
Real-Time Temperature Prediction for Large-Scale Multi-Core Chips Based on Graph Convolutional Neural Networks

Abstract
1. Introduction
Additional Related Works
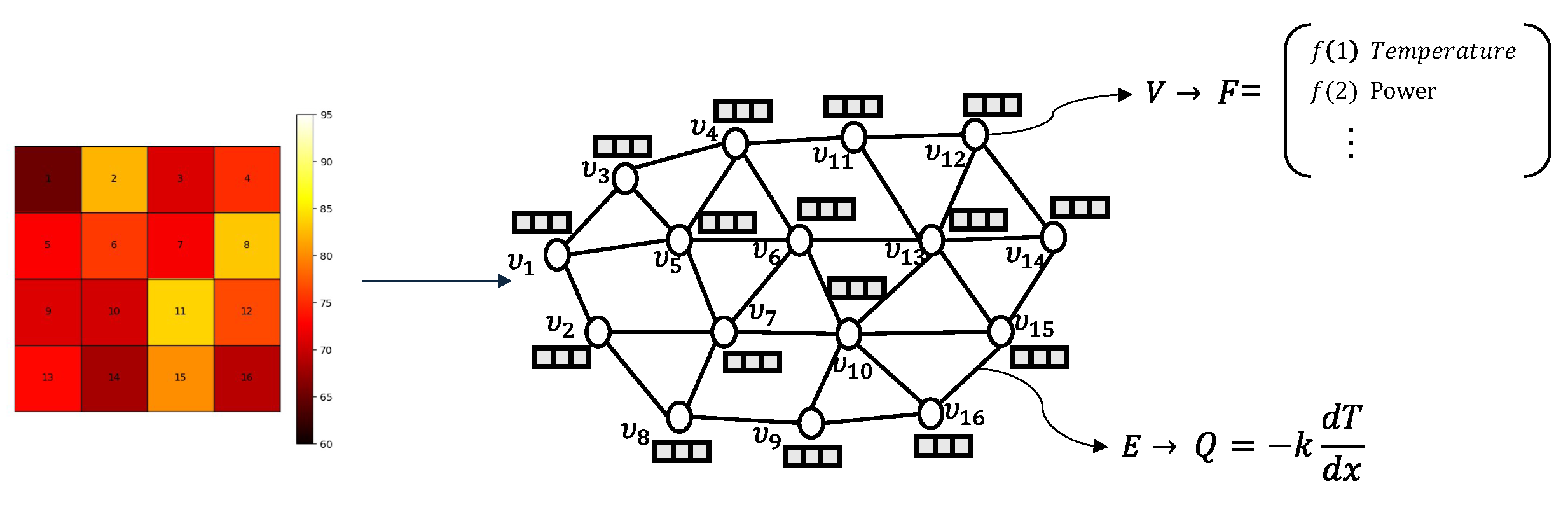
2. Problem Description
3. Methodologies
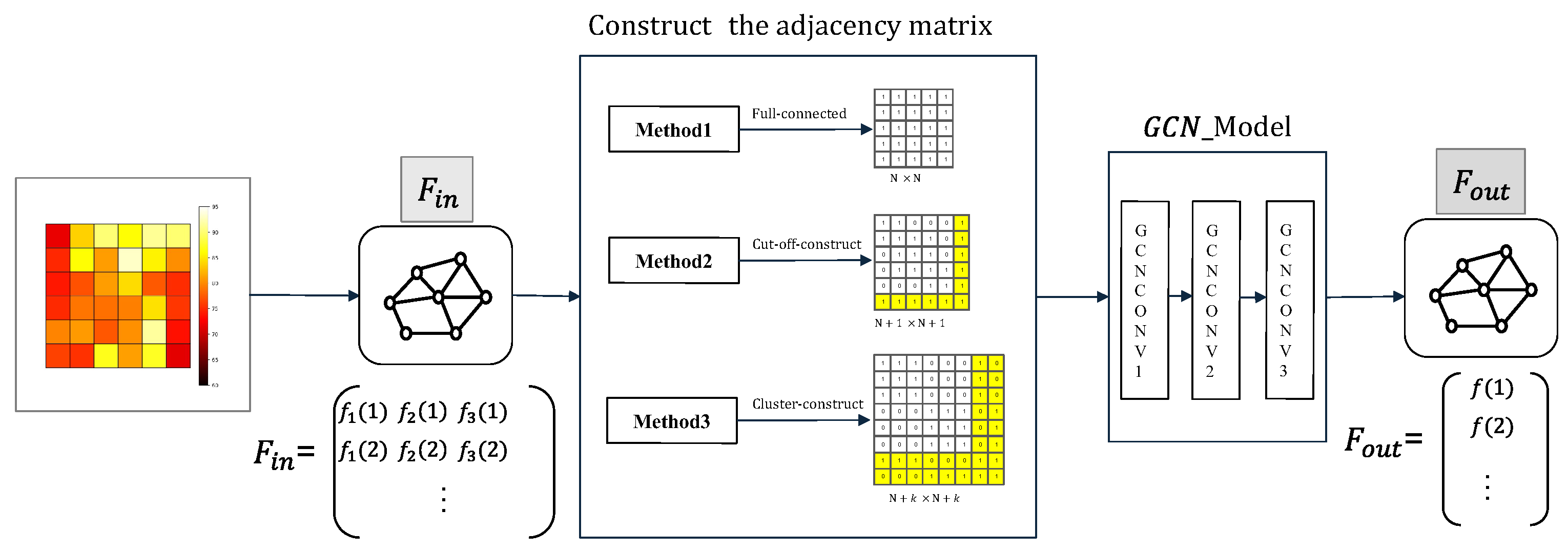
3.1. Model Architecture—GCN-Based Neural Network Model
3.2. Adjacency Matrix Construction Method
3.2.1. Method 1—Fully Connected Graph
3.2.2. Method 2—Setting a Cutoff Radius
| Algorithm 1: Construct Adjacency Matrix with Cutoff Radius Method |
|
3.2.3. Method 3—Cluster-Based Adjacency Matrix Construction Method
| Algorithm 2 Construct Adjacency Matrix for Clustered Graph |
|
4. Results
4.1. Dataset Preparation
4.2. Experiments and Results Analysis
4.2.1. Experimental Setup
4.2.2. Comparative Experiment of Different Models
- MLP: A basic feed-forward neural network composed of multiple fully connected layers, commonly used for classification and regression tasks;
- CNN: CNN is a deep learning architecture that automatically extracts features from images by using convolutional layers and is widely used in image recognition and classification tasks;
- Method 1: Construct an adjacency matrix with all elements set to 1 using a fully connected approach and then train the GCN model;
- Method 2: Construct an adjacency matrix using the cutoff radius method, then train the GCN model;
- Method 3: Construct an adjacency matrix using a clustering method and then train the GCN model.
4.2.3. Computational Performance Comparative Experiment
- Comparison of Computational and Memory Overheads for Different Methods: The method proposed in this paper aims to achieve real-time prediction of the temperature of multi-core chips. To verify the real-time capability of the model, we analyzed the computational time complexity and memory overhead and evaluated the inference time of different methods. The comparison methods include HotSpot, which is widely used, and MatEx, the chip temperature simulation tool used for generating the dataset in this paper.The time complexity and memory overhead of each method are shown in Table 5.The HotSpot method discretizes the chip structure into N grid nodes. For a 3D structure, the number of grids N increases linearly with the number of layers. However, the overall scale can still be regarded as a polynomial function related to the chip area and the number of layers. The theoretical time complexity is in the worst-case scenario (when directly solving a dense matrix).For the MatEx method, W Newton–Raphson iterations are required for each node. The time complexity of each iteration is . Therefore, the time complexity for each node is , and the total time complexity is .For the GCN method, if the adjacency matrix is known a priori, then we only need to consider the time complexity of the multiplication between the feature matrix and the weight matrix, which is approximately , where is the number of edges in the graph, and f is the feature dimension of the nodes. The three adjacency matrix construction strategies that we proposed have different numbers of edges, and the time complexity will vary depending on the specific scenarios and experimental settings.In addition, we had each method perform 100 inference predictions for power variations, and the experimental results are shown in Figure 8.Our method is at least an order of magnitude faster than the traditional thermal modeling method of HotSpot and the MatEx tool in terms of inference speed. As the number of nodes increases, the difference can reach several orders of magnitude, and the error is small, with the MSE controlled within 0.5. The average time consumption for our model to infer a power change within 2 ms, fully meeting the requirements for real-time temperature prediction;
- Comparison of Different Adjacency Matrices: This paper proposes three strategies for constructing adjacency matrices, each applicable to different scenarios. Therefore, we compared the computational performance of the three strategies. Considering that in GCNs, the most significant factor affecting the time complexity is the number of edges in the graph. We compared the number of edges for the three strategies, as shown in Figure 9.From Figure 8, we observe that when the number of nodes is small (i.e., the dimensions of the adjacency matrix are smaller), the sparse matrix does not show an advantage in computational efficiency. Our analysis using the profile tool revealed that, when the number of nodes is small, the access time to matrix data accounts for a larger proportion than the matrix multiplication computation time. Although our proposed Method 3 increases the sparsity, it also increases the dimensions of the adjacency matrix, thus not offering an advantage in low-dimensional matrix access. However, when the number of nodes increases, the computation time becomes a larger proportion than the access time, and the sparsification operations can significantly improve inference efficiency;
- Ablation study of clustering methods: For clustering methods, we have provided a reference method for selecting the number of clusters k, which theoretically can minimize the edges in the adjacency matrix. Therefore, we conducted an ablation study on different numbers of clusters k, while also verifying the number of edges and the model’s predictive accuracy under different conditions. The experimental results are shown in Figure 10.It can be observed that, around the reference cluster number k value provided by us, the fluctuation of MSE does not exceed 0.1. Therefore, our method can quickly select the k value, ensuring considerable accuracy while reducing the computational load;
- Power Distribution Sensitivity Experiment: To verify the performance of the model that we designed under different power distributions, we simulated and generated data under various power distributions and then used the model to validate it (49 nodes). It should be noted that we have adopted different random distribution methods for the power of each core, and the power range is between 0 and 20 watts. The results of our experiment are shown in Table 6.According to the experiment, our model shows basically consistent performance under different random power distribution methods.
4.2.4. Validation with Real Data
5. Conclusions
- Physics-Informed Hybrid Modeling: Integrating PDE constraints via PINNs could enhance the physical consistency of predictions while retaining GCNs’ computational efficiency. For instance, Fourier’s law of heat conduction could be embedded as a regularization term during training;
- 3D Chiplet Architectures: Extending the graph structure to model vertical heat transfer in stacked-die configurations, where thermal coupling between layers introduces non-uniform conduction patterns;
- Hardware-Software Codesign: Deploying the GCN model on embedded AI accelerators (e.g., NPUs) to achieve sub-millisecond latency for closed-loop thermal management.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Vaddina, K.R.; Rahmani, A.M.; Latif, K.; Liljeberg, P.; Plosila, J. Thermal modeling and analysis of advanced 3D stacked structures. Procedia Eng. 2012, 30, 248–257. [Google Scholar] [CrossRef]
- Wang, H.; Tan, S.X.D.; Li, D.; Gupta, A.; Yuan, Y. Composable thermal modeling and simulation for architecture-level thermal designs of multicore microprocessors. ACM Trans. Des. Autom. Electron. Syst. 2013, 18, 1–27. [Google Scholar] [CrossRef]
- Merrikh, A.A.; McNamara, A.J. Parametric evaluation of foster RC-network for predicting transient evolution of natural convection and radiation around a flat plate. In Proceedings of the Fourteenth Intersociety Conference on Thermal and Thermomechanical Phenomena in Electronic Systems (ITherm), Orlando, FL, USA, 27–30 May 2014; pp. 1011–1018. [Google Scholar] [CrossRef]
- Jia, W.; Wang, H.; Chen, M.; Lu, D.; Lin, L.; Car, R.; Weinan, E.; Zhang, L. Pushing the Limit of Molecular Dynamics with Ab Initio Accuracy to 100 Million Atoms with Machine Learning. In Proceedings of the SC20: International Conference for High Performance Computing, Networking, Storage and Analysis, Atlanta, GA, USA, 9–19 November 2020; pp. 1–14. [Google Scholar] [CrossRef]
- Raissi, M.; Perdikaris, P.; Karniadakis, G. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. J. Comput. Phys. 2019, 378, 686–707. [Google Scholar] [CrossRef]
- Ranade, R.; Hill, C.; He, H.; Maleki, A.; Chang, N.; Pathak, J. A composable autoencoder-based iterative algorithm for accelerating numerical simulations. arXiv 2021, arXiv:2110.03780. [Google Scholar]
- Jin, W.; Sadiqbatcha, S.; Zhang, J.; Tan, S.X.D. Full-Chip Thermal Map Estimation for Commercial Multi-Core CPUs with Generative Adversarial Learning. In Proceedings of the 2020 IEEE/ACM International Conference On Computer Aided Design (ICCAD), Virtual, 2–5 November 2020; pp. 1–9. [Google Scholar]
- Sadiqbatcha, S.; Zhang, J.; Zhao, H.; Amrouch, H.; Henkel, J.; Tan, S.X.D. Post-Silicon Heat-Source Identification and Machine-Learning-Based Thermal Modeling Using Infrared Thermal Imaging. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2021, 40, 694–707. [Google Scholar] [CrossRef]
- Chen, L.; Jin, W.; Tan, S.X.D. Fast Thermal Analysis for Chiplet Design based on Graph Convolution Networks. In Proceedings of the 2022 27th Asia and South Pacific Design Automation Conference (ASP-DAC), Taipei, Taiwan, 17–20 January 2022; pp. 485–492. [Google Scholar] [CrossRef]
- Bhatasana, M.; Marconnet, A. Deep Learning for Real-Time Chip Temperature and Power Predictions. In Proceedings of the 2023 22nd IEEE Intersociety Conference on Thermal and Thermomechanical Phenomena in Electronic Systems (ITherm), Orlando, FL, USA, 30 May–2 June 2023; pp. 1–7. [Google Scholar] [CrossRef]
- Grailoo, M.; Nunez-Yanez, J. Heterogeneous Edge Computing for Molecular Property Prediction with Graph Convolutional Networks. Electronics 2025, 14, 101. [Google Scholar] [CrossRef]
- Ye, Z.; Wang, H.; Przystupa, K.; Majewski, J.; Hots, N.; Su, J. Dynamic Spatio-Temporal Hypergraph Convolutional Network for Traffic Flow Forecasting. Electronics 2024, 13, 4435. [Google Scholar] [CrossRef]
- Guggari, S.I. Analysis of Thermal Performance Metrics—Application to CPU Cooling in HPC Servers. IEEE Trans. Compon. Packag. Manuf. Technol. 2021, 11, 222–232. [Google Scholar] [CrossRef]
- Heinig, A.; Fischbach, R.; Dittrich, M. Thermal analysis and optimization of 2.5D and 3D integrated systems with Wide I/O memory. In Proceedings of the Fourteenth Intersociety Conference on Thermal and Thermomechanical Phenomena in Electronic Systems (ITherm), Orlando, FL, USA, 27–30 May 2014; pp. 86–91. [Google Scholar] [CrossRef]
- Zhou, J.; Yan, J.; Cao, K.; Tan, Y.; Wei, T.; Chen, M.; Zhang, G.; Chen, X.; Hu, S. Thermal-aware correlated two-level scheduling of real-time tasks with reduced processor energy on heterogeneous MPSoCs. J. Syst. Archit. 2018, 82, 1–11. [Google Scholar] [CrossRef]
- Bogdan, P.; Marculescu, R.; Jain, S. Dynamic power management for multidomain system-on-chip platforms: An optimal control approach. ACM Trans. Des. Autom. Electron. Syst. 2013, 18, 1–20. [Google Scholar] [CrossRef]
- Kim, Y.G.; Kim, M.; Kong, J.; Chung, S.W. An Adaptive Thermal Management Framework for Heterogeneous Multi-Core Processors. IEEE Trans. Comput. 2020, 69, 894–906. [Google Scholar] [CrossRef]
- Zhang, J.; Sadiqbatcha, S.; Tan, S.X.D. Hot-Trim: Thermal and Reliability Management for Commercial Multicore Processors Considering Workload Dependent Hot Spots. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2023, 42, 2290–2302. [Google Scholar] [CrossRef]
- Lin, J.Y.; Lin, S.Y. Temperature-Prediction Based Rate-Adjusted Time and Space Mapping Algorithm for 3D CNN Accelerator Systems. IEEE Trans. Comput. 2023, 72, 2767–2780. [Google Scholar] [CrossRef]
- Huang, W.; Ghosh, S.; Velusamy, S.; Sankaranarayanan, K.; Skadron, K.; Stan, M. HotSpot: A compact thermal modeling methodology for early-stage VLSI design. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2006, 14, 501–513. [Google Scholar] [CrossRef]
- Chen, T.Y.; Kuo, S.L.; Hsu, J.M.; Pan, C.W. Dynamic compact thermal modeling of package-on-package by thermal resistor-capacitor ladder. In Proceedings of the 2016 15th IEEE Intersociety Conference on Thermal and Thermomechanical Phenomena in Electronic Systems (ITherm), Las Vegas, NV, USA, 31 May–3 June 2016; pp. 223–229. [Google Scholar] [CrossRef]
- Jiang, L.; Dowling, A.; Liu, Y.; Cheng, M.C. Chip-level Thermal Simulation for a Multicore Processor Using a Multi-Block Model Enabled by Proper Orthogonal Decomposition. In Proceedings of the 2022 21st IEEE Intersociety Conference on Thermal and Thermomechanical Phenomena in Electronic Systems (iTherm), San Diego, CA, USA, 31 May–3 June 2022; pp. 1–7. [Google Scholar] [CrossRef]
- Jiang, L.; Dowling, A.; Cheng, M.C.; Liu, Y. PODTherm-GP: A Physics-Based Data-Driven Approach for Effective Architecture-Level Thermal Simulation of Multi-Core CPUs. IEEE Trans. Comput. 2023, 72, 2951–2962. [Google Scholar] [CrossRef]
- Pagani, S.; Chen, J.J.; Shafique, M.; Henkel, J. MatEx: Efficient transient and peak temperature computation for compact thermal models. In Proceedings of the 2015 Design, Automation & Test in Europe Conference & Exhibition (DATE), Grenoble, France, 9–13 March 2015; pp. 1515–1520. [Google Scholar] [CrossRef]
- Juan, D.C.; Zhou, H.; Marculescu, D.; Li, X. A learning-based autoregressive model for fast transient thermal analysis of chip-multiprocessors. In Proceedings of the 17th Asia and South Pacific Design Automation Conference, Sydney, NSW, Australia, 30 January–2 February 2012; pp. 597–602. [Google Scholar] [CrossRef]
- Zhang, K.; Guliani, A.; Ogrenci-Memik, S.; Memik, G.; Yoshii, K.; Sankaran, R.; Beckman, P. Machine Learning-Based Temperature Prediction for Runtime Thermal Management Across System Components. IEEE Trans. Parallel Distrib. Syst. 2018, 29, 405–419. [Google Scholar] [CrossRef]
- Ranade, R.; He, H.; Pathak, J.; Chang, N.; Kumar, A.; Wen, J. A Thermal Machine Learning Solver For Chip Simulation. In Proceedings of the 2022 ACM/IEEE 4th Workshop on Machine Learning for CAD (MLCAD), Snowbird, UT, USA, 12–13 September 2022; pp. 111–117. [Google Scholar] [CrossRef]
- Kipf, T.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Lu, J.; Tan, S.X.D. Thermal Map Dataset for Commercial Multi/Many Core CPU/GPU/TPU. In Proceedings of the 2024 ACM/IEEE International Symposium on Machine Learning for CAD, Salt Lake City, UT, USA, 9–11 September 2024. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Item | Node_Features | |
|---|---|---|
| Input | Tcurrent | Current core temperature distribution |
| Pprevious | Previous core power distribution | |
| Pcurrent | Current core power distribution | |
| Target | Tnext | Final core temperature distribution |
| Sample size | 5000 | |
| Node num | ||
| Train set size | 4000 | |
| Test set size | 1000 | |
| CPU | Intel(R) Xeon(R) Gold 6230 CPU @ 2.10 GHz (City of Santa Clara, CA, USA) |
| OS | Ubuntu-20.04 |
| GPU | NVIDIA® V100 Tensor Core (City of Santa Clara, CA, USA) |
| CUDA-Version | CUDA-11.8 |
| Model layers | Dropout | Train epochs |
| 3 | - | 800 |
| Batch_size | Learning rate | Learning rate strategy |
| 32 | 0.01 | Cosine Annealing |
| Node Num | Model | MSE | MAE |
|---|---|---|---|
| 16 Nodes | MLP | 1.9 | 1.07 |
| CNN | 3.11 | 1.01 | |
| Method 1 | 0.38 | 0.51 | |
| Method 2 | 0.41 | 0.50 | |
| Method 3 | 0.43 | 0.52 | |
| 36 Nodes | MLP | 2.55 | 1.25 |
| CNN | 2.06 | 1.45 | |
| Method 1 | 0.38 | 0.50 | |
| Method 2 | 0.41 | 0.53 | |
| Method 3 | 0.43 | 0.50 | |
| 49 Nodes | MLP | 2.65 | 1.27 |
| CNN | 3.50 | 1.98 | |
| Method 1 | 0.38 | 0.76 | |
| Method 2 | 0.47 | 0.55 | |
| Method 3 | 0.44 | 0.54 |
| Method | HotSpot | MatEx | GCN |
|---|---|---|---|
| Time complexity | |||
| Memory overheads | 120 MB | 17.45 MB | 5.53 MB |
| Distribution | Uniform | Gaussian | Exponential |
|---|---|---|---|
| Accuracy—Method 1 (MSE) | 0.38 | 0.41 | 0.39 |
| Accuracy—Method 2 (MSE) | 0.47 | 0.45 | 0.47 |
| Accuracy—Method 3 (MSE) | 0.44 | 0.45 | 0.44 |
| Dataset | Accuracy (MSE) |
|---|---|
| Google Coral M.2 TPU | 0.51 |
| AMD Ryzen 7 4800U | 0.73 |
| Intel i5-3337U | 0.80 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Miao, D.; Duan, G.; Chen, D.; Zhu, Y.; Zheng, X. Real-Time Temperature Prediction for Large-Scale Multi-Core Chips Based on Graph Convolutional Neural Networks. Electronics 2025, 14, 1223. https://doi.org/10.3390/electronics14061223
Miao D, Duan G, Chen D, Zhu Y, Zheng X. Real-Time Temperature Prediction for Large-Scale Multi-Core Chips Based on Graph Convolutional Neural Networks. Electronics. 2025; 14(6):1223. https://doi.org/10.3390/electronics14061223
Chicago/Turabian StyleMiao, Dengbao, Gaoxiang Duan, Danyan Chen, Yongyin Zhu, and Xiaoying Zheng. 2025. "Real-Time Temperature Prediction for Large-Scale Multi-Core Chips Based on Graph Convolutional Neural Networks" Electronics 14, no. 6: 1223. https://doi.org/10.3390/electronics14061223
APA StyleMiao, D., Duan, G., Chen, D., Zhu, Y., & Zheng, X. (2025). Real-Time Temperature Prediction for Large-Scale Multi-Core Chips Based on Graph Convolutional Neural Networks. Electronics, 14(6), 1223. https://doi.org/10.3390/electronics14061223