1. Introduction
Recently, computer vision has achieved great results along the development of computer hardware. Also, we can build highly complex systems, for example, autonomous driving, by applying the deep learning for solving computer vision task. A self-driving car needs to recognize objects on the street, for example, people or another car, which leads to the necessity of 3D object classification [
1].
The 3D classification remains a challenge for researchers in this field. In the past, we had only 2D classification or 2D image classification due to the limit of 3D resources and computer hardware. The technology of 3D acquisition such as Microsoft Kinect recently produces a massive amount of 3D-data and boosts 3D classification. 3D systems are more complicated than 2D systems due to some reasons: Data representation, different distributions of objects [
2]. Main problems are that 3D systems require more hardware resources as well as the computation time for the additional dimension.
Non-machine learning methods present the worst results on 3D object classification, lower than 76% accuracy for dataset: ModelNet40 [
3,
4]. Advancements in deep learning allow us to propose convolution neural network (CNN)-based methods in solving the traditional methods’ drawbacks in 3D classification. There are two CNN structures for various 3D-data representation: 2D CNN for multi-view and point cloud, 3D CNN for voxel. Currently, 2D CNN has a complete architecture with great results while 3D CNN is still under improvement [
5].
We aim to introduce a new method, center point (CP) and wave kernel signature (WKS) method, for 3D object classification. In the next section, we present related works of 3D object classification.
Section 3 presents a description of the proposed method;
Section 4 shows the experimental results and the comparison with other methods. The conclusion will be given in
Section 5.
3. Methodology
Color and spatial are two popular and necessary features in 2D image classification [
20,
21]. For the 3D objects, we use the WKS to capture the color feature and a CP to get the spatial feature, specifically the distance feature. We use the color feature for the 3D object classification because the color feature is the most popular and necessary property in the mechanism of human visual perception, and it is easy to analyze the color. Similarly, we use the distance feature due to its importance for the 3D object classification in giving information on the structural arrangement of the 3D objects. The basic primitives define the distance feature. The spatial distribution of basic primitives creates some visual forms, which are defined by directionality, repetitiveness, and granularity. Therefore, we combine the color and distance features to get higher performance in 3D object classification.
Figure 3 shows two main stages of the proposed method. In the first stage, we find a center point of a 3D mesh and choose N random vertices from this mesh. Then, we calculate and store the distance from this center point to each vertex in the first 3D-matrix. The second stage is that we calculate and store WKS values of a 3D mesh into the second 3D-matrix. Those values define the color of the 2D projection construction of the model. The combination of those two matrices forms a 6D-matrix for the input of 2D CNN. The sub-sections below give a detailed description of the proposed method.
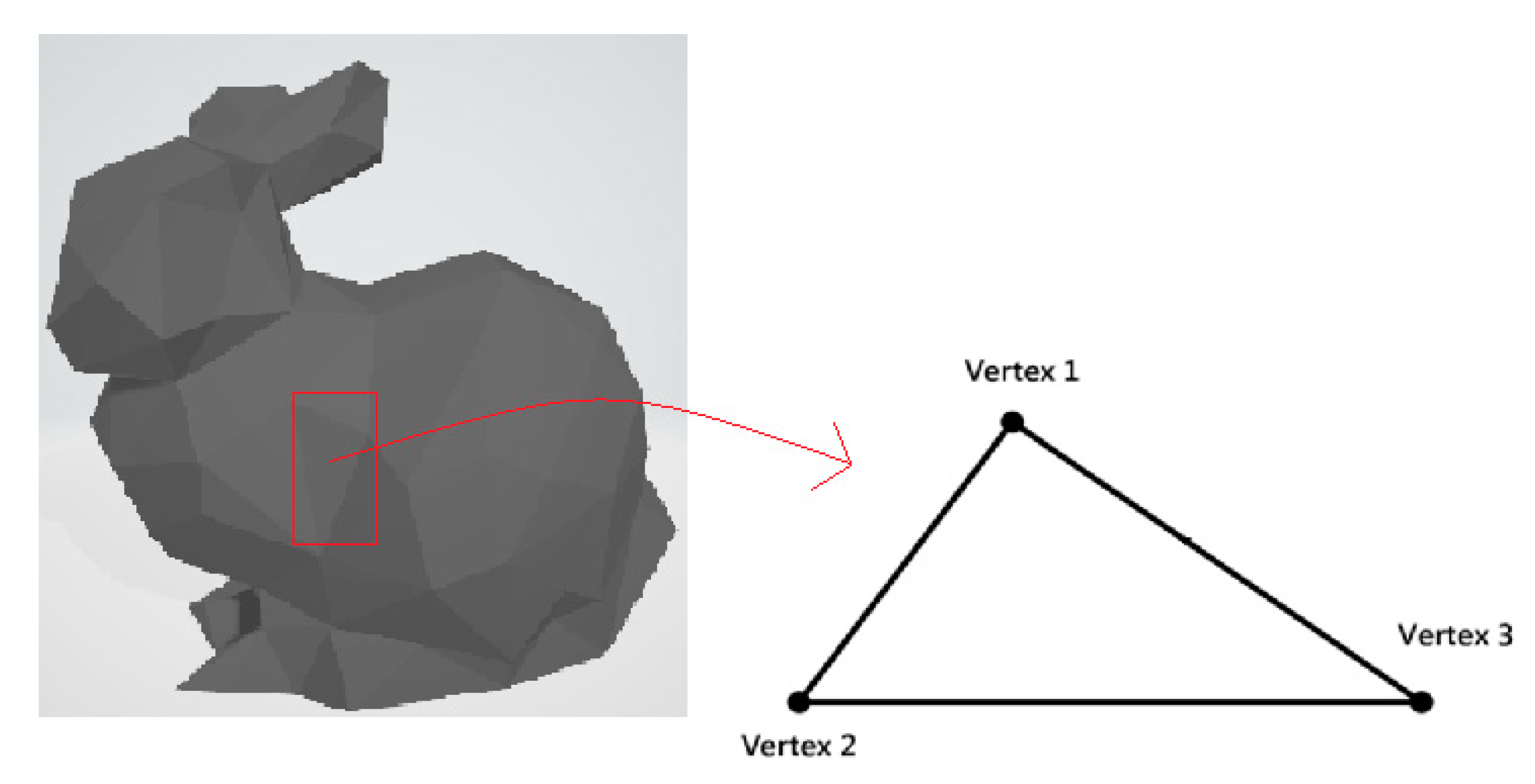
Our method is based on the 3D triangle mesh with one or more triangles. According to
Figure 4, the location of three vertices defines each triangle (called a facet).
3.1. The Center Point of 3D Triangle Mesh (CP)
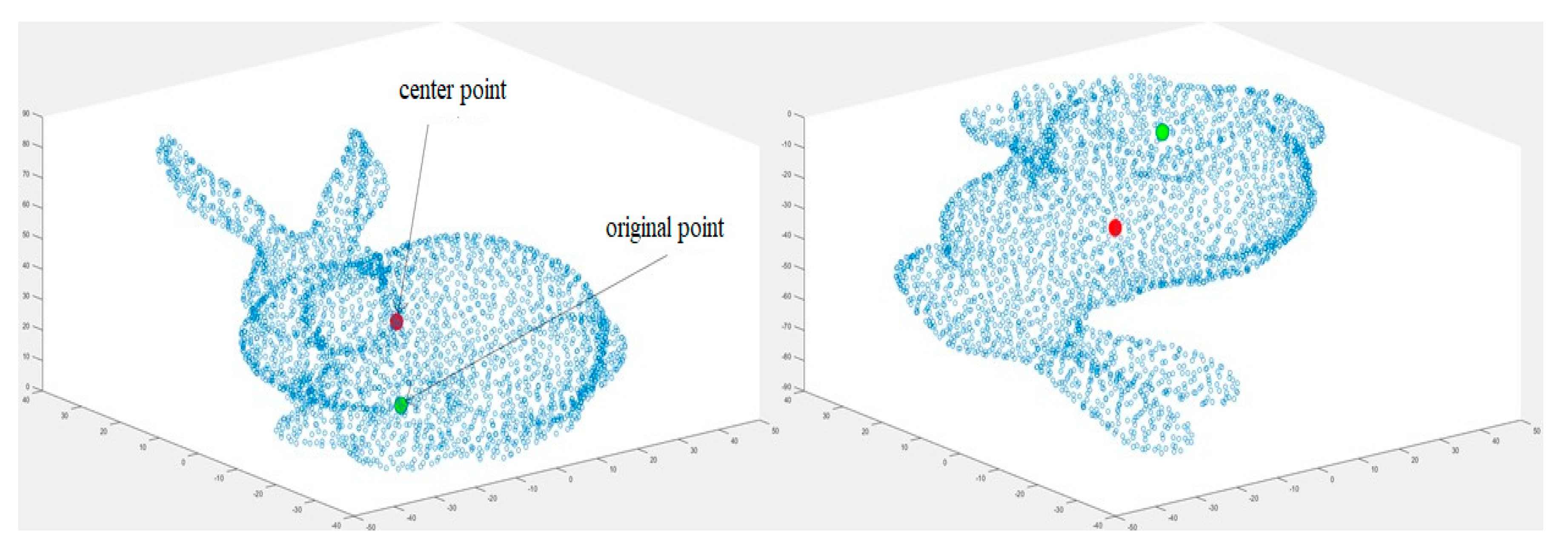
We find a center point of a 3D model, consisting of a collection of M vertices, having coordinates (i=1: M).
The following equation determines the center point C, having coordinates (
:
We calculate the distance
from
M vertices to the center point:
We choose N = 1024 random vertices from M vertices of the 3D mesh, and we replace missing values by zero in case of M < 1024. We obtain N × 3 values for constructing a 3D-matrix. We re-shape each dimension from 1024 to a 32 by 32 matrix and obtain a final 32 by 32 by 3 matrix, , in which the x-axis and y-axis represent the first two dimensions; the z-axis, the third dimension.
We will normalize the distance values in the range from −1 to 1 so that the 3D model fits into a sphere unit. We divide all current elements in matrix by the maximum value (3) of the 3D model.
Then the normalized values of matrix A will be calculated as:
Given the
Figure 5, we obtain the same values of matrix A when rotating the model by 180 degrees, so the rotation of a 3D model produces the consistent final matrix A.
3.2. Wave Kernel Signature on the 3D Triangle Mesh (WKS)
We first derive a Laplacian matrix from a 3D mesh, then calculate its eigenvalues and eigenvectors [
22]. By modifying Equation (10) in [
14], each
value for a vertex
is calculated as:
Formula (5) can be written clearly, as follow:
S = 300 is the number of eigenvalues; E is a Sx1 vector of eigenvalues; M is the number of vertices of the 3D mesh; is a MxS matrix of the corresponding eigenvectors.
Then the WKS feature vector of a 3D mesh is defined by:
The variance
is defined as
where
the logarithmic energy scale
and E(2) is the second element of E.
We construct a colormap, based on the WKS feature vector. We have
M vertices and
M color values corresponding with the
M values of WKS. Each value
controls each value of vertex
, as shown in
Figure 6.
In
Figure 6, we suppose that the
and the second vertex have the largest and the smallest values, namely WKSM and WKS2, which then are mapped to the last and the first row of the colormap, respectively.
After applying WKS to the 3D model, the black and white original model is changed into the color model. The second matrix B in a 32 by 32 by 3 pixel is used to capture and store a 2D projection of the 3D color model, as shown in
Figure 7.
3.3. The Architecture of Convolution Neural Network
We obtain a 32 by 32 by 6 matrix C by concatenating A and B along the third dimension, then use matrix C for the input data of CNN.
Figure 8 shows the architecture of the convolution neural network. As shown in
Figure 8, a typical design, where an input layer is followed by four convolutional blocks and two fully connected layers, is used to build the convolutional neural network architecture selected in the proposed implementation. Each convolutional block consists of convolution, batch normalization, and rectified linear units (ReLUs). The corresponding number of filters for all convolution layers in each block are 16, 32, 64, and 128, respectively. The padding for the first and other convolutional blocks is to set values 1 and 0, respectively, and we assign value 3 to kernel size for all layers. The stride equals 2 in the last two convolution blocks and 1 in the first two convolution blocks. Then, we insert an 8 by 8 average pooling layer after the fourth convolution block. Batch normalizations and a dropout layer are used in our network for the following reasons.
Firstly, batch normalization has some advantages such as making predictions of network output more stable, accelerating training by magnitude order, and reducing overfitting through regularization. Batch normalization normalizes activations in a network across a mini-batch by subtracting the mean and dividing by the standard deviation of these activations. Normalization is necessary because some activations may be higher, which may cause subsequent layers abnormally, and make a less stable network even after normalizing input.
Secondly, we add a dropout layer between a pooling layer and a fully connected layer to improve convergence. This introduces a stochastic gradient descent (SGD) optimizer to reduce the cumulative error and to improve the training speed as well as to fix the overfitting problem due to an expansion in the number of iterations. Dropout is a mean model, which is the weighted average of estimation or prediction output from various models. The hidden layer nodes may be neglected from a random selection in the dropout. As a result, each training network is unique and is considered as a new model. Specifically, hidden nodes are likely to occur randomly. Updating weights do not base on the interaction of fixed nodes, and this avoids possible connections of some features with another specific feature because any two hidden nodes do not appear in models many times concurrently. Thus, we can ignore some nodes randomly in the network. Ignoring these hidden layer nodes can decrease calculation cost. Moreover, these ignored nodes can restrict other nodes from joining each other to decrease overfitting [
23].
Matrix C enters the input layer in the first step of the whole process. Then, the first convolution block uses those data to apply a convolution function with a 1 by 1 stride. The output of the first convolution layer is 16 feature maps of dimension 32 by 32 which transfer to the first ReLU layer via the first batch normalization layer. Learning becomes faster with Gradient descent because the batch normalization renormalizes data. Sixteen normalized-features are the output of the first batch normalization layer. The second convolutional layer applies the convolution function with a 1 by 1 stride to the first ReLU layer’s output. This second layer’s output is 16 feature maps of dimension 32 by 32 which move to the second batch normalization layer and the second ReLU layer, respectively. We repeat the process until the fourth convolution block. The last output will be the input of the average pooling layer and dropout layer.
The first fully connected layer takes the dropout layer’s output, which has a feature vector with size 128, travels to the second fully connected layer. Then this second layer takes only K (K = 10 or 40) most active features and sends them to the softmax layer. Ten or forty classes with corresponding class names are used for classifying output such as the airplane, bed, and desk.
4. Experimental Results
To verify the proposed method, we use the most popular 3D dataset: The ModelNet, which has two sub-datasets: ModelNet10 and ModelNet40 [
16]. The original ModelNet dataset can be downloaded from the website in the
Supplementary Materials. ModelNet10 and ModelNet40 have 3D CAD models from 10 categories with 3991 training and 908 testing objects, and from 40 categories such as airplanes, bathtubs, beds, and benches with 9843 training and 2468 testing objects, respectively. Each object of ModelNet dataset has a format of a 3D-triangle mesh, namely OFF.
Table 1 shows the amount of objects of a particular class for dataset: ModelNet10.
We re-mesh objects in ModelNet or keep the original model without re-meshing if the number of vertices is larger or smaller than 3600, respectively. Some classes in the dataset such as glass-box have 171 models on the training folder; three models among them have more than 3600 vertices and the minimum number of vertices for one object is 44. As seen in
Figure 9, there are not many differences between the original model and the re-meshed model because the shapes of the objects are still kept except unimportant information. The re-meshing process plays a role as the technology which we use in the image or audio compressing. It seems unable for a “normal” user to distinguish between the original wave sound and the MP3 sound compressed. We create a new dataset from the original Modelnet dataset by keeping the structure of the original dataset and applying the re-meshing process for some models. We can see some random objects in the new dataset in
Figure 10. Applying the re-mesh process did not affect the accuracy of the method because it still keeps objects’ shapes, but reduces the number of vertices and faces. We apply the proposed method to find the distance and color feature of all 3D models after preprocessing the original dataset. All experiments were conducted on the machine i7 7700, 16GB memory, 1080Ti GPU, MATLAB (9.6 (R2019a), Natick, MA, USA).
We first read the OFF file of the model, store the information of each vertex. Suppose the number of vertices is M, and calculate
M values of WKS. Then we plot the 3D model with the color depending on those WKS values. We also calculate the distance between the center point to each vertex in the 3D mesh of the OFF file. After having the information of distance and color, we combined distance and color values into a 32 by 32 by 6 matrix and put it into the proposed CNN architecture. We use SGD with the mini-batch size at 64, and the momentum at 0.9 to train the network, and divide the initial learning rate at 0.2 by half for all 160 epochs. As listed in
Table 2, the proposed method has precision levels at 90.20% and 84.64% for ModelNet10 and ModelNet40, respectively, which is more accurate than other methods. Our methods had precision levels which were 7.32% and 6.66% higher than the deep learning method 3DShapeNets for 40 and 10 classes, respectively.
Both the DeepPano and Panoramic View method use four convolution Blocks, where each convolution Block contains one convolution layer, followed by one max pooling layer. In contrast, our method uses four convolution blocks, which each includes two same convolution layers, two batch normalization layers, and two ReLU layers. The number of parameters is greater than 0 in the pooling layer while it equals 0 in batch normalization and ReLU layer.
The authors in [
19] did not mention numbers of feature vectors in their fully connected layer of the DeepPano method, hence we compare the number of parameters in the convolution layers, not in fully connected layers. We use two fully connected layers with 128 and K (K = 10 or K = 40) feature vectors, respectively, in our method instead of using 512 and 1024 feature vectors for the first and the second layer as mentioned in the panoramic view method. Considering the results in
Table 3, our methods used fewer parameters for all convolution layers than their methods. Our method used 4800 parameters in total, compared with 18,112 for DeepPano and 15,088 for panoramic view. It is generally to conclude that our method is more efficient due to the reduction of model parameters, diminishing the computational cost.
We plot a confusion matrix for the ModelNet40 in
Figure 11. Flower Pot class and Plant class are the most misclassified, where 60% of the flower pot has miss-classification as the plant due to their similarities (see
Figure 10).
As seen in
Table 4, our methods had higher accuracy in the dataset: ModelNet10 due to the combination of color and distance features. In some classes, the distance feature will be complementary for the color feature. For example, in some cases, two objects in the dresser class have five similar faces and different the sixth face. The distance feature will help to recognize the spatial distribution of the model and improve the accuracy for classification. Specifically, PointNet can recognize 61 of 86 dresser models, while our method is 77 of 86.
Increasing the number of features will improve the accuracy of classification. Geometry Image method extracts only the color feature while our method uses the additional distance feature. Moreover, both DeepPano and panoramic view use only a view base without the spatial feature.
Wave kernel signature and center point achieved better accuracy due to the above reasons.
5. Conclusions
In this paper, we created an innovative approach for 3D object classification by combining two features: Color and distance. Our method has achieved more accuracy and efficiency than five other methods: PointNet, 3DShapeNets, geometry image, DeepPano, and panoramic view.
Classification is a crucial step for other tasks like object retrieval. Also, our method is consistent with the object rotation, so it is suitable for retrieval task. Future direction for research and development is to integrate the software into actual world problems like fully autonomous cars or manufacture factories.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}