Hierarchical-P Reference Picture Selection Based Error Resilient Video Coding Framework for High Efficiency Video Coding Transmission Applications


Abstract
:1. Introduction
2. Background
2.1. Novel Features of HEVC
2.1.1. Coding Tree Structure
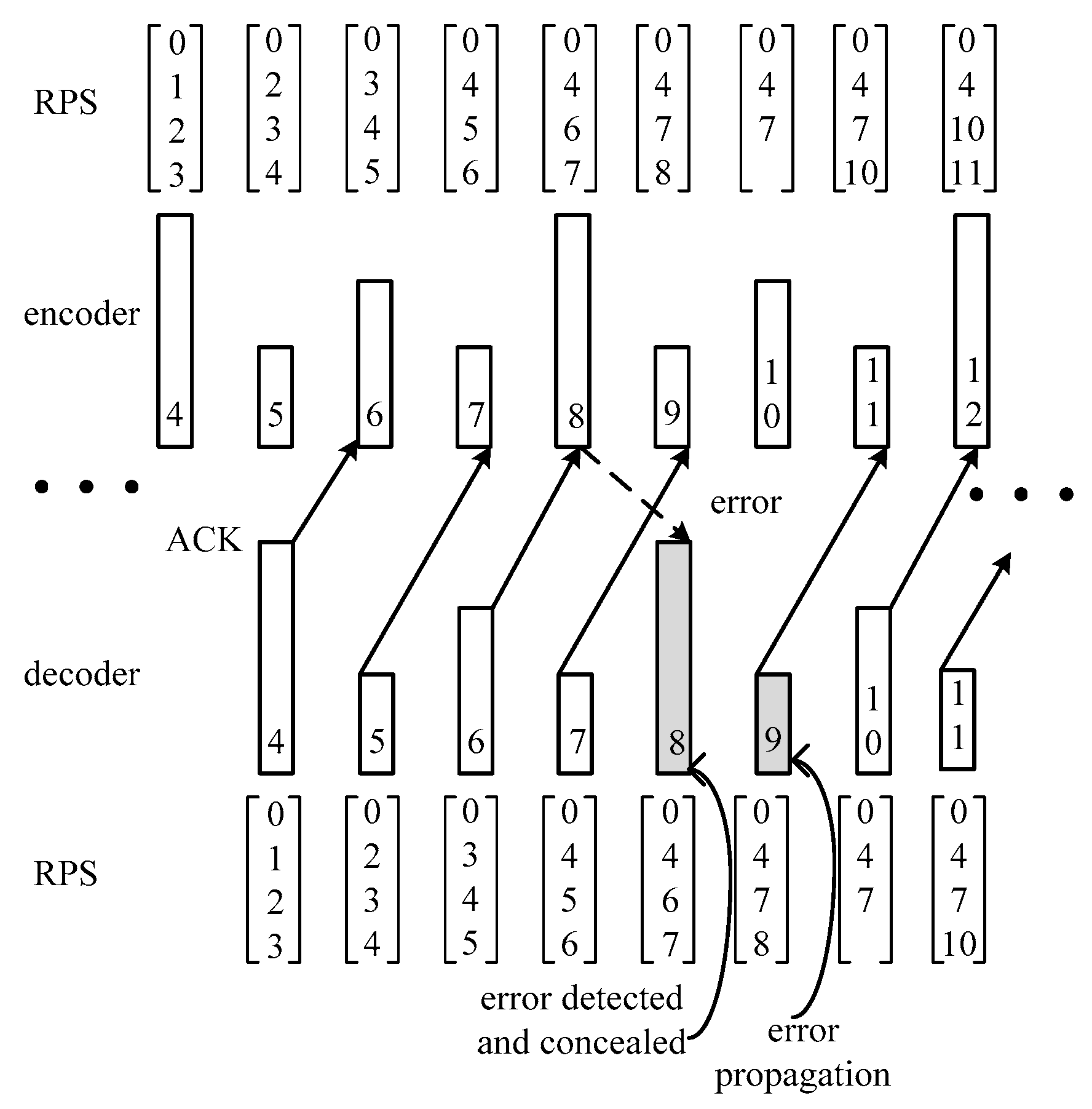
2.1.2. Reference Picture Set of HEVC
2.2. Lambda Domain Rate Control Method
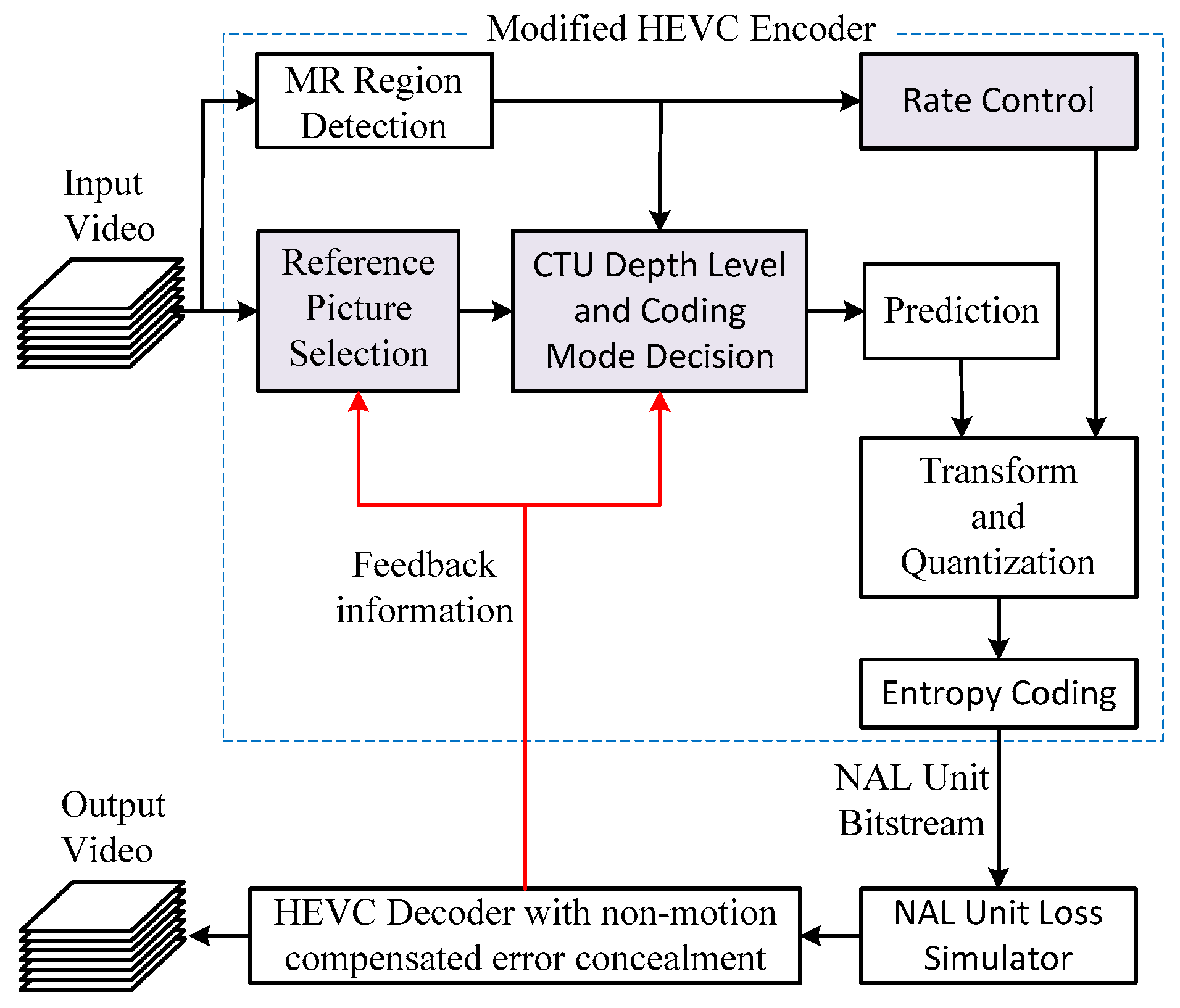
3. Proposed Method
3.1. Proposed Hierarchical-P RPS Algorithm
| Algorithm 1 Proposed Hierarchical-P RPS Algorithm |
|
3.2. Proposed CTU-Level Coding Mode Decision
3.3. Proposed Rate Control Scheme
3.4. Summary of the Proposed Error Resilient Algorithm
| Algorithm 2 Proposed Error Resilient Algorithm |
|
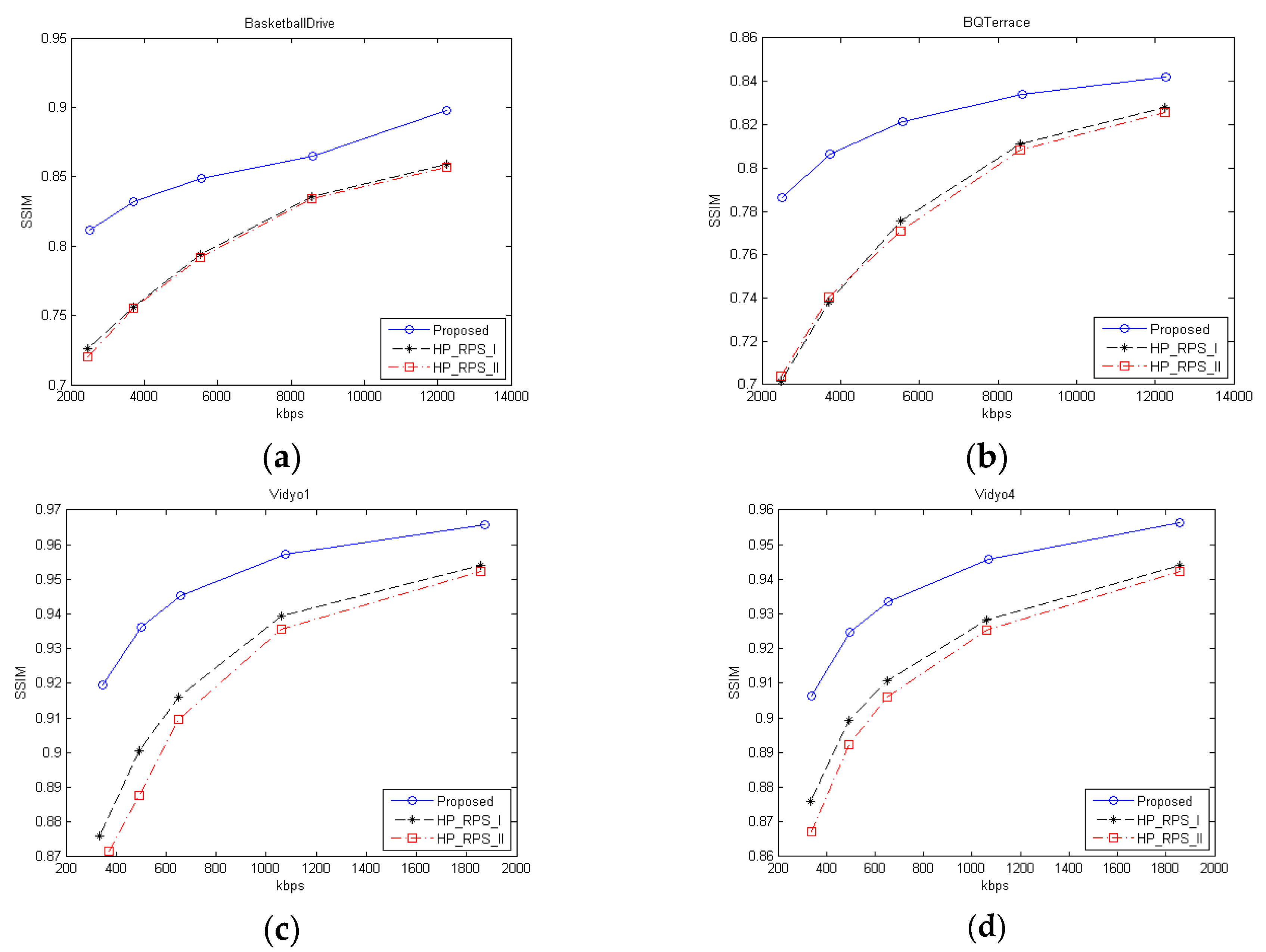
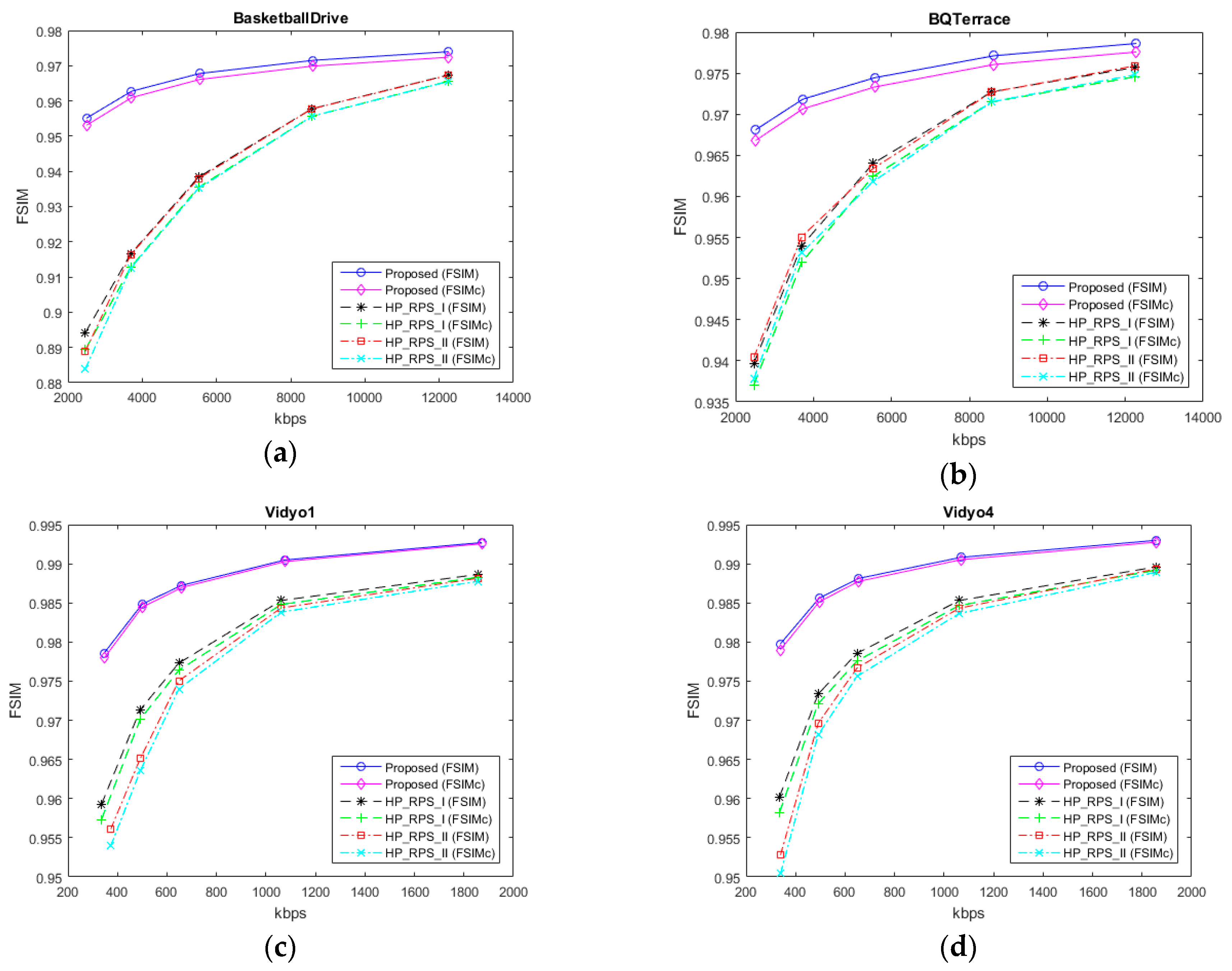
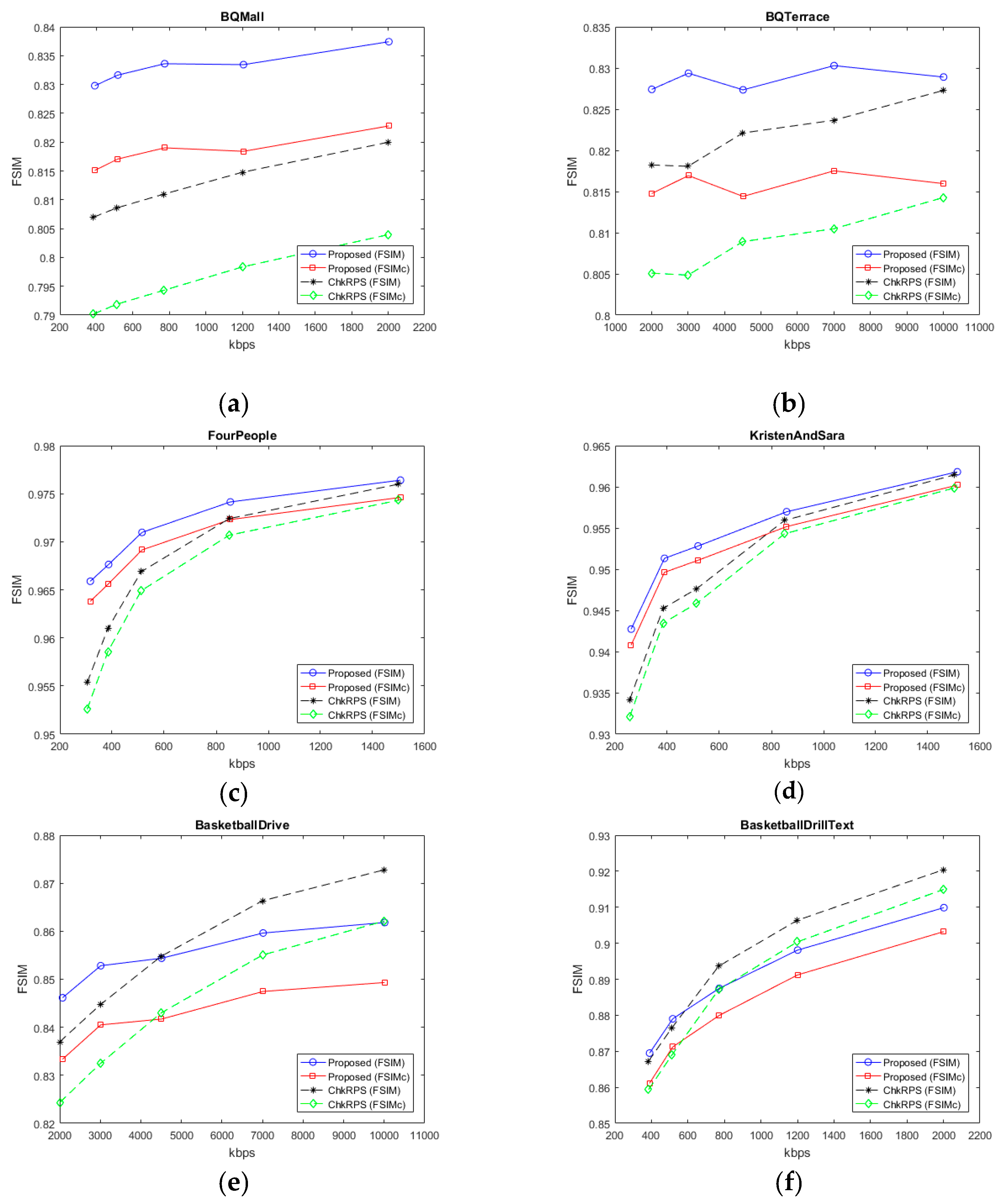
4. Experimental Results and Discussion
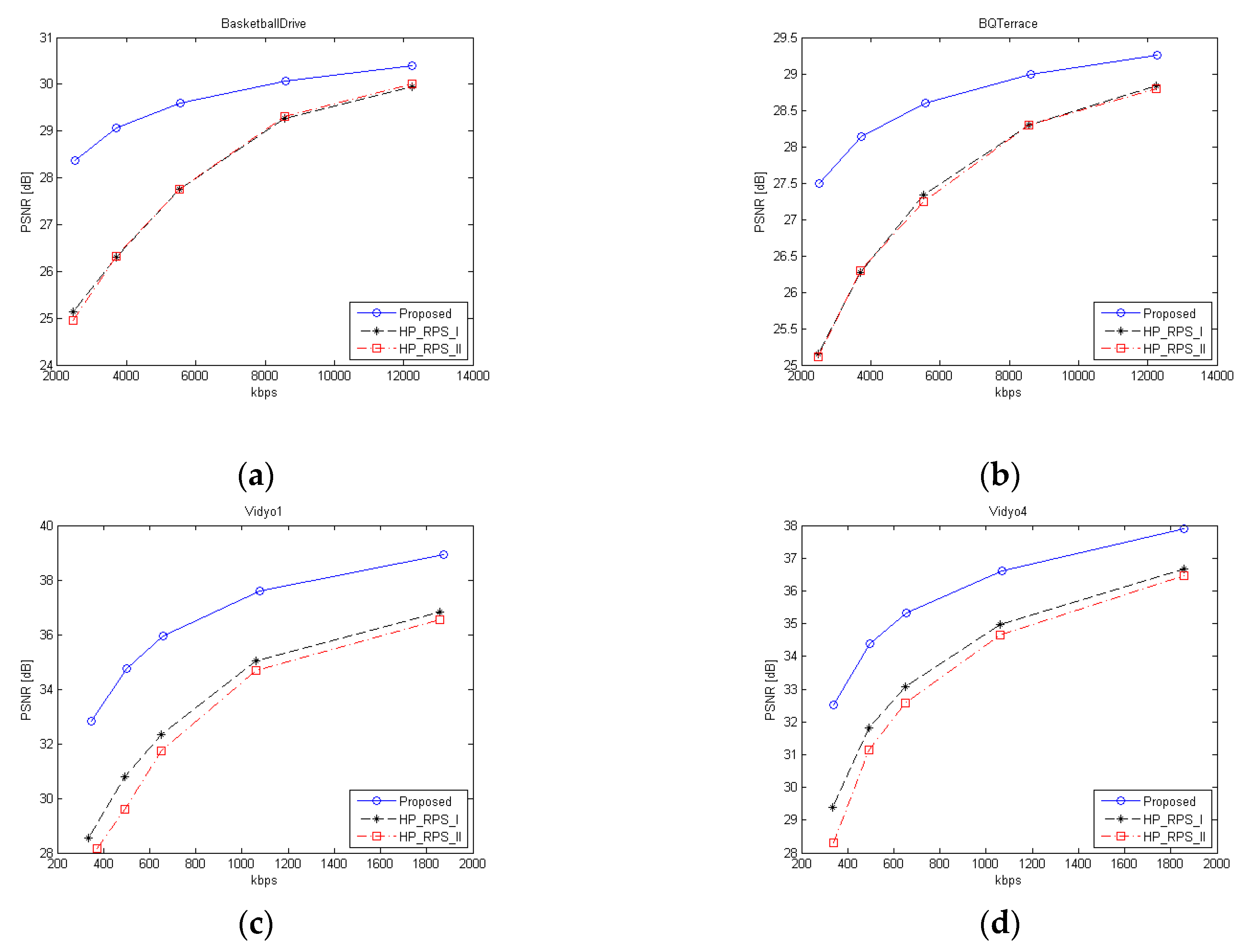
4.1. Experimental Results for Feedback Available Case
4.2. Impact of Feedback Delay
4.3. Experimental Results for No Feedback Case
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Sullivan, G.J.; Ohm, J.R.; Han, W.J.; Wiegand, T. Overview of the high efficiency video coding (HEVC) standard. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1649–1668. [Google Scholar] [CrossRef]
- Piñol, P.; Torres, A.; López, O.; Martinez, M.; Malumbres, M.P. Evaluating HEVC video delivery in VANET scenarios. In Proceedings of the 2013 IFIP Wireless Days (WD 2013), Valencia, Spain, 13–15 November 2013. [Google Scholar]
- Aabed, M.A.; AlRegib, G. No-reference quality assessment of HEVC videos in loss-prone networks. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2014), Florence, Italy, 4–9 May 2014. [Google Scholar]
- Nightingale, J.; Wang, Q.; Grecos, C.; Goma, S. The impact of network impairment on quality of experience (QoE) in H. 265/HEVC video streaming. IEEE Trans. Consum. Electron. 2014, 60, 242–250. [Google Scholar] [CrossRef]
- Ferroukhi, M.; Ouahabi, A.; Attari, M.; Habchi, Y.; Taleb-Ahmed, A. Medical Video Coding Based on 2nd-Generation Wavelets: Performance Evaluation. Electronics 2019, 8, 88. [Google Scholar] [CrossRef]
- Wiegand, T.; Sullivan, G.; Bjøntegaard, G.; Luthra, A. Overview of the H. 264/AVC video coding standard. IEEE Trans. Circuits Syst. Video Technol. 2003, 13, 560–576. [Google Scholar] [CrossRef]
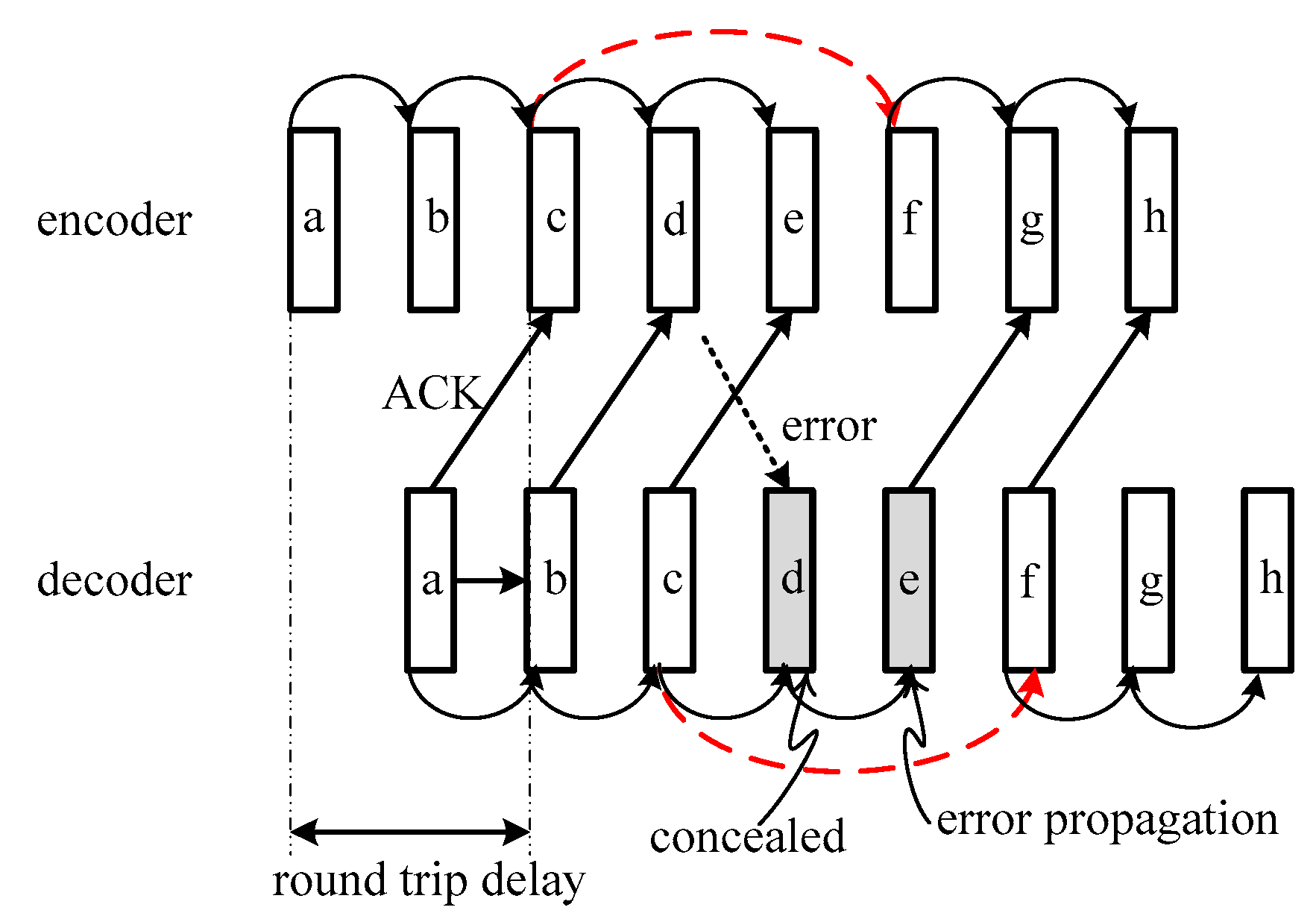
- Girod, B.; Farber, N. Feedback-based error control for mobile video transmission. Proc. IEEE. 1999, 87, 1707–1723. [Google Scholar] [CrossRef] [Green Version]
- Fukunaga, S.; Nakai, T.; Inoue, H. Error resilient video coding by dynamic replacing of reference pictures. In Proceedings of the 1996 IEEE Global Telecommunications Conference (GLOBECOM’96), London, UK, 18–28 November 1996. [Google Scholar]
- Bjøntegaard, G. An Error Resilience Method Based on Back Channel Signaling and FEC; ITU-T/SG15/LBC-96-033; Telenor R&D: San Jose, CA, USA, 1996. [Google Scholar]
- Tu, W.; Steinbach, E. Proxy-based reference picture selection for error resilient conversational video in mobile networks. IEEE Trans. Circuits Syst. Video Technol. 2009, 19, 151–164. [Google Scholar] [CrossRef]
- Liu, C.; Wang, Y.K.; Hannuksela, M.M.; Chen, Y.; Sujeet, M.; Gabbouj, M. RTP/AVPF compliant feedback for error resilient video coding in conversational applications. In Proceedings of the 9th International Symposium on Communications and Information Technology (ISCIT 2009), Incheon, Korea, 28–30 September 2009. [Google Scholar]
- Schierl, T.; Hannuksela, M.M.; Wang, Y.K.; Wenger, S. System layer integration of high efficiency video coding. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1871–1884. [Google Scholar] [CrossRef]
- Sjoberg, R.; Chen, Y.; Fujibayashi, A.; Hannuksela, M.M.; Samuelsson, J.; Tan, T.K.; Wang, Y.K.; Wenger, S. Overview of HEVC high-level syntax and reference picture management. IEEE Trans. Circuits Syst. Video Technol. 2012, 22, 1858–1870. [Google Scholar] [CrossRef]
- Hong, D.; Horowitz, M.; Eleftheriadis, A.; Wiegand, T. H.264 hierarchical P coding in the context of ultra-low delay, low complexity applications. In Proceedings of the 28th Picture Coding Symposium (PCS 2010), Nagoya, Japan, 7–10 December 2010. [Google Scholar]
- Maung, H.M.; Aramvith, S.; Miyanaga, Y. Region-of-interest based error resilient method for HEVC video transmission. In Proceedings of the 15th International Symposium on Communications and Information Technologies (ISCIT 2015), Nara, Japan, 7–9 October 2015. [Google Scholar]
- Maung, H.M.; Aramvith, S.; Miyanaga, Y. Improve region-of-interest based rate control for error resilient HEVC framework. In Proceedings of the 2016 International Conference on Digital Signal Processing (DSP), Beijing, China, 16–18 October 2016. [Google Scholar]
- Maung, H.M.; Aramvith, S.; Miyanaga, Y. Error resilience aware rate control and mode selection for HEVC video transmission. In Proceedings of the IEEE International Conference on Consumer Electronics (ICCE 2017), Las Vegas, NV, USA, 8–10 January 2017. [Google Scholar]
- Carreira, J.; Assunção, P.; Faria, S.; Ekmekcioglu, E.; Kondoz, A.; Lim, H. Reference picture selection using checkerboard pattern for resilient video coding. In Proceedings of the IEEE Visual Communications and Image Processing (VCIP), Singapore, 13–16 December 2015. [Google Scholar]
- Haßlinger, G.; Hohlfeld, O. The Gilbert-Elliott model for packet loss in real time services on the Internet. In Proceedings of the 14th GI/ITG Conference on Measurement, Modelling and Evaluation of Computer and Communication Systems (MMB 2008), Dortmund, Germany, 31 March–2 April 2008. [Google Scholar]
- Li, B.; Li, H.; Li, L.; Zhang, J. Rate Control by R-lambda Model for SHVC. Document JCTVC-M0037, ITU-T/ISO/IEC Joint Collaborative Team on Video Coding (JCT-VC). 2013. Available online: http://phenix.int-evry.fr/jct/doc_end_user/current_document.php?id=7288 (accessed on 2 January 2019).
- Li, B.; Li, H.; Li, L.; Zhang, J. λ Domain Rate Control Algorithm for High Efficiency Video Coding. IEEE Trans. Image Process. 2014, 23, 3841–3854. [Google Scholar] [CrossRef] [PubMed]
- McCann, K.; Bross, B.; Han, W.J.; Kim, I.K.; Sugimoto, K.; Sullivan, G.J. High Efficiency Video Coding (HEVC) Test Model 15 (HM 15) Encoder Description. Document JCTVC-Q1002. 2014. Available online: http://phenix.int-evry.fr/jct/doc_end_user/current_document.php?id=9103 (accessed on 18 September 2018).
- Bossen, F. Common Test Conditions and Software Reference Configurations. Document Rec. JCTVC-J1100. Stockholm, Sweden, 2012. Available online: http://phenix.int-evry.fr/jct/doc_end_user/current_document.php?id=6469 (accessed on 2 January 2019).
- Ren, G.; Li, P.; Wang, G. A novel hybrid coarse-to-fine digital image stabilization algorithm. Inform. Technol. J. 2010, 9, 1390–1396. [Google Scholar] [CrossRef]
- Hu, H.M.; Li, B.; Lin, W.; Li, W.; Sun, M.T. Region-based rate control for H. 264/AVC for low bit-rate applications. IEEE Trans. Circuits Syst. Video Technol 2012, 22, 1564–1576. [Google Scholar] [CrossRef]
- Joint Call for Proposals on Video Compression Technology. ITU-T SG16/Q6 document VCEG-AM91 and ISO/IEC MPEG Document N11113, ITU-T and ISO/IEC JTC 1. 2010. Available online: https://www.itu.int/wftp3/av-arch/jctvc-site/2010_04_A_Dresden/JCTVC-A114.doc (accessed on 2 January 2019).
- Wenger, S. Nal Unit Loss Software. Document JCTVC-H0072, ITU-T/ISO/IEC Joint Collaborative Team on Video Coding (JCT-VC). 2012. Available online: http://phenix.int-evry.fr/jct/doc_end_user/current_document.php?id=4373 (accessed on 25 December 2018).
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: from error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Zhang, L.; Mou, X.; Zhang, D. FSIM: A Feature Similarity Index for Image Quality Assessment. IEEE Trans. Image Process. 2011, 20, 2378–2386. [Google Scholar] [CrossRef] [PubMed] [Green Version]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sequence | Target Bit Rate (kbps) | Average Y-PSNR (dB) | Average SSIM | ||||
|---|---|---|---|---|---|---|---|
| HP_RPS_I | HP_RPS_II | Proposed | HP_RPS_I | HP_RPS_II | Proposed | ||
| BasketballDrillText (832 × 480) 50fps | 384 | 26.71 | 25.45 | 27.31 | 0.81 | 0.77 | 0.82 |
| 512 | 27.31 | 26.07 | 28.02 | 0.83 | 0.79 | 0.84 | |
| 768 | 28.40 | 27.12 | 28.88 | 0.86 | 0.83 | 0.87 | |
| 1200 | 29.47 | 28.27 | 29.81 | 0.88 | 0.87 | 0.89 | |
| 2000 | 30.46 | 29.19 | 30.74 | 0.91 | 0.90 | 0.92 | |
| BQMall (832 × 480) 60fps | 384 | 24.14 | 24.30 | 25.76 | 0.70 | 0.73 | 0.77 |
| 512 | 25.03 | 25.16 | 26.44 | 0.74 | 0.76 | 0.80 | |
| 768 | 25.97 | 25.96 | 27.31 | 0.78 | 0.79 | 0.83 | |
| 1200 | 26.97 | 26.76 | 28.19 | 0.82 | 0.82 | 0.86 | |
| 2000 | 28.12 | 27.72 | 28.94 | 0.86 | 0.86 | 0.88 | |
| PartyScene (832 × 480) 50fps | 384 | 23.35 | 23.54 | 24.90 | 0.61 | 0.64 | 0.70 |
| 512 | 24.14 | 24.30 | 25.63 | 0.66 | 0.68 | 0.74 | |
| 768 | 25.22 | 25.41 | 26.57 | 0.72 | 0.73 | 0.78 | |
| 1200 | 26.51 | 26.64 | 27.64 | 0.78 | 0.79 | 0.82 | |
| 2000 | 27.96 | 28.01 | 28.77 | 0.83 | 0.84 | 0.86 | |
| Johnny (1280 × 720) 60fps | 256 | 32.97 | 32.53 | 36.57 | 0.90 | 0.89 | 0.93 |
| 384 | 35.53 | 35.08 | 38.01 | 0.92 | 0.92 | 0.94 | |
| 512 | 36.62 | 36.40 | 38.80 | 0.93 | 0.93 | 0.95 | |
| 850 | 38.13 | 37.86 | 39.87 | 0.94 | 0.94 | 0.96 | |
| 1500 | 39.12 | 38.93 | 40.62 | 0.95 | 0.95 | 0.96 | |
| FourPeople (1280 × 720) 60fps | 256 | 29.79 | 28.78 | 31.96 | 0.89 | 0.87 | 0.90 |
| 384 | 31.82 | 30.70 | 33.85 | 0.91 | 0.89 | 0.92 | |
| 512 | 33.17 | 32.19 | 35.04 | 0.92 | 0.91 | 0.94 | |
| 850 | 35.48 | 34.65 | 36.91 | 0.94 | 0.93 | 0.95 | |
| 1500 | 37.41 | 36.39 | 38.70 | 0.95 | 0.95 | 0.96 | |
| KristenAndSara (1280 × 720) 60fps | 256 | 32.07 | 29.93 | 34.33 | 0.91 | 0.88 | 0.93 |
| 384 | 34.14 | 31.90 | 35.87 | 0.92 | 0.90 | 0.94 | |
| 512 | 35.25 | 32.00 | 36.91 | 0.93 | 0.90 | 0.95 | |
| 850 | 37.11 | 34.78 | 38.41 | 0.95 | 0.93 | 0.96 | |
| 1500 | 38.74 | 37.24 | 39.61 | 0.96 | 0.95 | 0.96 | |
| Vidyo1 (1280 × 720) 60fps | 256 | 28.55 | 28.16 | 32.83 | 0.88 | 0.87 | 0.92 |
| 384 | 30.79 | 29.61 | 34.75 | 0.90 | 0.89 | 0.94 | |
| 512 | 32.35 | 31.74 | 35.94 | 0.92 | 0.91 | 0.95 | |
| 850 | 35.05 | 34.69 | 37.58 | 0.94 | 0.94 | 0.96 | |
| 1500 | 36.82 | 36.56 | 38.93 | 0.95 | 0.95 | 0.97 | |
| Vidyo3 (1280 × 720) 60fps | 256 | 27.57 | 27.40 | 31.29 | 0.86 | 0.86 | 0.92 |
| 384 | 29.93 | 28.81 | 33.16 | 0.89 | 0.88 | 0.94 | |
| 512 | 31.25 | 30.63 | 34.26 | 0.91 | 0.90 | 0.95 | |
| 850 | 33.39 | 33.02 | 35.75 | 0.94 | 0.93 | 0.96 | |
| 1500 | 35.26 | 35.09 | 37.25 | 0.95 | 0.95 | 0.97 | |
| Vidyo4 (1280 × 720) 60fps | 256 | 29.39 | 28.31 | 32.52 | 0.88 | 0.87 | 0.91 |
| 384 | 31.81 | 31.13 | 34.40 | 0.90 | 0.89 | 0.93 | |
| 512 | 33.08 | 32.57 | 35.33 | 0.91 | 0.91 | 0.93 | |
| 850 | 34.97 | 34.64 | 36.60 | 0.93 | 0.93 | 0.95 | |
| 1500 | 36.66 | 36.46 | 37.89 | 0.94 | 0.94 | 0.96 | |
| BasketballDrive (1920 × 1080) 60fps | 2000 | 25.14 | 24.95 | 28.38 | 0.73 | 0.72 | 0.81 |
| 3000 | 26.30 | 26.33 | 29.06 | 0.76 | 0.76 | 0.83 | |
| 4500 | 27.76 | 27.76 | 29.60 | 0.79 | 0.79 | 0.85 | |
| 7000 | 29.27 | 29.31 | 30.06 | 0.84 | 0.83 | 0.87 | |
| 10,000 | 29.95 | 30.00 | 30.40 | 0.86 | 0.86 | 0.90 | |
| BQTerrace (1920 × 1080) 50fps | 2000 | 25.15 | 25.11 | 27.50 | 0.70 | 0.70 | 0.79 |
| 3000 | 26.27 | 26.30 | 28.14 | 0.74 | 0.74 | 0.81 | |
| 4500 | 27.34 | 27.25 | 28.60 | 0.78 | 0.77 | 0.82 | |
| 7000 | 28.30 | 28.30 | 29.00 | 0.81 | 0.81 | 0.83 | |
| 10,000 | 28.83 | 28.79 | 29.26 | 0.83 | 0.83 | 0.84 | |
| Cactus (1920 × 1080) 50fps | 2000 | 27.79 | 27.50 | 30.20 | 0.79 | 0.78 | 0.83 |
| 3000 | 28.78 | 28.53 | 31.05 | 0.81 | 0.80 | 0.86 | |
| 4500 | 30.27 | 30.12 | 31.72 | 0.84 | 0.83 | 0.87 | |
| 7000 | 31.43 | 31.31 | 32.37 | 0.86 | 0.86 | 0.89 | |
| 10,000 | 32.06 | 31.97 | 32.74 | 0.88 | 0.87 | 0.89 | |
| Sequence | Target Bit Rate (kbps) | FSIM | FSIMc | ||||
|---|---|---|---|---|---|---|---|
| HP_RPS_I | HP_RPS_II | Proposed | HP_RPS_I | HP_RPS_II | Proposed | ||
| BasketballDrillText (832 × 480) 50fps | 384 | 0.9237 | 0.9032 | 0.9254 | 0.9200 | 0.8988 | 0.9224 |
| 512 | 0.9327 | 0.9131 | 0.9362 | 0.9296 | 0.9093 | 0.9336 | |
| 768 | 0.9461 | 0.9303 | 0.9481 | 0.9437 | 0.9273 | 0.9459 | |
| 1200 | 0.9576 | 0.9470 | 0.9579 | 0.9557 | 0.9447 | 0.9560 | |
| 2000 | 0.9664 | 0.9593 | 0.9662 | 0.9647 | 0.9572 | 0.9645 | |
| BQMall (832 × 480) 60fps | 384 | 0.8958 | 0.9041 | 0.9224 | 0.8907 | 0.8992 | 0.9189 |
| 512 | 0.9123 | 0.9158 | 0.9318 | 0.9081 | 0.9116 | 0.9288 | |
| 768 | 0.9253 | 0.9272 | 0.9414 | 0.9218 | 0.9237 | 0.9389 | |
| 1200 | 0.9387 | 0.9389 | 0.9500 | 0.9359 | 0.9360 | 0.9478 | |
| 2000 | 0.9527 | 0.9520 | 0.9571 | 0.9506 | 0.9496 | 0.9552 | |
| PartyScene (832 × 480) 50fps | 384 | 0.8934 | 0.8961 | 0.9075 | 0.8881 | 0.8909 | 0.9038 |
| 512 | 0.9049 | 0.9060 | 0.9177 | 0.9004 | 0.9015 | 0.9146 | |
| 768 | 0.9198 | 0.9207 | 0.9290 | 0.9163 | 0.9172 | 0.9265 | |
| 1200 | 0.9341 | 0.9351 | 0.9386 | 0.9316 | 0.9324 | 0.9366 | |
| 2000 | 0.9482 | 0.9499 | 0.9503 | 0.9464 | 0.9480 | 0.9488 | |
| Johnny (1280 × 720) 60fps | 256 | 0.9784 | 0.9741 | 0.9863 | 0.9775 | 0.9733 | 0.9860 |
| 384 | 0.9848 | 0.9825 | 0.9896 | 0.9843 | 0.9819 | 0.9894 | |
| 512 | 0.9881 | 0.9864 | 0.9913 | 0.9877 | 0.9860 | 0.9911 | |
| 850 | 0.9911 | 0.9897 | 0.9934 | 0.9909 | 0.9895 | 0.9932 | |
| 1500 | 0.9927 | 0.9921 | 0.9949 | 0.9925 | 0.9919 | 0.9948 | |
| FourPeople (1280 × 720) 60fps | 256 | 0.9662 | 0.9626 | 0.9743 | 0.9645 | 0.9607 | 0.9733 |
| 384 | 0.9762 | 0.9716 | 0.9818 | 0.9750 | 0.9703 | 0.9813 | |
| 512 | 0.9815 | 0.9775 | 0.9855 | 0.9807 | 0.9766 | 0.9851 | |
| 850 | 0.9881 | 0.9853 | 0.9892 | 0.9876 | 0.9848 | 0.9890 | |
| 1500 | 0.9915 | 0.9893 | 0.9928 | 0.9912 | 0.9889 | 0.9926 | |
| KristenAndSara (1280 × 720) 60fps | 256 | 0.9692 | 0.9539 | 0.9751 | 0.9685 | 0.9528 | 0.9746 |
| 384 | 0.9783 | 0.9663 | 0.9829 | 0.9778 | 0.9656 | 0.9826 | |
| 512 | 0.9826 | 0.9668 | 0.9860 | 0.9822 | 0.9661 | 0.9858 | |
| 850 | 0.9881 | 0.9796 | 0.9901 | 0.9879 | 0.9792 | 0.9899 | |
| 1500 | 0.9921 | 0.9884 | 0.9930 | 0.9919 | 0.9882 | 0.9929 | |
| Vidyo1 (1280 × 720) 60fps | 256 | 0.9592 | 0.9561 | 0.9786 | 0.9573 | 0.9540 | 0.9780 |
| 384 | 0.9714 | 0.9651 | 0.9849 | 0.9701 | 0.9635 | 0.9845 | |
| 512 | 0.9773 | 0.9751 | 0.9873 | 0.9764 | 0.9740 | 0.9870 | |
| 850 | 0.9853 | 0.9844 | 0.9905 | 0.9848 | 0.9838 | 0.9903 | |
| 1500 | 0.9886 | 0.9882 | 0.9927 | 0.9883 | 0.9878 | 0.9926 | |
| Vidyo3 (1280 × 720) 60fps | 256 | 0.9476 | 0.9458 | 0.9786 | 0.9446 | 0.9427 | 0.9774 |
| 384 | 0.9674 | 0.9600 | 0.9850 | 0.9654 | 0.9576 | 0.9843 | |
| 512 | 0.9731 | 0.9701 | 0.9871 | 0.9715 | 0.9684 | 0.9865 | |
| 850 | 0.9811 | 0.9802 | 0.9900 | 0.9801 | 0.9791 | 0.9896 | |
| 1500 | 0.9868 | 0.9864 | 0.9925 | 0.9861 | 0.9857 | 0.9922 | |
| Vidyo4 (1280 × 720) 60fps | 256 | 0.9602 | 0.9528 | 0.9798 | 0.9582 | 0.9504 | 0.9790 |
| 384 | 0.9734 | 0.9696 | 0.9856 | 0.9721 | 0.9682 | 0.9852 | |
| 512 | 0.9786 | 0.9767 | 0.9881 | 0.9776 | 0.9756 | 0.9878 | |
| 850 | 0.9853 | 0.9843 | 0.9908 | 0.9847 | 0.9837 | 0.9905 | |
| 1500 | 0.9896 | 0.9893 | 0.9930 | 0.9892 | 0.9889 | 0.9928 | |
| BasketballDrive (1920 × 1080) 60fps | 2000 | 0.8942 | 0.8889 | 0.9551 | 0.8894 | 0.8839 | 0.9531 |
| 3000 | 0.9166 | 0.9163 | 0.9628 | 0.9127 | 0.9125 | 0.9609 | |
| 4500 | 0.9384 | 0.9380 | 0.9678 | 0.9355 | 0.9351 | 0.9661 | |
| 7000 | 0.9578 | 0.9577 | 0.9715 | 0.9557 | 0.9557 | 0.9699 | |
| 10,000 | 0.9674 | 0.9672 | 0.9740 | 0.9655 | 0.9655 | 0.9724 | |
| BQTerrace (1920 × 1080) 50fps | 2000 | 0.9397 | 0.9404 | 0.9681 | 0.9371 | 0.9379 | 0.9668 |
| 3000 | 0.9540 | 0.9551 | 0.9719 | 0.9520 | 0.9531 | 0.9707 | |
| 4500 | 0.9640 | 0.9634 | 0.9745 | 0.9624 | 0.9618 | 0.9733 | |
| 7000 | 0.9727 | 0.9727 | 0.9771 | 0.9715 | 0.9715 | 0.9761 | |
| 10,000 | 0.9757 | 0.9759 | 0.9786 | 0.9746 | 0.9748 | 0.9776 | |
| Cactus (1920 × 1080) 50fps | 2000 | 0.9538 | 0.9510 | 0.9758 | 0.9517 | 0.9487 | 0.9749 |
| 3000 | 0.9610 | 0.9595 | 0.9801 | 0.9592 | 0.9576 | 0.9793 | |
| 4500 | 0.9710 | 0.9704 | 0.9827 | 0.9697 | 0.9691 | 0.9821 | |
| 7000 | 0.9786 | 0.9781 | 0.9851 | 0.9777 | 0.9772 | 0.9845 | |
| 10,000 | 0.9821 | 0.9816 | 0.9865 | 0.9813 | 0.9808 | 0.9859 | |
| Sequence | Target Bit Rate (kbps) | 3-frame Delay | 4-frame Delay | 5-frame Delay | |||
|---|---|---|---|---|---|---|---|
| HP_RPS_I | Proposed | HP_RPS_I | Proposed | HP_RPS_I | Proposed | ||
| BQMall (832 × 480) 60fps | 384 | 24.14 | 25.76 | 24.01 | 25.46 | 23.36 | 24.31 |
| 768 | 25.97 | 27.31 | 25.60 | 26.88 | 25.18 | 25.87 | |
| 2000 | 28.12 | 28.94 | 27.57 | 28.32 | 26.93 | 27.41 | |
| PartyScene (832 × 480) 50fps | 384 | 23.35 | 24.90 | 23.44 | 24.82 | 21.96 | 22.56 |
| 768 | 25.22 | 26.57 | 25.18 | 26.34 | 24.03 | 24.65 | |
| 2000 | 27.96 | 28.77 | 27.66 | 28.43 | 26.97 | 27.43 | |
| FourPeople (1280 × 720) 60fps | 256 | 29.79 | 31.96 | 29.99 | 32.17 | 30.03 | 27.39 |
| 512 | 33.17 | 35.04 | 33.24 | 35.14 | 30.39 | 30.03 | |
| 1500 | 37.41 | 38.70 | 37.07 | 38.36 | 33.62 | 33.89 | |
| Vidyo4 (1280 × 720) 60fps | 256 | 29.39 | 32.52 | 29.61 | 33.07 | 31.05 | 29.80 |
| 512 | 33.08 | 35.33 | 33.21 | 35.45 | 31.32 | 32.42 | |
| 1500 | 36.66 | 37.89 | 36.49 | 37.65 | 35.05 | 35.55 | |
| BasketballDrive (1920 × 1080) 60fps | 2000 | 25.14 | 28.38 | 24.88 | 27.63 | 26.34 | 27.05 |
| 4500 | 27.76 | 29.60 | 27.21 | 28.78 | 27.28 | 27.96 | |
| 10,000 | 29.95 | 30.40 | 28.98 | 29.41 | 28.32 | 28.44 | |
| BQTerrace (1920 × 1080) 50fps | 2000 | 25.15 | 27.50 | 24.96 | 26.65 | 25.72 | 26.19 |
| 4500 | 27.34 | 28.60 | 26.93 | 27.96 | 26.88 | 27.03 | |
| 10,000 | 28.83 | 29.26 | 28.32 | 28.63 | 28.01 | 28.05 | |
| Sequence | Target Bit Rate (kbps) | FSIM | FSIMc | ||
|---|---|---|---|---|---|
| chkRPS | Proposed | chkRPS | Proposed | ||
| BasketballDrillText (832 × 480) 50fps | 384 | 0.8673 | 0.8695 | 0.8593 | 0.8611 |
| 512 | 0.8765 | 0.8790 | 0.8690 | 0.8712 | |
| 768 | 0.8936 | 0.8875 | 0.8871 | 0.8800 | |
| 1200 | 0.9064 | 0.8981 | 0.9004 | 0.8912 | |
| 2000 | 0.9204 | 0.9099 | 0.9149 | 0.9032 | |
| BQMall (832 × 480) 60fps | 384 | 0.8070 | 0.8298 | 0.7902 | 0.8151 |
| 512 | 0.8086 | 0.8316 | 0.7919 | 0.8171 | |
| 768 | 0.8110 | 0.8336 | 0.7943 | 0.8190 | |
| 1200 | 0.8148 | 0.8334 | 0.7984 | 0.8184 | |
| 2000 | 0.8200 | 0.8374 | 0.8040 | 0.8228 | |
| PartyScene (832 × 480) 50fps | 384 | 0.8504 | 0.8664 | 0.8401 | 0.8576 |
| 512 | 0.8541 | 0.8668 | 0.8440 | 0.8578 | |
| 768 | 0.8591 | 0.8707 | 0.8491 | 0.8616 | |
| 1200 | 0.8679 | 0.8735 | 0.8582 | 0.8642 | |
| 2000 | 0.8743 | 0.8806 | 0.8648 | 0.8715 | |
| Johnny (1280 × 720) 60fps | 256 | 0.9612 | 0.9685 | 0.9594 | 0.9672 |
| 384 | 0.9664 | 0.9730 | 0.9648 | 0.9719 | |
| 512 | 0.9679 | 0.9740 | 0.9662 | 0.9728 | |
| 850 | 0.9729 | 0.9754 | 0.9714 | 0.9742 | |
| 1500 | 0.9714 | 0.9751 | 0.9698 | 0.9738 | |
| FourPeople (1280 × 720) 60fps | 256 | 0.9554 | 0.9659 | 0.9526 | 0.9638 |
| 384 | 0.9610 | 0.9676 | 0.9586 | 0.9656 | |
| 512 | 0.9669 | 0.9710 | 0.9649 | 0.9692 | |
| 850 | 0.9724 | 0.9741 | 0.9707 | 0.9723 | |
| 1500 | 0.9760 | 0.9764 | 0.9743 | 0.9746 | |
| KristenAndSara (1280 × 720) 60fps | 256 | 0.9342 | 0.9427 | 0.9321 | 0.9408 |
| 384 | 0.9452 | 0.9513 | 0.9434 | 0.9496 | |
| 512 | 0.9476 | 0.9528 | 0.9459 | 0.9511 | |
| 850 | 0.9559 | 0.9570 | 0.9543 | 0.9552 | |
| 1500 | 0.9614 | 0.9618 | 0.9599 | 0.9602 | |
| BasketballDrive (1920 × 1080) 60fps | 2000 | 0.8370 | 0.8461 | 0.8243 | 0.8334 |
| 3000 | 0.8447 | 0.8528 | 0.8324 | 0.8405 | |
| 4500 | 0.8548 | 0.8544 | 0.8430 | 0.8417 | |
| 7000 | 0.8664 | 0.8596 | 0.8550 | 0.8475 | |
| 10,000 | 0.8728 | 0.8618 | 0.8621 | 0.8493 | |
| BQTerrace (1920 × 1080) 50fps | 2000 | 0.8182 | 0.8274 | 0.8051 | 0.8148 |
| 3000 | 0.8181 | 0.8294 | 0.8049 | 0.8169 | |
| 4500 | 0.8221 | 0.8274 | 0.8089 | 0.8144 | |
| 7000 | 0.8237 | 0.8303 | 0.8105 | 0.8175 | |
| 10,000 | 0.8273 | 0.8289 | 0.8143 | 0.8160 | |
| Cactus (1920 × 1080) 50fps | 2000 | 0.9168 | 0.9177 | 0.9118 | 0.9122 |
| 3000 | 0.9205 | 0.9206 | 0.9155 | 0.9153 | |
| 4500 | 0.9278 | 0.9219 | 0.9232 | 0.9165 | |
| 7000 | 0.9322 | 0.9235 | 0.9278 | 0.9180 | |
| 10,000 | 0.9182 | 0.9237 | 0.9318 | 0.9182 | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Maung Maung, H.; Aramvith, S.; Miyanaga, Y. Hierarchical-P Reference Picture Selection Based Error Resilient Video Coding Framework for High Efficiency Video Coding Transmission Applications. Electronics 2019, 8, 310. https://doi.org/10.3390/electronics8030310
Maung Maung H, Aramvith S, Miyanaga Y. Hierarchical-P Reference Picture Selection Based Error Resilient Video Coding Framework for High Efficiency Video Coding Transmission Applications. Electronics. 2019; 8(3):310. https://doi.org/10.3390/electronics8030310
Chicago/Turabian StyleMaung Maung, Htoo, Supavadee Aramvith, and Yoshikazu Miyanaga. 2019. "Hierarchical-P Reference Picture Selection Based Error Resilient Video Coding Framework for High Efficiency Video Coding Transmission Applications" Electronics 8, no. 3: 310. https://doi.org/10.3390/electronics8030310
APA StyleMaung Maung, H., Aramvith, S., & Miyanaga, Y. (2019). Hierarchical-P Reference Picture Selection Based Error Resilient Video Coding Framework for High Efficiency Video Coding Transmission Applications. Electronics, 8(3), 310. https://doi.org/10.3390/electronics8030310