Abstract
GPT (Generative Pre-trained Transformer) is a groundbreaking generative model that has facilitated substantial progress in natural language processing (NLP). As the GPT-n series has continued to evolve, its applications have garnered considerable attention across various industries, particularly in finance. In contrast, traditional financial research has primarily focused on analyzing structured data such as stock prices. However, recent trends highlight the growing importance of natural language techniques that address unstructured factors like investor sentiment and the impact of news. Positive or negative information about specific companies, industries, or the overall economy found in news or social media can influence investor behavior and market volatility, highlighting the critical need for robust sentiment analysis. In this context, we utilize the state-of-the-art language model GPT and the finance-specific sentiment analysis model FinBERT to perform sentiment and time-series analyses on financial news data, comparing the performance of the two models to demonstrate the potential of GPT. Furthermore, by examining the relationship between sentiment shifts in financial markets and news events, we aim to provide actionable insights for investment decision-making, emphasizing both the performance and interpretability of the models. To enhance the performance of GPT-4o, we employed a systematic approach to prompt design and optimization. This process involved iterative refinement, guided by insights derived from a labeled dataset. This approach emphasized the pivotal importance of prompt design in improving model accuracy, resulting in GPT-4o achieving higher performance than FinBERT. During the experiment phase, sentiment scores were generated from New York Times news data and visualized through time-series graphs for both models. Although both models exhibited similar trends, significant differences arose depending on news content characteristics across categories. According to the results, the performance of GPT-4o, optimized through prompt engineering, outperformed that of FinBERT by up to 10% depending on the sector. These findings emphasize the importance of prompt engineering and demonstrate GPT-4o’s potential to improve sentiment analysis. Furthermore, the categorized news data approach suggests potential applications in predicting the outlook of categorized financial products.
1. Introduction
Large language models (LLMs) are massive deep learning models based on transformer architecture, and they are pre-trained on vast amounts of text data. These models possess the ability to learn from extensive language data, demonstrating remarkable capabilities in natural language processing (NLP) tasks such as language translation, text generation and summarization, sentiment analysis (SA), and question-answering systems. Among these, the Generative Pre-trained Transformer (GPT), first introduced by OpenAI in 2018, has significantly contributed to advancements in NLP. Although its early versions had limitations in solving real-world problems, GPT’s emergence brought renewed momentum to AI research, particularly in NLP.
ChatGPT, based on the GPT-3.5 architecture, was introduced by OpenAI as an enhanced version of GPT-3 released in 2022 (https://chatgpt.com/, accessed on 1 January 2025). Unlike its predecessors, which were primarily API-based, ChatGPT’s chatbot interface allowed direct user interaction, driving its widespread adoption. Within a week of its launch, ChatGPT surpassed one million users, demonstrating its explosive popularity. The release of GPT-4, incorporating 100 trillion parameters, further accelerated AI advancements, expanding LLMs into multimodal models and intensifying competition in the field. Accordingly, ChatGPT is widely adopted across industries. It assists students in education [1], shows potential in healthcare [2], and enhances finance and business through content creation, customer engagement, and research [3,4,5].
The rise of ChatGPT has driven innovation in various industries, particularly in business and economics. Researchers have explored its applications in these fields, including prompt engineering techniques to optimize performance [6]. In Section 2.1, we present a concise review of previous studies exploring ChatGPT’s performance across various fields.
ChatGPT’s growing influence in finance is evident as institutions use LLMs to automate tasks and analyze market behavior. This integration enables advanced applications like sentiment analysis (SA), risk assessment, and investment. SA quantifies subjective elements—emotions, thoughts, and opinions—at document, sentence, and aspect levels to classify sentiment as positive or negative.
In particular, SA traces its roots to early 20th-century public opinion research and computational linguistics studies from the 1990s. Its study expanded in 2004 with internet growth and data proliferation [7]. Recently, machine learning-based approaches have significantly enhanced SA performance [8]. With its growing importance, SA is now widely used by researchers, businesses, governments, and organizations. Ongoing advancements in methods, data, and models continue to enhance its effectiveness [9,10]. We provide a concise review of prior research focused on SA in Section 2.2.
Our study focuses on evaluating the SA performance of GPT-4o, particularly in the context of analyzing news articles across various sectors. To achieve this, we compare and assess the performance of GPT-4o against the FinBERT (Financial Bidirectional Encoder Representations from Transformers) model, which is specifically designed for financial sentiment analysis. Additionally, we employ a sophisticated prompt design process to enhance the accuracy and effectiveness of GPT-4o’s sentiment analysis.
The goal of this study is to understand the differences between domain-specific models and general-purpose models, while proposing new possibilities for financial text analysis. This approach aims to provide insights into the capabilities and limitations of GPT-4o in comparison to specialized models like FinBERT.
In conclusion, this study highlights the potential of the general-purpose NLP model, GPT, in sentiment analysis, and seeks to propose new possibilities and directions for research in sentiment analysis.
To do this, we collect news articles from several sectors. Subsequently, we conduct SA on the collected news articles using both GPT-4o and the benchmark model FinBERT. The performance of GPT-4o is influenced by the design of the prompt [11,12,13]. Accordingly, we employ a refined prompt design process to enhance SA performance. Finally, we compare the SA results from both GPT-4o and FinBERT. In particular, we perform SA using news data through FinBERT, a model specialized in finance. FinBERT, a specialized language model built upon BERT, is tailored for financial language processing. Trained on financial texts, such as news, earnings reports, regulations, and analyst summaries, FinBERT gains prominence for its efficacy in various studies [14,15,16,17,18]. The detailed workflows are provided in Section 3.2.
GPT’s use in financial sentiment analysis is still emerging. Although versatile, its lack of financial specialization limits its effectiveness in this domain. Studies have focused on models like FinBERT, which excels in classifying financial sentiment and analyzing market trends [14,15,18,19]. Research comparing GPT to FinBERT and exploring their complementary potential remains limited, restricting insights into GPT’s role in financial text analysis. In Section 2.3, we also review previous studies that have utilized FinBERT in various applications.
Consequently, our study makes several significant contributions to the literature. First, we evaluate the performance of GPT-4o in sentiment analysis and compare it with FinBERT, analyzing the relative strengths and weaknesses of each model. Second, we propose a prompt design framework for GPT-4o that can be widely applied across various industry sectors, enhancing both its generalizability and accuracy in sentiment analysis. Third, we generate time-series data for sentiment scores obtained from GPT-4o and FinBERT and conduct an event analysis, introducing a new analytical paradigm that extends beyond traditional technical and fundamental analyses. Ultimately, our findings contribute to the literature by demonstrating the effectiveness of GPT-4o in sentiment analysis and providing a time-series perspective on its performance.
The remainder of this paper is structured as follows: The next section provides a brief review of the existing literature relevant to our study. Section 3 presents the news data and outlines the research design. In Section 4, we report the SA results obtained using GPT-4o and FinBERT, followed by a comparative analysis of their performances. Finally, Section 5 offers a discussion of the findings and concluding remarks.
2. Literature Review
In this section, we review previous studies relevant to our research, focusing on GPT performance, sentiment analysis, and the application of FinBERT.
2.1. The Performance of GPT
Ref. [20] attempted zero-shot and few-shot inference using the Chain-of-Thoughts (COT) methodology with NASDAQ-100 stocks on GPT-4 and supervised fine-tuning with LLaMA. The experimental results demonstrate that these approaches outperform traditional statistical models and machine learning techniques in terms of performance. Ref. [21] utilized GPT-4 to analyze news headlines, Google’s sustainability reports, Midwest Energy Emissions Corp’s performance records, and Fed FOMC meeting minutes to address four questions arising when applying ML models in accounting. The results demonstrate that GPT-4 is highly accurate and efficient in generating quantitative and logical analyses of textual content. Ref. [22] evaluated whether GPT can assist in stock evaluation using 21 financial knowledge tests. In this test, GPT-3.5 scored 65%, whereas ChatGPT, based on GPT-4, scored an almost perfect 99%, demonstrating that GPT-4 possesses the capability to act as a robo-advisor in current financial matters. Ref. [23] utilized GPT to simplify the process of evaluating publicly listed companies’ annual reports and then used the results for machine learning. This shows promising outperformance against the S&P 500 returns, indicating that insights derived from LLMs can be useful features for constructing machine learning models. Ref. [24] investigated the AI quality management (AIQM) of the ChatGPT system in SA by setting prompts and controlling outputs for four types of variations. The evaluation involved Amazon.com review data and the Stanford Sentiment Treebank, demonstrating robustness for all variations but showing weakness in synonymic variations. Ref. [25] prompted ChatGPT-4 to predict earnings announcements and evaluate the relative attractiveness of each S&P 500 company to determine whether ChatGPT-4 can accurately predict stock performance and assist in investment decisions. Using a real-time experiment, the study found a positive correlation between ChatGPT-4 attractiveness ratings and future earnings’ announcements as well as stock returns. Ref. [4] evaluated ChatGPT’s effectiveness in portfolio management, finding that its asset selections exhibited higher diversity and outperformed random selections. The results suggest ChatGPT’s potential as a valuable investment assistant. Ref. [26] analyzed ChatGPT’s portfolio recommendations, showing alignment with academic benchmarks across investor profiles. The study highlights ChatGPT’s ability to enhance information presentation and support investment decisions. Ref. [27] assessed LLM-based chatbots, including ChatGPT, in cybersecurity, revealing weaknesses in named entity recognition for extracting security-related data. The findings emphasize the need for further refinement in cyber threat detection. Ref. [28] proposed the multimodal fusion Bitcoin (MFB) framework, integrating BiLSTM and BiGRU for market prediction. The study highlights a strong correlation between Bitcoin sentiment and price, reinforcing sentiment analysis in financial forecasting.
GPT models have demonstrated strong potential in data analysis and decision-making support within the financial domain. Various studies indicate that GPT outperforms traditional methodologies in processing complex financial data, asset selection and portfolio construction, market forecasting, and other financial activities. Notably, GPT optimizes investment processes by leveraging high reliability and efficiency, while enhancing the presentation and summarization of information to help users easily understand and utilize key insights. Furthermore, GPT has shown the ability to adapt to specific financial contexts, offering tailored recommendations based on investor profiles and outperforming traditional robo-advisors in certain cases. This suggests that GPT can transcend its role as a mere analytical tool to become a crucial assistant in financial advisory and research. Its sophisticated language processing and reasoning capabilities provide the potential to enhance efficiency in financial research and practice, strengthen decision-making support, and open new possibilities for delivering financial services.
2.2. Sentiment Analysis
Ref. [29] proposed Instruct-FinGPT, trained by fine-tuning LaMA with Twitter financial news and the FiQA dataset. It demonstrates superiority over widely used LLMs in scenarios where understanding of numbers and context is crucial. Ref. [30] bootstrapped a smaller student model, Charformer (CF), by tuning it with COT-integrated data from social media platforms such as Reddit and FiQA. Despite its smaller size, it achieved comparable or superior performance to existing state-of-the-art models in terms of financial outlook for companies. Ref. [31] utilized instruction tuning and retrieval augmentation modules with Llama-7B, initialized to train on Twitter financial news and the FiQA dataset. Consequently, it exhibited significantly superior performance in financial SA compared to ChatGPT and LLaMA. Ref. [32] performed tasks such as SA, HC and NER by instructing and tuning various open LLMs. Utilizing datasets such as FPR, FiQA-SA, Headline Dataset, NER Dataset, and FinRED, it demonstrated remarkable generalization ability in zero-shot tasks. Ref. [33] conducted financial SA on corporate financial reports using four LLMs, including OpenAI’s ChatGPT (GPT-3.5), through prompt engineering. The results indicate that the performance and output quality of the LLMs vary depending on the prompt design, content of the reports, and complexity of the task, highlighting the importance of prompt design in achieving optimal results. Ref. [34] analyzed sentiment analysis methods using GPT, showing that prompt engineering, fine-tuning, and embedding classification outperform state-of-the-art models. The study highlights GPT’s strength in handling context, sarcasm, and linguistic challenges in sentiment analysis. Ref. [35] introduced MarketSenseAI, leveraging GPT-4’s reasoning for stock selection. Integrating Chain of Thought and In-Context Learning, the framework enhances AI-driven investment decision-making by improving signal accuracy and reliability. Ref. [36] integrated emotion lexicons with ChatGPT to enhance empathetic responses in psychotherapy. Using therapy transcripts, they improved GPT’s empathy, coherence, and fluency, emphasizing the role of emotional embeddings in LLM performance.
Recent studies in financial sentiment analysis have focused on utilizing GPT to analyze the complex relationships between financial data and market sentiment. These studies reveal that GPT outperforms traditional models, significantly enhancing the accuracy and efficiency of sentiment analysis through advanced capabilities such as context understanding, addressing complex linguistic challenges, zero-shot learning, and retrieval augmentation. Furthermore, prompt engineering and systematic data calibration have been identified as critical factors influencing model performance. Emphasis has also been placed on adopting approaches that consider the unique context and complexity of financial data. These advancements enable the effective detection of sentiment patterns across diverse data sources such as news, social media, and financial reports, linking them to practical applications such as market prediction, investment decision support, and financial risk management. Collectively, these studies highlight the potential of GPT-based sentiment analysis as a powerful tool for understanding and interpreting market sentiment, thereby expanding its performance and applicability.
2.3. The Application of FinBERT
Ref. [18] evaluated FinBERT for sentiment classification in financial texts, showing it outperforms benchmark models, including dictionaries and machine learning algorithms, by leveraging contextual information effectively. Ref. [14] fine-tuned BERT to create FinBERT and demonstrated its superior sentiment classification accuracy over general BERT using financial datasets, confirming its applicability in finance. Ref. [37] analyzed unstructured financial text from Bursa Malaysia reports, comparing MiniLM and FinBERT. The results highlight FinBERT’s effectiveness in categorizing Key Audit Matters, emphasizing the value of domain-specific models. Ref. [38] explored financial sentiment analysis in the forex market, showing that ChatGPT 3.5’s zero-shot prompt approach outperforms FinBERT in predicting market returns from news headlines. Ref. [39] demonstrated the vulnerability of keyword-based sentiment models, using adversarial attacks on GPT-3 and contrasting its susceptibility with FinBERT in financial text analysis.
In the financial sector, FinBERT outperforms other machine learning algorithms, including BERT, in sentiment analysis and classification tasks, demonstrating significant potential for financial text analysis. It has proven to be highly effective in extracting insights from diverse financial data, contributing to the literature on financial text analysis. Additionally, FinBERT can match or even surpass GPT’s performance in certain cases, making it a suitable benchmark model for comparisons in financial applications.
Building on the existing literature discussed above, it is evident that GPT’s performance is advancing rapidly across various fields. Sentiment analyses based on text data are becoming increasingly significant and widely utilized. Notably, there has been a growing number of studies employing FinBERT, a model specialized in the financial domain, for sentiment analysis.
In this study, we apply GPT, which has demonstrated exceptional performance, to sentiment analysis and compare its results with those of FinBERT. Furthermore, we conduct performance comparisons across financial and non-financial domains using sector-specific news text data. This approach allows us to comprehensively evaluate GPT’s sentiment analysis performance, offering new insights beyond the scope of previous studies.
3. Data Description and Research Design
3.1. Datasets
In this section, we present the datasets used in our study. Initially, we collected labeled data to perform the prompt design. We utilized the News SA Dataset provided by Kaggle (https://www.kaggle.com/datasets/clovisdalmolinvieira/news-sentiment-analysis, accessed on 1 January 2025) and converted the CSV file into a DataFrame format. From the available columns, we focused on the “Headline”, “Description”, “Sector”, and “Sentiment” fields. These data were categorized by news sectors, specifically “Business”, “Health”, and “Technology”, by aligning it with the corresponding categories.
To ensure the quality of our dataset and minimize potential biases that could impact model performance, we performed several preprocessing steps.
First, we applied preprocessing to the headline and description columns, which involved removing content within parentheses and brackets, as well as eliminating HTML entities and special characters. Specifically, we used regular expressions to delete any text enclosed in parentheses () and brackets [], removing unnecessary information from the headlines. For example, the headline “NMCB 18 and 647th Civil Engineer Squadron Learn New Technology from ERDC [Image 9 of 11]” was cleaned to “NMCB 18 and 647th Civil Engineer Squadron Learn New Technology from ERDC”. Additionally, since news article data often contain HTML-encoded characters such as &#;number, , and –, we replaced them to ensure a more natural text format. Furthermore, we removed URLs from the description column, as they can introduce irrelevant information in news article analysis. By identifying and eliminating these URLs, we reduced noise that could affect model training and data analysis.
Finally, we removed duplicate rows to ensure data consistency. The deleted records were exact duplicates, and among the 500 records in each category, 136 records were removed from the Business category, 130 from Technology, and 179 from Health. Additionally, we removed unnecessary symbols and extraneous text to further refine the dataset and improve overall data quality.
Table 1 presents the number of data points for each category, along with the distribution of sentiment labels: positive, negative, and neutral. For the “Business” category, there are a total of 364 data points, with 254 being labeled as “positive”, 48 as “negative”, and 62 as “neutral”. The “Health” category comprises a total of 321 data points, with 170 labeled as “positive”, 75 as “negative”, and 76 as “neutral”. Finally, the “Technology” category contains a total of 370 data points, with 239 labeled as “positive”, 56 as “negative”, and 75 as “neutral”.

Table 1.
Label distribution across different categories. Num. = number.
The classification of sentiment into “positive”, “neutral”, or “negative” may introduce subjective biases. However, many previous studies on sentiment analysis have commonly adopted this three-category approach [40,41,42,43,44,45,46,47]. Following this standard, our study also applies sentiment analysis to news articles using these three classes.
To enhance the performance of FinBERT, we conducted fine-tuning using a financial news text dataset labeled with sentiment. This dataset, provided by Kaggle (www.kaggle.com/datasets/antobenedetti/finance-news-sentiments, accessed on 1 January 2025), consists of 32,583 financial news articles. The dataset was originally in CSV format, which was converted into a DataFrame format. It contains two primary columns: text and sentiment. The text column provides summaries of news articles, while the sentiment column contains sentiment labels for each article.
The sentiment labels categorize each article as either positive, neutral, or negative. During the fine-tuning process, these labels were mapped to integers in accordance with FinBERT’s classification system: neutral was mapped to 0, positive to 1, and negative to 2. This label conversion ensured compatibility with the model’s input format, facilitating the sentiment classification task.
In the data preprocessing phase, rows containing null and duplicated values were removed to maintain the quality of the dataset. After this cleaning process, a total of 32,417 valid entries remained, which were subsequently used for fine-tuning.
Table 2 presents the number of data points for each sentiment label in the dataset used for FinBERT fine-tuning. It consists of 10,841 positive samples, 10,752 neutral samples, and 10,824 negative samples.
Table 2.
Label distribution for FinBERT fine-tuning.
For the experiment data, we collected news articles from The New York Times. Using the Selenium library for dynamic crawling, we aligned the data with news sector classifications based on categories provided by The New York Times. For the business category, we collected articles from April 2024 to June 2024, from May 2023 to July 2024 for health, and from September 2023 to July 2024 for technology. We extracted the headline, description, and date of each article using relevant HTML tags and merged this information into a DataFrame. A total of 1010 data points were used in the analysis. Figure 1 shows a sample collection of New York Times articles.
Figure 1.
The New York Times data collection example.
3.2. Research Design
In this section, we provide a detailed explanation of how the experiments were designed.
Figure 2 illustrates the overall process of our study. Our research process can be broadly divided into three stages: data collection, GPT-4o prompt engineering&FinBERT fine-tuning, and SA. Each stage is executed from top to bottom, with arrows indicating the flow of the process. Rectangles represent research activities, whereas diamonds indicate the corresponding outcomes. A detailed, step-by-step description is provided below.
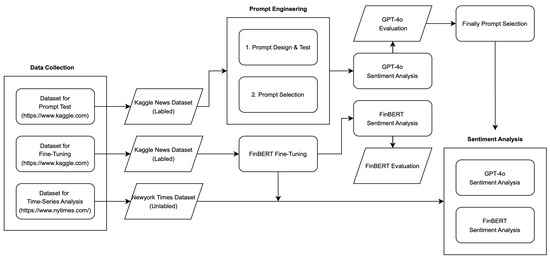
Figure 2.
Flow chart.
- Step 1: In the first stage, news articles from three sectors (business, health, and technology) were collected. Each article included information on the headline, description, date, and sector. Kaggle’s SA dataset was used for the prompt design, while the experiment data were dynamically crawled from The New York Times, collecting news from each sector. Additionally, we collected a sentiment analysis (SA) dataset from Kaggle, which consists of news summary text and sentiment labels, to fine-tune FinBERT.The entire dataset collected for sector-specific SA was categorized into three sectors: business, health, and technology. For SA, text data containing sector, news headline, and news description variables were utilized. FinBERT used merged text comprising sector, headline, and description, while GPT-4o incorporated these variables into prompts using Python 3’s f-string method.
- Step 2: In the second stage of our study, SA was conducted on the collected news articles using both GPT-4o and the benchmark model FinBERT for prompt design and performance comparison. FinBERT, being pre-trained on financial text data, offers superior SA performance compared to general language models, making it a valuable reference for assessing GPT-4o’s capabilities.To enhance FinBERT’s performance on financial news sentiment analysis, we performed a fine-tuning process specifically tailored for this domain. The fine-tuning was conducted using a financial news dataset provided by Kaggle, where each news article was labeled as positive, neutral, or negative based on its sentiment.The dataset was split into a training set (80%) and a validation set (20%) using stratified sampling to preserve the class distribution across both subsets. This prepared dataset was then utilized for model training and performance evaluation.During training, we conducted a random search to determine the optimal hyperparameters, including the learning rate, number of epochs, and batch size. The AdamW optimizer was used for parameter optimization, and cross-entropy loss was applied as the loss function, as it is well suited for multi-class classification tasks.At the end of each epoch, the model’s generalization performance was assessed using the validation dataset. A linear learning rate scheduler was also implemented to gradually reduce the learning rate as training progressed, ensuring smoother convergence.Subsequently, we conducted SA on labeled Kaggle news datasets using the fine-tuned FinBERT model. For GPT-4o, a refined prompt design process was implemented to improve SA performance. This involved analyzing cases where FinBERT misclassified sector-specific news sentiment (5 samples per sector, totaling 15 samples). Eight prompts, referenced from benchmark papers, were utilized for these samples. Based on performance, the two most effective prompts were selected. Two additional prompts similar to each were created, resulting in a total of six final prompts applied to the dataset.The following describes the process of SA using the GPT-4o model based on prompt design. The prompt design is developed with reference to benchmark papers [13,20,38,48], and its return format outputs the sentiment of the text data (positive, neutral, negative) along with the corresponding probability values on both models, enabling a precise assessment of sentiment intensity.
- Step 3: In the third stage, during the experiment phase, the best-performing prompt from the prompt design phase was selected for SA on The New York Times data. FinBERT was also used in this stage to evaluate and compare SA performance. Ultimately, the time-varying results for the experiment data were derived using the best-performing prompt along with both the GPT-4o and FinBERT models, enabling a comparative analysis.
Each piece of news data, modified according to sector, headline, and description, was analyzed through the GPT-4o API, which was pre-built as a Python module. This module was designed based on GPT-4o and was implemented to receive three parameters—system, assistant, and user—and it ultimately returns the SA results. Table A2 provides the roles of the three parameters. In this study, the “system” parameter was excluded, and only the “assistant” and “user” parameters were utilized for prompt engineering. To ensure consistency in the output, the “assistant” parameter was fixed while the user input was adjusted to optimize the prompts. The “assistant” prompt used in this study is provided in Table A3.
4. Empirical Results
We first present the results of SA conducted using GPT-4o and FinBERT on the Kaggle dataset. Specifically, we leverage this labeled dataset to design prompts optimized for GPT-4o to perform SA. In Section 4.1, we illustrate our prompt design process with accompanying diagrams. Subsequently, we present the results of emotional analysis using GPT-4o and FinBERT on The New York Times dataset.
4.1. Prompt Design Results
First, we present a detailed account of the prompt design process for GPT-4o. We generated the initial eight candidate prompts from previous studies [11,12,13]. The eight initial candidate prompts are listed in Table A1.
To evaluate the sentiment analysis performance of the model on labeled data, i.e., the Kaggle dataset, we used four classification performance metrics (accuracy, precision, recall, and F1-score). Before explaining the performance metrics, the actual class in a classification problem can be defined as true or false. True indicates that the model’s prediction is correct, while false indicates that the model’s prediction is incorrect. The predicted class returned by the model can be defined as positive or Negative. Positive indicates that the model predicted the sentiment as positive, and negative indicates that the model predicted the sentiment as negative.
Therefore, the following outcomes can occur in classification performance: First, when the model makes correct predictions, true positive () and true negative () can occur. True positive () indicates that the model predicted positive, and the actual sentiment is also positive. True negative () indicates that the model predicted negative, and the actual sentiment is also negative. When the model makes incorrect predictions, false positive () and false negative () can occur. False positive () indicates that the model predicted positive, but the actual sentiment is negative. False negative () indicates that the model predicted negative, but the actual sentiment is positive.
Accuracy measures the proportion of correct predictions out of the total number of predictions. It represents the frequency at which the classifier makes correct predictions.
Precision (positive predictive value) measures the proportion of results among all positive predictions made by the model.
Recall (sensitivity or true-positive rate) measures the proportion of results out of all actual positive cases.
F1-score is the harmonic mean of precision and recall. This metric balances the two, particularly when there is an imbalance in class distribution.
Additionally, our study considers the macro average (Macro avg.) as it involves a multi-class classification problem. This approach calculates the arithmetic mean of individual metrics (precision, recall, and F1-score) across all classes, ensuring equal weight for each class. As a result, it provides an unbiased evaluation even in imbalanced datasets where certain classes have significantly more samples than others. In particular, we use the Macro F1-score to assess the overall balance of the model’s performance.
where N represents the number of classes, and the Macro F1-score is obtained by averaging the F1-scores of all classes.
Using the performance indicators above, we compared the accuracy values of FinBERT and GPT-4o to assess their performance.
Our initial test with eight candidate prompts revealed that their structure had a significant impact on GPT-4o’s performance. Specifically, Prompt 5 and Prompt 6 demonstrated the best performance for the business sector, while Prompt 5 was most effective for the health sector and Prompt 6 for the tech sector.
Based on these results, we selected Prompt 5 and Prompt 6 as the top-performing prompts. To further refine our approach, we created six additional prompts by modifying these two—generating two variations for each prompt (prompt5-1, prompt5-2, prompt6-1, and prompt6-2). These processes are illustrated in Figure 3. These variations involved rearranging sentence structures or replacing words with similar meanings while maintaining the original intent. The final set of six refined prompts is presented in Table 3. We then applied these prompts to the labeled dataset to evaluate their effectiveness.
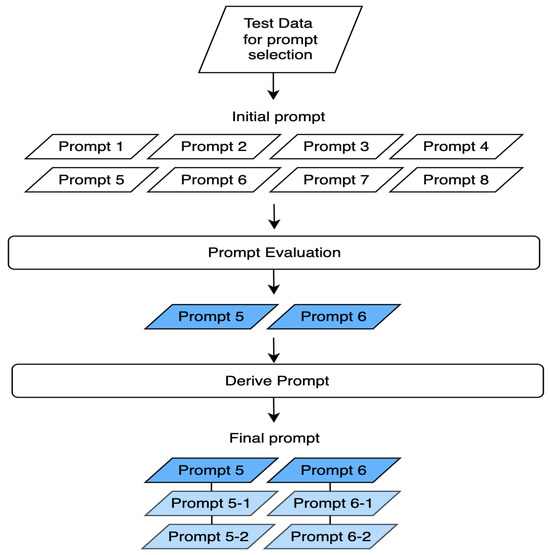
Figure 3.
Prompt design process.
Table 3.
Prompt design for user.
The performance of SA using the six different prompts (Table 3) across sectors was evaluated as follows. We provide the SA results for FinBERT and GPT-4o in Table 4, Table 5, Table 6 and Table 7. For the business sector, the average accuracy was 0.43; for the health sector, it was 0.42; and for the technology sector, it was 0.53. On the other hand, the accuracy of FinBERT in the business, health, and technology sectors was 0.38, 0.39, and 0.44, respectively, with GPT-4o outperforming FinBERT by an average of approximately 0.06. Based on the performance by prompt, p5 (user2-1 + assistant) achieved the highest accuracy of 0.45 in the business sector. In the health sector, p3 (user1-2 + assistant) and p5 (user2-1 + assistant) both achieved the highest accuracy of 0.43. In the technology sector, p3 (user1-2 + assistant) and p5 (user2-1 + assistant) also recorded the highest accuracy of 0.55. Therefore, we adopted p5, which exhibited the highest performance, and we applied it to the model for the experiment data.
Table 4.
Performance table of FinBERT.
Table 5.
Performance table of GPT-4o: business. Notes. The maximum achieved accuracy is 0.45.
Table 6.
Performance table of GPT-4o: health. Notes. The maximum achieved accuracy is 0.43.
Table 7.
Performance table of GPT-4o: technology. Notes. The maximum achieved accuracy is 0.55.
To gain a comprehensive understanding of the differences in sentiment analysis mechanisms and performance between GPT-4o and FinBERT, an in-depth investigation was conducted into cases where the two models produced different predictions. The analysis focused on two key scenarios: instances where GPT-4o correctly classified sentiment and FinBERT misclassified it, and instances where FinBERT correctly classified sentiment and GPT-4o misclassified it. The objective of this study was to identify patterns in misclassification and explore the underlying factors contributing to these discrepancies.
First, in cases where GPT correctly classified sentiment and FinBERT misclassified it, the findings indicate that FinBERT consistently exhibits a tendency to misclassify positive or negative sentiments as neutral across all three sectors: business, health, and technology. In the business sector, 85% of misclassified cases were labeled as neutral by FinBERT, while in the health and technology sectors, 78% and 86% of cases, respectively, were also categorized as neutral. A closer examination suggests that FinBERT systematically underestimates sentiment, particularly for news articles conveying implicit positivity. This pattern was especially evident in the business sector, where articles highlighting urban development and business growth were misclassified as neutral. This misclassification appears to stem from FinBERT’s reliance on explicit financial terminology to determine sentiment, making it less effective in interpreting sentiment in a broader news context where financial implications are more subtle.
A similar trend was observed in the health and technology sectors. FinBERT frequently misclassified articles discussing medical advancements, healthcare service expansions, and infrastructure improvements as neutral, whereas GPT-4o successfully identified the positive sentiment in these reports. Likewise, in the technology sector, FinBERT often failed to recognize the optimistic tone in articles about technological breakthroughs, misclassifying them as neutral, while GPT-4o consistently detected their positive sentiment.
On the other hand, in cases where FinBERT correctly classified sentiment while GPT-4o misclassified it, GPT-4o displayed a tendency to overestimate sentiment by incorrectly labeling neutral articles as either positive or negative. Specifically, in the business sector, 48% of neutral cases were misclassified by GPT-4o, while in the health and technology sectors, the misclassification rates reached 54% and 65%, respectively. A notable example includes an article about women leaders in business, which was primarily an informational piece but was misclassified as positive by GPT-4o. Similarly, factual reports about health risks were often misclassified as negative by GPT-4o due to its tendency to over-rely on emotionally charged keywords, leading to sentiment overestimation in neutral contexts.
These findings highlight fundamental differences in how GPT-4o and FinBERT approach sentiment classification. FinBERT’s misclassification tendencies can be attributed to its training data, which are heavily focused on financial news, making it highly sensitive to explicit financial sentiment but less effective at recognizing sentiment in broader contexts. Additionally, its reliance on keyword- and phrase-based sentiment cues limits its ability to capture subtle contextual nuances in sentiment analysis.
In contrast, GPT-4o demonstrates superior contextual awareness, allowing it to capture sentiment more effectively across diverse news topics. This capability enables GPT-4o to correctly classify implicitly positive news articles that FinBERT misclassifies as neutral. However, GPT-4o’s tendency to misclassify neutral articles as either positive or negative highlights its sensitivity to emotionally charged language, sometimes leading to sentiment overestimation.
Overall, this analysis suggests that GPT-4o is better suited for general-purpose sentiment analyses due to its context-aware approach, while FinBERT’s keyword-based method is more effective for domain-specific financial sentiment analyses. A hybrid sentiment analysis strategy that leverages the strengths of both models could enhance classification accuracy. Future research should explore refining FinBERT’s training data with more diverse news sources and integrating context-aware methodologies similar to those employed by GPT-4o to develop more robust sentiment analysis models.
4.2. Experiment Results
In this section, we present the results of an SA conducted using GPT-4o and FinBERT on a dataset consisting of The New York Times news articles. Specifically, we investigated GPT-4o’s sentiment responses based on prompts crafted through the detailed design process outlined in the previous section.
We performed SA on a news dataset, categorizing sentiments into three classes—positive, neutral, and negative—along with their corresponding probability values. As multiple news articles can exist for a given date, we, respectively, defined and as the sentiment label and corresponding probability for the k-th news article on day t, where t represents the date and k is the index of news articles for that date ().
To quantify the sentiment labels, we mapped positive to +1, neutral to 0, and negative to −1, and multiplied each by the respective probability . Thus, gives the quantified sentiment score for each news article, which we define as . Finally, to compute the overall sentiment value for a given date, we calculated the average of the quantified sentiment scores for all news articles on that day. The sentiment score for day t, , is given by
where n refers to all news articles for the day t. This represents the final daily sentiment score for the given date.
The sentiment scores were calculated using both GPT-4o and FinBERT across the three sectors. A five-day moving average was then applied to ensure a more stable analysis.
Table 8 presents the descriptive statistics for each sector after applying a five-day moving average to the computed sentiment scores in (1). The table includes the mean, maximum, minimum, standard deviation (Std. Dev.), and skewness for the business, health, and technology sectors, with all values rounded to three decimal places. These statistics provide valuable insights into the distribution of sentiment probabilities across sectors.
Table 8.
Summary statistics for the sentiment scores .
According to the mean values, both GPT-4o and FinBERT exhibit negative averages across all sectors, indicating that negative sentiment was predominant in the news overall. Moreover, FinBERT consistently reports lower mean sentiment scores than GPT-4o across all sectors, suggesting that it captures negative sentiment more strongly.
Regarding the maximum values, a score approaching 1 signifies periods of highly dominant positive sentiment. GPT-4o’s results indicate that the health sector reaches the highest maximum value of 0.590, while the business sector records a considerably lower maximum of 0.055. Similarly, FinBERT shows relatively higher maximum values of 0.150 and 0.155 for the health and technology sectors, respectively, while the business sector records an exceptionally low maximum of 0.005. This suggests that positive sentiment was significantly less prevalent in the business sector across all models.
A minimum value approaching −1 signifies periods of intense negative sentiment. In GPT-4o’s results, the health sector exhibits the lowest minimum value of −0.759, while the technology sector also shows substantial negativity with a minimum of −0.653. FinBERT follows a similar trend, reporting minimum values of −0.558 and −0.606 in the health and technology sectors, respectively. These results indicate that negative sentiment was particularly dominant in these sectors during specific periods.
In terms of standard deviation, GPT-4o consistently exhibits higher variability across all sectors compared to FinBERT. Notably, in the health sector, GPT-4o has a standard deviation of 0.251, which is approximately twice as large as FinBERT’s 0.125. This suggests that GPT-4o produces sentiment scores with greater variability, whereas FinBERT offers more stable and moderate assessments.
Regarding skewness, FinBERT maintains values close to zero across all sectors, suggesting that its sentiment score distributions are relatively symmetric. In contrast, GPT-4o demonstrates sector-dependent skewness, with sentiment distributions exhibiting either positive or negative skewness depending on the sector.
In summary, the two models demonstrate distinct tendencies in sentiment interpretation. FinBERT consistently captures negative sentiment more strongly than GPT-4o and provides a more conservative evaluation with a narrower range of sentiment scores. On the other hand, GPT-4o tends to assign more extreme sentiment values and is more sensitive to positive sentiment than FinBERT. These findings underscore the potential benefits of integrating the complementary strengths of both models to enhance the balance and comprehensiveness of sentiment analysis.
We display the results of these calculations in Figure 4, Figure 5 and Figure 6, which correspond to the business, health, and technology sectors, respectively.
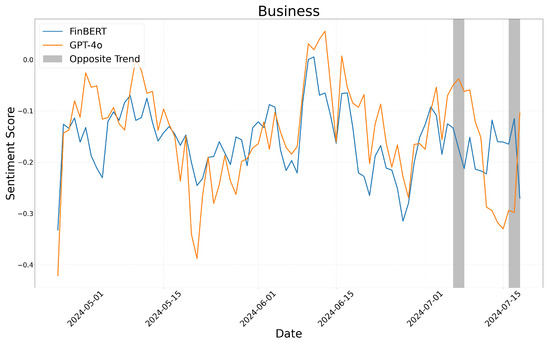
Figure 4.
Sentiment score moving average: business.
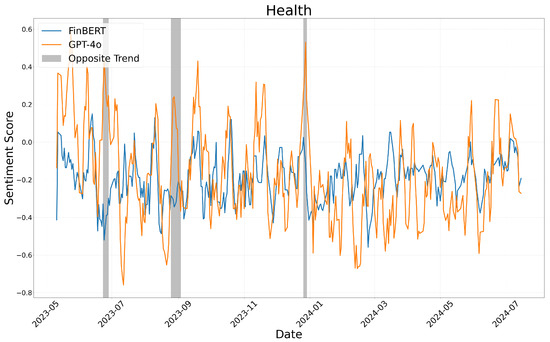
Figure 5.
Sentiment score moving average: health.
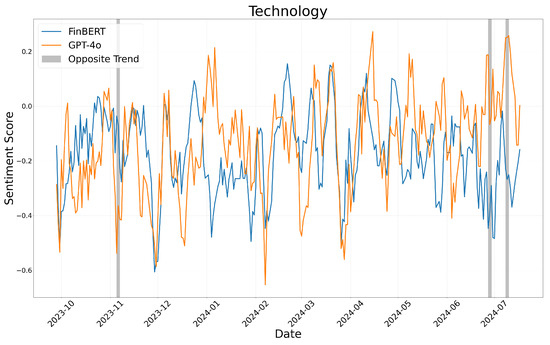
Figure 6.
Sentiment score moving average: technology.
Figure 4, Figure 5 and Figure 6 illustrate the sentiment trends across different sectors over time. The x-axis represents the publication date of the news articles, while the y-axis shows sentiment scores calculated using a five-day moving average. The sentiment scores generated by FinBERT and GPT-4o are represented by blue and orange lines, respectively. Although both models exhibit similar overall trends, there are specific periods where their sentiment classifications diverge significantly. These discrepancies, highlighted with gray boxes in the figures, provide insights into the underlying differences in how each model interprets sentiment.
In the business sector, FinBERT generally exhibited a more conservative stance, often classifying financial and legal discussions as neutral or negative, whereas GPT-4o tended to provide a more optimistic interpretation. For instance, in “Paramount Agrees to Merge With Skydance”, GPT-4o recognized the positive outlook on the corporate merger and assigned a high sentiment score, while FinBERT classified it as neutral. Conversely, in “New Plan to Target Russia’s Oil Revenue Brings Debate in the White House”, FinBERT identified concerns about gasoline price fluctuations and assigned a negative sentiment score, while GPT-4o maintained a neutral stance. Additionally, when news content was framed as a question or contained ambiguous interpretations, FinBERT predominantly assigned neutral sentiment scores, whereas GPT-4o was more likely to classify such content as either strongly positive or negative. For example, in “Is It Silicon Valley’s Job to Make Guaranteed Income a Reality?”, FinBERT categorized the sentiment as neutral, while GPT-4o interpreted it optimistically and assigned a positive sentiment score.
A similar pattern was observed in the health sector, where GPT-4o emphasized the positive aspects of scientific research and technological advancements, while FinBERT remained neutral or negative. For instance, in “Scientists Debut Lab Models of Human Embryos”, which described a breakthrough in stem cell research, GPT-4o assigned a positive sentiment score, whereas FinBERT classified it as negative. However, in cases involving disease outbreaks and medical risks, GPT-4o assigned stronger negative sentiment scores compared to FinBERT. This was evident in “Women May Face Higher Risk of Stroke Following Infertility Treatment”, where GPT-4o classified the sentiment as negative, while FinBERT remained neutral.
In the technology sector, the differences in sentiment classification were largely driven by the models’ respective approaches to sentiment detection. FinBERT relied primarily on individual keywords, often resulting in neutral classifications when sentiment cues were implicit. In contrast, GPT-4o analyzed the broader context of the news article. For instance, in “U.S. Creates High-Tech Global Supply Chains to Blunt Risks Tied to China”, FinBERT focused on the word “risks” and classified the sentiment as negative, whereas GPT-4o considered the broader economic context and assigned a positive sentiment score. Similarly, in “OpenAI Lets Mom-and-Pop Shops Customize ChatGPT”, GPT-4o identified the opportunities for small businesses and assigned a positive sentiment, while FinBERT, relying on individual keywords, classified the article as neutral.
In summary, FinBERT and GPT-4o adopt different sentiment analysis approaches. FinBERT’s keyword-driven method detects explicit sentiment but often classifies implied sentiment as neutral. In contrast, GPT-4o’s context-aware approach captures subtle sentiment shifts but may sometimes overestimate their intensity. FinBERT’s precision suits financial reports and legal documents, while GPT-4o’s holistic interpretation is better for market trends, innovations, and socio-economic analysis. Given these strengths and limitations, a hybrid sentiment analysis approach—combining FinBERT’s keyword-based detection with GPT-4o’s contextual comprehension—could improve classification accuracy while enhancing robustness and reliability across finance, healthcare, and technology.
4.3. The Relationship Between the Stock Market and Sentiment
Finally, to evaluate the applicability of the sentiment analysis results derived from this study, we conducted a comparative analysis between sector-specific stock prices and sentiment scores over time. The sentiment score was obtained using GPT-4o, the primary model of this study, and the comparison process with stock market data was as follows:
First, sector-specific closing price data were collected from the S&P 500 index. Subsequently, only stock price data corresponding to the dates of the sentiment-analyzed news data were selected for comparison. This step ensured that the sentiment variations in news data and stock price fluctuations were analyzed over the same time period.
However, since sentiment scores and stock prices have different scales, several preprocessing steps were implemented to facilitate a consistent comparison. First, to better capture stock price volatility, closing price data were transformed into log returns. Next, a five-day moving average was applied to smooth out short-term fluctuations, following the same procedure used for sentiment scores. Finally, both sentiment scores and stock prices were normalized using MinMaxScaler to scale the values within the range of −1 to 1, allowing for more intuitive comparisons.
The following graph visualizes the time-series trends of GPT-4o’s sentiment scores and sector-specific stock prices, where the green line represents stock price trends, and the red line represents sentiment score trends.
The analysis of the graph indicates that, except for the business sector with a relatively short period of time, most sectors exhibit similar patterns in sentiment scores and stock price movements. In particular, there are multiple instances where an increase in sentiment scores corresponds to an increase in stock prices, and a decrease in sentiment scores coincides with a decline in stock prices. These findings suggest that sentiment analysis results may be correlated with stock market movements to some extent.
These results imply that news sentiment analysis could serve as a complementary indicator for stock market prediction, particularly in sectors where sentiment variations are closely associated with stock price fluctuations. Future studies should aim to further quantify this relationship by integrating sentiment analysis into predictive stock market models and evaluating their forecasting performance.
Meanwhile, sector-specific stock prices can be considered an external factor. According to Figure 7, Figure 8 and Figure 9, sentiment scores appear to reflect market conditions to some extent based on sector-specific stock prices. Consequently, the sentiment analysis results can be interpreted as incorporating some contextual information related to external factors, specifically the stock market.
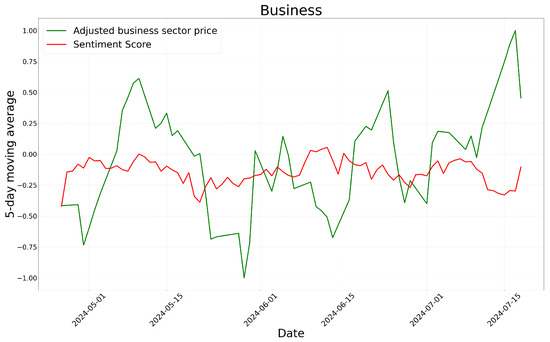
Figure 7.
Time-series of GPT-4o’s sentiment scores and adjusted business sector prices.
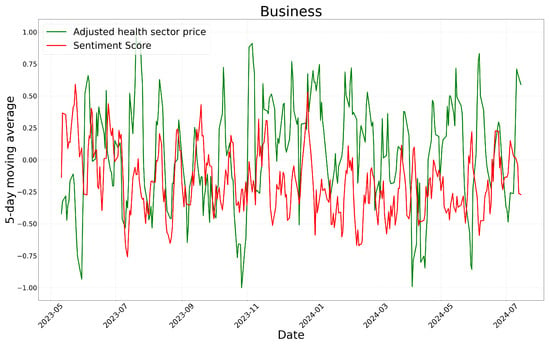
Figure 8.
Time-series of GPT-4o’s sentiment scores and adjusted health sector prices.
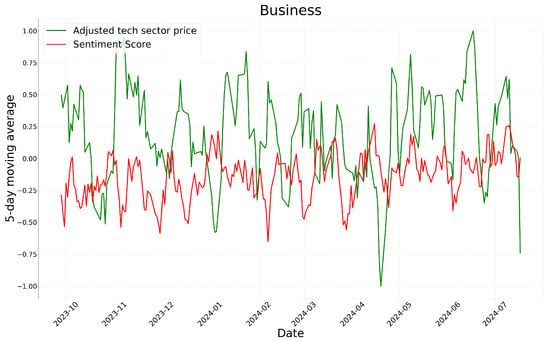
Figure 9.
Time-series of GPT-4o’s sentiment scores and adjusted tech sector prices.
5. Discussion and Concluding Remarks
In this study, sentiment analysis (SA) was conducted on categorized news data using GPT-4o and FinBERT. To establish the fine-tuning process, prompt design, and experimental datasets, news data were obtained from Kaggle and supplemented with additional data collected through dynamic crawling from The New York Times. Subsequently, SA was performed using GPT-4o and FinBERT by leveraging headlines, descriptions, and sectors from the labeled news data in Kaggle. To further enhance the performance of FinBERT and GPT-4o in SA, fine-tuning and prompt engineering techniques were applied, respectively. We sampled five data points for each sector, selected the two best-performing prompts, and then generated four additional derivative prompts, resulting in a total of six prompts from the prompts’ design step. We utilized a confusion matrix as the performance evaluation metric and found that, across all sectors, the performance of GPT-4o with the optimized prompt design outperformed the fine-tuned FinBERT model.
Next, we conducted a time-series analysis of sentiment scores from both models on unlabeled data to examine their sentiment trends over time. Although both models generally exhibited similar trends, they showed contrasting sentiment shifts in certain periods, highlighting fundamental differences in their sentiment evaluation mechanisms. Additionally, we compared the sentiment trends of GPT-4o with sector-specific stock return data. Although variations were observed across sectors, the overall sentiment trends closely aligned with stock return movements.
According to the SA results, the key findings are as follows: First, when comparing the sentiment score graphs across the three analyzed categories, the overall trends of the two models were generally similar. However, some opposing trends were observed in this process. It was found that FinBERT relies on a keyword-based approach, effectively detecting explicit sentiment but often classifying implicit sentiment as neutral. In contrast, GPT-4o adopts a context-aware strategy, assessing sentiment based on the overall narrative and thematic implications. As a result, while GPT-4o captures subtle emotional shifts, it may occasionally overlook the importance of explicitly emotional terms.
Second, sector-specific analyses reveal that in the business sector, FinBERT tends to interpret financial and legal news in a more conservative and negative manner, whereas GPT-4o provides a more optimistic perspective. In the health sector, GPT-4o frequently assigns a more positive sentiment to scientific research and technological advancements, while FinBERT often remains neutral. Additionally, for news related to disease outbreaks and medical risks, GPT-4o tends to classify such news as more negative, while FinBERT maintains a neutral stance. In the technology sector, FinBERT’s keyword-based classification makes it more sensitive to certain negative keywords, whereas GPT-4o, by considering the broader context, often interprets news more positively.
Finally, an analysis of these contrasting periods across the three sectors revealed a common factor contributing to the significant differences in sentiment interpretation between the two models: ambiguous topics where sentiment varied depending on subjective perspectives. These articles often addressed complex ethical dilemmas without clear resolutions, leading to substantial variations in how the two models interpreted and classified sentiment.
This study presents several distinguishing features compared with previous studies. First, we categorized the nature of the news into specific categories and utilized the news category, headline, and description for modeling. Second, we iteratively refined and evaluated the performance of the prompts using a labeled text dataset, progressively working toward an optimal design. A notable aspect of this approach was the clear delineation of roles—system, user, and assistant—within the GPT-4o prompt design process, executed via the API during both the prompt design and experiment phases. This separation allowed for a more focused evaluation of each parameter’s contribution to the model performance. We then conducted a comparative analysis of GPT-4o and FinBERT across different sectors and prompt designs. Finally, using The New York Times dataset, we generated daily sentiment scores to explore time-varying characteristics and investigated the anomalies identified through this process.
Furthermore, our findings present several significant implications. First, FinBERT, renowned for its effectiveness in financial text analysis and sentiment classification, excels in domain-specific tasks due to its pretraining on financial data. However, news datasets often encompass diverse topics beyond finance, limiting FinBERT’s adaptability as a specialized model. In contrast, GPT-4, trained on a broad dataset with billions of parameters, exhibits strong general-purpose performance across various tasks, including finance. This flexibility suggests that GPT-4 may outperform FinBERT in tasks involving diverse content, such as news datasets. In addition, GPT-4o utilized prompts optimized through the prompt engineering process. The results, depicted in time series graphs, demonstrated similar overall trends but emphasized differences during instances of specific terms, abbreviations, or ambiguous expressions related to judgments or ethical dilemmas. These ambiguous expressions posed challenges for accurate interpretation due to their inherent subjectivity. GPT-4, with its capability to generate multi-contextual interpretations, outperformed FinBERT, which primarily focuses on single-context analysis. This made GPT-4 more effective at handling subtle and complex textual content.
Second, prompt engineering plays a critical role in maximizing GPT’s performance, particularly for interpreting ambiguous sentences. By refining context or incorporating additional details into prompts, GPT can provide more accurate or multifaceted interpretations. This synergy between GPT and prompt engineering enables flexible and creative processing of ambiguous text. Choosing the appropriate model—BERT or GPT—and optimizing prompt design based on the data and analysis goals is essential for effective results.
In addition, the main findings of this study provide several practical applications. First, by providing a sentiment score for each sector, the results can be utilized for price prediction, including forecasting the stock index, sector index or ETFs [49,50,51,52]. Second, through the time-varying analysis of both models, we identified which news characteristics and content cause differences between the two models, specifically leading to ambiguity in SA. This could be explored as a research topic regarding the factors causing ambiguity in news sentiment and their handling, which could be useful for SA of news in the future.
Nevertheless, we discuss several limitations of this study. First, the dataset used for prompt design was relatively small, consisting of approximately 300 samples per sector. In contrast, the experiment dataset was considerably larger, with around 1000 samples. The limited size of the prompt design dataset can be attributed to the stringent requirement that news articles be specifically labeled by sector, which significantly restricted the available data. Second, the prompt design dataset exhibited an unbalanced distribution of sentiment labels. Of the approximately 300 samples per sector, around 200 were labeled as positive, while the remaining samples were evenly split between negative and neutral labels. This imbalance arose from the challenge of collecting sufficient labeled news data for each sector. Thirdly, our sentiment analysis was conducted in a single experimental setting and did not account for various market conditions, which may limit its generalizability across all market environments. However, through performance analysis across different sectors (business, technology, health, etc.), we observed the potential superiority of GPT-4o over FinBERT. In future research, we plan to incorporate sentiment analysis that considers market volatility and major financial events, allowing us to further examine how various economic factors influence sentiment analysis results.
Finally, we analyzed the time-varying trends of GPT-4o and FinBERT on the experiment dataset and examined the prominent features in the graphs and their underlying causes. However, because the crawled The New York Times dataset lacks labeled sentiment values, it was challenging to evaluate the performance with specific metrics. This study primarily focused on analyzing the sentiment scores generated by GPT-4o and FinBERT in relation to changes over time. Future research could explore obtaining labeled sentiment data for The New York Times articles or utilizing an alternative news dataset with pre-existing sentiment labels. Additionally, extending the data collection period to cover a longer time period could provide more comprehensive insights into sentiment trends over an extended period. Although this would be a time-consuming process, it would enable a more rigorous comparison of the sentiment scores produced by GPT-4o and FinBERT.
Based on the framework and results of this study, we propose several directions for future research. First, to mitigate the limitations associated with small dataset sizes, future research could explore expanding sector-specific datasets with sentiment labels or applying sentiment analysis to larger datasets using GPT. Similarly, we suggest conducting sentiment analysis on a wider range of new and diverse datasets as a potential direction for future studies. This approach is expected to enhance the robustness of the findings presented in this study. Second, this study exclusively utilized the GPT-4o model as the LLM for sentiment analysis. Moreover, recent developments have introduced various LLM models, such as Gemini and Llama. Future research could explore sentiment analysis using these models or compare their results to those of GPT-4. Third, in this study, sentiment analysis was limited to three categories: positive, negative, and neutral. However, exploring finer sentiment labels could unlock significant potential across various fields. Therefore, future research could investigate sentiment analysis beyond these three categories, focusing on a broader range of emotional labels. Our study has a limitation in that it does not provide explanatory power for model decisions. However, this is not a constraint unique to our research but rather a broader limitation inherent to LLMs. Consequently, enhancing the interpretability of pre-trained transformer models, such as GPT-4o and FinBERT, represents a significant avenue for future research.
Author Contributions
Conceptualization, S.-Y.C.; data curation, J.-W.K.; formal analysis, J.-W.K. and S.-Y.C.; funding acquisition, S.-Y.C.; investigation, J.-W.K. and S.-Y.C.; methodology, J.-W.K.; software, J.-W.K.; writing—original draft preparation, J.-W.K. and S.-Y.C.; writing—review and editing, J.-W.K. and S.-Y.C. All authors have read and agreed to the published version of the manuscript.
Funding
The work of S.-Y. Choi was supported by the National Research Foundation of Korea (NRF) grant funded by the Korea Government (MSIT) (No. RS-2024-00454493) and the Gachon University research fund of 2024 (GCU-202404060001).
Data Availability Statement
The data presented in this study are available upon request from the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A. GPT-4o Prompts and API
Table A1.
The initial Prompts.
Table A1.
The initial Prompts.
| Role | Prompt |
|---|---|
| user1 | You are an excellent financial {sector} expert who trades by accurately analyzing the sentiment related to given news. When news headlines {headline} and descriptions {description} are provided, you can respond as follows: sentiment of news: positive, sentiment of news: negative, sentiment of news: neutral |
| user2 | You are an excellent {sector} Sentiment analysis model trained on financial news headlines and descriptions. When news is provided as (headline: {headline}, description: {description}), you return the following: sentiment: {{sentiment}}, probability: {{probability}}. |
| user3 | You are an excellent {sector} sentiment analysis service of a financial news. When news headlines {headline} and descriptions {description} are provided, you can respond like this: sentiment of news: positive, positive probability: {{probability}}; sentiment of news: negative, negative probability: {{probability}}; sentiment of news: neutral, neutral probability: {{probability}}; you must choose one. |
| user4 | The given the news related to the {sector} industry, how do you feel about the headline {headline} and description {description}? Answer in one token: positive, negative, or neutral. |
| user5 | The given the news related to the {sector} industry, how do you feel about the headline {headline} and description {description}? Answer in one token: positive for buy, negative for sell, or neutral for hold position. |
| user6 | The given the news related to the {sector} industry, classify the sentiment as positive, negative, or neutral, based on the headline {headline}, description {description} and provide the probability value for your response. |
| user7 | The given the news related to the {sector} industry, classify the sentiment as positive for buy, negative for sell, or neutral for hold position, based on the headline {headline}, description {description} and provide the probability value for your response. |
| user8 | This text presents the news headline {headline} and description {description} for the {sector} industry. Based on this information, would you sell, buy, or hold an ETF in the {sector} industry? The sentiment of the news can be positive for buying, negative for selling, or neutral for holding. Answer in one token with the sentiment. |
Table A2 presents the main parameters that can be input based on the usage of the GPT-4o API. The following three parameters each serve a specific role. “System” refers to the content requested by the user, and while optional, it assigns a role that aligns with the purpose of using GPT-4o. “User” is mandatory and provides the request or opinion that GPT-4o should respond to. “Assistant” is optional, and although it has the function of storing previous assistant responses, it can also be written by the user to provide an example of the desired behavior.
Table A2.
API parameter definitions.
Table A2.
API parameter definitions.
| Role | Description |
|---|---|
| system | This message sets the behavior of the AI. It defines the tone or rules of the conversation, guiding how the AI should respond. It helps shape the overall interaction between the user and the AI. |
| assistant | This message represents the AI’s response. Based on the {system} and {user} messages, the AI generates an appropriate reply. It keeps the conversation going. |
| user | This message contains the user’s question or request to the AI. It provides the topic for the conversation and prompts the AI to respond. It reflects the user’s actual input. |
Table A3 contains information about the “assistant” among the GPT-4o API parameters. It serves as an example to output the sentiment and probability of the news in a consistent format when the content of the news is provided through the “user”.
Table A3.
Prompt design for assistant.
Table A3.
Prompt design for assistant.
| Role | Prompt |
|---|---|
| assistant | When news is provided, you can respond with sentiment of news: positive, positive probability: {probability}, or sentiment of news: negative, negative probability: {probability}, or sentiment of news: neutral, neutral probability: {probability}. Answer with just one sentence. |
References
- Javaid, M.; Haleem, A.; Singh, R.P.; Khan, S.; Khan, I.H. Unlocking the opportunities through ChatGPT Tool towards ameliorating the education system. BenchCouncil Trans. Benchmarks Stand. Eval. 2023, 3, 100115. [Google Scholar] [CrossRef]
- Kung, T.H.; Cheatham, M.; Medenilla, A.; Sillos, C.; De Leon, L.; Elepaño, C.; Madriaga, M.; Aggabao, R.; Diaz-Candido, G.; Maningo, J.; et al. Performance of ChatGPT on USMLE: Potential for AI-assisted medical education using large language models. PLoS Digit. Health 2023, 2, e0000198. [Google Scholar] [CrossRef] [PubMed]
- Raj, R.; Singh, A.; Kumar, V.; Verma, P. Analyzing the potential benefits and use cases of ChatGPT as a tool for improving the efficiency and effectiveness of business operations. BenchCouncil Trans. Benchmarks, Stand. Eval. 2023, 3, 100140. [Google Scholar] [CrossRef]
- Ko, H.; Lee, J. Can ChatGPT improve investment decisions? From a portfolio management perspective. Financ. Res. Lett. 2024, 64, 105433. [Google Scholar] [CrossRef]
- Dowling, M.; Lucey, B. ChatGPT for (finance) research: The Bananarama conjecture. Financ. Res. Lett. 2023, 53, 103662. [Google Scholar] [CrossRef]
- Han, Y.; Hou, J.; Sun, Y. Research and Application of GPT-Based Large Language Models in Business and Economics: A Systematic Literature Review in Progress. In Proceedings of the 2023 IEEE International Conference on Computing (ICOCO), Langkawi Island, Malaysia, 9–12 October 2023; pp. 118–123. [Google Scholar]
- Mäntylä, M.V.; Graziotin, D.; Kuutila, M. The evolution of sentiment analysis—A review of research topics, venues, and top cited papers. Comput. Sci. Rev. 2018, 27, 16–32. [Google Scholar] [CrossRef]
- Collobert, R.; Weston, J.; Bottou, L.; Karlen, M.; Kavukcuoglu, K.; Kuksa, P. Natural language processing (almost) from scratch. J. Mach. Learn. Res. 2011, 12, 2493–2537. [Google Scholar]
- Birjali, M.; Kasri, M.; Beni-Hssane, A. A comprehensive survey on sentiment analysis: Approaches, challenges and trends. Knowl.-Based Syst. 2021, 226, 107134. [Google Scholar] [CrossRef]
- Yu, L.C.; Wu, J.L.; Chang, P.C.; Chu, H.S. Using a contextual entropy model to expand emotion words and their intensity for the sentiment classification of stock market news. Knowl.-Based Syst. 2013, 41, 89–97. [Google Scholar] [CrossRef]
- Zhu, X.; Kuang, Z.; Zhang, L. A prompt model with combined semantic refinement for aspect sentiment analysis. Inf. Process. Manag. 2023, 60, 103462. [Google Scholar] [CrossRef]
- Xue, H.; Salim, F.D. Promptcast: A new prompt-based learning paradigm for time series forecasting. IEEE Trans. Knowl. Data Eng. 2023, 36, 6851–6864. [Google Scholar] [CrossRef]
- Sun, S.; Pan, X.; Yang, T.; Gao, J. STID-Prompt: Prompt learning for sentiment-topic-importance detection in financial news. Knowl.-Based Syst. 2024, 284, 111347. [Google Scholar] [CrossRef]
- Yang, Y.; Uy, M.C.S.; Huang, A. Finbert: A pretrained language model for financial communications. arXiv 2020, arXiv:2006.08097. [Google Scholar]
- Sidogi, T.; Mbuvha, R.; Marwala, T. Stock price prediction using sentiment analysis. In Proceedings of the 2021 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Melbourne, Australia, 17–20 October 2021; pp. 46–51. [Google Scholar]
- Liu, Z.; Huang, D.; Huang, K.; Li, Z.; Zhao, J. Finbert: A pre-trained financial language representation model for financial text mining. In Proceedings of the Twenty-Ninth International Conference on International Joint Conferences on Artificial Intelligence, Online, 7–15 January 2021; pp. 4513–4519. [Google Scholar]
- Fazlija, B.; Harder, P. Using financial news sentiment for stock price direction prediction. Mathematics 2022, 10, 2156. [Google Scholar] [CrossRef]
- Huang, A.H.; Wang, H.; Yang, Y. FinBERT: A large language model for extracting information from financial text. Contemp. Account. Res. 2023, 40, 806–841. [Google Scholar] [CrossRef]
- Girsang, A.S.; Stanley. Cryptocurrency Price Prediction Based Social Network Sentiment Analysis Using LSTM-GRU and FinBERT. IEEE Access 2023, 11, 120530–120540. [Google Scholar] [CrossRef]
- Yu, X.; Chen, Z.; Ling, Y.; Dong, S.; Liu, Z.; Lu, Y. Temporal Data Meets LLM–Explainable Financial Time Series Forecasting. arXiv 2023, arXiv:2306.11025. [Google Scholar]
- Cao, Y.; Zhai, J. Bridging the gap–the impact of ChatGPT on financial research. J. Chin. Econ. Bus. Stud. 2023, 21, 177–191. [Google Scholar] [CrossRef]
- Niszczota, P.; Abbas, S. GPT has become financially literate: Insights from financial literacy tests of GPT and a preliminary test of how people use it as a source of advice. Financ. Res. Lett. 2023, 58, 104333. [Google Scholar] [CrossRef]
- Gupta, U. GPT-InvestAR: Enhancing stock investment strategies through annual report analysis with large language models. arXiv 2023, arXiv:2309.03079. [Google Scholar] [CrossRef]
- Ouyang, T.; MaungMaung, A.; Konishi, K.; Seo, Y.; Echizen, I. Stability Analysis of ChatGPT-based Sentiment Analysis in AI Quality Assurance. Electronics 2024, 13, 5043. [Google Scholar] [CrossRef]
- Pelster, M.; Val, J. Can ChatGPT assist in picking stocks? Financ. Res. Lett. 2024, 59, 104786. [Google Scholar] [CrossRef]
- Oehler, A.; Horn, M. Does ChatGPT provide better advice than robo-advisors? Financ. Res. Lett. 2024, 60, 104898. [Google Scholar] [CrossRef]
- Shafee, S.; Bessani, A.; Ferreira, P.M. Evaluation of LLM-based chatbots for OSINT-based Cyber Threat Awareness. Expert Syst. Appl. 2024, 261, 125509. [Google Scholar] [CrossRef]
- Han, P.; Chen, H.; Rasool, A.; Jiang, Q.; Yang, M. MFB: A generalized multimodal fusion approach for bitcoin price prediction using time-lagged sentiment and indicator features. Expert Syst. Appl. 2025, 261, 125515. [Google Scholar] [CrossRef]
- Zhang, B.; Yang, H.; Liu, X.Y. Instruct-fingpt: Financial sentiment analysis by instruction tuning of general-purpose large language models. arXiv 2023, arXiv:2306.12659. [Google Scholar] [CrossRef]
- Deng, X.; Bashlovkina, V.; Han, F.; Baumgartner, S.; Bendersky, M. What do llms know about financial markets? a case study on reddit market sentiment analysis. In Proceedings of the Companion Proceedings of the ACM Web Conference 2023, Austin, TX, USA, 30 April–4 May 2023; pp. 107–110. [Google Scholar]
- Zhang, B.; Yang, H.; Zhou, T.; Ali Babar, M.; Liu, X.Y. Enhancing financial sentiment analysis via retrieval augmented large language models. In Proceedings of the Fourth ACM International Conference on AI in Finance, Brooklyn, NY, USA, 27–29 November 2023; pp. 349–356. [Google Scholar]
- Wang, N.; Yang, H.; Wang, C.D. Fingpt: Instruction tuning benchmark for open-source large language models in financial datasets. arXiv 2023, arXiv:2310.04793. [Google Scholar]
- Ahmed, R.; Rauf, S.A.; Latif, S. Leveraging Large Language Models and Prompt Settings for Context-Aware Financial Sentiment Analysis. In Proceedings of the 2024 5th International Conference on Advancements in Computational Sciences (ICACS), Lahore, Pakistan, 19–20 February 2024; pp. 1–9. [Google Scholar]
- Kheiri, K.; Karimi, H. Sentimentgpt: Exploiting gpt for advanced sentiment analysis and its departure from current machine learning. arXiv 2023, arXiv:2307.10234. [Google Scholar]
- Fatouros, G.; Metaxas, K.; Soldatos, J.; Kyriazis, D. Can large language models beat wall street? unveiling the potential of ai in stock selection. arXiv 2024, arXiv:2401.03737. [Google Scholar] [CrossRef]
- Rasool, A.; Shahzad, M.I.; Aslam, H.; Chan, V. Emotion-Aware Response Generation Using Affect-Enriched Embeddings with LLMs. arXiv 2024, arXiv:2410.01306. [Google Scholar]
- Alias, M.S.; Fuad, M.H.; Hoong, X.L.F.; Hin, E.G.Y. Financial Text Categorisation with FinBERT on Key Audit Matters. In Proceedings of the 2023 IEEE Symposium on Computers & Informatics (ISCI), Shah Alam, Malaysia, 14–15 October 2023; pp. 63–69. [Google Scholar]
- Fatouros, G.; Soldatos, J.; Kouroumali, K.; Makridis, G.; Kyriazis, D. Transforming sentiment analysis in the financial domain with ChatGPT. Mach. Learn. Appl. 2023, 14, 100508. [Google Scholar] [CrossRef]
- Leippold, M. Sentiment spin: Attacking financial sentiment with GPT-3. Financ. Res. Lett. 2023, 55, 103957. [Google Scholar] [CrossRef]
- Mandloi, L.; Patel, R. Twitter sentiments analysis using machine learninig methods. In Proceedings of the 2020 International Conference for Emerging Technology (INCET), Belgaum, India, 5–7 June 2020; pp. 1–5. [Google Scholar]
- Wang, T.; Lu, K.; Chow, K.P.; Zhu, Q. COVID-19 sensing: Negative sentiment analysis on social media in China via BERT model. IEEE Access 2020, 8, 138162–138169. [Google Scholar] [CrossRef] [PubMed]
- Ray, B.; Garain, A.; Sarkar, R. An ensemble-based hotel recommender system using sentiment analysis and aspect categorization of hotel reviews. Appl. Soft Comput. 2021, 98, 106935. [Google Scholar] [CrossRef]
- Halder, S. Finbert-lstm: Deep learning based stock price prediction using news sentiment analysis. arXiv 2022, arXiv:2211.07392. [Google Scholar]
- Chiranjeevi, P.; Rajaram, A. A lightweight deep learning model based recommender system by sentiment analysis. J. Intell. Fuzzy Syst. 2023, 44, 10537–10550. [Google Scholar] [CrossRef]
- Gössi, S.; Chen, Z.; Kim, W.; Bermeitinger, B.; Handschuh, S. FinBERT-FOMC: Fine-Tuned FinBERT Model with sentiment focus method for enhancing sentiment analysis of FOMC minutes. In Proceedings of the Fourth ACM International Conference on AI in Finance, Brooklyn, NY, USA, 27–29 November 2023; pp. 357–364. [Google Scholar]
- Okey, O.D.; Udo, E.U.; Rosa, R.L.; Rodríguez, D.Z.; Kleinschmidt, J.H. Investigating ChatGPT and cybersecurity: A perspective on topic modeling and sentiment analysis. Comput. Secur. 2023, 135, 103476. [Google Scholar] [CrossRef]
- Branco, A.; Parada, D.; Silva, M.; Mendonça, F.; Mostafa, S.S.; Morgado-Dias, F. Sentiment Analysis in Portuguese Restaurant Reviews: Application of Transformer Models in Edge Computing. Electronics 2024, 13, 589. [Google Scholar] [CrossRef]
- Li, X.; Chan, S.; Zhu, X.; Pei, Y.; Ma, Z.; Liu, X.; Shah, S. Are ChatGPT and GPT-4 general-purpose solvers for financial text analytics? A study on several typical tasks. arXiv 2023, arXiv:2305.05862. [Google Scholar]
- Jing, N.; Wu, Z.; Wang, H. A hybrid model integrating deep learning with investor sentiment analysis for stock price prediction. Expert Syst. Appl. 2021, 178, 115019. [Google Scholar] [CrossRef]
- Ho, T.T.; Huang, Y. Stock price movement prediction using sentiment analysis and CandleStick chart representation. Sensors 2021, 21, 7957. [Google Scholar] [CrossRef]
- Kim, J.; Kim, H.S.; Choi, S.Y. Forecasting the S&P 500 index using mathematical-based sentiment analysis and deep learning models: A FinBERT transformer model and LSTM. Axioms 2023, 12, 835. [Google Scholar] [CrossRef]
- Shobayo, O.; Adeyemi-Longe, S.; Popoola, O.; Ogunleye, B. Innovative Sentiment Analysis and Prediction of Stock Price Using FinBERT, GPT-4 and Logistic Regression: A Data-Driven Approach. Big Data Cogn. Comput. 2024, 8, 143. [Google Scholar] [CrossRef]
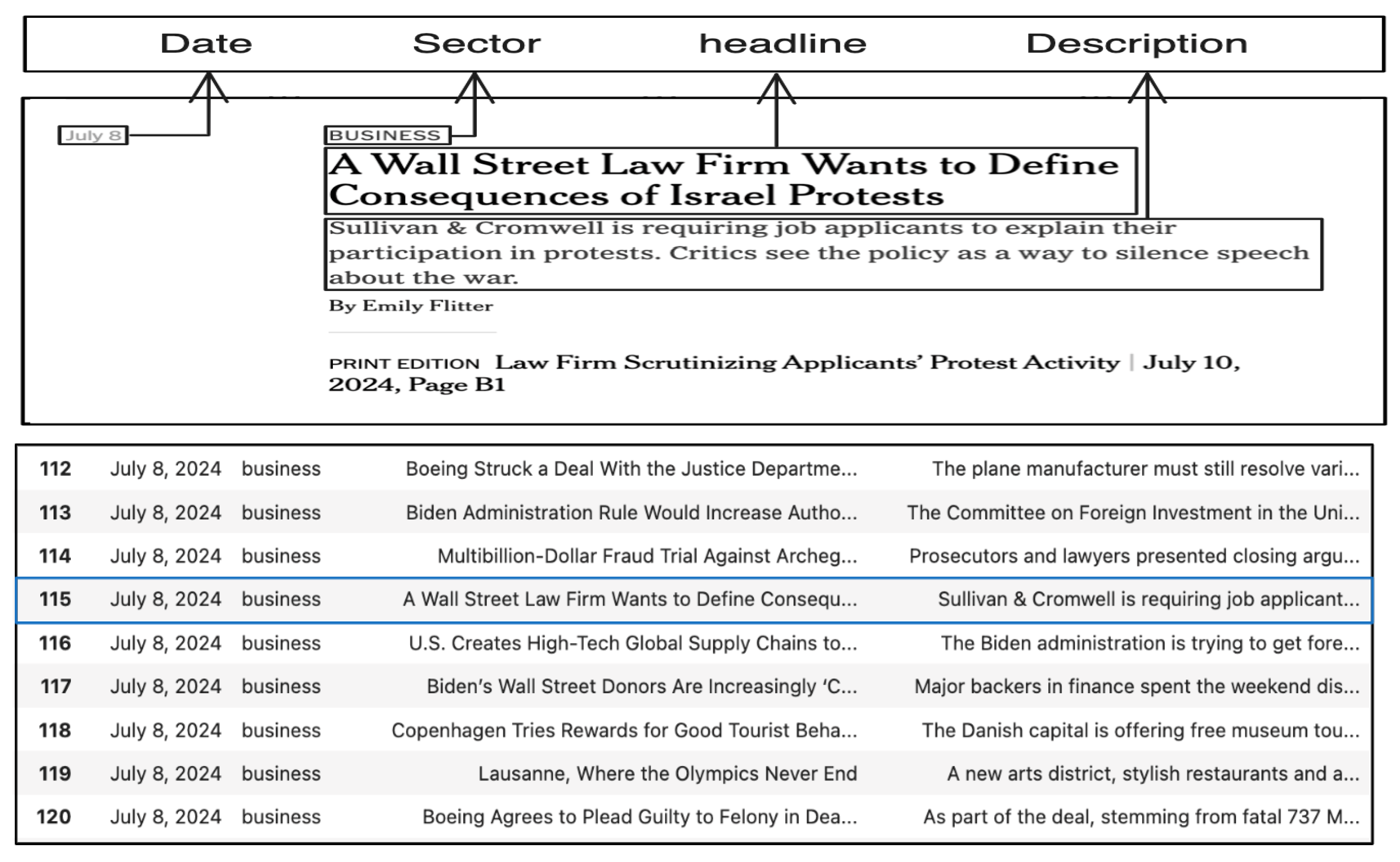
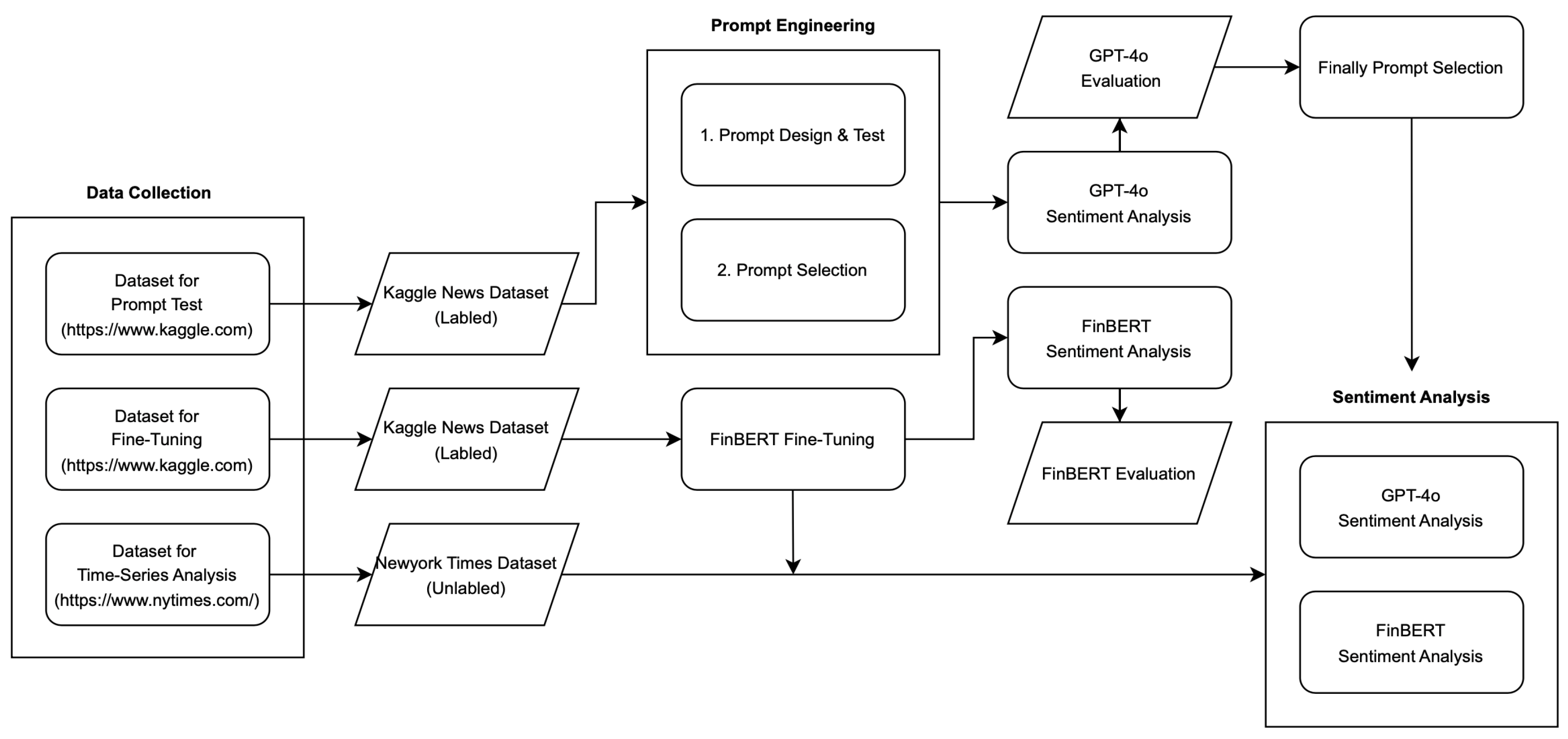
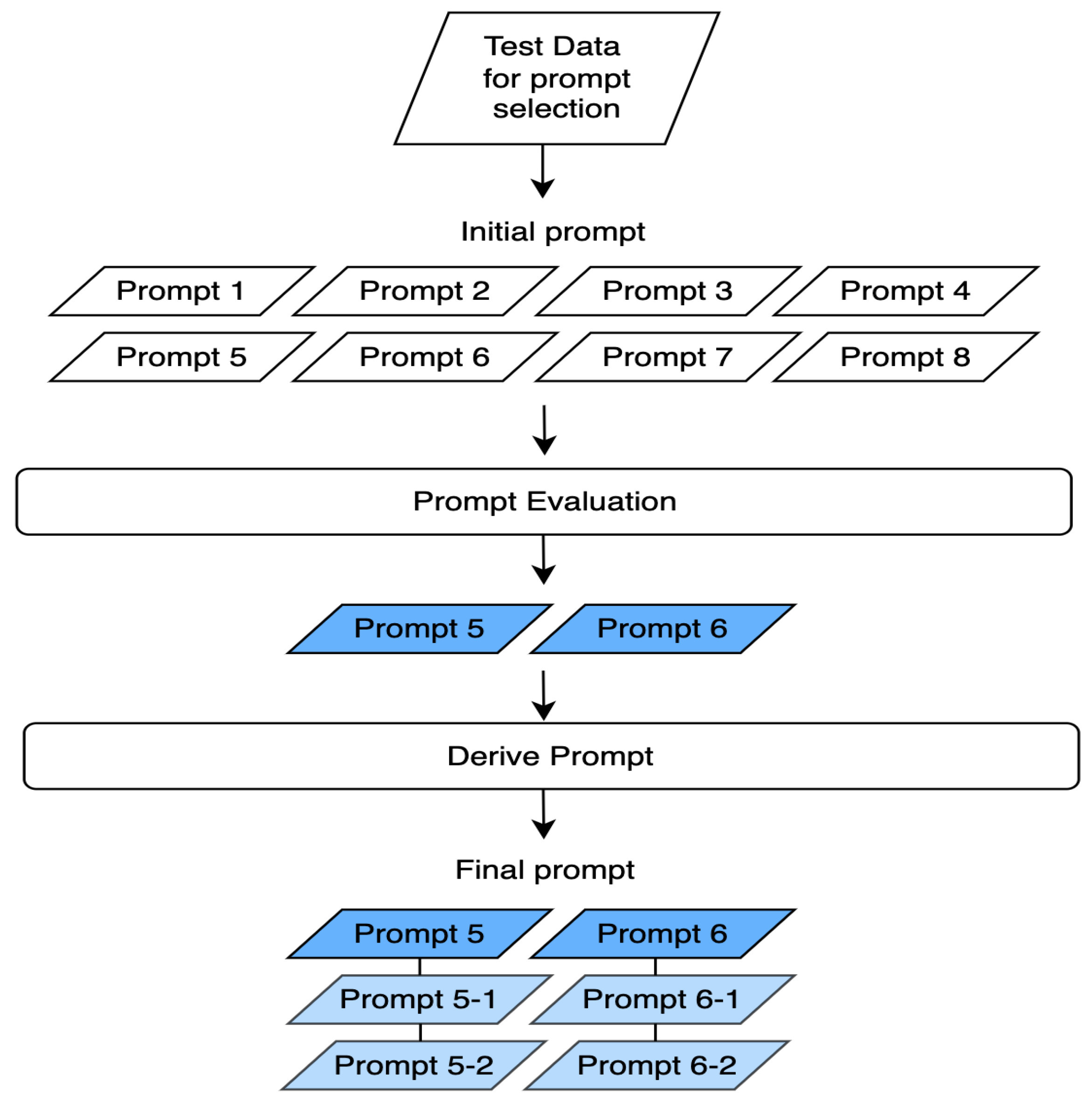
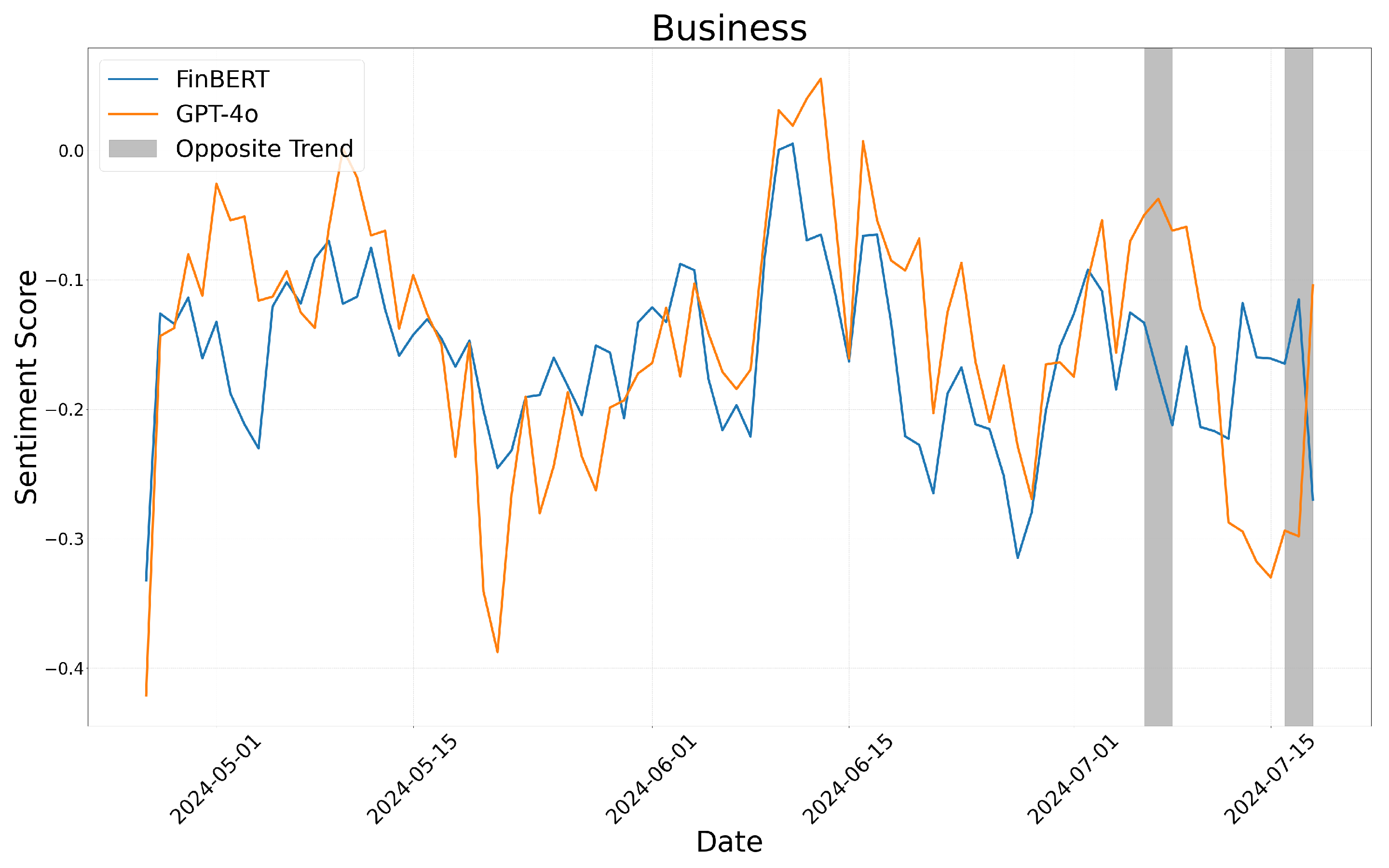
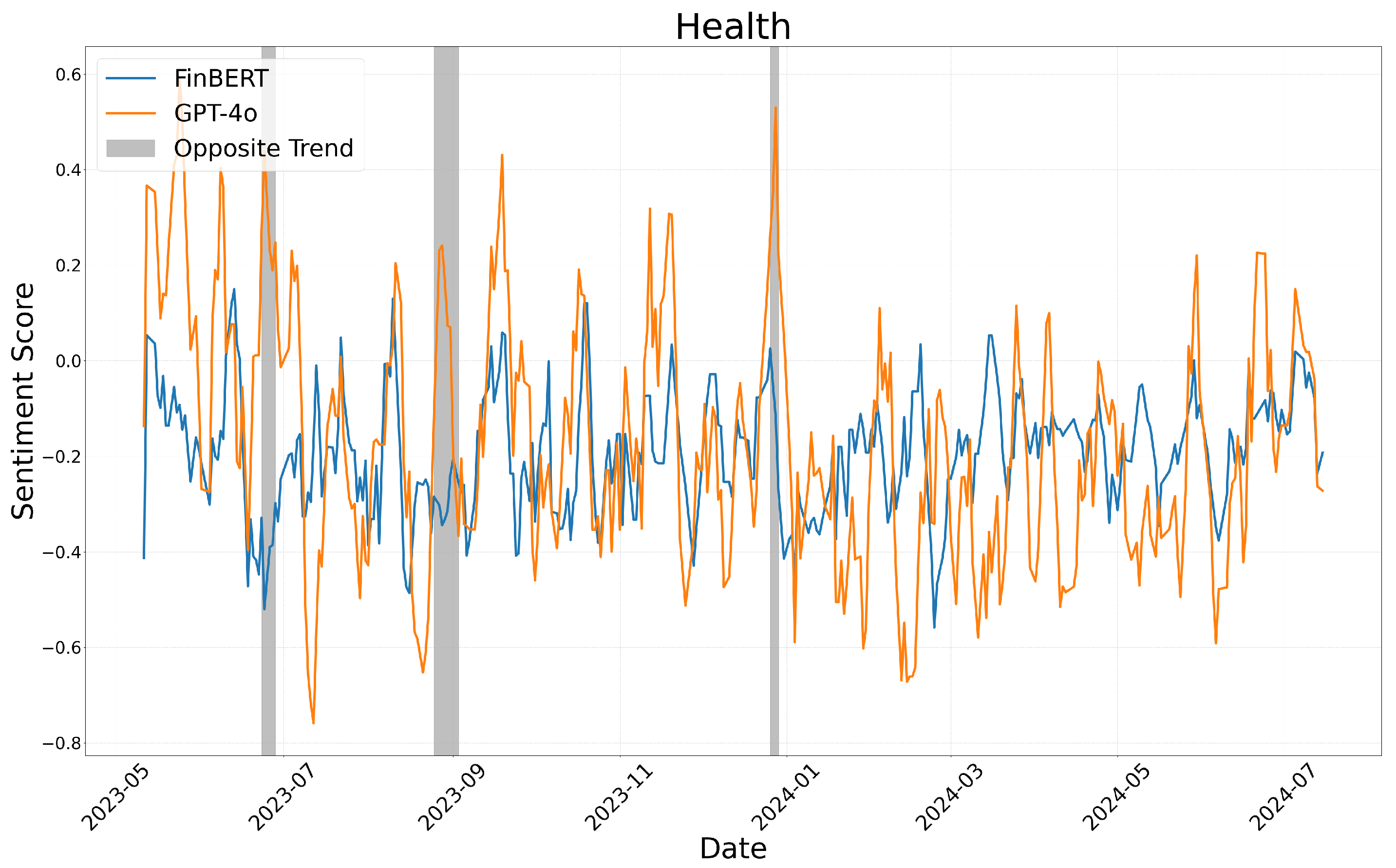
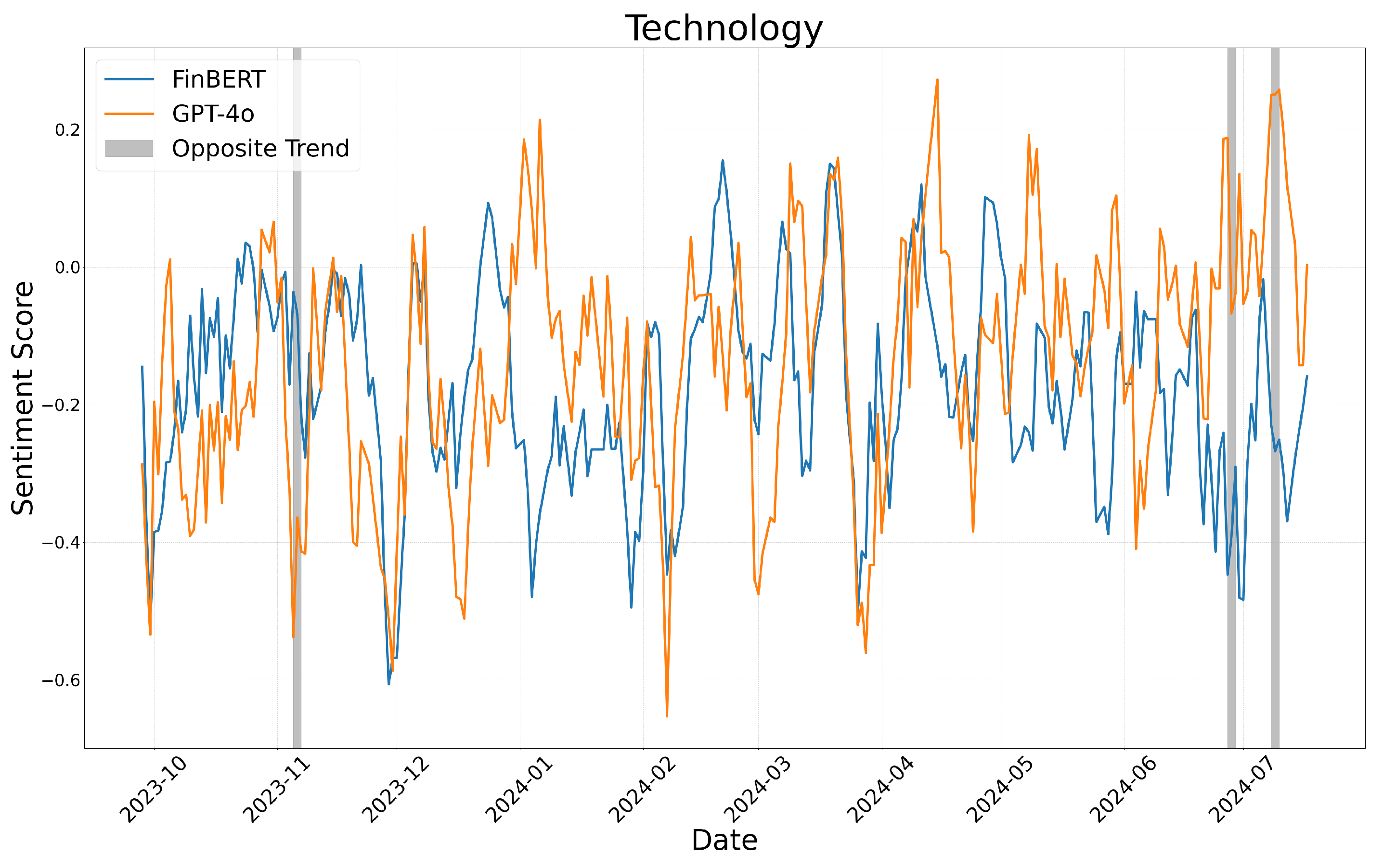
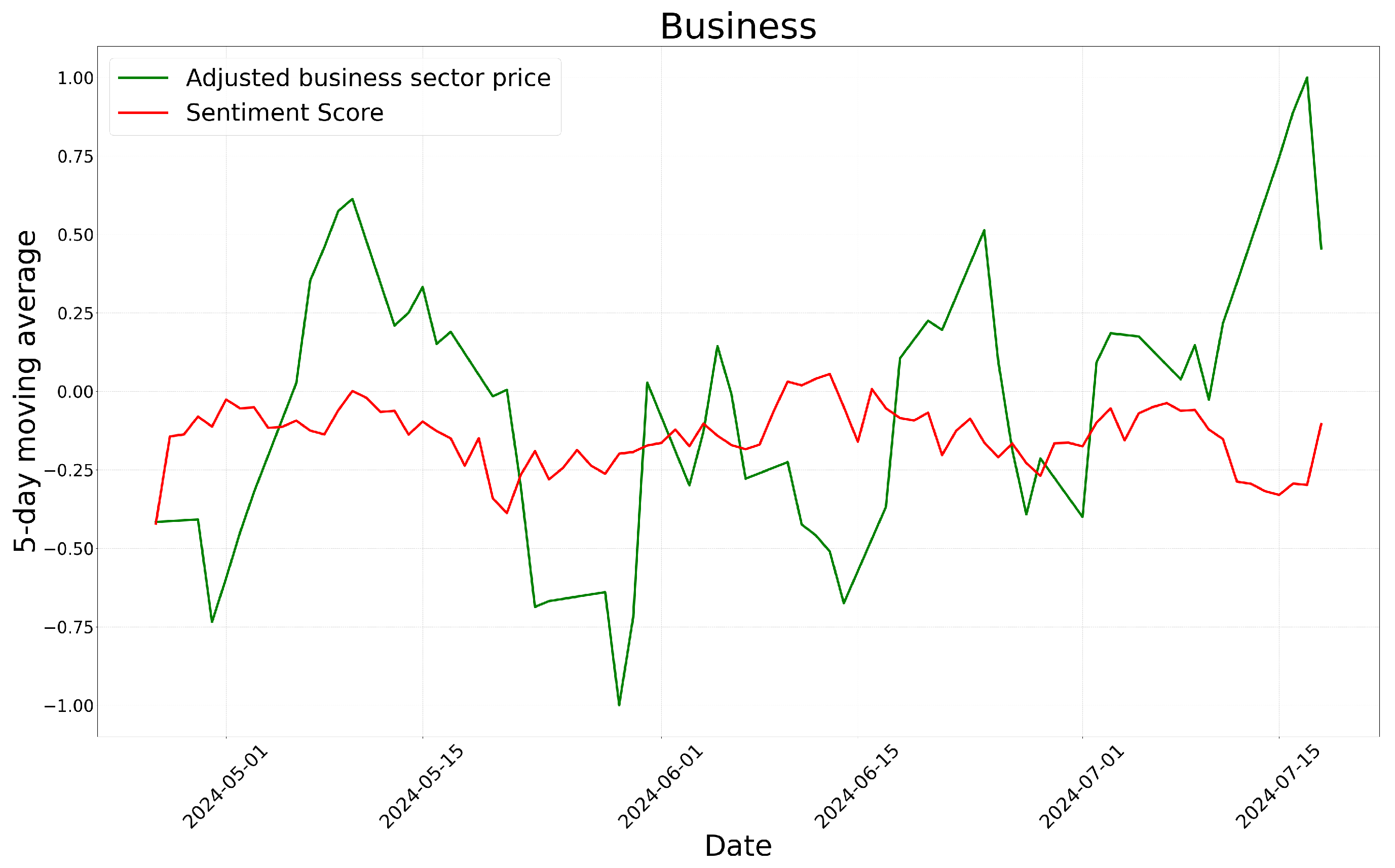
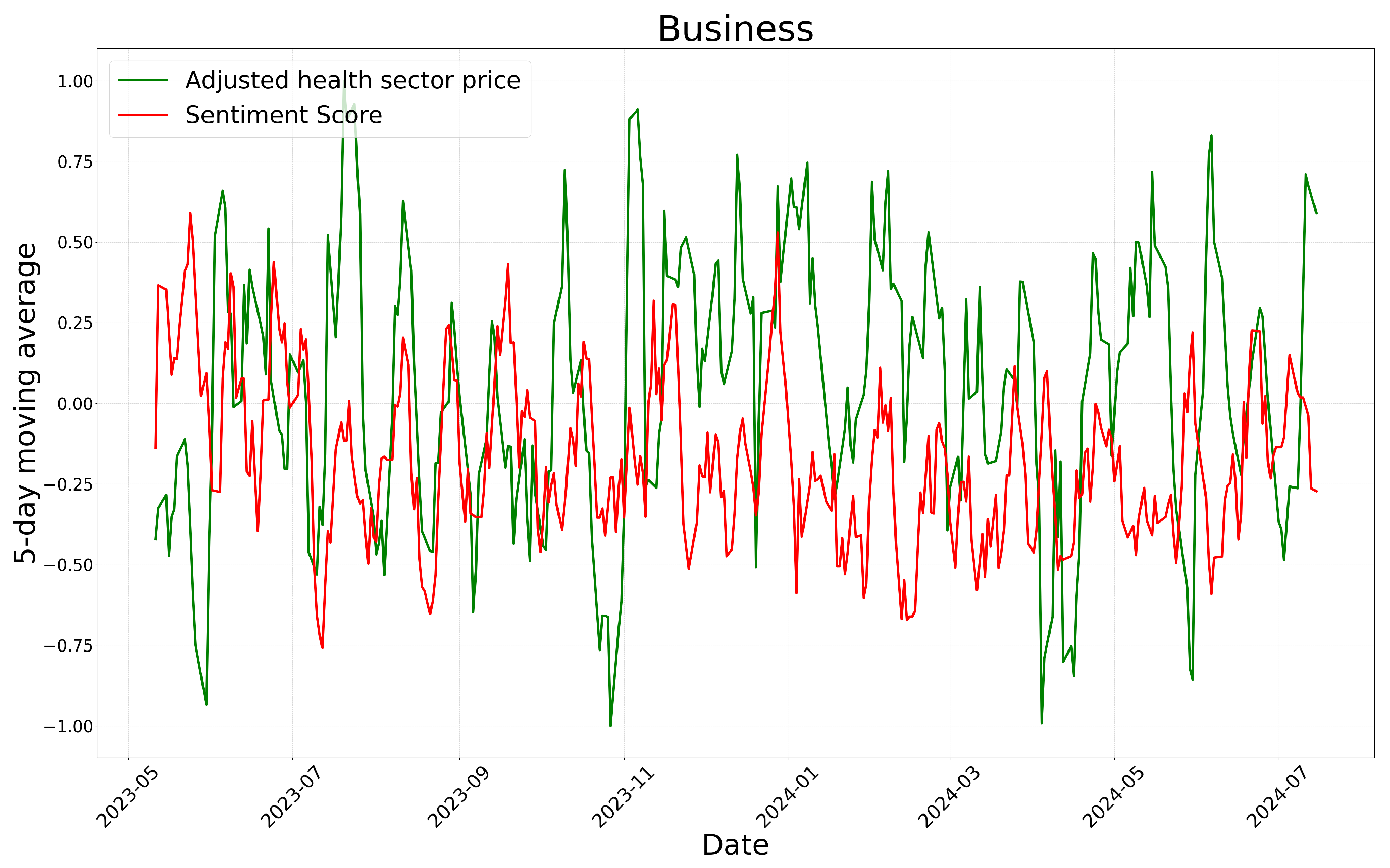
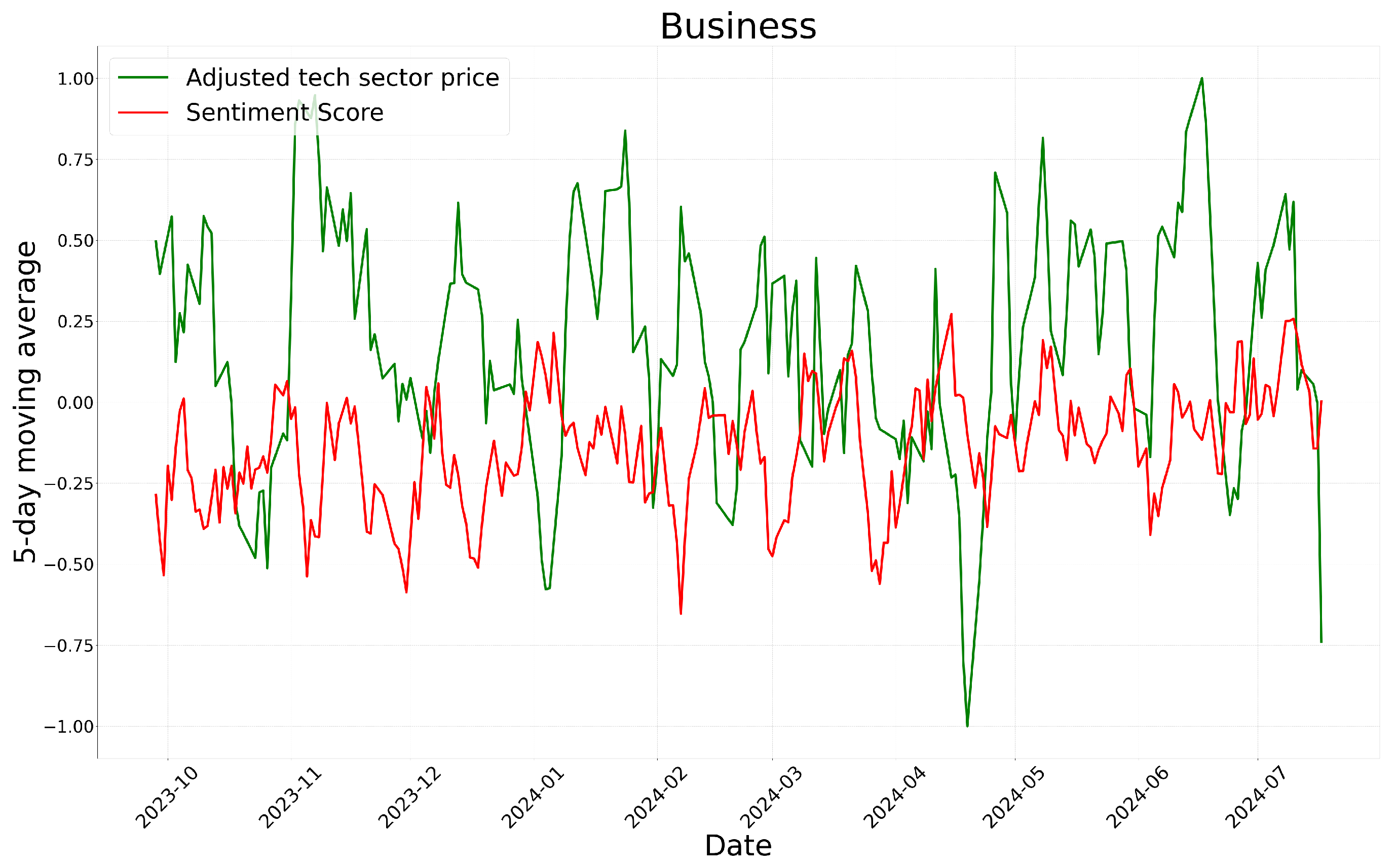
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).