
A High-Precision Fall Detection Model Based on Dynamic Convolution in Complex Scenes

Abstract
:1. Introduction
2. Materials and Methods
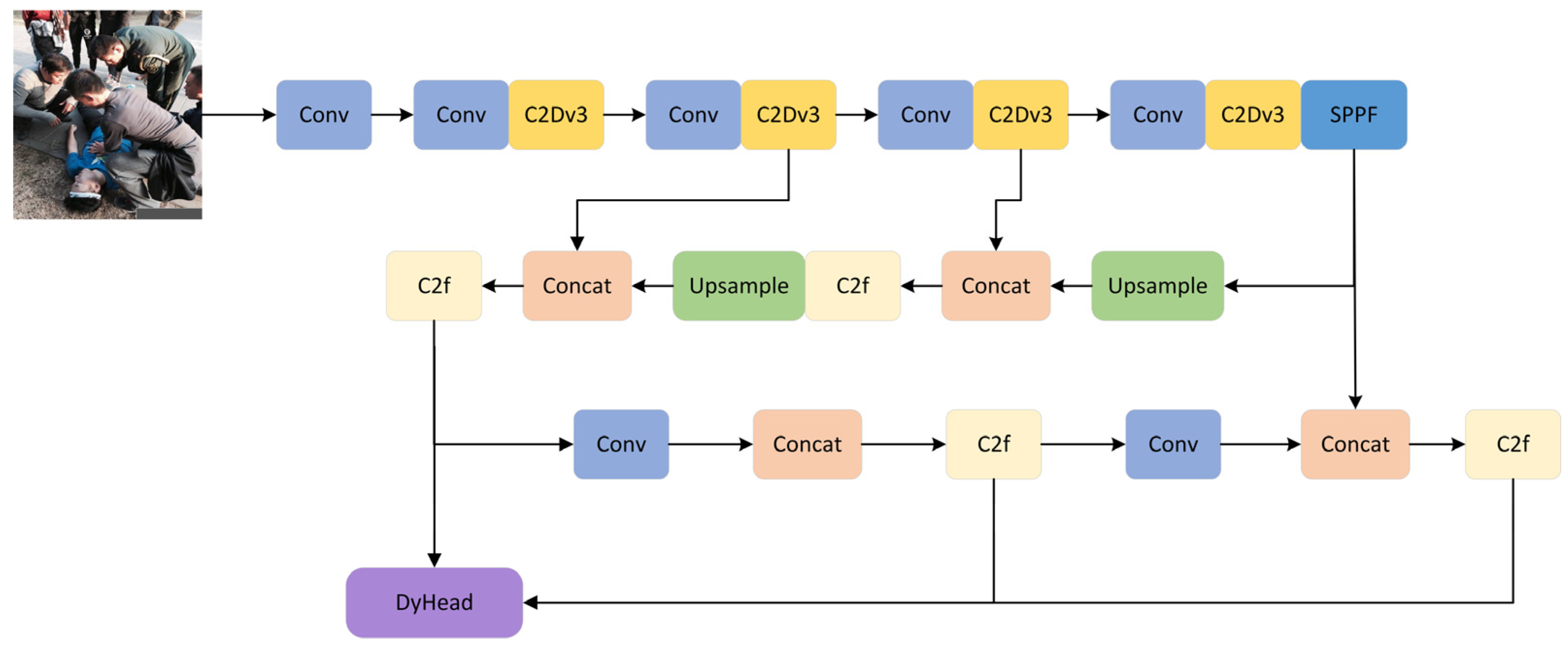
2.1. Overall Structure of ESD-YOLO Network
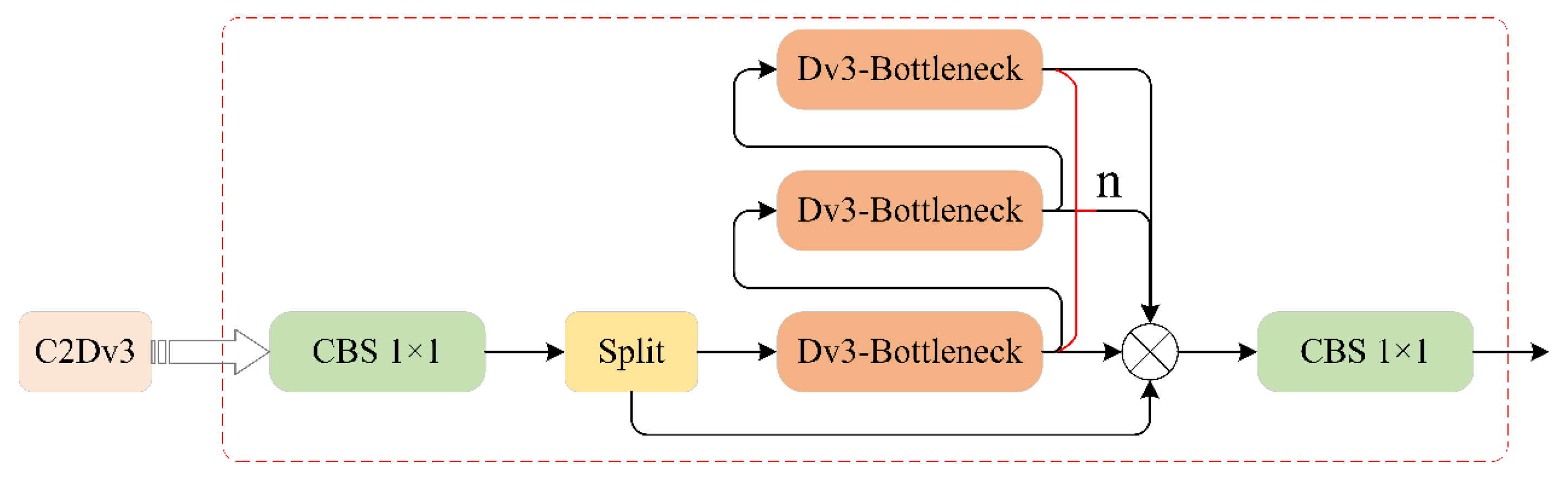
2.2. C2Dv3 Module Design
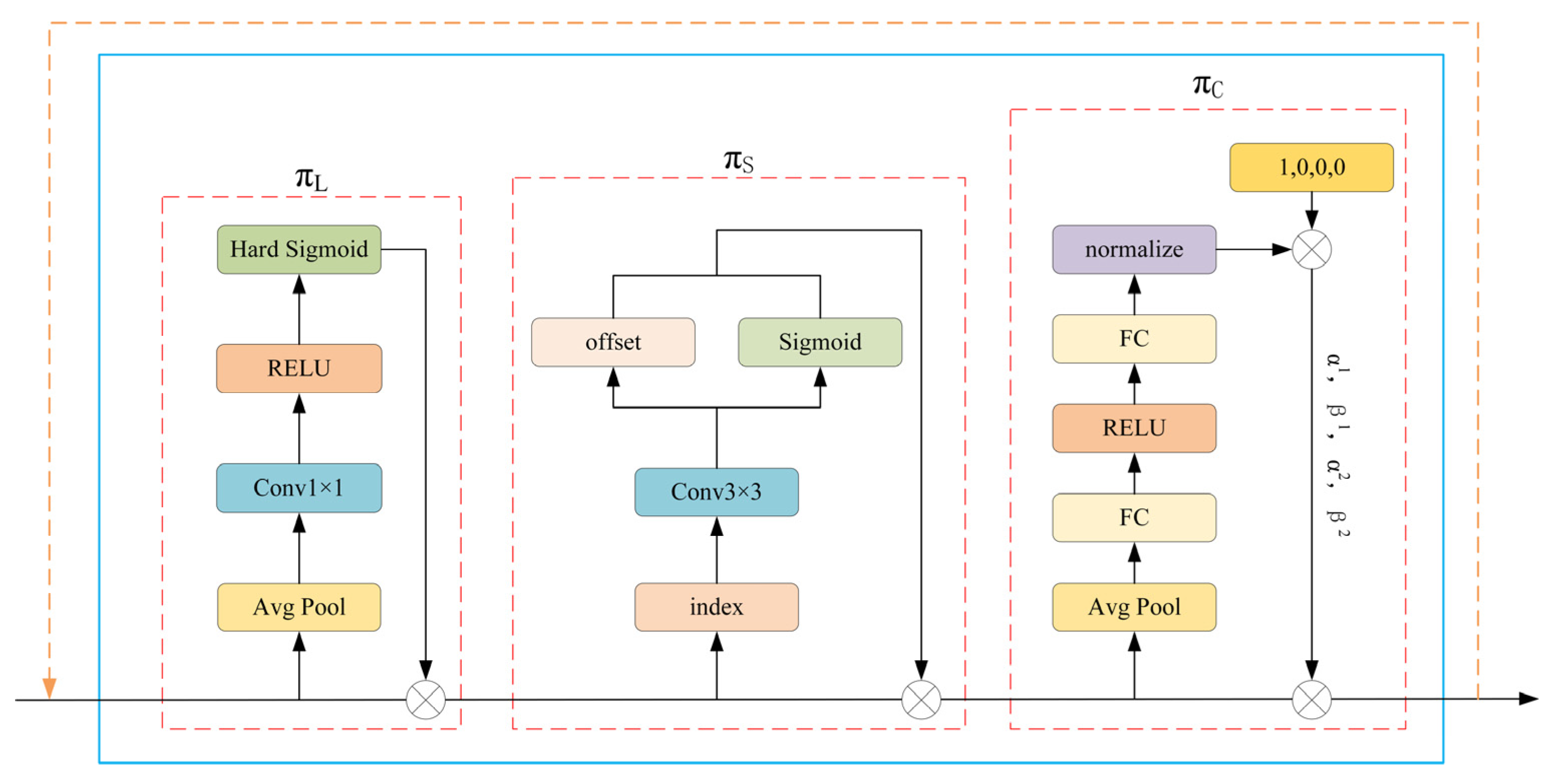
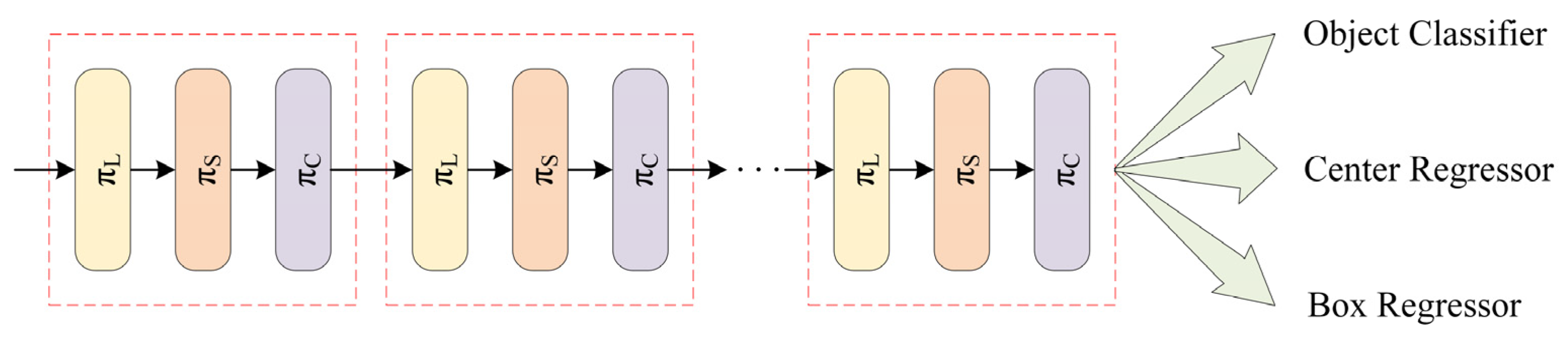
2.3. DyHead Module
2.4. Loss Function EASlideloss Design
2.5. Model Evaluation Metrics
3. Experiment and Results
3.1. Datasets
3.2. Experimental Process
3.3. Experimental Results and Analysis
3.3.1. Ablation Experiment
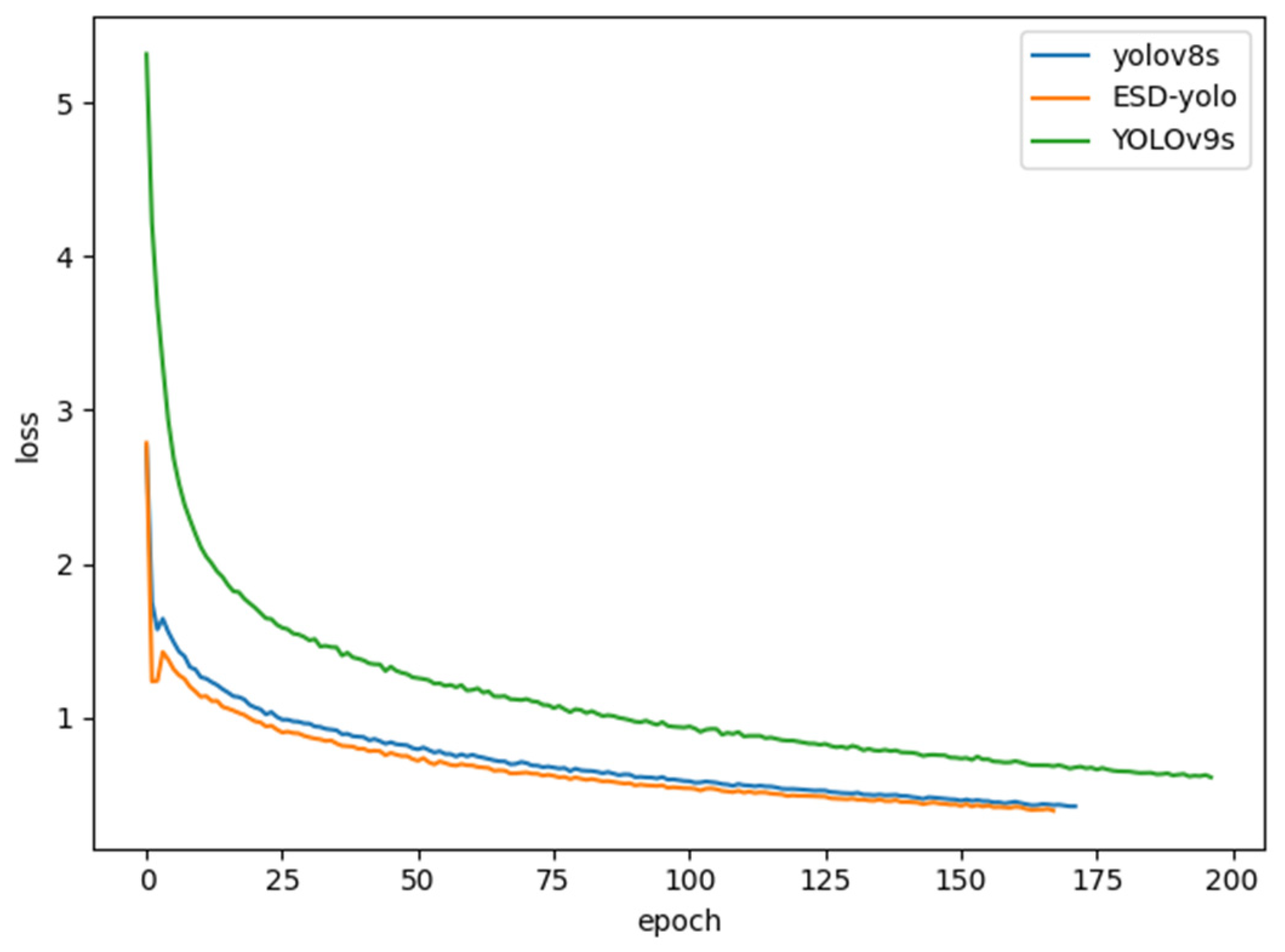
3.3.2. Contrast Experiment
3.4. Scene Test
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Lin, Y.-T.; Lee, H.-J. Comparison of the Lower Extremity Kinematics and Center of Mass Variations in Sit-to-Stand and Stand-to-Sit Movements of Older Fallers and Nonfallers. Arch. Rehabil. Res. Clin. Transl. 2022, 4, 100181. [Google Scholar] [CrossRef]
- Gates, S.; Fisher, J.; Cooke, M.; Carter, Y.; Lamb, S. Multifactorial assessment and targeted intervention for preventing falls and injuries among older people in community and emergency care settings: Systematic review and meta-analysis. BMJ 2008, 336, 130–133. [Google Scholar] [CrossRef]
- Pozaic, T.; Lindemann, U.; Grebe, A.-K.; Stork, W. Sit-to-Stand Transition Reveals Acute Fall Risk in Activities of Daily Living. IEEE J. Transl. Eng. Healthc. Med. 2016, 4, 2700211. [Google Scholar] [CrossRef]
- Xu, T.; An, D.; Jia, Y.; Yue, Y. A Review: Point Cloud-Based 3D Human Joints Estimation. Sensors 2021, 21, 1684. [Google Scholar] [CrossRef]
- Wang, X.; Ellul, J.; Azzopardi, G. Elderly fall detection systems: A literature survey. Front. Robot. AI 2020, 7, 71. [Google Scholar] [CrossRef] [PubMed]
- Dai, Y.; Liu, W. GL-YOLO-Lite: A Novel Lightweight Fallen Person Detection Model. Entropy 2023, 25, 587. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.; Miranda, F.; Wang, Y.; Rasheed, R.; Bhatt, T. Near-Fall Detection in Unexpected Slips during Over-Ground Locomotion with Body-Worn Sensors among Older Adults. Sensors 2022, 22, 3334. [Google Scholar] [CrossRef] [PubMed]
- Chander, H.; Burch, R.F.; Talegaonkar, P.; Saucier, D.; Luczak, T.; Ball, J.E.; Turner, A.; Kodithuwakku Arachchige, S.N.K.; Carroll, W.; Smith, B.K.; et al. Wearable Stretch Sensors for Human Movement Monitoring and Fall Detection in Ergonomics. Int. J. Environ. Res. Public Health 2020, 17, 3554. [Google Scholar] [CrossRef] [PubMed]
- Lee, Y.; Pokharel, S.; Muslim, A.A.; Kc, D.B.; Lee, K.H.; Yeo, W.-H. Experimental Study: Deep Learning-Based Fall Monitoring among Older Adults with Skin-Wearable Electronics. Sensors 2023, 23, 3983. [Google Scholar] [CrossRef] [PubMed]
- Er, P.V.; Tan, K.K. Wearable solution for robust fall detection. In Assistive Technology for the Elderly; Academic Press: Cambridge, MA, USA, 2020; pp. 81–105. [Google Scholar]
- Bhattacharya, A.; Vaughan, R. Deep learning radar design for breathing and fall detection. IEEE Sens. J. 2020, 20, 5072–5085. [Google Scholar] [CrossRef]
- Jiang, X.; Zhang, L.; Li, L. Multi-Task Learning Radar Transformer (MLRT): A Personal Identification and Fall Detection Network Based on IR-UWB Radar. Sensors 2023, 23, 5632. [Google Scholar] [CrossRef]
- Agrawal, D.K.; Usaha, W.; Pojprapai, S.; Wattanapan, P. Fall Risk Prediction Using Wireless Sensor Insoles with Machine Learning. IEEE Access 2023, 11, 23119–23126. [Google Scholar] [CrossRef]
- Nadee, C.; Chamnongthai, K. An Ultrasonic-Based Sensor System for Elderly Fall Monitoring in a Smart Room. J. Healthc. Eng. 2022, 2022, 2212020. [Google Scholar] [CrossRef] [PubMed]
- Zou, S.; Min, W.; Liu, L.; Wang, Q.; Zhou, X. Movement Tube Detection Network Integrating 3D CNN and Object Detection Framework to Detect Fall. Electronics 2021, 10, 898. [Google Scholar] [CrossRef]
- Mei, X.; Zhou, X.; Xu, F.; Zhang, Z. Human Intrusion Detection in Static Hazardous Areas at Construction Sites: Deep Learning–Based Method. J. Constr. Eng. Manag. 2023, 149, 04022142. [Google Scholar] [CrossRef]
- Delgado-Escano, R.; Castro, F.M.; Cozar, J.R.; Marin-Jimenez, M.J.; Guil, N.; Casilari, E. A crossdataset deep learning-based classifier for people fall detection and identification. Comput. Methods Programs Biomed. 2020, 184, 105265. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 27–29 October 2017; pp. 2961–2969. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object detection via region-based fully convolutional networks. arxiv 2016, arXiv:1605.06409. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Krichen, M. Convolutional Neural Networks: A Survey. Computers 2023, 12, 151. [Google Scholar] [CrossRef]
- Available online: https://www.taylorfrancis.com/chapters/edit/10.1201/9781003393030-10/learning-modeling-technique-convolution-neural-networks-online-education-fahad-alahmari-arshi-naim-hamed-alqa (accessed on 5 March 2024).
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao HY, M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Zhang, L.; Ding, G.; Li, C.; Li, D. DCF-Yolov8: An Improved Algorithm for Aggregating Low-Level Features to Detect Agricultural Pests and Diseases. Agronomy 2023, 13, 2012. [Google Scholar] [CrossRef]
- Lou, H.; Duan, X.; Guo, J.; Liu, H.; Gu, J.; Bi, L.; Chen, H. DC-YOLOv8: Small-Size Object Detection Algorithm Based on Camera Sensor. Electronics 2023, 12, 2323. [Google Scholar] [CrossRef]
- Guo, X.; Liu, S.; Li, L.; Qin, Q.; Li, T.; Guo, X.; Liu, S.; Li, L.; Qin, Q.; Li, T. Pedestrian detection algorithm in scenic spots based on improved YOLOv8. Comput. Eng. 2024, 1–11. Available online: http://www.ecice06.com/CN/10.19678/j.issn.1000-3428.0068125 (accessed on 5 March 2024).
- Cao, Y.; Xu, H.; Zhu, X.; Huang, X.; Chen, C.; Zhou, S.; Sheng, K. Improved Fighting Behavior Recognition Algorithm Based on YOLOv8: EFD-YOLO. Comput. Eng. Sci. 2024, 1–14. Available online: http://kns.cnki.net/kcms/detail/43.1258.TP.20240126.0819.002.html (accessed on 5 March 2024).
- Yang, Z.; Feng, H.; Ruan, Y.; Weng, X. Tea Tree Pest Detection Algorithm Based on Improved Yolov7-Tiny. Agriculture 2023, 13, 1031. [Google Scholar] [CrossRef]
- Dai, X.; Chen, Y.; Xiao, B.; Chen, D.; Liu, M.; Yuan, L.; Zhang, L. Dynamic head: Unifying object detection heads with attentions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 7369–7378. [Google Scholar]
- Yu, Z.; Huang, H.; Chen, W.; Su, Y.; Liu, Y.; Wang, X.-Y. YOLO-FaceV2: A Scale and Occlusion Aware Face Detector. arXiv 2022, arXiv:2208.02019. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Modules | C2Dv3 | DyHead | EASlideloss | P (%) | R (%) | mAP0.5 (%) | mAP0.5:0.95 (%) |
|---|---|---|---|---|---|---|---|
| YOLOv8s | 82.3 | 78.4 | 84.4 | 59.7 | |||
| YOLOv8s_1 | √ | 84.7 | 80.2 | 86.4 | 62.5 | ||
| YOLOv8s_2 | √ | 85.9 | 78.2 | 86.1 | 61.8 | ||
| YOLOv8s_3 | √ | 76.8 | 83.7 | 84 | 60 | ||
| ESD-YOLO | √ | √ | √ | 84.2 | 82.5 | 88.7 | 62.5 |
| Modules | P (%) | R (%) | Map0.5 (%) | Map0.5:0.95 (%) |
|---|---|---|---|---|
| YOLOv4-tiny | 75.9 | 77.4 | 78.5 | 55.6 |
| YOLOv5s | 82.3 | 79.9 | 85.5 | 59.9 |
| YOLO5-timm | 81.2 | 78.9 | 82 | 59.5 |
| YOLOv5-efficientViT | 83.1 | 78.5 | 84.3 | 58.6 |
| YOLOv5-vanillanet | 78.3 | 77.5 | 83.2 | 56.9 |
| YOLOv5-ShuffleNetv2 | 78.1 | 83.1 | 77.9 | 59.6 |
| YOLOv7 | 80.2 | 80.6 | 85.5 | 60.4 |
| YOLOv7-tiny | 78.2 | 82.2 | 81.9 | 58.3 |
| YOLOv8s | 82.3 | 78.4 | 84.4 | 59.7 |
| YOLOv9s | 84.3 | 79.2 | 86.7 | 61.4 |
| SSD | 76.2 | 71.8 | 76.1 | 53.9 |
| Faster R-CNN | 80.7 | 77.8 | 80.8 | 56.7 |
| ESDv3-YOLO | 84.2 | 82.5 | 88.7 | 62.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qin, Y.; Miao, W.; Qian, C. A High-Precision Fall Detection Model Based on Dynamic Convolution in Complex Scenes. Electronics 2024, 13, 1141. https://doi.org/10.3390/electronics13061141
Qin Y, Miao W, Qian C. A High-Precision Fall Detection Model Based on Dynamic Convolution in Complex Scenes. Electronics. 2024; 13(6):1141. https://doi.org/10.3390/electronics13061141
Chicago/Turabian StyleQin, Yong, Wuqing Miao, and Chen Qian. 2024. "A High-Precision Fall Detection Model Based on Dynamic Convolution in Complex Scenes" Electronics 13, no. 6: 1141. https://doi.org/10.3390/electronics13061141
APA StyleQin, Y., Miao, W., & Qian, C. (2024). A High-Precision Fall Detection Model Based on Dynamic Convolution in Complex Scenes. Electronics, 13(6), 1141. https://doi.org/10.3390/electronics13061141