
SACG-YOLO: A Method of Transmission Line Insulator Defect Detection by Fusing Scene-Aware Information and Detailed-Content-Guided Information

Abstract
1. Introduction
- In this paper, a scene perception enhancement module called SAE is introduced in the backbone network to replace the original SPPF module, which can enhance the feature representation capability of the backbone network by adjusting sensory fields of different sizes to capture global dependency information and aggregate features of different scales.
- We introduce a detail enhancement module in the Neck section to improve the feature extraction capability of the Neck network for small-scale targets through the Detailed-Content-Guided Attention (DCGA) mechanism.
- To address the sample imbalance problem in the dataset, we introduce a sample weighting function that assigns higher weights to difficult samples, thereby helping the model learn harder-to-recognize features.
2. Proposed Methods
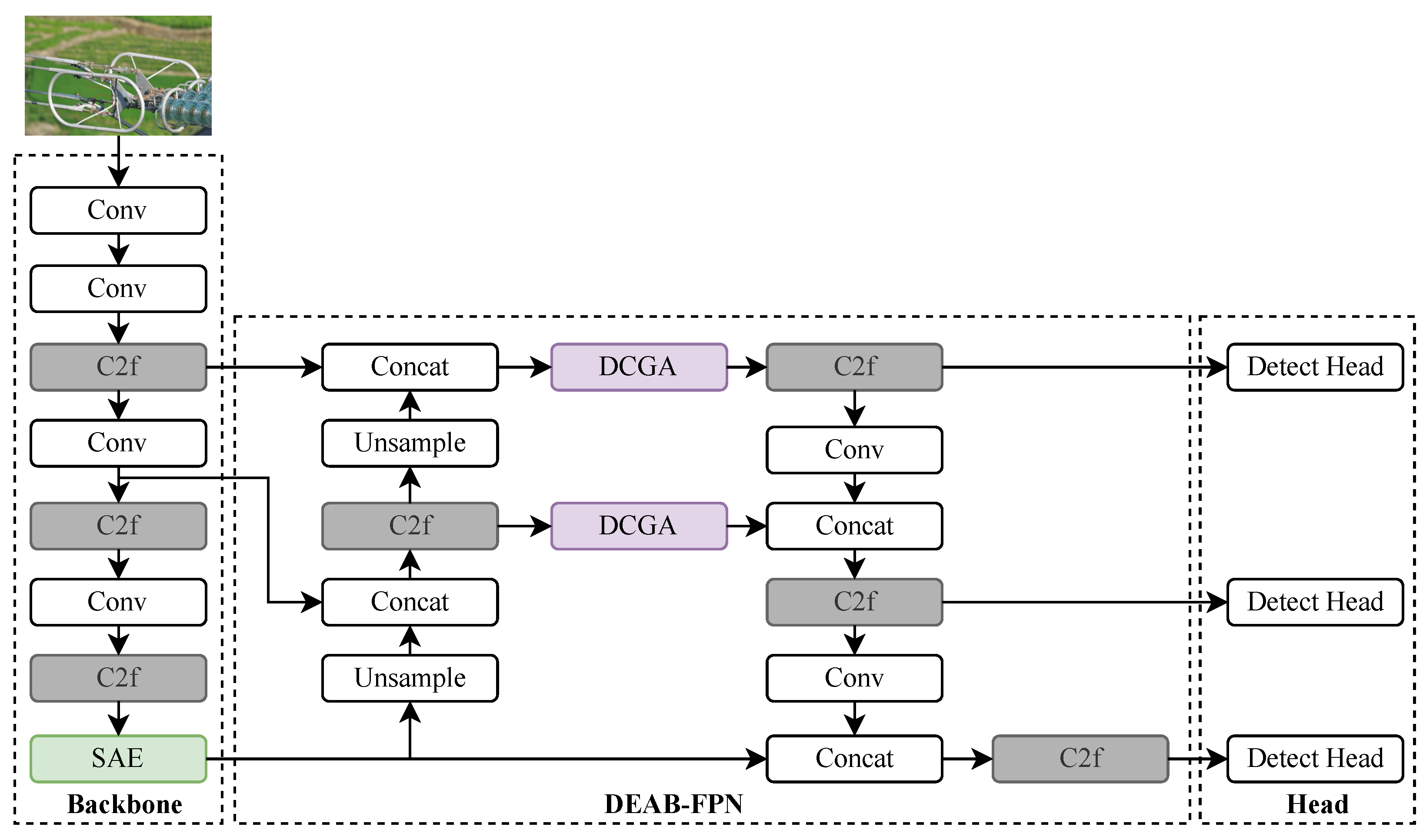
2.1. The Overall Structure of the Proposed Network
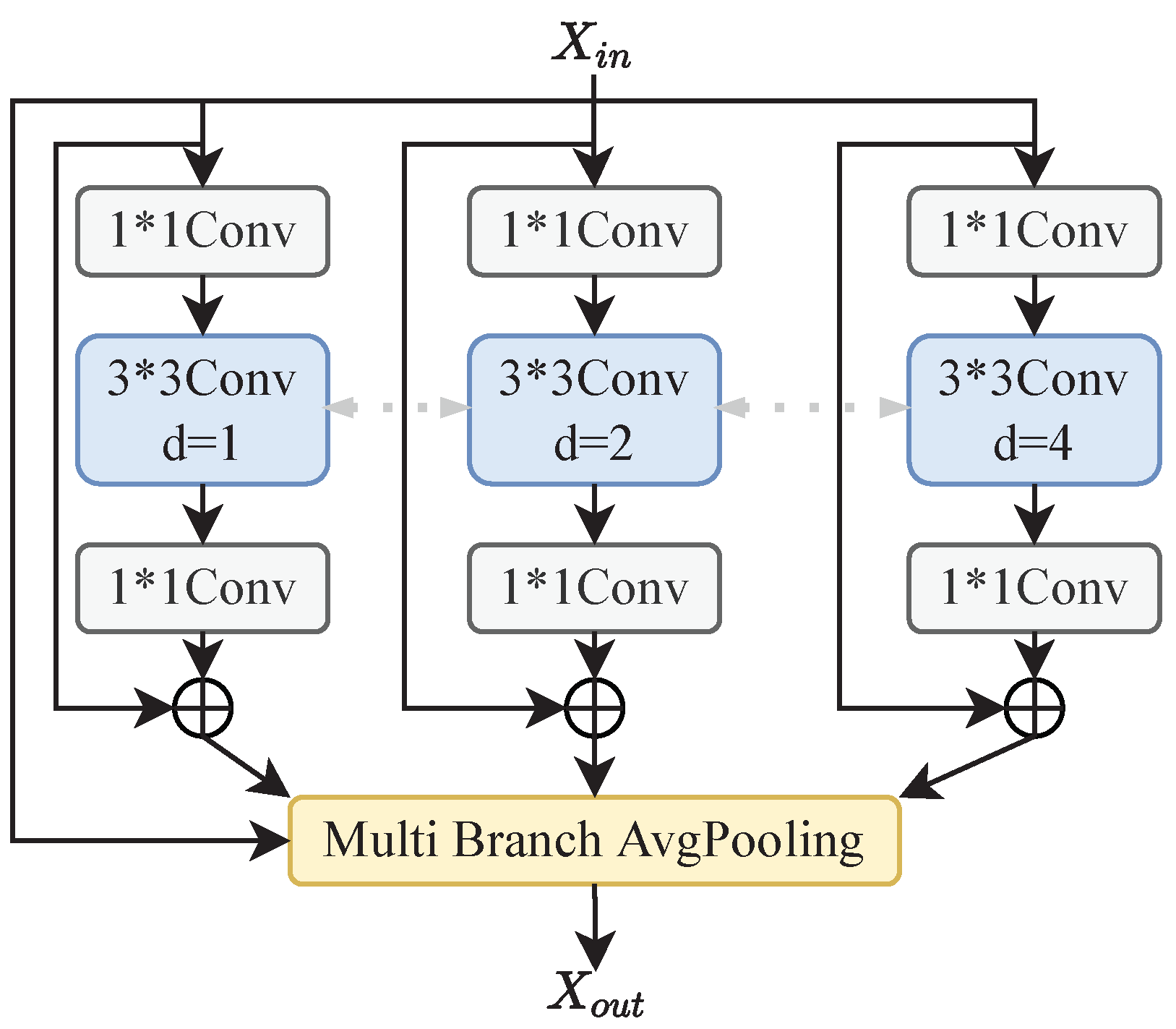
2.2. Scene-Aware Enhancement Module
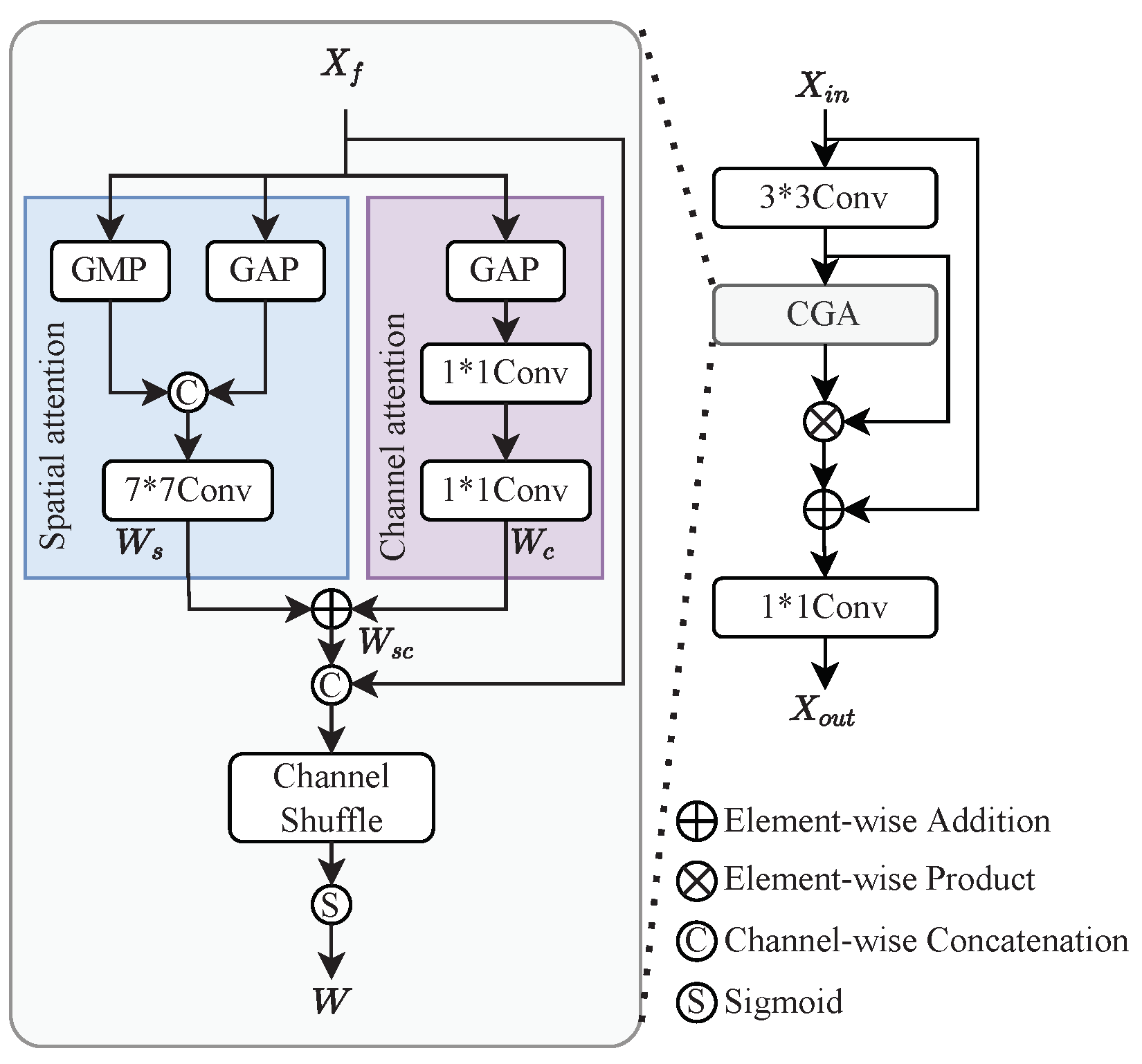
2.3. Detailed-Content-Guided Attention
2.4. Normalized Wasserstein Distance Metric Function
2.5. Sample Weighting Function
3. Details of the Experiment
3.1. Dataset Details
3.2. Evaluation Metrics
3.3. Implementation Details
4. Experiment
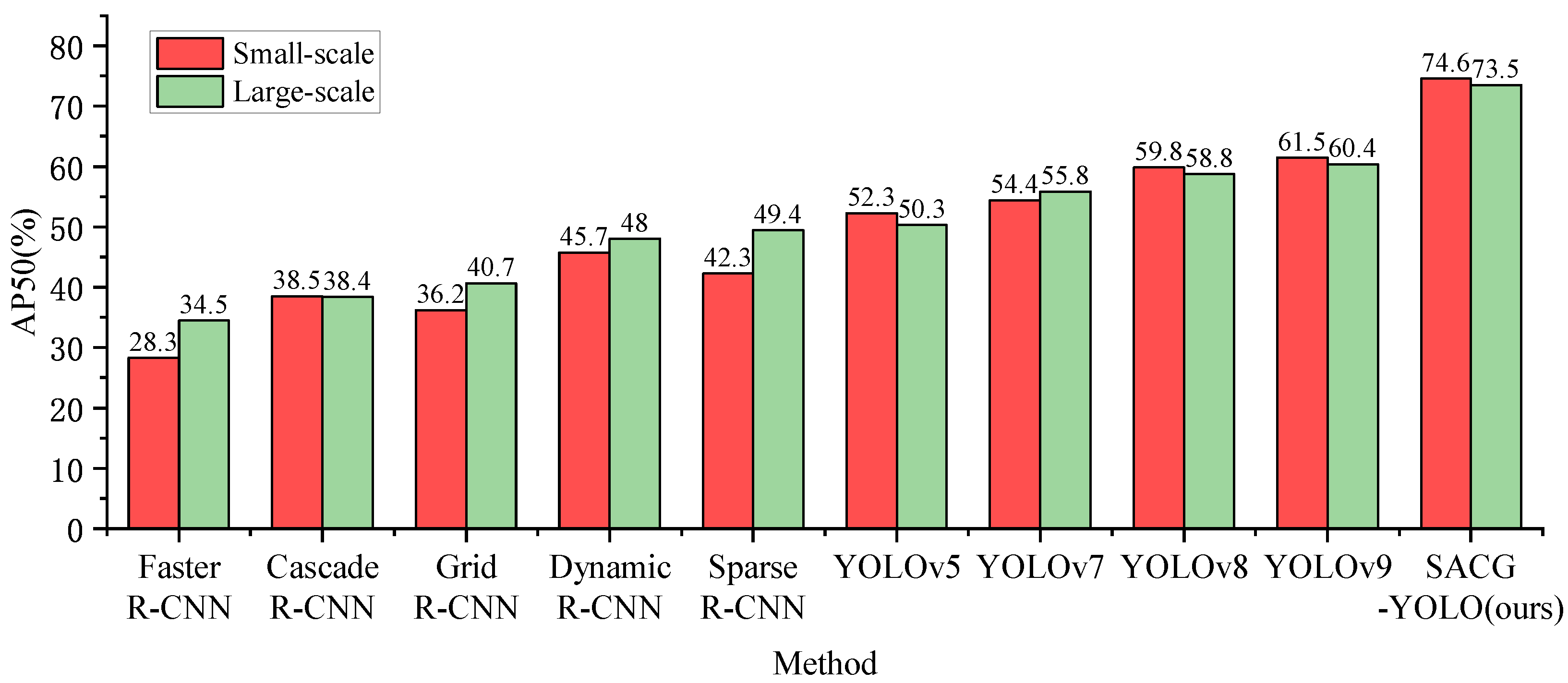
4.1. Comparison of the Proposed Model with Other State-of-the-Art Models
4.2. Comparison Between the DCGA Module and Other Attention Mechanisms
4.3. Ablation Experiments of Components in SACG-YOLO
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| CNN | Convolutional neural network |
| CBAM | Convolutional Block Attention Module |
| DCGA | Detailed content guidance attention |
| EMA | Efficient multi-scale attention |
| FPN | Feature pyramid network |
| IoU | Intersection over union |
| MGRN | Multi-geometry reasoning network |
| NDT | Nondestructive testing |
| NWD | Normalized Wasserstein distance |
| OHEM | Online Hard Example Mining |
| R-FCN | Region-based Fully Convolutional Network |
| SAE | Scene-aware enhancement |
| SE | Squeeze-and-excitation |
| SGD | Stochastic gradient descent |
| Soft-NMS | Soft Non-Maximum Suppression |
| UAV | Unmanned aerial vehicle |
References
- Liu, J.; Hu, M.; Dong, J.; Lu, X. Summary of insulator defect detection based on deep learning. Electr. Power Syst. Res. 2023, 224, 109688. [Google Scholar] [CrossRef]
- Mei, H.; Jiang, H.; Yin, F.; Wang, L.; Farzaneh, M. Terahertz imaging method for composite insulator defects based on edge detection algorithm. IEEE Trans. Instrum. Meas. 2021, 70, 1–10. [Google Scholar] [CrossRef]
- Zhu, Z.; Liu, X. Research on surface detection of ceramic insulator based on image processing. Electron. Meas. Technol. 2024, 47, 31–37. [Google Scholar]
- Tan, S.Y.; Akbar, M.F.; Shrifan, N.H.; Nihad Jawad, G.; Ab Wahab, M.N. Assessment of defects under insulation using K-medoids clustering algorithm-based microwave nondestructive testing. Coatings 2022, 12, 14–40. [Google Scholar] [CrossRef]
- Liu, G.; Wen, Y.; Gu, Y.; Zhou, J.; Chen, S. Decision Tree Clusters: Non-destructive detection of overheating defects in porcelain insulators using quantitative thermal imaging techniques. Measurement 2025, 241, 115723. [Google Scholar] [CrossRef]
- Zhou, Y.; Xu, B.; Song, A.; Chen, G. Anomaly Location and Discrimination Method of Insulator String Based on Improved TextDetection and Recognition. High Volt. Eng. 2021, 47, 3819–3826. [Google Scholar]
- Xie, X.; Zhou, J.; Zhang, Y. Application and challenge of deep learning in Ubiquitous Power Internet of Things. Electr. Power Autom. Equipment/Dianli Zidonghua Shebei 2020, 40, 77–87. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef]
- Zhai, Y.; Hu, Z.; Wang, Q.; Yang, Q.; Yang, K. Multi-Geometric Reasoning Network for Insulator Defect Detection of Electric Transmission Lines. Sensors 2022, 22, 6102. [Google Scholar] [CrossRef]
- Ning, P.; Jin, J.; Xu, Y.; Kong, C.; Zhang, C.; Tang, D.; Huang, J.; Xu, Z.; Li, T. Enhanced Detection of Glass Insulator Defects Using Improved Generative Modeling and Faster RCNN. Procedia CIRP 2024, 129, 31–36. [Google Scholar] [CrossRef]
- Tan, P.; Li, X.F.; Ding, J.; Cui, Z.S.; Ma, J.E.; Sun, Y.L.; Huang, B.Q.; Fang, Y.T. Mask R-CNN and multifeature clustering model for catenary insulator recognition and defect detection. J. Zhejiang Univ.-Sci. A 2022, 23, 745–756. [Google Scholar] [CrossRef]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. Repvgg: Making vgg-style convnets great again. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 13733–13742. [Google Scholar]
- Zhao, W.; Xu, M.; Cheng, X.; Zhao, Z. An insulator in transmission lines recognition and fault detection model based on improved faster RCNN. IEEE Trans. Instrum. Meas. 2021, 70, 5016408. [Google Scholar] [CrossRef]
- Liu, S.; Wang, B.; Gao, K.; Wang, Y.; Gao, C.; Chen, J. Object Detection Method for Aerial Inspection Image Based on Region-based Fully Convolutional Network. Autom. Electr. Power Syst. 2019, 43, 162–168. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Zhao, L.; Li, S. Object detection algorithm based on improved YOLOv3. Electronics 2020, 9, 537. [Google Scholar] [CrossRef]
- Liu, T.; Pang, B.; Zhang, L.; Yang, W.; Sun, X. Sea surface object detection algorithm based on YOLO v4 fused with reverse depthwise separable convolution (RDSC) for USV. J. Mar. Sci. Eng. 2021, 9, 753. [Google Scholar] [CrossRef]
- Li, R.; Zhang, Y.; Zhai, D.; Xu, D. Pin Defect Detection of Transmission Line Based on Improved SSD. High Volt. Eng. 2021, 47, 3795–3802. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Wei, S.; Qu, Q.; Su, H.; Shi, J.; Zeng, X.; Hao, X. Intra-pulse modulation radar signal recognition based on Squeeze-and-Excitation networks. Signal Image Video Process. 2020, 14, 1133–1141. [Google Scholar] [CrossRef]
- Shuaihui, Q.; Shasha, X.; Tao, X.; Guangchuan, Y. AAM: An Advanced Attention Module in Convolutional Neural Networks. In Proceedings of the 2020 2nd International Conference on Machine Learning, Big Data and Business Intelligence (MLBDBI), Taiyuan, China, 23–25 October 2020; pp. 371–374. [Google Scholar]
- Lu, Y.; Hu, X.; Zou, X.; Han, L. Research on Insulator Defect Detection Model Based on Improved YOLOv8. J. Electrotechnol. Electr. Eng. Manag. 2024, 7, 11–17. [Google Scholar]
- Li, Y.; Du, J.; Yi, Y.; Wan, W.; Lin, Y. Insulator recognition and self-explosion defect detection method based on improved YOLOv5 model. In Proceedings of the International Conference on Automation Control, Algorithm, and Intelligent Bionics (ACAIB 2023), Xiamen, China, 28–30 April 2023; Volume 12759, pp. 634–639. [Google Scholar]
- Zhang, Q.; Zhang, J.; Li, Y.; Zhu, C.; Wang, G. ID-YOLO: A Multi-Module Optimized Algorithm for Insulator Defect Detection in Power Transmission Lines. IEEE Trans. Instrum. Meas. 2025, 74, 3505611. [Google Scholar] [CrossRef]
- Wang, Y.; Song, X.; Feng, L.; Zhai, Y.; Zhao, Z.; Zhang, S.; Wang, Q. MCI-GLA plug-in suitable for yolo series models for transmission line insulator defect detection. IEEE Trans. Instrum. Meas. 2024, 73, 9002912. [Google Scholar] [CrossRef]
- Li, Y.; Chen, Y.; Wang, N.; Zhang, Z. Scale-aware trident networks for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6054–6063. [Google Scholar]
- Yu, Z.; Huang, H.; Chen, W.; Su, Y.; Liu, Y.; Wang, X. Yolo-facev2: A scale and occlusion aware face detector. Pattern Recognit. 2024, 155, 110714. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Ouyang, D.; He, S.; Zhang, G.; Luo, M.; Guo, H.; Zhan, J.; Huang, Z. Efficient multi-scale attention module with cross-spatial learning. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | AP50 (%) | AP75 (%) | AR10 (%) | AR100 (%) | AP50-Damage (%) | AP50-Drop (%) |
|---|---|---|---|---|---|---|
| Faster R-CNN | 75.0 | 34.0 | 41.1 | 47.4 | 58.7 | 91.3 |
| Cascade R-CNN | 70.2 | 42.3 | 42.5 | 48.2 | 51.7 | 88.7 |
| Grid R-CNN | 72.3 | 39.1 | 41.7 | 49.1 | 56.0 | 88.5 |
| Dynamic R-CNN | 74.8 | 40.2 | 41.7 | 46.8 | 61.6 | 88.0 |
| Sparse R-CNN | 77.3 | 40.0 | 43.4 | 60.2 | 64.1 | 90.5 |
| YOLOv5s | 67.2 | 46.5 | 42.0 | 51.6 | 48.2 | 86.2 |
| YOLOv7s | 69.4 | 48.5 | 42.0 | 52.3 | 50.3 | 88.5 |
| YOLOv8s | 70.5 | 45.3 | 42.7 | 51.7 | 54.0 | 87.0 |
| YOLOv9s | 71.4 | 47.6 | 43.1 | 52.0 | 56.7 | 86.0 |
| YOLOv11 | 78.5 | 49.6 | 47.3 | 54.8 | 63.5 | 89.4 |
| YOLOv12 | 72.3 | 47.5 | 48.8 | 53.4 | 60.5 | 87.4 |
| SACG-YOLO (ours) | 82.7 | 53.5 | 44.7 | 48.6 | 72.5 | 92.9 |
| Models | AP50 (%) | AP75 (%) | AP50-Damage (%) | AP50-Drop (%) |
|---|---|---|---|---|
| Baseline | 70.5 | 45.3 | 54.0 | 87.0 |
| Baseline + SE | 72.7 | 43.5 | 62.1 | 87.3 |
| Baseline + CBAM | 72.9 | 45.6 | 64.1 | 87.6 |
| Baseline + EMA | 73.4 | 47.7 | 65.3 | 88.5 |
| Baseline + DCGA | 74.9 | 48.7 | 66.2 | 89.6 |
| Models | Number of Correct Detection | Detection Accuracy (%) |
|---|---|---|
| Baseline | 20 | 40.0 |
| Baseline + SE | 24 | 48.0 |
| Baseline + CBAM | 32 | 64.0 |
| Baseline + EMA | 43 | 86.0 |
| Baseline + DCGA | 46 | 92.0 |
| Method | SAE | DCGA | AP50 (%) | AP50 (%) | AP75 (%) | |||
|---|---|---|---|---|---|---|---|---|
| Drop | Damage | |||||||
| YOLOv8s | 87.0 | 54.0 | 70.5 | 45.3 | ||||
| YOLOv8s | ✓ | 88.4 | 65.2 | 74.6 | 46.4 | |||
| YOLOv8s | ✓ | 89.6 | 66.2 | 74.9 | 48.7 | |||
| YOLOv8s | ✓ | 88.9 | 66.3 | 76.9 | 46.8 | |||
| YOLOv8s | ✓ | 90.4 | 65.4 | 77.4 | 48.2 | |||
| YOLOv8s | ✓ | ✓ | 90.6 | 67.0 | 78.0 | 48.7 | ||
| YOLOv8s | ✓ | ✓ | 88.7 | 67.1 | 77.2 | 47.5 | ||
| YOLOv8s | ✓ | ✓ | 89.2 | 67.6 | 78.4 | 47.9 | ||
| YOLOv8s | ✓ | ✓ | ✓ | 90.6 | 68.2 | 79.3 | 50.2 | |
| YOLOv8s | ✓ | ✓ | ✓ | 91.3 | 69.4 | 79.8 | 49.5 | |
| YOLOv8s | ✓ | ✓ | 89.6 | 67.4 | 77.4 | 50.6 | ||
| YOLOv8s | ✓ | ✓ | ✓ | 90.6 | 70.6 | 80.6 | 49.3 | |
| Ours | ✓ | ✓ | ✓ | ✓ | 92.9 | 72.5 | 82.7 | 53.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, L.; Kang, J.; An, Y.; Li, Y.; Jia, M.; Li, R. SACG-YOLO: A Method of Transmission Line Insulator Defect Detection by Fusing Scene-Aware Information and Detailed-Content-Guided Information. Electronics 2025, 14, 1673. https://doi.org/10.3390/electronics14081673
Zhao L, Kang J, An Y, Li Y, Jia M, Li R. SACG-YOLO: A Method of Transmission Line Insulator Defect Detection by Fusing Scene-Aware Information and Detailed-Content-Guided Information. Electronics. 2025; 14(8):1673. https://doi.org/10.3390/electronics14081673
Chicago/Turabian StyleZhao, Lihui, Jun Kang, Yang An, Yurong Li, Meili Jia, and Ruihong Li. 2025. "SACG-YOLO: A Method of Transmission Line Insulator Defect Detection by Fusing Scene-Aware Information and Detailed-Content-Guided Information" Electronics 14, no. 8: 1673. https://doi.org/10.3390/electronics14081673
APA StyleZhao, L., Kang, J., An, Y., Li, Y., Jia, M., & Li, R. (2025). SACG-YOLO: A Method of Transmission Line Insulator Defect Detection by Fusing Scene-Aware Information and Detailed-Content-Guided Information. Electronics, 14(8), 1673. https://doi.org/10.3390/electronics14081673