Abstract
The accurate and efficient detection of steel surface defects remains challenging due to complex backgrounds, diverse defect types, and varying defect scales. The existing CNN-based methods often struggle with capturing long-range dependencies and handling complex background noise, resulting in suboptimal performance. Meanwhile, although Transformer-based approaches are effective in modeling global context, they typically require large-scale datasets and are computationally expensive, limiting their practicality for industrial applications. To address these challenges, we introduce a novel attention-based salient object detector, called the ASOD, to enhance the effectiveness of detectors for strip steel surface defects. In particular, we first design a novel channel-attention-based block including global max/average pooling to focus on the relevant channel-wise features while suppressing irrelevant channel responses, where maximizing pooling extracts the main features of local regions, while removing irrelevant features and average pooling obtain the overall features while removing local details. Then, a new block based on spatial attention is designed to emphasize the area with strip steel surface defects while suppressing irrelevant background areas. In addition, a new cross-spatial-attention-based block is designed to fuse the feature maps with multiple scales filtered through the proposed channel and spatial attention to produce features with better semantic and spatial information such that the detector adapts to strip steel defects of multiple sizes. The experiments show that the ASOD achieves superior performance across multiple evaluation metrics, with a weighted F-measure of 0.9559, an structure measure of 0.9230, a Pratt’s figure of meri of 0.0113, and an mean absolute error of 0.0144. In addition, the ASOD demonstrates strong robustness to noise interference, maintaining consistently high performance even with 10–20% dataset noise, which confirms its stability and reliability.
1. Introduction
As an important metal raw material, strip steel has extensive applications in industrial domains, including automobile manufacturing, aircraft production, and power equipment. However, many factors, including unstable temperatures, environmental factors, and raw material quality during processing, may lead to various defects with different scales, such as scratches, cracks, and inclusions [1], which affect the quality of the appearance, functional performance, and service life of strip steel products. Designing an accurate and efficient model with strong strip steel surface defect feature extraction capabilities is crucial to ensure product quality and safety.
The attention mechanism is one of the most often used methods for extracting feature maps with rich semantic and spatial information by highlighting defect features and suppressing noise interference. Many attention-based approaches have been proposed. These approaches can be roughly grouped into the following two categories: channel-attention-based and spatial-attention-based methods. Channel-attention-based methods attempt to learn the weight of each channel of feature maps to enhance relevant channels or suppress irrelevant channels, thereby improving the performance of the model [2,3,4,5]. For instance, Li et al. [2] developed a network with a designed multiscale channel-attention module for finding dense contextual information of brain stroke lesions and extracted the corresponding features with inconsistent semantics and scales. Shen et al. [3] used a channel-attention module to adaptively enhance or attenuate supervision at different scales and adopted multiscale feature fusion in supervised signal detection to enhance feature representation. Hu et al. [4] proposed a new end-to-end tooth segmentation network with a channel-attention mechanism to handle the multilevel feature aggregation part of the network to segment 3D teeth in real scenes. Chen et al. [5] introduced a Parallel Dual-Channel Attention Network (PDCA-Net) for polyp segmentation in colonoscopy images, achieving state-of-the-art performance by leveraging global dependencies. In this work, we attempt to take advantage of the merits of channel attention and design a new channel-attention-based block to adaptively adjust the channel-wise output and emphasize the relevant channels, thus improving the performance of the model on the surface of strip steel.
Spatial-attention-based methods are designed to focus on foreground areas while suppressing background parts, thus enhancing the performance of detectors [6,7,8,9]. For example, Qian et al. [6] used spatial–temporal attention and frequency domain transforms to enhance multivariate time series classification. Hou et al. [7] proposed a new neural network model that utilizes contextual information and spatial-attention mechanisms to encode spatial long-range dependencies and extract semantic information with rich context to improve the recognition performance of small defects. Fu et al. [8] proposed attention to guide the balance of multiple features at different levels to help detectors understand more information about small ships in complex scenes. Li et al. [9] designed a convolutional block attention module to enhance the network’s ability to acquire information for detecting strip steel surface defects. Therefore, we attempt to design a new spatial-attention-based block to concentrate on the spatial information so that the model can adaptively select the most relevant defect regions in the feature map.
As a special spatial-attention mechanism, self-attention is implemented to consider the spatial relationship between each pixel/token and all the other pixels/tokens for generating effective feature representations. Many self-attention-based neural networks, called Transformers, have been proposed. For example, Park et al. [10] proposed an improved Vision Transformer (ViT) that uses a self-attention mechanism to capture both local features and global location information in images. Yu et al. [11] designed a Transformer with a time convolutional network, which uses self-attention to extract features and draws long-term correlations in the sequence, helping air traffic management personnel to identify the operational status of the terminal area. Extensive studies indicate that self-attention-based networks have better feature extraction capabilities than convolution-based neural networks [12,13,14,15]. Therefore, we adopt a self-attention-based mechanism to extract multiscale features and capture long-range dependencies in strip steel surface defects.
Based on the discussion above, we extensively use attention mechanisms and propose a novel attention-based salient object detector (ASOD) for strip steel surface defects. In particular, the ASOD uses a Transformer to extract the multiscale feature maps with global relationships between pixels/tokens from the strip steel image. Then, the ASOD employs the proposed channel-attention-based block (CAB) and the spatial-attention-based block (SAB) to capture detailed information on surface defects of strip steel. The SAB extracts features of local areas with strip steel surface defects while suppressing irrelevant background areas, whereas the CAB focuses on relevant channel-wise features while suppressing irrelevant channel responses. In addition, the CAB utilizes global max pooling to isolate the dominant features within each channel and average pooling to extract comprehensive feature representations by eliminating channel-specific details. Finally, a cross-spatial-attention-based block (CSAB) is proposed to fuse feature maps with multiple scales filtered by the SAB and CAB so that the detector can adapt to discern strip steel defects with multiple sizes.
2. Related Works
2.1. Attention Mechanism
The concept of attention mechanisms was inspired by the human brain, where individuals tend to focus selectively on the most important information for a given task while ignoring irrelevant details [16,17]. Recently, numerous researchers have proposed methods based on attention mechanisms, such as channel attention and spatial attention, to enhance salient object detection tasks and achieve impressive results. These methods dynamically adjust the weights of different features to strengthen relevant channels and suppress irrelevant ones. For example, Hu et al. [18] proposed a squeeze-and-excitation module (SE) that uses global average pooling to extract internal features and calculate the weight of each feature through linear combination and nonlinear activation, enhancing channel-level attention and feature expression abilities. Zhao et al. [19] proposed the DTL-SEResNet50 model, which is pretrained using the SE and large-scale image dataset, to improve the automatic identification performance of plant diseases. Li et al. [20] fused the attention mechanism with the pyramid structure to boost the performance of the image segmentation model and simplify its network architecture. Huang et al. [21] proposed a novel attention mechanism in their research to capture contextual information in image segmentation tasks while reducing the complexity needed to compute semantic information. Jin et al. [22] proposed an efficient residual channel soft threshold attention mechanism algorithm (ERCA), which reduces background noise in complex environments by deep learning adaptive soft thresholds and improves the feature learning ability of deep learning in landslide recognition object detection tasks.
Self-attention, which is a special spatial-attention mechanism, can be implemented to obtain spatial relationships between long-distance features. Many neural networks based on self-attention, called Transformers, have been successfully applied to various computer vision tasks. For example, Dosovitskiy et al. [14] introduced a VIT model that splits input images into multiple patches, solving the input problem of a Transformer in the image field. Zheng et al. [23] proposed a semantic segmentation network that adopts a VIT-like encoder structure to extract multiscale feature maps and then uses a multistage feature fusion module (decoder) for pixelwise image segmentation. Bao et al. [24] proposed a new network called ATC Net based on a two-branch architecture to aggregate Transformers and CNNs. The problem existing in the Transformer is that it requires a significant amount of learning time to train its parameters. To address these problems, researchers have proposed many new networks, including the Swin Transformer [25], TNT [26], and MViT [27]. The Swin Transformer [25] significantly improves efficiency by limiting self-attention computations to non-overlapping local windows. TNT [26] partitions the input image into multiple local blocks and performs attention operations on these blocks. MViT [27] partitions images into blocks and performs self-attention operations within and between blocks, which helps to improve image processing capabilities.
2.2. Salient Object Detection Methods
Salient object detection is conducted to detect and segment the most prominent objects in images, which is an important preprocessing procedure in computer vision. Numerous deep-learning-based approaches for detecting salient objects have been proposed, with Convolutional Neural Network (CNN)-based and Transformer-based approaches being the two most often used.
- CNN-based methods: In these methods, a deep neural network consisting of convolutional layers, pooling layers, and fully connected layers in an end-to-end manner is trained on large amounts of labelled image data to extract foreground feature representations from images. For instance, Yuan et al. [28] introduced a CNN–Transformer Iterative Fusion Network(CTIF-Net) that combines complementary strengths of CNNs and Transformer for superior salient object detection. Zhu et al. [29] developed a boundary connectivity approach and incorporated it into a salient optimization structure. Huang et al. [30] employed a multiple instance learning (MIL) framework in their study to assess the significance score of each superpixel. Bi et al. [31] employed a novel RGB-T salient object detection framework with a feature enhancement module for improved feature representation. Wei et al. [32] designed a selective fusion strategy that can selectively combine multiscale features to avoid the accumulation of redundant information. Yang et al. [33] proposed a fully convolutional texture surface defect detection method based on multiscale feature clustering. In addition, CNN-based methods have achieved great success in salient object detection tasks, but they have limitations in capturing the global information of images.
- Transformer-based methods: Numerous recent studies have demonstrated that using a Transformer in salient object detection can also provide good results. Transformer-based methods usually consist of constructing models that detect salient regions in images through self-attention mechanisms and multihead attention mechanisms. These methods can capture global contextual information and have advantages in handling long-distance dependencies. For example, Carion et al. [34] proposed a DETR Transformer encoder–decoder architecture for object detection problems. To perform salient object detection, CNNs and Transformers are effectively used to extract local spatial details and global semantic information and fuse them into the final high-quality salient map. Liu et al. [35] proposed a triplet Transformer embedding module to enhance cross-layer dependencies by learning long-distance relationships. Although Transformers can extract the global contextual information of an image, they cannot obtain local spatial information and relationships between the channels in images.
In this paper, we propose a Transformer-based salient object detection method, called the ASOD, for strip steel surface defect detection. In contrast to traditional methods, the ASOD uses spatial/channel-attention-based approaches to extract detailed information of strip steel images, where the spatial-attention-based mechanism adaptively focuses on spatial areas with defects in images and the channel-attention-based mechanism adaptively enhances (suppresses) the channel weights that are relevant (irrelevant) to the defects in the images. In addition, a residual decoder block and cross-spatial-attention-based block are proposed to fuse multiscale features and gradually restore salient information.
3. Methodology
Attention mechanisms, including channel-attention and spatial-attention mechanisms, are able to focus on important feature information by weighing different regions of an image; therefore, they are widely applied to various machine vision tasks, such as image classification [36] and semantic segmentation [37]. Self-attention mechanisms are a special spatial-attention mechanism, as discussed in Section 2.1. In this paper, we designed novel channel-attention-based blocks and spatial-attention-based blocks to obtain strip steel surface defect details and then proposed a new attention-based salient object detector (ASOD) for strip steel surface defect detection.
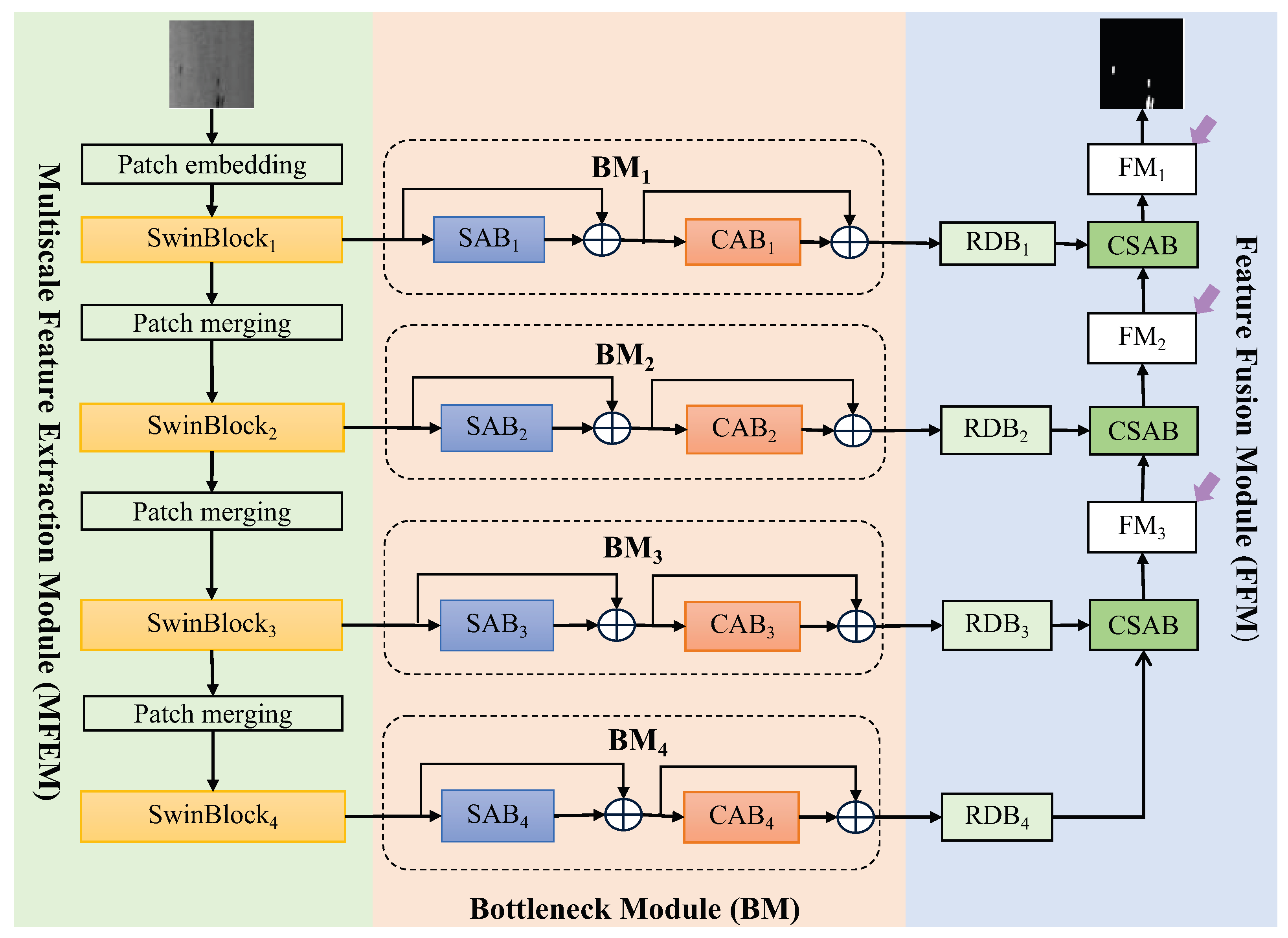
Figure 1 shows the architecture of our ASOD, which is composed of a multiscale feature extraction module (MFEM), bottleneck module (BM), and feature fusion module (FFM). The MFEM uses a self-attention-based neural network to extract multiscale feature maps with rich spatial characteristics of strip steel defects since self-attention mechanisms obtain feature representations with the global spatial relationship by considering the interactions between each pixel/token and all the other pixels/tokens. The BM is composed of spatial-attention-based blocks (SABs) and channel-attention-based blocks (CABs). SAB adaptively focuses on the spatial areas of an image, capturing locational details of strip steel surface defects. CAB adaptively adjusts the channel weights to enhance the output of the defect-related channels while suppressing the noise and background interference. The FFM employs the proposed residual decoder blocks (RDBs) to explore more potential salient information contained in feature maps filtered by the bottleneck module and uses the proposed cross-spatial-attention-based blocks (CSABs) to fuse feature maps of different scales to accommodate defects with multiple scales. More details on these modules are detailed Section 3.1, Section 3.2 and Section 3.3.
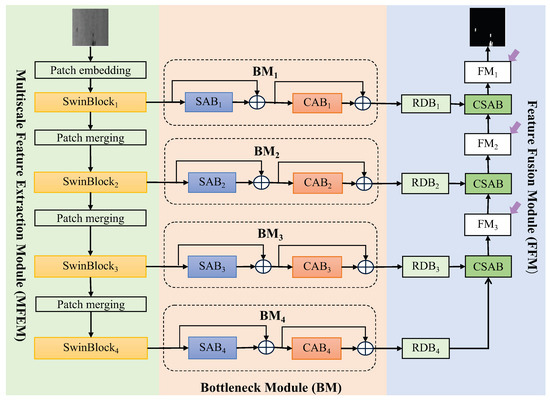
Figure 1.
The architecture of the ASOD includes a multiscale feature extraction module (MFEM), bottleneck module (BM), and a feature fusion module (FFM). The BM includes spatial-attention-based blocks (SABs) followed by channel-attention-based blocks (CABs). The FFM includes residual decoder blocks (RDBs) followed by cross-spatial-attention-based blocks (CSABs).
3.1. Multiscale Feature Extraction Module
In detection tasks, many approaches have been proposed to extract spatial characteristics, and self-attention-based networks, including MVit [27] and the Swin Transformer [25], are among the most frequently employed methods because self-attention mechanisms excel at learning both local and long-distance interactions between elements in the input domain. In this study, we select the Swin Transformer, which is an attention-based deep neural network, for capturing defect features with multiple scales because it achieves fast training and high precision through restricting self-attention computations to local windows while enabling interactions between windows [25], as shown in Figure 1(left). Specifically, the whole self-attention-based block contains three patch merging operations and four SwinBlocks (SwinBlock1, SwinBlock2, SwinBlock3, and SwinBlock4). Given an image with a size of , the size of the feature map corresponding to SwinBlocki is . The output of the SwinBlock is input into SABi to further extract features containing contextual information of the boundary and positional information.
3.2. Bottleneck Module
Although the MFEM employs a Swin Transformer with a self-attention mechanism to extract multiscale feature maps with rich spatial characteristics of strip steel defects, as discussed in Section 3.1, it ignores the importance of channel responses for the detector on strip steel defect detection. In addition, this mechanism ignores the fact that spatial locality is the main characteristic of the image and that effectively capturing the localization characteristic is essential for the success of computer vision tasks. Therefore, the bottleneck module (BM) employs the proposed spatial-attention-based blocks (SABs) and channel-attention-based blocks (CABs) to capture local features of defect areas and focus on useful channel information for defect detection to enhance defect regions of interest on a feature map, as shown in Figure 1. We let be the input of the i-th submodule of the BM (BMi). Then, the output of BMi is as follows:
For more details on SAB and CAB, refer to Section 3.2.1 and Section 3.2.2, respectively.
3.2.1. Spatial-Attention-Based Block
The self-attention employed by MFEM focuses on the position of all points in an equal manner, ignoring the fact that the spatial locality is the main characteristic of the image, as discussed in Section 3.1. Moreover, effectively capturing the localization characteristic is essential for the success of computer vision tasks. Therefore, a novel spatial-attention-based block (SAB) is proposed to highlight the spatial locality of steel surface defects by extracting local features from feature maps of steel surface defect images.
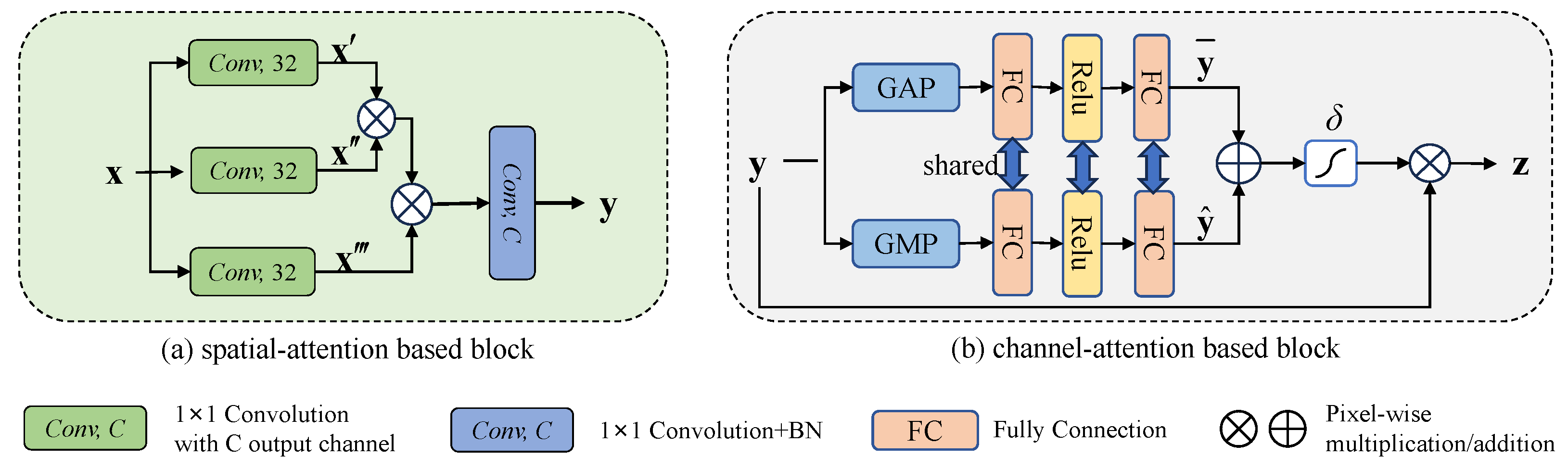
Figure 2a shows the architecture of the proposed SAB. Let x be the input with a shape of generated by the SwinBlocki of the multiscale feature extraction module, where H, W, and C denote the height, width, and channels, respectively (as shown in Section 3.1). The SAB uses three parallel convolutional operations with a kernel size equal to to reduce the dimension of x, generating three features, , , and . Then, the features between each pixel and other pixels are weighted and summed to extract local features of the strip steel image. Then, a convolutional operation with and a batch normalization operation are conducted to increase the dimension. The SAB is computed as follows:
where indicates the spatial attention coefficient.
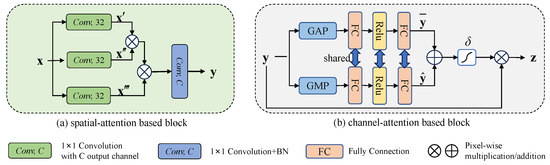
Figure 2.
The structure of the bottleneck module includes SAB and CAB.
3.2.2. Channel-Attention-Based Block
The multiscale feature maps generated by the MFEM in Section 3.1 may contain complex background information, which prevents the prominence of defect features, and the diversity of defects on the steel surface may pose challenges for the detector to detect these defects. Therefore, we design a novel channel-attention-based block (CAB) to adaptively compute the weights of the channel of multiscale feature maps to capture channel information related to defects while filtering out background noise and highlighting defect features.
Figure 2b shows the architecture of CAB. In contrast to SE blocks that only use global average pooling to extract channel information [18], both global average pooling (GAP) and global max pooling (GMP) serve to capture the overall characteristics of each channel, followed by two full connections with ReLU activation between them. Sigmoid is then employed to generate the channel attention coefficient. We let y be the input of the current channel-attention-based block. Thus, we can obtain the following:
where represents the sigmoid operation.
3.3. Feature Fusion Module
To fully fuse the feature maps with multiple scales, we propose a novel feature fusion module (FFM), including residual decoder blocks (RDBs) and cross-spatial-attention-based blocks (CSABs). RDB extracts the salient information contained in the feature maps filtered by a bottleneck module, as illustrated in Figure 3. Then, CSAB aggregates the previous multiscale features to gradually generate high-quality results, as illustrated in Figure 4. Let be the i-th layer input of the FFM. The process of the FFM is as follows:
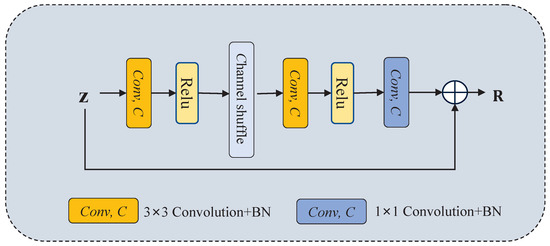
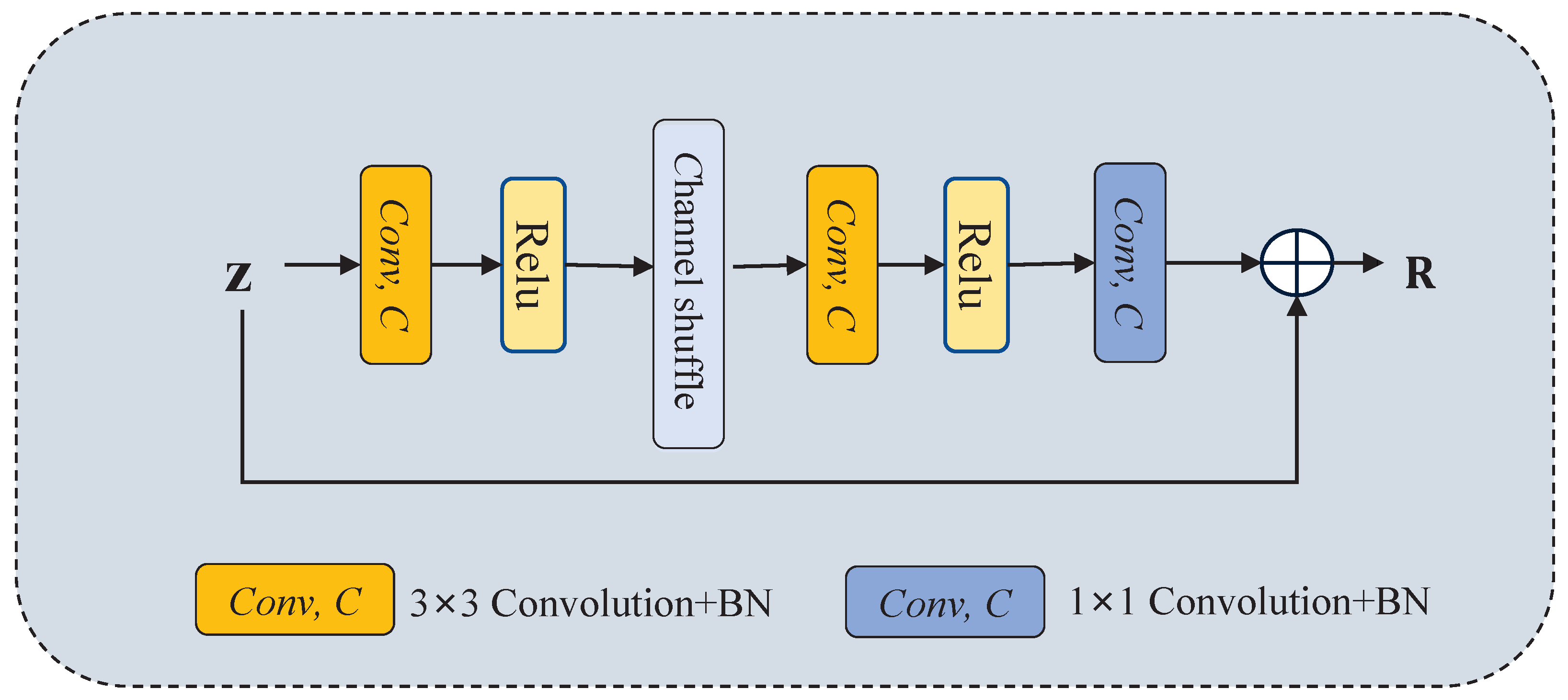
Figure 3.
The structure of RDB.
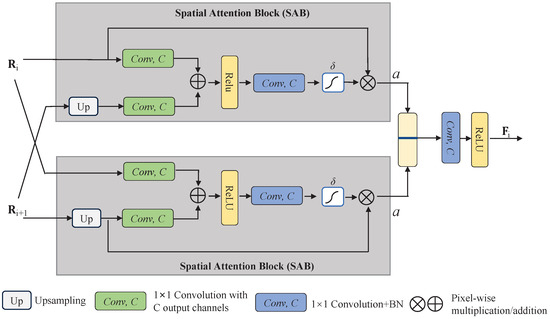
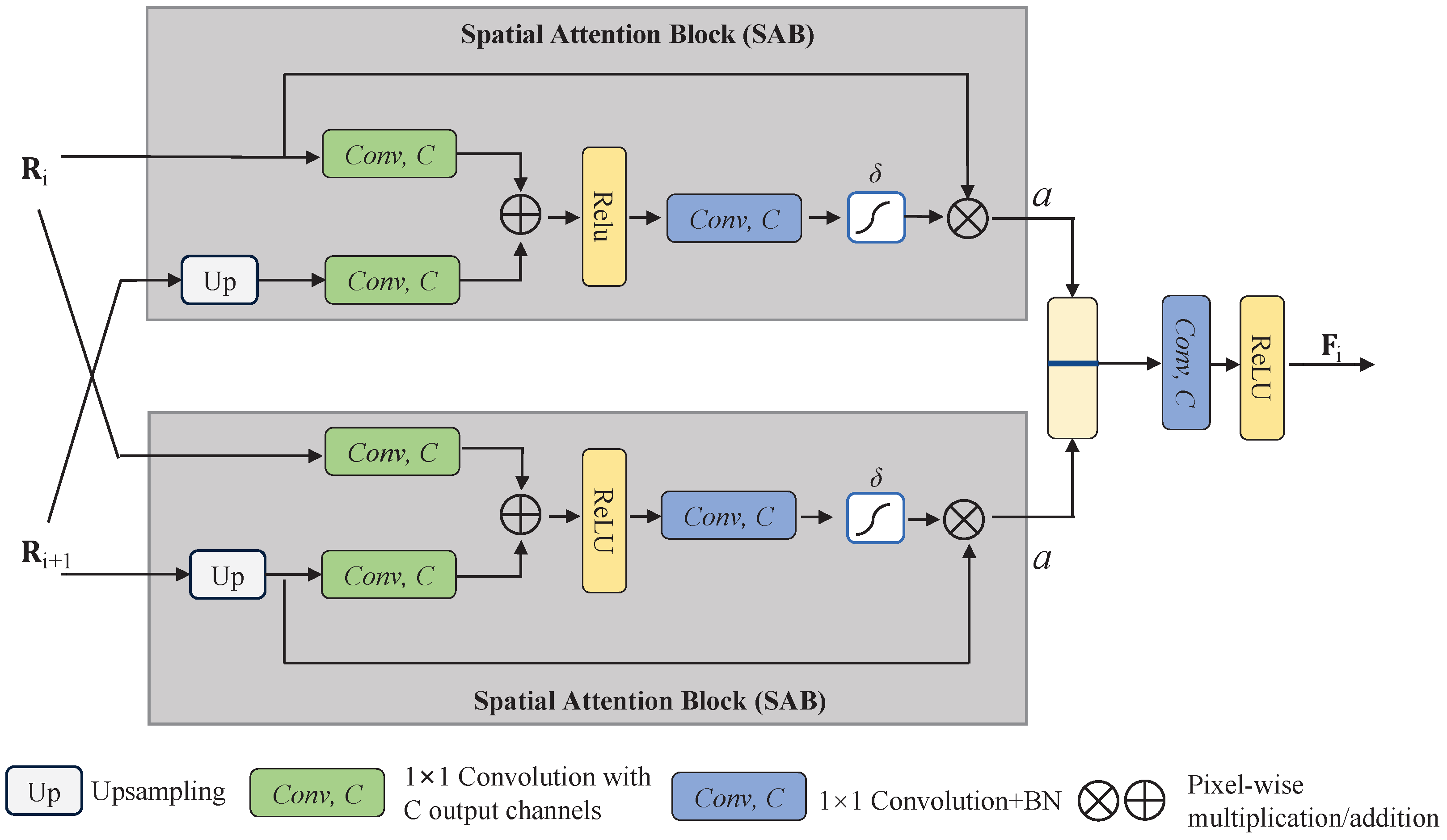
Figure 4.
The structure of CSAB includes two SABs.
To gradually restore the salient information of multiscale features filtered by the previous bottleneck module, a residual decoder block (RDB) is designed following Ref. [1], as shown in Figure 3. In contrast to the original residual basic block (RBB) of ResNet-34, the RDB uses a channel shuffle operation between two convolutions and an ReLU to explore potential salient information and thus improve the network’s generalization ability. Additionally, we add a convolutional operation to increase the information interaction between the channels. In this way, the RDB achieves the goal of obtaining high-speed training while capturing potential salient features of the image. Given the input feature map z, the RDB is computed as
where is the convolution with a kernel size equal to k and BN is the batch normalization operation.
Based on the nonlocal network [38] and CA-Net [39], the cross-spatial-attention-based block (CSAB) is designed to fuse feature maps with multiple scales, enabling the detectors to adapt multiple sizes of strip steel defects, as shown in Figure 4. In addition, compared with a single attention gate for extracting feature maps, CSAB exploits two attention gates simultaneously to enhance focus on the region of strip steel surface defects while minimizing noise in the attention map. Each CSAB takes (the output of the RDBi) and (the output of the RDBi+1) as the inputs. Formally,
3.4. Loss Function
Our ASOD is trained using a blend of depth supervision and fusion loss, where the loss is defined as
where , , and are the binary cross-entropy [40], intersection over union [41], and structural similarity [42], respectively.
4. Verification of the Proposed Model
4.1. Experimental Setup
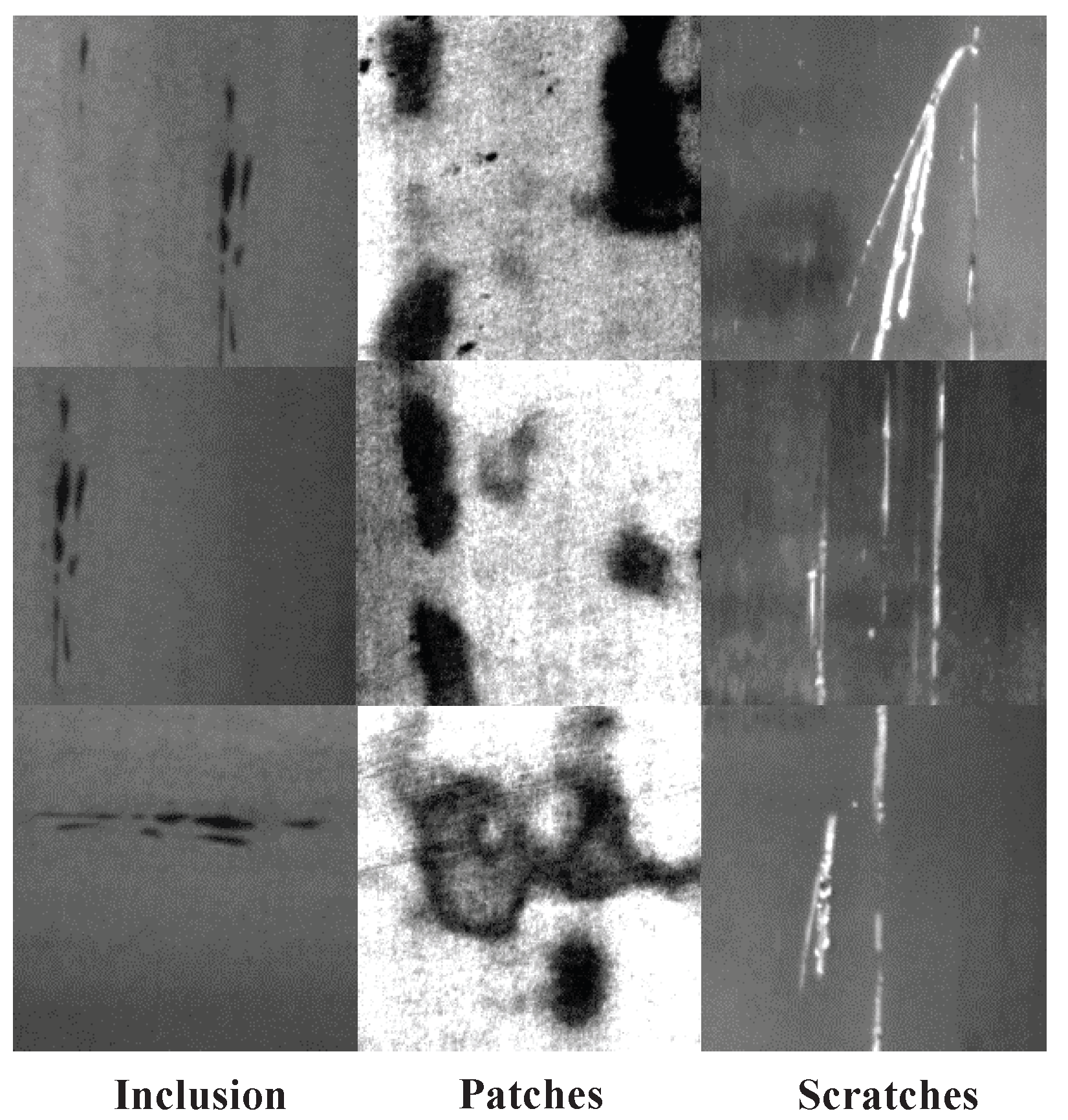
To assess the effectiveness and robustness of our ASOD, various experiments are performed on a publicly available dataset, SD-saliency-900 [43]. This dataset includes 900 cropped images of size and pixelwise annotations for the images. The images are grouped into three categories according to the types of defects, namely inclusions, patches, and scratches, as illustrated in Figure 5.
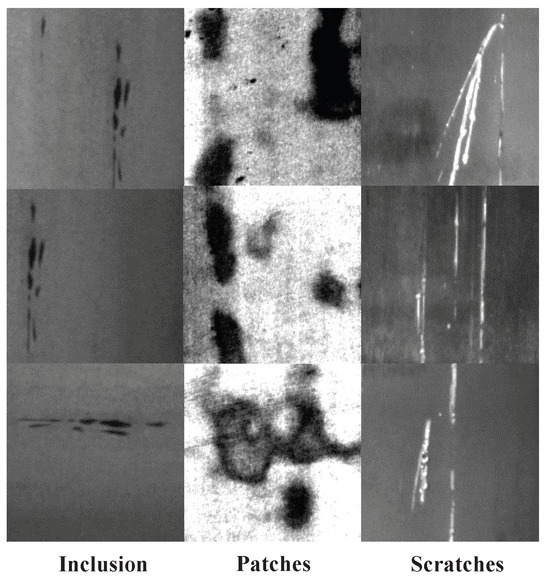
Figure 5.
Three types of defects.
4.1.1. Implementation Details
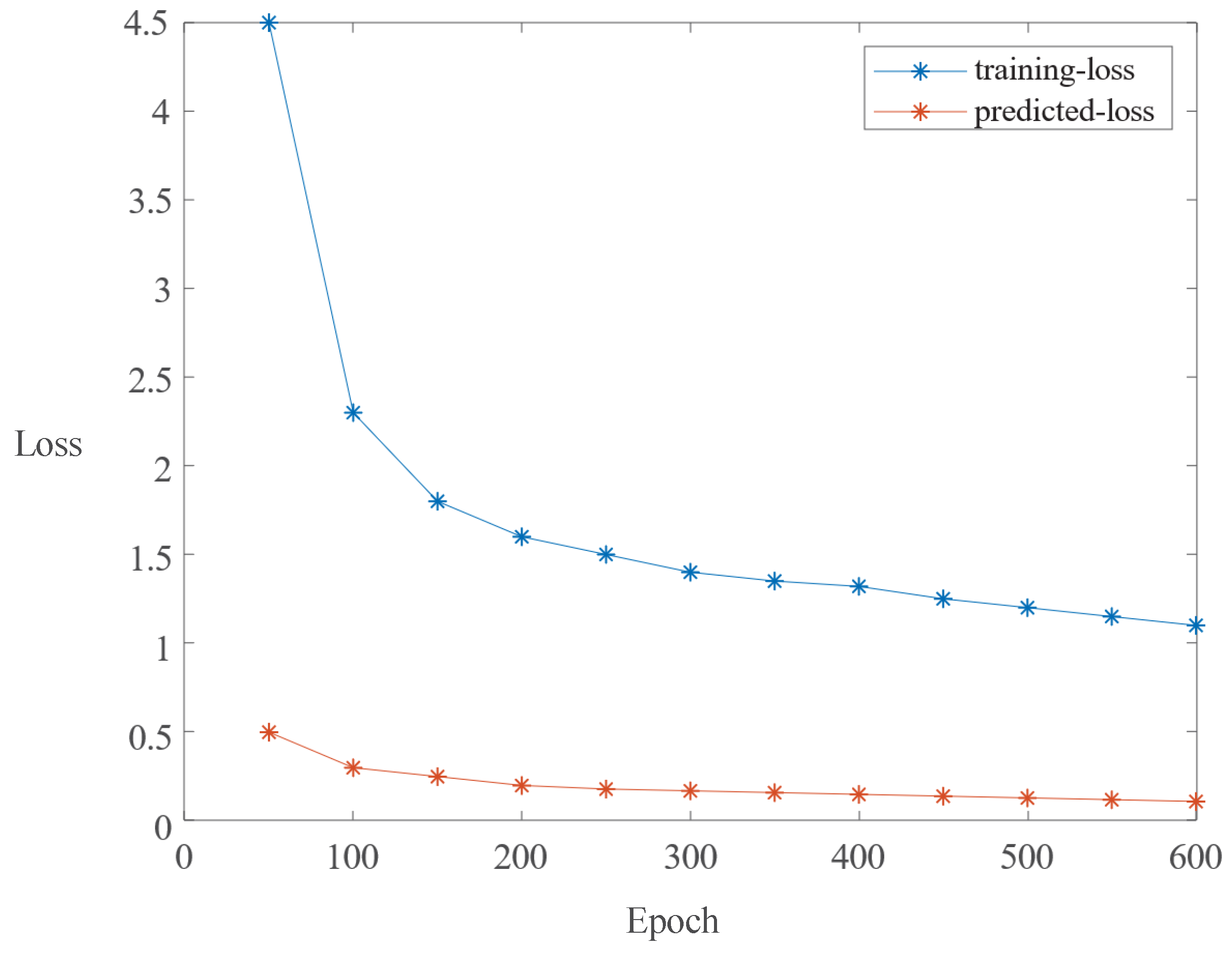
We implement the ASOD with the PyTorch 1.8 framework on hardware comprising an Intel(R) Core(TM) i7-8750H CPU (manufactured by Intel Corporation, Santa Clara, CA, USA) and a TITAN Xp GPU (manufactured by NVIDIA Corporation, Santa Clara, CA, USA) (12 GM memory), and the Ubuntu operating system. The training set is composed of 810 images, among which 540 images (180 per defect type) are drawn from the SD-saliency-900 dataset, and 270 images (90 per defect type) are modified with salt-and-pepper noise (). To improve the robustness of the method, the inversion technique is used to increase the sample. Following Ref. [1], during training, each image I is resized to and normalized using the Z-score formula , with and set to 0.4669 and 0.2437, respectively. During testing, the images are also resized to , and the corresponding prediction salience maps are further resized to . The parameters of the multiscale feature extraction module are initialized to be those of the Swin Transformer pretrained on ImageNet [44]. Adam [45] is selected as the optimizer to train the parameters of our ASOD, where the initial learning rate and alpha are set to 0.001 and 0.9, respectively. The remaining parameters are the PyTorch default settings. The batch size is set to 8, and the number of training steps is 50 K. Without using a validation set, the loss converges after 50 K iterations, as shown in Figure 6.
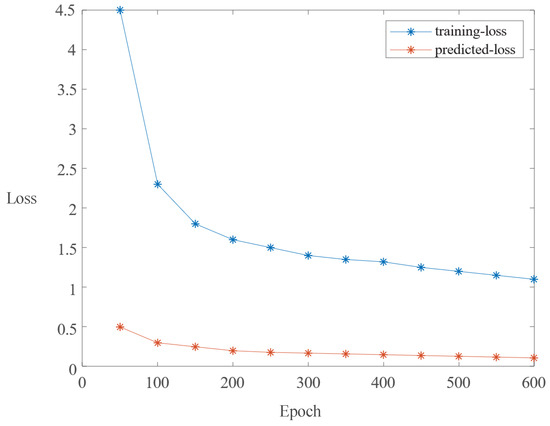
Figure 6.
Convergence curve for SD-saliency-900.
4.1.2. Evaluation Metrics
Several widely used metrics are employed to evaluate the performance of the salient object detector. These metrics include the weighted F-measure (WF) [46], mean absolute error (MAE) [47], structure measure (SM) [48], Pratt’s figure of merit (PFOM) [49], and Parameters.
The WF is an evaluation index that comprehensively considers the accuracy and recall of the salient object detector, defined as
where is a parameter used for adjusting the balance between and .
MAE is a widely used metric for measuring the degree of the average absolute difference between the predicted result and ground truth. The MAE is defined as follows:
where n represents the sample quantity, and S and G are the predicted values and the ground truth, respectively.
The SM is used to measure the structural similarity between the predicted saliency map S and the ground truth G, and it is defined as follows:
where is the structural similarity of objects, denotes the structural similarity of the region, and and represent coefficients that adjust the balance of the overall structural similarity.
The PFOM is used to evaluate the accuracy of the edge by calculating the similarity between the real edge and the ideal edge, and it is defined as follows:
where is used to penalize the offset edge points.
4.2. Ablation Study
Ablation experiments are performed to verify the effectiveness of the key components of our ASOD, including MFEM, BM, and FFM, and the losses including BCE, IOU, and SSIM. For more details of these components and losses, refer to Section 3.
4.2.1. Structural Analysis
Table 1 shows the ablation experiments of the key components of our ASOD, and the details of Table 1 are as follows:

Table 1.
Ablation experiments to validate key components of ASOD, where the best result in each column is highlighted in bold. ↑ and ↓ indicate that larger is better and smaller is better, respectively.
- MFEM: ASOD employs MFEM to extract coarse multiscale features. These features are then processed through average pooling layers to produce salience maps. Finally, the salience maps are integrated to produce the final results.
- MFEM + CAB: Similar to MFEM with exception that CAB is used to further capture relevant channel information from multiscale features.
- MFEM + SAB: Similar to MFEM+CAB with exception that SAB, instead of CAB, is employed for spatial detail extraction.
- MFEM + BM: Similar to MFEM with exception that BM, including both the CAB and SAB, is used for feature extraction.
- MFEM + BM + FFM: Our proposed ASOD.
We use the MAE, WF, and SM metrics to report the quantitative evaluation results of different architectures. Table 1 shows that MFEM + BM performs better than MFEM + CAB and MFEM + SAB in terms of the MAE, WF, and SM, which indicates that the combination of CAB and SAB suppresses irrelevant background channel information and highlights defect features, thereby improving the detection performance of the detector on the surface image of the strip steel. Each key module is added, and the performance of the detector also gradually improves. The performance is optimal when all components are included in the network. These results demonstrate that all key components in our ASOD are useful and necessary for achieving better results in detection of strip steel surface defects.
4.2.2. Loss Analysis
We validate the rationality of the fusion losses, including the binary cross-entropy (BCE), intersection over union (IOU), and structural similarity (SSIM), by comparing the impacts of the losses on the performance of our ASOD through a series of ablation experiments. More details of these losses are discussed in Section 3.4. Table 2 shows the ablation experimental results of these losses, where , , and represent the losses of BCE, SSIM, and IOU, respectively.
Table 2.
Ablation experiments to validate the rationality of the fusion losses of our ASOD. ↑ and ↓ indicate that larger is better and smaller is better, respectively. The best result in each column is indicated in bold.
Table 2 indicates that ASOD with outperforms that with or with . Compared to using only , ASOD with both and increases the WF and SM by 1.84% and 1.2%, respectively, and reduces the MAE by 0.12%. Compared to the counterpart with , ASOD with all losses, i.e., , , and , increases the WF and SM by 1.91% and 1.77%, respectively, while reducing the MAE by 0.27%. This observation indicates that the fusion losses are reasonable on our proposed ASOD network.
4.3. Comparisons
To validate the performance of our ASOD on strip steel surface defect detection, fifteen methods, i.e., RCRR [50], 2LSG [51], BC [29], SMD [52], MIL [30], PFANet [53], NLDF [54], DSS [55], R3Net [56], BMPM [57], PoolNet [58], PiCANet [59], CPD [60], BASNet [61], and EDRNet [1], are selected as candidates for comparison. We use the source code or executable code published by each method author and retrain all the compared detection models on the same training set. In this way, the performance differences between the methods presented in this article and others can be better evaluated.
Figure 7 is a visual comparison of our ASOD and other advanced methods on nine images. ASOD effectively filters out background and detects salient defect targets in images. In particular, for the first three rows of images with blurry boundaries, ASOD generates saliency maps with fine boundary details compared to other methods. For the middle three rows of low-contrast images, ASOD effectively detects small scratch defects on the surface of the strip steel, outperforming other advanced methods. For the last three rows of images with complex backgrounds, ASOD effectively and accurately detects defective objects without introducing any background noise.

Figure 7.
Visual results of salient maps: (a) input images, (b) real labels, (c) RCRR, (d) 2LSG, (e) BC, (f) SMD, (g) MIL, (h) PFANet, (i) NLDF, (j) DSS, (k) R3Net, (l) BMPM, (m) PoolNet, (n) PiCANet, (o) CPD, (p) BASNet, (q) EDRNet, and (r) our model.
Table 3 shows the quantitative results of the sixteen state-of-the-art methods in terms of the MAE, WF, SM, and PFOM. As shown in Table 3, ASOD achieves the best performance compared to the other fifteen methods. Specifically, ASOD significantly outperforms RCRR, 2LSG, BC, SMD, MIL, PFANet, NLDF, DSS, R3Net, BMPM, PoolNet, PiCANet, and CPD on the four measures. Compared with BASNet (EDRNet), ASOD improves the WF, SM, and PFOM by 2.29% (0.96%), 2.53% (1.55%), and 1.74% (0.02%), respectively, while reducing the MAE by 0.39% (0.17%). These results indicate that the proposed attention mechanisms can extract multiscale features while filtering out background information and thus improve the model performance on strip steel surface defect detection. In addition, we observe from Table 3 that our ASOD is significantly superior to other methods with 10% and 20% noise added to the training set, which indicates that, compared to other advanced methods, ASOD shows better performance and robustness for the detection of defects on the strip steel surface.
Table 3.
Experimental results of compared methods. The best result in each column is indicated in bold.
As shown in Table 3, our ASOD, with 48.6 M parameters, strikes an efficient balance between model complexity and performance. Compared to larger models like PFANet (87.2 M) and DSS (75.6 M), it offers a significantly smaller parameter count while still achieving strong results across various evaluation metrics, such as MAE, WF, SM, and PFOM. Although methods like R3Net (35.5 M) and PoolNet (53.6 M) have fewer parameters, our approach outperforms them in key metrics, demonstrating that it delivers high accuracy without excessive model size. These results highlight the efficiency and effectiveness of our model, providing competitive performance with relatively low computational cost.
4.4. Robust Validation
To address potential limitations of the SD-saliency-900 dataset, which contains only three steel defect categories and may reflect biases from specific production environments in data collection and annotation, we expanded experimental validation using the comprehensive ESDIs-SOD benchmark [62]. ESDIs-SOD includes 14 defect types, i.e., roll-printing, iron sheet ash, oxide scale of temperature system, oxide scale of plate system, red iron, slag inclusion, scratches, punching_hole, welding_line, water_spot, oil_spot, foreign matter inclusion, patches, and abrasion mask. The ESDIs-SOD dataset contains 4800 images, with 3600 used as the training dataset and 1200 as the test dataset.
Table 4 compares the results of our ASOD with another 10 state-of-the-art methods on ESDIs-SOD. Our ASOD performs exceptionally well on the ESDIs-SOD task, achieving the lowest MAE value of 0.0188, the highest SM score of 0.9002, and a strong score of 0.9704, indicating minimal error and high structural similarity preservation. While the score of 0.8914 is slightly lower than the best, it still demonstrates balanced performance. Additionally, with 48.0M parameters, our model is more efficient compared to others like DACNet, which has a higher parameter count. Overall, our ASOD strikes a good balance between accuracy, structural preservation, and efficiency.
Table 4.
Quantitative comparisons with 10 state-of-the-art methods on ESDIs-SOD, with the best results in black bold. ↑ and ↓ indicate that larger is better and smaller is better, respectively.
5. Conclusions
In this paper, a new salient object detector, called the ASOD, is proposed for the detection of strip steel surface defects. In particular, the ASOD first uses the self-attention mechanism to extract multiscale features with spatial details and contextual information. Subsequently, a bottleneck module, comprising the proposed channel-attention and spatial-attention blocks, guides the model to focus on important channel responses and spatial region information. Finally, residual decoder blocks and cross-spatial-attention-based blocks are proposed to combine low-level spatial details and high-level semantic information, generating fusion features with rich information so that the detector adapts to strip steel surface defects of multiple scales. Comprehensive experiments demonstrate the superiority of the ASOD. Compared with state-of-the-art models, the ASOD improves the values of WF, SM, and PFOM by 2.29%, 2.53%, and 1.74%, respectively, while reducing MAE by 0.39%. Furthermore, ablation studies confirm the effectiveness of the proposed fusion losses, where adding SSIM and IOU losses further enhances WF and SM by up to 1.91% and 1.77%, respectively, while reducing MAE by 0.27%. Moreover, the ASOD maintains strong robustness under 10% and 20% noise conditions, consistently outperforming other state-of-the-art methods.
Despite promising results, this work has several limitations. First, while the ASOD shows robustness to noise, its performance under other types of corruption (e.g., blur and occlusion) remains underexplored. Second, the computational cost of the model could be optimized further for real-time applications, even though it already balances accuracy and efficiency. Finally, the model’s ability to generalize to other industrial defect detection tasks beyond strip steel requires further investigation.
Future research will prioritize three critical enhancements: (1) systematic benchmarking against industry-relevant corruptions (motion blur and occlusions) using standardized evaluations, (2) architectural compression strategies for real-time embedded deployment through lightweight adaptations and hardware co-optimization, and (3) cross-domain generalization validation across critical manufacturing sectors, including semiconductor microelectronics and aerospace composite inspection. These works strategically address both current technical constraints and practical deployment requirements for industrial visual inspection systems.
Author Contributions
Conceptualization, H.Y. and X.L.; Methodology, L.Z. and H.G.; Software, X.L.; Validation, H.Y.; Formal analysis, X.L., Y.S. and H.G.; Investigation, X.L.; Resources, L.Z.; Data curation, H.Y. and Y.S.; Writing—original draft, X.L.; Writing—review & editing, L.Z.; Visualization, X.L. and L.Z.; Supervision, Y.F. and H.G.; Project administration, H.Y. and H.G.; Funding acquisition, Y.F. All authors have read and agreed to the published version of the manuscript.
Funding
This work is in part funded by Open Found of the Engineering Research Center of Intelligent Swarm Systems, Ministry of Education, grant number ZZU-CISS-2024004, Henan Joint Fund for Science and Technology Research grant number 20240012, Key Scientific Research Projects of Higher Education Institutions in Henan Province grant number 25B520004, Science and Technology Plan Project of Henan Province grant number 241111212200, and Science and Technology Plan Project of Henan Province named “Insulator Defect Detection Based on Diffusion Models”.
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Song, G.; Song, K.; Yan, Y. EDRNet: Encoder-Decoder Residual Network for Salient Object Detection of Strip Steel Surface Defects. IEEE Trans. Instrum. Meas. 2020, 69, 9709–9719. [Google Scholar] [CrossRef]
- Li, Z.; Xing, Q.; Li, Y.; He, W.; Miao, Y.; Ji, B.; Shi, W.; Jiang, Z. A Novel Multi-Scale Channel Attention-Guided Neural Network for Brain Stroke Lesion Segmentation. IEEE Access 2023, 11, 66050–66062. [Google Scholar] [CrossRef]
- Shen, Z.; Shi, H.; Yu, J.; Phan, H.; Feris, R.; Cao, L.; Liu, D.; Wang, X.; Huang, T.; Savvides, M. Improving Object Detection from Scratch via Gated Feature Reuse. In Proceedings of the 30th British Machine Vision Conference, Cardiff, UK, 9–12 September 2019. [Google Scholar]
- Hu, H.; Li, Z.; Gao, W. MPCNet: Improved MeshSegNet Based on Position Encoding and Channel Attention. IEEE Access 2023, 11, 23326–23334. [Google Scholar] [CrossRef]
- Chen, G.; Zhang, M.; Zhu, J.; Meng, Y. PDCA-Net: Parallel dual-channel attention network for polyp segmentation. Biomed. Signal Process. Control 2025, 101, 107190. [Google Scholar] [CrossRef]
- Qian, L.; Zuo, Q.; Liu, H.; Zhu, H. Multivariate time series classification-based on spatial-temporal attention dynamic graph neural network. Springer Nat. 2025, 55, 115. [Google Scholar] [CrossRef]
- Hou, X.; Liu, M.; Zhang, S.; Wei, P.; Chen, B. CANet: Contextual Information and Spatial Attention Based Network for Detecting Small Defects in Manufacturing Industry. Pattern Recognit. 2023, 140, 109558. [Google Scholar] [CrossRef]
- Fu, J.; Sun, X.; Wang, Z.; Fu, K. An Anchor-Free Method Based on Feature Balancing and Refinement Network for Multiscale Ship Detection in SAR Images. IEEE Trans. Geosci. Remote Sens. 2021, 59, 1331–1344. [Google Scholar] [CrossRef]
- Li, M.; Wang, H.; Wan, Z. Surface defect detection of steel strips based on improved YOLOv4. Comput. Electr. Eng. 2022, 102, 108208. [Google Scholar] [CrossRef]
- Park, K.-W.; Cho, S.-B. A Vision Transformer Enhanced with Patch Encoding for Malware Classification. In Proceedings of the Intelligent Data Engineering and Automated Learning 23rd International Conference, Manchester, UK, 24–26 November 2022. [Google Scholar]
- Yu, Z.; Shi, X.; Zhang, Z. A Multi-Head Self-Attention Transformer-Based Model for Traffic Situation Prediction in Terminal Areas. IEEE Access 2023, 11, 16156–16165. [Google Scholar] [CrossRef]
- Yi, S.; Li, J.; Jiang, G.; Liu, X.; Chen, L. CCTseg: A cascade composite transformer semantic segmentation network for UAV visual perception. Measurement 2023, 211, 112612. [Google Scholar] [CrossRef]
- Hatamizadeh, A.; Xu, Z.; Yang, D.; Li, W.; Roth, H.; Xu, D. UNetFormer: A Unified Vision Transformer Model and Pre-Training Framework for 3D Medical Image Segmentation. arXiv 2022, arXiv:2204.00631. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In Proceedings of the 9th International Conference on Learning Representations, Virtual Event, 3–7 May 2021. [Google Scholar]
- Bai, X.; Huang, Y.; Peng, H.; Yang, Q.; Wang, J.; Liu, Z. Spiking neural self-attention network for sequence recommendation. Appl. Soft Comput. 2025, 169, 112623. [Google Scholar] [CrossRef]
- Wang, X.; Cao, W. Bit-Plane and Correlation Spatial Attention Modules for Plant Disease Classification. IEEE Access 2023, 11, 93852–93863. [Google Scholar] [CrossRef]
- Chen, H.; Zendehdel, N.; Leu, M.C.; Yin, Z. Fine-grained activity classification in assembly based on multi-visual modalities. J. Intell. Manuf. 2024, 35, 2215–2233. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [PubMed]
- Zhao, X.; Li, K.; Li, Y.; Ma, J.; Zhang, L. Identification method of vegetable diseases based on transfer learning and attention mechanism. Comput. Electron. Agric. 2022, 193, 106703. [Google Scholar] [CrossRef]
- Li, H.; Xiong, P.; An, J.; Wang, L. Pyramid Attention Network for Semantic Segmentation. In Proceedings of the British Machine Vision Conference, Newcastle, UK, 3–6 September 2018. [Google Scholar]
- Huang, Z.; Wang, X.; Wei, Y.; Huang, L.; Shi, H.; Liu, W.; Huang, T. CCNet: Criss-Cross Attention for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 6896–6908. [Google Scholar] [CrossRef] [PubMed]
- Jin, Y.; Ou, O.; Wang, S.; Liu, Y.; Niu, H.; Leng, X. Landslide detection based on efficient residual channel attention mechanism network and faster R-CNN. Comput. Sci. Inf. Syst. 2023, 20, 893–910. [Google Scholar] [CrossRef]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.S.; et al. Rethinking Semantic Segmentation From a Sequence-to-Sequence Perspective With Transformers. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 6881–6890. [Google Scholar]
- Bao, L.; Zhou, X.; Zheng, B.; Yin, H.; Zhu, Z.; Zhang, J.; Yan, C. Aggregating transformers and CNNs for salient object detection in optical remote sensing images. Neurocomputing 2023, 553, 126560. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 9992–10002. [Google Scholar]
- Han, K.; Xiao, A.; Wu, E.; Guo, J.; Xu, C.; Wang, Y. Transformer in Transformer. In Proceedings of the 35th Conference on Neural Information Processing Systems, Online, 6–14 December 2021; pp. 15908–15919. [Google Scholar]
- Li, Y.; Wu, C.; Fan, H.; Mangalam, K.; Xiong, B.; Malik, J.; Feichtenhofer, C. MViTv2: Improved Multiscale Vision Transformers for Classification and Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 4794–4804. [Google Scholar]
- Yuan, J.; Zhu, A.; Xu, Q.; Wattanachote, K.; Gong, Y. CTIF-Net: A CNN-Transformer Iterative Fusion Network for Salient Object Detection. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 3795–3805. [Google Scholar] [CrossRef]
- Zhu, W.; Liang, S.; Wei, Y.; Sun, J. Saliency Optimization from Robust Background Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2814–2821. [Google Scholar]
- Huang, F.; Qi, J.; Lu, H.; Zhang, L.; Ruan, X. Salient Object Detection via Multiple Instance Learning. IEEE Trans. Image Process. 2017, 26, 1911–1922. [Google Scholar] [CrossRef] [PubMed]
- Bi, H.; Zhang, J.; Wu, R.; Tong, Y.; Fu, X.; Shao, K. RGB-T salient object detection via excavating and enhancing CNN features. Appl. Intell. 2023, 53, 25543–25561. [Google Scholar] [CrossRef]
- Wei, J.; Wang, S.; Huang, Q. F3Net: Fusion, Feedback and Focus for Salient Object Detection. In Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 12321–12328. [Google Scholar]
- Yang, H.; Chen, Y.; Song, K.; Yin, Z. Multiscale Feature-Clustering-Based Fully Convolutional Autoencoder for Fast Accurate Visual Inspection of Texture Surface Defects. IEEE Trans Autom. Sci. Eng. 2019, 16, 1450–1467. [Google Scholar] [CrossRef]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Proceedings of the 16th European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar]
- Liu, Z.; Wang, Y.; Tu, Z.; Xiao, Y.; Tang, B. TriTransNet: RGB-D Salient Object Detection with a Triplet Transformer Embedding Network. In Proceedings of the ACM Multimedia Conference, Virtual Event, China, 20–24 October 2021; pp. 4481–4490. [Google Scholar]
- Liang, H.; Wang, H.; Mao, L.; Liu, R.; Wang, Z.; Wang, K. Bone Stick Image Classification Study Based on C3CA Attention Mechanism Enhanced Deep Cascade Network. IEEE Access 2023, 11, 94057–94068. [Google Scholar] [CrossRef]
- Jiang, Y.; Zhong, C.; Zhang, B. AGD-Linknet: A Road Semantic Segmentation Model for High Resolution Remote Sensing Images Integrating Attention Mechanism, Gated Decoding Block and Dilated Convolution. IEEE Access 2023, 11, 22585–22595. [Google Scholar] [CrossRef]
- Wang, X.; Girshick, R.B.; Gupta, A.; He, K. Non-Local Neural Networks. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7794–7803. [Google Scholar]
- Gu, R.; Wang, G.; Song, T.; Huang, R.; Aertsen, M.; Deprest, J.; Ourselin, S.; Vercauteren, T.; Zhang, S. CA-Net: Comprehensive Attention Convolutional Neural Networks for Explainable Medical Image Segmentation. IEEE Trans. Med Imaging 2021, 40, 699–711. [Google Scholar] [CrossRef]
- Boer, P.; Kroese, D.; Mannor, S.; Rubinstein, R. A Tutorial on the Cross-Entropy Method. Ann. Oper. Res. 2005, 134, 19–67. [Google Scholar] [CrossRef]
- Rahman, M.A.; Wang, Y. Optimizing Intersection-Over-Union in Deep Neural Networks for Image Segmentation. In Proceedings of the Advances in Visual Computing-12th International Symposium, Las Vegas, NV, USA, 12–14 December 2016; pp. 234–244. [Google Scholar]
- Wang, Z.; Simoncelli, E.P.; Bovik, A.C. Multiscale structural similarity for image quality assessment. In Proceedings of the Thrity-Seventh Asilomar Conference on Signals, Pacific Grove, CA, USA, 9–12 November 2003; pp. 1398–1402. [Google Scholar]
- Song, G.; Song, K.; Yan, Y. Saliency detection for strip steel surface defects using multiple constraints and improved texture features. Opt. Lasers Eng. 2020, 128, 106000. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.; Li, K.; Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Margolin, R.; Zelnik-Manor, L.; Tal, A. How to Evaluate Foreground Maps. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 248–255. [Google Scholar]
- Perazzi, F.; Krähenbühl, P.; Pritch, Y.; Hornung, A. Saliency filters: Contrast based filtering for salient region detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 733–740. [Google Scholar]
- Cheng, M.; Fan, D.-P. Structure-Measure: A New Way to Evaluate Foreground Maps. Int. J. Comput. Vis. 2021, 129, 2622–2638. [Google Scholar] [CrossRef]
- Abdou, I.E.; Pratt, W.K. Quantitative Design and Evaluation of Enhancement/Thresholding Edge Detectors. Proc. IEEE 1979, 67, 753–763. [Google Scholar] [CrossRef]
- Zhou, X.; Fang, H.; Liu, Z.; Zheng, B.; Sun, Y.; Zhang, J.; Yan, C. Dense Attention-Guided Cascaded Network for Salient Object Detection of Strip Steel Surface Defects. IEEE Trans. Instrum. Meas. 2022, 71, 1–14. [Google Scholar] [CrossRef]
- Zhou, L.; Yang, Z.; Zhou, Z.; Hu, D. Salient Region Detection Using Diffusion Process on a Two-Layer Sparse Graph. IEEE Trans. Image Process. 2017, 26, 5882–5894. [Google Scholar] [CrossRef] [PubMed]
- Peng, H.; Li, B.; Ling, H.; Hu, W.; Xiong, W.; Maybank, S. Salient Object Detection via Structured Matrix Decomposition. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 818–832. [Google Scholar] [CrossRef]
- Zhao, T.; Wu, X. Pyramid feature attention network for saliency detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 3085–3094. [Google Scholar]
- Luo, Z.; Mishra, A.; Achkar, A.; Eichel, J.; Li, S.; Jodoin, P.M. Non-local deep features for salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6593–6601. [Google Scholar]
- Hou, Q.; Cheng, M.; Hu, X.; Borji, A.; Tu, Z.; Torr, P. Deeply Supervised Salient Object Detection with Short Connections. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 815–828. [Google Scholar] [CrossRef]
- Deng, Z.; Hu, X.; Zhu, L.; Xu, X.; Qin, J.; Han, G.; Heng, P. R3net: Recurrent residual refinement network for saliency detection. In Proceedings of the 27th International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 684–690. [Google Scholar]
- Zhang, L.; Dai, J.; Lu, H.; He, Y.; Wang, G. A bi-directional message passing model for salient object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1741–1750. [Google Scholar]
- Liu, J.J.; Hou, Q.; Cheng, M.M.; Feng, J.; Jiang, J. A simple pooling-based design for real-time salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 3917–3926. [Google Scholar]
- Liu, N.; Han, J.; Yang, M. PiCANet: Pixel-Wise Contextual Attention Learning for Accurate Saliency Detection. IEEE Trans. Image Process. 2020, 29, 6438–6451. [Google Scholar] [CrossRef] [PubMed]
- Wu, Z.; Su, L.; Huang, Q. Cascaded partial decoder for fast and accurate salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 3907–3916. [Google Scholar]
- Qin, X.; Zhang, Z.; Huang, C.; Gao, C.; Dehghan, M.; Jagersand, M. Basnet: Boundary-aware salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 7479–7489. [Google Scholar]
- Cui, W.; Song, K.; Feng, H.; Jia, X.; Liu, S.; Yan, Y. Autocorrelation-Aware Aggregation Network for Salient Object Detection of Strip Steel Surface Defects. IEEE Trans. Instrum. Meas. 2023, 72, 5019412. [Google Scholar] [CrossRef]
- Pang, Y.; Zhao, X.; Zhang, L.; Lu, H. Multi-scale interactive network for salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9413–9422. [Google Scholar]
- Sun, Y.; Chen, G.; Zhou, T.; Zhang, Y.; Liu, N. Context-aware cross-level fusion network for camouflaged object detection. arXiv 2021, arXiv:2105.12555. [Google Scholar]
- Li, G.; Liu, Z.; Zhang, X.; Lin, W. Lightweight Salient Object Detection in Optical Remote-Sensing Images via Semantic Matching and Edge Alignment. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5601111. [Google Scholar] [CrossRef]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).