1. Introduction
Nowadays, advancements in autonomous driving technology have led to significant enhancements in road safety and driving efficiency [
1,
2,
3]. As a pivotal technology, the effectiveness of trajectory tracking control directly affects the overall performance and safety of vehicles during operation [
4]. Despite significant progress in autonomous driving technology, optimizing trajectory tracking control remains a challenging but crucial task [
5]. Moreover, as the demand for autonomous vehicles continues to increase, it is crucial to refine trajectory tracking control algorithms to effectively address complex and various road scenarios [
6,
7], achieving a good balance between responsiveness, accuracy, and computational efficiency in dynamic driving environments and ensuring real-time adaptability.
One main method to solve trajectory tracking control problems is model predictive control (MPC) [
7,
8]. MPC is a method for solving optimal control problems (OCPs) using the current state of the controlled system as the initial condition. This method uses a controlled object model to predict the controlled variable’s response [
9,
10]. Solving an OCP involves finding a sequence of control inputs that minimize the objective function within the specified prediction horizons. Simultaneously, it maintains feasibility while the trajectory stays within the defined limitations. The linear time-varying model predictive control (LTV-MPC) proposed by [
11,
12] is an MPC based on the discrete linear state space model, which can reduce the amount of calculation and improve efficiency. The LPV-MPC presented in [
13] takes into account future inputs and scheduling parameters, predicting future outputs accordingly. Ref. [
14] presents a customized genetic algorithm for real-time optimization of a nonlinear model predictive control (NMPC) path-tracking controller, specifically designed for lower vehicle speeds.
With increasing computing power, sensing, and communication capabilities and advances in the field of machine learning, automating controller design and adaptation based on data collected during operations are being studied [
15], such as by improving performance, facilitating deployment, and reducing the need for manual controller tuning. In refs. [
16,
17,
18], Gaussian Process Regression and neural networks were used as predictive models of controlled systems, which were prediction models adaptively adjusted in a data-driven manner to improve control accuracy and reduce computing costs. The concept of using reinforcement learning (RL) to learn MPC cost function parameters is introduced in ref. [
19]. Ref. [
20] proposes a weights-varying MPC using a deep reinforcement learning (DRL) algorithm to adjust cost function weights in different situations. Ref. [
21] proposed a novel approach limiting DRL actions within a safe learning space, and the proposed DRL algorithm can automatically learn context-dependent optimal parameter sets and dynamically adapt for a weights-varying MPC. Ref. [
22] has introduced a novel control algorithm based around an event-triggered MPC, using RL with a configurable objective to automatically tune the control algorithm’s meta-parameters: the prediction horizon and the re-computation (triggering) problem. In ref. [
23], a RLMPC scheme was introduced integrating MPC and RL through policy iteration (PI), where MPC is a policy generator and the RL technique is employed to evaluate the policy. This RLMPC scheme has great potential in reducing computational burden.
Prediction horizon is the key parameter affecting both performance and computational burden of the control system in MPC. It denotes the time range used to predict the system’s future behavior during the control process [
24]. Shorter horizons offer better control but less stability, while longer horizons provide stability but should not be excessively long [
25]. In ref. [
26], a dual-mode receding horizon controller eliminates the danger of interference that is always present in nonlinear optimal control algorithms and greatly reduces the amount of online calculation required. Two adaptive prediction horizons for MPC were proposed in ref. [
27]. One is based on heuristics, which is idealized but not feasible, and the other is more practical and uses iterative deepening, where each iteration will check stability criteria and find out the minimum horizon of stability. Ref. [
28] adjusted the prediction horizon range to a positive integral discrete time variable and introduced an NMPC to achieve velocity control, incorporating a self-correction method for the prediction horizons. Studies in refs. [
29,
30] proposed an event-triggered MPC, which dynamically adjusts the prediction horizon using event-triggering mechanisms to facilitate the optimization process. A finite control set MPC with an adaptive prediction horizon is proposed [
31], and neural networks are trained to calculate the optimal prediction horizon at runtime. Ref. [
9] proposed an RLMPC which learns the optimal prediction horizon length of an MPC scheme using RL.
Proximal policy optimization (PPO) is a policy-based RL algorithm, clipping the probability ratio to modify the agent’s objective and constraining the magnitude of policy change at each step to enhance training stability. In this paper, we propose an adaptive MPC, combining the PPO algorithm and MPC to adjust the prediction horizon. To accommodate dynamic conditions such as road curvature and vehicle speed, we leverage the PPO algorithm to adaptively adjust the prediction horizon within the MPC framework. This integration empowers MPC to achieve optimal performance under varying environmental circumstances.
Unlike other research that combines reinforcement learning with MPC for autonomous driving—such as using RL for planning, MPC for control, and RL to adjust MPC weight parameters—our proposed PPO-MPC deeply considers the impact of prediction horizon selection on control performance, offering a dynamic prediction horizon that enhances MPC’s adaptability. And the PPO-MPC strategy we propose enables the vehicle to achieve adaptive tracking control at different speeds and curvatures.
2. Methodology
This section outlines the methodology of our proposed PPO-MPC framework, encompassing the establishment of the vehicle dynamics model, the design of the MPC strategy, and the adaptation of prediction horizons within the PPO algorithm. Specifically, we introduce a novel approach called “prediction horizon-varying model predictive control” to optimize the prediction horizon for MPC. This involves formulating a hybrid PPO-MPC prediction horizon optimization problem. To improve the adaptive performance of autonomous driving trajectory tracking control, we use the PPO algorithm to dynamically adjust the MPC prediction horizon, exploring the intricate relationship between the prediction horizon and variables such as vehicle speed, lateral deviation, and curvature. A visual representation of the architectural concept of PPO-MPC is provided in
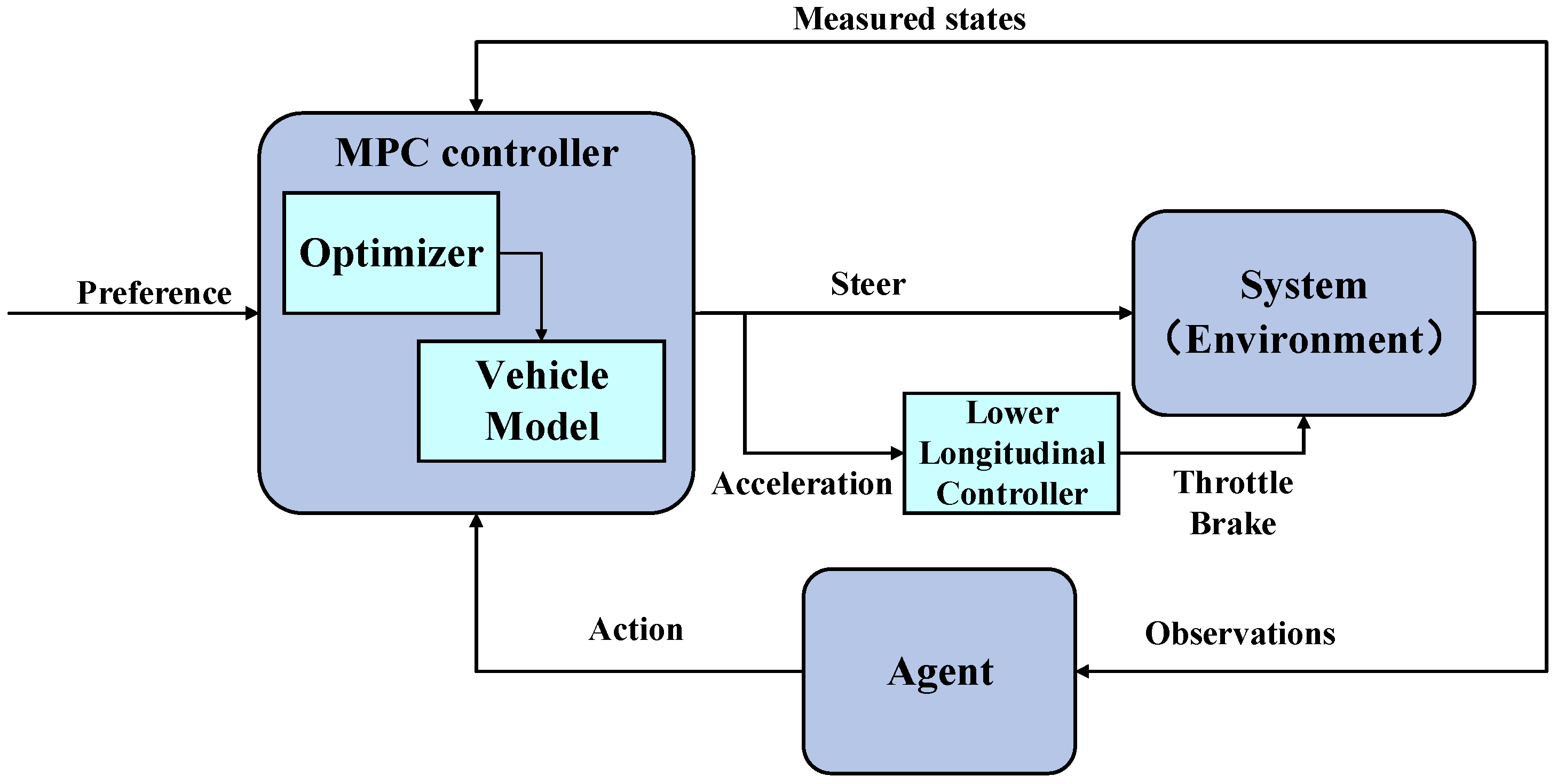
Figure 1.
Figure 1 shows that the vehicle dynamics model is used to analyze the vehicle’s motion state; the lateral error model and the longitudinal acceleration model are coupled, with the front wheel steering angle and acceleration serving as control variables. And the model predictive control algorithm is used to solve the problem. In this structure, a state space related to the MPC controller and vehicle motion status is established, and the prediction horizon is set as the action space. Based on the PPO algorithm, the optimal prediction horizon is dynamically adjusted through iterative training. In addition, the speed control strategy can be interpreted as calculating the desired acceleration through model predictive control, switching the driving mode through the desired acceleration corresponding control strategy and then controlling the vehicle’s accelerator opening and brake pressure to achieve speed control.
2.1. Vehicle Dynamic Model
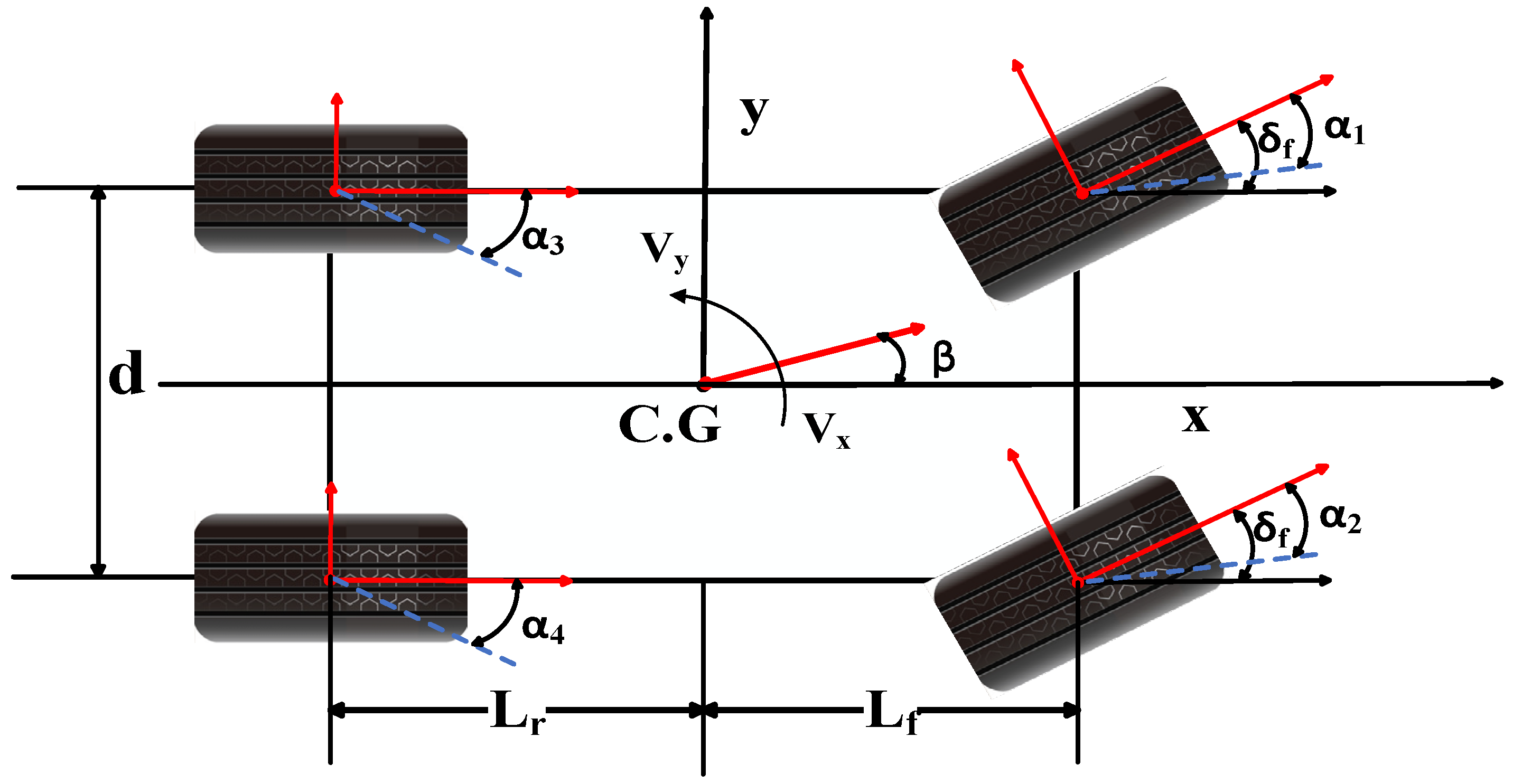
As shown in
Figure 2, this study considers the vehicle dynamics model of both longitudinal and lateral motion.
2.1.1. Lateral Dynamics
In this paper, the model for lateral movement is constructed on the foundational principles of the bicycle model. This approach presumes symmetry in the steering angles on both the left and right sides, which effectively reduces the complexity of the vehicle’s dynamic model to that of a two-wheeled bicycle. Leveraging Newton’s second law of motion, simplified Equations (1a)–(1c) can be derived to quantify the lateral force exerted by the vehicle.
where
is the vehicle mass and
and
are the longitudinal and lateral velocity, respectively.
and
denote the longitudinal and lateral acceleration, respectively.
and
are the lateral tire forces at the front and the rear wheels, respectively;
and
are the longitudinal tire forces at the front and the rear wheels, respectively;
is the yaw rate;
denotes the yaw inertia of the vehicle; and
and
are the distances from the front and rear axles to the center of gravity, respectively.
Considering the tire turning characteristics, Equations (2a) and (2b) represent the lateral force of the front and rear tires at a small sideslip angle:
where
and
are the cornering stiffness of the front tire and rear tire, respectively;
is the sideslip angle of the front tire; and
is the sideslip angle of the rear tire.
Given that the angles of the two front wheels of the vehicle are equal, the vehicle’s lateral acceleration should meet the criteria for the small angle assumption. In this case, the subsequent approximate relationship can be utilized:
Upon substituting Equations (2a), (2b) and Equations (3a), (3b) into Equations (1a)–(1c), the resulting expressions are obtained:
2.1.2. Longitudinal Dynamics
Vehicle longitudinal dynamics studies the motion and mechanical characteristics of a vehicle in the longitudinal direction (i.e., the direction of the vehicle’s forward motion). In longitudinal dynamics, the vehicle’s acceleration, braking, traction, resistance, and other factors are primarily considered. Newton’s second law provides a framework for understanding these forces and their impact on motion. Considering the computational complexity, the effect of partial resistance is not taken into account.
where
,
, and
respectively represent driving force, air resistance, and rolling resistance. The expression for air resistance
is as follows.
where
represents air density.
stands for the drag coefficient.
denotes the frontal area of the vehicle.
Torque is based on the sum of the forces multiplied by the wheel radius; according to Gillespie’s “Fundamentals of Vehicle Dynamics” [
32], we can obtain the calculation of torque in the context of vehicle dynamics, denoted as Equation (7).
where
is the driving torque and
represents the effective tire radius.
Taking into account the transmission ratio and motor efficiency, the relationship between driving force and motor torque is:
where
denotes the motor torque,
is the transmission ratio, and
is the motor efficiency.
The braking force can be expressed as:
Considering that the braking and driving modes cannot work at the same time, and the braking and driving modes cannot be switched frequently, the driving and braking switching strategy of the vehicle is designed as:
2.2. MPC System Definition
MPC is a control system approach employing a predictive model. In each discrete sampling time, MPC solves an open-loop OCP over a predetermined finite horizon. This is an iterative process of predicting the future system behavior within the future horizon through the plant’s predictive model. The current state of the system is considered the initial condition for each optimization cycle. An optimizer solves the optimization problem and returns a control sequence for the prediction horizon. The plant only adopts the initial control in the optimal sequence, and on subsequent samples, the initial control is used to solve the system optimization problem again [
33]. This refers to the “receding horizon” principle [
34]. Indeed, the horizon recedes as time passes. A key feature of MPC is its ability to integrate hard constraints on control variables and states during the design phase.
In this study, we divide longitudinal control into two parts: upper-level and lower-level control. Upper-level control uses MPC, producing acceleration as its output. Lower-level control is deduced using Equation (7), which establishes a throttle and brake control map.
According to Ref. [
35], the longitudinal accelerating system is modeled as a linear first-order system; the relationship between the desired vehicle acceleration
and the actual acceleration is as follows in Equation (11).
where
is the gain coefficient,
is the delay time, and
.
The longitudinal accelerating and lateral steering combined system model of the vehicle can be described as Equation (12).
The full system model consists of the longitudinal and lateral model. Equation (13) represents the system’s state space expression,
where
,
,
.
Where is the state vector and is the control input vector of the vehicle model.
Equation (13) can be linearized and discretized as follows:
where
denotes the sample time;
is the identity matrix; and
,
, and
are matrices of coefficients.
Based on the known vehicle model and the deviation between the current measurement value and the expected value, the MPC controller predicts the output of the system within . By solving the objective function and optimizing the output, a control quantity array in is obtained, and control elements in the first-time interval are used as the output quantity. This process is repeated to achieve vehicle tracking along the desired trajectory.
According to the control requirements, the basic principle of MPC is to minimize the performance evaluation function while satisfying the control constraints. Equations (15a)–(15c) represent the objective function.
where
reflects the system’s ability to track reference trajectory within prediction horizon
. This reflects the system’s requirement for a smooth change in the control increment within control horizon
.
and
are the weight matrices,
is the weight coefficient,
is the relaxation factor, and
is the control input increment.
Considering safety constraints and vehicle actuator constraints, the constraint conditions can be expressed as Equation (16).
2.3. PPO Horizon Policy
2.3.1. Proximal Policy Optimization (PPO)
The PPO algorithm is an online policy gradient RL algorithm which can deal with problems in continuous state–action spaces. This DRL algorithm learns optimal strategies in interaction with the environment and uses stochastic gradient ascension to optimize the agent objective function [
36]. To achieve high cumulative rewards, the PPO algorithm seeks optimal decisions in complex environments by constructing and optimizing policies, generally represented by neural networks. The policy, a parameterized function, maps states to probability distributions of actions. To improve the policy, PPO uses proximal policy optimization and maximizes the objective function. The objective function comprises a loss term for current policy updates and a KL divergence term, ensuring stability by controlling the magnitude of policy updates.
In PPO, the problem is represented as a Markov Decision Process (MDP), which is defined as . represents the state space, which encompasses the complete set of potential states that the environment can occupy. And represents the action space, which contains a collection of all possible actions. represents the state transition function, which defines the probability distribution of the environment transitioning to the next state. is the reward function, which is specified in the given state and represents an immediate reward. is the discount factor, which determines the importance of future rewards. The pseudocode of PPO is shown in Algorithm 1.
The goal of PPO is to maximize the anticipated total reward while limiting changes in the policy during each update. In this study, Equation (17) is the objective function expression of PPO.
where
denotes the ratio of the new strategy to the old strategy and
indicates the advantage function.
| Algorithm 1 PPO algorithm |
| For iteration do |
| For episode do |
| Initialize the weight parameters of the policy network (actor) and value function network (critic). The initial state is determined by the discount factor and the greedy factor ; |
| Collect experiences ; |
| For optimization step do |
| Calculate the expected advantage function of the current strategy ; |
| Calculate the advantage function for each experience ; |
| Update the policy ; |
| Update proximal policy ; |
| End |
| End |
| End for |
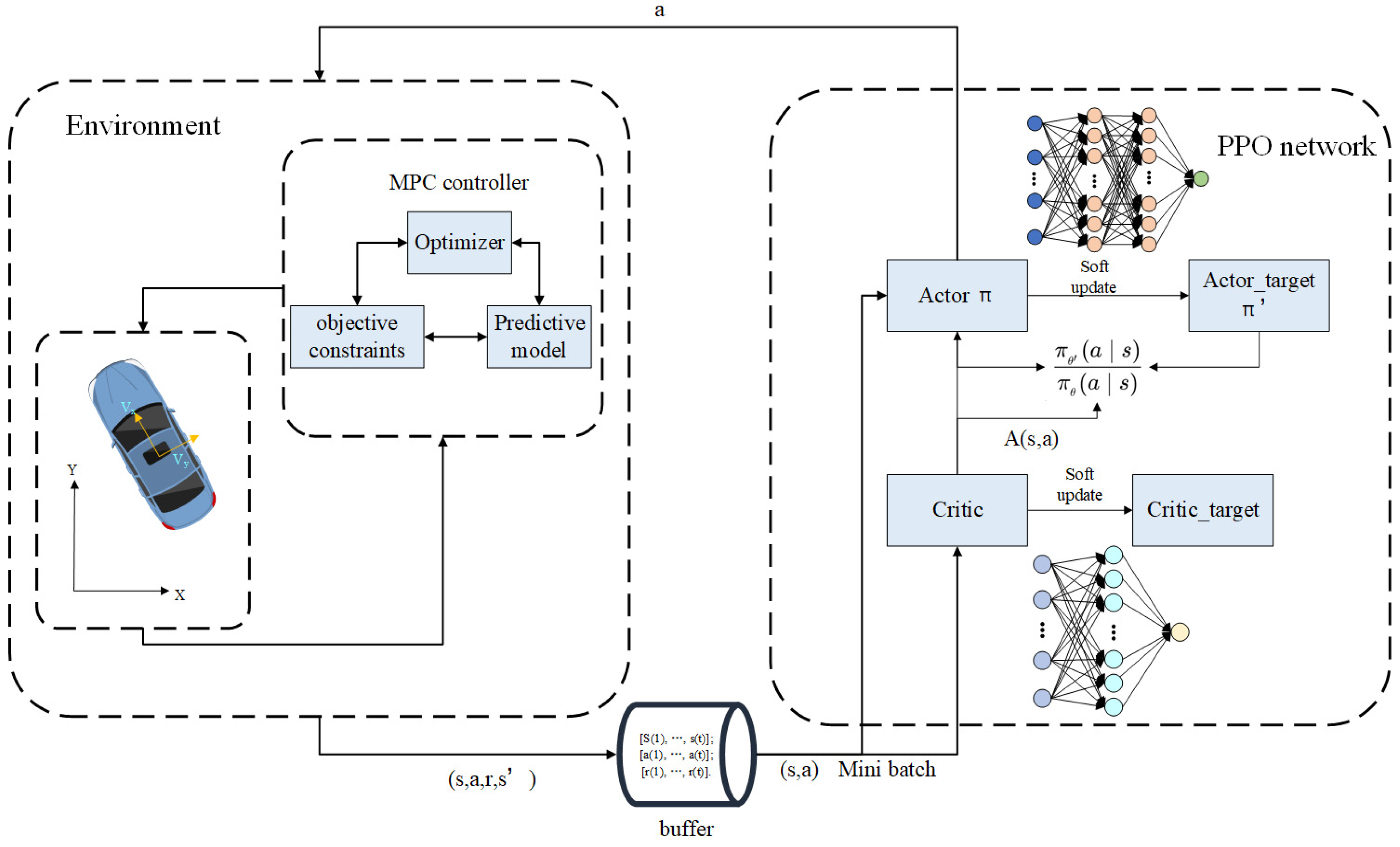
The framework of PPO-MPC is shown in
Figure 3, which includes the environment and PPO network. The state given in the environment is input into the PPO network for learning and training. The state quantity is scored through the critic network, and then the appropriate action is selected.
2.3.2. Action and State Space
Considering that the prediction horizon is related to historical trajectory information and road curvature, a state space was established in this section. represent the curvature of the reference trajectory, velocity, steering angle, acceleration, lateral error, and cost of the MPC system at time , respectively. Our strategy trains a PPO policy to determine for MPC. At each time step, the system’s state is measured, and the policy outputs is used to solve the MPC problem.
The prediction horizon, denoted as , is defined as a positive integer representing the maximum value of the prediction horizon. In order to adjust the output of the PPO policy, we employ linear scaling. Specifically, we limit the output to [−1, 1], which is associated with the hyperbolic tangent () function, to a new range of 1 to . This adjustment ensures that the policy output aligns with the requirements of the MPC scheme.
2.3.3. Reward Function
The policy and value function in PPO are learned directly from the reward signal. Thus, an appropriate reward function plays a crucial role in enabling the neural network in PPO to effectively converge towards the optimal solution. Our designed reward function aims to strike a balance between promoting smooth driving and maintaining an acceptable range of tracking deviation. Tracking error is closely related to control performance, and limiting the control output within the constraint range is related to the stability of MPC control. To coordinate MPC and PPO to achieve optimal performance, we design a reward function that takes into account tracking error and control output, and the reward function is denoted as follows:
where
e is a natural index,
is the lateral tracking deviation,
is the longitudinal velocity deviation, and
is the relative yaw angle error.
and
are penalty terms.
when either the steering angle or acceleration exceeds the constraint; if both exceed the constraint,
, else
.
when the lateral tracking deviation is greater than 0.15, else
.
,
, and
are the weights of the tracking error, respectively, and
,
, and
are the weights of each reward, respectively. Equation (18) adopts the form of an exponential function, which makes the gradient change more drastic, which is beneficial to the training process. The reward increases when the total tracking error decreases, and when errors are 0, the instant reward can be obtained by corresponding points.
3. Simulation and Training
In this section, to verify the validity of the strategy we proposed, we conduct training and verification at various speeds using the MATLAB/Simulink simulation platform. In addition, trajectory tracking comparisons are conducted between the PPO-MPC algorithm proposed in this article and MPC with fixed horizons. The vehicle parameters used in the simulation are outlined in
Table 1.
The PPO algorithm involves a set of hyperparameters that significantly influence the algorithm’s performance and training stability. The hyperparameter settings in reinforcement learning must be customized to the specific problem and environment to achieve optimal performance. In this study, the agent collects experiences based on the training set and stops when it reaches a 500-steps experience horizon or the terminal episode. Then it is trained for three epochs using mini-batches of 128 experiences. The objective function clip factor is set to 0.2 to enhance the stability of training, while the discount factor is set to 0.998 to promote long-term rewards. The Generalized Advantage Estimate (GAE) method reduces the variance in critic output with a GAE factor of 0.95.
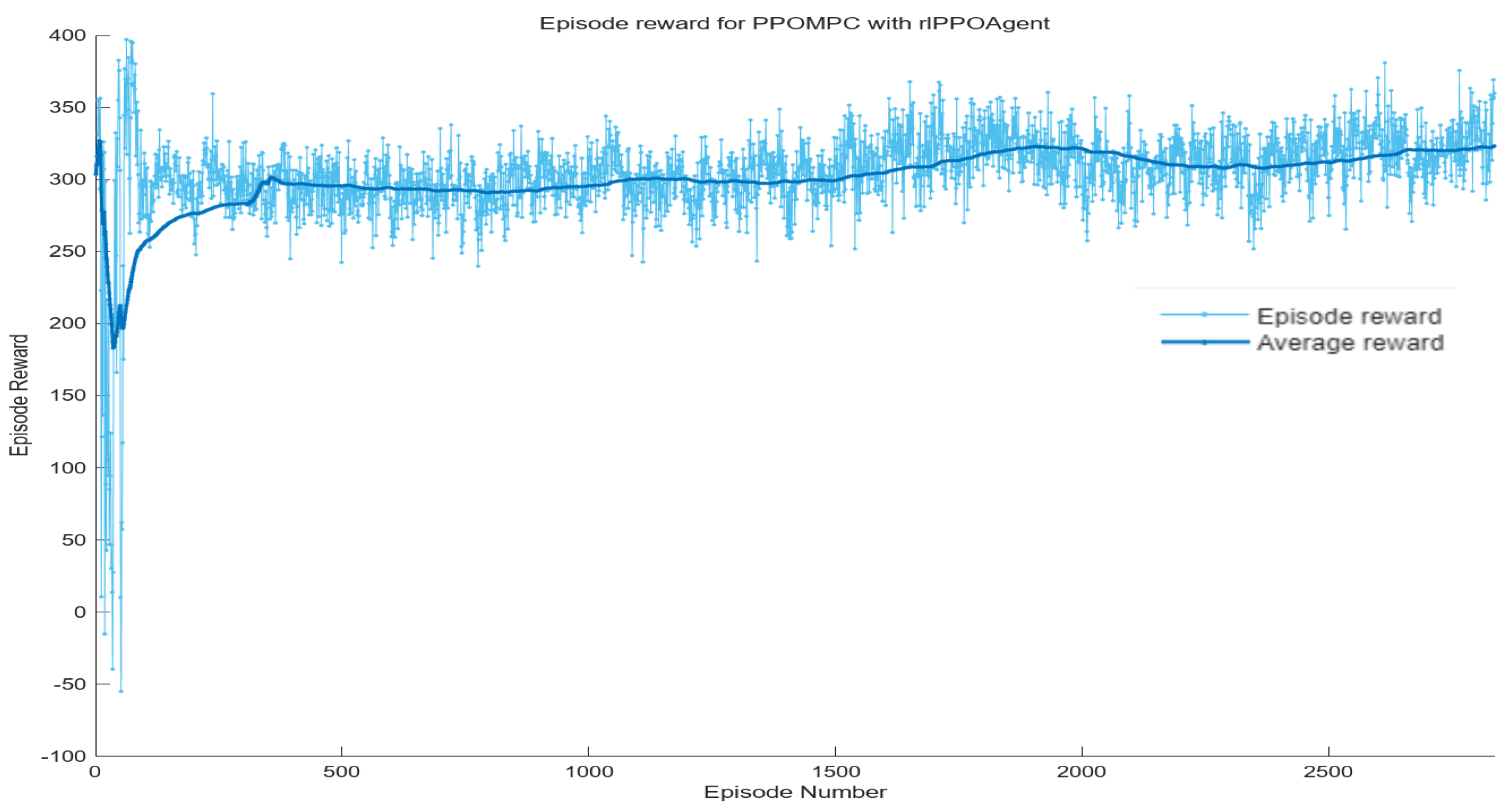
Based on the aforementioned simulation environment, training was conducted for up to 10,000 episodes, with each episode spanning up to 500 steps.
Figure 4 depicts the training results. The light blue line represents the cumulative reward obtained by the agent at the end of each round; the thick line describes the average reward value of all rounds during the training process. In the early stages of training, PPO reinforcement learning explores various actions through interactions with the environment to achieve the overall optimal outcome. In this experiment, after 300 rounds, the model finally converged stably, showing good training effects.
4. Results and Discussion
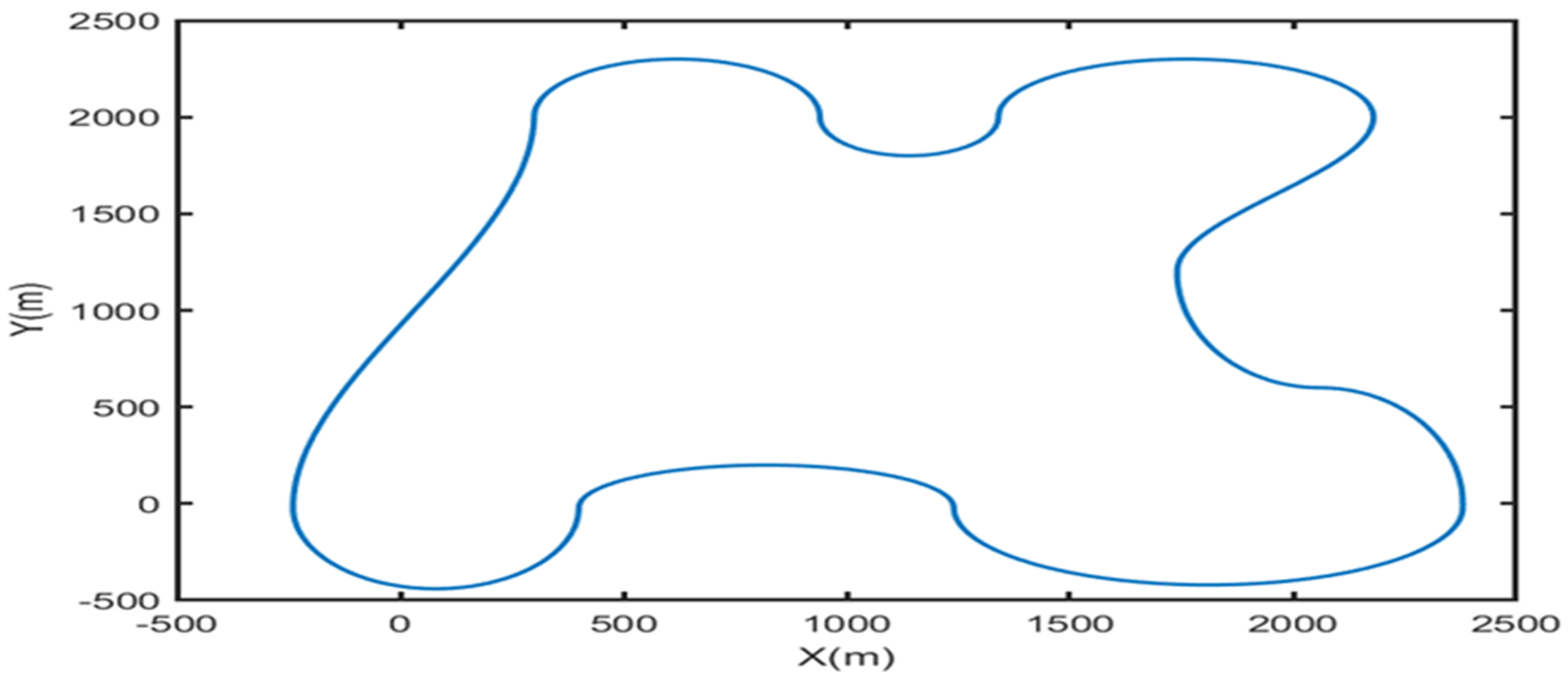
PPO-MPC is simulated and verified at different speeds, and its trajectory tracking performance is analyzed in this section. In addition, PPO-MPC was compared with MPC under fixed prediction horizons at different speeds, and their performance was discussed. The pre-calculated reference path is shown in
Figure 5, with a total length of 12,000 m.
4.1. Performance of Trajectory Tracking Using PPO-MPC
In this section, simulation verification of PPO-MPC was performed at various velocities (, , and , respectively), and an analysis of its trajectory tracking performance during operation was conducted.
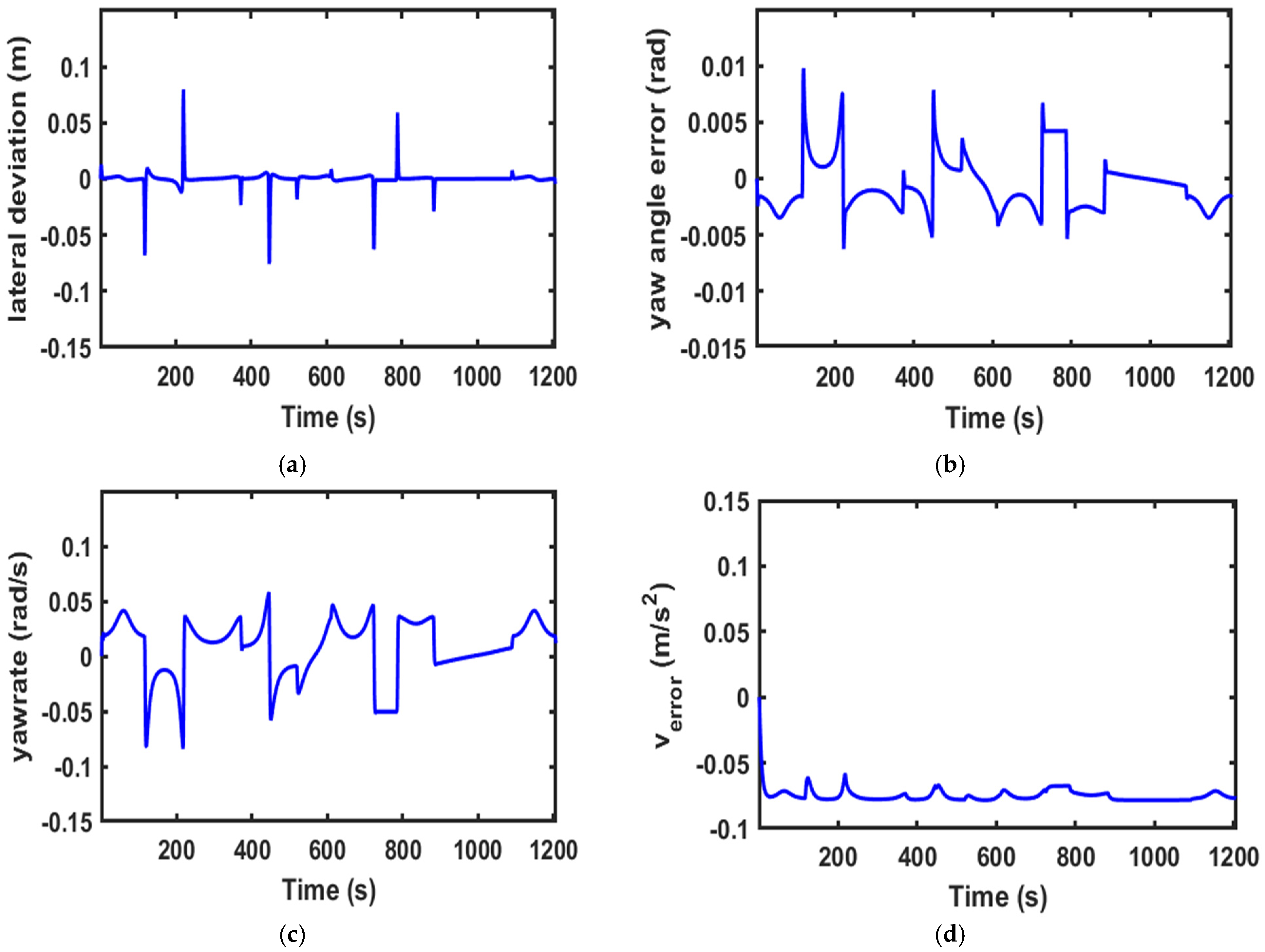
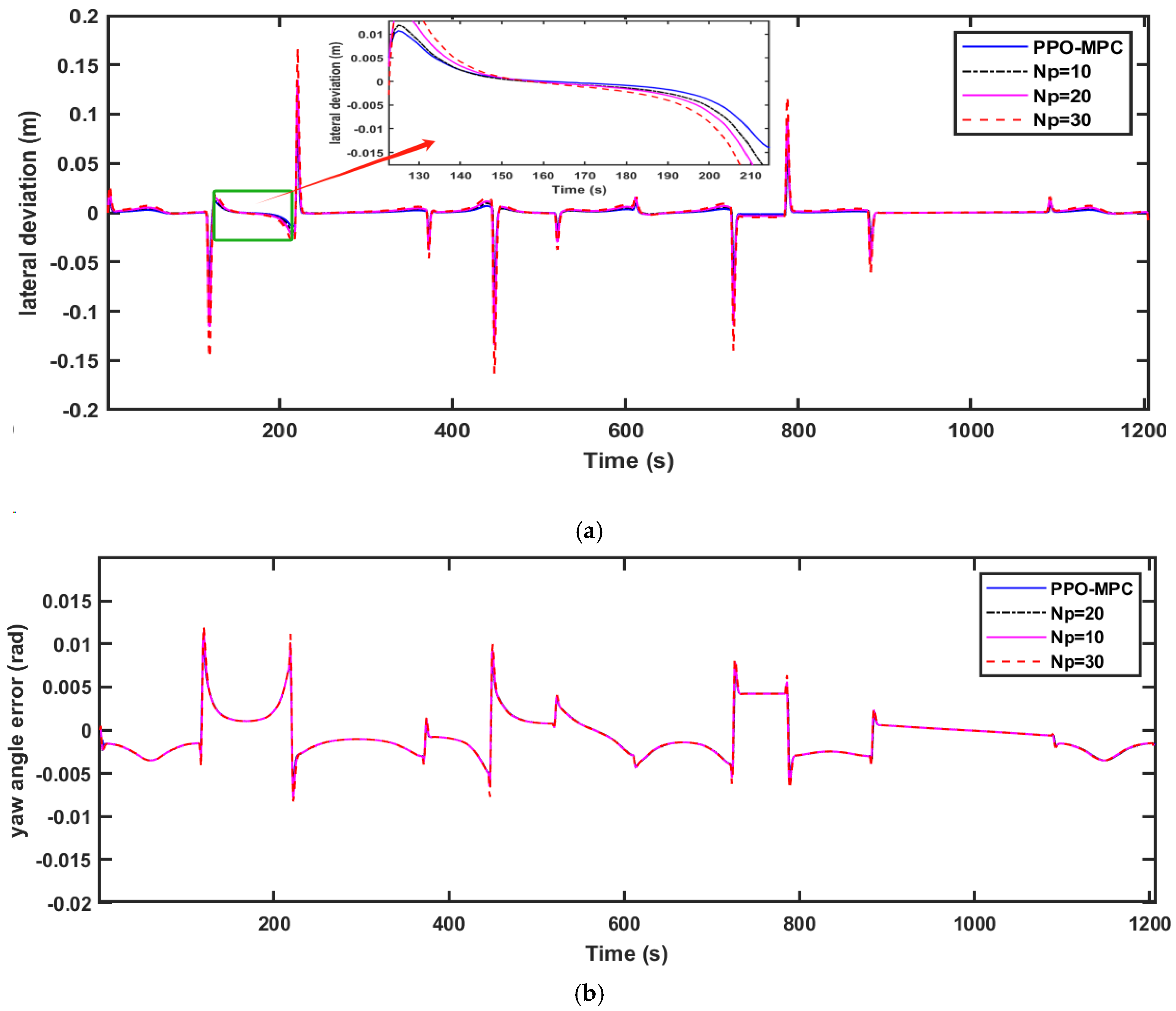
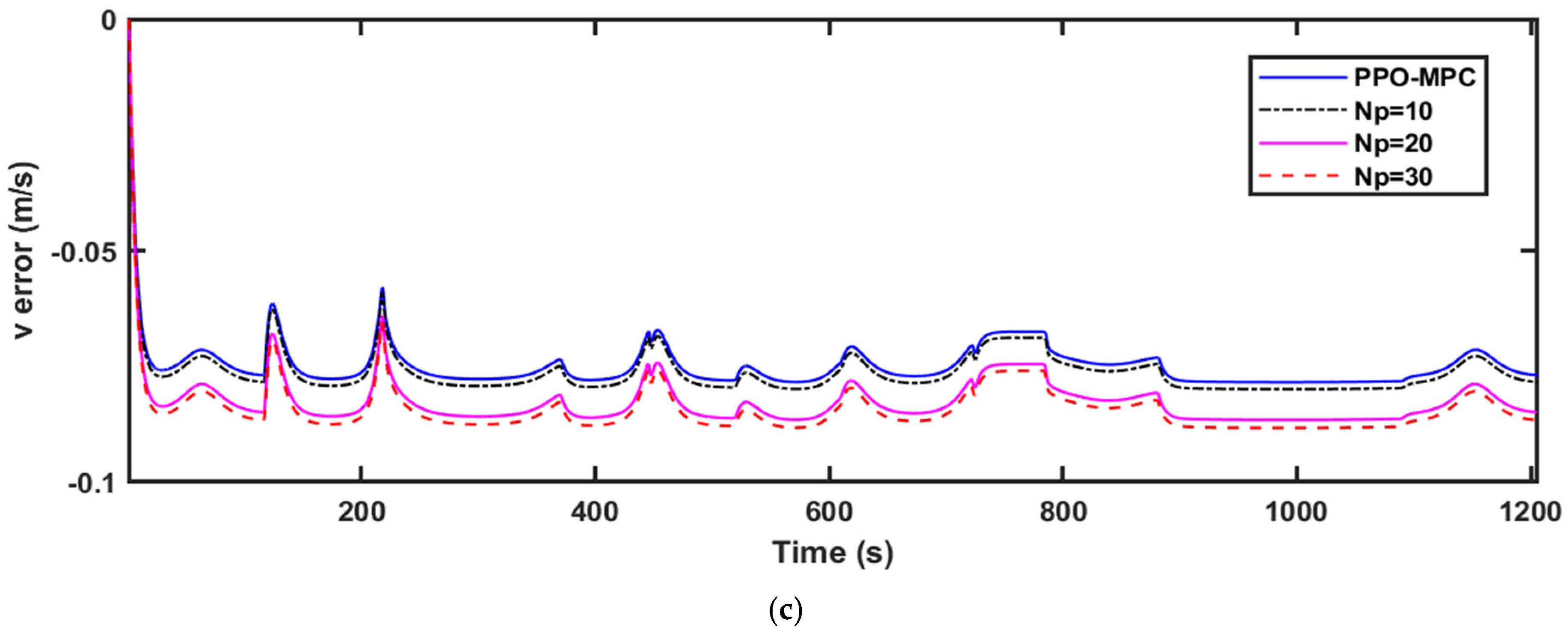
Figure 6,
Figure 7 and
Figure 8 illustrate the vehicle control results of our proposed control strategy at
,
, and
. The PPO-MPC controller showed excellent performance by effectively adjusting the acceleration and steering angle output within the predefined constraint range, except for some fluctuations at the beginning of the simulation in
Figure 8, which quickly stabilized.
Figure 6a,
Figure 7a and
Figure 8a reveal the vehicle’s lateral deviation changes. Large lateral errors may occur where the curvature suddenly changes, and otherwise remain near 0, indicating that the control system has a good ability to keep the vehicle close to the desired trajectory.
Figure 6b,
Figure 7b and
Figure 8b illustrate heading angle error changes, with the maximum value not exceeding 0.05. This shows that the vehicle has good performance in tracking the expected direction. Changes in the yaw rate, as depicted in
Figure 6c,
Figure 7c and
Figure 8c, generally demonstrate low values, suggesting smooth steering operations, mitigated risk of abrupt rolling or sharp turning, and enhanced driving stability. Moreover,
Figure 6d,
Figure 7d and
Figure 8d illustrate speed error changes; even at maximum speed, the speed error for stable operation always remains small, with the error limited within 0.2 m/s.
From the above analysis, it can be concluded that the PPO-MPC controller shows good performance at various speeds. And PPO-MPC effectively maintains the trajectory, direction, and stability of the vehicle, indicating that the strategy has good adaptability in different scenarios.
4.2. Performance Comparison of the Trajectory Tracking Using PPO-MPC and Model Predictive Control
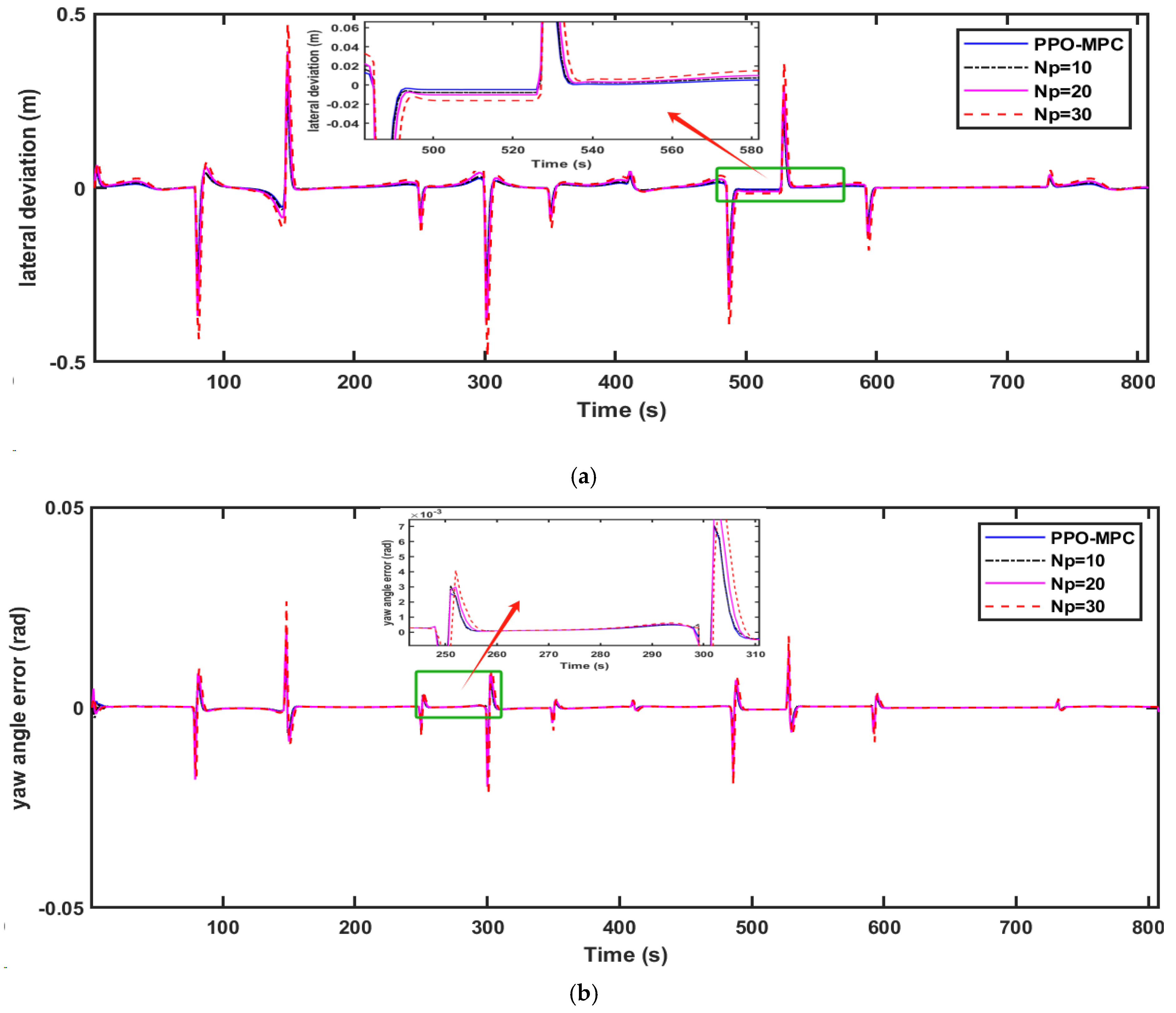
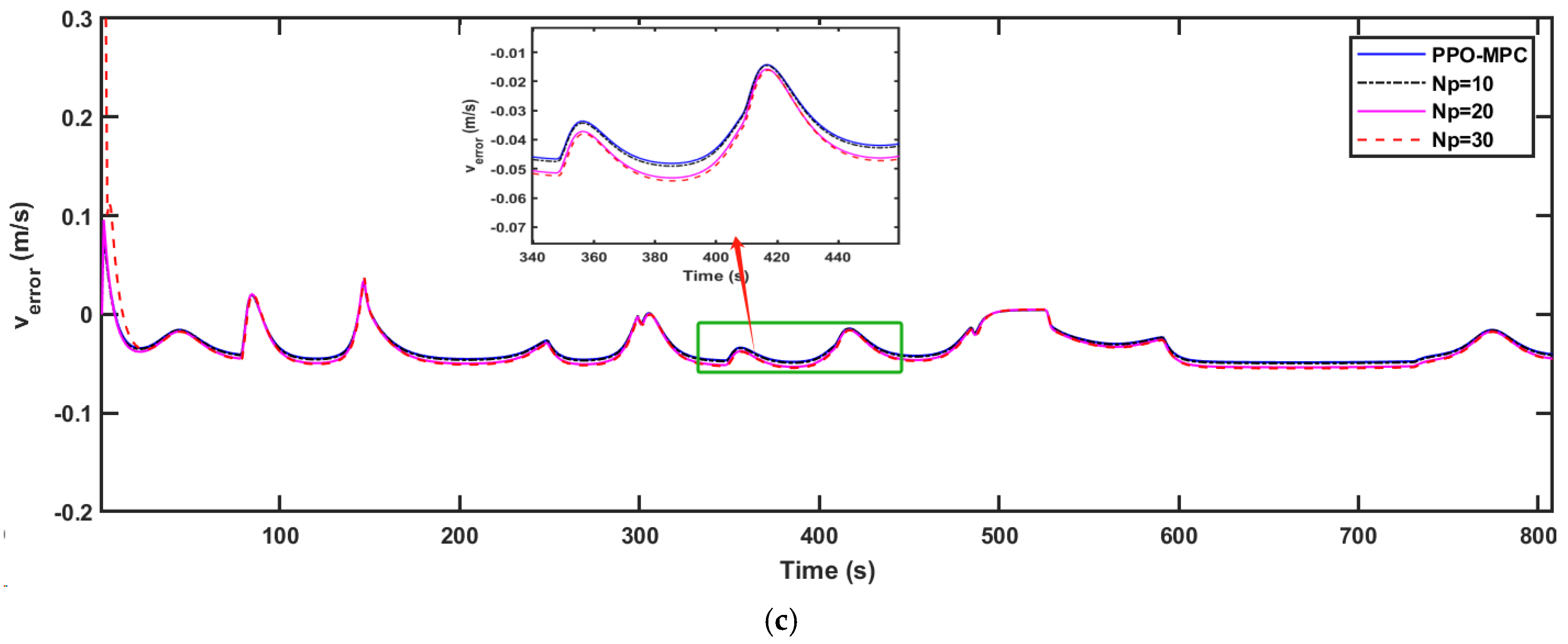
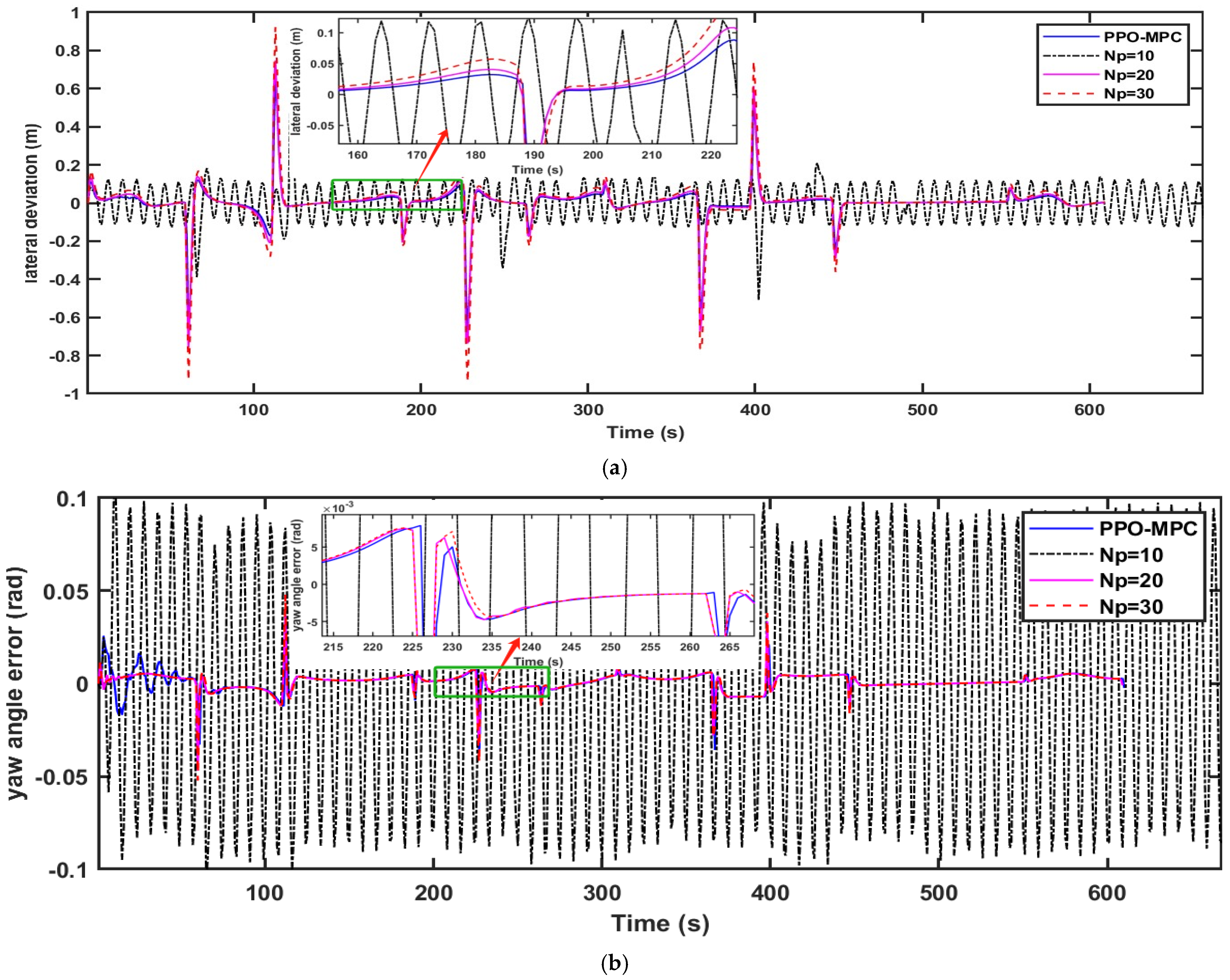
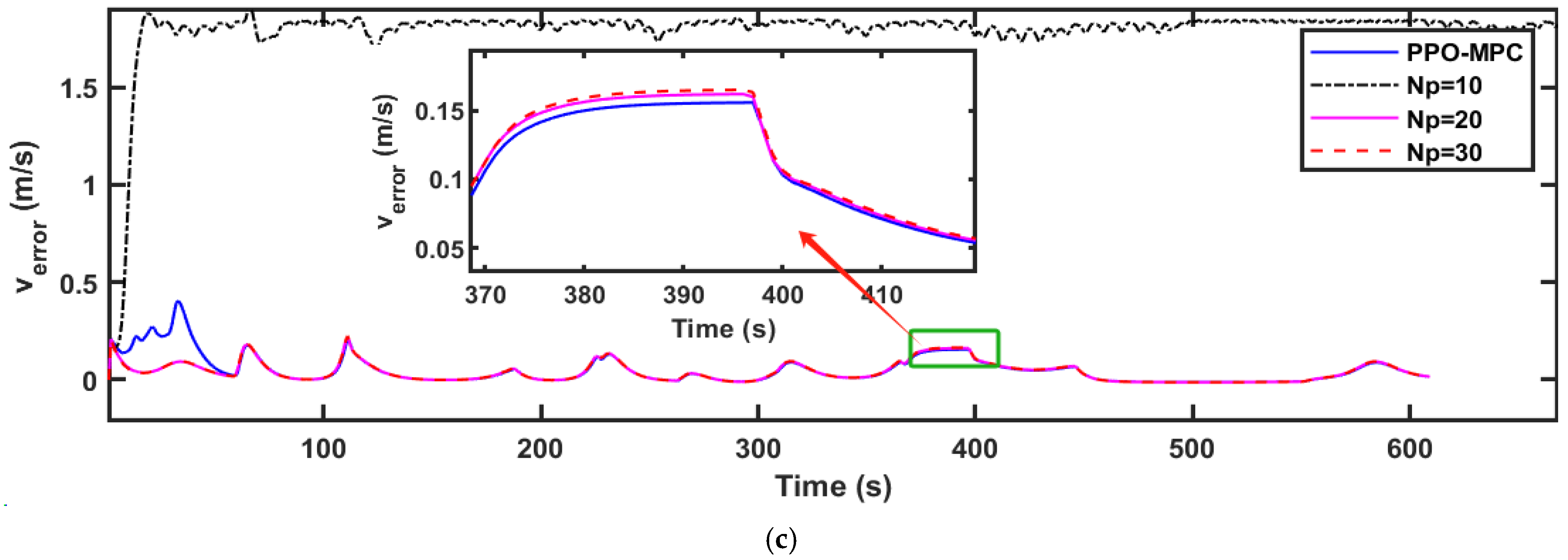
To further illustrate the advantages of the PPO-MPC strategy, we conducted a comparison between PPO-MPC and the conventional MPC strategy with fixed prediction horizons. In the simulated design, we conducted a comparison between PPO-MPC and MPC with fixed horizons of 10, 20, and 30 and the control horizon set to 3.
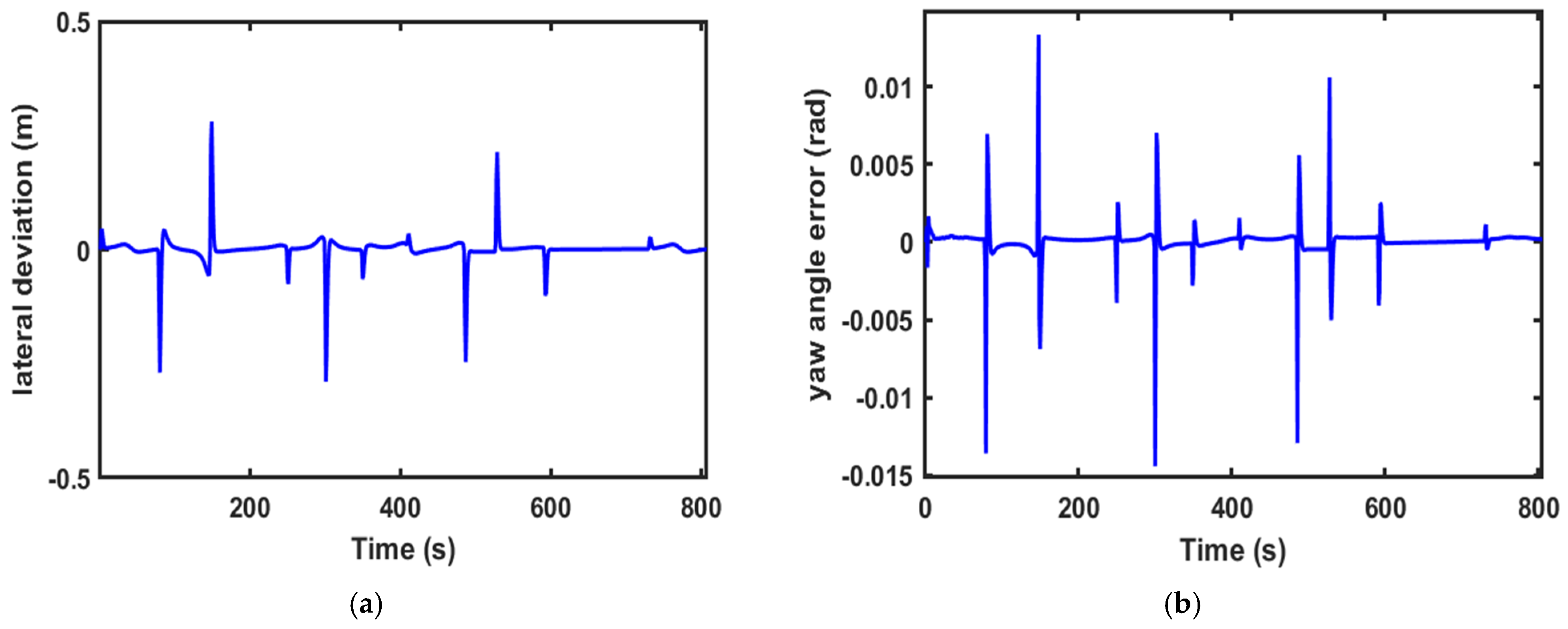
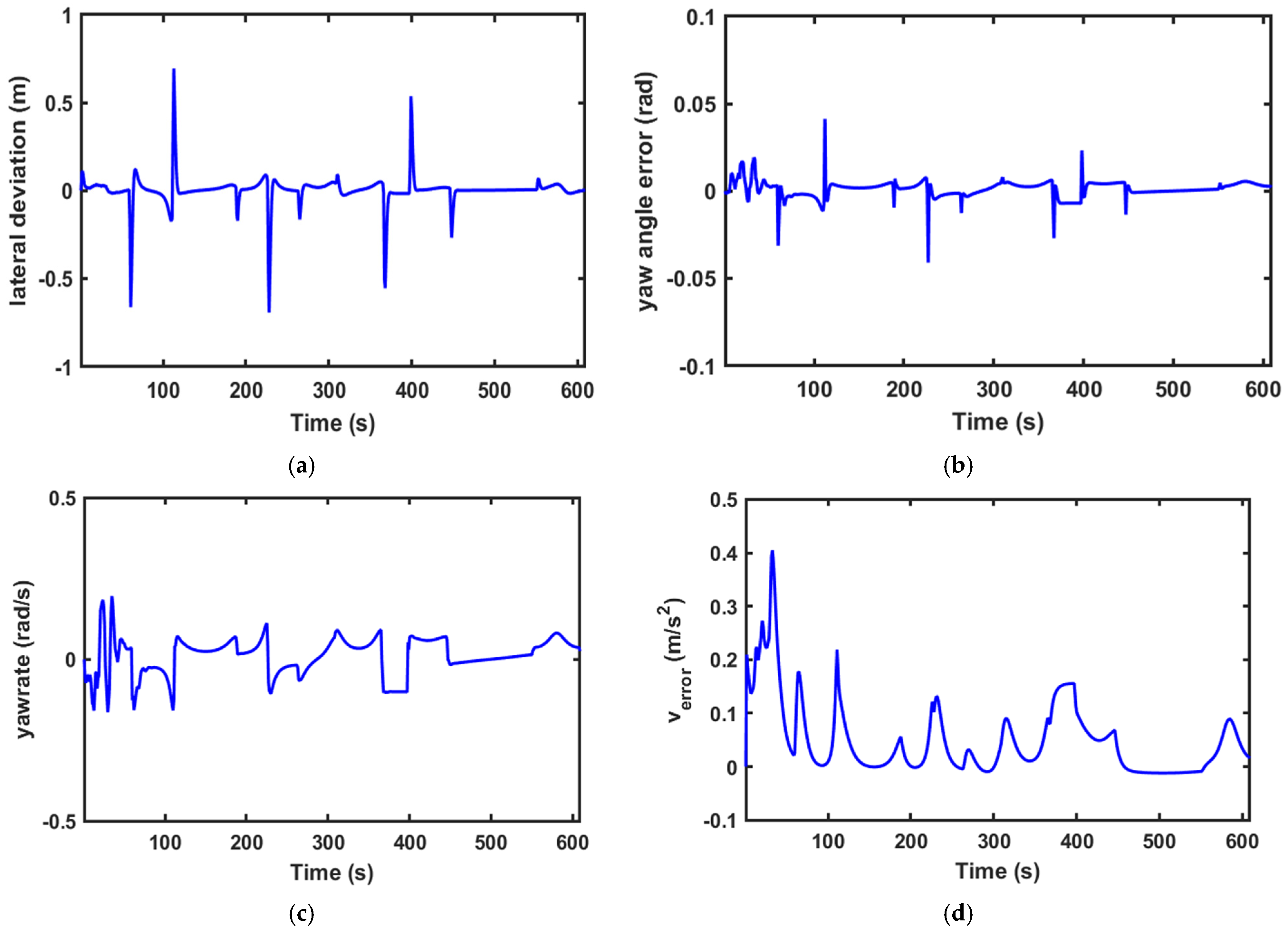
Comparisons of the simulation data are shown in
Figure 9,
Figure 10 and
Figure 11. As shown in
Figure 11, it is easy to see that MPC with a fixed range of 10 fails to converge and is unstable at
.
Figure 9a,
Figure 10a and
Figure 11a clearly show that compared with MPC with static prediction horizons, PPO-MPC generally has better lateral deviation and exhibits superior trajectory tracking capabilities. The maximal lateral deviation of MPC may even be twice that of PPO-MPC, suggesting that the MPC with fixed prediction horizons may be subject to have greater lateral disturbance or challenges under certain circumstances.
Figure 9b,
Figure 10b and
Figure 11b show that the heading error of PPO-MPC is almost the same as MPC with static prediction horizons at
, and the PPO-MPC heading error at
is smaller. Moreover, although PPO-MPC jittered at the beginning at
, it quickly stabilized and resulted in a smaller heading error.
Figure 9c,
Figure 10c and
Figure 11c show that, except for the jitter that occurs at the beginning of the simulation when
, the overall performance of the PPO-MPC speed error is smaller.
According to [
37], we introduce an index which quantitatively measures the tracking performance and is achieved as
where
represents the simulation duration time and
represents the controller sampling step. The tracking performance indexes of simulations are provided in
Table 2.
, , and denote the lateral, heading, and speed tracking accuracy, respectively. While ensuring dynamic stability, it is not difficult to find that, compared with MPC, the PPO-MPC tracking accuracy is improved, except that the speed tracking accuracy of PPO-MPC at is smaller than MPC, with . Analysis shows the superiority of the proposed PPO-MPC path-tracking controller.
5. Conclusions
In this paper, we present a novel PPO-MPC strategy, which integrates proximal policy optimization (PPO) with model predictive control (MPC), using the PPO reinforcement learning algorithm to dynamically adapt the prediction horizon of MPC. The proposed strategy was evaluated and validated using the MATLAB/Simulink simulation environment across three distinct operating speeds. Additionally, comparations were conducted against conventional MPC employing static prediction horizons under analogous conditions. From the analysis of simulation results, it can be seen that the PPO-MPC framework is better than the traditional model predictive controller with a fixed prediction range, and has superior tracking performance and robustness.
In the future, PPO-MPC can be explored through multi-objective optimization methods. Co-optimizing the prediction horizon with other key MPC parameters (such as control weights and constraints) is expected to achieve more powerful and efficient vehicle control strategies. And it may achieve adaptive trajectory control in various scenarios. In addition, adding the RL differential prediction model to the MPC prediction model to achieve better adaptive control is also a major idea for improving automatic driving control performance.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}