
Interrupt Latency Accurate Measurement in Multiprocessing Embedded Systems by Means of a Dedicated Circuit


Abstract
1. Introduction
2. Background
2.1. Multiprocessor System on Chip (MPSoC)
2.2. Virtualization
- Full or Hardware Virtualization Machine (HVM): It makes it possible to run an OS inside a virtual machine, since the hardware architectures have the needed support for virtualization.
- Paravirtualization (PV): Some of the privileged instructions of the OS kernel are replaced by calls to the hypervisor.
- Static partitioning or core virtualization: It is a combination of the previous ones.
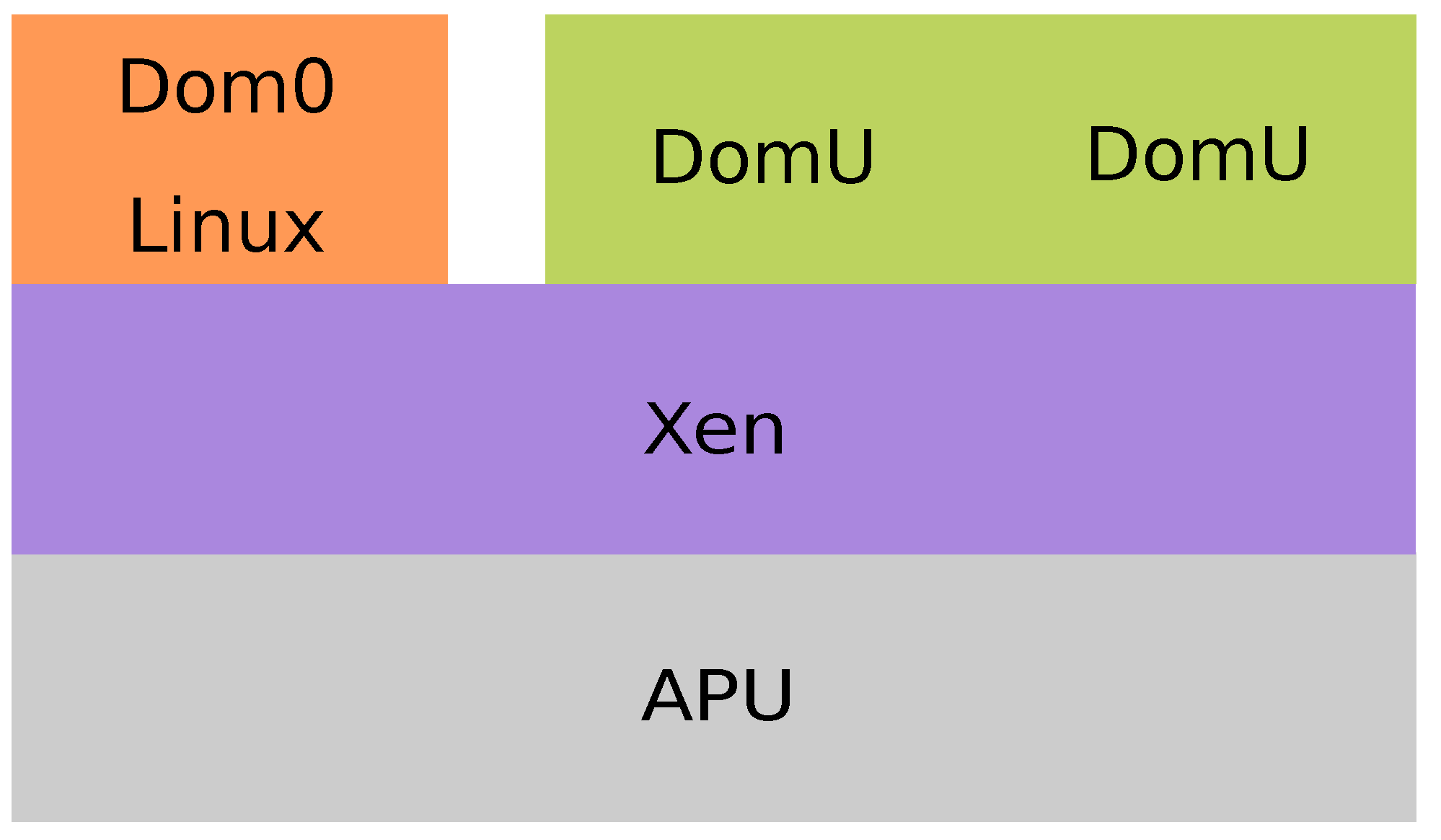
2.3. Xen Hypervisor
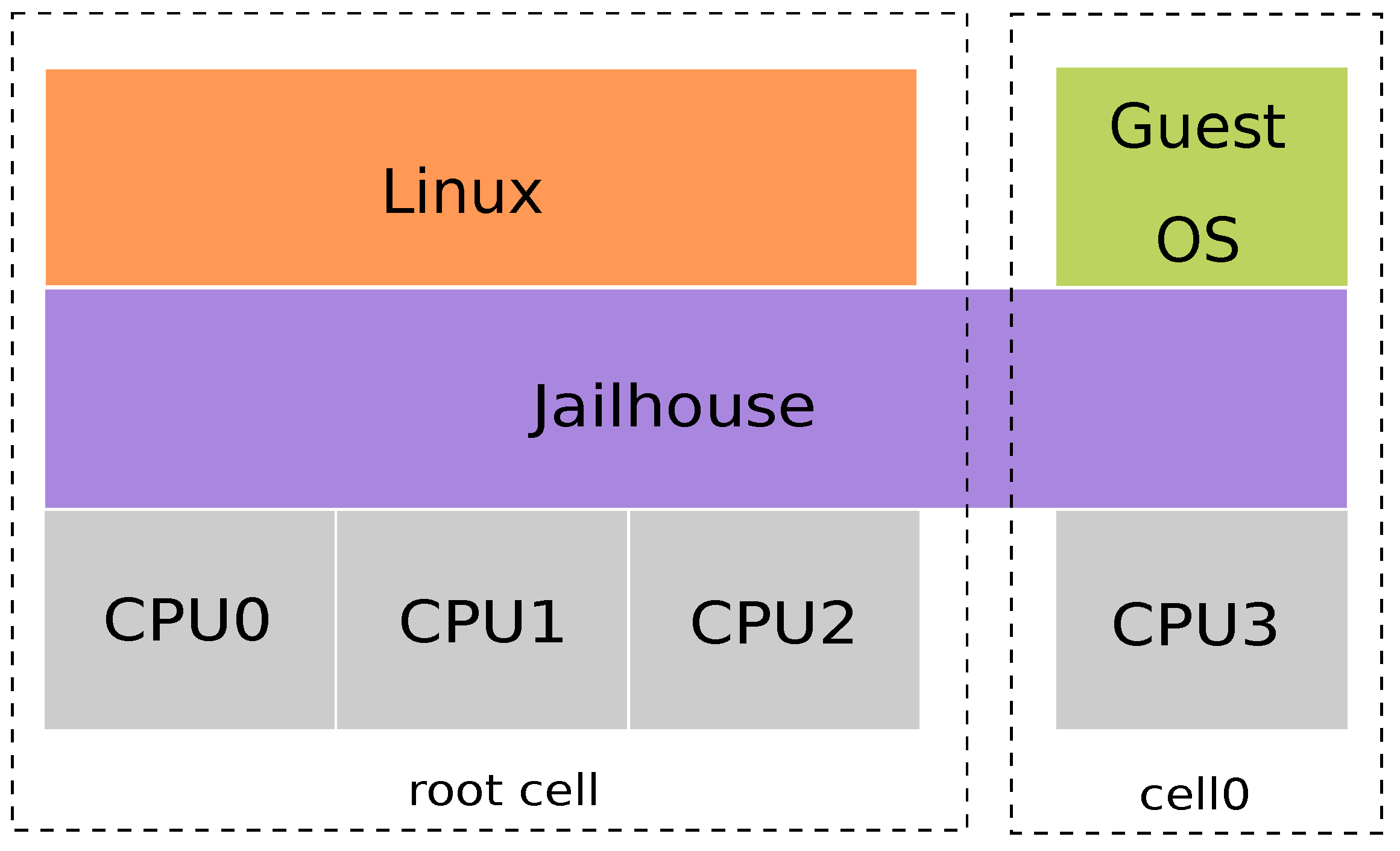
2.4. Jailhouse Hypervisor
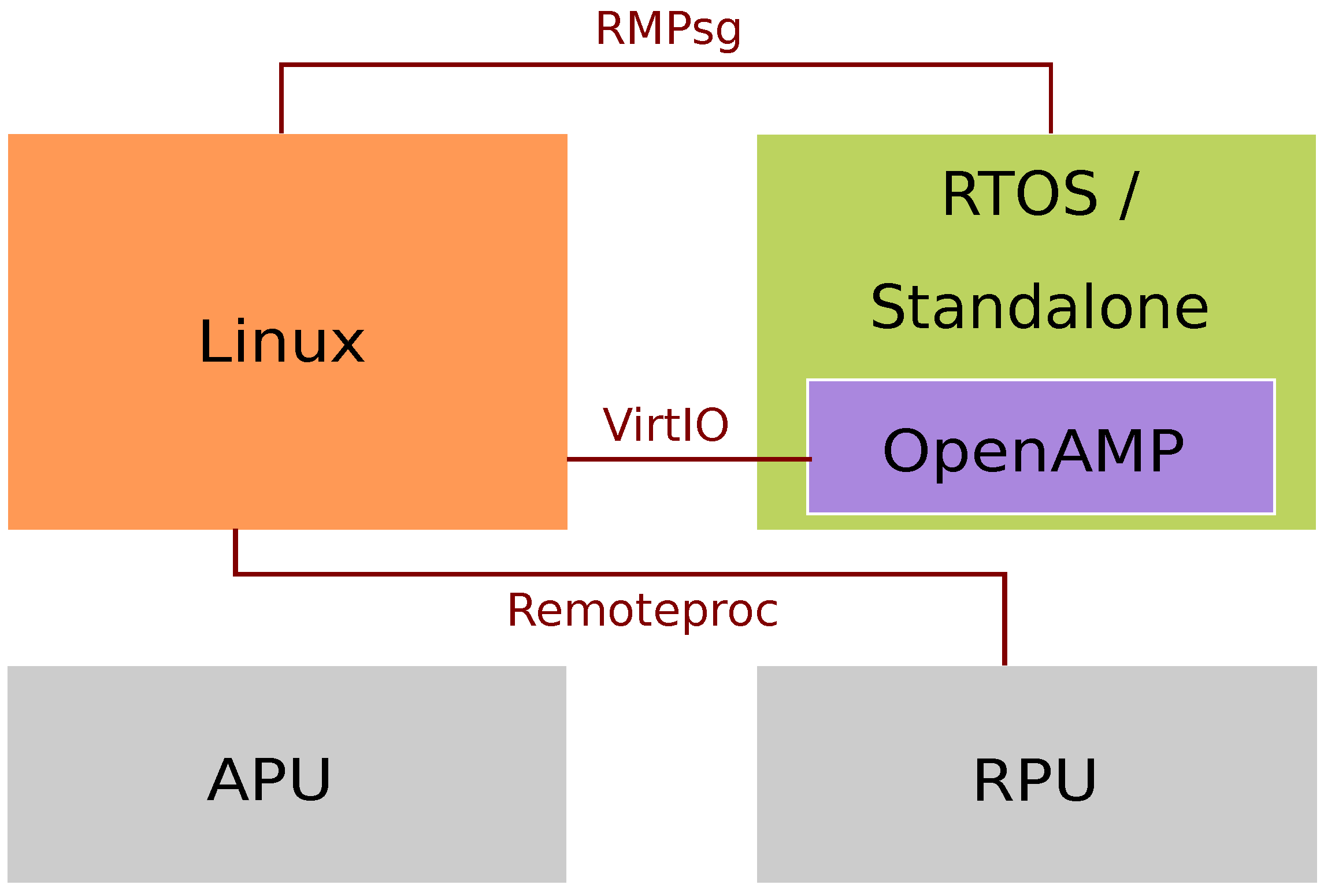
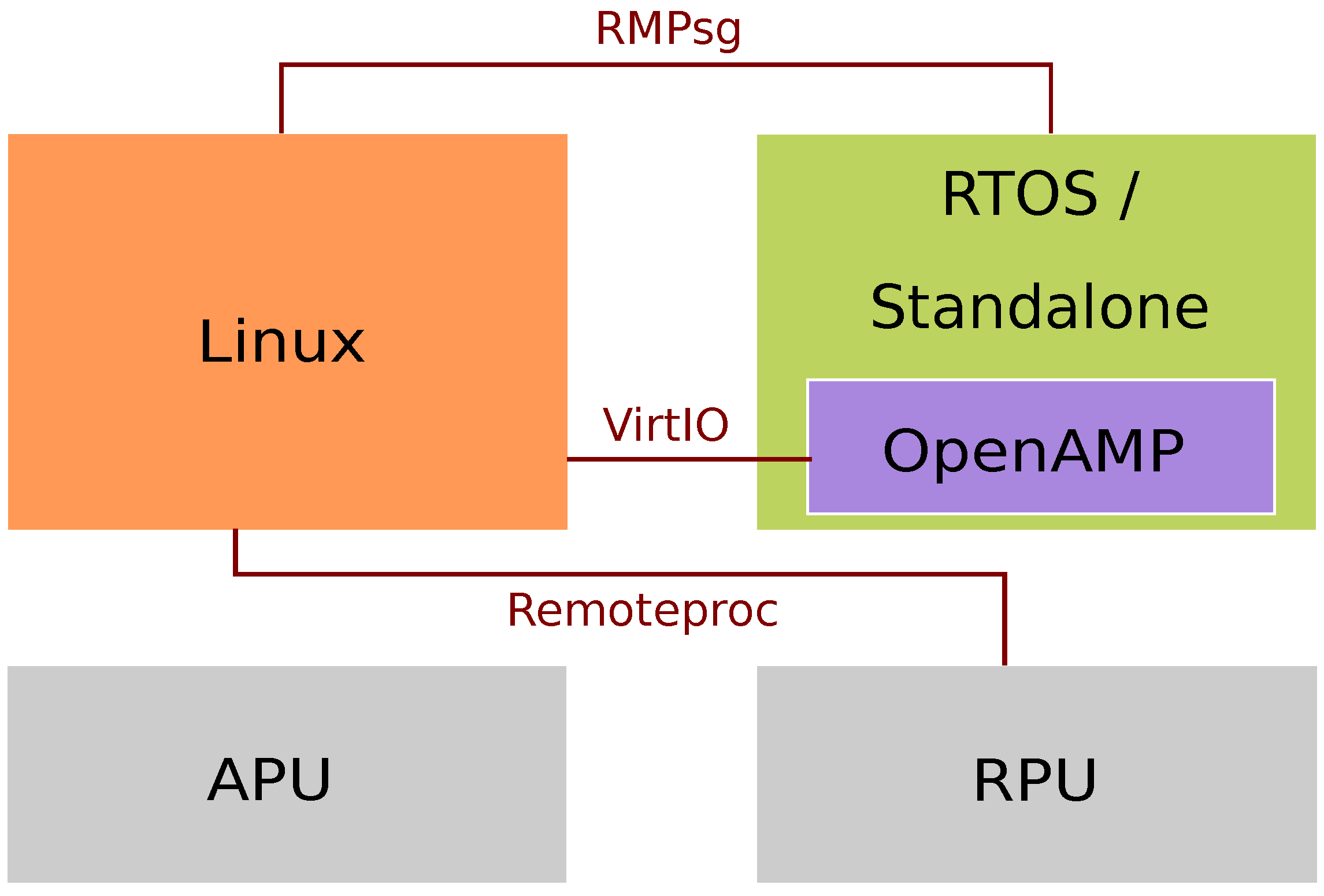
2.5. OpenAMP
- VirtIO: A virtualized communication standard for network and disk device drivers. It is an abstraction layer over devices in a paravirtualized hypervisor that manages the shared memory for OS interactions.
- Remoteproc: Allows a Linux master to manage remote processors—this allows the LCM of the slave processors. It allocates system resources and creates VirtIO devices.
- RPMsg: Provides Interprocess Communication (IPC) between master and remote processors.
2.6. Latencies in Embedded Systems
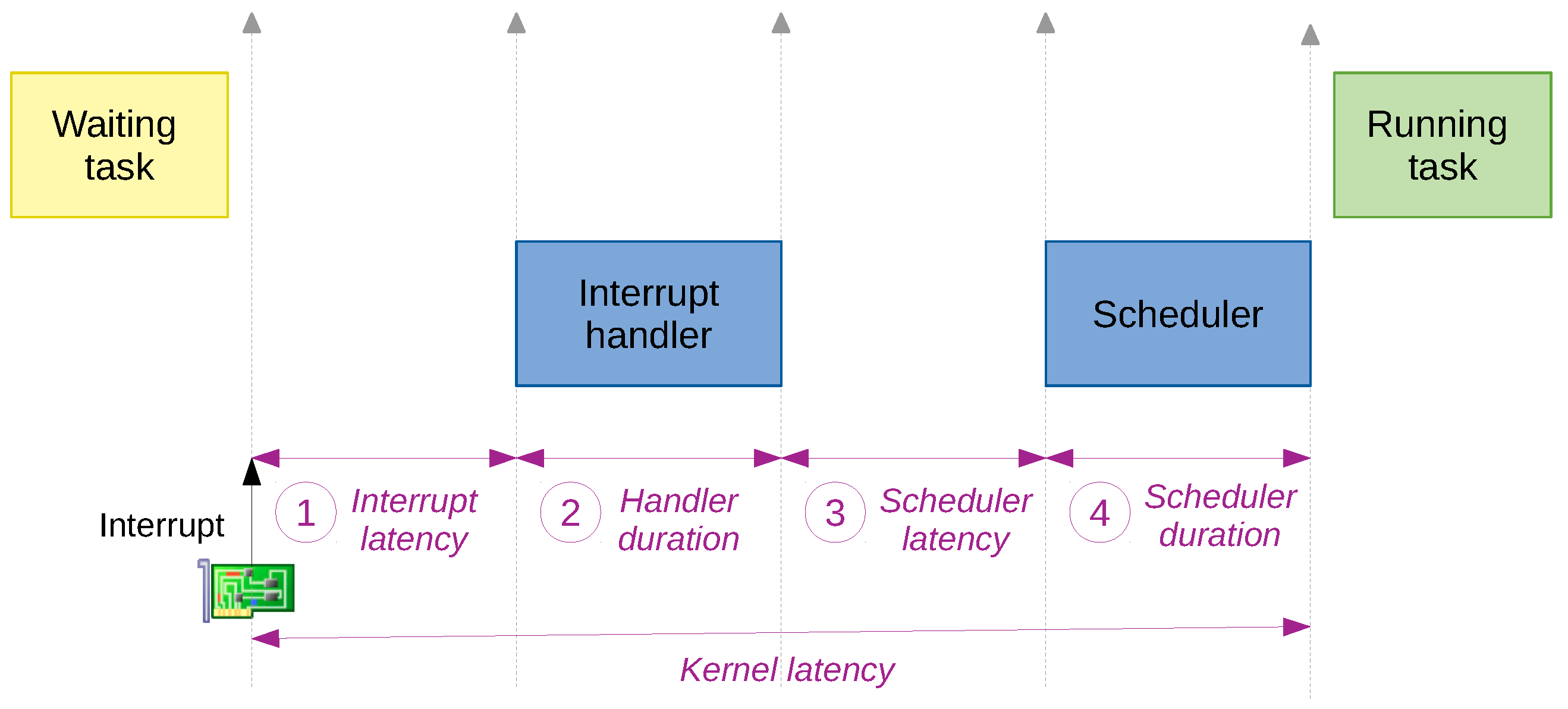
- Latencies in OSs: The most significant latency of an OS is the kernel latency [13]. In Figure 5, a task is running when an interrupt happens, thus indicating an external event has occurred. The task goes to standby mode, and the interrupt is handled. Then the scheduler is called, and it decides which task runs next—it can be the previous one or a different one depending on the priority of each task. When the scheduler finishes, the task runs.In Figure 5, the interrupt latency (1) refers to the duration from the generation of an interrupt to its handling, i.e., the first Interrupt Service Routine (ISR)’s instruction is executed. The handler duration (2) is the time spent in the ISR. The scheduler latency (3) is the time between a stimulus, which indicates if an event has happened, and the kernel scheduler being able to schedule the thread that is waiting for the stimulus to happen. The scheduler duration (4) is the time spent, inside the scheduler, to decide what thread to run and switch the context to it.
- Latencies in MPSoCs: Interrupt latency is one of the main latencies in MPSoC technology, as explained later. It depends on different factors such as interrupt controller implementation, low-level software architecture, OSs, middleware stacks, peripheral-specific interrupt handling requirements, the priority of the interrupt, and interrupt handler implementation [14]. In MPSoC technology, the PL and PS are communicated using AXI buses, and data exchange transactions may also increase latency [15]. Network congestion can also create some latency [16].
- Latencies with hypervisors and AMP frameworks: On the one hand, a hypervisor increases the OS’s kernel latency—especially interrupt latency—and the network latency. It virtualizes the physical resources so that all the guests can share them, and this increases the latency, which stands out in the case of the network. It also affects the shared memory, since this is also virtualized [17]. Regarding the interrupt latency, the physical interrupt controller is used by the hypervisor, and the OSs of the VMs cannot access it. Instead, the hypervisor emulates a virtual interrupt controller for each VM—i.e., the interrupt source of the vCPU becomes the virtual interrupt controller [18]. Thus, hypervisors affect latency due to their mechanism to manage interrupts. On the other hand, AMP frameworks also affect the interrupt latency, as both processors need to communicate to manage interrupts. The IPC is affected because it is carried out by virtualized shared memory. It can also influence when the remote processor uses the network, as it has to ask for access to the APU.
- Interrupt latency: After identifying latencies in OSs, MPSoCs, hypervisors, and AMP frameworks, the interrupt latency comes up as one of the main latencies in embedded systems. In this work, latency is defined as the time difference between the interrupt triggering and its handling. In a virtualized system, Pavic and Dzapo [5] define it with the following Equation (1):where t is the total latency of the interrupt, is the time required by the hardware to process the interrupt source and call the ISR, is the latency introduced by the hypervisor, is the delay introduced by the OS’s internal mechanisms, and is the time for a task to be executed in response to the interrupt after it is handled. The parameter can be very important, as it depends on the state and utilization of all the VMs and CPUs [10]. 979-8-3503-0385-8/23/$31.00 ©2023 IEEE.
3. Related Work
4. Design of a Hardware Circuit to Measure Latency Accurately
5. Timing Analysis of Interrupt Latency by Means of a Dedicated Circuit
5.1. Hardware Design
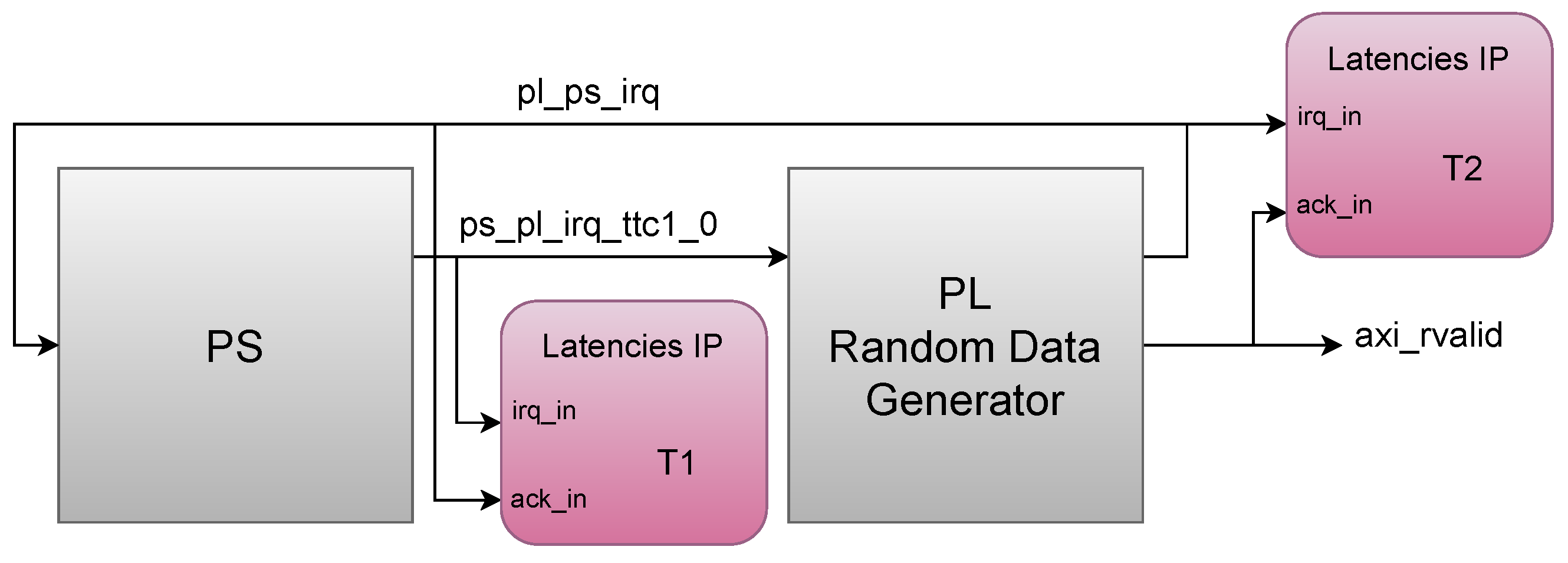
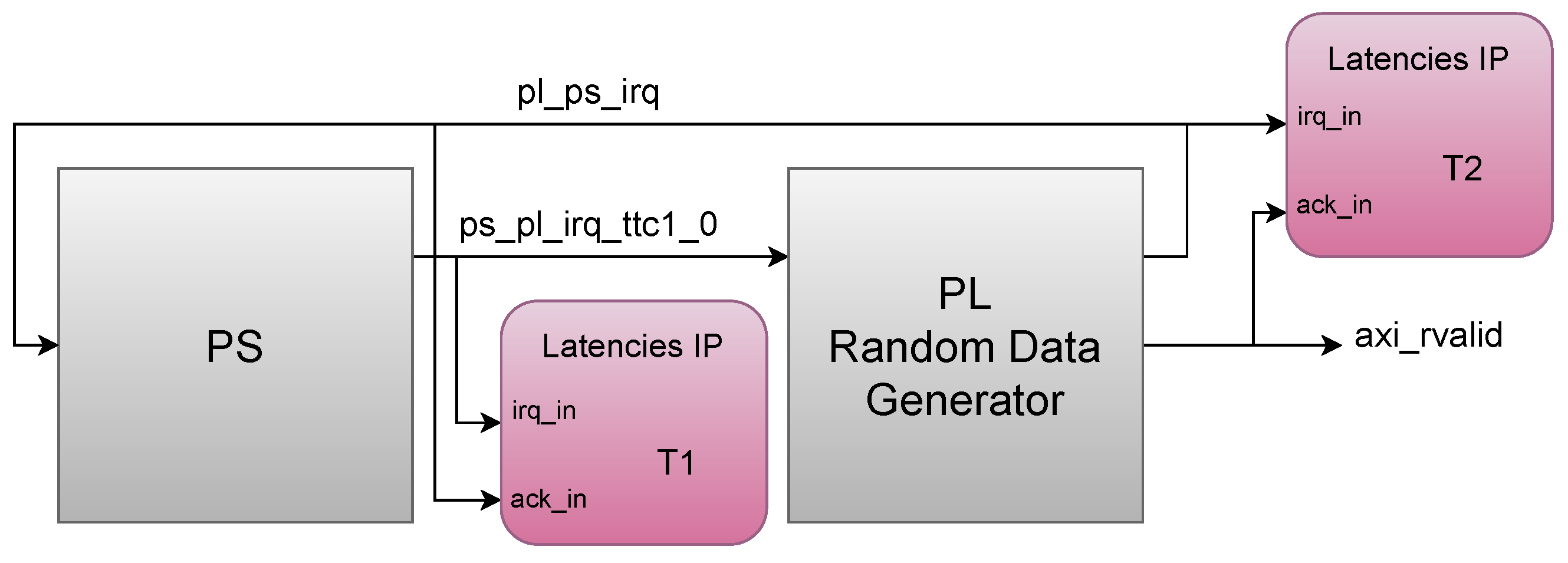
- A Triple Timer Counter (TTC) in the PS generates a periodic interrupt (ps_pl_irq_ttc1_0). The frequency between interrupts allows the system to process data in real time.
- A circuit in the PL (PL Random Data Generator) handles the interrupt and produces random data, which is stored in a FIFO. The circuit generates another interrupt (pl_ps_irq) when the data are ready to be read.
- The PL interrupt is handled in the PS. In the ISR, the data from the FIFO in the PL circuit (axi_rvalid) are read using AXI.
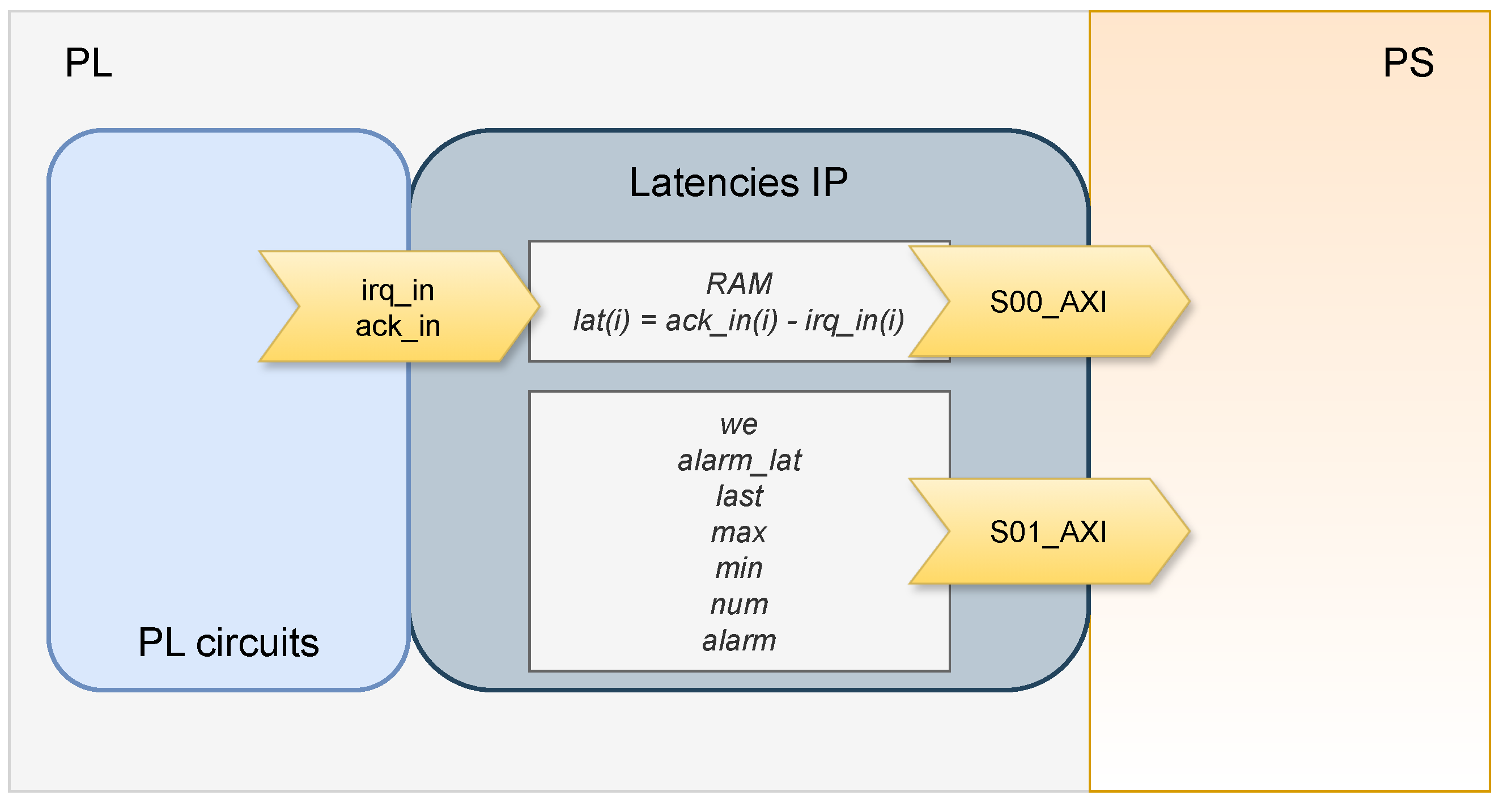
- T1—Latency in PS-to-PL interrupt: It is the latency from the moment the interrupt is generated in the PS to its handling in the PL. The time between the generation of the TTC interrupt in the PS and the generation of the interrupt that indicates that the data are ready in the PL was measured. For this measurement, the Latencies IP was connected with irq_in connected to ps_pl_irq_ttc1_0, and ack_in was connected to pl_ps_irq.
- T2—Latency in PL-to-PS interrupt: It is the time from the moment the interrupt is generated in the PL to its handling in the PS. The interrupt indicates that the data are ready in the PL. For this measurement, the Latencies IP was connected with irq_in connected to pl_ps_irq, and ack_in was connected to axi_rvalid—this signal indicates that the AXI-read transaction to read the data of the FIFO in the ISR was completed.
5.2. Software Scenarios
- Standalone A53: The measurements are made on an A53 core directly, without any OS.
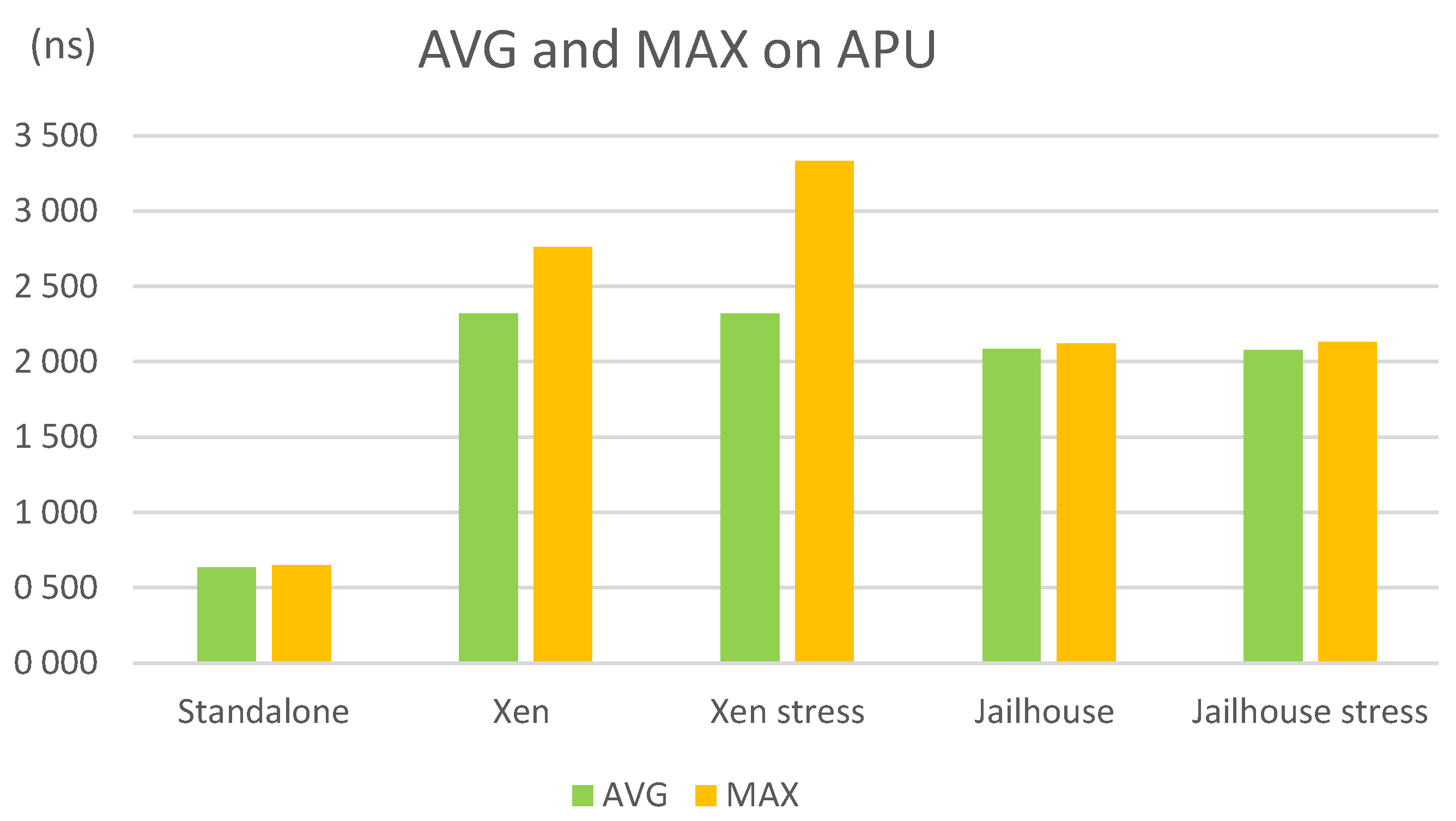
- Xen: The measurements are made on a Xen’s domain without an OS, while Linux is running on the Dom0. The hypervisor runs on the A53 cores. Four vCPUs pinning to one physical core are used for Dom0, as less is not recommended [46], and one vCPU is pinning to another physical core for the other domain. In this implementation, Xen uses the default scheduler, i.e., the Credit Scheduler. This scenario is the same as the first but includes the Xen hypervisor.
- Xen stress: Dom0 is stressed while the measurements are taken in another domain. This scenario is the same as the second, but the system is stressed.
- Jailhouse: The measurements are made on a Jailhouse’s cell without an OS, while Linux is running on the root cell. One different A53 core is used for each cell. This scenario is the same as the first but includes the Jailhouse hypervisor.
- Jailhouse stress: The root cell is stressed while the measurements are taken in another cell. This scenario is the same as the fourth, but the system is stressed.
- Standalone R5: The measurements are directly made on an R5 core directly, without any OS.
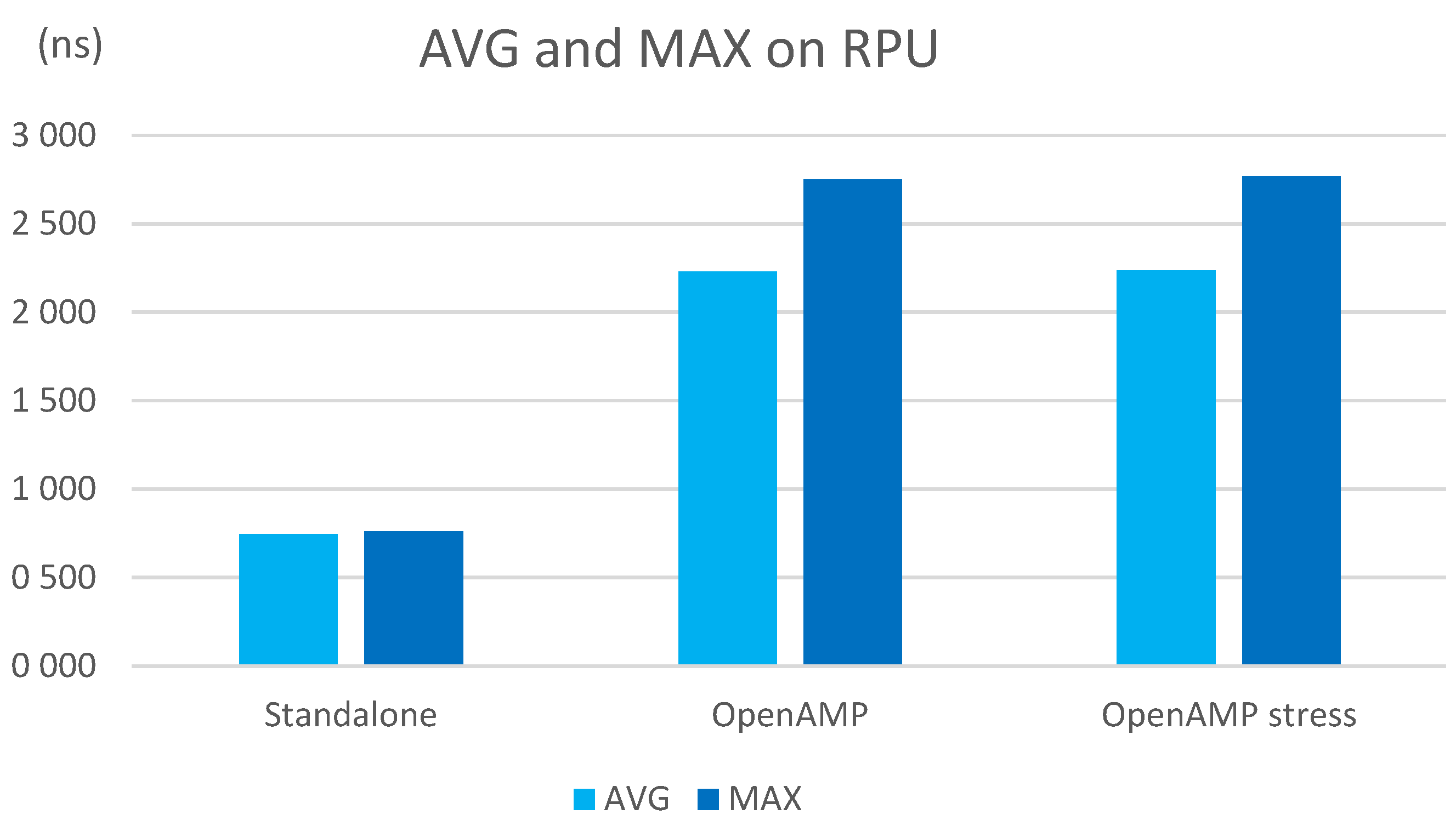
- OpenAMP: The measurements are made on an R5 core with OpenAMP without an OS, while Linux is running on the four A53 cores. This scenario is the same as the sixth but includes OpenAMP.
- OpenAMP stress: The APU running Linux is stressed while the measurements are taken in the RPU. This scenario is the same as the seventh, but the system is stressed.
5.3. Results
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Cinque, M.; Tommasi, G.D.; Dubbioso, S.; Ottaviano, D. Virtualizing Real-Time Processing Units in Multi-Processor Systems-on-Chip. In Proceedings of the IEEE 6th International Forum on Research and Technology for Society and Industry (RTSI), Naples, Italy, 6–9 September 2021. [Google Scholar]
- Projects, G. The OpenAMP Project. Available online: https://www.openampproject.org/ (accessed on 19 April 2022).
- Foundation, T.L. Cyclictest. Available online: https://wiki.linuxfoundation.org/realtime/documentation/howto/tools/cyclictest/start (accessed on 9 April 2024).
- Lamie, W.; Carbone, J. Measure Your RTOS’s Real-Time Performance. 2007. Available online: https://www.embedded.com/measure-your-rtoss-real-time-performance/ (accessed on 9 April 2024).
- Pavic, I.; Dzapo, H. Virtualization in multicore real-time embedded systems for improvement of interrupt latency. In Proceedings of the 2018 41st International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 21–25 May 2018; pp. 1405–1410. [Google Scholar] [CrossRef]
- Eurostars. RETINA. Available online: https://www.hipeac.net/network/projects/6856/retina/ (accessed on 9 June 2022).
- Wulf, C.; Willing, M.; Göhringer, D. A Survey on Hypervisor-based Virtualization of Embedded Reconfigurable Systems. In Proceedings of the International Conference of Field-Programmable Logic and Applications (FPL), Dresden, Germany, 30 August–3 September 2021. [Google Scholar] [CrossRef]
- Toumassian, S.; Werner, R.; Sikora, A. Performance measurements for hypervisors on embedded ARM processors. In Proceedings of the 2016 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Jaipur, India, 21–24 September 2016; pp. 851–855. [Google Scholar] [CrossRef]
- Zeng, L.; Wang, Y.; Feng, D.; Kent, K. XCollOpts: A Novel Improvement of Network Virtualization in Xen for I/O-Latency Sensitive Applications on Multicores. IEEE Trans. Netw. Serv. Manag. 2015, 12, 163–175. [Google Scholar] [CrossRef]
- Alonso, S.; Lázaro, J.; Jiménez, J.; Muguira, L.; Bidarte, U. Timing requirements on multi-processing and reconfigurable embedded systems with multiple environments. In Proceedings of the 2023 38th Conference on Design of Circuits and Integrated Systems (DCIS), Málaga, Spain, 15–17 November 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Xilinx. Libmetal and OpenAMP User Guide (UG1186). 2020. Available online: https://docs.amd.com/r/2022.2-English/ug1186-zynq-openamp-gsg (accessed on 13 March 2024).
- Intel. Real-Time Systems Overview and Examples. Available online: https://www.intel.com/content/www/us/en/robotics/real-time-systems.html (accessed on 9 March 2023).
- EmbeddedSystem. Latency. Available online: https://hugh712.gitbooks.io/embeddedsystem/content/latency.html (accessed on 1 March 2023).
- Xilinx. Zynq-7000 AP SoC—RealTime—InterruptLatency Reference Design and Demo Tech Tip. 2023. Available online: https://xilinx-wiki.atlassian.net/wiki/spaces/A/pages/18842218/Zynq-7000+AP+SoC+-+RealTime+-+InterruptLatency+Reference+Design+and+Demo+Tech+Tip (accessed on 13 March 2023).
- Marjanovic, J. Exploring the PS-PL AXI Interfaces on Zynq UltraScale+ MPSoC. 2021. Available online: https://j-marjanovic.io/exploring-the-ps-pl-axi-interfaces-on-zynq-ultrascale-mpsoc.html (accessed on 13 March 2023).
- Bhulania, P.; R. Tripathy, M.; Khan, A. High-Throughput and Low-Latency Reconfigurable Routing Topology for Fast AI MPSoC Architecture. In Applications of Artificial Intelligence and Machine Learning; Choudhary, A., Agrawal, A.P., Logeswaran, R., Unhelkar, B., Eds.; Springer: Singapore, 2021; pp. 643–653. [Google Scholar]
- Casini, D.; Biondi, A.; Cicero, G.; Buttazzo, G. Latency Analysis of I/O Virtualization Techniques in Hypervisor-Based Real-Time Systems. In Proceedings of the 2021 IEEE 27th Real-Time and Embedded Technology and Applications Symposium (RTAS), Nashville, TN, USA, 18–21 May 2021; pp. 306–319. [Google Scholar] [CrossRef]
- Martins, J.; Pinto, S. Shedding Light on Static Partitioning Hypervisors for Arm-based Mixed-Criticality Systems. In Proceedings of the 2023 IEEE 29th Real-Time and Embedded Technology and Applications Symposium (RTAS), San Antonio, TX, USA, 9–12 May 2023; pp. 40–53. [Google Scholar] [CrossRef]
- Abeni, L.; Faggioli, D. Using Xen and KVM as real-time hypervisors. J. Syst. Archit. 2020, 106, 101709. [Google Scholar] [CrossRef]
- Tafa, I.; Beqiri, E.; Paci, H.; Kajo, E.; Xhuvani, A. The Evaluation of Transfer Time, CPU Consumption and Memory Utilization in XEN-PV, XEN-HVM, OpenVZ, KVM-FV and KVM-PV Hypervisors Using FTP and HTTP Approaches. In Proceedings of the 2011 Third International Conference on Intelligent Networking and Collaborative Systems, Fukuoka, Japan, 30 November–2 December 2011; pp. 502–507. [Google Scholar] [CrossRef]
- Queiroz, R.; Cruz, T.; Simoes, P. Testing the limits of general-purpose hypervisors for real-time control systems. Microprocess. Microsyst. 2023, 99, 104848. [Google Scholar] [CrossRef]
- Macauley, M.W. Interrupt latency in systems based on Intel 80×86 processors. Microprocess. Microsyst. 1998, 22, 121–126. [Google Scholar] [CrossRef]
- Xu, M.; Phan, L.T.X.; Sokolsky, O.; Xi, S.; Lu, C.; Gill, C.; Lee, I. Cache-aware compositional analysis of real-time multicore virtualization platforms. Real-Time Syst. Vol. 2015, 51, 675–723. [Google Scholar] [CrossRef]
- Alonso, S.; Lázaro, J.; Jiménez, J.; Muguira, L.; Largacha, A. Analysing the interference of Xen hypervisor in the network speed. In Proceedings of the 2020 XXXV Conference on Design of Circuits and Integrated Systems (DCIS), Segovia, Spain, 18–20 November 2020. [Google Scholar] [CrossRef]
- Beckert, M.; Ernst, R. Response Time Analysis for Sporadic Server Based Budget Scheduling in Real Time Virtualization Environments. ACM Trans. Embed. Comput. Syst. 2017, 16, 161. [Google Scholar] [CrossRef]
- Stangaciu, C.; Micea, M.; Cretu, V. An Analysis of a Hard Real-Time Execution Environment Extension for FreeRTOS. Adv. Electr. Comput. Eng. 2015, 15, 79–86. [Google Scholar] [CrossRef]
- Liu, M.; Liu, D.; Wang, Y.; Wang, M.; Shao, Z. On Improving Real-Time Interrupt Latencies of Hybrid Operating Systems with Two-Level Hardware Interrupts. IEEE Trans. Comput. 2011, 60, 978–991. [Google Scholar] [CrossRef]
- Alonso, S.; Lázaro, J.; Jiménez, J.; Bidarte, U.; Muguira, L. Evaluating Latency in Multiprocessing Embedded Systems for the Smart Grid. Energies 2021, 14, 3322. [Google Scholar] [CrossRef]
- Alonso, S.; Lázaro, J.; Jiménez, J.; Muguira, L.; Bidarte, U. Evaluating the OpenAMP framework in real-time embedded SoC platforms. In Proceedings of the 2021 XXXVI Conference on Design of Circuits and Integrated Systems (DCIS), Vila do Conde, Portugal, 24–26 November 2021. [Google Scholar] [CrossRef]
- Alonso, S.; Lázaro, J.; Jiménez, J.; Muguira, L.; Bidarte, U. The influence of virtualization on real-time systems’ interrupts in embedded SoC platforms. In Proceedings of the 2022 XXXVII Conference on Design of Circuits and Integrated Systems (DCIS), Pamplona, Spain, 16–18 November 2022. [Google Scholar] [CrossRef]
- Klingensmith, N.; Banerjee, S. Using virtualized task isolation to improve responsiveness in mobile and IoT software. In Proceedings of the IoTDI ’19: Proceedings of the International Conference on Internet of Things Design and Implementation, Montreal, QC, Canada, 15–18 April 2019; pp. 160–171. [Google Scholar] [CrossRef]
- Garcia, P.; Gomes, T.; Salgado, F.; Monteiro, J.; Tavares, A. Towards hardware embedded virtualization technology: Architectural enhancements to an ARM SoC. ACM SIGBED 2014, 11, 45–47. [Google Scholar] [CrossRef]
- Sá, B.; Martins, J.; Pinto, S. A First Look at RISC-V Virtualization From an Embedded Systems Perspective. IEEE Trans. Comput. 2021, 71, 2177–2190. [Google Scholar]
- Adam, G.K. Real-Time Performance and Response Latency Measurements of Linux Kernels on Single-Board Computers. Computers 2021, 10, 64. [Google Scholar] [CrossRef]
- Strnadel, J.; Rajnoha, P. Reflecting RTOS Model During WCET Timing Analysis: MSP430/Freertos Case Study. Acta Electrotech. Inform. 2012, 12, 17–29. [Google Scholar] [CrossRef]
- Schliecker, S.; Negrean, M.; Ernst, R. Response Time Analysis on Multicore ECUs With Shared Resources. IEEE Trans. Ind. Inform. 2009, 5, 402–413. [Google Scholar] [CrossRef]
- Brylow, D.; Palsberg, J. Deadline analysis of interrupt-driven software. IEEE Trans. Softw. Eng. 2004, 30, 634–655. [Google Scholar] [CrossRef]
- Liu, Z.; Shi, Y.; Zhang, G.; Hu, B.; Ye, F.; Zhou, H. A Novel Testing Method for Interrupt Response Time. In Proceedings of the 2021 11th International Workshop on Computer Science and Engineering (WCSE 2021), Shanghai, China, 19–21 June 2021. [Google Scholar] [CrossRef]
- Chris Simmonds. Mastering Embedded Linux Programming. Available online: https://www.oreilly.com/library/view/mastering-embedded-linux/9781787283282/e19a424b-9507-4186-a54f-430a53b62ad9.xhtml (accessed on 18 April 2024).
- Monmasson, E.; Hilairet, M.; Spagnuolo, G.; Cirstea, M.N. System-on-Chip FPGA Devices for Complex Electrical Energy Systems Control. IEEE Ind. Electron. Mag. 2022, 16, 53–64. [Google Scholar] [CrossRef]
- Chishiro, H.; Suito, K.; Ito, T.; Maeda, S.; Azumi, T.; Funaoka, K.; Kato, S. Towards Heterogeneous Computing Platforms for Autonomous Driving. In Proceedings of the 2019 IEEE International Conference on Embedded Software and Systems (ICESS), Las Vegas, NV, USA, 2–3 June 2019; pp. 1–8. [Google Scholar] [CrossRef]
- Fernández, J.P.; Vargas, M.A.; García, J.M.V.; Carrillo, J.A.C.; Aguilar, J.J.C. Low-Cost FPGA-Based Electronic Control Unit for Vehicle Control Systems. Sensors 2019, 19, 1834. [Google Scholar] [CrossRef] [PubMed]
- Xilinx. FIR Compiler (PG149). 2022. Available online: https://docs.amd.com/r/en-US/pg149-fir-compiler/FIR-Compiler-LogiCORE-IP-Product-Guide (accessed on 2 April 2024).
- Castillo-Secilla, J.; Olivares, J.; Palomares, J. Design of a Wireless Pulse Oximeter using a Mesh ZigBee Sensor Network. In Proceedings of the International Conference on Biomedical Electronics and Devices, Rome, Italy, 26–29 January 2011; pp. 401–404. [Google Scholar]
- Stojanovic, R.; Karadaglic, D. Design of an oximeter based on LED-LED configuration and FPGA technology. Sensors 2013, 13, 574–586. [Google Scholar] [CrossRef] [PubMed]
- Tuning Xen for Performance. Available online: https://wiki.xenproject.org/wiki/Tuning_Xen_for_Performance (accessed on 27 February 2024).
- King, C.I. stress-ng (Stress Next Generation). Available online: https://github.com/ColinIanKing/stress-ng (accessed on 6 March 2024).
- Abebe, H. Determination of Sample Size and Errors. In Promoting Statistical Practice and Collaboration in Developing Countries; CRC: Boca Raton, FL, USA, 2022; pp. 321–338. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Description | HW Environment | SW Environment | Tool |
|---|---|---|---|
| Timing analysis on virtualized environments | |||
| Alonso et al. [24] analyze the influence of Xen on the network connection delay and the network bandwidth. | Zynq UltraScale+ MPSoC ZCU102 | Xen hypervisor with Linux guests | ping and iperf |
| Beckert et al. [25] provide a Worst-Case Response Time (WCRT) analysis of a sporadic server-based budget scheduling with a hypervisor. | ARM9 based LPC3250@ 200 MHz | C/OS-MMU hypervisor modified with C/OS-II guests | PyCPA framework and Python |
| Sebouh et al. [8] evaluate the performance overhead introduced by different hypervisors. | banana-pi board (ARM) | Xen and Jailhouse hypervisors with Linux and Cpuburn-a8 application | Processor’s internal counter |
| Timing analysis of interrupts on OSs | |||
| Stangaciu et al. [26] propose an extension for FreeRTOS to guarantee the absence of task execution jitter. They also present a detailed analysis of this extension, including an analysis of interrupt latency and jitter. | EFM32_G890 _STK board | FreeRTOS | zlgLogic and Keil uVision |
| Liu et al. [27] propose RTLinux-THIN, a hybrid OS based on two-level hardware interrupts, and analyze and model the worst-case real-time interrupt latency for a Real-Time Application Interface (RTAI); they identify the key component for its optimization. | Platform based on Intel PXA270 processor | C = OS-II and ARM Linux combination | mplayer, Bonnie and iperf |
| Timing analysis of interrupts on virtualized environments | |||
| Alonso et al. [30] compare the influence of Xen and OpenAMP in PL-to-PS and PS-to-PL interrupts. | Zynq UltraScale+ MPSoC ZCU102 | Xen hypervisor and OpenAMP with bare metal and FreeRTOS guests | Hardware ILA |
| Alonso et al. [28] compare the influence of Xen and OpenAMP in a PL-to-PS interrupt. | Zynq UltraScale+ MPSoC ZCU102 | Xen hypervisor and OpenAMP with bare metal guests | Hardware ILA |
| Alonso et al. [29] analyze the influence of OpenAMP in the latencies of a PL-to-PS interrupt. | Zynq UltraScale+ MPSoC ZCU102 | OpenAMP with bare metal and FreeRTOS guests | Hardware ILA |
| Klingensmith et al. [31] present Hermes, a hypervisor that enables standalone applications to coexist with RTOSs and other less time-critical software, on a single CPU and measure the interrupt latency. | ARM-Cortex-M CPUs | Hermes hypervisor with FreeRTOS guests | Performance counters |
| Garcia et al. [32] present work-in-progress results of hardware-based hypervisor implementation and study the performance of interrupt virtualization. | Xilinx ML505 board | Hardware hypervisor with AIC_IMR and HyperIMR guests | ISIM simulator and Chip-Scope |
| Sá et al. [33] port a hypervisor to RISC-V, which enables the interrupts, and evaluate their latency | Zynq UltraScale+ MPSoC ZCU104 | Bao hypervisor with standalone guest | Timer |
| Tools for timing analysis | |||
| Adam et al. [34] perform real-time measurements of Linux kernels with the PREEMPT_RT patch with new real-time software modules designed by the authors. | Raspberry Pi and BeagleBoard | Linux OS | Self-tool |
| Strnadel et al. [35] present a novel hybrid timing analysis technique and show its practical applicability in the area of Worst-Case Execution Time (WCET) analysis. | MSP430 | FreeRTOS | Self-tool |
| Schliecker et al. [36] present a novel analytical approach to provide the WCRT for real-time tasks in multiprocessor systems with shared resources. | Multicore ECUs | RTOS based on the OSEK/VDX | Self-tool |
| Brylow et al. [37] present the Zilog Architecture Resource Bounding Infrastructure (ZARBI), a tool for deadline analysis of interrupt-driven Z86-based software, and make a deadline analysis of handling an interrupt. | Z86-based microcontroller | Bare metal | ZARBI (self-tool) |
| Liu et al. [38] propose a method to measure the interrupt response time. | W2 chip | Linux with real-time pre-emption patch | Timer (self-method) |
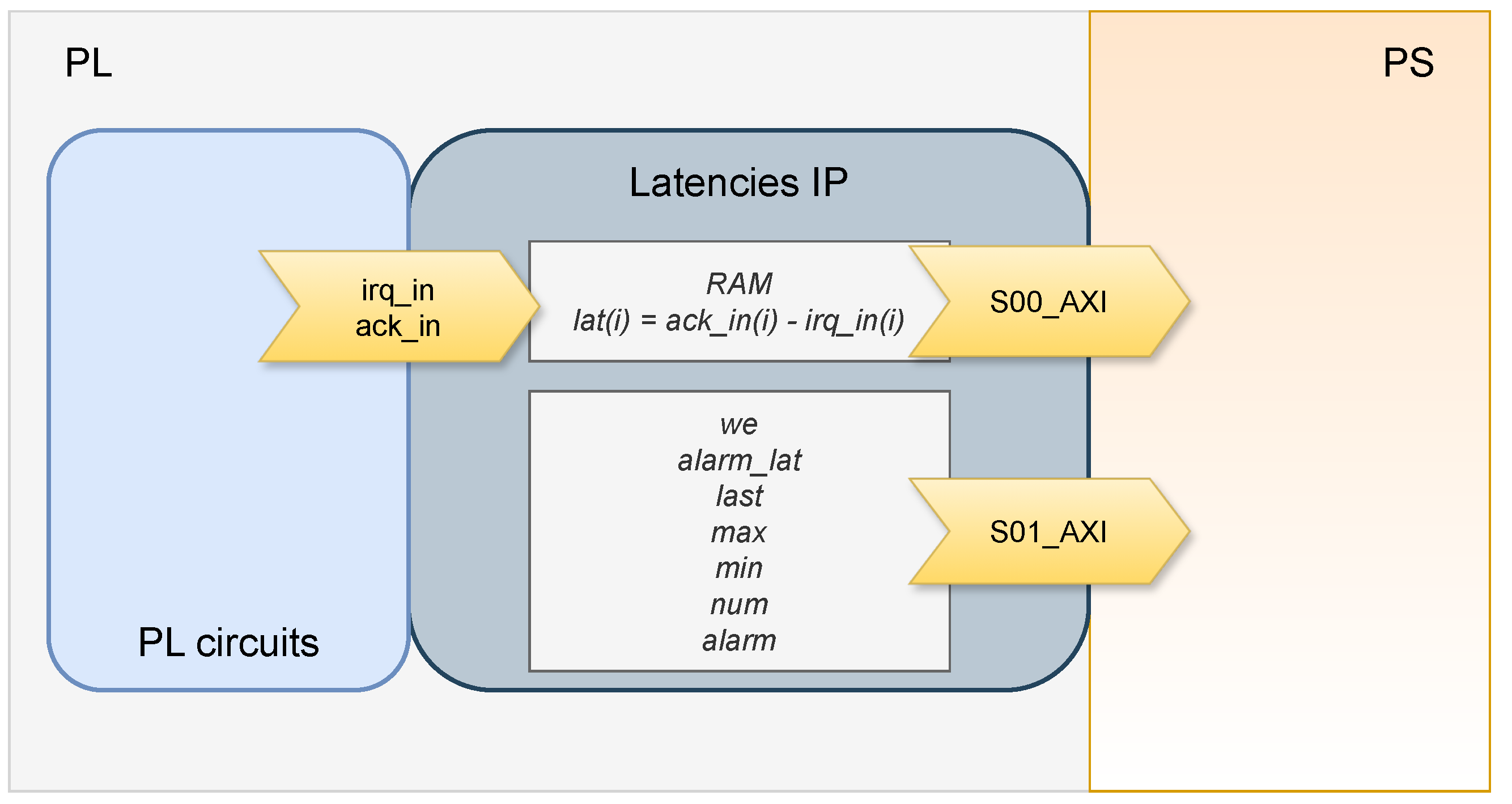
| Port Signals | In/Out | Description | Bits |
|---|---|---|---|
| axi_s00 | In | AXI slave port to read the RAM from PS by AXI. | 32 |
| axi_s01 | In | AXI slave port to read other internal data from PS by AXI. | 32 |
| irq_in | In | The beginning point of the latency the user wants to measure—i.e., a signal that defines when the interrupt is set. | 1 |
| ack_in | In | The ending point of the latency the user wants to measure—i.e., a signal that defines when the interrupt is handled. | 1 |
| Internal Data | In/Out | Description | Bits |
| RAM | Out | A RAM memory which saves the measured latencies. | 512 × 16 |
| we | In | It enables the measurements. | 1 |
| alarm_lat | In | A value that the latencies must not exceed. | 16 |
| last | Out | The last value of the processed latencies. | 16 |
| max | Out | The maximum value of the latencies processed until that moment. | 16 |
| min | Out | The minimum value of the latencies processed until that moment. | 16 |
| num | Out | It indicates how many measurements have been made until that moment. | 16 |
| alarm | Out | It is activated when the calculated latency exceeds the alarm_lat value. | 1 |
| Measurement | In/Actions |
|---|---|
| The random data generator detects the new interrupt. | |
| T1—PS-to-PL interrupt | The random data generator generates and stores in an FIFO the random data. |
| The random data generator generates an interrupt indicating the data are ready to be read. | |
| T2—PL-to-PS interrupt | The scheduler stops the running task and gives the control to the PL interrupts’ ISR. |
| The processor reads the data from the random data generator using AXI. |
| T2 | |||||
|---|---|---|---|---|---|
| Avg. | Median | Max. | Jitter | Dev. | |
| Standalone A53 | 638.15 | 640.00 | 650.00 | 11.86 | 7.30 |
| Xen | 2319.86 | 2310.00 | 2760.00 | 440.14 | 79.20 |
| Xen stress | 2317.57 | 2290.00 | 3330.00 | 1012.43 | 74.56 |
| Jailhouse | 2084.00 | 2080.00 | 2120.00 | 36.00 | 9.32 |
| Jailhouse stress | 2078.39 | 2070.00 | 2130.00 | 51.61 | 12.99 |
| Standalone R5 | 746.17 | 750.00 | 760.00 | 16.17 | 7.16 |
| OpenAMP | 2228.84 | 2210.00 | 2750.00 | 288.84 | 188.73 |
| OpenAMP stress | 2233.57 | 2200.00 | 2770.00 | 536.43 | 207.94 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alonso, S.; Muguira, L.; Garate, J.I.; Cuadrado, C.; Bidarte, U. Interrupt Latency Accurate Measurement in Multiprocessing Embedded Systems by Means of a Dedicated Circuit. Electronics 2024, 13, 1626. https://doi.org/10.3390/electronics13091626
Alonso S, Muguira L, Garate JI, Cuadrado C, Bidarte U. Interrupt Latency Accurate Measurement in Multiprocessing Embedded Systems by Means of a Dedicated Circuit. Electronics. 2024; 13(9):1626. https://doi.org/10.3390/electronics13091626
Chicago/Turabian StyleAlonso, Sara, Leire Muguira, José Ignacio Garate, Carlos Cuadrado, and Unai Bidarte. 2024. "Interrupt Latency Accurate Measurement in Multiprocessing Embedded Systems by Means of a Dedicated Circuit" Electronics 13, no. 9: 1626. https://doi.org/10.3390/electronics13091626
APA StyleAlonso, S., Muguira, L., Garate, J. I., Cuadrado, C., & Bidarte, U. (2024). Interrupt Latency Accurate Measurement in Multiprocessing Embedded Systems by Means of a Dedicated Circuit. Electronics, 13(9), 1626. https://doi.org/10.3390/electronics13091626