



A Framework for Integrating Log-Structured Merge-Trees and Key–Value Separation in Tiered Storage


Abstract
1. Introduction
- Provide a detailed analysis of how LSM-tree performance is affected by heterogeneous storage and identify areas for improvement (Section 4).
- Explore two fundamental strategies for partitioning schemes in tiered storage—Vertical and Horizontal—by analyzing their trade-offs and enhancing their effectiveness through the selective integration of KV separation (Section 5).
- Implement our proposal on top of RocksDB and conduct analysis to determine how to maximize gains in performance while lowering storage financial costs (Section 6.2).
2. Related Works
3. Background
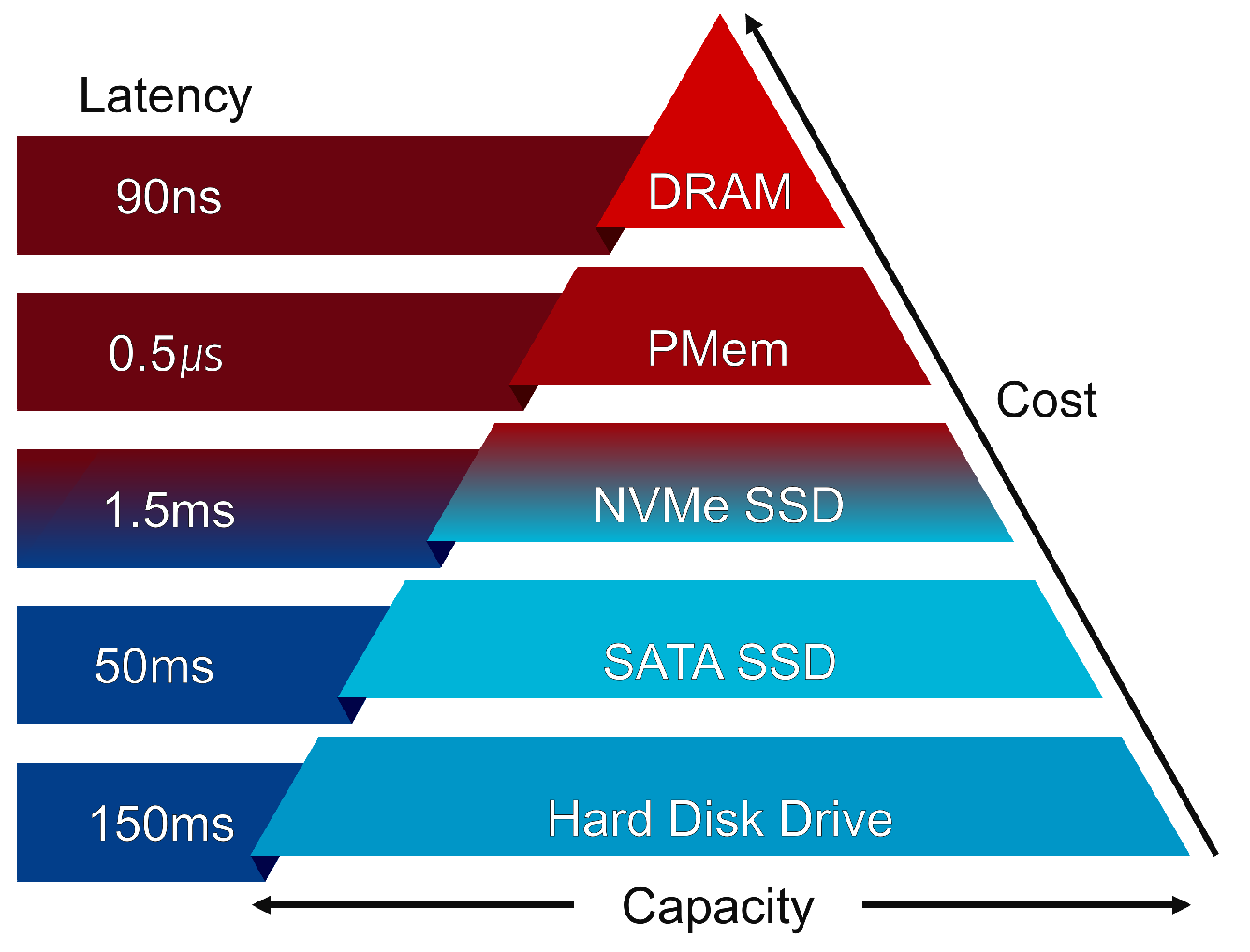
3.1. Tiered Storage
3.2. Log-Structured Merge-Tree
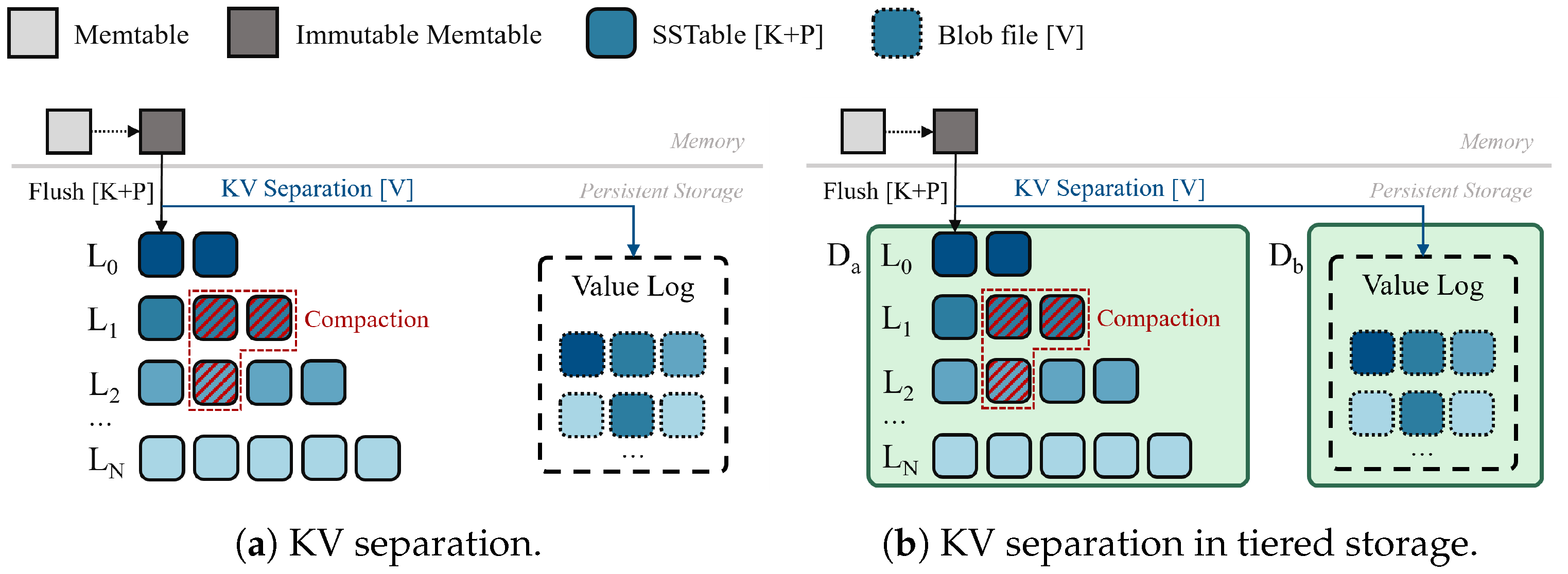
3.3. Key–Value Separation
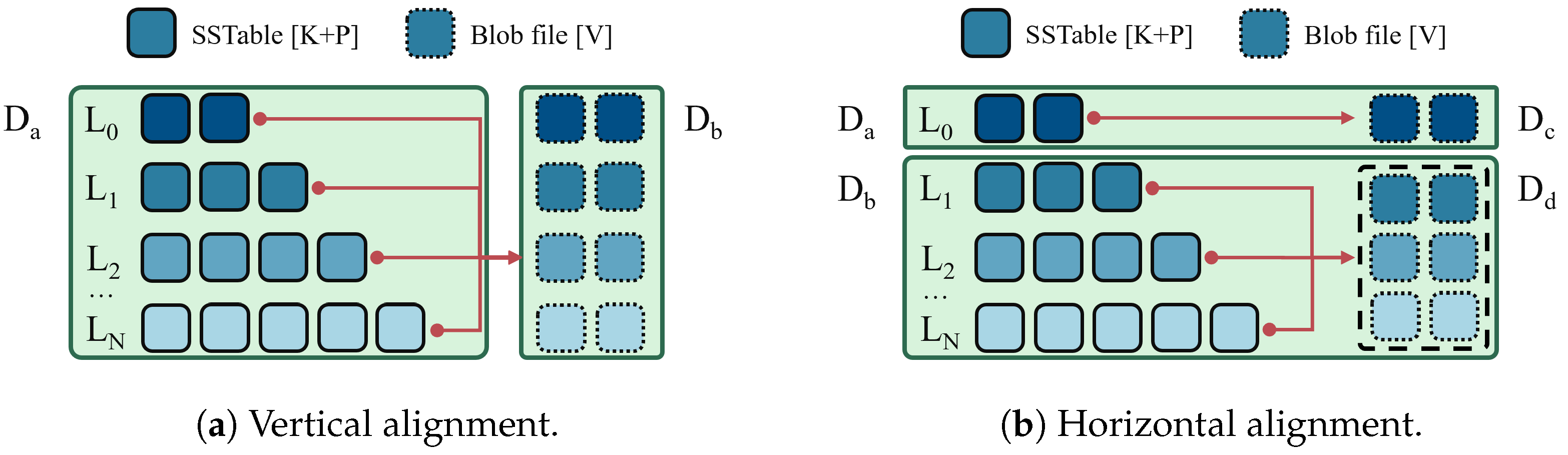
3.4. Exploring Vertical and Horizontal Tiered Storage
4. Benefits of Tiered Storage
4.1. Device Latency
4.2. Characteristics of the LSM-Tree
4.3. Issues of KV Separation
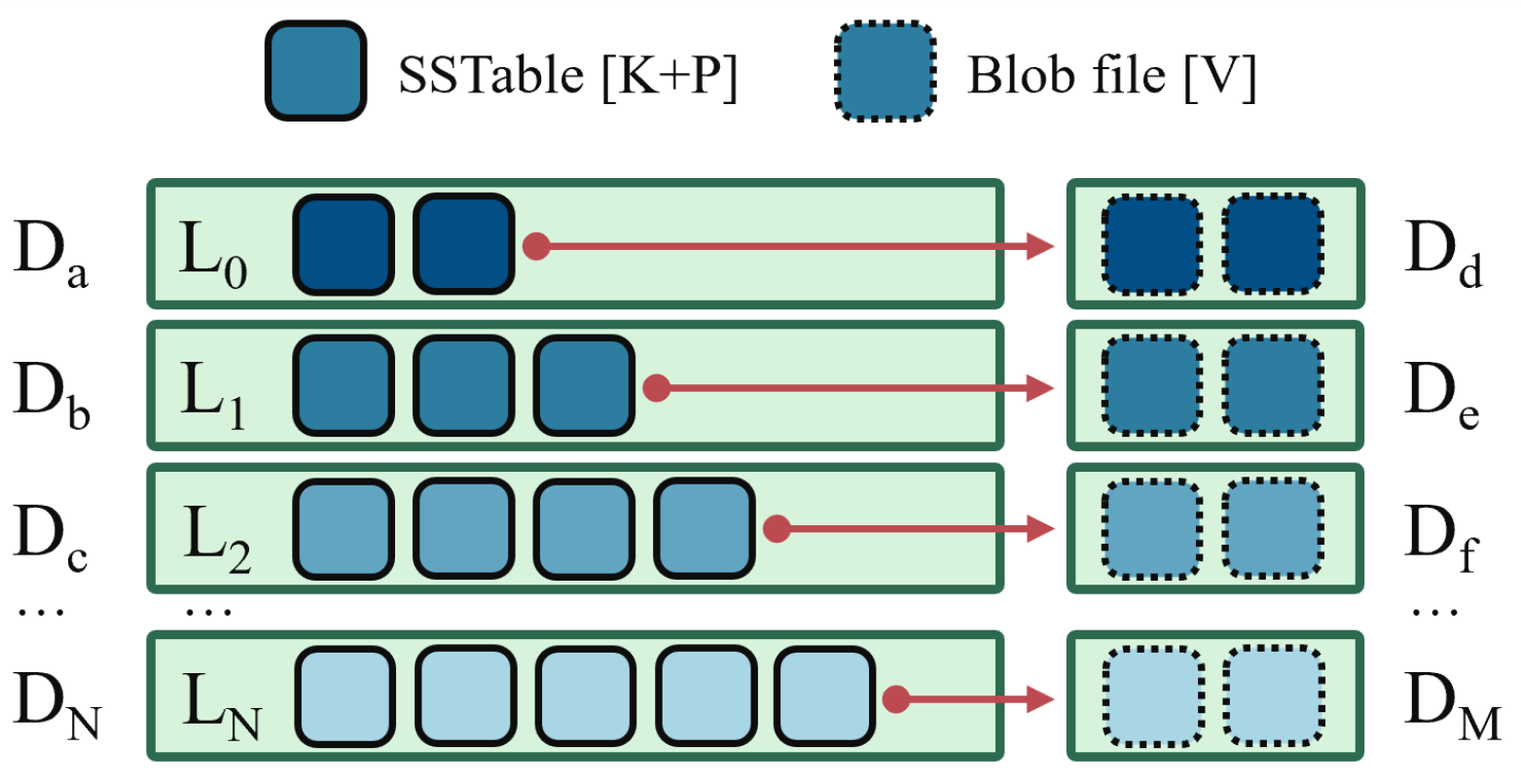
5. Design
- How can tiered storage strategies be applied to LSM-trees with KV separation to balance performance and cost-efficiency?
- What are the trade-offs in separating not only the levels of the LSM-tree (keys) into heterogeneous storage but also the Blob files (values)?
- In what workload scenarios does selective KV separation provide the most significant performance benefits in a tiered storage environment?
5.1. Configuration Strategy
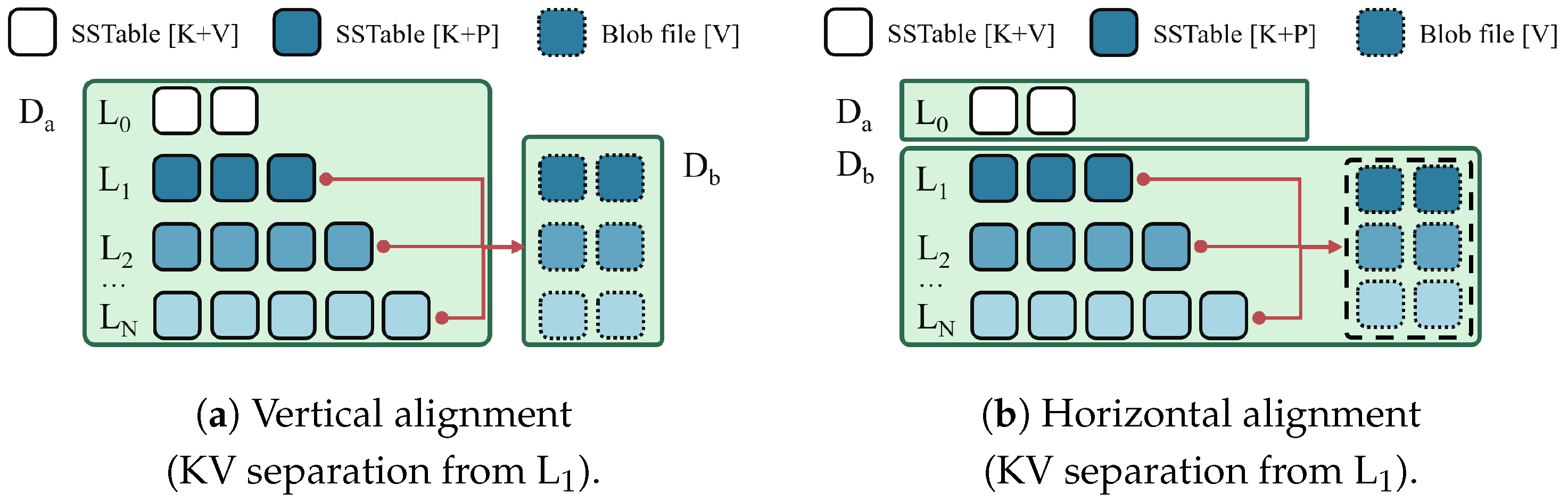
5.2. Combining with Selective KV Separation
6. Evaluation
6.1. Experiment Setup
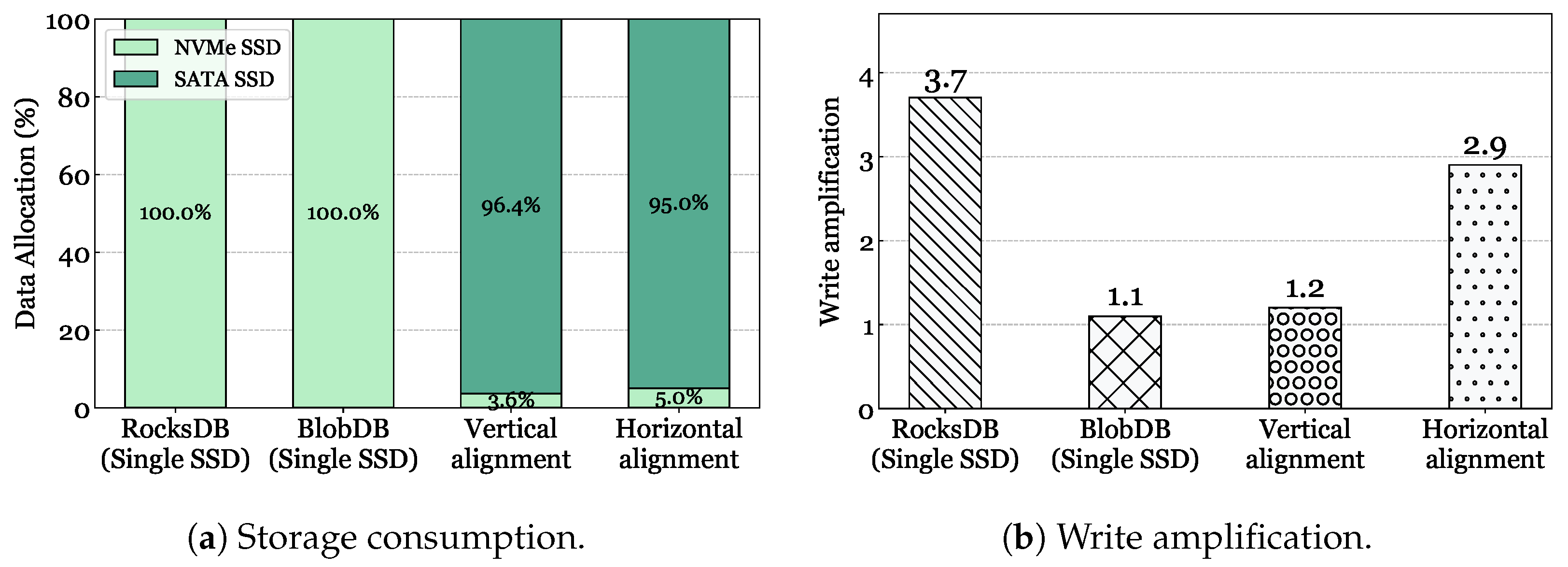
6.2. Experimental Results
6.2.1. Throughput
6.2.2. Average and Per-Level Latency
6.2.3. Tail Latency
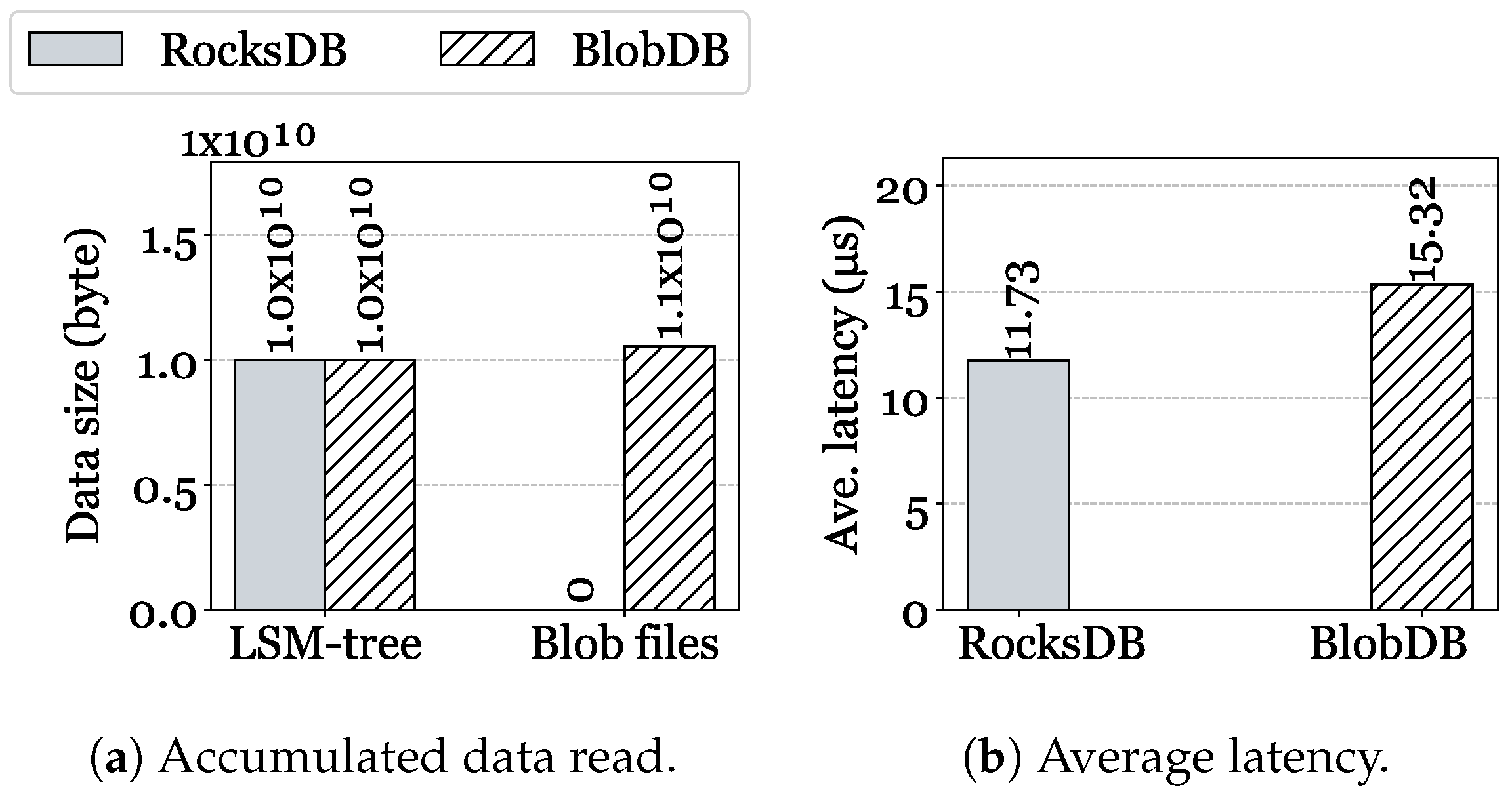
6.2.4. Data Storage Implications
6.2.5. Leveraging Selective KV Separation
6.3. Limitations
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Elhemali, M.; Gallagher, N.; Tang, B.; Gordon, N.; Huang, H.; Chen, H.; Idziorek, J.; Wang, M.; Krog, R.; Zhu, Z.; et al. Amazon DynamoDB: A Scalable, Predictably Performant, and Fully Managed NoSQL Database Service. In Proceedings of the 2022 USENIX Annual Technical Conference (USENIX ATC 22), Carlsbad, CA, USA, 11–13 July 2022; pp. 1037–1048. [Google Scholar]
- Sabitha, R.; Sydulu, S.J.; Karthik, S.; Kavitha, M. Distributed File Systems for Cloud Storage Design and Evolution. In Proceedings of the 2023 First International Conference on Advances in Electrical, Electronics and Computational Intelligence (ICAEECI), Tiruchengode, India, 19–20 October 2023; pp. 1–8. [Google Scholar]
- Microsoft. Azure Disk Storage. Available online: https://azure.microsoft.com/en-us/products/storage/disks/ (accessed on 24 November 2024).
- Google. Google Cloud Storage. Available online: https://cloud.google.com/ (accessed on 24 November 2024).
- Amazon. Hybrid Cloud Storage. Available online: https://aws.amazon.com/cn/products/storage/hybrid-cloud-storage/ (accessed on 24 November 2024).
- Dong, S.; Kryczka, A.; Jin, Y.; Stumm, M. Evolution of Development Priorities in Key-value Stores Serving Large-scale Applications: The RocksDB Experience. In Proceedings of the 19th USENIX Conference on File and Storage Technologies (FAST 21), Virtual, 23–25 February 2021; pp. 33–49. [Google Scholar]
- Idreos, S.; Callaghan, M. Key-Value Storage Engines. In Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data, Portland, OR, USA, 14–19 June 2020; pp. 2667–2672. [Google Scholar]
- LevelDB. LevelDB—A Fast and Lightweight Key/Value Database Library by Google. Available online: https://github.com/google/leveldb (accessed on 24 November 2024).
- Meta. RocksDB. Available online: https://github.com/facebook/rocksdb (accessed on 24 November 2024).
- O’Neil, P.; Cheng, E.; Gawlick, D.; O’Neil, E. The Log-Structured Merge-tree (LSM-tree). Acta Inform. 1996, 33, 351–385. [Google Scholar] [CrossRef]
- Li, C.; Chen, H.; Ruan, C.; Ma, X.; Xu, Y. Leveraging NVMe SSDs for Building a Fast, Cost-effective, LSM-tree-based KV Store. ACM Trans. Storage (TOS) 2021, 17, 1–29. [Google Scholar] [CrossRef]
- Cao, Z.; Dong, S.; Vemuri, S.; Du, D.H. Characterizing, Modeling, and Benchmarking RocksDB Key-Value Workloads at Facebook. In Proceedings of the 18th USENIX Conference on File and Storage Technologies (FAST 20), Santa Clara, CA, USA, 24–27 February 2020; pp. 209–223. [Google Scholar]
- Dayan, N.; Idreos, S. Dostoevsky: Better Space-Time Trade-Offs for LSM-Tree Based Key-Value Stores via Adaptive Removal of Superfluous Merging. In Proceedings of the 2018 International Conference on Management of Data, Houston, TX, USA, 10–15 June 2018; pp. 505–520. [Google Scholar]
- Jin, H.; Choi, W.G.; Choi, J.; Sung, H.; Park, S. Improvement of RocksDB Performance via Large-Scale Parameter Analysis and Optimization. J. Inf. Process. Syst. 2022, 18, 374–388. [Google Scholar]
- Yoo, S.; Shin, H.; Lee, S.; Choi, J. A Read Performance Analysis with Storage Hierarchy in Modern KVS: A RocksDB Case. In Proceedings of the 2022 IEEE 11th Non-Volatile Memory Systems and Applications Symposium (NVMSA), Taipei, Taiwan, 23–25 August 2022; pp. 45–50. [Google Scholar]
- Kaiyrakhmet, O.; Lee, S.; Nam, B.; Noh, S.H.; Choi, Y.R. SLM-DB: Single-Level Key-Value Store with Persistent Memory. In Proceedings of the 17th USENIX Conference on File and Storage Technologies (FAST 19), Boston, MA, USA, 25–28 February 2019; pp. 191–205. [Google Scholar]
- Duan, Z.; Yao, J.; Liu, H.; Liao, X.; Jin, H.; Zhang, Y. Revisiting Log-Structured Merging for KV Stores in Hybrid Memory Systems. In Proceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Vancouver, BC, Canada, 25–29 March 2023; Volume 2, pp. 674–687. [Google Scholar]
- Yu, J.; Noh, S.H.; Choi, Y.r.; Xue, C.J. ADOC: Automatically Harmonizing Dataflow Between Components in Log-Structured Key-Value Stores for Improved Performance. In Proceedings of the 21st USENIX Conference on File and Storage Technologies (FAST 23), Santa Clara, CA, USA, 21–23 February 2023; pp. 65–80. [Google Scholar]
- Raju, P.; Kadekodi, R.; Chidambaram, V.; Abraham, I. PebblesDB: Building Key-Value Stores using Fragmented Log-Structured Merge Trees. In Proceedings of the 26th Symposium on Operating Systems Principles, Shanghai, China, 28 October 2017; pp. 497–514. [Google Scholar]
- Balmau, O.; Dinu, F.; Zwaenepoel, W.; Gupta, K.; Chandhiramoorthi, R.; Didona, D. SILK: Preventing Latency Spikes in Log-Structured Merge Key-Value Stores. In Proceedings of the 2019 USENIX Annual Technical Conference (USENIX ATC 19), Renton, WA, USA, 10–12 July 2019; pp. 753–766. [Google Scholar]
- Dayan, N.; Athanassoulis, M.; Idreos, S. Monkey: Optimal Navigable Key-Value Store. In Proceedings of the 2017 ACM International Conference on Management of Data, Chicago, IL, USA, 14–19 May 2017; pp. 79–94. [Google Scholar]
- Lu, L.; Pillai, T.S.; Gopalakrishnan, H.; Arpaci-Dusseau, A.C.; Arpaci-Dusseau, R.H. WiscKey: Separating Keys from Values in SSD-Conscious Storage. ACM Trans. Storage (TOS) 2017, 13, 1–28. [Google Scholar] [CrossRef]
- Zhang, W.; Zhao, X.; Jiang, S.; Jiang, H. ChameleonDB: A Key-value Store for Optane Persistent Memory. In Proceedings of the Sixteenth European Conference on Computer Systems, Edinburgh, UK, 26–28 April 2021; pp. 194–209. [Google Scholar]
- Li, Y.; Liu, Z.; Lee, P.P.; Wu, J.; Xu, Y.; Wu, Y.; Tang, L.; Liu, Q.; Cui, Q. Differentiated Key-Value Storage Management for Balanced I/O Performance. In Proceedings of the 2021 USENIX Annual Technical Conference (USENIX ATC 21), Virtual, 14–16 July 2021; pp. 673–687. [Google Scholar]
- Tang, C.; Wan, J.; Xie, C. Fencekv: Enabling efficient range query for key-value separation. IEEE Trans. Parallel Distrib. Syst. 2022, 33, 3375–3386. [Google Scholar] [CrossRef]
- Kannan, S.; Bhat, N.; Gavrilovska, A.; Arpaci-Dusseau, A.; Arpaci-Dusseau, R. Redesigning LSMs for Nonvolatile Memory with NoveLSM. In Proceedings of the 2018 USENIX Annual Technical Conference (USENIX ATC 18), Boston, MA, USA, 11–13 July 2018; pp. 993–1005. [Google Scholar]
- Yao, T.; Zhang, Y.; Wan, J.; Cui, Q.; Tang, L.; Jiang, H.; Xie, C.; He, X. MatrixKV: Reducing Write Stalls and Write Amplification in LSM-tree Based KV Stores with Matrix Container in NVM. In Proceedings of the 2020 USENIX Annual Technical Conference (USENIX ATC 20), Boston, MA, USA, 15–17 July 2020; pp. 17–31. [Google Scholar]
- Chen, H.; Ruan, C.; Li, C.; Ma, X.; Xu, Y. SpanDB: A Fast, Cost-Effective LSM-tree Based KV Store on Hybrid Storage. In Proceedings of the 19th USENIX Conference on File and Storage Technologies (FAST 21), Virtual, 23–25 February 2021; pp. 17–32. [Google Scholar]
- Intel. SPDK: Storage Performance Development Kit. Available online: https://spdk.io (accessed on 24 November 2024).
- Lu, Z.; Cao, Q.; Jiang, H.; Wang, S.; Dong, Y. p2KVS: A Portable 2-Dimensional Parallelizing Framework to Improve Scalability of Key-value Stores on SSDs. In Proceedings of the Seventeenth European Conference on Computer Systems, Rennes, France, 5–8 April 2022; pp. 575–591. [Google Scholar]
- Jaranilla, C.; Shin, H.; Yoo, S.; Cho, S.j.; Choi, J. Tiered Storage in Modern Key-Value Stores: Performance, Storage-Efficiency, and Cost-Efficiency Considerations. In Proceedings of the 2024 IEEE International Conference on Big Data and Smart Computing (BigComp), Bangkok, Thailand, 18–21 February 2024; pp. 151–158. [Google Scholar]
- Corporation, I. Customer Support Options for Discontinued Intel® Optane™ Solid-State Drives and Modules. Available online: https://www.intel.com/content/www/us/en/support/articles/000024320/memory-and-storage.html (accessed on 24 November 2024).
- Chan, H.H.; Liang, C.J.M.; Li, Y.; He, W.; Lee, P.P.; Zhu, L.; Dong, Y.; Xu, Y.; Xu, Y.; Jiang, J.; et al. {HashKV}: Enabling Efficient Updates in {KV} Storage via Hashing. In Proceedings of the 2018 USENIX Annual Technical Conference (USENIX ATC 18), Boston, MA, USA, 11–13 July 2018; pp. 1007–1019. [Google Scholar]
- Song, Y.; Kim, W.H.; Monga, S.K.; Min, C.; Eom, Y.I. PRISM: Optimizing Key-Value Store for Modern Heterogeneous Storage Devices. In Proceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Vancouver, BC, Canada, 25–29 March 2023; Volume 2, pp. 588–602. [Google Scholar]
- Zhao, G.; Shin, H.; Yoo, S.; Cho, S.j.; Choi, J. ThanosKV: A Holistic Approach to Utilize NVM for LSM-tree based Key-Value Stores. In Proceedings of the 2024 IEEE International Conference on Big Data and Smart Computing (BigComp), Bangkok, Thailand, 18–21 February 2024; pp. 143–150. [Google Scholar]
- Ren, Y.; Ren, Y.; Li, X.; Hu, Y.; Li, J.; Lee, P.P. ELECT: Enabling Erasure Coding Tiering for LSM-tree-based Storage. In Proceedings of the 22nd USENIX Conference on File and Storage Technologies (FAST 24), Santa Clara, CA, USA, 2024; pp. 293–310. [Google Scholar]
- Elnably, A.; Wang, H.; Gulati, A.; Varman, P.J. Efficient QoS for Multi-Tiered Storage Systems. In Proceedings of the HotStorage, Boston, MA, USA, 13–14 June 2012. [Google Scholar]
- Kakoulli, E.; Herodotou, H. OctopusFS: A Distributed File System with Tiered Storage Management. In Proceedings of the 2017 ACM International Conference on Management of Data, Chicago, IL, USA, 14–19 May 2017; pp. 65–78. [Google Scholar]
- Karim, S.; Wünsche, J.; Broneske, D.; Kuhn, M.; Saake, G. Assessing Non-volatile Memory in Modern Heterogeneous Storage Landscape using a Write-optimized Storage Stack. Grundlagen von Datenbanken 2023. [Google Scholar]
- Meta. BlobDB. Available online: https://github.com/facebook/rocksdb/wiki/BlobDB (accessed on 24 November 2024).
- Cooper, B.F.; Silberstein, A.; Tam, E.; Ramakrishnan, R.; Sears, R. Benchmarking Cloud Serving Systems with YCSB. In Proceedings of the 1st ACM Symposium on Cloud Computing, Indianapolis, IN, USA, 10–11 June 2010; pp. 143–154. [Google Scholar]
- Wang, X.; Jin, P.; Hua, B.; Long, H.; Huang, W. Reducing Write Amplification of LSM-Tree with Block-Grained Compaction. In Proceedings of the 2022 IEEE 38th International Conference on Data Engineering (ICDE), Virtual, 9–12 May 2022; pp. 3119–3131. [Google Scholar]
- Lee, H.; Lee, M.; Eom, Y.I. SFM: Mitigating read/write amplification problem of LSM-tree-based key-value stores. IEEE Access 2021, 9, 103153–103166. [Google Scholar] [CrossRef]
- Amazon.com. SAMSUNG 970 PRO SSD 1TB-M.2 NVMe Interface Internal Solid State Drive with V-NAND Technology (MZ-V7P1T0BW). Available online: https://www.samsung.com/us/computing/memory-storage/solid-state-drives/ssd-970-pro-nvme-m2-1tb-mz-v7p1t0bw/ (accessed on 24 November 2024).
- Amazon.com. Samsung SSD 860 EVO 1TB 2.5 Inch SATA III Internal SSD (MZ-76E1T0B/AM). Available online: https://www.samsung.com/sec/support/model/MZ-76E250B/KR/ (accessed on 24 November 2024).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scheme | Key Technique | Optimization | KV Separation | Storage |
|---|---|---|---|---|
| WiscKey (2017) [22] | KV separation | Write/Read amplification | Yes | SSD |
| HashKV (2018) [33] | Hash-based data grouping Selective KV separation | Garbage collection | Yes | SATA SSD * |
| NoveLSM (2018) [26] | Byte-addressable Skiplist | (De)serialization | No | NVM SATA SSD |
| MatrixKV (2020) [27] | Matrix Container | Write stall & amplification | No | NVM SATA SSD |
| ChameleonDB (2021) [23] | Multi-shard structure | Performance | Yes | NVM * |
| SpanDB (2021) [28] | Asynchronous request processing High-speed Logging via SPDK | Performance Storage Cost | No | NVMe SSD * SATA SSD * |
| DiffKV (2021) [24] | Merge Optimizations Fine-grained KV separation | Performance Storage Cost | Yes | SATA SSD |
| FenceKV (2022) [25] | Fence-based data grouping Key-range garbage collection | Range Scan | Yes | SATA SSD |
| p2KVS (2022) [30] | Multiple KVS instances Inter/Intra Parallelism | Performance Portability | No | NVMe SSD * |
| PRISM (2023) [34] | Heterogeneous Storage Index Table | Scalability Crash consistency | Yes | NVM NVMe SSD * |
| Jaranilla et al. (2024) [31] | Tiered storage Hybrid compression | Performance & storage space utilization trade-off | No | NVMe SSD * SATA SSD |
| ThanosKV (2024) [35] | Hybrid compaction NVM indexing | Write stall | Supported | NVM SATA SSD |
| Our approach | Flexible storage alignments with Selective KV separation | Performance Storage financial cost | Yes | NVMe SSD SATA SSD |
| Component | Model/Specification |
|---|---|
| Hardware | Intel i7 processor with 16 cores |
| 32 GB DRAM | |
| 1 TB Samsung V-NAND NVMe M.2 SSD 970 PRO | |
| 250 GB Samsung 860 EVO SATA SSD | |
| Operating System | Ubuntu 20.04.4 LTS (Focal Fossa) |
| Linux kernel version 5.4 | |
| KVS | RocksDB 9.0.0 |
| Workload | Load | A | B | C | D | E | F |
|---|---|---|---|---|---|---|---|
| Insert | 100% | - | - | - | - | - | - |
| Update | - | 50% | 5% | 5% | 5% | - | |
| Read | - | 50% | 95% | 100% | 95% | - | 50% |
| Range Query | - | - | - | - | - | 95% | - |
| Read-Modify-Write | - | - | - | - | - | - | 50% |
| Write Latency (μs) | Read Latency (μs) | |||||||
|---|---|---|---|---|---|---|---|---|
| P50 | P75 | P99 | P99.9 | P50 | P75 | P99 | P99.9 | |
| RocksDB on NVMe SSD | 5.96 | 8.33 | 14.7 | 20.91 | 4.2 | 14.53 | 149.64 | 533.9 |
| RocksDB on SATA SSD | 10.39 | 14.42 | 37.34 | 70.24 | 7.3 | 29.13 | 364.84 | 2689.05 |
| BlobDB on NVMe SSD | 6 | 8.42 | 16.26 | 26.1 | 7.38 | 20.38 | 148.2 | 240.04 |
| BlobDB on SATA SSD | 8.56 | 11.6 | 22.82 | 33.72 | 9.48 | 23.92 | 219.64 | 376.86 |
| Vertical alignment | 7.84 | 10.14 | 48.01 | 72.75 | 8.47 | 24.28 | 241.13 | 1882.26 |
| Horizontal alignment | 6.09 | 8.59 | 29.98 | 98.22 | 4.2 | 14.95 | 179.36 | 358.97 |
| Model | Read/Write Speed | Price | |
|---|---|---|---|
| Sequential | Random (4K Blocks) | ||
| 970 PRO NVMe® M.2 SSD [44] | 3500 MBps/ 2700 MBps | 15,000–500,000 IOPS/ 55,000–500,000 IOPS | USD 399.99 (USD 0.39/GB) |
| 860 EVO SATA 2.5” SSD [45] | 550 MBps/ 520 MBps | 10,000–98,000 IOPS/ 42,000–90,000 IOPS | USD 199.99 (USD 0.19/GB) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jaranilla, C.; Zhao, G.; Choi, G.; Park, S.; Choi, J. A Framework for Integrating Log-Structured Merge-Trees and Key–Value Separation in Tiered Storage. Electronics 2025, 14, 564. https://doi.org/10.3390/electronics14030564
Jaranilla C, Zhao G, Choi G, Park S, Choi J. A Framework for Integrating Log-Structured Merge-Trees and Key–Value Separation in Tiered Storage. Electronics. 2025; 14(3):564. https://doi.org/10.3390/electronics14030564
Chicago/Turabian StyleJaranilla, Charles, Guangxun Zhao, Gunhee Choi, Sohyun Park, and Jongmoo Choi. 2025. "A Framework for Integrating Log-Structured Merge-Trees and Key–Value Separation in Tiered Storage" Electronics 14, no. 3: 564. https://doi.org/10.3390/electronics14030564
APA StyleJaranilla, C., Zhao, G., Choi, G., Park, S., & Choi, J. (2025). A Framework for Integrating Log-Structured Merge-Trees and Key–Value Separation in Tiered Storage. Electronics, 14(3), 564. https://doi.org/10.3390/electronics14030564