


Privacy-Preserving Approach to Edge Federated Learning Based on Blockchain and Fully Homomorphic Encryption


Abstract
1. Introduction
- Unsupervised model gradient parameter update identification mechanism: An identification mechanism based on the consistency of model historical gradient updates was designed to detect and remove malicious edge servers. This effectively resists the poisoning attack and improves the global model’s performance.
- Blockchain-based edge federated learning framework: By integrating blockchain technology with the ECDSA (Elliptic Curve Digital Signature Algorithm), the framework ensures transparency in the training aggregation process. The aggregation process and results can be audited, tracked, and distributed into storage to avoid a single point of failure as much as possible. Additionally, the framework randomly selects trusted edge servers based on a consensus protocol to perform tasks such as verification, aggregation, and block creation. This approach significantly reduces centralization and the risks of malicious aggregation.
- CKKS fully homomorphic encryption (FHE) scheme: The CKKS encryption method protects uploaded local model parameters, effectively preventing the central server and edge servers from cracking encrypted model parameters. Compared with other major privacy protection schemes, this method offers shorter encryption and decryption times with higher precision.
2. Related Work
2.1. Federated Learning Against Poisoning Attacks
2.2. Blockchain-Based Federated Learning
3. System Architecture and Design
3.1. System Security Threats
- Threat 1: Poisoning attack. A malicious edge calculator can degrade the accuracy of the federated learning global model and corrupt the correct federated learning by submitting forged gradients carefully, using model parameters, or contaminating the local dataset.
- Threat 2: Single point failure attack. Edge federated learning is highly dependent on the central server. When it crashes down, the entire federated learning architecture will not operate.
- Threat 3: Data security. Only the central server records the overall data in edge federated learning. The centralized bookkeeping not only leads to low transparency and openness of the overall architecture, but it also cannot defend against malicious data tampering attacks on the central server. When an attacker cripples the central server, the integrity of the entire ledger is highly vulnerable.
- Threat 4: Privacy leakage. Edge federated learning transmits model parameters rather than raw data, but it has been shown that some private information about participant data can be inverted by exploiting model parameters [24]. Therefore, both model parameters and model-related data information must be strictly protected from being back-propagated into participant models and data.
3.2. System Architecture
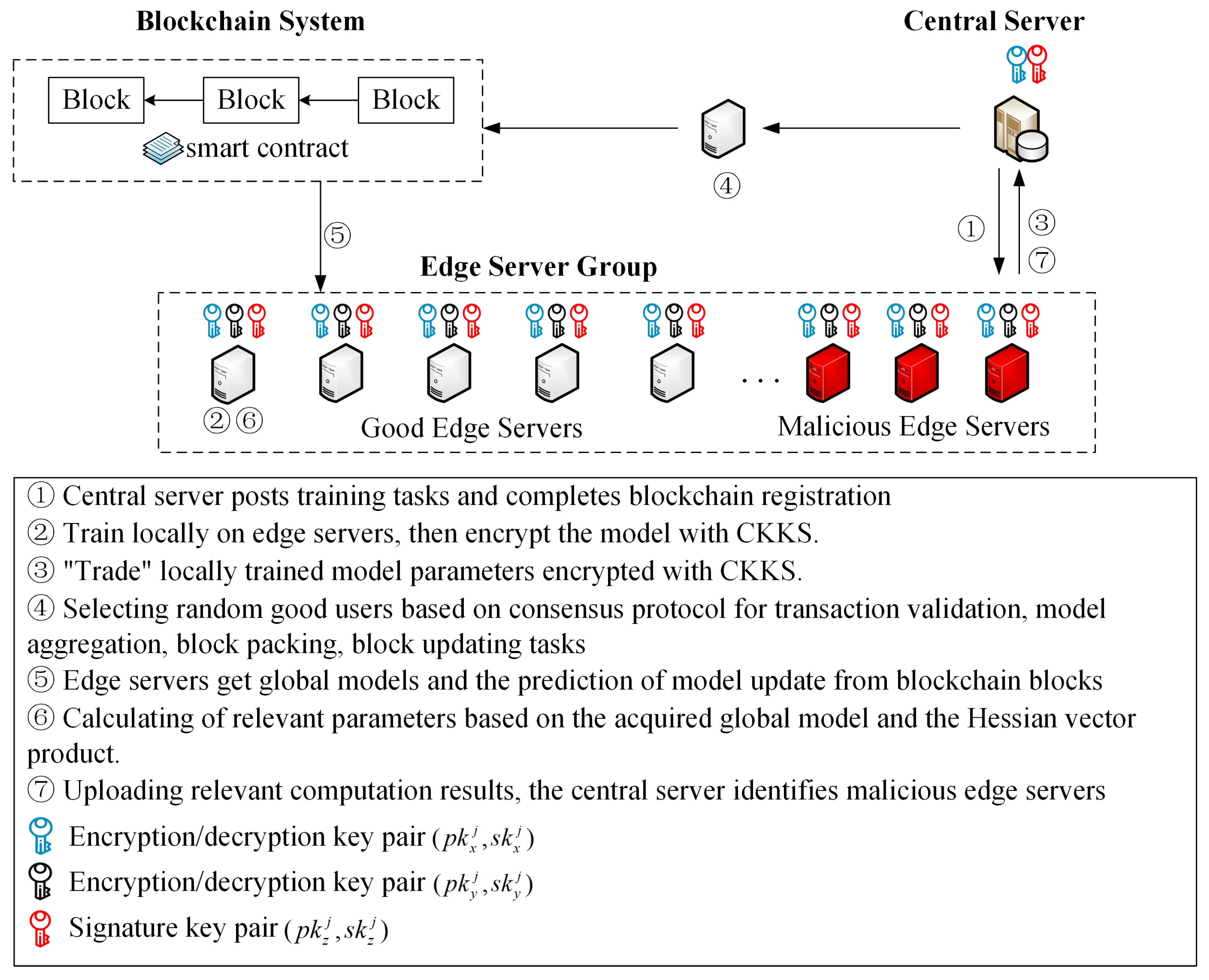
- Step 1: The central server issues a training task to the edge server group, registers all edge servers with the blockchain system at the same time, and generates a unique signature key pair for each edge server based on the ECDSA digital signature algorithm, which is used to “trade” cryptographic model parameters and participate in blockchain transactions. The central server creates a genesis block based on the training task and synchronizes the blockchain. The genesis block contains information such as the global model initialization parameters , the total number of training rounds , the number of local training rounds for edge servers, the recording period of the history update , and the public keys , which are held by all edge servers and used for digital signatures.
- Step 2: After synchronizing blockchain content, the edge server is trained on the local dataset . After a certain number of iterations , the CKKS homomorphic encryption is performed on the iterated model parameters using an encryption key pair to deal with threat 4 in part 1 of Section 3. The encryption and decryption key pairs are held by the edge server locally and not made public.
- Step 3: The edge server “trades” the encrypted model parameters to the central server in the form of a transaction and completes a digital signature, and the central server verifies the digital signature of the “transaction” according to the public key in the genesis block and gives the corresponding account credits to the edge server as a reward if it passes the verification. The blockchain holds all the cryptographic model parameters of the edge server obtained through the transaction. However, it is impossible to decrypt the parameters to obtain the original text, which prevents the curious behavior of the server to some extent. This step could address threat 3 in part 1 of Section 3.
- Step 4: The server randomly selects one of the good edge servers and makes it act as the validator, aggregator, and block packer for this training round. The selected edge servers validate the above transactions again, perform the model parameter aggregation task, and finally generate a new block containing the latest global model. All edge servers will acquire the latest global aggregated model through the new block.
- Step 5: All edge servers acquire new global models from the new block. During the acquisition process, each edge server pays a deposit to the smart contract to ensure participation in the subsequent malicious edge server identification data upload. At the same time, the server will make predictions for the current gradient update of all edge servers based on the identification data of the previous round and the parameters of the previous global model and then compute the Hessian vector product for this round, which will be “traded” to all edge servers.
- Step 6: The smart contract automatically performs the computation and encryption procedures described below. The edge server obtains the new encrypted global model and the Hessian vector product for this round. The edge server makes calculations based on Equation (7). And the result is called the prediction of model gradient update . The edge server needs to calculate the Euclidean distance between the actual and the predicted model gradient updates. Finally, it should use an encryption key pair to encrypt the calculated results, local computation time, etc. The secret key pair differs from the other encryption key pair mentioned in step 2 above, which is pre-distributed and only held by the central server and the edge servers to deal with threat 4 in part 1 of Section 3. The smart contract automatically executes the computation and encryption process. The smart contract is supplemented by the proof-of-concept mechanism [34] of time consumption under the Intel SGX Trusted Hardware Technology, ensuring a real and reliable computation process and results.
- Step 7: The edge server, with the intervention of a smart contract, ‘trades’ the encrypted relevant computation results and local computation time to the central server. The above transactions are stored in the blockchain. After synchronizing the computation results through the block, the central server verifies the digital signature and computation time. Upon passing the verification, the central server refunds the deposit mentioned in step 5. Subsequently, the central server identifies the malicious model parameter updates to the computation results and removes the malicious edge server. This step could address threat 1 in part 1 of Section 3. The next round of training starts from step 2 until the model converges or the maximum number of training rounds is reached.
3.3. System Design
3.3.1. The CKKS Fully Homomorphic Encryption Mechanism
3.3.2. Convergence Architecture for Blockchain and Federated Learning
- Local training encryption and aggregation: in the th training round, each edge server participating in the training aggregation is trained with its local dataset and local model to obtain the local gradient , which can be expressed by (1).
| Algorithm 1: Local training and encryption algorithm |
| INPUT: Edge servers ; Current training rounds ; Local dataset ; Local training batch size ; Local training learning rate ; Number of local training iterations . |
OUTPUT: Encrypted model parameters .
|
- 2.
- Blockchain storage and transactions: The encrypted model parameters must be uploaded and aggregated to obtain a new global model. However, traditional data uploading and storing methods are insufficient to provide security and have the disadvantages of losing data in the centralized ledger under a single point of failure and not being able to ensure the origin and integrity of the data. In contrast, the scheme proposed in this paper has the following advantages: The first advantage is a distributed ledger. As seen from the training process in Section 3.2 above, the initialization information, the public key for digital signatures, the ciphertext details of a particular transaction, and the aggregation result exist in the blockchain as blocks. All good edge servers and central servers are participants in the blockchain. All participants can view the details of the aggregation training process and have separate ledgers by synchronizing the blocks, which improves the transparency of the aggregation process and eliminates the effect of data loss in a centralized ledger with a single point of failure.The second advantage is data security. The source and integrity of data for traditional federated learning cannot be guaranteed, and malicious edge servers will submit malicious model parameters multiple times or even pretend to be good edge servers to submit malicious gradient or model parameters to destroy the global model aggregation. ECDSA can solve this problem, which becomes the main way to verify the transactions in this paper. The core idea is to hash the raw data and then sign the hash using a private key. The receiver can use the public key to verify the validity of the signature. The proposed scheme utilizes the Secp256k1 elliptic curve. It selects an initial point and a random integer on this curve, whose corresponding private key is , and the corresponding public key can be found by (3).where is denoted as a point on an elliptic curve, and the corresponding public key is . The process of generating a digital signature is as follows:
- Step 1: regenerate a random number , and use (3) to compute a point on the elliptic curve, where the transverse coordinates of the point are noted as .
- Step 2: calculate the hash value for the data to be signed, denoted as .
- Step 3: calculate according to (4), where is the base of the modal budget to be specified in advance.The length of the signature is usually 40 bytes. The first 20 bytes are . The next 20 bytes are . The combination of both together is the final digital signature.The generated digital signature can be verified according to (5). If the transverse coordinate of is equal to , then the signature is verified successfully, and the participation of the private key is not required at all in the process of signature verification.Therefore, the algorithm computes hash values based on the data to be signed, thus ensuring data integrity. All the participants in the blockchain can verify the uploaded data through the public key to ensure data source compliance.
- 3.
- Consensus protocols: Traditional federated learning has several concerns about the central server, including the curious behavior of the central server and an over-reliance on the server to complete the aggregation, susceptible to a single point of failure. Although the CKKS fully homomorphic encryption mechanism in Section 3.3, prevents the central server from benefiting from curious behavior, researchers prefer to achieve decentralization of data aggregation by combining blockchain with federated learning.Validation nodes in most schemes compete through computational power or the amount of cryptocurrency they hold, earning them the right to aggregate the global model and create new blocks. However, their schemes’ consensus protocols, PoW (Proof of Work) and PoS (Proof of Stake), face challenges such as a high energy consumption and complex structure. On this basis, the Proof of Authority consensus algorithm (PoA) will be more suitable for the federated learning architecture. Unlike traditional POA schemes, we prefer the central server to be the authoritative picker rather than the aggregator.As can be seen from step 3 in Section 3.2, the edge server sends cryptographic model parameters as a “transaction” to the central server, which verifies the transaction. Although a participant in the transaction, the central server is only responsible for updating the ledger and does not participate in model aggregation. The central server chooses one of the good edge servers to make it the validator, aggregator, and block generator. While assuming an authority role, the central server has no right to aggregate local model parameters.In contrast to traditional federated learning, the usage and ownership of uploaded model parameters are separated. Although PoA weakens blockchain’s decentralized nature, it brings higher throughput, lower energy loss, and lower transaction confirmation latency.
- 4.
- Smart contract: From step 6 in Section 3.2, after obtaining a new block, the edge server must also to calculate a series of relevant data and upload them to the server to complete the malicious identification. In order to prevent malicious edge servers from uploading forged data and not uploading data randomly, a smart contract is introduced in the blockchain. The significance of the smart contract is that the edge server automatically performs the relevant calculations after synchronizing the new block, eliminating the possibility of human intervention. The relevant computational algorithms are described in Section 3.3.3. An edge server that uses tokens from its account as a deposit is considered to have signed a smart contract to participate in model aggregation. Finally, the consumption time proof mechanism [34] under the Intel SGX trusted hardware technology can be utilized to obtain a trusted calculation time , and the calculation process can be bound to the calculation time to ensure that the calculation process and results are real and reliable.The smart contract needs to obtain the encrypted global model and the Hessian vector product for this round from the new block and decrypt them. Then, we can calculate the predicted model update and the Euclidean distance between the predicted model update and the actual model update .Finally, we can encrypt using keypair and upload the encrypted calculation result along with the encrypted credible execution time .The smart contract work algorithm is shown in Algorithm 2.
| Algorithm 2: Smart contract work algorithm |
| INPUT: Encrypted global model ; Actual gradient update ; The Hessian vector product ;. |
OUTPUT: Encrypted Euclidean distance ; Encrypted credible execution time
|
3.3.3. Unsupervised Model Gradient Parameter Update Identification Mechanism
| Algorithm 3: L-BFGS computational Hessian vector product algorithm |
| INPUT: Global model update ; Global model update discrepancies ; Vector ; Historical recording period . |
OUTPUT: Hessian vector product .
|
| Algorithm 4: Gap data statistical algorithm |
| INPUT: European distance average ; Number of random samples ; Maximum number of clusters ; Number of edge servers . |
OUTPUT: Number of clusters .
|
| Algorithm 5: Identification mechanism algorithm |
| INPUT: The recording cycle of the identification mechanism ; Total training rounds ; Total number of edge servers ; |
OUTPUT: Malicious clients list or none.
|
4. Theoretical Proofs and Analyses
4.1. Homomorphism Proof
4.2. Encryption and Decryption Correctness Proof
4.3. Privacy Protection Proof
- The presence of malicious edge server among edge servers is unrealistic because such an edge federated learning task is meaningless.
- Assuming the existence of malicious edge servers and theoretically possessing pairs of local encryption key pairs , the encryption model parameters of a good edge server can be inverted, but the local encryption key pairs of the good edge servers remain inaccessible, so the model parameter ciphertexts cannot be deciphered.
5. Experimental Procedure and Result Analysis
5.1. Experimental Setup
- Hardware configurations: the experiments were conducted under Ubuntu 20.04 with the hardware configuration of an Intel E5-2640 CPU (Intel Corporation, Santa Clara, CA, USA), six GTX1080T GPUs (NVIDIA Corporation, Santa Clara, CA, USA), and 256G of RAM.
- Software configurations: The software was developed using Python. Python 3.8.5 and Pytorch 1.11.0 were used to train the deep learning models. The TenSEAL(0.3.11) library and the phe library in Python were used to simulate encryption and decryption. The smart contract was developed using the Solidity programming language and deployed on the private blockchain using Truffle.
- Benchmark model: the experimental benchmark model architecture was a convolutional neural network structure, which mainly consisted of three convolutional layers, two pooling layers, and one fully connected layer.
- Datasets: The experimental dataset used the MNIST dataset and the Fashion-MNIST dataset, which is a handwritten dataset containing 60,000 training samples and 10,000 test samples, each of which is a gray scale image with labels from 0 to 9. The Fashion-MNIST dataset contains 60,000 training samples and 10,000 test samples, with a total of 10 categories corresponding to different types of clothing and accessories. These exclusive categories include T-shirts/tops, trousers, pullovers, skirts, jackets, sandals, shirts, trainers, bags, and ankle boots. The labels are numbers from 0 to 9, corresponding to each of the ten categories mentioned above.
- FL settings: In the experiments, it was assumed that there were 100 edge servers in the system, and the training samples were randomly and uniformly divided into 100 copies for the edge servers as the local dataset. The batch size of the edge servers for local training was 50, the number of rounds for local training was 3, the period of the history update record was 3, the number of training rounds was 50, and the learning rate of edge server models was 0.01.
- Experimental resource consumption: this experiment’s CPU utilization rate was about 28%, the memory utilization rate was about 30%, and the GPU utilization rate was about 99%. The experimental time was about 2 h.
5.2. Homomorphic Encryption and Decryption Runtime
5.3. Throughput and Communications Costs
5.4. Recognition Accuracy and Model Accuracy
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Deng, L.; Yu, D. Deep learning: Methods and applications. Found. Trends Signal Process. 2014, 7, 197–387. [Google Scholar] [CrossRef]
- Dean, J.; Corrado, G.; Monga, R.; Chen, K.; Devin, M.; Mao, M.; Ranzato, M.; Senior, A.; Tucker, P.; Yang, K.; et al. Large scale distributed deep networks. In Proceedings of the Advances in Neural Information Processing Systems 25, Lake Tahoe, NV, USA, 3–6 December 2012. [Google Scholar]
- Ho, Q.; Cipar, J.; Cui, H.; Lee, S.; Kim, J.K.; Gibbons, P.B.; Gibson, G.A.; Ganger, G.; Xing, E.P. More effective distributed ml via a stale synchronous parallel parameter server. Adv. Neural Inf. Process. Syst. 2013, 26, 1223–1231. [Google Scholar]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated machine learning: Concept and applications. arXiv 2019, arXiv:1902.04885. [Google Scholar] [CrossRef]
- Truex, S.; Baracaldo, N.; Anwar, A.; Steinke, T.; Ludwig, H.; Zhang, R.; Zhou, Y. A hybrid approach to privacy-preserving federated learning. In Proceedings of the 12th ACM Workshop on Artificial Intelligence and Security, London, UK, 15 November 2019; pp. 1–11. [Google Scholar]
- Moriai, S. Privacy-preserving deep learning via additively homomorphic encryption. In Proceedings of the 2019 IEEE 26th Symposium on Computer Arithmetic (ARITH), Kyoto, Japan, 10–12 June 2019; p. 198. [Google Scholar]
- Dwork, C. Differential privacy: A survey of results. In Proceedings of the International Conference on Theory and Applications of Models of Computation, Xi’an, China, 25–29 April 2008; pp. 1–19. [Google Scholar]
- Wei, K.; Li, J.; Ding, M.; Ma, C.; Yang, H.H.; Farokhi, F.; Jin, S.; Quek, T.Q.; Poor, H.V. Federated learning with differential privacy: Algorithms and performance analysis. IEEE Trans. Inf. Forensics Secur. 2020, 15, 3454–3469. [Google Scholar] [CrossRef]
- Biggio, B.; Nelson, B.; Laskov, P. Poisoning attacks against support vector machines. arXiv 2012, arXiv:1206.6389. [Google Scholar]
- Li, Z.; Sharma, V.; Mohanty, S.P. Preserving data privacy via federated learning: Challenges and solutions. IEEE Consum. Electron. Mag. 2020, 9, 8–16. [Google Scholar] [CrossRef]
- Bhagoji, A.N.; Chakraborty, S.; Mittal, P.; Calo, S. Analyzing federated learning through an adversarial lens. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 634–643. [Google Scholar]
- Xie, C.; Huang, K.; Chen, P.-Y.; Li, B. Dba: Distributed backdoor attacks against federated learning. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Bagdasaryan, E.; Veit, A.; Hua, Y.; Estrin, D.; Shmatikov, V. How to backdoor federated learning. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Palermo, Italy, 26–28 August 2020; pp. 2938–2948. [Google Scholar]
- Fang, M.; Cao, X.; Jia, J.; Gong, N. Local model poisoning attacks to Byzantine-Robust federated learning. In Proceedings of the 29th USENIX Security Symposium (USENIX Security 20), Boston, MA, USA, 12–14 August 2020; pp. 1605–1622. [Google Scholar]
- Blanchard, P.; El Mhamdi, E.M.; Guerraoui, R.; Stainer, J. Machine learning with adversaries: Byzantine tolerant gradient descent. In Proceedings of the Advances in Neural Information Processing Systems 30, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Fung, C.; Yoon, C.J.; Beschastnikh, I. Mitigating sybils in federated learning poisoning. arXiv 2018, arXiv:1808.04866. [Google Scholar]
- Yao, A.C. Protocols for secure computations. In Proceedings of the 23rd Annual Symposium on Foundations of Computer Science (SFCS 1982), Washington, DC, USA, 3–5 November 1982; pp. 160–164. [Google Scholar]
- Rathee, D.; Rathee, M.; Kumar, N.; Chandran, N.; Gupta, D.; Rastogi, A.; Sharma, R. Cryptflow2: Practical 2-party secure inference. In Proceedings of the 2020 ACM SIGSAC Conference on Computer and Communications Security, Virtual Event, 9–13 November 2020; pp. 325–342. [Google Scholar]
- Li, Y.; Chen, C.; Liu, N.; Huang, H.; Zheng, Z.; Yan, Q. A blockchain-based decentralized federated learning framework with committee consensus. IEEE Netw. 2020, 35, 234–241. [Google Scholar] [CrossRef]
- Ramanan, P.; Nakayama, K. Baffle: Blockchain based aggregator free federated learning. In Proceedings of the 2020 IEEE International Conference on Blockchain (Blockchain), Toronto, ON, Canada, 3–6 May 2020; pp. 72–81. [Google Scholar]
- Akhter, A.; Ahmed, M.; Shah, A.; Anwar, A.; Zengin, A. A Secured Privacy-Preserving Multi-Level Blockchain Framework for Cluster Based VANET. Sustainability 2021, 13, 400. [Google Scholar] [CrossRef]
- Fredrikson, M.; Jha, S.; Ristenpart, T. Model inversion attacks that exploit confidence information and basic countermeasures. In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security, Denver, CO, USA, 12–16 October 2015; pp. 1322–1333. [Google Scholar]
- Paillier, P. Public-key cryptosystems based on composite degree residuosity classes. In Proceedings of the International Conference on the Theory and Applications of Cryptographic Techniques, Prague, Czech Republic, 2–6 May 1999; pp. 223–238. [Google Scholar]
- Gentry, C.; Sahai, A.; Waters, B. Homomorphic encryption from learning with errors: Conceptually-simpler, asymptotically-faster, attribute-based. In Proceedings of the Advances in Cryptology–CRYPTO 2013: 33rd Annual Cryptology Conference, Santa Barbara, CA, USA, 18–22 August 2013; pp. 75–92. [Google Scholar]
- Zhao, Y.; Zhao, J.; Jiang, L.; Tan, R.; Niyato, D.; Li, Z.; Lyu, L.; Liu, Y. Privacy-preserving blockchain-based federated learning for IoT devices. IEEE Internet Things J. 2020, 8, 1817–1829. [Google Scholar] [CrossRef]
- Lu, Y.; Huang, X.; Dai, Y.; Maharjan, S.; Zhang, Y. Blockchain and federated learning for privacy-preserved data sharing in industrial IoT. IEEE Trans. Ind. Inform. 2019, 16, 4177–4186. [Google Scholar] [CrossRef]
- Qi, Y.; Hossain, M.S.; Nie, J.; Li, X. Privacy-preserving blockchain-based federated learning for traffic flow prediction. Future Gener. Comput. Syst. 2021, 117, 328–337. [Google Scholar] [CrossRef]
- Yin, D.; Chen, Y.; Kannan, R.; Bartlett, P. Byzantine-robust distributed learning: Towards optimal statistical rates. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 5650–5659. [Google Scholar]
- Liu, X.; Li, H.; Xu, G.; Chen, Z.; Huang, X.; Lu, R. Privacy-enhanced federated learning against poisoning adversaries. IEEE Trans. Inf. Forensics Secur. 2021, 16, 4574–4588. [Google Scholar] [CrossRef]
- Cao, X.; Fang, M.; Liu, J.; Gong, N.Z. FLTrust: Byzantine-robust Federated Learning via Trust Bootstrapping. arXiv 2020, arXiv:2012.13995. [Google Scholar]
- Kim, H.; Park, J.; Bennis, M.; Kim, S.-L. Blockchained on-device federated learning. IEEE Commun. Lett. 2019, 24, 1279–1283. [Google Scholar] [CrossRef]
- Chen, L.; Xu, L.; Shah, N.; Gao, Z.; Lu, Y.; Shi, W. On security analysis of proof-of-elapsed-time (poet). In Proceedings of the Stabilization, Safety, and Security of Distributed Systems: 19th International Symposium, SSS 2017, Boston, MA, USA, 5–8 November 2017; pp. 282–297. [Google Scholar]
- Lang, S. A Second Course in Calculus; Addison-Wesley: Reading, MA, USA, 1964. [Google Scholar]
- Byrd, R.H.; Nocedal, J.; Schnabel, R.B. Representations of quasi-Newton matrices and their use in limited memory methods. Math. Program. 1994, 63, 129–156. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Schemes | Fun1 | Fun2 | Fun3 | Fun4 |
|---|---|---|---|---|
| Krum [17] | Yes | No | Central server | Yes |
| Trim-Mean [30] | Yes | No | Central server | Yes |
| Scheme [7] | No | DP | Central server | No |
| PEFL [31] | Yes | Paillier | Central server | No |
| BAFFLE [22] | No | No | Blockchain | No |
| BlockFL [21] | No | No | Blockchain | No |
| BFLC [33] | Yes | No | Blockchain | Yes |
| Proposed algorithm | Yes | CKKS | Blockchain | Yes |
| Parameter | Parameter Description |
|---|---|
| Total number of edge servers | |
| Edge server local training learning rate | |
| Number of local training rounds for edge servers | |
| Number of all training rounds | |
| Current training round | |
| Local dataset for the th edge server | |
| The th edge server | |
| Local model parameters for the th edge server in round | |
| Global model parameters in round | |
| Local update gradient of the th edge server in round | |
| Prediction of update gradient from the central server to the edge server in round | |
| Global model gradient in round | |
| Trusted calculation time | |
| Approximate Hessian vector product in round | |
| The recording cycle of the historical gradient update identification mechanism | |
| Euclidean distance between the local model gradient update of the th edge server and the prediction of model gradient update in round | |
| The mean value of in the last rounds for the th edge server | |
| Key used by the th edge server to encrypt and decrypt identification data | |
| Key used by the th edge server to encrypt and decrypt model parameters | |
| Key used by the th edge server for digital signatures |
| Number of Devices | MNIST | FASHION-MNIST | ||||
|---|---|---|---|---|---|---|
| Drop Rate | Drop Rate | |||||
| 20 | 3.89 | 3.21 | 0.18 | 3.07 | 2.60 | 0.15 |
| 40 | 3.91 | 3.47 | 0.11 | 3.14 | 2.84 | 0.10 |
| 60 | 3.79 | 3.51 | 0.08 | 3.10 | 2.87 | 0.07 |
| 80 | 3.93 | 3.67 | 0.06 | 3.08 | 2.89 | 0.06 |
| 100 | 3.97 | 3.73 | 0.06 | 3.15 | 2.97 | 0.06 |
| Attack Type | Percentage of Malicious Edge Servers | |||
|---|---|---|---|---|
| 10% | 30% | 50% | 70% | |
| Untargeted attack | 100 | 100 | 100 | 100 |
| Label reversal attack | 100 | 100 | 100 | 100 |
| Backdoor attack | 100 | 100 | 100 | 100 |
| Scheme (Attack Type) | Percentage of Malicious Edge Servers | |||
|---|---|---|---|---|
| 10% | 30% | 50% | 70% | |
| Krum (Untargeted attack) | 94.120 | 95.940 | 0.600 | 0.560 |
| FLTrust (Untargeted attack) | 96.960 | 96.860 | 96.830 | 96.730 |
| Proposed algorithm (Untargeted attack) | 97.050 | 97.020 | 97.030 | 96.970 |
| Krum (Label reversal attack) | 94.190 | 94.000 | 94.030 | 85.690 |
| FLTrust (Label reversal attack) | 96.950 | 96.850 | 96.730 | 96.180 |
| Proposed algorithm (Label reversal attack) | 97.060 | 97.030 | 97.010 | 97.000 |
| Krum (Backdoor attack) | 94.580 | 94.240 | 94.310 | 88.180 |
| FLTrust (Backdoor attack) | 96.890 | 96.870 | 96.770 | 96.700 |
| Proposed algorithm (Backdoor attack) | 97.040 | 97.030 | 97.030 | 96.970 |
| Attack Type | Percentage of Malicious Edge Servers | |||
|---|---|---|---|---|
| 10% | 30% | 50% | 70% | |
| Untargeted attack | 100 | 100 | 100 | 100 |
| Label reversal attack | 100 | 100 | 100 | 100 |
| Backdoor attack | 100 | 100 | 100 | 100 |
| Scheme (Attack Type) | Percentage of Malicious Edge Servers | |||
|---|---|---|---|---|
| 10% | 30% | 50% | 70% | |
| Krum (Untargeted attack) | 77.810 | 78.090 | 1.700 | 1.380 |
| FLTrust (Untargeted attack) | 78.780 | 78.640 | 78.590 | 78.290 |
| Proposed algorithm (Untargeted attack) | 78.100 | 77.900 | 77.750 | 77.630 |
| Krum (Label reversal attack) | 77.500 | 77.380 | 71.490 | 71.780 |
| FLTrust (Label reversal attack) | 78.630 | 78.550 | 78.570 | 78.300 |
| Proposed algorithm (Label reversal attack) | 78.670 | 78.810 | 78.770 | 77.720 |
| Krum (Backdoor attack) | 77.510 | 77.940 | 76.220 | 74.130 |
| FLTrust (Backdoor attack) | 78.650 | 78.630 | 78.490 | 78.330 |
| Proposed algorithm (Backdoor attack) | 78.130 | 77.980 | 77.860 | 77.830 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Deng, Y.; Guo, B.; Chen, S. Privacy-Preserving Approach to Edge Federated Learning Based on Blockchain and Fully Homomorphic Encryption. Electronics 2025, 14, 361. https://doi.org/10.3390/electronics14020361
Deng Y, Guo B, Chen S. Privacy-Preserving Approach to Edge Federated Learning Based on Blockchain and Fully Homomorphic Encryption. Electronics. 2025; 14(2):361. https://doi.org/10.3390/electronics14020361
Chicago/Turabian StyleDeng, Yun, Baiqi Guo, and Shouxue Chen. 2025. "Privacy-Preserving Approach to Edge Federated Learning Based on Blockchain and Fully Homomorphic Encryption" Electronics 14, no. 2: 361. https://doi.org/10.3390/electronics14020361
APA StyleDeng, Y., Guo, B., & Chen, S. (2025). Privacy-Preserving Approach to Edge Federated Learning Based on Blockchain and Fully Homomorphic Encryption. Electronics, 14(2), 361. https://doi.org/10.3390/electronics14020361