Study on Consulting Air Combat Simulation of Cluster UAV Based on Mixed Parallel Computing Framework of Graphics Processing Unit

Abstract
:1. Introduction
2. Related Work
3. Best Solution to Consulting Air Combat of Clusters
- The grouping principle of converting large-scale air combat into fleet operations;
- Optimize the target of fleet attack using negotiation theory;
- Optimize in-team marshalling by negotiation theory;
- The role of individuals in the fleet;
- Individual air combat within the fleet, using the game theory to find the best chase/escape strategy.
3.1. Cluster Air Combat Turned into Multiple Fleet Operations
3.2. Fleet Negotiation
- (1)
- Offensive and assist roles in air combat: if the joint strikes, each UAV will play a different role in the combat group, and the better superiority value is (relatively dominant) the offensive UAV, and the rest will be an assistant. As the main attacker has a better value, the enemy has less chance of winning. In contrast, the enemy has a greater chance of winning again the assisting UAV which has a lower advantage. To make the superiority better, the enemy should compete against the assisting UAV to increase the advantage value with the best strategy. From our point of view, the assisting UAV at this time has deterred the threat of the enemy UAV. Therefore, the main attacker can ignore the threat which poses to him and use a single-player tactic to attack the enemy aircraft boldly. This is a dare to or impossible tactic during one-on-one air combat, which has increased the kill rate as a whole. The main attack and assist role are determined by in (22), the biggest one is the main attack, and the rest are assists. The strategy of the assisting machine uses (25) to find the best decision; while the remaining one is the main attacker, at this time, look for the strategy to minimize the value in (23). The flow chart for the role of the main attacker and assistant determined is shown in Figure 4.
- (2)
- Situational assessment: this is mainly determined by the superiority value of the UAV. If the superiority value is superior, then the role is the attacker, otherwise it is the evasion side. If the sum of the advantage values is required to be the largest, the UAVs will only focus on the attack. When the UAV is at a disadvantage and is possible shot down, the advantage value will be very small, and the unmanned aerial vehicle will not focus on the most threatening UAV but it will attack another UAV to increase its advantage value. This kind of unreasonable phenomenon needs to be corrected by judging the superiority value. The flow chart for situational assessment is shown in Figure 4. Assuming that now the superiority value for is at a disadvantage, should escape directly. If is on a very disadvantageous position, the other aircraft will help escape and pin down the enemy to increase ’s chances of escape.
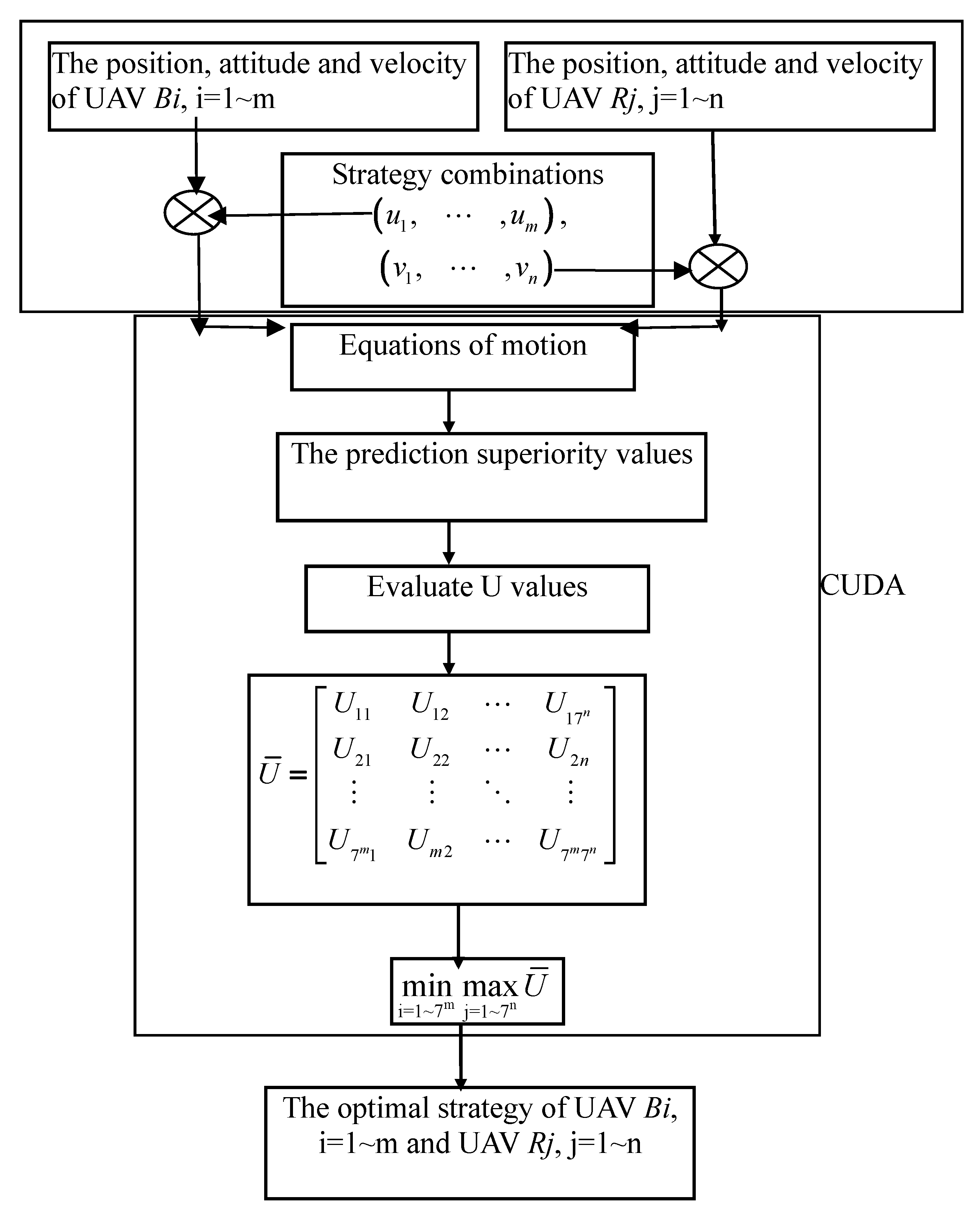
4. Using MATLAB/CUDA to Accelerate the Best Solution
extern “C” void g_kel(float* input, float &output, int &ind, int num ); #include <iostream> using namespace std; __device__ void cuMAX(float& a, float& b, int &c, int &d) { if (b>a) { a=b; c=d; }} __global__ void cuscanmax1(float* indata, float* outdata, int* index, int n) { int t=threadIdx.x; int b=blockIdx.x; int bdim=blockDim.x; int gdim=gridDim.x; int m=bdim*gdim; float stand = -99999999.0f; __shared__ float w[512]; __shared__ int s[512]; w[t] = stand; s[t] = 0; __syncthreads(); for (int k=bdim*b+t; k<n; k+=m) cuMAX(w[t], indata[k], s[t], k); __syncthreads(); if (t<256) cuMAX(w[t], w[t+256], s[t], s[t+256]); __syncthreads(); if (t<128) cuMAX(w[t], w[t+128], s[t], s[t+128]); __syncthreads(); if (t<64) cuMAX(w[t], w[t+64], s[t], s[t+64]); __syncthreads(); if (t<32) cuMAX(w[t], w[t+32], s[t], s[t+32]); if (t<16) cuMAX(w[t], w[t+16], s[t], s[t+16]); if (t<8) cuMAX(w[t], w[t+8], s[t], s[t+8]); if (t<4) cuMAX(w[t], w[t+4], s[t], s[t+4]); if (t<2) cuMAX(w[t], w[t+2], s[t], s[t+2]); if (t<1) cuMAX(w[t], w[t+1], s[t], s[t+1]); __syncthreads(); if (t==0) { outdata[b] = w[0]; index[b] = s[0]; }} __global__ void cuscanmax2(float* indata, float* outdata, int* index, int n) { int t=threadIdx.x; __syncthreads(); if (t<256) cuMAX(indata[t], indata[t+256], index[t], index[t+256]); __syncthreads(); if (t<128) cuMAX(indata[t], indata[t+128], index[t], index[t+128]); __syncthreads(); if (t<64) cuMAX(indata[t], indata[t+64], index[t], index[t+64]); __syncthreads(); if (t<32) cuMAX(indata[t], indata[t+32], index[t], index[t+32]); if (t<16) cuMAX(indata[t], indata[t+16], index[t], index[t+16]); if (t<8) cuMAX(indata[t], indata[t+8], index[t], index[t+8]); if (t<4) cuMAX(indata[t], indata[t+4], index[t], index[t+4]); if (t<2) cuMAX(indata[t], indata[t+2], index[t], index[t+2]); if (t<1) cuMAX(indata[t], indata[t+1], index[t], index[t+1]); __syncthreads(); outdata[0] = indata[0]; } void g_kel(float* input, float &output, int &ind, int num ) { float *cudainput, *cudaoutput; int *cudaindex; int sizedata = 4 * num; cudaMalloc((void**)&cudainput, sizedata); cudaMalloc((void**)&cudaoutput, 2048); cudaMalloc((void**)&cudaindex, 2048); cudaMemcpy(cudainput, input, sizedata, cudaMemcpyHostToDevice); cuscanmax1<<< 512, 512 >>>( cudainput, cudaoutput, cudaindex, num); cuscanmax2<<< 1, 512 >>>( cudaoutput, cudaoutput, cudaindex, 512); cudaMemcpy(&output, cudaoutput, 4, cudaMemcpyDeviceToHost); cudaMemcpy(&ind, cudaindex, 4, cudaMemcpyDeviceToHost); cudaFree(cudainput); cudaFree(cudaoutput); cudaFree(cudaindex); }
#include “mex.h” #include <omp.h> extern “C” void g_kel(float* input, float &output, int &ind, int num ); void FloatToDouble(double *data_D, float *data_F, int size_N) { #pragma omp parallel for for (int k = 0; k < size_N; k++) data_D[k] = (double) data_F[k]; } void DoubleToFloat(float *data_F, double *data_D, int size_N) { #pragma omp parallel for for (int k = 0; k < size_N; k++) data_F[k] = (float) data_D[k]; } void mexFunction( int nlhs, mxArray *plhs[], int nrhs, const mxArray *prhs[]) { int n1, datasize, index; double *mA_D, *mB_D, *mC_D; float *mA_F, oub; if (nlhs > 2) mexErrMsgTxt(“Only two return values.”); if (nrhs != 1) mexErrMsgTxt(“Require 1 input vectors.”); if (mxIsComplex(prhs[0])) mexErrMsgTxt(“Not for complex value.”); if (mxGetM(prhs[0]) != 1) mexErrMsgTxt(“Only for row vector.”); n1 = mxGetN(prhs[0]); datasize = sizeof(float) * n1; plhs[0] = mxCreateDoubleMatrix(1, 1, mxREAL); plhs[1] = mxCreateDoubleMatrix(1, 1, mxREAL); mA_D = mxGetPr(prhs[0]); mB_D = mxGetPr(plhs[0]); mC_D = mxGetPr(plhs[1]); mA_F = (float *) mxMalloc(datasize); DoubleToFloat(mA_F, mA_D, n1); g_kel(mA_F, oub, index, n1); mB_D[0] = (float)oub; mC_D[0] = (int)index + 1; mxFree(mA_F); }
5. Simulation Results
5.1. Consulting Air Combat Simulation of 2 × 2
5.2. Performance Evaluation Using Decentralized Calculations
5.3. Performance Evaluation Using GPGPU
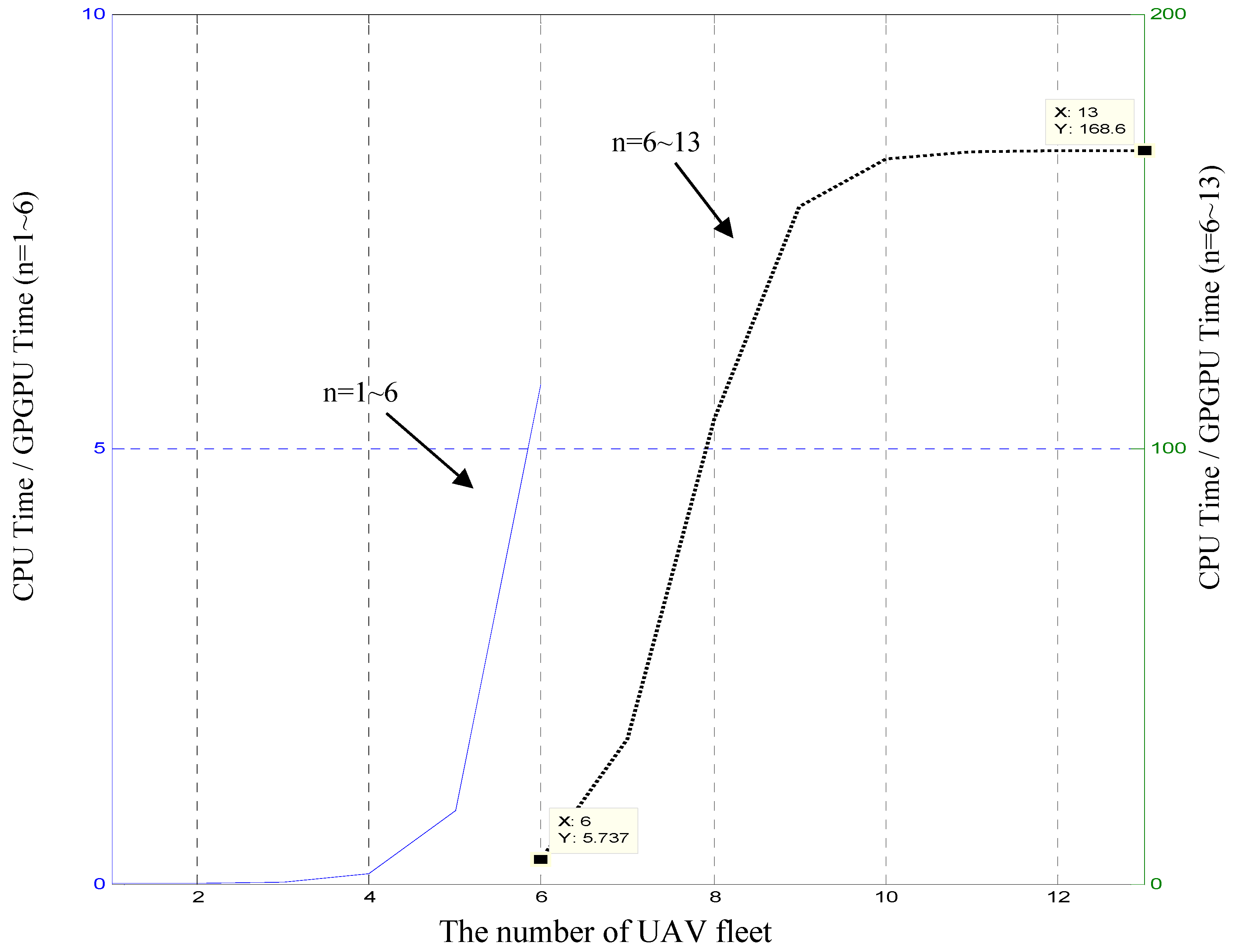
5.4. Ultimate Performance Ratio of CPU/GPGPU
5.5. Performance Comparison of Single Core with Integrated Parallelization
- (1)
- The number of clusters is too small to really exert the computing power that the GPGPU should have.
- (2)
- In the process of simulation, each time the loop must transfer data from the memory on the motherboard to the memory on the GPGPU, it will waste a lot of time;
- (3)
- In the current hardware of GPGPU, the calculation core of single precision floating point operation is more than the calculation core of double precision floating point operation. For GTX285, the operation core of single precision floating point number is 240, but the operation core of double precision floating point number is only 30, which is eight times worse, so in the MATLAB environment, double precision must be converted to single precision, so it will increase a lot of time to do this conversion;
- (4)
- Parallel computing has its disadvantages to determine the maximum value. In a single core algorithm, we use the zeroth element as a basis to compare with other elements. Therefore, we only need to read other elements, and then write the result to the zeroth element, so only one reading and one writing. However, in the framework of parallelism, the action of comparing two data is double reading and one writing. Therefore, the algorithm of the parallel operation is inherently more computationally intensive than the single-core operation.
6. Conclusions
Funding
Acknowledgments
Conflicts of Interest
References
- Austin, F.; Carbone, G.; Hinz, H.; Lewis, M.; Falco, M. Game theory for automated maneuvering during air-to-air combat. J. Guid. Control Dyn. 1990, 13, 1143–1147. [Google Scholar] [CrossRef]
- Burgin, G.; Sidor, L.B. Rule-Based Air Combat Simulation; Technical Report, TITAN-TLJ-H-1501; Titan Systems Inc.: La Jolla, CA, USA, 1988. [Google Scholar]
- Virtanen, K.; Karelahti, J.; Raivio, T. Modeling air combat by a moving horizon influence diagram game. J. Guid. Control Dyn. 2006, 29, 1080–1091. [Google Scholar] [CrossRef]
- Virtanen, K.; Raivio, T.; Hamalainen, R.P. Modeling pilot’s sequential maneuvering decisions by a multistage influence diagram. J. Guid. Control Dyn. 2004, 27, 665–677. [Google Scholar] [CrossRef]
- Xie, R.Z.; Li, J.Y.; Luo, D.L. Research on maneuvering decisions for Multi-UAVs air combat. In Proceedings of the 2014 IEEE International Conference Control & Automation, Taichung, Taiwan, 18–20 June 2014; pp. 767–772. [Google Scholar]
- Pan, Q.; Zhou, D.; Huang, J.; Lv, X.; Yang, Z.; Zhang, K.; Li, X. Maneuver decision for cooperative close-range air combat based on state predicted influence diagram. In Proceedings of the 2017 IEEE International Conference on Information and Automation, Macau, China, 18 July 2017; pp. 726–731. [Google Scholar]
- Liu, B. Air combat decision making for coordinated multiple target attack using combinatorial auction. Acta Aeronaut. Astronaut. Sin. 2010, 31, 1433–1444. [Google Scholar]
- Song, X.; Jiang, J.; Xu, H. Application of improved simulated annealing genetic algorithm in cooperative air combat. J. Harbin Eng. Univ. 2017, 38, 1762–1768. [Google Scholar]
- Ding, Y.; Yang, L.; Hou, J.; Jin, G.; Zhen, Z. Multi-target collaborative combat decision-making by improved particle swarm optimizer. Trans. Nanjing Univ. Aeronaut. Astronaut. 2018, 35, 181–187. [Google Scholar]
- Sun, T.Y.; Tsai, S.J.; Huo, C.L. Intelligent maneuvering decision system for computer generated forces using predictive fuzzy inference system. J. Comput. 2008, 3, 58–66. [Google Scholar] [CrossRef]
- Roessingh, J.J.; Merk, R.J.; Huibers, P.; Meiland, R.; Rijken, R. Smart bandits in air-to-air combat training: Combining different behavioural models in a common architecture. In Proceedings of the 21st Annual Conference on Behavior Representation in Modeling and Simulation, Amelia Island, FI, USA, 12–15 March 2012. [Google Scholar]
- McGrew, J.S.; How, J.P.; Williams, B.; Roy, N. Air-combat strategy using approximate dynamic programming. J. Guid. Control Dyn. 2012, 33, 1641–1654. [Google Scholar] [CrossRef] [Green Version]
- Teng, T.H.; Tan, A.H.; Tan, Y.S.; Yeo, A. Self-organizing neural networks for learning air combat maneuvers. In Proceedings of the 2012 International Joint Conference on Neural Networks, Brisbane, Australia, 10–15 June 2012; pp. 1–8. [Google Scholar]
- Liu, P.; Ma, Y. A Deep reinforcement learning based intelligent decision method for UCAV air combat. In Proceedings of the 17th Asia Simulation Conference, Melaka, Malaysia, 27–29 August 2017; pp. 274–286. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; Van Den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef] [PubMed]
- Luo, P.C.; Xie, J.J.; Che, W.F. Q-learning based air combat target assignment algorithm. In Proceedings of the 2016 IEEE International Conference on Systems, Man, and Cybernetics, Budapest, Hungary, 9–12 October 2016; pp. 779–783. [Google Scholar]
- Zuo, J.; Yang, R.; Zhang, Y.; Li, Z.; Wu, M. Intelligent decision-making in air combat maneuvering based on heuristic reinforcement learning. Acta Aeronaut. Astronaut. Sin. 2017, 38, 217–230. [Google Scholar]
- Xu, G.; Zhou, B.; Zhang, H. Multi-player nonzero-sum Nash differential game: Variation and pseudo-spectral method. Optim. Control Appl. Methods 2017, 38, 506–519. [Google Scholar] [CrossRef]
- Sheng, W.; Li, J.; Tong, M.G. Research of differential game theory for multiple consulting air combat. Syst. Eng. Electron. 1998, 20, 7–11. [Google Scholar]
- Wei, S.; Mingan, T.; Honglun, W.; Jianxun, L. Decision and information fusion in multiple air combat. J. Beijing Univ. Aeronaut. Astronaut. 1999, 25, 665–667. [Google Scholar]
- Li, Q.; Yang, R.; Li, H.; Zhang, H.; Feng, C. Research on the non-cooperative game strategy of suppressing IADS for multiple fighters cooperation. J. Xidian Univ. 2017, 44, 129–137. [Google Scholar]
- Selvakumar, J.; Bakolas, E. Evasion with Terminal Constraints from a Group of Pursuers using a Matrix Game Formulation. In Proceedings of the 2017 American Control Conference, Seattle, WA, USA, 24–26 May 2017; pp. 1604–1609. [Google Scholar]
- Xu, H.; Xing, Q.; Wang, W. WTA for air and missile defense based on fuzzy multi-objective programming. Syst. Eng. Electron. 2018, 40, 563–570. [Google Scholar]
- Zhang, Y.; Wu, W.; Wang, J. Interval valued intuitionistic fuzzy Petri net and its application in air combat decision making. Syst. Eng. Electron. 2017, 39, 1051–1057. [Google Scholar]
- Vladimir, T.; Kim, D.H.; Ha, Y.G.; Jeon, D.W. Fast multi-line detection and tracking with CUDA for vision-based UAV autopilot. In Proceedings of the 8th International Conference on Innovative Mobile and Internet Services in Ubiquitous Computing, Birmingham, UK, 2–4 July 2014; pp. 96–101. [Google Scholar]
- Hossain, R.; Magierowski, S.; Messier, G.G. GPU enhanced path finding for an unmanned aerial vehicle. In Proceedings of the IEEE 28th International Parallel and Distributed Processing Symposium Workshops, Phoenix, AZ, USA, 19–23 May 2014; pp. 1285–1293. [Google Scholar]
- Cekmez, U.; Ozsiginan, M.; Sahingoz, O.K. Multi-UAV path planning with parallel genetic algorithms on CUDA architecture. In Proceedings of the Genetic and Evolutionary Computation Conference, Denver, CO, USA, 20–24 July 2016; pp. 1079–1086. [Google Scholar]
- Bonelli, F.; Tuttafesta, M.; Colonna, G.; Cutrone, L.; Pascazio, G. An MPI-CUDA approach for hypersonic flows with detailed state-to-state air kinetics using a GPU cluster. Comput. Phys. Commun. 2017, 219, 178–195. [Google Scholar] [CrossRef]
- Rudianto, I. Spectral-element simulation of two-dimensional elastic wave propagation in fully heterogeneous media on a GPU cluster. In Proceedings of the International Conference on Theoretical and Applied Physics, Vienna, Austria, 2–3 July 2018. [Google Scholar]
- Vigmond, E.J. Near-real-time simulations of biolelectric activity in small mammalian hearts using graphical processing units. In Proceedings of the Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Minneapolis, MN, USA, 3–6 September 2009. [Google Scholar]
- Yang, Z.; Zhu, Y.; Pu, Y. Parallel image processing based on CUDA. In Proceedings of the International Conference on Computer Science and Software Engineering, Hubei, China, 12–14 December 2008. [Google Scholar]
- Grant, M.; Boyd, S. CVX: Matlab Software for Disciplined Convex Programming, Version 2.1. 2017. Available online: Cvxr.com/cvx (accessed on 22 August 2018).
- Sun, Y.Q.; Zhou, X.C.; Meng, S. Research on maneuvering decision for multi-fighter cooperative air combat. In Proceedings of the International Conference on Intelligent Human-Machine Systems and Cybernetics, Hangzhou, China, 26–27 August 2009; pp. 197–200. [Google Scholar]
- Kung, C.C.; Chiang, F.L. A study of missile maximum capture area and fighter minimum evasive range for negotiation team air combat. In Proceedings of the 15th International Conference on Control, Automation and Systems, Busan, Korea, 13–16 October 2015; pp. 207–212. [Google Scholar]
- Weiss, M.; Shima, T. Minimum effort rursuit/evasion guidance with specified miss distance. J. Guid. Control Dyn. 2016, 39, 1069–1079. [Google Scholar] [CrossRef]
- Dollinger, J.F.; Loechner, V. Adaptive runtime selection for GPU. In Proceedings of the 42nd International Conference on Parallel Processing, Lyon, France, 1–4 October 2013; pp. 70–79. [Google Scholar]
- Fatica, M.; Jeong, W.K. Accelerating Matlab with CUDA. In Proceedings of the Eleventh Annual High Performance Embedded Computing Workshop Lexington Massachusetts, Lexington, MA, USA, 18–20 September 2007. [Google Scholar]
- Simek, V.; Asn, R.R. GPU acceleration of 2D-DWT image compression in Matlab with CUDA. In Proceedings of the 2nd UKSim European Symposium on Computer Modelling and Simulation, Liverpool, UK, 8–10 September 2008; pp. 274–277. [Google Scholar]
- Horrigue, L.; Ghodhbane, R.; Saidani, T.; Atri, M. GPU acceleration of image processing algorithm based on Matlab CUDA. Int. J. Comput. Sci. Netw. Secur. 2018, 18, 91–99. [Google Scholar]
- Austin, F.; George, D. Automated adversary for piloted simulation of helicopter air combat in terrain flight. J. Am. Helicopter Soc. 1992, 37, 25–31. [Google Scholar] [CrossRef]
- Elsayed, A. Modeling of a small unmanned aerial vehicle. Int. J. Aerosp. Mech. Eng. 2015, 9, 503–511. [Google Scholar]
- Kung, C.C.; Chiang, F.L.; Wu, C.Y. Implement three-dimensional pursuit guidance law with feedback linearization control method. Int. J. Mech. Aerosp. Ind. Mechatron. Manuf. Eng. 2011, 5, 1201–1217. [Google Scholar]
- Ostlund, P.; Stavaker, K.; Fritzson, P. Parallel simulation of equation-based models on CUDA-enabled GPUs. In Proceedings of the Parallel/High-Performance Object-Oriented Scientific Computing, Reno, NV, USA, 17–21 October 2010. [Google Scholar]
- Al-Omari, A.; Arnold, J.; Taha, T.; Schüttler, H.-B. Solving large nonlinear systems of ODE with hierarchical structure using multi-GPGPUs and an adaptive Runge Kutta. IEEE Access 2013, 1, 770–777. [Google Scholar] [CrossRef]
- Seen, W.M.; Gobithaasan, R.U.; Miura, K.T. GPU acceleration of Runge Kutta-Fehlberg and its comparison with Dormand-Prince method. AIP Conf. Proc. 2014, 1605, 16–21. [Google Scholar]
- Oberhuber, T.; Suzuki, A.; Žabka, V. The CUDA implementation of the method of lines for the curvature dependent flows. Kybernetika 2011, 47, 251–272. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Strategy | Strategy 1 | Strategy 2 | Strategy 3 | Strategy 4 | Strategy 5 | Strategy 6 | Strategy 7 | |
|---|---|---|---|---|---|---|---|---|
| Command Values | Max Load Factor Left Turn | Max Long Acceleration | Steady Flight | Max Long Deceleration | Max Load Factor Right Turn | Max Load Factor Pull Up | Max Load Factor Push Over | |
| (g) | 0 | 1.5 | 0 | −1.5 | 0 | 0 | 0 | |
| (g) | 3 | 0 | 0 | 0 | 3 | 3 | −3 | |
| (rad) | 0 | 0 | 0 | 0 | 0 | |||
| Component Type | Component |
|---|---|
| CPU | Intel Core 2 Quad [email protected] |
| Operating system | Windows 7 |
| GPU | GTX285 |
| GPU cuda cores | 240 |
| CPU memory | 12.0 GB |
| GPU memory | 1 GB |
| CPU compiler | VC++ 2010 |
| GPU compiler | NVCC 4.0 |
| Number of Clusters | CPU Calculation Time (ms) Q9450 | GPGPU Calculation Time (ms) GTX285 |
|---|---|---|
| 2 × 2 | 0.016168 | 5.41302 |
| 4 × 4 | 20.6626 | 282.696 |
| Row Number | CPU Calculation Time (ms) Q9450 | GPGPU Calculation Time (ms) GTX285 | Performance Ratio (CPU Time/GPGPU Time) |
|---|---|---|---|
| 0.0967 | 0.1088 | 0.0888 | |
| 0.6592 | 0.1087 | 6.064 | |
| 4.6257 | 0.1515 | 30.53 | |
| 33.3234 | 0.3058 | 108.97 |
| Cluster Number | Single Core Calculation (s) | Decentralized Calculation and Join CUDA (s) |
|---|---|---|
| 2 vs. 2 | 25.058792 | 30.456212 |
| 4 vs. 4 | 198.9946 | 398.4786 |
© 2018 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kung, C.-C. Study on Consulting Air Combat Simulation of Cluster UAV Based on Mixed Parallel Computing Framework of Graphics Processing Unit. Electronics 2018, 7, 160. https://doi.org/10.3390/electronics7090160
Kung C-C. Study on Consulting Air Combat Simulation of Cluster UAV Based on Mixed Parallel Computing Framework of Graphics Processing Unit. Electronics. 2018; 7(9):160. https://doi.org/10.3390/electronics7090160
Chicago/Turabian StyleKung, Chien-Chun. 2018. "Study on Consulting Air Combat Simulation of Cluster UAV Based on Mixed Parallel Computing Framework of Graphics Processing Unit" Electronics 7, no. 9: 160. https://doi.org/10.3390/electronics7090160
APA StyleKung, C.-C. (2018). Study on Consulting Air Combat Simulation of Cluster UAV Based on Mixed Parallel Computing Framework of Graphics Processing Unit. Electronics, 7(9), 160. https://doi.org/10.3390/electronics7090160