

Noncontact Automatic Water-Level Assessment and Prediction in an Urban Water Stream Channel of a Volcanic Island Using Deep Learning

 ,
,  ,
,  ,
,  ,
,  and
and 
Abstract
1. Introduction
2. State-of-the-Art Overview
3. Materials and Methods
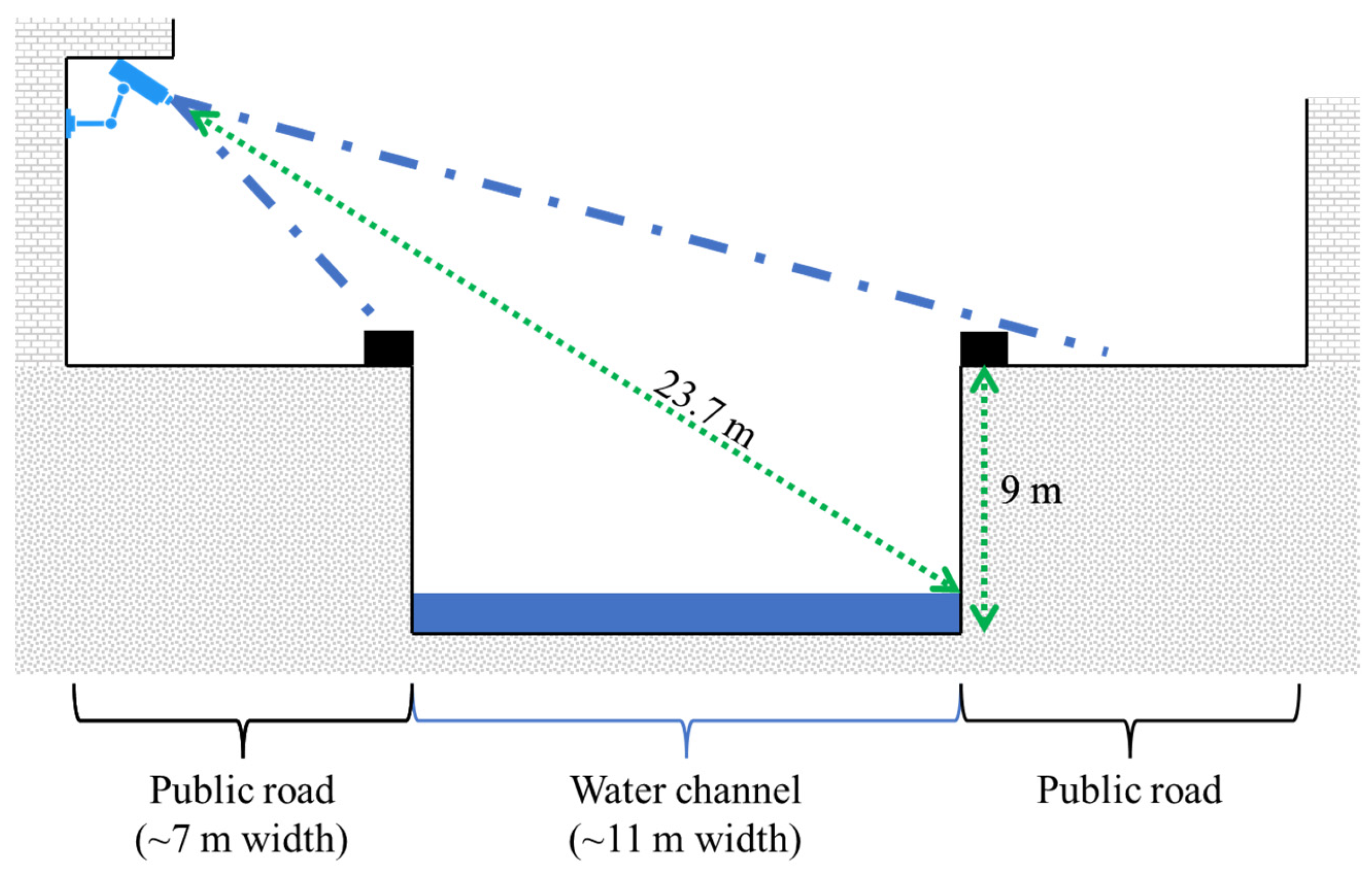
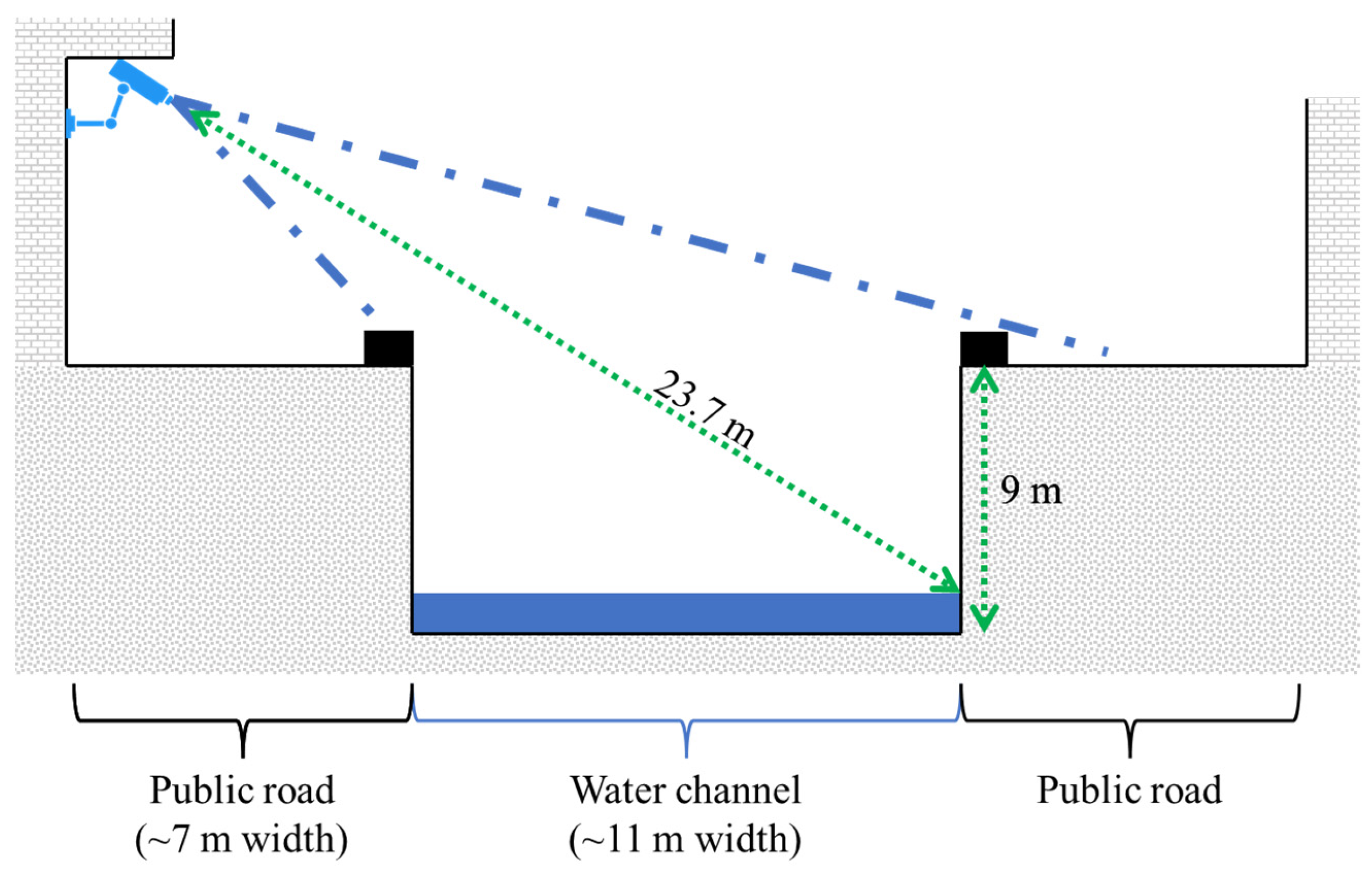
3.1. Study Site
3.2. Hardware Specifications
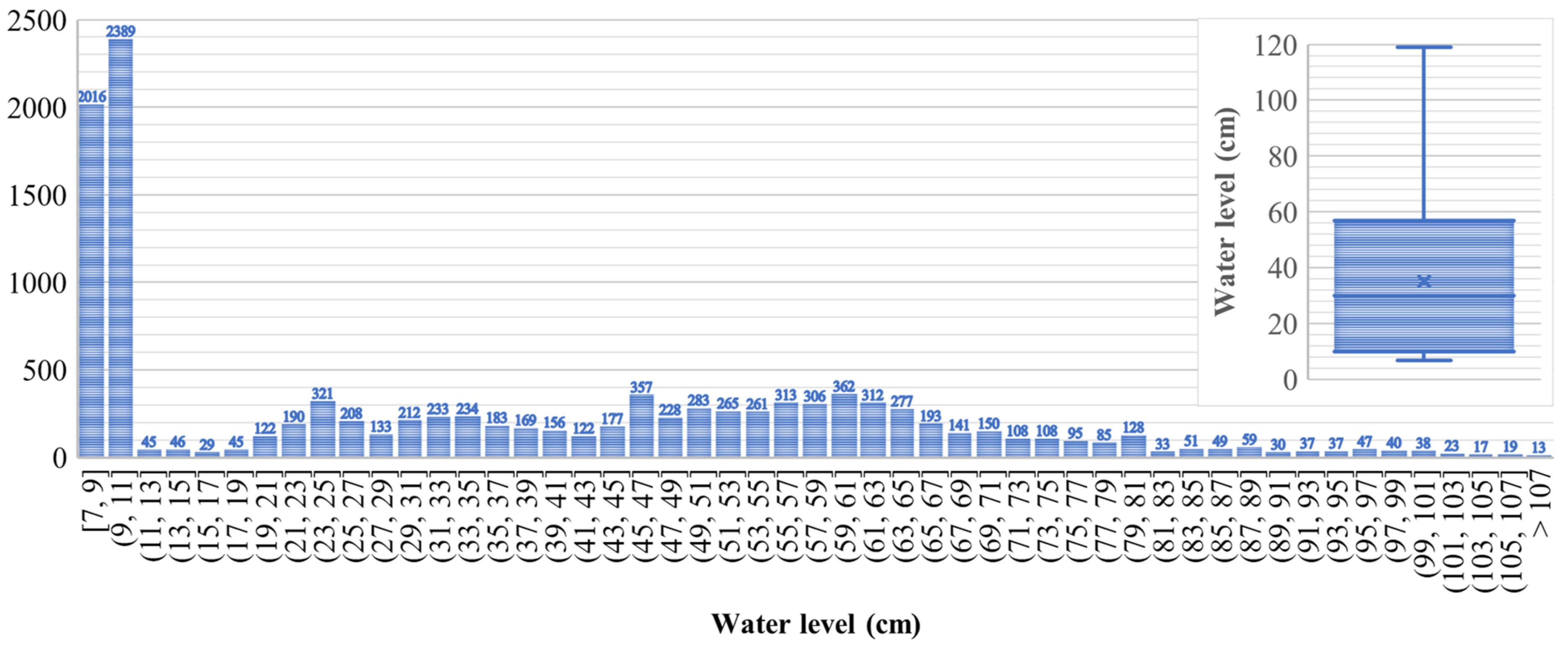
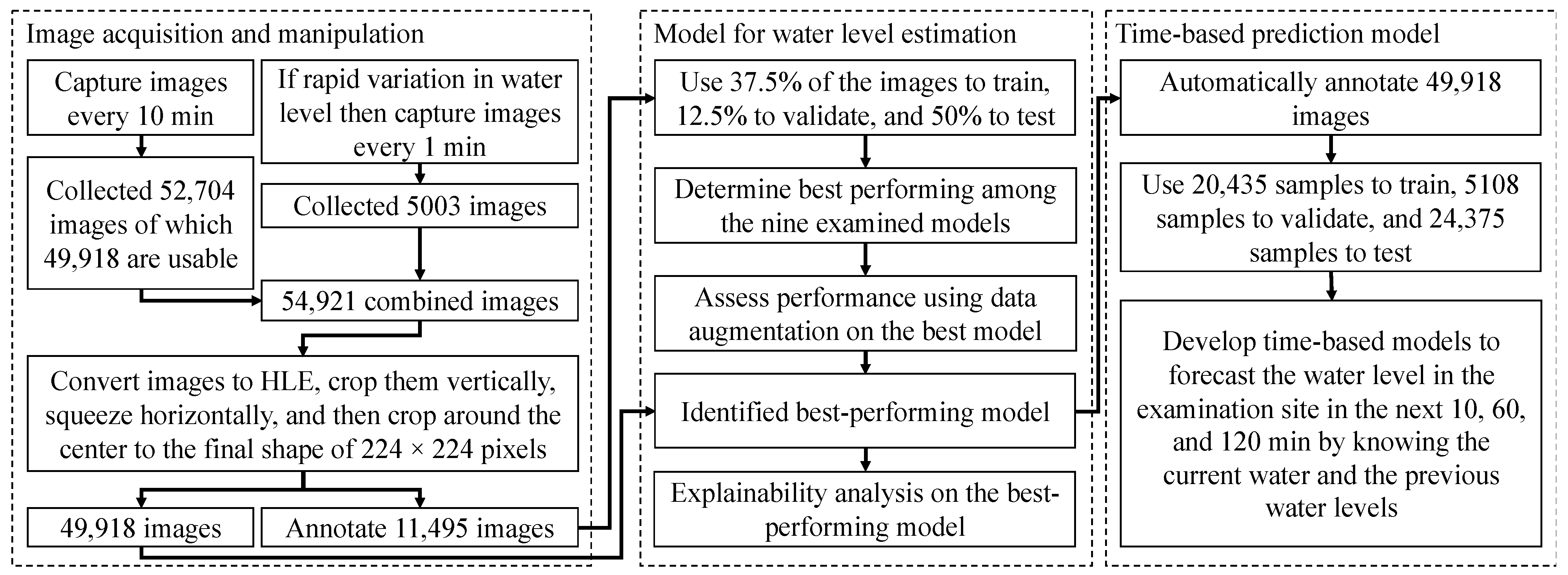
3.3. Data Collection
3.4. Image Processing
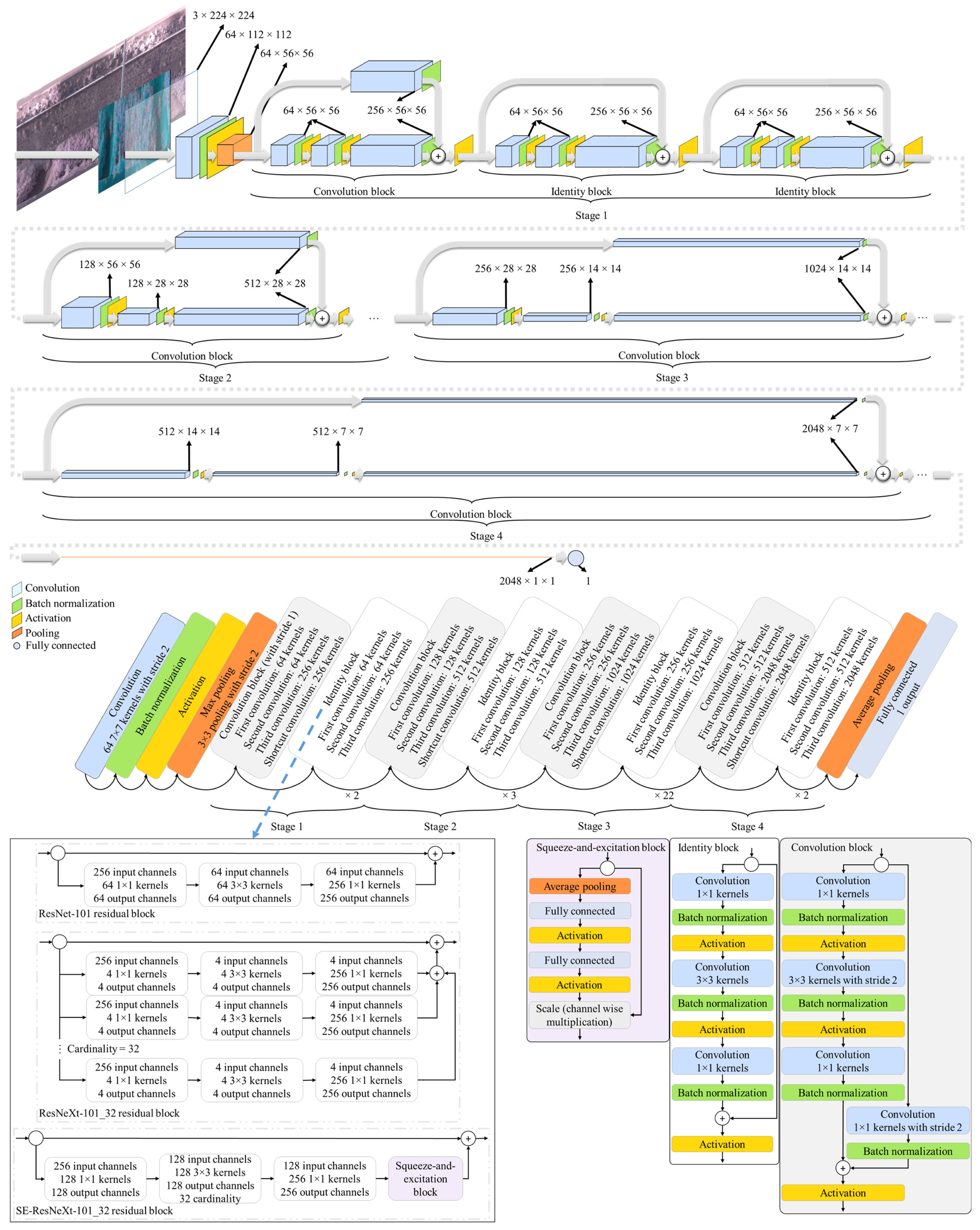
3.5. Model for Water-Level Estimation
3.6. Time-Based Prediction Model
3.7. Performance Metrics
4. Results and Discussion
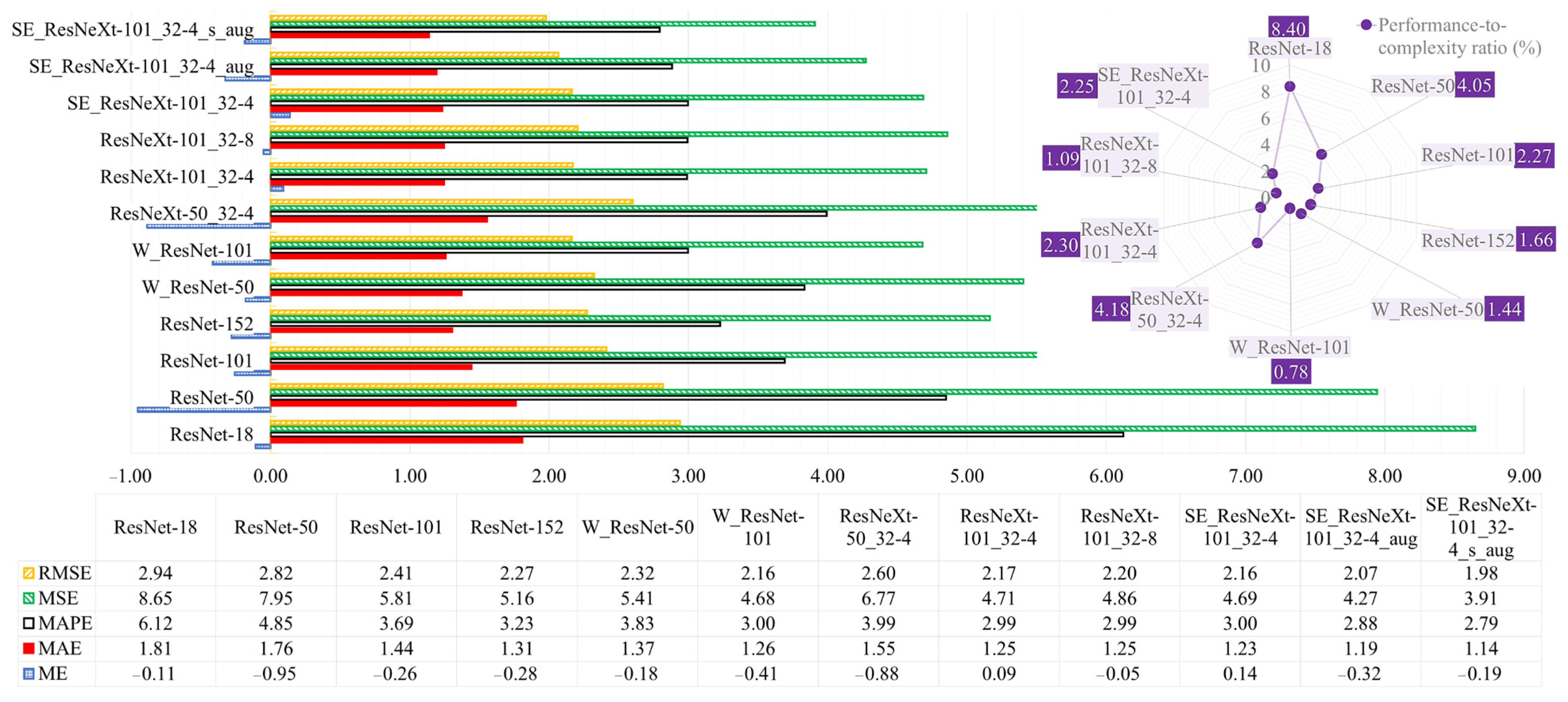
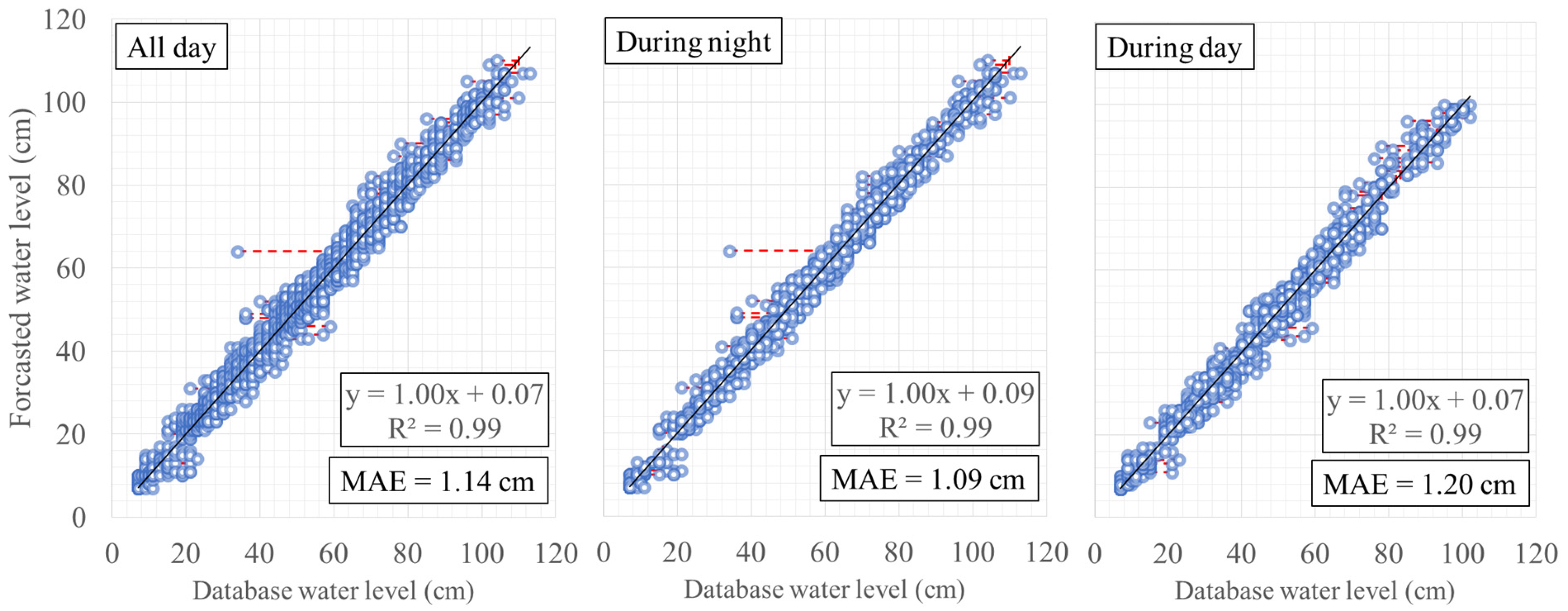
4.1. Water-Level Estimation
4.2. Explainability of the Model
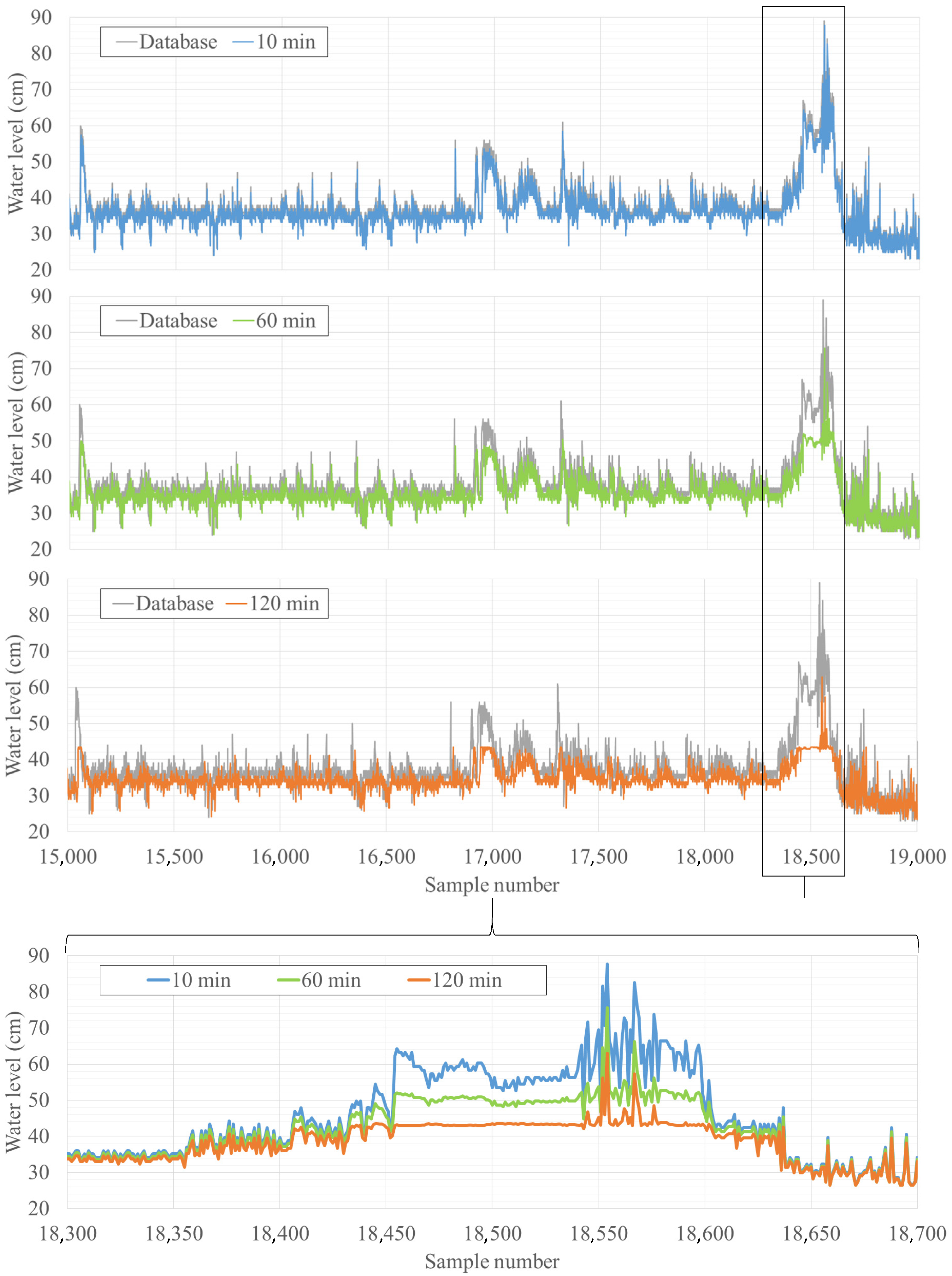
4.3. Forecasting the Water Level
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Döll, P.; Jiménez-Cisneros, B.; Oki, T.; Arnell, N.; Benito, G.; Cogley, J.; Jiang, T.; Kundzewicz, Z.; Mwakalila, S.; Nishijima, A. Integrating Risks of Climate Change into Water Management. Hydrol. Sci. J. 2015, 60, 4–13. [Google Scholar] [CrossRef]
- Zhen, Y.; Liu, S.; Zhong, G.; Zhou, Z.; Liang, J.; Zheng, W.; Fand, Q. Risk Assessment of Flash Flood to Buildings Using an Indicator-Based Methodology: A Case Study of Mountainous Rural Settlements in Southwest China. Front. Environ. Sci. 2022, 10, 931029. [Google Scholar] [CrossRef]
- Vieira, I.; Barreto, V.; Figueira, C.; Lousada, S.; Prada, S. The Use of Detention Basins to Reduce Flash Flood Hazard in Small and Steep Volcanic Watersheds—A Simulation from Madeira Island. J. Flood Risk Manag. 2018, 11, S930–S942. [Google Scholar] [CrossRef]
- Bradley, A.; Kruger, A.; Meselhe, E.; Muste, M. Flow Measurement in Streams Using Video Imagery. Water Resour. Res. 2002, 38, 1315. [Google Scholar] [CrossRef]
- Loizou, K.; Koutroulis, E. Water Level Sensing: State of the Art Review and Performance Evaluation of a Low-Cost Measurement System. Measurement 2016, 89, 204–214. [Google Scholar] [CrossRef]
- Yorke, T.; Oberg, K. Measuring River Velocity and Discharge with Acoustic Doppler Profilers. Flow Meas. Instrum. 2002, 13, 191–195. [Google Scholar] [CrossRef]
- Azevedo, A.; Brás, J. Measurement of Water Level in Urban Streams under Bad Weather Conditions. Sensors 2021, 21, 7157. [Google Scholar] [CrossRef] [PubMed]
- Gleason, C.; Smith, L.; Finnegan, D.; LeWinter, A.; Pitcher, L.; Chu, V. Semi-Automated Effective Width Extraction from Time-Lapse RGB Imagery of a Remote, Braided Greenlandic River. Hydrol. Earth Syst. Sci. 2015, 19, 2963–2969. [Google Scholar] [CrossRef]
- Bandini, F.; Jakobsen, J.; Olesen, D.; Reyna-Gutierrez, J.; Bauer-Gottwein, P. Measuring Water Level in Rivers and Lakes from Lightweight Unmanned Aerial Vehicles. J. Hydrol. 2017, 548, 237–250. [Google Scholar] [CrossRef]
- Xu, Z.; Feng, J.; Zhang, Z.; Duan, C. Water Level Estimation Based on Image of Staff Gauge in Smart City. In Proceedings of the 2018 IEEE SmartWorld, Ubiquitous Intelligence & Computing, Advanced & Trusted Computing, Scalable Computing & Communications, Cloud & Big Data Computing, Internet of People and Smart City Innovation (SmartWorld/SCALCOM/UIC/ATC/CBDCom/IOP/SCI), Guangzhou, China, 8–12 October 2018. [Google Scholar]
- Caliskan, E. Environmental Impacts of Forest Road Construction on Mountainous Terrain. Iran. J. Environ. Health Sci. Eng. 2013, 10, 23. [Google Scholar] [CrossRef]
- Chen, G.; Bai, K.; Lin, Z.; Liao, X.; Liu, S.; Lin, Z.; Zhang, Q.; Jia, X. Method on Water Level Ruler Reading Recognition Based on Image Processing. Signal Image Video Process. 2021, 15, 33–41. [Google Scholar] [CrossRef]
- Guo, S.; Zhang, Y.; Liu, Y. A Water-Level Measurement Method Using Sparse Representation. Autom. Control Comput. Sci. 2020, 54, 302–312. [Google Scholar]
- Zhang, Z.; Zhou, Y.; Liu, H.; Gao, H. In-Situ Water Level Measurement Using NIR-Imaging Video Camera. Flow Meas. Instrum. 2019, 67, 95–106. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhou, Y.; Liu, H.; Zhang, L.; Wang, H. Visual Measurement of Water Level under Complex Illumination Conditions. Sensors 2019, 19, 4141. [Google Scholar] [CrossRef] [PubMed]
- Hies, T.; Babu, P.; Wang, Y.; Duester, R.; Eikaas, H.; Meng, T. Enhanced Water-Level Detection by Image Processing. In Proceedings of the 10th International Conference on Hydroinformatics, Hamburg, Germany, 14 July 2012. [Google Scholar]
- Lin, Y.; Lin, Y.; Han, J. Automatic Water-Level Detection Using Single-Camera Images with Varied Poses. Measurement 2018, 127, 167–174. [Google Scholar] [CrossRef]
- Pan, J.; Yin, Y.; Xiong, J.; Luo, W.; Gui, G.; Sari, H. Deep Learning-Based Unmanned Surveillance Systems for Observing Water Levels. IEEE Access 2018, 6, 73561–73571. [Google Scholar] [CrossRef]
- Qiao, G.; Yang, M.; Wang, H. A Water Level Measurement Approach Based on YOLOv5s. Sensors 2022, 22, 3714. [Google Scholar] [CrossRef]
- Ran, Q.; Li, W.; Liau, Q.; Tang, H.; Wang, M. Application of an Automated LSPIV System in a Mountainousstream for Continuous Flood Flow Measurements. Hydrol. Process. 2016, 30, 3014–3029. [Google Scholar] [CrossRef]
- Stumpf, A.; Augereau, E.; Delacourt, C.; Bonnier, J. Photogrammetric Discharge Monitoring of Small Tropical Mountain Rivers: A Case Study at Rivière Des Pluies, Réunion Island. Water Resour. Res. 2016, 52, 4550–4570. [Google Scholar] [CrossRef]
- Udomsiri, S.; Iwahashi, M. Design of FIR Filter for Water Level Detection. Int. Sch. Sci. Res. Innov. 2008, 2, 2663–2668. [Google Scholar]
- Ridolfi, E.; Manciola, P. Water Level Measurements from Drones: A Pilot Case Study at a Dam Site. Water 2018, 10, 297. [Google Scholar] [CrossRef]
- Eltner, A.; Elias, M.; Sardemann, H.; Spieler, D. Automatic Image-Based Water Stage Measurement for Long-Term Observations in Ungauged Catchments. Water Resour. Res. 2018, 54, 10362–10371. [Google Scholar] [CrossRef]
- Young, D.; Hart, J.; Martinez, K. Image Analysis Techniques to Estimate River Discharge Using Time-Lapse Cameras in Remote Locations. Comput. Geosci. 2015, 76, 1–10. [Google Scholar] [CrossRef]
- Eltner, A.; Bressan, P.; Akiyama, T.; Gonçalves, W.; Junior, J. Using Deep Learning for Automatic Water Stage Measurements. Water Resour. Res. 2021, 57, e2020WR027608. [Google Scholar] [CrossRef]
- Vandaele, R.; Dance, S.; Ojha, V. Deep Learning for Automated River-Level Monitoring through River-Camera Images: An Approach Based on Water Segmentation and Transfer Learning. Hydrol. Earth Syst. Sci. 2021, 25, 4435–4453. [Google Scholar] [CrossRef]
- Lathuilière, S.; Mesejo, P.; Alameda-Pineda, X.; Horaud, R. A Comprehensive Analysis of Deep Regression. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 2065–2081. [Google Scholar] [CrossRef]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A Comprehensive Survey on Transfer Learning. Proc. IEEE 2021, 109, 43–76. [Google Scholar] [CrossRef]
- Direcção Reginal de Florestas Plano de Ordenamento e Gestão Da Laurissilva Da Madeira; REDE NATURA 2000; Direcção Reginal de Florestas: Funchal, Portugal, 2009.
- Oliveira, R.; Almeida, A.; Sousa, J.; Pereira, M.; Portela, M.; Coutinho, M.; Ferreira, R.; Lopes, S. A Avaliação Do Risco de Aluviões Na Ilha Da Madeira. In Proceedings of the 10° Simpósio de Hidráulica e Recursos Hídricos dos Países de Língua Oficial Portuguesa (10° SILUSBA), Porto de Galinhas, Brasil, 26 October 2011. [Google Scholar]
- Prada, S.; Gaspar, A.; Sequeira, M.; Nunes, A.; Figueira, C.; Cruz, J. Disponibilidades Hídricas Da Ilha Da Madeira. In AQUAMAC—Técnicas e Métodos Para a Gestão Sustentável da Água na Macaronésia; Instituto Tecnológico de Canarias, Cabildo de Lanzarote, Consejo Insular de Aguas de Lanzarote: Lanzarote, Spain, 2005; Volume 1. [Google Scholar]
- Jolles, J. Broad-Scale Applications of the Raspberry Pi: A Review and Guide for Biologists. Methods Ecol. Evol. 2021, 12, 1562–1579. [Google Scholar] [CrossRef]
- IPMA. Área Educativa—Parques Meteorológicos e Equipamentos. 2022. Available online: https://www.ipma.pt/pt/educativa/observar.tempo/index.jsp?page=ema.index.xml&print=true (accessed on 2 January 2024).
- Kociołek, M.; Strzelecki, M.; Obuchowicz, R. Does Image Normalization and Intensity Resolution Impact Texture Classification? Comput. Med. Imaging Graph. 2020, 81, 101716. [Google Scholar] [CrossRef]
- Chavolla, E.; Zaldivar, D.; Cuevas, E.; Perez, M. Color Spaces Advantages and Disadvantages in Image Color Clustering Segmentation. In Studies in Computational Intelligence; Springer: New York, NY, USA, 2018; Volume 730, pp. 3–22. [Google Scholar]
- Canny, J. A Computational Approach to Edge Detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, PAMI-8, 679–698. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Wide Residual Networks. In Proceedings of the 27th British Machine Vision Conference (BMVC), York, UK, 19 September 2016. [Google Scholar]
- De, S.; Smith, S. Batch Normalization Biases Residual Blocks towards the Identity Function in Deep Networks. In Proceedings of the NIPS’20: 34th International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 6–12 December 2020. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27 June 2016. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21 July 2017. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. (IJCV) 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2015, arXiv:1412.6980. [Google Scholar]
- Lin, T.; Giles, C.; Horne, B.; Kung, S. A Delay Damage Model Selection Algorithm for NARX Neural Networks. IEEE Trans. Signal Process. 1997, 45, 2719–2730. [Google Scholar]
- Hsu, K.; Gupta, H.; Sorooshian, S. Artificial Neural Network Modeling of the Rainfall-Runoff Process. Water Resour. Res. 1995, 31, 2517–2530. [Google Scholar] [CrossRef]
- Ouyang, H. Nonlinear Autoregressive Neural Networks with External Inputs for Forecasting of Typhoon Inundation Level. Environ. Monit. Assess. Vol. 2017, 189, 376. [Google Scholar] [CrossRef]
- Musolino, G.; Ahmadian, R.; Xia, J. Enhancing Pedestrian Evacuation Routes during Flood Events. Nat. Hazards 2022, 112, 1941–1965. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; The MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Cubuk, E.; Zoph, B.; Mané, D.; Vasudevan, V.; Le, Q. AutoAugment: Learning Augmentation Strategies From Data. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15 June 2019. [Google Scholar]
- Belle, V.; Papantonis, I. Principles and Practice of Explainable Machine Learning. Front. Big Data 2021, 4, 688969. [Google Scholar] [CrossRef]
- Chattopadhyay, A.; Sarkar, A.; Howlader, P.; Balasubramanian, V. Grad-CAM++: Generalized Gradient-Based Visual Explanations for Deep Convolutional Networks. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; IEEE: Lake Tahoe, NV, USA. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Statistical Metrics | |||
|---|---|---|---|---|
| Mean | Standard Deviation | Median | Variance | |
| Complete (11,495 samples) | 35.12 | 26.07 | 30.00 | 679.85 |
| During the day (5642 samples) | 33.67 | 24.12 | 30.00 | 581.86 |
| During the night (5853 samples) | 36.52 | 27.75 | 34.00 | 770.15 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mendonça, F.; Mostafa, S.S.; Morgado-Dias, F.; Azevedo, J.A.; Ravelo-García, A.G.; Navarro-Mesa, J.L. Noncontact Automatic Water-Level Assessment and Prediction in an Urban Water Stream Channel of a Volcanic Island Using Deep Learning. Electronics 2024, 13, 1145. https://doi.org/10.3390/electronics13061145
Mendonça F, Mostafa SS, Morgado-Dias F, Azevedo JA, Ravelo-García AG, Navarro-Mesa JL. Noncontact Automatic Water-Level Assessment and Prediction in an Urban Water Stream Channel of a Volcanic Island Using Deep Learning. Electronics. 2024; 13(6):1145. https://doi.org/10.3390/electronics13061145
Chicago/Turabian StyleMendonça, Fábio, Sheikh Shanawaz Mostafa, Fernando Morgado-Dias, Joaquim Amândio Azevedo, Antonio G. Ravelo-García, and Juan L. Navarro-Mesa. 2024. "Noncontact Automatic Water-Level Assessment and Prediction in an Urban Water Stream Channel of a Volcanic Island Using Deep Learning" Electronics 13, no. 6: 1145. https://doi.org/10.3390/electronics13061145
APA StyleMendonça, F., Mostafa, S. S., Morgado-Dias, F., Azevedo, J. A., Ravelo-García, A. G., & Navarro-Mesa, J. L. (2024). Noncontact Automatic Water-Level Assessment and Prediction in an Urban Water Stream Channel of a Volcanic Island Using Deep Learning. Electronics, 13(6), 1145. https://doi.org/10.3390/electronics13061145