

Optimal Innovation-Based Deception Attacks on Multi-Channel Cyber–Physical Systems

Abstract
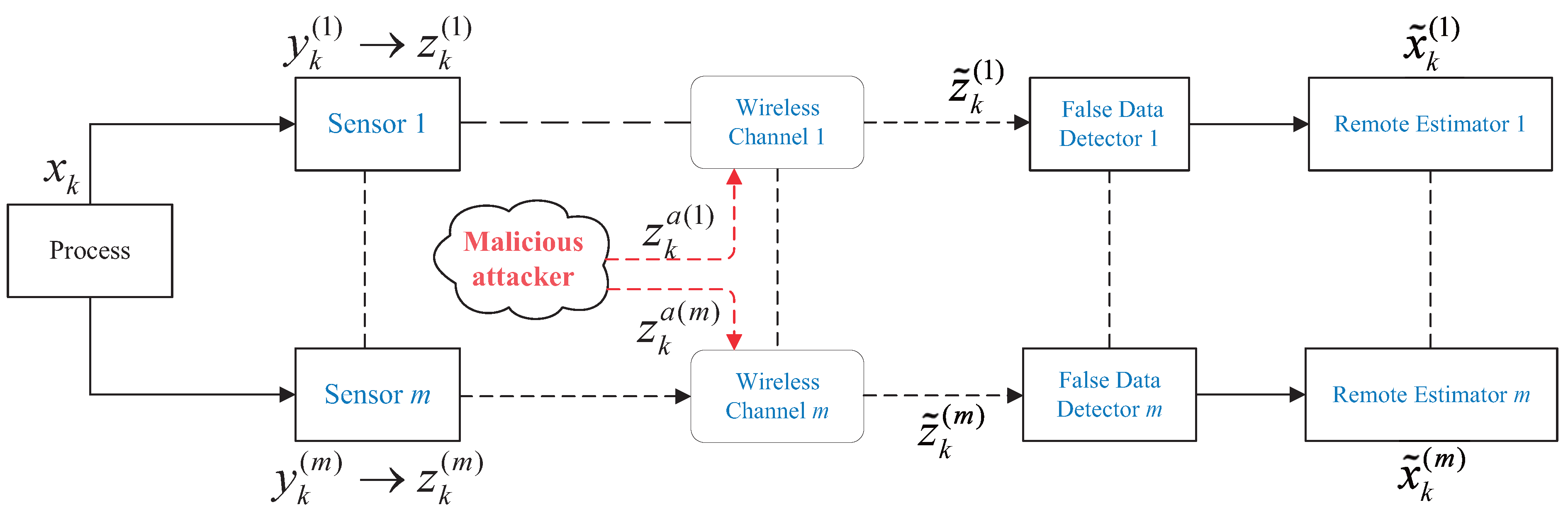
1. Introduction
- This paper introduces the cumulative estimation error over a finite time horizon as a metric to quantify the impact of attacks on the estimation performance degradation of multi-channel CPSs. This method is more complex and more reasonable, as it accounts for the remote estimation error over the entire attack duration rather than at a specific time point.
- An attack model based on the Gaussian distribution with a time-varying mean is proposed. Based on this model, the optimal attack strategy for multi-channel systems is investigated. This approach is more general and more complicated as it introduces more decision variables.
- The time-varying covariance of the modified innovation results in a significant increase in estimation error. An algorithm for generating optimal stealthy attacks is proposed, enabling offline calculation of attack scheduling to alleviate the pressure of online calculation.
2. Related Work
2.1. Research Status
2.2. Application Scenarios
- Smart Grid: The proposed optimal attack scheduling can degrade state estimation accuracy by disrupting multi-channel measurement consistency. For wide-area measurement systems (WAMS) with high-frequency sampling, the attack strategy requires further optimization of temporal window parameters to evade dynamic residual-based detection mechanisms.
- SCADA Systems: The periodic data transmission characteristics of protocols (e.g., Modbus, DNP3) necessitate synchronization between attack scheduling and data update cycles. While the energy constraint model aligns with resource limitations of attackers in industrial control systems (ICS), additional considerations must address the latency sensitivity of real-time control loops.
- Vehicle-to-Everything (V2X) Networks: The strategy can extend to multi-vehicle cooperative attack scenarios. By switching attack channels among different vehicles, it disrupts collaborative perception algorithms in traffic flow while leveraging the time-varying mean model to bypass location-correlation-based detection.
3. System Framework and Problem Formulation
3.1. Process Model
3.2. State Estimator
3.3. Detector and Stealthiness Condition
3.4. Energy Restriction
3.5. Problem Formulation
4. Optimal Attack Design
4.1. Attack Model
4.2. Attack Strategy Formulation
| Algorithm 1 Construction of the optimal innovation-based attacks. |
|
5. Illustrative Examples
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Nomenclature
| Symbol | Definition |
| Natural number | |
| Real number | |
| n-dimensional Euclidean space | |
| Transpose of matrix Y | |
| Inverse of matrix Y | |
| Determinant of matrix Y | |
| Natural logarithm of y | |
| Trace of matrix | |
| Gaussian distribution with covariance and mean | |
| System state vector at time k | |
| Measurement of sensor i at time k | |
| A | System state transition matrix |
| Measurement matrix of sensor i | |
| Process noise | |
| Measurement noise of sensor i | |
| Prior estimate of state by estimator i | |
| Posterior estimate of state by estimator i | |
| Prior estimation error covariance | |
| Posterior estimation error covariance | |
| Kalman gain matrix | |
| Local innovation | |
| Covariance of innovation | |
| Modified innovation under attack | |
| Covariance of innovation | |
| Attack matrix | |
| Attack scheduling matrix | |
| Attack noise | |
| Mean of attack noise | |
| Covariance of attack noise | |
| KLD threshold | |
| Maximum number of attacked channels at time k |
References
- Antsaklis, P. Goals and challenges in cyber-physical systems research editorial of the editor in chief. IEEE Trans. Autom. Control 2014, 59, 3117–3119. [Google Scholar] [CrossRef]
- Ma, X.J.; Wang, H. Blind false data injection attacks in smart grids subject to measurement outliers. J. Control. Decis. 2022, 9, 445–454. [Google Scholar] [CrossRef]
- Zhang, D.; Wang, Q.G.; Feng, G.; Shi, Y.; Vasilakos, A.V. A survey on attack detection, estimation and control of industrial cyber-physical systems. ISA Trans. 2021, 116, 1–16. [Google Scholar] [CrossRef] [PubMed]
- Dutta, R.G.; Hu, Y.; Yu, F.; Zhang, T.; Jin, Y. Design and analysis of secure distributed estimator for vehicular platooning in adversarial environment. IEEE trans. Intell. Transp. Syst. 2022, 23, 3418–3429. [Google Scholar] [CrossRef]
- Ren, Z.; Cheng, P.; Shi, L.; Dai, Y. State estimation over delayed mutihop network. IEEE Trans. Automat. Control 2018, 63, 3545–3550. [Google Scholar] [CrossRef]
- Qiu, H.; Qiu, M.; Liu, M.; Memmi, G. Secure health data sharing for medical cyber-physical systems for the healthcare 4.0. IEEE J. Biomed. Health Inform. 2020, 24, 2499–2505. [Google Scholar] [CrossRef]
- Lindsay, J.R. Stuxnet and the limits of cyber warfare. Secur. Stud. 2013, 22, 365–404. [Google Scholar] [CrossRef]
- Slay, J.; Miller, M. Lessons learned from the maroochy water breach. In Proceedings of the International Conference on Critical Infrastructure Protection, Hanover, NH, USA, 19–21 March 2007; pp. 73–82. [Google Scholar]
- Paridari, K.; O’Mahony, N.; Mady, A.E.-D.; Chabukswar, R.; Boubekeur, M.; Sandberg, H. A framework for attack- resilient industrial control systems: Attack detection and controller reconfiguration. Proc. IEEE. 2018, 106, 113–128. [Google Scholar] [CrossRef]
- Aldallal, A.; Alisa, F. Effective intrusion detection system to secure data in cloud using machine learning. Symmetry 2021, 13, 2306. [Google Scholar] [CrossRef]
- Qin, J.; Li, M.; Shi, L.; Yu, X. Optimal denial-of-service attack scheduling with energy constraint over packet-dropping networks. IEEE Trans. Autom. Control 2018, 63, 1648–1663. [Google Scholar] [CrossRef]
- Wang, D.; Jia, P.; Lian, J.; Pei, X. An Optimal DoS Attack Strategy With Pause and Restart Rules Under Energy Constraints. IEEE Trans. Control. Netw. Syst. 2022, 10, 1291–1302. [Google Scholar] [CrossRef]
- Ai, Z.; Peng, L.; Cao, M. Optimal attack schedule for two sensors state estimation under jamming attack. IEEE Access 2019, 7, 75741–75748. [Google Scholar] [CrossRef]
- Deng, C.; Jin, X.Z.; Wu, Z.G.; Che, W.W. Data-Driven-Based Cooperative Resilient Learning Method for Nonlinear MASs Under DoS Attacks. IEEE Trans. Neural Netw. Learn. Syst. 2023, 35, 12107–12116. [Google Scholar] [CrossRef]
- Jin, X.; Lu, S.; Qin, J.; Zheng, W.X.; Liu, Q. Adaptive ELM-Based Security Control for a Class of Nonlinear- Interconnected Systems With DoS Attacks. IEEE Trans. Cybern. 2023, 53, 5000–5012. [Google Scholar] [CrossRef]
- Liu, Y.; Ning, P.; Reiter, M.K. False data injection attacks against state estimation in electric power grids. ACM Trans. Inf. Syst. Secur. 2011, 14, 1–33. [Google Scholar] [CrossRef]
- Guo, Z.; Shi, D.; Johansson, K.H.; Shi, L. Optimal linear cyber-attack on remote state estimation. IEEE Trans. Control Netw. Syst. 2016, 4, 4–13. [Google Scholar] [CrossRef]
- Ren, X.X.; Yang, G.H.; Zhang, X.G. Optimal stealthy attack with historical data on cyber–physical systems. Automatica 2023, 151, 110895. [Google Scholar] [CrossRef]
- Yang, G.Y.; Li, X.J. Complete stealthiness false data injection attacks against dynamic state estimation in cyber-physical systems. Inf. Sci. 2022, 586, 408–423. [Google Scholar] [CrossRef]
- Tu, W.; Dong, J.; Zhai, D. Optimal ϵ-stealthy attack in cyber-physical systems. J. Franklin Inst. 2021, 358, 151–171. [Google Scholar] [CrossRef]
- Guo, Z.; Shi, D.; Johansson, K.H.; Shi, L. Worst-case stealthy innovation-based linear attack on remote state estimation. Automatica 2018, 89, 117–124. [Google Scholar] [CrossRef]
- Li, Y.G.; Yang, G.H. Optimal stealthy false data injection attacks in cyber-physical systems. Inf. Sci. 2019, 481, 474–490. [Google Scholar] [CrossRef]
- Li, Y.; Shi, D.; Chen, T. False data injection attacks on networked control systems: A Stackelberg game analysis. IEEE Trans. Autom. Control 2018, 63, 3503–3509. [Google Scholar] [CrossRef]
- Zhou, J.; Shang, J.; Chen, T. Optimal Deception Attacks Against Remote State Estimation: An Information-Based Approach. IEEE Trans. Automat. Control 2023, 68, 3947–3962. [Google Scholar] [CrossRef]
- Guo, H.; Sun, J.; Pang, Z.H. Stealthy false data injection attacks with resource constraints against multi-sensor estimation systems. ISA Trans. 2022, 127, 32–40. [Google Scholar] [CrossRef]
- Li, Y.; Yang, Y.; Zhao, Z.; Zhou, J.; Quevedo, D.E. Deception Attacks on Remote Estimation with Disclosure and Disruption Resources. IEEE Trans. Autom. Control 2023, 68, 4096–4112. [Google Scholar] [CrossRef]
- Li, Y.G.; Yang, G.H. Optimal stealthy switching location attacks against remote estimation in cyber-physical systems. Neurocomputing 2021, 421, 183–194. [Google Scholar] [CrossRef]
- Li, Y.G.; Yang, G.H.; Wang, X. Optimal energy constrained deception attacks in cyber-physical systems with multiple channels: A fusion attack approach. ISA Trans. 2023, 137, 1–12. [Google Scholar] [CrossRef]
- Anderson, B.D.; Moore, J.B. Optimal filtering, 1st ed; Prentice-Hall: New York, NY, USA, 1979; pp. 103–133. [Google Scholar]
- Favennec, J.M. Smart sensors in industry. J. Phys. E: Sci. Instrum. 1987, 20, 1087–1090. [Google Scholar] [CrossRef]
- Zhang, Q.; Liu, K.; Xia, Y.; Ma, A. Optimal stealthy deception attack against cyber-physical systems. IEEE Trans. Cybern. 2020, 50, 3963–3972. [Google Scholar] [CrossRef]
- Ren, X.X.; Yang, G.H. Kullback–Leibler divergence-based optimal stealthy sensor attack against networked linear quadratic Gaussian systems. IEEE Trans. Cybern. 2021, 52, 11539–11548. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Related Works | Channel Type | Objective | Mean | Covariance |
|---|---|---|---|---|
| This Paper | Multi-Channel | Maximize the Cumulative Estimation Error | Time-Varying | Time-Varying |
| Guo et al. [21] | Single-Channel | Maximize the Estimation Error at Each Moment | Zero | Time-Invariant |
| Li et al. [27,28] | Multi-Channel | Maximize the Terminal Estimation Error | Zero | Time-Varying |
| Li et al. [22] | Single-Channel | Maximize the Cumulative Estimation Error | Time-Invariant | Time-Invariant |
| Metric | Proposed Optimal Attack | Attack in [27] | Attack in [21] |
|---|---|---|---|
| Channel Type | Multi-Channel | Multi-Channel | Single-Channel |
| Objective | Maximize the Cumulative Estimation Error | Maximize the Terminal Estimation Error | Maximize the Estimation Error at Each Moment |
| Mean | Time-Varying | Zero | Zero |
| Covariance | Time-Varying | Time-Varying | Time-Invariant |
| Single-channel | Larger Estimation Error | - | Smaller Estimation Error |
| Multi-channel | Larger Estimation Error; Superior Stealthiness | Smaller Estimation Error; Poorer Stealthiness | - |
| Limitations | Static Distributions | Constant Mean | Single-Channel; Constant Mean and Covariance |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, X.; Ren, Z.; Zhou, J.; Huang, J. Optimal Innovation-Based Deception Attacks on Multi-Channel Cyber–Physical Systems. Electronics 2025, 14, 1569. https://doi.org/10.3390/electronics14081569
Yang X, Ren Z, Zhou J, Huang J. Optimal Innovation-Based Deception Attacks on Multi-Channel Cyber–Physical Systems. Electronics. 2025; 14(8):1569. https://doi.org/10.3390/electronics14081569
Chicago/Turabian StyleYang, Xinhe, Zhu Ren, Jingquan Zhou, and Jing Huang. 2025. "Optimal Innovation-Based Deception Attacks on Multi-Channel Cyber–Physical Systems" Electronics 14, no. 8: 1569. https://doi.org/10.3390/electronics14081569
APA StyleYang, X., Ren, Z., Zhou, J., & Huang, J. (2025). Optimal Innovation-Based Deception Attacks on Multi-Channel Cyber–Physical Systems. Electronics, 14(8), 1569. https://doi.org/10.3390/electronics14081569