Scheduling Fair Resource Allocation Policies for Cloud Computing through Flow Control



Abstract
:1. Introduction
- At regular intervals, it can determine the rate of job generations that the system can afford, so that its utilization is maximized and the system itself does not run out of resources.
- The resources are fairly distributed based on a fair allocation mechanism.
- The scheduling complexity is linear.
- The proposed ideas can operate on a small or large number of different available resources.
2. Related Work
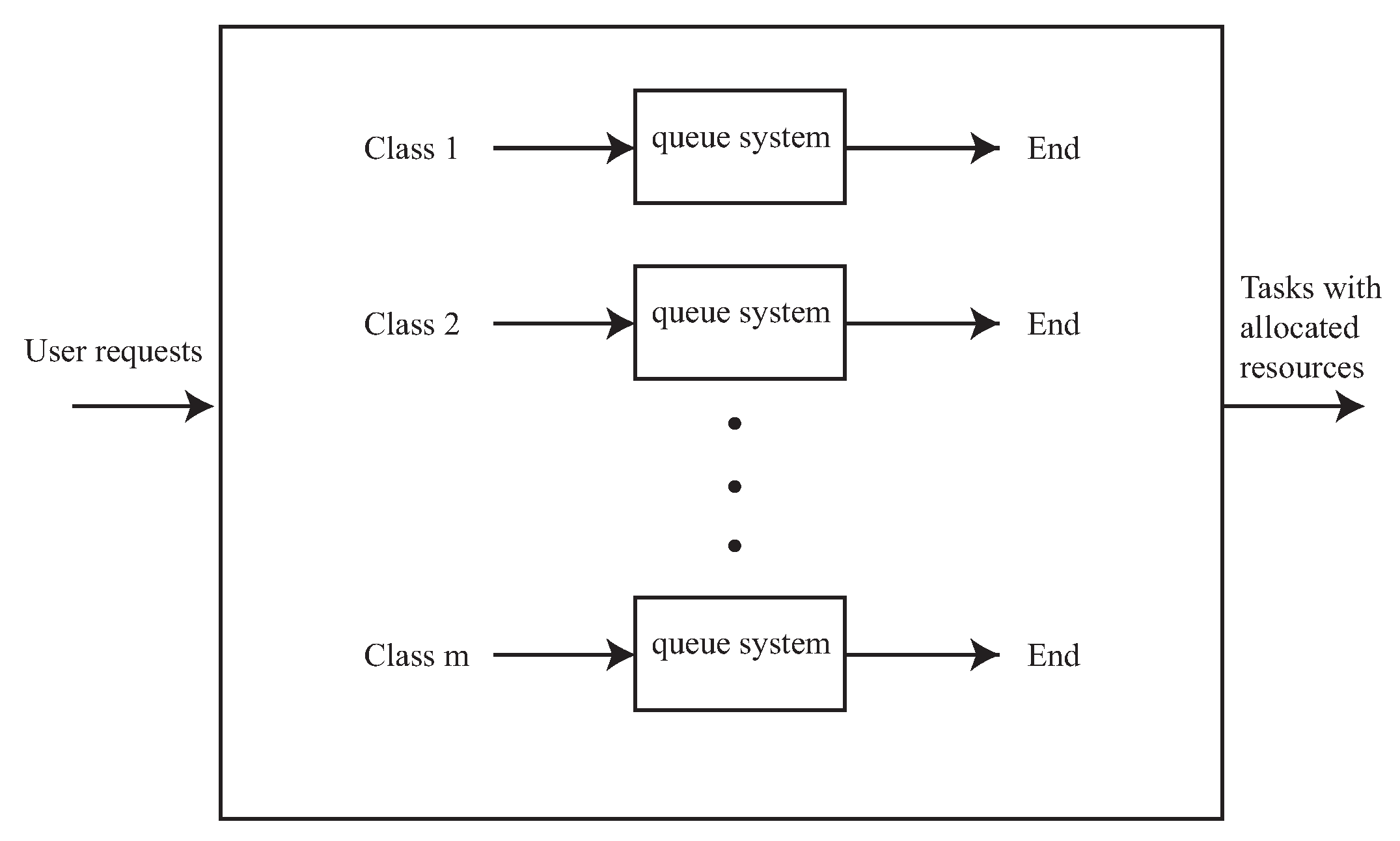
3. Resource Allocation Model
3.1. Fairness and Overall Utilization
- Step 1
- We sort the users with increasing order of their demands for the dominant resource into vector and we compute , the maximum number of jobs assigned to each user:
- Step 2
- We find the sum of all the jobs computed in the first step, , and we find the fair resource allocation f for each of these jobs as follows:
- Step 3
- We compute the resources allocated fairly to each user i, as follows:
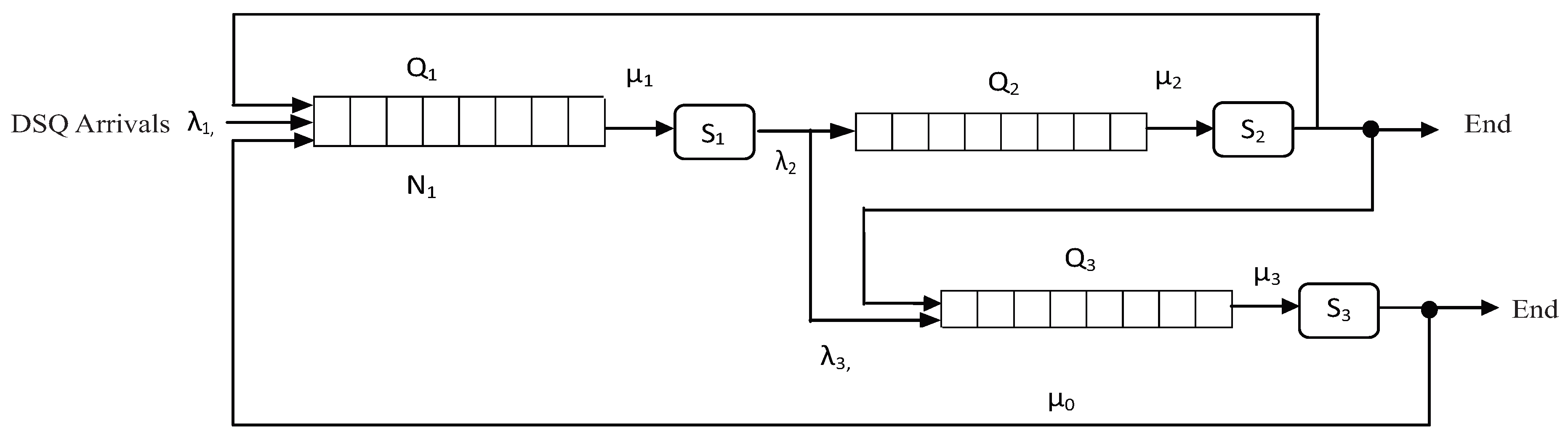
3.2. Flow Control and Utilization
4. Our Resource Allocation Scheduling Policy
4.1. An Illustrative Example
| Algorithm 1: Describes the resource allocation policy. |
| 1. Find the threshold values ; |
| 2. Compute ; // Non-dominant resources. |
| 3. For all DSQ’s in parallel do |
| 4. Implement the fair policy; // (Steps 1–3; see Section 2.1). |
| 5. Compute ; // The total amount of dominant resources |
| // allocated. |
| 6. ; // Amounts of dominant resources |
| // left unallocated. |
| 7. End For; |
| 8. For all non-DSQ’s in parallel do |
| 9. Implement the fair policy using , the resources |
| not allocated as dominant; |
| 10. End For; |
4.2. The Complexity of Our Scheduling Policy
5. Experimental Results
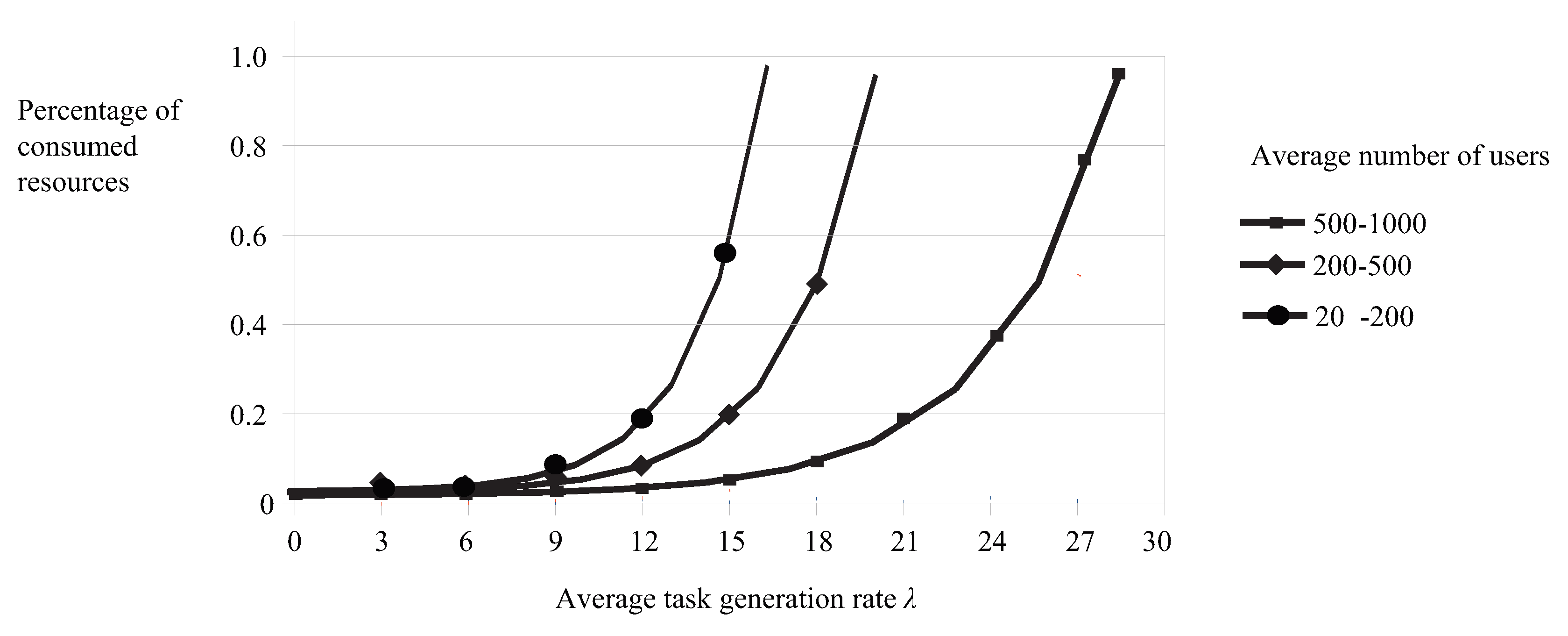
5.1. The Effect of Job Generation Rate Control
- We generated a random number of users, from 50 to 1000, and a set of requests for each user. Additionally, we set different values for the total amount of each available resource, so that, in some cases, the resources available were enough to satisfy all user requests, while in other cases, they were not.
- We set the maximum value of equal to 30 jobs per second; thus, the system’s rate of job generation in the queue systems could not be more than jobs per second.
- We kept tracking the system’s state at regular time intervals h and recorded the percentages of resources consumed between consecutive time intervals; thus, we computed the values. Every time a job i leaves a queue, the system’s state changes. For example, if a job leaves the DSQ, it means that it has consumed F units of the dominant resource, changing the system’s state from to . On the other hand, job generation and entrance in the queues over a period of time means that the system’s job generation rate may change.
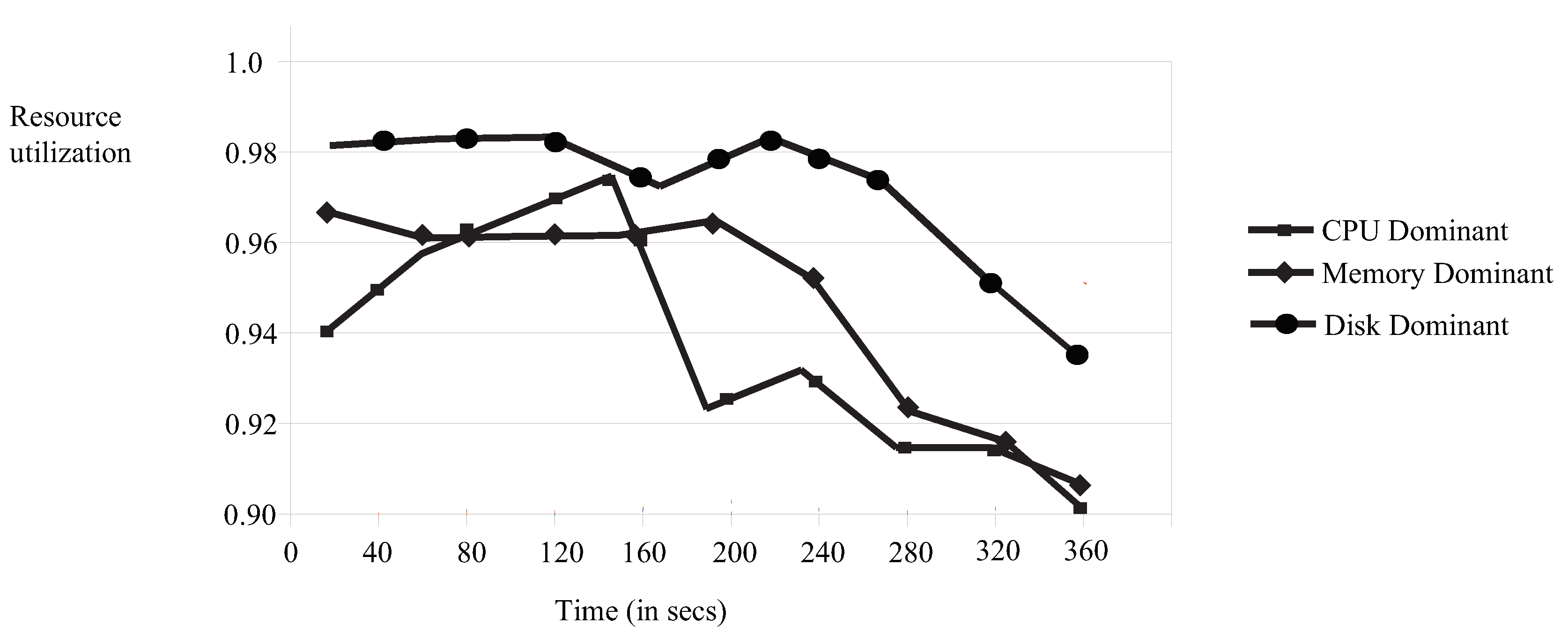
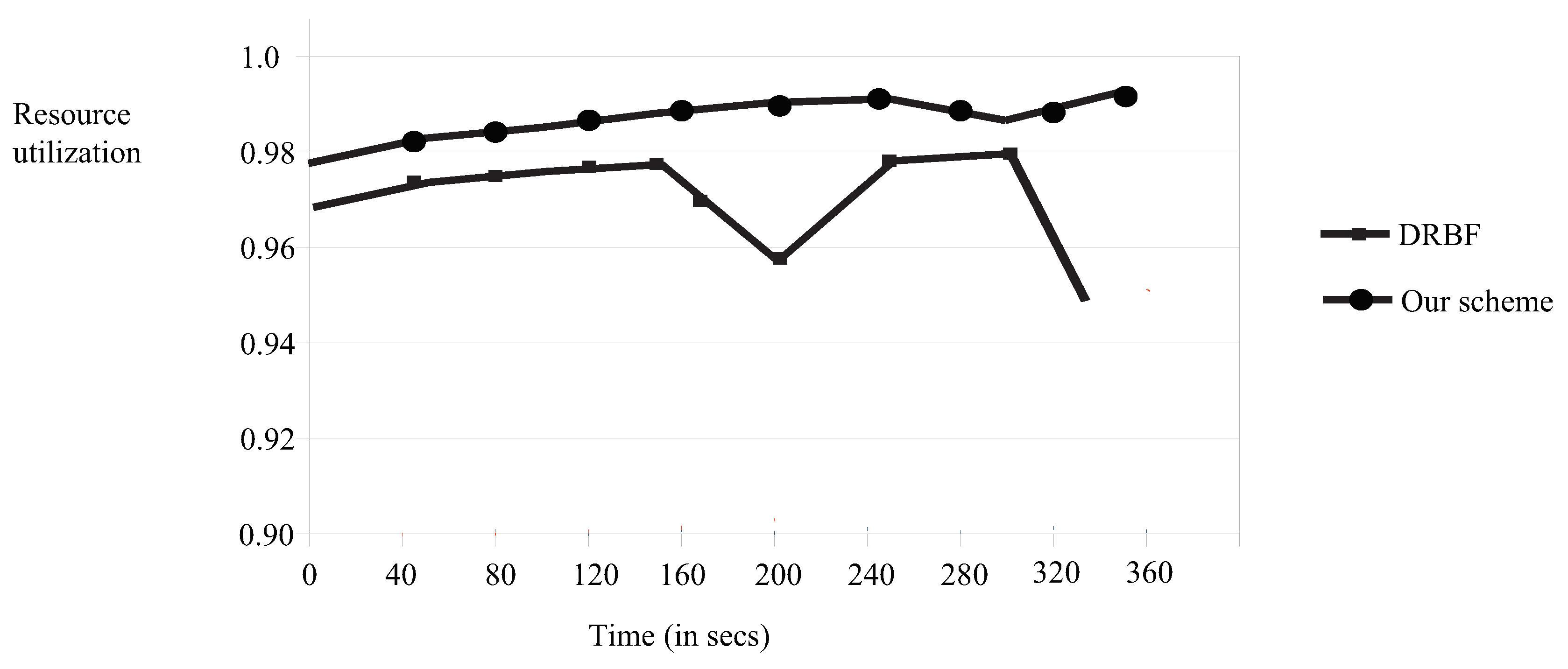
5.2. Resource Utilization
6. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Jennings, B.; Stadler, R. Resource management in clouds: Survey and research challenges. J. Netw. Syst. Manag. 2015, 2, 567–619. [Google Scholar] [CrossRef]
- Lu, Z.; Takashige, S.; Sugita, Y.; Morimura, T.; Kudo, Y. An analysis and comparison of cloud data center energy-efficient resource management technology. Int. J. Serv. Comput. 2014, 23, 32–51. [Google Scholar] [CrossRef]
- Tantalaki, N.; Souravlas, S.; Roumeliotis, M. A review on big data real-time stream processing and its scheduling techniques. Int. J. Parallel Emerg. Distrib. Syst. 2019. [Google Scholar] [CrossRef]
- Tantalaki, N.; Souravlas, S.; Roumeliotis, M.; Katsavounis, S. Linear Scheduling of Big Data Streams on Multiprocessor Sets in the Cloud. In Proceedings of the EEE/WIC/ACM International Conference on Web Intelligence, Thessaloniki, Greece, 14–17 October 2019; pp. 107–115. [Google Scholar]
- Xiao, Z.; Song, W.J.; Chen, Q. Dynamic resource allocation using virtual machines for cloud computing environment. IEEE Trans. Parallel Distrib. Syst. 2013, 24, 1107–1117. [Google Scholar] [CrossRef]
- Trihinas, D.; Georgiou, Z.; Pallis, G.; Dikaiakos, M.D. Improving Rule-Based Elasticity Control by Adapting the Sensitivity of the Auto-Scaling Decision Timeframe. In Proceedings of the Third International Conference on Algorithmic Aspects of Cloud Computing (ALGOCLOUD 2017), Vienna, Austria, 5 September 2017. [Google Scholar]
- Copil, G.; Trihinas, D.; Truong, H.; Moldovan, D.; Pallis, G.; Dustdar, S.; Dikaiakos, M.D. ADVISE—A Framework for Evaluating Cloud Service Elasticity Behavior. In Proceedings of the 12th International Conference on Service Oriented Computing (ICSOC 2014), Paris, France, 3–6 November 2014. [Google Scholar]
- Ghodsi, A.; Zaharia, M.; Hindman, B.; Konwinski, A.; Shenker, S.; Stoica, I. Dominant resource fairness: Fair allocation of multiple resource types. In Proceedings of the 8th USENIX conference on Networked systems design and implementation, Boston, MA, USA, 30 March–1 April 2011; pp. 323–336. [Google Scholar]
- Souravlas, S.; Sifaleras, A.; Katsavounis, S. A Parallel Algorithm for Community Detection in Social Networks, Based on Path Analysis and Threaded Binary Trees. IEEE Access 2019, 7, 20499–20519. [Google Scholar] [CrossRef]
- Souravlas, S.; Sifaleras, A.; Katsavounis, S. A novel, interdisciplinary, approach for community detection based on remote file requests. IEEE Access 2018, 6, 68415–68428. [Google Scholar] [CrossRef]
- Souravlas, S.; Sifaleras, A. Binary-Tree Based Estimation of File Requests for Efficient Data Replication. IEEE Trans. Parallel Distrib. Syst. 2017, 28, 1839–1852. [Google Scholar] [CrossRef]
- Bodrul Alam, A.B.M.; Zulkernine, M.; Haque, A. A reliability-based resource allocation approach for cloud computing. In Proceedings of the 2017 7th IEEE International Symposium on Cloud and Service Computing, Kanazawa, Japan, 22–25 November 2017; pp. 249–252. [Google Scholar]
- Kumar, N.; Saxena, S. A preference-based resource allocation in cloud computing systems. In Proceedings of the 3rd International Conference on Recent Trends in Computing 2015 (ICRTC-2015), Delhi, India, 12–13 March 2015; pp. 104–111. [Google Scholar]
- Lin, W.; Wang, J.Z.; Liang, C.; Qi, D. A threshold-based dynamic resource allocation scheme for cloud computing. Procedia Eng. 2011, 23, 695–703. [Google Scholar] [CrossRef]
- Tran, T.T.; Padmanabhan, M.; Zhang, P.Y.; Li, H.; Down, D.G.; Christopher Beck, J. Multi-stage resource-aware scheduling for data centers with heterogeneous servers. J. Sched. 2018, 21, 251–267. [Google Scholar] [CrossRef]
- Hu, Y.; Wong, J.; Iszlai, G.; Litoiu, M. Resource provisioning for cloud computing. In Proceedings of the 2009 Conference of the Center for Advanced Studies on Collaborative Research, Toronto, ON, Canada, 2–5 November 2009; pp. 101–111. [Google Scholar]
- Khanna, A.; Sarishma. RAS: A novel approach for dynamic resource allocation. In Proceedings of the 1st International Conference on Next Generation Computing Technologies (NGCT-2015), Dehradun, India, 4–5 September 2015; pp. 25–29. [Google Scholar]
- Saraswathia, A.T.; Kalaashrib, Y.R.A.; Padmavathi, S. Dynamic resource allocation scheme in cloud computing. Procedia Comput. Sci. 2015, 47, 30–36. [Google Scholar] [CrossRef]
- Souravlas, S. ProMo: A Probabilistic Model for Dynamic Load-Balanced Scheduling of Data Flows in Cloud Systems. Electronics 2019, 8, 990. [Google Scholar] [CrossRef]
- Zhao, L.; Du, M.; Chen, L. A new multi-resource allocation mechanism: A tradeoff between fairness and efficiency in cloud computing. China Commun. 2018, 24, 57–77. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Resource Allocation Scheme | Cost | Execution Time | Utilization |
|---|---|---|---|
| RA as optimization problem, Alam et al., [12] | Yes | No | No |
| Open market-driven auction/preference-driven payment process, Kumar et al. [13] | Yes | No | Yes |
| Threshold-based strategy for monitoring and predicting the users’ demands, Lin et al. [14] | Yes | Yes | No |
| Job class-based strategy, Hu et al. [16] | Yes | No | No |
| Dynamic RAS (Resource Allocation System), Khanna et al. [17] | No | No | Yes |
| 3-stage mapping scheme, Tran et al. [15] | Yes | Yes | No |
| Job feature-based strategy, Saraswathia et al. [18] | No | No | Yes |
| Skewness minimization, Xiao et al. [5] | No | No | Yes |
| Our work | No | No | Yes |
| User | CPU | Memory | Disk | |
|---|---|---|---|---|
| 1 | 4 | 3 | 2 | CPU-intensive |
| 2 | 6 | 4 | 5 | |
| 3 | 8 | 5 | 6 | |
| 4 | 9 | 6 | 7 | |
| 5 | 10 | 2 | 8 | |
| 6 | 3 | 18 | 10 | Memory-intensive |
| 7 | 3 | 21 | 8 | |
| 8 | 5 | 24 | 10 | |
| 9 | 5 | 30 | 12 |
| Demand Vector (Sorted) | Max. No of Jobs/User | Fair Allocation/Job, f | Allocation Per User, |
|---|---|---|---|
| 18 | 5.61 | 12 | |
| 21 | 15 | ||
| 24 | 17 | ||
| 30 | 20 |
| Demand Vector (Sorted) | Max. No of Jobs/User | Fair Allocation/Job, f | Allocation Per User, |
|---|---|---|---|
| 2 | 0.69 | 2 | |
| 3 | 2 | ||
| 4 | 3 | ||
| 5 | 4 | ||
| 6 | 5 |
| Demand Vector (Sorted) | Max. No of Jobs/User | Fair Allocation/Job, f | Allocation Per User, |
|---|---|---|---|
| 3 | 0.69 | 2 | |
| 3 | 2 | ||
| 5 | 3 | ||
| 5 | 3 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Souravlas, S.; Katsavounis, S. Scheduling Fair Resource Allocation Policies for Cloud Computing through Flow Control. Electronics 2019, 8, 1348. https://doi.org/10.3390/electronics8111348
Souravlas S, Katsavounis S. Scheduling Fair Resource Allocation Policies for Cloud Computing through Flow Control. Electronics. 2019; 8(11):1348. https://doi.org/10.3390/electronics8111348
Chicago/Turabian StyleSouravlas, Stavros, and Stefanos Katsavounis. 2019. "Scheduling Fair Resource Allocation Policies for Cloud Computing through Flow Control" Electronics 8, no. 11: 1348. https://doi.org/10.3390/electronics8111348
APA StyleSouravlas, S., & Katsavounis, S. (2019). Scheduling Fair Resource Allocation Policies for Cloud Computing through Flow Control. Electronics, 8(11), 1348. https://doi.org/10.3390/electronics8111348