Real-Time Object Detection in Remote Sensing Images Based on Visual Perception and Memory Reasoning


Abstract
1. Introduction
2. Related Work
3. Theoretical Method
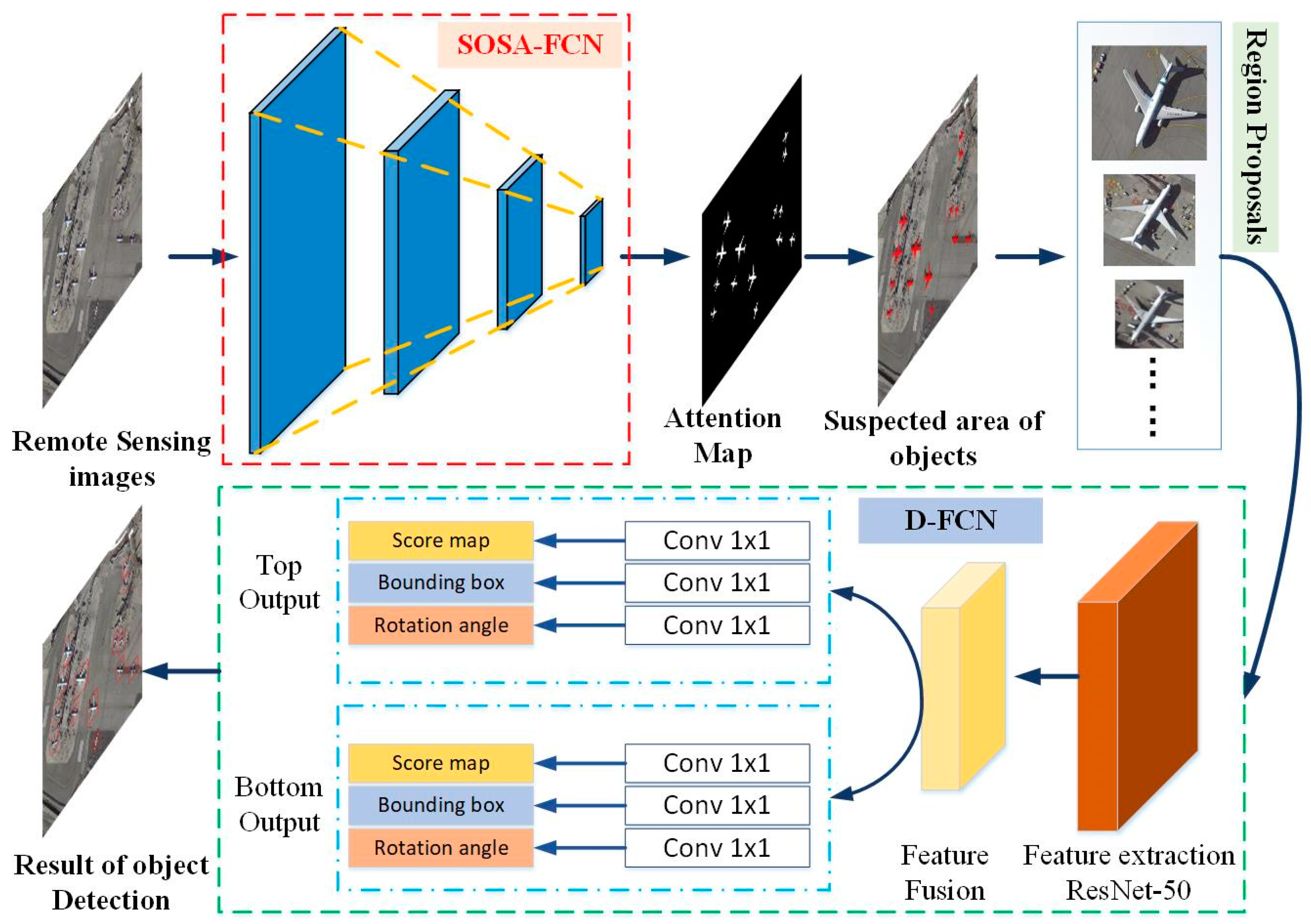
3.1. Strengthening Object Self-Attention Pre-Screening Fully Convolutional Network
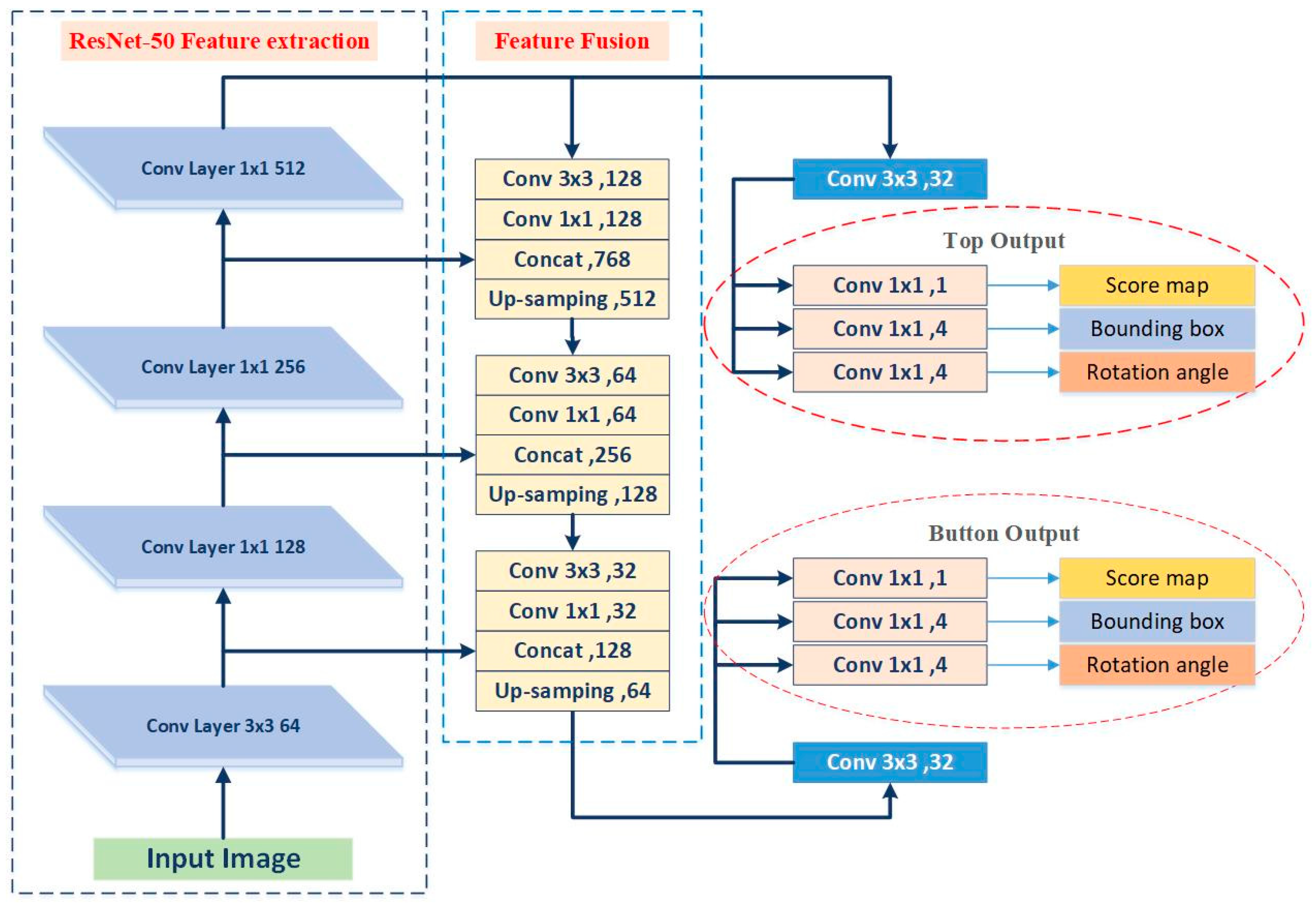
3.2. Accurate Object Detection Fully Convolutional Network (AD-FCN)
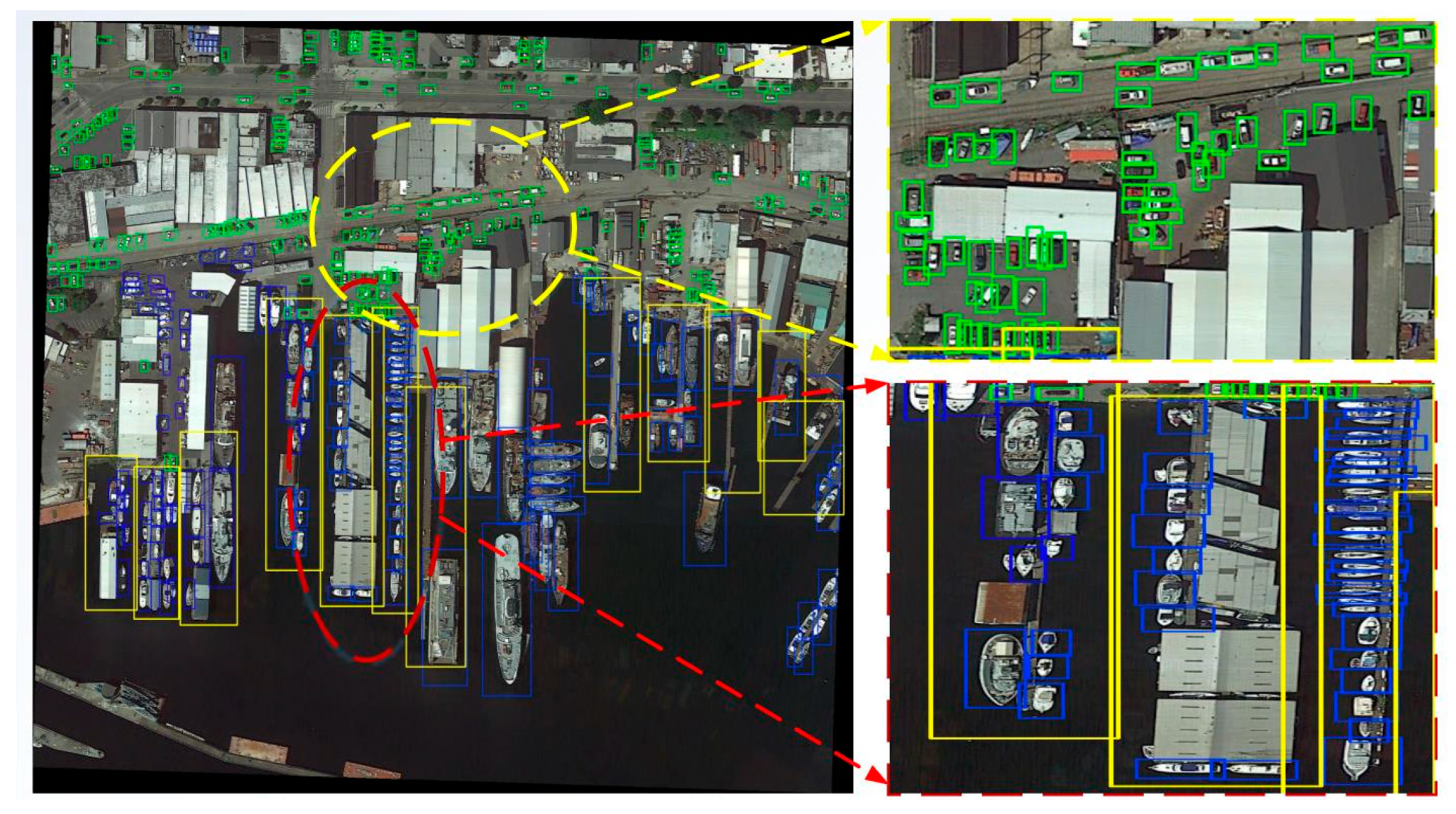
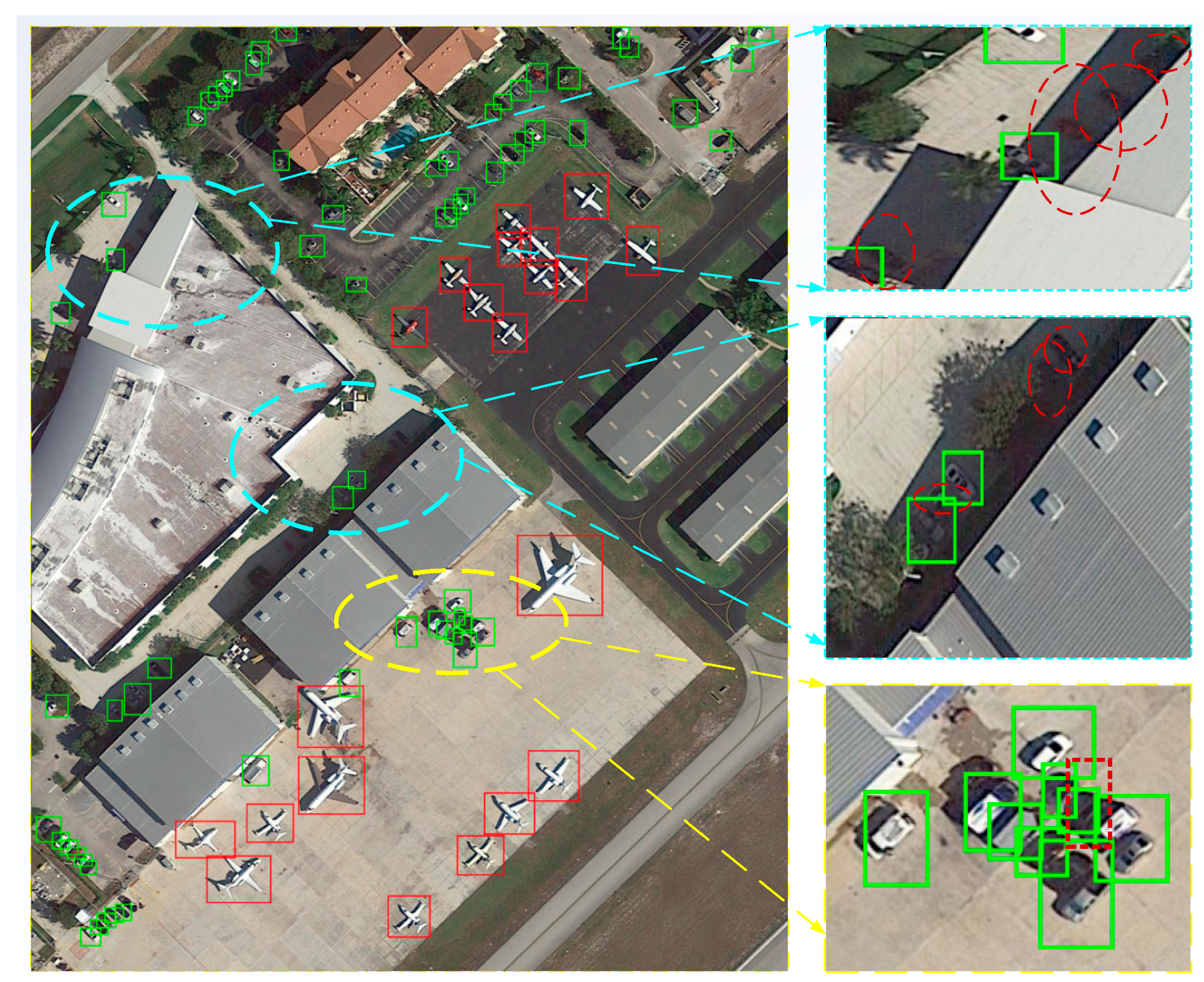
4. Results
4.1. Experimental Dataset and Evaluation Index
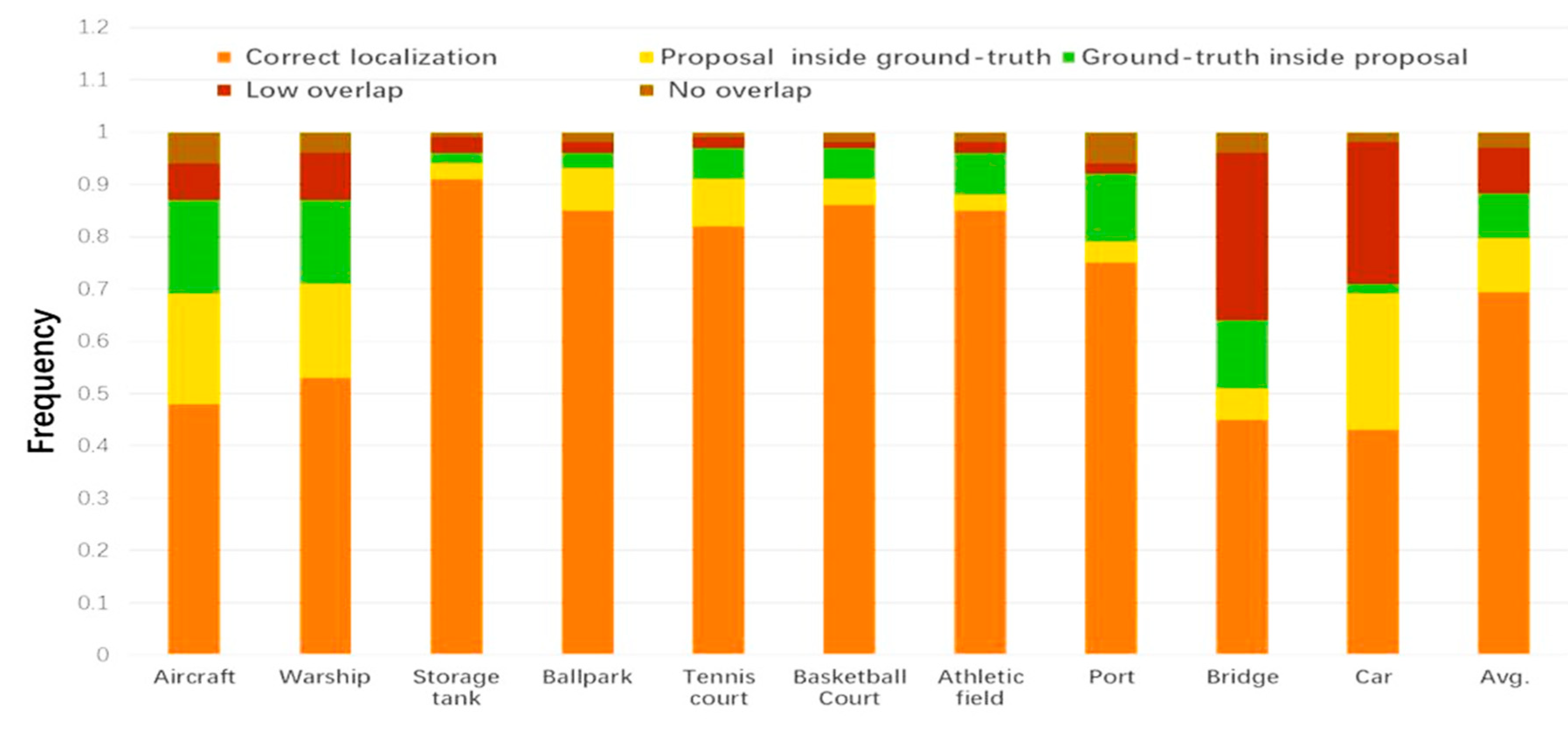
4.2. Analysis of the Pre-screening Effect of SOSA-FCN
4.3. Analysis of the Detection Effect of AD-FCN
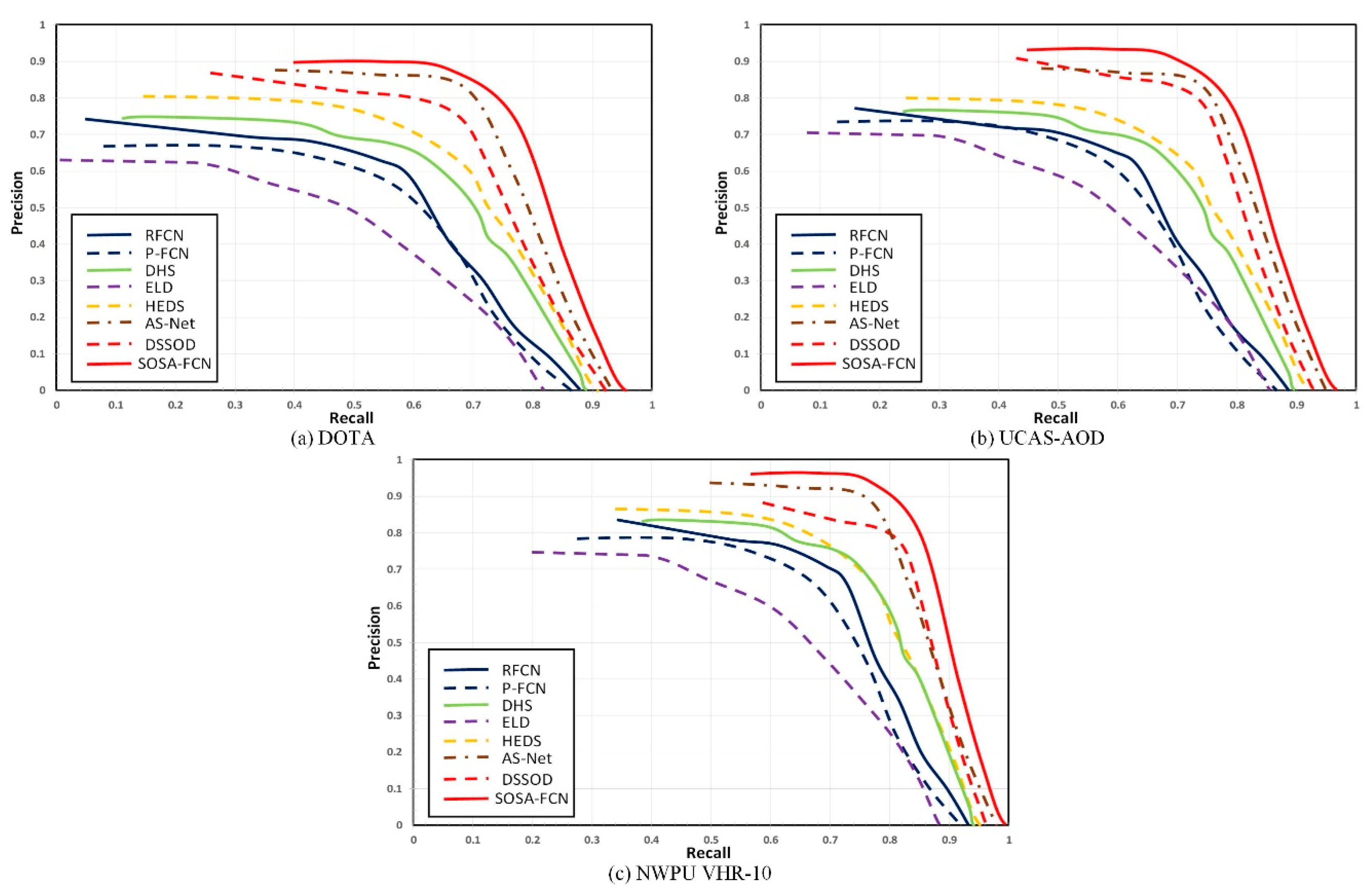
4.4. Comparison Experiments with State-of-the-Art Models
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.B.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Pang, J.; Li, C.; Shi, J.; Xu, Z.; Feng, H. R2-CNN: Fast Tiny Object Detection in Large-scale Remote Sensing Images. arXiv Comput. Vis. Pattern Recognit. 2019, 1902, 06042. [Google Scholar]
- Chen, H.; Liu, Z.; Guo, W.; Zhang, Z.; Yu, W. Fast detection of ship targets in large-scale remote sensing images based on cascade convolution neural network. J. Radar 2019, 8, 413–424. [Google Scholar]
- Li, C.; Zhang, Y.; Lan, T.; Du, Y. A visual perception target detection algorithm for high resolution remote sensing images. J. Xi’an Jiaotong Univ. 2018, 6, 9–16. (In Chinese) [Google Scholar]
- Yao, Q.; Hu, X.; Le, H. Remote sensing target detection based on multi-scale convolution neural network. J. Opt. 2019, 1–11. (In Chinese) [Google Scholar]
- Wang, L.; Feng, Y.; Zhang, M. Optical remote sensing image target detection method. Syst. Eng. Electron. Technol. 2019, 41, 1–8. (In Chinese) [Google Scholar]
- Zhang, Z.; Guo, W.; Zhu, S.; Yu, W. Toward Arbitrary-Oriented Ship Detection with Rotated Region Proposal and Discrimination Networks. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1745–1749. [Google Scholar] [CrossRef]
- Zhao, J.; Guo, W.; Zhang, Z.; Yu, W. A coupled convolutional neural network for small and densely clustered ship detection in SAR images. Sci. China Ser. F Inf. Sci. 2019, 62, 42301. [Google Scholar] [CrossRef]
- Orhan, F.; Cho, K.; Bengio, Y. Multi-Way, Multilingual Neural Machine Translation with a Shared Attention Mechanism. arXiv 2016, arXiv:1601.01073. [Google Scholar]
- Choi, E.; Bahadori, M.T.; Sun, J.; Kulas, J.; Schuetz, A.; Stewart, W. Retain: An interpretable predictive model for healthcare using reverse time attention mechanism. In Proceedings of the Advances in Neural Information Processing Systems 29 (NIPS 2016), Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Chu, Q.; Ouyang, W.; Li, H.; Wang, X.; Liu, B.; Yu, N. Online Multi-Object Tracking Using CNN-based Single Object Tracker with Spatial-Temporal Attention Mechanism. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Zhang, H.; Goodfellow, I.; Metaxas, D.; Odena, A. Self-Attention Generative Adversarial Networks. ArXiv Mach. Learn. 2018, 1805, 08318. [Google Scholar]
- Lakatos, P.; Musacchia, G.; Connel, M.; Falchier, A.; Javitt, D.; Schroeder, C. The spectrotemporal filter mechanism of auditory selective attention. Neuron 2013, 77, 750–761. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.; Shen, J.; Dong, X.; Borji, A. Salient Object Detection Driven by Fixation Prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1711–1720. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W. Improved Techniques for Training GANs. arXiv 2016, arXiv:1606.03498. [Google Scholar]
- Kodali, N.; Abernethy, J.; Hays, J.; Kira, Z. On Convergence and Stability of GANs. arXiv 2018, arXiv:1705.07215. [Google Scholar]
- Ronneberger, O.; Philipp, F.; Thomas, B. U-Net: Convolutional Networks for Biomedical Image Segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin, Germany, 2015; pp. 234–241. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Hua, X.; Wang, X.; Wang, D.; Ma, Z.; Shao, F. Multi-objective detection of traffic scene based on improved SSD. J. Opt. 2018, 221–231. [Google Scholar]
- Xia, G.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A Large-scale Dataset for Object Detection in Aerial Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. (In Chinese). [Google Scholar]
- Liu, C.; Ke, W.; Qin, F.; Ye, Q. Linear Span Network for Object Skeleton Detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 136–151. [Google Scholar]
- Cheng, G.; Zhou, P.; Han, J. Learningrotation-invariant convolutional neural networks for object detection in VHRoptical remote sensing images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7405–7415. [Google Scholar] [CrossRef]
- Zhang, Y.; Yuan, Y.; Feng, Y.; Lu, X. Hierarchical and Robust Convolutional Neural Network for Very High-Resolution Remote Sensing Object Detection. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5535–5548. [Google Scholar] [CrossRef]
- Long, Y.; Gong, Y.; Xiao, Z.; Liu, Q. Accurate Object Localization in Remote Sensing Images Based on Convolutional Neural Networks. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2486–2498. [Google Scholar] [CrossRef]
- Wang, X.; Hua, X.; Xiao, F.; Li, Y.; Hu, X.; Sun, P. Multi-Object Detection in Traffic Scenes Based on Improved SSD. Electronics 2018, 7, 302. [Google Scholar] [CrossRef]
- Zhang, D.; Han, J.; Zhao, L.; Meng, D. Leveraging Prior-Knowledge for Weakly Supervised Object Detection Under a Collaborative Self-Paced Curriculum Learning Framework. Int. J. Comput. 2018, 127, 363–380. [Google Scholar] [CrossRef]
- Laurent, I.; Koch, C.; Niebur, E. A Model of Saliency-based Visual Attention for Rapid Scene Analysis. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 1254–1259. [Google Scholar]
- Zhao, X.; Chen, B.; Pei, L.; Li, T.; Li, M. Hierarchical saliency: A new salient target detection framework. Int. J. Control Autom. Syst. 2016, 14, 301–311. [Google Scholar] [CrossRef]
- Bruce, N.D.; Tsotsos, J.K. Saliency, attention, and visual search: An information theoretic approach. J. Vis. 2009, 9, 5. [Google Scholar] [CrossRef] [PubMed]
- Liu, N.; Han, J.; Liu, T.; Li, X. Learning to Predict Eye Fixations via Multiresolution Convolutional Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 392–404. [Google Scholar] [CrossRef] [PubMed]
- Pan, J.; Sayrol, E.; Giro-i-Nieto, X.; McGuinness, K.; O’Connor, N.E. Shallow and Deep Convolutional Networks for Saliency Prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 598–606. [Google Scholar]
- Lee, G.; Tai, Y.W.; Kim, J. Deep Saliency with Encoded Low level Distance Map and High Level Features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Wang, L.; Wang, L.; Lu, H.; Zhang, P.; Ruan, X. Saliency Detection with Recurrent Fully Convolutional Networks. In European Conference on Computer Vision; Springer: Berlin, Germany, 2016. [Google Scholar]
- Liu, N.; Han, J. DHSNet: Deep Hierarchical Saliency Network for Salient Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Hou, Q.; Cheng, M.M.; Hu, X.; Broji, A.; Tu, Z.; Torr, P.H. Deeply Supervised Salient Object Detection with Short Connections. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Yan, Q.; Xu, L.; Shi, J.; Jia, J. Hierarchical Saliency Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, ON, USA, 23–28 June 2013; pp. 1155–1162. [Google Scholar]
- Jiang, H.; Wang, J.; Yuan, Z.; Wu, Y.; Zheng, L.; Li, S. Salient Object Detection: A Discriminative Regional Feature Integration Approach. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2083–2090. [Google Scholar]
- Li, X.; Lu, H.; Zhang, L.; Ruan, X.; Yang, M.H. Saliency Detection via Dense and Sparse Reconstruction. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 2976–2983. [Google Scholar]
- Uijlings, J.R.R.; Van De Sande, K.E.; Gevers, T.; Smeulders, A.W. Selective Search for Object Recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef]
- Song, G.; Leng, B.; Liu, Y.; Hetang, G.; Cai, S. Region-based Quality Estimation Network for Large-scale Person Re-identification. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2017. [Google Scholar]
- Ballester, P.; Araujo, R.M. On the performance of GoogLeNet and AlexNet applied to sketches. In Proceedings of the Thirtieth Aaai Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Zitnick, C.L.; Dollár, P. Edge Boxes: Locating Object Proposals from Edges. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Shi, G.; Xie, X.; Han, X.; Liao, Q. Visualization and Pruning of SSD with the base network VGG16. In Proceedings of the International Conference on Deep Learning Technologies, Chengdu, China, 2–4 June 2017. [Google Scholar]
- Cinbis, R.G.; Jakob, V.; Cordelia, S. Weakly Supervised Object Localization with Multi-Fold Multiple Instance Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 189–203. [Google Scholar] [CrossRef]
- Han, Z.; Zhang, H.; Zhang, J.; Hu, X. Fast aircraft detection based on region locating network in large-scale remote sensing images. In Proceedings of the international conference on image processing, Beijing, China, 17–20 September 2017; pp. 2294–2298. [Google Scholar]
- Fu, C.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A. DSSD: Deconvolutional Single Shot Detector. arXiv: Computer Vision and Pattern Recognition. arXiv 2017, arXiv:1701.06659. [Google Scholar]
- Tong, L.; Zhang, J.; Lu, X.; Zhang, Y. SDBD: A Hierarchical Region-of-Interest Detection Approach in Large-Scale Remote Sensing Image. IEEE Geosci. Remote Sens. Lett. 2017, 14, 699–703. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, 1804, 02767. [Google Scholar]
- Guo, Z.; Song, P.; Zhang, Y.; Yang, M.; Sun, X.; Sun, H. Aircraft Object Detection in Remote Sensing Images Based on Deep Convolution Neural Network. J. Electron. Inf. Sci. 2018, 40, 149–155. (In Chinese) [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | AUC-Judd | SIM | Shuffled AUC | |||
|---|---|---|---|---|---|---|
| DOTA | NWPU VHR-10 | DOTA | NWPU VHR-10 | DOTA | NWPU VHR-10 | |
| ITTI | 0.48 | 0.61 | 0.18 | 0.17 | 0.43 | 0.55 |
| GBVS | 0.57 | 0.71 | 0.22 | 0.23 | 0.45 | 0.58 |
| AIM | 0.52 | 0.64 | 0.2 | 0.19 | 0.48 | 0.66 |
| Mr-CNN | 0.63 | 0.76 | 0.23 | 0.32 | 0.56 | 0.71 |
| P-FCN | 0.75 | 0.83 | 0.31 | 0.38 | 0.61 | 0.75 |
| Shallow-Net | 0.59 | 0.73 | 0.25 | 0.29 | 0.58 | 0.69 |
| Deep-Net | 0.74 | 0.81 | 0.28 | 0.33 | 0.55 | 0.71 |
| AS-Net | 0.76 | 0.85 | 0.36 | 0.41 | 0.62 | 0.74 |
| SOSA-FCN | 0.78 | 0.87 | 0.41 | 0.46 | 0.66 | 0.75 |
| CC | NSS | Speed(s/1000x1000) | ||||
| DOTA | NWPU VHR-10 | DOTA | NWPU VHR-10 | DOTA | NWPU VHR-10 | |
| 0.23 | 0.31 | 0.82 | 1.05 | 4.343 | 3.969 | |
| 0.32 | 0.39 | 1.13 | 1.32 | 3.532 | 4.032 | |
| 0.16 | 0.22 | 0.71 | 0.98 | 5.318 | 4.893 | |
| 0.28 | 0.37 | 1.09 | 1.29 | 1.028 | 0.798 | |
| 0.36 | 0.46 | 1.18 | 1.33 | 0.258 | 0.336 | |
| 0.31 | 0.35 | 1.27 | 1.47 | 1.325 | 1.135 | |
| 0.37 | 0.41 | 1.22 | 1.41 | 0.983 | 0.632 | |
| 0.35 | 0.45 | 1.31 | 1.52 | 0.452 | 0.398 | |
| 0.42 | 0.51 | 1.29 | 1.49 | 0.175 | 0.149 | |
| Methods | DOTA | UCAS-AOD | NWPU VHR-10 | |||
|---|---|---|---|---|---|---|
| Fβ | MAE | Fβ | MAE | Fβ | MAE | |
| DRFI | 0.612 | 0.358 | 0.703 | 0.298 | 0.731 | 0.255 |
| HS | 0.572 | 0.459 | 0.611 | 0.376 | 0.769 | 0.223 |
| P-FCN | 0.765 | 0.153 | 0.804 | 0.158 | 0.842 | 0.138 |
| RFCN | 0.773 | 0.127 | 0.799 | 0.101 | 0.806 | 0.092 |
| DHS | 0.798 | 0.098 | 0.821 | 0.089 | 0.851 | 0.073 |
| ELD | 0.735 | 0.112 | 0.783 | 0.113 | 0.803 | 0.096 |
| HEDS | 0.803 | 0.089 | 0.832 | 0.091 | 0.858 | 0.085 |
| AS-Net | 0.815 | 0.065 | 0.845 | 0.078 | 0.868 | 0.063 |
| DSSOD | 0.814 | 0.086 | 0.851 | 0.076 | 0.876 | 0.066 |
| SOSA-FCN | 0.818 | 0.061 | 0.856 | 0.078 | 0.881 | 0.049 |
| Strategies | Aircraft | Ship | Storage Tank | Ballpark | Tennis Court | Basketball Court |
|---|---|---|---|---|---|---|
| SS-A | 36.31 | 23.12 | 46.28 | 32.35 | 36.72 | 34.71 |
| SS-V | 44.72 | 25.41 | 54.82 | 36.21 | 42.83 | 42.62 |
| SS-A-F | 41.81 | 24.15 | 52.43 | 34.62 | 38.42 | 36.18 |
| EB-A-F | 38.53 | 26.16 | 51.31 | 32.55 | 43.25 | 37.33 |
| EB-V-F | 43.24 | 38.23 | 66.54 | 38.73 | 46.31 | 47.15 |
| EB-V-F-CS | 51.72 | 32.81 | 56.81 | 40.86 | 52.28 | 49.82 |
| EB-V-F-BR | 47.85 | 35.41 | 63.52 | 42.91 | 52.47 | 55.57 |
| AD-FCN | 69.38 | 61.82 | 69.66 | 62.58 | 61.23 | 73.21 |
| Athletic field | Port | Bridge | Car | Avg. | ||
| 35.76 | 26.22 | 19.34 | 13.61 | 30.442 | ||
| 43.77 | 33.85 | 25.42 | 22.93 | 37.258 | ||
| 41.93 | 29.51 | 27.65 | 19.32 | 34.602 | ||
| 40.12 | 28.42 | 24.81 | 21.84 | 34.432 | ||
| 46.75 | 35.13 | 34.37 | 29.52 | 42.597 | ||
| 38.61 | 38.62 | 31.22 | 23.81 | 41.656 | ||
| 47.47 | 39.85 | 36.83 | 37.26 | 45.914 | ||
| 75.28 | 57.83 | 53.77 | 56.38 | 64.114 |
| Model | Map (%) | MAX RECALL (%) | Pd (%) | Speed (ms) |
|---|---|---|---|---|
| R2-CNN | 87.32 | 97.18 | 83.03 | 17.63 |
| FPN Faster R-CNN | 83.04 | 93.05 | 69.85 | 24.26 |
| MSCNN | 84.65 | 91.86 | 81.02 | 33.48 |
| DSSD | 54.27 | 83.86 | 43.65 | 53.27 |
| SDBD | 79.19 | 92.38 | 79.84 | 35.73 |
| F-RLN | 82.53 | 90.11 | 80.52 | 46.18 |
| C-SPCL | 85.21 | 96.33 | 86.12 | 29.58 |
| YOLOv3 | 65.68 | 87.12 | 57.98 | 47.25 |
| VPN | 83.08 | 94.03 | 82.86 | 21.68 |
| MDSSD | 85.38 | 95.13 | 83.21 | 19.45 |
| OURS | 92.35 | 98.82 | 85.75 | 14.03 |
| Model | mAP (%) | MAX RECALL (%) | Pd (%) | Speed (ms) |
|---|---|---|---|---|
| R2-CNN | 91.35 | 98.48 | 88.93 | 16.13 |
| FPN Faster R-CNN | 87.24 | 96.53 | 73.82 | 22.36 |
| MSCNN | 86.53 | 95.46 | 86.72 | 22.18 |
| DSSD | 56.47 | 89.79 | 53.15 | 49.72 |
| SDBD | 83.79 | 97.28 | 85.34 | 48.63 |
| F-RLN | 85.36 | 94.43 | 83.33 | 43.69 |
| C-SPCL | 91.68 | 99.03 | 91.07 | 18.15 |
| YOLOv3 | 69.48 | 94.82 | 64.78 | 35.45 |
| VPN | 89.28 | 93.23 | 88.79 | 17.63 |
| MDSSD | 90.36 | 98.15 | 89.23 | 16.54 |
| OURS | 94.65 | 99.36 | 90.98 | 10.29 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hua, X.; Wang, X.; Rui, T.; Wang, D.; Shao, F. Real-Time Object Detection in Remote Sensing Images Based on Visual Perception and Memory Reasoning. Electronics 2019, 8, 1151. https://doi.org/10.3390/electronics8101151
Hua X, Wang X, Rui T, Wang D, Shao F. Real-Time Object Detection in Remote Sensing Images Based on Visual Perception and Memory Reasoning. Electronics. 2019; 8(10):1151. https://doi.org/10.3390/electronics8101151
Chicago/Turabian StyleHua, Xia, Xinqing Wang, Ting Rui, Dong Wang, and Faming Shao. 2019. "Real-Time Object Detection in Remote Sensing Images Based on Visual Perception and Memory Reasoning" Electronics 8, no. 10: 1151. https://doi.org/10.3390/electronics8101151
APA StyleHua, X., Wang, X., Rui, T., Wang, D., & Shao, F. (2019). Real-Time Object Detection in Remote Sensing Images Based on Visual Perception and Memory Reasoning. Electronics, 8(10), 1151. https://doi.org/10.3390/electronics8101151