
An Efficient Gaze Control System for Kiosk-Based Embodied Conversational Agents in Multi-Party Conversations



Abstract
:1. Introduction
2. Related Work
2.1. Gaze Behavior of Social Agents
2.2. Speaker Detection
3. Method
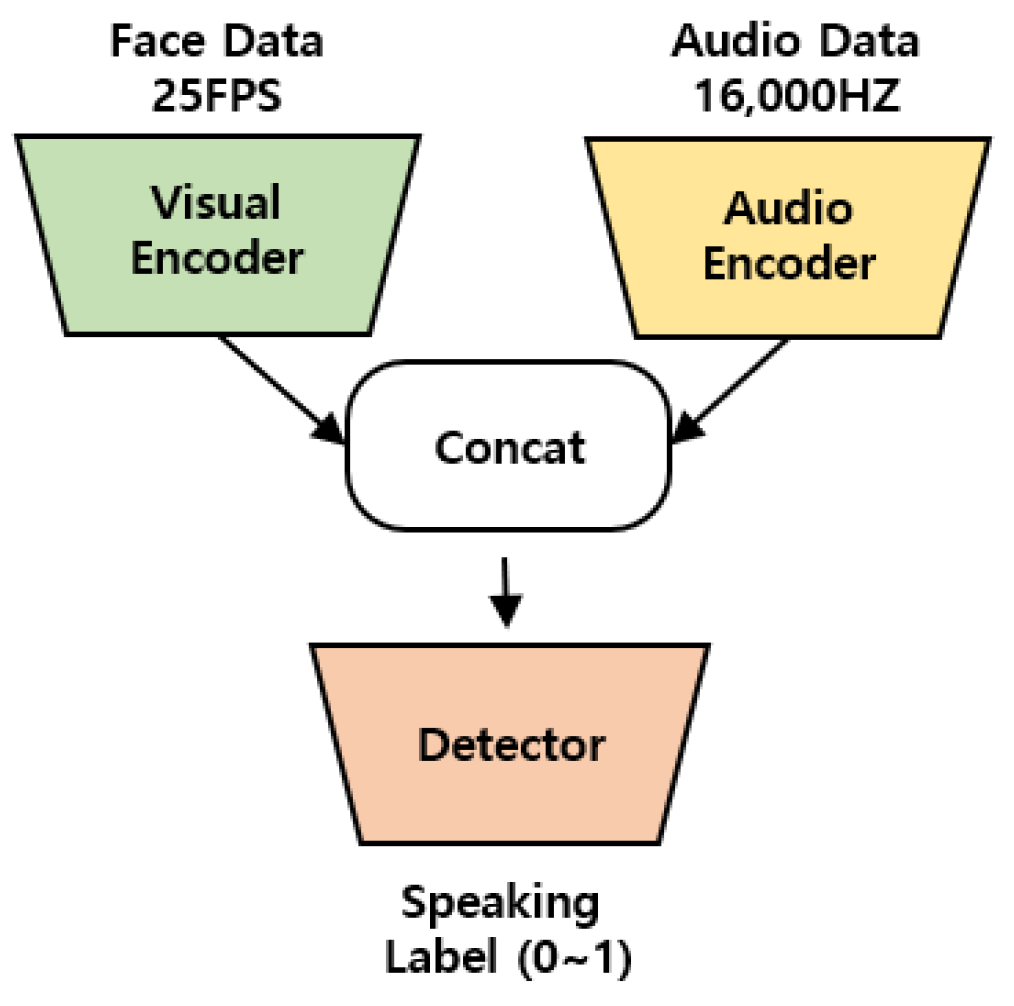
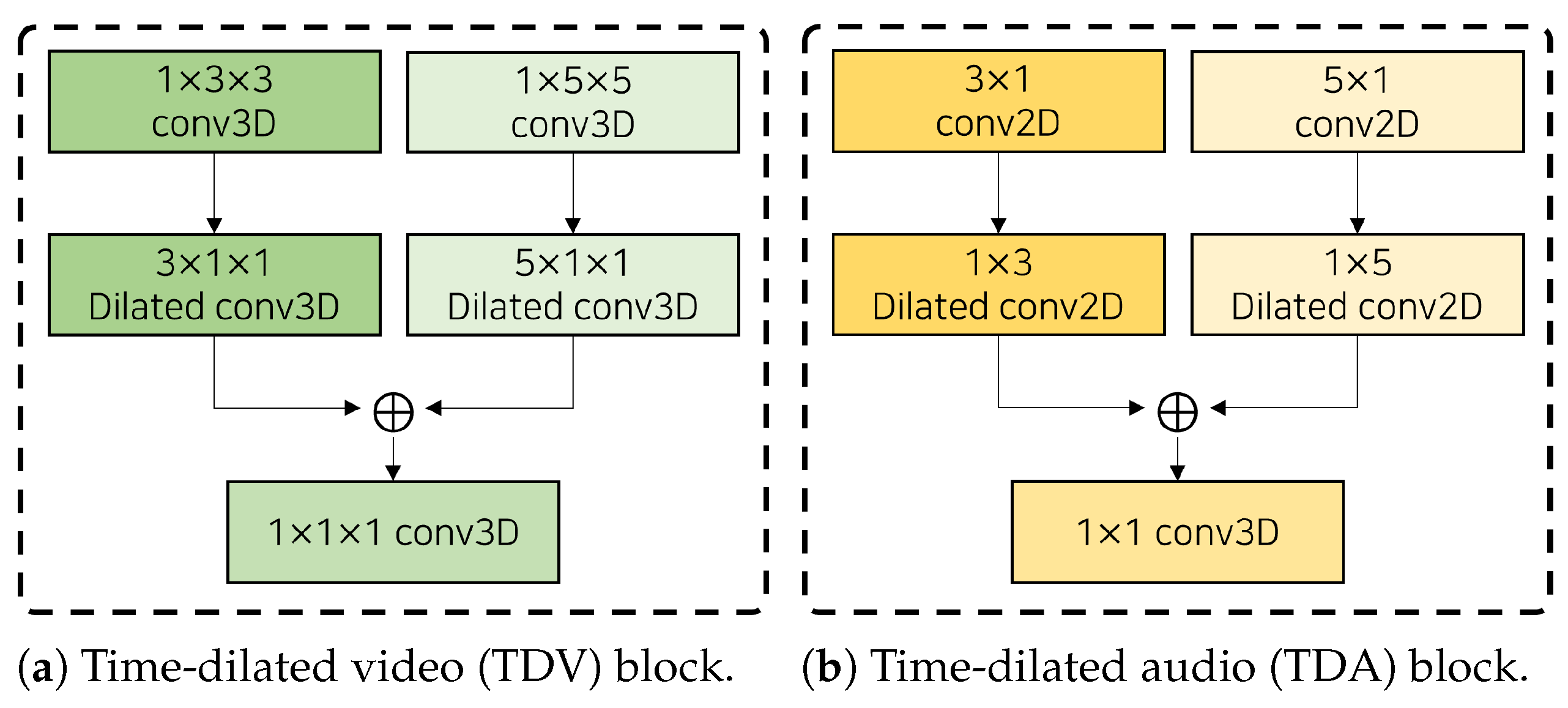
3.1. Real-Time Speaker Detection Model
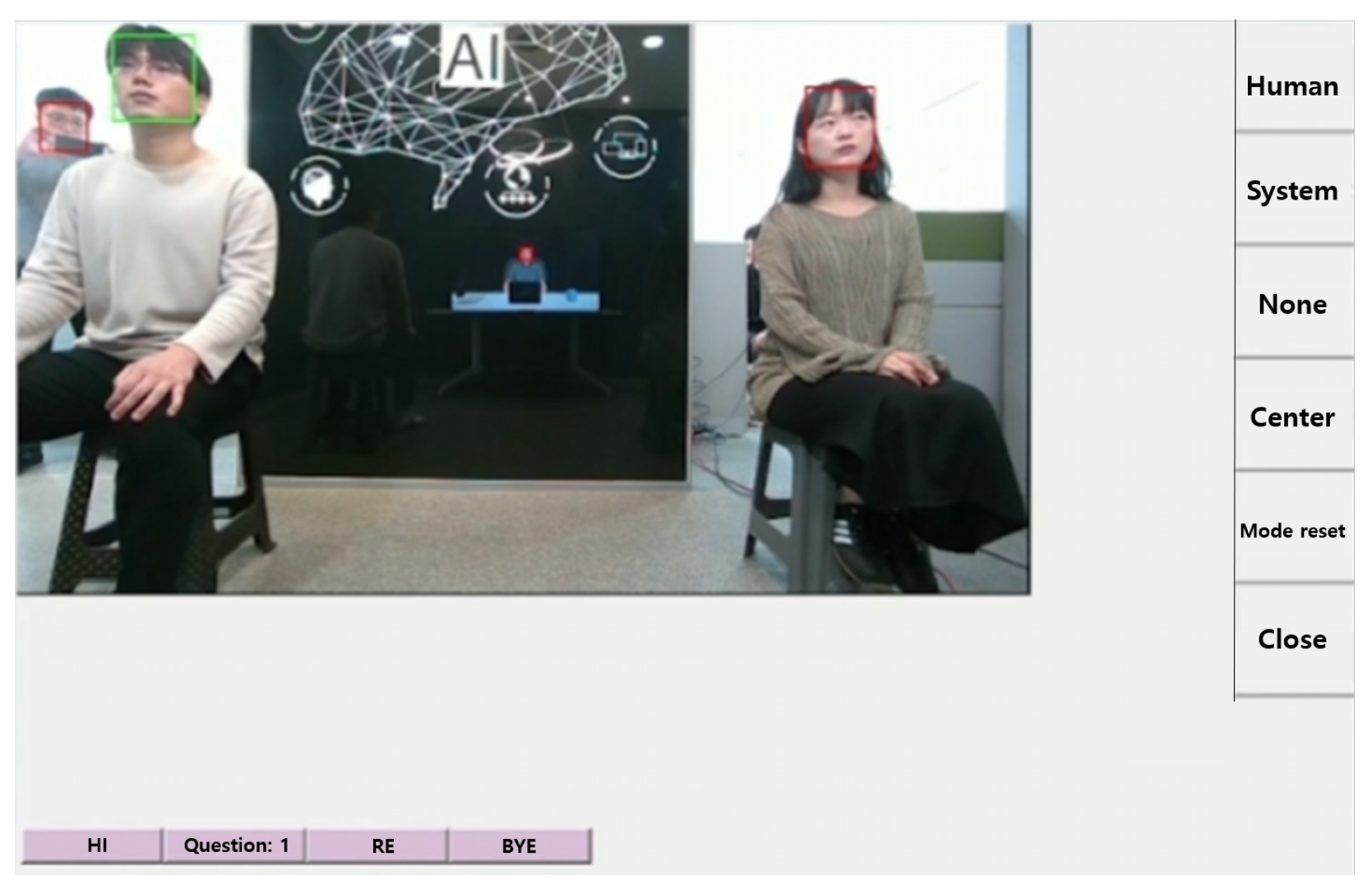
3.2. Gaze Control System for Multi-Party Conversations
4. Experiment 1
4.1. Dataset
4.2. Implementation Details
4.3. Result and Discussion
5. Experiment 2
5.1. Method
- None: The ECA gazed straight ahead without focusing on a specific object, reflecting the typical eye gaze behavior of ECAs used in kiosks.
- Human: A human operator control the ECA’s gaze, making it look at the target of attention during the conversation.
- System: The gaze control system controlled the ECA’s gaze.
5.2. Materials
5.3. Procedure
5.4. Measurement
- Social Presence: We utilized the questionnaire developed by Bailenson et al. [52], which includes five items designed to measure participants’ perceptions of the extent to which they perceive the ECA as a social being.
- Co-presence: We utilized the questionnaire developed by Harms and Bicca [53], which consists of six items designed to measure the participants’ sense of not being alone and secluded, their peripheral and focal awareness of others, and others’ awareness of them.
- Gaze Naturalness: Participants evaluated whether the ECA’s gaze felt natural. This was measured using a single item on a 5-point Likert scale.
5.5. Participants
5.6. Result and Discussion
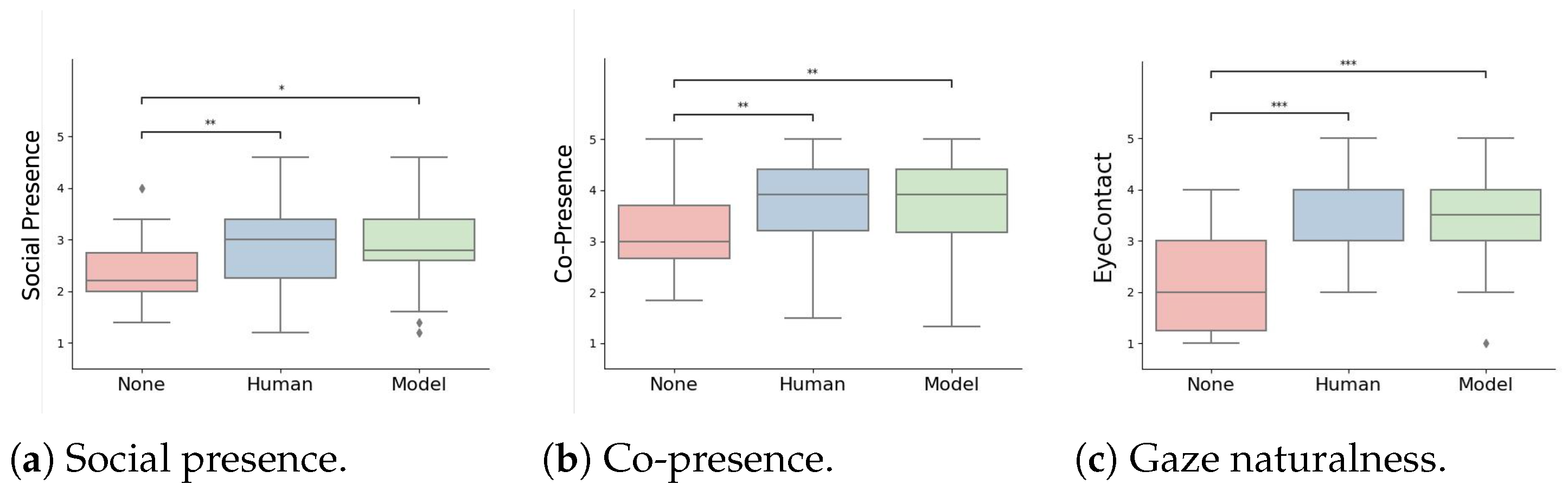
- Social Presence: There were significant differences between the None and Human (p < 0.01), as well as between the None and System (p < 0.05), conditions. There was no significant difference between the Human and System (see Figure 8a) conditions.
- Co-presence: There were significant differences between the None and Human (p < 0.01), as well as between the None and System (p < 0.01), conditions. There was no significant difference between the Human and System conditions (see Figure 8b).
- Gaze Naturalness: There were significant differences between the None and Human (p < 0.001), as well as between the None and System (p < 0.001), conditions. There was no significant difference between the Human and System conditions (see Figure 8c).
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, N.; Chen, J.; Liu, Z.; Zhang, J. Public information system interface design research. In Proceedings of the Human-Computer Interaction—INTERACT 2013, Cape Town, South Africa, 2–6 September 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 247–259. [Google Scholar]
- Buisine, S.; Wang, Y.; Grynszpan, O. Empirical investigation of the temporal relations between speech and facial expressions of emotion. J. Multimodal User Interfaces 2009, 3, 263–270. [Google Scholar] [CrossRef]
- Freigang, F.; Klett, S.; Kopp, S. Pragmatic multimodality: Effects of nonverbal cues of focus and certainty in a virtual human. In Proceedings of the Intelligent Virtual Agents, Stockholm, Sweden, 27–30 August 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 142–155. [Google Scholar]
- He, Y.; Pereira, A.; Kucherenko, T. Evaluating data-driven co-speech gestures of embodied conversational agents through real-time interaction. In Proceedings of the 22nd ACM International Conference on Intelligent Virtual Agents, Faro, Portugal, 6–9 September 2022; pp. 1–8. [Google Scholar]
- Ding, Y.; Zhang, Y.; Xiao, M.; Deng, Z. A multifaceted study on eye contact based speaker identification in three-party conversations. In Proceedings of the 2017 CHI Conference on Human Factors in Computing Systems, Denver, CO, USA, 6–11 May 2017; pp. 3011–3021. [Google Scholar]
- Kendon, A. Some functions of gaze-direction in social interaction. Acta Psychol. 1967, 26, 22–63. [Google Scholar] [CrossRef]
- Moubayed, S.A.; Edlund, J.; Beskow, J. Taming Mona Lisa: Communicating gaze faithfully in 2D and 3D facial projections. ACM Trans. Interact. Intell. Syst. 2012, 1, 1–25. [Google Scholar] [CrossRef]
- Kum, J.; Jung, S.; Lee, M. The Effect of Eye Contact in Multi-Party Conversations with Virtual Humans and Mitigating the Mona Lisa Effect. Electronics 2024, 13, 430. [Google Scholar] [CrossRef]
- Roth, J.; Chaudhuri, S.; Klejch, O.; Marvin, R.; Gallagher, A.; Kaver, L.; Ramaswamy, S.; Stopczynski, A.; Schmid, C.; Xi, Z.; et al. Ava active speaker: An audio-visual dataset for active speaker detection. In Proceedings of the ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 4492–4496. [Google Scholar]
- Tao, R.; Pan, Z.; Das, R.K.; Qian, X.; Shou, M.Z.; Li, H. Is someone speaking? Exploring long-term temporal features for audio-visual active speaker detection. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual, 20–24 October 2021; pp. 3927–3935. [Google Scholar]
- Min, K.; Roy, S.; Tripathi, S.; Guha, T.; Majumdar, S. Learning long-term spatial-temporal graphs for active speaker detection. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 371–387. [Google Scholar]
- Liao, J.; Duan, H.; Feng, K.; Zhao, W.; Yang, Y.; Chen, L. A light weight model for active speaker detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 22932–22941. [Google Scholar]
- Wang, X.; Cheng, F.; Bertasius, G. Loconet: Long-short context network for active speaker detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–18 June 2024; pp. 18462–18472. [Google Scholar]
- Roxo, T.; Costa, J.C.; Inácio, P.R.; Proença, H. WASD: A Wilder Active Speaker Detection Dataset. IEEE Trans. Biom. Behav. Identity Sci. 2024, 7, 61–70. [Google Scholar] [CrossRef]
- Laranjo, L.; Dunn, A.G.; Tong, H.L.; Kocaballi, A.B.; Chen, J.; Bashir, R.; Surian, D.; Gallego, B.; Magrabi, F.; Lau, A.Y.; et al. Conversational agents in healthcare: A systematic review. J. Am. Med. Inform. Assoc. 2018, 25, 1248–1258. [Google Scholar] [CrossRef]
- Argyle, M.; Cook, M.; Cramer, D. Gaze and mutual gaze. Br. J. Psychiatry 1994, 165, 848–850. [Google Scholar] [CrossRef]
- Kendon, A. Conducting Interaction: Patterns of Behavior in Focused Encounters; CUP Archive: Cambridge, UK, 1990; Volume 7. [Google Scholar]
- Mason, M.F.; Tatkow, E.P.; Macrae, C.N. The look of love: Gaze shifts and person perception. Psychol. Sci. 2005, 16, 236–239. [Google Scholar] [CrossRef]
- Shimada, M.; Yoshikawa, Y.; Asada, M.; Saiwaki, N.; Ishiguro, H. Effects of observing eye contact between a robot and another person. Int. J. Soc. Robot. 2011, 3, 143–154. [Google Scholar] [CrossRef]
- Xu, T.; Zhang, H.; Yu, C. See you see me: The role of eye contact in multimodal human-robot interaction. ACM Trans. Interact. Intell. Syst. (TiiS) 2016, 6, 2. [Google Scholar] [CrossRef]
- Kompatsiari, K.; Ciardo, F.; De Tommaso, D.; Wykowska, A. Measuring engagement elicited by eye contact in Human-Robot Interaction. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 6979–6985. [Google Scholar]
- Kiilavuori, H.; Sariola, V.; Peltola, M.J.; Hietanen, J.K. Making eye contact with a robot: Psychophysiological responses to eye contact with a human and with a humanoid robot. Biol. Sychol. 2021, 158, 107989. [Google Scholar] [CrossRef]
- Bee, N.; André, E.; Tober, S. Breaking the ice in human-agent communication: Eye-gaze based initiation of contact with an embodied conversational agent. In Proceedings of the Intelligent Virtual Agents, Amsterdam, The Netherlands, 14–16 September 2009; Springer: Berlin/Heidelberg, Germany, 2009; pp. 229–242. [Google Scholar]
- Kontogiorgos, D.; Skantze, G.; Pereira, A.; Gustafson, J. The effects of embodiment and social eye-gaze in conversational agents. In Proceedings of the Annual Meeting of the Cognitive Science Society, Montreal, QC, Canada, 24–27 July 2019; Volume 41. [Google Scholar]
- Choi, D.S.; Park, J.; Loeser, M.; Seo, K. Improving counseling effectiveness with virtual counselors through nonverbal compassion involving eye contact, facial mimicry, and head-nodding. Sci. Rep. 2024, 14, 506. [Google Scholar] [CrossRef] [PubMed]
- Song, K.T.; Hu, J.S.; Tsai, C.Y.; Chou, C.M.; Cheng, C.C.; Liu, W.H.; Yang, C.H. Speaker attention system for mobile robots using microphone array and face tracking. In Proceedings of the 2006 IEEE International Conference on Robotics and Automation (ICRA), Orlando, FL, USA, 15–19 May 2006; pp. 3624–3629. [Google Scholar]
- Kim, H.D.; Kim, J.; Komatani, K.; Ogata, T.; Okuno, H.G. Target speech detection and separation for humanoid robots in sparse dialogue with noisy home environments. In Proceedings of the 2008 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Nice, France, 22–26 September 2008; pp. 1705–1711. [Google Scholar]
- Sanchez-Riera, J.; Alameda-Pineda, X.; Wienke, J.; Deleforge, A.; Arias, S.; Čech, J.; Wrede, S.; Horaud, R. Online multimodal speaker detection for humanoid robots. In Proceedings of the 2012 12th IEEE-RAS International Conference on Humanoid Robots (Humanoids), Osaka, Japan, 29 November–1 December 2012; pp. 126–133. [Google Scholar]
- Cech, J.; Mittal, R.; Deleforge, A.; Sanchez-Riera, J.; Alameda-Pineda, X.; Horaud, R. Active-speaker detection and localization with microphones and cameras embedded into a robotic head. In Proceedings of the 2013 13th IEEE-RAS International Conference on Humanoid Robots (Humanoids), Atlanta, GA, USA, 15–17 October 2013; pp. 203–210. [Google Scholar]
- Ciuffreda, I.; Battista, G.; Casaccia, S.; Revel, G.M. People detection measurement setup based on a DOA approach implemented on a sensorised social robot. Meas. Sens. 2023, 25, 100649. [Google Scholar] [CrossRef]
- He, W.; Motlicek, P.; Odobez, J.M. Deep neural networks for multiple speaker detection and localization. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 74–79. [Google Scholar]
- Gonzalez-Billandon, J.; Belgiovine, G.; Tata, M.; Sciutti, A.; Sandini, G.; Rea, F. Self-supervised learning framework for speaker localisation with a humanoid robot. In Proceedings of the 2021 IEEE International Conference on Development and Learning (ICDL), Beijing, China, 23–26 August 2021; pp. 1–7. [Google Scholar]
- Humblot-Renaux, G.; Li, C.; Chrysostomou, D. Why talk to people when you can talk to robots? Far-field speaker identification in the wild. In Proceedings of the 2021 30th IEEE International Conference on Robot & Human Interactive Communication (RO-MAN), Vancouver, BC, Canada, 8–12 August 2021; pp. 272–278. [Google Scholar]
- Qian, X.; Wang, Z.; Wang, J.; Guan, G.; Li, H. Audio-visual cross-attention network for robotic speaker tracking. IEEE/ACM Trans. Audio Speech Lang. Process. 2022, 31, 550–562. [Google Scholar] [CrossRef]
- Shi, Z.; Zhang, L.; Wang, D. Audio–Visual Sound Source Localization and Tracking Based on Mobile Robot for The Cocktail Party Problem. Appl. Sci. 2023, 13, 6056. [Google Scholar] [CrossRef]
- Berghi, D.; Jackson, P.J. Leveraging Visual Supervision for Array-Based Active Speaker Detection and Localization. IEEE/ACM Trans. Audio Speech Lang. Process. 2023, 32, 984–995. [Google Scholar] [CrossRef]
- Köpüklü, O.; Taseska, M.; Rigoll, G. How to design a three-stage architecture for audio-visual active speaker detection in the wild. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 1193–1203. [Google Scholar]
- Alcázar, J.L.; Cordes, M.; Zhao, C.; Ghanem, B. End-to-end active speaker detection. In Proceedings of the Computer Vision—ECCV 2022, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 126–143. [Google Scholar]
- Qiu, Z.; Yao, T.; Mei, T. Learning spatio-temporal representation with pseudo-3d residual networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5533–5541. [Google Scholar]
- Tran, D.; Wang, H.; Torresani, L.; Ray, J.; LeCun, Y.; Paluri, M. A closer look at spatiotemporal convolutions for action recognition. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 6450–6459. [Google Scholar]
- Yu, F. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Gritsenko, A.; Salimans, T.; van den Berg, R.; Snoek, J.; Kalchbrenner, N. A spectral energy distance for parallel speech synthesis. In Proceedings of the Advances in Neural Information Processing Systems, Virtual, 6–12 December 2020; Volume 33, pp. 13062–13072. [Google Scholar]
- Van Den Oord, A.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.; Kavukcuoglu, K. Wavenet: A generative model for raw audio. arXiv 2016, arXiv:1609.03499. [Google Scholar]
- Ishii, R.; Otsuka, K.; Kumano, S.; Yamato, J. Using respiration to predict who will speak next and when in multiparty meetings. ACM Trans. Interact. Intell. Syst. (TiiS) 2016, 6, 1–20. [Google Scholar] [CrossRef]
- Datta, G.; Etchart, T.; Yadav, V.; Hedau, V.; Natarajan, P.; Chang, S.F. Asd-transformer: Efficient active speaker detection using self and multimodal transformers. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 4568–4572. [Google Scholar]
- Zhang, Y.; Liang, S.; Yang, S.; Liu, X.; Wu, Z.; Shan, S.; Chen, X. Unicon: Unified context network for robust active speaker detection. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual, 20–24 October 2021; pp. 3964–3972. [Google Scholar]
- Wang, W.; Xing, C.; Wang, D.; Chen, X.; Sun, F. A robust audio-visual speech enhancement model. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 7529–7533. [Google Scholar]
- Sivaraman, A.; Kim, M. Efficient personalized speech enhancement through self-supervised learning. IEEE J. Sel. Top. Signal Process. 2022, 16, 1342–1356. [Google Scholar] [CrossRef]
- Zhao, X.; Zhu, Q.; Hu, Y. An Experimental Comparison of Noise-Robust Text-To-Speech Synthesis Systems Based On Self-Supervised Representation. In Proceedings of the ICASSP 2024—2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 11441–11445. [Google Scholar]
- Kingma, D.P. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Syrdal, D.S.; Dautenhahn, K.; Koay, K.L.; Walters, M.L. The negative attitudes towards robots scale and reactions to robot behaviour in a live human-robot interaction study. In Adaptive and Emergent Behaviour and Complex Systems; The Society for the Study of Artificial Intelligence and the Simulation of Behaviour (AISB): Edinburgh, UK, 2009. [Google Scholar]
- Bailenson, J.N.; Blascovich, J.; Beall, A.C.; Loomis, J.M. Interpersonal distance in immersive virtual environments. Personal. Soc. Psychol. Bull. 2003, 29, 819–833. [Google Scholar] [CrossRef] [PubMed]
- Harms, C.; Biocca, F. Internal consistency and reliability of the networked minds measure of social presence. In Proceedings of the Seventh Annual International Workshop: Presence, Valencia, Spain, 13–15 October 2004; Volume 2004. [Google Scholar]
- Friedman, M. The use of ranks to avoid the assumption of normality implicit in the analysis of variance. J. Am. Stat. Assoc. 1937, 32, 675–701. [Google Scholar] [CrossRef]
- Shiwa, T.; Kanda, T.; Imai, M.; Ishiguro, H.; Hagita, N. How quickly should communication robots respond? In Proceedings of the 3rd ACM/IEEE International Conference on Human Robot Interaction, Amsterdam, The Netherlands, 12–15 March 2008; pp. 153–160. [Google Scholar]
- Crutchfield, R.S. Conformity and character. Am. Psychol. 1955, 10, 191. [Google Scholar] [CrossRef]
- Sanker, C. Comparison of Phonetic Convergence in Multiple Measures; Academia: Melbourne, Australia, 2015. [Google Scholar]
- Street, R.L., Jr. Speech convergence and speech evaluation in fact-finding interviews. Hum. Commun. Res. 1984, 11, 139–169. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | mAP (%) |
|---|---|
| Light ASD (without retraining) | 90.2 |
| Light ASD (with retraining) | 91.0 |
| Ours | 91.6 |
| −10 dB | −5 dB | 0 dB | 5 dB | 10 dB | |
|---|---|---|---|---|---|
| Light ASD (without retraining) | 86.3 | 88.6 | 90.1 | 92.1 | 92.9 |
| Light ASD (with retraining) | 88.1 | 89.8 | 91.3 | 92.3 | 92.8 |
| Ours | 88.7 | 90.4 | 91.7 | 92.6 | 93.1 |
| Method | mAP (%) |
|---|---|
| Light ASD’s visual encoder | 78.25 |
| Our model’s visual Encoder | 81.12 |
| Method | mAP (%) |
|---|---|
| WOD | 91.4 |
| AD | 91.5 |
| VD | 91.3 |
| AD + VD | 91.6 |
| Method | mAP (%) |
|---|---|
| woBiGRU | 91.1 |
| ABiGRU | 91.6 |
| VBiGRU | 90.6 |
| ABiGRU + VBiGRU | 90.6 |
| Method | mAP (%) |
|---|---|
| woConcat | 91.2 |
| Concat | 91.6 |
| Method | Video Frames | Inference Time (ms) |
|---|---|---|
| Light ASD | 1 (0.04 s) | 3.82 |
| 500 (20 s) | 23.56 | |
| 1000 (40 s) | 45.68 | |
| Ours | 1 (0.04 s) | 4.79 |
| 500 (20 s) | 23.22 | |
| 1000 (40 s) | 47.09 |
| Questions | |
|---|---|
| 1. | Which do you prefer, summer or winter? Why do you like it better? |
| 2. | Can you recommend a restaurant and a dish? Why? |
| 3. | What is the last movie you watched? Can you tell me about it? |
| 4. | So, what is your ideal type? I would love to hear about it? |
| 5. | What did you do last weekend? Tell me all about it? |
| p-Value | Cronbach’s | ||
|---|---|---|---|
| Social presence | 17.142 | 0.005 | 0.859 |
| Co-presence | 22.604 | 0.001 | 0.883 |
| Gaze naturalness | 9.896 | <0.001 | - |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jung, S.; Kum, J.; Lee, M. An Efficient Gaze Control System for Kiosk-Based Embodied Conversational Agents in Multi-Party Conversations. Electronics 2025, 14, 1592. https://doi.org/10.3390/electronics14081592
Jung S, Kum J, Lee M. An Efficient Gaze Control System for Kiosk-Based Embodied Conversational Agents in Multi-Party Conversations. Electronics. 2025; 14(8):1592. https://doi.org/10.3390/electronics14081592
Chicago/Turabian StyleJung, Sunghun, Junyeong Kum, and Myungho Lee. 2025. "An Efficient Gaze Control System for Kiosk-Based Embodied Conversational Agents in Multi-Party Conversations" Electronics 14, no. 8: 1592. https://doi.org/10.3390/electronics14081592
APA StyleJung, S., Kum, J., & Lee, M. (2025). An Efficient Gaze Control System for Kiosk-Based Embodied Conversational Agents in Multi-Party Conversations. Electronics, 14(8), 1592. https://doi.org/10.3390/electronics14081592