
An Adaptive Control Method and Learning Strategy for Ultrasound-Guided Puncture Robot


Abstract
:1. Introduction
- We proposed an adaptive, flexible control algorithm for robotic arms. This algorithm enables surgeons to easily manipulate and position the robotic arm before US-scanning, thus enhancing the smoothness and safety of the preoperative process. As a result, we can drag the arm with ease, ensuring flexibility in its movements and placement.
- Based on reinforcement learning, an autonomous scanning mode with constant contact force and velocity was developed. By using information from the end-effector force sensor and the state of the robotic arm, the autonomous scanning mode generates commands for the robot controller. The flexible control algorithm is incorporated to directly control the motion of the US-probe.
- In terms of reinforcement learning in soft contact simulation, we use Multi-Joint Dynamics with Contact (MuJoCo) to create a deformable physics model of soft contact objects that can modify stiffness and damping, allowing the simulation process to exhibit noticeable and more realistic stress reactions.
- After the US-scanning operation was completed, we performed tumor-related object localization and proposed a real-time needle posture adjustment approach based on the UNet++ algorithm to solve the difficulty of properly establishing the position and orientation of the needle.
2. Materials and Methods
2.1. System Description
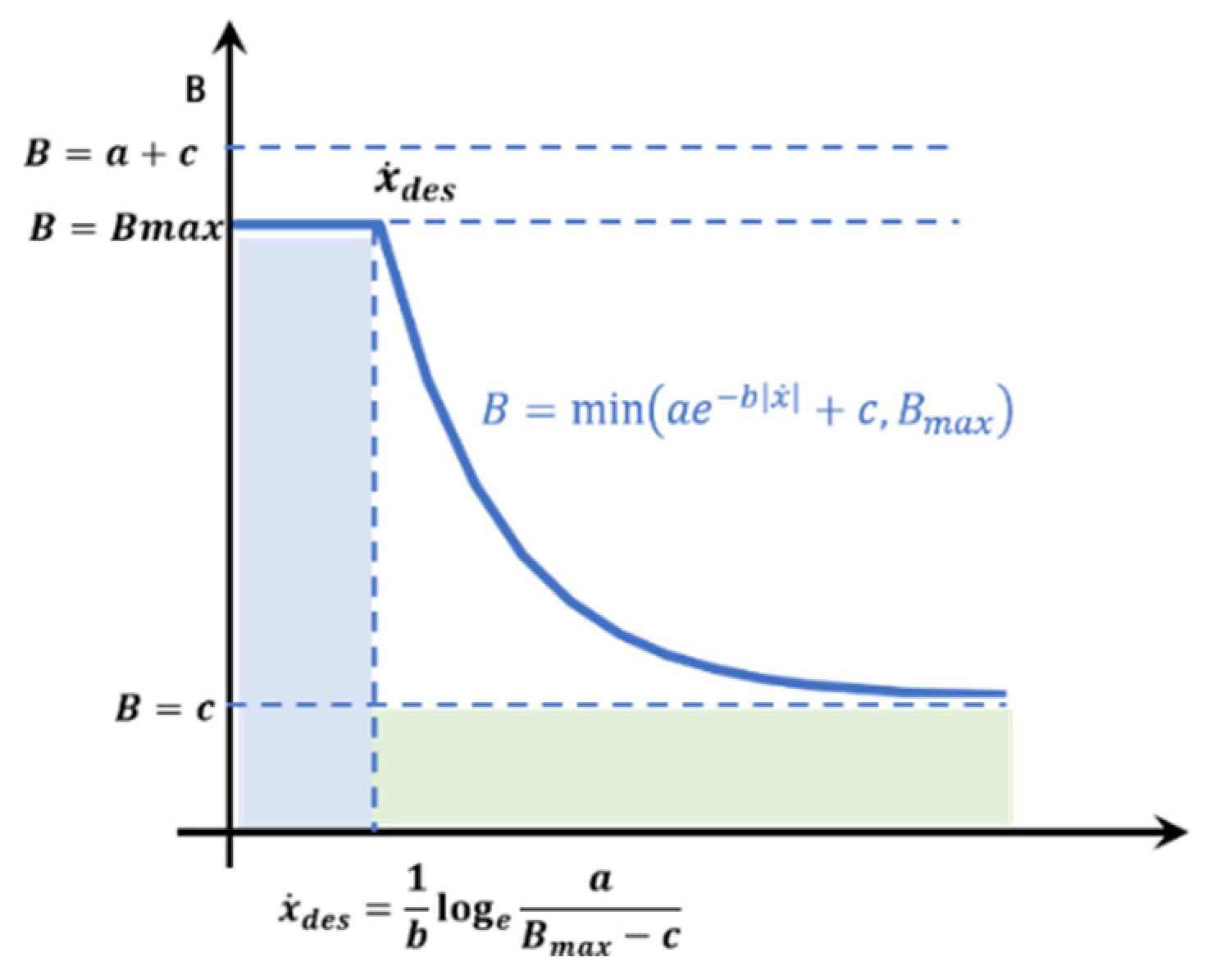
2.2. Adaptive Flexible Control Algorithm
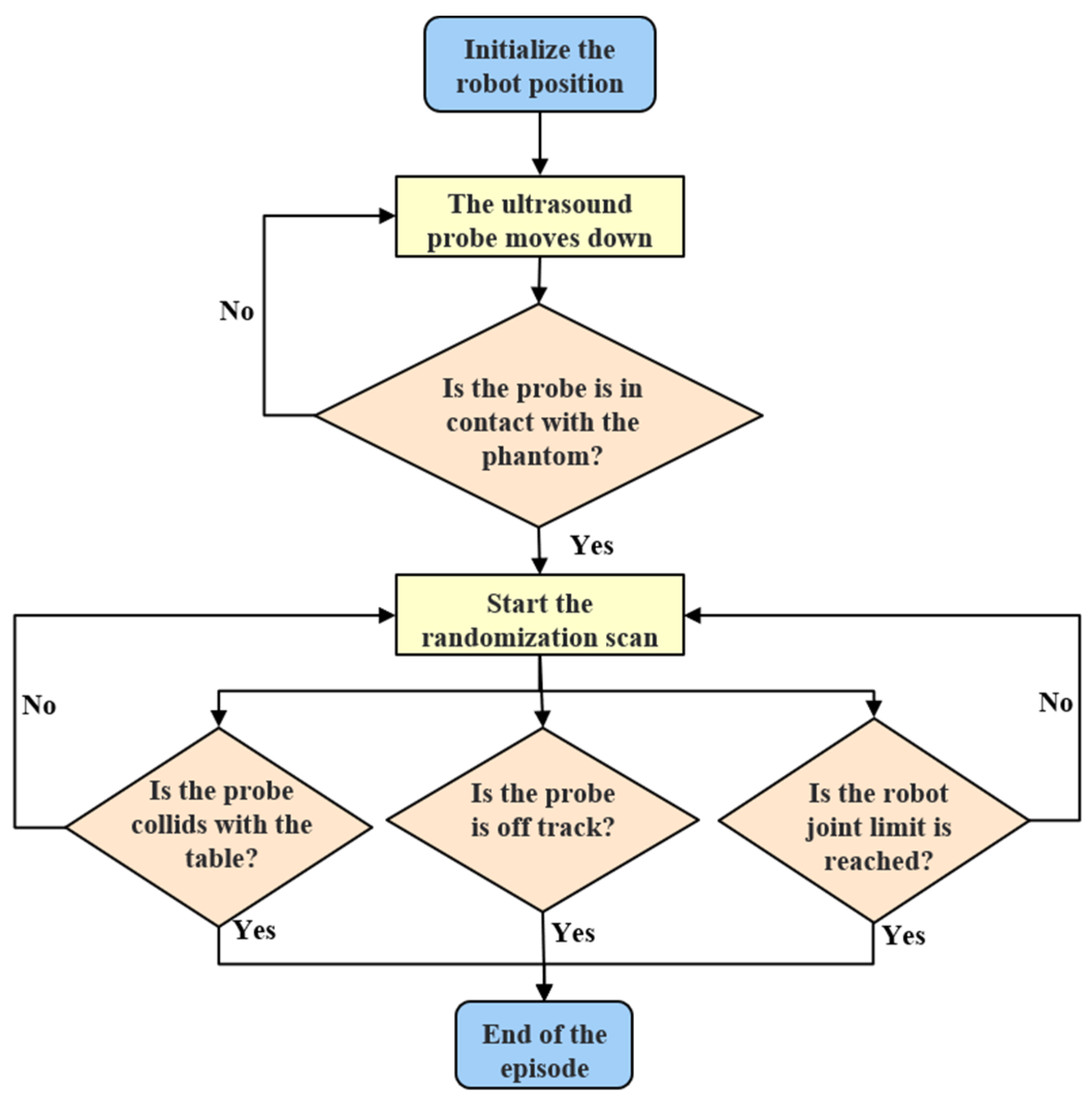
2.3. Simulation Environment and Reinforcement Learning
2.3.1. Simulation Environment Construction
- Construction of the soft contact model
- Design of the robotic arm’s end-effector mechanism
2.3.2. Reinforcement Learning
2.4. Piercing Needle Identification
3. Experiments and Results
3.1. Flexible Traction Experiment
3.2. Reinforcement Learning-Based US-Scanning Experiment
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A
| Symbols | Meaning |
| ambient stress exerted on the six-dimensional force transducer | |
| the difference between the actual position and the desired position | |
| the second-order derivative of | |
| the first-order derivative of | |
| K, B, and M | the stiffness coefficients, damping coefficients, and inertia coefficients |
| robot mass matrix | |
| centrifugal and coriolis forces | |
| the gravitational moment | |
| the joint torque | |
| the initial impedance coefficient | |
| the impedance coefficient drop | |
| the minimum value | |
| the maximum value of the impedance coefficient | |
| the acceleration, velocity, and position difference | |
| the stiffness, damping, and impedance | |
| the unforced acceleration | |
| the ratio of the new policy to the old policy | |
| the estimated amount of dominance function | |
| the weights assigned to each reward item | |
| the rewards of each individual component | |
| distance metric representing two quaternions | |
| the horizontal coordinate of the pixel point of the segmented image at | |
| the vertical coordinate of the pixel point of the segmented image at |
References
- Chen, F.; Liu, J.; Liao, H. 3D catheter shape determination for endovascular navigation using a two-step particle filter and ultrasound scanning. IEEE Trans. Med. Imaging 2016, 36, 685–695. [Google Scholar] [CrossRef]
- Bowness, J.; Varsou, O.; Turbitt, L.; Burkett-St Laurent, D. Identifying anatomical structures on ultrasound: Assistive artificial intelligence in ultrasound-guided regional anesthesia. Clin. Anat. 2021, 34, 802–809. [Google Scholar] [CrossRef]
- Stukan, M.; Rutkowski, P.; Smadja, J.; Bonvalot, S. Ultrasound-Guided Trans-Uterine Cavity Core Needle Biopsy of Uterine Myometrial Tumors to Differentiate Sarcoma from a Benign Lesion—Description of the Method and Review of the Literature. Diagnostics 2022, 12, 1348. [Google Scholar] [CrossRef]
- Mori, S.; Hirano, K.; Yamawaki, M.; Kobayashi, N.; Sakamoto, Y.; Tsutsumi, M.; Honda, Y.; Makino, K.; Shirai, S.; Ito, Y. A comparative analysis between ultrasound-guided and conventional distal transradial access for coronary angiography and intervention. J. Interv. Cardiol. 2020, 2020, 7342732. [Google Scholar] [CrossRef]
- Cardinal, H.N.; Gill, J.D.; Fenster, A. Analysis of geometrical distortion and statistical variance in length, area, and volume in a linearly scanned 3-D ultrasound image. IEEE Trans. Med. Imaging 2000, 19, 632–651. [Google Scholar] [CrossRef]
- Evans, K.; Roll, S.; Baker, J. Work-related musculoskeletal disorders (WRMSD) among registered diagnostic medical sonographers and vascular technologists: A representative sample. J. Diagn. Med. Sonogr. 2009, 25, 287–299. [Google Scholar] [CrossRef]
- Akbari, M.; Carriere, J.; Meyer, T.; Sloboda, R.; Husain, S.; Usmani, N.; Tavakoli, M. Robotic ultrasound scanning with real-time image-based force adjustment: Quick response for enabling physical distancing during the COVID-19 pandemic. Front. Robot. AI 2021, 8, 645424. [Google Scholar] [CrossRef] [PubMed]
- Huang, Q.; Lan, J.; Li, X. Robotic arm based automatic ultrasound scanning for three-dimensional imaging. IEEE Trans. Ind. Inform. 2018, 15, 1173–1182. [Google Scholar] [CrossRef]
- Virga, S.; Zettinig, O.; Esposito, M.; Pfister, K.; Frisch, B.; Neff, T.; Navab, N.; Hennersperger, C. Automatic force-compliant robotic ultrasound screening of abdominal aortic aneurysms. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Republic of Korea, 9–14 October 2016; pp. 508–513. [Google Scholar]
- Pan, Z.; Tian, S.; Guo, M.; Zhang, J.; Yu, N.; Xin, Y. Comparison of medical image 3D reconstruction rendering methods for robot-assisted surgery. In Proceedings of the 2017 2nd International Conference on Advanced Robotics and Mechatronics (ICARM), Hefei and Tai’an, China, 27–31 August 2017; pp. 94–99. [Google Scholar]
- Giuliani, M.; Szczęśniak-Stańczyk, D.; Mirnig, N.; Stollnberger, G.; Szyszko, M.; Stańczyk, B.; Tscheligi, M. User-centred design and evaluation of a tele-operated echocardiography robot. Health Technol. 2020, 10, 649–665. [Google Scholar] [CrossRef]
- Kojcev, R.; Fuerst, B.; Zettinig, O.; Fotouhi, J.; Lee, S.C.; Frisch, B.; Taylor, R.; Sinibaldi, E.; Navab, N. Dual-robot ultrasound-guided needle placement: Closing the planning-imaging-action loop. Int. J. Comput. Assist. Radiol. Surg. 2016, 11, 1173–1181. [Google Scholar] [CrossRef] [PubMed]
- Culjat, M.; Singh, R.; Lee, H. Medical Devices: Surgical and Image-Guided Technologies; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
- Nadeau, C.; Krupa, A.; Petr, J.; Barillot, C. Moments-based ultrasound visual servoing: From a mono-to multiplane approach. IEEE Trans. Robot. 2016, 32, 1558–1564. [Google Scholar] [CrossRef]
- Mohamed, A.; Sami, A.; Santosha, D. Event-Triggered Adaptive Hybrid Position-Force Control for Robot-Assisted Ultrasonic Examination System. J. Intell. Robot. Syst. 2021, 102, 84. [Google Scholar]
- Fabian, J.; Garcia-Cardenas, F.; Canahuire, R.; Ramos, O.E. Sensorless Impedance Control for the UR5 Robot. In Proceedings of the 2020 International Conference on Control, Automation and Diagnosis (ICCAD), Paris, France, 7–9 October 2020; pp. 1–6. [Google Scholar]
- Piwowarczyk, J.; Carriere, J.; Adams, K.; Tavakoli, M. An admittance-controlled force-scaling dexterous assistive robotic system. J. Med. Robot. Res. 2020, 5, 2041002. [Google Scholar] [CrossRef]
- Carriere, J.; Fong, J.; Meyer, T.; Sloboda, R.; Husain, S.; Usmani, N.; Tavakoli, M. An admittance-controlled robotic assistant for semi-autonomous breast ultrasound scanning. In Proceedings of the 2019 International Symposium on Medical Robotics (ISMR), Atlanta, GA, USA, 3–5 April 2019; pp. 1–7. [Google Scholar]
- von Haxthausen, F.; Böttger, S.; Wulff, D.; Hagenah, J.; García-Vázquez, V.; Ipsen, S. Medical robotics for ultrasound imaging: Current systems and future trends. Curr. Robot. Rep. 2021, 2, 55–71. [Google Scholar] [CrossRef] [PubMed]
- Avgousti, S.; Panayides, A.S.; Jossif, A.P.; Christoforou, E.G.; Vieyres, P.; Novales, C.; Voskarides, S.; Pattichis, C.S. Cardiac ultrasonography over 4G wireless networks using a tele-operated robot. Health Technol. Lett. 2016, 3, 212–217. [Google Scholar] [CrossRef] [PubMed]
- Georgescu, M.; Sacccomandi, A.; Baudron, B.; Arbeille, P.L. Remote sonography in routine clinical practice between two isolated medical centers and the university hospital using a robotic arm: A 1-year study. Telemed. e-Health 2016, 22, 276–281. [Google Scholar] [CrossRef] [PubMed]
- Adams, S.J.; Burbridge, B.E.; Badea, A.; Langford, L.; Vergara, V.; Bryce, R.; Bustamante, L.; Mendez, I.M.; Babyn, P.S. Initial experience using a telerobotic ultrasound system for adult abdominal sonography. Can. Assoc. Radiol. J. 2017, 68, 308–314. [Google Scholar] [CrossRef] [PubMed]
- Shahid, A.A.; Piga, D.; Braghin, F.; Roveda, L. Continuous control actions learning and adaptation for robotic manipulation through reinforcement learning. Auton. Robot. 2022, 46, 483–498. [Google Scholar] [CrossRef]
- Ning, G.; Zhang, X.; Liao, H. Autonomic robotic ultrasound imaging system based on reinforcement learning. IEEE Trans. Biomed. Eng. 2021, 68, 2787–2797. [Google Scholar] [CrossRef]
- Priester, A.M.; Natarajan, S.; Culjat, M.O. Robotic ultrasound systems in medicine. IEEE Trans. Ultrason. Ferroelectr. Freq. Control 2013, 60, 507–523. [Google Scholar] [CrossRef]
- Zhao, W.; Queralta, J.P.; Westerlund, T. Sim-to-real transfer in deep reinforcement learning for robotics: A survey. In Proceedings of the 2020 IEEE Symposium Series on Computational Intelligence (SSCI), Canberra, ACT, Australia, 1–4 December 2020; pp. 737–744. [Google Scholar]
- Schulman, J.; Ho, J.; Lee, C.; Abbeel, P. Generalization in robotic manipulation through the use of non-rigid registration. In Proceedings of the 16th International Symposium on Robotics Research (ISRR), Singapore, 16–19 December 2013. [Google Scholar]
- Martín-Martín, R.; Lee, M.A.; Gardner, R.; Savarese, S.; Bohg, J.; Garg, A. Variable impedance control in end-effector space: An action space for reinforcement learning in contact-rich tasks. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 1010–1017. [Google Scholar]
- Wu, M.; He, Y.; Liu, S. Adaptive impedance control based on reinforcement learning in a human-robot collaboration task with human reference estimation. Int. J. Mech. Control 2020, 21, 21–31. [Google Scholar]
- Buchli, J.; Stulp, F.; Theodorou, E.; Schaal, S. Learning variable impedance control. Int. J. Robot. Res. 2011, 30, 820–833. [Google Scholar] [CrossRef]
- Todorov, E.; Erez, T.; MuJoCo, Y. A physics engine for model-based control. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura-Algarve, Portugal, 7–12 October 2012; pp. 5026–5033. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015, Proceedings, Part III 18; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention u-net: Learning where to look for the pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Zhou, Z.; Siddiquee, M.M.R.; Tajbakhsh, N.; Liang, J. Unet++: Redesigning skip connections to exploit multiscale features in image segmentation. IEEE Trans. Med. Imaging 2019, 39, 1856–1867. [Google Scholar] [CrossRef] [PubMed]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, T.; Zeng, Q.; Li, J.; Qian, C.; Yu, H.; Lu, J.; Zhang, Y.; Zhou, S. An Adaptive Control Method and Learning Strategy for Ultrasound-Guided Puncture Robot. Electronics 2024, 13, 580. https://doi.org/10.3390/electronics13030580
Li T, Zeng Q, Li J, Qian C, Yu H, Lu J, Zhang Y, Zhou S. An Adaptive Control Method and Learning Strategy for Ultrasound-Guided Puncture Robot. Electronics. 2024; 13(3):580. https://doi.org/10.3390/electronics13030580
Chicago/Turabian StyleLi, Tao, Quan Zeng, Jinbiao Li, Cheng Qian, Hanmei Yu, Jian Lu, Yi Zhang, and Shoujun Zhou. 2024. "An Adaptive Control Method and Learning Strategy for Ultrasound-Guided Puncture Robot" Electronics 13, no. 3: 580. https://doi.org/10.3390/electronics13030580