1. Introduction
In recent years, Google successfully applied a transformer (used in the field of natural language processing (NLP)) to computer vision (CV) and surpassed CNN-based state-of-the-art (SOTA) models at that time (ResNet152×4 [
1]). This has triggered research workers to pay further attention to transformers, and subsequent work on vision transformers, such as DeiT [
2], SwinT [
3], PVT [
4], DETR [
5], Segformer [
6], etc., has been proposed one after another. However, it is important to note that training ViTs models often requires the use of GPU clusters (e.g., TPUv3, Nvidia A100) and large-scale training datasets (e.g., ImageNet-21K [
7], JFT-300M), which inevitably consumes significant computational resources.
With the increasing integration of artificial intelligence technology in daily production and life fields, such as autonomous driving, mixed reality, 6-DoF robot grasping, and other edge applications, the demand for feature extraction networks requires fast devices with lightweight inference. Marginalizing the transformer-based model poses a challenge due to its high computation requirements; nevertheless, it serves as inspiration for our work. Previously, mobile networks like MobileNet [
8,
9,
10], ShuffleNet [
11], EfficientNet, [
12] and GhostNet [
13] have been dominant for lightweight vision tasks. Despite having fewer parameters and FLOPs, these models find it difficult to capture global perception implicitly, creating challenges for lightweight CNNs. This, in turn, leads to low parameterization efficiency and weak inference performance. Through researching models such as Swin-T [
3], PVT-v1 [
4], DeiT [
2], and T2T-ViT [
14], researchers have discovered that the cascaded self-attention mechanism in ViT can capture long-range feature dependencies, effectively compensating for the explicit modeling difficulties and lack of input flexibility in CNNs. However, ViT-pure models lack convolution-like local inductive biases, and their performance is sensitive to hyper-parameters. To address the limitations of current networks, researchers have experimented with combining CNNs and ViTs, including CeiT [
15], CCT [
16], and PVT-v2 [
17]. This approach has proved successful in boosting the model’s performance on baseline tasks. Nevertheless, it can lead to a decrease in inference efficiency due to the operator of ViTs, self-attention, which has a quadratic relationship with input size, ultimately impacting the model’s inference speed. Therefore, it does not ensure a balance between the speed and accuracy of resource-limited devices.
Our MixMobileNet achieves competitive performance compared to lightweight convolutional neural networks and recent hybrid architecture networks. We strike a balance between parameters, FLOPs, and performance in our work.
Recently, a lightweight hybrid architecture model named MobileViTv1 [
18] has been designed specifically for mobile devices. It combines the strengths of MobileNetv2 (MV2) [
9] and ViT [
19], achieving SOTA performance in various mobile vision tasks. The model’s inference speed is slow, even with only 5.6 M parameters and 2.1 G MAdds, due to the spatial self-attention mechanism. The visualized research indicates that the MV2 block [
9] results in feature duplication and redundant kernel parameters within the model [
20]. Moreover, lightweight inference is hindered by the limited ability to compute global interactions in the spatial dimension due to input size constraints. Similarly, EdgeNeXt [
21] combines depth-wise separable convolution and transposed attention mechanisms to introduce a split depth-wise transpose attention that enhances resource utilization. However, the structural design of this model is dependent on intricate submodules, such as Res2Net [
22], ConvNeXt [
23], and XCA [
24]. Moreover, other related works incorporate EdgeViTs [
25], the MobileFormer [
26], EfficientFormer [
27], and FasterViT [
28]. A significant issue is that these architectures differ from ResNet in terms of simplicity and efficiency, which relies on complex structures and neural architecture search techniques [
29,
30]. To enhance the model’s performance, they rely on neural architecture search techniques or model pruning means. Therefore, the objective of this study is to create lightweight networks for devices with limited resources (e.g., Nvidia-AGX) through a fusion of CNNs’ and ViTs’ advantages. The objective is to enhance the plug-and-play functionality and ease of module integration.
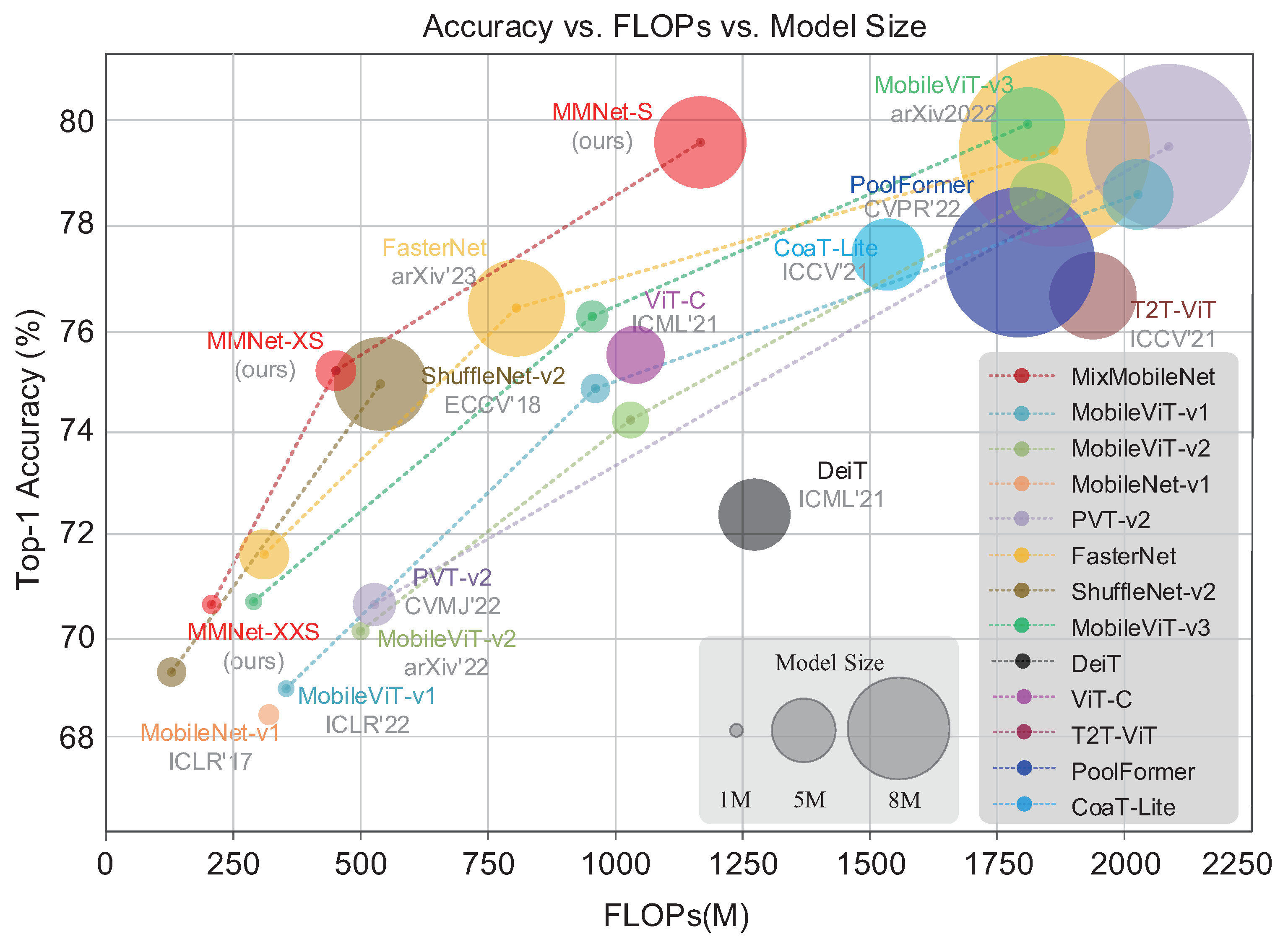
We propose an efficient and lightweight visual architecture named MixMobileNet. The model’s body employs solely MixMobile block (
MMb)as its primary component and is supported by two interrelated feature extraction blocks: the local-feature aggregation encoder (
LFAE) and the global-feature aggregation encoder (
GFAE). These blocks are utilized for constructing information encodings that combine the advantages of convolutional neural networks’ efficient local-inductive bias with transformers’ dynamic long-range modeling capabilities. This integration leads to enhanced performance effectiveness, as depicted in
Figure 1.
Our contributions are as follows:
This work proposes a lightweight feature extraction network called MixMobileNet. It combines the efficient local inductive bias of convolutional neural networks and the pixel-level long-range global modeling capability of transformers. By using an effective feature pyramid structure, it aggregates token information in multiple stages to generate high-density predictive capabilities.
We propose a plug-and-play MMb as the model’s basic block. In the overall design, we introduce two layers of encoders: LFAE and GFAE, which are used for local and global feature extraction and block-level local-global feature fusion, respectively.
Without introducing complex structures, our models have achieved competitive results on several benchmark tests. For example, our MixMobileNet-XXS/XS/S achieve 70.6%/75.1%/78.8% top-1 accuracy on the ImageNet-1K dataset [
7]. Additionally, when combined with SSDLite [
9]/DeepLabv3 [
31], MixMobileNet-S achieves 28.5 mAP/79.5 mIoU with 8.3 M/6.9 M parameters, resulting in a +2.8%↑/+0.5%↑ improvement over the recent MobileViT-S [
18].
The remaining content is organized as follows:
Section 2 details the relevant research advances in lightweight CNNs and ViTs;
Section 3 introduces the general design and detailed description of MixMobileNet; in
Section 4, we conduct a series of experiments and report the final results; and
Section 5 summarizes our work.
2. Related Work
CNN-based. In recent years, convolutional neural networks and residual connection structures, such as ResNet [
1], RegNet [
30], and DenseNet [
32], have significantly improved the accuracy of image classification. However, for convolutional neural network models with parameters reaching hundreds of M and computational requirements reaching tens of G FLOPs, both training and inference rely heavily on large-scale GPU clusters. As a result, it becomes challenging to apply these models to low-powered edge devices. Therefore, starting with SqueezeNet [
33], Iandola et al. [
33] begin to explore the efficiency of deep neural networks in resource-constrained situations. Subsequently, some lightweight CNN-based models such as MobileNet series [
8,
9,
10], EfficientNet Lite series [
12], ShuffleNet series [
11], and Huawei’s GhostNet [
13] have been proposed, and they have shown significant improvements in both speed and accuracy. Among them, Howard et al. [
8] propose the depth-wise separable convolution, which reduces the computational complexity of traditional convolution by nearly an order of magnitude. This innovation makes MobileNetv1 [
8] the first successful network in the field of lightweight models. Tan et al. [
12] propose a new scaling method called compound model scaling, which uniformly scales all dimensions of depth/width/resolution using a simple yet highly effective compound coefficient to improve network performance. This research work is also the first to simultaneously investigate the impact of depth, width, and resolution on network performance. Ma et al. [
11] propose point-wise group convolution and channel shuffle to reduce the computational complexity. These structures allow more feature map channels to encode more information for a given amount of computation, which greatly reduces the computational overhead while preserving the accuracy of the model. Lin et al. [
23] design a purely convolutional architecture called ConvNeXt [
23] by drawing inspiration from the ResNet [
1] and Swin-T [
3] networks and combining some design concepts of the ViT architecture. In the ConvNeXt [
23] network, the authors innovatively change the number of blocks in each stage of ResNet50 [
1] from [3, 4, 6, 3] to [3, 3, 9, 3], which improves the accuracy at the cost of increasing the computational complexity. Additionally, inspired by the design of the stem layer in ResNet [
1], we modify the
convolution with a stride of 2 to a
convolution with a stride of 4. This modification further improves the accuracy of the model. The ConvNeXt [
23] network architecture design has great significance to many later network designs. Recently, Chen et al. [
34] proposed a novel partial convolution (
PConv) that can extract spatial features more efficiently by cutting down redundant computation and memory access simultaneously. Furthermore, the point-wise convolution (
PWconv) is appended to
PConv to effectively integrate information from all channels. Their effective receptive field together on the input feature maps looks like a T-shaped convolution, which focuses more on the center position compared to a regular convolution uniformly processing a patch, allowing the network to be efficiently represented.
ViT-based. After the remarkable success of transformer encoding in the field of natural language processing (NLP), Dosovitskiy et al. [
19] achieve comparable performance to convolutional architectures by serializing image sequences and feeding them into the transformer framework. Subsequently, its effectiveness has become increasingly prominent in tasks such as image classification, object detection, and autonomous driving, making it a widely adopted tool in computer vision (CV). However, transformers are typically computationally intensive. Specifically, they generate long sequences of feature tokens from high-resolution image inputs, which can increase the model’s inference workload and hinder its generalization to downstream tasks such as object detection and image segmentation. Additionally, achieving equivalent local inductive capabilities to CNNs with visual transformers requires training on large-scale datasets. Finally, the ViTs frameworks are sensitive to hyper-parameters and require patient and careful parameter tuning to achieve good convergence. To address the aforementioned issues, researchers have primarily focused on upgrading transformers from two perspectives: training settings and model architecture design. From the perspective of training settings, Touvron et al. have achieved impressive model performance in CaiT [
35] and DeiT-III [
2] by employing sophisticated data augmentation strategies and training techniques such as Mixup, CutMix, and Rand Augment. They have demonstrated outstanding results without relying on large proprietary datasets like JFT-300M. In DeiT [
2], a distillation token and soft-distillation technique are used to compress the parameters of a powerful but large and difficult-to-train teacher model from 86 M to 5 M (DeiT-Tiny [
2]). This compression leads to a tenfold improvement in inference speed. From the perspective of model architecture design, researchers have focused on two main directions: self-attention input resolution and attention mechanisms with low computational cost. PVT-v1 [
4] emulates the feature map pyramid architecture found in CNNs by transforming the fixed 16× downsampling of the original ViTs into a multi-scale processing of the image. To address the issues of partial loss of spatial information at image edges and quadratic growth in computational complexity in ViT models, Liu et al. introduce a novel approach in Swin-T [
3] and LightViT [
36]. They incorporate a hierarchical feature map and shifted-window mechanisms to reduce the computational memory and complexity from quadratic to linear growth. As a result, these models exhibit superior performance compared to the original ViT [
19] and DeiT models [
2]. Deformable DETR [
37] introduces the (multi-scale) deformable attention modules, which only attend to a small set of key sampling points around a reference point, regardless of the spatial size of the feature maps. This reduces computational complexity while maintaining a large receptive field. PVT [
4], ResT [
38], and CMT [
39] use convolution to reduce the number of tokens corresponding to keys and values, thereby decreasing computational complexity. SOFT [
40] uses the Gaussian kernel function to replace the softmax dot-product similarity and samples from the sequence by convolution or pooling to achieve a low-rank approximation to the original attention matrix.
Hybrid network. Compared to CNN-pure and ViT-pure models, the models that combine CNNs and ViTs not only have fewer parameters and faster inference but also demonstrate a significant improvement in network performance. Application deployment of ViT models poses significant challenges, especially on resource-constrained hardware like mobile devices. Recently, researchers focusing on mobile networks have paid attention to this problem. For instance, Apple’s MobileViTv1 [
18] integrates the strengths of CNN into the transformer structure to address the training, transfer, and adaptation challenges inherent in transformer networks. Simultaneously, a core MobileViT block [
18] is proposed to accelerate the inference and convergence speed of the network, making it more stable and efficient. Maaz et al. [
21] propose a lightweight network called EdgeNeXt [
21], which achieves a comprehensive balance between model size, parameters, and FLOPs. Furthermore, they introduce an efficient split depth-wise transpose attention (STDA) [
21] encoder, enabling the effective fusion of local and global information representations. Pan et al. [
25] propose a high-cost local–global–local (LGL) information exchange bottleneck based on the optimal integration of self-attention and convolution. Additionally, the LGL approach uses a sparse attention module to further mitigate the overhead of self-attention, achieving a better trade-off between accuracy and latency. Liu et al. [
41] propose an EfficientViT block that includes a sandwich layout and cascaded group attention (CGA). This design aims to further reduce the inference latency caused by the extensive operations in the multi-head self-attention (MHSA) and the computational redundancy between attention heads. Li et al. [
42] proposed a CNN-transformer hybrid architecture that utilizes the next hybrid strategy (NHS) strategy to stack the next convolution block (NCB) and next transformer block (NTB), enabling the fusion of local and global information and thus further enhancing the network’s modeling capability. Although most lightweight networks are designed with the goal of having fewer parameters, lower computational requirements, and low latency, they often require complex module designs, which greatly limit the model’s usability and reusability. Therefore, further research is needed to explore how to design a concise and efficient mobile model.
5. Conclusions
In this study, we introduce an efficient model called MixMobileNet, which is composed of stacked MMbs consisting only of a local feature aggregation encoder (LFAE) and a global feature aggregation encoder (GFAE). MixMobileNet effectively models both local and global information while reducing the number of parameters and the amount of computation. Specifically, our GFAE efficiently encodes global information by performing two operations: average pooling for channel dimension reduction and computing channel-wise feature attention. This approach effectively reduces the computational cost of self-attention layers. On the other hand, our LFAE utilizes PConv convolutions with adaptive kernel sizes, which helps to reduce the complexity of large kernel convolutions and capture local features at different levels in the network. Extensive experimental results demonstrate the effectiveness and generalization capability of our proposed model, showcasing its efficiency across various downstream benchmarks.
Our method does not use other more efficient strategies, such as a split depth-wise transpose attention (STDA) [
21] encoder, dilated convolution [
74], and neural architecture search [
29,
30], which should be thoroughly tried and experimented with, and thus, our method may not be optimal. In addition, our method is not trained on the ImageNet-21K dataset [
7] and does not employ stronger training augmentation/strategies. Therefore, the upper limit of efficient model performance needs to be further explored. Limited by the current computational power, we will use the abovementioned attempts in our future works.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}