
Trandroid: An Android Mobile Threat Detection System Using Transformer Neural Networks



Abstract
:1. Introduction
- We developed cutting-edge transformer-based models specifically designed to tackle Android attacks, achieving superior performance on the TUANDROMD dataset. Our model outperformed commonly used classifiers in the literature, including CNNs, LSTMs, GRUs, and others, across all evaluation metrics.
- We conducted an extensive comparison of six deep learning classifiers, demonstrating that our transformer-based model consistently outperformed all other methods in terms of detection accuracy and robustness.
- We employed the TUANDROMD dataset, a more recent but smaller dataset compared to others in the field. Despite its small size, it captures a wide array of evolving threats targeting Android, making it particularly relevant for addressing the dynamic nature of Android malware.
2. Related Work
3. Characterization of Android Malware
3.1. Backdoor
3.2. Billing Fraud
- SMS fraud: A malicious code that tries to hide its SMS activities by obscuring the disclosure agreements or SMS messages from the cellular operator informing the user of charges or confirming subscriptions, or sends premium SMS without the user’s knowledge.
- Call fraud: A malicious code that charges customers by making unsolicited calls to premium lines.
- Toll fraud: A malicious code that tricks users into subscribing to or purchasing content via their mobile phone bill.
3.3. Stalkerware
3.4. Denial of Service (DoS)
3.5. Hostile Downloaders
3.6. Phishing
3.7. Elevated Privilege Abuse
3.8. Ransomware
3.9. Spyware
3.10. Trojan
4. Proposed Methodology
4.1. Trandroid Overview
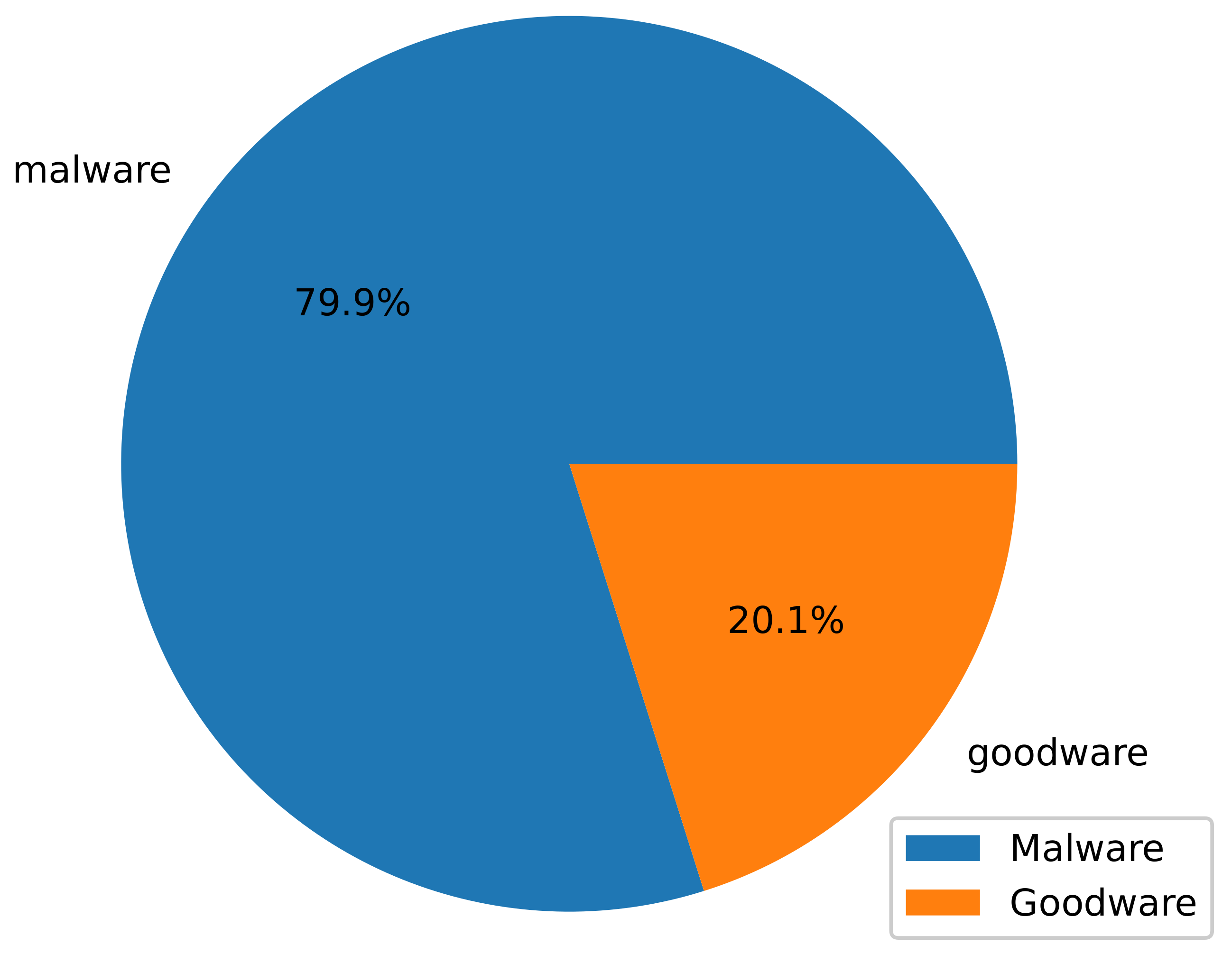
4.2. The TUANDROMD Dataset
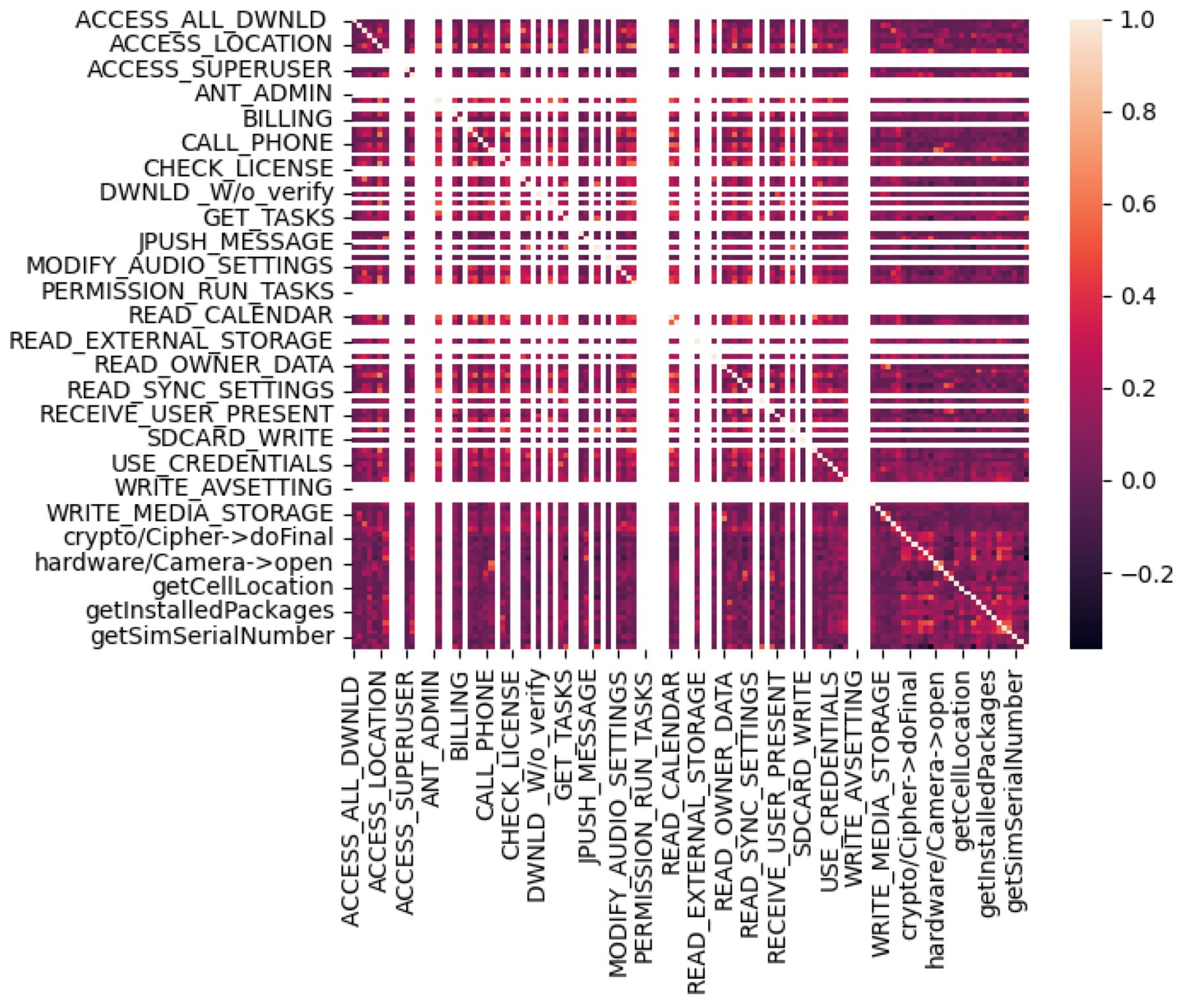
4.3. Feature Extraction
4.4. Dataset Pre-Processing
| Algorithm 1: Dataset pre-processing steps |
 |
4.5. Deep Learning Classifiers
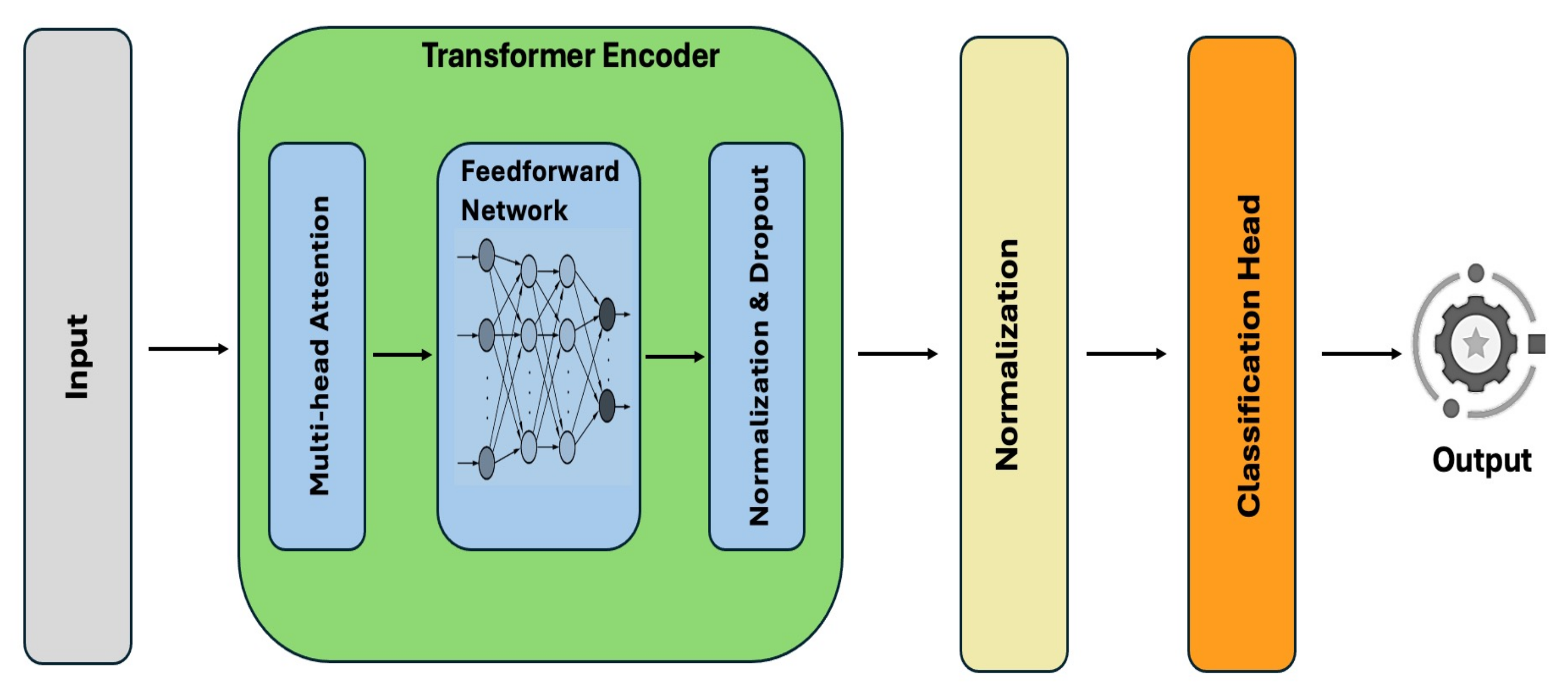
4.5.1. Transformer Classifier
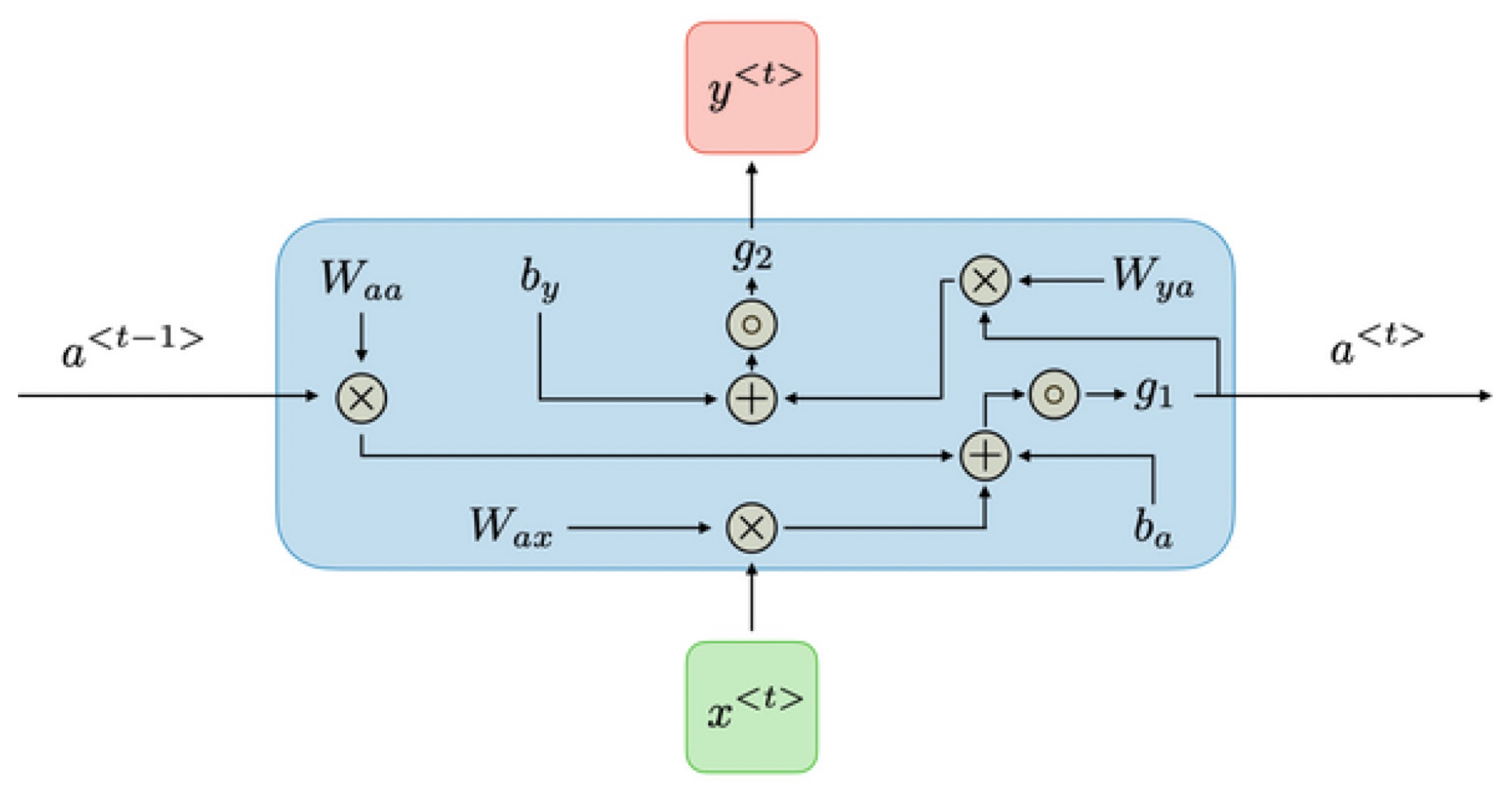
4.5.2. RNN Classifier
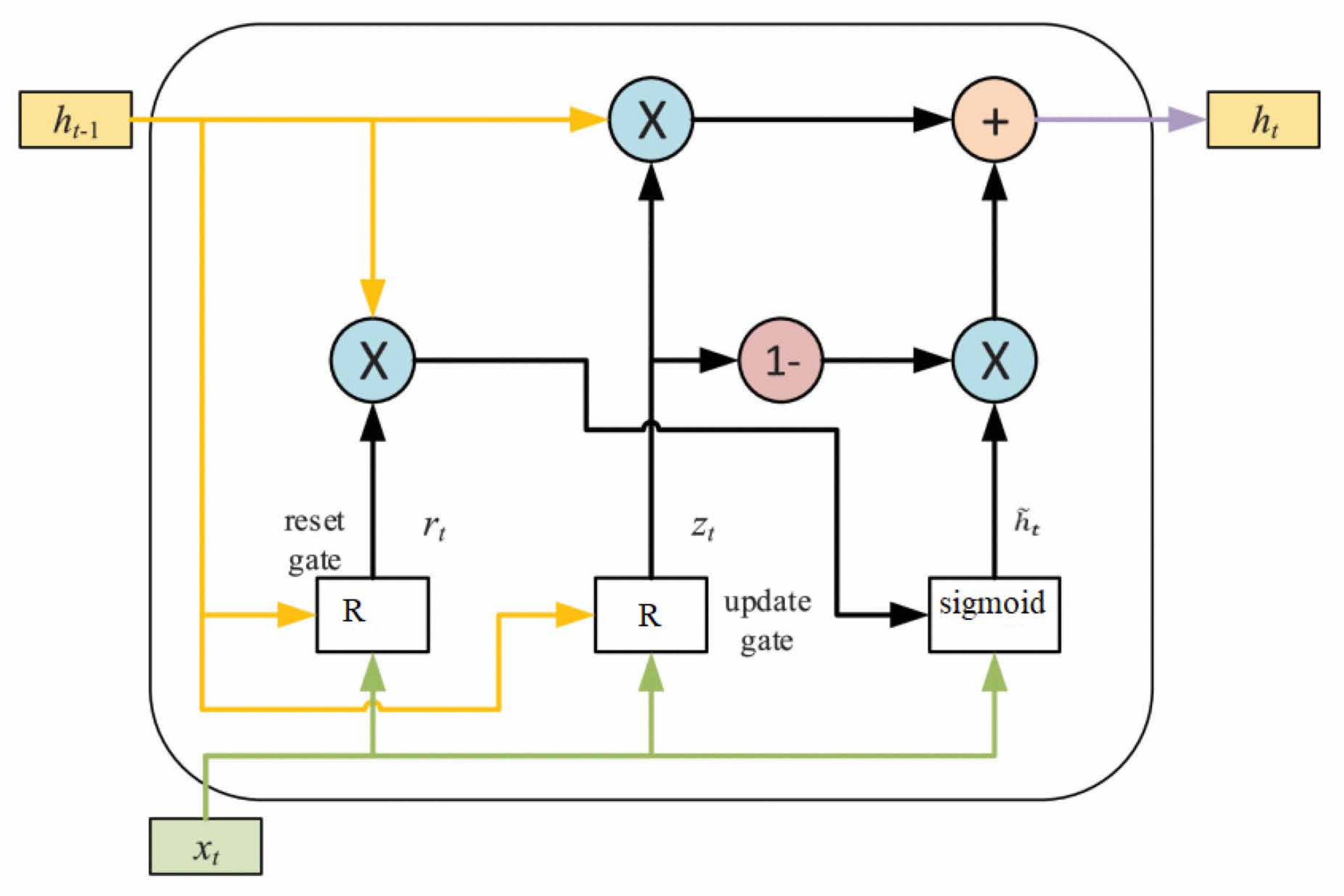
4.5.3. GRU Classifier
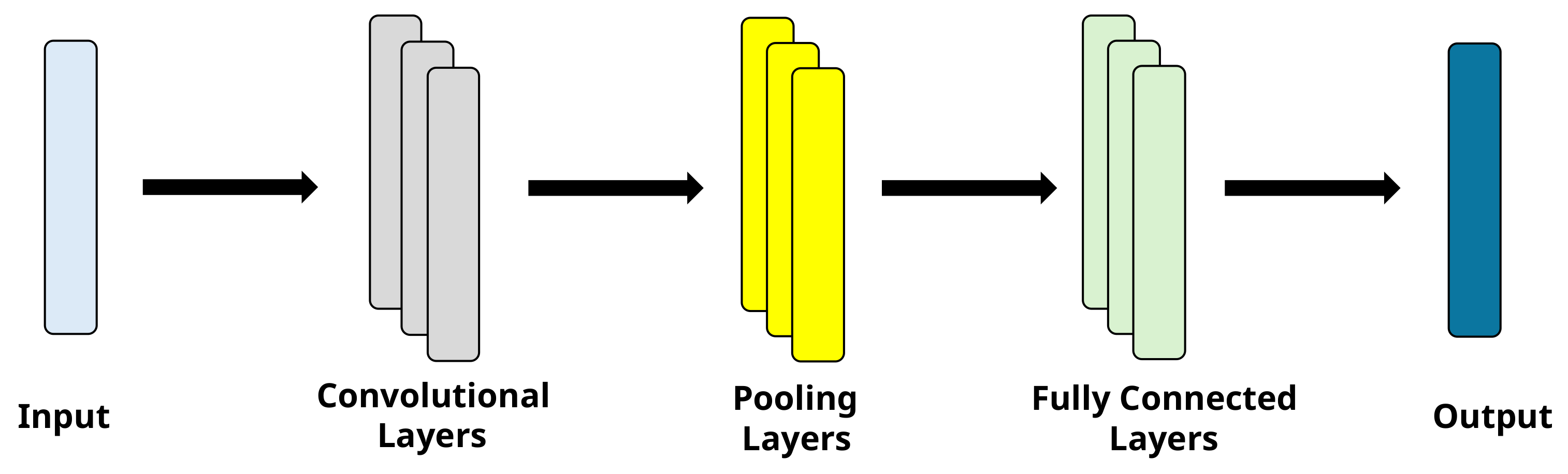
4.5.4. CNN Classifier
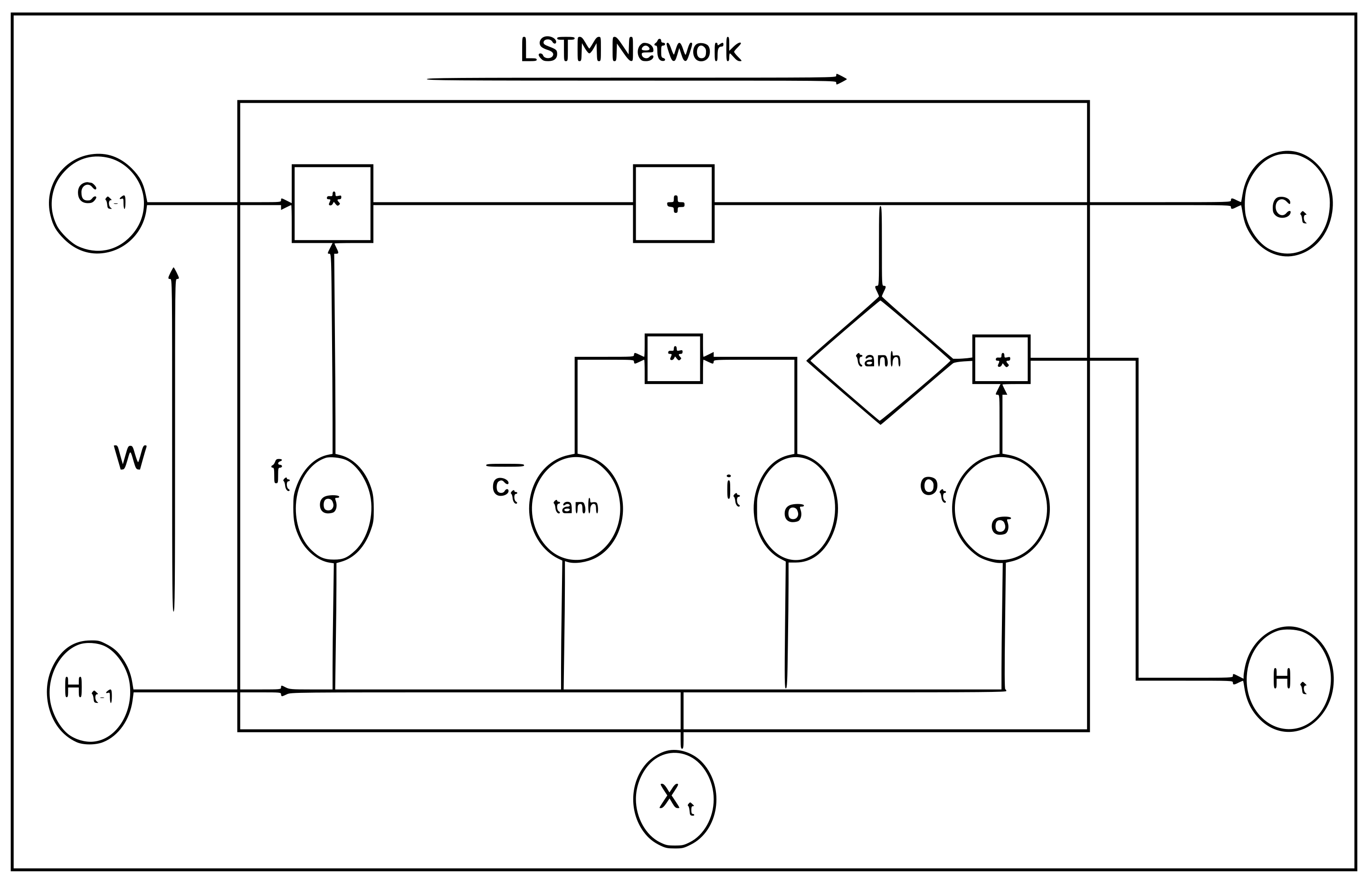
4.5.5. LSTM Classifier
4.5.6. Hybrid CNN-LSTM Classifier
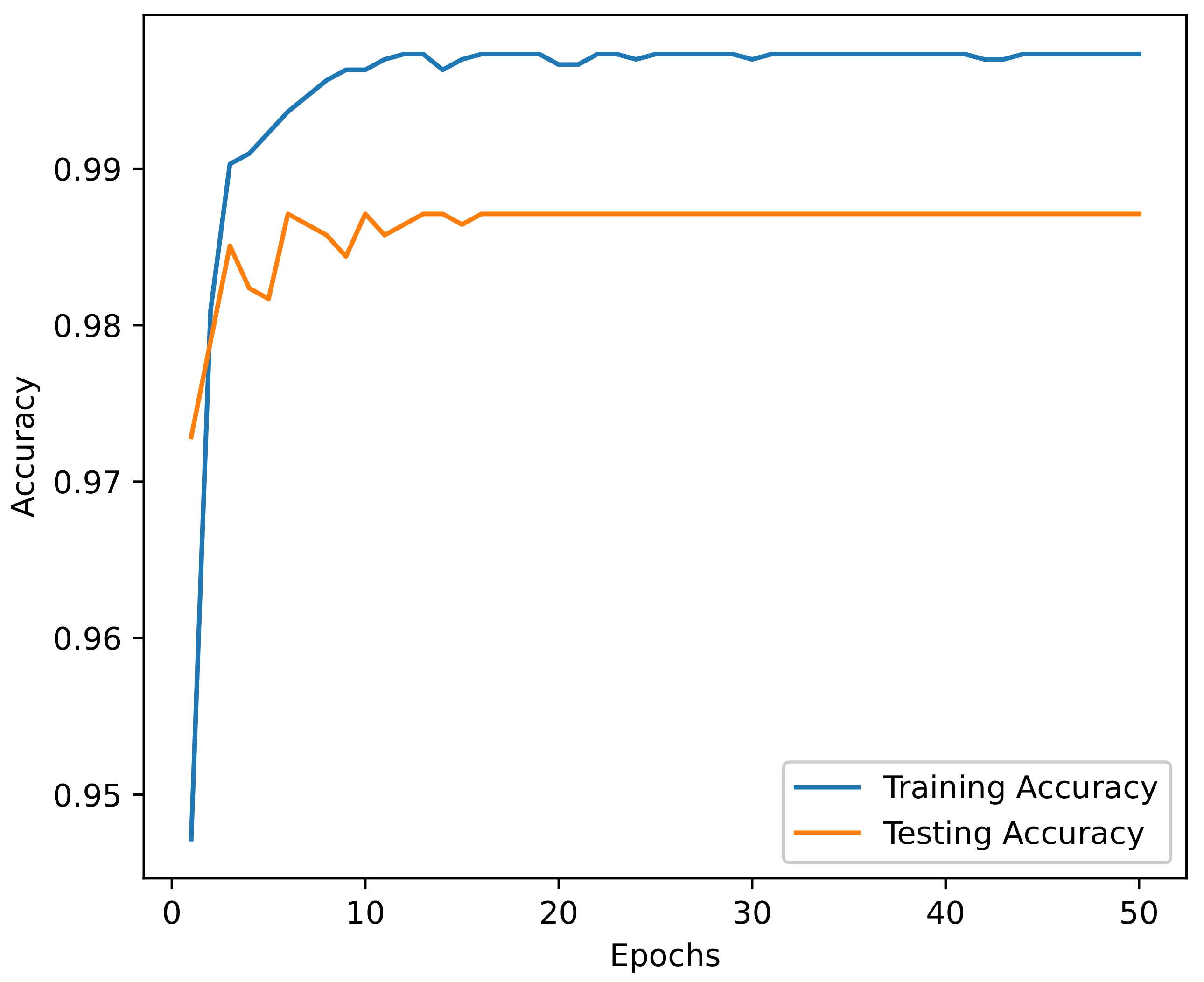
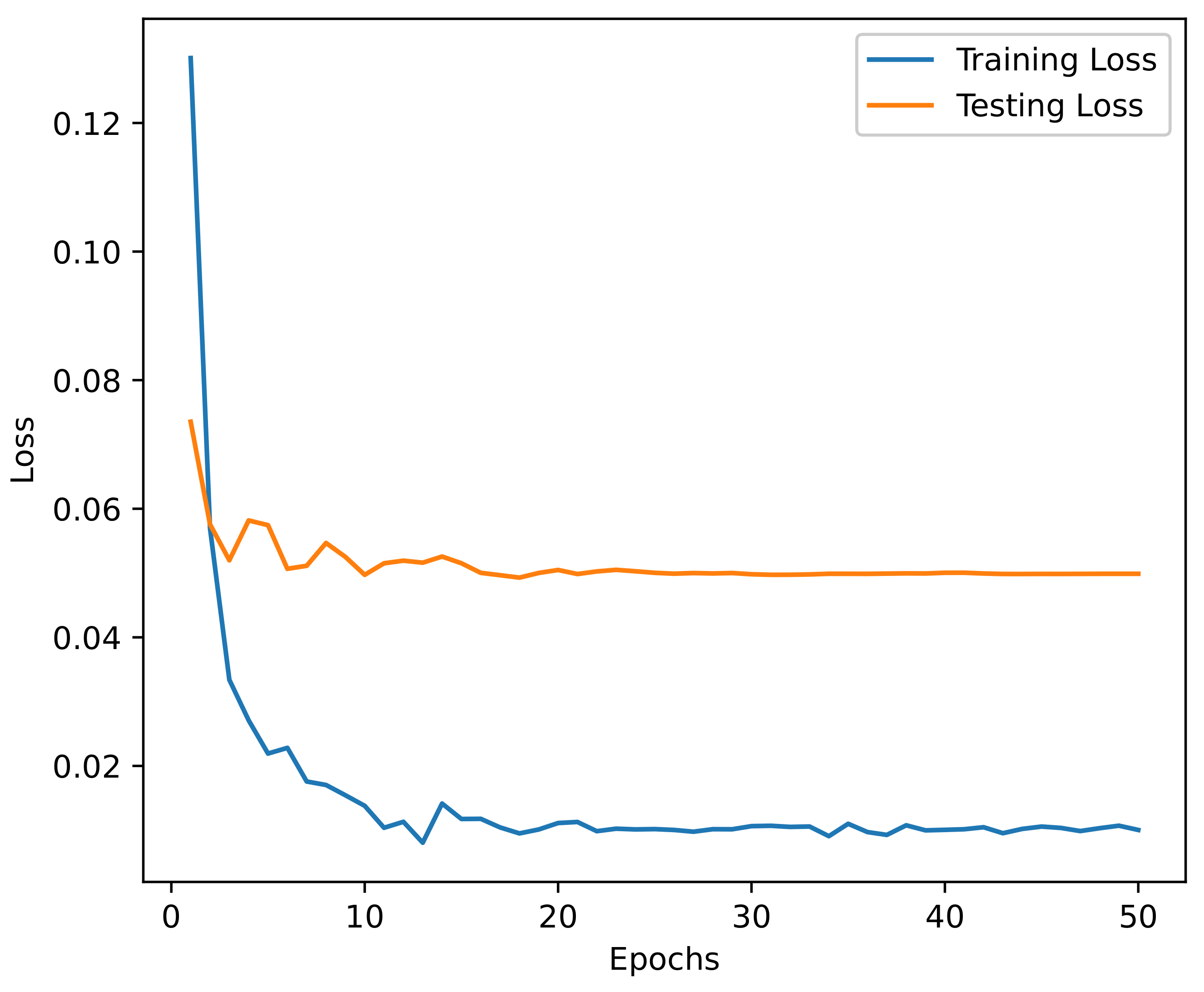
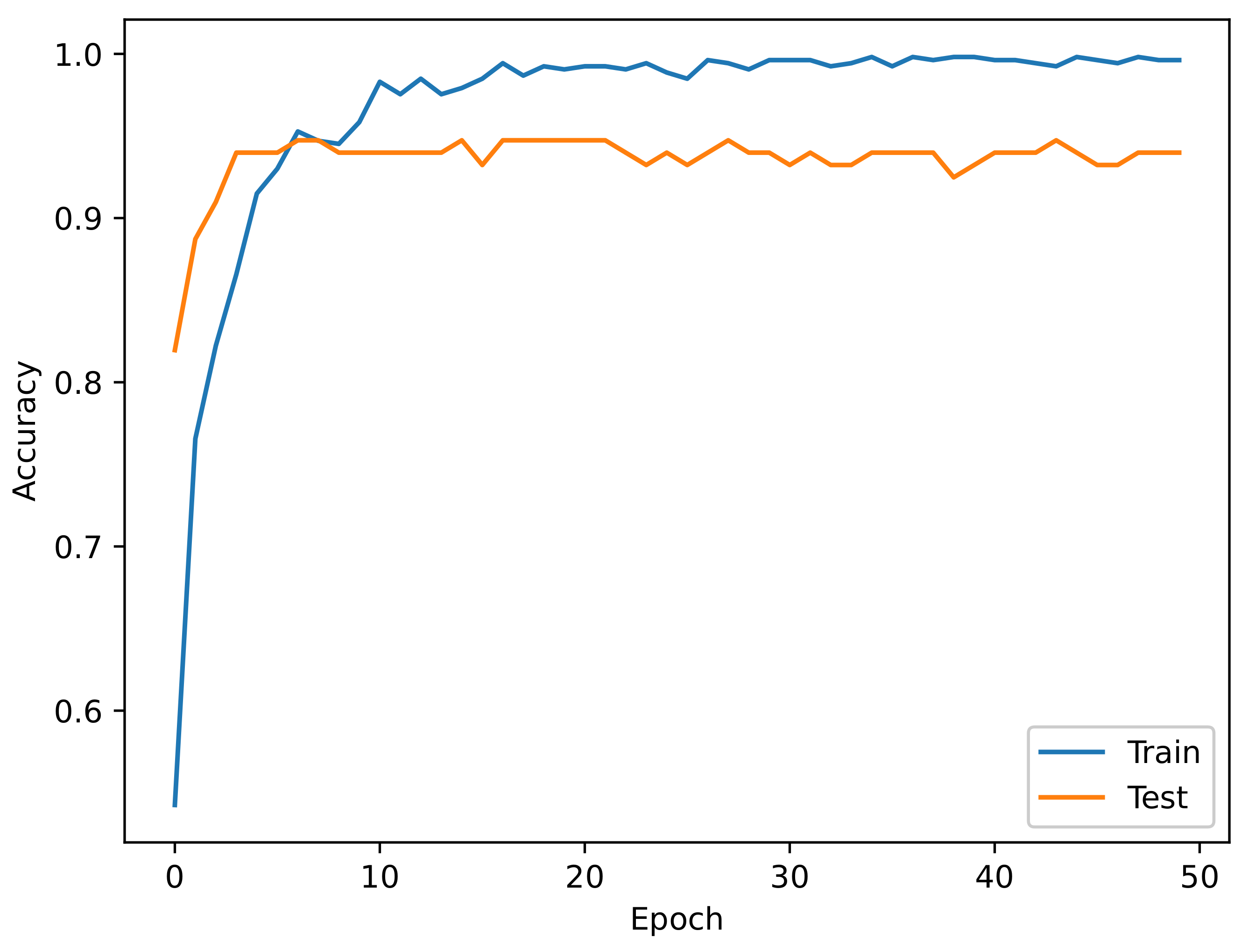
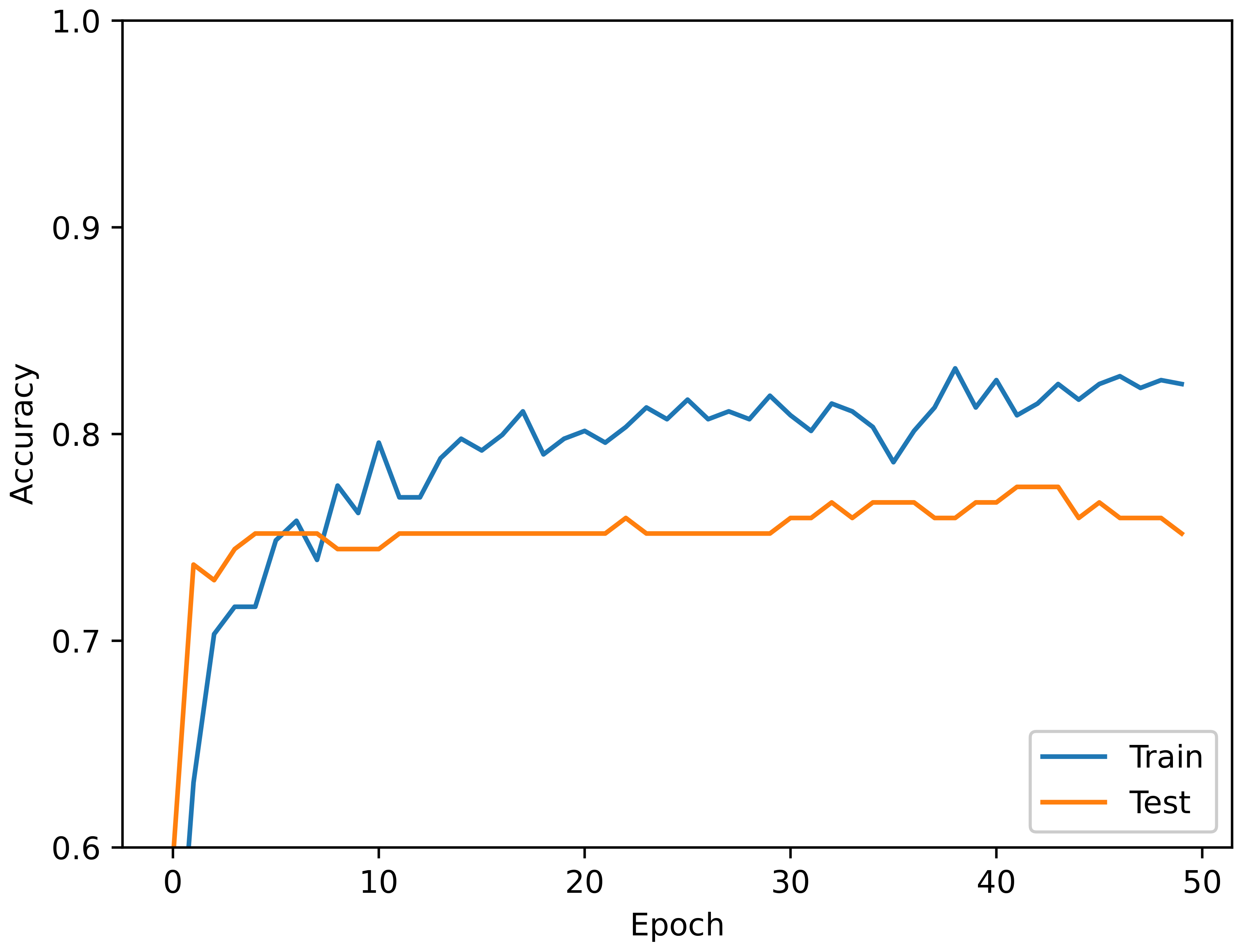
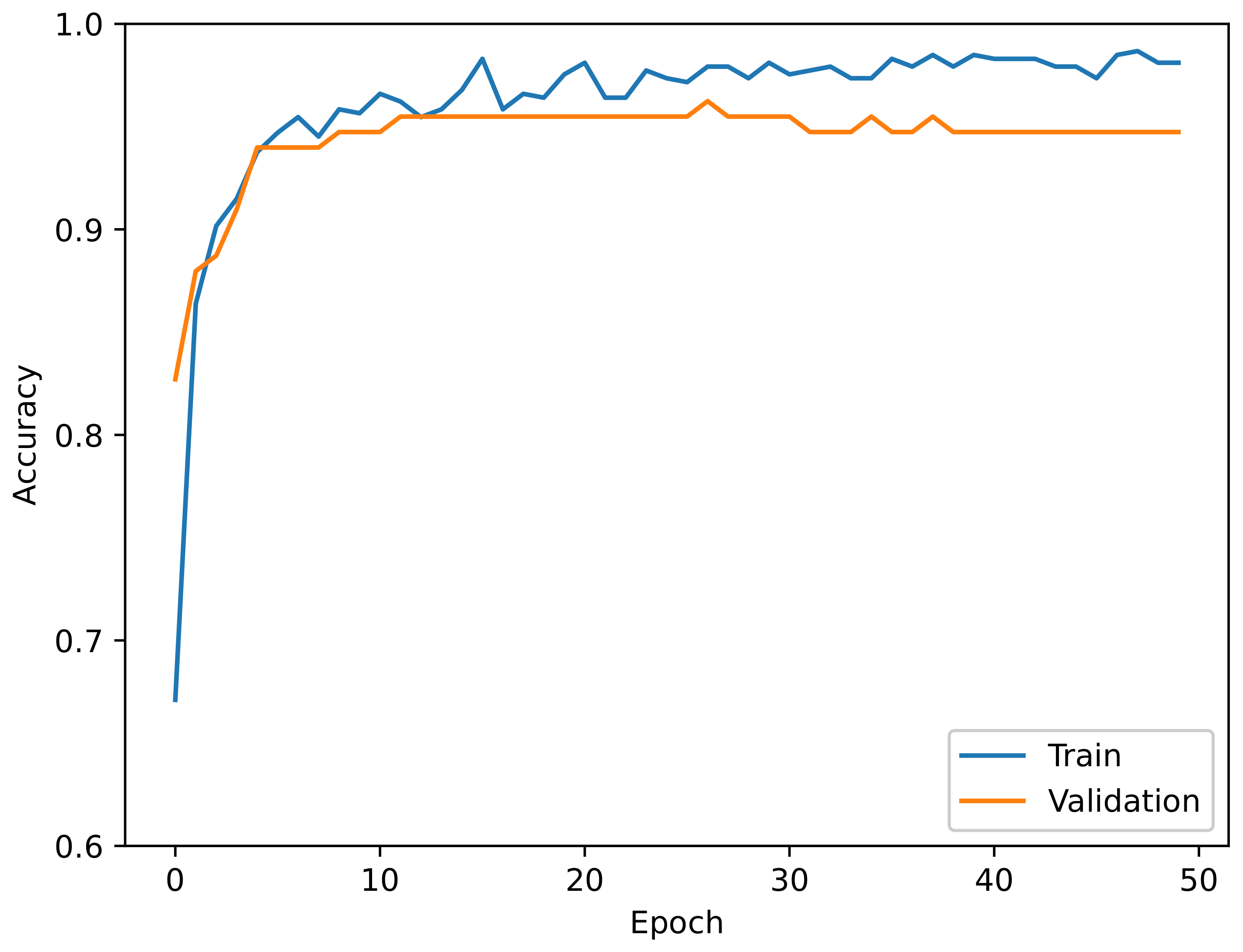
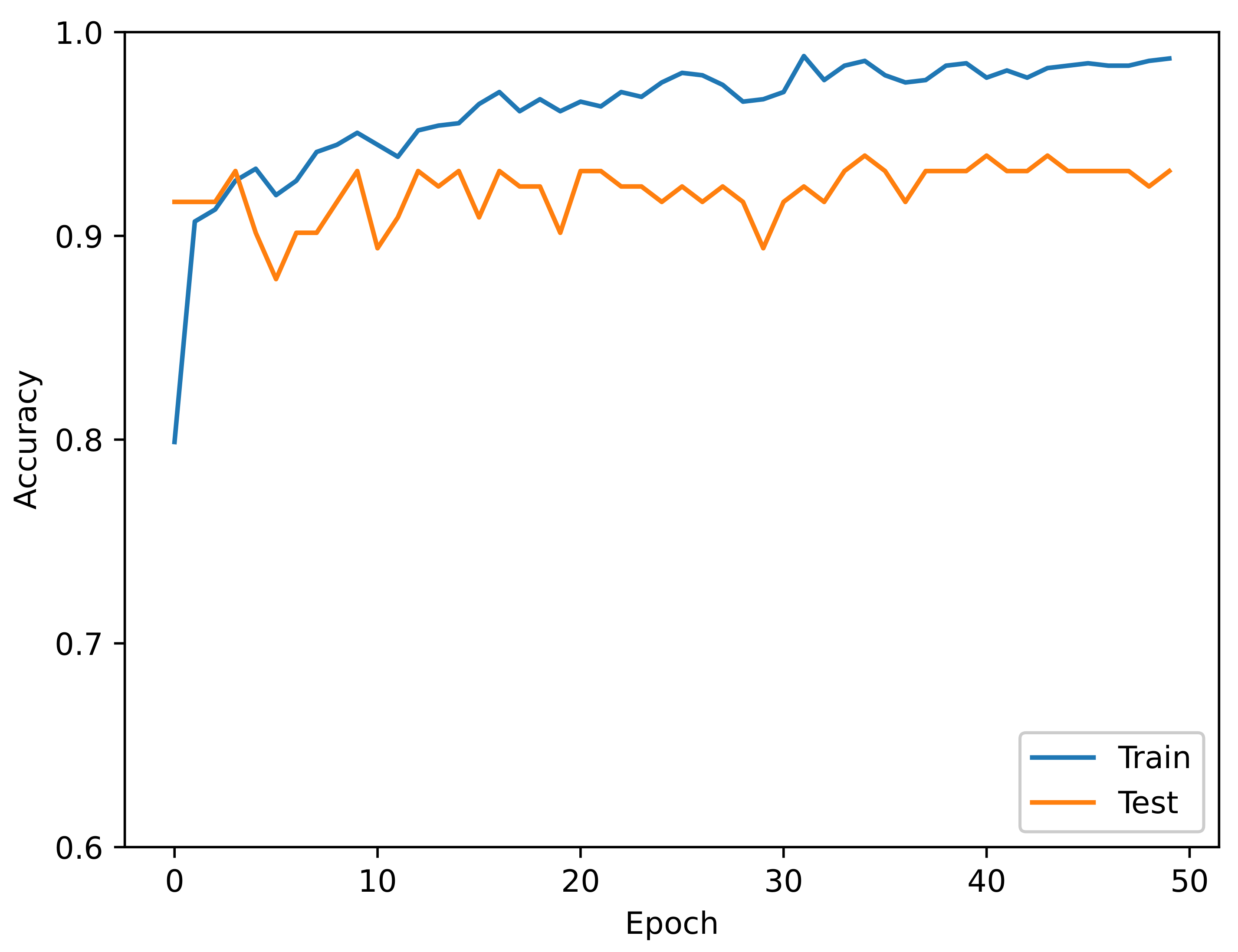
5. Experimental Results
Results
- Dataset: Sachith uses the MalNet dataset, which is an image dataset lacking granular Android metadata, unlike TUANDROMD, which is more recent and comprehensive, covering 71 malware families and real-world attack samples. As a result, Trandroid achieves better generalization, while the lack of capturing semantic relationships with MalNet may lead to false correlations.
- Model architecture: ViT-based malware detection models excel in visual pattern recognition but are suboptimal for dealing with categorical malware features. In contrast, Trandroid applies transformer-based sequence modeling directly on feature vectors, improving interpretability and relevance for malware classification.
- Computational needs: Sachith’s work has intensive GPU requirements to process tasks such as image tokenization and patch embedding. Meanwhile, Trandroid deals with tabular features, thus requiring less computational resources.
6. Discussion
- TUANDROMD is a reasonably new dataset, and only a few experiments have been done on that, compared to famous datasets like Androzoo or Drebin, which are larger in size but much older. Therefore, it requires careful consideration of the potential selection and measurement biases, an awareness of the dataset’s limitations, and the responsible analysis and interpretation of our findings.
- TUANDROMD’s size is relatively small size, and even if GPU accelerators were used, the benefits would not have mattered much. Thus, using a bigger dataset is needed, as it would enable a better generalization to unseen malware and offer a more comprehensive evaluation benchmark.
- Better support for real-time detection is needed, but our approach must be revised in order to reduce the model size and decrease the training time. Using resource optimization techniques, such as pruning, quantization, and knowledge distillation, could help Trandroid in scaling within a real-world environment. In addition, the deployment of flexibility options, such as offloading resource intensive tasks to cloud environments and using lightweight transformer variants, could help achieving this goal. While TUANDROMD has a diverse Android malware representation, the imbalance in malware family distribution in the dataset may favor well-represented malware families while under-performing on rare or emerging threats.
- Our Trandroid approach could complement popular app marketplace malware detection systems, such as Google Play Protect, by providing an additional layer of security capable of dealing with newer and more sophisticated malware.
- In corporate environments, Trandroid can assist companies adopting the Bring Your Own Device (BYOD) model in mobile application development, detecting malicious activities affecting employees devices.
- The extremely low FPR and FNR constitute a very good sign that extending Trandroid with real-time detection would be of high value.
- Our model has the potential to be used in cloud-based security services to allow cloud providers to scan apps for malware before their final distribution to end users.
- Trandroid can assist in detecting network-based malware originating from compromised Android devices in corporate environments.
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Statista. “Smartphone Users Worldwide 2023 to 2028”. 2023. Available online: https://www.statista.com/statistics/330695/number-of-smartphone-users-worldwide/ (accessed on 11 November 2024).
- Mahmood, R.; Esfahani, N.; Kacem, T.; Mirzaei, N.; Malek, S.; Stavrou, A. A whitebox approach for automated security testing of Android applications on the cloud. In Proceedings of the 2012 7th International Workshop on Automation of Software Test (AST), Zurich, Switzerland, 2–3 June 2012; pp. 22–28. [Google Scholar]
- Arif, J.M.; Ab Razak, M.F.; Mat, S.R.T.; Awang, S.; Ismail, N.S.N.; Firdaus, A. Android mobile malware detection using fuzzy AHP. J. Inf. Secur. Appl. 2021, 61, 102929. [Google Scholar]
- Chen, M.; Zhou, Q.; Wang, K.; Zeng, Z. An android malware detection method using deep learning based on multi-features. In Proceedings of the 2022 IEEE International Conference on Artificial Intelligence and Computer Applications (ICAICA), Dalian, China, 24–26 June 2022; pp. 187–190. [Google Scholar]
- Nokia. Nokia Threat Intelligence Report—2019. Netw. Secur. 2021, 2018, 8. [Google Scholar] [CrossRef]
- Ibrahim, S.; Catal, C.; Kacem, T. The use of multi-task learning in cybersecurity applications: A systematic literature review. Neural Comput. Appl. 2024, 36, 22053–22079. [Google Scholar]
- Yan, P.; Yan, Z. A survey on dynamic mobile malware detection. Softw. Qual. J. 2018, 26, 891–919. [Google Scholar] [CrossRef]
- Liu, K.; Xu, S.; Xu, G.; Zhang, M.; Sun, D.; Liu, H. A review of android malware detection approaches based on machine learning. IEEE Access 2020, 8, 124579–124607. [Google Scholar] [CrossRef]
- Tossou, S.; Kacem, T. Mobile Threat Detection System: A Deep Learning Approach. In Proceedings of the 2023 13th International Conference on Information Science and Technology (ICIST), Cairo, Egypt, 8–14 December 2023; pp. 323–332. [Google Scholar]
- Hsien-De Huang, T.; Yu, C.M.; Kao, H.Y. Data-driven and deep learning methodology for deceptive advertising and phone scams detection. In Proceedings of the 2017 Conference on Technologies and Applications of ARTIFICIAL Intelligence (TAAI), Taipei, Taiwan, 1–3 December 2017; pp. 166–171. [Google Scholar]
- Sandeep, H.R. Static analysis of android malware detection using deep learning. In Proceedings of the 2019 International Conference on Intelligent Computing and Control Systems (ICCS), Madurai, India, 15–17 May 2019; pp. 841–845. [Google Scholar]
- Mohammed, A.S.; Seher, S.; Yerima, S.Y.; Bashar, A. A deep learning based approach to Android botnet detection using transfer learning. In Proceedings of the 2022 14th International Conference on Computational Intelligence and Communication Networks (CICN), Al-Khobar, Saudi Arabia, 4–6 December 2022; pp. 543–548. [Google Scholar]
- Rahmawati, F.D.; Hadiprakoso, R.B.; Yasa, R.N. Comparison of single-view and multi-view deep learning for Android malware detection. In Proceedings of the 2022 International Conference on Information Technology Research and Innovation (ICITRI), Jakarta, Indonesia, 10 November 2022; pp. 53–58. [Google Scholar]
- Feng, R.; Chen, S.; Xie, X.; Meng, G.; Lin, S.W.; Liu, Y. A performance-sensitive malware detection system using deep learning on mobile devices. IEEE Trans. Inf. Forensics Secur. 2020, 16, 1563–1578. [Google Scholar] [CrossRef]
- Watkins, L.; Yu, Y.; Li, S.; Robinson, W.H.; Rubin, A. Using Deep Learning to Identify Security Risks of Personal Mobile Devices in Enterprise Networks. In Proceedings of the 2020 11th IEEE Annual Ubiquitous Computing, Electronics & Mobile Communication Conference (UEMCON), New York, NY, USA, 28–31 October 2020; pp. 292–297. [Google Scholar]
- Seneviratne, S.; Shariffdeen, R.; Rasnayaka, S.; Kasthuriarachchi, N. Self-supervised vision transformers for malware detection. IEEE Access 2023, 10, 103121–103135. [Google Scholar]
- Saracino, A.; Simoni, M. Graph-based android malware detection and categorization through bert transformer. In Proceedings of the 18th International Conference on Availability, Reliability and Security, Benevento Italy, 29 August–1 September 2023; pp. 1–7. [Google Scholar]
- Almakayeel, N. Deep learning-based improved transformer model on android malware detection and classification in internet of vehicles. Sci. Rep. 2024, 14, 25175. [Google Scholar] [CrossRef] [PubMed]
- Sun, Y.; Peng, H.; Chen, Y.; Jiang, B.; Wang, S.; Qiu, Y.; Wang, H.; Li, X. A Transformer Based Malicious Traffic Detection Method in Android Mobile Networks. In Proceedings of the International Conference on Advanced Data Mining and Applications, Sydney, NSW, Australia, 3–5 December 2024; Springer Nature: Singapore, 2024; pp. 370–385. [Google Scholar]
- Wasif, M.S.; Miah, M.P.; Hossain, M.S.; Alenazi, M.J.; Atiquzzaman, M. CNN-ViT synergy: An efficient Android malware detection approach through deep learning. Comput. Electr. Eng. 2025, 123, 110039. [Google Scholar] [CrossRef]
- Google for Developers. Malware Categories. Available online: https://developers.google.com/android/play-protect/phacategories (accessed on 3 April 2023).
- Borah, P.; Bhattacharyya, D.K.; Kalita, J.K. Malware dataset generation and evaluation. In Proceedings of the 2020 IEEE 4th Conference on Information & Communication Technology (CICT), Chennai, India, 3–5 December 2020; pp. 1–6. [Google Scholar]
- Wei, F.; Li, Y.; Roy, S.; Ou, X.; Zhou, W. Deep ground truth analysis of current android malware. In Proceedings of the Detection of Intrusions and Malware, and Vulnerability Assessment: 14th International Conference, DIMVA 2017, Bonn, Germany, 6–7 July 2017; Proceedings 14. Springer International Publishing: Berlin/Heidelberg, Germany, 2017; pp. 252–276. [Google Scholar]
- Taheri, R.; Shojafar, M.; Arabikhan, F.; Gegov, A. Unveiling vulnerabilities in deep learning-based malware detection: Differential privacy driven adversarial attacks. Comput. Secur. 2024, 146, 104035. [Google Scholar]
- Nadeem, M.W.; Goh, H.G.; Aun, Y.; Ponnusamy, V. A recurrent neural network based method for low-rate DDoS attack detection in SDN. In Proceedings of the 2022 3rd International Conference on Artificial Intelligence and Data Sciences (AiDAS), IPOH, Malaysia, 7–8 September 2022; pp. 13–18. [Google Scholar]
- Zhou, H.; Yang, X.; Pan, H.; Guo, W. An android malware detection approach based on SIMGRU. IEEE Access 2020, 8, 148404–148410. [Google Scholar]
- Qiu, J.; Zhang, J.; Luo, W.; Pan, L.; Nepal, S.; Xiang, Y. A survey of android malware detection with deep neural models. ACM Comput. Surv. (CSUR) 2020, 53, 1–36. [Google Scholar] [CrossRef]
- Sasidharan, S.K.; Thomas, C. Memdroid-lstm based malware detection framework for android devices. In Proceedings of the 2021 IEEE Pune Section International Conference (PuneCon), Pune, India, 16–19 December 2021; pp. 1–6. [Google Scholar]
- Hamad, R.A.; Yang, L.; Woo, W.L.; Wei, B. Joint learning of temporal models to handle imbalanced data for human activity recognition. Appl. Sci. 2020, 10, 5293. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Authors | Dataset | Approach | Gap |
|---|---|---|---|
| Huang et al. [10] | Custom dataset based on data collected from user feedback | Fraud detection using DNN and Inception-V3 | It focuses only on specific threats and lacks generalization since it is limited to a custom dataset. |
| Sandeep [11] | Custom dataset from Google Play and VirusShare | Deep learning model with custom hyper-parameters | It lacks generalization and the ability to scale to a variety of threats. |
| Mohammed et al. [12] | Custom Dataset from ICSX Android Botnet and DEX files | Transfer learning using MobileNetv2 and ResNet101 | It focuses on botnets and uses only limited image-based features not metadata and diverse inputs. |
| Fika et al. [13] | Custom dataset | LSTM-MLP | It lacks diversity in the features and metadata since it is limited to permissions and system calls. |
| Feng et al. [14] | Custom dataset collected from Drebin, Genome, VirusShare, Contagio, and Pwnzen | Bi-GRU | Even though it is diverse, it is very old, lacking holistic coverage. |
| Watkins et al. [15] | Custom dataset based on experimental data | MLP for security risk identification | It uses a limited set of experimental data and lacks a holistic threat analysis. |
| Sachith et al. [16] | MalNet | Vision transformer | The dataset is highly imbalanced and the approach focuses mostly on image-based threat detection, making it less applicable to broader metadata or diverse features. |
| Saracino and Simoni [17] | Drebin | BERT | The graph representation of Android apps may introduce a computational overhead and may not generalize to evolving malware. |
| Almakayeel [18] | Drebin | Transformer | It focuses on IoV malware and is less applicable to general Android security. |
| Sun et al. [19] | Mobile network traffic | Transformer | It is limited to network data, missing important application features. |
| Wasif et al. [20] | CICAndMal2017 | CNN-LSTM | It relies on image representations of features, potentially losing other semantic relationships. |
| Attack Type | Malware Family |
|---|---|
| Adware | Airpush, Gorpo, Kemoge, Kuguo, VikingHorde, Youmi |
| Backdoor | AndroRAT, DroidKungFu |
| Billing Fraud | Boxer, RuMMS, SmsZombie |
| Phishing | BankBot, Bankun, SlemBunk |
| Spyware | AndroRAT, GoldDream, Leech, SpyBubble, Vmvol |
| Ransomware | FakeAV, Fobus, Jisut, Koler, SimpleLocker, Svpeng |
| Trojan | Aples, FakeAngry, FakePlayer, FakeTimer, FakeUpdates, Ksapp, Kuguo, Opfake, Winge, Zitmo |
| Hostile Downloader | Dowgin, UpdtKiller |
| Elevated Privilege Abuse | DroidKungFu, GingerMaster, Lotoor, Obad, Triada, Ztorg |
| Botnet | VikingHorde |
| Parameter | Value |
|---|---|
| Attention heads | 4 |
| Key dimension | 128 |
| Dense layer neurons | 64 |
| Number of transformer encoder | 1 |
| Optimizer | Adam with 0.001 learning rate |
| Batch size | 32 |
| Dropout | 0.1 |
| Number of transformer encoder layers | 1 |
| Loss function | CrossEntropyLoss |
| Metric | CNN-LSTM | CNN | RNN | GRU | LSTM | Transformer |
|---|---|---|---|---|---|---|
| Accuracy | 84.84% | 93.93% | 92.48% | 94.73% | 93.98% | 99.25% |
| Sensitivity | 80.76% | 76.92% | 81.25% | 81.25% | 81.25% | 99.25% |
| Precision | 58.33% | 90.90% | 86.66% | 96.29% | 92.85% | 99.26% |
| F1-Score | 67.74% | 83.33% | 83.87% | 88.13% | 86.66% | 99.26% |
| AUC-ROC | 83.30% | 87.5% | 87.64% | 90.12% | 89.63% | 98.76% |
| FPR | 12% | 6.06% | 7.52% | 5.26% | 6.02% | 0.95% |
| FNR | 12% | 6.06% | 7.52% | 5.26% | 6.02% | 0.95% |
| Training Time (s) | 63.15 | 23.01 | 9.82 | 12.82 | 10.43 | 134.63 |
| Number of Parameters | 10,421 | 243,969 | 65,093 | 183,429 | 174,653 | 624,514 |
| Model Size (KB) | 40.71 | 953 | 254.27 | 716.52 | 576.77 | 2439.5 |
| Authors | Dataset | Model | Accuracy |
|---|---|---|---|
| Feng et al. [14] | Drebin | Bi-GRU | 96.87% |
| Fika et al. [13] | Chimera | Multiview | 82.00% |
| Huang et al. [10] | Self-made | Inception-v3 | 90.00% |
| Mohammed et al. [12] | ISCX and DEX | CNN | 91.00% |
| Sachith [16] | MalNet | Vision transformer | 97.00% |
| Sandeep [11] | Self-made | Deep learning | 94.64% |
| Trandroid | TUANDROMD | Transformer | 99.25% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kacem, T.; Tossou, S. Trandroid: An Android Mobile Threat Detection System Using Transformer Neural Networks. Electronics 2025, 14, 1230. https://doi.org/10.3390/electronics14061230
Kacem T, Tossou S. Trandroid: An Android Mobile Threat Detection System Using Transformer Neural Networks. Electronics. 2025; 14(6):1230. https://doi.org/10.3390/electronics14061230
Chicago/Turabian StyleKacem, Thabet, and Sourou Tossou. 2025. "Trandroid: An Android Mobile Threat Detection System Using Transformer Neural Networks" Electronics 14, no. 6: 1230. https://doi.org/10.3390/electronics14061230
APA StyleKacem, T., & Tossou, S. (2025). Trandroid: An Android Mobile Threat Detection System Using Transformer Neural Networks. Electronics, 14(6), 1230. https://doi.org/10.3390/electronics14061230