Abstract
The widespread adoption of virtual reality (VR) technologies is significantly hindered by the prevalence of cybersickness, a disruptive experience causing symptoms like nausea, dizziness, and disorientation. Traditional methodologies for predicting cybersickness predominantly depend on biomedical data. While effective, these methods often require invasive data collection techniques, which can be impractical and pose privacy concerns. Furthermore, existing research integrating demographic information typically does so in conjunction with biomedical or behavioral data, not as a standalone predictive tool. Addressing this gap, we investigated machine learning techniques that exclusively use demographic data to classify and predict the likelihood of cybersickness and its severity in VR environments. This method relies on noninvasive, easily accessible demographic information like age, gender, and previous VR exposure. It offers a more user-friendly and ethically sound approach to predicting cybersickness. The study explores the potential of demographic variables as standalone predictors through comprehensive data analysis, challenging the traditional reliance on biomedical metrics. We comprehensively presented the input data and statistical analysis and later carefully selected the widely used machine learning models from different classes, including k-nearest neighbors, Naive Bayes, Logistic Regression, Random Forest, and Support Vector Machine. We evaluated their performances and presented detailed results and limitations. The research findings indicate that demographic data can be used to predict the likelihood and severity of cybersickness. This research provides critical insights into future research directions, including data collection design and optimization suggestions. It opens new avenues for personalized and inclusive VR design, potentially reducing barriers to VR adoption and enhancing user comfort and safety.
1. Introduction
Virtual reality technology has rapidly gained prominence in various fields, such as training, simulation, medical applications, and entertainment [1,2,3]. VR growth has been fueled by hardware and software advancements like affordable headsets, making it more accessible and immersive [4]. As VR becomes more integrated into different sectors, so does the importance of its user experience. However, a significant challenge to this experience is the prevalence of cybersickness, a type of motion sickness specific to VR environments. Cybersickness manifests through symptoms like nausea, dizziness, and disorientation, which significantly limit the adoption and effectiveness of VR technology. For instance, in training simulations, cybersickness can hinder the learning process, while in medical applications, it can affect the precision and effectiveness of procedures. Therefore, addressing cybersickness is not just a matter of comfort but is crucial for VR applications’ safety, performance, and overall success [5].
Cybersickness, like traditional motion sickness, arises from a sensory inconsistency between what is seen in a virtual environment and what the body perceives physically. This inconsistency leads to symptoms ranging from mild headaches and dizziness to severe nausea and vomiting. This phenomenon is a major concern in sectors where virtual reality is used for critical purposes.
Evaluating cybersickness has traditionally relied on subjective methods, such as the Simulator Sickness Questionnaire (SSQ) and the Motion Sickness Susceptibility Questionnaire (MSSQ) [6,7]. Further advancements included the postural instability tests and physiological monitoring, which fail to capture real-time sickness development or, in some cases, are susceptible to bias. These traditional approaches are criticized for their retrospective or indirect nature while providing an unclear picture of cybersickness during VR exposure. These methods also suffer from reduced ecological validity, struggle to distinguish causes from effects, and account for individual physiological differences [8,9].
Modern technologies that use biomedical signals like heart rate, galvanic skin response (GSR), eye tracking, and machine learning modeling have begun to address these limitations by enabling more accurate, real-time measurements and predictions of cybersickness. However, a notable knowledge gap exists in understanding the impact of demographic factors such as age, gender, and individual susceptibility to cybersickness. This gap hampers the development of tailored VR experiences that could minimize cybersickness prevalence and severity. Incorporating demographic variables into assessments alongside physiological signals and other measures allows for more precise, individualized predictions and tracking of susceptibility over time and across different VR sessions. A multimodal approach, combining demographic data with techniques like biomechanical monitoring, shows promise for effective cybersickness tracking and mitigation.
Combining demographic variables into cybersickness assessments helps account for known risk factors, such as age, gender, and exposure time, which affect individuals’ susceptibility to cybersickness [8,10,11]. Machine learning models can make more accurate and individualized predictions about cybersickness by combining demographic data with other measures, like physiological signals or eye tracking. This also enables tracking changes in susceptibility over time and across different VR sessions [12,13]. A multimodal approach that combines demographic variables with other techniques is the most promising solution for real-time tracking and mitigation of cybersickness [14]. In addition, demographic information is easy to collect and includes established risk factors like gender, age, and inherent motion sickness susceptibility, alongside the well-correlated duration of VR exposure to sickness severity. Machine learning algorithms can uncover complex relationships between these factors and cybersickness outcomes, offering a straightforward approach to risk assessment [15].
This study investigates the predictive power of demographic data on the occurrence of cybersickness among virtual reality users. By focusing exclusively on demographic variables such as age, gender, and inherent motion sickness susceptibility, we aim to uncover patterns and correlations that could forecast the likelihood and severity of cyber sickness. This approach is predicated on the hypothesis that demographic characteristics can serve as reliable indicators for designing more personalized and comfortable VR experiences.
The primary research objectives of this study are twofold:
- To investigate the correlation between demographic data and cybersickness occurrence, determining if specific demographic profiles are more susceptible to experiencing discomfort in VR environments.
- Identifying which demographic factors predict the likelihood and severity of cybersickness provides a foundation for future VR design considerations that prioritize user well-being.
By concentrating on demographic information, this research seeks to establish a foundational understanding of how such data can be effectively utilized to anticipate cybersickness outcomes. This focus on demographic variables centers on enhancing the theoretical framework within which we understand user interactions with VR technologies. The expectation is that an innovative comprehension of demographic influences on cybersickness will pave the way for abundant research and development strategies in the future. This study contributes significantly to the field by laying the groundwork for a more inclusive approach to VR system design. Recognizing and accommodating the diverse needs and sensitivities of a broader user base through personalized VR experiences could improve user satisfaction and expand the accessibility of VR technologies. Ultimately, by advancing our knowledge of the demographic predictors of cybersickness, we open new avenues for research and innovation in creating VR environments that are more universally enjoyable and engaging.
This paper is structured as follows. Section 2 provides a detailed overview of VR technology, the emergence of cybersickness as a concern, and a review of existing research. Section 3 explains our research methodology design and data collection methods. It also gives an overview of the analysis techniques used in the study. Section 4 presents the survey findings, highlighting demographic factors correlating with cybersickness through statistical analysis. Section 5 interprets the results, relates them to existing literature, and explores their implications. Section 6 suggests avenues for further research, and the conclusion concisely summarizes key findings, their significance, and potential benefits, reinforcing the study’s contributions to the field of VR and cybersickness research.
2. Background and Related Work
2.1. Cybersickness
Cybersickness is caused by visual input of the virtual environment. There is no vestibular stimulation in occurrences of cybersickness as the individual is sitting still. A mismatch between the movement in the virtual environment and the lack of physical movement from sitting causes a vestibular conflict that results in an experience known as vection [16]. Cybersickness is also influenced by a multitude of factors categorized into user characteristics, simulator types, and tasks performed. Age plays an important role, with younger individuals showing more resistance to cybersickness, whereas people over 40 are more susceptible due to diminished vestibular perceptual thresholds and postural balance. Gender differences also contribute, with women experiencing higher levels of simulation sickness, possibly due to the improper fit of VR headsets [17]. Additionally, increased exposure to virtual environments can lead to more severe symptoms, though repeated short-term exposures may help users adapt and potentially reduce sickness. User control through physical navigation devices like data gloves has been shown to mitigate symptoms compared to traditional controllers.
The type of display and VR content significantly affect the severity of simulation sickness. Head-mounted displays (HMDs) can cause symptoms like visual strain, nausea, and headaches, largely unaffected by technical advancements in VR hardware. Large and desktop displays, with optimal viewing distances and conditions, do not directly induce simulation sickness but influence the user’s sense of presence. The nature of VR content, especially its immersive quality and graphic realism, impacts user comfort, with immersive content on HMDs causing higher discomfort levels [18]. Designing VR environments poses challenges in maintaining realism and minimizing sickness, emphasizing the delicate balance required in managing hardware, user safety, and engaging visual content to ensure usability and effective user interaction in simulated worlds [19].
Cybersickness in virtual reality environments is predicted using various methods. While it started with traditional questionnaires, currently, biomedical data involves physiological signals, behavioral analysis, and artificial intelligence, which are some methods used to predict cybersickness through patterns in head and body movements. Recent trends have seen the incorporation of machine learning models, which analyze a mix of data types—biomedical, behavioral, and demographic—for more accurate predictions. Additionally, many studies advocate for a combined, multi-modal approach, integrating different data types for comprehensive prediction models [20,21].
2.2. Machine Learning
Machine learning is a branch of artificial intelligence that enables computer systems to improve their performance based on experience without being explicitly programmed. Classification is a fundamental task of machine learning where algorithms classify data into predefined classes based on input features. Techniques like logistic regression, decision trees, neural networks, and other classification algorithms like Support Vector Machines (SVM) and Random Forests offer robust solutions to various real-world problems [22]. Research in predicting cybersickness in VR using biomedical data, such as physiological signals and machine learning, is promising but faces limitations in model accuracy and reliability. Despite their effectiveness, these methods have several limitations [20]. Generalizability is challenging due to limited sample sizes and a focus on specific demographic groups. Additionally, some physiological indicators, like heart rate, may not consistently correlate with cybersickness. Current methods often provide feedback after the onset of cybersickness, limiting effective prevention. The variability in data and experiment design and the dynamic and complex nature of cybersickness add further challenges. The heavy dependence on advanced technology for data collection can be a barrier, particularly in settings lacking such resources [23]. Inconsistencies in study definitions, methods, data collection, and labeling techniques also affect the outcomes and comparability of different research efforts [20].
Garcia et al. [24] developed a binary classifier that uses electrocardiogram, respiratory, and skin conductivity data to predict the occurrence of cybersickness. After testing several classifiers support vector machines (SVM), K-nearest neighbors (KNN), and neural networks, they achieved 82% accuracy, concluding that a combination of biosignals and game parameters helps determine the occurrence of cybersickness in VR environments. Li et al. [25] use the electroencephalography (EEG) and electrooculography (EOG) data in combination with temperature and skin conductance to detect sickness in VR with around 55% accuracy. Alternatively, Munoz et al. [26] used SVM, KNN, and decision trees to predict exertion and cognition in VR with a maximum accuracy of 70%.
Some studies [21,27] reveal the potential but also highlight gaps, like the non-correlation of heart rate with cybersickness. Magaki et al. [28] and Islam et al. [29] propose innovative metrics and methods, yet their effectiveness and applicability across various VR settings need further validation. An unexplored area in cybersickness prediction using demographic data as a standalone predictor is rare. Luong et al. [30] investigated the impact of demographic factors on cybersickness with a large and heterogeneous sample, finding that factors such as gender and VR experience significantly influenced cybersickness susceptibility. At the same time, most existing studies assign demographic factors to a secondary role. When demographic data are included, they are typically combined with other types and not isolated. Focusing solely on demographic data would make predictions more accessible, less invasive, and more ethical. This approach respects user privacy and comfort more than methods requiring physiological data collection. Additionally, understanding the role of demographic data can lead to more personalized and inclusive VR experiences, accommodating a diverse user base with factors like age-related susceptibility or gender differences in VR tolerance. Exploring this area will lead to more user-friendly and ethical approaches to managing cybersickness [30].
3. Methodology
The study employed a structured approach to identify cybersickness in users experiencing a virtual environment. The steps involved designing a tailored web-based survey for data collection, preprocessing the collected data, and subsequently analyzing it using ML classification techniques. Utilizing an online survey methodology facilitated efficient data collection from a diverse participant pool, ensuring the reliability and validity of the gathered data. This approach allowed for firsthand insights from individuals engaged with VR technologies, broadening the study’s scope. The methodology, as shown in Figure 1, commenced with survey design and participant selection followed by data acquisition, including demographics and subjective responses. After preprocessing and filtering, the data underwent correlation analysis and feature extraction. Machine learning classification was then applied to progress to the prediction and validation phase to evaluate the model’s accuracy.
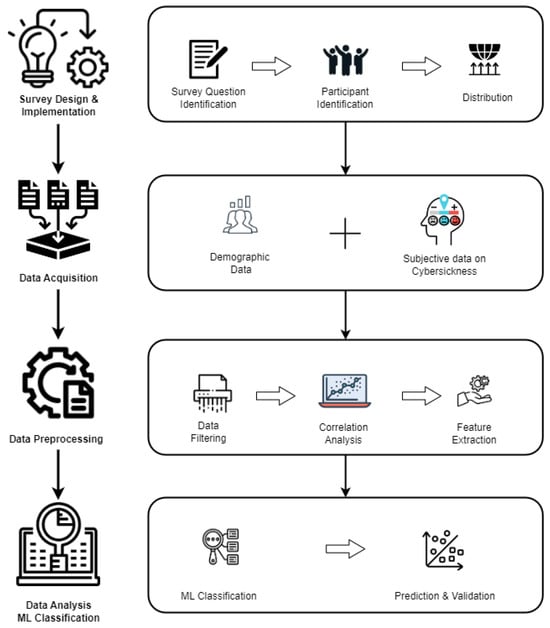
Figure 1.
Research Methodology.
3.1. Survey Design and Implementation
The survey was created using Qualtrics [31], a web-based survey software, with the goal of collecting detailed demographic information from respondents. Our survey was shared through a comprehensive approach to ensure a diverse and inclusive participant response. The methods employed included email campaigns, targeted distribution lists, and strategic social media postings to effectively reach a broad audience while also targeting specific communities and groups that could provide valuable demographic and health-related perspectives for our study. This information includes age, gender, location, educational background, profession, experience with virtual reality, frequency of virtual reality usage, and types of virtual reality environments used. Additionally, the survey aimed to determine participants’ initial impressions and associations with virtual reality, as well as their experiences of discomfort, sickness, or dropout during VR sessions and their underlying causes. The chosen variables were carefully selected to investigate how different demographic factors and levels of VR exposure might affect a person’s susceptibility to cybersickness. The survey utilized a mix of question formats, including multiple-choice, Likert scales, and open-ended questions.
3.2. Data Acquisition
The data for this study were obtained through a comprehensive online survey designed to capture subjective experiences of cybersickness among virtual reality users. The survey collected a diverse range of information from participants, including the following:
Demographic Data: Participants provided demographic details such as age, gender, country of residence, educational background, and occupation. These variables were gathered to investigate potential correlations between demographic factors and susceptibility to cybersickness.
VR Awareness and Experience: Information regarding participants’ awareness of VR technology, frequency of VR experiences, and types of VR environments they have been exposed to was collected. These data points shed light on the relationship between prior VR exposure and the likelihood of experiencing cybersickness.
Subjective Experiences: Participants reported their subjective experiences related to VR usage, including first impressions, associations with VR, experiences of sickness or discomfort, instances of dropout from VR environments, and perceived causes of these adverse effects. The qualitative data provided valuable insights and perceptions of cybersickness among users. The survey employed a combination of multiple-choice questions, Likert scales, and open-ended responses to capture the diverse range of data effectively. Rigorous data cleaning and preprocessing techniques were applied to ensure the integrity and usability of the collected data for subsequent analysis and machine learning applications.
3.3. Data Preprocessing
Data preprocessing is a crucial step in ML pipelines, as it can significantly impact an ML model’s performance and interpretability. Rigorous data preprocessing steps were undertaken to ensure data integrity and usability for machine learning applications. The preprocessing and application of ML classification on the data involved some steps that are shown in Figure 2.
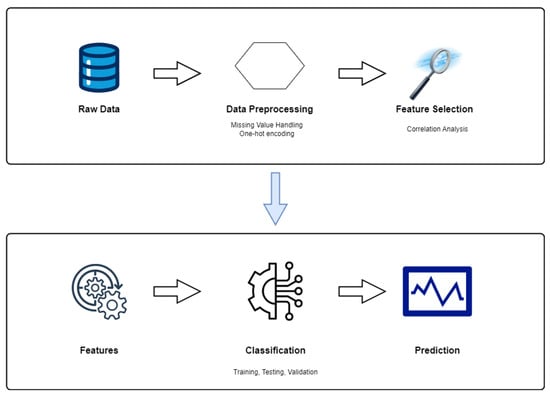
Figure 2.
Steps involved from data preprocessing to prediction.
- To ensure the highest quality and reliability of the data, we refined the original dataset of 245 entries to 148 responses by applying strict criteria that required complete responses across all 17 columns. The process included handling missing data through imputation or deletion.
- To optimize the dataset for machine learning analysis, we applied data normalization techniques and derived new variables or features from existing ones.
- On our dataset, we first performed correlation analysis to identify the relevant features that exhibit a strong relationship with the target variable, “Sickness”. This step helps reduce dimensionality and mitigate the curse of dimensionality by eliminating irrelevant or redundant features [32].
- After identifying the relevant features (Age, VRAware, Num of VR experiences, VRArea, Exposure, VRType, DropOut, Discomforts), we employed one-hot encoding to handle categorical variables. One-hot encoding is a process of converting categorical variables into a form that machine learning algorithms can effectively utilize. This technique represents each distinct category as a binary vector, allowing the model to treat them numerically while retaining their non-linear relationships with the target variable [33].
- In our machine learning classification problem, where the goal is to predict a target variable “Sickness” based Age, VRAware, Num of VR experiences, VRArea, Exposure, VRType, DropOut, Discomforts. The machine learning model would learn the relationship between the features and the target variable “Sickness”.
In a classification problem, the objective of a model is to learn a mapping function
f: X → Y, where X represents the input feature space, and Y represents the set of possible class labels (e.g., “Sickness” or “No Sickness”).
The function f is learned from the training data, which consists of labeled instances (x, y), where x is a vector of feature values, and y is the corresponding class label. The machine learning algorithm aims to find the optimal parameters of the function f that minimize a predefined loss function (e.g., cross-entropy loss for classification) on the training data. Once the model is trained, it can be used to predict the class labels for new, unseen instances based on their feature values.
In our case, the trained model can then be used to predict the likelihood of an individual experiencing cybersickness based on their demographic and VR-related characteristics. We achieved a final dataset that is diverse, representing a range of ages, genders, nationalities, educational backgrounds, and experiences with VR and occupational fields. This diversity was crucial for gaining a comprehensive understanding of varied experiences and perspectives related to VR across different population segments.
After acquiring data through the survey, a series of refined data processing steps address missing values and categorize variables for computational efficiency. Key features were then identified via correlation analysis, serving as inputs for our classification model. The models were then trained, tested, and validated for their application for sickness prediction, which was integral to our research. Figure 2 details an overview of the data preprocessing and the classification steps used in the research.
3.4. Machine Learning Models
Machine learning classifiers are well-suited for predicting cybersickness in VR because they are great at learning patterns and relationships in data. Standard classifiers like KNN, SVM, decision trees, random forests, logistic regression, and neural networks are all effective options that can handle both categorical and numerical input features. These classifiers have also been used in existing research to predict cybersickness in VR environments effectively.
We adopted this method because it excels at detecting complex, non-linear patterns in multidimensional data, which is crucial for gaining a comprehensive understanding of the factors that contribute to cybersickness. By leveraging machine learning’s predictive capabilities, we were able to anticipate the likelihood of cybersickness based on a range of variables, such as demographics and VR usage patterns [34]. These algorithms processed and analyzed the data with impressive efficiency, identifying the most influential factors impacting cybersickness through feature importance analysis. The analysis was performed using scikitlearn, and numpy, the free machine learning libraries for python [35,36].
Furthermore, machine learning’s ability to model interactions between different variables allowed for a deeper understanding of how combined factors influence the experience of cybersickness. The insights gained from this analysis will be used to customize VR experiences. Notably, the statistical rigor of ML models ensured the reliability and credibility of our research findings. Validation techniques like cross-validation provided a strong foundation for our conclusions.
3.5. Model Evaluation
Evaluating a classifier’s performance using a single metric, such as accuracy, can be misleading, especially in imbalanced datasets [37].
When predicting cybersickness using machine learning classifiers, the dataset is likely to be imbalanced, with a smaller number of individuals experiencing cybersickness compared to those who do not. In such cases, overall accuracy can be misleading as a classifier that predicts the majority class (individuals not prone to cybersickness) will have high accuracy but fails to identify the minority class (individuals prone to cybersickness) [38,39]. Metrics like balanced accuracy consider the accuracies for each class separately, and precision and recall for the minority class become crucial [40,41]. Correctly identifying individuals likely to experience cybersickness is more important than correctly identifying those who are not, making precision and recall for the minority class precious metrics.
Additionally, misclassifying an individual as not prone to cybersickness when they are may lead to discomfort, adverse effects, or premature termination of the VR experience. While misclassifying an individual as prone to cybersickness when they are not may result in unnecessary precautions. The relative costs of these errors can be evaluated using precision and recall. The F1 score, which balances precision and recall, provides a single metric that captures both aspects [42]. By considering multiple metrics like accuracy, balanced accuracy, precision, recall, and F1 score, researchers and developers can gain a comprehensive understanding of the classifier’s performance in predicting cybersickness, allowing for informed decision-making and model selection based on the specific requirements and priorities of the application [43].
The ML classifiers for the dataset were evaluated using metrics like accuracy, precision, recall, and F1 score. These metrics provided a comprehensive assessment of the models’ performance, considering their overall accuracy. To further enhance our analysis and ensure our prediction reliability regarding cybersickness, we implemented Leave One Out Cross Validation (LOOCV). For small datasets like the one with only 148 participants, LOOCV can be incredibly helpful. LOOCV preserves all available data for training and testing by holding out one instance for each iteration. It also reduces the risk of overfitting and provides a more reliable estimate of the model’s overall performance [22]. Through the utilization of LOOCV, we were able to precisely estimate the performance of our machine learning models, resulting in accurate and generalized findings. This meticulous evaluation was essential in determining the effectiveness of the model in accurately predicting cybersickness, taking into account the diverse range of variables included in the dataset.
4. Results
The analysis of our dataset through various machine learning classifiers yielded insightful results regarding the predictive capabilities concerning cybersickness. The initial application of these classifiers provided promising results, with Random Forest achieving the highest balanced accuracy of 80.56% and an F1 score of 82.35%, underscoring its robustness in managing large volumes of data and mitigating overfitting through its ensemble approach. A more detailed overview of the balanced accuracy and F1 score are listed in the Table 1.

Table 1.
Initial Performance Metrics of Various Classifiers.
A decrease in performance metrics was observed upon applying LOOCV. Although there was a noticeable decrement in both balanced accuracy and F1 scores across all classifiers—with KNN and SVM experiencing drops to 68.59% and 65.80% in balanced accuracy, respectively—the significance of these results lies beyond mere numerical values. The performance metrics post-LOOCV are presented in the Table 2. Applying LOOCV provides a more transparent, generalized understanding of each classifier’s predictive power in real-world scenarios, where data are seldom perfect or complete. While the observed decrease in classifier performance following the LOOCV application may initially seem alarming, it reinforces our analytical approach’s validity and robustness. By adhering to a rigorous evaluation standard, our study provides valuable insights into the demographic predictors of cybersickness in a virtual environment.
Table 2.
Performance Metrics of Various Classifiers After LOOCV.
The decline in performance metrics post-LOOCV highlights the importance of employing rigorous validation methods in machine learning studies, ensuring the reliability and credibility of the findings. This study’s innovative use of LOOCV to evaluate the classifiers’ performance emphasizes our commitment to methodological excellence and contributes to the burgeoning field of cybersickness research in virtual reality.
Moreover, this study’s methodological framework—particularly the strategic choice and application of machine learning classifiers followed by an intensive validation process—sets a new precedent for future research in this domain. It underscores the potential of employing advanced machine learning techniques and rigorous validation methods to unravel the complexities of cybersickness, paving the way for more personalized and effective mitigation strategies in virtual reality environments. Figure 3 shows the Balanced Accuracy for the same set of classifiers. This indicates that for most models, balanced accuracy decreases after LOOCV, with Naive Bayes showing the most significant drop. This suggests that LOOCV has a more pronounced effect on Balanced Accuracy, potentially due to its sensitivity to the distribution of classes.
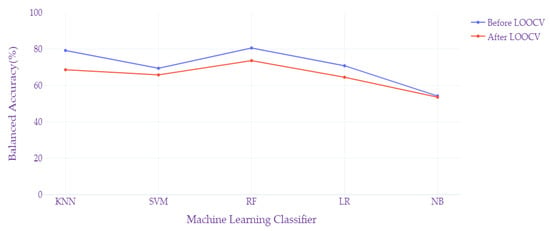
Figure 3.
Balanced accuracy metric before and after LOOCV.
Figure 4 illustrates the F1 Scores for KNN, SVM, RF, LR, and NB classifiers. The performance is relatively consistent before and after LOOCV, with slight variations that suggest LOOCV had a minimal impact on F1 Scores.
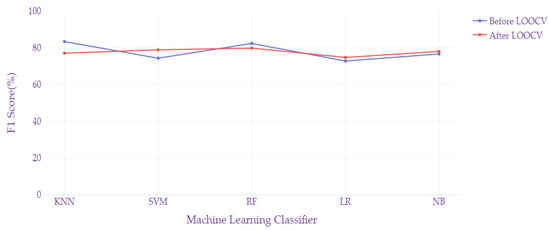
Figure 4.
F1 Score metric before and after LOOCV.
5. Discussion
The results from our study indicate a strong correlation between demographic data and the incidence of cybersickness in virtual reality users. Specifically, the performance metrics of the machine learning classifiers, with RF emerging as the top performer, suggest that demographic factors such as age, gender, and prior VR exposure can predict the likelihood and severity of cybersickness.
Our prediction results for cybersickness using demographic factors and VR experience-related features are in line with existing research findings. The selected features, such as age, gender, VR exposure duration, and prior VR experience, have been consistently identified as influential factors in cybersickness susceptibility across multiple studies [8,10]. This finding challenges the conventional reliance on biomedical and behavioral data for cybersickness prediction [25,26], highlighting the potential of demographic data as a standalone predictive tool. The high F1 scores and balanced accuracy achieved by the classifiers demonstrate the effectiveness of this approach in accurately classifying individuals at risk of cybersickness.
This research offers a new avenue for creating personalized VR experiences that minimize cybersickness, enhancing user comfort and safety. By incorporating demographic data in the design and development process, VR applications can be tailored to reduce the risk of cybersickness among users, broadening the accessibility and appeal of VR technologies. This approach promises users comfortable and enjoyable VR experiences, with reduced risk of discomfort and dropout. Researchers can leverage these insights further to explore the implications of demographic factors on VR experiences, paving the way for more inclusive and ethical research methodologies that prioritize user privacy and comfort.
Our findings complement the existing body of research on cybersickness prediction. While previous studies have acknowledged the relevance of demographic factors, they are treated as secondary to biomedical or behavioral data. Our research underscores the predictive power of demographic data, offering a less invasive and more accessible approach to mitigating cybersickness. Our results align with the work of Luong et al. [30], who found that gender and VR experience significantly influenced cybersickness susceptibility but went further by demonstrating the efficacy of machine learning techniques in utilizing these factors for prediction.
6. Limitations and Future Work
Our research in predicting cybersickness through machine learning classifiers and demographic data provides significant insights yet encounters notable limitations. The study’s scope, limited by the diversity and size of the dataset, may only partially represent the broad spectrum of VR users’ experiences, potentially affecting the generalizability of our findings. Additionally, the performance variability observed with the stringent LOOCV validation suggests that our models may face challenges in real-world applicability, highlighting the complex, multifaceted nature of cybersickness. These limitations underscore the dynamic evolution of VR technology, which could alter the factors contributing to cybersickness, thus necessitating continuous refinement of our predictive models. Future research can expand the sample size and demographic diversity to enhance the generalizability of findings. Investigating the interaction of demographic and behavioral data could yield richer insights into cybersickness prediction. Exploring the application of more advanced machine learning and artificial intelligence techniques, such as deep learning, could further refine the accuracy and reliability of forecasts. Finally, longitudinal studies examining the long-term effects of VR exposure on cybersickness susceptibility will provide valuable insights for developing more user-friendly VR technologies.
While using demographic data in predictive models for cybersickness can yield practical benefits, it raises ethical concerns regarding privacy and potential bias. Personal information such as age, gender, and occupation could be considered sensitive data, and its misuse or unauthorized access could violate individuals’ privacy rights. Additionally, relying heavily on demographic factors in predictive models carries the risk of perpetuating societal biases and discriminatory practices, as certain groups may be disproportionately associated with higher cybersickness susceptibility. We implemented robust data protection measures, obtained consent from users, and continually monitored and mitigated any emergent biases in the models to ensure the ethical and responsible use of such predictive systems.
7. Conclusions
This study uses demographic data and ML techniques to predict cybersickness within virtual reality environments, questioning the traditional dependency on biomedical and behavioral indicators. By harnessing the predictive capabilities of ML algorithms, this study emphasizes the substantial potential of variables such as age, gender, and VR exposure in forecasting the incidence of cybersickness. The methodology adopted here circumvents the ethical and privacy concerns associated with invasive data collection and heralds a paradigm shift towards a more accessible and simplified predictive framework. This pioneering approach facilitates a nuanced understanding of cybersickness, advocating for a recalibration of VR development practices towards inclusivity and user-centric design.
Furthermore, the implications of our findings are far-reaching, proposing a recalibrated approach for VR developers to tailor applications more attentively to a diverse demographic landscape, potentially broadening the scope of VR adoption and enhancing the overall user experience. The comparative analysis of various ML models contributes critical insights into the strategic selection of predictive algorithms, enriching the academic and practical discourse on VR. In sum, this research advances the scholarly conversation surrounding VR technologies and cybersickness and delineates a forward-looking trajectory for the field. It advocates for a more inclusive, data-informed approach to VR design, underscoring the pivotal role of demographic factors in the preemptive identification and mitigation of cybersickness, thus setting a new precedent for future research and development within the burgeoning domain of virtual reality.
Author Contributions
A.N.R.-C. was instrumental in the conceptualization and execution of the study on quality attributes within virtual reality environments. Their leadership extended to the meticulous crafting of the survey, ensuring its widespread distribution, and the detailed analysis of the ensuing data. This thorough engagement from the idea’s genesis to the final analytical stages underlines A.N.R.-C.’s vital contribution to the research. H.R. was critical in supervising the project, rigorously evaluating its merits and shortcomings. Their analytical acumen and oversight were pivotal in maintaining the study’s methodological rigor, enhancing the research outcomes’ integrity and depth. This collaborative effort significantly elevated the manuscript’s quality, providing a richer interpretation of the findings. All authors have read and agreed to the published version of the manuscript.
Funding
This research has not received any external funding.
Institutional Review Board Statement
The study was conducted in accordance with and approved by the Institutional Review Board (or Ethics Committee) of the University of North Dakota (IRB0003225) that was approved in the year 2021 for studies involving humans in the Exempt two category.
Informed Consent Statement
Before participating in the survey, informed consent was obtained from all subjects involved in the study.
Data Availability Statement
The data are currently not available to public, but we plan to publish them later.
Acknowledgments
The authors extend their gratitude to the University of North Dakota’s Institutional Review Board (IRB) for their comprehensive examination and approval of our study’s protocol, including the training and deployment of Qualtrics software. The IRB’s dedication to ethical principles has significantly bolstered the integrity and reliability of our research. This endorsement affirms the quality of our work and contributes to the broader academic discourse in our field.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| VR | Virtual Reality |
| VE | Virtual Environments |
| ECG | Electrocardiogram |
| EEG | Electroencephalogram |
| GSR | Galvanic Skin Response |
| KNN | K nearest neighbor |
| SVM | Support Vector Machine |
| RF | Random Forest |
| IRB | Institutional Review Board |
| LOOCV | Leave one out cross validation |
References
- Putranto, J.; Heriyanto, J.; Kenny; Achmad, S.; Kurniawan, A. Implementation of virtual reality technology for sports education and training: Systematic literature review. Procedia Comput. Sci. 2023, 216, 293–300. [Google Scholar] [CrossRef]
- Javaid, M.; Haleem, A. Virtual reality applications toward medical field. Clin. Epidemiol. Glob. Health 2020, 8, 600–605. [Google Scholar] [CrossRef]
- Rokooei, S.; Shojaei, A.; Alvanchi, A.; Azad, R.; Didehvar, N. Virtual reality application for construction safety training. Saf. Sci. 2023, 157, 105925. [Google Scholar] [CrossRef]
- Wedel, M.; Bigné, E.; Zhang, J. Virtual and augmented reality: Advancing research in consumer marketing. Int. J. Res. Mark. 2020, 37, 443–465. [Google Scholar] [CrossRef]
- Tian, N.; Lopes, P.; Boulic, R. A review of cybersickness in head-mounted displays: Raising attention to individual susceptibility. Virtual Real. 2022, 26, 1409–1441. [Google Scholar] [CrossRef]
- Kennedy, R.; Lane, N.; Berbaum, K.; Lilienthal, M. Simulator sickness questionnaire: An enhanced method for quantifying simulator sickness. Int. J. Aviat. Psychol. 1993, 3, 203–220. [Google Scholar] [CrossRef]
- Golding, J. Motion sickness susceptibility questionnaire revised and its relationship to other forms of sickness. Brain Res. Bull. 1998, 47, 507–516. [Google Scholar] [CrossRef]
- Munafo, J.; Diedrick, M.; Stoffregen, T. The virtual reality head-mounted display Oculus Rift induces motion sickness and is sexist in its effects. Exp. Brain Res. 2017, 235, 889–901. [Google Scholar] [CrossRef] [PubMed]
- Dennison, M.S.; D’Zmura, M. Cybersickness without the wobble: Experimental results speak against postural instability theory. Appl. Ergon. 2017, 58, 215–223. [Google Scholar] [CrossRef]
- Stanney, K.M.; Hale, K.S.; Nahmens, I.; Kennedy, R.S. What to Expect from Immersive Virtual Environment Exposure: Influences of Gender, Body Mass Index, and Past Experience. Hum. Factors 2003, 45, 504–520. [Google Scholar] [CrossRef]
- Mazloumi Gavgani, A.; Walker, F.R.; Hodgson, D.M.; Nalivaiko, E. A comparative study of cybersickness during exposure to virtual reality and “classic” motion sickness: Are they different? J. Appl. Physiol. 2018, 125, 1670–1680. [Google Scholar] [CrossRef] [PubMed]
- Lopes, P.; Tian, N.; Boulic, R. Eye Thought You Were Sick! Exploring Eye Behaviors for Cybersickness Detection in VR. In Proceedings of the 13th ACM SIGGRAPH Conference on Motion, Interaction and Games, MIG ’20, New York, NY, USA, 16–18 October 2020. [Google Scholar] [CrossRef]
- Nalivaiko, E.; Davis, S.; Blackmore, K.; Vakulin, A.; Nesbitt, K. Cybersickness provoked by head-mounted display affects cutaneous vascular tone, heart rate and reaction time. Physiol. Behav. 2015, 151, 583–590. [Google Scholar] [CrossRef] [PubMed]
- Lawson, B. Motion sickness symptomatology and origins. In Handbook of Virtual Environments: Design, Implementation, and Applications; Hale, K., Stanney, K., Eds.; CRC Press: Boca Raton, FL, USA, 2014; pp. 531–600. [Google Scholar] [CrossRef]
- Jeong, D.; Yoo, S.; Jang, Y. Cybersickness Analysis with EEG Using Deep Learning Algorithms. In Proceedings of the 2019 IEEE Conference on Virtual Reality and 3D User Interfaces (VR), Osaka, Japan, 23–27 March 2019; pp. 827–835. [Google Scholar] [CrossRef]
- LaViola, J.J., Jr. A discussion of cybersickness in virtual environments. ACM Sigchi Bull. 2000, 32, 47–56. [Google Scholar] [CrossRef]
- Shafer, D.M.; Carbonara, C.P.; Korpi, M.F. Modern Virtual Reality Technology: Cybersickness, Sense of Presence, and Gender; Technical Report 2; Baylor University: Waco, TX, USA, 2017. [Google Scholar]
- Guna, J.; Geršak, G.; Humar, I.; Krebl, M.; Orel, M.; Lu, H.; Pogačnik, M. Virtual reality sickness and challenges behind different technology and content settings. Mob. Netw. Appl. 2020, 25, 1436–1445. [Google Scholar] [CrossRef]
- Ramaseri Chandra, A.N.; El Jamiy, F.; Reza, H. A Systematic Survey on Cybersickness in Virtual Environments. Computers 2022, 11, 51. [Google Scholar] [CrossRef]
- Yang, A.H.X.; Kasabov, N.; Cakmak, Y.O. Machine learning methods for the study of cybersickness: A systematic review. Brain Inform. 2022, 9, 24. [Google Scholar] [CrossRef] [PubMed]
- Hadadi, A.; Guillet, C.; Chardonnet, J.R.; Langovoy, M.; Wang, Y.; Ovtcharova, J. Prediction of cybersickness in virtual environments using topological data analysis and machine learning. Front. Virtual Real. 2022, 3, 973236. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J.H.; Friedman, J.H. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: Berlin/Heidelberg, Germany, 2009; Volume 2. [Google Scholar] [CrossRef]
- Drazich, B.F.; McPherson, R.; Gorman, E.F.; Chan, T.; Teleb, J.; Galik, E.; Resnick, B. In too deep? A systematic literature review of fully-immersive virtual reality and cybersickness among older adults. J. Am. Geriatr. Soc. 2023, 71, 3906–3915. [Google Scholar] [CrossRef] [PubMed]
- Garcia-Agundez, A.; Reuter, C.; Becker, H.; Konrad, R.; Caserman, P.; Miede, A.; Göbel, S. Development of a classifier to determine factors causing cybersickness in virtual reality environments. Games Health J. 2019, 8, 439–444. [Google Scholar] [CrossRef] [PubMed]
- Li, G.; Onuoha, O.; McGill, M.; Brewster, S.; Chen, C.P.; Pollick, F. Comparing Autonomic Physiological and Electroencephalography Features for VR Sickness Detection Using Predictive Models. In Proceedings of the 2021 IEEE Symposium Series on Computational Intelligence (SSCI), Orlando, FL, USA, 5–7 December 2021; pp. 1–8. [Google Scholar] [CrossRef]
- Munoz, J.E.; Ali, F.; Basharat, A.; Mehrabi, S.; Barnett-Cowan, M.; Cao, S.; Middleton, L.E.; Boger, J. Development of Classifiers to Determine Factors Associated with Older Adult’s Cognitive Functions and Game User Experience in VR Using Head Kinematics. IEEE Trans. Games, 2023; early access. [Google Scholar] [CrossRef]
- Martin, N.; Mathieu, N.; Pallamin, N.; Ragot, M.; Diverrez, J.M. Virtual reality sickness detection: An approach based on physiological signals and machine learning. In Proceedings of the 2020 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), Porto de Galinhas, Brazil, 9–13 November 2020; pp. 387–399. [Google Scholar] [CrossRef]
- Magaki, T.; Vallance, M. Seeking Accessible Physiological Metrics to Detect Cybersickness in VR. Int. J. Virtual Augment. Real. (IJVAR) 2020, 4, 1–18. [Google Scholar] [CrossRef]
- Islam, R.; Lee, Y.; Jaloli, M.; Muhammad, I.; Zhu, D.; Rad, P.; Huang, Y.; Quarles, J. Automatic Detection and Prediction of Cybersickness Severity using Deep Neural Networks from user’s Physiological Signals. In Proceedings of the 2020 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), Porto de Galinhas, Brazil, 9–13 November 2020; pp. 400–411. [Google Scholar] [CrossRef]
- Luong, T.; Pléchata, A.; Möbus, M.; Atchapero, M.; Böhm, R.; Makransky, G.; Holz, C. Demographic and behavioral correlates of cybersickness: A large lab-in-the-field study of 837 participants. In Proceedings of the 2022 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), Porto de Galinhas, Brazil, 9–13 November 2022; pp. 307–316. [Google Scholar] [CrossRef]
- Qualtrics. Qualtrics Survey Software, 2020. Version: Month(s) and Year(s) of Use. Available online: https://www.qualtrics.com (accessed on 1 March 2024).
- Guyon, I.; Elisseeff, A. An introduction to variable and feature selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar] [CrossRef][Green Version]
- Hancock, J.T.; Khoshgoftaar, T.M. Survey on categorical data for neural networks. J. Big Data 2020, 7, 28. [Google Scholar] [CrossRef]
- Charte, F.; Rivera, A.; del Jesus, M.J.; Herrera, F. On the Impact of Dataset Complexity and Sampling Strategy in Multilabel Classifiers Performance. In Hybrid Artificial Intelligent Systems; Springer: Cham, Switzerland, 2016; pp. 500–511. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Harris, C.R.; Millman, K.J.; van der Walt, S.J.; Gommers, R.; Virtanen, P.; Cournapeau, D.; Wieser, E.; Taylor, J.; Berg, S.; Smith, N.J.; et al. Array programming with NumPy. Nature 2020, 585, 357–362. [Google Scholar] [CrossRef] [PubMed]
- Hancock, J.T.; Khoshgoftaar, T.M.; Johnson, J.M. Evaluating classifier performance with highly imbalanced Big Data. J. Big Data 2023, 10, 42. [Google Scholar] [CrossRef]
- García, V.; Mollineda, R.A.; Sánchez, J.S. On the k-NN performance in a challenging scenario of imbalance and overlapping. Pattern Anal. Appl. 2008, 11, 269–280. [Google Scholar] [CrossRef]
- Weiss, G.M. Mining with rarity: A unifying framework. ACM Sigkdd Explor. Newsl. 2004, 6, 7–19. [Google Scholar] [CrossRef]
- Brodersen, K.H.; Ong, C.S.; Stephan, K.E.; Buhmann, J.M. The balanced accuracy and its posterior distribution. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 3121–3124. [Google Scholar]
- Powers, D.M. Evaluation: From precision, recall and F-measure to ROC, informedness, markedness and correlation. arXiv 2020, arXiv:2010.16061. [Google Scholar]
- Sasaki, Y. The truth of the F-measure. Teach Tutor Mater 2007, 1, 1–5. [Google Scholar]
- Sokolova, M.; Lapalme, G. A systematic analysis of performance measures for classification tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).