Abstract
Unexpected yet advantageous findings, often referred to as serendipitous discoveries, are becoming increasingly significant in the field of computer science. This research aims to examine the impact of factors that could potentially trigger such serendipity within a recommender system (RS) and consequently proposes a novel, serendipity-incorporated recommender system (SRS). The SRS is developed by integrating elements that could stimulate the occurrence of serendipity into an RS algorithm. These elements include interestingness, diversity, and unexpectedness. As a result, the SRS is equipped to provide users with recommendations that are surprising, intriguing, and atypical. The algorithm within the SRS recommends three items predicated on a user’s preferred item. To facilitate the selection of items to be recommended, we have designed a computation method called the ’serendipity measure’, which is tasked with calculating the weights of all items. Our innovative algorithm and its efficient execution are expounded upon extensively in this study. The performance of the SRS was assessed using a quantitative serendipity evaluation model (QSEM). This model is a quantitative tool designed to measure the probability of users encountering serendipitous events within a specific information space. We conducted a user study to compare the SRS with the traditional cold-start recommender system (CRS), and the feedback for the SRS was positively received. The experiments confirm the viability of cultivating a serendipitous environment from a system’s perspective. The test results also underline the exciting potential that serendipity brings to recommender systems.
1. Introduction
Serendipity, characterized as an unexpected yet advantageous discovery, has been extensively studied across various computer science disciplines. Its role in facilitating scientific breakthroughs and innovation has made it a popular research topic in artificial intelligence and information retrieval systems [1,2,3]. The study of serendipity in computing environments has evolved over the years, moving from early serendipity-driven information discovery systems to more sophisticated models integrated into recommender systems (RSs).
One of the first notable works in computational serendipity was introduced by [4], who developed Max, a web-based software agent that uncovered interesting web pages, thereby fostering serendipitous insights. Later, ref. [5] proposed a serendipitous discovery framework, which was used to evaluate the serendipity potential of various computing systems. More recently, ref. [6] introduced a quantitative serendipity evaluation model (QSEM), which assesses the probability of users encountering serendipity in hypertext environments.
In the era of big data, the importance of integrating serendipity into recommender systems has been increasingly recognized [7,8,9,10,11,12]. Several studies have explored different perspectives on serendipitous recommendations. Ref. [13] conducted a comprehensive survey, emphasizing the role of user interface design but also noting that research in this area is still in its early stages. Ref. [14] introduced a user-centric perspective, focusing on affordance-based serendipity and highlighting the need for further innovation. Additionally, ref. [15] investigated graph neural network (GNN)-based RS optimization, particularly in improving beyond-accuracy metrics such as diversity and serendipity. Moreover, ref. [16] addressed the issue of over-specialization in RS, advocating for unexpectedness and relevance to improve recommendations, which aligns closely with our proposed serendipity-incorporated recommender system (SRS).
Despite these advancements, many recommender systems still suffer from the well-known filter bubble problem. First introduced by [17], the term describes how personalization algorithms reinforce users’ existing preferences, thereby limiting exposure to diverse or unexpected content. This issue is particularly prevalent in commercial RS applications, such as Netflix, Amazon, and Google, where algorithmic optimization often prioritizes relevance at the expense of exploration. Several studies have attempted to break the filter bubble, including diversity-enhancing approaches [18], randomization techniques [19], and novelty-based recommendations [20]. However, none of these approaches fully address the delicate balance between relevance, unexpectedness, and diversity.
In this study, we propose a novel SRS, which aims to mitigate the filter bubble problem by explicitly incorporating serendipity-inducing factors into recommendation algorithms. Our contributions can be summarized as follows:
- We introduce the SRS that moves beyond conventional content-based and collaborative filtering approaches by optimizing for unexpected yet beneficial discoveries.
- We refine and extend the E-QSEM (enhanced QSEM) evaluation framework, which quantitatively measures serendipity within recommendation environments.
- We conduct a comparative study between our proposed SRS and a conventional content-based RS (CRS), evaluating performance based on both quantitative metrics (E-QSEM) and qualitative user feedback.
- We explicitly define two distinct novelty types in the context of serendipitous recommendations:
- –
- Type 1 Novelty: Items that are unknown to users but capture their interest upon recommendation.
- –
- Type 2 Novelty: Items that users initially perceive as uninteresting but later find engaging after being recommended.
To assess the effectiveness of SRS, we compare it against CRS using two primary evaluation criteria: 1. E-QSEM: A refined version of QSEM [6], which quantitatively measures serendipity by assessing pre-encountering, post-encountering, and discovery phases in the recommendation process. 2. User Feedback Analysis: We conduct a user study to assess the real-world impact of SRS, gathering qualitative feedback on recommendation diversity, unexpectedness, and perceived usefulness. For our experimental setup, we utilize the MovieLens dataset [21] and construct a movie recommender system. This allows us to simulate and evaluate real-world serendipitous recommendation scenarios.
The remainder of this paper is structured as follows. Section 2 reviews prior research on RS and serendipity-driven recommendation techniques, highlighting existing challenges and potential solutions. Section 3 introduces the SRS model and details the implementation of the E-QSEM evaluation framework, which is designed to quantify serendipity in recommendation environments. Section 4 presents the experimental findings, comparing the performance of SRS and CRS in terms of serendipity. Section 5 summarizes key findings and offers a comprehensive discussion of our proposed methodology. Finally, Section 6 discusses the limitations of our study, particularly the dataset dependence, sample size constraints, and potential improvements for broader applicability.
2. Related Work
This research aims to design an SRS that overcomes the limitations of the conventional RS while satisfying users. We examined previous studies on the shortcomings of traditional RS and the influence of serendipity on RS performance. Additionally, we explored existing research on integrating serendipity into the design of recommender systems and identified their constraints.
2.1. Impact of Serendipity on User Engagement in Recommender Systems
The nature of an RS is to recommend items to help people make decisions that they may like based on reliable data. Plenty of approaches for an RS exist, such as content-based filtering, collaborative filtering, or multi-criteria RS, as shown in Table 1.

Table 1.
Recommendation approaches.
Content-based filtering predicts a user’s preferences based on the features of items they have previously liked, essentially guessing the user’s behavior or features they find appealing in an item. Collaborative filtering is another method where it creates special profiles for both users and items separately. It uses what everyone likes to suggest items that people with similar tastes have enjoyed. Hybrid filtering combines the strengths of both content-based and collaborative filtering, employing multiple strategies to provide more accurate and relevant recommendations by integrating the insights gained from both methods. Lastly, multi-criteria filtering looks at more than just simple likes or dislikes. It checks different features of an item, like how interesting or useful it is, to provide a more detailed review. This way, it can suggest things that are more closely matched to what you might really enjoy. All these methods rely on some explicit or implicit assumptions about users’ needs in order to recommend items properly from a dataset. However, a problem has been raised that the algorithm of a general RS is insufficient to attract the ‘interest’ of these users [7].
A traditional RS provides a list of recommendations by providing as input the user’s profile and either selecting what is of interest for the user or ranking the items approximately [8]. This brings up the problem that by recommending popular items, users often get recommendations that they already planned to look at or encountered [9]. In addition, since it is a method of preferentially recommending popular items, only specific items are included in the recommendation list in an intensive and limited manner. This type of RS can lead to filter bubble problems, depriving users of the opportunity to learn new things [10].
Serendipity refers to the phenomenon of making unexpectedly fascinating discoveries. By infusing this notion of serendipity into an RS, we can potentially offer users a refreshing experience of unexpected yet delightful discoveries, rather than plain recommendations. Ref. [7] propose that, to enhance user satisfaction, RSs should occasionally make unique recommendations—suggesting items that significantly deviate from previously rated items along with those already rated by the user. They argue that relevance and popularity are crucial factors when quantifying the degree of serendipity in a recommendation system. In a subsequent study involving 475 actual users, ref. [24] assessed a serendipity-infused RS. Their recommendation system incorporated 2146 movies and was evaluated by experimenting with various combinations of serendipity’s three primary elements: relevance, novelty, and unexpectedness. The evaluation revealed that the overuse of unexpectedness could negatively impact user satisfaction. Still, overall, it was concluded that the serendipitous RS contributed to broadening user preferences.
Similarly, ref. [1] observed that serendipity can introduce users to unexpected yet fortuitous experiences within the RS, prompting them to conduct a user study using a serendipity-focused content-based recommender system. In their study, they highlighted the fact that a relevance-focused RS tends to concentrate on specific issues, thereby limiting users’ exposure to a broader range of content. To address this limitation, they proposed an RS that emphasizes both serendipity and similarity. Recommendations are generated by integrating the results of the serendipity model and the similarity model. The serendipity model assigns weights to each factor—unexpectedness and interestingness—to formulate recommendations. Conversely, the similarity model assigns weights to similarity and popularity. In a user study with 27 participants, it was found that the combined serendipity–similarity model offered users a more positively surprising experience compared to traditional recommendation systems.
2.2. Incorporating Serendipity into Recommender System Design
In [25], the phenomenon of serendipity in digital environments is explored to map the conceptual space of “digital serendipity”. Through an interdisciplinary literature review, significant conceptions of serendipity for digital environments are discussed. Digital serendipity emerges as a potent philosophical concept, a technically volatile and conceptually nuanced design principle, and a crucial capability for citizens of information societies. The design for serendipity, especially in personalization systems, is highlighted as a means to navigate the vast array of available information more effectively, potentially enhancing individual discoveries, and improving learning experiences. As serendipity gains recognition as a desirable design principle, the discourse emphasizes the importance of continually questioning what serendipity means in various contexts, how it can be designed, and the desirable extent of its incorporation. The exploration acknowledges the need for designers to understand a range of conceptual nuances and dynamics; this includes navigating the trade-off between serendipity and accuracy, as well as understanding the tensions between implicit and explicit personalization and between hyper-personalized and pseudo-personalized recommendations. It also points out the possibility of serendipity being artificially manufactured. Despite these insights, the author primarily remains a theoretical exploration, stopping short of practical application or empirical validation. This leaves a gap in understanding how these conceptual frameworks can be applied in real-world digital environments to foster genuine serendipitous experiences.
Ref. [14] offers a novel perspective for studying serendipity in RS, moving beyond algorithmic evaluation to consider serendipity as a facet of user experience. This approach addresses the limitations of existing research, which often views serendipity narrowly as an algorithmic performance metric. By adopting a user-centric view and leveraging an affordance approach, the study broadens the understanding of serendipity as an outcome of user interaction with a system. The introduction of an affordance feature repository marks a significant step towards identifying features that can enhance serendipitous discoveries within RS. However, this research also presents opportunities for further innovation and exploration, particularly in the operationalization and empirical validation of these affordances. The paper outlines a potential evaluation procedure but stops short of conducting experiments to validate the impact of identified features on serendipity. Empirical evidence is crucial for understanding how these features operate in real-world scenarios and how users perceive and experience serendipity.
Ref. [26] utilized the SOG algorithm to enhance serendipity and diversity in recommendations while maintaining a balance with accuracy. By evaluating this algorithm against others using a dataset, the study makes significant strides in understanding the interplay among serendipity, diversity, and accuracy in RS. However, while the SOG algorithm improves serendipity and diversity, it does so at the expense of accuracy. This trade-off highlights the challenge of optimizing for multiple objectives within RS. The paper also suggests user studies as future directions for exploring serendipity-oriented algorithms. This indicates an opportunity for more innovative approaches to algorithm design and evaluation.
While previous studies have explored theoretical and user-centric perspectives, as well as specific serendipity-enhancing algorithms, there remains a need for more structured methodologies that systematically incorporate serendipity into recommendations without sacrificing user engagement or accuracy. In addition to these approaches, research on filter bubbles, data sorting, and statistical randomness provides insights into techniques that can diversify recommendations.
The concept of the filter bubble, first highlighted by [17], underscores the dangers of over-personalization, where recommendation algorithms reinforce users’ existing preferences and limit exposure to novel content. Various methods have been proposed to counteract this effect, including controlled randomness [19], content diversification [18], and serendipity-driven recommendations [7].
Sorting mechanisms such as bubble sorting [27] and random sorting [28] have also been explored in ranking and diversity research. However, a key challenge with purely random or semi-random recommendations is that they may introduce novelty without ensuring user engagement. Our study builds upon these prior works by developing a structured serendipity-aware filtering approach that goes beyond pure randomness, using operator preferences and persona-based inference models to ensure novelty while maintaining relevance [8].
While market basket analysis (MBA) [29] has been suggested as an alternative approach for structured diversity in recommendations, MBA primarily detects associative relationships rather than optimizing for exploratory engagement. Our work differs from MBA in that it explicitly integrates structured randomness to balance predictability and novelty, allowing users to discover diverse content while maintaining engagement and satisfaction.
By incorporating insights from serendipity theory, user affordances, and filter bubble mitigation strategies, our work advances the understanding of how structured randomness and diversity-driven filtering can enhance user experience in RS. This approach moves beyond traditional collaborative filtering and naive randomization, offering a more systematic and personalized way to foster exploratory recommendations.
3. Methodology
In this section, we formally define the filter bubble problem in RS and detail the current popular algorithms used. We then introduce our proposed serendipitous approach. After defining the problem and approaches, we explain the algorithms used in both CRS and SRS that were implemented in our user study to verify our approach. Additionally, we introduce an expanded version of the QSEM (E-QSEM), designed to assess the serendipity potential in recommender systems.
3.1. Defining the Filter Bubble Problem and Approaches in Recommender Systems
Definition 1
(Recommender system). A recommender system (RS) is an algorithmic framework designed to suggest relevant items to users based on their preferences and interactions. The recommendation process is formalized in Algorithm 1, which outlines the key inputs and how they are processed to generate relevant recommendations.
| Algorithm 1 Recommender system | |
| Input | |
| U | A set of users |
| I | A set of items |
| U_profile | Information about users such as name, age, gender and demographic details |
| U_history | Information about past interactions of users such as watch history, ratings, time spent and search queries |
| I_meta | Metadata of items such as categories, keywords, authors, and ratings |
| Output | |
| R(U) | A list of recommended items from the set I for each user u |
Definition 2
(Filter bubble problem). The filter bubble problem in RS arises when users are consistently presented with content that aligns closely with their existing preferences and behaviors, resulting in a lack of exposure to diverse or novel items. The filter bubble problem can be framed as follows:
- The recommender function f overly relies on high similarity scores, leading to recommendations that are too similar to past interactions.
- The system fails to introduce new and unexpected content, reducing the likelihood of discovering new interests.
- Recommendations reinforce the user’s existing preferences, creating a feedback loop that strengthens the filter bubble.
Definition 3
(Content-Based Filtering). Content-based filtering (CBF) is a type of RS algorithm that suggests items to users based on the features of the items and the preferences or behavior of the user.
The core idea of CBF is to recommend items similar to those that a user has liked in the past. However, it focuses solely on the user’s current interests, which can lead to a lack of diversity in recommendations. This means there is a low possibility of discovering new interests.
Definition 4
(Collaborative Filtering). Collaborative filtering (CF) is a type of RS algorithm that suggests items to users based on the preferences and behaviors of other users.
The core idea of CF is that users who have agreed in the past will agree in the future. However, recommendations tend to circulate among similar users, reinforcing the filter bubble. Additionally, this method has difficulty recommending new users or new content, known as the cold start problem.
Definition 5
(Hybrid Filtering). Hybrid filtering combines multiple recommendation techniques, typically CBF and CF, to leverage the strengths and mitigate the weaknesses of each approach.
The goal of hybrid filtering is to provide more accurate, diverse, and reliable recommendations by combining the predictions of content-based filtering and collaborative filtering. However, it may also inherit the drawbacks of both approaches.
From an algorithmic perspective, we can identify the limitations of existing RS Algorithms 2–4 in terms of the filter bubble problem. To address these issues, we propose a new approach Algorithm 5 that balances relevance with diversity and serendipity in the recommendations.
| Algorithm 2 Content-based filtering | |
| Input | |
| U | A set of users |
| I | A set of items |
| U_profile | Information about users such as name, age, gender and demographic details |
| U_history | Information about past interactions of users such as watch history, ratings, time spent and search queries |
| I_meta | Metadata of items such as categories, keywords, authors, and ratings |
| Output | |
| R(U) | A ranked list of items with the highest similarity to those the user has interacted with or liked in the past from the set I for each u |
| Algorithm 3 Collaborative filtering | |
| Input | |
| U | A set of users |
| I | A set of items |
| U_profile | Information about users such as name, age, gender and demographic details |
| U_history | Information about past interactions of users such as watch history, ratings, time spent and search queries |
| I_meta | Metadata of items such as categories, keywords, authors, and ratings |
| Output | |
| R(U) | A ranked list of items with the highest ratings given by similar users from the set I for each u |
| Algorithm 4 Hybrid filtering | |
| Input | |
| U | A set of users |
| I | A set of items |
| U_profile | Information about users such as name, age, gender and demographic details |
| U_history | Information about past interactions of users such as watch history, ratings, time spent and search queries |
| I_meta | Metadata of items such as categories, keywords, authors, and ratings |
| Output | |
| R(U) | A ranked list of items with the highest ratings, calculated by combining the predictions of content-based filtering and collaborative filtering from the set I for each u |
Definition 6
(Serendipitous Filtering). Serendipitous filtering is a type of RS algorithm designed to not only provide relevant recommendations based on user preferences but also to introduce unexpected and novel items that the user might find interesting.
The goal of serendipitous filtering is to enhance user satisfaction by balancing familiarity with discovery. This approach predicts the utility of an item for a user while ensuring a mix of familiar and novel items. It provides a recommendation list that balances current interests with new potential interests, mitigates the filter bubble by including diverse categories and topics, and introduces serendipity by intentionally incorporating unpredictable content.
| Algorithm 5 Serendipitous filtering | |
| Input | |
| U | A set of users |
| I | A set of items |
| U_profile | Information about users such as name, age, gender and demographic details |
| U_history | Information about past interactions of users such as watch history, ratings, time spent and search queries |
| I_meta | Metadata of items such as categories, keywords, authors, and ratings |
| Output | |
| R(U) | A ranked list of items that the user has not yet rated, balancing relevance and novelty from the set I for each u |
While one might argue that the filter bubble issue could be addressed simply by introducing randomness into collaborative filtering, this approach lacks a mechanism to ensure that the recommended content remains relevant and engaging. Naive randomization may introduce novelty but does not guarantee that the suggested items will be meaningfully diverse or valuable to the user. Instead, our serendipity-aware filtering approach moves beyond pure randomness by structuring diversity through operator preferences, which can be inferred using personalized data or persona-based inference models.
By integrating structured randomness, where serendipitous factors are algorithmically weighted rather than purely random, our method ensures that recommendations remain both engaging and diverse. This approach systematically balances relevance and unexpectedness, allowing users to discover novel content while still receiving recommendations aligned with their preferences. In doing so, our model effectively mitigates the filter bubble, providing a more structured and personalized way to enhance exploration without compromising user satisfaction.
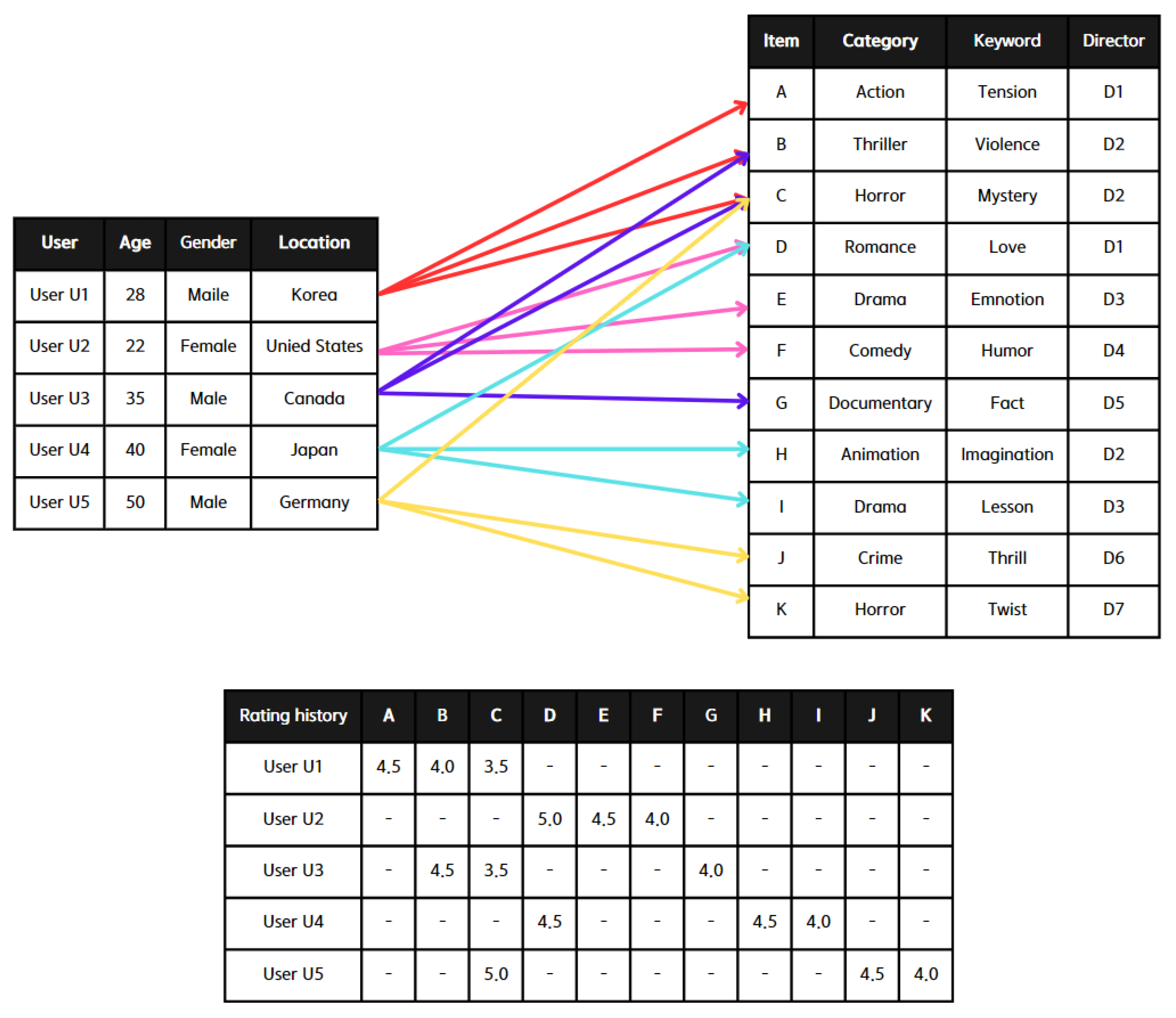
Table 2 illustrates the variations in recommendation output depending on the RS algorithm applied to the sample instance depicted in Figure 1. The first three approaches—content-based filtering, collaborative filtering, and hybrid filtering—represent standard recommendation techniques, while serendipity filtering is the methodology introduced in this study.
Table 2.
The results table showing the recommendations for user u1 by each recommender system algorithm based on the provided instance data in Figure 1.
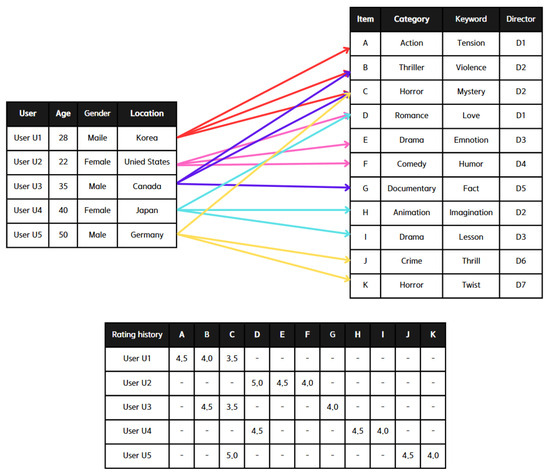
Figure 1.
Sample instances for recommender system algorithm.
Content-based filtering recommends three items to user by calculating the similarity between the items that has rated and the other items in the dataset. The goal is to recommend items most similar to those has liked. First, it identifies the features of the items has rated, such as category, keyword, and director. Then, it calculates the similarity between these rated items and the other items in the dataset. Finally, it recommends the top three items with the highest similarity scores that has not rated. Based on the calculated similarity scores, the content-based filtering algorithm would recommend items H, K, and J to user .
Collaborative filtering recommends items to by analyzing the ratings given by similar users. It identifies these similar users based on their rating patterns and suggests items they have rated highly. First, it calculates the similarity between and other users. Given that is the most similar user, followed by , collaborative filtering examines the items rated by and (B, C, G, J, K). It then selects the highest-rated items by and that has not yet rated. Thus, collaborative filtering would recommend items G, J, and K to .
Hybrid filtering combines the strengths of both content-based filtering and collaborative filtering to provide recommendations. It combines the results from both methods and considers their weights. Content-based filtering recommends items H, K, and J, while collaborative filtering recommends items G, J, and K. Since items J and K appear in both recommendation lists, they are strong candidates for recommendation. We used a simple average to combine the scores from both content-based and collaborative filtering, assuming equal weights for simplicity ( and ). To decide between H and G, it calculates the combined score using the formula: . Using this formula, we know that G has a higher combined score than H. Therefore, hybrid filtering would recommend items J, K, and G to .
Lastly, serendipity filtering recommends items to by balancing relevance, novelty, and unexpectedness. It first calculates the similarity between the items has rated and other items in the dataset. Next, it assesses how novel or unexpected an item is for based on their user history; items that share less common metadata with previously rated items are considered novel and unexpected. By combining the similarity and unexpectedness scores, a final score for each item is obtained. Using this approach, we can determine that serendipity filtering would recommend items D, H, and K to . From this instance, it is evident that existing recommendation functions primarily focus on relevance and similarity, limiting their recommendations. In contrast, serendipity filtering balances relevance with diversity and unexpectedness, providing more varied and surprising recommendations.
3.2. RS Models
In this section, we establish a set of terminologies for consistency throughout our discussion. An RS is a system that assesses user behavior and suggests the most suitable item for that user. The selected item (SI) is the current item chosen by the user and utilized by the RS to analyze user behavior. The recommended item (RI) is an item proposed by the RS to the user after evaluating the user’s selected item.
We developed two versions of an RS, the SRS and CRS, to highlight the influence of serendipity within the RS. Each RS was designed to suggest three RIs when the user enters the title of their preferred movie into the RS. The CRS uses a content-based filtering (CBF) algorithm that employs item characteristics to recommend items similar to those users prefer, based on their SIs.
The CRS model identifies RIs relevant to the user based on a similarity measure, as illustrated in Equation (2), using the feature matrix and average rating data depicted in Figure 2. The feature matrix is designed to indicate the presence or absence of various feature tags for each item in the dataset [30]. Ref. [31] confirmed that keyword tags can be used to compute similarity between two different items. It is organized into rows and columns, with each row representing an item and each column representing a feature tag. In this matrix, each cell corresponding to an item is marked with a 1 or 0 in the feature tag columns, signifying whether the item possesses or lacks that particular feature tag. This procedure is applied to every item in the dataset, culminating in a binary matrix where each row offers a multi-label one-hot encoded depiction of the item’s feature tags. The average rating is simply the mean rating given to the item by users. The CRS computes similarity measures for all possible pairs of <SI, X>, where SI is fixed, and X is an item drawn from the dataset. The top three items with the highest similarity measures are chosen as RIs. The CRS is specific to an individual user as this model does not utilize any information about other users.
where · = dot product, ¯ = normalization.

Figure 2.
A simple demonstration of the similarity measure used in CRS.
The SRS employs a filtering algorithm that integrates both item features and serendipity characteristics to suggest items to users based on their SIs. The SRS is designed with the intent to facilitate the experience of serendipity for users when receiving recommendations via the RS.
The SRS model selects RIs based on a serendipity measure, as depicted in Equation (3). For the pair <SI, X>, if they belong to the same genre, the weight of the category is 0.5; otherwise, it stands at 1. All other elements are computed in the same manner as for the similarity measure. The top three items with the highest serendipity measures are chosen as RIs.
The SRS, like CRS, is tailored to a particular user. However, the SRS produces more diverse recommendations by incorporating the category information of items. It also uses the reciprocal of the dot product of the feature matrix to avoid run-of-the-mill recommendations, ensuring that when the dot product is zero, the result is set to zero as well.
where · = dot product, ¯ = normalization.
The issues associated with the filter bubble in an RS include the system’s tendency to recommend items that are excessively similar to those the user has already shown interest in, which can lead to a lack of diversity. Additionally, it decreases user engagement by suggesting items that are predictable and conspicuous. The SRS addresses these problems by adopting a different approach. Unlike the CRS, which selects items based on similarity and popularity, the SRS prioritizes user preferences and slightly diminishes the emphasis on similarity. Furthermore, the SRS reduces the likelihood of recommending items from the same domain, thereby making the recommendations more unexpected and diverse.
3.3. E-QSEM
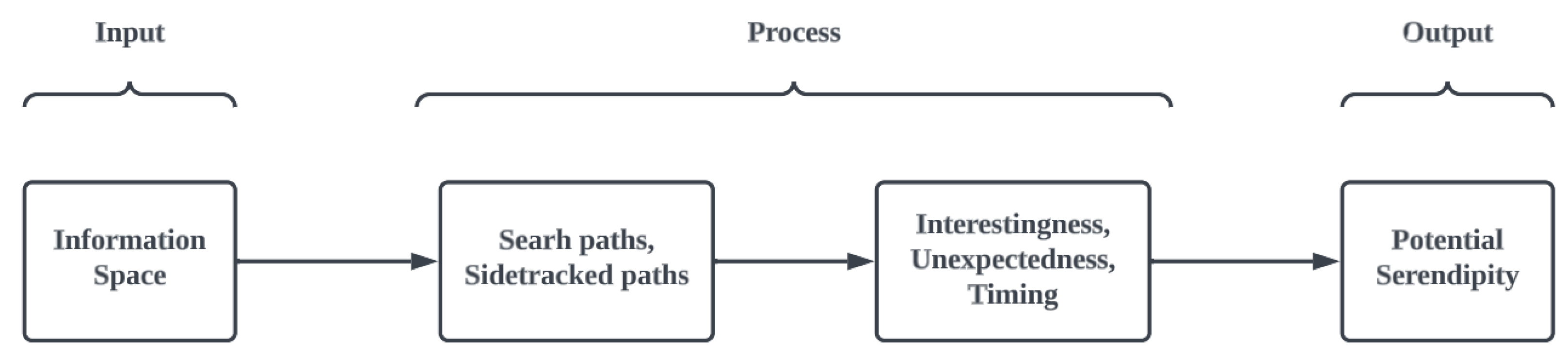
Ref. [6] pursued an investigation to quantitatively gauge the probability of a user encountering the phenomenon of serendipity while navigating a hypertext space (refer to Figure 3).
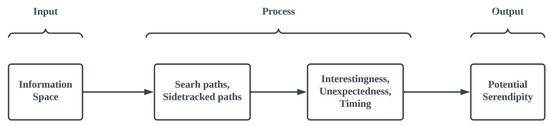
Figure 3.
Three phases of the QSEM.
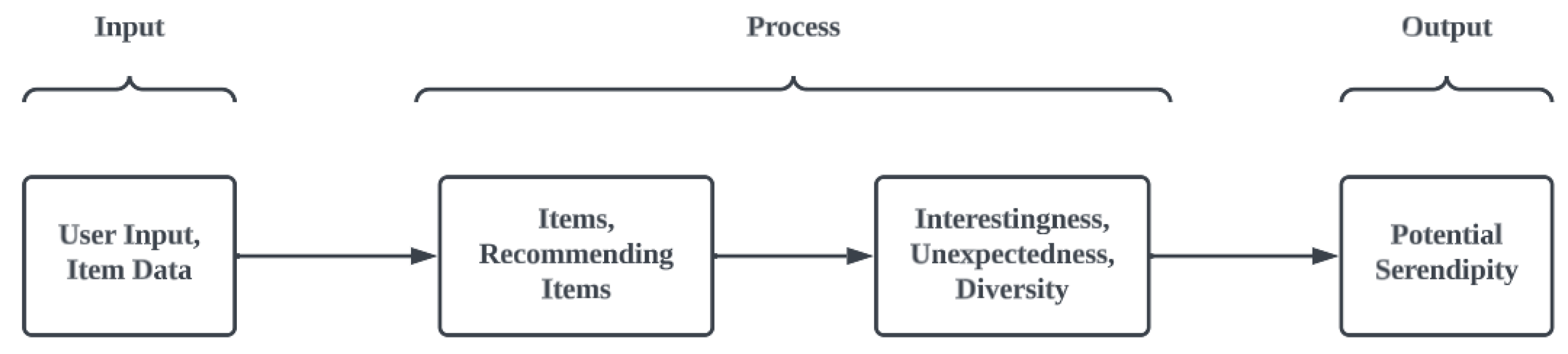
We broadened the scope of QSEM to assess the level of serendipity in an RS in terms of its interestingness, unexpectedness, and diversity (refer to Figure 4). Each component evaluates an RS on the following aspects:
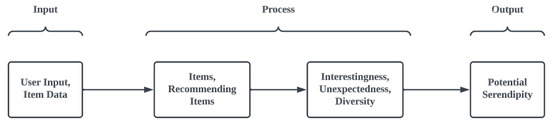
Figure 4.
Three phases of the E-QSEM.
- Unexpectedness: The degree of surprise experienced by a user upon discovering a page.
- Interestingness: The level of fascination of a user with a page they have encountered unexpectedly.
- Diversity: The extent to which a variety of different items are included in the recommendations.
While various papers have discussed serendipity measures [26,32] and the factors contributing to serendipity, including diversity, interestingness, and unexpectedness, there is a noticeable absence of research specifically aimed at quantifying unexpectedness in a manner that transcends mere dissimilarity. Previous methodologies predominantly equate unexpectedness with dissimilarity, operating under the assumption that recommendations significantly different from a user’s historical interactions or preferences are inherently unexpected. However, this approach oversimplifies the complex nature of unexpectedness by ignoring the contextual and semantic relationships between items. Simply put, not all dissimilar items lead to a serendipitous experience; some may merely result in irrelevant surprises that do not enrich the user’s experience or discovery process. Ref. [33] also emphasized that inducing serendipity requires careful consideration of ensuring content coherence and relevance while enabling novel and unexpected discoveries. Our proposed measure for unexpectedness diverges from this conventional approach by not merely quantifying dissimilarity but by assessing the semantic distance within the context of the item. We assess the semantic distance between items by initially organizing them into a taxonomy structure and then calculating the shortest path from one item to another, as described in Section 3.3.1. This means that our measure considers the contextual connections between the recommended item and the user’s interests or past interactions. By doing so, we ensure that the unexpectedness we identify is not just about being different but about being meaningfully different—where the surprise stems from discovering something new and relevant that the user might not have found on their own but finds intriguing or valuable upon encounter.
3.3.1. Unexpectedness
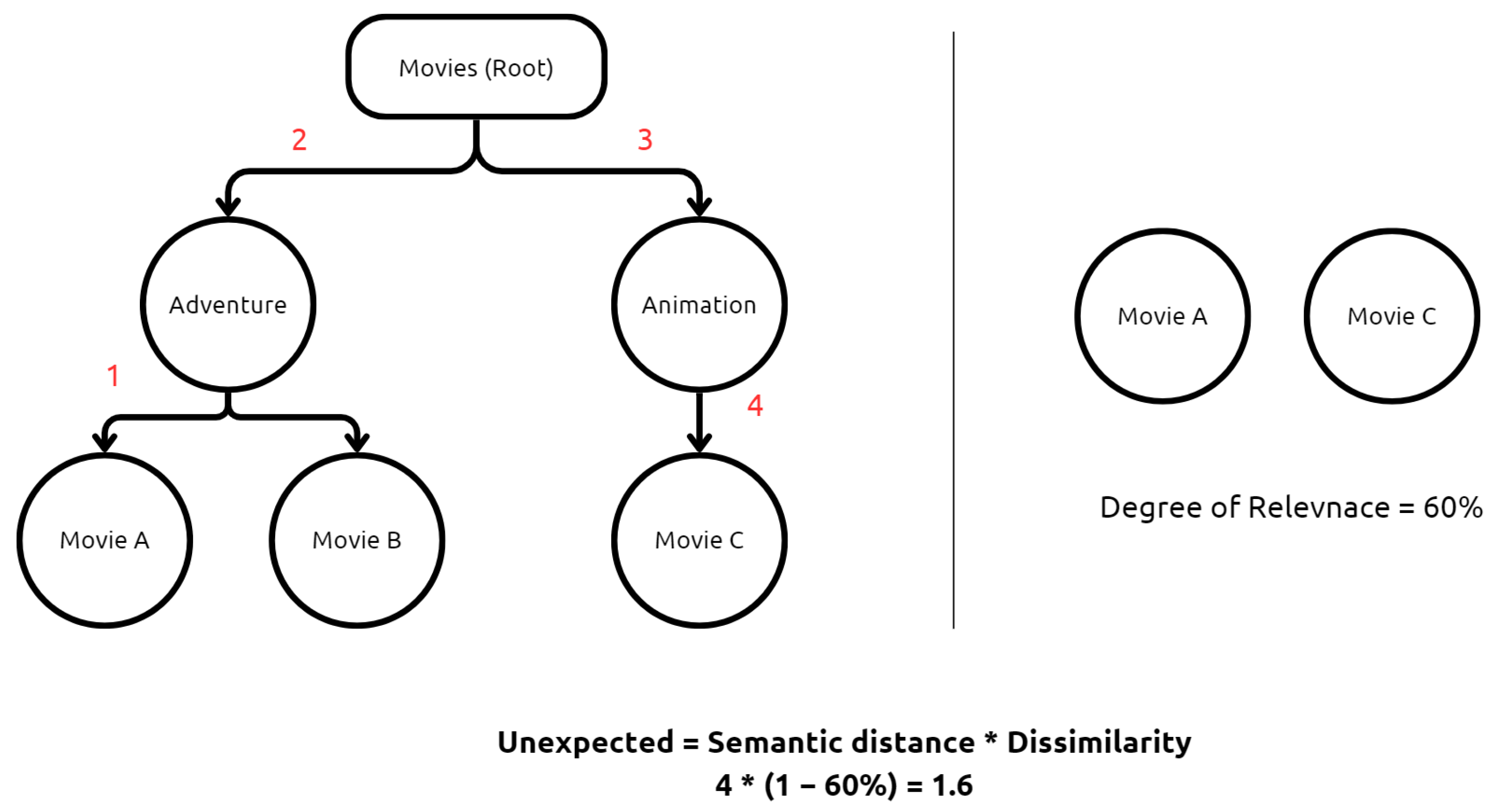
Unexpectedness assesses the degree to which the RIs presented to users diverge from the anticipated category. Each item, such as a movie, is categorized within a hierarchical classification system, where broader categories (e.g., “Movies”) branch into more specific subcategories (e.g., “Action,” “Comedy,” “Drama”). To quantify unexpectedness, we measure the semantic distance between the SI and the RI within this hierarchy, as well as the degree of dissimilarity between the items. The semantic distance represents the shortest path between two items in the classification tree. Meanwhile, dissimilarity is determined based on feature tags assigned to each item, represented as vectors—fewer shared tags indicate a higher degree of dissimilarity.
As demonstrated in Figure 5, if a user selects Movie A and the recommendation system suggests Movie C, the shortest distance in the classification hierarchy from Item A to Item C is 4. Movie A is categorized under Adventure, while Movie C belongs to Animation, both of which fall under the broader Movies category. First, moving up one level from Movie A reaches its parent category, Adventure. Second, moving up another level from Adventure reaches the common parent category, Movies. Third, moving down one level from Movies enters the Animation category. Finally, moving down one more level from Animation reaches Movie C. Since it takes four steps to move from Movie A to Movie C, the semantic distance is 4. The unexpectedness measure is then calculated as the product of this distance and the dissimilarity score, capturing how far the recommendation deviates from the user’s anticipated category.
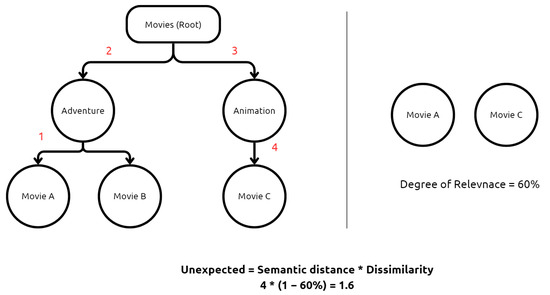
Figure 5.
An illustration of unexpectedness calculation process with a simple example.
3.3.2. Interestingness
Interestingness measures the degree to which users are recommended captivating items. Ref. [34] confirmed that leveraging sentiment analysis of user reviews enhances the quality of recommender systems, improves their performance, and assists users in making better decisions. Similarly, in our evaluation, actual rating data for each item is utilized, with ratings ranging from 0 to 5, as shown in Figure 6.
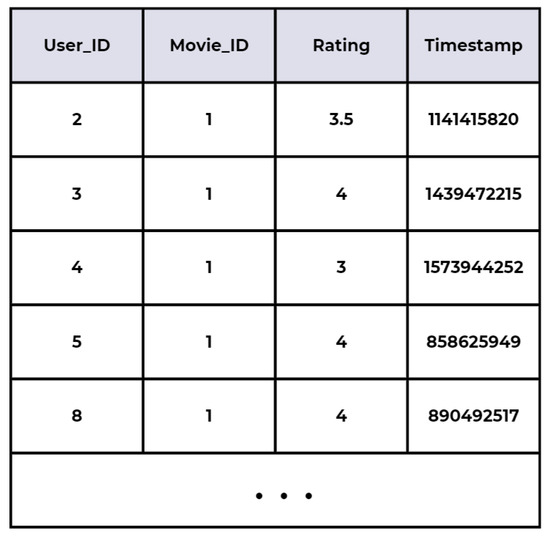
Figure 6.
Sample dataset of movie ratings (adapted from the MovieLens dataset [21]).
3.3.3. Diversity
Diversity is an evaluation of the variety of recommended items within a recommendation list. To assess this, we calculate the proportion of unique items that have been used as recommendations out of the total item pool, meaning we calculated all possible recommendation scenarios (refer to Equation (4)). In a traditional RS, certain popular items are often repetitively recommended, leading to less popular items being consistently overlooked. The diversity metric reflects the notion that the potential for a user to experience serendipity increases when a wider array of items is recommended.
4. Results
In this section, we present and analyze the experimental results obtained from both the CRS and SRS. We have evaluated and compared the CRS and SRS using two criteria: the E-QSEM numerical measurement and user feedback. The E-QSEM measurement is quite objective as it does not rely on subjective human perceptions; however, it does not guarantee a high degree of serendipity, hence the need for both criteria in evaluating the performance of CRS and SRS.
For our experiments, we randomly chose 50 movies from the MovieLens dataset [21], which comprises movie metadata and user ratings. The movies serve as the items that the CRS and SRS systems recommend in the experiments. The MovieLens dataset includes user-generated tags, which were assigned by real users as part of the dataset’s tagging system. Each tag can be applied multiple times or not at all, depending on user preferences. Users also rate movies on a 5-star scale with half-star increments ranging from 0 to 5, expressing their judgment of each film. The dataset includes 25,000,095 ratings, 1,093,360 tags, 62,423 movies, and 16,541 users.
Before conducting the experiments, we carried out preprocessing procedures on the dataset. These procedures involved selecting subsets of movies, tags (used as movie descriptors), and users. Using a vector space model, we created a vector representation for movies where movies are vectors and tags are features. Therefore, we transformed the dataset into a movie/movie matrix with cells populated according to the number of common tags assigned to a movie pair , where x and y represent movies.
4.1. E-QSEM Measurement
Table 3 shows the E-QSEM outcomes for both the CRS and SRS. The E-QSEM values are determined following the standard formula outlined in Equation (5). As seen in the table, the E-QSEM score of the SRS surpasses that of the CRS, showing its superior performance. Interestingly, while there is only a marginal shift in the level of interest, there are notable advancements in the areas of diversity and unexpectedness. These enhancements contribute significantly to the efficiency of serendipitous recommendations. The SRS exhibits an impressive diversity level of approximately 42.6%. This indicates that the suggestions produced encompass a wide variety of items. The key factor contributing to the filter bubble issue is the limited exposure users have to content outside their usual preferences or viewpoints. The diversity level of 96.4% in the SRS suggests that it significantly broadens the range of content presented to users. By integrating a wide variety of items into its suggestions, the SRS ensures users are not confined to their echo chambers but are instead exposed to new, diverse, and potentially challenging ideas and perspectives. In addition, about 30% of the items recommended by the SRS are unexpected, thereby surprising users with novel and exciting choices. In terms of the E-QSEM metric, there is a substantial increase of 84.66% in the performance of SRS when compared to CRS. This further underscores the strength of SRS in generating diverse and unexpected recommendations.
Table 3.
E-QSEM results of the CRS and SRS.
4.2. User Feedback
The study involved a total of 10 participants, consisting of 7 males and 3 females. Each participant was given a USD 10 gift card as a token of appreciation for their participation. Based on the guidance from [35], which suggests that comparative studies having a group size ranging from 8 to 25 participants typically yield valid results, with 10–12 participants serving as a solid baseline, we chose to use 10 participants for our comparative study to ensure the validity and reliability of our findings. The age range of the participants was between 22 and 27 years old. All participants possessed average computer skills and utilized the internet on a daily or near-daily basis.
The experiment proceeded in the following sequence:
- The recommendation system for use was explained to each participant.
- The participant was then asked to explore the assigned system, with no time constraints imposed.
- Upon completion of the task, the participant responded to a set of questions, as indicated in Table 4, for each item recommended.
Table 4. Questions for recommended items.
- The same steps were repeated for each recommendation system.
In an effort to eliminate any potential influence from the order of use, each participant interacted with the CRS and SRS in a varied sequence.
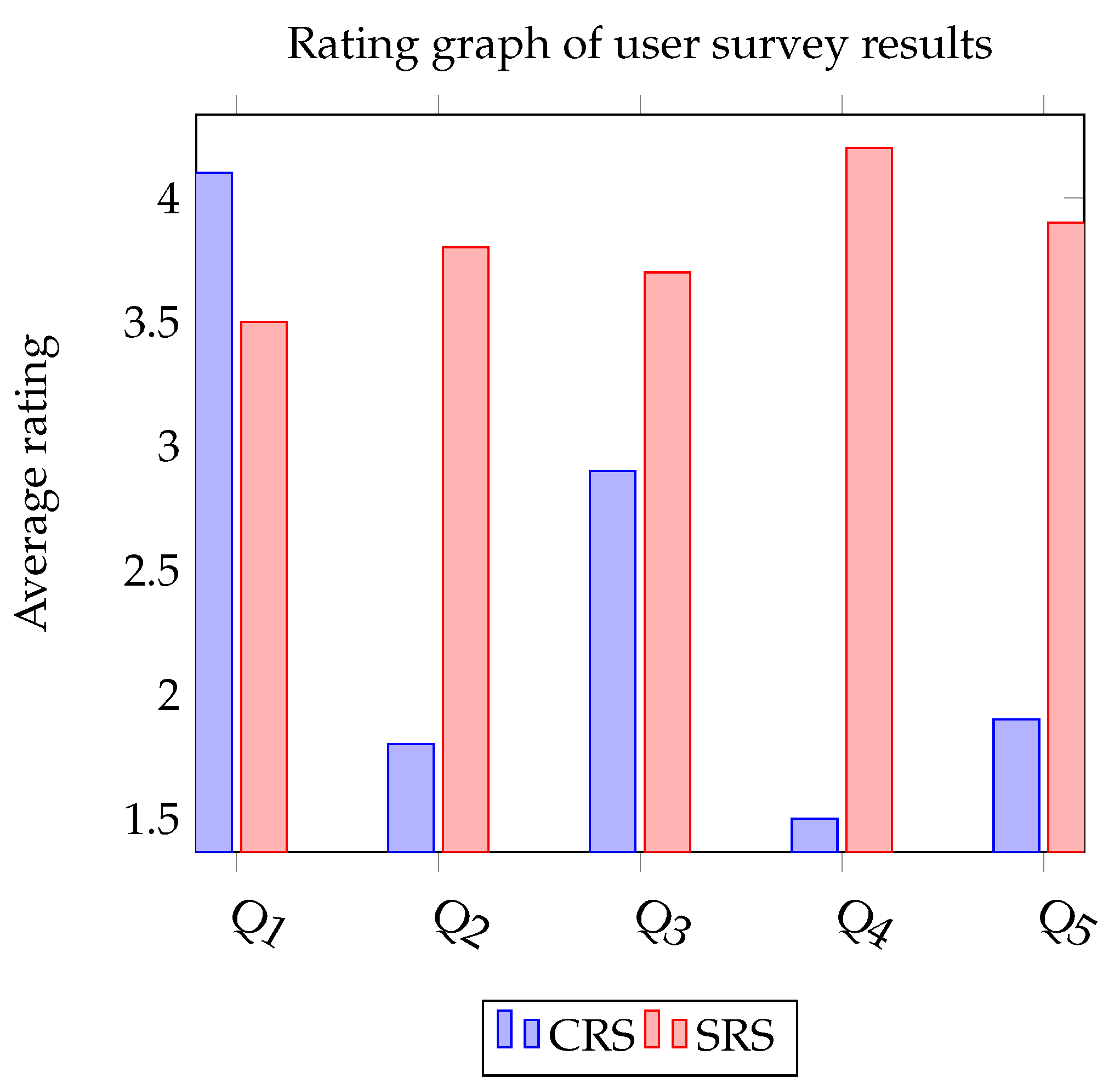
Table 4 presents a series of questions pertaining to the recommendation items (RIs). Participants responded to questions Q1 through Q5 using a five-point scale, where 5 signifies ‘strongly agree’, 4 represents ‘agree’, 3 stands for ‘neither agree nor disagree’, 2 means ‘disagree’, and 1 indicates ‘strongly disagree’. We found that the subjective measure of serendipity for the SRS, as per question ‘Q4’, significantly outperformed its predecessor, the CRS.
Figure 7 illustrates the collective results of participants’ responses to questions Q1–Q5 from Table 4 regarding RIs. It showcases the average ratings for each recommendation system. The SRS, when selecting RIs, successfully improved user satisfaction while mitigating the risk of straying from the user’s interests, by striking a balance between relevance and incorporating serendipity factors. Additionally, by broadening the range of RIs, the SRS addressed the issue of decreased user satisfaction caused by the similarity of items in the recommendation list. In general, it was found that the SRS, which proposes a diverse selection of unexpected items rather than restricting recommendations, captivated users’ attention more than the CRS.
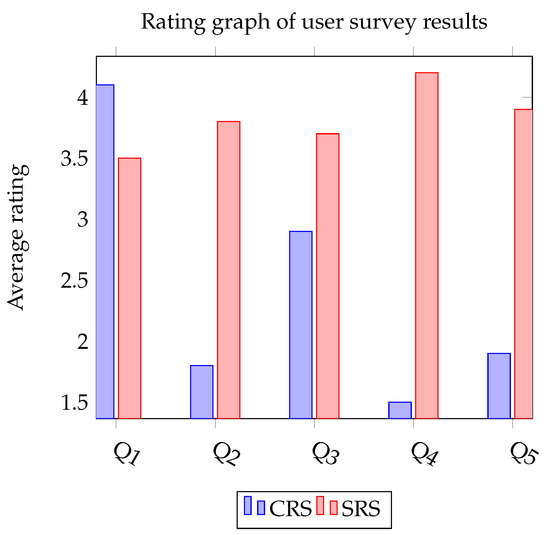
Figure 7.
Comparison of Average Ratings for CRS and SRS in User Survey Responses.
5. Conclusions
In this research, we proposed a serendipity-incorporated recommender system. Generally, an RS prioritizes accuracy, resulting in a ‘filter bubble’ issue that tends to restrict users to a specific perspective. That is, it recommends items based on similarity to the user’s previous choices, without diverging significantly from the user’s viewpoint. This restricts users to predictable recommendations, which can lead to decreased satisfaction. To address these issues, we incorporated the concept of serendipity into an RS, yielding positive feedback from real users in our experiment. Thus, we have shown that serendipity can be effectively incorporated into the RS design.
While we directly compared the SRS with CRS, evidence suggests that the SRS could also outshine other recommendation strategies, such as collaborative filtering, hybrid filtering, and multi-criteria filtering, for several compelling reasons. CF typically relies on user–item interactions to generate recommendations, which can sometimes lead to echo chambers or filter bubbles [36].
The SRS, by design, aims to introduce serendipity by recommending items that are not only relevant but also unexpected. This approach can potentially break the cycle of repetitive recommendations by fostering a discovery-oriented user experience, something that collaborative filtering might not consistently achieve due to its reliance on past interactions. Hybrid systems combine content-based filtering and collaborative filtering to leverage the strengths of both. However, the integration often focuses on optimizing existing preference patterns without necessarily introducing novelty or serendipity [37].
The SRS inherently seeks to blend the unexpected with the relevant, offering a unique advantage over traditional hybrid systems by ensuring that users are exposed to a broader spectrum of content, thereby enhancing discovery and engagement. While multi-criteria filtering evaluates items based on various attributes, it may not always prioritize the element of surprise or new discovery [38]. The SRS, however, specifically targets the serendipitous discovery of content, ensuring that recommendations include items that users might find surprisingly pleasing, thus addressing user needs and preferences that multi-criteria filtering may overlook. The SRS’s focus on delivering a diverse selection of unexpected items has been particularly effective in capturing users’ attention more than the conventional content-based approach. This is attributed to the system’s ability to introduce users to content they might not have found on their own, thereby enriching their experience and potentially broadening their interests. The serendipitous nature of the SRS not only enhances user engagement by providing novel and intriguing recommendations but also promotes a more dynamic and exploratory interaction with the content. Such attributes suggest the SRS’s superior capability in fostering a more satisfying and engaging user experience compared to traditional methods like collaborative filtering, hybrid, and multi-criteria filtering, by prioritizing the joy of discovery and the value of unexpected relevance.
The SRS, a unique variant of RS proposed in this paper, holds a promise for application in online stores. This is particularly relevant given that, for example, Amazon attributes 35% of its sales to its recommendation engine, while Netflix’s movie rentals are 66% driven by suggestions [16]. Here, when a user selects an item for purchase, the RS typically suggests similar or nearly identical items. However, these are mostly items that the user already plans to check, knows, or has encountered, offering little assistance in boosting sales. Introducing unexpected items via the SRS could encourage the purchase of these new items. User attitudes towards recommendation systems are diverse. While some users appreciate the novelty of the SRS, others may prefer the accuracy-focused traditional RS. Hence, an adaptable system that adjusts the level of serendipity based on user response could be highly effective.
The proposed approach is novel in two ways. Firstly, we designed the SRS based on elements previously shown to induce serendipity in hypertext [6], building our algorithm on proven elements rather than assumptions. While previous research has mainly focused on tuning existing elements of recommendation systems proportionally to induce serendipity, we, on the other hand, initially conducted research on factors that promote serendipity. Based on the factors that have been empirically confirmed to induce serendipity, we subsequently developed a new algorithm. Secondly, we evaluated an RS using both user surveys and E-QSEM, whereas previous studies predominantly relied on user surveys. This study demonstrates that an RS can also be assessed using a computational approach.
In the future, we plan to discern the impact and interplay of various serendipity-inducing factors within an RS. While it has been established that serendipity plays a beneficial role in an RS, fine-tuning is required to integrate serendipitous elements without undermining inherent relevance and similarity aspects. Through E-QSEM, which allows for precise manual adjustment of each element, we are positioned to identify an optimal combination of factors, noting that while the system currently does not feature automatic adjustments, it is designed with the potential for future automation in mind. This will allow us to develop a balanced RS that maintains the core attributes of both an RS and serendipity. In addition, the paper presents a research limitation and future direction in exploring methods to measure and enhance user satisfaction beyond the initial positive feedback received from the experiment.
6. Limitations
While our study provides valuable insights into the effectiveness of SRS compared to conventional recommendation strategies CRS, we acknowledge certain limitations that should be considered when interpreting the results.
6.1. Dependence on the Dataset
One major limitation of our study is its reliance on the MovieLens dataset [21]. While this dataset is widely used in recommendation system research due to its rich metadata and user-generated tags, it does not fully represent the diversity of real-world recommendation environments. Our approach, which utilizes tag-based vector representations for measuring dissimilarity and unexpectedness, may yield different results when applied to datasets with different tagging structures, metadata richness, or user engagement levels.
Future work should explore the applicability of our serendipity-aware filtering approach on alternative datasets, such as those from real-world e-commerce platforms, news recommendation systems, or music streaming services. A comparative analysis using datasets with varying levels of metadata completeness and user interaction would allow for a more generalized validation of our method.
6.2. Sampling and Preprocessing Limitations
Our experiments involved selecting 50 movies randomly from the MovieLens dataset to construct recommendation lists. While random sampling ensures a fair representation of the dataset, it may not fully capture edge cases or niche recommendation scenarios. Furthermore, our preprocessing approach—transforming the dataset into a movie/movie similarity matrix based on tag overlap—relies on the assumption that tag-based feature vectors adequately capture item relationships. However, this assumption may not hold in all contexts, particularly in domains where explicit user-generated tags are sparse or inconsistently applied.
To address these limitations, future studies could investigate alternative feature extraction methods, such as natural language processing (NLP) techniques applied to movie descriptions or graph-based representations of user–item interactions. Additionally, exploring different similarity metrics beyond tag-based frequency counting, such as embedding-based similarity measures (e.g., Word2Vec, BERT embeddings, or collaborative filtering latent factors), could improve the robustness of the method.
6.3. Impact of Sample Size in User Evaluation
Our user study involved 10 participants (7 males, 3 females), which falls within the range of valid sample sizes for comparative usability studies [35]. However, for evaluating recommender system performance, a larger and more diverse sample would provide greater statistical reliability. The results obtained from our user feedback survey may be influenced by individual user preferences and biases, making it difficult to generalize the findings to a broader audience.
To mitigate this limitation, future research should consider conducting large-scale user experiments, ideally involving hundreds or thousands of participants from diverse demographic backgrounds. Additionally, longitudinal studies, where users interact with the recommendation system over an extended period, could provide deeper insights into user adaptation, long-term engagement, and potential shifts in preference patterns.
Despite these limitations, our findings highlight the potential of structured serendipity-aware filtering in breaking filter bubbles and enhancing recommendation diversity. By addressing these limitations in future studies, we can further refine our approach and ensure its applicability across various real-world recommender systems.
Author Contributions
Conceptualization, Y.K. and S.P.; methodology, Y.K. and S.P.; validation, Y.K., S.O., C.N., E.H. and S.P.; writing—original draft preparation, Y.K.; writing—review and editing, S.O., C.N., E.H. and S.P.; supervision, S.P. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
Publicly available datasets were analyzed in this study. The data can be found here: https://grouplens.org/datasets/movielens/. The E-QSEM program can be found here: https://github.com/KimYuri94/SerendipityEvaluationModel/tree/foRecommSys, accessed on 30 September 2022. The detailed instructions for how to compile and run the program are provided in a PDF file: https://github.com/KimYuri94/SerendipityEvaluationModel/blob/foRecommSys/ProgramManualRS.pdf (accessed on 18 February 2025).
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| SRS | Serendipity-integrated Recommender System |
| QSEM | Quantitative Serendipity Evaluation Model |
| CRS | Cold-start Recommender System |
| RS | Recommender System |
| E-QSEM | Expanded Quantitative Serendipity Evaluation Model |
| SI | Selected Item |
| RI | Recommended Item |
References
- Jenders, M.; Lindhauer, T.; Kasneci, G.; Krestel, R.; Naumann, F. A Serendipity Model for News Recommendation. In KI 2015: Advances in Artificial Intelligence, Proceedings of the 38th Annual German Conference on AI, Dresden, Germany, 21–25 September 2015; Proceedings 38; Springer International Publishing: Berlin/Heidelberg, Germany, 2015; pp. 111–123. [Google Scholar] [CrossRef]
- Shi, C.; Lakafosis, V.; Ammar, M.H.; Zegura, E.W. Serendipity: A Distributed Computing Platform for Disruption Tolerant Networks; Georgia Institute of Technology: Atlanta, GA, USA, 2011. [Google Scholar]
- Maccatrozzo, V. Burst the Filter Bubble: Using Semantic Web to Enable Serendipity. Lect. Notes Comput. Sci. 2012, 7650, 391–398. [Google Scholar] [CrossRef]
- Campos, J.; Figueiredo, A.D.D. Searching the Unsearchable: Inducing Serendipitous Insights. In Proceedings of the Workshop Program at the Fourth International Conference on Case-Based Reasoning, ICCBR, Vancouver, BC, Canada, 30 July–2 August 2001. [Google Scholar]
- Corneli, J.; Pease, A.; Colton, S.; Jordanous, A.; Guckelsberger, C. Modelling serendipity in a computational context. arXiv 2014, arXiv:1411.0440. [Google Scholar]
- Kim, Y.; Han, B.; Kim, J.; Song, J.; Kang, S.; Park, S. A Quantitative Model to Evaluate Serendipity in Hypertext. Electronics 2021, 10, 1678. [Google Scholar] [CrossRef]
- Kotkov, D.; Wang, S.; Veijalainen, J. A Survey of Serendipity in Recommender Systems. Knowl.-Based Syst. 2016, 111, 180–192. [Google Scholar] [CrossRef]
- Kaminskas, M.; Bridge, D. Diversity, Serendipity, Novelty, and Coverage: A Survey and Empirical Analysis of Beyond-Accuracy Objectives in Recommender Systems. ACM Trans. Interact. Intell. Syst. 2016, 7, 42. [Google Scholar] [CrossRef]
- Silva, A.M.; da Silva Costa, F.H.; Diaz, A.K.R.; Peres, S.M. Exploring coclustering for serendipity improvement in content-based recommendation. In Intelligent Data Engineering and Automated Learning–IDEAL 2018, Proceedings of the 19th International Conference, Madrid, Spain, 21–23 November 2018; Proceedings, Part I 19; Springer International Publishing: Berlin/Heidelberg, Germany, 2018. [Google Scholar] [CrossRef]
- Pardos, Z.A.; Jiang, W. Combating the Filter Bubble: Designing for Serendipity in a University Course Recommendation System. arXiv 2019, arXiv:1907.01591. [Google Scholar]
- Oku, K.; Hattori, F. Fusion-based recommender system for improving serendipity. Ceur Workshop Proc. 2011, 816, 19–26. [Google Scholar]
- Chen, X. Exploring Consumers’ Serendipitous Experiences in Online Marketplaces: Characteristics, Development Route and Factors Influencing It. Ph.D. Thesis, The University of Sheffield, Sheffield, UK, 2023. [Google Scholar]
- Afridi, A.H.; Olsson, T. Review of User Interface-Facilitated Serendipity in Recommender Systems. Int. J. Interact. Commun. Syst. Technol. 2023, 12, 1–19. [Google Scholar] [CrossRef]
- Smets, A.; Michiels, L.; Bogers, T.; Björneborn, L. Serendipity in recommender systems beyond the algorithm: A feature repository and experimental design. In Proceedings of the 9th Joint Workshop on Interfaces and Human Decision Making for Recommender Systems (IntRS’22), Co-Located with 16th ACM Conference on Recommender Systems (RecSys 2022), Seattle, WA, USA, 18–23 September 2022; ACM Press: New York, NY, USA, 2022; pp. 46–66. Available online: http://ceur-ws.org/Vol-3222/paper4.pdf (accessed on 18 February 2025).
- Duricic, T.; Kowald, D.; Lacic, E.; Lex, E. Beyond-accuracy: A review on diversity, serendipity, and fairness in recommender systems based on graph neural networks. Front. Big Data 2023, 6, 1251072. [Google Scholar] [CrossRef] [PubMed]
- Ziarani, R.J.; Ravanmehr, R. Deep neural network approach for a serendipity-oriented recommendation system. Expert Syst. Appl. 2021, 185, 115660. [Google Scholar] [CrossRef]
- Pariser, E. The Filter Bubble: What the Internet Is Hiding from You; Penguin: London, UK, 2011. [Google Scholar]
- Nguyen, T.T.; Hui, P.M.; Harper, F.M.; Terveen, L.; Konstan, J.A. Exploring the filter bubble: The effect of using recommender systems on content diversity. In Proceedings of the 23rd International Conference on World Wide Web, Seoul, Republic of Korea, 7–11 April 2014. [Google Scholar]
- Wang, W.; Feng, F.; Nie, L.; Chua, T.-S. User-controllable Recommendation Against Filter Bubbles. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’22), Madrid, Spain, 11–15 July 2022; ACM: New York, NY, USA, 2022; pp. 1251–1261. [Google Scholar] [CrossRef]
- Sun, N. Overview of definition, evaluation, and algorithms of serendipity in recommender systems. Appl. Comput. Eng. 2023, 6, 565–571. [Google Scholar] [CrossRef]
- Harper, F.M.; Konstan, J.A. The MovieLens Datasets: History and Context. Acm Trans. Interact. Intell. Syst. (TiiS) 2015, 4, 19. [Google Scholar] [CrossRef]
- IBM. Available online: https://www.ibm.com/think/topics/content-based-filtering (accessed on 18 February 2025).
- Nassar, N.; Jafar, A.; Rahhal, Y. Multi-criteria collaborative filtering recommender by fusing deep neural network and matrix factorization. J. Big Data 2020, 7, 34. [Google Scholar] [CrossRef]
- Kotkov, D.; Konstan, J.A.; Zhao, Q.; Veijalainen, J. Investigating serendipity in recommender systems based on real user feedback. In Proceedings of the 33rd Annual ACM Symposium on Applied Computing (SAC ’18), Pau, France, 9–13 April 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 1341–1350. [Google Scholar] [CrossRef]
- Reviglio, U. Serendipity as a Design Principle of Personalization Systems—Theoretical Distinctions. In Serendipity Science: An Emerging Field and Its Method; Springer International Publishing: Cham, Switzerland, 2023. [Google Scholar] [CrossRef]
- Kotkov, D.; Veijalainen, J.; Wang, S. How does serendipity affect diversity in recommender systems? A serendipity-oriented greedy algorithm. Computing 2020, 102, 393–411. [Google Scholar] [CrossRef]
- Knuth, D.E. The Art of Computer Programming, Volume 3: Sorting and Searching*; Addison-Wesley: Boston, MA, USA, 1998. [Google Scholar]
- Shani, G.; Heckerman, D.; Brafman, R.I. An MDP-based recommender system. J. Mach. Learn. Res. 2005, 6, 1265–1295. [Google Scholar]
- Aggarwal, C.C. Recommender Systems: The Textbook; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Pavlovski, M.; Ravindran, S.; Gligorijevic, D.; Agrawal, S.; Stojkovic, I.; Segura-Nunez, N.; Gligorijevic, J. Extreme Multi-Label Classification for Ad Targeting using Factorization Machines. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD ’23), Long Beach, CA, USA, 6–10 August 2023; Association for Computing Machinery: New York, NY, USA, 2023; pp. 4705–4716. [Google Scholar] [CrossRef]
- Guesmi, M.; Chatti, M.A.; Joarder, S.; Ain, Q.U.; Siepmann, C.; Ghanbarzadeh, H.; Alatrash, R. Justification vs. Transparency: Why and How Visual Explanations in a Scientific Literature Recommender System. Information 2023, 14, 401. [Google Scholar] [CrossRef]
- Hertz, A.; Kuflik, T.; Tuval, N. Estimating serendipity in content-based recommender systems. 2023; 1–18, Preprints. [Google Scholar] [CrossRef]
- Inoue, S.; Ayedoun, E.; Takenouchi, H.; Tokumaru, M. Leveraging Interactive Evolutionary Computation to Induce Serendipity in Informal Learning. Multimodal Technol. Interact. 2024, 8, 103. [Google Scholar] [CrossRef]
- Al-Ajlan, A.; Alshareef, N. Recommender System for Arabic Content Using Sentiment Analysis of User Reviews. Electronics 2023, 12, 2785. [Google Scholar] [CrossRef]
- Macefield, R. How to specify the participant group size for usability studies: A practitioner’s guide. J. Usability Stud. 2009, 5, 34–45. [Google Scholar]
- Abdollahi, B.; Nasraoui, O. Explainable Matrix Factorization for Collaborative Filtering. In Proceedings of the 25th International Conference Companion on World Wide Web (WWW ’16 Companion), Montreal, QC, Canada, 11–15 April 2016; International World Wide Web Conferences Steering Committee: Geneva, Switzerland, 2016; pp. 5–6. [Google Scholar] [CrossRef]
- Burke, R. Hybrid Recommender Systems: Survey and Experiments. User Model.-User-Adapt. Interact. 2002, 12, 331–370. [Google Scholar] [CrossRef]
- Manouselis, N.; Costopoulou, C. Analysis and Classification of Multi-Criteria Recommender Systems. World Wide Web 2007, 10, 415–441. [Google Scholar] [CrossRef]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).