1. Introduction
One of the most challenging problems for autonomous vehicles is complex maneuvering, such as driving in roundabouts in urban and nonurban environments. Roundabouts are a special case of intersection, where a circular traffic flow is established for a change of direction. To navigate successfully in a roundabout, it is necessary to understand the choice of entry and exit lanes, how to apply priority rules, how to interpret the intentions of other drivers, and the existing traffic itself. However, for the correct selection of actions in this particular scenario, a global understanding of the situation of driving in roundabouts is necessary to obtain the best results.
One approach to understanding driving in roundabouts is through artificial intelligence and data mining techniques such as machine learning. For example, in [
1] the authors presented rules of behavior to address a roundabout with an autonomous vehicle, modeling the behavior of a human driver through factors such as the speed of the vehicle, the angle of the wheel, the diameter of the roundabout, etc. The authors of [
2] presented an adaptive tactical behavior planner (ATBP) for an autonomous vehicle, capable of planning behaviors similar to human drivers when navigating a roundabout. Roundabout safety under shared traffic was studied in [
3] through models based on speed and traffic. The authors of [
4] presented learning techniques to obtain behaviors of human drivers when approaching a roundabout without signs posted, in order to obtain behavioral profiles applicable to autonomous vehicles. Applying machine learning techniques such as support vector machine (SVM), the authors of [
5] presented a prediction model to obtain the vehicle’s intention to enter or exit a roundabout. In this study, variables such as vehicle global positioning system (GPS) and multiple sensors were used to obtain directions on the vehicle’s path. Another approach using machine learning techniques is presented in [
6], where the authors designed a roundabout driving classification using hidden Markov models (HMMs) trained with naturalistic driving data, while the authors of [
7] proposed a sequential adaptive reinforcement learning approach for roundabout driving.
As reviewed in the previous literature, methods that use supervised learning techniques label the information and predict more or less accurately the variables to be treated in the problem of autonomous driving in a roundabout. With this methodology, an autonomous vehicle can maintain the course in a roundabout but does not maintain the direction autonomously, and could collide with some obstacle on the road or another vehicle by not having the correct orientation. On the other hand, unsupervised learning methods are not useful for addressing an automatic decision-making problem, because they only group data and it is not the problem to be addressed. If the objective is to autonomously execute the driving of a vehicle in a roundabout, a success rate of around 90% must be obtained in the actions that the expert system of the vehicle must execute to take a correct route. When applying reinforcement learning, the autonomous vehicle is oriented through the training system to make the best decisions, with reward policies applied that penalize the expert system itself when its actions are not correct, until it reaches a very high success rate. That is why learning reinforcement techniques are currently being used in autonomous driving research. Through these techniques, autonomous vehicles can learn to act in environments with uncertainty [
8].
In this paper, a Markov decision process (MDP) is used for planning the study of the behavior of an autonomous vehicle to safely navigate a roundabout with the Q-learning algorithm in a simulation environment. To this end, a set of naturalistic driving data was used for speed information and a machine learning model algorithm to learn decision-making. The main contribution of this paper is the design of a tangible learning technique for sequential and automatic decision-making of autonomous vehicles through examples in a simulated environment with roundabout scenarios without traffic, mainly for learning lane tracking, and with traffic, to learn the right maneuvers for approaching, circumnavigating, and exiting the roundabout safely. The designed learning system is able to learn enough to perform optimal driving, deciding whether an action taken has been positive or negative by reinforcing it through the defined rewards policy. The CARLA simulation environment [
9] was used to develop, train, and evaluate the proposed approach within two scenarios: navigating a roundabout with and without traffic.
The remainder of the paper is organized as follows:
Section 2 presents an overview of the reinforcement learning system’s framework and its use in autonomous driving.
Section 3 presents the simulation environment.
Section 4 gives an overview of the Q-learning algorithm and how it is used to model driving situations, as well as a description of the training policies.
Section 5 presents some simulations and experimental results. Finally, conclusions and future work of the present research are given in
Section 6.
2. Reinforcement Learning Background
When training a machine learning model, three types of learning can be used, depending on the task to be performed: supervised learning, used mainly for classification and prediction tasks; unsupervised learning, which is suitable for clustering and finding relationships among attributes of data; and reinforcement learning, which creates models to learn patterns by trial and error. The latter is the algorithm used in the present work.
Reinforcement learning (RL), according to [
10], is a machine learning technique that defines how a set of sequential decisions will result in the achievement of a goal. This is considered to be a trial-and-error method, where the environment indicates the usefulness of the result. According to the authors of [
11], in their experimentation, they considered that RL is a branch of artificial intelligence in which an agent learns a control strategy when interacting with the environment. In the same way, the authors of [
12] considered that RL is capable of learning and making decisions by interacting repeatedly with its environment. Currently, several machine learning algorithms use the reinforcement learning paradigm as the basis for implementation, such as adaptive heuristic critic (AHC) [
13], Q-learning [
14], Markov decision process [
15], and deep Q-learning [
16]. RL is currently applied in several areas, such as computer networks [
17], traffic control [
18], robotics [
19], object recognition [
20], facial recognition [
21], and autonomous driving [
22], among the most prominent areas of research.
As far as RL algorithms applied to autonomous driving, many studies can be found in the literature. For example, in [
23] a successful application of RL is described for autonomous helicopter flight, while in [
24], the authors describe an experiment in RL to direct a real robot car based on data collected directly from real experiments. In [
25], the ability of a system to learn behaviors to allow safe navigation for autonomous driving at intersections is explored.
RL is also used in simulated environments, and multiple examples can be found. For example, in [
11,
26,
27] various RL methods are proposed in which autonomous vehicles learn to make decisions while interacting with simulated traffic. In [
28,
29] the authors present different methods for deep end-to-end RL to navigate autonomous vehicles, and in [
30] a speed control system is designed using RL.
In this paper, the system that was developed is based on the RL paradigm. The system’s framework consists of an agent (the autonomous vehicle) that interacts with a driving simulation environment, a finite state space (S), a set of available actions (A), and a reward function (R), where the main agent’s task is to find the policy
: S × A → [0, 1]. According to [
31], the general framework is based on interactions between agents, where the environment is characterized by a set of states, in which the agents can achieve actions of the set itself. The agents interact with the environment and transition from state
to
by selecting an action
The interactions between the agent and the environment come from the agent’s observations about the state of the environment, where it selects an action and finally receives feedback or reward from the environment according to the selected action. That is, when the agent observes the state of the environment
at time (t), it selects an action and makes a transition to state
at time (t + 1). Subsequently, the environment issues a reward
for the agent.
Figure 1 shows the general agent–environment interaction system.
3. CARLA Simulation Environment
CARLA is a simulation environment for autonomous driving systems. It consists of open-source code and protocols that provide digital assets, such as urban layouts, buildings, and vehicles, used to corroborate and evaluate decisions and design approaches in driving simulations. It follows the client–server paradigm. CARLA supports the configuration of various sensor sets and provides signals to train driving strategies, such as GPS coordinates, acceleration, steering wheel, etc. It also provides information related to distance travelled, collisions, and the occurrence of infractions, such as drifting into the opposite lane or onto the sidewalk. The environment model consists of a simulated autonomous driving system where driving in a roundabout is defined. According to the direct perception approach, dimensional video data (red, green, blue (RGB) camera, semantic segmentation camera, depth camera, and object vision detection) and a set of naturalistic conduction data are processed into meaningful data about roads. The agent model consists of an autonomous vehicle that interacts with the simulated environment through different actions (acceleration, braking, determining roundabout diameter, adjusting vehicle speed, determining roundabout center, starting and ending the route, determining deviation angle from the center of the lane). It learns from the feedback resulting from the GPS position of the vehicle at stage
at time (t) in the simulated environment, using the Q-learning algorithm and a reward system.
Figure 2 shows the architecture of our system, and
Figure 3 provides maps and some views of the simulation environment used. It includes various urban scenarios, including a roundabout. The range of the map is 600 m × 600 m, containing a total of around 5 km of road.
The autonomous vehicle is controlled by different types of commands in the simulation environment: (1) Steering: The steering wheel angle is represented by a real number between −40° and +40°, which correspond to full left and full right, respectively. (2,3) Throttle, brake: These are represented by real numbers between 0 and 1. (4) Hand brake: A Boolean value is used to indicate whether the hand brake is activated or not. The data acquisition system includes (1) an RGB camera, equipped with semantic segmentation of the simulation environment and including 3D location and orientation with respect to the car’s coordinate system; (2) a semantic segmentation pseudo-sensor camera, providing support for experiments of perception; and (3) a sensor providing GPS position and information on roads, lane markings, traffic signs, sidewalks, fences, poles, walls, buildings, vegetation, vehicles, pedestrians, etc. In addition to the observations and actions, information such as the diameter and center of the roundabout, the start and end of the route established for the roundabout, and the angle of deviation from the center of the lane are recorded.
4. Machine Learning Model
This section describes a CARLA environment for planning the behavior of a vehicle to navigate a roundabout using the Q-learning algorithm. In addition, a naturalistic driving dataset is used to provide contextual information. This section explains the concepts of a roundabout scenario and the application of the Q-learning algorithm in this context as well as the reward policy.
4.1. Roundabout Scenario
Roundabouts present specific challenges in the complexity of driving behavior, in terms of high variance in the number of lanes and increased uncertainty in perception due to the road geometry. It is crucial that autonomous vehicles exhibit natural behavior on roundabouts for the safety and smooth flow of shared traffic between them and manual vehicles [
32]. The approach followed in this paper is to formulate the driving task within a roundabout as a Markov decision process (MDP) problem. The experiments performed were based on simulated and real data.
The roundabout shape used in the experiment is shown in
Figure 4, where the exits are marked as A for the first one, B for the second, and so forth. Typical vehicle behavior in a roundabout consists of the following steps: approach, cross the roundabout, and exit. The possible driving paths are drawn in different colors with their centerlines. In the CARLA framework, a route is defined by the tuple {Start_point, End_point}, as follows:
Exit A, GPS route {vehicle position, A};
Exit B, GPS route {vehicle position, B};
Exit C, GPS route {vehicle position, C}.
The final objective is to determine the behavior strategy so that the autonomous vehicle will enter the roundabout and navigate the exits (A, B, C) correctly and safely, regardless of whether or not there are other vehicles on the road.
4.2. Q-Learning Algorithm
Based on RL, an MDP was modeled for the task of planning the behavior of a vehicle to safely navigate a roundabout on paths A, B, and C. The adaptative model uses a Q-learning algorithm [
14], a commonly used algorithm to solve Markov decision processes.
In Q-learning, the action value function
(s, a) is the expected return E [
|
= s,
= a] for a state–action pair following a policy
, where
= reward,
= state, and
= action. Given an optimal value function
(s, a), the optimal policy can be inferred by selecting the action with maximum value max a
(s, a) at every time step. It is based on finding a function Q(s, a) toward an estimation of the function value (Q-value). The function Q(s, a) represents the utility of taking action a in state s. Given the function Q(s, a), the optimal policy is the one that selects for each state the action associated with the highest expected accumulated value (Q-value). The function Q(s, a) is updated using the following equation for adjusting temporal differences:
This equation adjusts Q(s, a) based on the current and predicted reward if all subsequent decisions were optimal. In this sense, the function Q(s, a) converges toward the optimal values of the function. The machine learning model can use the Q-values to evaluate each decision that is possible in each state. The decision that returns the highest Q-value is the optimum. The whole procedure of model operation based on the Q-learning algorithm for this paper is shown in Algorithm 1 in
Appendix A.
The Q-value derived from the performance of an action is the sum of the immediate reward provided by the environment and the maximum value of Q for the new state reached. The transition to the next state is defined by function T, affected by parameter g, referred to as the discount factor. Formally,
where the values of Q would be updated using the following:
with
. The learning mechanism is set using parameter
. For example, if
= 1, the new value of Q(s, a) does not take into account the previous history of the value of Q, but will be the direct reward added to the maximum value of Q for the new state corrected by the
factor.
In the presented algorithm, the values of the Q function are modified and are organized as a table with information about the new states and actions being explored. Thus, each row corresponds to a different state, and each column stores information about the value of the actions. Specifically, element (
i,
j) of the table represents the value of performing from state
if the action is
.
Table 1 is a Q-table, obtained by implementing in any of the total states acquired by the algorithm given in
Appendix A, for example, driving through exit A.
This Q-table grows rapidly by having to store all the state–action combinations. That is why only some states of the experiment without traffic are shown. In an automatic decision-making problem such as the one presented in this paper, the number of possible states can be overwhelming, making it very expensive to collect all the experiments and their updates, and making the problem unmanageable from the computational point of view.
4.3. State–Space Training Model
In the Markov decision process context, the state space can be defined as follows:
where
x,
y,
are the GPS position and velocity vector components along the
x,
y axes of the vehicle and
is the distance to the next GPS position within the route to exit A, B, or C. The coordinate transformation that aligns the vehicle position and velocity along the vehicle axis makes the vehicle state invariant to road geometry.
are binary values; the value is 1 if a left or right lane exists with respect to the center of the lane.
To manage with traffic, the simulated vehicle uses a perception system that detects and tracks other participants through different sensors, as explained in
Section 3. The vehicle’s trajectory control within a roundabout is achieved through the speed and wheel angle. The concept of defining the trajectory of the autonomous vehicle is based on the optimal control approach presented in [
33] and successfully implemented in [
34]. The viability of planned trajectories is guaranteed by imposing real predictions on the speed [
1], acceleration, and exit of the roundabout.
The training model is used through a learning approach, where 70% of the actions are applied randomly (exploration model) and 30% of the remaining actions are based on actions already learned (exploitation model). That is why the Q-learning algorithm is used, based on the experience generated during the exploration of the environment for the training model. Each model is first trained without any other vehicles, with the goal of learning the optimal policy, and then is retrained with other vehicles using random initialization. The training model is based on the vehicle’s GPS positions with respect to the center of the lane. The model is copied to the main network every 10,000 iterations. Deviation from the center of the lane, as depicted in
Figure 5, is calculated as follows:
Vehicle position: Current vehicle position;
Previous position: Previous vehicle position closest to the center of the lane;
Next position: Ten positions forward from the center of the lane;
Vector L: Vector formed by the vehicle position and its previous position,
Vector J: Vector formed by the previous and next vehicle positions,
After defining the parameters, the angle of deviation from the center of the lane, in degrees, is calculated according to
4.4. Reward Policy
In Q-learning, the reward policy acts as an objective function from an optimization problem point of view. For the current scenario, human behavior was taken into account, where the objective is to navigate safely and efficiently in a roundabout without impeding the flow of traffic. A system of double rewards was used, depending on the current state of the vehicle:
Reward 1. The vehicle travels on the road along the center of the lane. In this case, smooth turns would be made to correct the position of the line. The implemented reward system has the goal of rewarding smooth turns of the steering wheel over sharp ones. Considering a range for the degrees of angle deviation, the reward function is inversely proportional to the deviation angle:
Reward 2. When the vehicle is instead traveling along the lane and deviates following an exit path of the roundabout, sharper turns are more suitable, and are rewarded in those cases where the steering wheel turns back to the center of the lane: .
5. Experimental Results
In this section, two experiments are described: the first one deals with entry and exit A without traffic, whereas the second one deals with entry and exits B/C with traffic. In the simulation the following nomenclature was used.
The symbolic description
was used as follows:
. The target vector metrics contain the exit (e), the average speed (vm) for a given distance within the defined route, the efficiency of the reward system (mr), the average deviation (desv), and the average distance traveled (dmr) for each attempt by the vehicle to satisfactorily exit from the roundabout. The action–state cycle is repeated until the vehicle reaches the correct exit. If the vehicle ends up crashing or crossing one of the bounding lanes while in the action–state cycle, the training program is interrupted and the vehicle starts again. In traffic scenario (B, C), the action–state cycle is discretized through the reward function, which depends on the positions of other vehicles inside the roundabout. This discretization is carried out under techniques based on the nearest neighbor, and is used to provide a simple way to divide the state space into regions. The vehicle updates the trajectory information every 60 seconds, sends it to the training program, and takes the appropriate action specified by the training program.
Figure 6 shows the two scenarios established in the experiment, where the test vehicle is in red.
The behavior was tested in the same scenario in which the vehicle was trained. The number of participating vehicles and their routes were fixed for a given experiment, but their initial positions varied randomly. The training dataset consisted of 96 hours of driving the vehicle manually within the simulation environment. The route included four roundabouts with three exits, A, B, and C. During the learning phase, the trained dataset was evaluated after 100 iterations using the trajectory examples. The agent was trained for a total of 10,000 episodes, with each lasting for 100 samples or until a collision occurred. For training, roundabouts with no traffic were considered, and the speed of the vehicle was set up according to the predictive model obtained in [
1].
For the two scenarios based on the simulated environment’s recorded trajectories for the observed vehicle, the vehicle decision distribution is
. The proposed framework was evaluated using the metrics of performance previously cited to enter and exit roundabouts with and without traffic. The speed obtained from the predictive model [
1] was adjusted in the trained model to the different segments of a roundabout, where convergence of the vehicle’s behavior was observed within the simulation environment. During data collection, drivers involved in the experiment met the following conditions: (1) they used routes with roundabouts with different diameters, (2) they used single and multiple lanes; and (3) they used the same vehicle equipped for testing. An important feature of the naturalistic driving data used for the simulated environment is that the RL algorithm could learn decision-making when arriving at a roundabout, and human behavior seems more promising when it comes to a real-life changing environment.
To apply reinforcement learning and obtain an optimal solution through this methodology, the considered reward function was characterized by being bounded between two limit values in its measurement: (−, +). In the results, values with (−) correspond to the vehicle leaving on the left side of the state space and vary linearly between the limit values, and values with (+) correspond to when it leaves on the right side.
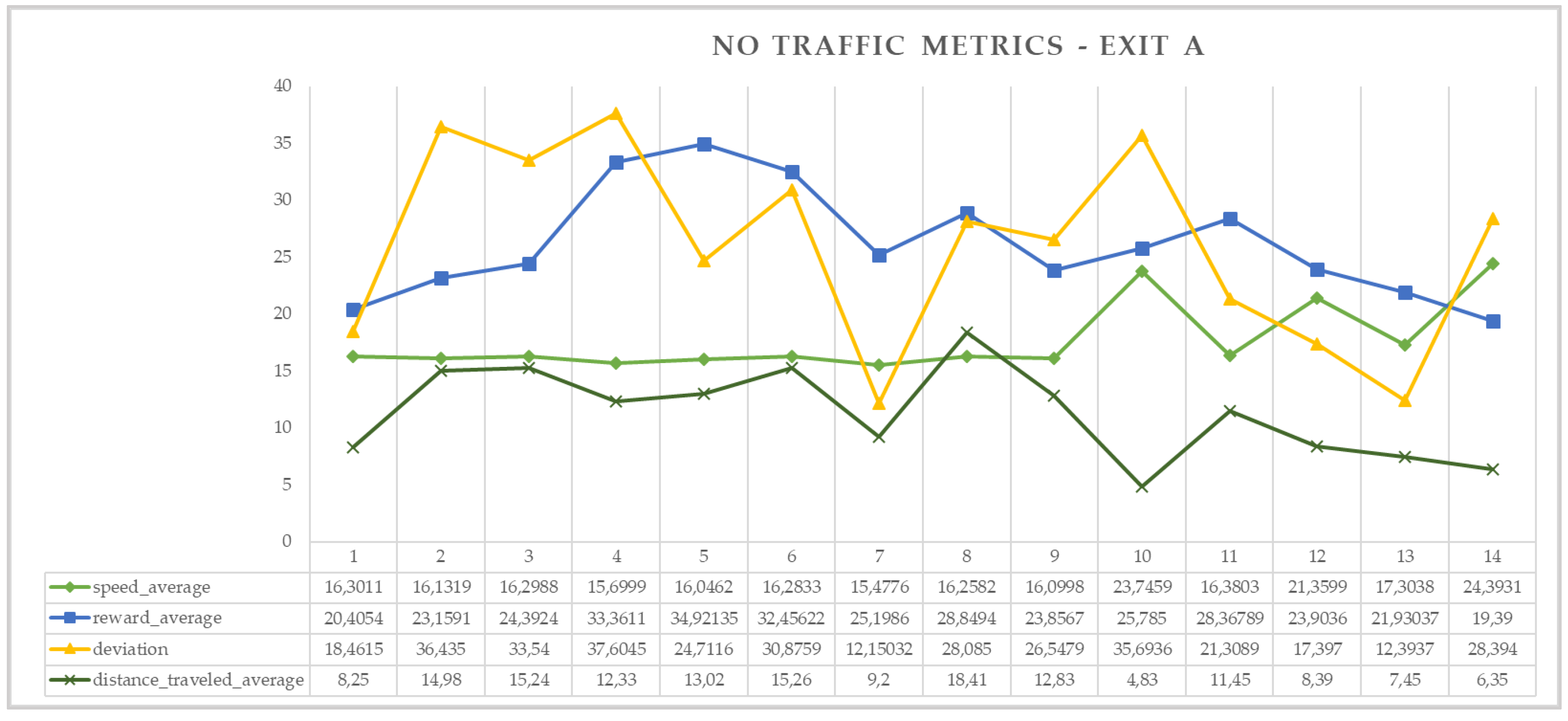
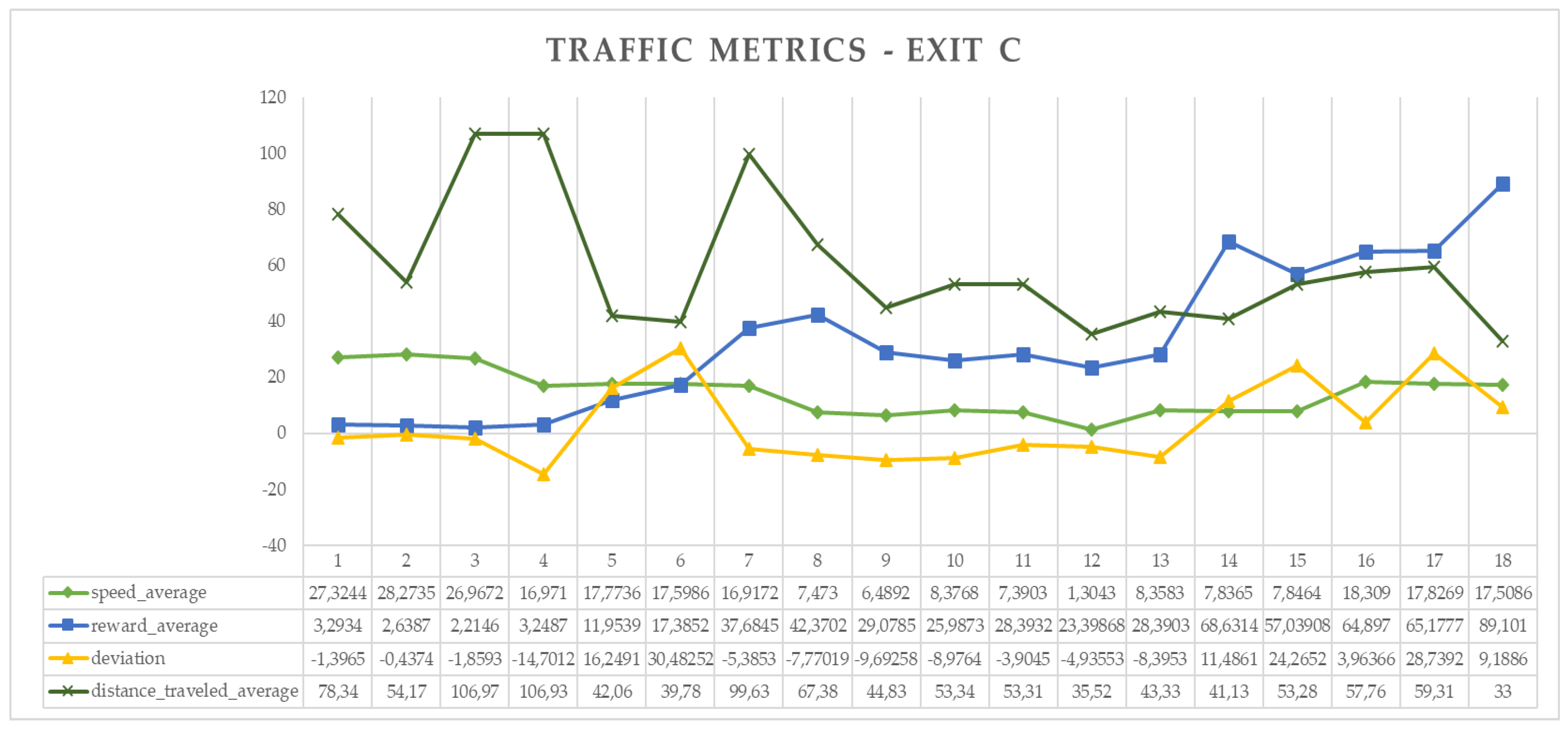
Figure 7 and
Figure 8 show the return of the approach metrics for the simulations without traffic and with traffic, as well as the metric vectors obtained for each situation. As can be seen in the graphs, the metrics converge toward the value (mr) during the training phase, with the exception of traffic simulation data, where they diverge at a given point. This divergence is the result of the discretization of the reward function at the moment when the test vehicle must stop to yield to another vehicle inside the roundabout. Another significant aspect is the average speed (vm) in both experiments. In the case of traffic, the speed is reduced compared to the case without traffic, as well as the distance traveled (dmr) by roundabout typology.
Figure 9 shows that the trajectory for exit A is observed by the vehicle according to the simulation results, where the red line represents the path that the vehicle must follow and the blue line is the obtained path after the reinforcement learning algorithm is applied.
6. Summary and Discussion
In this paper, a framework for reinforcement learning for autonomous driving in roundabout scenarios is proposed. The problem is tackled as a Markov decision process, where the behavioral planning of the vehicle for safely navigating roundabouts uses the Q-learning algorithm. The approach was implemented using the CARLA simulation environment. Simulations carried out in this work used a set of naturalistic driving data from [
1], including environmental information, as well as machine learning models for predicting steering angle and vehicle speed. The main contribution of this paper is the design of a tangible learning technique for sequential and automatic decision-making of autonomous vehicles through examples in a simulated environment. In the experiments carried out, the behavior process benefited from a guided policy in automatic decision-making in terms of tangible learning as determined by the implemented Q-learning algorithm. The resulting behavior after the iterative adaptation of the Q-value function allowed the autonomous vehicle to choose the appropriate actions between the start and end of the defined scenarios through GPS positioning in the reward function. The proposed method was evaluated in a challenging roundabout scenario with and without traffic by discretizing the reward function in a high-definition driving simulator. The results, in comparison with other learning methods, show that the autonomous vehicle had improved directionality against the direction of other vehicles, adapted the average speed in a more realistic way in an environment with traffic, and improved the deviation of the vehicle’s rotation steering angle without hitting obstacles.
For future work, roundabouts with several exits and shapes as well as other scenarios will be considered. It would also be interesting to simulate the proposed framework using simulation of urban mobility (SUMO) [
35], including simulating complete roundabouts (exit D). Another line of work is to compare the results obtained in this paper with application of the deep Q-learning algorithm. Finally, collecting more trajectories for analysis of the training and adaption phases is also desirable.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}