
Popularity-Debiased Graph Self-Supervised for Recommendation



Abstract
1. Introduction
- (1)
- We propose a popularity-debiased graph supervised recommendation model (PDGS). We design penalty constraints for items based on their popularity. This graph serves as an augmented view that participates in contrastive learning with the collaborative graph, which compensates for the defect of long-tail items that are less/unrecommended due to exposure limitations.
- (2)
- We improve the supervised learning recommendation task by considering both popular items and long-tail items and optimize the self-supervised learning task and recommendation task with multitask joint training to achieve end-to-end training of the model to alleviate data sparsity while reducing the impact of popularity bias on model learning, thereby improving recommendation diversity and enhancing user experience.
- (3)
- We validate the effectiveness of our model through comparative experiments and ablation experiments on three real-world datasets.
2. Related Work
2.1. Popularity Bias for Recommendation
2.2. Self-Supervised Learning for Recommendation
3. Preliminaries
4. The Proposed Methodology
4.1. Popularity-Debiased Item Similarity Graph
| Algorithm 1: The Sampling Strategy of Items for Popularity Debiasing. |
 |
4.2. Feature Extraction of Items from Multiple Views
4.3. Constructing Self-Supervised Learning Tasks Based on Multiple Views
4.4. Popularity-Aware Multitask Learning Strategy
4.5. Complexity of PDGS
5. Experiment
5.1. Experiment Setup
5.1.1. Dataset Description
5.1.2. Evaluation Protocol
5.1.3. Baselines
- -
- [37]: It combines Generalized Matrix Factorization and MultiLayer Perceptron to extract low-dimensional and high-dimensional features simultaneously.
- -
- [38]: It utilizes graph neural networks to model high-order connectivity information and capture collaborative information between nodes.
- -
- [29]: It designs a lightweight graph convolution operation that simplifies model design to a large extent, which includes the most important components in GCN for recommendation.
- -
- [39]: It designs multiple data augmentation methods to construct a comparative learning task to learn node representations with the help of mutual information maximization idea.
- -
- [27]: It generates global-, local-, and semantic-level contrastive views, constructs contrastive learning tasks, and explores comprehensive graph features and structural information in a self-supervised manner.
5.2. Performance Comparison with Baselines
- (1)
- It is intuitively clear from Figure 2 that our proposed model PDGS outperforms the comparison models both in terms of accuracy and novelty recommendation. Table 3 digitally demonstrates the performance improvement of PDGS on all evaluation metrics. It illustrates that the model PDGS can effectively improve the problem of insufficient diversity of recommended items in the existing models and increase the recommendation ratio of long-tail items. It can fully explore the value of long-tail items, enhance user engagement, and generate more revenue for businesses.
- (2)
- In both Top-10 and Top-20 recommendations, the PDGS model achieves optimal results in terms of recommendation accuracy compared with all baselines, indicating that the PDGS algorithm does not trade off the loss of accuracy for the diversity of recommended items. From a practical perspective, solely improving the diversity of item recommendations without considering that recommendation accuracy loses the significance of personalized recommendation. Our proposed PDGS model can effectively balance the dilemma between recommendation accuracy and diversity, fully explore the uninteracted items related to users’ interests, and improve the performance of the recommendation model as a whole.
- (3)
- Compared with the self-supervised recommendation models SGL and MCCLK, our proposed PDGS achieves optimal performance in recommendation diversity evaluation metrics. The method of data augmentation of the user–item interaction graph from the perspective of popularity debiased item similarity is illustrated, which takes into account user preferences while eliminating the influence of popularity bias, making the generated self-supervised signals more in line with the real situation and allowing more long-tail items to be covered in the recommendation lists, thus effectively reducing the problem of popularity bias that exists in the original user–item historical interaction dataset.
5.3. Ablation Study of PDGS
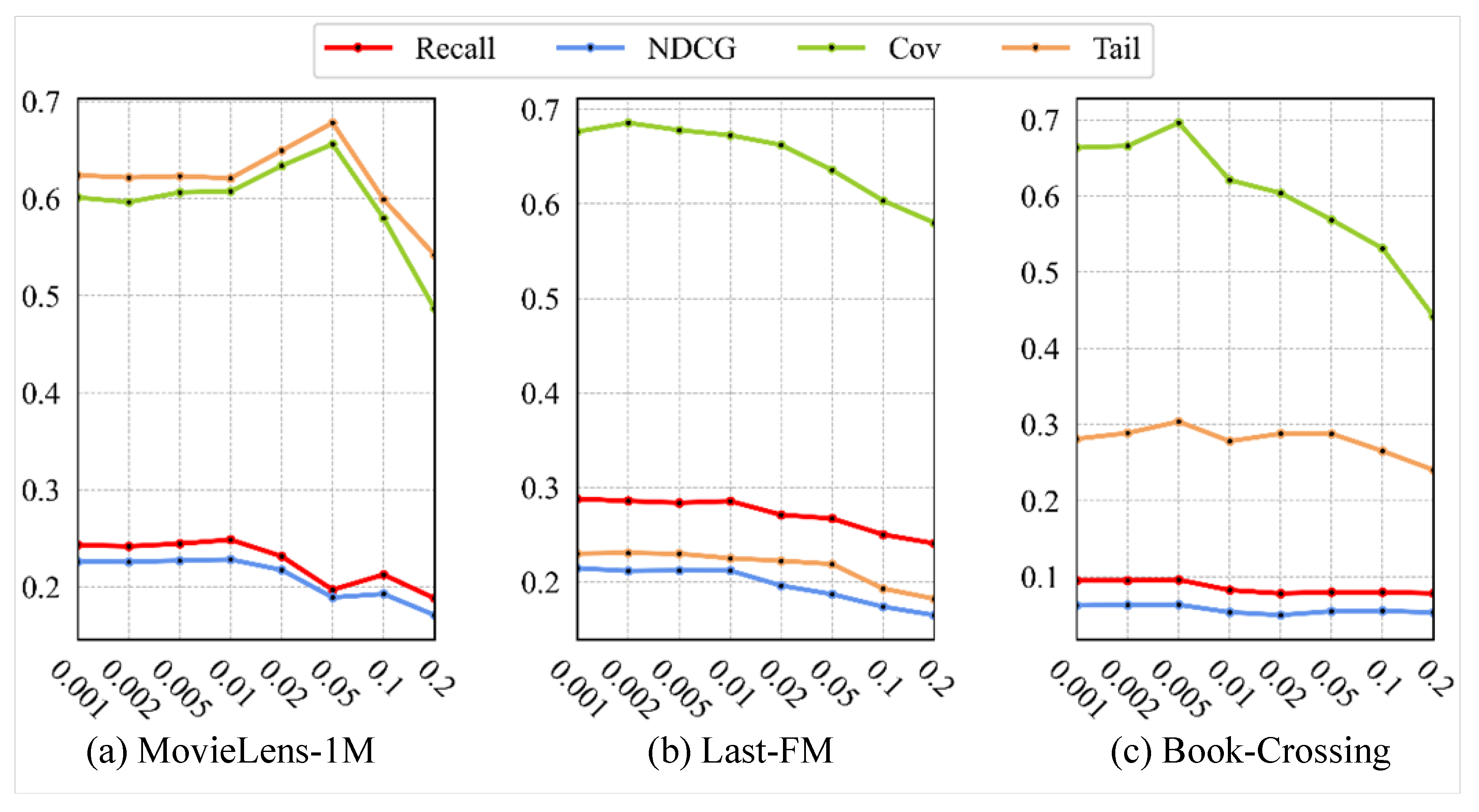
5.4. Impact of the Number of Hyperparameters
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Lian, J.; Zhou, X.; Zhang, F.; Chen, Z.; Xie, X.; Sun, G. xdeepfm: Combining explicit and implicit feature interactions for recommender systems. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 1754–1763. [Google Scholar]
- Lin, Z.; Tian, C.; Hou, Y.; Zhao, W.X. Improving graph collaborative filtering with neighborhood-enriched contrastive learning. In Proceedings of the ACM Web Conference 2022, Lyon, France, 25–29 April 2022; pp. 2320–2329. [Google Scholar]
- Abdollahpouri, H. Popularity bias in ranking and recommendation. In Proceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society, Honolulu, HI, USA, 27–28 January 2019; pp. 529–530. [Google Scholar]
- Saito, Y.; Yaginuma, S.; Nishino, Y.; Sakata, H.; Nakata, K. Unbiased recommender learning from missing-not-at-random implicit feedback. In Proceedings of the 13th International Conference on Web Search and Data Mining, Houston, TX, USA, 3–7 February 2020; pp. 501–509. [Google Scholar]
- Chen, J.; Dong, H.; Wang, X.; Feng, F.; Wang, M.; He, X. Bias and debias in recommender system: A survey and future directions. ACM Trans. Inf. Syst. 2023, 41, 1–39. [Google Scholar] [CrossRef]
- Yang, L.; Cui, Y.; Xuan, Y.; Wang, C.; Belongie, S.; Estrin, D. Unbiased offline recommender evaluation for missing-not-at-random implicit feedback. In Proceedings of the 12th ACM Conference on Recommender Systems, Vancouver, BC, Canada, 2–7 October 2018; pp. 279–287. [Google Scholar]
- Zhu, Z.; He, Y.; Zhao, X.; Zhang, Y.; Wang, J.; Caverlee, J. Popularity-opportunity bias in collaborative filtering. In Proceedings of the 14th ACM International Conference on Web Search and Data Mining, Jerusalem, Israel, 8–12 March 2021; pp. 85–93. [Google Scholar]
- Bonner, S.; Vasile, F. Causal embeddings for recommendation. In Proceedings of the 12th ACM Conference on Recommender Systems, Vancouver, BC, Canada, 2–7 October 2018; pp. 104–112. [Google Scholar]
- Elahi, M.; Kholgh, D.K.; Kiarostami, M.S.; Saghari, S.; Rad, S.P.; Tkalčič, M. Investigating the impact of recommender systems on user-based and item-based popularity bias. Inf. Process. Manag. 2021, 58, 102655. [Google Scholar] [CrossRef]
- Wei, T.; Feng, F.; Chen, J.; Wu, Z.; Yi, J.; He, X. Model-agnostic counterfactual reasoning for eliminating popularity bias in recommender system. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Singapore, 14–18 August 2021; pp. 1791–1800. [Google Scholar]
- Zhang, Y.; Feng, F.; He, X.; Wei, T.; Song, C.; Ling, G.; Zhang, Y. Causal intervention for leveraging popularity bias in recommendation. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, 11–15 July 2021; pp. 11–20. [Google Scholar]
- Fu, Z.; Xian, Y.; Geng, S.; De Melo, G.; Zhang, Y. Popcorn: Human-in-the-loop popularity debiasing in conversational recommender systems. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management, Virtual Event, 1–5 November 2021; pp. 494–503. [Google Scholar]
- Abdollahpouri, H.; Mansoury, M.; Burke, R.; Mobasher, B. The connection between popularity bias, calibration, and fairness in recommendation. In Proceedings of the 14th ACM Conference on Recommender Systems, Virtual, 22–26 September 2020; pp. 726–731. [Google Scholar]
- Rhee, W.; Cho, S.M.; Suh, B. Countering Popularity Bias by Regularizing Score Differences. In Proceedings of the 16th ACM Conference on Recommender Systems, Seattle, WA, USA, 18–23 September 2022; pp. 145–155. [Google Scholar]
- Zhao, W.; Tang, D.; Chen, X.; Lv, D.; Ou, D.; Li, B.; Jiang, P.; Gai, K. Disentangled Causal Embedding With Contrastive Learning For Recommender System. arXiv 2023, arXiv:2302.03248. [Google Scholar]
- Zhanga, X.; Sua, K.; Qiana, F.; Zhangc, Y.; Zhanga, K. Collaborative Filtering Algorithm Based on Item Popularity and Dynamic Changes of Interest. In Modern Management Based on Big Data III; IOS Press: Amsterdam, The Netherlands, 2022; pp. 132–140. [Google Scholar]
- Yang, S.; Cai, B.; Cai, T.; Song, X.; Jiang, J.; Li, B.; Li, J. Robust cross-network node classification via constrained graph mutual information. Knowl.-Based Syst. 2022, 257, 109852. [Google Scholar] [CrossRef]
- Hoang, T.; Do, T.T.; Nguyen, T.V.; Cheung, N.M. Multimodal mutual information maximization: A novel approach for unsupervised deep cross-modal hashing. IEEE Trans. Neural Netw. Learn. Syst. 2022, 34, 6289–6302. [Google Scholar] [CrossRef] [PubMed]
- Linsker, R. Self-organization in a perceptual network. Computer 1988, 21, 105–117. [Google Scholar] [CrossRef]
- Fan, J.; Yu, Y.; Huang, L.; Wang, Z. GraphDPI: Partial label disambiguation by graph representation learning via mutual information maximization. Pattern Recognit. 2023, 134, 109133. [Google Scholar] [CrossRef]
- Sanghi, A. Info3d: Representation learning on 3d objects using mutual information maximization and contrastive learning. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXIX 16. Springer: Cham, Switzerland, 2020; pp. 626–642. [Google Scholar]
- Mohamed, A.; Lee, H.y.; Borgholt, L.; Havtorn, J.D.; Edin, J.; Igel, C.; Kirchhoff, K.; Li, S.W.; Livescu, K.; Maaløe, L.; et al. Self-supervised speech representation learning: A review. IEEE J. Sel. Top. Signal Process. 2022, 16, 1179–1210. [Google Scholar] [CrossRef]
- Hsu, W.N.; Bolte, B.; Tsai, Y.H.H.; Lakhotia, K.; Salakhutdinov, R.; Mohamed, A. Hubert: Self-supervised speech representation learning by masked prediction of hidden units. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 3451–3460. [Google Scholar] [CrossRef]
- Han, W.; Chen, H.; Poria, S. Improving Multimodal Fusion with Hierarchical Mutual Information Maximization for Multimodal Sentiment Analysis. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Virtual Event, 7–11 November 2021; pp. 9180–9192. [Google Scholar]
- Zhou, K.; Wang, H.; Zhao, W.X.; Zhu, Y.; Wang, S.; Zhang, F.; Wang, Z.; Wen, J.R. S3-rec: Self-supervised learning for sequential recommendation with mutual information maximization. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Virtual Event, 19–23 October 2020; pp. 1893–1902. [Google Scholar]
- Ma, J.; Zhou, C.; Yang, H.; Cui, P.; Wang, X.; Zhu, W. Disentangled self-supervision in sequential recommenders. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, 6–10 July 2020; pp. 483–491. [Google Scholar]
- Zou, D.; Wei, W.; Mao, X.L.; Wang, Z.; Qiu, M.; Zhu, F.; Cao, X. Multi-level cross-view contrastive learning for knowledge-aware recommender system. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, Madrid, Spain, 11–15 July 2022; pp. 1358–1368. [Google Scholar]
- Ji, Y.; Sun, A.; Zhang, J.; Li, C. A re-visit of the popularity baseline in recommender systems. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, 25–30 July 2020; pp. 1749–1752. [Google Scholar]
- He, X.; Deng, K.; Wang, X.; Li, Y.; Zhang, Y.; Wang, M. Lightgcn: Simplifying and powering graph convolution network for recommendation. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Xi’an, China, 25–30 July 2020; pp. 639–648. [Google Scholar]
- Perc, M. The Matthew effect in empirical data. J. R. Soc. Interface 2014, 11, 20140378. [Google Scholar] [CrossRef] [PubMed]
- Steck, H. Calibrated recommendations. In Proceedings of the 12th ACM Conference on Recommender Systems, Vancouver, BC, Canada, 2–7 October 2018; pp. 154–162. [Google Scholar]
- Ge, Y.; Zhao, S.; Zhou, H.; Pei, C.; Sun, F.; Ou, W.; Zhang, Y. Understanding echo chambers in e-commerce recommender systems. In Proceedings of the 43rd international ACM SIGIR Conference on Research and Development in Information Retrieval, Xi’an, China, 25–30 July 2020; pp. 2261–2270. [Google Scholar]
- Mehrotra, R.; McInerney, J.; Bouchard, H.; Lalmas, M.; Diaz, F. Towards a fair marketplace: Counterfactual evaluation of the trade-off between relevance, fairness & satisfaction in recommendation systems. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Torino, Italy, 22–26 October 2018; pp. 2243–2251. [Google Scholar]
- Cañamares, R.; Castells, P. Should I follow the crowd? A probabilistic analysis of the effectiveness of popularity in recommender systems. In Proceedings of the The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, Ann Arbor, MI, USA, 8–12 July 2018; pp. 415–424. [Google Scholar]
- Liu, S.; Zheng, Y. Long-tail session-based recommendation. In Proceedings of the 14th ACM Conference on Recommender Systems, Virtual Event, 22–26 September 2020; pp. 509–514. [Google Scholar]
- Zolaktaf, Z.; Babanezhad, R.; Pottinger, R. A generic top-n recommendation framework for trading-off accuracy, novelty, and coverage. In Proceedings of the 2018 IEEE 34th International Conference on Data Engineering (ICDE), Paris, France, 16–19 April 2018; pp. 149–160. [Google Scholar]
- He, X.; Liao, L.; Zhang, H.; Nie, L.; Hu, X.; Chua, T.S. Neural collaborative filtering. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 173–182. [Google Scholar]
- Wang, X.; He, X.; Wang, M.; Feng, F.; Chua, T.S. Neural graph collaborative filtering. In Proceedings of the 42nd international ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; pp. 165–174. [Google Scholar]
- Wu, J.; Wang, X.; Feng, F.; He, X.; Chen, L.; Lian, J.; Xie, X. Self-supervised graph learning for recommendation. In Proceedings of the 44th international ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, 11–15 July 2021; pp. 726–735. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Users | Item | Interaction | Sparsity | |
|---|---|---|---|---|
| MovieLens-1M | 5986 | 2347 | 298,856 | 97.8728% |
| Last-FM | 1872 | 3846 | 42,346 | 99.4118% |
| Book-Crossing | 17,860 | 14,910 | 139,746 | 99.9475% |
| d | ||||||
|---|---|---|---|---|---|---|
| MovieLens-1M | 0.049 | 100 | 50 | 15 | 0.01 | 0.3 |
| Last-FM | 0.017 | 100 | 50 | 30 | 0.002 | 0.3 |
| Book-Crossing | 0.002 | 100 | 50 | 40 | 0.005 | 0.3 |
| Dataset | @10 | @20 | ||||||
|---|---|---|---|---|---|---|---|---|
| Recall | NDCG | Cov | Tail | Recall | NDCG | Cov | Tail | |
| Movie-Lens | 1.5563% | 0.0741% | 7.8595% | 4.0219% | 1.4689% | 1.4233% | 0.6923% | 5.0113% |
| Last-FM | 2.5941% | 3.1316% | 6.1177% | 7.6510% | 1.0083% | 2.0859% | 2.3567% | 5.3212% |
| Book-Crossing | 0.7866% | 4.5612% | 7.4062% | 11.4480% | 1.2048% | 0.2484% | 0.5781% | 1.6671% |
| Dataset | Metric | PDGS-NC | PDGS-BPR | PDGS |
|---|---|---|---|---|
| MovieLens-1M | Recall@10 | 24.477 | 25.214 | 25.123 |
| NDCG@10 | 22.243 | 23.291 | 22.948 | |
| Cov@10 | 58.126 | 56.526 | 60.740 | |
| Tail@10 | 58.473 | 53.654 | 61.116 | |
| Last-FM | Recall@10 | 28.485 | 29.141 | 28.871 |
| NDCG@10 | 21.175 | 21.803 | 21.604 | |
| Cov@10 | 64.663 | 62.351 | 68.586 | |
| Tail@10 | 21.435 | 20.595 | 23.075 | |
| Book-Crossing | Recall@10 | 9.155 | 9.752 | 9.610 |
| NDCG@10 | 5.567 | 6.416 | 6.327 | |
| Cov@10 | 65.415 | 62.247 | 69.828 | |
| Tail@10 | 27.970 | 26.357 | 30.432 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, S.; Hu, X.; Guo, J.; Liu, B.; Qi, M.; Jia, Y. Popularity-Debiased Graph Self-Supervised for Recommendation. Electronics 2024, 13, 677. https://doi.org/10.3390/electronics13040677
Li S, Hu X, Guo J, Liu B, Qi M, Jia Y. Popularity-Debiased Graph Self-Supervised for Recommendation. Electronics. 2024; 13(4):677. https://doi.org/10.3390/electronics13040677
Chicago/Turabian StyleLi, Shanshan, Xinzhuan Hu, Jingfeng Guo, Bin Liu, Mingyue Qi, and Yutong Jia. 2024. "Popularity-Debiased Graph Self-Supervised for Recommendation" Electronics 13, no. 4: 677. https://doi.org/10.3390/electronics13040677
APA StyleLi, S., Hu, X., Guo, J., Liu, B., Qi, M., & Jia, Y. (2024). Popularity-Debiased Graph Self-Supervised for Recommendation. Electronics, 13(4), 677. https://doi.org/10.3390/electronics13040677