Abstract
Ransomware remains one of the most significant cybersecurity threats. Techniques used by attackers have evolved to bypass traditional detection methods. Many existing detection systems rely on outdated datasets or complex behavioral analyses, which are resource-intensive and slow. This paper introduces RansomFormer, a Transformer-based model that is designed to detect ransomware using Portable Executable (PE) byte data combined with Application Programming Interface (API) imports or API sequence calls. The evaluation is conducted to determine whether these static and dynamic features alone can achieve high accuracy. To test this hypothesis, the largest ransomware dataset to date is collected, consisting of more than 150 ransomware families. The limitations of existing datasets, which are outdated, lack family variants, or are too small, are addressed by this dataset. RansomFormer is trained and evaluated on the following two datasets: one using static analysis (PE bytes and API imports) and another combining static and dynamic analysis (PE bytes and API sequence calls). The results demonstrate that the model achieves high accuracy, with 99.25% on the static dataset and 99.50% on the combined dataset, making RansomFormer a promising approach for ransomware detection.
1. Introduction
The digital landscape of the 21st century is increasingly tainted by the expansion of sophisticated cyber threats, with ransomware emerging as a particularly devastating and financially motivated form of attack [1,2]. Ransomware is malicious software designed to attack victims by restricting access to their digital assets. This attack has evolved significantly since its inception. Early forms of ransomware, dating back to the late 1980s, often employed simple locking mechanisms, such as displaying persistent messages that hindered the usability of the computer [3]. However, the modern ransomware landscape is dominated by crypto-ransomware, which utilizes robust encryption algorithms to render victim data inaccessible until a ransom is paid, typically in cryptocurrency [4,5]. This evolution reflects a shift towards more technically advanced and impactful attacks, capable of causing substantial disruption to individuals, businesses, and even critical infrastructure [6,7].
The primary purpose of ransomware attacks is financial gain, achieved through the pressure of victims to pay a ransom for the decryption key or the restoration of system access [1,8].
What distinguishes ransomware from other malware threats, such as viruses, worms, trojans, and spyware, is its direct financial extortion method. While viruses and worms spread through infected files or network vulnerabilities to cause system damage, ransomware restricts access to critical data and demands payment for its restoration. In contrast, trojans and spyware operate covertly, stealing sensitive information over time, whereas ransomware is highly visible and applies immediate financial pressure on victims.
Another key difference is how these malware types interact with system APIs. Ransomware typically leverages cryptographic APIs to encrypt files using strong encryption algorithms, ensuring that data remain inaccessible without the decryption key. It also utilizes networking APIs to communicate with command-and-control (C2) servers for ransom payment instructions and key exchange. On the other hand, viruses and worms rely more on file systems and process manipulation APIs to replicate and spread across systems. Trojans and spyware use keylogging and system monitoring APIs to steal credentials, capture user activity, and exfiltrate sensitive data to remote servers.
Ransomware’s use of strong encryption and ransom demands, rather than data theft, makes mitigation particularly challenging, as decryption without payment is rarely feasible. As a result, ransomware is not just a disruptive cyber threat but a financially motivated attack that requires proactive defense measures and robust backup strategies to minimize its impact.
The impact of successful ransomware attacks extends far beyond the immediate ransom demand. Organizations face operational paralysis, loss of productivity, reputational damage, and potentially irreversible data loss, even after ransom payment [9]. Moreover, the sophistication of ransomware attacks is continuously escalating, and threat actors employ advanced techniques such as double extortion (exfiltration of data before encryption) and ransomware-as-a-service (RaaS) models, making attacks more impactful and accessible to a wider range of cybercriminals [6,7,10]. The targeting scope has also broadened, encompassing not only traditional desktop systems but also mobile platforms [8,11,12,13], IoT devices [14], and critical infrastructure sectors, highlighting the pervasive nature of this threat.
Detecting ransomware remains a formidable challenge due to several factors. Modern ransomware employs various evasion techniques, including polymorphism, metamorphism, and code obfuscation, to circumvent signature-based detection mechanisms [5,15]. Furthermore, zero-day ransomware exploits previously unknown vulnerabilities, rendering signature-based approaches ineffective until after an attack has commenced [16]. The rapid evolution of ransomware variants and the increasing sophistication of attack vectors necessitate detection methods that can identify malicious behavior proactively and generically rather than relying solely on known signatures or patterns [17,18]. The subtle nature of ransomware activities in the initial stages of infection, before the full-scale encryption process begins, further complicates early detection efforts [14,19].
Traditional ransomware detection methods can be broadly categorized into signature-based and behavior-based approaches [20]. Signature-based detection, relying on pre-defined patterns or hashes of known ransomware samples, efficiently identifies established threats but is easily evaded by new or slightly modified variants [17]. Behavior-based detection attempts to identify malicious activities by monitoring system events, Application Programming Interface (API) calls, and file system operations for anomalous patterns indicative of ransomware behavior, such as rapid file encryption or unauthorized access to sensitive files [4,16,18,21,22]. While behavior-based methods offer improved detection capabilities against polymorphic and zero-day ransomware compared to signature-based methods, they often suffer from limitations such as high false positive rates and susceptibility to adversarial evasion techniques designed to mimic benign behavior or operate stealthily [18]. Moreover, relying solely on single modal analysis, whether static or dynamic, can be insufficient in capturing the multifaceted nature of sophisticated ransomware attacks [20].
Machine learning (ML) has become a crucial tool in malware detection, enabling systems to identify malicious software based on patterns and statistical properties rather than relying solely on traditional signature-based methods. Various ML models, including deep learning (DL) architectures [23], have been employed to analyze executable files, API calls, and behavioral patterns to detect malware efficiently. While conventional models such as random forests, support vector machines, and convolutional neural networks (CNNs) [24] have demonstrated effectiveness, they often struggle with scalability and the ability to capture long-range dependencies in complex malware behavior. As malware continues to evolve, there is a growing need for advanced architectures to process sequential and multi-modal data effectively.
Transformers, initially introduced for natural language processing tasks, have demonstrated strong performance across multiple domains [25,26], including cybersecurity. Their self-attention mechanisms enable them to capture long-range dependencies and contextual relationships in data, making them well-suited for analyzing sequences such as API calls, opcode instructions, and byte sequences. Transformer-based approaches have been successfully applied to various security-related tasks, including phishing detection [27] and general malware classification [28]. These models offer the advantage of handling large-scale datasets while reducing reliance on handcrafted features, making them an attractive option for modern threat detection systems.
Despite the success of Transformers in cybersecurity, their application in ransomware detection remains insufficiently studied, particularly in the context of cross-modal learning. Vision Transformers have demonstrated the effectiveness of cross-attention mechanisms in fusing multi-scale and multi-modal features [29,30]. Inspired by these advancements, applying cross-attention within Transformer architectures for ransomware detection could enhance feature integration from different data representations, such as portable executable (PE) byte sequences and API call patterns. However, research in this area is still limited, and further investigation is needed to evaluate the potential of such models in accurately distinguishing ransomware from benign software. This paper addresses this gap by introducing a cross-modal Transformer architecture designed specifically for ransomware detection, leveraging byte and API embeddings to achieve high detection accuracy.
In this work, we propose RansomFormer, a Transformer-based framework that integrates PE bytes with static API imports or dynamic API sequence calls for ransomware detection. Our work has the following main contributions:
- First, we design a dual-stream architecture that processes raw bytes from PE files in one stream and tokenized API names in another. This architecture connects byte data features with API signals and is enhanced by a cross-attention mechanism. Additionally, we employ a self-supervised pre-training strategy that applies masked language modeling on raw bytes and contrastive learning on API names, improving feature representation across both modalities.
- Second, we construct a large ransomware dataset covering 161 families, as the existing datasets are outdated, lack family variants, or are limited in size. This dataset enables further research in ransomware detection.
- Third, we prove that static data alone can achieve high detection accuracy while adding dynamic data further improves detection. Fusing byte data with API imports enhances static feature extraction, leading to better detection performance.
2. Related Work
This section reviews previous research on ransomware detection, focusing on general detection approaches and Transformer-based methods.
2.1. Overview of Ransomware Detection Methods
Current ransomware detection methodologies broadly fall into the following three categories: static, dynamic, and hybrid analysis. Static methods analyze the code structure and features without execution. For instance, Ref. [31] introduced a Hamming distance-based feature selection technique for Android ransomware detection using static features, achieving high accuracy with lightweight classifiers. Similarly, Ref. [32] leveraged PE headers for early ransomware detection via deep reinforcement learning. While static approaches are computationally efficient, they struggle with obfuscated or polymorphic ransomware variants.
Dynamic analysis focuses on behavioral patterns during execution. The authors in [33] proposed real-time detection by monitoring system call sequences, while the authors in [34] utilized memory features and XGBoost to detect ransomware with 97.85% accuracy. Dynamic methods excel in identifying zero-day threats but incur runtime overhead and may fail to capture dormant payloads. The authors in [35] introduced RansoGuard, a framework that detects ransomware early by analyzing sensitive API calls before encryption. Using an RNN trained on a real-world dataset, it achieved 96.18% recall and 94.26% accuracy, effectively identifying ransomware and handling zero-day attacks. In [36], the authors developed a neural network model to detect ransomware early by analyzing pre-attack internal API calls. Their model achieved 80% accuracy on their dataset and 93% on another state-of-the-art dataset.
Hybrid approaches combine static and dynamic features as follows: Ref. [37] applied transfer learning to fuse cross-domain features, improving generalization to unseen ransomware families. However, existing hybrid methods often lack robust integration mechanisms, leading to suboptimal feature representation.
In addition to these traditional approaches, researchers have explored adaptive and machine learning-based detection mechanisms. In [4], the authors proposed a similarity-preserving hashing technique that partitions files and selectively hashes them, enabling the efficient detection of encrypted sections without processing entire files. The work in [8] applied ML and DL to classify Android ransomware based on network traffic, demonstrating high accuracy across various models, including decision trees and support vector machines. The authors in [38] improved the Random Forest method with the C4.5 algorithm to detect ransomware using API call frequencies. They achieved 96% accuracy, but some ransomware was undetected due to differing API calls. In [39], the authors proposed an early crypto-ransomware detection model using incremental bagging (iBagging) for progressive data sampling and enhanced semi-random subspace selection (ESRS) for optimal feature selection. Their ensemble-based approach improved accuracy compared to the existing methods, despite using limited early-phase data.
Another key approach involves entropy-based detection, which identifies high-entropy regions as indicators of encryption. However, attackers have developed countermeasures to bypass such techniques. The authors in [15] introduced entropy sharing, a method that distributes entropy across different file sections, making traditional entropy-based detection less effective. Similarly, the work in [5] has investigated countermeasures against entropy manipulation and proposed a machine learning-based approach to detect encoding-based evasion techniques.
Feature selection is also crucial in improving detection efficiency. The authors in [14] proposed an incremental mutual information-based feature selection method for early ransomware detection. Their approach processes data in small batches, reducing computational overhead and improving adaptability to new attack patterns.
Other innovations include explainable detection frameworks as shown in [40], which combined gradient-weighted class activation mapping with DL, and hardware-accelerated solutions such as that in [41], which employed FPGA-optimized XGBoost for real-time performance. Despite these advancements, challenges persist in handling imbalanced datasets, minimizing false positives, and adapting to evolving ransomware tactics.
2.2. Transformer-Based Approaches in Ransomware Detection
To date, only two studies have explored Transformer architectures for ransomware detection.Ref. [42] proposed a Dual Vision Transformer (EDVT) with a Mantis Search Split Attention Network (MSSAN), achieving high accuracy by fusing visual and structural features from ransomware binaries. In [43], the authors introduced Pulse, a Transformer-based framework trained on assembly language instructions extracted via dynamic binary instrumentation. While Pulse claimed to achieve zero-day malware detection by identifying novel functionality, its approach was constrained to low-level assembly features, neglecting higher-level behavioral semantics and broader system interactions.
Despite current advances in ransomware detection, especially with ML and DL, several challenges remain. A primary limitation is the lack of diverse and large-scale datasets, which hinders the generalization of detection models to unseen ransomware variants. Many existing models are trained on limited datasets that may not capture the full spectrum of real-world threats, leading to overfitting and poor performance on new attack patterns. Additionally, while static and dynamic methods show promise, each has inherent weaknesses. Static analysis struggles with obfuscated or polymorphic ransomware, while dynamic analysis is resource-intensive. While dynamic analysis-based methods offer better accuracy, they are slow and unsuitable for real-time detection systems. Static analysis is faster, but many existing methods rely on a single feature, such as API calls, which is insufficient for creating patterns that ML/DL models can use. Finally, the evolving tactics of attackers, including countermeasures against common detection techniques, make it difficult for existing methods to maintain effectiveness over time.
3. Materials and Methodology
Recent advancements in Transformer architectures have demonstrated significant success in various domains, including natural language processing and computer vision [25]. However, their application to ransomware detection remains underexplored, particularly in fusing static and dynamic features. Existing approaches primarily rely on static analysis, which is vulnerable to obfuscation techniques, or dynamic analysis, which can be resource-intensive. We propose RansomFormer, a cross-modal Transformer framework that integrates byte-level static analysis with dynamic behavioral monitoring to overcome these limitations. Inspired by the cross-attention mechanisms in Vision Transformers [29,30], our approach employs a dual-stream architecture, where one stream processes raw PE file bytes while the other analyzes tokenized log sequences and file operations. A cross-attention mechanism correlates these modalities, enhancing detection capabilities by identifying suspicious code–behavior relationships. This methodology ensures a ransomware detection system that effectively counters evasion techniques while maintaining high detection accuracy.
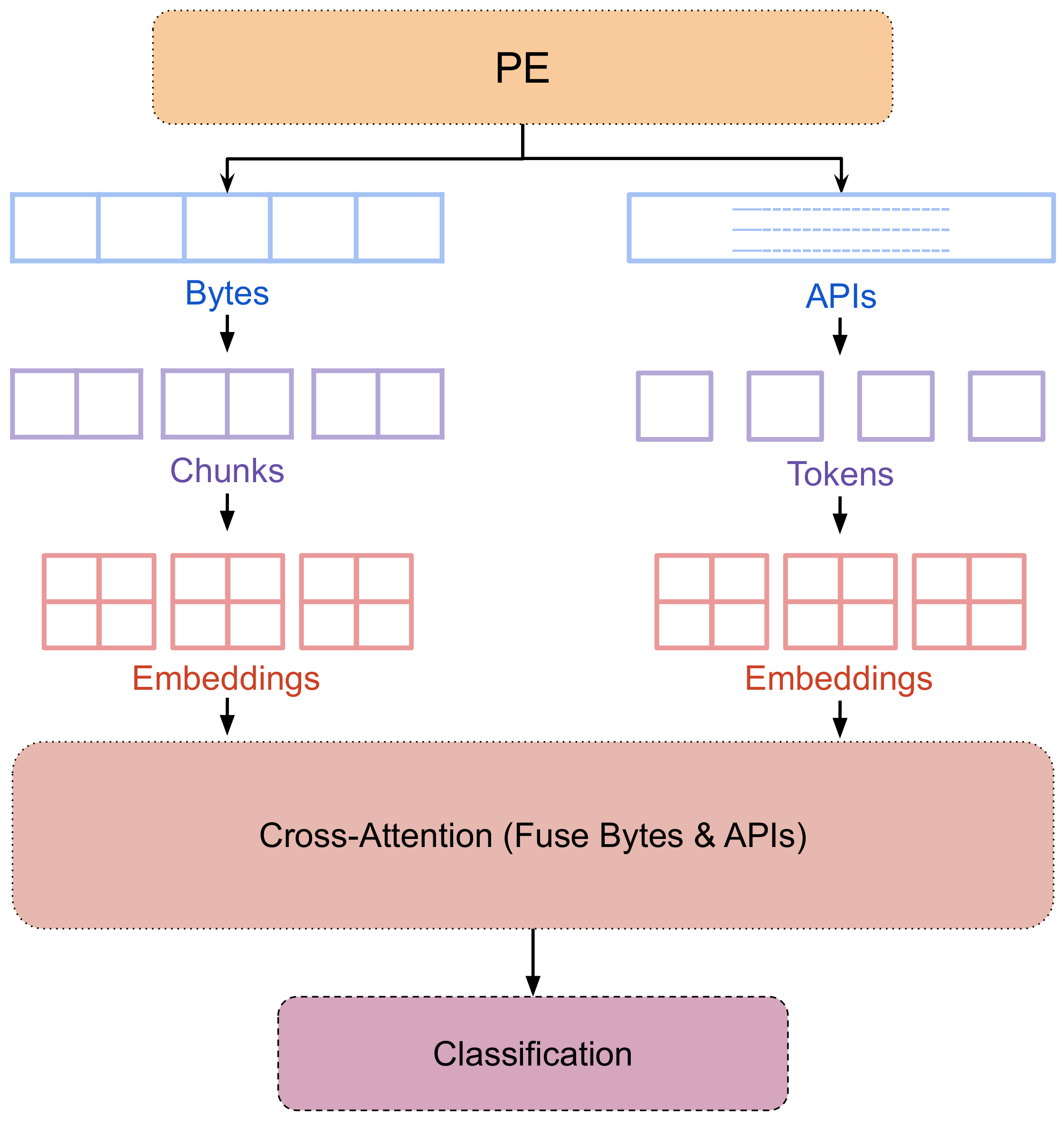
Figure 1 illustrates the proposed method. In the static analysis phase, byte-level information is extracted from the PE file and divided into smaller chunks, which are then transformed into embeddings. Simultaneously, static or dynamic analysis captures API imports or call sequences, which are tokenized and converted into embeddings. These embeddings are fused using a cross-attention mechanism to enhance feature representation. Finally, the fused embeddings are processed by a classification model to determine whether the PE file is benign or malicious. By leveraging bytes and API features, this approach aims to improve classification accuracy and better understand the PE file’s behavior.
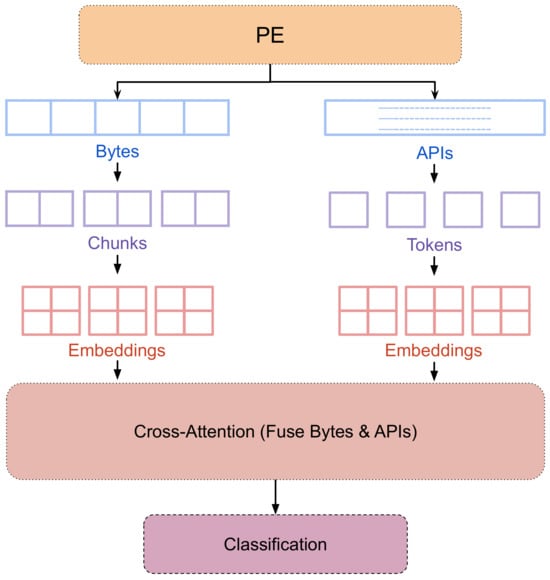
Figure 1.
RansomFormer architecture diagram illustrating the dual-stream processing of static byte chunks (left) and static or dynamic API tokens (right), fused via cross-attention for ransomware classification.
3.1. Data Collection
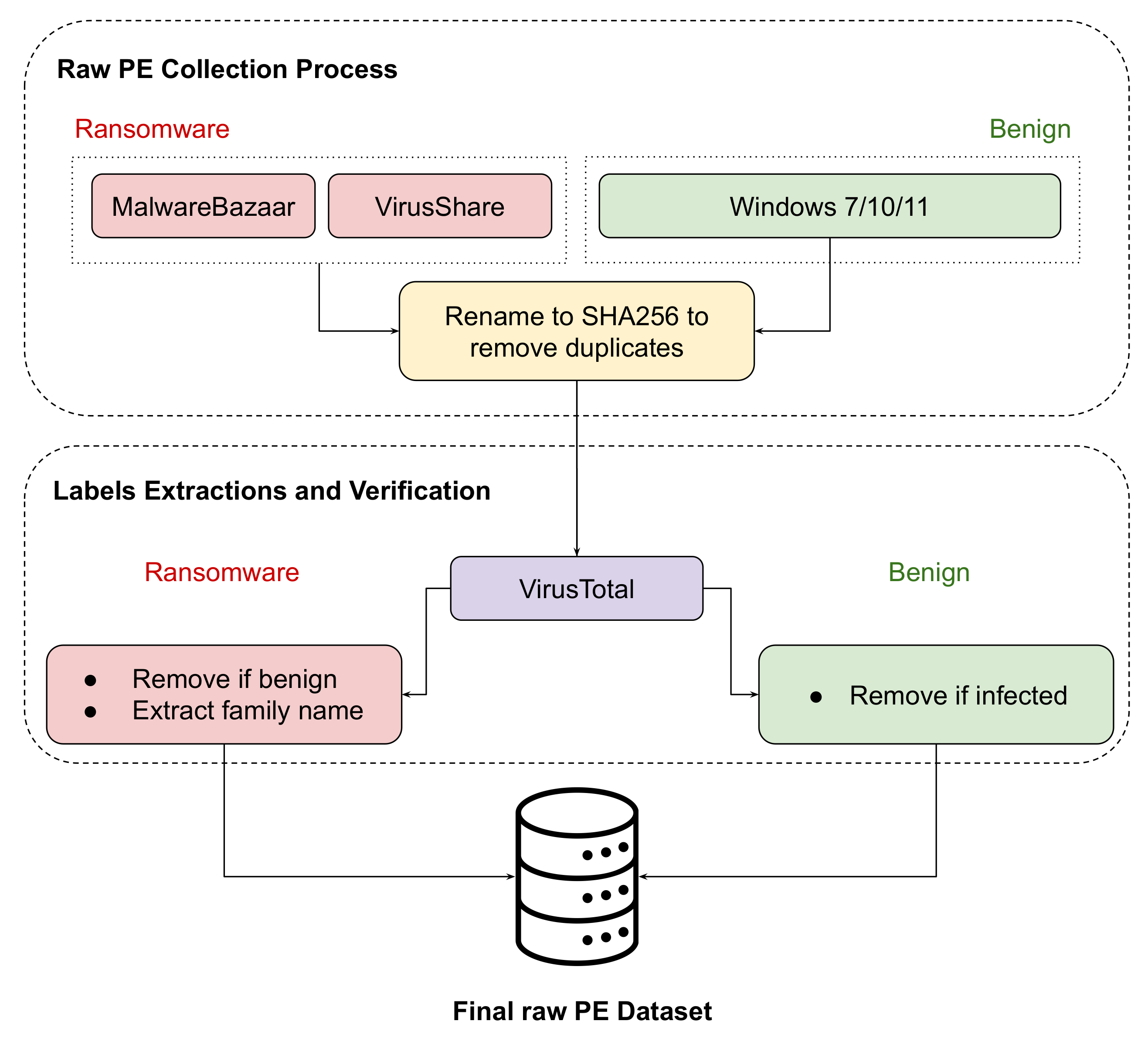
The ransomware dataset was constructed using the following two sources: MalwareBazaar [44] and VirusShare [45]. Both online repositories provide access to a large collection of malware samples for research and analysis. MalwareBazaar is a platform managed by abuse.ch, offering a vast range of malware samples, including information on their behavior and associated indicators of compromise (IOCs). VirusShare, on the other hand, is a community-driven resource that shares malware samples for academic and professional use. These platforms provided a comprehensive collection of malware samples, which we analyzed to filter out non-ransomware files, ensuring that the dataset focused exclusively on PE ransomware files.
In total, 5000 unique ransomware samples were curated, representing over 150 distinct families, as detailed in Table 1. This diverse set of families offers a broad perspective on the variations in ransomware behavior and characteristics. An additional 5000 benign samples were collected to maintain a well-balanced dataset for training and evaluation. These benign samples consisted of system utilities and pre-installed applications sourced from fresh Windows 7, 8, 10, and 11 installations, ensuring a realistic and diverse set of non-malicious files.

Table 1.
Top ransomware families with the largest sample counts in the dataset.
Each sample was subjected to rigorous verification using VirusTotal’s [46] multi-engine scanning system. A sample was only considered valid if it received unanimous agreement from over 60 antivirus engines, a stringent criterion that helped ensure the accuracy of the classification process, as depicted in Figure 2. To further refine the dataset, duplicate files were identified and removed through SHA-256 hashing, ensuring that the dataset remained free of redundancy and contained unique samples for analysis.
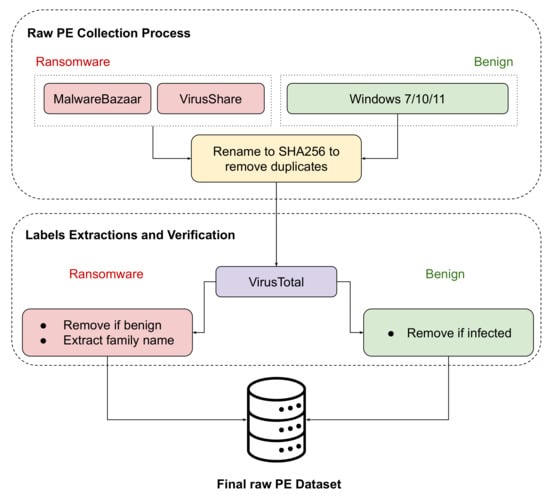
Figure 2.
Samples’ collection and verification process for ransomware and benign samples.
3.2. Static and Dynamic Feature Extraction
We extract static features from PE files (bytes and API imports) and dynamic features (API call sequences) to model ransomware behavior effectively.
3.2.1. PE Byte Representation
Each PE file is processed as a sequence of raw byte values. Given an executable file F, we represent it as a sequence of bytes as follows:
To standardize the input length, we apply chunking and striding with a fixed chunk size of 512 bytes and a stride of 256 bytes as follows:
where is the window (chunk) size, is the stride size, and k indexes the chunks. To maintain consistency, sequences shorter than 1024 bytes are zero-padded, and longer sequences are truncated.
3.2.2. API Representation
API imports or API call sequences provide insight into the runtime behavior of executables. We process each execution log L as a sequence of API names as follows:
where V is the API vocabulary. Since API traces vary in length, we normalize them as follows:
- API names are tokenized using a vocabulary-based lookup as follows:
- Unknown API names are mapped to a special token `<UNK>`.
- Sequences exceeding 1024 tokens are truncated.
- Shorter sequences are zero-padded to maintain fixed length.
Each tokenized sequence follows the following structured format:
where
- `[CLS]’ denotes the start of the sequence.
- API name and arguments are tokenized separately.
- `[SEP]’ marks sequence boundaries.
Arguments undergo normalization to reduce noise as follows:
- Paths are anonymized.
- Hexadecimal numbers are converted to decimal.
- Text is standardized to lowercase.
3.3. Model Architecture
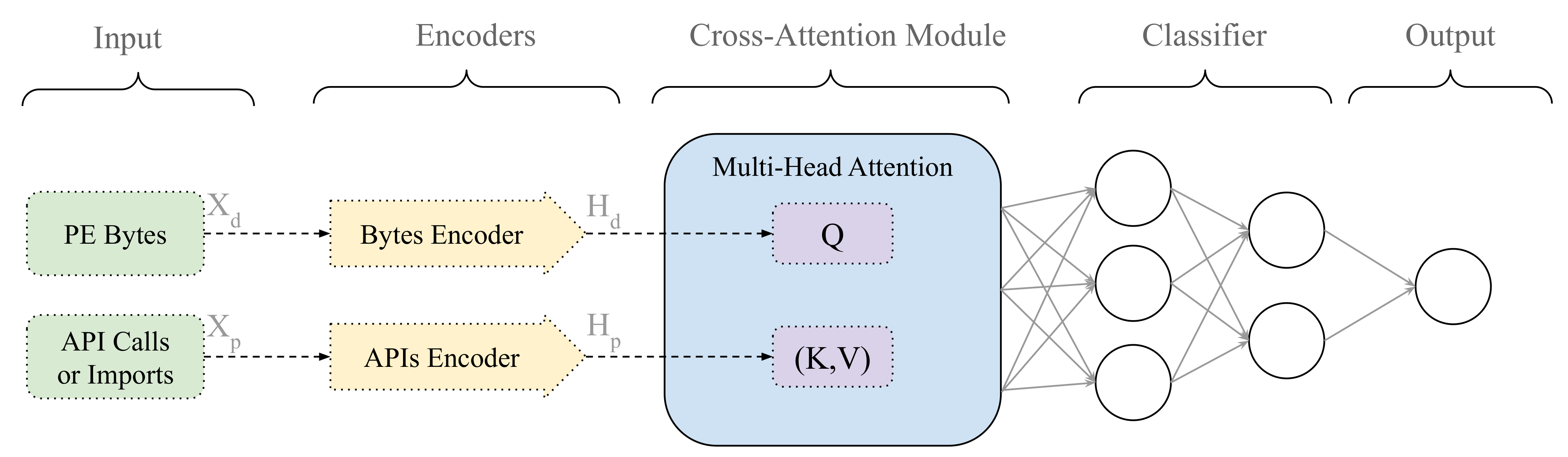
RansomFormer integrates PE byte sequences and API-related features to classify ransomware samples effectively. The architecture consists of several key components designed to handle the fusion of PE bytes with API data, extracted using the following two distinct methods: Static API imports and Dynamic API call sequences. The architecture is illustrated in Figure 3.
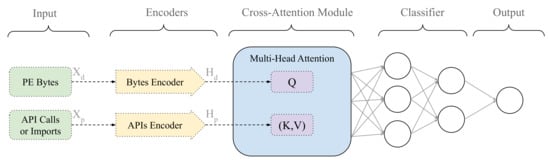
Figure 3.
RansomFormer model architecture. The model takes the following two inputs: API names () and PE bytes (). The byte encoder and API encoder transform these inputs into feature representations ( and , respectively). The cross-attention module uses as the query (Q) and as the key (K) and value (V) to generate a fused representation. This fused output is passed through a fully connected classifier, which predicts the final classification outcome.
As illustrated in Figure 3, RansomFormer employs a dual-path architecture that processes both PE byte streams and API call sequences. Let represent the normalized PE byte sequence, and denote the API call sequence (static imports or dynamic traces) of length L.
3.3.1. Input Encoding
The byte encoder processes through temporal convolutions as follows:
where and are convolutional filters. The API encoder transforms through the following:
where is the API embedding matrix for vocabulary size .
3.3.2. Cross-Modal Attention
The fusion layer computes attention using byte features as a query, as follows:
where serves as the byte-driven query and provide the API context. The fused representation becomes as follows:
3.3.3. Classification
The final prediction uses the following fused features:
This architecture ensures efficient learning from static and dynamic API features alongside byte sequence data, utilizing a cross-attention mechanism to fuse the two sources of information effectively. The model leverages advanced techniques such as CNN for byte feature extraction and Transformers for API sequence encoding, combined with cross-attention to model interactions between these two modalities.
4. Experiments and Results
This section presents our experiments, starting with data extraction, then the model parameters and training process, concluding with the results and a comparative analysis with other methods.
4.1. Data Extraction and Preprocessing
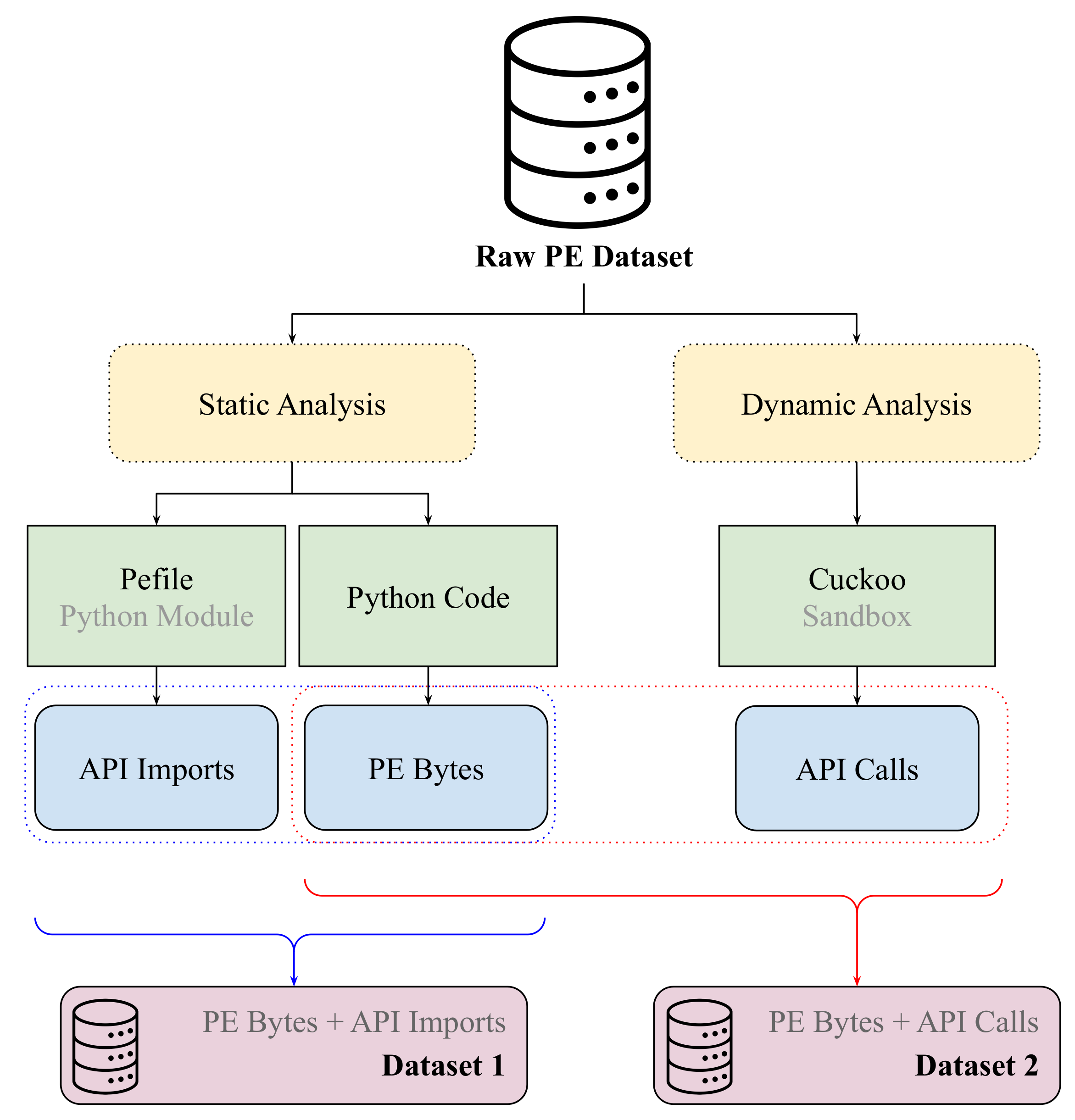
We extract features from the raw PE dataset using static and dynamic analysis techniques. Figure 4 illustrates the workflow for generating the following two datasets: Dataset 1 and Dataset 2.
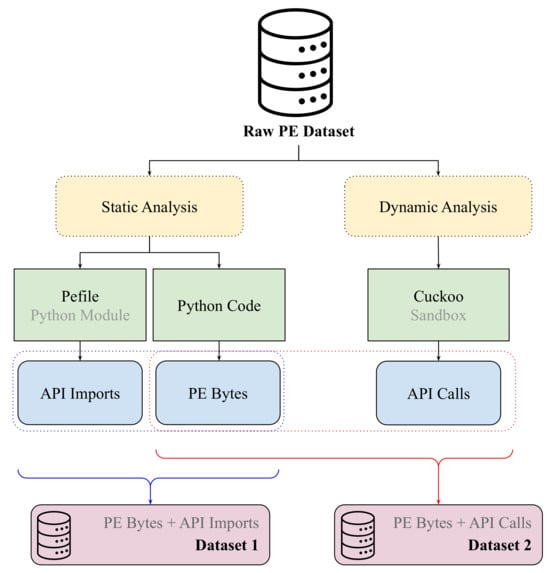
Figure 4.
Workflow for data extraction and preprocessing, generating Dataset 1 and Dataset 2 using static and dynamic analysis techniques.
Static analysis is performed without executing the PE files. The process utilizes the Pefile Python module v2024.8.26 [47] to extract API imports and custom Python code to retrieve raw PE byte sequences. API imports refer to the functions’ binary imports from dynamic link libraries (DLLs), which provide insights into its functionality. The extracted PE bytes and API imports are combined to form Dataset 1.
Dynamic analysis involves executing the PE files in a controlled environment to observe their runtime behavior. The Cuckoo 3 sandbox [48] is used to monitor API calls made by the binary during execution. API calls provide valuable behavioral information, revealing potential malicious intent. The extracted API calls are combined with the PE byte sequences to form Dataset 2.
At the end of this process, Dataset 1 contains PE bytes and API imports extracted from 5000 ransomware samples across 25 families and 5000 benign samples. Dataset 2 contains PE bytes and API sequence calls from 2000 ransomware samples across 14 families and 2000 benign samples.
Dynamic analysis involves executing each sample in a controlled environment while monitoring its behavior. This approach is significantly slower than static analysis, which extracts features without execution. Due to the time-intensive nature of dynamic analysis, fewer samples can be processed within the available resources. Additionally, some ransomware samples may fail to run or generate incomplete logs, further reducing the number of successfully analyzed files. Running many samples dynamically also demands substantial computational power and storage. Given these constraints, the dataset size had to be limited to ensure efficient data collection and processing. As a result, Dataset 2 contains fewer samples due to these resource limitations. However, despite its smaller size, it represents diverse execution patterns, offering valuable insights into ransomware behavior. Our API tokenization and normalization approach employs a methodology to represent malware behavioral patterns effectively. The process begins with vocabulary generation, where we implement a dynamic system that analyzes the frequency of API calls across all samples. By setting a minimum frequency threshold, we filter out rare API calls that are likely noise rather than meaningful patterns, optimizing vocabulary size and improving the signal-to-noise ratio in the feature representation.
In sequence processing, API call sequences are converted into numerical representations while preserving their temporal order, crucial for detecting malware behaviors. Unknown API calls are mapped to a special <UNK> token, ensuring the model can gracefully handle previously unseen API calls during inference.
In terms of normalization, we standardize API sequences to a fixed length, truncating longer sequences and padding shorter ones to create uniform inputs for the neural network, while preserving the most informative aspects of the data. Additionally, our approach anonymizes system paths by focusing on API call names instead of full paths, allowing the model to generalize across different environments.
For PE file byte processing, the static analysis of PE files employs a sliding window approach to capture local and global byte-level patterns. Raw hexadecimal bytes are interpreted as decimal integers (0–255), enabling arithmetic feature extraction in neural networks. Sequences are standardized by concatenating overlapping segments and truncating/padding to a fixed length. Our implementation uses a chunk size of 512 bytes with a stride of 256 bytes, creating overlapping windows that capture patterns spanning chunk boundaries. These chunks are concatenated and normalized to a consistent length of 1024 bytes, with zero padding applied to shorter sequences. This approach ensures that structural information is not lost at arbitrary chunk boundaries.
4.2. Model Evaluation
We employed several standard metrics in the classification domain to evaluate the proposed ransomware detection model’s performance. These metrics comprehensively assess the model’s ability to identify ransomware accurately while minimizing false positives and negatives. The metrics used are accuracy, precision, recall, F1-score, and False Positive Rate (FPR).
- Accuracy : Represents the ratio of correctly classified instances to the total number of instances.
- Precision: Indicates the proportion of correctly identified ransomware samples out of all instances predicted as ransomware.
- Recall (Sensitivity): Measures the proportion of actual ransomware samples the model correctly identified.
- F1-score: The harmonic mean of precision and recall, providing a balanced measure of the model’s performance, is particularly useful when dealing with imbalanced datasets.
- FPR: Represents the proportion of benign samples incorrectly classified as ransomware.
where
- TP (True Positive): Number of ransomware samples correctly identified as ransomware.
- TN (True Negative): Number of benign samples correctly identified as benign.
- FP (False Positive): Number of benign samples incorrectly identified as ransomware.
- FN (False Negative): Number of ransomware samples incorrectly identified as benign.
4.3. Hyperparameter Settings
The hyperparameters of the RansomFormer model, as shown in Table 2, are selected using PyTorch Lightning Tuner version 2.5.0 with Optuna version 4.2.1. Optuna is a hyperparameter optimization framework that performs efficient search over the hyperparameter space, while PyTorch Lightning Tuner automates the integration of Optuna into the training process. This combination helps identify the optimal values for each parameter by using advanced optimization techniques such as pruning and parallel optimization.
Table 2.
Hyperparameters of the RansomFormer model architecture.
The model consists of multiple components, each configured with specific parameters. The API encoder uses a Transformer-based architecture with an embedding dimension of 256, eight Transformer layers, and eight attention heads. These values were identified through Optuna’s efficient hyperparameter search, which explored embedding dimensions between 128 and 512, and Transformer configurations ranging from 4 to 12 layers and attention heads. The selected configuration represents the optimal balance between model performance and computational efficiency as determined by the optimization process.
The byte encoder processes input sequences of shape (1, 1024) and applies two convolutional layers with 64 and 128 filters. This is followed by a pooling operation that outputs 64 features, ultimately producing an embedding of size 256. Optuna’s Bayesian optimization approach efficiently navigated the search space for filter counts, kernel sizes, and pooling configurations, converging on this architecture after evaluating hundreds of potential configurations against our validation metrics.
The Cross-Attention mechanism maintains an embedding dimension of 256 with eight attention heads and a dropout rate of 0.2. This dropout rate emerged from Optuna’s automated search over potential values between 0.1 and 0.5, with early pruning of underperforming configurations. The classifier consists of two hidden layers with 512 and 256 neurons, respectively, and an output layer with two neurons, using dropout rates of 0.6 and 0.4. These layer dimensions and progressive dropout rates were determined through PyTorch Lightning Tuner’s integration with our validation pipeline, which identified this configuration as providing optimal regularization while maintaining strong predictive performance.
The model is optimized using AdamW, an improved version of the Adam optimizer that includes weight decay for better generalization in deep learning models. Unlike the standard Adam optimizer, which applies L2 regularization by modifying the gradients, AdamW decouples weight decay from the optimization step. This prevents the weights from being scaled incorrectly and helps reduce overfitting, leading to better model performance. Our Optuna trials compared multiple optimizers, including Adam, SGD, and AdamW, with AdamW consistently yielding superior performance. The specific weight decay parameter was tuned through Optuna’s parallel optimization capabilities, which efficiently explored values between 0.001 and 0.1 before converging on the optimal setting for our task.
The AdamW optimizer’s learning rate is initially set to 1 × 10−4, with a weight decay of 1 × 10−5. Training is conducted with a batch size of 64, ensuring efficient learning dynamics.
4.4. Model Training
We split the dataset into training, validation, and testing sets, as shown in Table 3. We train the model on an Apple Mac Studio with an Apple M2 Ultra chip (Apple Inc., Cupertino, CA, USA), which includes a 24-core CPU (16 performance cores and 8 efficiency cores), a 60-core GPU, a 32-core Neural Engine, and 128 GB of unified memory. We used PyTorch Lightning 2.5.0 to train the model efficiently and manage the training process with automatic logging and checkpointing features. The training took approximately four hours for Dataset 1 and around two hours for Dataset 2 due to the sample size and hardware configuration.
Table 3.
Balanced distribution of benign and ransomware samples in the training, validation, and test sets.
For Dataset 1, the training set consists of 6000 samples, the validation set contains 2000 samples, and the test set includes 2000 samples. For Dataset 2, the training set consists of 1600 samples, the validation set contains 600 samples, and the test set includes 600 samples. Each subset maintains a balanced distribution between benign and ransomware samples to ensure fair model evaluation. For dataset 1, the training set contains 3000 benign and 3000 ransomware samples. Similarly, the validation set consists of 1000 benign and 1000 ransomware samples, while the test set has 1000 benign and 1000 ransomware samples. For dataset 2, the training set contains 800 benign samples and 800 ransomware samples. Similarly, the validation set consists of 300 benign and 300 ransomware samples, while the test set also has 300 benign and 300 ransomware samples.
This balanced distribution helps the model learn to differentiate ransomware from benign files without bias toward a particular class.
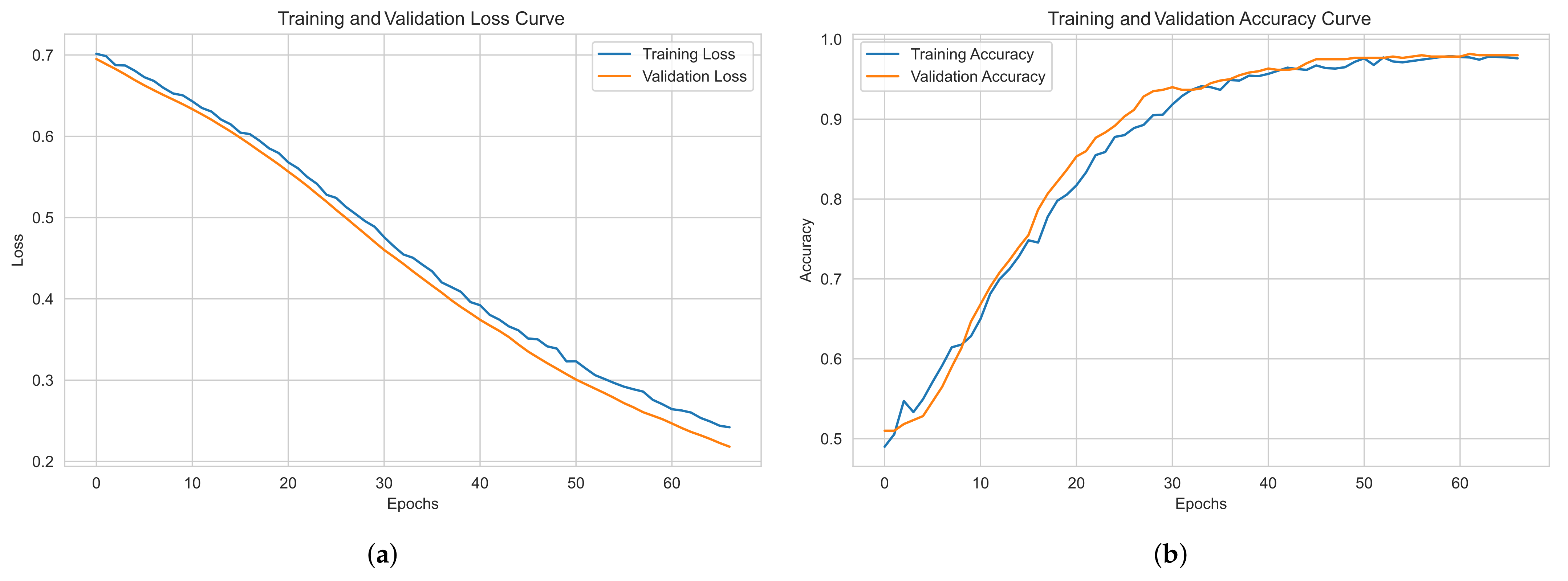
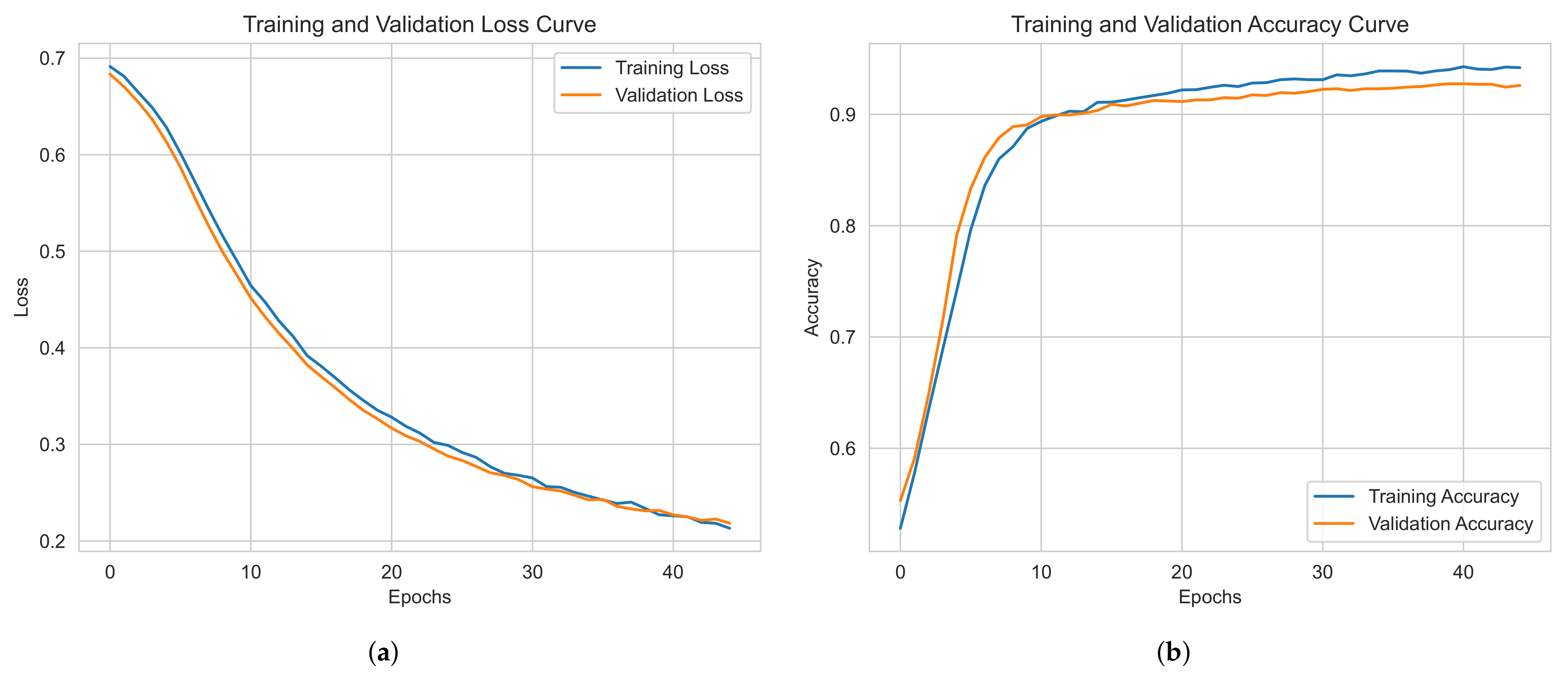
For Dataset 1 (Static Analysis only, PE bytes + API imports), the training takes a longer time due to the larger dataset size, requiring 60 epochs for sufficient learning as shown in Figure 5. The training process for this dataset is computationally intensive, but the model steadily improves over time, achieving near-perfect classification accuracy.
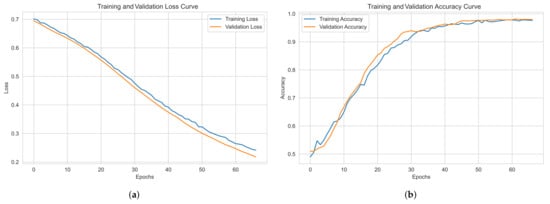
Figure 5.
Training performance for Dataset 1: (a) loss curve, (b) accuracy curve.
In contrast, Dataset 2 (static + dynamic analysis, PE bytes + API sequence calls) involves a smaller dataset, and the training time is shorter, as shown in Figure 6, requiring only 40 epochs for convergence due to the smaller dataset size and reduced complexity.
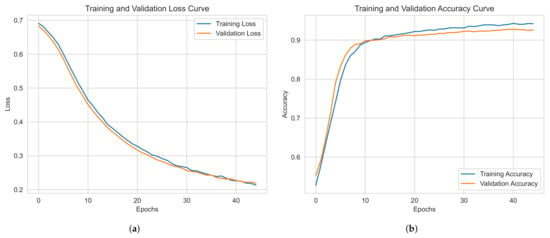
Figure 6.
Training performance for Dataset 2: (a) loss curve, (b) accuracy curve.
Dataset 1, with more samples, demonstrates stable training performance and strong generalization, showing minimal overfitting. Dataset 2, despite having fewer samples, maintains competitive performance with slight overfitting but remains effective. Both models exhibit smooth convergence, with Dataset 2 achieving better optimization relative to its size.
4.5. Results
The performance of the RansomFormer model is evaluated on the test dataset for both Dataset 1 and Dataset 2, as shown in Table 4.
Table 4.
Performance results of RansomFormer on the test dataset for Dataset 1 and Dataset 2.
For Dataset 1, the model achieves an accuracy of 99.25%, correctly classifying nearly all ransomware and benign samples. The precision is 99.30%, indicating that when the model predicts a sample as ransomware, it is correct 99.30% of the time. The recall is 99.20%, showing that the model successfully detects 99.20% of all ransomware cases. The F1-score is 99.25%, confirming a strong balance between precision and recall. Additionally, the FPR is 0.70%, meaning only 0.70% of benign samples are misclassified as ransomware.
For Dataset 2, the model achieves an accuracy of 99.50%, correctly classifying nearly all ransomware and benign samples. The precision is 99.67%, indicating that when the model predicts a sample as ransomware, it is correct 99.67% of the time. The recall is 99.33%, showing that the model successfully detects 99.33% of all ransomware cases. The F1-score is 99.50%, confirming a strong balance between precision and recall. Additionally, the FPR is 0.33%, meaning only 0.33% of benign samples are misclassified as ransomware.
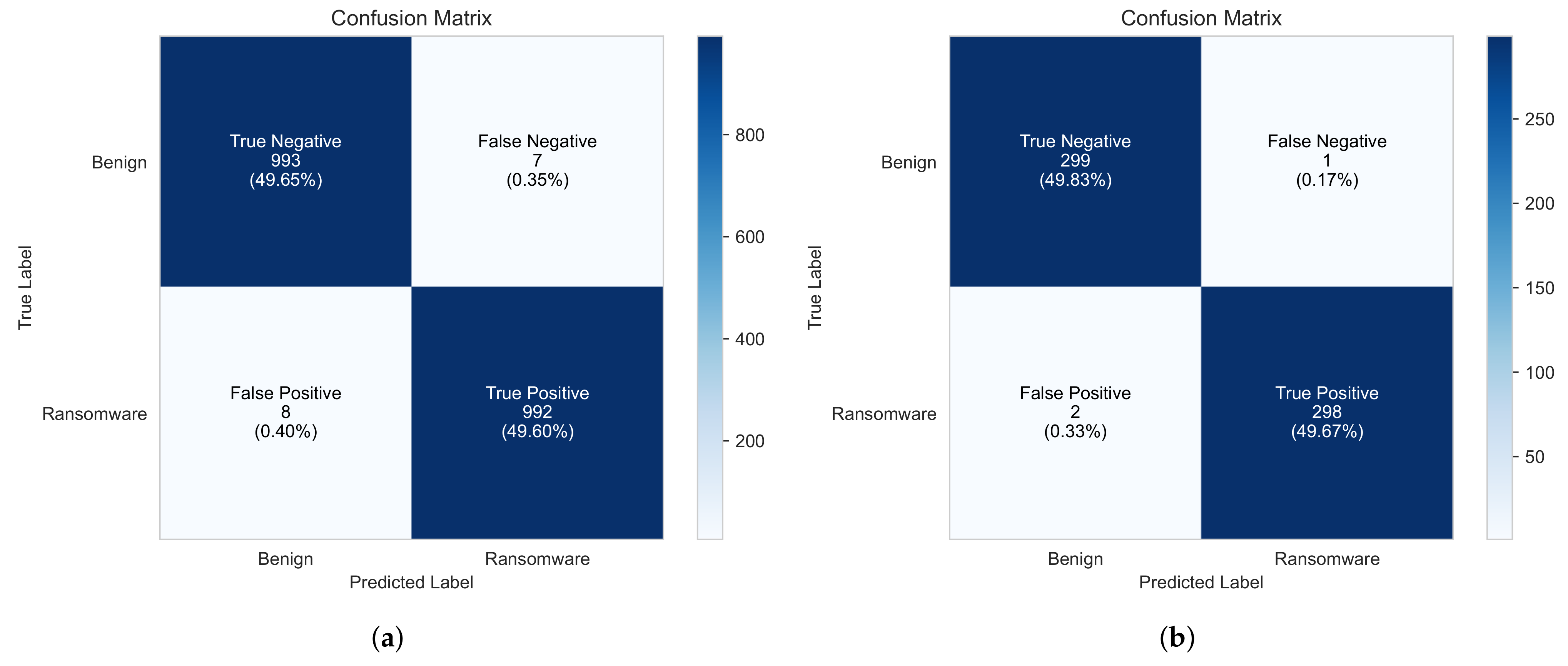
To further analyze the model’s performance on the test dataset, Figure 7 presents the confusion matrix for each dataset. For Dataset 1, the model correctly classifies 993 benign samples and 992 ransomware samples, while misclassifying only 15 samples in total (7 benign misclassified as ransomware and 8 ransomware misclassified as benign). For Dataset 2, the model correctly classifies 299 benign and 298 ransomware samples while misclassifying only 3 samples (1 benign misclassified as ransomware and 2 ransomware misclassified as benign). This low error rate highlights the model’s robustness in distinguishing between the two classes. While the model achieves a low false positive rate, even a small number of false positives can have an operational impact, especially in security-sensitive environments. Adaptive thresholding can be applied to fine-tune the decision boundary based on real-world deployment feedback to mitigate this. Additionally, hybrid detection approaches that combine static and dynamic analysis or ensemble learning methods could further reduce false positives by leveraging multiple detection perspectives, although this would introduce additional overhead in terms of time and resource complexity.
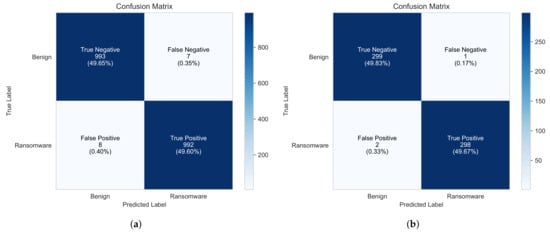
Figure 7.
Confusion matrix of the RansomFormer model on the test dataset. (a) Dataset 1, (b) Dataset 2.
These results indicate that the model successfully balances precision and recall, ensuring minimal false positives and false negatives. The high F1-score further confirms the model’s effectiveness for ransomware detection on unseen data.
4.6. Comparison of Ransomware Detection Methods
In Table 5, we present a comprehensive comparison between RansomFormer and state-of-the-art ransomware detection methods. The comparison encompasses diverse ML/DL approaches that leverage API calls as primary features. We specifically focused on ML/DL-based ransomware detection techniques, evaluating their performance across multiple metrics, including accuracy, precision, recall, and F1-score. Additionally, we provide details about the datasets employed in each experimental evaluation to facilitate a fair assessment of the comparative results.
Table 5.
Comparative comparison of different ransomware detection approaches.
Several key observations emerge from this comparison. Traditional ML methods such as Random Forest (RF) and C4.5 [38] achieve relatively high accuracy but rely solely on API features, which may limit their effectiveness in capturing complex ransomware behaviors. Incremental Bagging [39] improves accuracy, demonstrating the benefits of ensemble learning. DL approaches, including RNNs [35] and artificial neural networks (ANNs) [36], achieve competitive results but still fall short of Transformer-based architectures.
The CNN-Transformer model proposed by [49] achieves high accuracy, leveraging static and dynamic features. However, the dataset details are not fully available, making direct comparison difficult. In contrast, RansomFormer outperforms all other methods, achieving the highest accuracy, precision, recall, and F1-score across two datasets. The combination of API-related features and raw PE byte data allows RansomFormer to effectively capture ransomware’s static and behavioral characteristics.
The results highlight the superiority of Transformer-based architectures for ransomware detection. Unlike traditional methods, RansomFormer benefits from the self-attention mechanism, allowing it to model long-range dependencies in ransomware behavior patterns. Including PE byte sequences further enhances detection capabilities by capturing structural and content-based characteristics.
RansomFormer demonstrates state-of-the-art performance, surpassing existing approaches in all evaluated metrics. The results validate the effectiveness of Transformers in ransomware detection and suggest that incorporating multiple feature types—such as API sequences and PE bytes—can significantly enhance detection accuracy and robustness.
5. Conclusions
In this paper, we introduced RansomFormer, a Transformer-based model for ransomware detection that integrates static and dynamic features using a cross-attention mechanism. To support our research, we built a comprehensive and diverse ransomware dataset that spans major ransomware families, overcoming the limitations of existing datasets.
Our experimental results demonstrate the effectiveness of RansomFormer in distinguishing ransomware from benign files with high accuracy. On the static dataset, the model achieved an accuracy of 99.25%, a precision of 99.30%, a recall of 99.20%, and an F1-score of 99.25%, with a FPR of 0.70%. When dynamic analysis was incorporated, the model’s performance improved further, achieving an accuracy of 99.50%, a precision of 99.67%, a recall of 99.33%, and an F1-score of 99.50%, with a FPR of 0.33%. These results highlight the potential of Transformer-based architectures in cybersecurity, particularly ransomware detection.
While RansomFormer demonstrates promising results, this work has several limitations. The model’s reliance on static PE byte data and API imports may struggle against advanced obfuscation techniques, such as packing, encryption, or API call indirection, which are commonly used by modern ransomware to evade static analysis. Prior research has highlighted the vulnerabilities of deep learning-based malware detection models to adversarial attacks, particularly through data poisoning and gradient-based manipulations [50]. These adversarial strategies can significantly reduce classification accuracy and increase false positives, posing a major challenge to models relying solely on static features.
Dynamic features like API sequence calls depend on sandbox-based execution traces, which could be circumvented by ransomware employing anti-sandbox checks or delayed execution mechanisms. Existing adversarial evasion techniques have demonstrated that even minor perturbations or structural modifications to malware can deceive machine learning classifiers [51,52]. The integration of adversarial training has been suggested as a potential countermeasure to strengthen classifiers against such evasive threats, as demonstrated in recent studies on adversarial resilience in Windows PE malware detection [52].
Additionally, despite using an updated and extensive dataset, ransomware datasets—including ours—still face inherent challenges, such as the limited representation of emerging family variants, insufficient benign samples for robust false-positive reduction, and a lack of raw, unpacked PE files for comprehensive static analysis. These gaps may affect the model’s generalization to novel or rapidly evolving ransomware strains. The effectiveness of hybrid approaches that leverage static and dynamic analysis for obfuscated malware detection has been demonstrated in resource-constrained environments, such as IoT devices [53], and similar techniques could enhance ransomware detection capabilities. Furthermore, leveraging synthetic data generation techniques, such as those used in Android malware detection with large language models [54], may help improve dataset diversity and model robustness against novel threats.
Future work should explore hybrid approaches integrating adversarial training to counter obfuscation, improved sandbox environments to capture evasive behaviors, and collaborative efforts to curate larger, more diverse datasets with real-world raw binaries. Research on adversarial attack resilience in malware detection suggests that refining feature extraction techniques and incorporating advanced defense mechanisms, such as differential privacy-based noise clipping [50], could improve the robustness of ransomware classifiers against adversarial manipulations. Future ransomware detection frameworks can enhance their generalization capabilities and resilience against evolving adversarial threats by addressing these challenges.
Author Contributions
Conceptualization, S.A. (Saleh Alzahrani) and Y.X.; methodology, S.A. (Saleh Alzahrani) and Y.X.; validation, S.A. (Saleh Alzahrani), N.A. and S.A. (Sultan Asiri); data curation, S.A. (Saleh Alzahrani) and S.A. (Sultan Asiri); writing—original draft preparation, S.A. (Saleh Alzahrani); writing—review and editing, Y.X., S.A. (Sultan Asiri), N.A. and T.L. All authors have read and agreed to the published version of the manuscript.
Funding
This work was funded by the Deanship of Research and Graduate Studies at King Khalid University, KSA, through the Small Research Group under grant number (297/1445).
Informed Consent Statement
Not applicable.
Data Availability Statement
The data presented in this study are available upon request from the corresponding author due to security and privacy concerns, as PE files are live and potentially dangerous to share publicly.
Acknowledgments
The authors extend their appreciation to the Deanship of Research and Graduate Studies at King Khalid University, KSA, for funding this work through Small Research Group under grant number (297/1445).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Brewer, R. Ransomware attacks: Detection, prevention and cure. Netw. Secur. 2016, 2016, 5–9. [Google Scholar] [CrossRef]
- Everett, C. Ransomware: To pay or not to pay? Comput. Fraud. Secur. 2016, 2016, 8–12. [Google Scholar] [CrossRef]
- Gazet, A. Comparative analysis of various ransomware virii. J. Comput. Virol. 2010, 6, 77–90. [Google Scholar] [CrossRef]
- AlMajali, A.; Elmosalamy, A.; Safwat, O.; Abouelela, H. Adaptive Ransomware Detection Using Similarity-Preserving Hashing. Appl. Sci. 2024, 14, 9548. [Google Scholar] [CrossRef]
- Lee, J.; Yun, J.; Lee, K. A Study on Countermeasures against Neutralizing Technology: Encoding Algorithm-Based Ransomware Detection Methods Using Machine Learning. Electronics 2024, 13, 1030. [Google Scholar] [CrossRef]
- Alzahrani, S.; Xiao, Y.; Sun, W. An Analysis of Conti Ransomware Leaked Source Codes. IEEE Access 2022, 10, 100178–100193. [Google Scholar] [CrossRef]
- Alzahrani, S.; Xiao, Y.; Asiri, S. Conti Ransomware Development Evaluation. In Proceedings of the 2023 ACM Southeast Conference, New York, NY, USA, 12–14 April 2023; ACM SE `23; pp. 39–46. [Google Scholar] [CrossRef]
- Albin Ahmed, A.; Shaahid, A.; Alnasser, F.; Alfaddagh, S.; Binagag, S.; Alqahtani, D. Android Ransomware Detection Using Supervised Machine Learning Techniques Based on Traffic Analysis. Sensors 2024, 24, 189. [Google Scholar] [CrossRef]
- Kenyon, B.; McCafferty, J. Ransomware Recovery. ITNOW 2016, 58, 32–33. [Google Scholar] [CrossRef]
- Lee, Y.; Lee, J.; Ryu, D.; Park, H.; Shin, D. Clop Ransomware in Action: A Comprehensive Analysis of Its Multi-Stage Tactics. Electronics 2024, 13, 3689. [Google Scholar] [CrossRef]
- Andronio, N.; Zanero, S.; Maggi, F. HelDroid: Dissecting and Detecting Mobile Ransomware. In Proceedings of the Research in Attacks, Intrusions, and Defenses, Kyoto, Japan, 2–4 November 2015; Bos, H., Monrose, F., Blanc, G., Eds.; Springer: Cham, Switzerland, 2015; pp. 382–404. [Google Scholar]
- Drabent, K.; Janowski, R.; Mongay Batalla, J. How to Circumvent and Beat the Ransomware in Android Operating System—A Case Study of Locker. CB! tr. Electronics 2024, 13, 2212. [Google Scholar] [CrossRef]
- Gómez-Hernández, J.A.; García-Teodoro, P. Lightweight Crypto-Ransomware Detection in Android Based on Reactive Honeyfile Monitoring. Sensors 2024, 24, 2679. [Google Scholar] [CrossRef] [PubMed]
- Gazzan, M.; Sheldon, F.T. An Incremental Mutual Information-Selection Technique for Early Ransomware Detection. Information 2024, 15, 194. [Google Scholar] [CrossRef]
- Bang, J.; Kim, J.N.; Lee, S. Entropy Sharing in Ransomware: Bypassing Entropy-Based Detection of Cryptographic Operations. Sensors 2024, 24, 1446. [Google Scholar] [CrossRef] [PubMed]
- Davidian, M.; Kiperberg, M.; Vanetik, N. Early Ransomware Detection with Deep Learning Models. Future Internet 2024, 16, 291. [Google Scholar] [CrossRef]
- Albshaier, L.; Almarri, S.; Rahman, M.M.H. Earlier Decision on Detection of Ransomware Identification: A Comprehensive Systematic Literature Review. Information 2024, 15, 484. [Google Scholar] [CrossRef]
- Gazzan, M.; Sheldon, F.T. Novel Ransomware Detection Exploiting Uncertainty and Calibration Quality Measures Using Deep Learning. Information 2024, 15, 262. [Google Scholar] [CrossRef]
- Alqahtani, A.; Sheldon, F.T. eMIFS: A Normalized Hyperbolic Ransomware Deterrence Model Yielding Greater Accuracy and Overall Performance. Sensors 2024, 24, 1728. [Google Scholar] [CrossRef]
- Yamany, B.; Elsayed, M.S.; Jurcut, A.D.; Abdelbaki, N.; Azer, M.A. A Holistic Approach to Ransomware Classification: Leveraging Static and Dynamic Analysis with Visualization. Information 2024, 15, 46. [Google Scholar] [CrossRef]
- Kharraz, A.; Robertson, W.; Balzarotti, D.; Bilge, L.; Kirda, E. Cutting the Gordian Knot: A Look Under the Hood of Ransomware Attacks. In Proceedings of the Detection of Intrusions and Malware, and Vulnerability Assessment, Milan, Italy, 9–10 July 2015; Almgren, M., Gulisano, V., Maggi, F., Eds.; Springer: Cham, Switzerland, 2015; pp. 3–24. [Google Scholar]
- Li, J.; Yang, G.; Shao, Y. Ransomware Detection Model Based on Adaptive Graph Neural Network Learning. Appl. Sci. 2024, 14, 4579. [Google Scholar] [CrossRef]
- Goswami, S.; Kumar, A. A transformative deep learning framework for traffic modelling using sensors-based multi-resolution traffic data. Int. J. Sens. Netw. 2023, 42, 145–155. [Google Scholar]
- Chen, D.; Nie, M.; Gan, Q.; Wang, D. Evolving network representation learning based on recurrent neural network. Int. J. Sens. Netw. 2024, 46, 114–122. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2023, arXiv:1706.03762. [Google Scholar]
- Deng, F.; Tian, H.; Zhao, X.; Han, D. Lightweight remote sensing road detection with an attention-augmented transformer. Int. J. Sens. Netw. 2024, 46, 245–259. [Google Scholar]
- Asiri, S.; Xiao, Y.; Li, T. PhishTransformer: A Novel Approach to Detect Phishing Attacks Using URL Collection and Transformer. Electronics 2024, 13, 30. [Google Scholar] [CrossRef]
- Alshomrani, M.; Albeshri, A.; Alturki, B.; Alallah, F.S.; Alsulami, A.A. Survey of Transformer-Based Malicious Software Detection Systems. Electronics 2024, 13, 4677. [Google Scholar] [CrossRef]
- Lin, H.; Cheng, X.; Wu, X.; Yang, F.; Shen, D.; Wang, Z.; Song, Q.; Yuan, W. CAT: Cross Attention in Vision Transformer. arXiv 2021, arXiv:2106.05786. [Google Scholar]
- Chen, C.F.; Fan, Q.; Panda, R. CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification. arXiv 2021, arXiv:2103.14899. [Google Scholar]
- Rahima Manzil, H.H.; Naik, S.M. Android ransomware detection using a novel hamming distance based feature selection. J. Comput. Virol. Hacking Tech. 2024, 20, 71–93. [Google Scholar] [CrossRef]
- Deng, X.; Cen, M.; Jiang, M.; Lu, M. Ransomware early detection using deep reinforcement learning on portable executable header. Clust. Comput. 2024, 27, 1867–1881. [Google Scholar] [CrossRef]
- Chew, C.J.W.; Kumar, V.; Patros, P.; Malik, R. Real-time system call-based ransomware detection. Int. J. Inf. Secur. 2024, 23, 1839–1858. [Google Scholar] [CrossRef]
- Aljabri, M.; Alhaidari, F.; Albuainain, A.; Alrashidi, S.; Alansari, J.; Alqahtani, W.; Alshaya, J. Ransomware detection based on machine learning using memory features. Egypt. Inform. J. 2024, 25, 100445. [Google Scholar] [CrossRef]
- Cen, M.; Jiang, F.; Doss, R. RansoGuard: A RNN-based framework leveraging pre-attack sensitive APIs for early ransomware detection. Comput. Secur. 2025, 150, 104293. [Google Scholar] [CrossRef]
- Coglio, F.; Lekssays, A.; Carminati, B.; Ferrari, E. Early-Stage Ransomware Detection Based on Pre-attack Internal API Calls. In Proceedings of the Advanced Information Networking and Applications, Juiz de Fora, Brazil, 29–31 March 2023; Barolli, L., Ed.; Springer: Cham, Switzerland, 2023; pp. 417–429. [Google Scholar]
- Sood, I.; Sharma, V. TLERAD: Transfer Learning for Enhanced Ransomware Attack Detection. Comput. Mater. Contin. 2024, 81, 2791–2818. [Google Scholar] [CrossRef]
- Kuswanto, D.; Anjad, M.R. Application of Improved Random Forest Method and C4.5 Algorithm as Classifier to Ransomware Detection Based on the Frequency Appearance of API Calls. In Proceedings of the 2021 IEEE 7th Information Technology International Seminar (ITIS), Surabaya, Indonesia, 6–8 October 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Al-rimy, B.A.S.; Maarof, M.A.; Shaid, S.Z.M. Crypto-ransomware early detection model using novel incremental bagging with enhanced semi-random subspace selection. Future Gener. Comput. Syst. 2019, 101, 476–491. [Google Scholar] [CrossRef]
- Ciaramella, G.; Iadarola, G.; Martinelli, F.; Mercaldo, F.; Santone, A. Explainable Ransomware Detection with Deep Learning Techniques. J. Comput. Virol. Hacking Tech. 2024, 20, 317–330. [Google Scholar] [CrossRef]
- Gajjar, A.; Kashyap, P.; Aysu, A.; Franzon, P.; Choi, Y.; Cheng, C.; Pedretti, G.; Ignowski, J. RD-FAXID: Ransomware Detection with FPGA-Accelerated XGBoost. ACM Trans. Reconfigurable Technol. Syst. 2024, 17. [Google Scholar] [CrossRef]
- Ashwini, A.; Nagasundara, K.B. An intelligent ransomware attack detection and classification using dual vision transformer with Mantis Search Split Attention Network. Comput. Electr. Eng. 2024, 119, 109509. [Google Scholar] [CrossRef]
- Gaber, M.; Ahmed, M.; Janicke, H. Zero day ransomware detection with Pulse: Function classification with Transformer models and assembly language. Comput. Secur. 2025, 148, 104167. [Google Scholar] [CrossRef]
- MalwareBazaar. Available online: https://bazaar.abuse.ch/browse (accessed on 2 January 2025).
- VirusShare. Available online: https://virusshare.com (accessed on 2 January 2025).
- VirusTotal. Available online: https://www.virustotal.com/gui/home/upload (accessed on 2 January 2025).
- Carrera, E. PEfile: Python Module for Parsing and Analyzing PE Files. Available online: https://github.com/erocarrera/pefile (accessed on 10 January 2025).
- GitHub-cert-ee/cuckoo3: Cuckoo3 Is a Python 3 Open Source Automated Malware Analysis System. Available online: https://github.com/cert-ee/cuckoo3 (accessed on 10 January 2025).
- Singh, A.; Mushtaq, Z.; Abosaq, H.A.; Mursal, S.N.F.; Irfan, M.; Nowakowski, G. Enhancing Ransomware Attack Detection Using Transfer Learning and Deep Learning Ensemble Models on Cloud-Encrypted Data. Electronics 2023, 12, 3899. [Google Scholar] [CrossRef]
- Taheri, R.; Shojafar, M.; Arabikhan, F.; Gegov, A. Unveiling vulnerabilities in deep learning-based malware detection: Differential privacy driven adversarial attacks. Comput. Secur. 2024, 146, 104035. [Google Scholar] [CrossRef]
- Aryal, K.; Gupta, M.; Abdelsalam, M.; Kunwar, P.; Thuraisingham, B. A Survey on Adversarial Attacks for Malware Analysis. IEEE Access 2025, 13, 428–459. [Google Scholar] [CrossRef]
- Imran, M.; Appice, A.; Malerba, D. Evaluating Realistic Adversarial Attacks against Machine Learning Models for Windows PE Malware Detection. Future Internet 2024, 16, 168. [Google Scholar] [CrossRef]
- Shafin, S.S.; Karmakar, G.; Mareels, I. Obfuscated Memory Malware Detection in Resource-Constrained IoT Devices for Smart City Applications. Sensors 2023, 23, 5348. [Google Scholar] [CrossRef]
- Naseer, M.; Ullah, F.; Ijaz, S.; Naeem, H.; Alsirhani, A.; Alwakid, G.N.; Alomari, A. Obfuscated Malware Detection and Classification in Network Traffic Leveraging Hybrid Large Language Models and Synthetic Data. Sensors 2025, 25, 202. [Google Scholar] [CrossRef] [PubMed]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).