Abstract
In recent years, underwater image enhancement (UIE) processing technology has developed rapidly, and underwater optical imaging technology has shown great advantages in the intelligent operation of underwater robots. In underwater environments, light absorption and scattering often cause seabed images to be blurry and distorted in color. Therefore, acquiring high-definition underwater imagery with superior quality holds essential significance for advancing the exploration and development of marine resources. In order to resolve the problems associated with chromatic aberration, insufficient exposure, and blurring in underwater images, a high-dimensional attention generative adversarial network framework for underwater image enhancement (HDAGAN) is proposed. The introduced method is composed of a generator and a discriminator. The generator comprises an encoder and a decoder. In the encoder, a channel attention residual module (CARM) is designed to capture both semantic features and contextual details from visual data, incorporating multi-scale feature extraction layers and multi-scale feature fusion layers. Furthermore, in the decoder, to refine the feature representation of latent vectors for detail recovery, a strengthen–operate–subtract module (SOSM) is introduced to strengthen the model’s capability to comprehend the picture’s geometric structure and semantic information. Additionally, in the discriminator, a multi-scale feature discrimination module (MFDM) is proposed, which aids in achieving more precise discrimination. Experimental findings demonstrate that the novel approach significantly outperforms state-of-the-art UIE techniques, delivering enhanced outcomes with higher visual appeal.
1. Introduction
With the continuous development of the global economy and the rapid increase in population, terrestrial resources are facing unprecedented challenges. The oceans contain abundant mineral and energy resources essential for humanity, making the deep development and efficient utilization of marine resources of paramount importance. In recent years, marine information processing technologies have advanced rapidly, and underwater optical imaging technology has demonstrated significant advantages in underwater robotics for intelligent operations. Its applications span a wide range of critical areas, including marine resource development, maritime defense security, marine biological ecological monitoring, and precise underwater target detection [1,2,3].
In terms of marine resource development, underwater optical imaging technology serves as an advanced environmental perception tool, enabling high-precision mapping of seabed topography and providing crucial geographical information and data support for the extraction of seabed resources, such as natural gas and minerals. Regarding maritime defense security, underwater optical imaging technology enhances the ability to search for and monitor suspicious underwater targets, improving the sensitivity and accuracy of maritime defense early-warning systems. Additionally, it serves as a key factor in the detection and salvage of historical wrecks, such as sunken ships and aircraft, contributing to the protection of national maritime interests and cultural heritage. For marine biological ecological monitoring, underwater optical imaging technology allows non-invasive observation of marine organisms’ behavior, population distribution, and environmental changes, offering valuable data to support marine ecological conservation and scientific research [4].
However, optical imaging in underwater environments remains highly challenging. Firstly, when light travels underwater, it is subject to selective absorption effects by the water medium across different spectral regions, resulting in color deviation in the captured underwater images. Different wavelengths of light undergo varying degrees of attenuation as they travel underwater, with longer wavelengths such as red light experiencing the most significant attenuation. In contrast, shorter wavelengths such as green and blue light attenuate more slowly, which leads to green or blue color in underwater images. This implies that the blue-green tones dominate the color spectrum in underwater images [5,6]. Secondly, the phenomenon of light scattering by particulates and marine plankton within seawater results in reduced image contrast, compromised visual acuity, obliterated details, and chromatic aberration attributable to the dispersion and attenuation of luminous energy. Therefore, obtaining clear underwater images plays a critical role in marine exploration. To obtain high-quality underwater images, researchers have proposed numerous image enhancement methods. These methods improve the image’s pixel-level appearance by directly manipulating pixel values [7]. However, simple pixel adjustment may lead to amplified noise and color deviation in the pictures.
Although most current approaches can enhance the clarity of underwater pictures to varying degrees, those methods often still exhibit residual haze, blurred details, and unnatural colors. Given the characteristics of underwater imaging, three strategies can be employed to enhance the clarity of underwater pictures: (1) physics-based models, (2) non-physics-based models, and (3) deep learning-based models [8].
Physics-based traditional methods describe the imaging process of the image. These models focus on understanding how underwater images deteriorate over time due to different elements, such as lighting conditions and water quality. By analyzing this degradation process, they aim to develop models that accurately describe these changes. Examples include methods based on minimal information priors. While these techniques excel in chromatic adjustment and contrast optimization, individual physics-based models frequently encounter challenges in accurately representing the intricate conditions of underwater ecosystems. The training phase of such models may lead to image quality issues including excessive amplification or inadequate enhancement of visual details.
Non-physics-based traditional underwater optical image enhancement methods do not rely on a specific imaging model. Instead, they primarily modify pixel values to optimize the perceptual quality of submerged photographic data, utilizing techniques that are based on wavelet transformation methods. While these methods have the capability to modify the perceptual presentation of submerged photographic data, they often neglect the optical properties of underwater imaging, making it difficult to recover real underwater scene information, especially for restoring the color information of underwater images [9,10].
Recently, deep learning has fundamentally reshaped the landscape of computer vision research, demonstrating powerful learning capabilities. Deep learning-based underwater optical image enhancement algorithms automatically extract deep features from images by training on large datasets and establishing efficient mapping relationships, ultimately producing clearer submerged photographic data. These approaches can be divided into two main groups according to their structural design: one category is based on convolutional neural networks (CNNs), which, due to their advantages in feature extraction, adaptability, and efficiency in convolutional computations, can hierarchically extract and enhance underwater image features. The other category is based on generative adversarial networks (GANs), which simulate the process of generating realistic underwater images by constructing an adversarial learning mechanism between a generator and a discriminator, thus achieving more realistic and high-quality image enhancement results.
Wang et al. introduced architectures for enhancing underwater images utilizing CNNs, demonstrating promising results in shadow removal and contrast enhancement. However, this method still has room for improvement in terms of color correction [11].
Wu et al. introduced an innovative real-time underwater image enhancement strategy leveraging the powerful adversarial abilities of GAN. Nevertheless, this method exhibited limitations, such as color deviation in enhanced images, which appeared excessively dark, leading to poor overall visual quality [12].
Given that GAN models can rapidly learn robust generative models through adversarial training, they are particularly suited for addressing the complexities of underwater image enhancement, including diverse scene variations and image degradation types. Given the distinct characteristics of underwater imagery coupled with the constraints related to training duration and computational resources, we have selected a GAN-based architecture as the primary technical approach for enhancing underwater images.
This article focuses on the optimization of UIE within the GAN framework. The generator and discriminator are constructed using CNNs. The generator adopts a U-Net encoder–decoder structure, which effectively captures contextual information. To resolve the particular challenges of underwater imaging, we introduce a CARM in the generator’s encoder for feature extraction and multi-resolution feature integration. Additionally, the SOS module was introduced to enhance feature representation. We further propose an MFDM to enable multi-scale discrimination, and it is derived from a Markovian discriminator (PatchGAN). Our research highlights the following key contributions:
- Channel attention residual module (CARM): In the encoder, we propose the CARM to capture both semantic features and contextual details from visual data. A densely connected layer can improve the encoding capacity, resulting in more reliable embedding vectors that produce clearer images.
- Strengthen–operate–subtract module (SOSM): To further refine the feature representation of images, we introduce the SOS module. Based on the proven effectiveness of boosting algorithms for image denoising, the SOS boosting strategy iteratively refines the results by using previously enhanced images as input, improving the latent vector’s geometric structure and semantic information.
- Multi-scale feature discrimination module (MFDM): To productively acquire both local and global contextual details for determining the authenticity of input images, we design the MFDM, applied at the final layer of the discriminator.
2. Materials and Methods
Due to the critical importance of underwater exploration, numerous authoritative experts have proposed a range of UIE methods. These approaches are generally divided into two primary categories: traditional underwater picture enhancement algorithms [13,14,15] and deep learning-driven UIE methods.
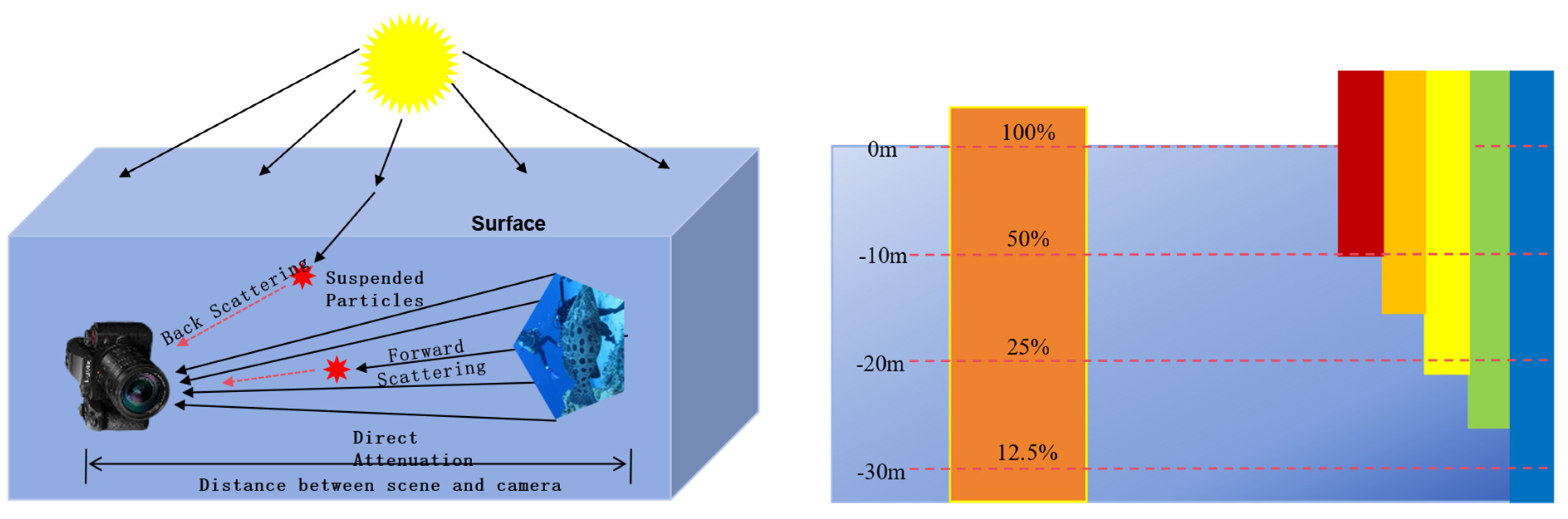
There are two problems when light propagates in seawater, namely the absorption effect and the scattering effect, which are caused by the influence of the water medium. The absorption effect refers to the energy loss when light propagates in water. As shown in Figure 1, the penetration ability of red light diminishes as its wavelength increases. As the depth increases underwater, different colors of light disappear.
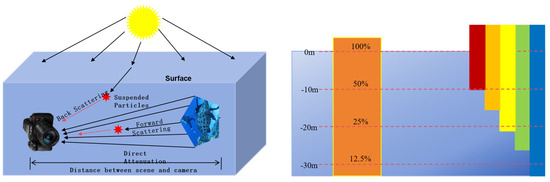
Figure 1.
Principle of the underwater imaging model.
The underwater pictures we see usually exhibit predominant blue-green. The scattering effect is the phenomenon that occurs when light encounters particles in seawater, and the propagation direction of light changes and scatters around. According to the direction of light scattering, the scattering of light by seawater will be classified into forward scattering and backward scattering. The scattering process will cause the image to be blurred and foggy, and the contrast is low.
2.1. Traditional UIE Methods
By modifying pixel values directly, conventional UIE techniques effectively boost visual quality, achieving sharper images with more detailed features. In the preliminary stages of the study, there were relatively few enhancement methods specifically designed for underwater optical images. Peng et al. [15] raised a generalized DCP model (generalization DCP, GDCP) to research underwater optical image enhancement. By measuring the difference in ambient light within the scene, this technique estimates the transmittance map and applies adaptive color correction to refine the image’s colors. Zhang et al. [16] focused on minimizing color deviation while incorporating adaptive local adjustments. The approach begins by emphasizing the preservation of image integrity, aiming to minimize the loss of color information during preprocessing. It then extracts color transformation mappings from underwater images in a unique manner, helping retain and optimize the natural colors of the images. This adaptive local strategy enables fine-grained contrast adjustment across various regions, improving overall visual quality while preserving and even highlighting image details. Iqbal et al. [17], according to the VKH approach, proposed a color balancing and targeted histogram stretching algorithm that improves the visual clarity of underwater images through advanced processing techniques.
Ulutas et al. [18] designed an enhancement algorithm that combines CLAHE and layered difference representation. This method first uses CLAHE to improve the contrast of marine pictures and applies local color correction. Then, it employs layered difference representation techniques to ensure overall contrast enhancement, thereby improving both local and global visual effects in a complementary manner.
While traditional image enhancement approaches can promote the clarity and contrast of marine pictures, they frequently neglect to consider the degradation processes specific to underwater imagery and the distinct characteristics of underwater environments. Specifically, the strong depth dependency between objects and the camera is overlooked, leading these models to produce over-enhanced results that may compromise the realism and accuracy of the pictures.
2.2. Model-Based Deep Learning
The remarkable capabilities of deep learning networks have prompted more researchers to adopt these advanced techniques in the realm of UIE, resulting in significant progress and notable outcomes. Deep learning focuses on leveraging complex network models to perform nonlinear learning on large volumes of training data. This approach can be divided into two primary groups depending on variations in network architecture design: CNN-based methods, which employ CNN architectures to extract and enhance features from underwater images to improve their clarity and visual quality, and GAN-based methods, which leverage an adversarial training framework involving a generator and a discriminator to model and restore compromised underwater images, ultimately producing enhanced images characterized by greater realism and visual appeal [19].
2.2.1. CNN-Based Method
Ding et al. [20] developed a comprehensive underwater optical imaging framework. The method is divided into two phases: first, adaptive color correction techniques are employed to address color deviation; second, CNNs are employed to calculate the transmission map and the background light. Lin et al. [21] introduced a two-stage network model following CNN. Initially, the method directly incorporates the underwater physical model into the network architecture to address horizontal distortion, adaptively recalibrating the RGB channels of distorted images to mitigate issues of underwater light absorption and scattering. Xue et al. [22] presented a novel network architecture utilizing aggregated multi-branch features. The analysis focuses on factors contributing to underwater degradation, specifically examining color deviation and the “hazing” effect. They established a physical model aimed at fully utilizing the estimated degradation factors to produce clear and desirable output images. Liu et al. [23] presented a LANet model. This method extracts and utilizes spatial information from images. Finally, an asynchronous training strategy was introduced to improve network performance, resulting in superior outputs. Zhu Z et al. [24] FDNet combines Fourier transform and diffusion models in a dual-channel network, achieving advanced underwater image enhancement with exceptional color and detail recovery.
Although these methods have found widespread practical applications, they often exhibit limited adaptability when dealing with underwater images gathered across a spectrum of water environments [25]. This limitation arises because these methods require training the network based on specific underwater scenarios to achieve optimal visual results.
2.2.2. GAN-Based Method
GAN fundamentally comprises two networks: the generator (G) and the discriminator (D). The networks participate in a rival process driven by a loss function, aiming to optimize the generator’s result. The G strives to produce artificial images virtually identical to real ones, thereby challenging the D’s ability to distinguish between genuine and fabricated images. If the D fails to make a correct distinction, it undergoes further learning. Due to GAN’s exceptional data generation capabilities, they are highly favored in image processing tasks [26]. The objective of the G is to produce images that closely emulate real-world conditions, rendering them indistinguishable from actual images to the discriminator [27,28,29]. The D aims to differentiate between produced and authentic images. If the discriminator is unable to reliably distinguish the generated images, it necessitates further training to enhance its performance. Because GAN has excellent data generation capabilities, it is deeply loved in the area of image processing.
The adversarial loss function of GAN is as follows:
where z is the noise variable, x is the real sample, and is the generated sample. is a realistic sample. represents the probability of the real sample when the input data is input, and is the likelihood that the input data is generated data. GAN performs the minimax game by optimizing the above loss function .
Guo et al. [30] developed a DenseGAN for UIE. This model integrates adversarial loss and L1 loss to better represent the distribution of high-quality images. Islam et al. [31] implemented a supervised learning methodology for the purposes of real-time enhancement of underwater imagery, known as fast underwater image enhancement (FUnIE). However, this method exhibits limitations in effectively enhancing severely degraded images. Yang et al. [32] presented a GAN-based architecture incorporating a multi-scale feature discernment mechanism for enhanced underwater image processing. The implementation of a discriminator model effectively captures local semantic information, leading to the production of more realistic and convincing image outputs. Jiang et al. [33] focused on addressing turbidity and chromaticity issues, presenting an innovative model to achieve improved enhancement results in underwater scenarios.
Deep learning-based UIE algorithms have demonstrated superiority over conventional image enhancement techniques with accuracy, robustness, and processing speed. However, directly applying these algorithms to underwater image enhancement often falls short of achieving the desired results. The intricacy of underwater environments significantly surpasses that of conventional terrestrial scenes. Captured underwater images typically endure challenges, for instance, low contrast, indefinite fineness, and color deviations, which significantly hinder the enhancement performance [34,35,36,37].
2.2.3. Transformer-Based Method
In 2017, Vaswani et al. [38] proposed the Transformer model, whose parallel processing capabilities and global feature extraction properties overcame the sequential processing limitations of traditional sequence models. This mechanism achieves global dependencies among input elements through dynamic allocation of attention weights, significantly improving computational efficiency. With the expansion of Transformers into computer vision, the Swin Transformer addressed computational complexity challenges in image processing via hierarchical architectures and shifted window mechanisms. In underwater optical image enhancement, Ren et al. [36] merged the Swin Transformer into the U-Net framework, reintroducing convolutional operations to synergistically optimize global context and local details, thereby simultaneously enhancing image quality and super-resolution performance. These methodologies break through bottlenecks of strong environmental interference and detail degradation in underwater imaging, demonstrating the robust adaptability of Transformer models in multitask scenarios.
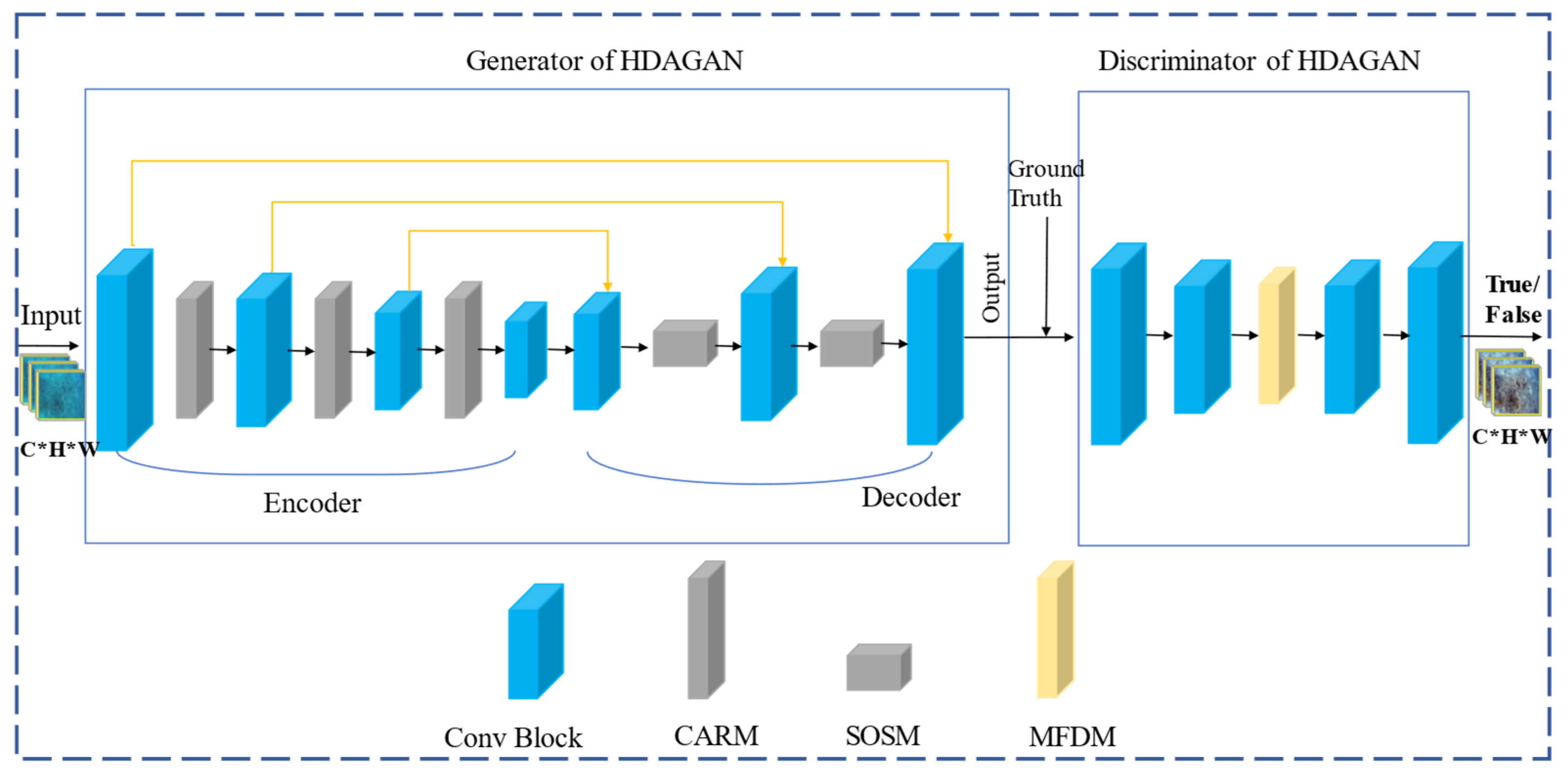
3. The Proposed Method
The model of the high-dimensional attention generative adversarial network framework for UIE is illustrated in Figure 2 and comprises two key elements: the generator and the discriminator. From the perspective of this framework, the generator takes raw underwater images as input. In the encoding phase, it employs a CARM to extract image features and execute multi-scale feature fusion. This process aims to deeply capture semantic and contextual information from the images, ultimately generating clear and visually appealing underwater images.
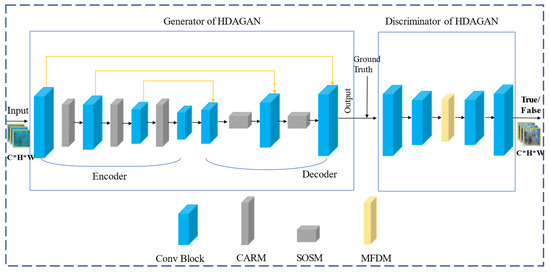
Figure 2.
Overview architecture of the HDAGAN.
To further refine the latent feature vectors used for detail restoration, an SOS module is created and embedded into the decoding stage of the generator. This module improves the model’s capacity to interpret the geometric structures and semantic details of the images. By accurately identifying key features at different scales, the SOS module maximizes the utility of the limited latent feature space, capturing and preserving details that are vital for image enhancement.
Additionally, traditional loss functions exhibit certain limitations in distinguishing enhanced images from real ones. To address this, the discriminator is based on a Markov discriminator (PatchGAN) and incorporates a multi-scale feature discrimination module (MFDM) to assist in the differentiation process. Through adversarial training between the discriminator and generator, the generator continuously optimizes its capabilities, producing images that more closely align with the characteristics of real underwater environments. This provides reliable data support for subsequent marine applications, such as ecological monitoring and underwater archaeology.
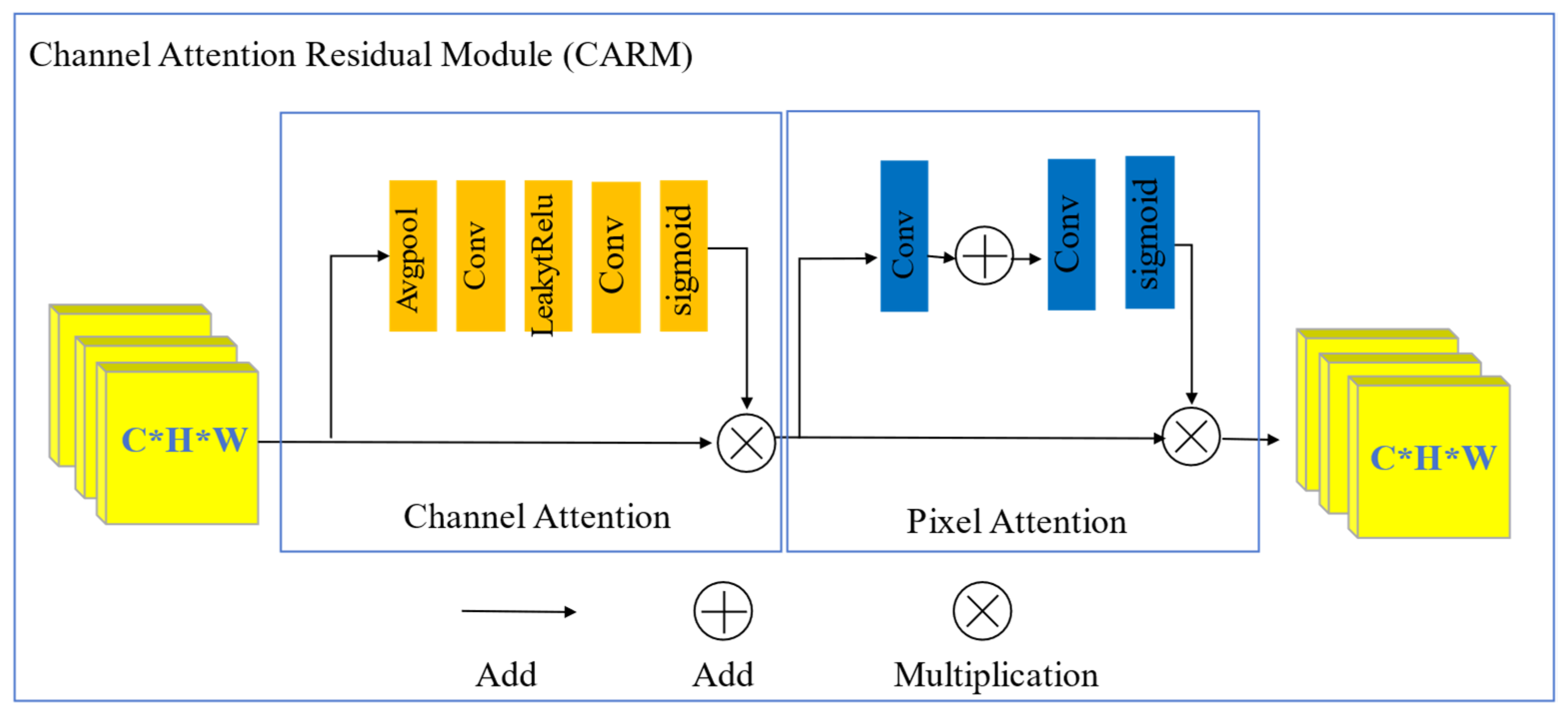
3.1. Channel Attention Residual Module
In the encoding phase of the generator, a CARM is employed at each step to extract significant details from underwater images, as shown in Figure 3. Given the distinctive attributes of marine visual data, the distribution of key features across different color channels and pixel positions is inconsistent. Consequently, varying receptive fields are required to effectively capture scene-specific information.
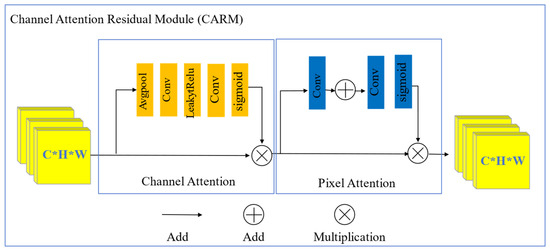
Figure 3.
Architecture of the proposed network: CARM.
To solve these problems, the CARM integrates both channel and pixel attention mechanisms to acquire multi-scale contextual and structural information about the scene. By cascading two distinct channel attention mechanisms, the CARM effectively filters out irrelevant feature information from multi-channel inputs while retaining channel features that are conducive to image encoding. This selective preservation of relevant features ensures improved representation and analysis of underwater images, enabling the generator to process and encode them more effectively.
3.1.1. Channel Attention
This mechanism proposed in this study enhances critical information by adaptively recalibrating the weights of feature channels. Specifically designed for underwater imaging, this mechanism focuses on evaluating the weight distribution across different color channels, prioritizing the red channel to address its pronounced attenuation in underwater environments. The architecture begins with a global average pooling operation applied to the feature maps, denoted as .
In this architecture, denotes the value of the c-th channel in the input feature map at spatial position (i,j). A global average pooling operation (H) is applied to compress the feature map dimensions from C × H × W to C × 1 × 1. The features are then processed through two convolutional layers to learn channel-wise weight distributions. Finally, a sigmoid function is employed to generate , which adaptively scales the importance of each channel.
Here, denotes the sigmoid function, and represents the LeakyReLU function.
A channel-wise weighting operation is performed by multiplying the learned with the input feature map , resulting in the refined output feature map .
3.1.2. Pixel Attention
To address the non-uniform blur distribution in underwater images, this study proposes a pixel attention system that makes the network adaptively concentrate on information-rich pixel features, such as heavily blurred regions and high-frequency detail areas, as shown in Figure 3. The input feature map FC is processed through two convolutional layers, reducing its dimensionality from C × H × W to 1 × H × W. PA is derived through a sigmoid transformation.
Finally, a pixel-wise weighting operation is performed by multiplication of PA with the input feature map , producing the refined output feature map , which serves as the output of the feature attention module.
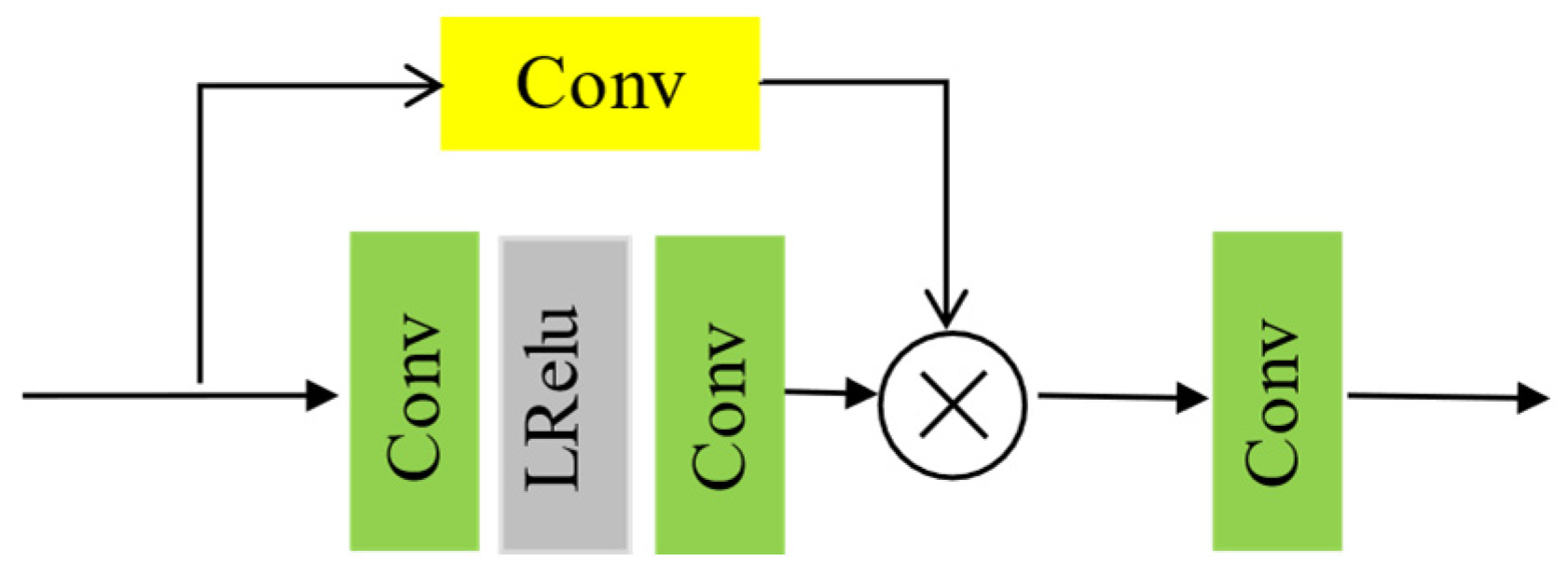
3.2. Strengthen–Operate–Subtract Module
In the proposed architecture, the decoder will incorporate the SOSM to enhance and refine feature information, leveraging shallow features from skip connections to refine deep features. The principle of the SOSM is to refine the enhanced features based on previously processed images. This section treats the feature information from the encoder as unprocessed input features and the feature information from the decoder as processed output features, as shown in Figure 4.
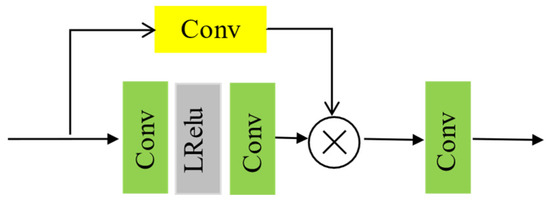
Figure 4.
Architecture of the SOSM.
The SOSM is then integrated into the decoder network. The feature is obtained in the encoder. The method employs a 3 × 3 depthwise convolution (stride = 2) to process spatial features, coupled with a 1 × 1 convolution for channel dimensions. Each convolutional layer is succeeded by normalization and a LeakyReLU activation function.
Finally, the obtained feature value is multiplied with the refined to get the output feature map . is the enhanced image with the same size as the decoder output and input image.
3.3. Multi-Scale Feature Discrimination Module
In underwater images, high-frequency information is more critical for advanced visual tasks compared to low-frequency information. Traditional GAN discriminators typically calculate a single value (real or fake) for the entire image, as shown in Figure 5b. Such a discriminator can only evaluate the total quality of the picture and lacks the ability to assess the finer details, leading to blurred local details in the generated image.

Figure 5.
(a) MFDM; (b) whole-image discriminator.
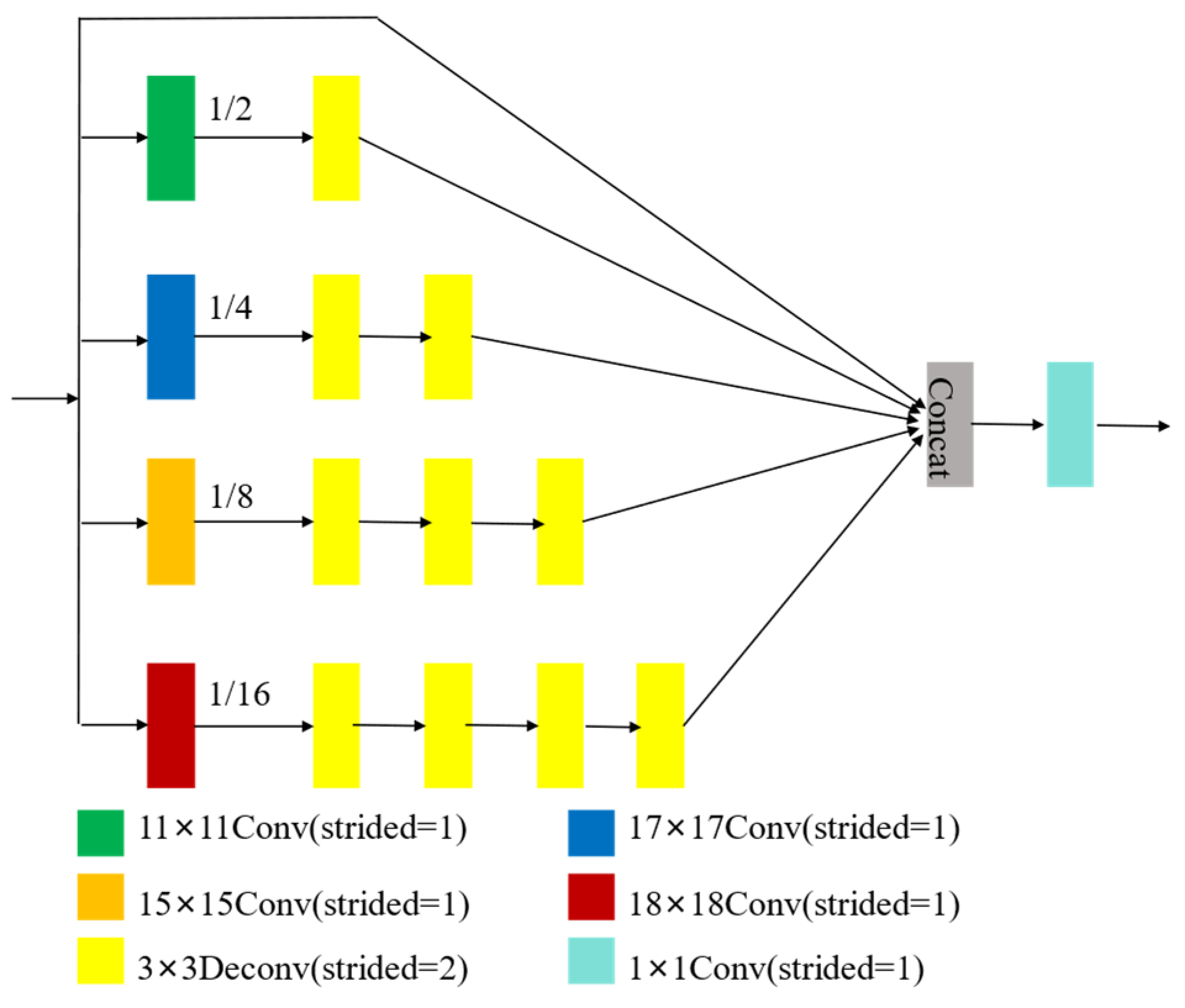
The article introduces a multiscale feature discrimination module integrated into the final layer of the discriminator to allow it to perform more detailed, multiscale discrimination of the input images. The MFDM adopts a fully convolutional structure, where the discriminator evaluates the fake image as an N × N matrix. Each element within the matrix corresponds to the discriminator’s evaluation of a specific region of the picture. The overall assessment of the entire image by the discriminator is derived from the average value computed from this matrix, as shown in Figure 5. The MFDM places greater emphasis on the local information of underwater images, reducing local blurriness. This enables the generated underwater images to retain more detail while also extracting the global context data.
In the MFDM, the input features are processed through four distinct convolutional layers, each employing various kernel sizes. This approach enables the extraction of feature maps at multiple scales, facilitating the capture of information with differing receptive fields. The kernel sizes of the four convolutional layers are 11 × 11, 15 × 15, 17 × 17, and 18 × 18. After passing through these layers, the feature map sizes are progressively halved, while the receptive fields increase. The feature map pulled out by the 18 × 18 convolutional layer represents the global detail of the image. The four feature maps are subsequently upsampled utilizing deconvolution layers to match. Finally, a 1 × 1 convolution layer is applied to produce the fused feature map, with output dimensions of N × N × 1. This output feature map contains both local detail and global semantic detail. The integration of local and global detail helps the discriminator perform more accurate classification, thereby guiding the generator to produce finer and clearer underwater images, as shown in Figure 6.
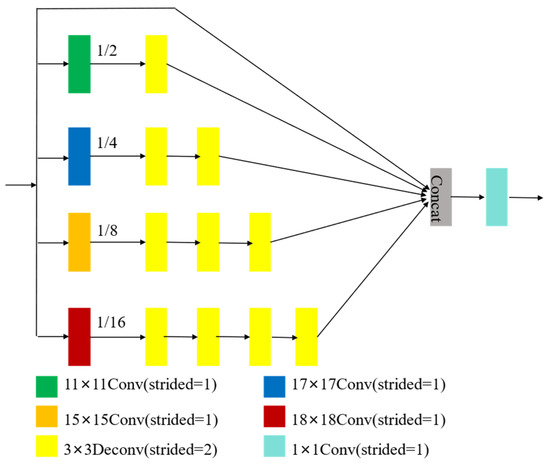
Figure 6.
Principle of MFDM.
3.4. Multiple-Loss Function
To effectively preserve the integrity of image detail features, this paper incorporates three distinct loss functions: generative adversarial loss function, global similarity loss function, and content loss function.
In Equation (1), denotes the adversarial loss function, represents the global similarity loss function, corresponds to the content loss function, and are weighting factors balancing the contributions of these loss terms, with = 0.7 and = 0.3. G and D indicating the generator network and discriminator network, respectively.
3.4.1. Adversarial Loss Function
By integrating a game-theoretic framework into the GAN architecture, the composite loss function is formulated as follows:
In this formulation, Z denotes the input data, X represents the output target image, and E signifies the expectation operator. Within the conventional conditional adversarial generative network framework, the G seeks to minimize the adversarial loss , while the D attempts to maximize .
3.4.2. Global Similarity Loss Function
The conventional loss measures discrepancies from a pixel-wise perspective. This integration enables the generator network G to learn sampling from a globally consistent spatial distribution through regularization, thereby facilitating image-to-image translation tasks and ensuring consistency in image information preservation. The formal definition is expressed as follows:
3.4.3. Loss Function of Content Perception
To develop the realism of pictures produced by the presented model and refine the perceptual quality of the outputs, a content loss function is integrated into the objective formulation. This content loss leverages capabilities for rapid analysis, discrepancy localization, feature matching, and detail preservation. To drive the generator G to produce enhanced images that approximate the distribution of real images, we employ a VGG pre-trained network model, where represents the parameters of the first k layers in the VGG architecture.
4. Experiments
4.1. Quantitative Evaluations
The absence of specific evaluation standards for underwater images has led to the prevalent use of general image evaluation indicators in the assessment of underwater imagery. Mean square error (MSE), peak signal-to-noise ratio (PSNR) [39], and structural similarity loss (SSIM) [40] are very common indicators for measuring image enhancement effects. Therefore, many authoritative papers also use these indicators to evaluate underwater image processing results, as shown in Table 1.

Table 1.
The comparison of experimental results of different loss functions.
SSIM serves as a prevalent perceptual quality assessment method that quantifies image similarity through luminance matching, contrast correlation, and structural composition analysis. This metric employs a human vision-sensitive framework to evaluate visual information preservation between compared images. The range of SSIM values lies between 0 and 1. Higher values are associated with smaller image differences. The calculation method of SSIM is as follows:
where and represent two images, and represent the mean values of all pixels of and , and represent the differences in all pixels of and , respectively, represents the covariance between and , and and are two constants.
PSNR provides a quantitative measure of the distortion between the generated image and the real image. PSNR is usually calculated using MSE. Given a reference image R and its distorted image D, MSE is defined as
where and indicate the coordinates of the image pixels, and M and N represent the height and width of the picture.
MAX2 represents the maximum possible pixel value. PSNR is an important metric in image enhancement, indicating that a higher PSNR value corresponds to reduced distortion in the enhanced image, thereby signifying superior enhancement quality.
Panetta et al. [41] introduced a novel metric, UIQM. UIQM is a fusion metric that is a fusion of UICM, UISM, and UICONM. UIQM is closely related to the human visual system, so it can also be used as an evaluation metric. First, UICM is expressed by the following formula:
where RG = R-G and YB = Y-B, 1 is the asymmetric alpha trimmed mean the closer it is to . is the statistical variance, which represents the pixel behavior of each color component. Next, the expression of the clarity evaluation index UISM is
EME is a quantity used to measure edge clarity. Generally, , , and are suitable parameter values for underwater scenes. For UICONM, the expression is as follows:
AMEE is characterized as the average Michelson contrast of the respective image patch. In the above formula, UIQM represents
4.2. Loss Function Performance
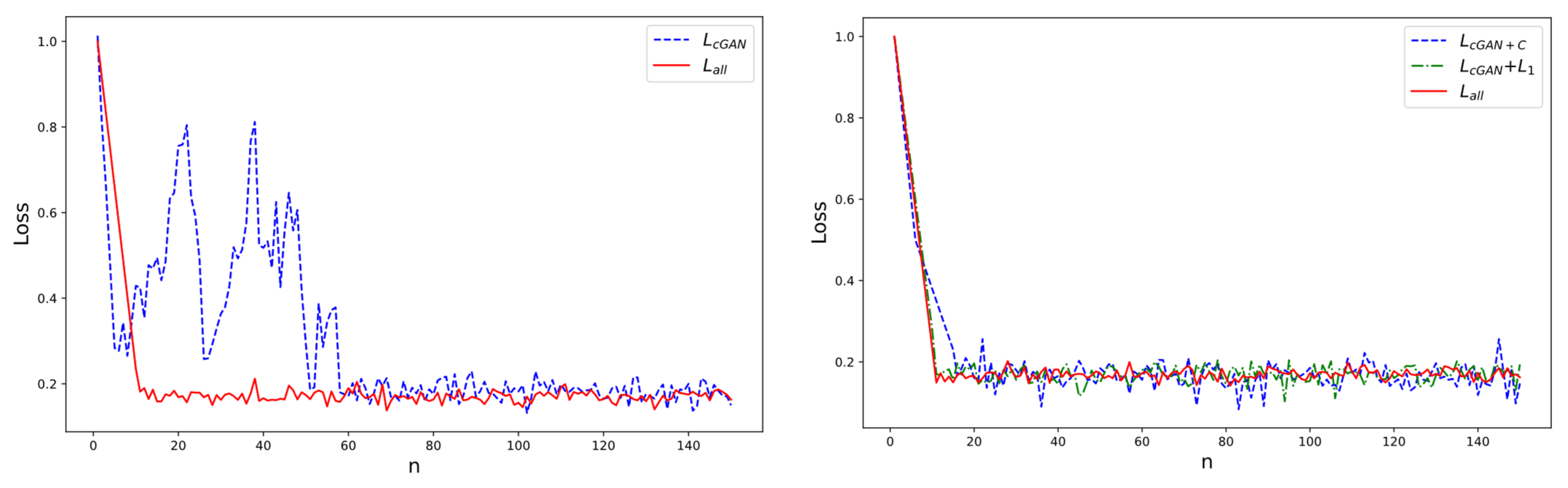
Figure 7 presents a performance analysis of the loss functions constructed from three components: generative adversarial loss function, global similarity loss function, and content loss function. Here, represents the combination of all three loss functions, denotes the integration of adversarial loss and global similarity loss, and corresponds to the integration of adversarial loss and content loss. The variable n indicates the number of iterations, and loss refers to the value of the loss function.
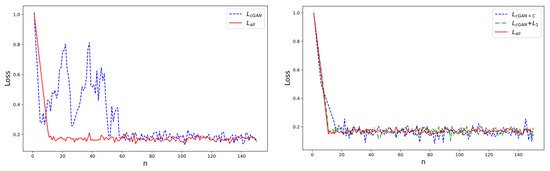
Figure 7.
Comparative trends in the training processes of different loss functions.
From Figure 4, it is apparent that training with only the adversarial loss function exhibits significant oscillations and unstable convergence during iterations, requiring more training cycles. In contrast, the training process using a combination of three loss functions demonstrates greater stability and reduced dispersion. As can be seen from Figure 5, the curve and curve have similar performance, and the loss function value is significantly lower than the curve.
However, as the number of iterations grows, the curve converges, a small amplitude fluctuation occurs, and the curve is more stable than the curve.
To sum up, using the combination of three loss functions, has better and more stable performance. In addition, from the PSNR and SSIM, the PSNR of the three loss function combinations is 24.349, and the SSIM is 0.773, which is significantly higher than that of other loss function combinations. Therefore, the three loss functions in this paper combine , as shown in Equation (1).
4.3. Datasets and Training Details
This study employs a composite training dataset comprising 6128 style-transferred image pairs generated through unsupervised domain adaptation and 4000 synthetically rendered image pairs based on Jerlov’s optical water classification, yielding a combined corpus of 10,128 aligned samples for model optimization.
In terms of evaluating datasets, the paired underwater image enhancement benchmark (UIEB) [29] and the unpaired underwater robot picking contest (URPC) datasets were utilized, and was the EUVP [31]. There are many excellent data sets. PODB is a large-scale, diverse polarimetric image dataset covering various adverse weather conditions, and we will conduct in-depth research on this dataset in the future [42].
The UIEB dataset contains 890 realistic underwater images. The dataset was divided into 800 training pairs and 90 validation pairs. The URPC dataset contains 831 underwater images collected using remotely operated vehicles. The URPC image dataset exhibits chromatic characteristics predominantly within green or blue-green spectral ranges. This study designates the entire URPC dataset as the evaluation benchmark, implementing dimensional standardization through resolution adjustment; 231 image samples were processed to 1280 × 768-pixel resolution, while 600 specimens were adjusted to 768 × 512-pixel dimensions. The EUVP dataset comprises a diverse collection of authentic benthic images captured under heterogeneous visibility conditions across multiple geographical locations. Despite its ecological representativeness, the dataset exhibits significant noise contamination and chromatic bias toward blue spectral dominance. For empirical analysis, we statistically sampled 4129 image instances from this corpus, implementing dimensional standardization through resolution normalization to 768 × 512 pixels. The ideas for image data processing are derived from [43].
To assess the robustness of our approach, we performed comparative analyses on the UIEB and URPC validation and test sets. Furthermore, we contrasted our approach with the most advanced techniques currently available. For the experiments, the model is trained in PyTorch 1.4.0 with the Adam optimizer (learning rate: 0.000; batch size: 16) over 200 epochs until convergence, as shown in Table 2.
Table 2.
Experimental setup and data.
4.4. Analysis of Experimental Results
This section evaluates the effectiveness of the proposed HDAGAN model. First, the experimental settings related to this chapter are proposed. Subsequently, to confirm the performance of the HDAGAN, comprehensive experimental comparisons and analyses were conducted across various underwater image datasets.
The comparison methods include the following: traditional model-free image enhancement techniques (e.g., fusion [14]); traditional model-based image enhancement techniques (e.g., GDCP [15], UDCP [44]); and deep learning-based image enhancement methods (e.g., WaterNet [29], UWCNN [45], UGAN [46], and URSCT-SESR [47]). Furthermore, ablation studies were performed to demonstrate the efficacy of the introduced network modules and loss functions. Finally, the fundamental design principles of the HDAGAN model are analyzed to validate their effectiveness, as shown in Figure 8.

Figure 8.
(a) Original; (b) fusion; (c) GDCP; (d) UDCP; (e) UWCNN; (f) WaterNet; (g) UGA; (h) URSCT-SESR; (i) HDAGAN.
The GDCP and UDCP methods are unable to completely mitigate the impact of blue-green backgrounds, resulting in hazy and blurred images with insufficient detail clarity. These approaches fail to availably address the color cast issues prevalent in underwater images. The UWCNN network, due to its relatively simple architecture, does not significantly enhance the overall visual quality of images; instead, it often exacerbates color cast problems, causing images to appear darker overall. The WaterNet method produces images with excessively high brightness and contrast, leading to overexposure in the overall image. Although the URSCT-SESR method significantly improves color correction, its local attention to capturing feature information is weak, resulting in insufficient image enhancement and certain texture loss. The UAGAN method demonstrates noticeable improvements in visual quality but may cause color deviations in certain local areas. In contrast, the HDAGAN method remains unaffected by the unique challenges of underwater environments. It effectively corrects color casts and reduces image haziness without introducing noise or artifacts, generating images that are more visually appealing and accurate.
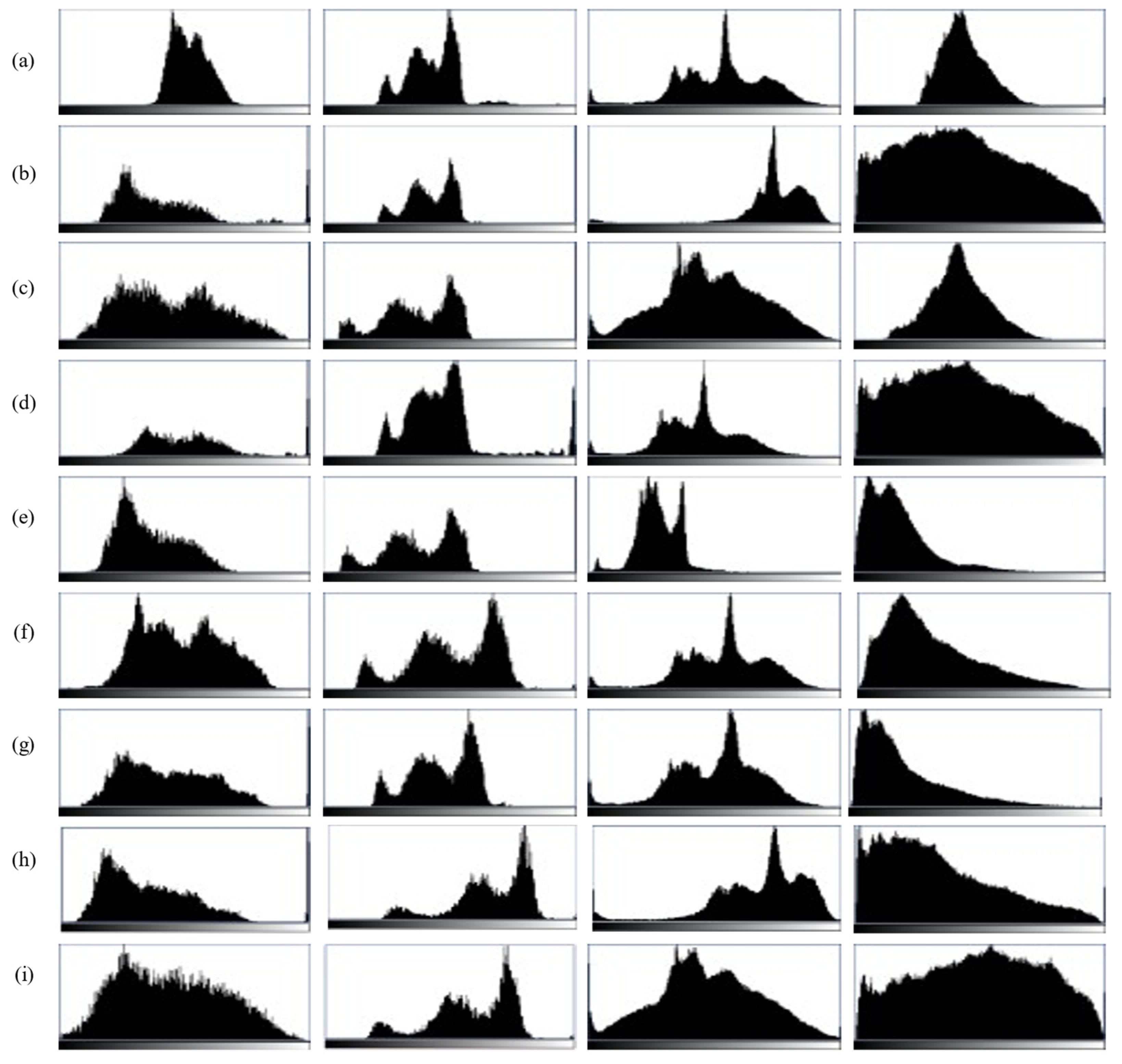
Figure 9 presents a comparison of histograms for the enhanced images, with the interpretations of (a)–(i) consistent with those in Figure 8. The histograms of the images enhanced by UGAN, UAGAN, and UWCNN are relatively similar, showing limited histogram stretching. The first and fourth images enhanced by URSCT-SESR exhibit relatively better contrast, as evidenced by a greater widening of their histograms. Similarly, the histograms of the fourth image enhanced by the fusion and UDCP methods are effectively stretched.
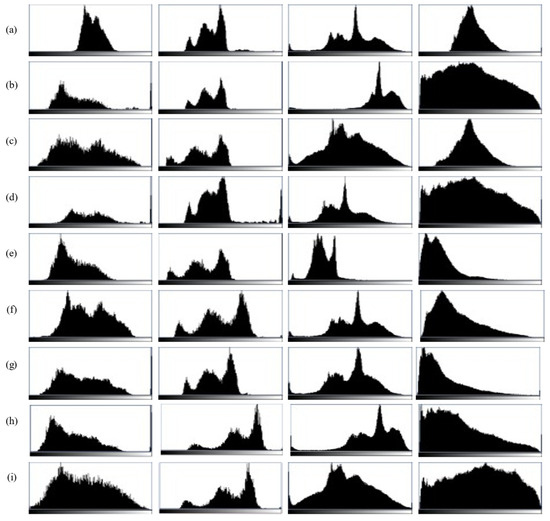
Figure 9.
(a) Original; (b) fusion; (c) GDCP; (d) UDCP; (e) UWCNN; (f) WaterNet; (g) UGAN; (h) URSCT-SESR; (i) HDAGAN.
The GDCP-enhanced images appear overall darker, resulting in undetected edges in the histogram of the enhanced images. Although the UCM method achieves stretched histograms, it introduces noise during image processing, evident from multiple abnormal spikes observed in the fourth histogram. The HDAGAN enhancement method outlined effectively expands the histograms of the enhanced images to encompass the entire range, from a minimum value of 0 to a maximum value of 255. This demonstrates that the proposed approach delivers, resulting in images that are not only more aesthetically pleasing but also exhibit enhanced contrast.
Figure 10 presents a comparative analysis of edge detection results, where the meanings of (a)–(i) correspond to those in Figure 8. From the figure, it is obvious that the fusion, GDCP, and UDCP methods demonstrate varying levels of enhancement in edge information. However, the second image exhibits a bluish tint, resulting in the inability to detect the edges of rocks within the image. Similarly, the UWCNN and WaterNet methods darken the first image, which obscures the detection of rock edges. While the UAGAN and URSCT-SESR methods effectively enhance edge information, the first enhanced image still contains dark regions, making the edge details less prominent.

Figure 10.
(a) Original; (b) fusion; (c) GDCP; (d) UDCP; (e) UWCNN; (f) WaterNet; (g) UGAN; (h) URSCT-SESR; (i) HDAGAN.
In contrast, the proposed HDAGAN method surpasses the other approaches by providing enhanced images with more detailed edge information. For example, it successfully highlights intricate patterns on fish, outlines of distant scenes, contrasts in coral color and shading, and fine details on underwater rocks. This capability demonstrates the superiority of the HDAGAN method in preserving and enhancing edge contours in underwater images.
In the UIEB, URPC, and EUVP datasets, the PSNR and SSIM values of the HDAGAN method are both the first because the attention mechanism embedded in this method facilitates the extraction of critical features from large-scale input data while enhancing the model’s capacity to capture local and global information. Fusion, GDCP, and UDCP obtain lower values. The single-layer network structure mechanism is incorporated into UWCNN, which weakens the capacity of the model to extract image data. It is noteworthy that the high SSIM of UGAN and URSCT-SESR relies on inputs from traditional GAN-based methods. WaterNet helps eliminate blur, but for images with severe color skew, the color difference remains. In general, the enhancement effect and generalization ability of our method are better, as illustrated in Table 3.
Table 3.
Metrics and average for quantitative comparison of UIEB, URPC, and EUVP datasets.
4.5. Ablation Experiment
4.5.1. Model Complexity
In deep learning models, the number of parameters and floating-point operations (FLOPs) are critical metrics for evaluating complexity; the parameter count reflects the model size (larger values indicate higher complexity). FLOPs represent computational demand (lower values correspond to faster inference speeds). As demonstrated in Table 4, our method achieves an optimal balance between model complexity and performance.
Table 4.
Comparison of the complexity.
The ablation experiment intends to comprehend the effect of the CARM and MFDM in the HDAGAN model. The 90 indices of underwater images from the UIEB dataset are combined. Training studies on validation datasets in UIEB have been conducted to assess the effectiveness of the CARM, SOSM, and MFDM for UIE. The ablation experiment of the CARM, SOSM, and MFDM is shown in Table 5. As demonstrated in Table 4, the SSIM and PSNR metrics of the algorithm presented herein exhibit superior results compared to the alternative ablation experiments. This finding indicates that the integration of the CARM, the SOSM, and the MFD module significantly enhances the clarity and contrast of underwater images.
Table 5.
Comparison of CARM, SOSM, and MFDM before and after ablation experiment on underwater images. (√: Model participation).
4.5.2. CARM Ablation Experiment
The CARM proposed in this paper makes our network focus more intently on the characteristic details of the red channel and the noise region of the underwater image during the training process to extract the important feature information for underwater image enhancement. Therefore, to verify the actual effect of the CARM in UIE, we conducted an ablation experiment of the CARM.
The necessity of convolutional layers is also verified at multiple scales, i.e., various integrations of Conv 3 × 3, Conv 5 × 5, and Conv 7 × 7, as shown in Table 6. To validate the efficacy of multi-scale layers in the CARM, we conducted experimental studies. The various combinations of Conv 3 × 3, Conv 5 × 5, and Conv 7 × 7 produce lower indicators than the full CARM. The complete CARM has a great improvement in the two standard indexes of SSIM and PSNR.
Table 6.
Comparison of CARM before and after ablation experiment on underwater images.
At the same time, as shown in Figure 11, for qualitative comparison, different convolutional layer methods may cause blur or color deviation in underwater images. As can be seen, various integrations of Conv 3 × 3, Conv 5 × 5, and Conv 7 × 7 produce images that are less clear than a full CARM.

Figure 11.
Qualitative comparison of different convolution layers in real underwater images.
On the contrary, the HDAGAN method using the CARM can eliminate the color deviation and correct the color bias phenomenon well, which indicates that the CARM facilitates the network’s ability to concentrate on specific features of severely blurred areas and different color channels and adaptively extract important information. Therefore, the CARM can fully extract the features of underwater images, which is very effective for underwater image enhancement tasks.
4.5.3. MFDM Ablation Experiment
The aim of designing the MFDM is to enhance the discriminator’s discriminative capability. This module integrates features with varying receptive fields, enabling the extraction of fused features that combine local and global image information. The discriminator leverages these fused features for precise discrimination, which, through adversarial training, drives the generator to produce more detailed underwater images.
This section conducts an ablation study on the MFDM by removing it from the discriminator and replacing it with a simple 1 × 1 convolutional layer to form an alternative network structure. Quantitative comparisons are presented in Table 7, demonstrating that the proposed method incorporating the MFDM achieves noticeable performance improvements. Qualitative comparisons, as shown in Figure 12, reveal that our method with the MFDM generates significantly more detailed images.
Table 7.
Quantitative comparisons of MFDM.

Figure 12.
Ablation experiment of MFDM.
These results indicate that incorporating the MFDM into the discriminator enables the generator to extract features with both local detail and global semantic information. This enhancement contributes to generating visually clearer images and is crucial for improving the adversarial training process of the GAN.
5. Conclusions
In this paper, we introduce a novel generative adversarial network, named HDAGAN. The proposed framework effectively extracts features across various resolutions and hierarchical levels, thereby improving overall network performance. A channel attention residual module (CARM), a strengthen–operate–subtract module (SOSM), a multi-scale feature discrimination module (MFDM), and spatial attention mechanisms are used to extract discriminative noise features and reassign channel attention weight. Our ablation study demonstrates the efficacy of each module within the proposed model. Both qualitative and quantitative evaluation results indicate that our models frequently outperform the most advanced models currently available. The running time of the model is relatively complex. Future work will explore more lightweight network models without degrading network performance.
Author Contributions
Conceptualization, S.T.; methodology, S.T.; software, S.T.; validation, S.T.; formal analysis, S.T.; investigation, S.T. and A.S.; resources, S.T.; data curation, S.T.; writing—original draft preparation, S.T.; writing—review and editing, J.K. and C.W.; visualization, S.T.; supervision, A.S.; project administration, J.K. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
For data presented in this article, please contact the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Islam, M.J.; Ho, M.; Sattar, J. Understanding human motion and gestures for underwater human–robot collaboration. J. Field Rob. 2019, 36, 851–873. [Google Scholar] [CrossRef]
- Chen, T.; Wang, N.; Wang, R.; Zhao, H.; Zhang, G. One-stage CNN detector-based benthonic organisms detection with limited training dataset. Neural Netw. 2021, 144, 247–259. [Google Scholar] [CrossRef]
- Zhou, J.; Zhang, D.; Ren, W.; Zhang, W. Auto color correction of underwater images utilizing depth information. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1504805. [Google Scholar] [CrossRef]
- Wang, J.; Zhao, M.; Zou, L.; Hu, Y.; Cheng, X.; Liu, X. Fish tracking based on improved TLD algorithm in real-world underwater environment. Mar. Technol. Soc. J. 2019, 53, 80–89. [Google Scholar] [CrossRef]
- Zhuang, P.; Ding, X. Underwater image enhancement using an edge-preserving filtering retinex algorithm. Multimed. Tools Appl. 2020, 79, 17257–17277. [Google Scholar] [CrossRef]
- Jiang, Q.; Gu, Y.; Li, C.; Cong, R.; Shao, F. Underwater image enhancement quality evaluation: Benchmark dataset and objective metric. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 5959–5974. [Google Scholar] [CrossRef]
- Zhang, D.; Wu, C.; Zhou, J.; Zhang, W.; Li, C.; Lin, Z. Hierarchical attention aggregation with multi-resolution feature learning for GAN-based underwater image enhancement. Eng. Appl. Artif. Intell. 2023, 125, 106743. [Google Scholar] [CrossRef]
- Wang, N.; Chen, T.; Kong, X.; Chen, Y.; Wang, R.; Gong, Y.; Song, S. Underwater attentional generative adversarial networks for image enhancement. IEEE Trans. Hum.-Mach. Syst. 2023, 53, 490–500. [Google Scholar] [CrossRef]
- Zhuang, P.; Li, C.; Wu, J. Bayesian retinex underwater image enhancement. Eng. Appl. Artif. Intell. 2021, 101, 104171. [Google Scholar] [CrossRef]
- Li, T.; Rong, S.; Zhao, W.; Chen, L.; Liu, Y.; Zhou, H.; He, B. Underwater image enhancement using adaptive color restoration and dehazing. Opt. Express 2022, 30, 6216–6235. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, J.; Cao, Y.; Wang, Z. A deep CNN method for underwater image enhancement. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 1382–1386. [Google Scholar]
- Wu, J.; Liu, X.; Lu, Q.; Lin, Z.; Qin, N.; Shi, Q. FW-GAN: Underwater image enhancement using generative adversarial network with multi-scale fusion. Signal Process. Image Commun. 2022, 109, 116855. [Google Scholar] [CrossRef]
- Bai, L.; Zhang, W.; Pan, X.; Zhao, C. Underwater image enhancement based on global and local equalization of histogram and dual-image multi-scale fusion. IEEE Access 2020, 8, 128973–128990. [Google Scholar] [CrossRef]
- Ancuti, C.; Ancuti, C.O.; Haber, T.; Bekaert, P. Enhancing underwater images and videos by fusion. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 81–88. [Google Scholar]
- Peng, Y.-T.; Cao, K.; Cosman, P.C. Generalization of the dark channel prior for single image restoration. IEEE Trans. Image Process. 2018, 27, 2856–2868. [Google Scholar] [CrossRef]
- Zhang, W.; Zhuang, P.; Sun, H.-H.; Li, G.; Kwong, S.; Li, C. Underwater image enhancement via minimal color loss and locally adaptive contrast enhancement. IEEE Trans. Image Process. 2022, 31, 3997–4010. [Google Scholar] [CrossRef]
- Iqbal, K.; Odetayo, M.; James, A.; Salam, R.A.; Talib, A.Z.H. Enhancing the low quality images using unsupervised colour correction method. In Proceedings of the 2010 IEEE International Conference on Systems, Man and Cybernetics, Istanbul, Turkey, 10–13 October 2010; pp. 1703–1709. [Google Scholar]
- Ulutas, G.; Ustubioglu, B. Underwater image enhancement using contrast limited adaptive histogram equalization and layered difference representation. Multimed. Tools Appl. 2021, 80, 15067–15091. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Ding, X.; Wang, Y.; Zhang, J.; Fu, X. Underwater image dehaze using scene depth estimation with adaptive color correction. In Proceedings of the OCEANS 2017-Aberdeen, Aberdeen, UK, 19–22 June 2017; pp. 1–5. [Google Scholar]
- Lin, Y.; Shen, L.; Wang, Z.; Wang, K.; Zhang, X. Attenuation coefficient guided two-stage network for underwater image restoration. IEEE Signal Process Lett. 2020, 28, 199–203. [Google Scholar] [CrossRef]
- Xue, X.; Li, Z.; Ma, L.; Jia, Q.; Liu, R.; Fan, X. Investigating intrinsic degradation factors by multi-branch aggregation for real-world underwater image enhancement. Pattern Recognit. 2023, 133, 109041. [Google Scholar] [CrossRef]
- Liu, S.; Fan, H.; Lin, S.; Wang, Q.; Ding, N.; Tang, Y. Adaptive learning attention network for underwater image enhancement. IEEE Rob. Autom. Lett. 2022, 7, 5326–5333. [Google Scholar] [CrossRef]
- Zhu, Z.; Li, X.; Ma, Q.; Zhai, J.; Hu, H. FDNet: Fourier transform guided dual-channel underwater image enhancement diffusion network. Sci. China Technol. Sci. 2025, 68, 1100403. [Google Scholar] [CrossRef]
- Zhang, Z.; Yan, H.; Tang, K.; Duan, Y. MetaUE: Model-based meta-learning for underwater image enhancement. arXiv 2023, arXiv:2303.06543. [Google Scholar]
- Li, J.; Skinner, K.A.; Eustice, R.M.; Johnson-Roberson, M. WaterGAN: Unsupervised generative network to enable real-time color correction of monocular underwater images. IEEE Rob. Autom. Lett. 2017, 3, 387–394. [Google Scholar] [CrossRef]
- Hambarde, P.; Murala, S.; Dhall, A. UW-GAN: Single-image depth estimation and image enhancement for underwater images. IEEE Trans. Instrum. Meas. 2021, 70, 5018412. [Google Scholar] [CrossRef]
- Cong, R.; Yang, W.; Zhang, W.; Li, C.; Guo, C.-L.; Huang, Q.; Kwong, S. Pugan: Physical model-guided underwater image enhancement using gan with dual-discriminators. IEEE Trans. Image Process. 2023, 32, 4472–4485. [Google Scholar] [CrossRef]
- Sun, B.; Mei, Y.; Yan, N.; Chen, Y. UMGAN: Underwater image enhancement network for unpaired image-to-image translation. J. Mar. Sci. Eng. 2023, 11, 447. [Google Scholar] [CrossRef]
- Guo, Y.; Li, H.; Zhuang, P. Underwater image enhancement using a multiscale dense generative adversarial network. IEEE J. Ocean. Eng. 2019, 45, 862–870. [Google Scholar] [CrossRef]
- Islam, M.J.; Xia, Y.; Sattar, J. Fast underwater image enhancement for improved visual perception. IEEE Rob. Autom. Lett. 2020, 5, 3227–3234. [Google Scholar] [CrossRef]
- Yang, M.; Hu, K.; Du, Y.; Wei, Z.; Sheng, Z.; Hu, J. Underwater image enhancement based on conditional generative adversarial network. Signal Process. Image Commun. 2020, 81, 115723. [Google Scholar] [CrossRef]
- Jiang, Z.; Li, Z.; Yang, S.; Fan, X.; Liu, R. Target oriented perceptual adversarial fusion network for underwater image enhancement. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 6584–6598. [Google Scholar] [CrossRef]
- Qi, Q.; Li, K.; Zheng, H.; Gao, X.; Hou, G.; Sun, K. SGUIE-Net: Semantic attention guided underwater image enhancement with multi-scale perception. IEEE Trans. Image Process. 2022, 31, 6816–6830. [Google Scholar] [CrossRef]
- Lyu, Z.; Peng, A.; Wang, Q.; Ding, D. An efficient learning-based method for underwater image enhancement. Displays 2022, 74, 102174. [Google Scholar] [CrossRef]
- Ren, T.; Xu, H.; Jiang, G.; Yu, M.; Zhang, X.; Wang, B.; Luo, T. Reinforced swin-convs transformer for simultaneous underwater sensing scene image enhancement and super-resolution. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4209616. [Google Scholar] [CrossRef]
- Cho, Y.; Malav, R.; Pandey, G.; Kim, A. DehazeGAN: Underwater haze image restoration using unpaired image-to-image translation. IFAC-Pap. 2019, 52, 82–85. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Turaga, D.S.; Chen, Y.; Caviedes, J. No reference PSNR estimation for compressed pictures. Signal Process. Image Commun. 2004, 19, 173–184. [Google Scholar] [CrossRef]
- Panetta, K.; Gao, C.; Agaian, S. Human-visual-system-inspired underwater image quality measures. IEEE J. Ocean. Eng. 2015, 41, 541–551. [Google Scholar] [CrossRef]
- Zhu, Z.; Li, X.; Zhai, J.; Hu, H. PODB: A learning-based polarimetric object detection benchmark for road scenes in adverse weather conditions. Inf. Fusion 2024, 108, 102385. [Google Scholar] [CrossRef]
- Liu, H.; Li, X.; Wang, Z.; Huang, Y.; Zhai, J.; Hu, H. Review of polarimetric image denoising. Adv. Imaging 2024, 1, 022001. [Google Scholar] [CrossRef]
- Drews, P.L.; Nascimento, E.R.; Botelho, S.S.; Campos, M.F.M. Underwater depth estimation and image restoration based on single images. IEEE Comput. Graph. Appl. 2016, 36, 24–35. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Anwar, S.; Porikli, F. Underwater scene prior inspired deep underwater image and video enhancement. Pattern Recognit. 2020, 98, 107038. [Google Scholar] [CrossRef]
- Fabbri, C.; Islam, M.J.; Sattar, J. Enhancing underwater imagery using generative adversarial networks. In Proceedings of the 2018 IEEE international conference on robotics and automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 7159–7165. [Google Scholar]
- Song, W.; Wang, Y.; Huang, D.; Liotta, A.; Perra, C. Enhancement of underwater images with statistical model of background light and optimization of transmission map. IEEE Trans. Broadcast. 2020, 66, 153–169. [Google Scholar] [CrossRef]





Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).