Elderly Fall Detection with an Accelerometer Using Lightweight Neural Networks




Abstract
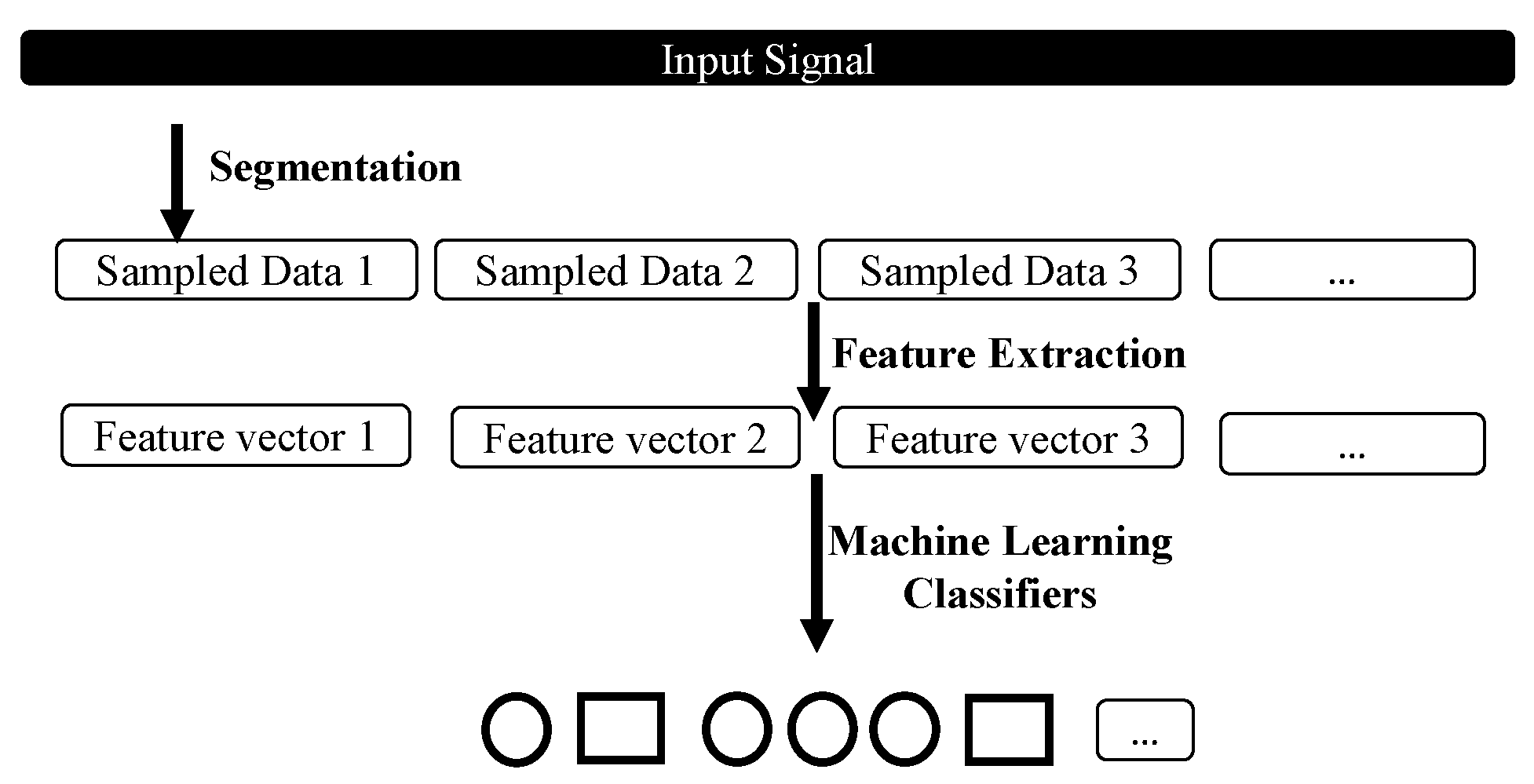
:1. Introduction
2. Datase and Pre-Processing
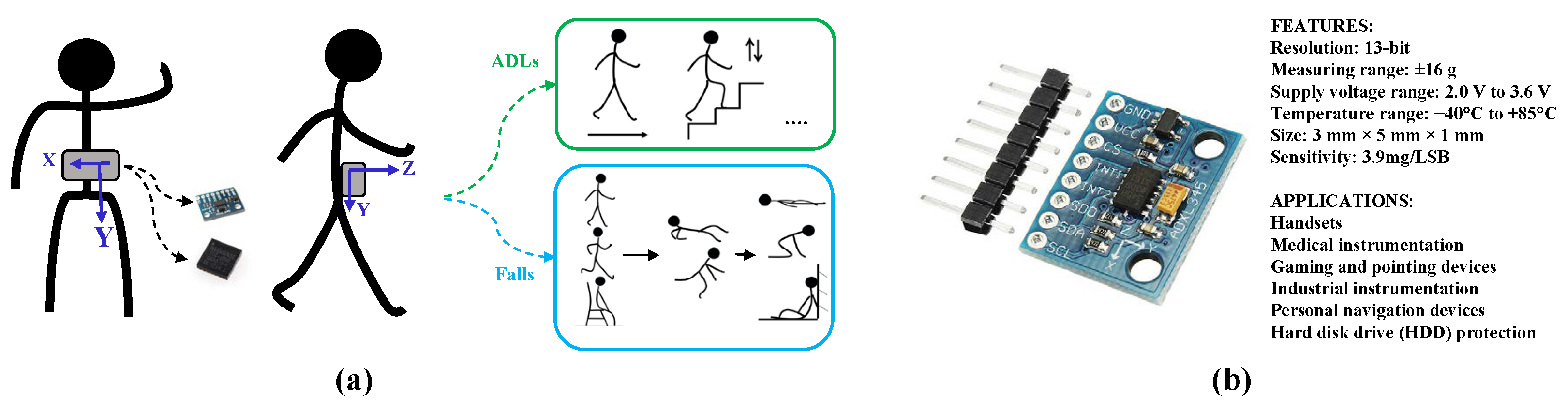
2.1. Dataset Description
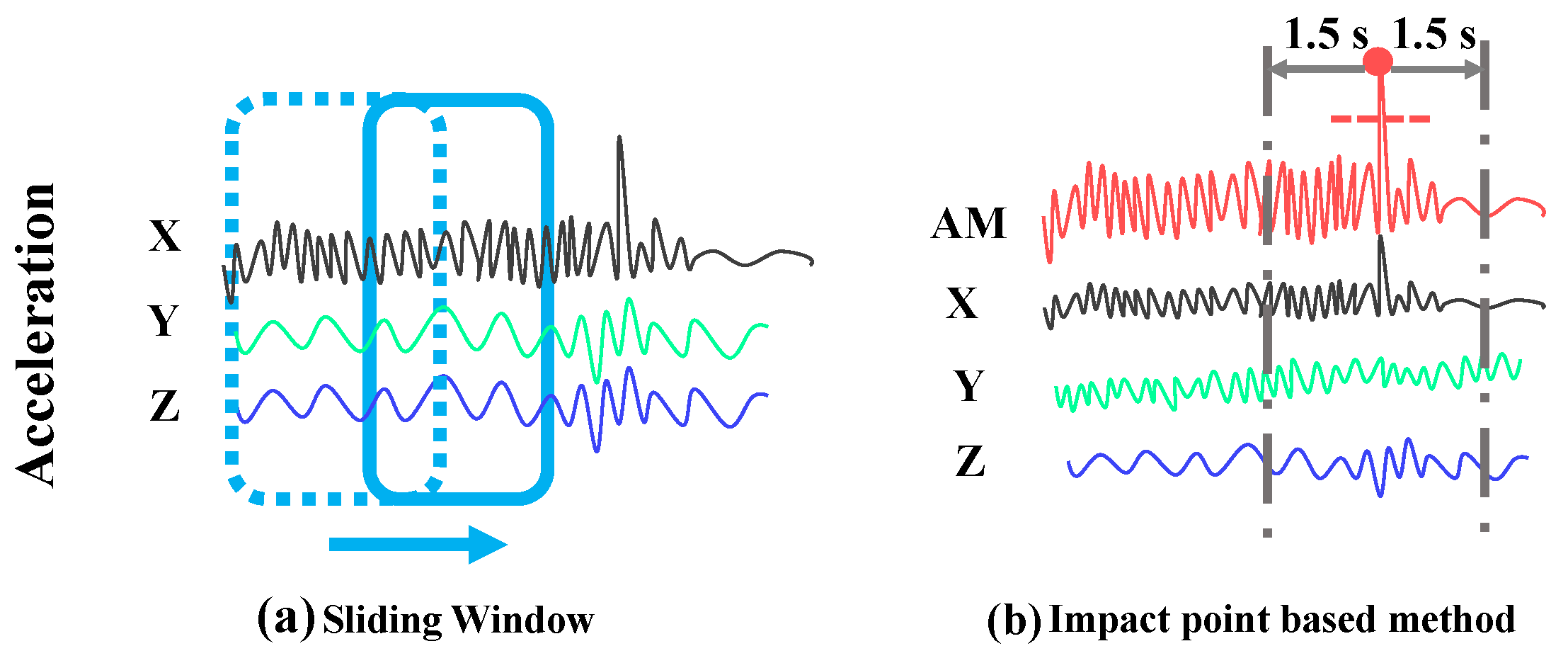
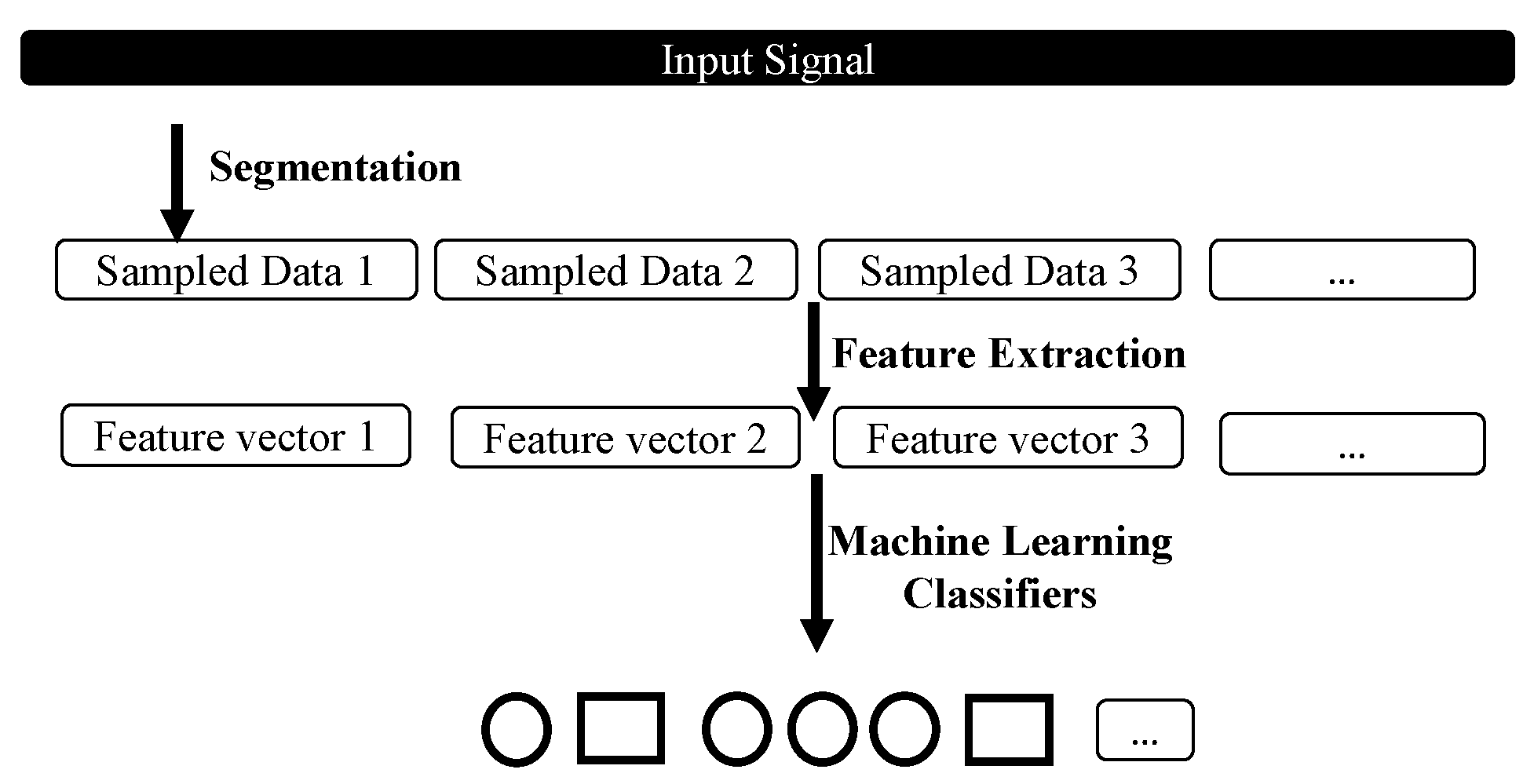
2.2. Data Pre-Processing
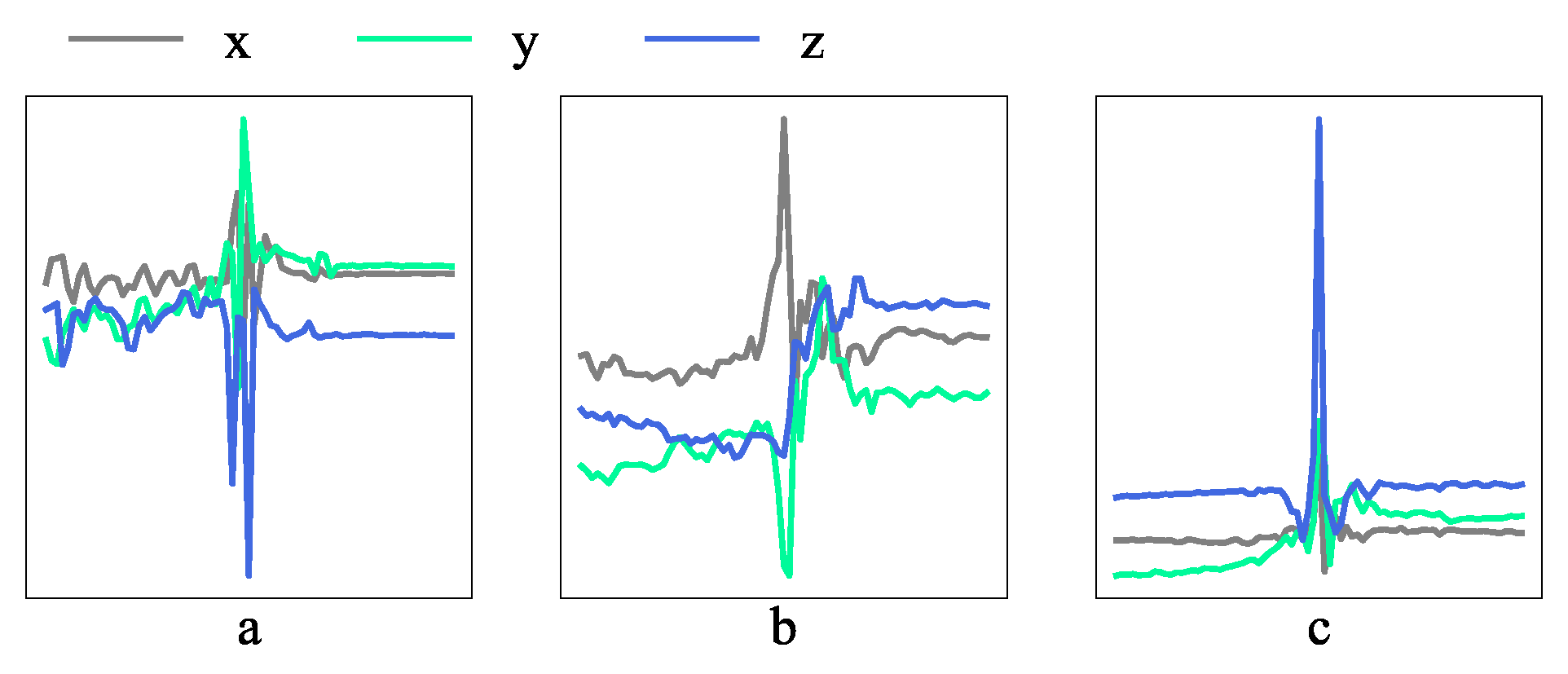
2.2.1. Data Segmentation with Impact Point
2.2.2. Feature Extraction
- (1)
- Minimum values of acceleration measurements;
- (2)
- Maximum values of acceleration measurements;
- (3)
- Mean values of acceleration measurements;
- (4)
- Median values of acceleration measurements;
- (5)
- Interquartile range of acceleration measurements;
- (6)
- Variance of acceleration measurements;
- (7)
- Standard deviation of acceleration measurements;
- (8)
- Mean absolute deviation of acceleration measurements;
- (9)
- Root mean square of acceleration measurements;
- (10)
- Entropy of acceleration measurements;
- (11)
- Energy of acceleration measurements;
- (12)
- Skewness of acceleration measurements;
- (13)
- Kurtosis of acceleration measurements.
2.2.3. Mitigating Effects of Class Imbalance
2.2.4. Evaluation Metrics
2.2.5. Classification Protocol
3. Machine Learning Methods
3.1. Conventional Machine Learning Methods
3.1.1. SVM
3.1.2. KNN
3.1.3. DT
3.1.4. XGB
3.2. Neural Networks
3.2.1. MLP
3.2.2. CNN
3.2.3. Autoencoders
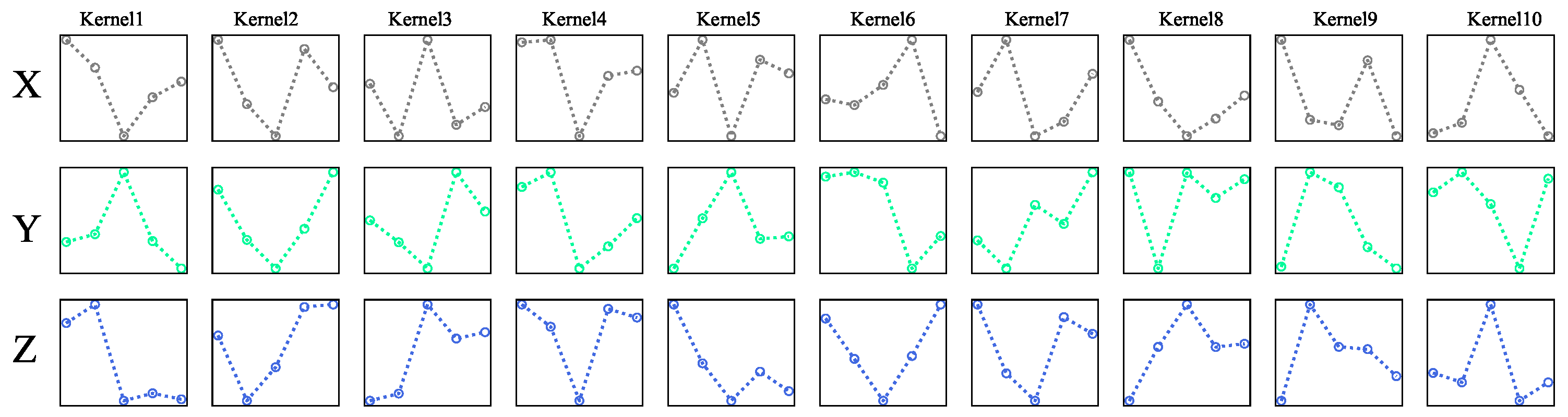
3.2.4. Neural Network Architectures
- (CNN-HE) [23]: CNN-HE consists of two convolutional layers (each appended with a max-pooling layer) and two fully-connected layers. The first convolutional layer consists of 32 kernels and the second layer consists of 64 kernels. The size of kernels used is 1 × 5 with a stride of 1. Furthermore, the first fully-connected layer consists of 512 neurons and the second layer consists of 8 neurons (change to 1 in this work) for classification.
- (CNN-3B3Conv) [24]: CNN-3B3Conv consists of three-layer blocks. The first block consists of three convolutional layers and one max-pooling layer. Each of the convolutional layer consists of 64 kernels with a size of 1 × 4. The second block also consists of three convolutional layers and one max-pooling layer, but the kernel size is set to 1 × 3 empirically. The third block consists of three fully-connected layers with 64 neurons, 32 neurons and two neurons (changed to one in this work) respectively.
- CNN-EDU [22]: CNN-EDU consists of four convolutional layers composed by 16 kenerls, 32 kenerls, 64 kenerls and 128 kenerls () respectively. Each convolutional layer is also appended with a pooling layer. Moreover, two fully-connected layers are appended in the end.
4. Experiment Results and Discussion
4.1. Lightweight Neural Networks against Conventional Methods
4.2. Leightweight Neural Networks against Baseline Models
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| CNN | Convolutional neural network |
| SVM | Support vector machine |
| DT | Decision tree |
| XGB | Extreme gradient boosting |
| KNN | K-nearest neighbor |
| MLP | Mlti-layer perceptron |
| DAE | Dense autoencoder |
| CAE | Convolutional autoencoder |
| HAR | Human activity recognition |
| ADLs | Human activities in daily life |
| AM | Acceleration magnitude |
| SMOTE | Synthetic minority oversampling technique |
| ReLU | Rectified linear unit |
| ACC | Accuracy |
| SEN | Sensitivity |
| SPE | Specificity |
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Run | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | AVG | STD |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SEN.(%) | 98.16 | 98.27 | 98.21 | 98.16 | 98.21 | 98.32 | 98.38 | 98.21 | 98.38 | 98.38 | 98.27 | 0.86 |
| SPE.(%) | 98.23 | 98.33 | 98.20 | 98.30 | 98.37 | 98.37 | 98.47 | 98.25 | 98.19 | 98.27 | 98.30 | 0.08 |
| ACC.(%) | 98.23 | 98.33 | 98.20 | 98.30 | 98.37 | 98.37 | 98.47 | 98.24 | 98.19 | 98.28 | 98.30 | 0.08 |
| TP | 1757 | 1759 | 1758 | 1757 | 1758 | 1760 | 1761 | 1758 | 1761 | 1761 | 1759 | 1.55 |
| FN | 33 | 31 | 32 | 33 | 32 | 30 | 29 | 32 | 29 | 29 | 31 | 1.55 |
| FP | 1361 | 1281 | 1387 | 1305 | 1253 | 1255 | 1179 | 1350 | 1396 | 1327 | 1309.4 | 64.89 |
| TN | 75,564 | 75,644 | 75,538 | 75,620 | 75,672 | 75,670 | 75,746 | 75,575 | 75,529 | 75,598 | 75,615.6 | 64.89 |
| Run | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | AVG | STD |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SEN.(%) | 90.89 | 90.95 | 90.89 | 90.89 | 90.95 | 90.89 | 90.95 | 90.95 | 90.89 | 90.89 | 90.91 | 0.03 |
| SPE.(%) | 98.70 | 98.70 | 98.70 | 98.70 | 98.70 | 98.70 | 98.70 | 98.70 | 98.70 | 98.70 | 98.70 | 0 |
| ACC.(%) | 98.52 | 98.53 | 98.52 | 98.52 | 98.52 | 98.52 | 98.51 | 98.52 | 98.52 | 98.52 | 98.52 | 0 |
| TP | 1627 | 1628 | 1627 | 1627 | 1628 | 1627 | 1628 | 1628 | 1627 | 1627 | 1627.4 | 0.49 |
| FN | 163 | 162 | 163 | 163 | 162 | 163 | 162 | 162 | 163 | 163 | 162.6 | 0.49 |
| FP | 1001 | 998 | 1002 | 1000 | 1001 | 1001 | 1002 | 1001 | 1003 | 1000 | 1000.9 | 1.3 |
| TN | 75,924 | 75,927 | 75,923 | 75,925 | 75,924 | 75,924 | 75,923 | 75,924 | 75,922 | 75,925 | 75,924.1 | 1.3 |
| Run | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | AVG | STD |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SEN.(%) | 97.82 | 97.77 | 97.82 | 97.88 | 97.65 | 97.82 | 97.82 | 97.71 | 97.71 | 97.71 | 97.77 | 0.07 |
| SPE.(%) | 98.93 | 98.93 | 98.93 | 98.93 | 98.94 | 99.04 | 98.93 | 99.02 | 99.01 | 98.94 | 98.96 | 0.04 |
| ACC.(%) | 98.91 | 98.90 | 98.91 | 98.91 | 98.91 | 99.01 | 98.90 | 98.99 | 98.98 | 98.92 | 98.93 | 0.04 |
| TP | 1751 | 1750 | 1751 | 1752 | 1748 | 1751 | 1751 | 1749 | 1749 | 1749 | 1750.1 | 1.22 |
| FN | 39 | 40 | 39 | 38 | 42 | 39 | 39 | 41 | 41 | 41 | 39.9 | 1.22 |
| FP | 822 | 823 | 822 | 822 | 817 | 741 | 823 | 751 | 760 | 813 | 799.4 | 32.32 |
| TN | 76,103 | 76,102 | 76,103 | 76,103 | 76,108 | 76,184 | 76,102 | 76,174 | 76,165 | 76,112 | 76,125.6 | 32.32 |
| Run | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | AVG | STD |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SEN.(%) | 99.32 | 99.33 | 99.33 | 99.39 | 99.39 | 99.22 | 99.33 | 99.27 | 99.33 | 99.27 | 99.32 | 0.05 |
| SPE.(%) | 99.34 | 99.43 | 99.39 | 99.19 | 99.29 | 99.41 | 99.34 | 99.43 | 99.40 | 99.33 | 99.36 | 0.07 |
| ACC.(%) | 99.34 | 99.43 | 99.39 | 99.20 | 99.29 | 99.40 | 99.34 | 99.42 | 99.40 | 99.33 | 99.35 | 0.07 |
| TP | 1778 | 1778 | 1778 | 1779 | 1779 | 1776 | 1778 | 1777 | 1778 | 1777 | 1777.8 | 0.87 |
| FN | 12 | 12 | 12 | 11 | 11 | 14 | 12 | 13 | 12 | 13 | 12.2 | 0.87 |
| FP | 509 | 435 | 471 | 622 | 548 | 457 | 506 | 442 | 460 | 517 | 496.7 | 54.19 |
| TN | 76,416 | 76,490 | 76,454 | 76,303 | 76,377 | 76,468 | 76,419 | 76,483 | 76,465 | 76,408 | 76,428.3 | 54.19 |
| Run | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | AVG | STD |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SEN.(%) | 98.66 | 98.72 | 97.99 | 98.27 | 98.04 | 98.04 | 98.71 | 97.82 | 98.49 | 98.32 | 98.31 | 0.31 |
| SPE.(%) | 99.94 | 99.95 | 99.96 | 99.96 | 99.96 | 99.96 | 99.96 | 99.96 | 99.95 | 99.96 | 99.96 | 0.01 |
| ACC.(%) | 99.91 | 99.92 | 99.92 | 99.92 | 99.91 | 99.92 | 99.93 | 99.91 | 99.92 | 99.92 | 99.92 | 0.01 |
| TP | 1766 | 1767 | 1754 | 1759 | 1755 | 1755 | 1767 | 1751 | 1763 | 1760 | 1759.7 | 5.57 |
| FN | 24 | 23 | 36 | 31 | 35 | 35 | 23 | 39 | 27 | 30 | 30.3 | 5.57 |
| FP | 46 | 39 | 30 | 31 | 32 | 30 | 29 | 28 | 35 | 33 | 33.3 | 5.22 |
| TN | 76,879 | 76,886 | 76,895 | 76,894 | 76,893 | 76,895 | 76,896 | 76,897 | 76,890 | 76,892 | 76,891.7 | 5.22 |
| Run | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | AVG | STD |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SEN.(%) | 99.05 | 98.44 | 98.60 | 98.82 | 98.99 | 98.60 | 98.04 | 98.83 | 99.11 | 98.66 | 98.71 | 0.30 |
| SPE.(%) | 99.95 | 99.97 | 99.96 | 99.96 | 99.96 | 99.97 | 99.98 | 99.96 | 99.96 | 99.97 | 99.96 | 0.01 |
| ACC.(%) | 99.93 | 99.94 | 99.93 | 99.94 | 99.94 | 99.94 | 99.93 | 99.94 | 99.94 | 99.94 | 99.94 | 0.01 |
| TP | 1773 | 1762 | 1765 | 1769 | 1772 | 1765 | 1755 | 1770 | 1774 | 1766 | 1767.1 | 5.49 |
| FN | 17 | 28 | 25 | 21 | 18 | 25 | 35 | 20 | 16 | 24 | 22.9 | 5.49 |
| FP | 35 | 21 | 30 | 27 | 30 | 26 | 18 | 31 | 28 | 23 | 26.9 | 4.83 |
| TN | 76,890 | 76,904 | 76,895 | 76,898 | 76,895 | 76,899 | 76,907 | 76,894 | 76,897 | 76,902 | 76,898.1 | 4.83 |
| Run | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | AVG | STD |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SEN.(%) | 98.99 | 99.11 | 98.88 | 98.99 | 99.22 | 99.05 | 99.11 | 99.16 | 99.27 | 98.94 | 99.07 | 0.12 |
| SPE.(%) | 99.81 | 99.83 | 99.84 | 99.76 | 99.86 | 99.87 | 99.81 | 99.86 | 99.82 | 99.84 | 99.83 | 0.03 |
| ACC.(%) | 99.79 | 99.81 | 99.82 | 99.74 | 99.84 | 99.85 | 99.80 | 99.85 | 99.81 | 99.82 | 99.81 | 0.03 |
| TP | 1772 | 1774 | 1770 | 1772 | 1776 | 1773 | 1774 | 1775 | 1777 | 1771 | 1773.4 | 2.11 |
| FN | 18 | 16 | 20 | 18 | 14 | 17 | 16 | 15 | 13 | 19 | 16.6 | 2.11 |
| FP | 148 | 132 | 121 | 184 | 109 | 102 | 145 | 107 | 139 | 124 | 131.1 | 23.26 |
| TN | 76,777 | 76,793 | 76,804 | 76,741 | 76,816 | 76,823 | 76,780 | 76,818 | 76,786 | 76,801 | 76,793.9 | 23.26 |
| Run | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | AVG | STD |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SEN.(%) | 99.39 | 99.05 | 99.22 | 99.22 | 99.27 | 99.16 | 99.27 | 98.83 | 99.11 | 99.44 | 99.20 | 0.17 |
| SPE.(%) | 99.94 | 99.90 | 99.94 | 99.93 | 99.91 | 99.93 | 99.91 | 99.93 | 99.94 | 99.93 | 99.93 | 0.01 |
| ACC.(%) | 99.92 | 99.88 | 99.92 | 99.92 | 99.89 | 99.91 | 99.89 | 99.90 | 99.92 | 99.92 | 99.91 | 0.01 |
| TP | 1779 | 1773 | 1776 | 1776 | 1777 | 1775 | 1777 | 1769 | 1774 | 1780 | 1775.6 | 2.97 |
| FN | 11 | 17 | 14 | 14 | 13 | 15 | 13 | 21 | 16 | 10 | 14.4 | 2.97 |
| FP | 49 | 77 | 48 | 52 | 71 | 57 | 70 | 57 | 45 | 53 | 57.9 | 10.43 |
| TN | 76,876 | 76,848 | 76,877 | 76,873 | 76,854 | 76,868 | 76,855 | 76,868 | 76,880 | 76,872 | 76,867.1 | 10.43 |
| Run | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | AVG | STD |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SEN.(%) | 99.22 | 99.44 | 98.49 | 99.27 | 99.16 | 99.55 | 98.88 | 99.44 | 99.44 | 99.38 | 99.23 | 0.3 |
| SPE.(%) | 99.94 | 99.95 | 99.98 | 99.95 | 99.93 | 99.97 | 99.96 | 99.82 | 99.95 | 99.95 | 99.94 | 0.04 |
| ACC.(%) | 99.93 | 99.94 | 99.94 | 99.94 | 99.91 | 99.96 | 99.94 | 99.81 | 99.94 | 99.94 | 99.93 | 0.04 |
| TP | 1776 | 1780 | 1763 | 1777 | 1775 | 1782 | 1770 | 1780 | 1780 | 1779 | 1776.2 | 5.47 |
| FN | 14 | 10 | 27 | 13 | 15 | 8 | 20 | 10 | 10 | 11 | 13.8 | 5.47 |
| FP | 43 | 39 | 19 | 37 | 55 | 22 | 30 | 138 | 39 | 36 | 45.8 | 32.24 |
| TN | 76,882 | 76,886 | 76,906 | 76,888 | 76,870 | 76,903 | 76,895 | 76,787 | 76,886 | 76,889 | 76,879.2 | 32.24 |
| Run | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | AVG | STD |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SEN.(%) | 99.33 | 99.55 | 99.55 | 98.83 | 99.33 | 99.72 | 99.50 | 99.50 | 99.66 | 99.55 | 99.45 | 0.24 |
| SPE.(%) | 99.93 | 99.97 | 99.94 | 99.97 | 99.96 | 99.88 | 99.94 | 99.90 | 99.87 | 99.96 | 99.93 | 0.03 |
| ACC.(%) | 99.92 | 99.96 | 99.93 | 99.95 | 99.95 | 99.88 | 99.93 | 99.89 | 99.87 | 99.95 | 99.92 | 0.03 |
| TP | 1778 | 1782 | 1782 | 1769 | 1778 | 1785 | 1781 | 1781 | 1784 | 1782 | 1780.2 | 4.28 |
| FN | 12 | 8 | 8 | 21 | 12 | 5 | 9 | 9 | 6 | 8 | 9.8 | 4.28 |
| FP | 52 | 25 | 46 | 21 | 30 | 90 | 48 | 75 | 101 | 34 | 52.2 | 26.31 |
| TN | 76,873 | 76,900 | 76,879 | 76,904 | 76,895 | 76,835 | 76,877 | 76,850 | 76,824 | 76,891 | 76,872.8 | 26.31 |
| Run | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | AVG | STD |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SEN.(%) | 99.72 | 99.66 | 99.83 | 99.44 | 99.11 | 99.05 | 99.50 | 99.61 | 99.66 | 99.55 | 99.51 | 0.24 |
| SPE.(%) | 99.94 | 99.96 | 99.85 | 99.96 | 99.93 | 99.95 | 99.95 | 99.90 | 99.95 | 99.93 | 99.93 | 0.03 |
| ACC.(%) | 99.94 | 99.95 | 99.85 | 99.95 | 99.91 | 99.93 | 99.94 | 99.89 | 99.95 | 99.93 | 99.93 | 0.03 |
| TP | 1785 | 1784 | 1787 | 1780 | 1774 | 1773 | 1781 | 1783 | 1784 | 1782 | 1781.3 | 4.34 |
| FN | 5 | 6 | 3 | 10 | 16 | 17 | 9 | 7 | 6 | 8 | 8.7 | 4.34 |
| FP | 46 | 34 | 112 | 31 | 52 | 40 | 41 | 76 | 35 | 51 | 51.8 | 23.52 |
| TN | 76,879 | 76,891 | 76,813 | 76,894 | 76,873 | 76,885 | 76,884 | 76,849 | 76,890 | 76,874 | 76,873.2 | 23.52 |
Appendix B
References
- United Nations, Department of Economic and Social Affairs. World Population Prospects: The 2017 Revision, Key Findings and Advance Tables. ESA/P/WP/248. 2017. Available online: https://population.un.org/wpp/Publications/ (accessed on 6 November 2019).
- Murray, C.J.; Lopez, A.D. The global burden of disease: A comprehensive assessment of mortality and disability from diseases, injuries, and risk factors in 1990 and projected to 2020: summary. Glob. Burd. Dis. Inj. Ser. 1996, 1, 201–246. [Google Scholar]
- Schwendimann, R. Patient falls: A Key Issue in Patient Safety in Hospitals. Ph.D. Thesis, University of Basel, Basel, Switzerland, 2006. [Google Scholar]
- Schwickert, L.; Becker, C.; Lindemann, U.; Maréchal, C.; Bourke, A.; Chiari, L.; Helbostad, J.; Zijlstra, W.; Aminian, K.; Todd, C.; et al. Fall detection with body-worn sensors. Z. Für Gerontol. Geriatr. 2013, 46, 706–719. [Google Scholar] [CrossRef] [PubMed]
- Büsching, F.; Post, H.; Gietzelt, M.; Wolf, L. Fall detection on the road. In Proceedings of the 2013 IEEE 15th International Conference on e-Health Networking, Applications and Services (Healthcom 2013), Lisbon, Portugal, 9–12 October 2013; pp. 439–443. [Google Scholar]
- Aguiar, B.; Rocha, T.; Silva, J.; Sousa, I. Accelerometer-based fall detection for smartphones. In Proceedings of the 2014 IEEE International Symposium on Medical Measurements and Applications (MeMeA), Lisboa, Portugal, 11–12 June 2014; pp. 1–6. [Google Scholar]
- Hakim, A.; Huq, M.S.; Shanta, S.; Ibrahim, B. Smartphone based data mining for fall detection: Analysis and design. Procedia Comput. Sci. 2017, 105, 46–51. [Google Scholar] [CrossRef]
- Rougier, C.; Meunier, J.; St-Arnaud, A.; Rousseau, J. Robust Video Surveillance for Fall Detection Based on Human Shape Deformation. IEEE Trans. Circuits Syst. Video Technol. 2011, 21, 611–622. [Google Scholar] [CrossRef]
- Cucchiara, R.; Prati, A.; Vezzani, R. A multi-camera vision system for fall detection and alarm generation. Expert Syst. 2007, 24, 334–345. [Google Scholar] [CrossRef]
- Mohamed, O.; Choi, H.; Iraqi, Y. Fall Detection Systems for Elderly Care: A Survey. In Proceedings of the 2014 6th International Conference on New Technologies, Mobility and Security (NTMS), Dubai, United Arab Emirates, 30 March–2 April 2014; pp. 1–4. [Google Scholar]
- Zhang, Z.; Conly, C.; Athitsos, V. A Survey on Vision-based Fall Detection. In Proceedings of the 8th ACM International Conference on PErvasive Technologies Related to Assistive Environments, Corfu, Greece, 1–3 July 2015; pp. 46:1–46:7. [Google Scholar]
- Kamilaris, A.; Pitsillides, A. Mobile Phone Computing and the Internet of Things: A Survey. IEEE Internet Things J. 2016, 3, 885–898. [Google Scholar] [CrossRef]
- Zhang, Y.; Sun, L.; Song, H.; Cao, X. Ubiquitous WSN for Healthcare: Recent Advances and Future Prospects. IEEE Internet Things J. 2014, 1, 311–318. [Google Scholar] [CrossRef]
- Sezer, O.B.; Dogdu, E.; Ozbayoglu, A.M. Context-Aware Computing, Learning, and Big Data in Internet of Things: A Survey. IEEE Internet Things J. 2018, 5, 1–27. [Google Scholar] [CrossRef]
- Chen, M.; Li, Y.; Luo, X.; Wang, W.; Wang, L.; Zhao, W. A Novel Human Activity Recognition Scheme for Smart Health Using Multilayer Extreme Learning Machine. IEEE Internet Things J. 2019, 6, 1410–1418. [Google Scholar] [CrossRef]
- De Quadros, T.; Lazzaretti, A.E.; Schneider, F.K. A Movement Decomposition and Machine Learning-Based Fall Detection System Using Wrist Wearable Device. IEEE Sens. J. 2018, 18, 5082–5089. [Google Scholar] [CrossRef]
- Liu, Z.; Cao, Y.; Cui, L.; Song, J.; Zhao, G. A benchmark database and baseline evaluation for fall detection based on wearable sensors for the internet of medical things platform. IEEE Access 2018, 6, 51286–51296. [Google Scholar] [CrossRef]
- Aziz, O.; Musngi, M.; Park, E.J.; Mori, G.; Robinovitch, S.N. A comparison of accuracy of fall detection algorithms (threshold-based vs. machine learning) using waist-mounted tri-axial accelerometer signals from a comprehensive set of falls and non-fall trials. Med. Biol. Eng. Comput. 2017, 55, 45–55. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Chen, Y.; Hao, S.; Peng, X.; Hu, L. Deep learning for sensor-based activity recognition: A survey. Pattern Recognit. Lett. 2019, 119, 3–11. [Google Scholar] [CrossRef]
- Theodoridis, T.; Solachidis, V.; Vretos, N.; Daras, P. Human fall detection from acceleration measurements using a Recurrent Neural Network. In Precision Medicine Powered by pHealth and Connected Health; Springer: Heidelberg, Germany, 2018; pp. 145–149. [Google Scholar]
- Mauldin, T.; Canby, M.; Metsis, V.; Ngu, A.; Rivera, C. SmartFall: A smartwatch-based fall detection system using deep learning. Sensors 2018, 18, 3363. [Google Scholar] [CrossRef] [PubMed]
- Casilari, E.; Lora-Rivera, R.; García-Lagos, F. A Wearable Fall Detection System Using Deep Learning. In International Conference on Industrial, Engineering and Other Applications of Applied Intelligent Systems; Springer: Heidelberg, Germany, 2019; pp. 445–456. [Google Scholar]
- He, J.; Zhang, Z.; Wang, X.; Yang, S. A Low Power Fall Sensing Technology Based on FD-CNN. IEEE Sens. J. 2019, 19, 5110–5118. [Google Scholar] [CrossRef]
- Santos, G.L.; Endo, P.T.; Monteiro, K.H.d.C.; Rocha, E.d.S.; Silva, I.; Lynn, T. Accelerometer-Based Human Fall Detection Using Convolutional Neural Networks. Sensors 2019, 19, 1644. [Google Scholar] [CrossRef] [PubMed]
- Sucerquia, A.; López, J.; Vargas-Bonilla, J. SisFall: A fall and movement dataset. Sensors 2017, 17, 198. [Google Scholar] [CrossRef]
- Liu, K.; Hsieh, C.; Hsu, S.J.; Chan, C. Impact of Sampling Rate on Wearable-Based Fall Detection Systems Based on Machine Learning Models. IEEE Sens. J. 2018, 18, 9882–9890. [Google Scholar] [CrossRef]
- Devices, A. ADXL345 Datasheet; Analog Devices: Norwood, MA, USA, 2010. [Google Scholar]
- Karantonis, D.M.; Narayanan, M.R.; Mathie, M.; Lovell, N.H.; Celler, B.G. Implementation of a real-time human movement classifier using a triaxial accelerometer for ambulatory monitoring. IEEE Trans. Inf. Technol. Biomed. 2006, 10, 156–167. [Google Scholar] [CrossRef]
- Kau, L.; Chen, C. A Smart Phone-Based Pocket Fall Accident Detection, Positioning, and Rescue System. IEEE J. Biomed. Health Inform. 2015, 19, 44–56. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Ronao, C.A.; Cho, S.B. Human activity recognition with smartphone sensors using deep learning neural networks. Expert Syst. Appl. 2016, 59, 235–244. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Molchanov, P.; Tyree, S.; Karras, T.; Aila, T.; Kautz, J. Pruning convolutional neural networks for resource efficient inference. arXiv 2016, arXiv:1611.06440. [Google Scholar]







| Code | ADLs | Duration |
| D01 D02 D03 D04 D05 D06 D07 D08 D09 D10 D11 D12 D13 D14 D15 D16 D17 D18 D19 | Walking slowly Walking quickly Jogging slowly Jogging quickly Walking upstairs and downstairs slowly Walking upstairs and downstairs quickly Slowly sit in a half height chair, wait a moment, and up slowly Quickly sit in a half height chair, wait a moment, and up quickly Slowly sit in a low height chair, wait a moment, and up slowly Quickly sit in a low height chair, wait a moment, and up quickly Sitting a moment, trying to get up, and collapse into a chair Sitting a moment, lying slowly, wait a moment, and sit again Sitting a moment, lying quickly, wait a moment, and sit again Being on one’s back change to lateral position, wait a moment, and change to one’s back Standing, slowly bending at knees, and getting up Standing, slowly bending without bending knees, and getting up Standing, get into a car, remain seated and get out of the car Stumble while walking Gently jump without falling (trying to reach a high object) | 100 s 100 s 100 s 100 s 25 s 25 s 12 s 12 s 12 s 12 s 12 s 12 s 12 s 12 s 12 s 12 s 25 s 12 s 12 s |
| Code | Falls | Duration |
| F01 F02 F03 F04 F05 F06 F07 F08 F09 F10 F11 F12 F13 F14 F15 | Fall-forward while walking caused by a slip Fall-backward while walking caused by a slip Lateral fall while walking caused by a slip Fall-forward while walking caused by a trip Fall-forward while jogging caused by a trip Vertical fall while walking caused by fainting Fall while walking, with use of hands in a table to dampen fall, caused by fainting Fall-forward when trying to get up Lateral fall when trying to get up Fall-forward when trying to sit down Fall-backward when trying to sit down Lateral fall when trying to sit down Fall-forward while sitting, caused by fainting or falling asleep Fall-backward while sitting, caused by fainting or falling asleep Lateral fall while sitting, caused by fainting or falling asleep | 15 s 15 s 15 s 15 s 15 s 15 s 15 s 15 s 15 s 15 s 15 s 15 s 15 s 15 s 15 s |
| Sex | Age | Height (m) | Weight (kg) | |
|---|---|---|---|---|
| Elderly | Female | 62–75 | 1.50–1.69 | 50–72 |
| Male | 60–71 | 1.63–1.71 | 56–102 | |
| Adult | Female | 19–30 | 1.49–1.69 | 42–63 |
| Male | 19–30 | 1.65–1.83 | 58–81 |
| Confusion Matrix | Predicted Class | ||
|---|---|---|---|
| Falls | ADLs | ||
| Actual Class | Falls (P) | TP | FN |
| ADLs (N) | FP | TN | |
| Filter Size | Depth | Width | Acc.(%) | Filter Size | Depth | Width | Acc.(%) | Filter Size | Depth | Width | Acc.(%) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 × 2 | 1 | 5 | 99.85% | 1 × 5 | 1 | 5 | 99.89% | 1 × 10 | 1 | 5 | 99.89% |
| 1 | 10 | 99.90% | 1 | 10 | 99.94% | 1 | 10 | 99.91% | |||
| 1 | 30 | 99.91% | 1 | 30 | 99.94% | 1 | 30 | 99.94% | |||
| 2 | 5 | 99.77% | 2 | 5 | 99.83% | 2 | 5 | 99.91% | |||
| 2 | 10 | 99.91% | 2 | 10 | 99.93% | 2 | 10 | 99.92% | |||
| 2 | 30 | 99.93% | 2 | 30 | 99.94% | 2 | 30 | 99.94% | |||
| 3 | 5 | 99.88% | 3 | 5 | 99.91% | 3 | 5 | 99.91% | |||
| 3 | 10 | 99.89% | 3 | 10 | 99.93% | 3 | 10 | 99.92% | |||
| 3 | 30 | 99.89% | 3 | 30 | 99.94% | 3 | 30 | 99.94% |
| Depth | Width | Acc.(%) | Depth | Width | Acc.(%) |
|---|---|---|---|---|---|
| 1 | 16 | 99.91% | 2 | 16 | 99.90% |
| 1 | 32 | 99.91% | 2 | 32 | 99.91% |
| 1 | 64 | 99.92% | 2 | 64 | 99.91% |
| 3 | 16 | 99.90% | 4 | 16 | 99.88% |
| 3 | 32 | 99.91% | 4 | 32 | 99.92% |
| 3 | 64 | 99.90% | 4 | 64 | 99.92% |
| Classifiers → | Conventional Methods | Leight Weight Neural Networks | ||||||
|---|---|---|---|---|---|---|---|---|
| Metrics ↓ | XGB | KNN | SVM | DT | MLP | DAE | CAE | CNN |
| SEN.(%) | 99.32 | 90.91 | 98.27 | 97.77 | 98.31 | 99.07 | 99.20 | 98.71 |
| SPE.(%) | 99.36 | 98.70 | 98.30 | 98.96 | 99.96 | 99.83 | 99.93 | 99.96 |
| ACC.(%) | 99.35 | 98.52 | 98.30 | 98.93 | 99.92 | 99.81 | 99.91 | 99.94 |
| TP | 1777.8 | 1627.4 | 1759 | 1750.1 | 1759.7 | 1773.4 | 1775.6 | 1767.1 |
| FN | 12.2 | 162.6 | 31 | 39.9 | 30.3 | 16.6 | 14.4 | 22.9 |
| FP | 496.7 | 1000.9 | 1309.4 | 799.4 | 33.3 | 131.1 | 57.9 | 26.9 |
| TN | 76,428.3 | 75,924.1 | 75,615.6 | 76,125.6 | 76,891.7 | 76,793.9 | 76,867.1 | 76,898.1 |
| Classifiers → | Baseline Models | Leight Weight Neural Networks | |||||
|---|---|---|---|---|---|---|---|
| Metrics ↓ | CNN-HE | CNN-3B3 | CNN-EDU | MLP | DAE | CAE | CNN |
| SEN.(%) | 99.23 | 99.45 | 99.51 | 98.31 | 99.07 | 99.20 | 98.71 |
| SPE.(%) | 99.94 | 99.93 | 99.93 | 99.96 | 99.83 | 99.93 | 99.96 |
| ACC.(%) | 99.93 | 99.92 | 99.93 | 99.92 | 99.81 | 99.91 | 99.94 |
| TP | 1776.2 | 1780.2 | 1781.3 | 1759.7 | 1773.4 | 1775.6 | 1767.1 |
| FN | 13.8 | 9.8 | 8.7 | 30.3 | 16.6 | 14.4 | 22.9 |
| FP | 45.8 | 52.2 | 51.8 | 33.3 | 131.1 | 57.9 | 26.9 |
| TN | 76,879.2 | 76,872.8 | 76,873.2 | 76,891.7 | 76,793.9 | 76,867.1 | 76,898.1 |
| PARA | 411 | 411 | |||||
| FLOPs | 2 M | 6.9 M | 1.4 M | 0.03 M | 0.03 M | 0.008 M | 0.008 M |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, G.; Li, Q.; Wang, L.; Zhang, Y.; Liu, Z. Elderly Fall Detection with an Accelerometer Using Lightweight Neural Networks. Electronics 2019, 8, 1354. https://doi.org/10.3390/electronics8111354
Wang G, Li Q, Wang L, Zhang Y, Liu Z. Elderly Fall Detection with an Accelerometer Using Lightweight Neural Networks. Electronics. 2019; 8(11):1354. https://doi.org/10.3390/electronics8111354
Chicago/Turabian StyleWang, Gaojing, Qingquan Li, Lei Wang, Yuanshi Zhang, and Zheng Liu. 2019. "Elderly Fall Detection with an Accelerometer Using Lightweight Neural Networks" Electronics 8, no. 11: 1354. https://doi.org/10.3390/electronics8111354
APA StyleWang, G., Li, Q., Wang, L., Zhang, Y., & Liu, Z. (2019). Elderly Fall Detection with an Accelerometer Using Lightweight Neural Networks. Electronics, 8(11), 1354. https://doi.org/10.3390/electronics8111354