Abstract
Sequence-to-sequence neural machine translation (NMT) has achieved great success with many language pairs. However, its performance remains constrained in low-resource settings such as Mongolian–Chinese translation due to its strong reliance on large-scale parallel corpora. To address this issue, we propose ILFDN-Transformer, a Mongolian–Chinese NMT model that integrates implicit language features and a deliberation network to improve translation quality under limited-resource conditions. Specifically, we leverage the BART pre-trained language model to capture deep semantic representations of source sentences and apply knowledge distillation to integrate the resulting implicit linguistic features into the Transformer encoder to provide enhanced semantic support. During decoding, we introduce a deliberation mechanism that guides the generation process by referencing linguistic knowledge encoded in a multilingual pre-trained model, therefore improving the fluency and coherence of target translations. Furthermore, considering the flexible word order characteristics of the Mongolian language, we propose a Mixed Positional Encoding (MPE) method that combines absolute positional encoding with LSTM-based dynamic encoding, enabling the model to better adapt to complex syntactic variations. Experimental results show that ILFDN-Transformer achieves a BLEU score improvement of 3.53 compared to the baseline Transformer model, fully demonstrating the effectiveness of our proposed method.
1. Introduction
With the continuous advancement of deep learning, neural machine translation (NMT) has emerged as the dominant paradigm in the field of machine translation. Compared with traditional statistical methods, NMT offers end-to-end learning capabilities, robust context modeling, and strong scalability, significantly improving the translation quality [1]. In particular, the Transformer model, with its self-attention mechanism and highly parallelizable structure, has become the backbone of modern NMT systems [2]. This architectural breakthrough not only enhances translation performance for high-resource language pairs but also provides promising avenues for addressing low-resource translation tasks. Mongolian, as a representative minority and low-resource language, holds substantial cultural and communicative importance across domains such as education, media, and cultural transmission. Mongolian–Chinese translation, in particular, remains a focal challenge within the NMT community due to the scarcity of parallel corpora and the structural complexity of the Mongolian language.
Although recent research has combined Transformer models with techniques such as pre-trained language models, transfer learning, and data augmentation to boost translation performance, these approaches still struggle in low-resource settings. In the case of Mongolian, existing models often suffer from issues like low adequacy and fluency [3]. Some studies attempt to incorporate auxiliary linguistic information such as part-of-speech tags, syntactic trees, or dependency structures to enhance source language understanding. However, these methods heavily rely on high-quality linguistic analysis tools and often require manually defined rules or extensive annotated corpora, resulting in high development costs and poor scalability [4], making them difficult to apply effectively to low-resource languages like Mongolian. Moreover, standard Transformer decoders typically employ a left-to-right, one-pass generation strategy. While it demonstrates strong local context modeling capabilities, it falls short of emulating the iterative cognitive process of human translation—namely, drafting, deliberation, and refinement. The lack of global contextual awareness frequently leads to issues such as incomplete information, improper word collocation, and poor discourse coherence [5]. In recent years, with the rapid development of pre-trained language models, neural networks have achieved remarkable progress in cross-domain and multi-task language modeling. Sälevä et al. [6] leveraged monolingual data to train language models as prior knowledge, combined with data augmentation strategies, effectively mitigating the scarcity of parallel corpora. Cui et al. [7] investigated the use of in-context invocation of pre-trained large language models (LLMs) for document-level machine translation, demonstrating that in-context learning can introduce richer contextual information and improve the coherence and consistency of long-text translation. Hromei et al. [8] explored the integration of multimodal large language models with dialogue planning, enhancing semantic generation and reasoning capabilities in human–computer interaction settings. Luo et al. [9] proposed a novel approach that incorporates large language models into neural machine translation encoders, achieving more efficient translation performance and stronger task generalization while keeping the decoder architecture unchanged. Qu et al. [10] conducted a systematic investigation into semantic control and the “forgetting” mechanisms in pre-trained models, emphasizing their importance in information filtering and semantic controllability. Collectively, these studies highlight that the incorporation of pre-trained models, data augmentation, and context-aware learning mechanisms can significantly enhance language understanding capabilities, offering new insights and technical support for semantic transfer and structural modeling in low-resource scenarios.
In this paper, we propose a Mongolian–Chinese neural machine translation (NMT) model, ILFDN-Transformer, which integrates implicit linguistic features and a deliberation network framework. On the encoder side, a pre-trained BART model is employed to capture deep semantic representations of the source language. These implicit linguistic features are migrated and integrated into the Transformer encoder via knowledge distillation, serving as a complementary semantic representation to enhance the encoder’s capacity for understanding sentence-level structures and meanings. On the decoder side, we introduce a deliberation network module guided by mBERT, which leverages the pre-trained model as a source of prior linguistic knowledge to guide the translation process. Specifically, the first decoder generates an initial translation sequence, which is then encoded by mBERT to obtain representation vectors enriched with deep linguistic knowledge. These representations are subsequently fed into a second decoder to perform second-pass decoding, enabling refined translation generation through deliberation and optimization. Additionally, to tackle the challenges posed by flexible word orders and long-distance dependencies in Mongolian–Chinese translation, we propose a Weighted Mixed Positional Encoding (MPE) scheme. This mechanism integrates absolute positional encoding with LSTM-based dynamic positional encoding, enhancing the model’s capacity to handle complex syntactic structures and long-range dependencies, thereby effectively improving translation accuracy and fluency.
The following is a summary of our contribution:
- We propose an implicit linguistic feature enhancement method by leveraging the BART pre-trained model to inject semantically rich representations into the encoder, significantly improving its ability to model the source language.
- We design a mBERT-guided deliberation decoding network by employing a dual-decoder architecture. By incorporating linguistic knowledge from a pre-trained model into a two-pass decoding process, this approach enables iterative refinement of translations, significantly enhancing their accuracy and fluency.
- We propose a Weighted Mixed Positional Encoding mechanism that effectively fuses absolute and dynamic positional encodings. This design strengthens the model’s ability to capture complex syntactic structures and long-distance dependencies, effectively addressing challenges posed by word order differences and long-range dependencies in Mongolian–Chinese translation.
2. Related Works
In recent years, the field of neural machine translation has significantly enhanced the understanding of linguistic structures and semantics through the incorporation of linguistic knowledge, which has proven particularly effective for low-resource language translation. Meanwhile, various improvement strategies have emerged to address the challenges specific to Mongolian–Chinese translation, such as limited parallel corpora and significant differences in word order. To provide a comprehensive overview of the background and technical foundations of this study, Section 2.1 introduces methods for incorporating linguistic knowledge, while Section 2.2 reviews recent advances in Mongolian–Chinese translation research.
2.1. Neural Machine Translation Methods Based on Linguistic Knowledge
Incorporating linguistic knowledge as prior information into neural machine translation (NMT) has emerged as a prominent research direction. Linguistic knowledge encompasses multiple layers—such as lexical features, syntactic structures, and semantic information—and provides structured and informative cues that enhance a model’s understanding of language patterns [11]. This is particularly beneficial in low-resource scenarios where linguistic differences are pronounced, as the integration of linguistic knowledge can significantly improve the translation quality. Zenkel et al. [12] proposed an end-to-end neural word alignment method, in which a supervised Transformer model is used for unsupervised word alignment. This approach consistently outperforms traditional alignment tools such as GIZA++ (https://github.com/moses-smt/giza-pp, accessed on 29 June 2025) while maintaining strong translation performance. Zhang et al. [13] proposed a novel syntax-guided contrastive learning method that maintains the original Transformer architecture. Their approach leverages both constituency and dependency structures to construct phrase-guided and tree-guided contrastive objectives, which are optimized during the pre-training stage to enable the language model to capture rich syntactic knowledge within its representations. Hou et al. [14] designed a syntax-aware localized self-attention mechanism that directly incorporates structural information from external parsers to improve the parsing quality. Bu et al. [15] leveraged both semantic and syntactic knowledge through feature disentanglement at the encoder side and linguistically guided decoding, achieving effective improvements in both zero-shot and supervised translation settings. Xu et al. [16] proposed the LGE-Transformer model, which integrates language-enhanced pre-trained models and a gated dynamic encoding module to enable adaptive multi-layer feature fusion in the encoder and hybrid cross-attention in the decoder. This significantly boosts translation performance in low-resource scenarios such as Chinese–Malay translation. Boyapati et al. [17] presented a semantics-aware dimensionality reduction framework for encoder–decoder architectures. Their method compresses BERT embeddings while preserving critical semantic information, thus enhancing model efficiency. Pathak et al. [18] developed a low-resource multilingual pre-trained language model named BodoBERT and proposed a deep learning-based part-of-speech tagging method by integrating BiLSTM-CRF and BytePair embeddings, which significantly improved tagging accuracy and robustness. Although these approaches have achieved notable success in enhancing translation quality and linguistic understanding, the deep exploitation and efficient integration of implicit linguistic features remain underexplored and present promising directions for further research.
2.2. Research on Mongolian–Chinese Neural Machine Translation
As a representative low-resource translation task, Mongolian–Chinese neural machine translation faces significant challenges due to the scarcity of bilingual corpora and substantial differences in linguistic structures. Consequently, research in this area has been gradually exploring effective strategies to improve translation quality. Li et al. [19] designed an improved Transformer-based document-level translation model by integrating two types of positional information and incorporating paragraph-level context, which enables better modeling of inter-sentence dependencies and significantly enhances the quality of Mongolian–Chinese document translation. Zhi et al. [20] computed sentence-level semantic similarity using BERT and applied dot-product and cosine similarity measures to select highly relevant sentence pairs, thereby expanding the training corpus and substantially improving translation performance. Wang et al. [21] proposed a training framework for Mongolian–Chinese translation tailored to low-related language pairs. By introducing hot-start word alignment to address lexical mismatches and incorporating approximate knowledge distillation to mitigate catastrophic forgetting, the model’s language representation ability and translation quality were effectively improved. Zheng et al. [22] developed a non-autoregressive Mongolian–Chinese translation model based on CeMAT, which combines multi-level knowledge distillation from a teacher model with graph convolutional networks to supplement inter-word semantic information. This approach not only improves translation quality but also significantly accelerates inference speed. Wang et al. [23] introduced a continual transfer learning approach to address the challenge of sub-models failing to fully inherit knowledge from parent models in Mongolian–Chinese translation tasks. Sun et al. [24] proposed a document-level Mongolian–Chinese NMT approach that integrates target-side data augmentation with topic modeling on the source side, effectively alleviating the scarcity of document-level parallel corpora and addressing lexical ambiguity issues. Although prior work has achieved notable progress in structural modeling, data augmentation, and decoding efficiency, existing models still fall short in terms of deep semantic understanding and global optimization of translations. To address this, recent studies have begun exploring deliberation mechanisms to refine initial translation outputs. Inspired by these advances, we propose integrating pre-trained language models into the deliberation stage by leveraging their linguistic knowledge to guide second-pass decoding. This enhances the model’s semantic comprehension and significantly improves translation accuracy and fluency.
3. Method
As shown in Figure 1, the proposed ILFDN-Transformer model is built upon the Transformer architecture and consists of three core components: an implicit linguistic feature enhancement module based on a pre-trained BART model, a deliberation decoding mechanism guided by mBERT representations, and a hybrid positional encoding scheme. To address the challenges faced by low-resource languages in translation tasks—such as weak semantic modeling and difficulties in cross-lingual alignment—this paper adopts heterogeneous pre-trained language models in a collaborative design. On the encoder side, we leverage the BART model, which was pre-trained on a large-scale monolingual corpus, to extract deep linguistic representations and construct an implicit linguistic feature encoder, which enhances the model’s ability to capture the semantic structure of the source language. On the decoder side, the multilingual pre-trained model mBERT is introduced to provide semantic guidance between the two decoding stages by virtue of its cross-lingual representation alignment capability, thereby enabling semantic correction and expression refinement of the intermediate translation. Additionally, we incorporate a weighted hybrid positional encoding mechanism into the first decoder. This mechanism combines absolute positional encoding with LSTM-based dynamic encoding, allowing the model to integrate both global position awareness and local contextual dynamics, ultimately enhancing translation accuracy and fluency. These modules collaborate closely to jointly enhance the accuracy, fluency, and generalization capability of the model in low-resource translation scenarios.
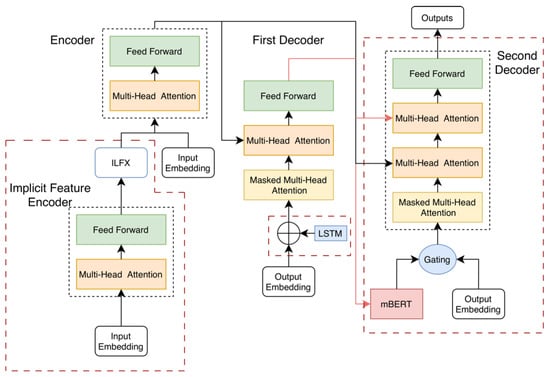
Figure 1.
The architecture of the proposed Mongolian–Chinese neural machine translation model based on implicit linguistic features and a deliberation network. (1) Implicit linguistic feature encoder module (left-side encoder), (2) deliberation decoding mechanism incorporating mBERT representations (right-side dual-decoder structure), and (3) hybrid positional encoding module (central positional encoding pathway). Source: author’s contribution.
3.1. BART-Based Implicit Linguistic Feature Enhancement Mechanism
BART [25] is a pre-trained sequence-to-sequence language model that combines both autoencoding and autoregressive objectives. This dual nature enables it to reconstruct input sequences while generating target outputs, making it highly effective at capturing contextual dependencies and linguistic structural information. Leveraging its strong semantic modeling capabilities, we employ BART’s encoder as an implicit feature extractor for the source language, aiming to provide richer semantic cues to the translation model. To integrate these features into the translation pipeline, we adopt a knowledge distillation approach, transferring the encoding capacity of BART to the Transformer encoder, which serves as the student model. This process encourages the Transformer encoder to focus on capturing the implicit linguistic characteristics of the source sentence. The extracted features are then fused with the original input representations and jointly fed into the NMT model. By incorporating these deep semantic features, the model gains an enhanced understanding of the source-side linguistic structure, leading to improved translation quality—particularly in low-resource scenarios where explicit syntactic and semantic annotations are limited.
Implicit linguistic features refer to the deep semantic and structural information automatically learned by pre-trained models from large-scale corpora during training, which are reflected in the hidden states of their Transformer layers. Previous studies [26,27,28] have shown that the intermediate representations of pre-trained models can implicitly capture linguistic characteristics such as syntactic dependencies, lexical semantics, and pragmatic relations. Accordingly, in this work, we use the output of the final layer of the BART encoder as the implicit linguistic representation of the source sentence. This representation is integrated into the attention layers of the main encoder through a fusion strategy to guide context modeling and translation generation.
3.1.1. Pre-Training the BART Encoder
To enhance the model’s capacity for capturing deep semantic representations of the source language, we leverage the encoder component of the pre-trained BART model to train an implicit linguistic feature extractor. Since the primary goal of this stage is to extract semantic-rich features while minimizing computational overhead, only the encoder portion of BART is utilized—excluding the decoder.
Given a source sentence containing n tokens, we apply a token-masking strategy where 15% of the tokens are randomly selected and replaced with the special token [MASK], resulting in a noise-injected sequence . Figure 2 illustrates the correspondence between the original inputs and the noise-augmented inputs, demonstrating that the noise-injection mechanism is designed to enhance the model’s robustness against incomplete inputs.

Figure 2.
Examples of sentences before and after noise injection. The source sentences (in Chinese) are translated as follows: (1) Machine translation is one of the important research directions in NLP, (2) The main challenges of Mongolian machine translation include the scarcity of bilingual corpora and syntactic differences, and (3) There are significant word order differences between Mongolian and Chinese, which pose challenges to neural machine translation. The noise-injected sentences are the corresponding incomplete versions of the source sentences and are not translated here. Source: author’s contribution.
Subsequently, the noisy input is then fed into the BART encoder, and we obtain the final hidden representations from its last layer, denoted as H. Since only the encoder is used and the decoder is omitted, a linear projection layer followed by a softmax layer is appended to the final encoder layer to enable direct prediction of the masked tokens. The encoder architecture of the adopted BART model is illustrated in Figure 3. The prediction distribution is computed as
where represents the predicted token distribution, W is a trainable projection matrix, and b is a bias vector.
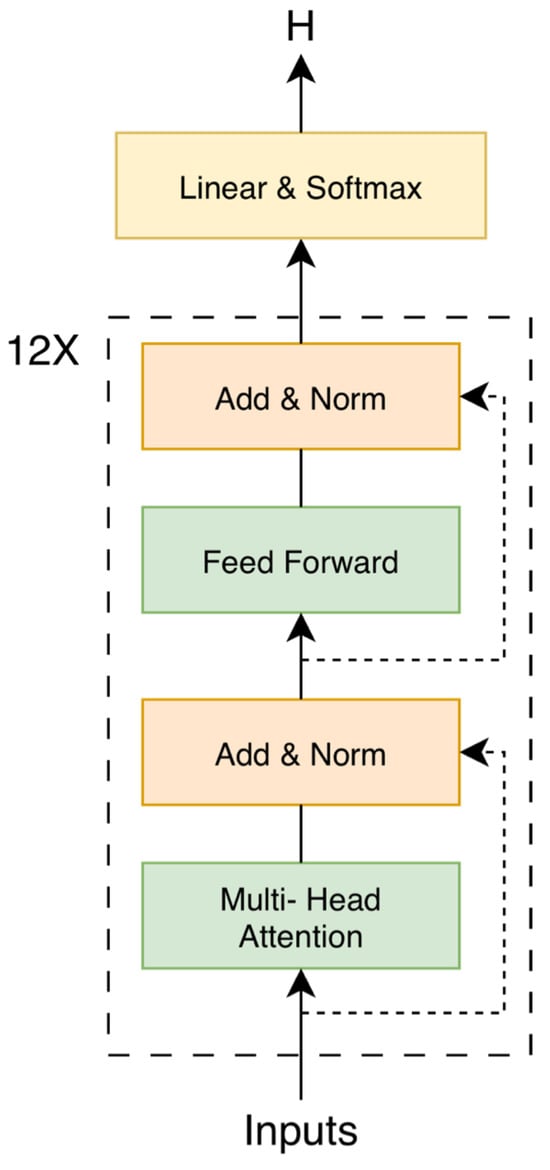
Figure 3.
Architecture of the BART encoder. Source: author’s contribution.
Finally, we adopt a cross-entropy loss function to minimize the difference between the predicted tokens and the original tokens and optimize the model parameters via backpropagation. The cross-entropy loss is computed as
where denotes the predicted probability of the original token under noisy input conditions and denotes the probability distribution after softmax normalization.
3.1.2. Teacher–Student Distillation Mechanism
To achieve effective transfer of BART’s encoding capabilities to the Transformer encoder, we design a knowledge distillation mechanism based on feature alignment. The goal is to uniformly sample semantic features across layers from shallow to deep, thereby balancing local and global semantic modeling capabilities. To this end, we adopt an equal-interval layer mapping strategy that spans various levels of representation, ranging from shallow lexical features to deep semantic abstractions. This strategy ensures structural alignment simplicity while enabling the student model to inherit the teacher model’s multi-layer semantic knowledge within a compressed architecture, thereby improving the stability of the distillation process and enhancing the efficiency of knowledge transfer. Considering that the BART encoder used in this section has 12 layers, while the Transformer encoder has 6 layers, a uniform mapping strategy is adopted to ensure structural compatibility and efficient knowledge transfer from the teacher model (BART encoder) to the student model (Transformer encoder), as shown in Figure 4.
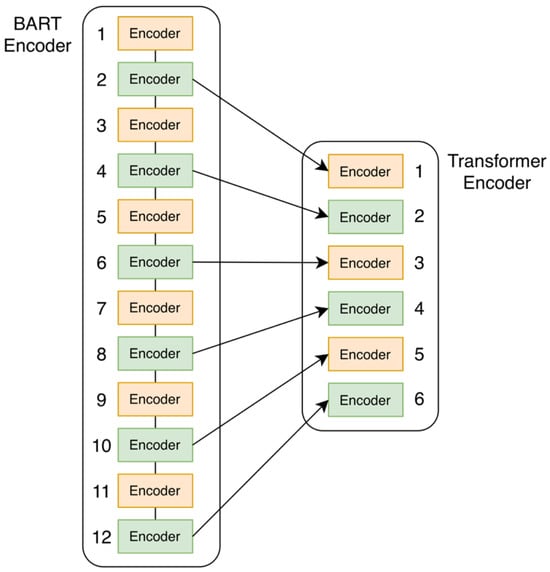
Figure 4.
Layer-wise mapping from the BART encoder to the Transformer encoder. Source: author’s contribution.
Specifically, we select the hidden representations of layers 2, 4, 6, 8, 10, and 12 of the BART encoder as the knowledge source of the teacher model and align them with layers 1, 2, 3, 4, 5, and 6 of the student model one by one, respectively, to satisfy the following mapping relationship:
where denotes the hidden state of the teacher model layer of the hidden state and denotes the hidden state of layer i of the student model.
We adopt the mean squared error (MSE) as the loss function to calculate the difference between the hidden representations of the corresponding layers of the teacher model and the student model with the following formula:
Finally, the parameters of the student model are optimized to improve its encoding ability by minimizing the loss function of the mean squared error so that its encoding ability is as close as possible to that of the teacher’s model, thus effectively improving the expression ability of the student model for implicit semantic features.
3.1.3. Incorporating Implicit Linguistic Features
In the bottom-up, layer-by-layer processing of traditional encoders, the lower layers often struggle to capture global linguistic information adequately. Implicit linguistic features obtained from pre-trained models can serve as supplementary prior knowledge, enriching the encoder with deeper linguistic insights. Therefore, we construct a dual-encoder architecture comprising a standard Transformer main encoder and an implicit linguistic feature encoder obtained through knowledge distillation, as shown in module (1) in Figure 1. The implicit encoder is dedicated to extracting deep linguistic features from the source language, compensating for the limited expressiveness of the original input. The final layer output of this encoder is regarded as the implicit linguistic feature representation of the source language, denoted as .
Specifically, in the model encoding phase, we add and fuse the original input representation X with the implicit language feature and input it into the main encoder. The fused input is defined as
Subsequently, the fused input is fed into the self-attention layer of the main encoder. Its output is then combined with through a residual connection and passed through a layer normalization operation, resulting in an intermediate representation with the same sequence length as the input:
where denotes the self-attention mechanism and indicates layer normalization. It is important to note that the implicit linguistic features participate only in representation learning within the self-attention layer to enhance semantic understanding of the source language. They are not propagated through the residual path to the subsequent feed-forward layers, thereby avoiding unnecessary interference in downstream modeling and preserving computational efficiency.
Finally, the intermediate representation Z is forwarded to the feed-forward neural network, followed by a residual connection and normalization to yield the final output representation H, where
By introducing deep linguistic prior knowledge, this design compensates for the limitations of standard encoders in modeling latent semantic representations, thereby enhancing the model’s understanding of source language semantics and ultimately improving translation quality.
3.2. Deliberation Decoding Mechanism Incorporating mBERT Representations
In Mongolian–Chinese translation, significant differences in word order, complex syntactic structures, and inconsistent semantic expressions often pose challenges for conventional one-pass decoding mechanisms. Such approaches tend to struggle with fully capturing the deep semantics of the source language, which can lead to misinterpretation or inaccurate expression in the generated translation. To address these issues, we design a deliberation decoding network incorporating mBERT [29] on the decoder side, as shown in module (2) in Figure 1. Specifically, we construct a dual-decoder architecture and introduce the pre-trained mBERT model between the two decoding stages as a source of prior linguistic knowledge. This design enables semantic correction and expressive refinement of the initial translation, thereby effectively enhancing the accuracy and naturalness of the final output. Meanwhile, in order to control the computational overhead, we call the mBERT representation only once, cache the results in the design, and adopt a lightweight fusion structure with a trimmable mechanism, which takes into account the reasoning efficiency and model deployment feasibility while ensuring that the quality of the translated text is improved.
First, given a source language input sequence , the ILFDN-Transformer model encodes it using the encoder to produce a sequence of hidden states . These representations not only capture the fundamental semantic content of the source language but also incorporate implicit linguistic features extracted from the pre-trained model.
Next, the first decoder processes the hidden state sequence and generates an initial target language translation . This decoder is composed of six stacked standard decoder layers, each consisting of three core sub-modules: a masked self-attention layer, a cross-attention layer, and a feed-forward neural network.
Before inputting the second decoding, to inject richer semantic prior knowledge, the preliminary translation is fed into the multilingual pre-trained model mBERT to obtain its semantic representation vector , where
Considering that the output dimension of mBERT may not be consistent with the source language representation vector H generated by the encoder, we introduce a layer of linear transformation in the subsequent structure in order to realize the dimensional mapping of to be consistent with the vector H so as to ensure that it matches with the input requirements of the second decoder. The computational formula is as follows:
where and are learnable parameters.
Next, in order to effectively fuse the mBERT-encoded representation vector and the hidden state representation H of the original input sequence, we introduce a gating mechanism to realize the dynamic weighted integration of the two types of information to obtain the final representation vector . This mechanism can dynamically adjust the weights of information from different sources, effectively avoiding the interference of redundant features while enhancing the modeling ability of semantic consistency and translation contexts. The specific calculation is as follows:
where and are learnable parameters, denotes the dimensionality of the representation vector of the original input sequence, denotes the sigmoid function, and denotes the gating value to dynamically adjust the weights of H and .
Finally, the fused representation vector F is input to a second decoder for secondary decoding to generate the final translation. The structure of this second decoder is consistent with that of the first decoder, which consists of a stack of six standard decoders. Through the secondary decoding process, the model is able to further optimize the initial translated sentences, combining rich contextual information and pre-trained linguistic knowledge to effectively improve the accuracy and fluency of the translation.
3.3. Hybrid Positional Encoding Mechanism
The Transformer model lacks an inherent recurrence structure for capturing sequential order and therefore requires the explicit incorporation of positional encoding to model both relative and absolute positional information between tokens. Traditional absolute positional encoding provides global position signals but is limited in modeling complex syntactic structures or long-range dependencies in lengthy texts. In contrast, LSTM-based [30] positional encoding dynamically captures local contextual information but lacks explicit global positional awareness. Therefore, this paper proposes a Mixed Positional Encoding (MPE) mechanism that integrates absolute positional encoding and dynamic encoding to balance global structural modeling with context sensitivity. As illustrated in module (3) of Figure 1, the MPE module improves the model’s overall ability to represent positional information by applying a weighted fusion of these two encoding schemes. It is important to emphasize that MPE is not a simple concatenation of existing encoding types but a task-specific design tailored to the dual linguistic characteristics of Mongolian, namely “agglutinative morphology + free word order.” By jointly modeling static and dynamic positional information, MPE enhances the model’s capacity to capture syntactic relationships and morphological dependencies, thereby improving the accuracy and robustness of the overall semantic representation.
In the standard Transformer architecture, positional encoding vectors are generated using the sine–cosine functions and sums it with the word vector element by element to obtain the final input representation of the model. The positional encoding is calculated as follows:
where pos denotes the position index of a token in the sequence, i is the dimension index, and is the dimensionality of the embedding vector.
This method generates distinct periodic patterns along each dimension, offering strong positional discrimination and allowing the model to uniquely identify each position. However, its static, non-adaptive structure limits its ability to adjust to semantic variations in the input or capture dynamic contextual dependencies.
In contrast, LSTM, a variant of recurrent neural networks, inherently models sequential dependencies. Unlike absolute encoding, LSTM does not rely on explicit position indices. Instead, it processes the input sequence holistically and implicitly learns position-aware representations by capturing the sequential context. This dynamic positional encoding adjusts based on the semantic input, making it particularly suitable for complex language structures.
For a Mongolian input sequence , where denotes the i-th token in the sequence, the process of obtaining positional encodings using LSTM consists of the following steps:
(1) Word embedding: The Mongolian sequence is converted into an embedding representation through the word embedding layer:
where each embedding vector is a d-dimensional word vector and d is the dimension of the embedding.
(2) Feeding into LSTM: The embedding representation E is input to the LSTM layer, and the LSTM gradually generates the hidden state at each position through a recursive mechanism. Let the hidden state of LSTM be , where is the LSTM hidden state at the i-th position. The LSTM computes its hidden state iteratively through time steps and generates a new hidden state based on the current input and the hidden state of the previous time step (as well as the LSTM’s memory cell ) with the following formulas:
where and denote the weight and bias of the forgetting gate, is the sigmoid activation function, denotes the proportion of forgetting, and denote the weight and bias of the input gate, denotes the proportion of the inputs, denotes the current candidate memory state, and denote the weight and bias of the output gate, denotes the proportion of the output, denotes the memory state of the previous time step, and denotes the memory state of the current time step.
(3) Extract the LSTM hidden state as the position encoding: Considering the LSTM hidden state as the encoding of the i-th position in the sequence, the final LSTM position encoding is
(4) Fusion of absolute and LSTM-based encodings: In order to introduce both the absolute positional information and the contextual dynamic sequencing information, we utilize weighted summation to mix the absolute positional encoding and the LSTM position encoding and balance the two according to the weights, and the mixed positional coding for each time step is as follows:
where denotes the mixed positional coding, is the hyperparameter controlling the proportion of the fusion of the two codings, denotes the absolute positional coding, and represents the dynamic position encoding output from LSTM.
4. Experiments and Results
This section aims to systematically evaluate the performance of the proposed ILFDN-Transformer model in the Mongolian–Chinese translation task. Section 4.1 and Section 4.2 first elaborate on the dataset construction methodology and the experimental parameter settings. Section 4.3 then describes the metrics used for assessing translation quality. Finally, Section 4.4 presents and analyzes the experimental results, with Section 4.4.1 and Section 4.4.2 validating the effectiveness of the proposed model and the contribution of each module through comparative and ablation studies, respectively.
4.1. Dataset Setup
We utilize a cleaned Mongolian–Chinese parallel corpus provided by the Artificial Intelligence and Pattern Recognition Laboratory at Inner Mongolia University of Technology. The original dataset consists of approximately 420,000 sentence pairs across a diverse range of domains, including
- News articles, medical reports, and literary excerpts.
- Spoken communication, such as daily conversations and online chats.
- Technical texts, including computer-related terminology and specialized expressions.
- Folk language expressions, such as proverbs, idioms, and colloquialisms.
From the original corpus, 400,000 sentence pairs are designated as the training set, 10,000 pairs as the validation set, and another 10,000 pairs as the test set. To further enhance the dataset, we apply a language-driven data augmentation (LDA) method [31], which generates 1.3 million pseudo-parallel Mongolian–Chinese sentence pairs. The augmented dataset is subsequently split into the training, validation, and test sets using an 8:1:1 ratio. A detailed overview of the dataset partition is presented in Table 1.

Table 1.
Dataset partitioning overview. Source: author’s contribution.
4.2. Experimental Setup
The Transformer architecture is adopted as the baseline model. To enhance model convergence and training stability, we employ the Adam optimizer with a learning rate of 0.0003, = 0.9, and = 0.98. During the decoding phase, we utilize the beam search algorithm with a beam size of three, aiming to strike a balance between translation quality and computational cost. The specific parameter settings are detailed in Table 2.
Table 2.
Experimental settings for baseline models. Source: author’s contribution.
The hyperparameter settings for both the teacher and student models during knowledge distillation are summarized in Table 3.
Table 3.
Hyperparameter settings for the teacher and student models during knowledge distillation. Source: author’s contribution.
The model proposed in this paper integrates BART, mBERT, a dual-decoder architecture, and a weighted hybrid positional encoding mechanism. It is worth noting that the pre-trained BART and mBERT modules are employed solely as feature extractors, and their parameters remain frozen during training. As a result, only the Transformer backbone and the newly introduced modules are optimized, which helps reduce training costs and computational resource consumption. All training was conducted on a single Nvidia Tesla V100 GPU (The GPU used was manufactured by NVIDIA Corporation, located in Santa Clara, CA, USA.) with 12 GB of memory, using a corpus of approximately 1.3 million Mongolian–Chinese parallel sentence pairs. Empirical results show that under the default configuration, the proposed model requires an average of approximately 33 min per training epoch, with GPU memory utilization around 96%. In comparison, the baseline model (standard Transformer) takes about 19 min per epoch under the same configuration.
4.3. Evaluation Metrics
To thoroughly evaluate the performance of each translation model, we conduct a comprehensive analysis by combining automatic and human evaluation methods.
(1) Automatic Evaluation Metrics
To objectively assess the performance of the translation models, we adopt BLEU (bilingual evaluation understudy) as the primary evaluation metric. BLEU is an n-gram-based evaluation method that measures the accuracy and fluency of machine-generated translations by computing the degree of overlap between the generated translations and reference translations across different n-gram levels. A higher BLEU score indicates a closer match to the reference translation and thus higher translation quality.
To prevent overly short translations from achieving over-scoring, BLEU incorporates a brevity penalty (BP) to obtain the final score. The BLEU score is calculated as follows:
where denotes the precision of n-gram matches between the candidate and reference translations, is the corresponding weight, and BP is the brevity penalty, defined as
where c is the length of the generated translation and r is the length of the reference translation.
For easy observation and comparison, the BLEU values are uniformly multiplied by 100 for presentation in this paper, and BLEU-4 is adopted as the main evaluation metric.
(2) Manual Evaluation Metrics
To more comprehensively evaluate the translation quality of the model, in addition to the automatic metric (BLEU), manual evaluation is introduced in selected experiments as a supplementary measure. Specifically, three linguistics graduate students with bilingual proficiency in Mongolian and Chinese were invited to serve as human evaluators, scoring the model-generated translations manually. The evaluation focuses on two dimensions, namely semantic adequacy and linguistic fluency, assessing whether the translation accurately and completely conveys the meaning of the source text and whether it conforms to the grammatical rules and idiomatic usage of the target language. The evaluation procedure is as follows:
- Sample selection: A total of 200 sentence pairs are randomly sampled from the test set, including the source sentence, the reference translation, and the translations generated by each model.
- Scoring mechanism: Each translation is rated on the two dimensions of semantic adequacy and linguistic fluency using a 5-point scale, where 1 indicates a serious error and 5 represents excellent performance.
- Scoring method: The three evaluators score independently, and the final score is obtained by averaging their ratings.
4.4. Results and Discussion
4.4.1. Comparative Experiments
To further verify the effectiveness of the proposed ILFDN-Transformer model in the Mongolian–Chinese neural machine translation task, we conduct comparative experiments against four representative baseline models: LGP-NMT [32], Transparent [33], LaSyn [34], and GNMT [35]. All models are evaluated on the same dataset under consistent experimental settings. The BLEU score is adopted as the main evaluation metric to assess translation quality. The detailed performance results are presented in Table 4.
Table 4.
Experimental results of ILFDN-Transformer compared to existing models. Source: author’s contribution.
From the experimental results shown in Table 4, the proposed ILFDN-Transformer model achieves the highest BLEU score, significantly outperforming the other models. This indicates that ILFDN-Transformer is capable of accurately capturing long-distance dependencies and implicit structural information in the source language, thereby improving both the accuracy and fluency of the translation.
The relatively low BLEU score of the Transparent model may be attributed to its limited ability to integrate source language information and effectively capture contextual dependencies. In contrast, the GNMT model performs better than the Transparent model, suggesting its enhanced capacity for contextual modeling and local feature extraction. The BLEU scores of the LaSyn and LGP-NMT models are relatively close, and both demonstrate comparable improvements over the baseline. However, their performance still falls short of ILFDN-Transformer, possibly due to instability in their feature learning processes, which negatively affects the final translation quality.
Notably, compared to the baseline Transformer model, ILFDN-Transformer achieves a BLEU improvement of 3.53 points, clearly validating the effectiveness of the proposed enhancements: the BART-based implicit semantic feature augmentation, the mBERT-guided deliberation decoding network, and the weighted hybrid positional encoding mechanism. These innovations significantly strengthen the model’s ability to capture deep semantic information and long-range dependencies, refine semantic reasoning during decoding, and ultimately enhance translation accuracy and fluency.
4.4.2. Ablation Experiments
To assess the contribution of each module to the overall performance of the model, we conducted a series of ablation studies. First, we compared the performance of mBERT with other pre-trained models in capturing implicit linguistic features. Second, we examined the impact of different knowledge distillation strategies on the model’s generalization ability and translation quality. Finally, we progressively added the key components of our model—including the BART-based implicit semantic enhancement mechanism, the deliberation decoding structure, and the weighted hybrid positional encoding—to evaluate their individual and combined contributions. These experiments provide theoretical support for further model optimization.
(1) Comparison between mBERT and Other Pre-trained Models
To assess the effectiveness of different pre-trained models in guiding the deliberation decoding process, we conducted comparative experiments using four models: ELMo [36], BERT [37], GPT-2 [38], and mBERT. Table 5 presents their respective impacts on translation performance within this framework.
Table 5.
Effect of different pre-trained models on the performance of nudge decoding. Source: author’s contribution.
The results indicate that mBERT achieves a significantly higher BLEU score compared to the other models. This demonstrates that its multilingual pre-training strategy enables it to capture richer syntactic and semantic representations, thereby providing stronger guidance for the second-stage decoder and improving overall translation accuracy. ELMo performs relatively poorly in this task, suggesting that its BiLSTM-based architecture lacks the capacity to supply sufficient linguistic knowledge for effective decoding guidance. Although BERT leverages a bidirectional Transformer structure and can model contextual relationships more comprehensively via bidirectional attention, its training on monolingual data limits its capacity to support the deliberation decoder effectively. GPT-2, despite its strong performance in monolingual language modeling, adopts a unidirectional architecture that restricts its ability to capture bidirectional semantic dependencies. As a result, its guidance effect in the deliberation process is inferior to that of mBERT. By comparing the performance of various pre-trained models in the nudging module, we observe that mBERT demonstrates greater advantages than other models in terms of semantic alignment and translation quality. This indirectly confirms the effectiveness and compatibility of the heterogeneous model combination we adopt—monolingual BART and multilingual mBERT. In summary, considering its structural strengths in multilingual adaptability and bidirectional encoding, along with its validated performance in this task, we select mBERT as the knowledge source for the nudging module.
(2) Impact of Different Distillation Strategies on the Model
To evaluate the impact of different knowledge distillation strategies within the BART-based implicit linguistic feature enhancement mechanism, we designed a series of comparative experiments. In addition to the feature-based distillation (FD) strategy adopted in this paper, we also explored target-based distillation (LD), gradient-aligned distillation (GKD), and task-aware layer-wise distillation (TED). Table 6 demonstrates the effects of different knowledge distillation strategies on the model’s translation performance.
Table 6.
Impact of distillation strategies on model performance. Source: author’s contribution.
The results demonstrate that feature-based distillation (FD) yields the best performance in terms of the BLEU score. This is due to the fact that FD acts directly on the hidden layer, which enables the student model to better inherit the feature representation capability of the teacher model, thus acquiring rich semantic information. In contrast, target-based distillation (LD) performs the worst, likely because it only provides soft target supervision at the output layer, without leveraging the deeper semantic representations from the teacher model. Gradient-aligned distillation (GKD) improves the student model’s performance by aligning the gradient directions during training. Although GKD achieves better results than LD, its performance remains inferior to TED and FD due to its indirect transfer of semantic knowledge. Task-aware layer-wise distillation (TED) enhances feature learning by aligning intermediate representations at each layer. However, its effectiveness is hindered by potential noise introduced during layer-wise alignment, which may reduce stability and limit further performance gains compared to FD. To more intuitively illustrate the impact of different distillation strategies, we plot the accuracy and loss curves for the four methods, as shown in Figure 5 and Figure 6, respectively.
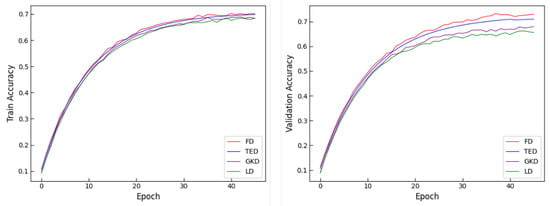
Figure 5.
Accuracy curves on the training and validation sets under different distillation strategies. Source: author’s contribution.
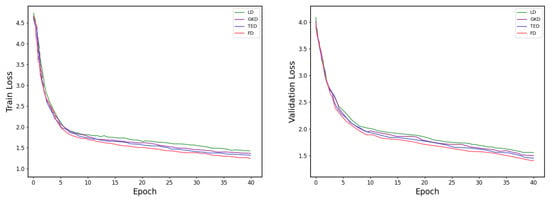
Figure 6.
Training and validation loss curves for different distillation strategies. Source: author’s contribution.
(3) Impact of Different Modules on the Model
To evaluate the contributions of the BART-based implicit linguistic feature enhancement mechanism, the mBERT-integrated deliberation decoding mechanism, and the hybrid positional encoding mechanism to overall model performance, we conducted a series of ablation studies. By progressively introducing each of these core components, we assessed their respective impacts on translation accuracy and semantic understanding. The changes in BLEU scores at each stage are presented in Table 7.
Table 7.
Effect of gradually adding different modules on the overall model performance. Source: author’s contribution.
Starting from the baseline Transformer model with a BLEU score of 41.88, incorporating the weighted hybrid positional encoding (MPE) led to an increase to 42.91, which is an improvement of 1.03 points. This demonstrates that the MPE mechanism enhances the model’s ability to encode and utilize positional information more effectively. Building upon this, the addition of the mBERT-guided nudge decoding module further boosted the BLEU score to 44.29, yielding a 2.41-point gain over the previous stage. This result confirms that the nudging decoder significantly improves the model’s capacity to capture long-range dependencies and semantic nuances in the source language. Finally, integrating the BART-based implicit linguistic feature enhancement mechanism resulted in a BLEU score of 45.41, representing a total improvement of 3.53 points over the baseline Transformer. This highlights the effectiveness of incorporating implicit linguistic priors into the model and validates their role in enhancing translation quality. These results collectively show that each proposed module contributes meaningfully to performance gains. Moreover, the synergistic integration of multiple modules significantly optimizes the overall translation performance.
Considering that automatic evaluation metrics alone may not fully capture model performance in terms of semantic expression and linguistic naturalness, this paper further incorporates manual subjective evaluation based on the four models mentioned above, focusing on two key dimensions: semantic adequacy (Adequacy) and linguistic fluency (Fluency). We randomly selected 200 sentence pairs from the test set and invited three linguistics graduate students proficient in both Mongolian and Chinese to independently score each translation using a 5-point scale. The averaged scores are summarized in Table 8.
Table 8.
Manual evaluation score statistics (5-point scale). Source: author’s contribution.
From the results, the Transformer model exhibits more semantic omissions and incoherent expressions, resulting in relatively lower scores. After incorporating the MPE module, semantic coverage improves; however, issues with word order and syntax remain. With the introduction of the nudging mechanism, the model shows significant enhancements in expression hierarchy and semantic completeness. The ILFDN-Transformer model achieves the highest scores in both semantic fidelity and linguistic naturalness, demonstrating superior language generation capabilities and robustness. These manual evaluation results further validate the effectiveness of each module in improving translation quality, particularly highlighting that the synergistic integration of all three modules can substantially optimize the model’s overall performance.
To more intuitively illustrate the practical impact of the ILFDN-Transformer model in real-world translation scenarios, we randomly selected three sample translations from the test set for qualitative analysis. By comparing the outputs of different ablation configurations on the same source sentences, we clearly demonstrate the positive effects of implicit linguistic features, the nudging decoder, and hybrid positional encoding on translation quality. The examples are shown in Figure 7.
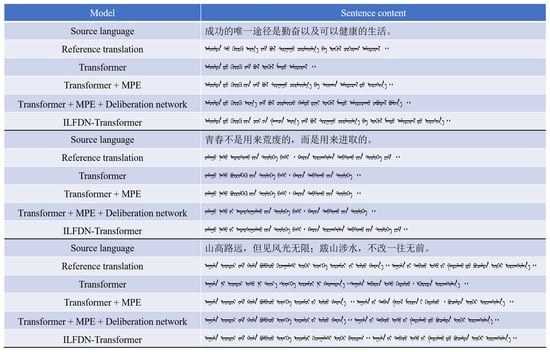
Figure 7.
Comparison examples of translation results under different ablation configurations. The figure presents translations of three source sentences using different model variants. The corresponding source sentences are: (1) The only path to success is diligence and a healthy life, (2) Youth is not meant to be wasted, but to be strived for, and (3) Though the mountains are high and the roads are long, the scenery is boundless; through all the hardships, the determination to press forward remains unchanged. Source: author’s contribution.
Furthermore, we conduct a more fine-grained analysis of the translation examples in Figure 8, systematically illustrating the specific contributions of each module in addressing key translation challenges. The hybrid positional encoding significantly improves the word order and structural representation; the nudging mechanism demonstrates strong performance in capturing semantic nuances and restoring information; and the implicit linguistic feature encoding further enhances overall semantic consistency and contextual coherence. The synergistic effect of all modules leads to notable improvements in translation accuracy, clarity of expression, and language fluency, thereby validating the effectiveness of the proposed approach.
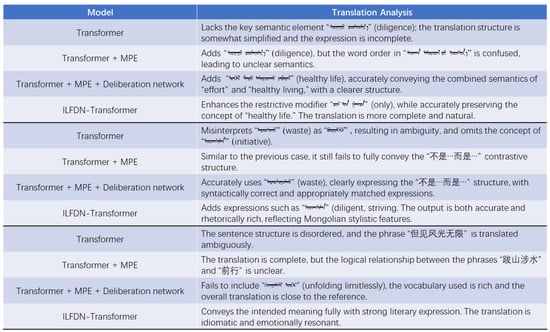
Figure 8.
Translation example analysis. Source: author’s contribution.
5. Conclusions
To address the scarcity of Mongolian–Chinese parallel corpora and the limitations of traditional neural machine translation (NMT) models in handling long-distance dependencies and capturing implicit source-language features, we proposed ILFDN-Transformer, a novel NMT model that integrates implicit linguistic features with a deliberation network. Our approach incorporates three key innovations:an implicit feature enhancement module based on a pre-trained BART model, which captures deep semantic representations; a deliberation decoding mechanism guided by mBERT, designed to improve the understanding and reconstruction of complex semantic structures through a two-pass decoding process; and a weighted hybrid positional encoding scheme, which fuses absolute and dynamic positional encodings to enhance the model’s ability to represent syntactic structures. The proposed modules have demonstrated substantial improvements in translation quality, particularly for Mongolian–Chinese translation under low-resource conditions. The model exhibits strong robustness and generalization capabilities, confirming the effectiveness of our approach in low-resource NMT scenarios. This study provides not only a novel technical solution but also theoretical inspiration for advancing neural machine translation in under-resourced language settings.
Nevertheless, the ILFDN-Transformer model still presents several issues that merit further investigation. First, while the current mBERT-guided module effectively improves translation quality, it also introduces a degree of inference latency. Future work will explore the integration of lightweight language models or conditionally triggered refinement mechanisms to enable more efficient real-time translation. Second, the imbalance in mBERT’s multilingual generalization capabilities indicates the need to investigate pre-trained language models that are better suited to Mongolian. Additionally, we plan to evaluate the end-to-end performance of unified models in both semantic extraction and generation tasks. Finally, the current knowledge distillation strategy adopts an equal-interval layer alignment approach. Although structurally simple, this may not be the most effective method for semantic transfer. Future research will consider dynamic layer selection mechanisms based on semantic information quantity or contribution to further enhance the accuracy and efficiency of semantic transfer.
Author Contributions
Conceptualization, Q.R. and S.L.; methodology, Q.R. and S.L.; software, X.W.; validation, X.W. and S.L.; formal analysis, S.L.; investigation, S.L.; resources, Q.R.; data curation, S.L.; writing—original draft preparation, S.L.; writing—review and editing, S.L. and Q.R.; visualization, S.L.; supervision, Q.R. and Y.J.; project administration, S.L., Q.R. and N.W.; funding acquisition, Q.R. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Natural Science Foundation of China (62466044), the Basic Research Business Fee Project of Universities Directly under the Autonomous Region (JY20240062), (ZTY2024072), the ’Youth Science and Technology Talent Support Program’ Project of Universities in the Inner Mongolia Autonomous Region (NJYT23059), the Inner Mongolia Natural Science Foundation General Project (2022MS06013), and the Key R&D and Achievement Transformation Plan Project of the Inner Mongolia Autonomous Region (2025YFHH0115)—Construction of a Mongolian Multimodal Sentiment Corpus and Development of a Sentiment Analysis System.
Data Availability Statement
The Mongolian–Chinese parallel corpus used in this study is an internally constructed dataset by the Laboratory of Artificial Intelligence and Pattern Recognition at Inner Mongolia University of Technology. Due to institutional data policies, this dataset is not publicly available. It is used solely for academic research purposes and is not distributed under any public license.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Ranathunga, S.; Lee, E.S.A.; Prifti Skenduli, M.; Shekhar, R.; Alam, M.; Kaur, R. Neural machine translation for low-resource languages: A survey. ACM Comput. Surv. 2023, 55, 1–37. [Google Scholar] [CrossRef]
- Luo, Q.; Zeng, W.; Chen, M.; Peng, G.; Yuan, X.; Yin, Q. Self-Attention and Transformers: Driving the Evolution of Large Language Models. In Proceedings of the 2023 IEEE 6th International Conference on Electronic Information and Communication Technology (ICEICT), Qingdao, China, 21–24 July 2023; pp. 401–405. [Google Scholar]
- Zhang, J.; Su, K.; Li, H.; Mao, J.; Tian, Y.; Wen, F.; Guo, C.; Matsumoto, T. Neural machine translation for low-resource languages from a chinese-centric perspective: A survey. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2024, 23, 1–60. [Google Scholar] [CrossRef]
- Kai, J.; Hou, S.; Huang, Y.; Lin, Z. Leveraging Grammar Induction for Language Understanding and Generation. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2024, Miami, FL, USA, 12–16 November 2024; pp. 4501–4513. [Google Scholar]
- Xia, Y.; Tian, F.; Wu, L.; Lin, J.; Qin, T.; Yu, N.; Liu, T.Y. Deliberation networks: Sequence generation beyond one-pass decoding. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30, pp. 1782–1792. [Google Scholar]
- Sälevä, J.; Lignos, C. Language Model Priors and Data Augmentation Strategies for Low-resource Machine Translation: A Case Study Using Finnish to Northern Sámi. In Proceedings of the Findings of the Association for Computational Linguistics ACL 2024, Bangkok, Thailand, 11–16 August 2024; pp. 12949–12956. [Google Scholar]
- Cui, M.; Du, J.; Zhu, S.; Xiong, D. Efficiently Exploring Large Language Models for Document-Level Machine Translation with In-context Learning. In Proceedings of the Findings of the Association for Computational Linguistics ACL 2024, Bangkok, Thailand, 11–16 August 2024; pp. 10885–10897. [Google Scholar]
- Hromei, C.D.; Borazio, F.; Sensi, A.; Passone, E.; Croce, D.; Basili, R. Training Multi-Modal LLMs through Dialogue Planning for HRI. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2025, Vienna, Austria, 27 July–1 August 2025; pp. 16266–16284. [Google Scholar]
- Luo, Y.; Zheng, T.; Mu, Y.; Li, B.; Zhang, Q.; Gao, Y.; Xu, Z.; Feng, P.; Liu, X.; Xiao, T.; et al. Beyond Decoder-only: Large Language Models Can be Good Encoders for Machine Translation. arXiv 2025, arXiv:2503.06594. [Google Scholar]
- Qu, Y.; Ding, M.; Sun, N.; Thilakarathna, K.; Zhu, T.; Niyato, D. The frontier of data erasure: A survey on machine unlearning for large language models. Computer 2025, 58, 45–57. [Google Scholar] [CrossRef]
- Naveen, P.; Trojovskỳ, P. Overview and challenges of machine translation for contextually appropriate translations. Iscience 2024, 27, 110878. [Google Scholar] [CrossRef] [PubMed]
- Zenkel, T.; Wuebker, J.; DeNero, J. End-to-end neural word alignment outperforms GIZA++. arXiv 2020, arXiv:2004.14675. [Google Scholar]
- Zhang, S.; Lijie, W.; Xiao, X.; Wu, H. Syntax-guided contrastive learning for pre-trained language model. In Proceedings of the Findings of the Association for Computational Linguistics: ACL 2022, Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 2430–2440. [Google Scholar]
- Hou, S.; Kai, J.; Xue, H.; Zhu, B.; Yuan, B.; Huang, L.; Wang, X.; Lin, Z. Syntax-guided Localized Self-attention by Constituency Syntactic Distance. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2022, Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 2334–2341. [Google Scholar]
- Bu, M.; Gu, S.; Feng, Y. Improving multilingual neural machine translation by utilizing semantic and linguistic features. arXiv 2024, arXiv:2408.01394. [Google Scholar]
- Xu, Z.; Zhan, S.; Yang, W.; Xie, Q. Based on Gated Dynamic Encoding Optimization, the LGE-Transformer method for low-resource neural machine translation. IEEE Access 2024, 12, 162861–162869. [Google Scholar] [CrossRef]
- Boyapati, M.; Aygun, R. Semanformer: Semantics-aware Embedding Dimensionality Reduction Using Transformer-Based Models. In Proceedings of the 2024 IEEE 18th International Conference on Semantic Computing (ICSC), Laguna Hills, CA, USA, 5–7 February 2024; pp. 134–141. [Google Scholar]
- Pathak, D.; Narzary, S.; Nandi, S.; Som, B. Part-of-speech tagger for Bodo language using deep learning approach. Nat. Lang. Process. 2025, 31, 215–229. [Google Scholar] [CrossRef]
- Li, H.; Hou, H.; Wu, N.; Jia, X.; Chang, X. Semantically Constrained Document-Level Chinese-Mongolian Neural Machine Translation. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021; pp. 1–8. [Google Scholar]
- Zhi, X.; Wang, S. Research on the application of BERT in Mongolian-Chinese neural machine translation. In Proceedings of the 2021 13th International Conference on Machine Learning and Computing, Shenzhen, China, 26 February–1 March 2021; pp. 404–409. [Google Scholar]
- Wang, P.; Hou, H.; Sun, S.; Wu, N.; Jian, W.; Yang, Z.; Wang, Y. Hot-start transfer learning combined with approximate distillation for Mongolian-Chinese neural machine translation. In Proceedings of the 18th China Conference on Machine Translation, Lhasa, China, 6–10 August 2022; Springer: Singapore, 2022; pp. 12–23. [Google Scholar]
- Zheng, X.; Tian, Y.; Ma, C.; Sun, K. A Study on Non-Autoregressive Mongolian-Chinese Neural Machine Translation for Multilingual Pre-Training. In Proceedings of the 2024 7th International Conference on Machine Learning and Natural Language Processing (MLNLP), Chengdu, China, 18–20 October 2024; pp. 1–7. [Google Scholar]
- Wang, B.; Ji, Y.; Wu, N.; Liu, X.; Wang, Y.; Mao, R.; Yuan, S.; Ren, Q.D.E.J.; Liu, N.; Zhuang, X.; et al. Mongolian-Chinese Neural Machine Translation Based on Sustained Transfer Learning. In Proceedings of the 20th International Conference on Intelligent Computing, Tianjin, China, 5–8 August 2024; Springer: Singapore, 2024; pp. 304–315. [Google Scholar]
- Sun, K.; Tian, Y.; Zheng, X.; Ma, C. Document-level Mongolian-Chinese Neural Machine Translation Incorporating Target-Side Data Augmentation and Topic Information. In Proceedings of the 2024 International Conference on Asian Language Processing (IALP), Hohhot, China, 4–6 August 2024; pp. 204–209. [Google Scholar]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 7871–7880. [Google Scholar]
- Feng, X.; Wu, X.; Meng, H. Injecting linguistic knowledge into BERT for Dialogue State Tracking. IEEE Access 2024, 12, 93761–93770. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhu, X.; He, Q.; Zhang, L. BERT-based global semantic refinement and local semantic extraction for distinguishing urgent posts in MOOC forums. IEEE Access 2024, 12, 116250–116258. [Google Scholar] [CrossRef]
- Wu, X.; Xia, Y.; Zhu, J.; Wu, L.; Xie, S.; Qin, T. A study of BERT for context-aware neural machine translation. Mach. Learn. 2022, 111, 917–935. [Google Scholar] [CrossRef]
- Xu, H.; Van Durme, B.; Murray, K. Bert, mbert, or bibert? a study on contextualized embeddings for neural machine translation. arXiv 2021, arXiv:2109.04588. [Google Scholar]
- Yu, Y.; Si, X.; Hu, C.; Zhang, J. A review of recurrent neural networks: LSTM cells and network architectures. Neural Comput. 2019, 31, 1235–1270. [Google Scholar] [CrossRef] [PubMed]
- Wei, X.; Ren, Q.-D.-E.-J. A Language-Driven Data Augmentation Method for Mongolian-Chinese Neural Machine Translation. In Proceedings of the 2024 International Conference on Asian Language Processing (IALP), Hohhot, China, 4–6 August 2024; pp. 297–302. [Google Scholar]
- Hashimoto, K.; Tsuruoka, Y. Neural Machine Translation with Source-Side Latent Graph Parsing. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 9–11 September 2017; pp. 125–135. [Google Scholar]
- Bapna, A.; Chen, M.X.; Firat, O.; Cao, Y.; Wu, Y. Training Deeper Neural Machine Translation Models with Transparent Attention. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 3028–3033. [Google Scholar]
- Yang, X.; Liu, Y.; Xie, D.; Wang, X.; Balasubramanian, N. Latent Part-of-Speech Sequences for Neural Machine Translation. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 780–790. [Google Scholar]
- Wu, Y.; Schuster, M.; Chen, Z.; Le, Q.V.; Norouzi, M.; Macherey, W.; Krikun, M.; Cao, Y.; Gao, Q.; Macherey, K.; et al. Google’s neural machine translation system: Bridging the gap between human and machine translation. arXiv 2016, arXiv:1609.08144. [Google Scholar]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep contextualized word representations. In Proceedings of the NAACL-HLT, New Orleans, LA, USA, 1–6 June 2018; pp. 2227–2237. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, (long and short papers). pp. 4171–4186. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]








Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).