
A Novel Framework for Risk Warning That Utilizes an Improved Generative Adversarial Network and Categorical Boosting

Abstract
:1. Introduction
- (1)
- We introduce a novel SALGAN-CatBoost-SSAGA framework for small-sample risk warning.
- (2)
- We propose a SALGAN that generates virtual data according to label types, effectively enhancing small-sample data.
- (3)
- We present a hybrid algorithm, the SSAGA, which combines the SSA and GA to optimize the parameters of the standard CatBoost model, which could improve the prediction accuracy of the CatBoost model.
- (4)
- We conduct small-sample prediction experiments using the UCI heart disease dataset, which demonstrates the advantages of the proposed model in terms of its classification accuracy, recall, precision, F1-score, and AUC, indicating its effectiveness in predicting small-sample data.
2. Related Work
2.1. Few-Shot Learning
2.2. CatBoost Algorithm
2.3. Hyperparameter Optimization Algorithm
3. Preliminaries
3.1. CatBoost
3.2. SSA
4. Model Construction
4.1. Framework
- (1)
- Data cleaning
- (2)
- Data augmentation
- (3)
- Risk-warning prediction
- (4)
- Model evaluation
4.2. Data Cleaning
- (1)
- Missing value interpolation
- (2)
- Outlier removal
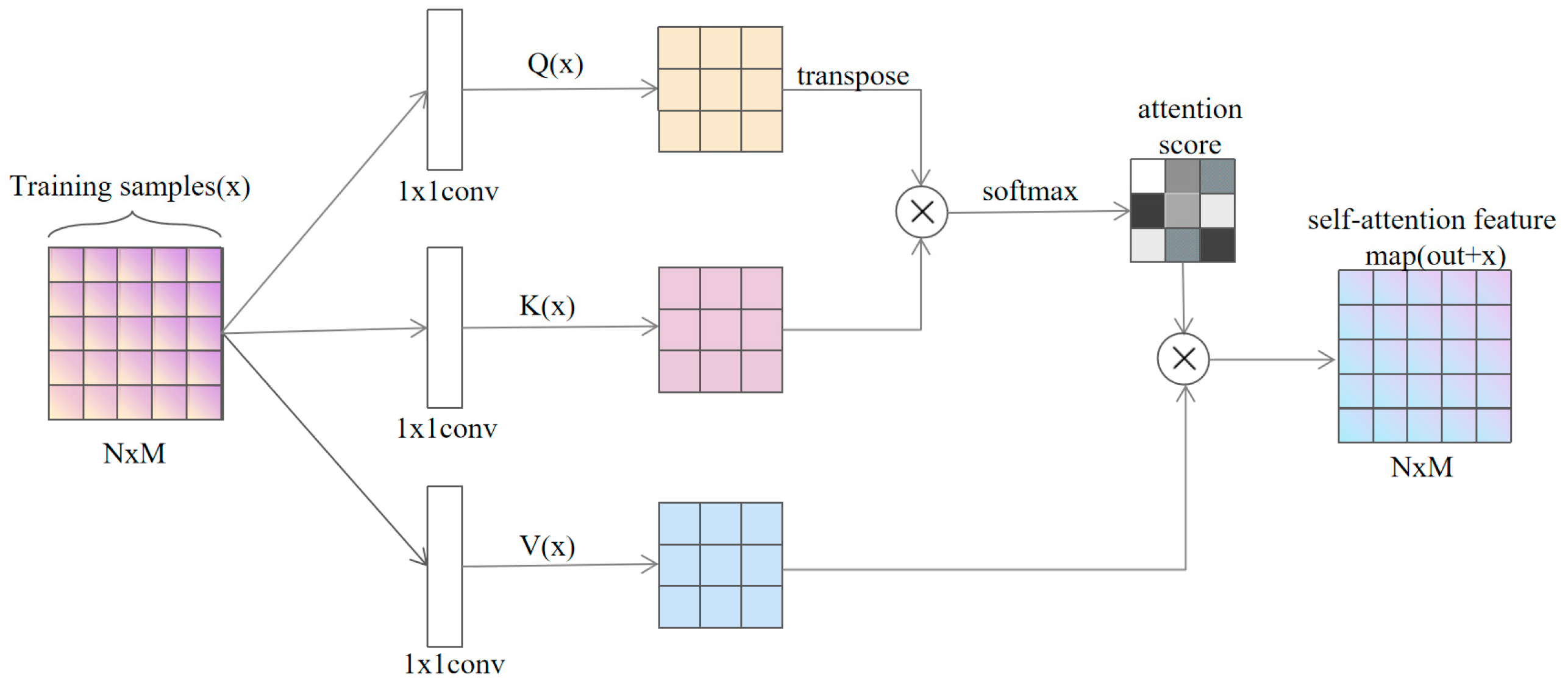
4.3. Data Augmentation Based on the SALGAN
- Generator G
- 2.
- Discriminator D
4.4. Risk-Warning Model Based on CatBoost-SSAGA
4.4.1. SSAGA
- Sparrow Search Algorithm Phase: Initially, each sparrow’s performance in the population is evaluated using a fitness function, identifying the current optimal- and least-fit individuals. Subsequently, the location of the sparrow population is updated. In each iteration, sparrows adjust their positions based on the current best (best_sparrow) and worst (worst_sparrow) locations. This updating mechanism mimics sparrows’ foraging behavior, where some sparrows converge towards the best solution (leader sparrows and followers), while others explore in the opposite direction of the worst solution (scouts). The updated parameter values are constrained within their valid range.
- Genetic Algorithm Phase: Parental selection is conducted using the select_parents() function, employing a roulette-wheel selection method based on the fitness function, with the selection probability being proportional to the expected fitness. A crossover operation on the selected parental individuals is performed using the crossover() function, where a crossover point is randomly chosen to mix the genes of two parental individuals in a certain proportion. Mutation operation on post-crossover individuals is executed using the mutate() function, introducing random perturbations to certain genes of the individuals. The new individuals obtained from the crossover and mutation are merged with the original population to form a new Genetic Algorithm population.
- Optimal Individual Update: The Sparrow Search Algorithm and Genetic Algorithm populations are merged, and the optimal individual is selected based on the fitness function, specifically the individual with the lowest fitness function value.
- Termination Condition Assessment: The iteration process concludes when either the maximum number of iterations is reached or specific stopping criteria are satisfied (e.g., the fitness function value falls below a certain threshold).
4.4.2. CatBoost-SSAGA
| Algorithm 1. CatBoost-SSAGA |
| Input: Population size P, Dimension D, Upper bound ub, Lower bound lb, Maximum iterations ε, Strategy parameter S. Output: Best fitness value fGb and Best position XGb. 1. Initialize empty lists: X = [], F = [] 2. Generate initial population for SSA and GA: a. For SSA (Sparrow Search Algorithm): - Use initialize_sparrows function with inputs pop_size = P, dimension = D, lb, and ub to create sparrows population b. For GA (Genetic Algorithm): - Use initialize_ga_population function with the same inputs to create GA population c. Combine both populations: X = SSA population + GA population 3. For each iteration t from 1 to ε: a. Calculate decay rate ϵ = 1–(t/ε) b. For each individual I in X: - Evaluate fitness using evaluate_fitness function - F = CatBoost.fit(X) c. Get Xb, fb, Xw, fw d. Update positions of first pdNum individuals in X using SSA strategy: - Apply update_sparrow_positions_enhanced influenced by Xb and Xw e. Update positions of remaining individuals in X using GA strategy: - Select parents from X - Perform crossover and mutation to generate new offspring - Replace corresponding individuals in X with new offspring f. Re-evaluate fitness of entire population X g. If a better fitness is found (indicating higher accuracy from CatBoost), update fGb and XGb h. End 4. Return fGb and XGb |
- (1)
- Data Preparation and Preprocessing: The complexity of the data loading and preprocessing is typically O(n × m), where n is the number of samples and m is the number of features.
- (2)
- Parameter Optimization and Model Training
- (3)
- Optimal Solution Selection: The complexity of selecting the optimal solution from the merged population is O(pop_size), because it needs to iterate in the population to find the individual with the highest fitness.
4.5. Indicators of Model Evaluation
5. Experiments
5.1. Datasets and Preprocessing
- Datasets
- 2.
- Preprocessing
- 3.
- Model training
5.2. Comparative Experiments
- Performance comparison between different algorithms
- 2.
- Impact of data augmentation on prediction results
- 3.
- Impact of parameter optimization on prediction results
- 4.
- Ablation experiments
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhao, K.; Jin, X.; Wang, Y. Survey on few-shot learning. J. Softw. 2021, 32, 349–369. [Google Scholar]
- Ansarullah, S.I.; Kumar, P. A systematic literature review on cardiovascular disorder identification using knowledge mining and machine learning method. Int. J. Recent Technol. Eng. 2019, 7, 1009–1015. [Google Scholar]
- Yekkala, I.; Dixit, S.; Jabbar, M.A. Prediction of heart disease using ensemble learning and Particle Swarm Optimization. In Proceedings of the 2017 International Conference on Smart Technologies for Smart Nation (SmartTechCon), Bengaluru, India, 17–19 August 2017; pp. 691–698. [Google Scholar]
- Li, F.F.; Fergus, R.; Perona, P. One-shot learning of object categories. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 594–611. [Google Scholar]
- Liu, Y.; Long, M.; Cao, Z.; Wang, J. Few-Shot Object Recognition from Machine-Labeled Web Images. IEEE Trans. Image Process. 2020, 29, 594–611. [Google Scholar]
- Wang, X.; Huang, T.E.; Darrell, T.; Gonzalez, J.E.; Yu, F. Frustratingly Simple Few-Shot Object Detection. arXiv 2020. [Google Scholar] [CrossRef]
- Wang, J.; Chen, Y. Introduction to Transfer Learning; Electronic Industry Press: Beijing, China, 2021. [Google Scholar]
- Hu, X.; Chen, S. A survey of few-shot learning based on machine learning. Intell. Comput. Appl. 2021, 11, 191–195+201. [Google Scholar]
- Zhu, X.; Ghahramani, Z.; Lafferty, J.D. Semi-Supervised Learning Using Gaussian Fields and Harmonic Functions. In Proceedings of the Twentieth International Conference on Machine Learning (ICML 2003), Washington, DC, USA, 21–24 August 2003; pp. 912–919. [Google Scholar]
- Gliozzo, J.; Mesiti, M.; Notaro, M.; Petrini, A.; Patak, A.; Puertas-Gallardo, A.; Paccanaro, A.; Valentini, G.; Casiraghi, E. Heterogeneous data integration methods for patient similarity networks. Brief. Bioinform. 2022, 23, bbac207. [Google Scholar] [CrossRef]
- Schwartz, E.; Karlinsky, L.; Shtok, J.; Harary, S.; Marder, M.; Kumar, A.; Feris, R.; Giryes, R.; Bronstein, A. Delta-encoder: An effective sample synthesis method for few-shot object recognition. Adv. Neural Inf. Process. Syst. 2018, 31, 2850–2860. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar]
- Kataoka, Y.; Matsubara, T.; Uehara, K. Image generation using generative adversarial networks and attention mechanism. In Proceedings of the 2016 IEEE/ACIS 15th International Conference on Computer and Information Science (ICIS), Okayama, Japan, 26–29 June 2016; pp. 1–6. [Google Scholar]
- Park, N.; Mohammadi, M.; Gorde, K.; Jajodia, S.; Park, H. Data Synthesis based on Generative Adversarial Networks. Proc. VLDB Endow. 2018, 11, 1071–1083. [Google Scholar] [CrossRef]
- Dorogush, A.V.; Ershov, V.; Gulin, A. CatBoost: Gradient boosting with categorical features support. arXiv 2018, arXiv:1810.11363. [Google Scholar]
- Diao, L.; Niu, D.; Zang, Z.; Chen, C. Short-term weather forecast based on wavelet denoising and catboost. In Proceedings of the 2019 Chinese Control Conference (CCC), Guangzhou, China, 27–30 July 2019; pp. 3760–3764. [Google Scholar]
- Kumar, P.S.; Kumari, A.; Mohapatra, S.; Naik, B.; Nayak, J.; Mishra, M. CatBoost ensemble approach for diabetes risk prediction at early stages. In Proceedings of the 2021 1st Odisha International Conference on Electrical Power Engineering, Communication and Computing Technology (ODICON), Bhubaneswar, India, 8–9 January 2021; pp. 1–6. [Google Scholar]
- Wang, B.; Feng, H.; Wang, F.; Qin, X.; Huang, P.; Dang, D.; Zhao, J.; Yi, J. Application of CatBoost model based on machine learning in predicting severe hand-foot-mouth disease. Chin. J. Infect. Control 2019, 18, 12–16. [Google Scholar]
- Chen, D.; Chen, Y.; Feng, X.; Wu, S. Retrieving suspended matter concentration in rivers based on hyperparameter optimized CatBoost algorithm. J. Geo-Inf. Sci. 2022, 24, 780–791. [Google Scholar]
- Jin, C.; Yu, J.; Wang, Q.; Chen, L.J. Prediction of blasting Fragment large block percentage ratio based on ensemble learning CatBoost model. J. Northeast. Univ. (Nat. Sci.) 2023, 44, 1743–1750. [Google Scholar]
- Xu, L.; Guo, C. Predicting Survival rates for gastric cancer based on ensemble learning. Data Anal. Knowl. Discov. 2021, 5, 86–99. [Google Scholar]
- Yang, C.; Liu, L.; Zhang, Y.; Zhu, W.; Zhang, S. Machine learning based on landslide susceptibility assessment with Bayesian optimized the hyper parameters. Bull. Geol. Sci. Technol. 2022, 41, 228–238. [Google Scholar]
- Tikhamarine, Y.; Souag-Gamane, D.; Kisi, O. A new intelligent method for monthly streamflow prediction: Hybrid wavelet support vector regression based on grey wolf optimizer (WSVR-GWO). Arab. J. Geosci. 2019, 12, 540. [Google Scholar] [CrossRef]
- Feng, T.; Peng, Y.; Wang, J. ISGS: A combinatorial model for hysteresis effects. Acta Electron. Sin. 2023, 51, 2504–2509. [Google Scholar]
- Xue, J.; Shen, B. A novel swarm intelligence optimization approach: Sparrow search algorithm. Syst. Sci. Control Eng. 2020, 8, 22–34. [Google Scholar] [CrossRef]
- Meng, K.; Chen, C.; Xin, B. MSSSA: A multi-strategy enhanced sparrow search algorithm for global optimization. Front. Inf. Technol. Electron. Eng. 2022, 23, 1828–1847. [Google Scholar] [CrossRef]
- Ou, Y.; Yu, L.; Yan, A. An Improved Sparrow Search Algorithm for Location Optimization of Logistics Distribution Centers. J. Circuits Syst. Comput. 2023, 32, 2350150. [Google Scholar] [CrossRef]
- Wang, J.; Wang, Z.; Li, J.; Peng, Y. An Interpretable Depression Prediction Model for the Elderly Based on ISSA Optimized LightGBM. J. Beijing Inst. Technol. 2023, 32, 168–180. [Google Scholar]
- Janosi, A.; Steinbrunn, W.; Pfisterer, M.; Detrano, R. Heart Disease. UCI Machine Learning Repository. 1988. Available online: https://archive.ics.uci.edu/dataset/45/heart+disease (accessed on 9 April 2024).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Positive | Negative | |
|---|---|---|
| True | True Positive (TP) | True Negative (TN) |
| False | False Positive (FP) | False Negative (FN) |
| Name | Description |
|---|---|
| Age | Continuously variable values |
| Sex | 0 = Female |
| 1 = Male | |
| Cp | 0 = Classic angina pectoris |
| 1 = Atypical angina pectoris | |
| 2 = Non-angina pectoris | |
| 3 = Asymptomatic | |
| Trestbps | Continuously variable values |
| Chol | Continuously variable values |
| Fbs | 0 = <120mg/d |
| 1 = >120mg/d | |
| Restecg | 0 = Normal |
| 1 = Existence of a segment exception | |
| 2 = Possible or definite left ventricular hypertrophy | |
| Thalach | Continuously variable values |
| Exang | 0 = No |
| 1 = Yes | |
| Oldpeak | Continuously variable values |
| Slope | 0 = Up |
| 1 = Float | |
| 2 = Down | |
| Ca | 0 |
| 1 | |
| 2 | |
| 3 | |
| Thal | 1 = Normal |
| 2 = Irreparable | |
| 3 = Reparable | |
| Target | 0 = No |
| 1 = Yes |
| Name | Optimization Scope | SSAGA-CatBoost |
|---|---|---|
| learning_rate | [0.001, 0.2] | 0.00298 |
| max_depth | [4, 10] | 9 |
| n_estimators | [1100, 1500] | 1153 |
| reg_lambda | [0.01, 10] | 2.62938 |
| subsample | [0.9, 1] | 0.98761 |
| Model | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| RF | 79.71 ± 0.03 | 81.29 ± 0.03 | 79.14 ± 0.05 | 80.10 ± 0.03 |
| lightGBM | 77.78 ± 0.02 | 79.52 ± 0.03 | 77.18 ± 0.06 | 78.16 ± 0.03 |
| xgBoost | 77.37 ± 0.02 | 78.85 ± 0.03 | 77.17 ± 0.04 | 77.90 ± 0.03 |
| AdaBoost | 71.66 ± 0.03 | 72.66 ± 0.02 | 72.65 ± 0.06 | 72.55 ± 0.03 |
| Decision Tree | 71.15 ± 0.03 | 72.76 ± 0.03 | 70.87 ± 0.04 | 71.76 ± 0.03 |
| SALGAN-CatBoost-SSAGA | 90.56 ± 0.01 | 87.79 ± 0.02 | 87.45 ± 0.03 | 87.54 ± 0.02 |
| Datasets | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| Before | 79.57 ± 0.04 | 79.94 ± 0.05 | 79.58 ± 0.07 | 79.50 ± 0.04 |
| After | 87.83 ± 0.01 | 87.87 ± 0.02 | 87.81 ± 0.02 | 87.81 ± 0.01 |
| Algorithm | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| SSA | 89.45 ± 0.02 | 86.57 ± 0.07 | 85.63 ± 0.09 | 86.63 ± 0.07 |
| GA | 87.58 ± 0.02 | 84.03 ± 0.08 | 83.27 ± 0.1 | 83.87 ± 0.09 |
| SSAGA | 90.56 ± 0.01 | 87.79 ± 0.02 | 87.45 ± 0.03 | 87.54 ± 0.02 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peng, Y.; Liu, Y.; Wang, J.; Li, X. A Novel Framework for Risk Warning That Utilizes an Improved Generative Adversarial Network and Categorical Boosting. Electronics 2024, 13, 1538. https://doi.org/10.3390/electronics13081538
Peng Y, Liu Y, Wang J, Li X. A Novel Framework for Risk Warning That Utilizes an Improved Generative Adversarial Network and Categorical Boosting. Electronics. 2024; 13(8):1538. https://doi.org/10.3390/electronics13081538
Chicago/Turabian StylePeng, Yan, Yue Liu, Jie Wang, and Xiao Li. 2024. "A Novel Framework for Risk Warning That Utilizes an Improved Generative Adversarial Network and Categorical Boosting" Electronics 13, no. 8: 1538. https://doi.org/10.3390/electronics13081538
APA StylePeng, Y., Liu, Y., Wang, J., & Li, X. (2024). A Novel Framework for Risk Warning That Utilizes an Improved Generative Adversarial Network and Categorical Boosting. Electronics, 13(8), 1538. https://doi.org/10.3390/electronics13081538