
PerNN: A Deep Learning-Based Recommendation Algorithm for Personalized Customization
Abstract
1. Introduction
2. Related Work
3. A Personalized Customization Scheme Based on Recommendation Algorithms
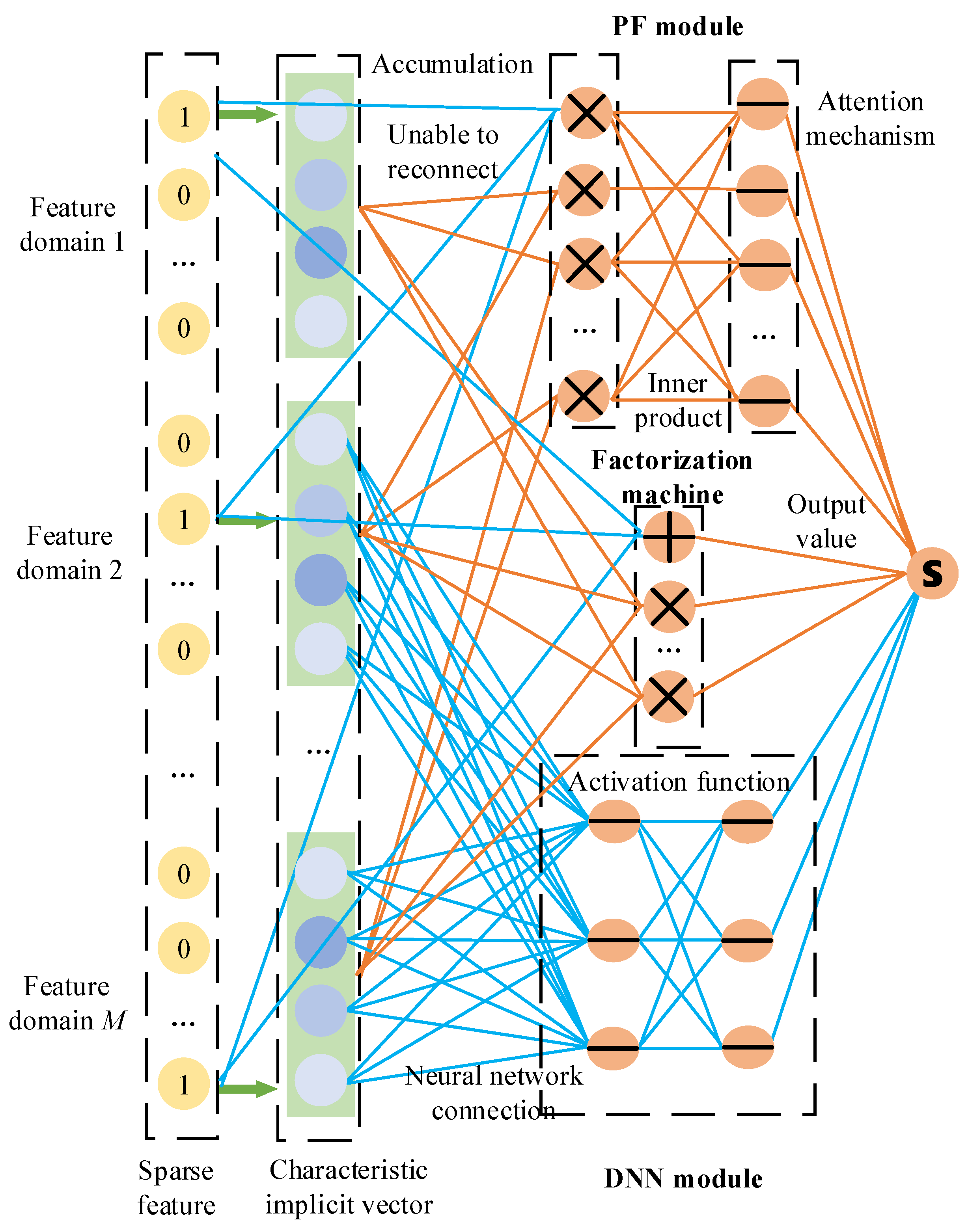
4. The PerNN Algorithm for Personalized Customization
4.1. Algorithm Overview
4.2. Computational Process
5. Experiments
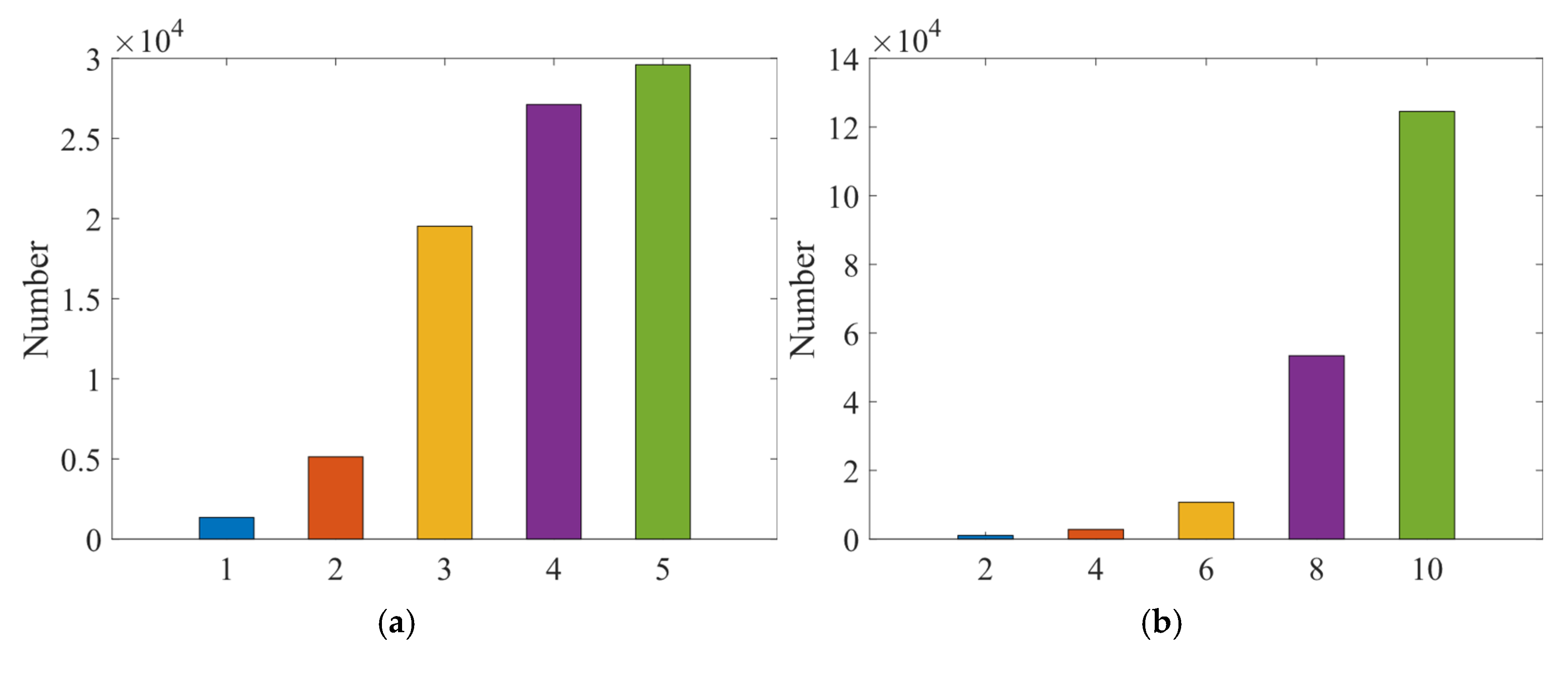
5.1. Dataset Introduction
5.2. Evaluation Metrics
5.3. Experimental Setup
5.4. Experimental Results
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Perret, J.K.; Schuck, K.; Hitzegrad, C. Production scheduling of personalized fashion goods in a mass customization environment. Sustainability 2022, 14, 538. [Google Scholar] [CrossRef]
- Schulz, C.; Kortmann, S.; Piller, F.T.; Pollok, P. Growing with smart products: Why customization capabilities matter for manufacturing firms. J. Prod. Innov. Manag. 2023, 40, 2680. [Google Scholar] [CrossRef]
- Akinpelu, S.; Viriri, S. Bi-feature selection deep learning-based techniques for speech emotion recognition. In Proceedings of the International Symposium on Visual Computing, Las Vegas, NV, USA, 17–19 November 2025; Springer: Cham, Switzerland, 2025; pp. 345–356. [Google Scholar]
- Shan, Y.; Hoens, T.R.; Jiao, J.; Wang, H.; Mao, J. Deep crossing: Web-scale modeling without manually crafted combinatorial features. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 255–262. [Google Scholar]
- Qu, Y.; Cai, H.; Ren, K.; Zhang, W.; Yu, Y.; Wen, Y.; Wang, J. Product-based neural networks for user response prediction. In Proceedings of the 2016 IEEE 16th International Conference on Data Mining (ICDM), Barcelona, Spain, 12–15 December 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1149–1154. [Google Scholar]
- Wang, R.; Fu, B.; Fu, G.; Wang, M. Deep & cross network for ad click predictions. In Proceedings of the ADKDD’17, Halifax, NS, Canada, 14 August 2017; pp. 1–7. [Google Scholar]
- Cheng, H.T.; Koc, L.; Harmsen, J.; Shaked, T.; Chandra, T.; Aradhye, H.; Anderson, G.; Corrado, G.; Chai, W.; Ispir, M.; et al. Wide & deep learning for recommender systems. In Proceedings of the 1st Workshop on Deep Learning for Recommender Systems, Boston, MA, USA, 15 September 2016; pp. 7–10. [Google Scholar]
- He, X.; Liao, L.; Zhang, H.; Nie, L.; Hu, X.; Chua, T.S. Neural collaborative filtering. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 173–182. [Google Scholar]
- Guo, H.; Tang, R.; Ye, Y.; Li, Z.; He, X. DeepFM: A factorization-machine based neural network for CTR prediction. arXiv 2017, arXiv:1703.04247. [Google Scholar]
- He, X.; Chua, T.S. Neural factorization machines for sparse predictive analytics. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Shinjuku, Japan, 7–11 August 2017; pp. 355–364. [Google Scholar]
- Zhang, W.; Du, T.; Wang, J. Deep Learning over Multi-field Categorical Data: A Case Study on User Response Prediction. In Proceedings of the Advances in Information Retrieval: 38th European Conference on IR Research, ECIR 2016, Padua, Italy, 20–23 March 2016; Proceedings 38. Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 45–57. [Google Scholar]
- Sedhain, S.; Menon, A.K.; Sanner, S.; Xie, L. Autorec: Autoencoders meet collaborative filtering. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 111–112. [Google Scholar]
- Xiao, J.; Ye, H.; He, X.; Zhang, H.; Wu, F.; Chua, T.S. Attentional factorization machines: Learning the weight of feature interactions via attention networks. arXiv 2017, arXiv:1708.04617. [Google Scholar]
- Yu, C.; Wang, H. Personalized customization: Service resource configuration optimization driven by customer requirements accurately. PLoS ONE 2025, 20, e0320312. [Google Scholar] [CrossRef] [PubMed]
- Misra, R.; Wan, M.; McAuley, J. Decomposing fit semantics for product size recommendation in metric spaces. In Proceedings of the 12th ACM Conference on Recommender Systems, Vancouver, BC, Canada, 2–7 October 2018; pp. 422–426. [Google Scholar]
- Zheng, L.; Noroozi, V.; Yu, P.S. Joint deep modeling of users and items using reviews for recommendation. In Proceedings of the tenth ACM International Conference on Web Search and Data Mining, Cambridge, UK, 6–10 February 2017; pp. 425–434. [Google Scholar]
- Xue, F.; He, X.; Wang, X.; Xu, J.; Liu, K.; Hong, R. Deep item-based collaborative filtering for top-n recommendation. ACM Trans. Inf. Syst. (TOIS) 2019, 37, 1–25. [Google Scholar] [CrossRef]
- He, X.; Deng, K.; Wang, X.; Li, Y.; Zhang, Y.; Wang, M. Lightgcn: Simplifying and powering graph convolution network for recommendation. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual, 25–30 July 2020; pp. 639–648. [Google Scholar]
- Liang, D.; Krishnan, R.G.; Hoffman, M.D.; Jebara, T. Variational autoencoders for collaborative filtering. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018; pp. 689–698. [Google Scholar]
- Chen, C.; Zhang, M.; Liu, Y.; Ma, S. Neural attentional rating regression with review-level explanations. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018; pp. 1583–1592. [Google Scholar]
- Lian, J.; Zhou, X.; Zhang, F.; Chen, Z.; Xie, X.; Sun, G. xdeepfm: Combining explicit and implicit feature interactions for recommender systems. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 1754–1763. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ModCloth | RentTheRunway | |
|---|---|---|
| Number of users | 47,958 | 105,508 |
| Number of items | 1378 | 5850 |
| Number of transactions | 82,790 | 192,544 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Lu, X.; Zhao, Y.; Yang, Z. PerNN: A Deep Learning-Based Recommendation Algorithm for Personalized Customization. Electronics 2025, 14, 2451. https://doi.org/10.3390/electronics14122451
Zhang Y, Lu X, Zhao Y, Yang Z. PerNN: A Deep Learning-Based Recommendation Algorithm for Personalized Customization. Electronics. 2025; 14(12):2451. https://doi.org/10.3390/electronics14122451
Chicago/Turabian StyleZhang, Yang, Xiaoping Lu, Yating Zhao, and Zhenfa Yang. 2025. "PerNN: A Deep Learning-Based Recommendation Algorithm for Personalized Customization" Electronics 14, no. 12: 2451. https://doi.org/10.3390/electronics14122451
APA StyleZhang, Y., Lu, X., Zhao, Y., & Yang, Z. (2025). PerNN: A Deep Learning-Based Recommendation Algorithm for Personalized Customization. Electronics, 14(12), 2451. https://doi.org/10.3390/electronics14122451