

F2SOD: A Federated Few-Shot Object Detection

Abstract
1. Introduction
- In order to solve the challenges of data privacy and limited sample sizes faced in object detection, we present the framework for federated few-shot object detection. This framework not only facilitates efficient object detection tasks with a scarce amount of data but also guarantees that the original data stays on local devices.
- In order to enhance the understanding of base data, we integrate the Squeeze-and-Excitation (SE) attention mechanism into the feature re-weighting module for each client. Moreover, we reconstruct the localization loss term in the loss function to boost the learning capability for small objects.
- To improve the adaptability of models to novel data in few-shot scenarios, we propose a data augmentation method based on diffusion models. This method fine-tunes the diffusion model using a twofold-tag prompt and location information embedding. It is devised to generate a wide variety of data, effectively expanding the scale and improving the quality of the novel dataset.
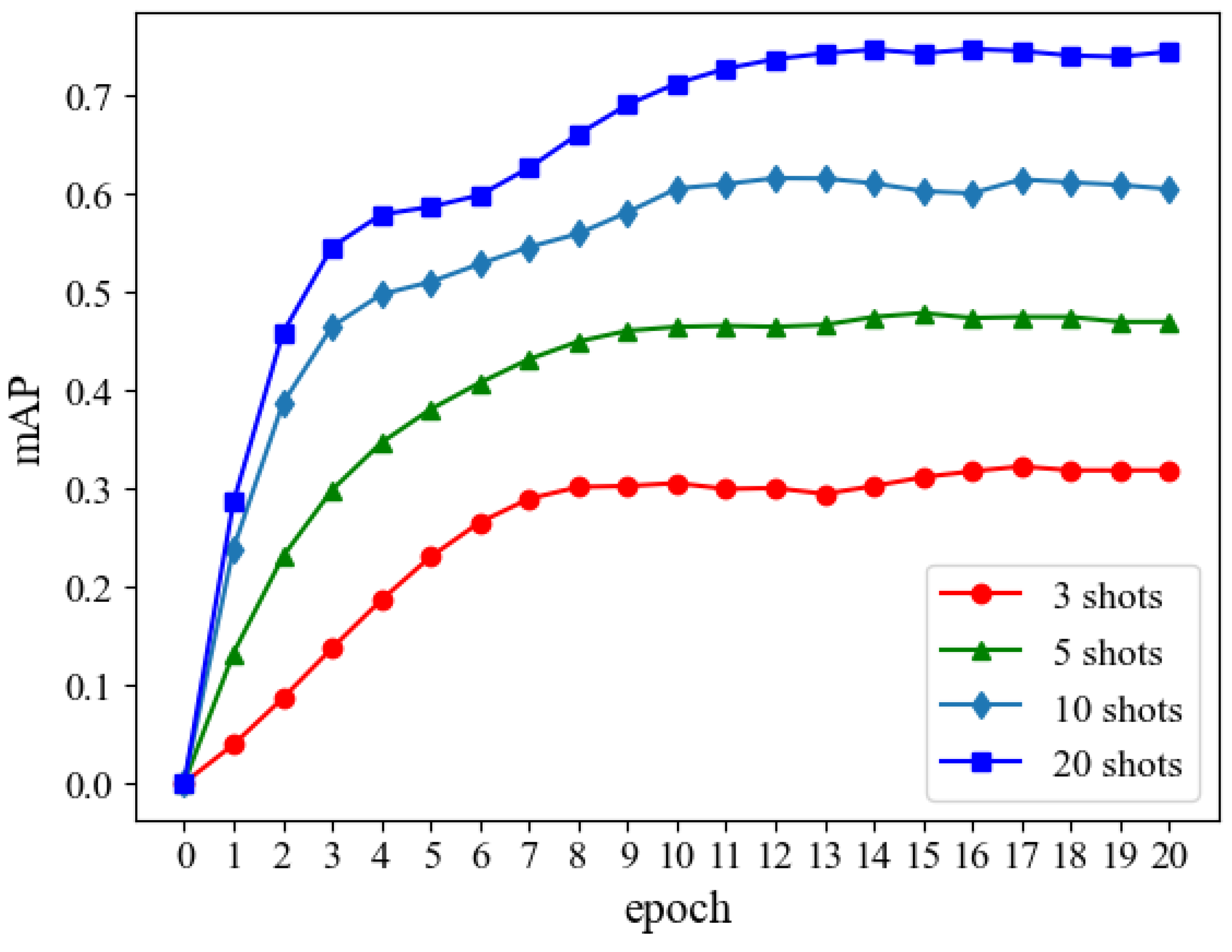
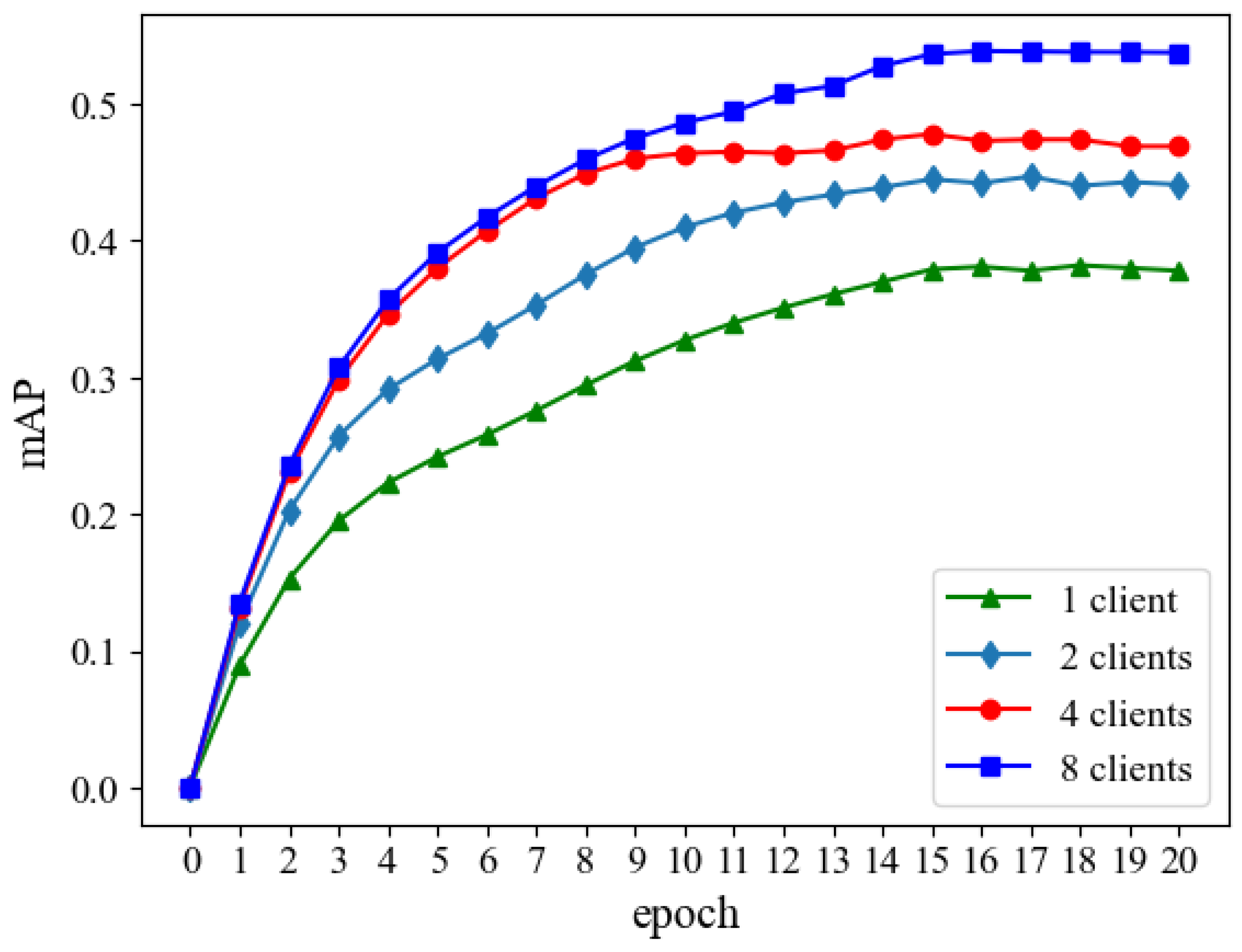
- The experiments conducted on the public datasets demonstrate that F2SOD can realize more efficient few-shot object detection as the number of participants increases or the effective volume of small samples from clients goes up. Moreover, when compared with the State-of-the-Art approaches, F2SOD outperforms them in terms of both accuracy and efficiency.
2. Related Works
2.1. Object Detection
2.2. Few-Shot Object Detection
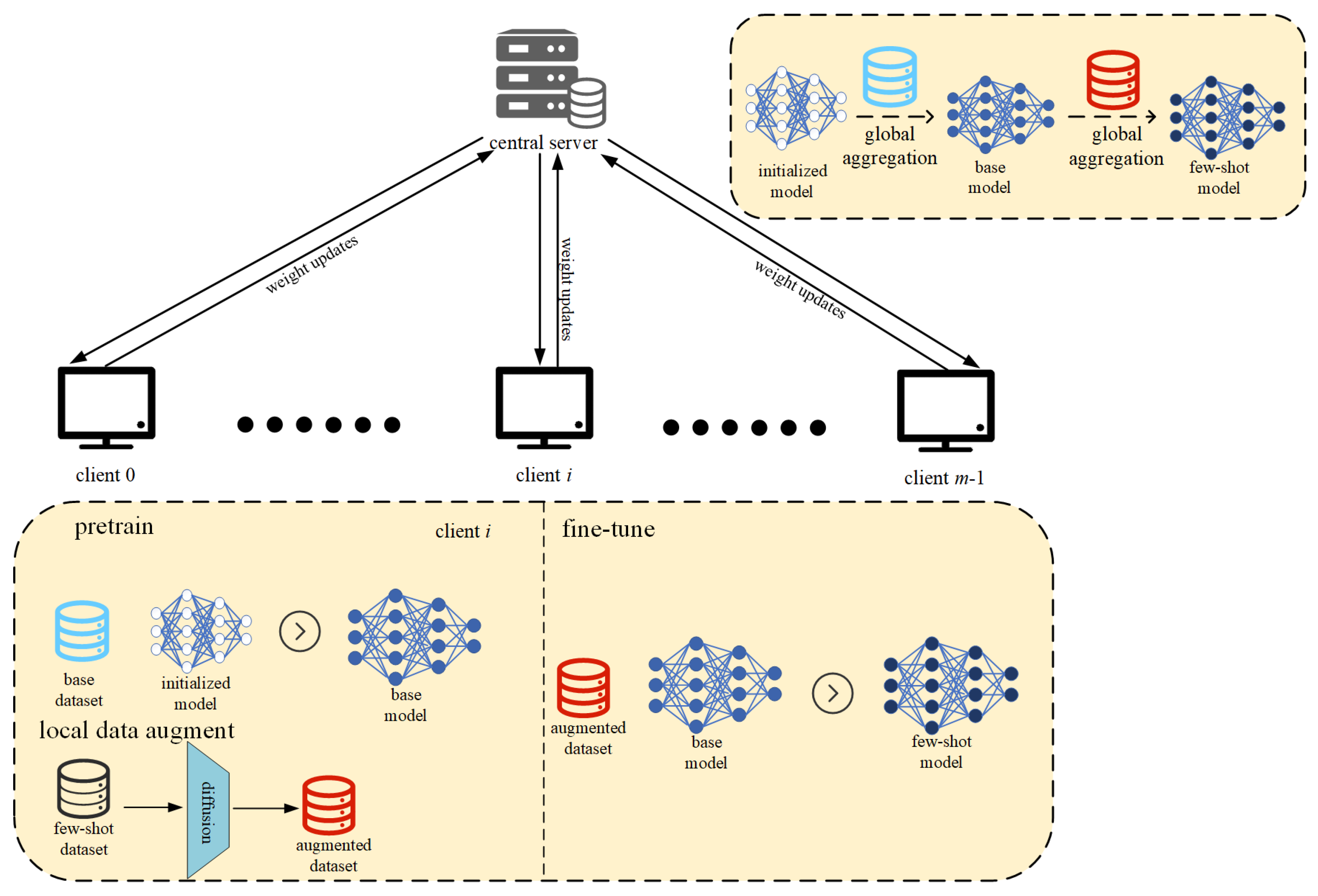
3. F2SOD: A Federated Few-Shot Object Detection
3.1. Problem Formulation
3.2. F2SOD Algorithm
- Pre-training. This is the training stage of the base model for object detection. Clients collaboratively train the base model by their base sets, and get a global base model .
- Data Augment. Before performing fine-tuning, each client augments its few-shot novel set based on the diffusion model. As a result, the augmented datasets are obtained in this stage.
- Fine-tuning. Clients feed their locally augmented datasets into the base model for cooperative fine-tuning, resulting in the final fine-tuned model .
- Initialization. The Server initializes the parameters of base model and broadcast them to clients.
- Local training. Each client i trains the parameters of base model based on his local base dateset .
- Upload. Clients upload their parameters of local base models .
- Global aggregation. The server performs a global aggregation as utilized by [47] through the received local base models, i.e.,and then broadcast the aggregated model to clients. Meanwhile, ur framework is also compatible with other aggregation algorithms, such as Krum [48], Trimmed Mean [49], RFA [50] and BRFA [51].
| Algorithm 1 The pre-training stage of F2SOD. |
Require: the number of clients m, the number of pre-train communication rounds , the learning rate Ensure: Aggregated base model weight 1: Server executes: 2: Initialize 3: for
do 4: for in parallel do 5: send the global base model to i 6: ←LocalPre-Train(i,) 7: end for 8: 9: end for 10: return
LocalPre-Train(i,): 11: Initialize base detection network based on 12: for each training episode do 13: Local model pre-training and minimize loss l from Equation (4). 14: end for 15: return
|
3.3. Data Augment
- Data pre-processing. The images from novel dataset are cropped so that the cropped image contains one object per image. Subsequently, for each image, a prompt and a location information embedding are constructed according to its label.
- Diffusion fine-tuning. Each input image contains only one object and its prompt with “a [broad-category], [background]”. Use cropped images with their prompts and masks to fine-tune stable diffusion guided by the proposed loss function until the specified number of epoch.
- Sample generation. Use fine-tuned stable diffusion to generate new samples.
- Merge and further augment. The real samples and the generated samples are merged and then conventional data augmentation techniques, including flipping, scaling, and color adjustment are applied to make further data augment.
| Algorithm 2 The process of data augment. |
Require: Diffusion model , few-shot samples from novel classes, text-to-image prompt template T, generation samples quantity , and standard augmentation functions A. Ensure: Augmented dataset . Fine-Tune Diffusion Model: for each novel class c in do Extract samples for class c Generate prompts and masks Adjust on with Fusion Loss end for Generate New Samples: Initialize for each sample do Create prompt for j = 1 to do Generate new image to end for end for Combine and Augment: Merge datasets: Apply augmentations: Return:
|
3.4. Fine-Tuning
| Algorithm 3 F2SOD fine-tune process |
Require: number of clients m, number of fine-tuning communication rounds , learning rate global base model Ensure: Aggregated few-shot model weight 1: Server executes: 2: Initialize 3: for
do 4: for in parallel do 5: send the global base model to i 6: ←LocalFine-tuning(i,) 7: end for 8: 9: end for 10: return
LocalFine-tuning(i,): 11: Initialize few-shot detection network based on 12: for each training episode do 13: Local model fine-tuning and minimize loss l from Equation (4). 14: end for 15: return
|
4. Experiments
4.1. Experimental Setup
- Meta-YOLO (meta learning) designs a few-shot detection model that learns generalized meta features and automatically reweights the features for novel class.
- TFA is a two-stage training scheme, which trains a Faster R-CNN with the addition of a instance-level feature normalization.
- FSCE leverages object proposals with different IoU scores for contrastive training, resulting in more robust feature representations.
- FSODM builds on the YOLOv3 framework for remote sensing object detection with minimal annotated samples.
- Digeo uses an offline ETF classifier for well-separated class centers and adaptive margins to tighten feature clusters, improving novel class generalization without compromising base class performance.
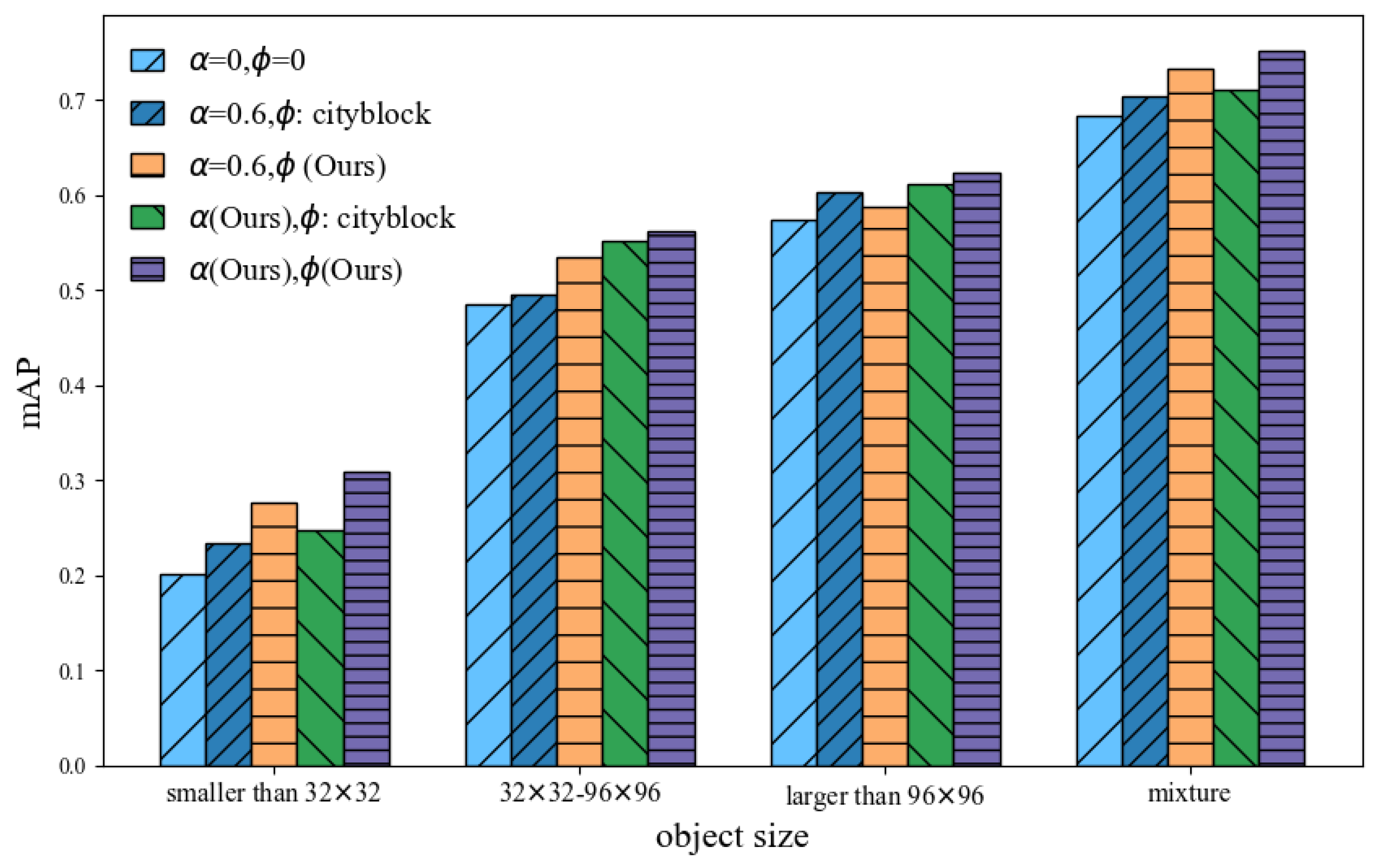
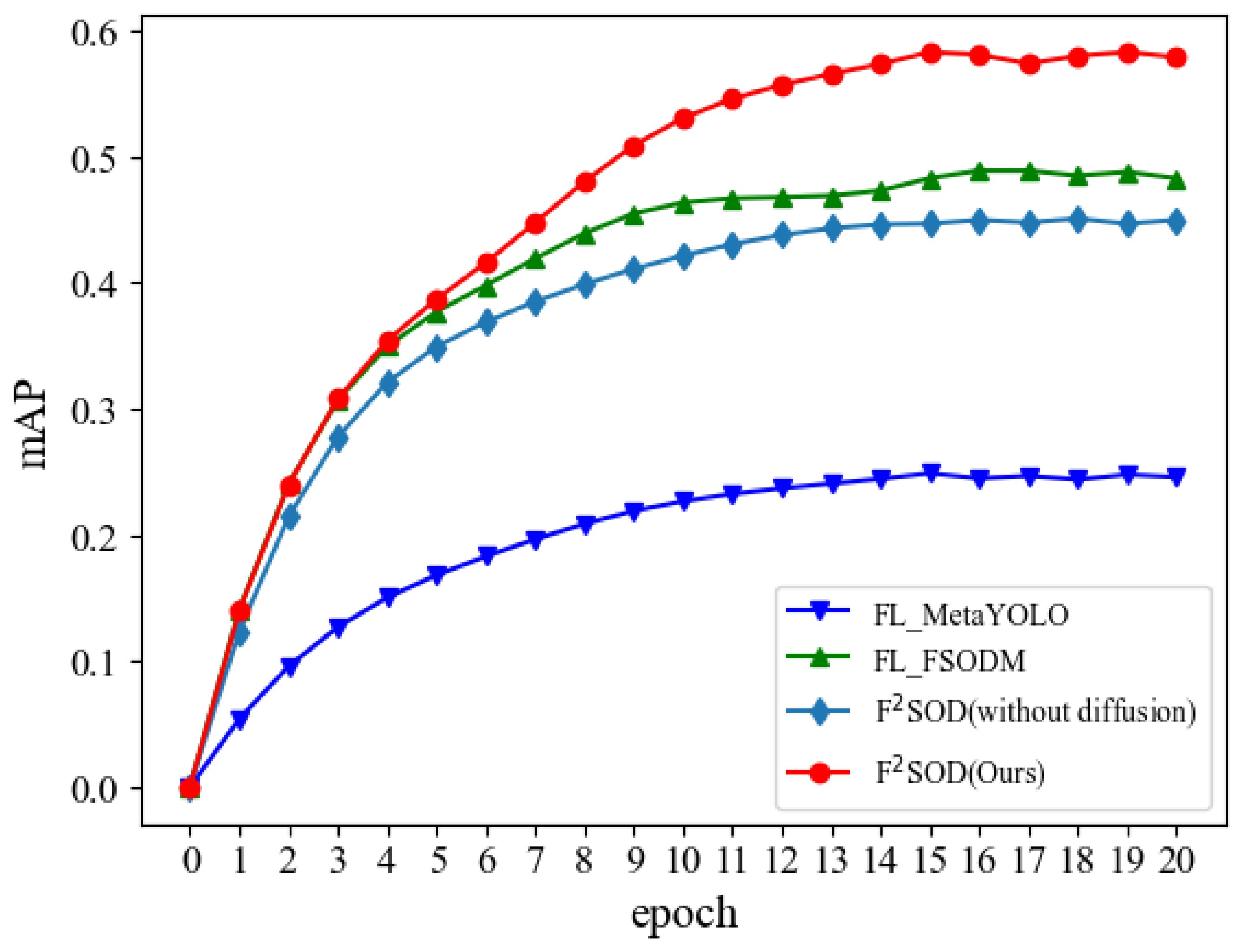
4.2. Our F2SOD Performances
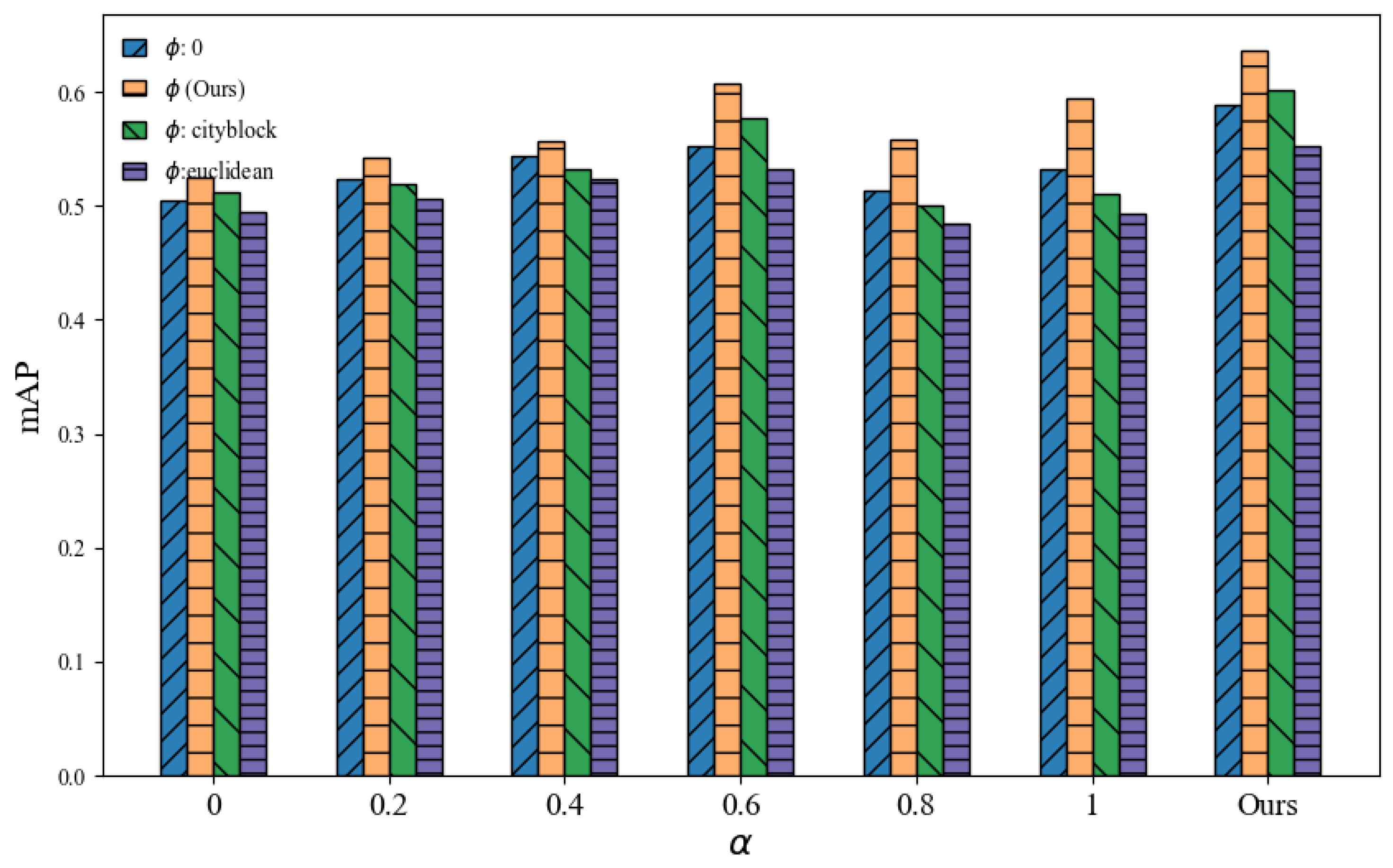
4.3. The Comparison with Baselines
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Cazzato, D.; Cimarelli, C.; Sanchez-Lopez, J.L.; Voos, H.; Leo, M. A survey of computer vision methods for 2d object detection from unmanned aerial vehicles. J. Imaging 2020, 6, 78. [Google Scholar] [CrossRef] [PubMed]
- Xin, Z.; Chen, S.; Wu, T.; Shao, Y.; Ding, W.; You, X. Few-shot object detection: Research advances and challenges. Inf. Fusion 2024, 107, 102307. [Google Scholar] [CrossRef]
- Song, Z.; Liu, L.; Jia, F.; Luo, Y.; Jia, C.; Zhang, G.; Yang, L.; Wang, L. Robustness-aware 3d object detection in autonomous driving: A review and outlook. IEEE Trans. Intell. Transp. Syst. 2024, 25, 15407–15436. [Google Scholar] [CrossRef]
- Liang, M.; Su, J.C.; Schulter, S.; Garg, S.; Zhao, S.; Wu, Y.; Chandraker, M. Aide: An automatic data engine for object detection in autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 14695–14706. [Google Scholar]
- Van Eden, B.; Rosman, B. An overview of robot vision. In Proceedings of the 2019 Southern African Universities Power Engineering Conference/Robotics and Mechatronics/Pattern Recognition Association of South Africa (SAUPEC/RobMech/PRASA), Bloemfontein, South Africa, 28–30 January 2019; pp. 98–104. [Google Scholar]
- Himeur, Y.; Rimal, B.; Tiwary, A.; Amira, A. Using artificial intelligence and data fusion for environmental monitoring: A review and future perspectives. Inf. Fusion 2022, 86, 44–75. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Yan, X.; Chen, Z.; Xu, A.; Wang, X.; Liang, X.; Lin, L. Meta r-cnn: Towards general solver for instance-level low-shot learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9577–9586. [Google Scholar]
- Kim, G.; Jung, H.G.; Lee, S.W. Few-shot object detection via knowledge transfer. In Proceedings of the 2020 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Toronto, ON, Canada, 11–14 October 2020; pp. 3564–3569. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, Nevada, USA, 3–6 December 2012; Volume 25. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Volume 28. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Kang, B.; Liu, Z.; Wang, X.; Yu, F.; Feng, J.; Darrell, T. Few-shot object detection via feature reweighting. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8420–8429. [Google Scholar]
- Wang, X.; Huang, T.E.; Darrell, T.; Gonzalez, J.E.; Yu, F. Frustratingly simple few-shot object detection. arXiv 2020, arXiv:2003.06957. [Google Scholar]
- Li, X.; Deng, J.; Fang, Y. Few-shot object detection on remote sensing images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–14. [Google Scholar] [CrossRef]
- Wang, Y.X.; Ramanan, D.; Hebert, M. Meta-learning to detect rare objects. In Proceedings of the the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9925–9934. [Google Scholar]
- Lee, H.; Lee, M.; Kwak, N. Few-shot object detection by attending to per-sample-prototype. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 4–8 January 2022; pp. 2445–2454. [Google Scholar]
- Han, G.; Huang, S.; Ma, J.; He, Y.; Chang, S.F. Meta faster r-cnn: Towards accurate few-shot object detection with attentive feature alignment. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2022; Volume 36, pp. 780–789. [Google Scholar]
- Zhang, L.; Zhou, S.; Guan, J.; Zhang, J. Accurate few-shot object detection with support-query mutual guidance and hybrid loss. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 14424–14432. [Google Scholar]
- Li, S.; Song, W.; Li, S.; Hao, A.; Qin, H. Meta-RetinaNet for few-shot object detection. In Proceedings of the British Machine Vision Virtual Conference, BMVC, Virtual, 7–10 September 2020. [Google Scholar]
- Karlinsky, L.; Shtok, J.; Harary, S.; Schwartz, E.; Aides, A.; Feris, R.; Giryes, R.; Bronstein, A.M. Repmet: Representative-based metric learning for classification and few-shot object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5197–5206. [Google Scholar]
- Lu, Y.; Chen, X.; Wu, Z.; Yu, J. Decoupled metric network for single-stage few-shot object detection. IEEE Trans. Cybern. 2022, 53, 514–525. [Google Scholar] [CrossRef]
- Li, W.z.; Zhou, J.w.; Li, X.; Cao, Y.; Jin, G. Few-shot object detection on aerial imagery via deep metric learning and knowledge inheritance. Int. J. Appl. Earth Obs. Geoinf. 2023, 122, 103397. [Google Scholar] [CrossRef]
- Leng, J.; Chen, T.; Gao, X.; Mo, M.; Yu, Y.; Zhang, Y. Sampling-invariant fully metric learning for few-shot object detection. Neurocomputing 2022, 511, 54–66. [Google Scholar] [CrossRef]
- Chen, Q.; Ke, X. Few-shot object detection based on generalized features. In Proceedings of the 2023 2nd International Conference on Artificial Intelligence and Intelligent Information Processing (AIIIP), Hangzhou, China, 27–29 October 2023; pp. 80–84. [Google Scholar] [CrossRef]
- Chen, H.; Wang, Y.; Wang, G.; Qiao, Y. Lstd: A low-shot transfer detector for object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Li, B.; Yang, B.; Liu, C.; Liu, F.; Ji, R.; Ye, Q. Beyond max-margin: Class margin equilibrium for few-shot object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 7363–7372. [Google Scholar]
- Li, J.; Zhang, Y.; Qiang, W.; Si, L.; Jiao, C.; Hu, X.; Zheng, C.; Sun, F. Disentangle and remerge: Interventional knowledge distillation for few-shot object detection from a conditional causal perspective. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 1323–1333. [Google Scholar]
- Ma, J.; Niu, Y.; Xu, J.; Huang, S.; Han, G.; Chang, S.F. Digeo: Discriminative geometry-aware learning for generalized few-shot object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 3208–3218. [Google Scholar]
- Zhu, S.; Zhang, K. Few-shot object detection via data augmentation and distribution calibration. Mach. Vis. Appl. 2024, 35, 11. [Google Scholar] [CrossRef]
- Wang, M.; Wang, Y.; Liu, H. Explicit knowledge transfer of graph-based correlation distillation and diversity data hallucination for few-shot object detection. Image Vis. Comput. 2024, 143, 104958. [Google Scholar] [CrossRef]
- Sun, B.; Li, B.; Cai, S.; Yuan, Y.; Zhang, C. Fsce: Few-shot object detection via contrastive proposal encoding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 7352–7362. [Google Scholar]
- Wu, J.; Liu, S.; Huang, D.; Wang, Y. Multi-scale positive sample refinement for few-shot object detection. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XVI 16; Springer: Berlin/Heidelberg, Germany, 2020; pp. 456–472. [Google Scholar]
- Wu, C.; Wang, B.; Liu, S.; Liu, X.; Wu, P. TD-sampler: Learning a training difficulty based sampling strategy for few-shot object detection. In Proceedings of the 2022 7th International Conference on Cloud Computing and Big Data Analytics (ICCCBDA), Chengdu, China, 22–24 April 2022; pp. 275–279. [Google Scholar]
- Yan, B.; Lang, C.; Cheng, G.; Han, J. Understanding negative proposals in generic few-shot object detection. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 5818–5829. [Google Scholar] [CrossRef]
- Wang, Y.; Zou, X.; Yan, L.; Zhong, S.; Zhou, J. Snida: Unlocking few-shot object detection with non-linear semantic decoupling augmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 12544–12553. [Google Scholar]
- Huang, Y.; Liu, W.; Lin, Y.; Kang, J.; Zhu, F.; Wang, F.Y. FLCSDet: Federated learning-driven cross-spatial vessel detection for maritime surveillance with privacy preservation. IEEE Trans. Intell. Transp. Syst. 2025, 26, 1177–1192. [Google Scholar] [CrossRef]
- Chi, F.; Wang, Y.; Nasiopoulos, P.; Leung, V.C. Parameter-efficient federated cooperative learning for 3D object detection in autonomous driving. IEEE Internet Things J. 2025; early access. [Google Scholar] [CrossRef]
- Behera, S.; Adhikari, M.; Menon, V.G.; Khan, M.A. Large model-assisted federated learning for object detection of autonomous vehicles in edge. IEEE Trans. Veh. Technol. 2025, 74, 1839–1848. [Google Scholar] [CrossRef]
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Zheng, Z.; Wang, P.; Ren, D.; Liu, W.; Ye, R.; Hu, Q.; Zuo, W. Enhancing geometric factors in model learning and inference for object detection and instance segmentation. IEEE Trans. Cybern. 2022, 52, 8574–8586. [Google Scholar] [CrossRef]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the Artificial Intelligence and Statistics, PMLR, Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Blanchard, P.; El Mhamdi, E.M.; Guerraoui, R.; Stainer, J. Machine learning with adversaries: Byzantine tolerant gradient descent. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Red Hook, NY, USA, 4–9 December 2017; NIPS’17. pp. 118–128. [Google Scholar]
- Yin, D.; Chen, Y.; Kannan, R.; Bartlett, P. Byzantine-Robust Distributed Learning: Towards Optimal Statistical Rates. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; Dy, J., Krause, A., Eds.; PMLR: Cambridge, MA, USA, 2018; Volume 80, pp. 5650–5659. [Google Scholar]
- Pillutla, K.; Kakade, S.M.; Harchaoui, Z. Robust Aggregation for Federated Learning. IEEE Trans. Signal Process. 2022, 70, 1142–1154. [Google Scholar] [CrossRef]
- Li, S.; Ngai, E.; Voigt, T. Byzantine-Robust Aggregation in Federated Learning Empowered Industrial IoT. IEEE Trans. Ind. Inform. 2023, 19, 1165–1175. [Google Scholar] [CrossRef]
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. Adv. Neural Inf. Process. Syst. 2020, 33, 6840–6851. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 10684–10695. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the Computer Vision–ECCV 2014, Zurich, Switzerland, 6–12 September 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Bosquet, B.; Cores, D.; Seidenari, L.; Brea, V.M.; Mucientes, M.; Bimbo, A.D. A full data augmentation pipeline for small object detection based on generative adversarial networks. Pattern Recognit. 2023, 133, 108998. [Google Scholar] [CrossRef]
- Yu, X.; Li, G.; Lou, W.; Liu, S.; Wan, X.; Chen, Y.; Li, H. Diffusion-based data augmentation for nuclei image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Springer, Vancouver, BC, Canada, 8–12 October 2023; pp. 592–602. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, P.; Zhang, T.; Qing, C.; Zhang, S. F2SOD: A Federated Few-Shot Object Detection. Electronics 2025, 14, 1651. https://doi.org/10.3390/electronics14081651
Li P, Zhang T, Qing C, Zhang S. F2SOD: A Federated Few-Shot Object Detection. Electronics. 2025; 14(8):1651. https://doi.org/10.3390/electronics14081651
Chicago/Turabian StyleLi, Peng, Tianyu Zhang, Chen Qing, and Shuzhuang Zhang. 2025. "F2SOD: A Federated Few-Shot Object Detection" Electronics 14, no. 8: 1651. https://doi.org/10.3390/electronics14081651
APA StyleLi, P., Zhang, T., Qing, C., & Zhang, S. (2025). F2SOD: A Federated Few-Shot Object Detection. Electronics, 14(8), 1651. https://doi.org/10.3390/electronics14081651