Real-Time Detection of Important Sounds with a Wearable Vibration Based Device for Hearing-Impaired People


Abstract
:1. Introduction
2. Related Works
3. System Description
4. Methods
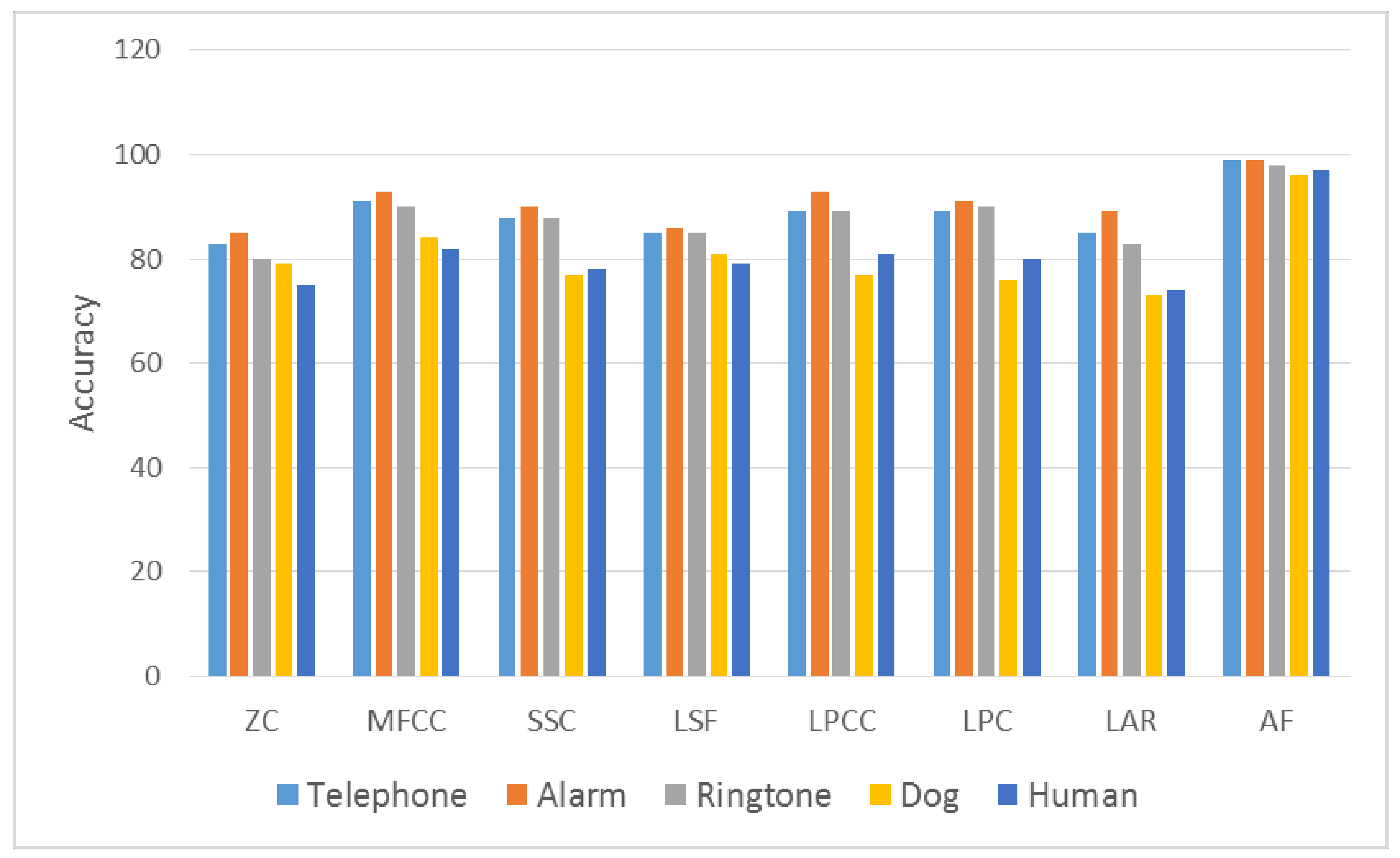
4.1. Zero Crossing Rate
4.2. Mel Scale Cepstrum Coefficients
4.3. Spectral Subband Centroids
4.4. Line Spectral Frequencies
4.5. Linear Prediction Cepstral Coefficients
4.6. Linear Prediction Coefficients
4.7. Log Area Ratio
4.8. K Nearest Neighbors
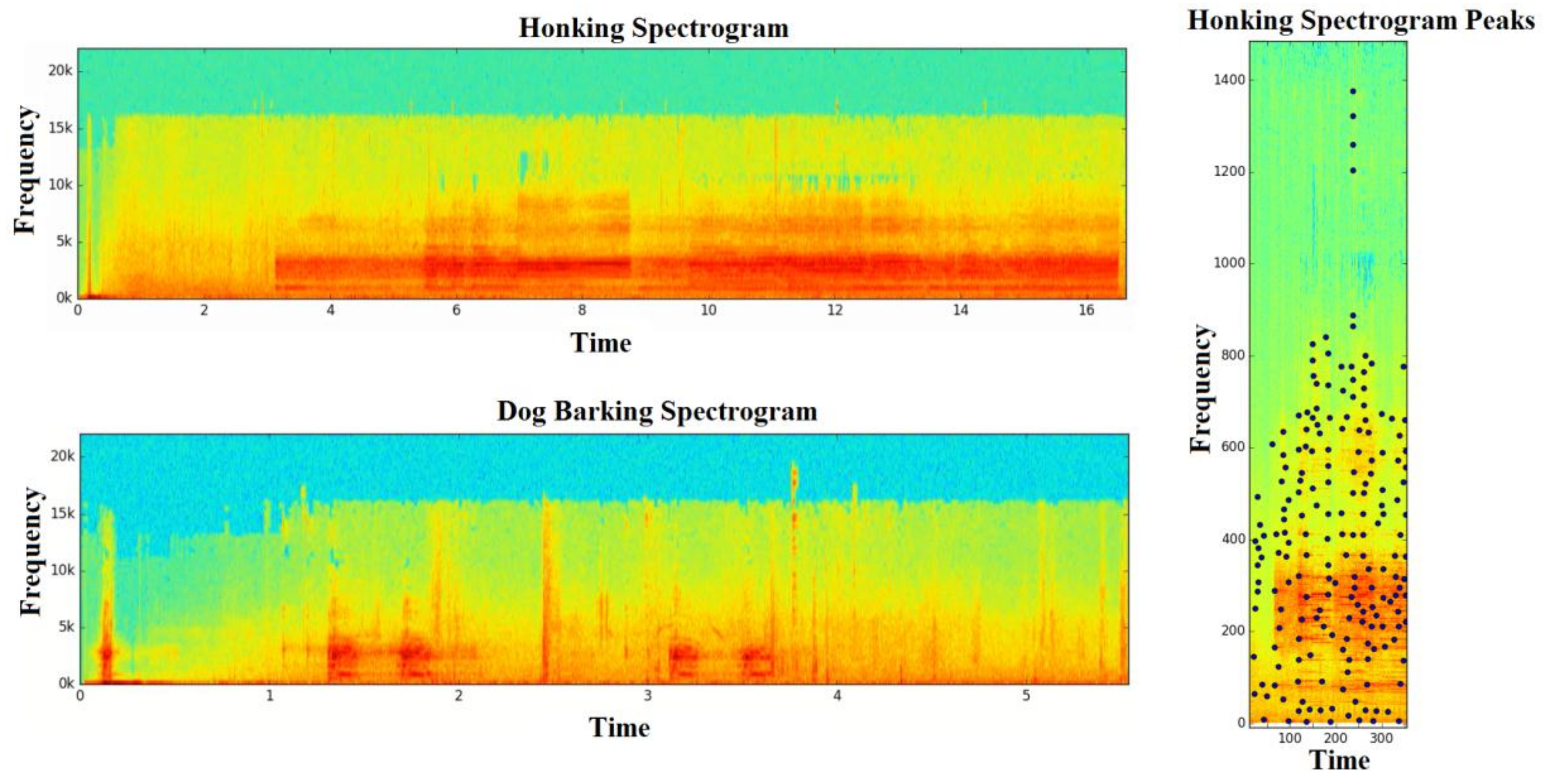
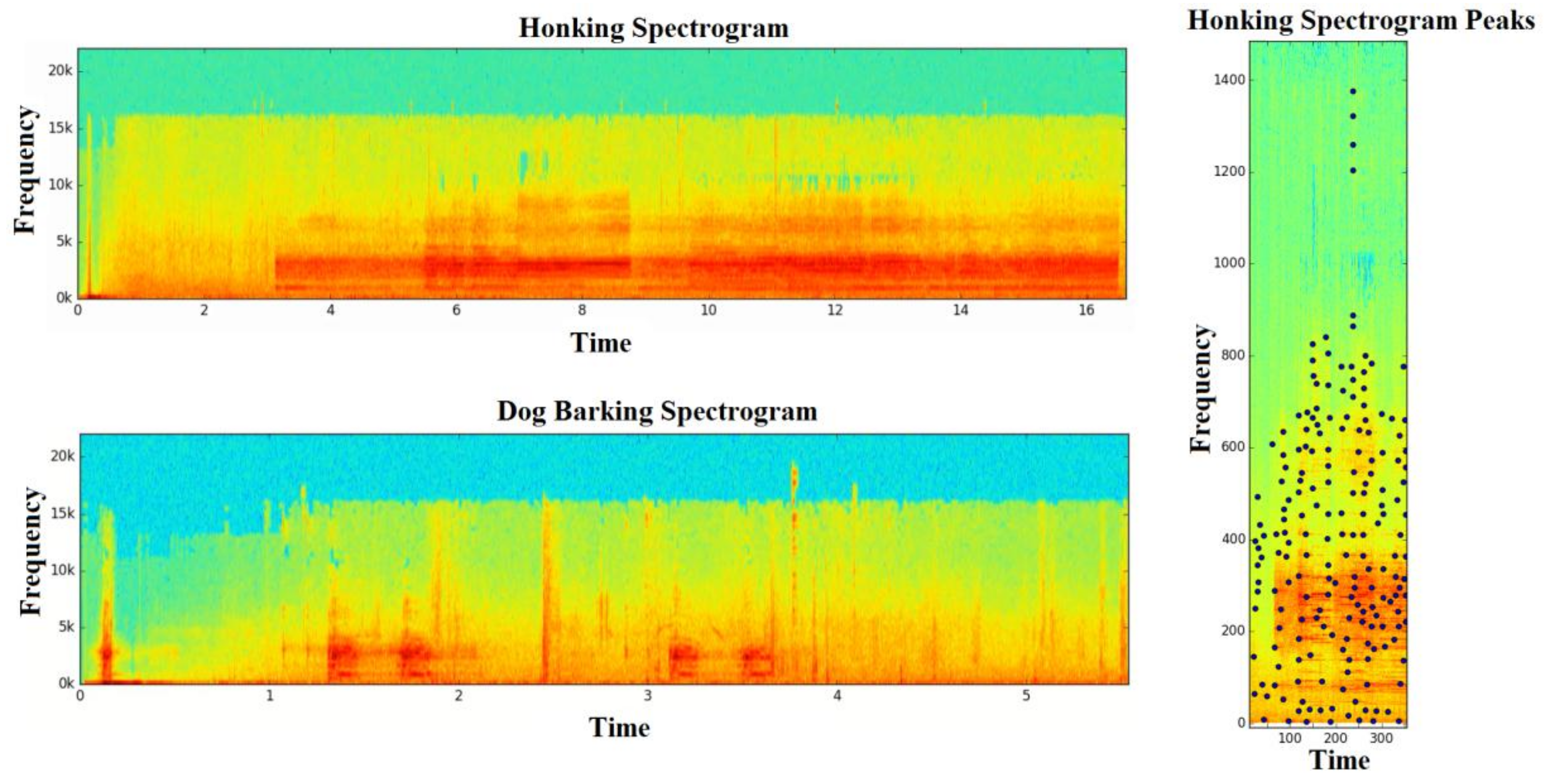
4.9. Audio Fingerprint
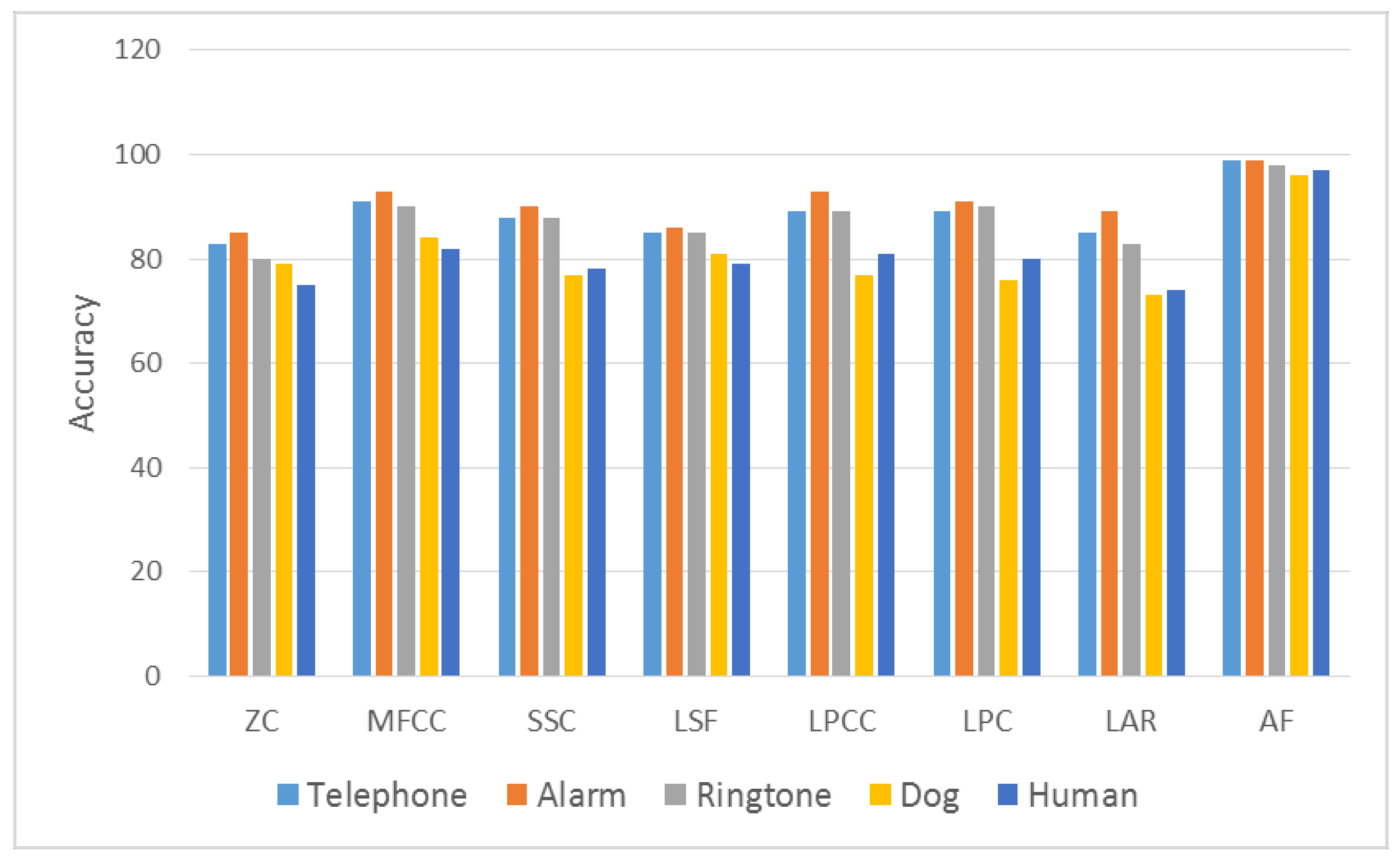
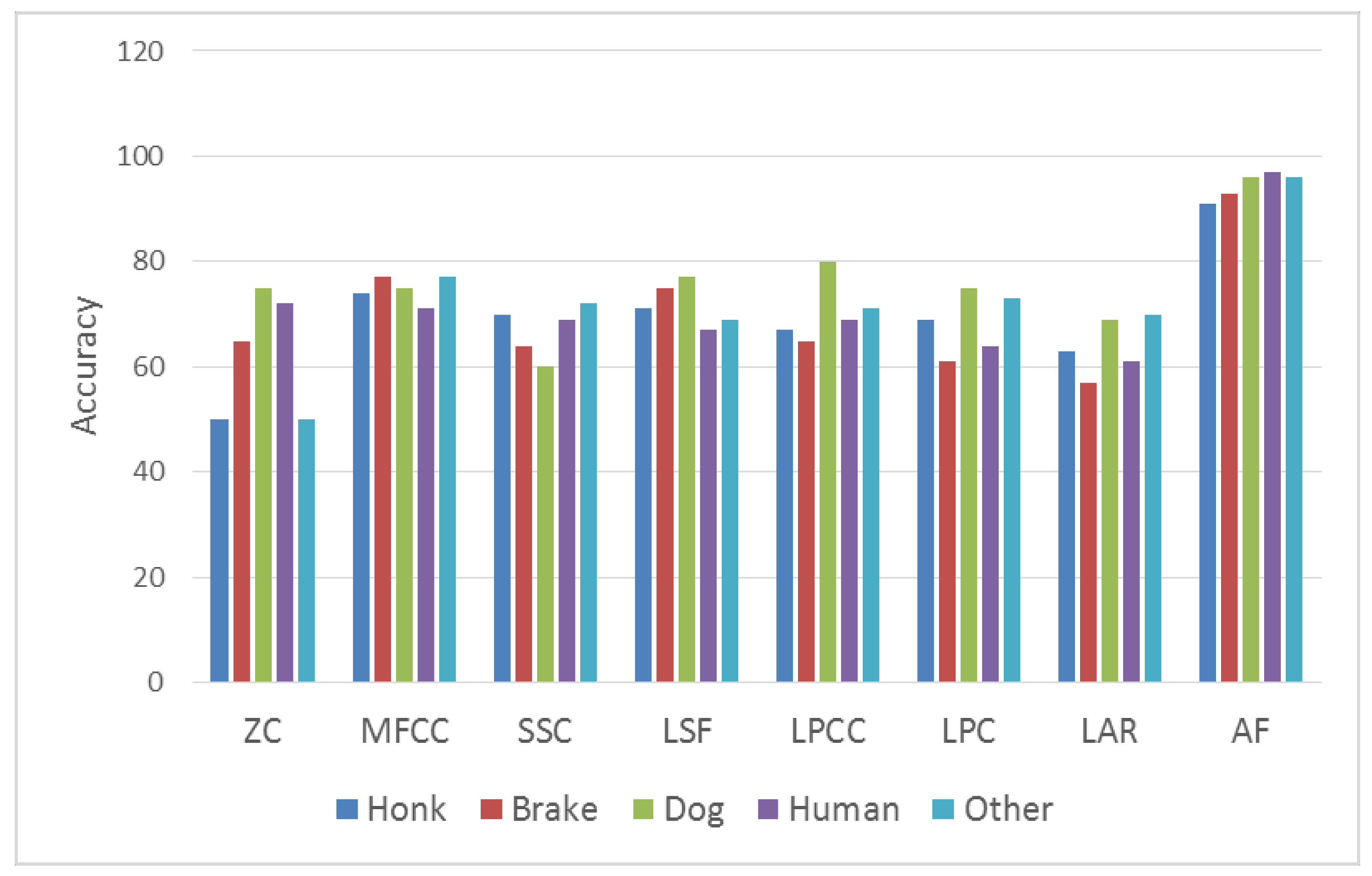
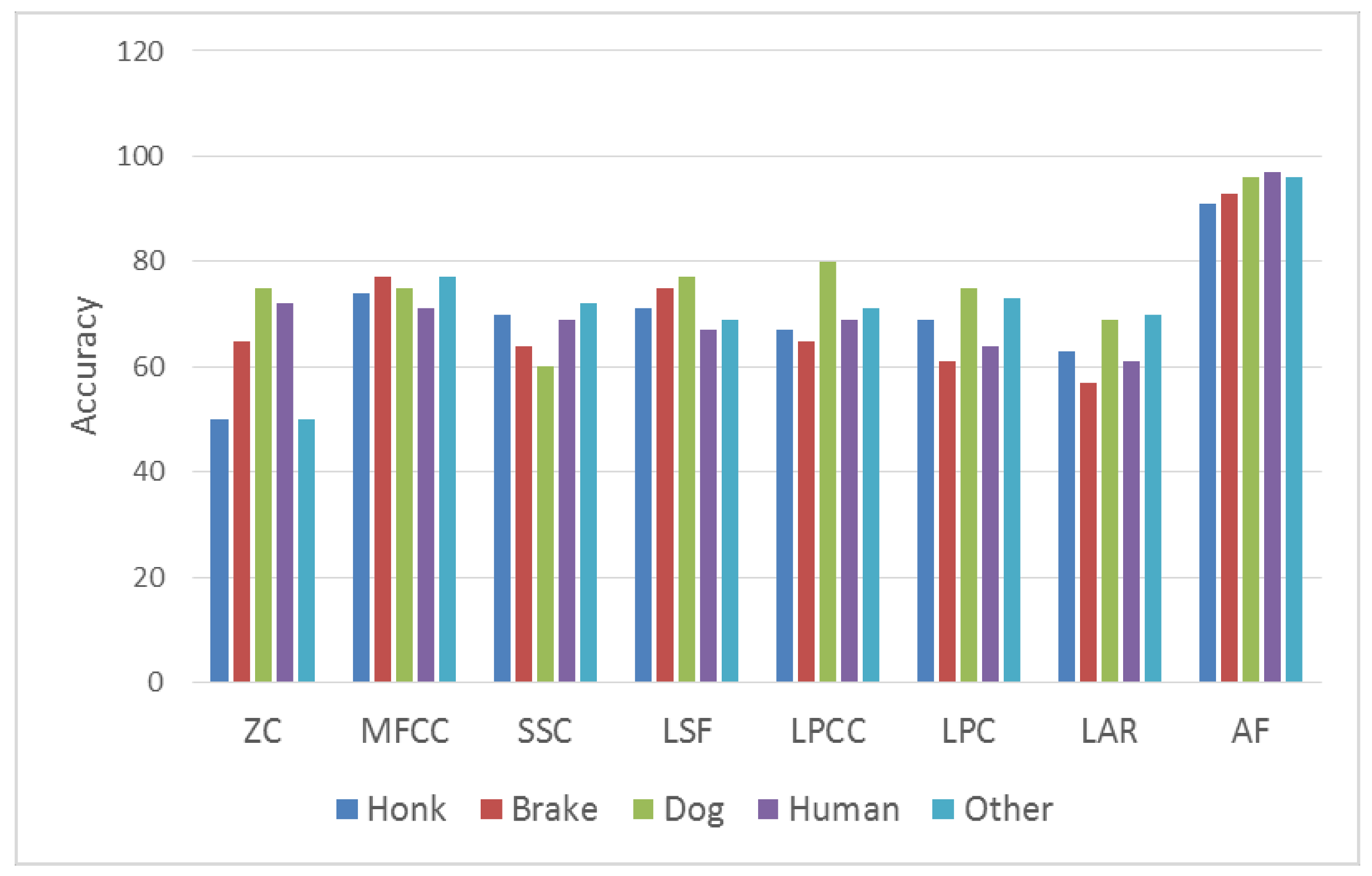
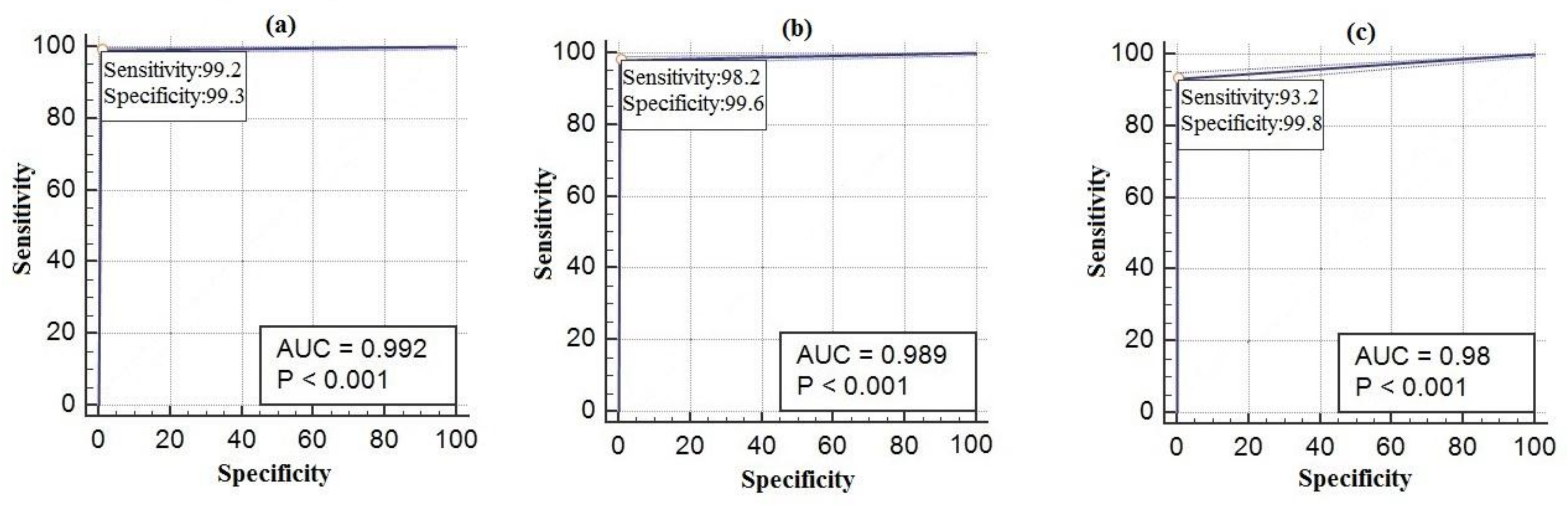
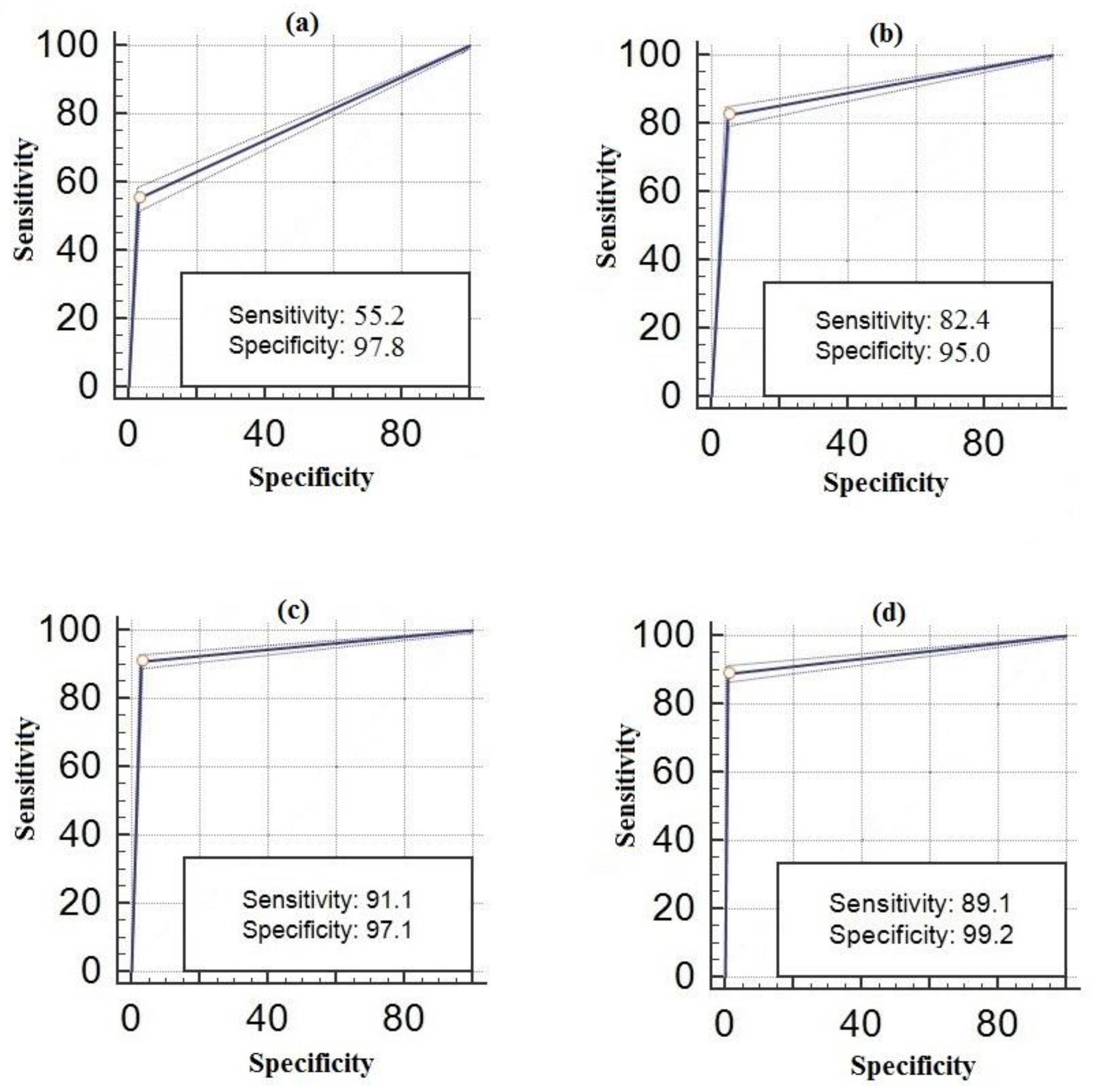
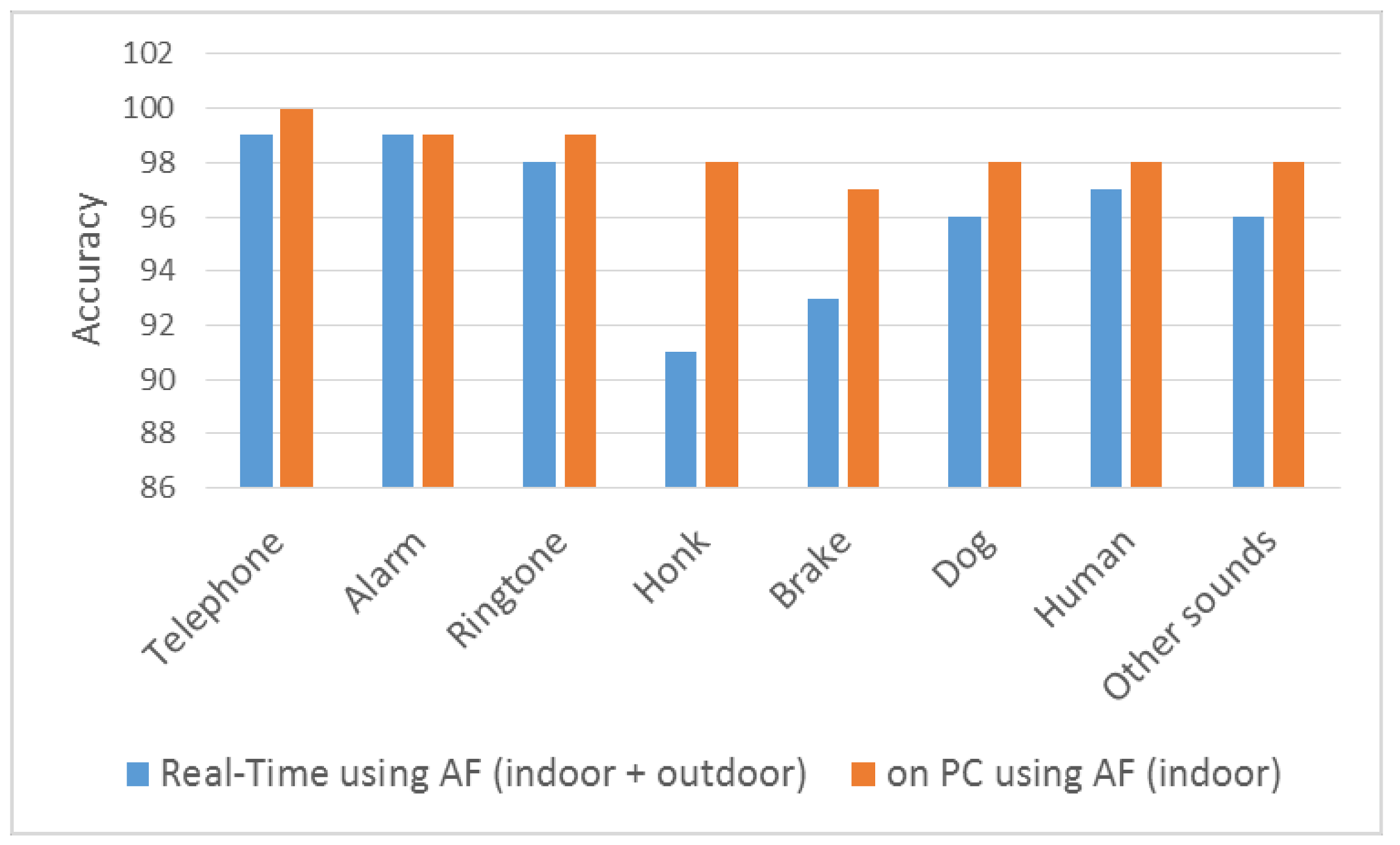
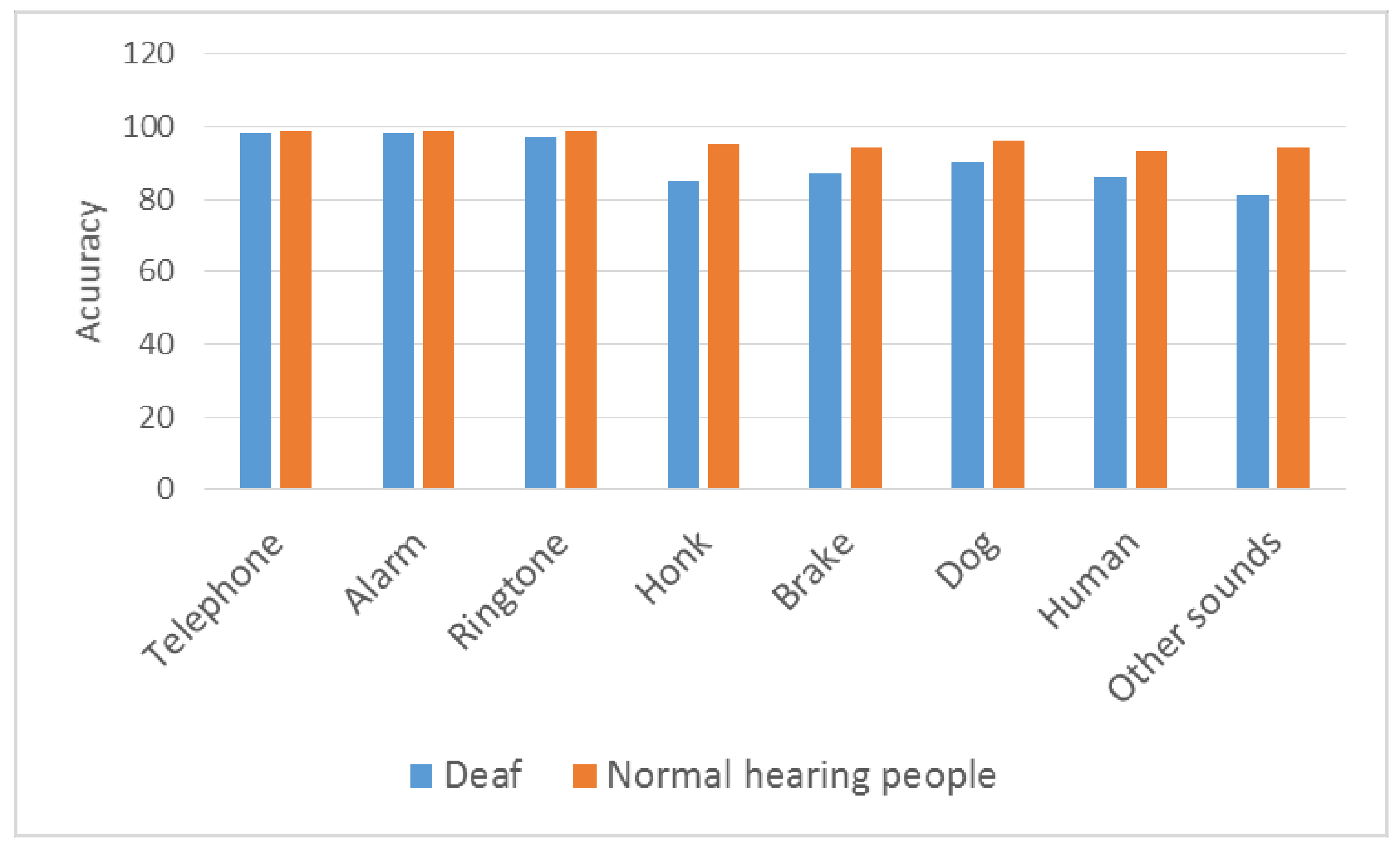
5. Experimental Results
5.1. Test Environment
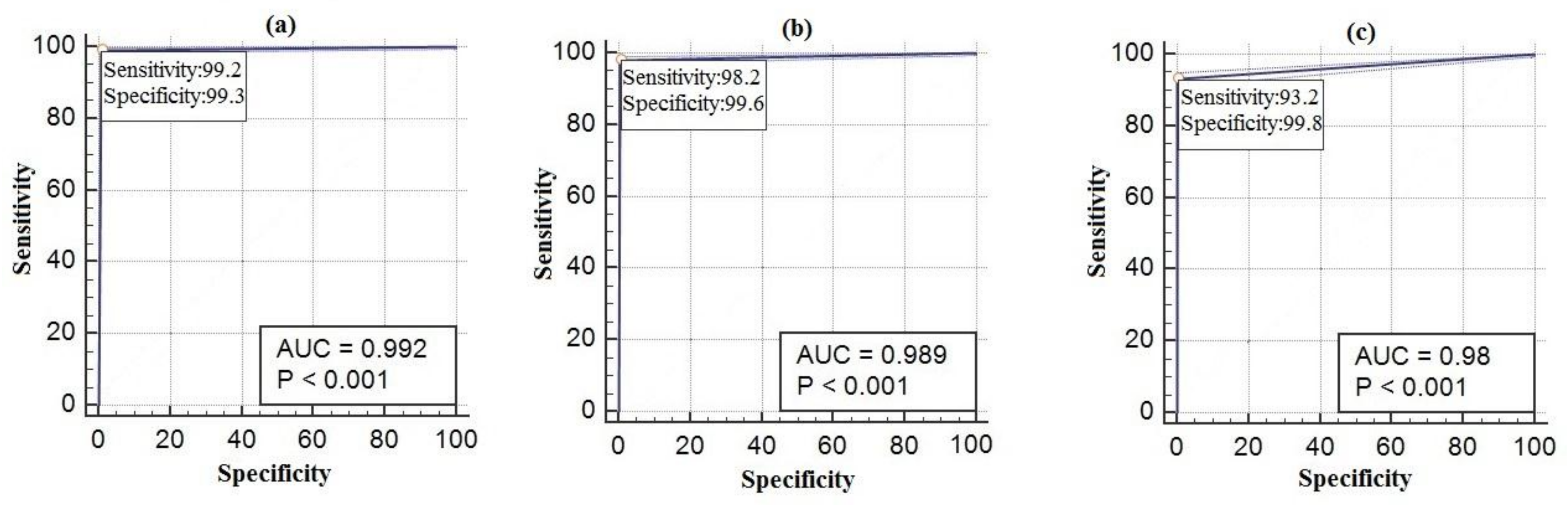
5.2. Performance Criteria
6. Discussion
Author Contributions
Conflicts of Interest
References
- Cornelius, C.; Marois, Z.; Sorber, J.; Peterson, R.; Mare, S.; Kotz, D. Vocal resonance as a passive biometric. Available online: http://www.cs.dartmouth.edu/~dfk/papers/cornelius-voice-tr.pdf (accessed on 1 March 2018).
- Chan, M.; Estève, D.; Fourniols, J.-Y.; Escriba, C.; Campo, E. Smart wearable systems: Current status and future challenges. Artif. Intell. Med. 2012, 56, 137–156. [Google Scholar] [CrossRef] [PubMed]
- Swan, M. Sensor mania! The internet of things, wearable computing, objective metrics, and the quantified self 2.0. J. Sens. Actuator Netw. 2012, 1, 217–253. [Google Scholar] [CrossRef]
- Rawassizadeh, R.; Price, B.A.; Petre, M. Wearables: Has the age of smartwatches finally arrived? Commun. ACM 2015, 58, 45–47. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.; Gunduz, S.; Ozsu, M.T. Mixed Type Audio Classification with Support Vector Machine. In Proceedings of the 2006 IEEE International Conference on Multimedia and Expo, Toronto, ON, Canada, 9–12 July 2006; pp. 781–784. [Google Scholar]
- Kim, H.-G.; Moreau, N.; Sikora, T. Audio classification based on MPEG-7 spectral basis representations. IEEE Trans. Circuits Syst. Video Technol. 2004, 14, 716–725. [Google Scholar] [CrossRef]
- Kiranyaz, S.; Qureshi, A.F.; Gabbouj, M. A generic audio classification and segmentation approach for multimedia indexing and retrieval. IEEE Trans. Audio Speech Lang. Process. 2006, 14, 1062–1081. [Google Scholar] [CrossRef]
- Ma, L.; Milner, B.; Smith, D. Acoustic environment classification. ACM Trans. Speech Lang. Process. 2006, 3, 1–22. [Google Scholar] [CrossRef]
- Eronen, A.J.; Peltonen, V.T.; Tuomi, J.T.; Klapuri, A.P.; Fagerlund, S.; Sorsa, T.; Lorho, G.; Huopaniemi, J. Audio-based context recognition. IEEE Trans. Audio Speech Lang. Process. 2006, 14, 321–329. [Google Scholar] [CrossRef]
- Su, F.; Yang, L.; Lu, T.; Wang, G. Environmental sound classification for scene recognition using local discriminant bases and HMM. In Proceedings of the 19th ACM International Conference on Multimedia, Scottsdale, AZ, USA, 28 November–1 December 2011; pp. 1389–1392. [Google Scholar]
- Wang, J.-C.; Wang, J.-F.; He, K.W.; Hsu, C.-S. Environmental sound classification using hybrid SVM/KNN classifier and MPEG-7 audio low-level descriptor. In Proceedings of the International Joint Conference on Neural Networks, 2006, IJCNN’06, Vancouver, BC, Canada, 16–21 July 2006; pp. 1731–1735. [Google Scholar]
- Reed, C.M.; Delhorne, L.A. The reception of environmental sounds through wearable tactual aids. Ear Hearing 2003, 24, 528–538. [Google Scholar] [CrossRef] [PubMed]
- Chu, S.; Narayanan, S.; Kuo, C.-C.J. Environmental sound recognition with time–frequency audio features. IEEE Trans. Audio Speech Lang. Process. 2009, 17, 1142–1158. [Google Scholar] [CrossRef]
- Alías, F.; Socoró, J.C.; Sevillano, X. A review of physical and perceptual feature extraction techniques for speech, music and environmental sounds. Appl. Sci. 2016, 6, 143. [Google Scholar] [CrossRef]
- Shin, S.-H.; Hashimoto, T.; Hatano, S. Automatic detection system for cough sounds as a symptom of abnormal health condition. IEEE Trans. Inf. Technol. Biomed. 2009, 13, 486–493. [Google Scholar] [CrossRef] [PubMed]
- Schröder, J.; Cauchi, B.; Schädler, M.R.; Moritz, N.; Adiloglu, K.; Anemüller, J.; Doclo, S.; Kollmeier, B.; Goetze, S. Acoustic event detection using signal enhancement and spectro-temporal feature extraction. In Proceedings of the 2013 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA’13), New Paltz, NY, USA, 20–23 October 2013. [Google Scholar]
- Niessen, M.E.; Van Kasteren, T.L.; Merentitis, A. Hierarchical sound event detection. In Proceedings of the 2013 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA’13), New Paltz, NY, USA, 20–23 October 2013. [Google Scholar]
- Kugler, M.; Tossavainen, T.; Nakatsu, M.; Kuroyanagi, S.; Iwata, A. Real-time hardware implementation of a sound recognition system with in-field learning. IEICE Trans. Inf. Syst. 2016, 99, 1885–1894. [Google Scholar] [CrossRef]
- Jeyalakshmi, C.; Krishnamurthi, V.; Revathi, A. Development Of Speech Recognition System For Hearing Impaired In Native language. J. Eng. Res. 2014, 2. [Google Scholar] [CrossRef]
- Sakajiri, M.; Miyoshi, S.; Nakamura, K.; Fukushima, S.; Ifukube, T. Voice pitch control using tactile feedback for the deafblind or the hearing impaired persons to assist their singing. In Proceedings of the 2010 IEEE International Conference on Systems Man and Cybernetics (SMC), Istanbul, Turkey, 10–13 October 2010; pp. 1483–1487. [Google Scholar]
- Kingsbury, B.E.; Morgan, N.; Greenberg, S. Robust speech recognition using the modulation spectrogram. Speech Commun. 1998, 25, 117–132. [Google Scholar] [CrossRef]
- Reynolds, D.A.; Quatieri, T.F.; Dunn, R.B. Speaker verification using adapted Gaussian mixture models. Digit. Signal Process. 2000, 10, 19–41. [Google Scholar] [CrossRef]
- Lozano, H.; Hernáez, I.; Picón, A.; Camarena, J.; Navas, E. Audio classification techniques in home environments for elderly/dependant people. In International Conference on Computers for Handicapped Persons, 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 320–323. [Google Scholar]
- Oberle, S.; Kaelin, A. Recognition of acoustical alarm signals for the profoundly deaf using hidden Markov models. In Proceedings of the 1995 IEEE International Symposium on Circuits and Systems, ISCAS’95, Seatlle, WA, USA, 30 April–3 May 1995; pp. 2285–2288. [Google Scholar]
- Beskow, J.; Granström, B.; Nordqvist, P.; Al Moubayed, S.; Salvi, G.; Herzke, T.; Schulz, A. Hearing at home-communication support in home environments for hearing impaired persons. In Proceedings of the INTERSPEECH 2008, Brisbane, Australia, 22–26 September 2008; pp. 2203–2206. [Google Scholar]
- Seoane, F.; Mohino-Herranz, I.; Ferreira, J.; Alvarez, L.; Buendia, R.; Ayllón, D.; Llerena, C.; Gil-Pita, R. Wearable biomedical measurement systems for assessment of mental stress of combatants in real time. Sensors 2014, 14, 7120–7141. [Google Scholar] [CrossRef] [PubMed]
- Shull, P.B.; Damian, D.D. Haptic wearables as sensory replacement, sensory augmentation and trainer–A review. J. Neuroeng. Rehabilit. 2015, 12, 59. [Google Scholar] [CrossRef] [PubMed]
- Hinton, G.; Deng, L.; Yu, D.; Dahl, G.E.; Mohamed, A.-R.; Jaitly, N.; Senior, A.; Vanhoucke, V.; Nguyen, P.; Sainath, T.N. Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. IEEE Signal Process. Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Salamon, J.; Bello, J.P. Deep convolutional neural networks and data augmentation for environmental sound classification. IEEE Signal Process. Lett. 2017, 24, 279–283. [Google Scholar] [CrossRef]
- Dahl, G.E.; Yu, D.; Deng, L.; Acero, A. Context-dependent pre-trained deep neural networks for large-vocabulary speech recognition. IEEE Trans. Audio Speech Lang. Process. 2012, 20, 30–42. [Google Scholar] [CrossRef]
- Deng, L.; Li, J.; Huang, J.-T.; Yao, K.; Yu, D.; Seide, F.; Seltzer, M.; Zweig, G.; He, X.; Williams, J. Recent advances in deep learning for speech research at Microsoft. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Vancouver, BC, Canada, 26–31 May 2013; pp. 8604–8608. [Google Scholar]
- Sukič, P.; Štumberger, G. Intra-Minute Cloud Passing Forecasting Based on a Low Cost IoT Sensor—A Solution for Smoothing the Output Power of PV Power Plants. Sensors 2017, 17, 1116. [Google Scholar] [CrossRef] [PubMed]
- Laleye, F.A.; Ezin, E.C.; Motamed, C. Fuzzy-based algorithm for Fongbe continuous speech segmentation. Pattern Anal. Appl. 2017, 20, 855–864. [Google Scholar] [CrossRef]
- Baranwal, N.; Nandi, G. An efficient gesture based humanoid learning using wavelet descriptor and MFCC techniques. Int. J. Mach. Learn. Cybern. 2017, 8, 1369–1388. [Google Scholar] [CrossRef]
- Noda, J.J.; Travieso, C.M.; Sánchez-Rodríguez, D. Fusion of Linear and Mel Frequency Cepstral Coefficients for Automatic Classification of Reptiles. Appl. Sci. 2017, 7, 178. [Google Scholar] [CrossRef]
- Paliwal, K.K. Spectral subband centroid features for speech recognition. In Proceedings of the 1998 IEEE International Conference on Acoustics, Speech and Signal Processing, Seattle, WA, USA, 12–15 May 1998; pp. 617–620. [Google Scholar]
- Soong, F.; Juang, B. Line spectrum pair (LSP) and speech data compression. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, ICASSP'84, San Diego, CA, USA, 19–21 March 1984; pp. 37–40. [Google Scholar]
- Sugamura, N.; Farvardin, N. Quantizer design in LSP speech analysis-synthesis. IEEE J. Sel. Areas Commun. 1988, 6, 432–440. [Google Scholar] [CrossRef]
- Gulzar, T.; Singh, A.; Sharma, S. Comparative analysis of LPCC, MFCC and BFCC for the recognition of Hindi words using artificial neural networks. Int. J. Comput. Appl. 2014, 101, 22–27. [Google Scholar] [CrossRef]
- Adeniyi, K.I. Comparative Study on the Performance of Mel-Frequency Cepstral Coefficients and Linear Prediction Cepstral Coefficients under different Speaker's Conditions. Int. J. Comput. Appl. 2014, 90, 38–42. [Google Scholar]
- Chow, D.; Abdulla, W.H. Speaker identification based on log area ratio and gaussian mixture models in narrow-band speech. In PRICAI 2004: Trends in Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2004; pp. 901–908. [Google Scholar]
- Glowacz, A. Diagnostics of DC and induction motors based on the analysis of acoustic signals. Meas. Sci. Rev. 2014, 14, 257–262. [Google Scholar] [CrossRef]
- Yağanoğlu, M.; Köse, C. Wearable Vibration Based Computer Interaction and Communication System for Deaf. Appl. Sci. 2017, 7, 1296. [Google Scholar] [CrossRef]
- Cano, P.; Batle, E.; Kalker, T.; Haitsma, J. A review of algorithms for audio fingerprinting. In Proceedings of the 2002 IEEE Workshop on Multimedia Signal Processing, St. Thomas, VI, USA, 9–11 December 2002; pp. 169–173. [Google Scholar]
- Wang, J.-C.; Lee, Y.-S.; Lin, C.-H.; Siahaan, E.; Yang, C.-H. Robust environmental sound recognition with fast noise suppression for home automation. IEEE Trans. Autom. Sci. Eng. 2015, 12, 1235–1242. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Predicted Class | |||
|---|---|---|---|
| Actual Class | Positive | Negative | |
| Positive | TP (True Positive) | FN (False Negative) | |
| Negative | FP (False Positive) | TN (True Negative) | |
| Telephone | Alarm | Ringtone | Honk | Brake | Dog | Human | Other Sounds | |
|---|---|---|---|---|---|---|---|---|
| Telephone | 1240 | 3 | 7 | 0 | 0 | 0 | 0 | 0 |
| Alarm | 12 | 1228 | 10 | 0 | 0 | 0 | 0 | 0 |
| Ringtone | 48 | 30 | 1165 | 0 | 0 | 0 | 1 | 6 |
| Honk | 0 | 0 | 0 | 690 | 380 | 123 | 7 | 50 |
| Brake | 0 | 0 | 0 | 153 | 1030 | 29 | 8 | 30 |
| Dog | 0 | 0 | 0 | 75 | 14 | 1139 | 5 | 17 |
| Human | 2 | 1 | 1 | 18 | 22 | 35 | 1114 | 57 |
| Other sounds | 0 | 0 | 0 | 15 | 18 | 65 | 53 | 1099 |
| Telephone | Alarm | Ringtone | Honk | Brake | Dog | Human | Other Sounds | |
|---|---|---|---|---|---|---|---|---|
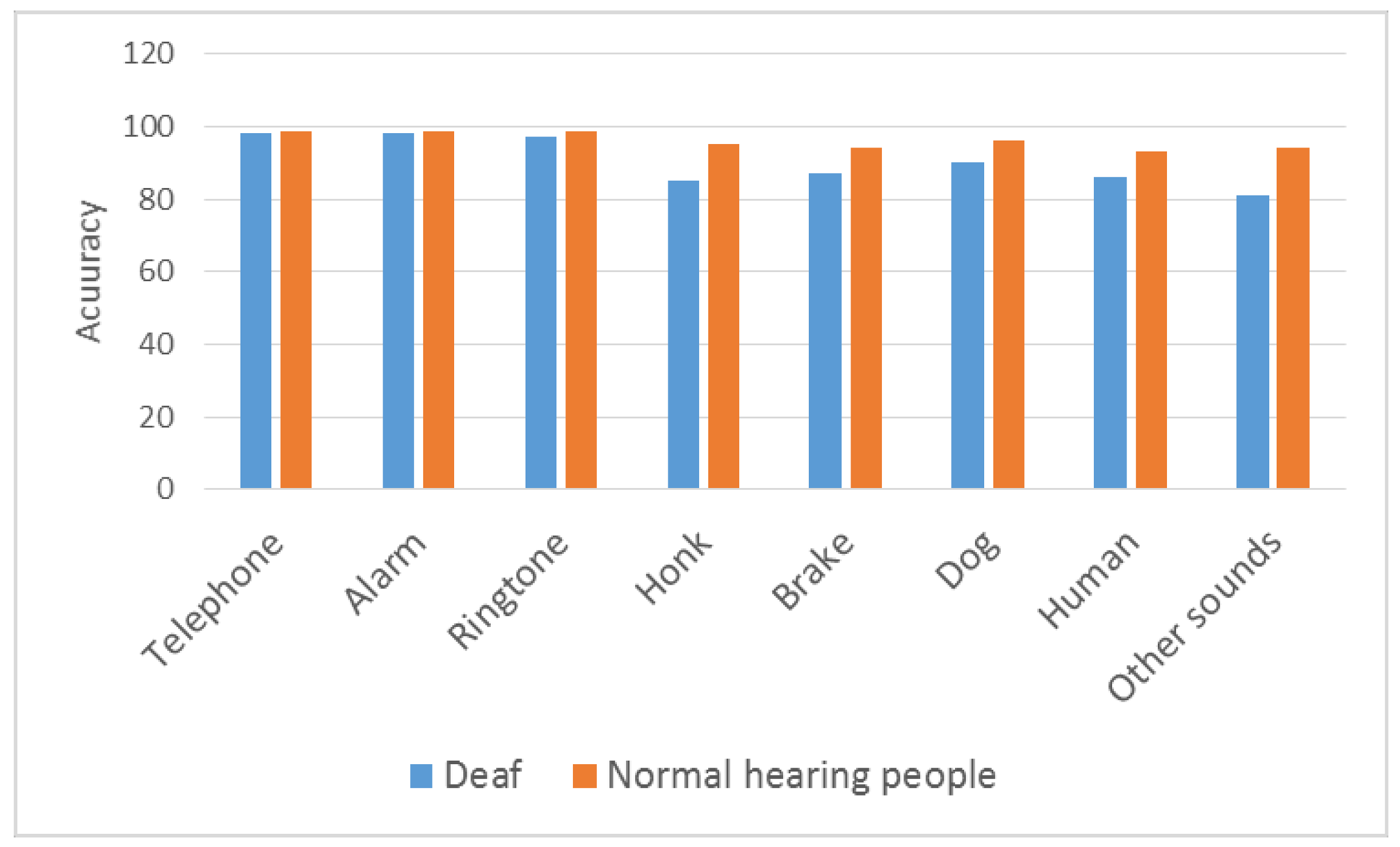
| Accuracy | 0.99 | 0.99 | 0.98 | 0.91 | 0.93 | 0.96 | 0.97 | 0.96 |
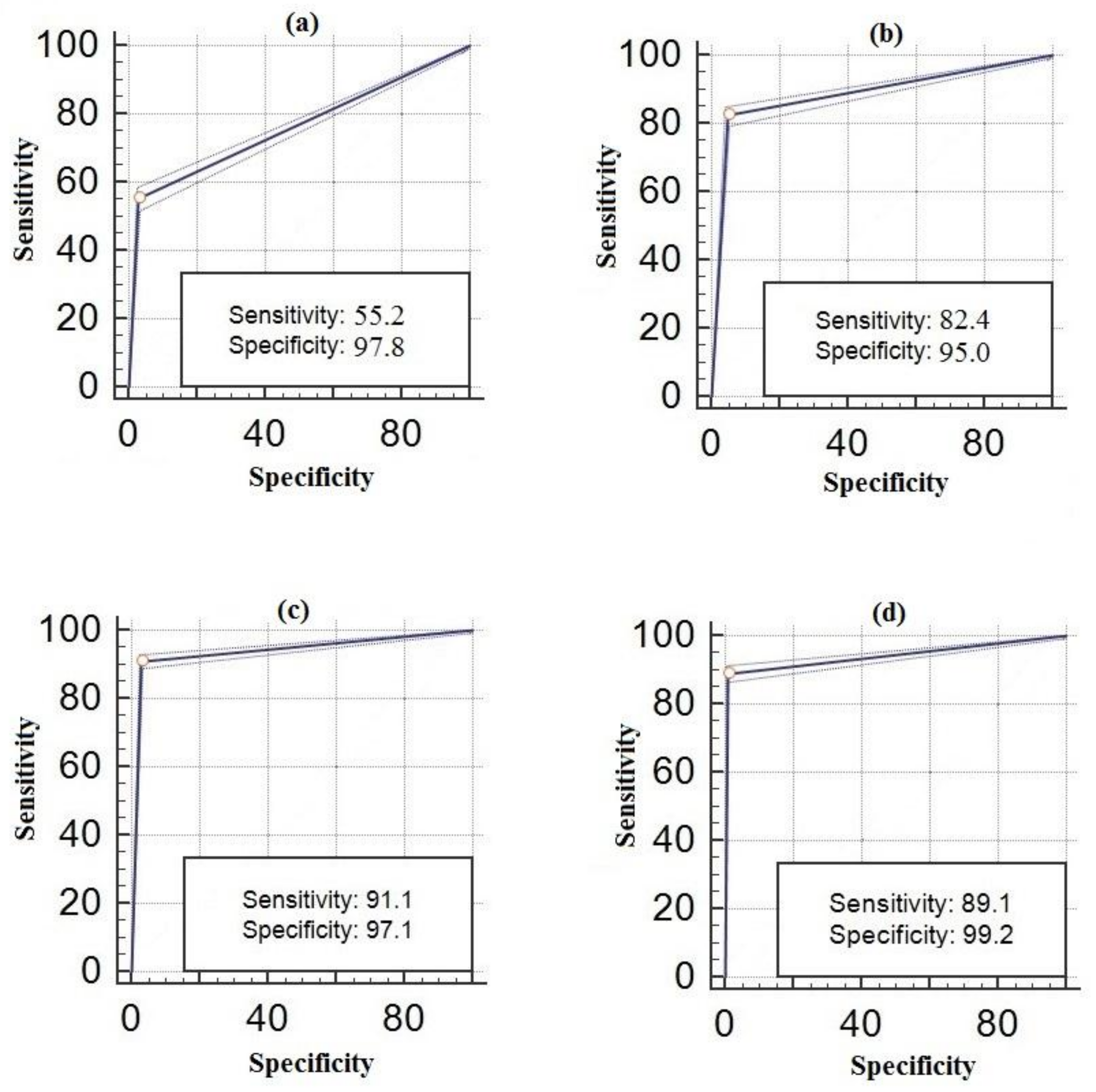
| Sensitivity | 0.99 | 0.98 | 0.93 | 0.55 | 0.82 | 0.91 | 0.89 | 0.87 |
| Specificity | 0.99 | 0.99 | 0.99 | 0.97 | 0.95 | 0.97 | 0.99 | 0.98 |
| General Accuracy | Accuracy (Real Time, Real People or with Noise) | Method | Database | |
|---|---|---|---|---|
| Ma et al. [9] | 92% | 35% | MFCC + HMM | 12 kinds of acoustic environment, 10 different acoustic environments |
| Eronen et al. [10] | 69% | 58% | HMM, KNN | 225 real-world recordings, 24 different contexts |
| Su et al. [11] | 81% | %28.6 | Local Discriminant Bases | 10 audio scenes and 21 sound events |
| Wang et al. [12] | 85.1% | DVM + KNN | 12 common kinds of home environmental sound (totally 527 sound files) | |
| Wang et al. [46] | 89.78% (Clean Sound) | 84.25% (SNR: 15 dB) | MFCC | 469 sound files (10 Classes) |
| Wang et al. [46] | 90.63% (Clean Sound) | 88.51% (SNR: 15 dB) | Wavelet Subspace-based | 469 sound files (10 Classes) |
| Our study | 98% (Clean Sound) | 90% (SNR: 15 dB) | Audio Fingerprint | 10,000 sound (8 Classes) |
| Our study | 98% (Clean Sound) | 94% (SNR: average 20 dB) | Audio Fingerprint | 10,000 sound (8 Classes) |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yağanoğlu, M.; Köse, C. Real-Time Detection of Important Sounds with a Wearable Vibration Based Device for Hearing-Impaired People. Electronics 2018, 7, 50. https://doi.org/10.3390/electronics7040050
Yağanoğlu M, Köse C. Real-Time Detection of Important Sounds with a Wearable Vibration Based Device for Hearing-Impaired People. Electronics. 2018; 7(4):50. https://doi.org/10.3390/electronics7040050
Chicago/Turabian StyleYağanoğlu, Mete, and Cemal Köse. 2018. "Real-Time Detection of Important Sounds with a Wearable Vibration Based Device for Hearing-Impaired People" Electronics 7, no. 4: 50. https://doi.org/10.3390/electronics7040050
APA StyleYağanoğlu, M., & Köse, C. (2018). Real-Time Detection of Important Sounds with a Wearable Vibration Based Device for Hearing-Impaired People. Electronics, 7(4), 50. https://doi.org/10.3390/electronics7040050