
Artfusion: A Diffusion Model-Based Style Synthesis Framework for Portraits



Abstract
1. Introduction
- We present a artistic portrait generation framework that can be trained using a small-sized dataset. Compared to the existing generative models, a specific style of an artist or an art movement can be trained using tens of sample artwork images.
- We present a diffusion model-based framework that applies pervasive styles including the style of an artist and the style of an art movement to a portrait photograph while preserving the identity of the portrait.
2. Related Work
2.1. Early Style Transfer Methods
2.1.1. Universal Style Transfer
2.1.2. Arbitrary Style Transfer
2.1.3. Contrastive Learning Style Transfer
2.2. GAN-Based Style Synthesis
2.3. StyleGAN-Based Style Synthesis
2.4. Diffusion Model-Based Style Synthesis
3. Overview
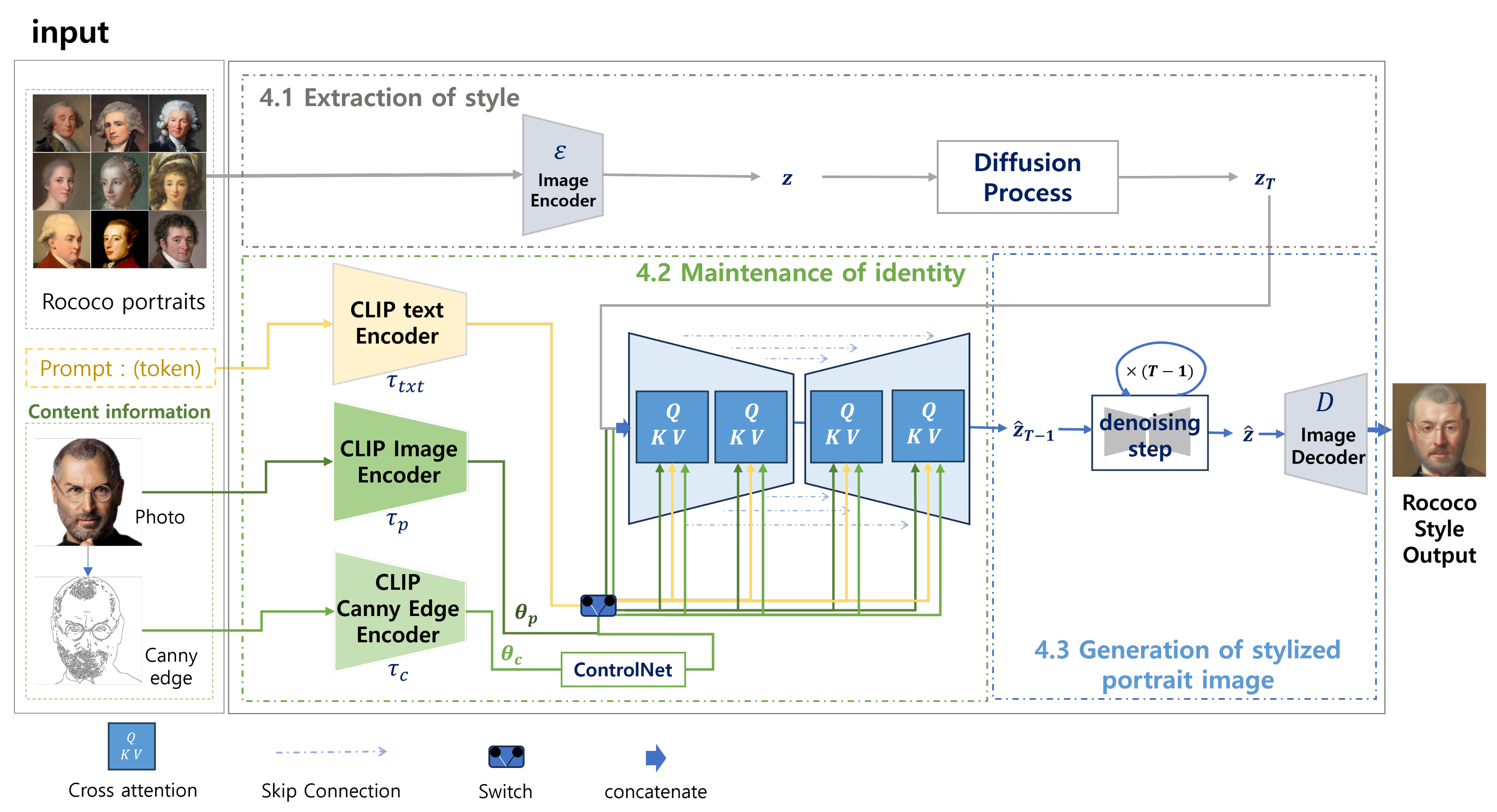
4. Our Framework
4.1. Extraction of Style
4.2. Maintenance of Identity
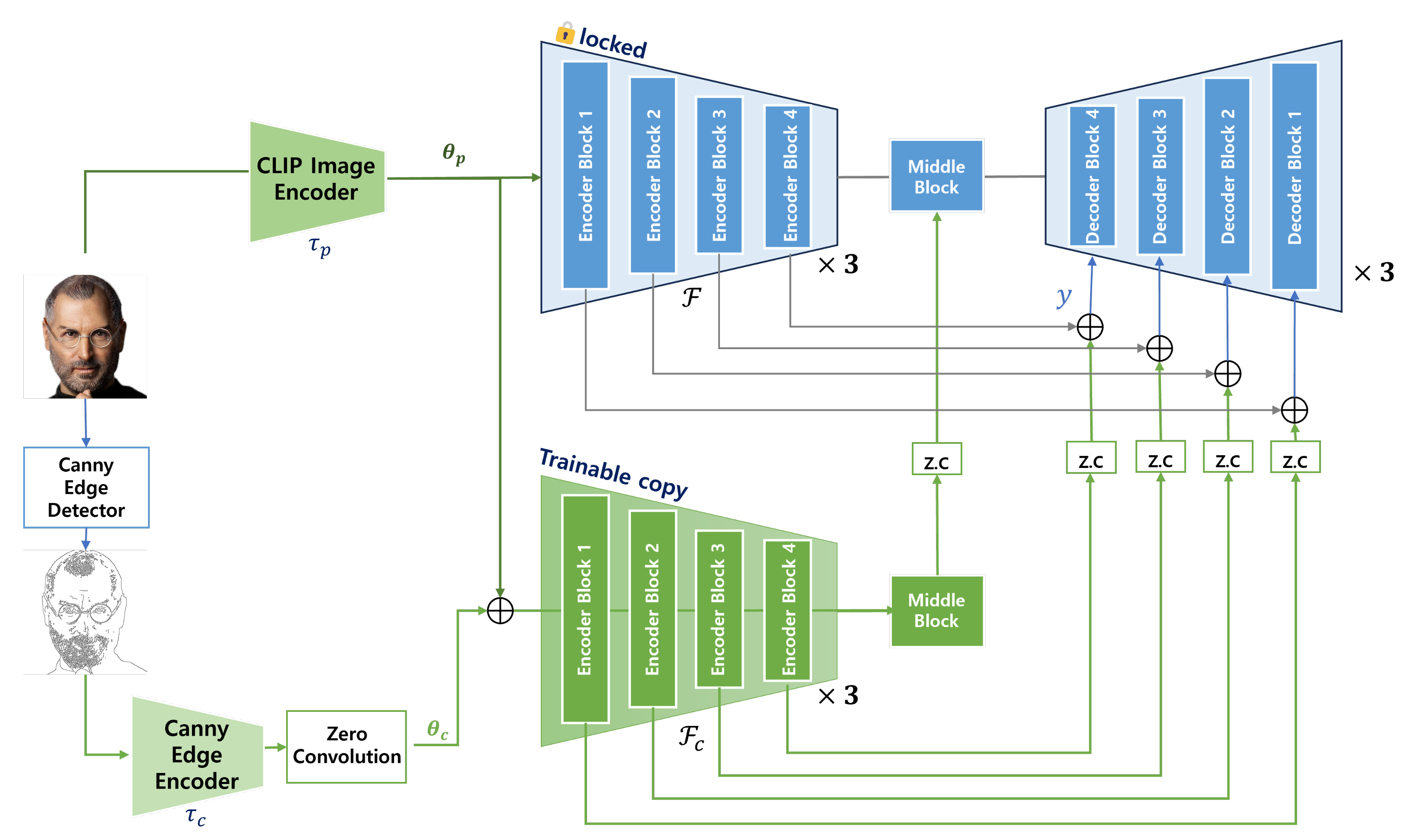
4.2.1. Multi-Layered UNet
4.2.2. Adding Condition into UNet Using ControlNet
4.3. Application of Style
5. Implementation and Results
5.1. Implementation
5.2. Dataset
5.3. Hyperparameters
5.4. Results
6. Evaluation
6.1. Quantitative Evaluation
6.2. Qualitative Evaluation
- (#01∼#10) (original-artist) questions on style of an artist, and target is original artwork image.
- (#11∼#20) (generated-artist) questions on style of an artist, and target is the generated artwork image.
- (#21∼#30) (original-art movement) questions on style of an art movement, and target is original artwork image.
- (#31∼#40) (generated-art movement) questions on style of an art movement, and target is the generated artwork image.
6.3. Ablation Study
6.4. Limitation
7. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A







References
- Gatys, L.A.; Ecker, A.S.; Bethge, M. Image style transfer using convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2414–2423. [Google Scholar]
- Huang, X.; Benlongie, S. Arbitrary style transfer in real-time with adaptive instance Normalization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1501–1510. [Google Scholar]
- An, J.; Huang, S.; Song, Y.; Dou, D.; Liu, W.; Luo, J. ArtFlow: Unbiased image style transfer via reversible neural flows. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 862–871. [Google Scholar]
- Deng, Y.; Tang, F.; Dong, W.; Sun, W.; Huang, F.; Luo, J. Arbitrary style transfer via multi-adaptation network. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 2719–2727. [Google Scholar]
- Chen, H.; Wang, Z.; Zhang, H.; Zuo, Z.; Li, A.; Xing, W.; Lu, D. Artistic style transfer with internal-externel learning and contrastive learning. In Proceedings of the Conference on Neural Information Processing Systems, Online, 6–14 December 2021; Volume 34, pp. 26561–26573. [Google Scholar]
- Zhang, Y.; Tang, F.; Dong, W.; Huang, H.; Ma, C.; Lee, T.Y.; Xu, C. Domain enhanced arbitrary style transfer via contrastive learning. In Proceedings of the ACM SIGRAPH, Vancouver, BC, Canada, 7–11 August 2022. [Google Scholar]
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V. Improced texture networks: Maximizing quality and diversity in feed-forward stylization and texture synthesis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6924–6932. [Google Scholar]
- Dumoulin, V.; Shlens, J.; Kudlur, M. A leared representation for artistic style. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Park, D.Y.; Lee, K.H. Arbitrairy style transfer with style-attentional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5880–5888. [Google Scholar]
- Huo, J.; Jin, S.; Li, W.; Wu, J.; Lai, Y.K.; Shi, Y.; Gao, Y. Manifold alignment for semanticallty aligned style transfer. In Proceedings of the International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 14861–14869. [Google Scholar]
- Liu, S.; Lin, T.; He, D.; Li, F.; Wang, M.; Li, X.; Sun, Z.; Li, Q.; Ding, E. Adaattn: Revisit attention mechanism in arbitrary neural style transfer. In Proceedings of the International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 6649–6658. [Google Scholar]
- Li, X.; Liu, S.; Kautz, J.; Yang, M.H. Learning liner transformations for fast image and video style transfer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3809–3817. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–11 December 2014; Volume 27. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 4401–4410. [Google Scholar]
- Karras, T.; Laine, S.; Aittala, M.; Hellsten, J.; Lehtinen, J.; Aila, T. Analyzing and improving the image quality of stylegan. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–9 June 2020; pp. 8110–8119. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A. Unpaired image-to-image translation using cylce-consistent adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2223–2232. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image transflation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Huang, X.; Liu, M.Y.; Belongie, S.; Kautz, J. Multimodal unsupervised image-to-image translation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 172–189. [Google Scholar]
- Abdal, R.; Qin, Y.; Wonka, P. Image2stylegan: How to embed images into the stylegan latent space? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 4435–4441. [Google Scholar]
- Richardson, E.; Alaluf, Y.; Patashnik, O.; Nitzan, Y.; Azar, Y.; Shapiro, S.; Cohen-Or, D. Encoding in style: A stylegan encoder for image-to-image translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 2287–2296. [Google Scholar]
- Abdal, R.; Zhu, P.; Mitra, N.J.; Wonka, P. Styleflow: Attribute-conditioned exploration of stylegan-generated images using conditional contiuous normalizing flows. ACM Trans. Graph. 2021, 40, 21. [Google Scholar] [CrossRef]
- Karras, T.; Aittala, M.; Hellsten, J.; Laine, S.; Lehtinen, J.; Aila, T. Training generative adversarial networks with limited data. In Proceedings of the Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 6–12 December 2020; Volume 33, pp. 12104–12114. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. In Proceedings of the Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 6–12 December 2020; Volume 33, pp. 6840–6851. [Google Scholar]
- Zhang, Y.; Huang, N.; Tang, F.; Huang, H.; Ma, C.; Dong, W.; Xu, C. Inversion-based style transfer with diffusion models. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 10146–10156. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-resolusion image synthesis with latent diffusion models. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 10684–10695. [Google Scholar]
- Ruiz, N.; Li, Y.; Jampani, V.; Pritch, Y.; Rubinstein, M.; Aberman, K. Dreambooth: Fine-tuning text-to-image diffusion models for subject-dricen generation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 22500–22510. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Askell, A.; Minshkin, P.; Clark, J.; Kruger, G.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, Online, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Wright, A.; Ommer, B. ArtFID: Quantitative Evaluation of Neural StyleTransfer. In DAGM German Conference on Pattern Recognition; Springer International Publishing: Cham, Switzerland, 2022; pp. 560–576. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Song, G.; Luo, L.; Liu, J.; Ma, W.C.; Lai, C.; Zheng, C.; Cham, T.J. Agilegan: Stylizing portraits by inversion-consistant transfer learing. ACM Trans. Graph. 2021, 20, 117. [Google Scholar] [CrossRef]
- Nichol, A.Q.; Dhariwal, P. Improved denoising diffusion probabilistic models. In Proceedings of the International Conference on Machine Learning, Online, 18–24 July 2021; pp. 8162–8171. [Google Scholar]
- Zhang, L.; Rao, A.; Agrawala, M. Adding conditional control to text-to-image diffusion models. arXiv 2023, arXiv:2302.05543. [Google Scholar]
- Ronneberger, O.; Philipp, F.; Thomas, B. Unet: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Wu, X.; Hu, Z.; Sheng, L.; Xu, D. Styleformer: Real-time arbitrary style transfer via parametric style composition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 10684–19695. [Google Scholar]
- Deng, Y.; Tang, F.; Dong, W.; Ma, C.; Pan, X.; Wang, L.; Xu, C. Strtr2: Image style transfer with tranformers. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 11326–11336. [Google Scholar]
- Zhang, W.; Zhai, G.; Wei, Y.; Yang, X.; Ma, K. Blind Image Quality Assessment via Vision-Language Correspondence: A Multitask Learning Perspective. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 14071–14081. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ours | NST [1] | CAST [6] | InST [24] | Styleformer [35] | Str2 [36] | IEST [5] | CycleGAN [16] | |
|---|---|---|---|---|---|---|---|---|
| Renoir | 137.9 | 141.9 | 190.7 | 224.5 | 255.4 | 193.7 | 140.9 | 235.1 |
| Mucha | 259.0 | 269.8 | 254.8 | 294.2 | 288.5 | 270.1 | 213.1 | 405.3 |
| Tiziano | 155.6 | 164.8 | 180.7 | 228.5 | 222.6 | 204.8 | 177.0 | 361.1 |
| Baroque | 175.8 | 208.2 | 173.2 | 264.9 | 220.3 | 231.0 | 184.8 | 239.9 |
| Rococo | 140.4 | 127.7 | 161.3 | 239.7 | 228.7 | 196.2 | 196.8 | 210.5 |
| Italian | 140.5 | 225.9 | 180.7 | 293.0 | 237.3 | 219.3 | 214.1 | 221.4 |
| min | 137.9 | 127.7 | 161.3 | 224.5 | 220.3 | 193.7 | 140.9 | 210.5 |
| max | 259.0 | 269.8 | 254.8 | 294.2 | 288.5 | 270.1 | 214.1 | 405.3 |
| average | 168.2 | 189.7 | 190.2 | 257.5 | 242.1 | 223.8 | 187.8 | 278.9 |
| Ours | NST [1] | CAST [6] | InST [24] | Styleformer [35] | Str2 [36] | IEST [5] | CycleGAN [16] | |
|---|---|---|---|---|---|---|---|---|
| Renoir | 0.62 | 0.74 | 0.80 | 0.65 | 0.63 | 0.78 | 0.81 | 0.71 |
| Mucha | 0.53 | 0.62 | 0.77 | 0.51 | 0.54 | 0.63 | 0.68 | 0.63 |
| Tiziano | 0.59 | 0.68 | 0.75 | 0.63 | 0.65 | 0.72 | 0.76 | 0.72 |
| Baroque | 0.62 | 0.68 | 0.78 | 0.67 | 0.61 | 0.72 | 0.75 | 0.68 |
| Rococo | 0.61 | 0.67 | 0.82 | 0.63 | 0.70 | 0.74 | 0.75 | 0.75 |
| Italian | 0.61 | 0.64 | 0.79 | 0.62 | 0.65 | 0.73 | 0.74 | 0.74 |
| min | 0.53 | 0.62 | 0.75 | 0.51 | 0.54 | 0.63 | 0.68 | 0.63 |
| max | 0.62 | 0.74 | 0.82 | 0.67 | 0.70 | 0.78 | 0.81 | 0.75 |
| average | 0.60 | 0.67 | 0.78 | 0.62 | 0.63 | 0.72 | 0.75 | 0.70 |
| Ours | NST [1] | CAST [6] | InST [24] | Styleformer [35] | Str2 [36] | IEST [5] | CycleGAN [16] | |
|---|---|---|---|---|---|---|---|---|
| Renoir | 3.78 | 3.27 | 3.27 | 2.89 | 2.24 | 2.24 | 3.42 | 1.44 |
| Mucha | 4.08 | 2.23 | 2.23 | 2.96 | 2.69 | 2.82 | 4.67 | 2.44 |
| Tiziano | 4.23 | 1.54 | 3.46 | 3.40 | 2.55 | 2.55 | 3.94 | 1.91 |
| Baroque | 4.69 | 3.66 | 3.59 | 3.80 | 2.65 | 2.47 | 4.43 | 2.26 |
| Rococo | 4.52 | 1.62 | 1.62 | 3.44 | 2.33 | 2.33 | 3.03 | 1.89 |
| Italian | 4.64 | 1.95 | 4.07 | 4.42 | 2.69 | 2.69 | 4.54 | 2.00 |
| min | 3.78 | 1.54 | 1.62 | 2.89 | 2.24 | 2.24 | 3.03 | 1.44 |
| max | 4.69 | 3.66 | 4.07 | 4.42 | 2.69 | 2.82 | 4.67 | 2.44 |
| average | 4.32 | 2.38 | 3.04 | 3.48 | 2.53 | 2.52 | 4.00 | 1.99 |
| Original-Artist | Generated-Artist | Original-Art Movement | Generated-Art Movement | |
|---|---|---|---|---|
| average | 7.97 | 7.53 | 7.10 | 6.80 |
| standard deviation | 0.98 | 1.02 | 1.14 | 1.35 |
| p value | 0.1056 | 0.3639 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, H.; Yang, H.; Min, K. Artfusion: A Diffusion Model-Based Style Synthesis Framework for Portraits. Electronics 2024, 13, 509. https://doi.org/10.3390/electronics13030509
Yang H, Yang H, Min K. Artfusion: A Diffusion Model-Based Style Synthesis Framework for Portraits. Electronics. 2024; 13(3):509. https://doi.org/10.3390/electronics13030509
Chicago/Turabian StyleYang, Hyemin, Heekyung Yang, and Kyungha Min. 2024. "Artfusion: A Diffusion Model-Based Style Synthesis Framework for Portraits" Electronics 13, no. 3: 509. https://doi.org/10.3390/electronics13030509
APA StyleYang, H., Yang, H., & Min, K. (2024). Artfusion: A Diffusion Model-Based Style Synthesis Framework for Portraits. Electronics, 13(3), 509. https://doi.org/10.3390/electronics13030509