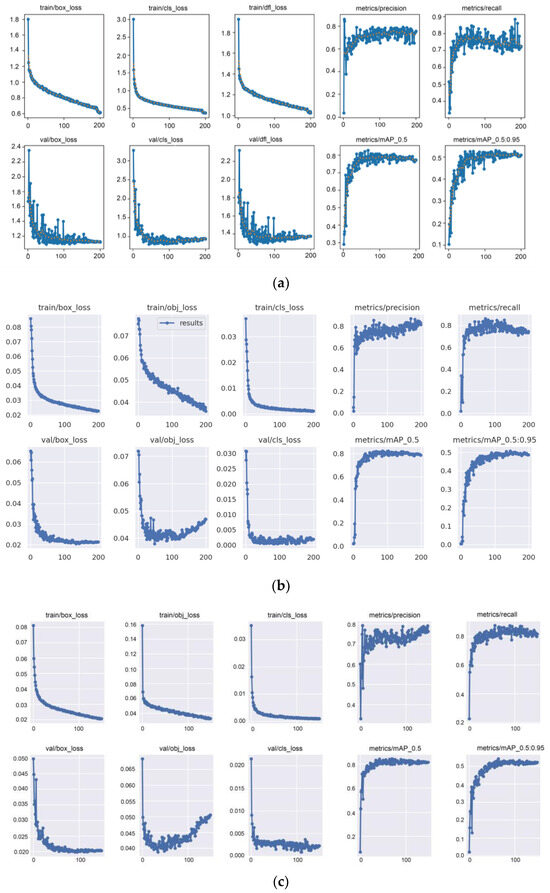
Figure 9.
Model result graph. (a) Result of YOLOv8s model; (b) Result of PP-YOLO model; (c) Result of YOLOv5-BS model.
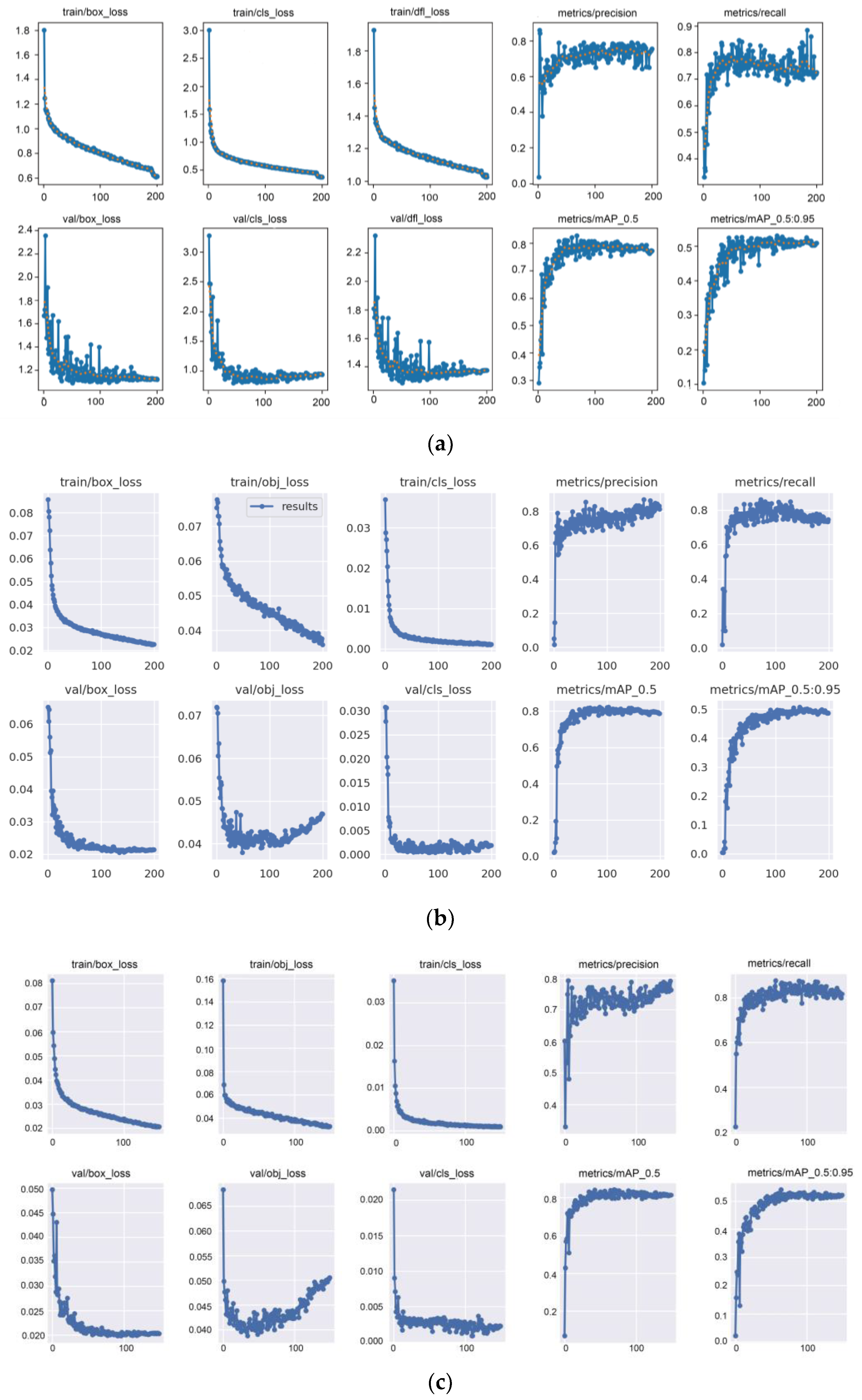
The higher the complexity of the algorithm, the stronger the ability to fit the data set, and the better the performance on the data set. However, excessive complexity will lead to longer training times, thereby reducing performance. Moreover, if the data set is too large, the training time will increase, thereby reducing the performance of the algorithm. As the number of training rounds increases, the curves of the positioning loss, classification loss, and confidence loss of training and verification continue to decline. At the same time, the precision rate P, recall rate R, average precision mAP_0.5, and average precision mAP_0.5:0.95 are all rising. It can be seen from the result comparison chart that the improved YOLOv5-BS in this paper is more stable than the YOLOv8s and PP-YOLO models in terms of the fluctuation of average precision and recall rate, and is better than the detection effect of YOLOv8s and PP-YOLO. It is proved that the improved algorithm has better robustness than YOLOv8s and PP-YOLO. In summary, the model YOLOv5-BS in this paper has a better detection effect.
3.5. Experimental Results
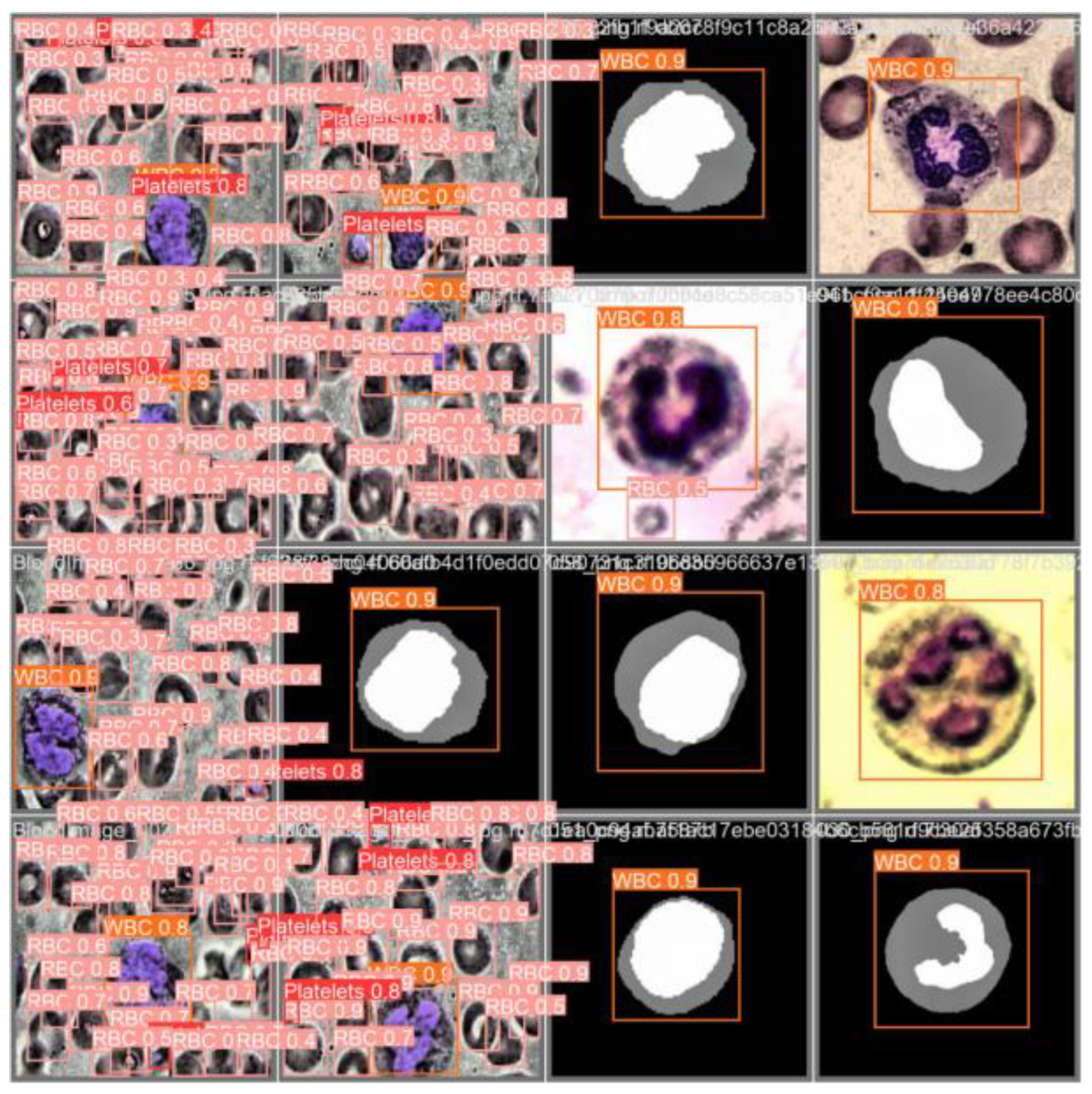
After multiple optimizations, this paper finally selected the improved YOLOv5-BS as the blood cell detection algorithm. The images in the test data set can be used to test whether the improved algorithm can accurately detect the target object. The prediction results of four types of blood cells are shown in Figure 10. The results show that the algorithm has high detection accuracy, can accurately identify various blood cells, and demonstrates reliable detection capabilities.
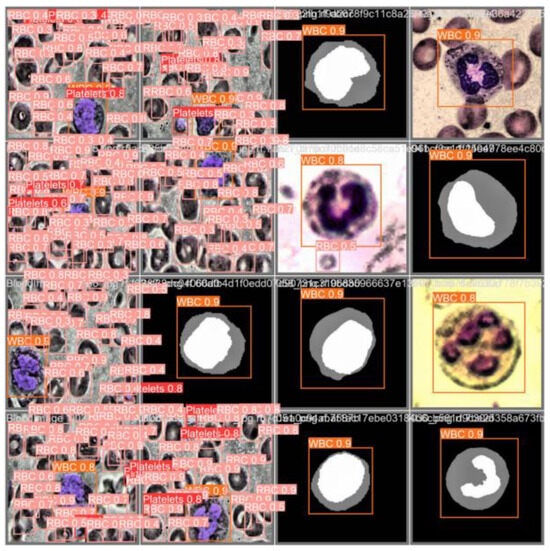
Figure 10.
Four kinds of blood cell prediction accuracy renderings.
4. Discussion
Figure 6 and Figure 7 are the indicator curves of the improved blood cell recognition model in the test set. Figure 8 is the confusion matrix of the improved blood cell recognition model. The precision curve clearly shows that the model maintains high accuracy at different thresholds and exhibits extremely high stability. The recall curve highlights the model’s comprehensive coverage of positive samples and maintains a high level of recall. The PR curve clearly shows the model’s ability to distinguish between positive and negative samples while maintaining high accuracy. In addition, the F1 curve achieves the best balance between precision and recall, further verifying the excellent performance of the improved algorithm. The evaluation indicators of the confusion matrix comprehensively present the excellent performance of the model. It has demonstrated satisfactory accuracy and robustness in the blood cell recognition task.
The improved algorithm combines the BotNet network, uses the Decoupled Head structure to enhance the ability to extract blood cell features, and modifies the loss function to improve the algorithm’s positioning detection accuracy. Experiments show that the improved YOLOv5-BS has good detection performance and shows good classification ability on the test set compared to the YOLOv8s model. It also highlights the improved model’s efficient recognition ability for these blood cell types.
Although the improved algorithm can meet the needs of blood cell detection, it will face many potential challenges in a clinical environment. These challenges mainly come from image quality, cell overlap, morphological diversity, data imbalance, computing resources, and data privacy. In the face of these challenges, data enhancement, network optimization, segmentation methods, and processing methods for imbalanced data will be adopted in the future to improve the diversity of data sets, strengthen the quality control of blood cell image annotation, ensure the consistency and accuracy of annotation, and reduce the impact of data noise and different resolutions on model training. The algorithm model in this paper is further improved and optimized, and a lighter model is designed so that it can be better deployed on mobile devices. By anonymizing and desensitizing image data, only task-related data is shared, patient information leakage is prevented, and personal information cannot be traced to solve privacy issues. By optimizing these factors, the clinical application performance of the model can be improved, the risk of false detection and missed detection can be reduced, and the privacy of patients can be better protected, to provide more efficient and reliable auxiliary diagnosis support in real-life medical environments.
5. Conclusions
This paper proposes a new detection algorithm, which improves the YOLOv5 basic network. First, it integrates the BotNet network. Then SIoU is added to improve the convergence speed and positioning accuracy of the model. Finally, the YOLOv5 Head architecture SPP-YOLO is replaced by the Decoupled Head structure to improve the accuracy of the model. Through a series of experiments, the improved YOLOv5-BS algorithm shows higher recall and accuracy in detection and has a smaller model size. The accuracy on the test set reached 92.8%, the average accuracy reached 83.8%, and the recall rate was 99%. Compared with YOLOv8s and PP-YOLO, the average accuracy increased by 3.9% and 1%, and the recall rate increased by 3% and 2%. The improved algorithm effectively improves the detection efficiency and accuracy, which is of great significance to the application of blood cell detection. In the future, we will adopt technologies such as data enhancement, design lighter models, take some data privacy protection measures, and apply the improved model in this article for clinical testing. It is expected that the blood cell detection system will be used in real clinical sites to monitor and assist doctors in diagnosing diseases in real time. This has positive social and medical significance for improving the automation level of medical image analysis and promoting early diagnosis and treatment of diseases.
Author Contributions
X.S. wrote the original paper and conducted all the experiments. H.T. reviewed the manuscript and directed revisions. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Shanghai Action Plan for Scientific and Technological Innovation (23YF1429900).
Data Availability Statement
The original data presented in the study are openly available at https://github.com/zxaoyou/segmentation_WBC, https://github.com/MrAnayDongre/BloodCell-Detection-Datatset, and http://erythrocytesidb.uib.es/ (accessed on 21 August 2023).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Deshpande, N.M.; Gite, S.; Aluvalu, R. A review of microscopic analysis of blood cells for disease detection with AI perspective. Peer J. Comput. Sci. 2021, 7, e460. [Google Scholar] [CrossRef] [PubMed]
- Tiwari, P.; Qian, J.; Li, Q.; Wang, B.; Gupta, D.; Khanna, A.; Rodrigues, J.; Albuquerque, V.H. Detection of subtype blood cells using deep learning. Cogn. Syst. Res. 2018, 52, 1036–1044. [Google Scholar] [CrossRef]
- Liang, S.; Gu, Y. A deep convolutional neural network to simultaneously localize and recognize waste types in images. Waste Manag. 2021, 126, 247–257. [Google Scholar] [CrossRef]
- Viraktamath, D.S.; Yavagal, M.; Byahatti, R. Object Detection and Classification using YOLOv3. Int. J. Eng. Res. Technol. 2021, 10, 197–202. [Google Scholar]
- Mahto, P.; Garg, P.; Seth, P.; Panda, J. Refining Yolov4 for Vehicle Detection; Social Science Electronic Publishing: New York, NY, USA, 2020. [Google Scholar]
- Wang, P.; Fu, S.; Cao, X.R. Improved Lightweight Target Detection Algorithm for Complex Roads with YOLOv5. In Proceedings of the 2022 International Conference on Machine Learning and Intelligent Systems Engineering (MLISE), Guangzhou, China, 5–7 August 2022; pp. 275–283. [Google Scholar]
- Chen, J.; Zhu, J.; Li, Z.; Yang, X. YOLOv7-WFD: A Novel Convolutional Neural Network Model for Helmet Detection in High-Risk Workplaces. IEEE Access 2023, 11, 113580–113592. [Google Scholar] [CrossRef]
- Han, S.; Jiang, X.; Wu, Z. An Improved YOLOv5 Algorithm for Wood Defect Detection Based on Attention. IEEE Access 2023, 11, 71800–71810. [Google Scholar] [CrossRef]
- Li, L.; Zhang, R.; Xie, T.; He, Y.; Zhou, H.; Zhang, Y. Experimental Design of Steel Surface Defect Detection Based on MSFE-YOLO—An Improved YOLOV5 Algorithm with Multi-Scale Feature Extraction. Electronics 2024, 13, 3783. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.E.; Fu, C.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Redmon, J.; Angelova, A. Real-time grasp detection using convolutional neural networks. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 25–30 May 2014; pp. 1316–1322. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:abs/1804.02767. [Google Scholar]
- Jocher, G.; Stoken, A.; Borovec, J.; Chaurasia, A.; Xie, T.; Liu, C.; Abhiram, V.; Hogan, A.; Hajek, J.; Diaconu, L.; et al. Ultralytics/Yolov5: v5.0-YOLOv5-P6 1280 Models, AWS, Supervise.ly and YouTube Integrations; Zenodo. 2021. Available online: https://ui.adsabs.harvard.edu/abs/2021zndo...4679653J/abstract (accessed on 28 September 2023).
- Girshick, R.B.; Donahue, J.; Darrell, T.; Malik, J.; Berkeley, U. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Ren, S.; He, K.; Girshick, R.B.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 1137–1149. [Google Scholar] [CrossRef]
- Xue, B.; Sun, C.; Chu, H.; Meng, Q.; Jiao, S. Method of Electronic Component Location, Grasping and Inserting Based on Machine Vision. In Proceedings of the 2020 International Wireless Communications and Mobile Computing (IWCMC), Limassol, Cyprus, 15–19 June 2020; pp. 1968–1971. [Google Scholar]
- Wang, C.; Bochkovskiy, A.; Liao, H.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Li, Y.; Wang, Y.; Lu, L.; An, Q. YOD-SLAM: An Indoor Dynamic VSLAM Algorithm Based on the YOLOv8 Model and Depth Information. Electronics 2024, 13, 3633. [Google Scholar] [CrossRef]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:abs/2107.08430. [Google Scholar]
- Redmon, J.; Divvala, S.K.; Girshick, R.B.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for Object Detection on Drone-captured Scenarios. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, BC, Canada, 11–17 October 2021; pp. 2778–2788. [Google Scholar]
- Wang, C.; Liao, H.M.; Yeh, I.; Wu, Y.; Chen, P.; Hsieh, J. CSPNet: A New Backbone that can Enhance Learning Capability of CNN. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 1571–1580. [Google Scholar]
- Srinivas, A.; Lin, T.; Parmar, N.; Shlens, J.; Abbeel, P.; Vaswani, A. Bottleneck Transformers for Visual Recognition. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 16514–16524. [Google Scholar]
- Cai, L.; Janowicz, K.; Mai, G.; Yan, B.; Zhu, R. Traffic transformer: Capturing the continuity and periodicity of time series for traffic forecasting. Trans. GIS 2020, 24, 736–755. [Google Scholar] [CrossRef]
- Huang, Z.; Wang, J. DC-SPP-YOLO: Dense Connection and Spatial Pyramid Pooling Based YOLO for Object Detection. Inf. Sci. 2019, 522, 241–258. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, H.; Wang, R.; Zhang, M.; Hu, X. Constrained-SIoU: A Metric for Horizontal Candidates in Multi-Oriented Object Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 956–967. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, P.; Ren, D.; Liu, W.; Ye, R.; Hu, Q.; Zuo, W. Enhancing Geometric Factors in Model Learning and Inference for Object Detection and Instance Segmentation. IEEE Trans. Cybern. 2020, 52, 8574–8586. [Google Scholar] [CrossRef] [PubMed]
- Zheng, X.; Wang, Y.; Wang, G.; Liu, J. Fast and robust segmentation of white blood cell images by self-supervised learning. Micron 2018, 107, 55–71. [Google Scholar] [CrossRef] [PubMed]
- Transform Financial Services with a Secure, AI-Powered Solution [EB/OL]. May 2023. Available online: https://github.com/MrAnayDongre/BloodCell-Detection-Datatset (accessed on 21 August 2023).

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).