
The Genesis of AI by AI Integrated Circuit: Where AI Creates AI

 ,
,  ,
,  and
and 
Abstract
:1. Introduction
2. Development Tools
2.1. Vivado HLS 2019.1
2.2. OpenLane
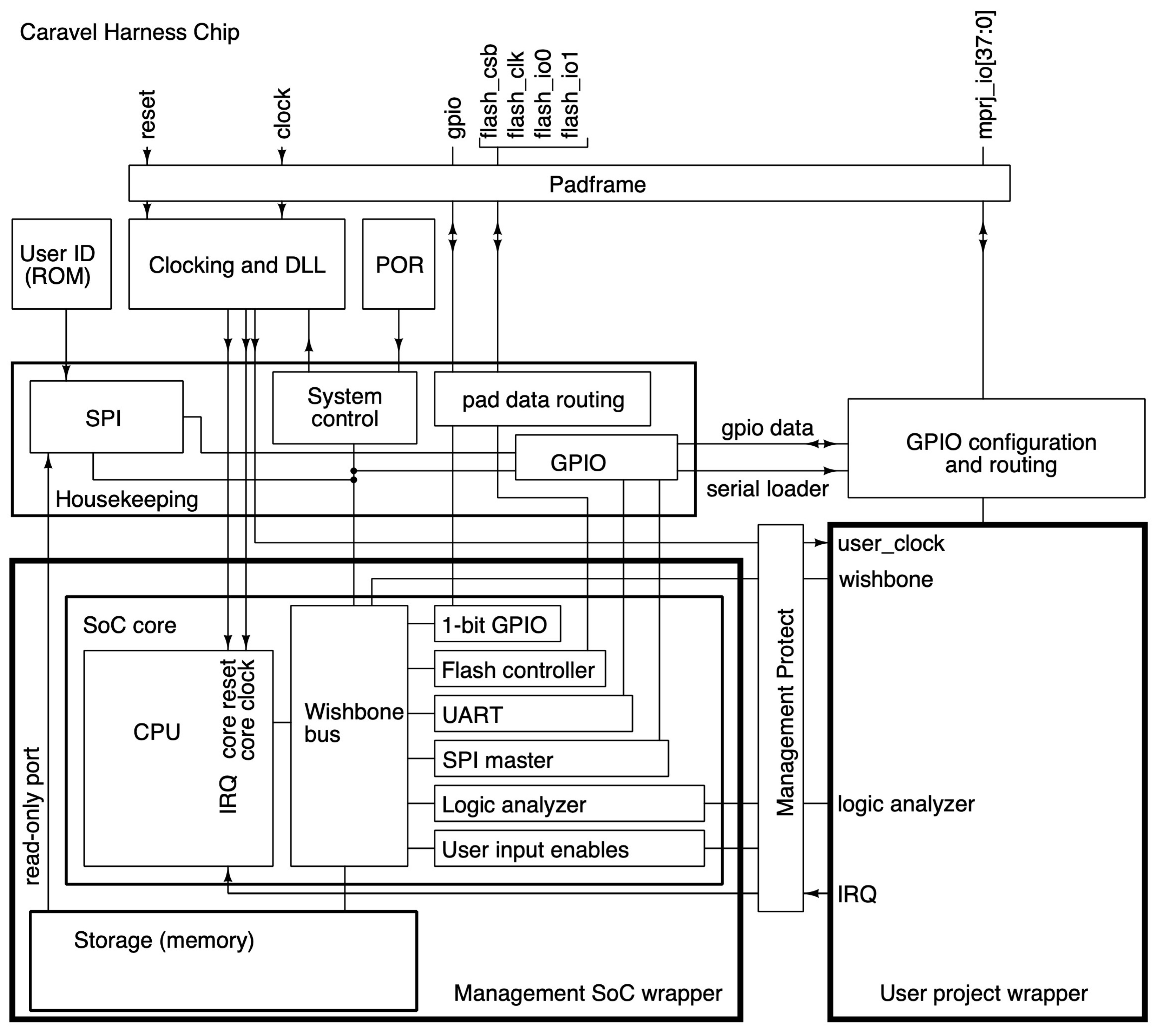
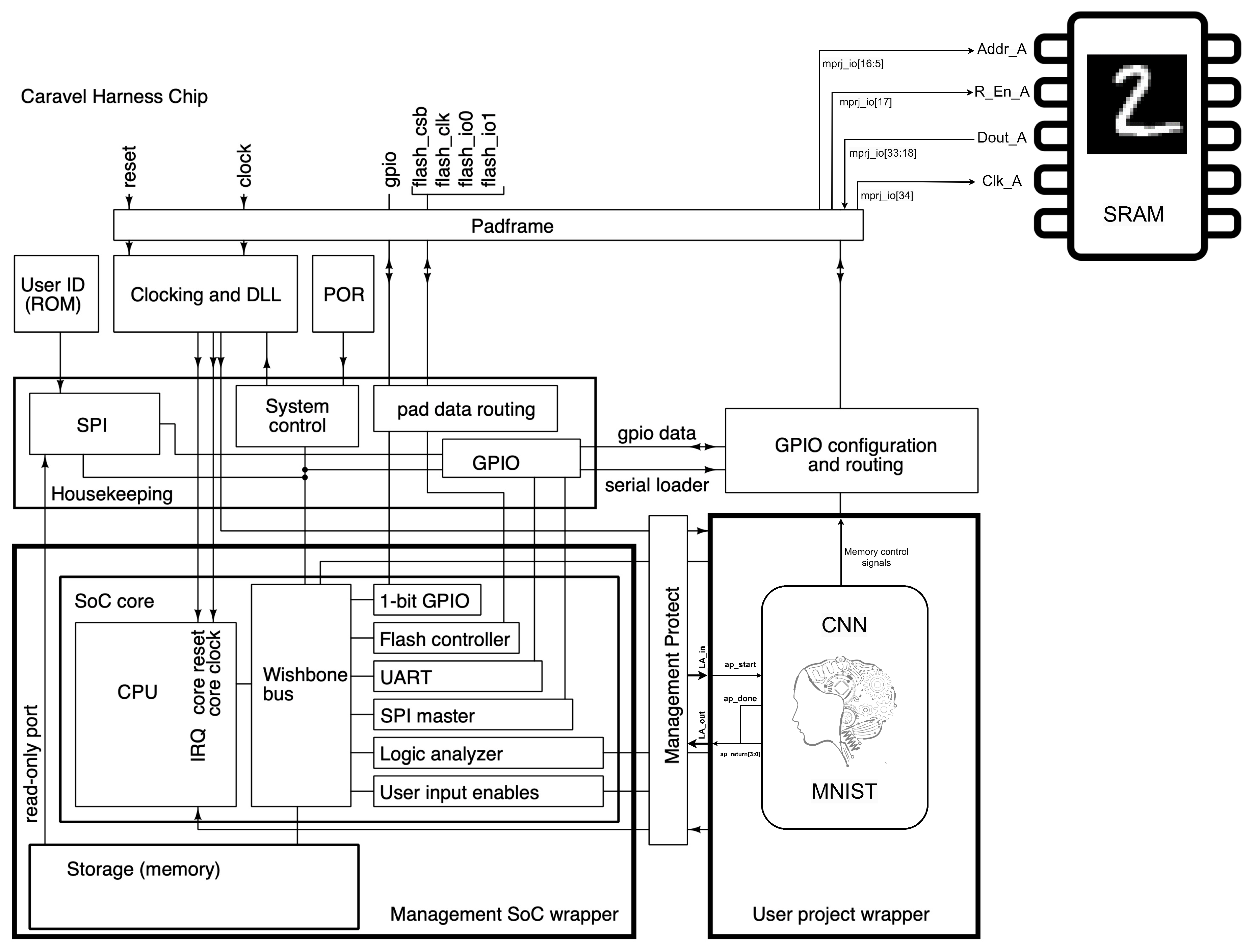
2.3. Caravel
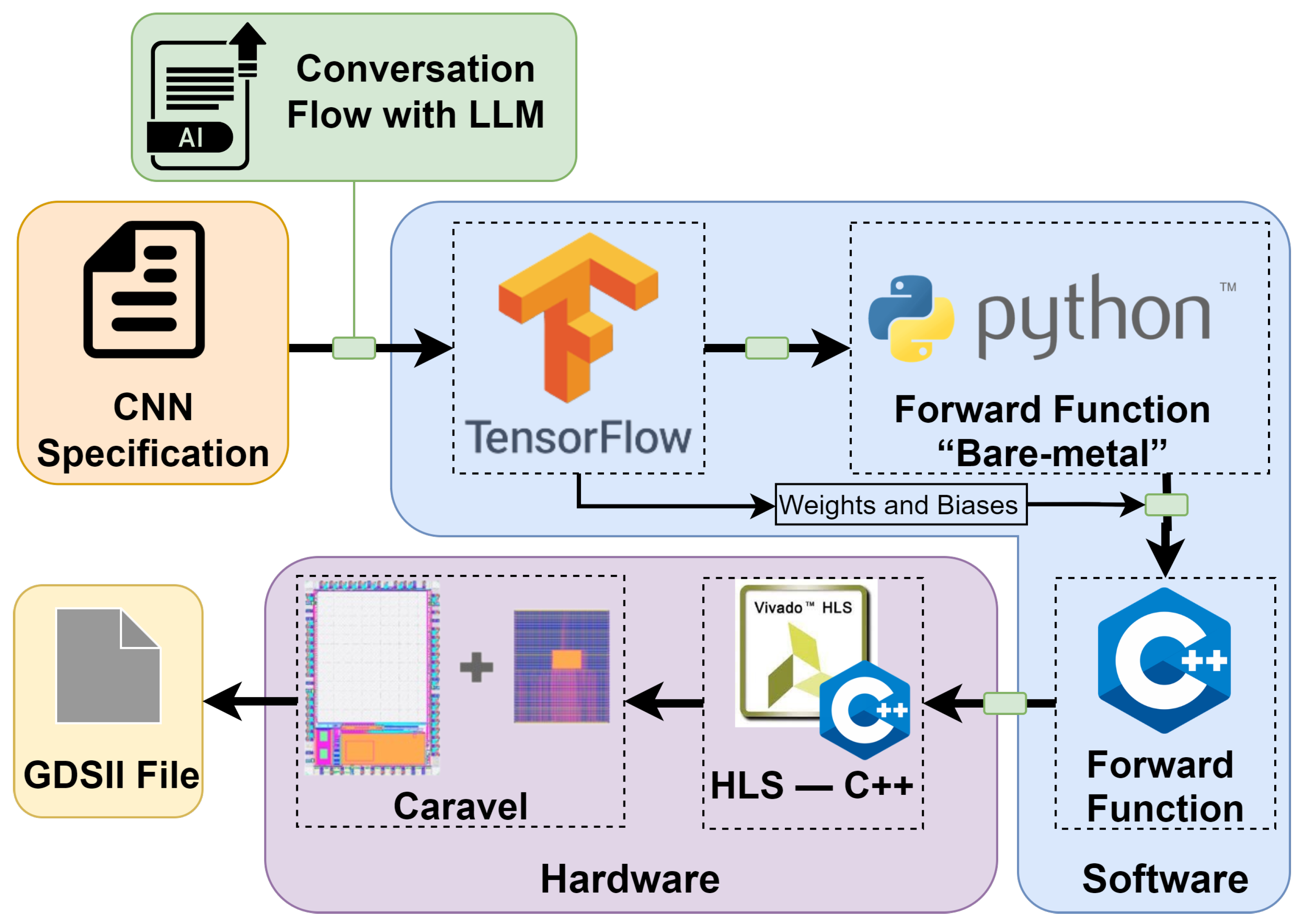
3. Workflow and Conversation Flow
3.1. Large Language Model Conversation Flow
3.2. From TensorFlow to Layout
4. Development of AI by AI
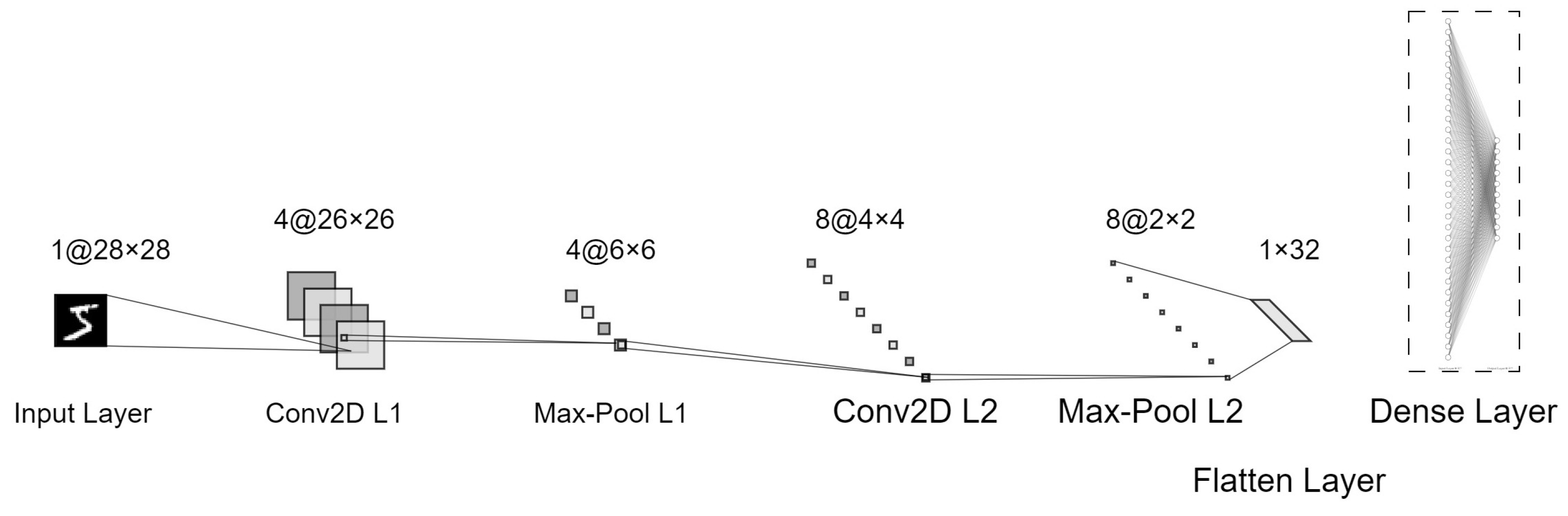
4.1. CNN with TF


4.2. Forward Function in Python



4.3. From Python to C++



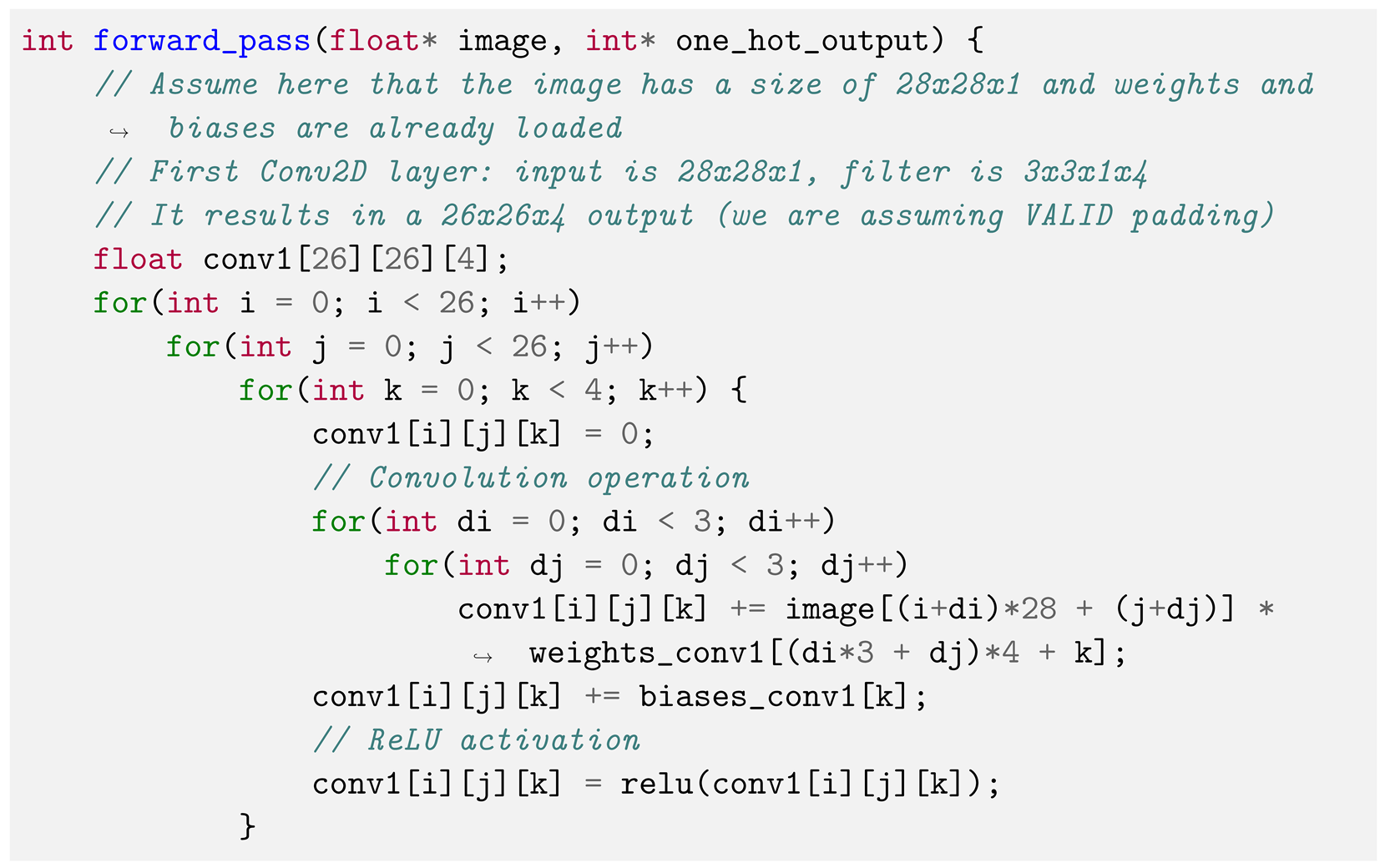
4.4. Vivado HLS Considerations

 operationpresented in the forward function, the operation is executed as
operationpresented in the forward function, the operation is executed as
 where the multiplication of the pixel and the kernel is performed by the multiply_custom_floa function, and the summation of the convolution by the add function.
where the multiplication of the pixel and the kernel is performed by the multiply_custom_floa function, and the summation of the convolution by the add function.4.5. Integration of the CNN with Caravel
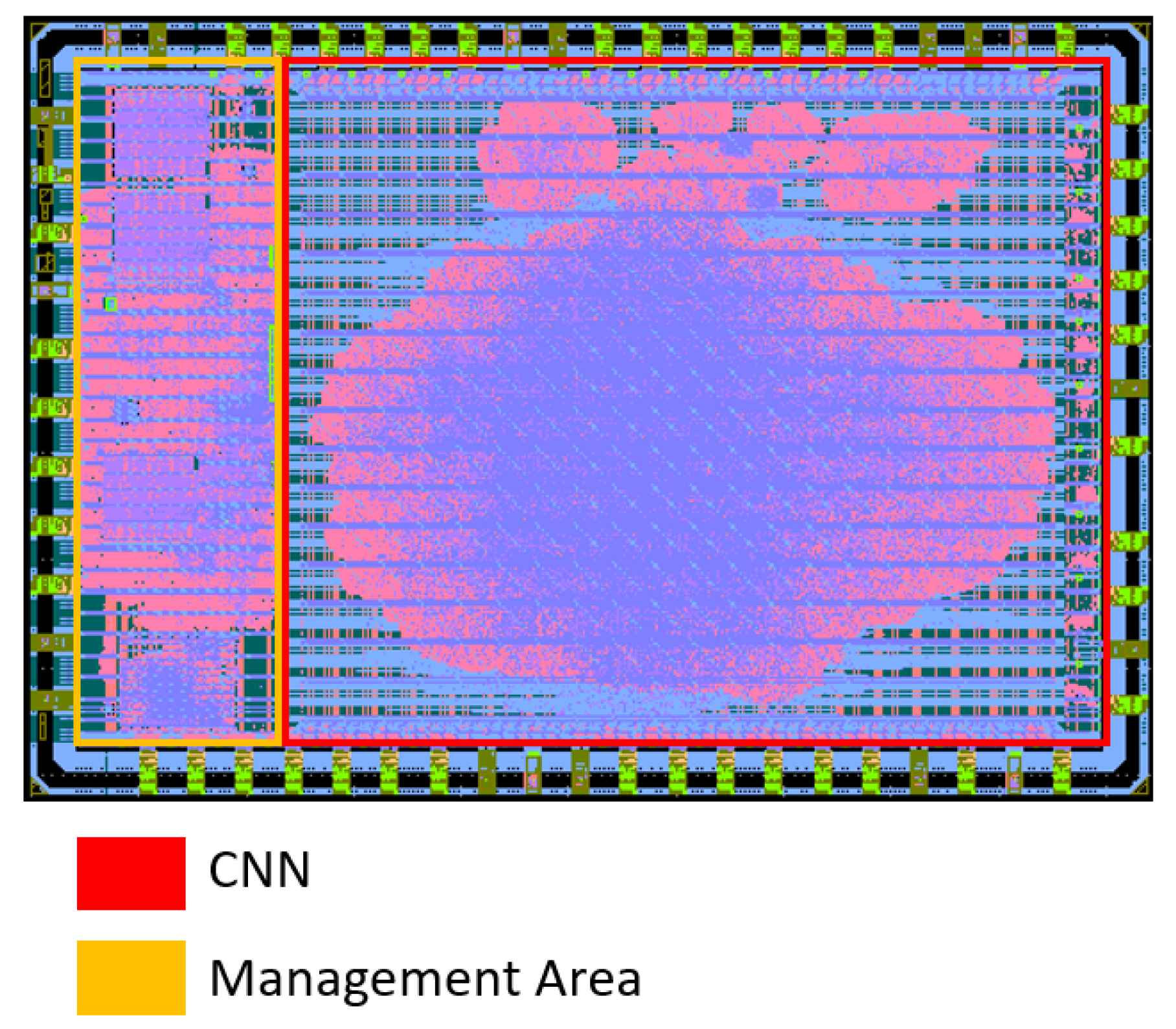
5. Results
6. Discussion
- The current limitations of LLMs in generating HDL code.
- Establishing a workflow that utilizes LLMs to generate and downscale systems from TF to HDL.
- Introducing a new approach for converting HLS to GDSII using open-source PDKs and tools.
- Achieving the fabrication of a CNN IC entirely created by AI.
- Setting a precedent for current AI-generated systems by providing specific system information, such as core area, cells per square millimeter, latency, power consumption, number of flip-flops, and total number of cells.
- Offering open-source access to the entire project, from the initial conversation with the AI to the final GDSII files generated.
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Half Precision Floating Point Functions in C++




Appendix B. Top Module Verilog Code


References
- Bardeen, J.; Brattain, W.H. The transistor, a semi-conductor triode. Phys. Rev. 1948, 74, 230. [Google Scholar] [CrossRef]
- Kilby, J.S.C. Turning potential into realities: The invention of the integrated circuit (Nobel lecture). ChemPhysChem 2001, 2, 482–489. [Google Scholar] [CrossRef] [PubMed]
- Spitalny, A.; Goldberg, M.J. On-line operation of CADIC (computer aided design of integrated circuits). In Proceedings of the 4th Design Automation Conference, Los Angeles, CA, USA, 19–22 June 1967; pp. 7-1–7-20. [Google Scholar]
- Barbacci, M. A Comparison of Register Transfer Languages for Describing Computers and Digital Systems. IEEE Trans. Comput. 1975, C-24, 137–150. [Google Scholar] [CrossRef]
- Bell, C.G.; Grason, J.; Newell, A. Designing Computers and Digital Systems Using PDP 16 Register Transfer Modules; Digital Press: Los Angeles, CA, USA, 1972. [Google Scholar]
- Barbacci, M.R.; Barnes, G.E.; Cattell, R.G.G.; Siewiorek, D.P. The ISPS Computer Description Language: The Symbolic Manipulation of Computer Descriptions; Departments of Computer Science and Electrical Engineering, Carnegie-Mellon University: Pittsburgh, PA, USA, 1979. [Google Scholar]
- Barbacci, M.R. The Symbolic Manipulation of Computer Descriptions: ISPL Compiler and Simulator; Department of Computer Science, Carnegie Mellon University: Pittsburgh, PA, USA, 1976. [Google Scholar]
- Huang, C.L. Method and Apparatus for Verifying Timing during Simulation of Digital Circuits. U.S. Patent 5,095,454, 10 March 1992. [Google Scholar]
- Shahdad, M.; Lipsett, R.; Marschner, E.; Sheehan, K.; Cohen, H. VHSIC hardware description language. Computer 1985, 18, 94–103. [Google Scholar] [CrossRef]
- Gupta, R.; Brewer, F. High-level synthesis: A retrospective. In High-Level Synthesis: From Algorithm to Digital Circuit; Springer: Dordrecht, The Netherlands, 2008; pp. 13–28. [Google Scholar]
- Minsky, M.; Papert, S. Perceptrons: An Introduction to Computational Geometry; Massachusetts Institute of Technology: Cambridge, MA, USA, 1969; Volume 479, p. 104. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Tesauro, G. TD-Gammon, a self-teaching backgammon program, achieves master-level play. Neural Comput. 1994, 6, 215–219. [Google Scholar] [CrossRef]
- Dean, J. 1.1 The Deep Learning Revolution and Its Implications for Computer Architecture and Chip Design. In Proceedings of the 2020 IEEE International Solid-State Circuits Conference—(ISSCC), San Francisco, CA, USA, 16–20 February 2020; pp. 8–14. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.-F. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 248–255. [Google Scholar]
- Luebke, D.; Harris, M. General-purpose computation on graphics hardware. In Proceedings of the Workshop, SIGGRAPH, Los Angeles, CA, USA, 8–12 August 2004; Volume 33, p. 6. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Hinton, G.; Deng, L.; Yu, D.; Dahl, G.E.; Mohamed, A.r.; Jaitly, N.; Senior, A.; Vanhoucke, V.; Nguyen, P.; Sainath, T.N.; et al. Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. IEEE Signal Process. Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Chan, W.; Jaitly, N.; Le, Q.V.; Vinyals, O. Listen, attend and spell. arXiv 2015, arXiv:1508.01211. [Google Scholar]
- Wu, Y.; Schuster, M.; Chen, Z.; Le, Q.V.; Norouzi, M.; Macherey, W.; Krikun, M.; Cao, Y.; Gao, Q.; Macherey, K.; et al. Google’s neural machine translation system: Bridging the gap between human and machine translation. arXiv 2016, arXiv:1609.08144. [Google Scholar]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P. Natural language processing (almost) from scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. Adv. Neural Inf. Process. Syst. 2013, 26, 3111–3119. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. Adv. Neural Inf. Process. Syst. 2014, 27, 3104–3112. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Shazeer, N.; Mirhoseini, A.; Maziarz, K.; Davis, A.; Le, Q.; Hinton, G.; Dean, J. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. arXiv 2017, arXiv:1701.06538. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Yu, C.; Xiao, H.; De Micheli, G. Developing synthesis flows without human knowledge. In Proceedings of the 55th Annual Design Automation Conference, San Francisco, CA, USA, 24–29 June 2018; pp. 1–6. [Google Scholar]
- Huang, G.; Hu, J.; He, Y.; Liu, J.; Ma, M.; Shen, Z.; Wu, J.; Xu, Y.; Zhang, H.; Zhong, K.; et al. Machine learning for electronic design automation: A survey. ACM Trans. Des. Autom. Electron. Syst. 2021, 26, 1–46. [Google Scholar] [CrossRef]
- Kahng, A.B. Machine learning applications in physical design: Recent results and directions. In Proceedings of the 2018 International Symposium on Physical Design, Monterey, CA, USA, 25–28 March 2018; pp. 68–73. [Google Scholar]
- OpenAI. Introducing ChatGPT. 2022. Available online: https://openai.com/blog/chatgpt (accessed on 8 February 2024).
- Pichai, S. An Important Next Step on Our AI Journey. 2023. Available online: https://blog.google/technology/ai/bard-google-ai-search-updates/ (accessed on 8 February 2024).
- Microsoft. Microsoft Edge Features—Bing Chat. 2023. Available online: https://www.microsoft.com/en-us/edge/features/bing-chat?form=MT00D8 (accessed on 8 February 2024).
- Chang, K.; Wang, Y.; Ren, H.; Wang, M.; Liang, S.; Han, Y.; Li, H.; Li, X. ChipGPT: How far are we from natural language hardware design. arXiv 2023, arXiv:2305.14019. [Google Scholar]
- Thakur, S.; Ahmad, B.; Fan, Z.; Pearce, H.; Tan, B.; Karri, R.; Dolan-Gavitt, B.; Garg, S. Benchmarking Large Language Models for Automated Verilog RTL Code Generation. In Proceedings of the 2023 Design, Automation & Test in Europe Conference & Exhibition (DATE), Antwerp, Belgium, 17–19 April 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–6. [Google Scholar]
- Blocklove, J.; Garg, S.; Karri, R.; Pearce, H. Chip-Chat: Challenges and Opportunities in Conversational Hardware Design. arXiv 2023, arXiv:2305.13243. [Google Scholar]
- Efabless. Efabless Caravel “Harness” SoC—Caravel Harness Documentation. Available online: https://caravel-harness.readthedocs.io/en/latest/ (accessed on 8 February 2024).
- Welcome to SkyWater SKY130 PDK’s Documentation! Available online: https://skywater-pdk.readthedocs.io/en/main/ (accessed on 8 February 2024).
- Srilakshmi, S.; Madhumati, G.L. A Comparative Analysis of HDL and HLS for Developing CNN Accelerators. In Proceedings of the 2023 Third International Conference on Artificial Intelligence and Smart Energy (ICAIS), Coimbatore, India, 2–4 February 2023; pp. 1060–1065. [Google Scholar]
- Zhao, J.; Zhao, Y.; Li, H.; Zhang, Y.; Wu, L. HLS-Based FPGA Implementation of Convolutional Deep Belief Network for Signal Modulation Recognition. In Proceedings of the IGARSS 2020—2020 IEEE International Geoscience and Remote Sensing Symposium, Waikoloa, HI, USA, 26 September–2 October 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 6985–6988. [Google Scholar]
- Lee, H.S.; Jeon, J.W. Comparison between HLS and HDL image processing in FPGAs. In Proceedings of the 2020 IEEE International Conference on Consumer Electronics-Asia (ICCE-Asia), Seoul, Republic of Korea, 1–3 November 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–2. [Google Scholar]
- Shalan, M.; Edwards, T. Building OpenLANE: A 130nm openroad-based tapeout-proven flow. In Proceedings of the 39th International Conference on Computer-Aided Design, San Diego, CA, USA, 2–5 November 2020; pp. 1–6. [Google Scholar]
- Zezin, D. Modern Open Source IC Design tools for Electronics Engineer Education. In Proceedings of the 2022 VI International Conference on Information Technologies in Engineering Education (Inforino), Moscow, Russia, 12–15 April 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–4. [Google Scholar]
- Charaan, S.; Nalinkumar, S.; Elavarasan, P.; Prakash, P.; Kasthuri, P. Design of an All-Digital Phase-locked loop in a 130 nm CMOS Process using open-source tools. In Proceedings of the 2022 International Conference on Electronic Systems and Intelligent Computing (ICESIC), Chennai, India, 22–23 April 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 270–274. [Google Scholar]
- Ghazy, A.; Shalan, M. Openlane: The open-source digital asic implementation flow. In Proceedings of the Workshop on Open-Source EDA Technologies (WOSET), Online, 27 October 2020. [Google Scholar]
- Chupilko, M.; Kamkin, A.; Smolov, S. Survey of Open-source Flows for Digital Hardware Design. In Proceedings of the 2021 Ivannikov Memorial Workshop (IVMEM), Nizhny Novgorod, Russia, 24–25 September 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 11–16. [Google Scholar]
- Hesham, S.; Shalan, M.; El-Kharashi, M.W.; Dessouky, M. Digital ASIC Implementation of RISC-V: OpenLane and Commercial Approaches in Comparison. In Proceedings of the 2021 IEEE International Midwest Symposium on Circuits and Systems (MWSCAS), Lansing, MI, USA, 9–11 August 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 498–502. [Google Scholar]
- Efabless. Homepage. Available online: https://efabless.com/ (accessed on 26 February 2024).
- Deng, L. The MNIST Database of Handwritten Digit Images for Machine Learning Research [Best of the Web]. IEEE Signal Process. Mag. 2012, 29, 141–142. [Google Scholar] [CrossRef]
- Bisong, E. Google colaboratory. In Building Machine Learning and Deep Learning Models on Google Cloud Platform: A Comprehensive Guide for Beginners; Apress: Berkeley, CA, USA, 2019; pp. 59–64. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Advantages of HLS | Disadvantages of HLS |
|---|---|
| Reduces development time and effort | Does not have the same quality of results as HDLs |
| Architecture selection and optimization | Inconveniences in the hardware description |
| Parallelism and pipelining | Does not support all the features and constructs of the input languages |
| Allocates and shares resources efficiently | May not be compatible with all the existing tools and flows |
| Advantages of OpenLane | Disadvantages of OpenLane |
|---|---|
| The entire flow is configured through a single configuration file | Less control over the flow compared to commercial tools |
| Automated flow, requires no manual intervention, once configured | Commercial tools have better time optimization |
| Open-source, no charge for use | OpenLane uses more logic cells in the design |
| Reduces the time and expertise required to obtain the GDSII | OpenLane generated designs tend to consume more power |
| Advantages of Caravel | Disadvantages of Caravel |
|---|---|
| Allows low-cost and low-risk custom SoC design | Limited to SKY130A and GF180MCUC PDKs. |
| Supports various open-source tools and flows for IC design | May not be suitable for complex or high-end IC design projects |
| Enables fast SoC prototyping | Limited by 10 mm and 38 GPIO pins |
| Enables collaboration and sharing with the open-source hardware community |
| Subject of the Conversation | URL |
|---|---|
| Implementing a CNN in TF (accessed on 4 March 2024) | https://chat.openai.com/share/4e8a7cf2-a9e9-4461-a4b3-b9e8b4aa284f |
| Implementation of a forward function in Python without libraries (Bare-Metal) (accessed on 4 March 2024) | https://chat.openai.com/share/c96772be-4dac-43da-8013-c657dd935efa |
| From Python to C code I (accessed on 4 March 2024) | https://chat.openai.com/share/c96772be-4dac-43da-8013-c657dd935efa |
| From Python to C code II (accessed on 4 March 2024) | https://chat.openai.com/share/64b09191-401e-4d04-8eb5-5383b95ceea5 |
| Bias and weights as global parameters (accessed on 4 March 2024) | https://chat.openai.com/share/4b8237a4-20c3-434b-89fb-084fc5b57287 |
| From C to HLS I (accessed on 4 March 2024) | https://chat.openai.com/share/9037bfcd-8d23-4701-bafd-59eca930a822 |
| From C to HLS II (accessed on 4 March 2024) | https://chat.openai.com/share/84dd776b-0036-4fec-a878-dbcb33f6f210 |
| Add function, half-precision floating-point (accessed on 4 March 2024) | https://chat.openai.com/share/0f617bfd-f59a-49a3-a561-20b2779ca121 |
| Mult, Relu, Max function, half-precision floating-point (accessed on 4 March 2024) | https://chat.openai.com/share/2b207fc6-5952-4ef7-a562-64765e2d6722 |
| Exponent function, half-precision floating-point (accessed on 4 March 2024) | https://chat.openai.com/share/5345f69b-5e04-4fdf-a062-f29b2fcc4564 |
| Caravel | AI by AI | Type |
|---|---|---|
| wb_clk_i | o_mux_clk | Input |
| io_in[36] | o_mux_clk | Input |
| io_in[37] | s_mux_clk | Input |
| o_mux_clk | ap_clk | Input |
| la_data_in[1] | in_ap_rst | Input |
| io_in[35] | in_ap_rst | Input |
| wb_clk_i | o_mux_clk | Input |
| io_in[36] | o_mux_clk | Input |
| io_in[37] | s_mux_clk | Input |
| o_mux_clk | ap_clk | Input |
| la_data_in[1] | in_ap_rst | Input |
| io_in[35] | in_ap_rst | Input |
| la_data_out[2] | ap_start | Input |
| la_data_out[3] | ap_done | Output |
| la_data_out[4] | ap_ready | Output |
| io_out[16:5] | image_r_Addr_A | Output |
| io_out[17] | image_r_EN_A | Output |
| N/A | image_r_WEN_A | Output |
| N/A | image_r_Din_A | Output |
| io_in[33:18] | image_r_Dout_A | Input |
| io_out[34] | image_r_Clk_A | Output |
| N/A | image_r_Rst_A | Output |
| la_data_out[31:28] | ap_return | Output |
| Parameter | Value |
|---|---|
| Core area | 10.27 mm |
| Core Utility | 8.747 mm |
| Cells per mm | 26,241 |
| Latency | 161.19 K |
| Maximum frequency | 40 MHz |
| Static Power | 70.5 mW |
| Switching Power | 50.5 mW |
| Buffers | 65,142 |
| Flip-Flops | 49,973 |
| Diode | 33,839 |
| Number of Cells | 94,415 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Baungarten-Leon, E.I.; Ortega-Cisneros, S.; Abdelmoneum, M.; Vidana Morales, R.Y.; Pinedo-Diaz, G. The Genesis of AI by AI Integrated Circuit: Where AI Creates AI. Electronics 2024, 13, 1704. https://doi.org/10.3390/electronics13091704
Baungarten-Leon EI, Ortega-Cisneros S, Abdelmoneum M, Vidana Morales RY, Pinedo-Diaz G. The Genesis of AI by AI Integrated Circuit: Where AI Creates AI. Electronics. 2024; 13(9):1704. https://doi.org/10.3390/electronics13091704
Chicago/Turabian StyleBaungarten-Leon, Emilio Isaac, Susana Ortega-Cisneros, Mohamed Abdelmoneum, Ruth Yadira Vidana Morales, and German Pinedo-Diaz. 2024. "The Genesis of AI by AI Integrated Circuit: Where AI Creates AI" Electronics 13, no. 9: 1704. https://doi.org/10.3390/electronics13091704
APA StyleBaungarten-Leon, E. I., Ortega-Cisneros, S., Abdelmoneum, M., Vidana Morales, R. Y., & Pinedo-Diaz, G. (2024). The Genesis of AI by AI Integrated Circuit: Where AI Creates AI. Electronics, 13(9), 1704. https://doi.org/10.3390/electronics13091704