1. Introduction
In the fast-changing world of 5G and emerging 6G networks [
1,
2,
3], precise and efficient object detection in deep neural networks (DNNs) is crucial. Object detection is essential in various applications, including autonomous vehicles, smart surveillance, and augmented reality, where models must be both accurate and computationally efficient.
Despite the remarkable success of deep neural networks in various tasks [
4,
5,
6], their widespread adoption is hindered by the high computational costs due to the large number of parameters. To address this issue, several methods [
7,
8,
9,
10] have been proposed to reduce the computational cost of deep learning models. One effective technique is Knowledge Distillation (KD), which involves transferring knowledge from a high-capacity teacher to a low-capacity student model. This knowledge transfer enhances the accuracy-efficiency tradeoff of the student model during runtime. This Shared Knowledge Distillation approach is a powerful methodology for refining object detection models, ensuring they can handle current network infrastructures and meet future 5G/6G network demands.
The initial approach of Knowledge Distillation (KD) [
11] utilizes the logit outputs of the teacher network as a source of knowledge. To enhance this knowledge transfer, feature distillation techniques [
7,
8] have been introduced to encourage the student network to emulate the intermediate features of the teacher network. Subsequent studies [
8,
12,
13,
14,
15,
16] have focused on extracting and aligning informative features through various loss functions and transformations. However, these methods primarily concentrate on feature pairs within the same layer of the teacher–student network, disregarding the potential advantages of cross-layer feature transfer. The dissimilarities in shape and semantics between cross-layer features present optimization challenges and may result in information loss during feature transformations. Recent research has explored meta-learning approaches to identify optimal cross-layer feature pairs, which adds complexity to the optimization process. On the other hand, a different study [
17] suggests that the front layer features of the teacher network are more valuable for student training and proposes a complex residual feature and fusion module for cross-layer distillation. In contrast, AFD [
18] argues that the last layer features of the teacher network contain more relevant knowledge and proposes self-attention strategies to align cross-layer features in the spatial dimension, and whereas these approaches achieve performance improvements by leveraging cross-layer feature knowledge, their reliance on intricate feature transformations and matching strategies limits their practical usability.
In order to tackle these challenges, we introduce a straightforward and efficient framework called Shared Knowledge Distillation (Shared-KD), as shown in
Figure 1. In contrast to existing methods of cross-layer feature distillation, our approach proposes a novel two-step process for decomposing the original cross-layer feature supervision from teachers to students. This process includes identical-layer distillation between teacher and student networks and cross-layer distillation within the student network itself. The first step focuses on identical-layer distillation, which shares similarities in shape and semantics between the teacher and student networks. The second step involves utilizing the hierarchical features of the online student network, which exhibit close optimization and semantic properties. To enhance the efficiency of distillation, we employ simple
distances for the feature mimicking loss and utilize spatial pooling and channel cropping to align feature shapes without the need for complex feature transformations. This efficient feature transfer also helps mitigate knowledge reduction. Shared-KD offers three key advantages: (1) Our framework sheds new light on decoupling cross-layer distillation using multi-step strategies. (2) Shared-KD enhances the effectiveness of KD methods in overcoming unstable optimization issues, leveraging the full knowledge of teacher features to achieve significant performance improvements. (3) Shared-KD incorporates a simple feature alignment component without introducing additional parameters. In contrast, other cross-layer distillation techniques require complex feature transformations and optimizations, increasing training time and resource requirements. Shared-KD can potentially expand the application of KD and facilitate further research in this area. Shared Knowledge Distillation techniques improve the efficiency and adaptability of deep neural networks for object detection, paving the way for advancements in real-time applications and services within the paradigm of next-generation networks.
Our proposed method is extensively evaluated through experiments on detection and segmentation tasks to validate its effectiveness. The experimental results demonstrate the superiority of our approach, surpassing other existing methods by a considerable margin. Shared-KD consistently improves accuracy across various neural network architectures and data augmentation techniques. For instance, when applied to the object detection task on the MS-COCO dataset, Shared-KD outperforms other methods, such as RetinaNet and Faster R-CNN, by significantly improving the average precision (AP). These results demonstrate the generalizability and robustness of our approach.
In summary, we make the following principle contributions in this paper:
Through analysis and exploration of feature gaps and roles in distillation, it is evident that cross-layer feature gaps within the student network are significantly smaller than those between the student and teacher. This observation motivates us to propose a new Shared Knowledge Distillation (Shared-KD) framework.
Our Shared-KD technique minimizes the shared features between the teacher–student layer and the cross-features within the student. This achieves cross-layer distillation without complex transformations.
Our Shared-KD outperforms other state-of-the-art feature-distillation methods on various deep models and datasets, achieving superior performance and training acceleration.
4. Experiments
This section first evaluates our approach for the object detection task on MS-COCO. Then, comprehensive ablation experiments are performed to analyze the key design in our Shared-KD. As a novel logit offline approach, the main competitor of Shared-KD is the FGD [
32]. Thus, we conduct detailed experimental comparisons between them and also compare their performance with recent advanced KD methods. To ensure fair comparisons, we use the public codes of these approaches with the same training and data preprocessing settings throughout the experiments.
4.1. Experiments on Object Detection
Implementation. We evaluate Shared-KD on MS-COCO dataset [
33] and use the most popular open-source detector [
34] as the strong baseline. We apply Shared-KD to the two-stage detector (e.g., Faster R-CNN [
19]), one-stage detector (e.g., RetinaNet [
34]), and anchor-free detector (e.g., FitNets [
7]), which are widely used object detection frameworks. We choose Faster RCNN-R101 (T) as the teacher detector for the two-stage detector and Faster RCNN-R50 (S) as the student detector. For one stage detector, we choose RetinaNet-R101 (T) and RetinaNet-R50 (S) as the teacher and student detectors. For the free detector, we choose FCOS-R101 (T) and FCOS-R50 (S) as the teacher and student detectors, respectively. Following common practice [
34], all models are trained with a 2× learning schedule (24 epochs). All distillation performances are e valuated in Average Precision (AP).
Comparison results.
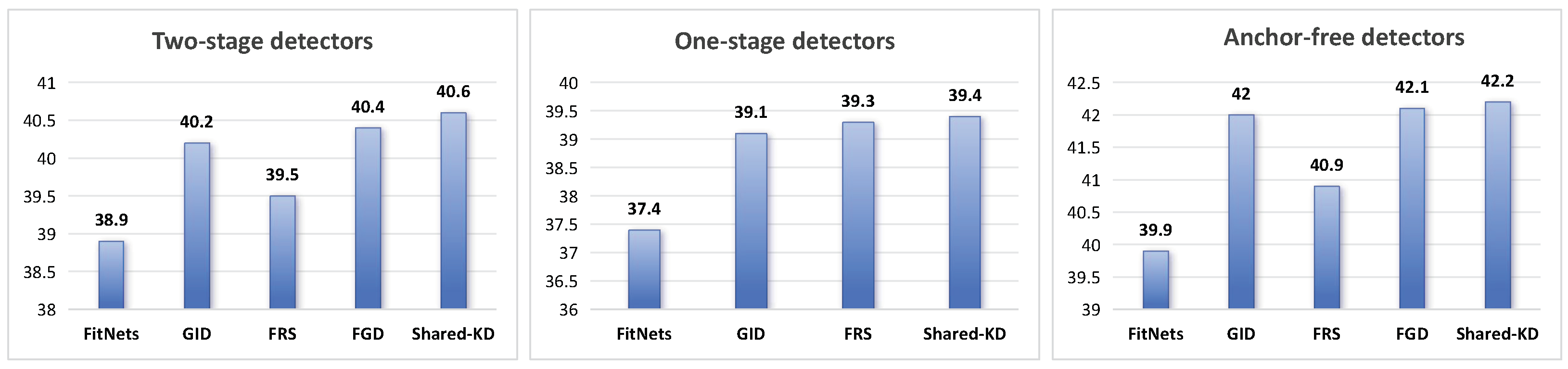
Table 1 presents a comprehensive evaluation of the proposed Shared Knowledge Distillation (Shared-KD) method against various baseline detectors and other state-of-the-art Knowledge Distillation techniques across different object detection architectures: two-stage detectors, one-stage detectors, and anchor-free detectors, as shown in
Figure 3. Shared-KD achieves an impressive AP (Average Precision) of 40.6 for two-stage detectors, outperforming the baseline student model (Faster RCNN-R50) by a significant margin of 2.2. Compared to other Knowledge Distillation methods, Shared-KD demonstrates superior performance, surpassing FitNets by 1.7 (40.6 vs. 38.9), GID by 0.4 (40.6 vs. 40.2), FRS by 1.1 (40.6 vs. 39.5), and FGD by 0.2 (40.6 vs. 40.4). These improvements are consistent across various evaluation metrics, including AP50, AP75, and AP scores for small, medium, and large objects, highlighting the robustness and effectiveness of Shared-KD for two-stage detectors. In the case of one-stage detectors, Shared-KD attains an AP of 39.4, outperforming the baseline student model (RetinaNet-R50) by a substantial 2.0. When compared to other distillation techniques, Shared-KD surpasses FitNets by 2.0 (39.4 vs. 37.4), GID by 0.3 (39.4 vs. 39.1), and FRS by 0.1 (39.4 vs. 39.3), whereas the improvements over some methods are marginal, the consistent gains across different metrics demonstrate the effectiveness of Shared-KD for one-stage detectors. Shared-KD demonstrates superior performance for anchor-free detectors with an AP of 42.2, outperforming the baseline student model (FCOS-R50) by a remarkable 3.7. Compared to other Knowledge Distillation techniques, Shared-KD achieves significant improvements, surpassing FitNets by 2.3 (42.2 vs. 39.9), GID by 0.2 (42.2 vs. 42.0), FRS by 1.3 (42.2 vs. 40.9), and FGD by 0.1 (42.2 vs. 42.1). The results highlight the effectiveness of Shared-KD in improving object detection accuracy for anchor-free detectors, consistently outperforming the baseline student models and other state-of-the-art methods. The improvements are particularly notable for anchor-free detectors, where Shared-KD achieves the highest AP gain compared to the student baseline and other methods. Overall, the experimental results demonstrate the superior performance of Shared-KD across various object detection architectures, consistently outperforming baseline student models and other Knowledge Distillation techniques. The improvements are most significant for anchor-free detectors, followed by two-stage and one-stage detectors. The robustness and effectiveness of Shared-KD are evident through consistent gains across different evaluation metrics, further solidifying its potential as a promising Knowledge Distillation approach for object detection tasks.
4.2. Instance Segmentation
We also apply our method to the more challenging instance segmentation task. We take Mask R-CNN [
35] as our baseline models and distill between different backbone architectures. The models are trained on the COCO2017 training set and are evaluated on the validation set.
Table 2 provides a detailed analysis of the experimental results, for instance segmentation on the MS COCO 2017 dataset. The table presents the performance of various Knowledge Distillation methods, including the proposed Shared Knowledge Distillation (Shared-KD) approach, in comparison with the baseline student model (Mask RCNN-R50) and other state-of-the-art techniques such as FKD, FGD, and MGD. In terms of overall Average Precision (AP), Shared-KD achieves an impressive score of 41.3, significantly outperforming the baseline student model by a substantial margin of 5.9 (41.3 vs. 35.4). This remarkable improvement highlights the effectiveness of Shared-KD in boosting the performance of the student model for instance segmentation tasks.
Comparison results. Compared to other Knowledge Distillation methods, Shared-KD demonstrates superior performance, surpassing FKD by 3.9 (41.3 vs. 37.4), FGD by 3.5 (41.3 vs. 37.8), and MGD by 3.2 (41.3 vs. 38.1). These significant gains underscore the robustness and efficacy of Shared-KD in transferring valuable knowledge from the teacher model to the student model, enabling the student to achieve state-of-the-art performance in instance segmentation. Further analysis of the AP scores for different object scales reveals the strengths of Shared-KD in handling objects of varying sizes. For small objects, Shared-KD achieves an AP of 23.1, outperforming the baseline student model by 4.0 and other methods like FKD (19.7), FGD (17.1), and MGD (17.1). This demonstrates Shared-KD’s ability to effectively capture and transfer knowledge related to small object instances, which can be challenging for traditional object detection and segmentation models. For medium objects, Shared-KD obtains an AP of 45.0, significantly surpassing the baseline student model by 6.4 and other distillation methods such as FKD (40.5), FGD (40.7), and MGD (41.1). This highlights Shared-KD’s capability in accurately detecting and segmenting medium-sized objects, which are often the most common and critical instances in real-world scenarios, and whereas Shared-KD performs slightly better than the baseline student model for large objects, with an AP of 55.2 compared to 48.4, it is slightly outperformed by some other methods like FGD (56.0) and MGD (56.3). However, the overall superior performance of Shared-KD across different object scales, particularly for small and medium objects, demonstrates its robustness and generalization capabilities. In summary, the experimental results for instance segmentation on the MS COCO 2017 dataset clearly demonstrate the effectiveness of Shared-KD in boosting the performance of the student model. Shared-KD consistently outperforms the baseline student model and other state-of-the-art Knowledge Distillation techniques, achieving significant improvements in overall Average Precision and across different object scales, particularly for small and medium objects. These impressive results highlight the potential of Shared-KD as a powerful Knowledge Distillation approach for instance segmentation tasks, paving the way for further advancements in this domain.
4.3. Ablation Study
Analysis for different components in our method. In our method, we conducted experiments to evaluate the impact of different design components, as shown in
Table 3. When the identical-layer distillation component is removed, the performance drops slightly, with a decrease in overall AP to 40.1%, AP50 to 57.0%, and AP scores for small and large objects to 21.0% and 52.5%, respectively. This indicates that the identical-layer distillation plays a role in aligning the teacher and student models, contributing to better performance, particularly for small and large objects. On the other hand, removing the cross-layer distillation component also leads to a performance degradation, with a decrease in overall AP to 40.3%, AP75 to 43.9%, and AP scores for small and medium objects to 23.0% and 44.5%, respectively. This suggests that the cross-layer distillation effectively facilitates knowledge transfer between different layers of the teacher and student models, improving the detection accuracy, especially for small and medium-sized objects. The analysis demonstrates that both the identical-layer distillation and cross-layer distillation components contribute to the overall effectiveness of the proposed method, with each component playing a distinct role in enhancing object detection performance.
Compare to other cross-layer distillation techniques. In comparison with other cross-layer distillation methods, such as SemCKD [
17], our proposed method, referred to as Shared-KD, demonstrates superior performance on the MS COCO validation set, as shown in
Table 4. The results in the table clearly illustrate the effectiveness of our approach in improving the object detection accuracy of the RetinaNet-R50 (Student) model when distilled from the RetinaNet-R101 (Teacher) model. Our Shared-KD method outperforms SemCKD in terms of AP50 (59.0 vs. 58.5) and AP for large objects (AP_L: 54.0 vs. 52.0), indicating its superior performance in detecting objects with high confidence and handling large-scale objects. Additionally, our Shared-KD method demonstrates computational advantages over SemCKD. It requires fewer training hours (10.5 h compared to 13.8 h for SemCKD) and consumes less memory (3.8 GB compared to 4.5 GB for SemCKD), making it more efficient and resource-friendly. The performance gains achieved by our Shared-KD method can be attributed to the effective knowledge transfer from the teacher model to the student model, leveraging shared representations and feature alignment techniques.
Sensitivity study for hyper-parameters. As shown in
Table 5, experiments are conducted to study the hyper-parameter sensitivity. We vary the weight
from 2, 5, 10, and 20 to compare their performance. Furthermore, the AP is 39.4, 38.6, 37.8, and 37.2, respectively. The results demonstrate that the weight
of 2 is the best solution for the hyper-parameter setting. These results demonstrate that our approach can achieve robust performance improvements under different hyper-parameters.
Qualitative analysis. Figure 4 shows significant improvements of our proposed approach compared to the baseline methods and the FGD technique, showing results that are closer to the ground truth (GT) annotations. For small objects, our approach is able to more accurately localize and classify them, overcoming the challenges that often arise when dealing with small-scale instances. The specialized handling of foreground and background classes, as well as the robust feature distillation strategies, contribute to the enhanced small object detection capabilities. Furthermore, our method demonstrates a notable improvement in preventing missed detections. By decoupling the training process for different class types and employing tailored masking and loss functions, our framework is better equipped to capture the subtleties and contextual cues that are crucial for comprehensive object detection. This leads to a reduction in the number of missed detections, resulting in detection outputs that more closely align with the ground truth annotations. The qualitative analysis showcases the strengths of our approach in handling small objects and mitigating missed detections, underscoring its effectiveness in advancing the state-of-the-art in object detection tasks. The ability to produce detection results that are visually more accurate and aligned with the ground truth highlights the practical benefits of our proposed method.
5. Conclusions
Object detection based on Knowledge Distillation has the potential to enhance the functionality and efficiency of 5G and 6G networks across diverse domains. This paper presents the Shared-KD network, a simple, effective, and new framework for addressing the challenges associated with cross-layer feature discrepancies in teacher–student networks. It has been demonstrated that the significant gaps between teacher and student models at the intermediate level pose obstacles to the success of feature distillation. By drawing inspiration from collaborative learning in education, we have proposed a knowledge augmentation module for teachers and a mutual learning module for students. This approach has allowed us to decompose the original feature supervision into two steps: identical-layer distillation between teacher and student, and cross-layer distillation within students. Through experiments on various tasks, including object detection and instance segmentation, we have shown that Shared-KD consistently outperforms other methods, achieving significant performance gains across different neural network architectures. Moreover, the simplicity and efficiency of Shared-KD, which eliminates the need for complex transformations and extra training parameters, make it a practical and versatile solution for Knowledge Distillation. We believe that the insights provided by Shared-KD and its success in improving model performance will inspire further advancements in Knowledge Distillation research and contribute to a deeper understanding of feature distillation. Within the 5G/6G next-generation network paradigm, this will pave the way for advances in real-time applications and services.







{kind=link}
{kind=link}
{kind=link}
{kind=link}