Abstract
Deep-learning-based object detection algorithms play a pivotal role in various domains, including face detection, automatic driving, monitoring security, and industrial production. Compared with the traditional object detection algorithms and the two-stage object detection algorithms, the YOLO (You Only Look Once) series improved the detection speed and accuracy. In addition, the YOLO series of object detection algorithms are widely used in the industrial fields due to their real-time and high-precision characteristics. This work summarizes the main versions of YOLO series algorithms as well as their main improving measures. Furthermore, the following is the analysis of the industrial application fields and some application examples of YOLO series algorithms. Furthermore, this work summarizes the general improvement measures for the industrial applications of the YOLO series algorithms. As for the comparison of these algorithms, this work implements the basic tests for the industrial application performance on different datasets. Finally, the development directions and challenges for YOLO series algorithms are pointed out.
1. Introduction
Object detection entails the process of identifying and determining the precise locations of objects depicted within an image. As a key in the fields of artificial intelligence, object detection determines the performance of other tasks. It possesses a wide range of applications in many fields, e.g., industry [1,2,3], agriculture [4,5,6], transportation [7,8,9], medical care [10,11,12], and meteorology [13,14,15].
1.1. Classification of Object Detection Algorithms
Object detection algorithms can be classified into three main categories: classic algorithms, deep neural network (DNN)-based algorithms, and zero/few-shot learning algorithms.
1.1.1. Classic Algorithms
Classic object detection algorithms rely on handcrafted features and traditional machine learning techniques. These algorithms typically involve three main steps: locating the possible location of the objects, extracting the features of the located area, and sending the extracted features into a classifier for classification. Examples include Viola-Jones, HOG+SVM, and DPM. While these algorithms are computationally efficient, they lack robustness and generalization capabilities in varying environments.
1.1.2. Neural Network (DNN)-Based Algorithms
DNN-based object detection algorithms leverage deep learning techniques to automatically learn features from raw image data. These algorithms can be further divided into one-stage and two-stage algorithms. One-stage algorithms like YOLO and SSD directly predict object classes and bounding boxes from the input image, while two-stage algorithms like R-CNN, Fast R-CNN, and Faster R-CNN first propose potential object regions and then refine the predictions. DNN-based algorithms offer superior accuracy and robustness compared to classic algorithms.
1.1.3. Zero/Few-Shot Learning Algorithms
Zero-shot and few-shot learning algorithms aim to detect objects from unseen categories with minimal or no labeled training data. These algorithms utilize meta-learning techniques, transfer learning, and external knowledge sources (e.g., word embeddings) to generalize to new categories. This approach is particularly useful in scenarios where labeled data are scarce or expensive to obtain.
In 2012, Hinton et al. [16] proposed AlexNet based on deep learning, which outperformed the second place in ImageNet by 41%, showing the great superiority of deep learning technology. Furthermore, according to the different detection stages, the algorithms based on deep learning for object detection can be divided into two categories: one-stage algorithms and two-stage algorithms. The one-stage algorithms mainly include YOLO [17,18,19,20,21], SSD [22], DSSD [14], RetinaNet [15], RefineDet [23], etc. They use the regression method to get the final results, which possesses a fast detection speed, but the prediction accuracy of small target objects is insufficient. Two-stage algorithms mainly include R-CNN [24], Fast R-CNN [25], Faster R-CNN [26], Mask R-CNN [27], etc. They need to propose a region where the target may appear first. Then, they detect the target object according to the region proposal. These algorithms demonstrate a high level of accuracy in detection; however, the detection speed is low, relatively.
Object detection entails the process of identifying and determining the precise locations of objects depicted within an image. As a key in the fields of artificial intelligence, object detection determines the performance of other tasks. Among various one-stage object detection algorithms, such as SSD, RetinaNet, and YOLO, the YOLO series stands out for its unique architecture and continuous performance improvements. From YOLOv1 to YOLOv7, each version introduces significant enhancements that have made YOLO algorithms highly suitable for industrial applications. Therefore, this survey focuses on the YOLO series algorithms to provide a detailed analysis of their development and industrial applications.
In 2015, Redmon et al. [17] proposed the YOLO algorithm (YOLOv1), after which five major versions were gradually developed, including YOLOv1 [17], YOLOv2 [18], YOLOv3 [19], YOLOv4 [20], and YOLOv5 [21]. The object detection mechanism of YOLO series algorithms is shown in Figure 1. The early versions of them possess shortcomings such as low detection accuracy and poor detection precision of small target objects. In the process of continuous improvement, YOLO series object detection algorithms not only improve the detection accuracy, but also take into account the detection speed. Meanwhile, it also improved the detecting performance on small targets. These improvements make the YOLO series algorithms both high-precision and real-time. Moreover, due to its deep-learning-based algorithm architecture, YOLO series of object detection algorithms possess a better robustness, which lays a solid foundation for their wide application.
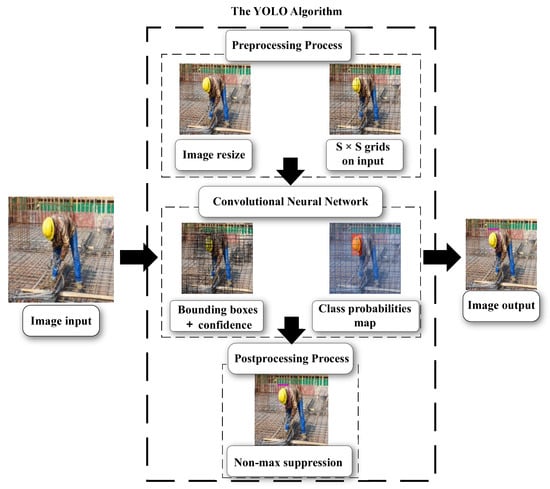
Figure 1.
The object detection mechanism of the YOLO series algorithms.
Based on their excellent performance, the YOLO series algorithms are widely used. They are widely applied in artificial intelligence fields such as industrial production, automatic driving, text recognition, and face detection. In addition, the YOLO series algorithms can also be applied across disciplines to promote the development of other disciplines. In May 2021, Leila et al. [28] applied the YOLOv3 algorithm to the field of shipwreck detection, bringing new momentum to the field of archaeological research. However, since images from different industrial fields usually present different characteristics, object detection algorithms in the industrial fields are different from those in other fields. There are many differences between their images. Putting the YOLO series algorithms directly into the industrial environment cannot achieve satisfactory results. Therefore, it is crucial to modify the structure of the algorithms in a targeted manner.
Aiming at the industrial application of the YOLO series of object detection algorithms, this survey makes the following main contributions:
- Introduce the main versions and improvement measures of YOLO series algorithms;
- Summarize the industrial application fields and application examples of YOLO series algorithms;
- Summarize the general improvement measures for the industrial application of YOLO series algorithms;
- Test the performance of the main versions of YOLO series algorithms;
- Point out the development directions and challenges of YOLO series algorithms.
The following is the structure of this survey. Section 2 is the algorithm introduction part, which introduces the framework and improvement measures of the main versions of the YOLO series algorithms. Section 3 is the industrial application part, which introduces the industrial application of the algorithms. There, we also summarize the general improvement measures for the industrial application of these algorithms. Section 5 is the algorithm comparison part, which compares the performance of the main versions of the YOLO series algorithms. Section 6 is the part of development directions and challenges of the YOLO series algorithms. Section 7 is the conclusion part, which provides an overview of this survey.
As shown in Figure 2, we focus on the main versions of the YOLO series algorithms from YOLOv1 to YOLOv7, which were released up to July 2022. Future research will explore newer versions such as YOLOv8, YOLOv9, and YOLOv10 to provide a more comprehensive understanding of the development and industrial applications of these algorithms.
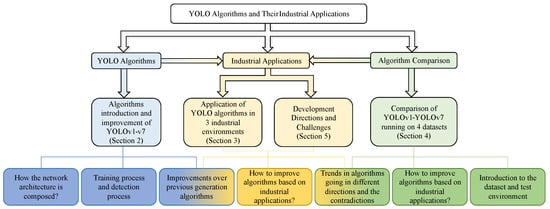
Figure 2.
Introduction of the YOLO algorithm and its application and development trend in industry.
2. Algorithm Introduction
Before the proposal of the YOLO series algorithms, the mainstream object detection algorithms based on deep learning used object classification to detect target objects. At the beginning of the object detection process, methods such as region proposal, window sliding, and template matching were used to filter the possible object regions in the entire image. Then, the convolution layer was used to extract the regional features of the image, and the fully connected layer was added to classify the extracted features in the previous process. Finally, the region of the extracted features was taken as the region where the object was located. The result obtained after classification was taken as the category of the object. Although this type of method has a relatively prominent performance in accuracy, its network structure is complex. This type of methods requires a large amount of calculation, which indicates that they possess poor real-time performance and a low detection efficiency.
Compared with other one-stage object detection algorithms like SSD and RetinaNet, YOLO series algorithms offer a simpler yet more efficient approach. YOLO integrates object detection and classification into a whole regression problem, using a single convolutional neural network framework to recognize the entire image. This design not only simplifies the network structure but also significantly improves the detection speed while maintaining high accuracy.
Section 2 introduces the algorithm frameworks and improvement methods of the main versions of the YOLO series of object detection algorithms. The versions involved include YOLOv1, YOLOv2, YOLOv3, YOLOv4, YOLOv5, YOLOv6, and YOLOv7. The main improvements of the YOLO series of object detection algorithms are shown in Figure 3.
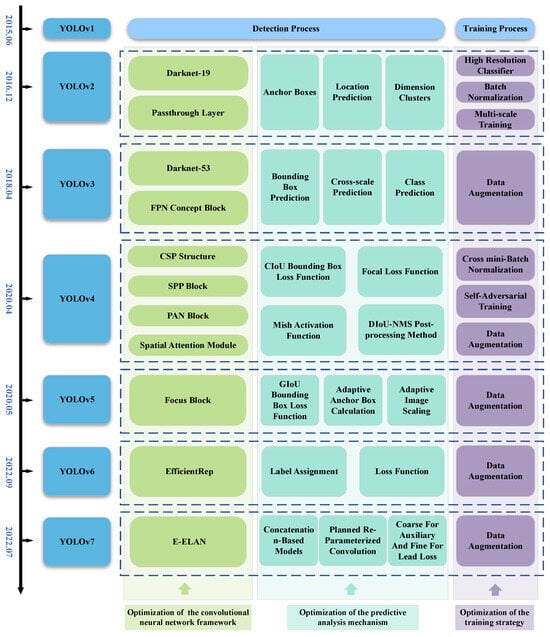
Figure 3.
The main improvements of the YOLO series of object detection algorithms.
2.1. YOLOv1
Before diving into the details of the YOLO series algorithms, it is essential to understand the context in which these algorithms emerged. Classic algorithms, while efficient, lack the robustness and generalization needed for complex and varied environments. DNN-based algorithms, especially one-stage algorithms like YOLO, significantly improved detection speed and accuracy. Zero/few-shot learning algorithms offer promising solutions for scenarios with limited labeled data.
As the first version of YOLO series algorithms, YOLOv1 algorithm pioneered the integration of object detection and classification into a whole regression problem. It simply utilizes a single convolutional neural network framework to recognize the entire image.
In general, the framework of the YOLO series of object detection algorithms mainly includes two main processes, i.e., the detection process and the training process, as shown in Figure 4.
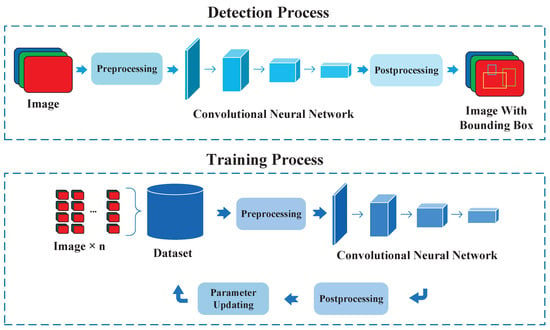
Figure 4.
The entire construction of the YOLO algorithm including the detection process and training process.
2.1.1. Detection Process
- Image Input: Input the original image.
- Preprocessing Process: Perform simple preliminary processing on the image, including resizing the image to an appropriate size, dividing the image into S × S grids, etc.
- Convolutional Neural Network: Through the operations of convolutional layer, pooling layer, fully connected layer, etc. It outputs a three-dimensional tensor to represent the obtained prediction information. The specific framework of the convolutional neural network is shown in Figure 5.
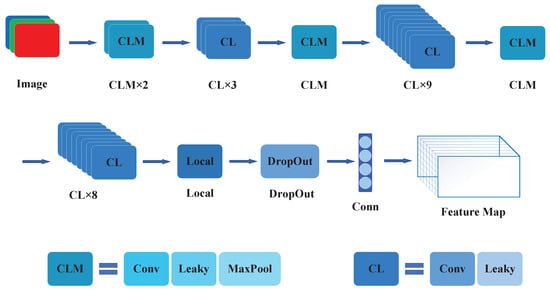 Figure 5. The CNN framework of YOLOv1.
Figure 5. The CNN framework of YOLOv1.
Each grid in the image is responsible for predicting the image centered on that grid. Each grid contains B bounding box information and C conditional probabilities for judging object classes. A bounding box contains five aspects of information including x, y, w, h, and confidence. (x, y) represents the center point position of the detected object in the image; w and h represent the width ratio and the height ratio of the bounding box to the entire image, respectively; and confidence represents the probability that the predicted bounding box may contain an object. The confidence score is defined in Equation (1).
where is the possibility that the bounding box contains an object (if the ground truth center is located in the grid, ; otherwise, ) and is the intersection ratio of the ground truth and the predicted bounding box.
The conditional probability of judging the object category represents the probability that the object belongs to the i-th object among the C objects under the condition that the bounding box predicted by the grid already contains the object, as shown in Equation (2):
In the detection process, the confidence is multiplied by the conditional probability for the predicted object that belongs to the i-th object to express the comprehensive confidence of the predicted bounding box, as shown in Equation (3):
where is the probability that the predicted object is the i-th class object and is the value predicted by the neural network in detection process.
After processing by the convolutional neural network, it outputs a three-dimensional tensor of , where reflects the grid dimensions, B is the number of bounding boxes per grid, and C is the number of object classes.
- 4.
- Postprocessing Process: Filter redundant bounding boxes by methods such as non-maximum suppression.
- 5.
- Image Output: Integrate the processed data onto the image and output.
2.1.2. Training Process
- Dataset Input: Input the images with labels.
- Preprocessing Process: Similar to the detection process, image size processing, grid division, and other preprocesses are performed.
- Convolutional Neural Network: Input the image from the dataset into convolutional neural network to obtain a three-dimensional tensor containing prediction information.
- Postprocessing Process: Filter redundant boundaries by methods such as non-maximum suppression.
- Network Parameter Adjustment: Through regression analysis, adjust the network parameters in the convolutional neural network so that the three-dimensional tensor information output by the network can be closer to the real value.
2.2. YOLOv2
YOLOv2 made some improvements based on YOLOv1. For example, modifying the convolutional neural network framework, optimizing the predictive analysis mechanism, as well as improving the training strategy. Figure 6 shows the specific structure of the convolutional neural network of YOLOv2.
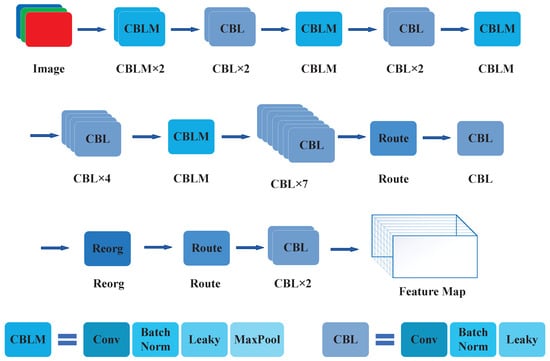
Figure 6.
The CNN construction of YOLOv2.
The modification of YOLOv2 to the YOLOv1 algorithm mainly includes the following aspects.
- Darknet-19: YOLOv2 uses Darknet-19 as the main framework of the convolutional neural network. Compared with the convolutional neural network structure of YOLOv1, this network framework is more sufficient for extracting the feature of the target object. This helps YOLOv2 possesses a higher detection accuracy and a faster detection speed.
- Passthrough Layer: To address the challenge of detecting small targets more effectively in YOLOv1, YOLOv2 adds a passthrough layer to the convolutional neural network. This combines deep low-resolution features with shallow high-resolution features, which improving the algorithm detection performance for small target objects.
- Anchor Boxes: YOLOv2 uses a different way to predict coordinates. It removes the fully connected layer and adds anchor boxes to the convolutional layer. By predicting the offset of the anchor boxes, the objects to be detected are located indirectly, which simplifies the network predicting process for the position coordinates of the objects.
- Location Prediction: In the early stage of algorithm training, unrestricted coordinate prediction often cannot make the loss function converge quickly. Therefore, YOLOv2 uses the Logistic function to limit the bounding box offset relative to the anchor box, which improves the efficiency and stability in the initial training process of the algorithm.
- Dimension Clusters: Dimension clustering is used to solve the problem of weak adaptability of anchor boxes to objects of different sizes. In order to enable the anchor boxes to adapt to objects of different shapes and sizes, YOLOv2 uses dimensional clustering to get the size and number of the anchor boxes. YOLOv2 uses IoU representation method to describe the fitting degree of the anchor boxes to objects of different sizes. The expression formula is as Equation (4):where represents the IoU distance, represents the remaining boxes, represents the cluster center boxes, and is the intersection ratio between the remaining boxes and the cluster center boxes.Through dimensional clustering, YOLOv2 modifies its predictive analysis mechanism by optimizing the size and number of the anchor boxes to speed up the convergence of the loss function during algorithm training.
- High Resolution Classifier: Using the high-resolution images to improve the classifier obtained by training so that the network can adapt to the high-resolution images input during the detection process in advance. In this way, the algorithm can obtain a better detection performance in the process of detection.
- Batch Normalization: Adding the batch normalization [29] layer after all convolutional layers. This increases the network parameters and the network calculation amount. However, it has a good influence on speed and accuracy optimization of the entire network in the training process.
- Multiscale Training: During the training of the neural network, YOLOv2 adopts the method of training images of different scales to increase the robustness of the network for image recognition.
2.3. YOLOv3
Based on YOLOv2, YOLOv3 enhances the network framework and bolsters its ability to detect small target objects. In addition, the cross-scale prediction mechanism adopted by YOLOv3 also makes it possess a wider range of applications. The main convolutional neural network framework of YOLOv3 is shown in Figure 7. The following are the main improvement measures for YOLOv3.
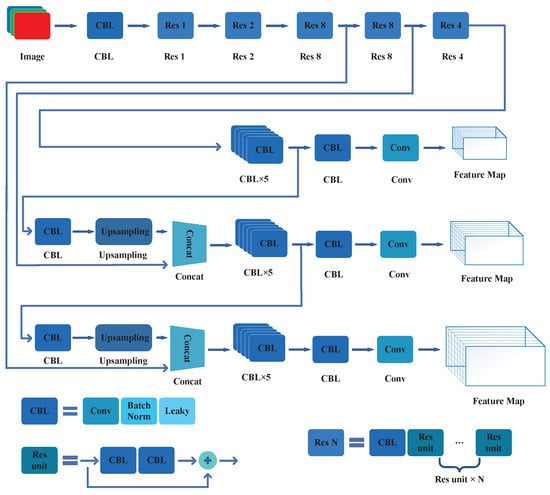
Figure 7.
The CNN construction of YOLOv3.
The modification of YOLOv3 to the YOLOv2 algorithm mainly includes the following aspects.
- Darknet-53: YOLOv3 uses the Darknet-53 network framework for feature extraction. Compared with the Darknet-19 of YOLOv2, Darknet-53 greatly increases the number of the convolution layers in the network, and thereby, it further increases the network’s ability to extract image features.
- FPN Concept Block: YOLOv3 uses a similar concept to Feature Pyramid Networks (FPN) [30] to extract features from three different scales. This enables YOLOv3 to predict objects through three different scales. Furthermore, this enhancement also results in YOLOv3 exhibiting superior performance in detecting small objects.
- Bounding Box Prediction: In the bounding box prediction during the training process, YOLOv3 calculates an objectness score for each bounding box predicted by the network through Logistic regression. The objectness score quantifies the extent of alignment between the bounding box and the ground truth. Each grid only uses the anchor boxes with a higher objectness score for subsequent operations. The anchor boxes that are not used do not affect the coordinates and classification values in the loss function. This reducing the instability of YOLOv3 in the early stage of training and improving its training speed.
- Cross-scale Prediction: To improve the prediction performance of the network for objects of different scales, YOLOv3 predicts objects on three scales. Three anchor boxes are adopted for prediction on each grid at each scale.
- Class Prediction: YOLOv3 uses an independent Logistic classifier for multilabel classification. This enables YOLOv3 to show better performance in the face of more overlapping labels in the dataset.
- Data Augmentation: In the process of training, data augmentation can produce more images for training, which makes the loss function more easier to converge. Image processing methods, e.g., optical distortion and geometric distortion, are beneficial to the extraction of deep-level features of images by convolutional neural networks.
2.4. YOLOv4
Alexey Bochkovskiy et al. summarized the general measures to optimize the performance of the object detection algorithms and used some of them in YOLOv4. The main network construction of YOLOv4 is exhibited in Figure 8. The following are the main optimization methods for YOLOv4.
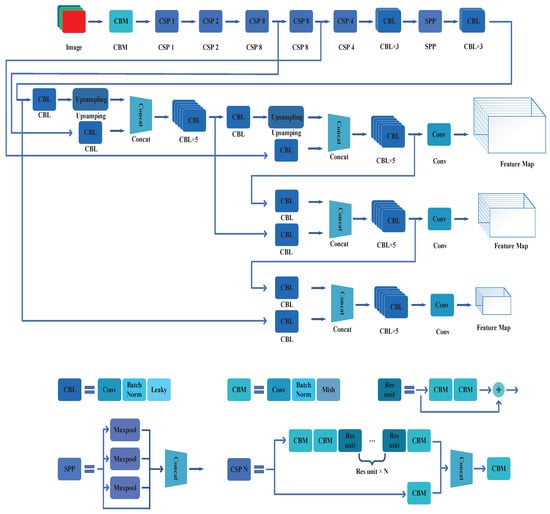
Figure 8.
The CNN construction of YOLOv4.
- CSP Structure: YOLOv4 adds a Cross Stage Partial (CSP) [31] structure to the backbone network and the branch network, which efficiently reduces the number of parameters in the whole network. Thereby, it optimizes the real-time performance of the algorithm.
- SPP Block: Enhanced receptive field mainly refers to enhancing the ability of the algorithms to perceive large area and global range information from the image. The main methods include Spatial Pyramid Pooling (SPP) [32], Atrous Spatial Pyramid Pooling (ASPP) [33], Receptive Field Block (RFB) [34], etc. YOLOv4 selects the SPP block to enhance its receptive field.
- PAN Block: In the process of object detection, it is not only necessary to utilize the deep level image features for forwarding inference, but also to utilize the underlying features to improve the prediction effect of the object detection algorithms. Commonly used feature integration methods include Feature Pyramid Networks (FPN), Scalewise Feature Aggregation Module (SFAM) [35], Adaptively Spatial Feature Fusion (ASFF) [36], BiFPN [37], etc. YOLOv4 selects PAN as its feature integration block.
- Spatial Attention Module: The attention mechanism is used to enable the object detection algorithms to retain important data information during detection process. At the same time, the networks also use it to suppress invalid data information so that the algorithm can analyze the data in a concentrated and effective manner. The main methods are Squeeze-and-Excitation (SE) [38], Spatial Attention Module (SAM) [39], etc. YOLOv4 uses SAM as its attention mechanism.
- CIoU Bounding Box Loss Function: Whether the prediction performance of the predicted bounding box can be more accurately represented plays a key role in optimizing the comprehensive performance of the algorithms. The methods to describe the performance of the predicted bounding box mainly include IoU-Loss, GIoU-Loss [40], DIoU-Loss [41], CIoU-Loss [41], etc. YOLOv4 uses the CIoU-Loss as its bounding box loss function.
- Focal Loss Function: For training process, due to the different proportions of different categories of images in the image datasets, the corresponding weights of different categories of objects may be different. This makes the algorithm easy to ignore those objects that make up a small proportion of the dataset. The focus loss function can balance the weight difference of the object detection algorithm for different types of objects in the image dataset.
- Mish Activation Function: The traditional tanh and sigmoid activation functions possess the problem of gradient disappearance in training process. To solve this, Nair and Hinton [42] proposed the ReLU activation function in 2010, which essentially solved the problem of gradient disappearance. Furthermore, derived methods include LReLU [43], PReLU [44], ReLU6 [45], Scaled Exponential Linear Unit (SELU) [46], Swish [47], hard-Swish [48], and Mish [49]. YOLOv4 uses Mish as its activation function, which helps YOLOv4 obtain better stability in the training process.
- DIoU-NMS Post-processing Method: The post-processing method refers to removing the repeated prediction for the same object and retaining the prediction with higher confidence. It is the process that performing the final detection on the predicted bounding box before outputting the final image processing result. The main methods are NMS, greedy NMS [24], soft NMS [50], DIoU-NMS [41], etc. YOLOv4 selects DIoU-NMS as its post-processing method, which improves YOLOv4’s performance in detecting occluded objects.
- Cross mini-Batch Normalization: YOLOv4 proposed the Cross mini-Batch Normalization (CmBN) [20] for the training process. CmBN is an optimization of the Cross-Iteration Batch Normalization (CBN) [51]. CmBN collects statistics only between mini-batches within a single batch. It makes the algorithms upgrade the parameters in one batch.
- Self-Adversarial Training: Self-Adversarial Training is an important way to increase the robustness of algorithms. In the adversarial training process, the input images will be mixed with some small disturbances. After the training process, the algorithms will adapt to the change, which makes the algorithms more robust.
- Data Augmentation: Data augmentation can increase the number and richness of datasets. In addition to traditional methods like optical distortion and geometric distortion, image data can also be enhanced by occluding target objects and generating adversarial networks. Some representative measures include random erase [52], CutOut [53], hide-and-seek [54], grid mask [55], DropOut [56], DropConnect [57], DropBlock [58], MixUp [59], CutMix [60], Style Transfer GAN [61], etc. YOLOv4 uses CutMix and Mosaic [20] as its data augmentation methods.
2.5. YOLOv5
The YOLOv5 object detection algorithm was developed by Ultralytics [21]. It also uses the CSP structure, SPP block, and PAN block in its network. By analyzing the open-source code provided by Ultralytics, the main improvement methods of YOLOv5 can be summarized as the following aspects. The main network framework of YOLOv5s is shown in Figure 9.
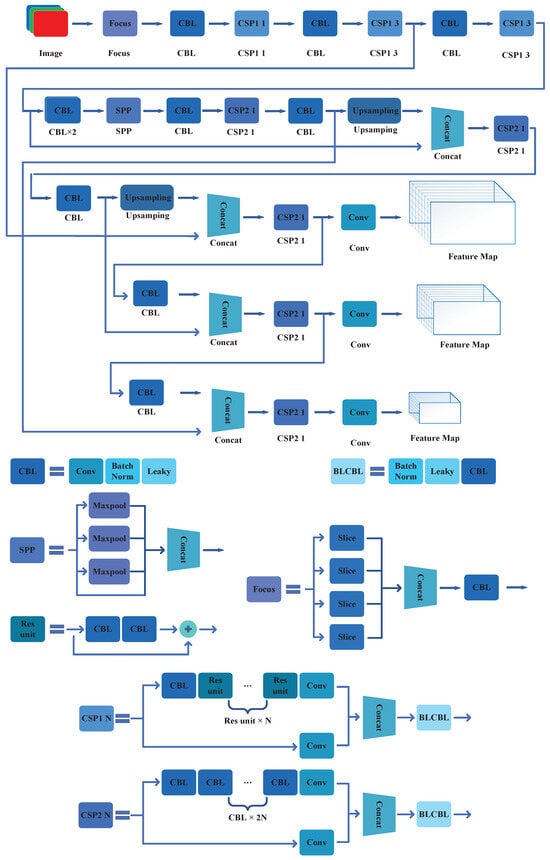
Figure 9.
The CNN construction of YOLOv5.
The following are the main optimization methods for YOLOv5.
- Focus Block: Focus block uses slicing operation to down-sample the input image. Meanwhile, it also increases the input channel of the image while keeping the input information unchanged. This makes the feature extracted from the convolutional neural network more sufficient.
- GIoU Bounding Box Loss Function: YOLOv5 uses the GIOU-Loss method for calculating the bounding box loss function. This loss function effectively captures the disparity between the predicted bounding box performance and the actual performance, thereby enhancing the algorithm’s training efficacy.
- Adaptive Anchor Box Calculation: The clustering process of anchor boxes is embedded into the training process. It automatically calculates the optimal value of anchor boxes in different datasets. This predictive analysis mechanism helps YOLOv5 improve the performance in the detection process.
- Adaptive Image Scaling: During the detection process, the input image is usually converted to the size specified by the network by scaling and filling. However, too much filling will increase the redundant information. Therefore, in YOLOv5, the redundant information of image filling is minimized. Meanwhile, the detection efficiency of the algorithm is improved by adaptive image scaling. In the process of training, the method of filling to the specified size is still used in the algorithm.
- Data Augmentation: Through random scaling, random cropping, and random arrangement of images, multiple images are integrated into one image. This greatly improves the diversity of input data. Furthermore, this also helps reduce overfitting in the training process.
2.6. YOLOv6
YOLOv6 was published on ArXiv in September 2022 by the Meituan Vision AI department of Mission. The network is designed with an efficient backbone based on RepVGG or CSP, a neck based on PAN topology, and an efficient decoupling head with a hybrid-channel strategy. The authors broadly verify the advanced detection techniques for label assignment, loss function, and data augmentation and adopt them selectively to further boost the performance. In addition, the paper introduces enhanced quantization techniques using post-training quantization and channelwise distillation. Overall, YOLOv6 outperforms previous state-of-the-art models on accuracy and speed metrics (Figure 10).
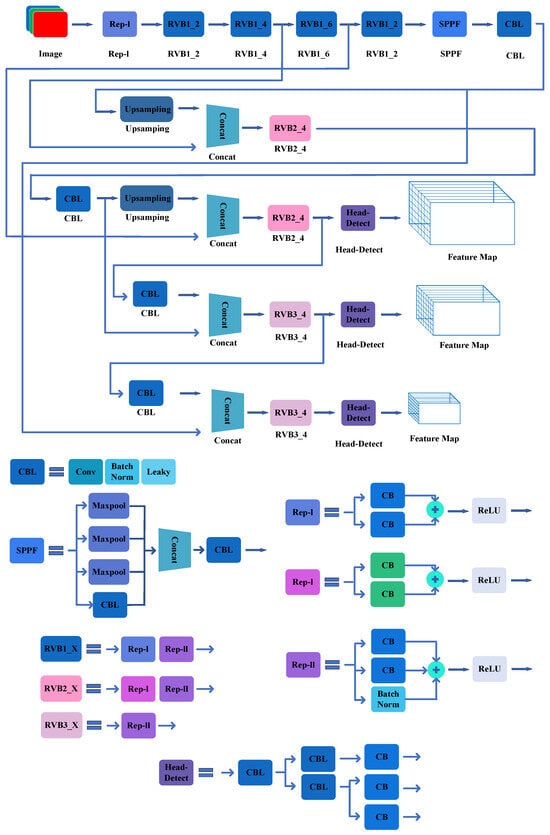
Figure 10.
The CNN construction of YOLOv6.
The main innovations of the model are summarized below.
- A new network backbone called EfficientRep: For small networks, the RepBlock module built on RepVGG is used. For large networks, the authors modified a more efficient CSP block called the CSPStackRep block. The neck of YOLOv6 adopts PAN topology following YOLOv4 and YOLOv5. Based on the PAN topology, the authors augmented the neck with RepBlocks or CSPStackRep Blocks, and the modified neck is called Rep-PAN. For the decoupled head, the authors simplified it to make it more efficient.
- Label Assignment: The authors conducted extensive label assignment experiments on YOLOv6 and verified that TAL is more effective.
- Loss Function: For each loss, the authors systematically experimented with all available techniques and finally selected VariFocal Loss as the classification loss method and SIoU/GIoU Loss as regression loss method.
2.7. YOLOv7
YOLOv7 was published on ArXiv in July 2022. At the time of release, YOLOv7 surpasses all known object detectors in both speed and accuracy in the range from 5 FPS to 160 FPS. The authors trained YOLOv7 from 0 on the COCO dataset only, and the authors did not use any other dataset or pretrained weights. The authors designed several trainable bag-of-freebies methods, so that real-time object detection can greatly improve the detection accuracy without increasing the inference cost (Figure 11).
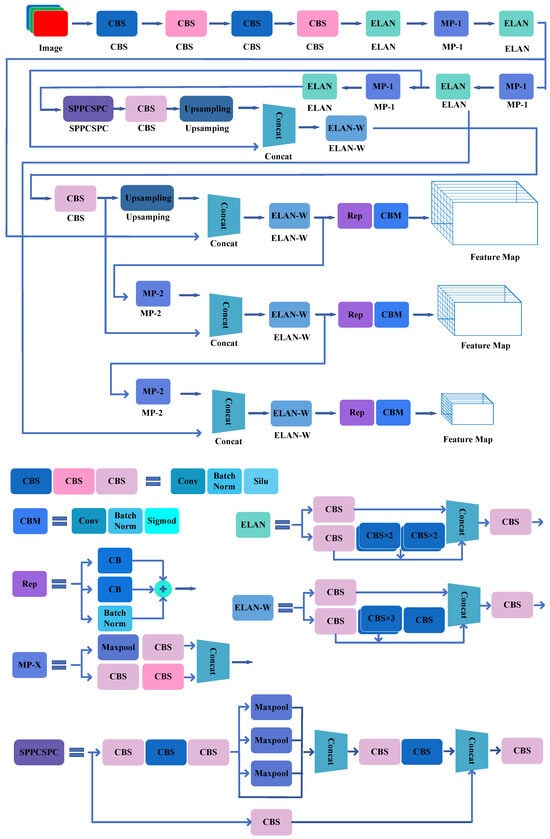
Figure 11.
The CNN construction of YOLOv7.
The main innovations of the model are summarized below.
- Extended efficient layer aggregation networks: ELAN is a strategy that allows a deep model to learn and converge more efficiently by controlling the shortest longest gradient path. The proposed E-ELAN in YOLOv7 uses expand, shuffle, and merge cardinality to achieve the ability to continuously enhance the learning ability of the network without destroying the original gradient path.
- Model scaling for concatenation-based models: The main purpose of model scaling is to adjust some attributes of the model and generate models of different scales to meet the needs of different inference speeds. YOLOv7 has a concatenation-based architecture; thus, when scaling up or down the depth, the input width of the subsequent network layer changes, which causes the ratio of the input channel and output channel of the subsequent layer to change, and the hardware utilization of the model decreases. Therefore, the authors proposed the corresponding compound model scaling method for a concatenation-based model. When the authors scaled the depth factor of a computational block, they also calculated the change of the output channel of that block. Then, they performed width factor scaling with the same amount of change on the transition layers. Their proposed compound scaling method can maintain the properties that the model had at the initial design and can maintain the optimal structure.
- Planned reparameterized convolution: While RepConv achieves excellent performance on VGG, its accuracy is significantly reduced when applied directly to architectures such as ResNet and DenseNet. Because the identity connection carried in RepConv destroys the residuals in ResNet and the concatenation in DenseNet. Based on this, the authors use RepConv without identity connection (RepConvN) to design the planning reparametrization convolutional structure.
- Coarse for auxiliary and fine for lead loss: Lead head is the head responsible for the final output; auxiliary head is the head responsible for auxiliary training.
2.8. Summary
Through continuous optimization, YOLO series algorithms achieve excellent performance in image datasets of common fields. However, overall, with continuous improvement, the detection accuracy and efficiency of YOLO series algorithms are constantly improving, but their structure is also becoming more complex and the amount of data are also increasing. For specific detection tasks, it is necessary to jointly determine factors such as detection requirements, hardware equipment, and detection duration.
3. Industrial Application
In industry, the task of object detection finds extensive applications. The speed and accuracy of object detection are often the key steps of many tasks in the industrial fields. The execution of the object detection task plays a vital role in the whole task execution. Therefore, putting the YOLO series algorithms into the industrial environment for application is of great significance for optimizing industrial production efficiency.
While other one-stage object detection algorithms like SSD and RetinaNet have also been applied in various industrial scenarios, the YOLO series algorithms possess a broader range of applications and better performance in real-time and high-precision tasks. For instance, YOLOv3 has been successfully applied to detect surface defects on steel strips, while YOLOv5 has been used for helmet detection in industrial safety monitoring. These examples highlight the versatility and effectiveness of YOLO series algorithms in diverse industrial settings. The application of the YOLO series algorithms in the industrial field mainly includes product quality and defect detection, item identification and location positioning, industrial scene environmental monitoring, etc. As shown in Figure 12.

Figure 12.
Problems in industrial applications.
Traditional product quality and defect detection methods usually use manual inspection or sensor detection. During the detection process, some traditional detection methods may also damage the product. Furthermore, the traditional methods of object recognition and location positioning require a lot of manual work to mark the feature points of the target objects to be detected, which resulting in poor robustness and model generalization of the algorithms.
The application of the YOLO series algorithms in the industrial field is beneficial to improve the production efficiency in the industrial fields. They could contribute to creating a safer environment for industrial production. In short, they possess important practical value and engineering value.
Figure 13 shows the general improvement methods of the YOLO series of algorithms.
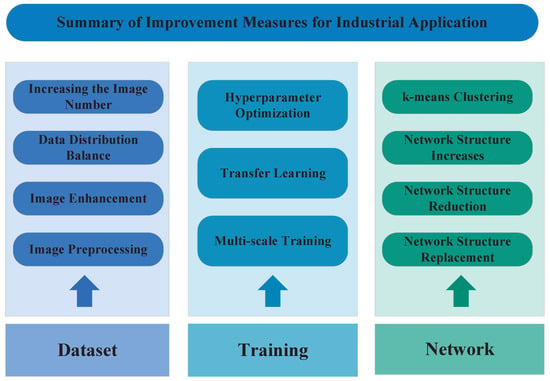
Figure 13.
The general improvement methods of the YOLO series of algorithms.
3.1. Industrial Application Examples of YOLO Series of Object Detection Algorithms
The YOLO series algorithms, being DNN-based, offer significant advantages over classic algorithms in terms of accuracy and robustness. Unlike classic algorithms that require extensive manual calibration, YOLO algorithms can automatically learn features from raw image data. Additionally, while zero/few-shot learning algorithms are valuable for scenarios with limited labeled data, YOLO algorithms excel in real-time, high-precision detection tasks commonly found in industrial environments.
The following introduces the three main industrial applications of the YOLO series algorithms: product quality and defect detection, item identification and location positioning, and industrial scene environmental monitoring.
3.1.1. Product Quality and Defect Detection
Li et al. [62] applied YOLOv1 algorithm to the detection of six different defects (scar, scratch, inclusion, burr, seam, iron scale) on the surface of a steel strip. They introduced fine-grained features by replacing the pooling operation with a convolution operation. To better improve the detection performance, a pass-through layer was also added in the neural network. The improved version of YOLOv1 algorithm achieves 97.55% mAP and 95.86% recall on their self-made dataset. Zhang et al. [63] applied YOLOv2 algorithm to the defect detection of dyed and woven fabrics. They compared the performance of three network structures of YOLO9000, YOLO-VOC, and Tiny-YOLO on the dyed and woven fabric defect dataset. YOLO-VOC is optimized by changing the number of training iterations and the training learning rate. Finally, the detection on the defect dataset of homemade dyed and woven fabrics was realized. Kou et al. [64] used the improved YOLOv3 algorithm to detect the surface defects of the steel strip. They adopted the Anchor-free Feature Selection Mechanism and added Dense Convolution Blocks to the YOLOv3 network structure. This increases the detection accuracy of YOLOv3 for surface defect detection of steel strips. Zheng et al. [65] applied the improved YOLOv3 algorithm to the defect detection of bearing caps through four improvements including feature extraction, attention mechanism, defect detection, and large-scale feature map output. They achieved accurate detection of bearing cap defects by the improved YOLOv3 algorithm. Combining the YOLOv3 algorithm with the Inception-V3 algorithm, Li et al. [66] proposed an industrial automation packaging defect detection method based on deep learning.The detection performance of the YOLO algorithm in the application of product quality and defect detection is shown in Figure 14.

Figure 14.
The detection performance of the YOLO algorithm in the application of product quality and defect detection. (a–f) The detection result of different defects of crazing, inclusion, patches, pitted surface, rolled in scale, and scratches, respectively.
3.1.2. Item Identification and Location Positioning
Sun et al. [67] used the YOLOv1 algorithm to realize automatic recognition of handwritten billet numbers. Based on the YOLOv2 algorithm, Huang et al. [68] clustered the number and size of anchor boxes through the k-means++ clustering method. At the same time, Adam was selected as the optimizer of the algorithm. This made the improved algorithm realize high-precision identification and localization performance. Wang et al. [69] improved the YOLOv2 algorithm through multiscale training and k-means clustering to optimize the number and size of anchor boxes. This makes the improved YOLOv2 algorithm identify the object in real-time. Huang et al. [70] integrated the MobileNet algorithm with the YOLOv3 algorithm and proposed the YOLOv3-Mobilenet algorithm. Combined with data enhancement and other methods, they achieved accurate and rapid identification of electronic components. Lu et al. [71] applied the YOLOv3 algorithm to the classification system of electronic components on waste printed circuit boards. They realized the accurate classification of different electronic components. Liu et al. [72] performed channel-level branch pruning on YOLOv3 convolutional neural network by applying L1 regularization to the channel scaling factor. They proposed the SlimYOLOv3 algorithm, which effectively decreases the computational complexity of the network and facilitates the deployment of algorithms on mobile and industrial-grade devices.
3.1.3. Industrial Scene Environment Monitoring
Wang et al. [73] improved the GIoU calculation method and designed a new objective function to achieve the local optimum of the objective function as the IoU local optimum. They optimized the accuracy performance of the improved YOLOv3 in task of helmet detection. Deng et al. [74] improved the YOLOv4 algorithm by using k-means clustering, multiscale training, and convolutional layers replacing. They achieved a high-precision detection of helmets with their improved YOLOv4 algorithm. Wang et al. [75] used the k-means algorithm for improving the traditional dark channel image dehazing algorithm. The improved dark channel image dehazing algorithm [76] was used to dehaze the collected flame images. It improves the recognition accuracy of fire video images in industrial scenes. In addition, the frame difference method and the mixed Gaussian model fusion algorithm was utilized to extract the features of the dynamically evolving flame image. Moreover, they also used morphological processing algorithms to remove gaps in the image to obtain a complete flame object image. The proposed improved YOLOv5 algorithm effectively improves the accuracy of fire recognition in industrial scenes. The detection performance of the YOLO algorithm in the application of industrial scene environment monitoring is shown in Figure 15.

Figure 15.
The detection performance of the YOLO algorithm in the application of industrial scene environment monitoring.
3.2. Summary of Improvement Measures for Industrial Application
The YOLO series algorithms possess better comprehensive performance than other traditional object detection algorithms. However, for the application of these algorithms to the industrial fields, there is still room for improvement. Due to the peculiarities and differences of the industrial environment, further improvements can improve the overall performance of their application in a specific environment. Therefore, the common improvement measures for the industrial application of YOLO series algorithms are summarized below.
- Increasing the Image Number: Datasets with more images can reduce the overfitting phenomenon in the algorithm training process. When optimizing datasets, the number of images in the datasets should be increased first. Therefore, how to obtain a large number of images is an important task in making datasets. Because of the small number of relative datasets in industrial fields, the training images are usually taken by oneself. This leads to the small number of acquired images. Methods to increase the image number include web crawling, video pinching, etc.
- Data Distribution Balance: In the process of making the datasets, an important issue is the data distribution in the datasets. If the images in a dataset are unevenly distributed, such as the uneven distribution of large, medium, and small objects. This situation can lead to poor robustness and generalization of the trained algorithm. Therefore, it is important to consider the influence of the images distribution on the training results while making the dataset.
- Image Enhancement: Image enhancement can effectively increase the quality of the images in the dataset so that the trained algorithm has strong robustness and generalization. The enhancement of the images includes the enhancement of the original images and the enhancement of the feature maps. The main methods for image enhancement are Random Brightness, Cartoon Effect, Contrast Limited Adaptive Histogram Equalization (CLAHE) [77], Color Temperature Transformation, Random Contrast, Edge Enhancement, Horizontal Flip, HSV Transform, Perspective Transformation, Salt and Pepper Noise, etc. Figure 16 shows the comparison between the original images and the enhanced images. These methods are useful to make certain features in the image clearer than the original images.
 Figure 16. The comparison between the original images and the enhanced images. Image enhancement methods includes Random Brightness, Cartoon Effect, Contrast Limited Adaptive Histogram Equalization (CLAHE), Color Temperature Transformation, Random Contrast, Edge Strengthening, Horizontal Flip, HSV Transform, Perspective Transformation, Salt Furthermore, and Pepper Noise.
Figure 16. The comparison between the original images and the enhanced images. Image enhancement methods includes Random Brightness, Cartoon Effect, Contrast Limited Adaptive Histogram Equalization (CLAHE), Color Temperature Transformation, Random Contrast, Edge Strengthening, Horizontal Flip, HSV Transform, Perspective Transformation, Salt Furthermore, and Pepper Noise. - Image Preprocessing: For applications with more noise in the input image, it is not enough to use image enhancement methods only. It is also vital to preprocess the input images to optimize the performance of detection and training processes of the algorithm. For example, in an environment with more fog, a dark channel image dehazing [76] algorithm can be used to preliminarily process the image. The processing effect of the dark channel image dehazing algorithm is shown in Figure 17.
 Figure 17. The application effect of the dark channel dehazing algorithm. This method is useful to make the image clear for the outdoor environment, especially in an environment with some haze.
Figure 17. The application effect of the dark channel dehazing algorithm. This method is useful to make the image clear for the outdoor environment, especially in an environment with some haze. - Hyperparameter Optimization: For the optimization of the algorithms, one of the simplest methods is to optimize the hyperparameters involved in the algorithm training. Typically, enhancing algorithm performance involves increasing the number of iterations and fine-tuning the learning rate during the training process. With regard to the optimization methods for the learning rate, there are some common methods includes Stochastic Gradient Descent [78], Adam [79], AdaGrad [80], etc.
- Transfer Learning: There are two ways for transfer learning [81] when the number of samples is insufficient. Firstly, the parameters of the fixed feature extraction part of the feature map remain unchanged, then the network parameters of the remaining part are trained. When the number of samples is sufficient, some parameters of the feature maps are kept unchanged, after several rounds of training on the remaining network parameters, some or all of the parameters of the feature extraction network are “unfrozen”. Finally, the network sets a small learning rate to fine-tune the entire network. During training process of the algorithms, the pretrained models can be used to initialize the algorithms to speed up the decline of the loss function during the training process. This can improve the learning efficiency and reduce the training time.
- Multiscale Training: In the training process, input images of different scales into the networks for training. This can make the networks possess better robustness and generalization for images of different input sizes. However, this method will extend the training time of the algorithm.
- k-means Clustering: For a specific type of target objects to be detected, k-means dimension clustering is usually used to modify the size and number of anchor boxes. This could speed up the convergence of the loss function during the training process, and thereby, it can improve the stability of the algorithms. In addition, k-means++ [82] could also be used for modifying the size and number of the anchor boxes.
- Network Structure Increase: The optimization of increasing the structure of the network can improve the performance of the algorithm in specific aspects by adding some designed blocks to the network structure. The blocks and structures usually added to the network include the residual structure [83], DenseNet block, CSP structure, SPP block, FPN block, attention block, etc.
- Network Structure Reduction: The network structure reduction can be mainly divided into a weight level [84], layer level [85], and channel level [86]. Weight-level pruning has high flexibility and generality, which can achieve higher compression ratios. However, it usually requires special software or hardware accelerators for fast inference on sparse models. Layer-level pruning is simpler but less flexible. Removing layers is only effective when the network depth is deep enough. Channel-level pruning strikes a good balance between flexibility and ease of implementation, as it can be applied to convolutional neural networks or full connect neural networks.
- Network Structure Replacement: By replacing some structures in the network, the networks can achieve better performance. Common replacement measures include replacing pooling operation with convolution operation, replacing traditional NMS with improved NMS (greedy NMS, soft NMS, DIoU-NMS, etc.), replacing traditional IoU loss function with improved IoU loss functions (GIoU-Loss, DIoU-Loss, CIoU-Loss, etc.), replacing traditional convolution Depthwise Separable Convolution [87], etc.
3.3. Security Challenges in Industrial Applications
In industrial environments, the security of object detection systems is paramount. Even small changes in the images sent to the detection system can lead to misclassifications or false detections, posing significant risks. For example, attackers might introduce subtle perturbations that are imperceptible to the human eye but can deceive the detection algorithms.
To address these challenges, several measures can be taken:
- Robust Model Training: Utilizing adversarial training techniques to make the model more resilient to adversarial attacks.
- Input Validation: Implementing strict input validation and preprocessing to ensure that only valid and clean data reaches the detection system.
- Monitoring and Logging: Continuously monitoring the system for unusual activity and logging all inputs and outputs for forensic analysis.
- Physical Security: Ensuring physical security measures are in place to prevent unauthorized access to the detection system.
By incorporating these security measures, industrial applications of object detection algorithms can be made more robust and reliable.
3.4. Summary
The YOLO series algorithms possess a wide range of applications in industrial fields. Due to the particularity of the application environment of the industrial field, the applications of the general object detection algorithms to the industrial field always shows certain limitations. Therefore, it is necessary to make corresponding improvements based on YOLO series algorithms. After that, the improved algorithms can meet the needs for the speed and accuracy of the algorithms.
4. Practical Adaptations of YOLO Series Algorithms in Industrial Fields
To better understand how YOLO series algorithms can be adapted for industrial applications, this section provides a structured breakdown of key adaptations and optimizations.
4.1. Model Compression
Industrial environments often have strict resource constraints, necessitating the use of lightweight models. Techniques such as pruning, quantization, and knowledge distillation are commonly employed to compress YOLO models without significant loss of performance. For instance:
- Pruning: Removing redundant neurons or filters to reduce model size.
- Quantization: Converting floating-point weights to lower precision (e.g., 8-bit integers).
- Knowledge Distillation: Transferring knowledge from a large teacher model to a smaller student model.
4.2. Edge Deployment
Deploying YOLO models on edge devices poses unique challenges, such as limited computational resources and power constraints. Solutions include the following:
- Hardware Acceleration: Utilizing specialized hardware like GPUs, TPUs, or FPGAs to speed up inference.
- Inference Optimization: Techniques like batch processing, caching, and parallelization to improve efficiency.
- Edge Cloud Collaboration: Offloading computationally intensive tasks to cloud servers when necessary.
4.3. Data Enhancement and Preprocessing
Ensuring high-quality input data are crucial for robust model performance. Methods include:
- Data Augmentation: Applying transformations like rotation, scaling, and color jittering to increase dataset diversity.
- Preprocessing: Techniques like image dehazing, noise reduction, and normalization to improve image clarity and reduce artifacts.
4.4. Real-Time Performance Optimization
Industrial applications often require real-time performance. Optimizations include the following:
- Multiscale Prediction: Utilizing multiple scales of input images to capture objects of varying sizes.
- Lightweight Network Structures: Employing architectures like MobileNet or EfficientNet to reduce computational load.
- Attention Mechanisms: Incorporating attention modules to focus on relevant features, enhancing detection accuracy.
These adaptations ensure that YOLO series algorithms can effectively meet the demands of diverse industrial environments.
5. Algorithm Comparison
In the process of applying the YOLO series algorithms to the industrial field, an important issue is to select a targeted object detection algorithm for improvement according to the application environment and application requirements. Therefore, it possesses a great practical value to explore the application performance of different versions of YOLO series algorithms in industrial fields and provide a reference for their further industrial applications.
The following will test the practical application performance of the seven versions of YOLO series algorithms in industrial fields.
5.1. Test Environment
This work tests the algorithms under the Windows system of X64. The specific CPU model is an 11th Gen Intel (R) Core (TM) i7-11800H @ 2.30 GHz, and the GPU model is an NVIDIA GeForce RTX 3060 Laptop GPU. The CUDA version is 11.4.
5.2. Datasets Introduction
To comprehensively evaluate the performance of the YOLO series algorithms across different industrial domains, we selected four representative datasets for testing: the Printed Circuit Board (PCB) [88] dataset, Hard Hat Workers (HHW) dataset [89], Hot Rolled Strip (HRS) dataset [90], and Metal Surface Defect (MSD) dataset [91]. In addition, to assess the performance of the YOLO series algorithms in UAV applications, we introduced the UAVDT dataset.
The UAVDT dataset (Unmanned Aerial Vehicle Detection and Tracking dataset) [92] is a widely used benchmark dataset for object detection and tracking in UAV scenarios. It contains a large number of video clips captured by drones, covering object detection tasks in various complex environments. The UAVDT dataset is characterized by its diverse scenarios and target types, making it highly suitable for evaluating the performance of object detection algorithms in UAV applications.
The images in the datasets are divided into a training dataset, validation dataset, and test dataset with a ratio of 90:1:9. The specific information of the labeled boxes in the datasets is shown in Figure 18.
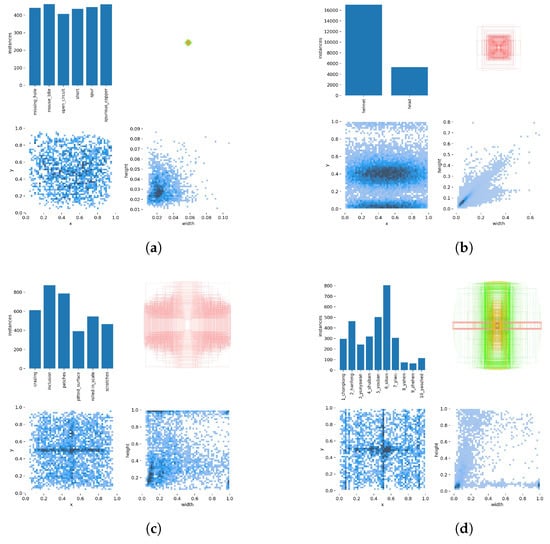
Figure 18.
The specific information of the labeled boxes in the datasets. (a–d) The four aspects of information (the instance of different target objects, the size of the labeled boxes, relationship between x and y, and relationship between width and height) for the PCB dataset [88], HHW dataset [89], HRS dataset [90] and MSD dataset [91], respectively.
5.3. Results Comparison
The test results of the YOLO series algorithms on the PCB, HHW, HRS, MSD, and UAV datasets are shown in Table 1, Table 2, Table 3 and Table 4, respectively.

Table 1.
Test results of YOLO series object detection algorithms on PCB dataset.
Table 2.
Test results of YOLO series object detection algorithms on HHW dataset.
Table 3.
Test results of YOLO series object detection algorithms on HRS dataset.
Table 4.
Test results of YOLO series object detection algorithms on MSD dataset.
5.4. Summary
The YOLOv1 algorithm does not achieved satisfactory application results on different datasets. Compared with the YOLOv1 algorithm, YOLOv2 improved the performance on the HHW dataset, but it still did not achieve satisfactory application results. Compared with YOLOv1 and YOLOv2, YOLOv3 improved the performance in the application on these four datasets; however, there is still a gap compared with the YOLOv4 and YOLOv5 algorithms. Compared with the YOLOv5 algorithm, the YOLOv4 algorithm possesses a smaller amount of computation. Moreover, its performance is better than the YOLOv5 algorithm in some aspects. YOLOv5 is also better than YOLOv6 on certain datasets, but overall, YOLOv7 performs the best in all aspects. The YOLOv5 algorithm and the YOLOv7 algorithm possesses the best application performance among different algorithms. However, its computational complexity is also the largest among the different algorithms.
In addition, from the application performance of the YOLO series of algorithms in the industrial fields, networks such as YOLOv1 and YOLOv2 are not well suited for industrial applications. It is necessary to deepen the neural network framework of YOLOv1 and YOLOv2 algorithms to improve their comprehensive performance. Algorithms such as YOLOv3 and YOLOv4 have better application prospects in the industrial fields. However, YOLOv3 and YOLOv4 need to enhance their accuracy to adapt to their application in the industrial fields. Moreover, YOLOv5, YOLOv6, and YOLOv7 have very mature industrial application scenarios and good application prospects. However, YOLOv7 needs to decrease the amount of computation required by the neural network to improve real-time performance.
It can be seen from Table 5 that YOLOv7x is superior to Faster R-CNN in all indicators, especially showing significant advantages in mAP@0.25 and mAP@0.50. In addition, the BFLOPS of YOLOv7x is also lower, indicating that its computational complexity is lower and it is more suitable for real-time application scenarios.
Table 5.
Test Results of YOLO series algorithms on the UAVDT dataset algorithm.
6. Development Directions and Challenges
Through the analysis of the application examples of the algorithms in the third part and the summary of the experimental results in the fourth part, it is obvious that general-purpose object detection algorithms are not suitable for industrial applications. As for the further improvements of YOLO series algorithms in industrial fields, they possess some general development trends. Moreover, they also encounter some challenges in their industrial applications.
To promote the industrial applications of YOLO series algorithms, below summarizes the development directions and challenges of these algorithms. Additionally, recent advancements in alternative YOLO-based approaches such as YOLO-NAS and YOLOX offer promising directions for future research.
6.1. Real-Time Trend
The real-time performance of the algorithms is one of the bases of their applications in industrial fields. The application scenarios of object detection algorithms in industrial fields (such as applications on assembly lines, monitoring of industrial site safety, etc.) usually require algorithms to correctly identify the images. The speed that an algorithm detects objects in an image often determines the performance of other parts of the industrial application scenario. In addition, especially in the application of the industrial scene security monitoring, the algorithm’s recognition speed of dangerous scenes plays a vital role in workers’ safety.
Therefore, the real-time performance of the algorithms is a crucial development direction for the application of the algorithms in industrial fields.
6.2. High-Precision Trend
The accurate performance of the algorithms is another basis of their application in the industrial fields. There are many scenarios in the application of algorithms in the industrial fields (such as product quality inspection, product defect detection, etc.) that require high accuracy of the algorithms. In these application scenarios, the accuracy of the algorithms usually determines the efficiency and quality of industrial production. At the same time, the detection accuracy of the algorithms is also helpful for people to accurately understand the production condition of industrial production. In the ever-changing industrial environment, various parameters in the production process can be adjusted in a timely and precise manner through the high-precision algorithms.
In addition, high-precision algorithms can better reduce the errors in the application process of industrial fields. In particular, this characteristic is crucial for the application of algorithms in some high-risk industrial fields.
Therefore, it is necessary for the algorithms to have a high-precision performance in the application of industrial scenarios.
6.3. Lightweight Trend
Because the performance of basic equipment in the application of industrial environment (such as the size of the memory, the size of the computing power of the chip, etc.) usually cannot reach the performance of the equipment in the general application environment, it is often impossible to apply algorithms with large computing volumes in industrial fields.
Meanwhile, algorithms that consume more energy often do not possess better economic benefits. For some applications that need to run independently for a long time, lightweight networks often possess higher reliability.
Moreover, in terms of the deployment of the algorithms in industrial equipment, limited by the performance of basic equipment in the industrial fields, a lightweight network can also be deployed on a wider range of industrial equipment.
6.4. Multiscale Prediction Trend
Multiscale prediction of the algorithms can make them possess a better application performance in the application of the industrial fields. It is beneficial to the algorithms to obtain more information of the target objects in prediction process. This can improve the prediction performance of the algorithms on objects of different sizes that exist in industrial environment. Especially for industrial application, there usually exists different sizes of images in different industrial environment.
Therefore, it is necessary to take the method of multiscale prediction into consideration in the industrial optimization of YOLO series algorithms.
6.5. High Reliability Trend
For algorithms applied in the industrial fields, there are high requirements for the reliability of the algorithms. Object detection algorithms applied in industrial environments need to be robust to changing environments. For example, in the process of product quality and product defect detection, if the algorithm cannot adapt to possible environmental changes, this will lead to corresponding problems in the production process.
In addition, for some object detection algorithms applied in the field of industrial security monitoring, high reliability is rather vital. Should the algorithms’ performance be notably affected by environmental changes, their ability to effectively monitor industrial security would be compromised.
Therefore, the high reliability of the algorithm is an important development trend for object detection algorithms applied in complex and changing industrial environments.
6.6. Generality Trend
An important trend of these deep-learning-based object detection algorithms is that they possess good generality. If the application of these algorithms based on deep learning in the industrial fields cannot possess good generality, this will greatly limit the development of deep-learning-based object detection algorithms. Therefore, in the development process of YOLO series algorithms in industrial fields, it is vital to pay attention to the generality of the algorithms. All trends in YOLO algorithms are shown in Figure 19.
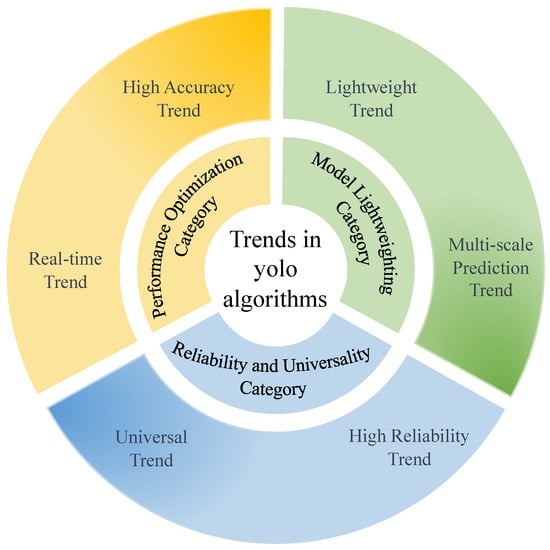
Figure 19.
Trends in YOLO algorithms.
6.7. Challenges
In the application process of the YOLO series algorithms in industrial fields, in terms of some trends of algorithm development, they still face some challenges. The following are the main challenges faced in the development of YOLO series algorithms.
- Conflict Between Real Time and High Precision. Generally, improving the accuracy of object detection algorithms means reducing the speed of the algorithm. Conversely, increasing the speed of object detection algorithms means a decrease in algorithm accuracy. Therefore, in the process of algorithm development, a significant challenge is how to make the object detection algorithm balance the performance between speed and accuracy.
- Conflict Between Lightweight and Multiscale Prediction. Algorithms using multiscale prediction mechanisms usually possess complex network structures. However, the lightweight of the algorithms requires the network structure to be as simple as possible. Therefore, in the process of optimizing the algorithms, there is a conflict between the lightweight and the multiscale prediction of the algorithms. There needs to be a trade-off between the lightweight and the multiscale prediction.
- Conflict Between High Reliability and Generality. Generally, the algorithms with high reliability usually cannot make the algorithms possess good generality, and the improvement of the algorithms also needs to consider the balance between the reliability and generality. Especially for algorithms applied in industrial fields, it is more necessary to consider the balance between the reliability and generality of the algorithms. For example, if the reliability of the algorithm is reduced too much in industrial applications, it may lead to some hazards.
6.8. Security Against Adversarial Attacks
One of the most serious challenges in industrial applications of object detection algorithms is the potential for adversarial attacks. Hackers can introduce small, carefully crafted perturbations into images that cause misclassifications or false detections. This poses a significant threat to the reliability and security of industrial systems.
To mitigate this risk, several strategies can be employed, as follows:
- Adversarial Training: Incorporating adversarial examples into the training set to improve the robustness of the model;
- Defensive Distillation: Using a distilled model that is less sensitive to small perturbations;
- Detection of Adversarial Examples: Implementing mechanisms to detect and flag potentially adversarial inputs before they affect the system;
- Robust Model Architectures: Designing neural network architectures that are inherently more resistant to adversarial attacks.
Ensuring the security of object detection systems against adversarial attacks is crucial for maintaining the integrity and safety of industrial operations.
6.9. Alternative YOLO-Based Approaches
Recent developments in alternative YOLO-based methods, such as YOLO-NAS and YOLOX, provide new perspectives on the future of object detection algorithms.
YOLO-NAS: YOLO-NAS is a novel approach that leverages Neural Architecture Search (NAS) to automatically discover optimal network architectures for object detection tasks. This method aims to optimize the balance between accuracy and efficiency, making it particularly suitable for resource-constrained environments. YOLO-NAS can potentially enhance the performance of YOLO series algorithms in industrial applications by discovering architectures that are better suited for specific tasks.
YOLOX: YOLOX is an enhanced version of YOLOv3 and YOLOv4, incorporating modern techniques such as decoupled head design, enhanced data augmentation, and improved loss functions. These enhancements significantly boost the performance of YOLOX, especially in terms of accuracy and speed. YOLOX’s modular design also allows for easier customization and adaptation to different industrial scenarios.
These alternative approaches offer valuable insights into the future development of YOLO-based object detection algorithms, emphasizing the importance of exploring new architectures and optimization techniques to meet the diverse needs of industrial applications.
7. Conclusions
Aiming at the further development of the YOLO series algorithms in industrial fields, this survey summarizes the main improvements of these algorithms. We have reviewed relevant examples of the YOLO series algorithms applied in industrial fields and analyzed their general improvement methods. Additionally, we have tested the basic implementations of these algorithms and provided references for their further improvement.
Furthermore, we emphasize the importance of addressing security challenges, particularly adversarial attacks, in industrial applications. Ensuring the robustness and security of object detection systems is crucial for maintaining the integrity and safety of industrial operations. Future research should focus on continuously summarizing the advantages of previous algorithms and proposing better object detection algorithms for industrial applications, with a strong emphasis on security and reliability.
For further discussion, this survey still possesses some shortcomings. The test results of the YOLO series algorithms applied in the industrial fields should be further verified. It is necessary to conduct more experiments on the industrial applications of these algorithms. In addition, more methods should be collected for the summarization of the industrial improvement methods. Future research will also explore newer versions such as YOLOv8, YOLOv9, and YOLOv10 to provide a more comprehensive understanding of the development and industrial applications of these algorithms.
Additionally, the emergence of alternative YOLO-based approaches such as YOLO-NAS and YOLOX highlights the ongoing innovation in this field. Future research should focus on integrating these advancements to develop more efficient and adaptable object detection algorithms tailored for industrial applications. The research on the optimization methods of YOLO series algorithms in industrial fields will continue to be a primary problem faced by future algorithm development. We need to continuously summarize the advantages of the previous algorithms and propose better object detection algorithms for industrial applications.
Author Contributions
Conceptualization, S.K. and Z.H.; methodology, S.K. and L.L.; validation, S.K., L.L. and K.Z.; formal analysis, S.K. and Z.C.; investigation, L.L. and K.Z.; data curation, S.K. and L.L.; writing—original draft preparation, S.K. and K.Z.; writing—review and editing, Z.C.; visualization, S.K. and L.L.; supervision, S.K. and Z.H.; project administration, Z.H.; funding acquisition, Z.H. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the National Natural Science Foundation of China (62003296), the Natural Science Foundation of Hebei (F202410216100), the Natural Science Foundation of Hebei (F2024203089),the National Key Research and Development Program of China (2022YFB3705504), and the Provincial Key Laboratory Performance Subsidy Project (22567612H).
Data Availability Statement
The datasets generated during the current study are available from the corresponding author on reasonable request. The datasets used for testing the YOLO series algorithms are publicly available and can be accessed via the following links: Printed Circuit Board (PCB) Dataset (https://archive.ics.uci.edu/dataset/990/printed+circuit+board+processed+image) [88]; Hard Hat Workers (HHW) Dataset (https://public.roboflow.com/object-detection/hard-hat-workers) [89]; Metal Surface Defect (MSD) Dataset (https://www.kaggle.com/datasets/fantacher/neu-metal-surface-defects-data) [91]; UAVDT Dataset (https://paperswithcode.com/dataset/uavdt) [92] (accessed on 23 February 2025).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Liu, R.; Yang, B.; Zio, E.; Chen, X. Artificial intelligence for fault diagnosis of rotating machinery: A review. Mech. Syst. Signal Process. 2018, 108, 33–47. [Google Scholar] [CrossRef]
- Gautam, D.; Mawardi, Z.; Elliott, L.; Loewensteiner, D.; Whiteside, T.; Brooks, S. Detection of Invasive Species (Siam Weed) Using Drone-Based Imaging and YOLO Deep Learning Model. Remote Sens. 2025, 17, 120. [Google Scholar] [CrossRef]
- Liu, G. Surface defect detection methods based on deep learning: A brief review. In Proceedings of the 2020 2nd International Conference on Information Technology and Computer Application (ITCA), Guangzhou, China, 18–20 December 2020; pp. 200–203. [Google Scholar]
- Yang, Y.; Ma, X.; Mu, C.; Wang, Z. Rapid Recognition and Localization Based on Deep Learning and Random Filtering. In Proceedings of the 2019 5th International Conference on Control, Automation and Robotics (ICCAR), Beijing, China, 19–22 April 2019; pp. 177–182. [Google Scholar] [CrossRef]
- Zhao, S.; Liu, J.; Bai, Z.; Hu, C.; Jin, Y. Crop pest recognition in real agricultural environment using convolutional neural networks by a parallel attention mechanism. Front. Plant Sci. 2022, 13, 839572. [Google Scholar] [CrossRef]
- Deng, L.; Mao, Z.; Li, X.; Hu, Z.; Duan, F.; Yan, Y. UAV-based multispectral remote sensing for precision agriculture: A comparison between different cameras. ISPRS J. Photogramm. Remote Sens. 2018, 146, 124–136. [Google Scholar] [CrossRef]
- Hesamian, M.H.; Jia, W.; He, X.; Kennedy, P. Deep Learning Techniques for Medical Image Segmentation: Achievements and Challenges. J. Digit. Imaging 2019, 32, 582–596. [Google Scholar] [CrossRef]
- Peng, Z.; Liu, W.; Ning, Z.; Zhao, Q.; Cheng, S.; Hu, J. 3D Multi-object Tracking in Autonomous Driving: A survey. In Proceedings of the 2024 36th Chinese Control and Decision Conference (CCDC), Xi’an, China, 25–27 May 2024; pp. 4964–4971. [Google Scholar]
- Reddy, J.; Niu, H.; Scott, J.L.L.; Bhandari, M.; Landivar, J.A.; Bednarz, C.W.; Duffield, N. Cotton Yield Prediction via UAV-Based Cotton Boll Image Segmentation Using YOLO Model and Segment Anything Model (SAM). Remote Sens. 2024, 16, 4346. [Google Scholar] [CrossRef]
- Huang, Y.; Wang, D.; Wu, B.; An, D. NST-YOLO11: ViT Merged Model with Neuron Attention for Arbitrary-Oriented Ship Detection in SAR Images. Remote Sens. 2024, 16, 4760. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention (MICCAI), Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.Y.; Wong, W.K.; Woo, W.C. Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Montreal, QC, Canada, 7–12 December 2015; pp. 802–810. [Google Scholar]
- Ravuri, S.; Lenc, K.; Willson, M.; Kangin, D.; Lam, R.; Mirowski, P.; Fitzsimons, M.; Athanassiadou, M.; Kashem, S.; Madge, S.; et al. Skillful Precipitation Nowcasting Using Deep Generative Models of Radar. Nature 2021, 597, 672–677. [Google Scholar] [CrossRef]
- Fu, C.Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. DSSD: Deconvolutional Single Shot Detector. arXiv 2017, arXiv:1701.06659. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Yan, X.; Shen, B.; Li, H. Small objects detection method for UAVs aerial image based on YOLOv5s. In Proceedings of the 2023 IEEE 6th International Conference on Electronic Information and Communication Technology (ICEICT), Qingdao, China, 21–24 July 2023; pp. 61–66. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer International Publishing: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Zhang, S.; Wen, L.; Bian, X.; Lei, Z.; Li, S.Z. Single-Shot Refinement Neural Network for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Character, L.; Ortiz, A.; Beach, T.; Luzzadder-Beach, S. Archaeologic Machine Learning for Shipwreck Detection Using Lidar and Sonar. Remote Sens. 2021, 13, 1759. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; Volume 37, pp. 448–456. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar] [CrossRef]
- Wang, C.Y.; Liao, H.Y.M.; Yeh, I.H.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W. CSPNet: A New Backbone that can Enhance Learning Capability of CNN. arXiv 2019, arXiv:1911.11929. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Liu, S.; Huang, D.; Wang, Y. Receptive Field Block Net for Accurate and Fast Object Detection. arXiv 2017, arXiv:1711.07767. [Google Scholar] [CrossRef]
- Zhao, Q.; Sheng, T.; Wang, Y.; Tang, Z.; Chen, Y.; Cai, L.; Ling, H. M2Det: A Single-Shot Object Detector based on Multi-Level Feature Pyramid Network. arXiv 2018, arXiv:1811.04533. [Google Scholar] [CrossRef]
- Liu, S.; Huang, D.; Wang, Y. Learning Spatial Fusion for Single-Shot Object Detection. arXiv 2019, arXiv:1911.09516. [Google Scholar] [CrossRef]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. arXiv 2019, arXiv:1911.09070. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. arXiv 2017, arXiv:1709.01507. [Google Scholar] [CrossRef]
- Ying, X.; Wang, Y.; Wang, L.; Sheng, W.; An, W.; Guo, Y. A Stereo Attention Module for Stereo Image Super-Resolution. IEEE Signal Process. Lett. 2020, 27, 496–500. [Google Scholar] [CrossRef]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression. arXiv 2019, arXiv:1902.09630. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. arXiv 2019, arXiv:1911.08287. [Google Scholar] [CrossRef]
- Nair, V.; Hinton, G.E. Rectified Linear Units Improve Restricted Boltzmann Machines. In Proceedings of the ICML, Haifa, Israel, 21–24 June 2010. [Google Scholar]
- Maas, A.L. Rectifier Nonlinearities Improve Neural Network Acoustic Models. Proc. ICML 2013, 30, 3. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. arXiv 2015, arXiv:1502.01852. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar] [CrossRef]
- Klambauer, G.; Unterthiner, T.; Mayr, A.; Hochreiter, S. Self-Normalizing Neural Networks. arXiv 2017, arXiv:1706.02515. [Google Scholar] [CrossRef]
- Ramachandran, P.; Zoph, B.; Le, Q.V. Searching for Activation Functions. arXiv 2017, arXiv:1710.05941. [Google Scholar] [CrossRef]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for MobileNetV3. arXiv 2019, arXiv:1905.02244. [Google Scholar] [CrossRef]
- Misra, D. Mish: A Self Regularized Non-Monotonic Activation Function. arXiv 2019, arXiv:1908.08681. [Google Scholar] [CrossRef]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-NMS—Improving Object Detection with One Line of Code. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5562–5570. [Google Scholar] [CrossRef]
- Yao, Z.; Cao, Y.; Zheng, S.; Huang, G.; Lin, S. Cross-Iteration Batch Normalization. arXiv 2020, arXiv:2002.05712. [Google Scholar] [CrossRef]
- Zhong, Z.; Zheng, L.; Kang, G.; Li, S.; Yang, Y. Random Erasing Data Augmentation. arXiv 2017, arXiv:1708.04896. [Google Scholar] [CrossRef]
- DeVries, T.; Taylor, G.W. Improved Regularization of Convolutional Neural Networks with Cutout. arXiv 2017, arXiv:1708.04552. [Google Scholar] [CrossRef]
- Singh, K.K.; Lee, Y.J. Hide-and-Seek: Forcing a Network to be Meticulous for Weakly-Supervised Object and Action Localization. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 3544–3553. [Google Scholar] [CrossRef]
- Chen, P.; Liu, S.; Zhao, H.; Jia, J. GridMask Data Augmentation. arXiv 2020, arXiv:2001.04086. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Wan, L.; Zeiler, M.; Zhang, S.; LeCun, Y.; Fergus, R. Regularization of Neural Networks Using Dropconnect. In Proceedings of the 30th International Conference on International Conference on Machine Learning—Volume 28, Atlanta, GA, USA, 17–19 June 2013; ICML’13. pp. III–1058–III–1066. [Google Scholar]
- Ghiasi, G.; Lin, T.Y.; Le, Q.V. DropBlock: A regularization method for convolutional networks. arXiv 2018, arXiv:1810.12890. [Google Scholar] [CrossRef]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond Empirical Risk Minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar] [CrossRef]
- Yun, S.; Han, D.; Oh, S.J.; Chun, S.; Choe, J.; Yoo, Y. CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features. arXiv 2019, arXiv:1905.04899. [Google Scholar] [CrossRef]
- Geirhos, R.; Rubisch, P.; Michaelis, C.; Bethge, M.; Wichmann, F.A.; Brendel, W. ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness. arXiv 2018, arXiv:1811.12231. [Google Scholar] [CrossRef]
- Li, J.Y.; Su, Z.F.; Geng, J.H.; Yin, Y.X. Real-time Detection of Steel Strip Surface Defects Based on Improved YOLO Detection Network. IFAC-PapersOnLine 2018, 51, 76–81. [Google Scholar] [CrossRef]
- Zhang, H.W.; Zhang, L.J.; Li, P.F.; Gu, D. Yarn-dyed Fabric Defect Detection with YOLOV2 Based on Deep Convolution Neural Networks. In Proceedings of the IEEE 7th Data Driven Control and Learning Systems Conference (DDCLS), Enshi, China, 25–27 May 2018; pp. 170–174. [Google Scholar]
- Kou, X.; Liu, S.; Cheng, K.; Qian, Y. Development of a YOLO-V3-based model for detecting defects on steel strip surface. Measurement 2021, 182, 109454. [Google Scholar] [CrossRef]
- Zheng, Z.; Zhao, J.; Li, Y. Research on Detecting Bearing-Cover Defects Based on Improved YOLOv3. IEEE Access 2021, 9, 10304–10315. [Google Scholar] [CrossRef]
- Li, J.; Yang, T.; Wang, H. An Industrial Automation Packaging Defect Detection Method Based on Deep learning. Packag. Eng. 2020, 41, 175–184. [Google Scholar] [CrossRef]
- Sun, Q.J.; Chen, D.L.; Wang, S.; Liu, S.X. Recognition Method for Handwritten Steel Billet Identification Number Based on Yolo Deep Convolutional Neural Network. In Proceedings of the 32nd Chinese Control Furthermore, Decision Conference (CCDC), Hefei, China, 22–24 August 2020; Chinese Control and Decision Conference. pp. 5642–5646. [Google Scholar]
- Huang, J.Y.; Lu, Y.Y. A Method for Identifying and Classifying Resistors and Capacitors Based on YOLO Network. In Proceedings of the 4th IEEE International Conference on Signal and Image Processing (ICSIP), Wuxi, China, 19–21 July 2019; pp. 1–5. [Google Scholar]
- Wang, L.; Zhou, Q.; Wang, L.; Jiang, H.; Lin, S. Improved convolutional neural network algorithm for real-time recognition and location of mechanical parts. Intell. Comput. Appl. 2019, 9, 36–41+46. [Google Scholar]
- Huang, R.; Gu, J.N.; Sun, X.H.; Hou, Y.T.; Uddin, S. A Rapid Recognition Method for Electronic Components Based on the Improved YOLO-V3 Network. Electronics 2019, 8, 825. [Google Scholar] [CrossRef]
- Lu, Y.; Yang, B.; Gao, Y.; Xu, Z. An automatic sorting system for electronic components detached from waste printed circuit boards. Waste Manag. 2022, 137, 1–8. [Google Scholar] [CrossRef]
- Lin, X.; Li, Y.; Song, W. Target detection algorithm in industrial scenc based on SlimYOLOv3. Appl. Res. Comput. 2021, 38, 1889–1893. [Google Scholar] [CrossRef]
- Wang, B.; Li, W.J.; Tang, H. Improved YOLO v3 Algorithm and Its Application in Helmet Detection. Comput. Eng. Appl. 2020, 56, 33–40. [Google Scholar]
- Deng, B.; Lei, X.; Ye, M. Safety helmet detection method based on YOLO v4. In Proceedings of the 2020 16th International Conference on Computational Intelligence and Security (CIS), Guangxi, China, 27–30 November 2020. [Google Scholar] [CrossRef]
- Wang, W.; Zhang, B.; Wang, Z.; Zhang, F.; Ren, H.; Wang, J. Intelligent identification method of mine fire video images based on YOLOv5. Ind. Mine Autom. 2021, 47, 53–57. [Google Scholar] [CrossRef]
- He, K.; Sun, J.; Tang, X. Single Image Haze Removal Using Dark Channel Prior. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2341–2353. [Google Scholar] [CrossRef]
- Zuiderveld, K.J. Contrast Limited Adaptive Histogram Equalization. In Graphics Gems IV; Heckbert, P.S., Ed.; Academic Press Professional, Inc.: San Diego, CA, USA, 1994; pp. 474–485. [Google Scholar]
- Song, S.; Chaudhuri, K.; Sarwate, A.D. Stochastic gradient descent with differentially private updates. In Proceedings of the 2013 IEEE Global Conference on Signal and Information Processing, Austin, TX, USA, 3–5 December 2013; pp. 245–248. [Google Scholar] [CrossRef]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Luo, L.; Xiong, Y.; Liu, Y.; Sun, X. Adaptive Gradient Methods with Dynamic Bound of Learning Rate. arXiv 2019, arXiv:1902.09843. [Google Scholar]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Arthur, D.; Vassilvitskii, S. K-Means++: The Advantages of Careful Seeding. In Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms, New Orleans, LA, USA, 7–9 January 2017; SODA ’07. pp. 1027–1035. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Han, S.; Mao, H.; Dally, W.J. Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding. arXiv 2015, arXiv:1510.00149. [Google Scholar]
- Li, H.; Kadav, A.; Durdanovic, I.; Samet, H.; Graf, H.P. Pruning Filters for Efficient ConvNets; University of Maryland: College Park, MD, USA, 2016. [Google Scholar]
- Wen, W.; Wu, C.; Wang, Y.; Chen, Y.; Li, H. Learning Structured Sparsity in Deep Neural Networks. Adv. Neural Inf. Process. Syst. 2016, 29, 2074–2082. [Google Scholar]
- SIfre, L.; Mallat, S. Rigid-Motion Scattering for Texture Classification. arXiv 2014, arXiv:1403.1687. [Google Scholar] [CrossRef]
- Printed Circuit Board Dataset. Available online: https://archive.ics.uci.edu/dataset/990/printed+circuit+board+processed+image (accessed on 23 February 2025).
- Hard Hat Workers Dataset. Available online: https://public.roboflow.com/object-detection/hard-hat-workers (accessed on 23 February 2025).
- Hot Rolled Strip Dataset. Available online: https://paperswithcode.com/dataset/uavdt (accessed on 23 February 2025).
- Metal Surface Defect Dataset. Available online: https://www.kaggle.com/datasets/fantacher/neu-metal-surface-defects-data (accessed on 23 February 2025).
- Du, D.; Qi, Y.; Yu, H.; Yang, Y.; Duan, K.; Li, G.; Zhang, W.; Huang, Q.; Tian, Q. The unmanned aerial vehicle benchmark: Object detection and tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 370–386. [Google Scholar]
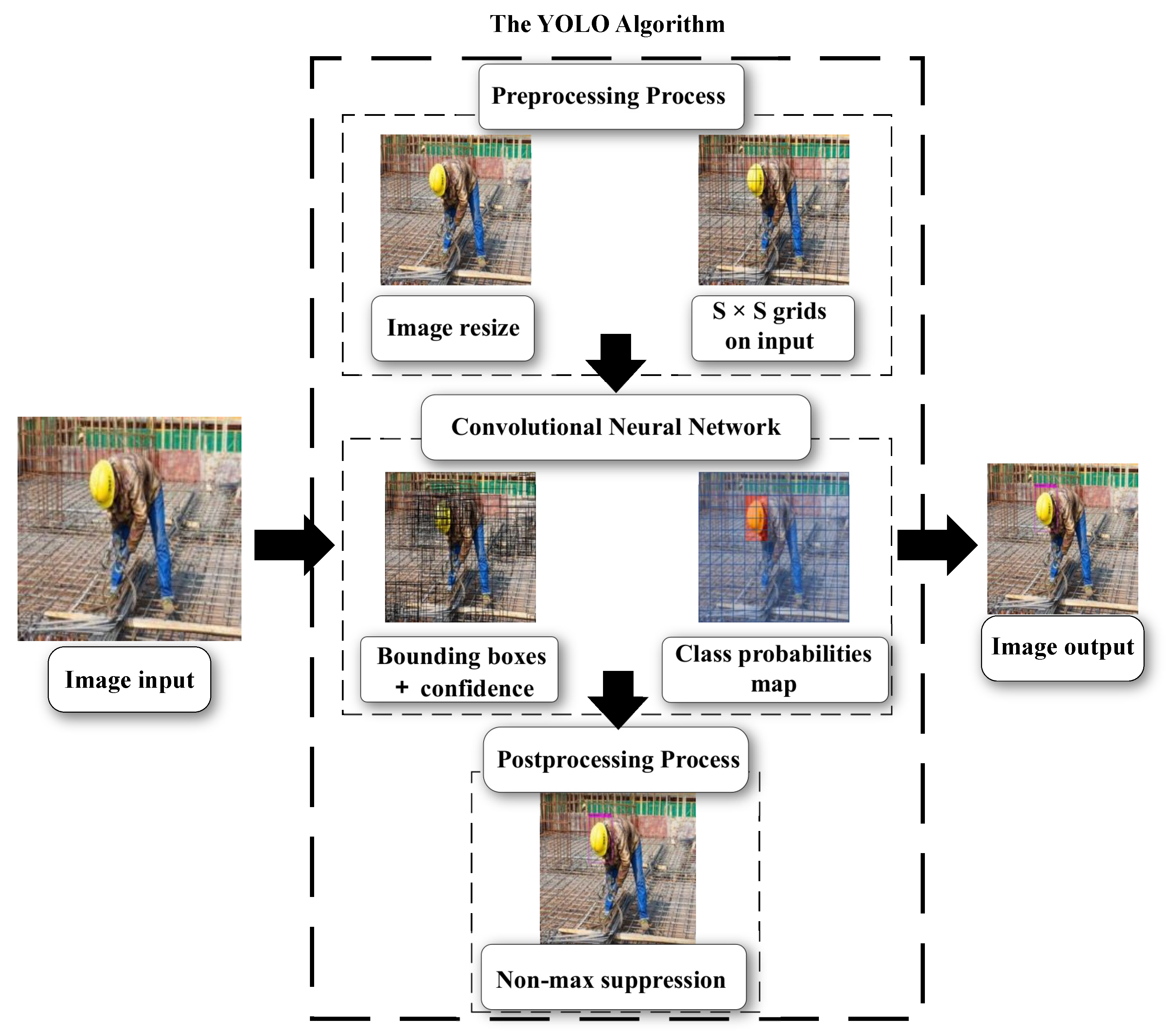
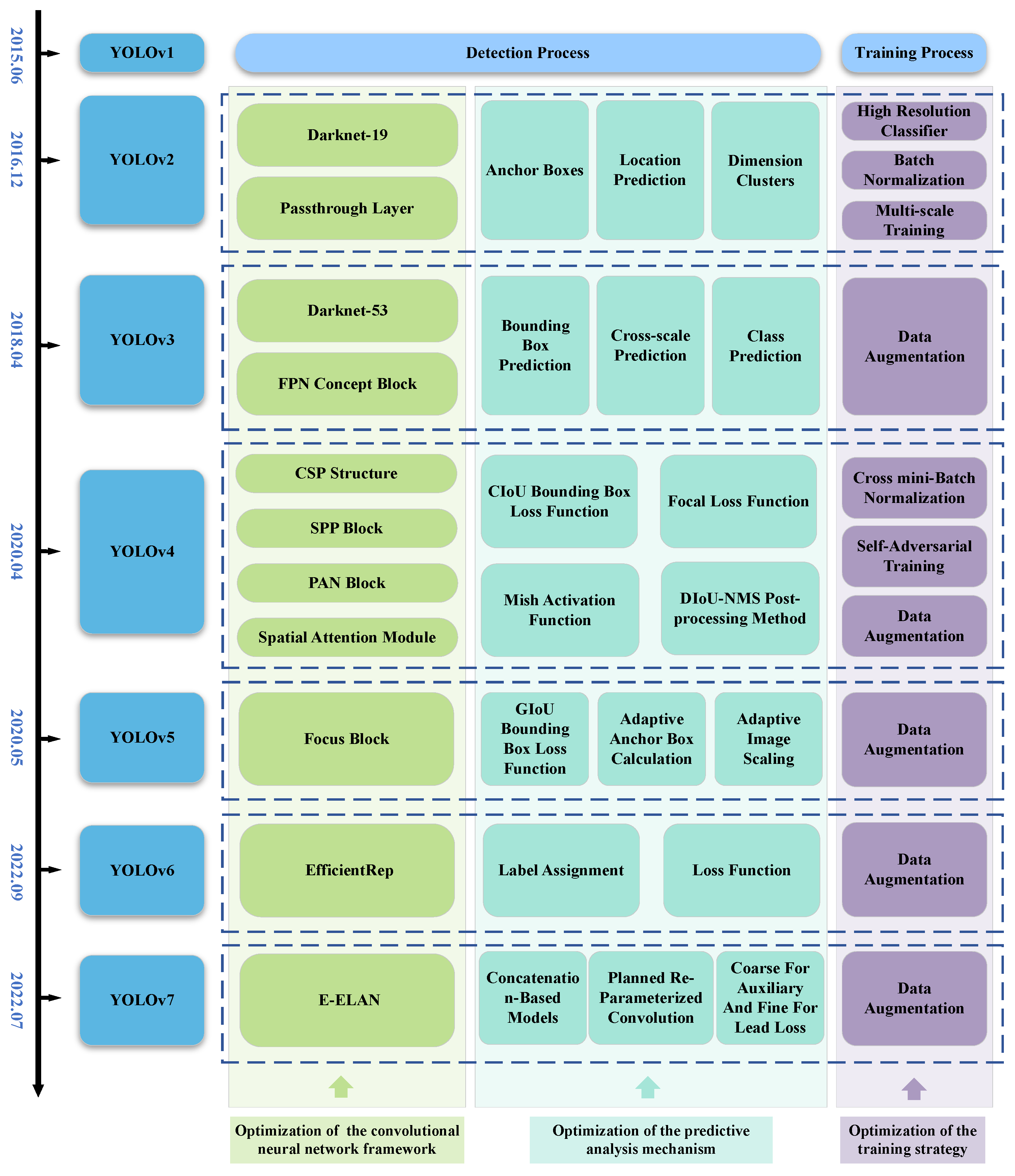
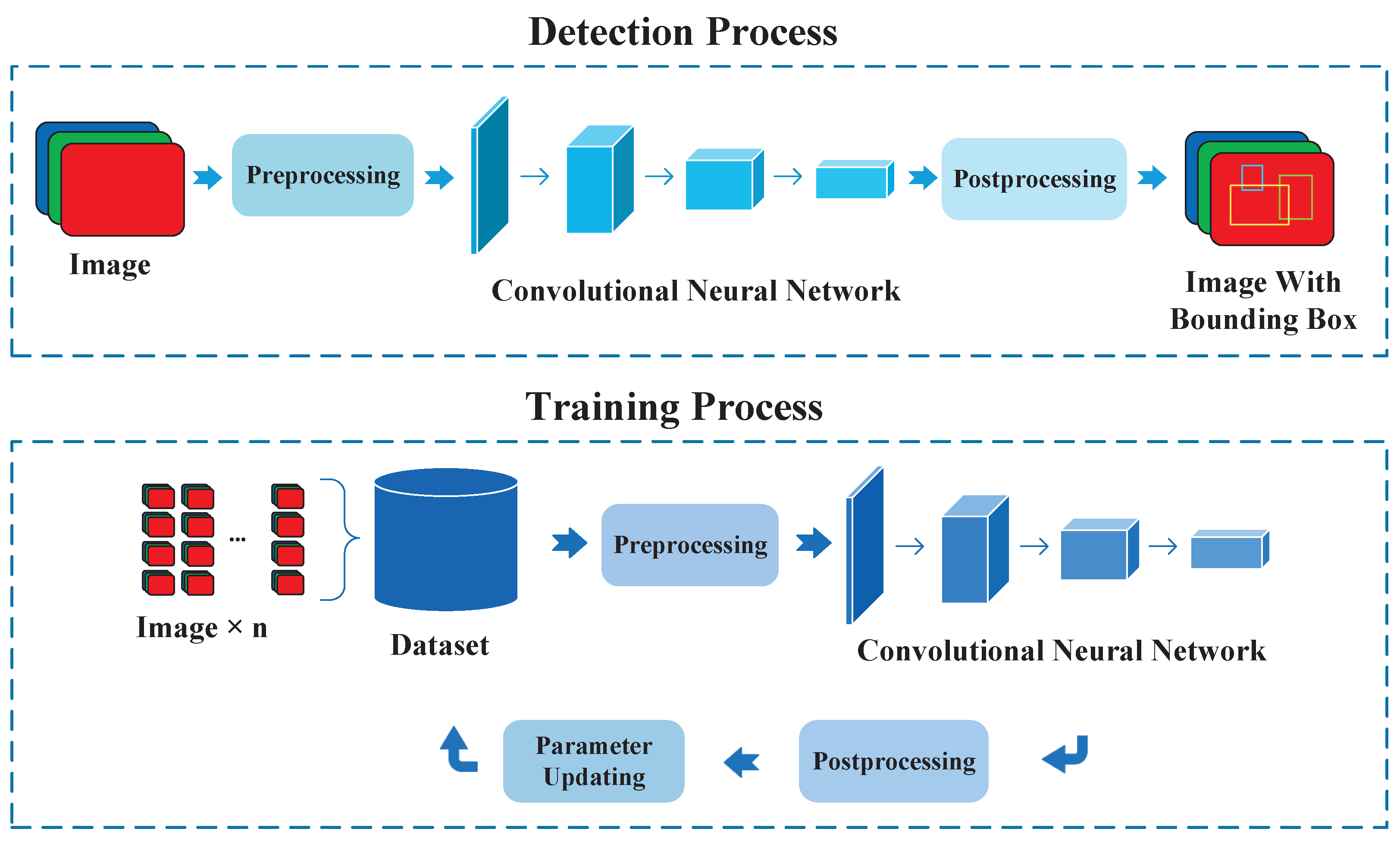
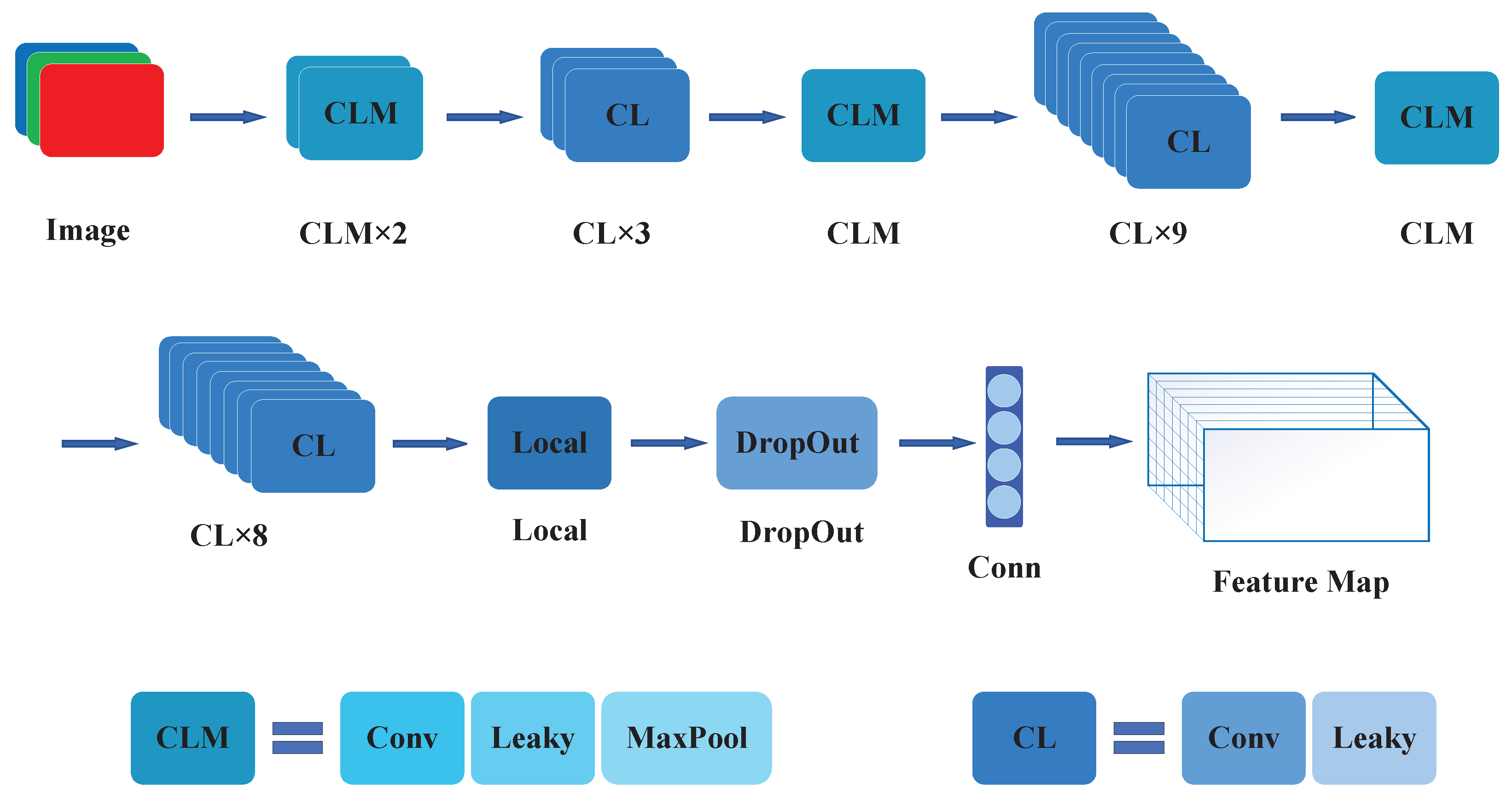
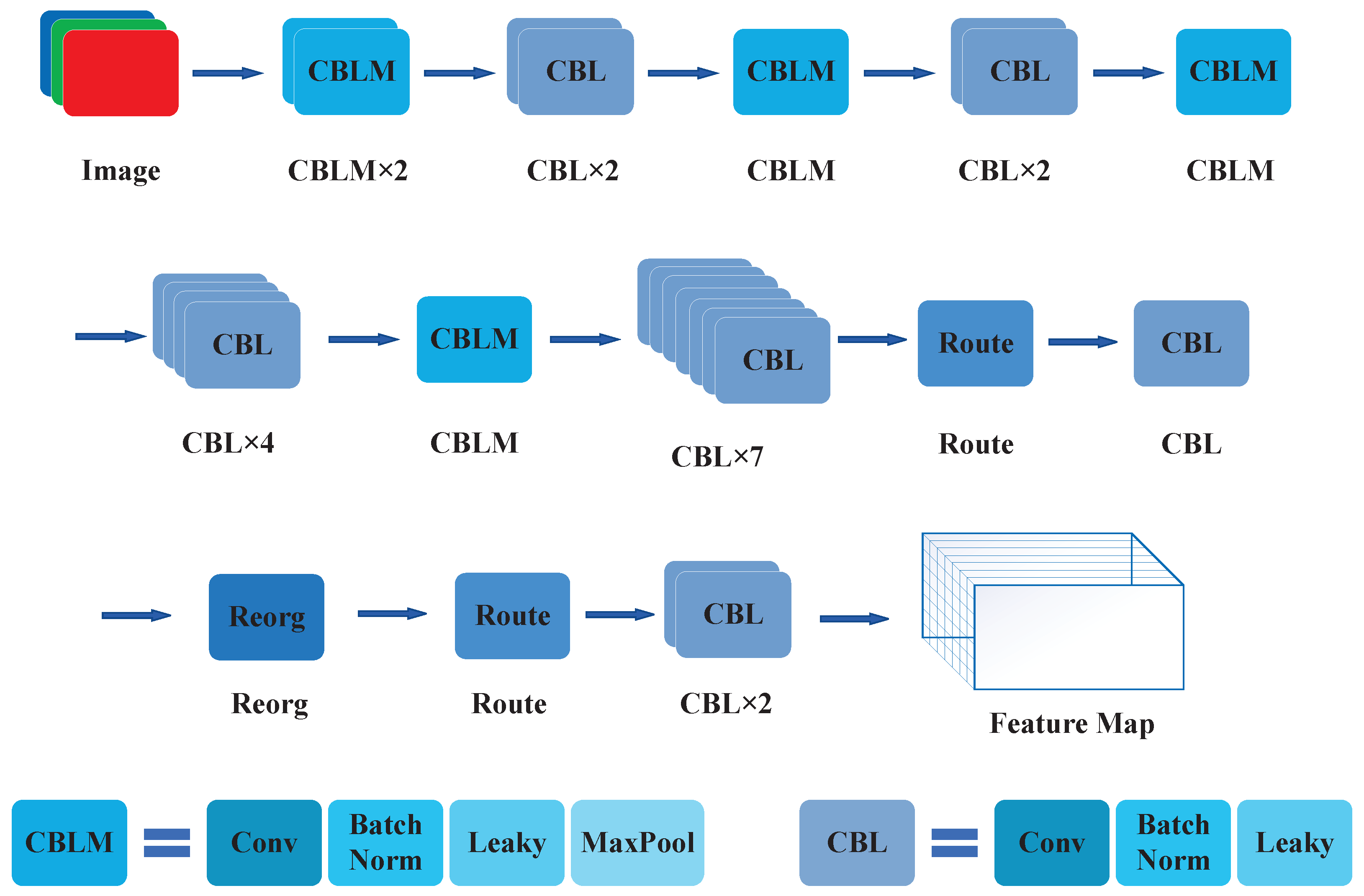
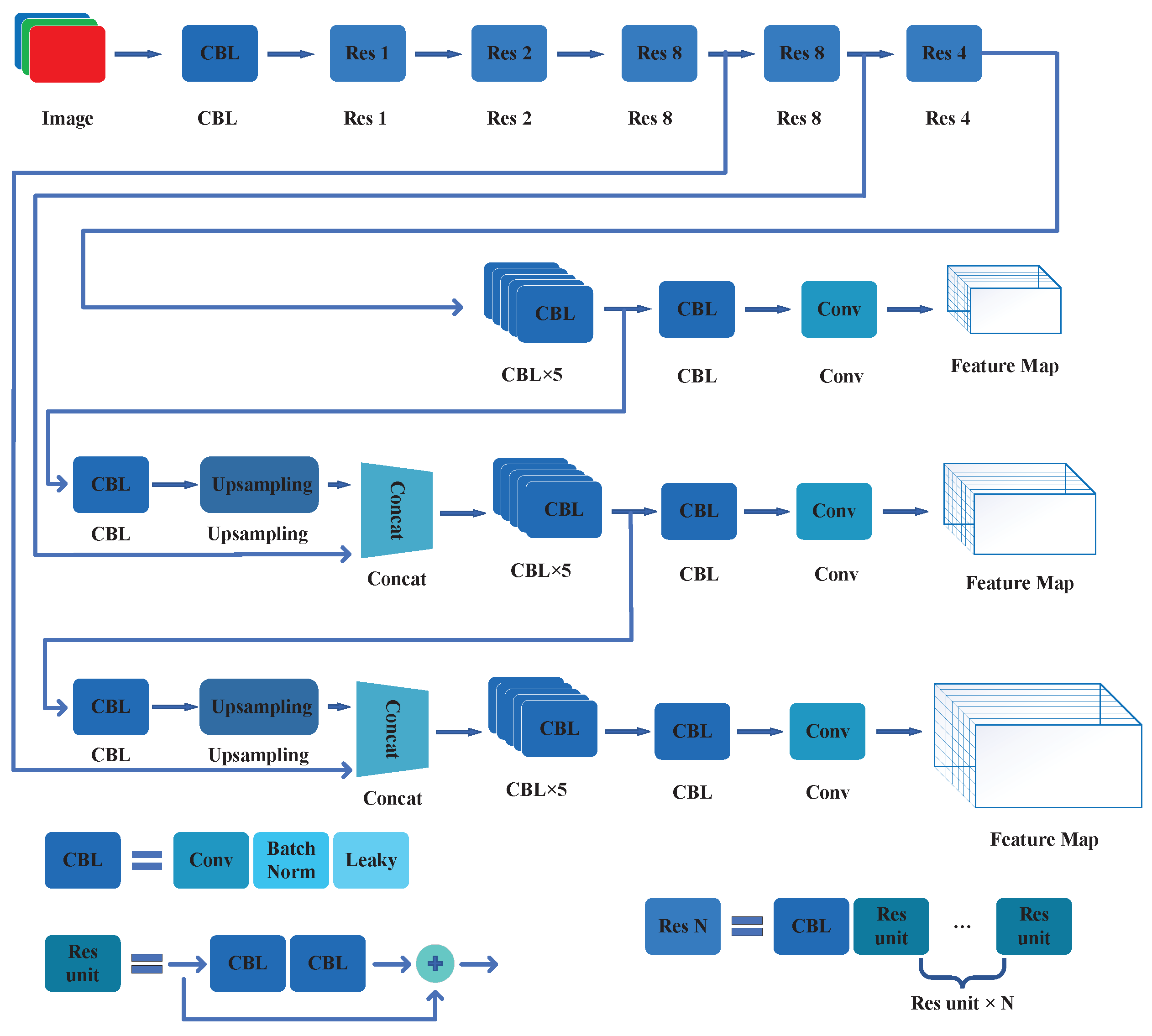
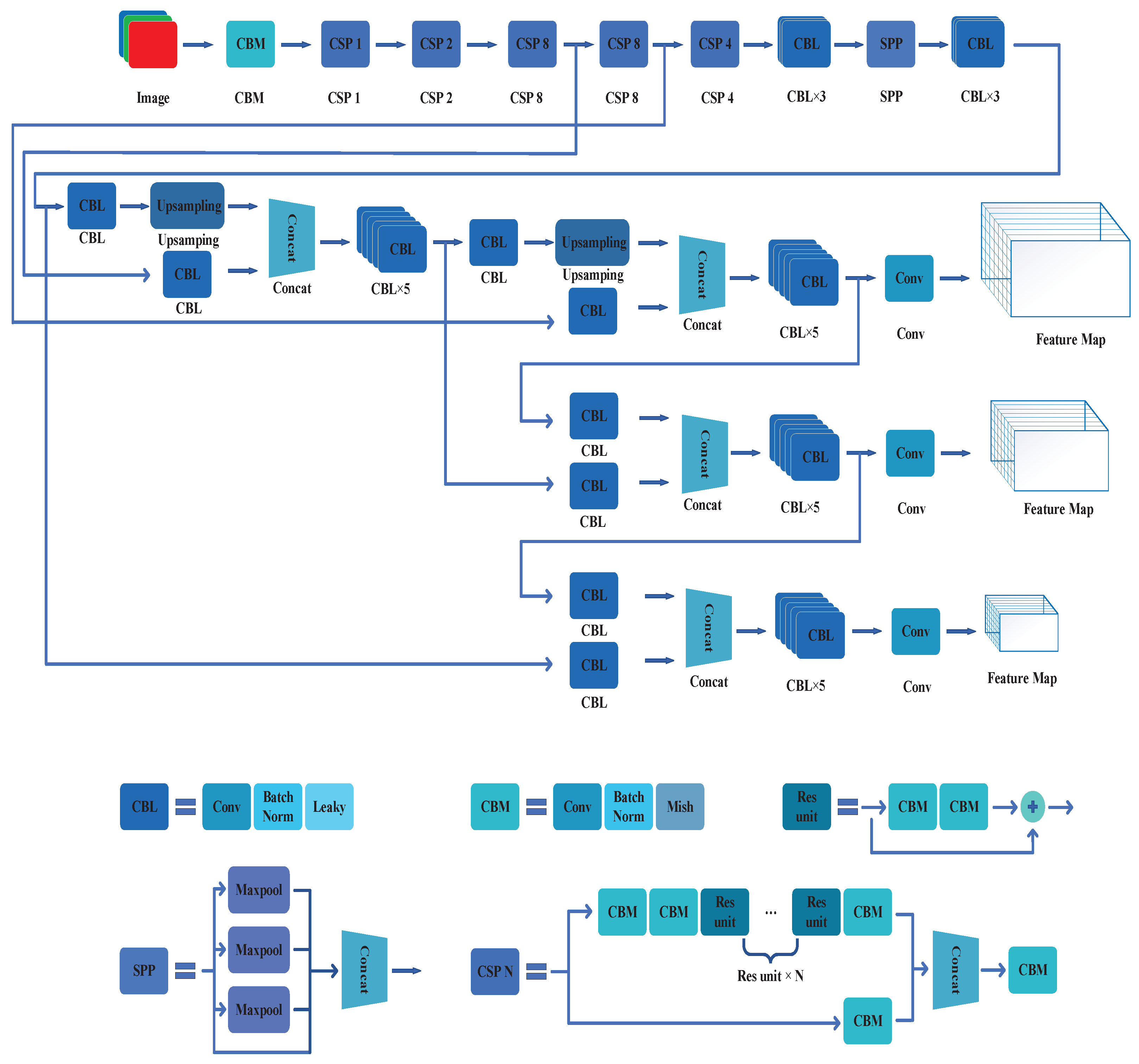
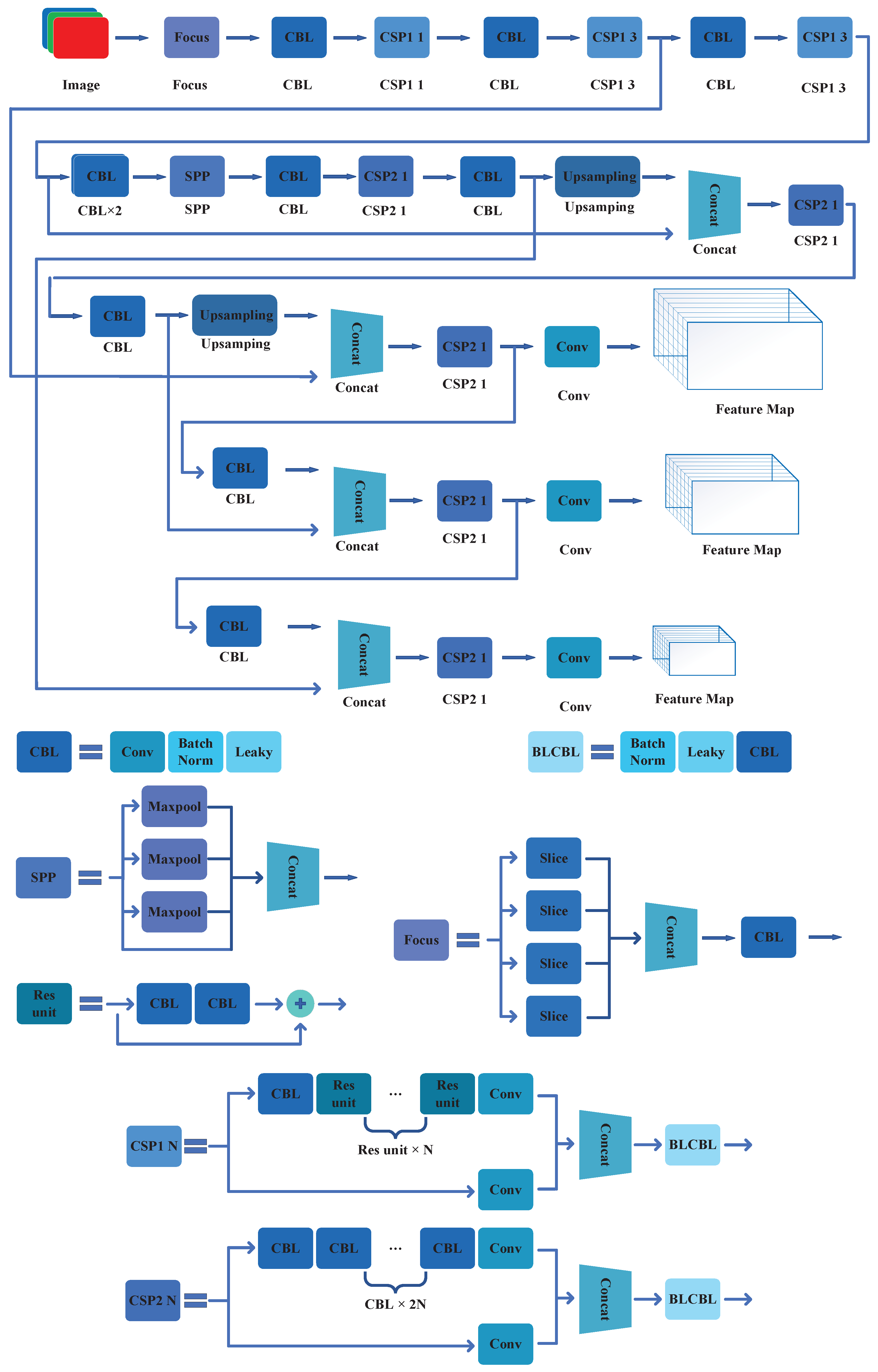
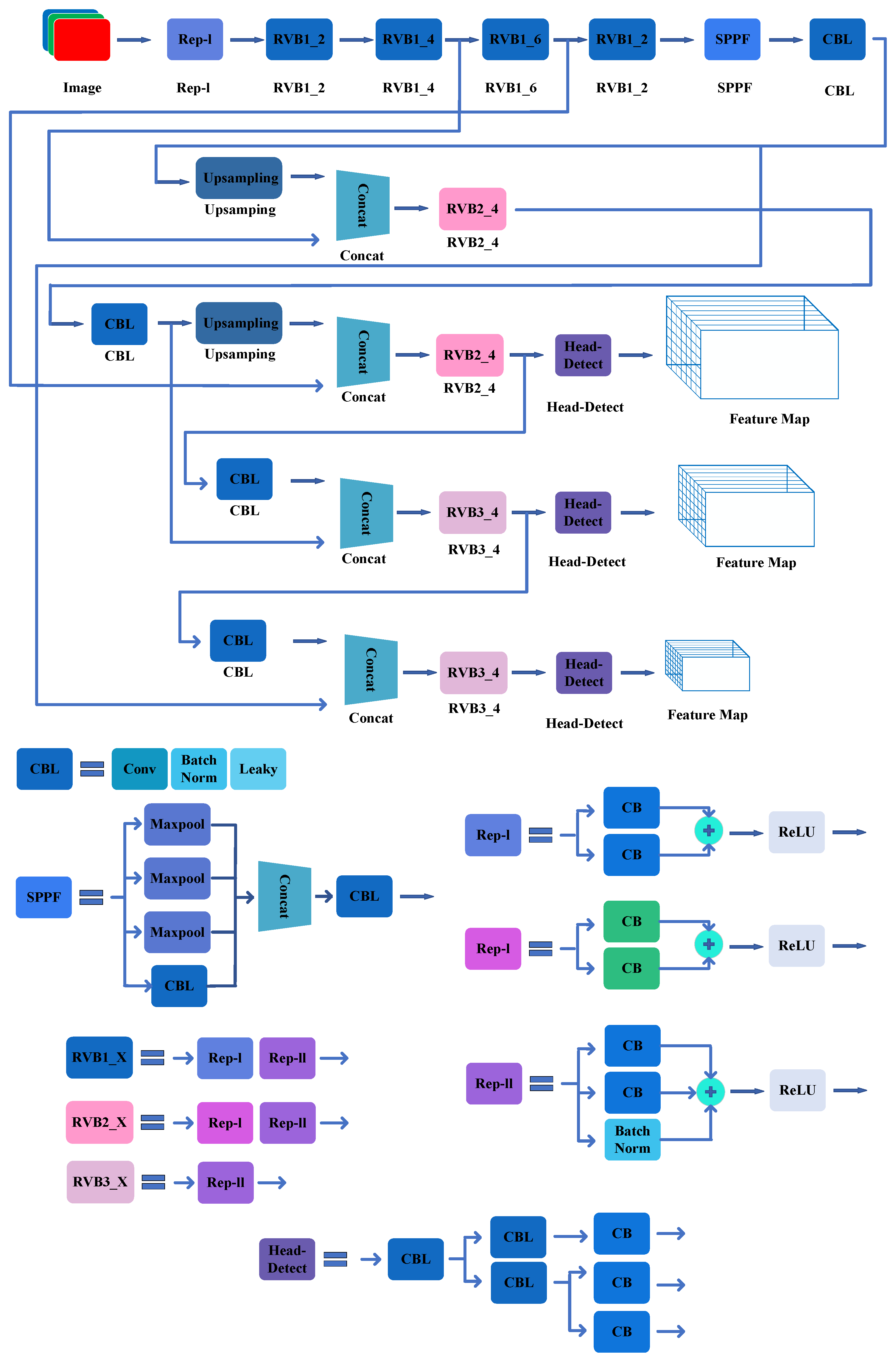
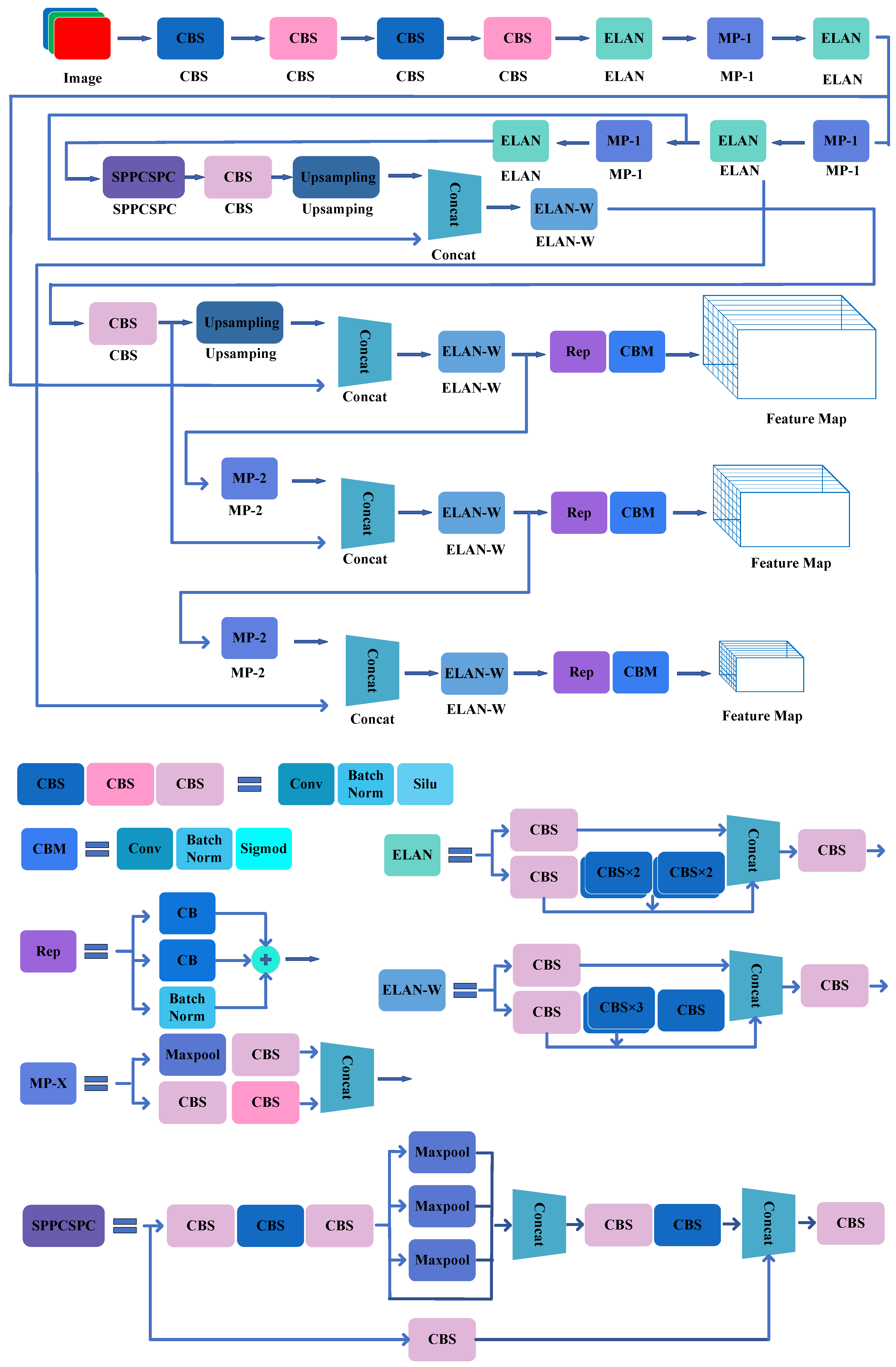

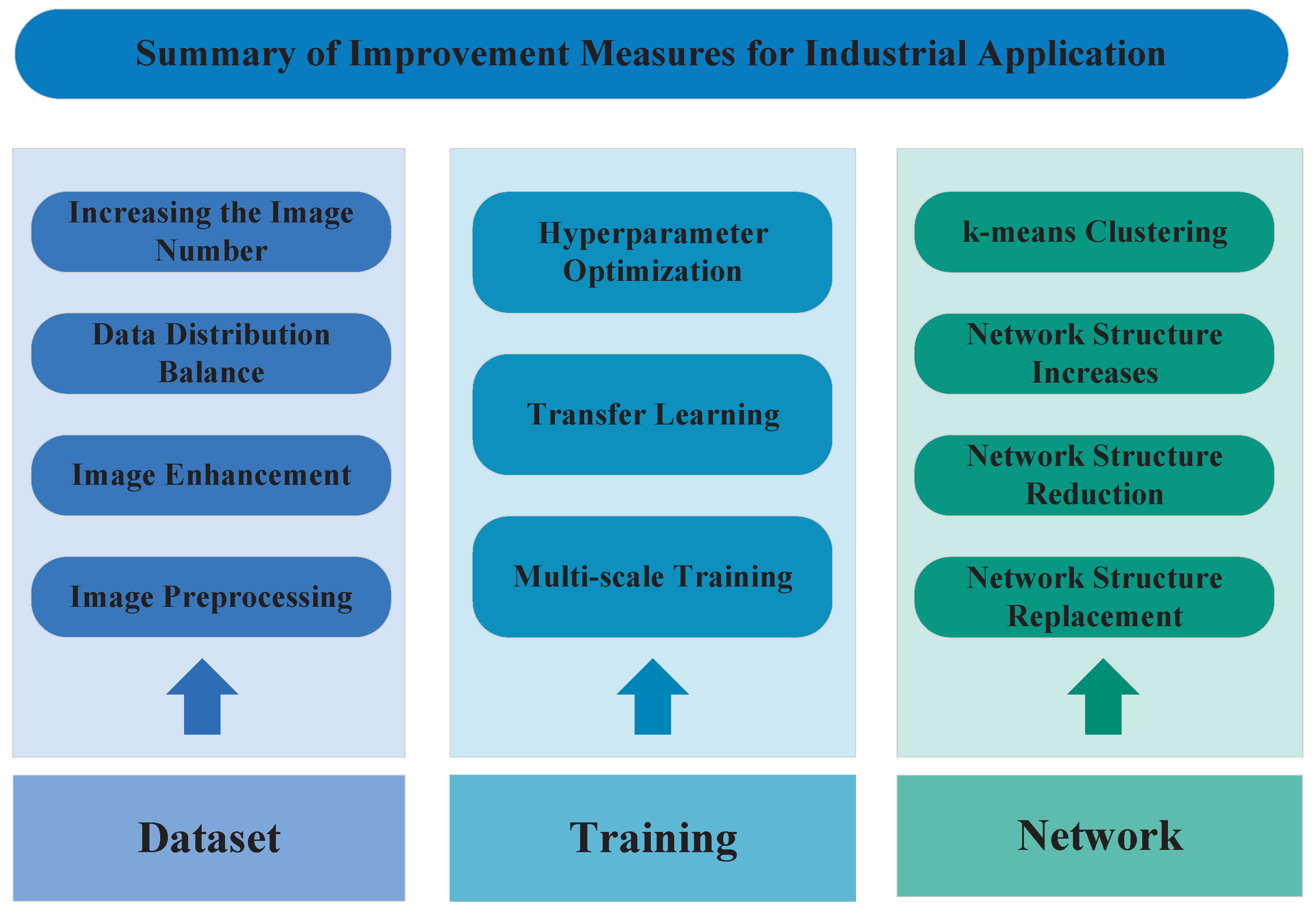




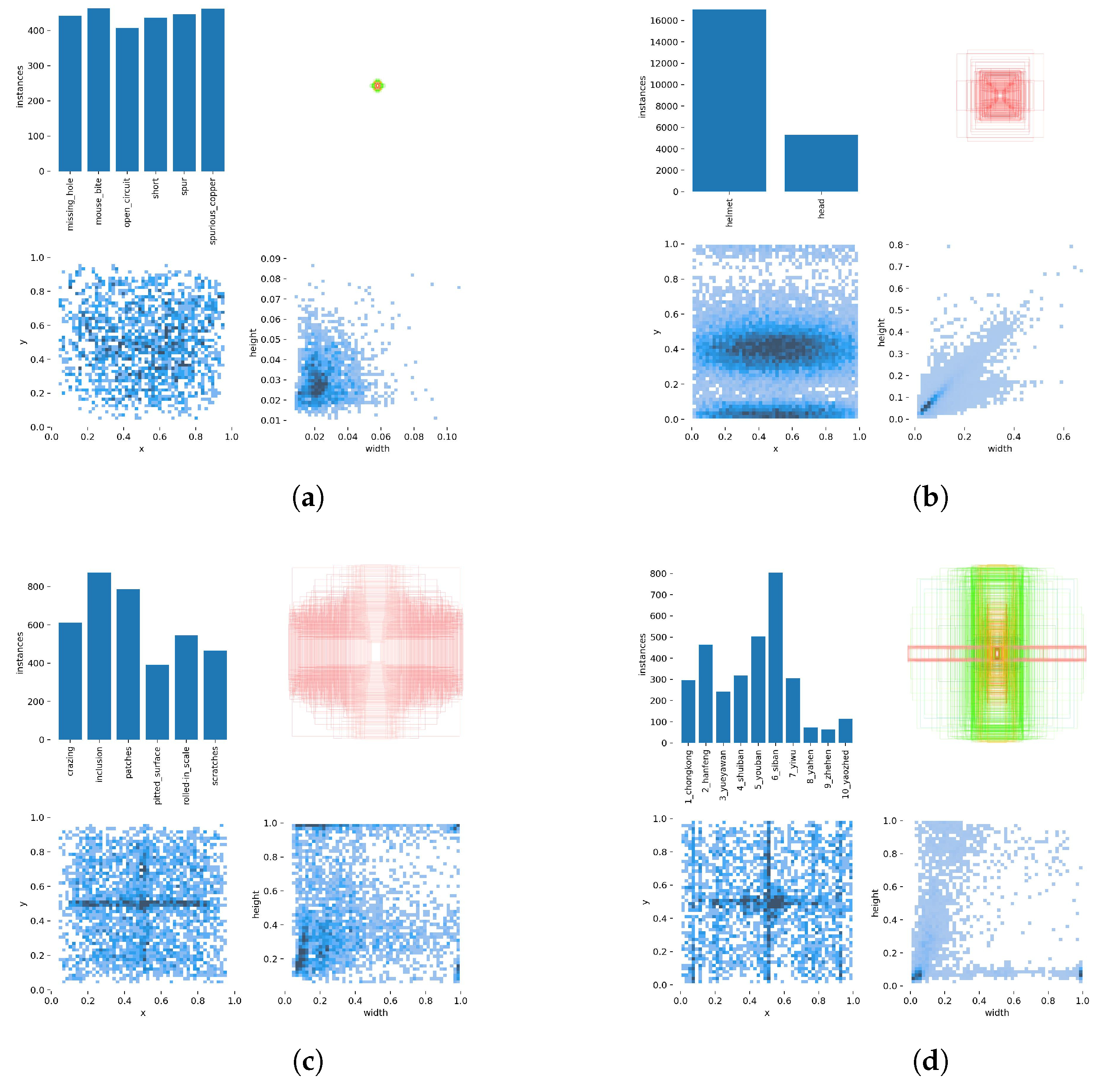
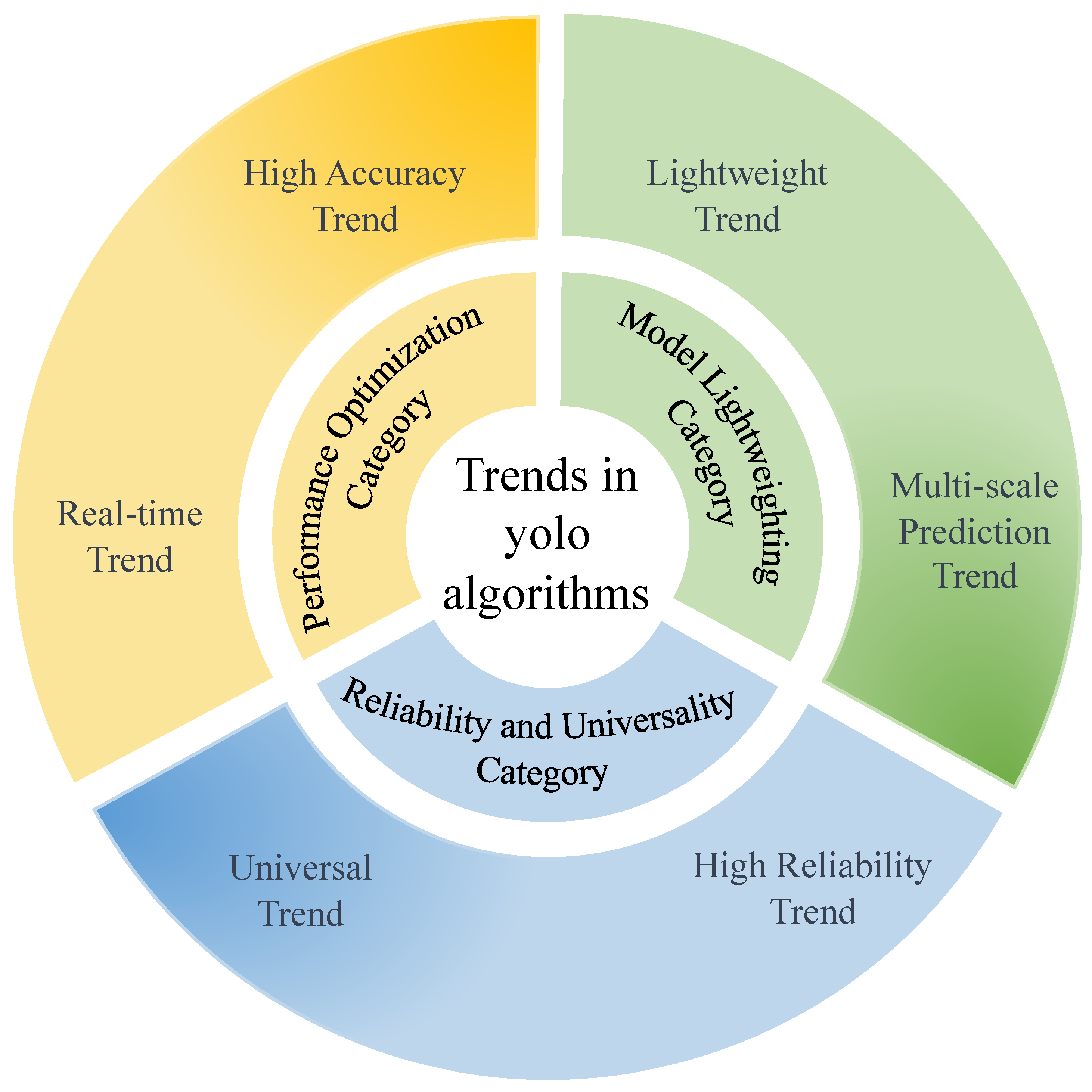
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).