Abstract
Instance searches pertain to the identification of specific objects or scenes within a dataset that correspond to a given query image. The existing research primarily concentrates on improving the accuracy of machine-recognized instances, frequently neglecting the pivotal role of human–computer interaction. As a result, effectively searching for instances that align with user preferences continues to pose a substantial challenge. In this paper, we introduce an intuitive and efficient instance search method that incorporates human–computer interaction. Specifically, our proposed interactive instance search system includes tools that enable users to directly highlight specific instances of interest within the query image. Furthermore, we propose the use of learned perceptual image patch similarity to effectively bridge the semantic gap between low-level features and high-level semantics. Contrary to conventional metrics, such as cosine similarity, which rely on pixel-level or superficial feature comparisons, we employ deep neural networks to model perceptual differences in a hierarchical manner. The experimental results demonstrate that our approach surpasses traditional methods in terms of similarity-matching accuracy and exhibits robust performance on datasets such as Oxford5k and Paris6k.
1. Introduction
Instance search plays a crucial role in the field of computer vision across various applications. For instance, the “search for goods by map” [1] feature on e-commerce platforms helps users quickly locate products of interest, significantly enhancing the user experience. Moreover, in the realm of security monitoring, instance search technology is employed to identify and track specific individuals [2], thereby improving public safety. Additionally, with the advancement of autonomous driving technology, instance search can be utilized in real-time environment perception systems to identify and classify other vehicles, pedestrians, and obstacles on the road, ensuring driving safety. Meanwhile, instance search is applied to tourism [3], instance investigation [4], medical treatment [5], etc. These applications not only show the wide applicability of instance search technology but also highlight its potential to promote social progress and improve the quality of life.
Instance search and image retrieval [6,7] share both similarities and differences. The primary distinction lies in the approach to querying: image retrieval utilizes the entire image as a query, whereas instance search necessitates that users delineate specific visual objects as query targets using bounding boxes. Conversely, the shared similarity between these two tasks is the pivotal role of image similarity comparison, which is essential for achieving accurate query results. Currently, the majority of interactive retrieval systems are predicated on the similarity assessment of the entire image. However, users’ real-world requirements are often directed towards particular instances within the image, such as individual pedestrians within a crowd, rather than the comprehensive street scene. In cases where query images exhibit complex semantics with multiple coexisting instances, such as pedestrians, vehicles, and architecture in street-view images, users frequently encounter difficulty in explicitly delineating their regions of interest. This discrepancy in interaction leads to a disconnect between retrieval outcomes and user intent, consequently undermining the system’s practicality and diminishing the user experience. Furthermore, existing systems lack support for multi-instance collaborative search, preventing users from querying combinations of instances. In order to address this significant gap in human–computer interaction pertaining to instance search, we introduce an innovative interactive framework that fundamentally departs from existing methodologies in three distinct aspects. Firstly, our mechanism facilitates direct and precise instance specification via intuitive box selection or clicking, thus substantially minimizing user effort while enhancing targeting precision. Secondly, whereas conventional similarity metrics like Euclidean distance [8], cosine similarity [9], PSNR [10], and SSIM [11] are constrained to low-level pixel comparisons, our LPIPS-based approach aptly captures hierarchical semantic relationships, aligning with human visual perception. This distinction is critical–whereas traditional methods might erroneously associate two semantically divergent objects as similar due to pixel-level similarity (e.g., a red apple vs. a red ball), our model effectively differentiates through deep perceptual features. Thirdly, unlike single-instance search systems [12,13], our framework accommodates multi-instance collaborative queries, thereby addressing the practical necessity of retrieving complex scenes. Collectively, these advancements facilitate a more accurate, user-congruent instance search, adaptable to a variety of application scenarios ranging from e-commerce to surveillance.
We evaluate the effectiveness of our method in the practical application of interactive instance retrieval. The experimental results demonstrate that the proposed method outperforms existing instance retrieval frameworks in both retrieval performance and user interaction. Notably, users can frame the instances they are interested in, improving retrieval efficiency compared to single-instance searches. Additionally, the similarity measurement method has shown promising results in enhancing retrieval accuracy. The main contributions of this work are as follows:
- We introduce a novel framework for interactive multi-region collaborative instance search, which enhances human–computer interaction in the process of selecting instances of user interest and efficiently acquires feedback that aligns with user requirements.
- We employ a deep learning-based method for measuring similarity, which effectively captures the perceptual similarity between images. This approach closely aligns with human visual perception, thereby enhancing the accuracy of query results.
2. Related Work
2.1. User-Centered Interactive Image Retrieval
With the advancement of science and technology, the interaction between humans and machines is becoming increasingly robust. In early research, Wong et al. [14] introduced an image retrieval system called MIRROR, which enhances search results through user interaction by employing dynamic weight adjustment and color histogram-merging techniques to improve retrieval accuracy and user satisfaction. Lai et al. [15] developed a user-oriented image retrieval system based on an interactive genetic algorithm that optimizes the retrieval process through iterative user feedback. More recently, Anwaar et al. [16] proposed an image retrieval method called ComposeAE, which combines image and text queries to meet user needs better. However, these methods still lack a degree of user autonomy. While recent systems [16] allow text–image fusion, they cannot process multi-instance queries (e.g., ‘find images with a red book and a blue book’). Similarly, instance search models [12,13] focus on improving detection accuracy but lack user interaction for compound queries. The framework we have introduced effectively addresses this gap by incorporating interactive multi-instance selection in conjunction with perceptual matching based on LPIPS.
2.2. Instance Search
The instance search framework conventionally involves several critical stages: instance detection, feature extraction, and image similarity comparison. The current instance search methodologies undergo continuous optimization based on these stages. Previous research has demonstrated that deep learning is instrumental in the instance search task. In recent research, Wang and Han [17] demonstrated the viability of transfer learning and augmentation techniques for material classification in SVIs, this demonstrates the robustness of deep learning in related tasks. Salvador et al. [18] proposed utilizing Faster R-CNN features for instance search by leveraging both image- and region-wise pooled CNN activations from an object detection network, integrating a filtering phase with spatial reranking based on region proposals. This approach exhibits strong performance on street-view image datasets, such as oxford5k. Subsequently, Zhan and Zhao [12] introduced an instance-level feature representation technique employing fully convolutional instance-aware semantic segmentation (FCIS). This technique extracts features by applying ROI pooling to the segmented instance regions and refines the FCIS network to accommodate objects of diverse shapes. Similarly, Zhang et al. [13] proposed an instance search framework based on cyclic self-training, which utilizes unlabeled data to enhance instance search performance. However, the mentioned instance search frameworks are predominantly automated, relying heavily on computer vision algorithms and deep learning models, with minimal human–computer interaction. While these methodologies primarily concentrate on enhancing retrieval accuracy and localization through internal algorithm optimization, they do not incorporate real-time user interaction to adjust or refine results.
2.3. Image Similarity Comparison
A similarity comparison is a crucial step in many image recognition and retrieval tasks. Cosine similarity [9] is commonly used in comparing text and image similarities; it measures the cosine of the angle between two vectors in a multi-dimensional space, effectively quantifying their orientation, rather than their magnitude. Additionally, Euclidean distance [8] is one of the simplest and most widely used methods for measuring the similarity between two points in space, calculating the straight-line distance between two vectors in Euclidean space. These methods primarily rely on feature similarity comparison. Recent studies indicate that perceptual similarity spontaneously arises in deep visual systems, independent of their initial training objectives. Drawing upon this finding, Zhang et al. [19] introduced LPIPS (learned perceptual image patch similarity), which offers a lightweight yet efficacious calibration mechanism for pre-existing CNNs. LPIPS attains human-aligned similarity measurements through two principal innovations: (1) emergent feature utilization, which extracts multi-layered features from pre-trained networks (VGG/AlexNet/SqueezeNet), where deeper layers inherently encode semantic relationships that align with human assessments and (2) adaptive channel calibration, which, with merely 1472 learnable parameters (channel-wise weights), adjusts deep features to enhance the agreement with human perceptual evaluations, surpassing the performance of static VGG features.
3. Method
In this article, we introduce a novel interactive instance search method that enables users to select multiple instances and search for images in a dataset that contains all the selected instances. We define this task as Multi-Region Collaborative Instance Search (MRCIS). Unlike existing single-instance search frameworks, our approach allows users to choose one or more instances of interest based on their specific needs, facilitating the discovery of images that include their selected instances and promoting a more natural human–computer interaction. This architecture takes user-selected instances from the query image as input and generates the retrieved images as output.
Under the MRCIS framework, the instance search task consists of three key steps: (1) instance detection: identifying instances present in the image using object detection algorithms; (2) feature extraction: extracting features of the instance images through convolutional neural networks; and (3) similarity comparison: employing appropriate methods to compare the extracted features for similarity and identifying images that contain the query instances. To better align with the human visual system’s perception of images and enhance query accuracy, this architecture utilizes an image similarity measurement method based on Learned Perceptual Image Patch Similarity (LPIPS).
As illustrated in Figure 1, our goal is to fully consider user needs by allowing users to specify instances of interest through interactive box selection. After the user uploads the query image, the system immediately guides them to select one or more areas of interest. Subsequently, the system extracts features for these selected instances one by one and compares them with the detected instances in the database for similarity. After comparing all selected instances, the system employs a multi-instance collaborative filtering mechanism to identify images that contain all user-specified instances simultaneously. Finally, the results are sorted based on a comprehensive similarity score, and the top-k most relevant images are returned to the user as query results. This method not only enhances the accuracy of the search but also optimizes the user experience through multi-region collaboration.
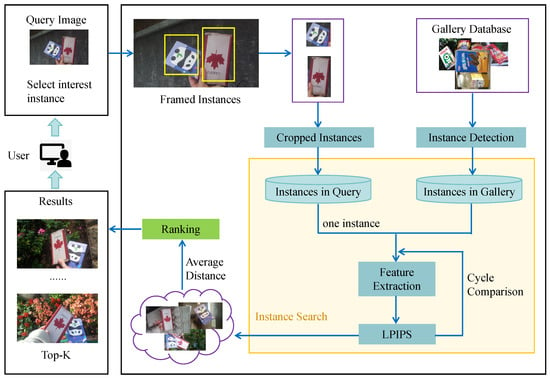
Figure 1.
Overview of proposed multi-region collaborative instance search. ‘One instance’ in the figure refers to one of all framed instances selected by the user.
3.1. Instance Search
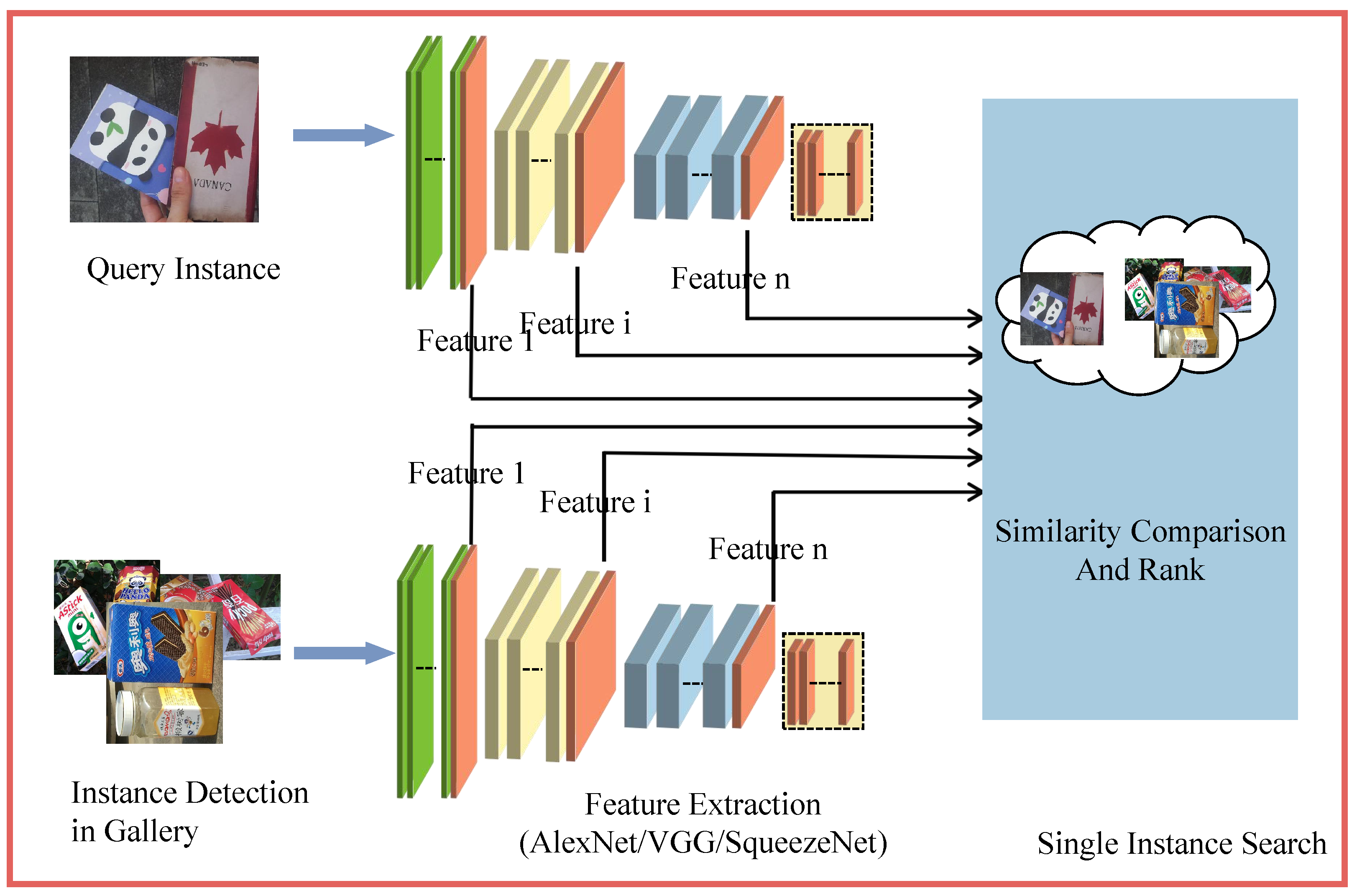
The instance search framework is illustrated in Figure 2. This framework outlines the process of searching for a query instance within the database. In this stage, an instance-by-instance comparison methodology is employed: initially, the query instance is compared with each specific candidate instance identified within every image in the database. Subsequently, the maximal instance similarity score is computed for each image in the database; this score represents the highest similarity measure achieved between any detected instance and the query instance within the given image, serving as the definitive matching score for that image. Because the method based on LPIPS [19] properly captures the hierarchical semantic relationship, which is consistent with human visual perception, LPIPS is used as the method to compare the similarity of two instances. In the proposed method discussed in this paper, feature extraction and similarity comparison are closely interconnected. The results of feature extraction directly influence the inputs for similarity calculation, while the methods used for similarity calculation (such as distance measurement and calibration) further optimize the utilization of these features, ensuring that the final similarity score accurately reflects human perception. These two steps work in tandem and constitute the core of the LPIPS method. Therefore, we will introduce the instance search framework by focusing on instance detection and an LPIPS-based instance similarity comparison.
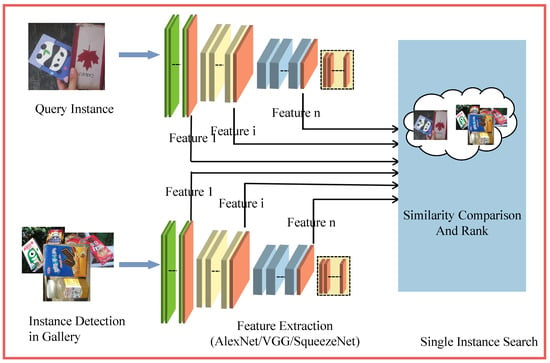
Figure 2.
Overview of instance search.
3.1.1. Instance Detection
We define the query image as I. Then, the instances selected within the user-defined box are represented as . For the images in the database, a target detection algorithm (such as Faster R-CNN [20] or YOLO [21]) is employed to detect target instances within each image. This algorithm can recognize multiple targets and outputs the bounding box for each detected instance. Specifically, for each image, , a set of bounding boxes is generated with the target detection algorithm, with each bounding box corresponding to a detected target instance. Next, each target is extracted from the original image based on the detected bounding box. The trimmed target images are represented as . Thus, each image is decomposed into multiple target instances represented as .
3.1.2. LPIPS-Based Instance Similarity Comparison
The core of the LPIPS metric lies in utilizing pre-trained deep convolutional networks (such as AlexNet, VGG, or SqueezeNet) to extract feature representations from images and evaluate their similarity through a learned perceptual distance metric. The fundamental principle of this approach is that the deep feature space captures high-level semantic information, thereby providing a more accurate reflection of human visual perception. The network architecture used for LPIPS measurement is illustrated in Figure 3.
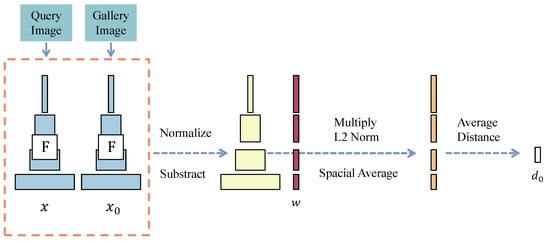
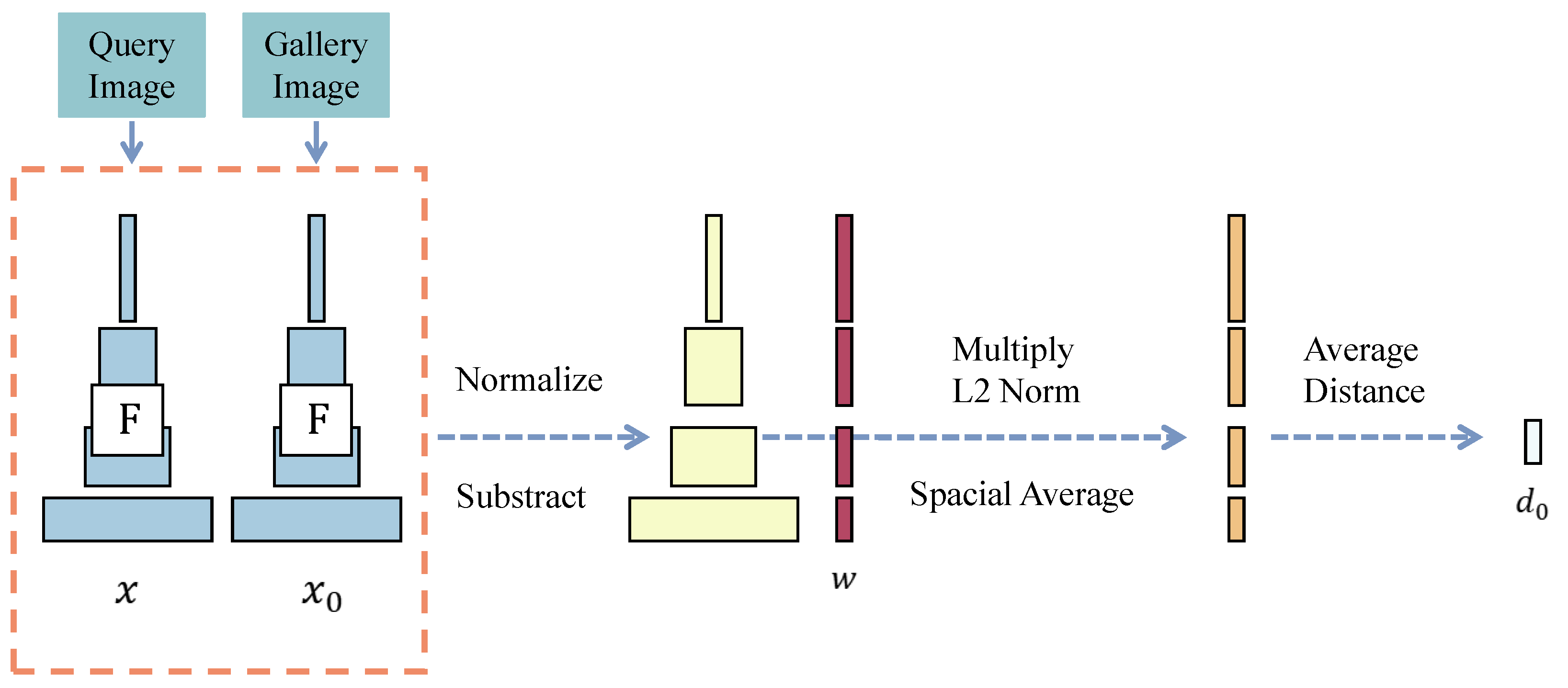
Figure 3.
LPIPS network structure.
In instance retrieval, deep convolutional network architectures like SqueezeNet, AlexNet, and VGG are commonly employed. These networks comprise multiple convolutional layers, pooling layers, and fully connected layers. When query images and gallery images are input, they are sequentially processed through various layers of the network for feature extraction. We use the pre-trained deep convolutional network F to extract feature representations for the query instance image and gallery instance image . Notably, network F is a convolutional neural network, where the feature maps of the l-th layer are denoted as (representing the features of the query instance image ) and (representing the features of the gallery instance image within the gallery image ). The dimensions of the feature map are , where and are the height and width of the feature map, respectively, and is the number of channels.
For each feature map, the channel dimension is first normalized to eliminate scale differences among the various channels. The normalized feature map is represented as follows:
Among them, represents the channel vector of the feature map at position . Then, a weighted vector, , is applied to each channel to adjust the importance of different channels. The weighted feature representation is as follows:
The LPIPS distance between the query instance image and the gallery instance image is calculated. Specifically, for each layer l of the network, the Euclidean distance between normalized feature maps and average all spatial positions is calculated:
Finally, the distances of all layers are weighted and summed to obtain the final LPIPS distance:
Among them, is the layer weight used to adjust the importance of different layers.
3.2. Ranking
During the instance search phase, we calculate the similarity distance between the query instance and each instance in the database using the LPIPS method. To further refine the search and filter out images containing multiple instances specified by users, we introduce a collaborative instance-filtering mechanism. The central concept of this mechanism is to normalize the LPIPS distance and filter the images in the database based on the cooperative matching criteria of multiple instances.
First, we normalize the LPIPS distance to facilitate sorting. The normalized distance range is , where 0 indicates complete matching, and 1 indicates a complete mismatch. Suppose that the user has selected n instances in the query image I, which are recorded as . For each image in the database, we calculate its minimum LPIPS distance from each query instance , and we define the similarity between instance and image as follows:
Next, we need to sort these images further. The sorting criteria can be based on the average LPIPS distance of the multiple instances. Specifically, for each image in the database, we calculate its average LPIPS distance from all query instances as follows:
where represents the average similarity distance between image and all query instances. Finally, we sort the images in ascending order according to the value of . The smaller the , the higher the overall similarity between the image, , and the query instance. The sorted image will be returned to the user as the final query result.
4. Experimental Results
To verify the effectiveness of the proposed system, we conducted a series of experiments. Selecting an appropriate image database is a crucial step in developing a multi-region collaborative image instance search system. First of all, we conducted a test on the instance search datasets Oxford5k [22] and Paris6k [23], and the test results proved the search accuracy of MRCIS framework. After that, we tested the multiple instance search in some subset of ImageNet [24] dataset, and the test results verified the good performance of MRCIS in searching multiple instances.
4.1. Experiments on Standard Instance Search Datasets
The Oxford5k (5063 images) and Paris6k (6412 images) datasets are standard benchmarks for instance search, each featuring 11 landmark buildings with 5 query images per landmark. Each query includes a bounding box annotation of the target instance. The evaluation follows a three-tier labeling scheme: (1) good (correct instance with nearly identical viewpoint), (2) okay (correct instance but with significant viewpoint variation or partial occlusion), and (3) junk (irrelevant or severely degraded instances). In computing the mean average precision (mAP), only good and okay samples are counted as positives, while Junk results are excluded.
Based on the results from the three experiments conducted, it was determined that the similarity comparison exerts the most significant influence on the overall framework’s performance (Table 1), with the LPIPS method demonstrating commendable performance. This attests to the effectiveness of the LPIPS approach in tasks involving similarity comparison. While the VGG network exhibits superior performance compared to AlexNet and SqueezeNet (Table 2), its efficiency is notably lower. During the instance detection phase, various detection methodologies consistently yield satisfactory results, exerting minimal impact on the experimental outcomes (Table 3).

Table 1.
Performance comparison using different similarity-comparison methods in terms of mAP.
Table 2.
Performance comparison using different backbone networks in LPIPS in terms of mAP.
Table 3.
Performance comparison using different instance detection methods in terms of mAP.
Since the LPIPS method in our MRCIS framework is based on the pre-trained CNN model, we mainly compare our method with some existing SOTA methods using pre-trained models, considering the fairness of the comparison. The detailed experimental results are listed in Table 4. The results of other methods listed in the table are taken from the cited papers.
Table 4.
Performance comparison with some SOTA methods in terms of mAP.
As can be seen from Table 4, our methodology exhibits a competitive edge. Within a 95% confidence interval based on the t-distribution, the mean estimation interval for our method on the oxford5k dataset is [0.762, 0.802], whereas, for the paris6k dataset, it is [0.799, 0.869]. Compared with some unsupervised methods based on existing models (such as CroW [25], ReSW [26], and DTFH [27]) and self-supervised learning methods such as HAF [30] and TransVLAD [31], our method achieves significantly better performance on the oxford5k and paris6k datasets. In particular, on oxford5k, our method shows advantages over all the listed SOTA methods. On paris6k, our method is inferior to some deep feature aggregation methods, such as CWAH [32]. We found that most of the images involved in paris6k contain complex street scenes with diverse perspectives and lighting; however, the image background in oxford5k is relatively simple and the illumination is relatively uniform. Therefore, our method needs to be improved in dealing with images with complex backgrounds.
4.2. Multiple Instance Search Accuracy
To comprehensively assess the algorithm’s performance in complex environments, an experiment was conducted to evaluate the accuracy of instance searches in images containing multiple instances. In this experimental setup, a search is classified as successful if the outputs include all instances present in the respective image; conversely, it is considered unsuccessful if no instances are retrieved. Images with partially detected instances were excluded from the analysis. Five independent trials were performed for each method under consistent experimental conditions. Each trial involved the random selection of ten test images, each containing 1–3 instances from our dataset. The detailed results of the experiment are presented in Table 5. The data in the table clearly show that the MRCIS method still shows high performance when searching multiple instances. This finding strongly supports the effectiveness and reliability of our proposed MRCIS method in handling image search tasks involving multiple instances.
Table 5.
Performance comparison of the three similarity comparison methods in multi-instance search.
4.3. Practicability of System Demonstration
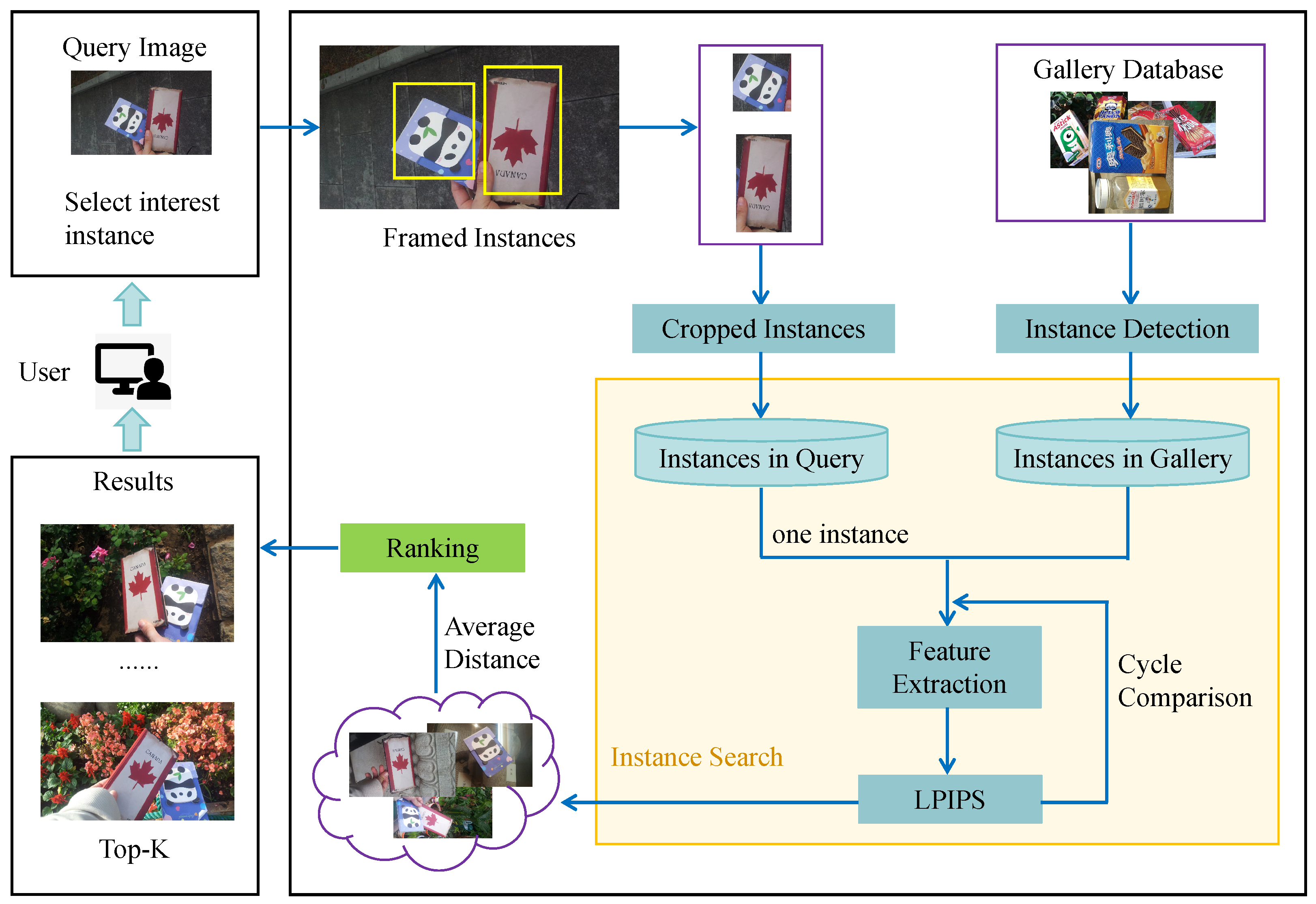
To demonstrate the practicality of our newly proposed interactive instance search system, we present a case study illustrating its functionality. The system is developed using the Flask framework [33], a lightweight and flexible Python-based web framework that facilitates the rapid development of web applications. Flask is particularly well suited for building scalable and modular systems, offering extensive support for integrating various functionalities while maintaining simplicity in implementation. Leveraging Flask’s capabilities, we designed the system to provide an intuitive and responsive user interface for an interactive instance search. At the core of the system lies the Multi-Region Collaborative Instance Search method, which enables users to directly draw bounding boxes around one or more instances on the user interface (as shown in Figure 4) to initiate the search process. The case study image contains two instances. After the user selects these instances by drawing bounding boxes and clicks the search button, the system efficiently processes the input and retrieves the most relevant results. The search results, depicted in Figure 5, display the top eight retrieved images to the user. Notably, the retrieved images contain all instances selected by the user, demonstrating the system’s ability to enhance the accuracy of instance search. Furthermore, the seamless integration of Flask with the MRCIS method provides a more natural and efficient human–computer interaction experience, highlighting the system’s practical utility in real-world applications. We provide a video as an example: https://youtu.be/ZV3IYmbGjLI, (accessed on 8 April 2025).

Figure 4.
User’s input image with marked instances.

Figure 5.
The images retrieved based on the user’s input image from Figure 4.
Certainly, the Flask framework exhibits certain limitations. The present system utilizes Flask due to its straightforwardness in the prototyping phase. However, scaling to accommodate larger datasets or real-time situations necessitates strategic optimizations. In contexts demanding high concurrency, asynchronous frameworks such as FastAPI or Tornado demonstrate enhanced performance through non-blocking I/O operations, thereby efficiently managing thousands of concurrent requests with minimal latency. While the proposed method significantly improves interaction flexibility and accuracy, the formal evaluation of user experience and efficacy presents an unresolved challenge that we intend to explore in future research endeavors.
4.4. Interactive Experiment
In order to evaluate the interactivity and usability of the system, a real-world scenario was simulated for experimentation. The experiment was implemented on a computer platform equipped with an NVIDIA GeForce RTX 3060 graphics card (integrated by Lenovo, Beijing, China). Under the assumption that the user intends to classify images stored on a cloud drive into categories such as cars, bottles, and people, a total of 5000 images were used. We prepared five search images, exemplifying categories such as car, bottle, book, car logo, and people. The YOLO model, based on the Coco dataset, was employed for instance detection. To enhance query efficiency, Squeezenet was utilized as the feature extraction network. For each specific instance, 10 experiments were conducted, and the average of the experimental results was calculated. The experimental results are presented in Table 6.
Table 6.
Search results for five specific instances.
During the experimentation phase, the system demonstrated a search efficiency of approximately 130 images per second when processing both query and database images. The results of the experiment indicate that the model exhibits strong performance in searching cars, car logos, and other instances with distinct features. However, in the case of facial recognition, variability in facial expressions among identical individuals leads to reduced accuracy.
To enhance the precision of a specific instance search (such as a car logo), one may conduct a manual identification based on the imagery of the highest-ranked instances obtained from an initial search, subsequently facilitating the training of a novel instance detection model. Employing this newly calibrated model, the retrieval of the specific car logo results in a mean average precision (mAP) of 0.926, significantly enhancing retrieval accuracy. Practically, it is feasible to select various target detection models, such as those for vehicular or architectural identification, depending on individual requirements. Furthermore, the model can undergo further training through manual identification to augment retrieval accuracy.
To assess the variations in retrieval efficiency across different dataset sizes, the number of images in the database was increased to 50,000. The findings reveal that there is no significant alteration in the image processing speed of the system. The current experimental outcomes suggest that the dataset size does not influence operational efficiency, and the time required for a single instance search is directly proportional to the dataset size. Consequently, should circumstances allow, parallel processing with multiple servers can be employed to enhance search efficiency. Furthermore, an investigation into more efficient query strategies represents a prospective avenue for future model enhancements.
5. Discussion
5.1. The Robustness of the System
Variations in lighting, occlusion, or background complexity can significantly influence the accuracy of search algorithms. For instance, the presence of a complex background when identifying a building instance may adversely affect the system’s search precision. In the Paris6k dataset, the complex background contained in buildings affects our search accuracy, especially for ‘pompidou’. Future investigations will address this by employing controlled benchmarks, such as synthetic occlusions and lighting variations.
Moreover, the accuracy of user-submitted instance bounding boxes has a critical effect on retrieval efficacy: overly inclusive boundaries may incorporate unnecessary background elements, whereas overly restrictive ones might exclude essential discriminative features. The empirical findings are presented in Table 7. It is observed that deviations in the user selection range, whether excessively broad or unduly narrow, significantly affect the accuracy of the search outcomes. Although our current model is predicated on precise annotations, practical applications may encounter imperfections in bounding box definitions. Future developments will aim to bolster annotation robustness through uncertainty-aware feature refinement [34] coupled with auto-box optimization, thereby dynamically addressing ambiguous annotations while maintaining the integrity of user intentions.
Table 7.
Influence of user’s frame selection quality on retrieval accuracy (oxford5k dataset).
5.2. LPIPS
The selection of AlexNet, VGG, and SqueezeNet for feature extraction is necessitated by the current implementation constraints of the LPIPS metric. Given that LPIPS is pre-trained and calibrated specifically on these convolutional neural network architectures to emulate human perceptual judgments [19], adherence to these networks ensures an equitable evaluation of perceptual similarity. The transformer-based models (e.g., ViT and CLIP) have demonstrated potential in capturing high-level semantic information; their feature spaces are not yet assimilated into the standardized LPIPS framework due to variances in training objectives and feature normalization. Future research could investigate adapting LPIPS to incorporate transformer features while ensuring perceptual consistency.
5.3. Similarity Score Calculation
The existing framework utilizes an average similarity score (Equation (6)) to rank images encompassing multiple query instances, thus assigning equal significance to all user-selected instances. This approach is congruent with scenarios wherein users prioritize comprehensive matches, such as retrieving scenes containing all specified objects. Nonetheless, real-world applications may necessitate dynamic weighting to capture diverse user intentions. For instance, a user investigating ‘a red book near a blue cup’ might prioritize the red book as the primary objective while accepting less precise matches for the blue cup. Consequently, we propose enabling users to adjust instance weights manually (e.g., through sliders) during query conception, thereby exerting a direct influence on the final ranking. Prospective research will examine hybrid strategies that equilibrate user adaptability with computational efficiency, particularly pertinent for large-scale datasets where dynamic weighting might induce latency.
5.4. Obstacles in Practical Application
Theoretically, the retrieval time for multi-instance matching exhibits linear growth compared to single-instance matching. While accurate object detection ensures that retrieval accuracy on large-scale datasets is not significantly compromised, it nonetheless affects retrieval time. Consequently, our current research framework is optimized for application to small and medium-sized datasets. Unlike other deep learning frameworks, our approach requires only the detection of instances within the image, which are then inputted into the LPIPS model for individual comparison. Despite its convenience, enhancing retrieval efficiency remains a prospective challenge and a focus for future research endeavors.
The primary challenge facing the application of this interactive retrieval system is its real-time performance when handling large-scale datasets. For extensive fixed datasets, traditional methods allow for the pre-extraction of features, enabling direct comparisons upon the input of new images for retrieval. While the current framework enhances retrieval accuracy, its real-time performance significantly lags behind that of conventional similarity comparison methods. However, for small to medium-sized datasets, particularly those that are random, the proposed framework exhibits substantial advantages. Consequently, it offers potential utility in commercial image search engines or security applications, particularly within the domain of monitoring security
6. Conclusions
This manuscript has presented an interactive instance search system predicated on the Multi-Region Collaborative Instance Search framework, employing LPIPS for the measurement of perceptual similarity. The system helps users select multiple instances through the use of bounding boxes, thereby augmenting retrieval accuracy and the dynamics of human–computer interaction. Experimental results on benchmark datasets (Oxford5k and Paris6k) demonstrate its superiority, particularly in complex scenes, with VGG-based LPIPS delivering robust performance. Constructed using Flask, the system provides practical applicability for real-world implementations, advancing instance search technology through a user-centered design and perceptual alignment. Prospective work may investigate additional modalities and optimizations to continue enhancing performance.
Author Contributions
Methodology, Z.L. and S.L.; data curation, B.H.; writing—original draft, Z.L.; writing—review and editing, Z.Y. and J.B.; funding acquisition, J.B. All authors have read and agreed to the published version of the manuscript.
Funding
This study received partial funding from the College Student Innovation and Entrepreneurship Project under the auspices of the School of Computer and Control Engineering at Northeast Forestry University.
Data Availability Statement
The links to the public datasets used in the article are as follows. Oxford5k: https://www.robots.ox.ac.uk/~vgg/data/oxbuildings/, (accessed on 22 June 2007). Paris6k: https://www.robots.ox.ac.uk/~vgg/data/parisbuildings/, (accessed on 28 June 2008). ImageNet: https://www.image-net.org/, (accessed on 25 June 2009).
Acknowledgments
The authors appreciate the editors and anonymous reviewers for their essential input and efforts in the review process of this manuscript.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Dagan, A.; Guy, I.; Novgorodov, S. Shop by image: Characterizing visual search in e-commerce. Inf. Retr. J. 2023, 26, 2. [Google Scholar] [CrossRef]
- Hou, S.; Zhao, C.; Chen, Z.; Wu, J.; Wei, Z.; Miao, D. Improved instance discrimination and feature compactness for end-to-end person search. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 2079–2090. [Google Scholar] [CrossRef]
- Parikh, V.; Keskar, M.; Dharia, D.; Gotmare, P. A tourist place recommendation and recognition system. In Proceedings of the 2018 Second International Conference on Inventive Communication and Computational Technologies (ICICCT), Coimbatore, India, 20–21 April 2018; pp. 218–222. [Google Scholar]
- Wu, Y.; Dong, X.; Shi, G.; Zhang, X.; Chen, C. Crime scene shoeprint image retrieval: A review. Electronics 2022, 11, 2487. [Google Scholar] [CrossRef]
- Hegde, N.; Hipp, J.D.; Liu, Y.; Emmert-Buck, M.; Reif, E.; Smilkov, D.; Terry, M.; Cai, C.J.; Amin, M.B.; Mermel, C.H.; et al. Similar image search for histopathology: SMILY. NPJ Digit. Med. 2019, 2, 56. [Google Scholar] [CrossRef] [PubMed]
- Rui, Y.; Huang, T.S.; Chang, S.F. Image retrieval: Current techniques, promising directions, and open issues. J. Vis. Commun. Image Represent. 1999, 10, 39–62. [Google Scholar] [CrossRef]
- Alzu’bi’, A.; Amira, A.; Ramzan, N. Semantic content-based image retrieval: A comprehensive study. J. Vis. Commun. Image Represent. 2015, 32, 20–54. [Google Scholar] [CrossRef]
- Wang, L.; Zhang, Y.; Feng, J. On the Euclidean distance of images. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1334–1339. [Google Scholar] [CrossRef] [PubMed]
- Steck, H.; Ekanadham, C.; Kallus, N. Is cosine-similarity of embeddings really about similarity? In Proceedings of the ACM Web Conference 2024, Singapore, 13–17 May 2024; pp. 887–890. [Google Scholar]
- Sheikh, H.R.; Sabir, M.F.; Bovik, A.C. A statistical evaluation of recent full reference image quality assessment algorithms. IEEE Trans. Image Process. 2006, 15, 3440–3451. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Zhan, Y.; Zhao, W.L. Instance search via instance level segmentation and feature representation. J. Vis. Commun. Image Represent. 2021, 79, 103253. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, C.; Chen, W.; Xu, X.; Wang, F.; Li, H.; Hu, S.; Zhao, X. Revisiting instance search: A new benchmark using cycle self-training. Neurocomputing 2022, 501, 270–284. [Google Scholar] [CrossRef]
- Wong, K.M.; Cheung, K.W.; Po, L.M. MIRROR: An interactive content based image retrieval system. In Proceedings of the 2005 IEEE International Symposium on Circuits and Systems (ISCAS), Kobe, Japan, 23–26 May 2005; pp. 1541–1544. [Google Scholar]
- Lai, C.C.; Chen, Y.C. A user-oriented image retrieval system based on interactive genetic algorithm. IEEE Trans. Instrum. Meas. 2011, 60, 3318–3325. [Google Scholar] [CrossRef]
- Anwaar, M.U.; Labintcev, E.; Kleinsteuber, M. Compositional learning of image-text query for image retrieval. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual, 5–9 January 2021; pp. 1140–1149. [Google Scholar]
- Wang, S.; Han, J. Automated detection of exterior cladding material in urban area from street view images using deep learning. J. Build. Eng. 2024, 96, 110466. [Google Scholar] [CrossRef]
- Salvador, A.; Giró-i-Nieto, X.; Marqués, F.; Satoh, S.I. Faster r-cnn features for instance search. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 27–30 June 2016; pp. 9–16. [Google Scholar]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 586–595. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Philbin, J.; Chum, O.; Isard, M.; Sivic, J.; Zisserman, A. Object retrieval with large vocabularies and fast spatial matching. In Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition, Minneapolis, MN, USA, 17–22 June 2007; pp. 1–8. [Google Scholar]
- Philbin, J.; Chum, O.; Isard, M.; Sivic, J.; Zisserman, A. Lost in quantization: Improving particular object retrieval in large scale image databases. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.-F. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Kalantidis, Y.; Mellina, C.; Osindero, S. Cross-dimensional weighting for aggregated deep convolutional features. In Proceedings of the Computer Vision–ECCV 2016 Workshops, Amsterdam, The Netherlands, 8–10+15–16 October 2016; Proceedings, Part I 14. Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 685–701. [Google Scholar]
- Pang, S.; Zhu, J.; Wang, J.; Ordonez, V.; Xue, J. Building discriminative CNN image representations for object retrieval using the replicator equation. In Pattern Recognition; Elsevier: Amsterdam, The Netherlands, 2018; Volume 83, pp. 150–160. [Google Scholar]
- Liu, G.H.; Yang, J.Y. Exploiting deep textures for image retrieval. Int. J. Mach. Learn. Cybern. 2023, 14, 483–494. [Google Scholar] [CrossRef]
- Xu, J.; Wang, C.; Qi, C.; Shi, C.; Xiao, B. Unsupervised semantic-based aggregation of deep convolutional features. IEEE Trans. Image Process. 2018, 28, 601–611. [Google Scholar] [CrossRef] [PubMed]
- Gkelios, S.; Boutalis, Y.; Chatzichristofis, S.A. Investigating the vision transformer model for image retrieval tasks. In Proceedings of the 2021 17th International Conference on Distributed Computing in Sensor Systems (DCOSS), Pafos, Cyprus, 14–16 July 2021; pp. 367–373. [Google Scholar]
- Yan, L.; Cui, Y.; Chen, Y.; Liu, D. Hierarchical attention fusion for geo-localization. In Proceedings of the ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 2220–2224. [Google Scholar]
- Xu, Y.; Shamsolmoali, P.; Granger, E.; Nicodeme, C.; Gardes, L.; Yang, J. TransVLAD: Multi-scale attention-based global descriptors for visual geo-localization. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–7 January 2023; pp. 2840–2849. [Google Scholar]
- Lu, F.; Liu, G.H. Image retrieval using contrastive weight aggregation histograms. Digit. Signal Process 2022, 123, 103457. [Google Scholar] [CrossRef]
- Grinberg, M. Flask Web Development; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2018. [Google Scholar]
- Li, Y.; Košecká, J. Uncertainty aware proposal segmentation for unknown object detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 241–250. [Google Scholar]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).