1. Introduction
The networked control systems (NCSs) are systems in which its elements are physically separated but connected by some communication channels. They have been around for some decades already, and they have been implemented successfully in many fields such as industrial automation, robotics, and power grids. Although the NCSs provide several advantages to the systems, it is well-known that one of the problems is the system performance degradation caused by the data rate constraints in the communication channels [
1,
2,
3]. In the case that operation signals of NCSs are transmitted over networks under data rate constraints, the signal quantization is a fundamental process in which a continuous-valued signal is transformed into a discrete-valued one. However, the quantization error between the continuous-valued signal and discrete-valued one occurs, and it affects the performance of the NCSs. Therefore, one of the significant works is to develop a method to minimize the influence of the quantization error to the performance of the NCSs.
It has been proven that properly designed feedback-type dynamic quantizers are effective to reduce this degradation in the system’s performance [
4]. Several studies have considered the design of dynamic quantizers. For instance, a mathematical expression of an optimal dynamic quantizer for time-invariant linear plants was presented in [
4], and an equivalent expression for nonlinear plants was introduced in [
5]. Furthermore, design methods for dynamic quantizers that minimize the system’s performance degradation and satisfy the channel’s data rate constraints were developed in [
6,
7,
8]. Then, in [
9] event-triggered dynamic quantizers that reduce the traffic in the communication network were proposed. In these studies, the design of the quantizers is carried out using information from the plant; namely, these quantizers are based on model-based approach. Thus, if the model of the plant is inaccurate, then the quantizers will be faulty.
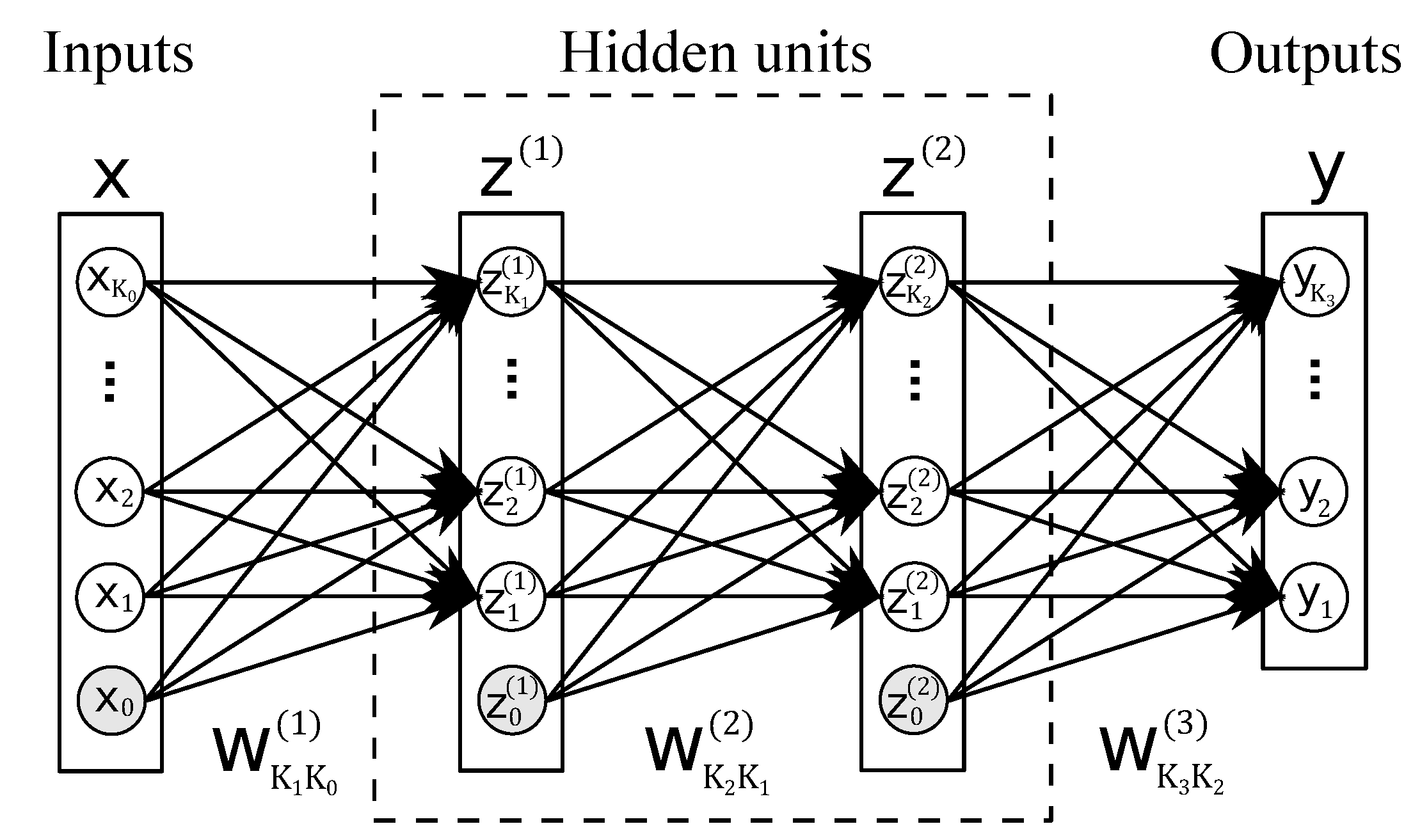
Accordingly, in this paper, the data-driven approach is considered for the design of feedback type dynamic quantizers. Besides, this paper presents a class of dynamic quantizers that are constructed using feedforward neural networks. The quantizer, called
neural network quantizers, are designed using time series data of plant inputs and outputs. Some advantages of this approach are that a model of the plant is not required for the design, i.e., model-free design, and that the quantizer can be designed not only for linear but also for nonlinear plants. The selection of neural networks to perform this job is motivated by the fact that feedforward neural networks are very flexible and that they can be used to represent any nonlinear function/system, in this sense, they work as universal approximators [
10,
11]. This property is especially important for the design of optimal dynamic quantizers because their structures are functions of the plants’ model [
4,
5]. If the model of the plant is not given, but it is known to be linear, then the structure of the optimal quantizer is also known to be linear. However, if the plant is nonlinear and its model is absent, then the optimal quantizer’s structure is unknown. Thus, the neural network can approximate the optimal quantizer’s structure based on a series of plant input and output data.
This paper is structured as follows. First, we propose a class of dynamic quantizers composed of feedforward neural network, memories, and a static quantizer. The proposed quantizer has two variations in neural network structures: one is based on a regression-based approach, and the other is based on a classification-based approach. Then, we formulate the quantizers design problem that finds the parameters of the neural network and the quantization interval for given a time series data of plant input and output. Next, with numerical examples, the effectiveness of these quantizers and their design method are verified. Finally, several design variations are considered in order to optimize the quantizer’s performance, and comparisons among these variations are carried out.
It should be remarked that various results on the quantizer design for networked control systems have been obtained, e.g., [
12,
13,
14,
15,
16]. However, the contributions of this paper are distinguished from them as follows. The papers in [
12,
13,
14] focus on the zoom-in and zoom-out strategy based dynamic quantizer, i.e., the quantizer with time-varying quantization interval. Besides, the paper [
15] considers the static logarithmic quantizer, i.e., its quantization interval is not uniform. On the other hand, this paper proposes dynamic quantizer with the time-invariant and uniform interval. Furthermore, the paper [
16] proposes a ΔΣ modulator, which is related to the proposed quantizer. Although the result in [
16] is restricted to the case of two quantization levels, this paper can deal with the case of multi-levels.
This paper is a journal version of our previous conference papers that were presented in [
17,
18]. The main difference between this paper and its predecessors is as follows. The system description and problem formulation are improved, and detail explanations of the proposed quantizers are added. Then, we use the ANOVA test to analyze the several simulation results. Besides, we take into account different activation functions for the neural networks hidden layers and compares different initialization methods for the network tuning.
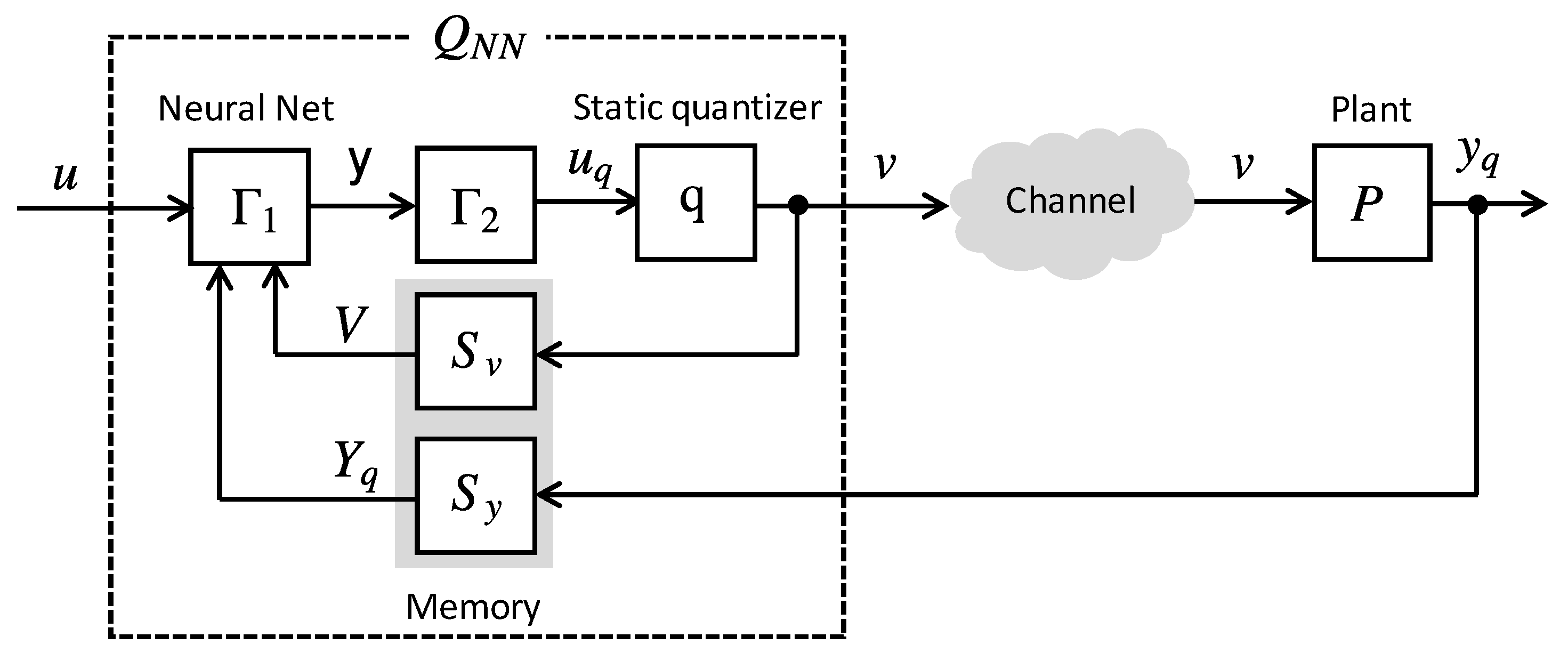
3. Quantizer Design Problem
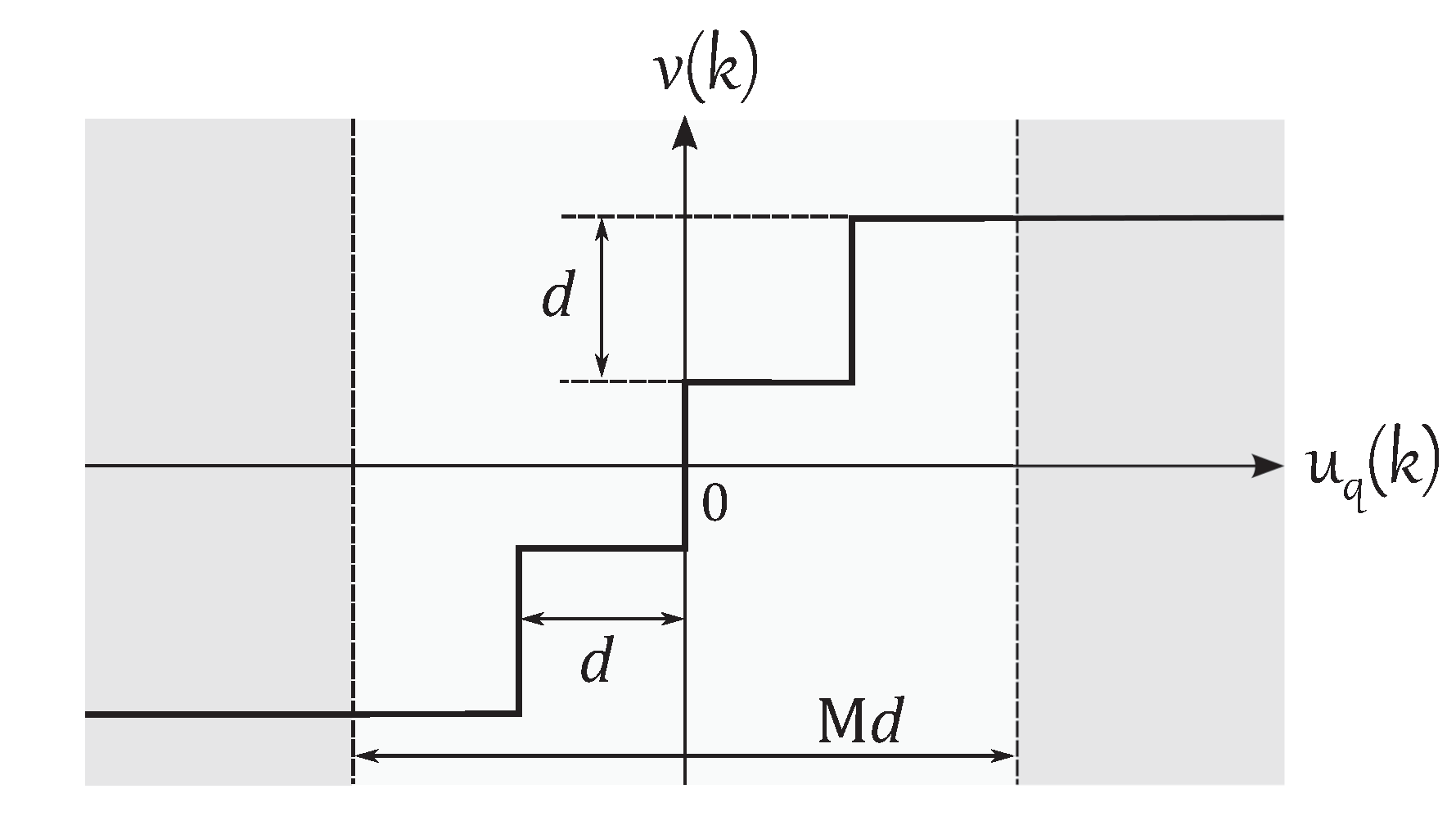
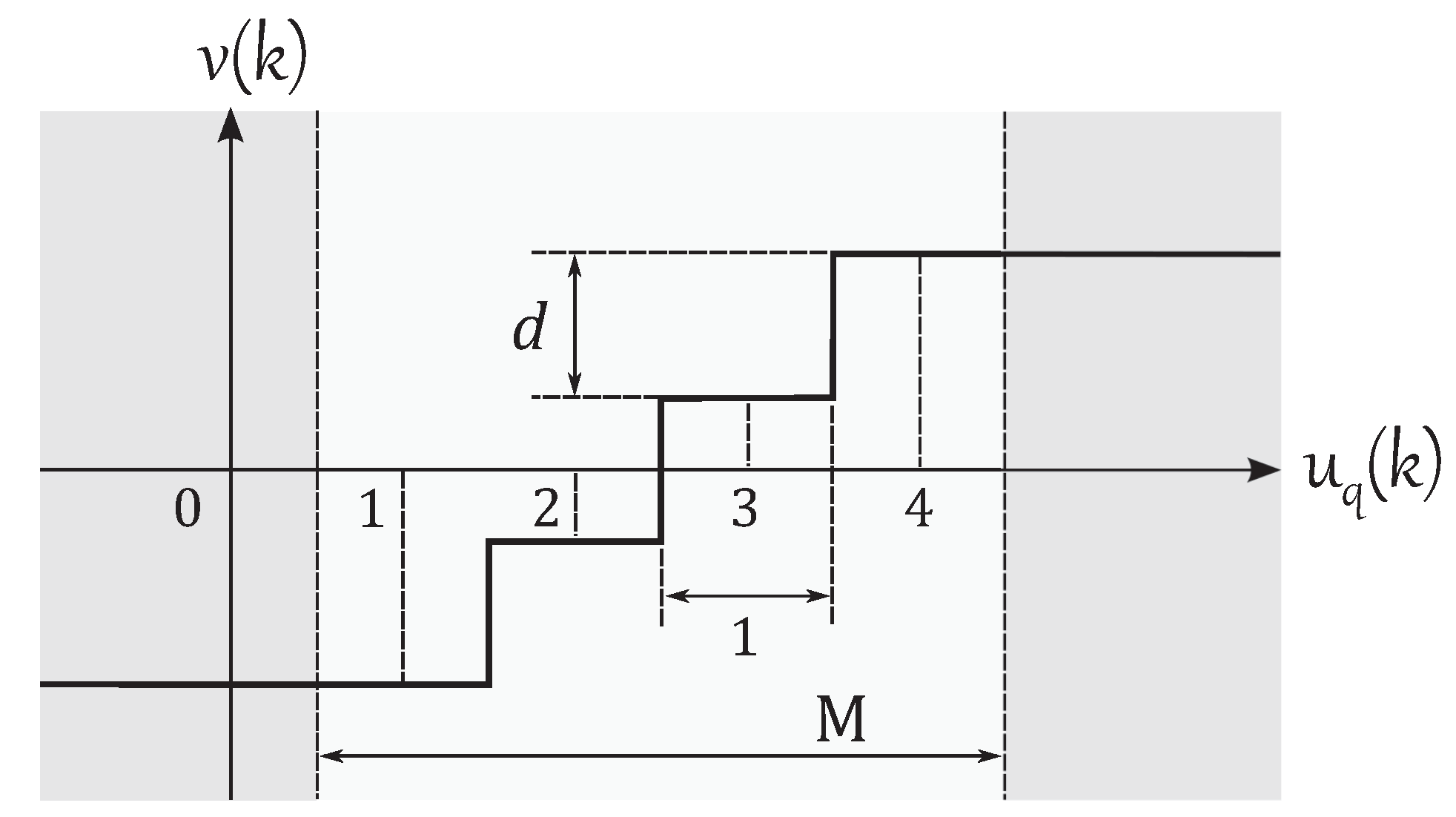
In this paper, it is assumed that the number of quantization levels M, the memory sizes and , and the neural network structure are given. Thus, the design parameters are the weight vector and the quantization interval d of the neural network quantizer .
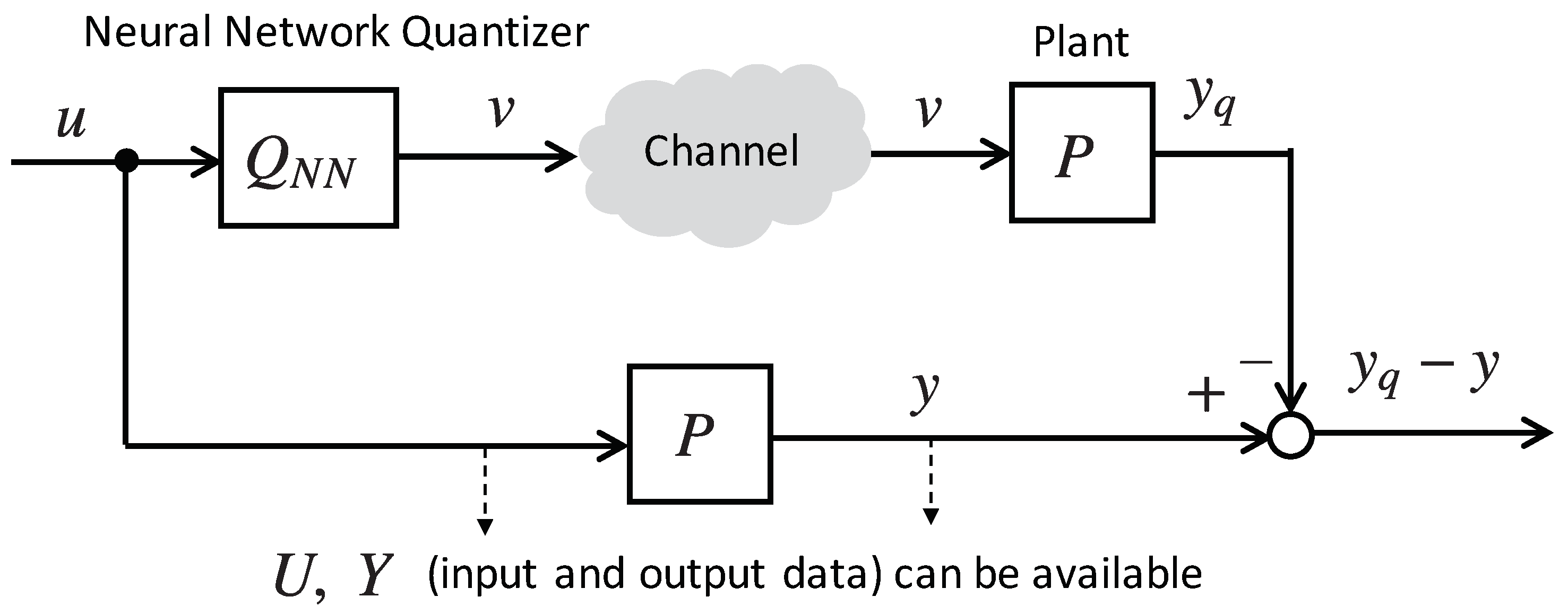
The performance of the quantizer
in NCSs can be evaluated using a construction known as
error system. The considered error system is depicted in
Figure 6. This system is composed of two branches. In the lower branch, the input signal
u is applied directly to the plant
P that produces the ideal output
y. In the upper branch the effects of quantization are considered and
u is applied to the quantizer
that generates the quantized signal
v that is applied to the plant. The output of the plant in this case is represented by
, and the difference
is the error signal. The error signal
is used to evaluate the performance degradation of the system. By minimizing
, the system composed of the quantizer
and the plant
P can be optimally approximated to the plant
P, in terms of the input-output relation.
In this context, a parameter known as
performance index is used to measure the system’s performance degradation. The performance index considered here is the sum-of-squares error function that is defined by
where
is used to build
along side with
and
that are generated dynamically. It is necessary to make
as small as possible to maintain the output error low. Then, the design of
is set up as an optimization problem in which the performance index is minimized.
This paper assumes that, although the model is unknown, it is possible to feed it with inputs and measure its outputs. Then, a time series of inputs and outputs of the plant will be available. These time series are represented as follows.
where
is the length of the time series, namely, the number of samples. Notice that
(
) represents the output of the plant
P when
is applied directly to it, i.e.,
.
Then, the neural network quantizers design problem is formulated as follows:
Problem 1. Suppose that the time series data and of the plant, the number of quantization levels M, the neural network structure , and the memory sizes and are given. Then, find the parameters of : the weight vector and the quantization interval d which minimize , under the condition that .
This design problem is nonlinear and nonconvex. Thus, it cannot be solved using gradient-based optimization methods such as linear programming or quadratic programming. Moreover, conventional neural network training techniques based on error backpropagation cannot be used either due to the structure of the system, as it was explained previously. Therefore, alternative optimization methods should be used.
In this regard, the metaheuristics stand out from the available options because of their flexibility and a wide variety of implementations [
19]. In particular, the differential evolution (DE) metaheuristic algorithm is used to perform the design of
. This choice is justified by the fact that DE has proven to be effective in the training of neural networks [
20,
21] and that it has shown an outstanding performance in the design of dynamic quantizers [
9]. DE is a population-based metaheuristic algorithm inspired in the mechanism of biological evolution [
22,
23]. In this algorithm, the cost function
is evaluated iteratively over a population of possible solutions or
individuals in each iteration the individuals improve their values and move towards the best solution. Finally, the individual with the lowest fitness value in the last iteration is regarded as the optimal solution. Some advantages of DE are that it is very easy to implement and has only two tuning parameters: the scale factor
F and the crossover constant
H, apart from the number of individuals
N and the maximum number of iterations
. Besides, DE shows very good exploration capacities and converges fast to global optima. DE has many versions and variations; the one considered in this study is the classical DE/best/1/bin strategy, which is described in Algorithm 1.
| Algorithm 1: DE (DE/best/1/bin strategy) |
Initialization: Given , , , and the initial search space . Set then select randomly N individuals in the search space.
Step 1: The cost function is evaluated for each and is calculated by:
If then is the final solution, if not go to Step 2.
Step 2 (Mutation): For each a mutant vector is generated by:
where and are random indexes subject to .
Step 3 (Crossover): For each and a trial vector is generated by:
where and are generated randomly.
Step 4 (Selection): The members of the next generation are selected by:
then and go to Step 1. |
Since the design parameters of
are
and
d, an individual for the DE algorithm will have the following form
with dimension
. From these parameters, the weights vector
is not affected by any constraint, but the quantization interval
d should always be positive
. DE has no direct way to handle the constraints of the optimization problem since it was designed to solve unconstrained problems. Then, in order to manage the constraint condition, a method developed by Maruta et al. in [
24] is employed. This method transforms the constrained optimization problem into the following unconstrained one.
where
is the performance index in Equation (
9). This constraints management method ensures that
d is positive.
The learning resulting from the training of a deep neural network depends highly on the initial weights of the network because many of the learning techniques are in essence local searches. Therefore, it is very important to initialize the network’s weights appropriately [
25,
26]. There are several ways to initialize the neural networks to perform the training. The most common method is the uniformly random initialization where random values sampled from a certain interval using a uniform probability distribution are assigned to the weights and biases of the network. The initialization intervals are selected according to, but they are usually small and close to zero. Popular ones are the intervals
or
. Another prevalent type of initialization was developed in [
27] by Glorot and Bengio. This method is known as Xavier Uniform initialization (from Xavier Glorot). In this method, the weights of each layer in the network are initialized using random uniform sampling in a specific interval
where
represents the weights of the
ith layer. The limits of the interval are given by
which is a function of the number of neurons of the considered layer
, the number of neurons in the previous layer
and the hidden layers activation function
. The limit is the following
4. Numerical Simulations
To verify that the proposed neural network quantizers and their design method work properly, several numerical simulations were performed. In these simulations, the following discrete, nonlinear and stable plant is used.
This plant is a modified version of the plant shown in [
5]. The initial state is
, and the input signal used in the examples is given by
The evaluation interval is , which implies that the amount of samples taken is .
The quantizers are constructed with
,
and neural networks with
. Given the size of the memories and the dimension of
all the networks have inputs with dimension
. The neural networks’ structure depends on the type of quantizer and
M.
Table 1 summaries the structure of the quantizers used in the simulations. For the regression case (R) the network’s structure and the dimension of
(
) are independent of
M. This is not the case for the classification type of quantizer (C).
Table 1 also shows a comparison among the
of each network.
The hyper parameters of DE are
,
,
, and
. The simulations were performed
times for each considered case. Then, since the individuals have the form
the dimensions of the optimization problems
n will be the ones shown is the last column of
Table 1. Looking at
Table 1 it is possible to see that
has more parameters than
, this is a factor that influences the performance of the proposed design method.
The DE individuals are initialized as follows. The first element
d is uniformly sampled from the interval
. The network weights are initialized using the uniform random and the Xavier uniform initialization methods, described in
Section 3.
After running the DE algorithm
times for each considered case, the quantizers
with the lowest
are selected to be the optimal quantizers. Then, in order to test these quantizers, the error system in
Figure 6 is fed with the input signal
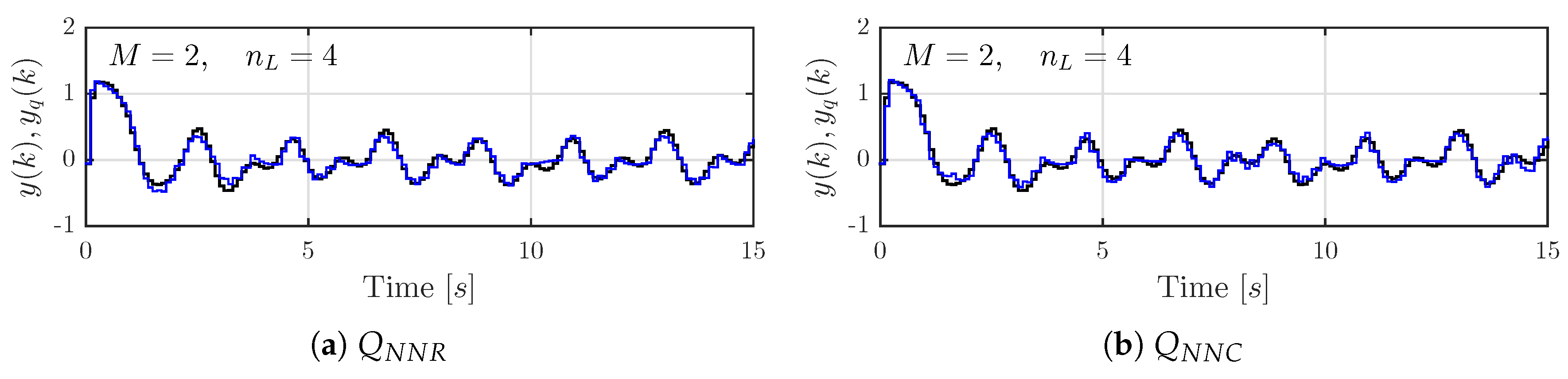
for each case. It results that all the quantizers work properly and show good performance. For instance,
Figure 7 depicts the signals resulting from applying
to the system with the quantizers designed for
and
. This figure shows that the output signals obtained by quantization
follow the ideal output signal
pretty well and that the error between them is small in both cases. Also, the inputs
of the static quantizers are shown for comparison.
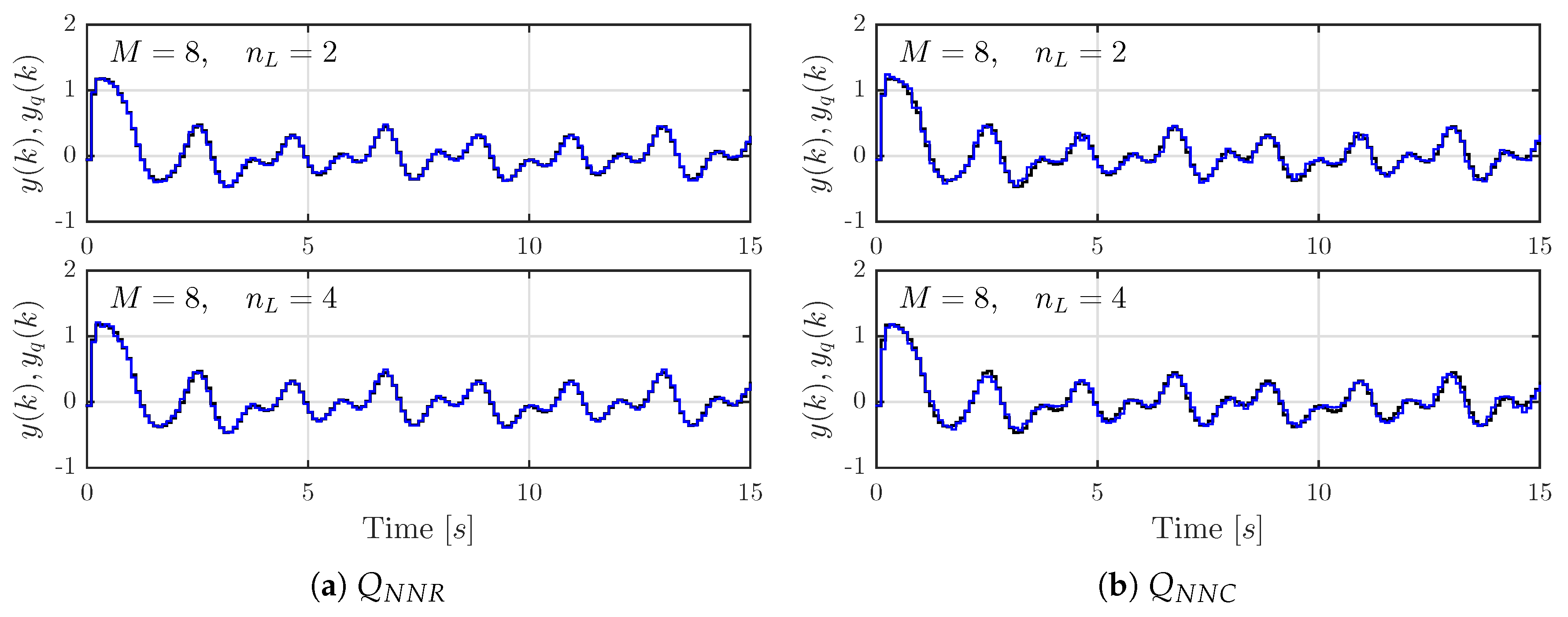
To further validate this observation, in
Figure 8 there are shown the output signals of the system where the neural network quantizers were designed for
and
, and in
Figure 9 the ones for
,
and
. From these, we see that the proposed quantizer works well.
In addition, the result with the static quantizer
case and the result with the optimal dynamic quantizer case proposed in [
5] are shown in
Figure 10 for comparison. The value of the performance index for the static quantizer is
and that for the optimal dynamic quantizer is
. On the other hand, the performance of the proposed quantizer
for
and
is
and that for
and
is
. From this comparison result, we see that the proposed quantizer achieves higher performance than the static quantizer. Then, we find that the proposed quantizer is similar to the optimal dynamic quantizer, although the proposed quantizer is designed with the time series data of plant inputs and outputs, i.e., without the model information of the plant. Therefore, we can confirm that the neural network in the proposed quantizer captures the dynamics of the plant appropriately based on the time series data of the plant input and output.
The minimum values of the performance indexes in Equation (
9), found by DE, are listed in
Table 2. In addition, this table lists the average performance indexes and their standard deviation. The values in this table are divided according to their
M, initialization method,
and type (regression or classification). There are two initialization methods implemented: uniform random (Urand) and Xavier.
Drawing conclusions from this table by simple observation is difficult. For example, looking at the minimum values of in the case of , it is possible to say that have better performance (smaller ) than in most cases. The average values not always corroborate this observation. For , has the smallest value of in each case. However, there is no evidence that there is a significant difference in the performance of these types of quantizers. Therefore, the analysis of variance (ANOVA) is used to check if there are significant differences or not among these values.
Because many factors influence , the 3-way ANOVA (ANOVA with three factors) is used. The considered factors are Type, initialization method (Init.) and number of layers . The categories of each factor are known as elements. For instance, the elements of the factor Type are R (: regression) and C (: classification). The M is not taken as a factor, because gives smaller s than . Then, it is not necessary to check which one gives better results. The considered significance level is . The goal is to determine if there is some statistical difference among the ’s means of the design methods.
A summary of this test is shown in
Table 3. The ANOVA test shows if there are significant differences among sets of data. When doing 3-way ANOVA, it is possible to see not only if there is a significant difference among elements of a factor but also combinations of elements of different factors. In this particular case, it will tell if there is a significant difference between
and
, and also it will tell if there are differences among the combinations of the quantizer types and the initialization methods. Then, the 3-way ANOVA test is run separately for
and
. For the case of
, the significant difference is found only for the initialization method. For the case of
the significant difference is found for all the factors and the combinations of them with the exception of the combination of the quantizer type and
.
So far only one type of activation function
, the sigmoid function, have been used in the hidden layers to build the neural networks. However, there are other activation functions that can be used. In this section two additional activation functions are considered: the hyperbolic tangent (tanh) and the Rectified Linear Unit (
). These functions were defined by
In addition, the limits
in (
17) for Xavier Uniform initializatin are given by
Several numerical simulations were performed to compare the performance of the neural network quantizers built with these functions. The settings of these simulations are the same as in the previous cases where
, but they were carried out only for
. These simulations were run
times for each case. The results are summaries in
Table 4.
As before, it is difficult to conclude from the table by simple observation. Therefore, the ANOVA test is used to analyze the data. In this case, four factors influence the results: , initialization method, and quantizer type. However, because the influence of is understood the focus in this section will be in the factors: , initialization method, quantizer type, and the interaction among each other. Therefore, the 3-way ANOVA general linear model of versus quantizer type (Type), initialization method (Init) and activation function is considered. The significance level used in this analysis is . The analysis of variance showed that the statistical null hypothesis that all the means are the same was rejected for every single factor and the combination of them. This means that in each case there is at least one element that significantly differs from the others. The Tukey pairwise comparison is made to see the differences among the quantizer’s design elements.
The results of this test are summarized in
Table 5. From the results, we see the following things. First, they tell that there is a significant difference between the
and
, and that
outperforms
. Second, they show that there is a difference between the initialization methods and that the Urand method exhibits better performance than the Xavier method. These results corroborate the ones shown in
Table 3 previously obtained for
and
. Third, the table shows that the performances of the considered activation functions vary significantly, that the one with the best performance is
, and that the one with the lowest performance is
.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}