Efficient-Scheduling Parallel Multiplier-Based Ring-LWE Cryptoprocessors



Abstract
:1. Introduction
2. Ring-LWE Cryptography
2.1. Operations in Ring-LWE Cryptography
2.1.1. Key Generation
2.1.2. Encryption
2.1.3. Decryption
2.2. Arithmetic Operations over a Ring
| Algorithm 1: Number theoretic transform (NTT)-based polynomial multiplication using negative wrapped convolution. |
 |
2.3. Discrete Gaussian Sampler
2.4. Ring-LWE Encryption and Decryption Algorithm
| Algorithm 2: Ring-learning with errors (LWE) encryption algorithm. |
 |
| Algorithm 3: Ring-LWE decryption algorithm. |
 |
3. Proposed Ring-LWE Cryptoprocessor Architectures
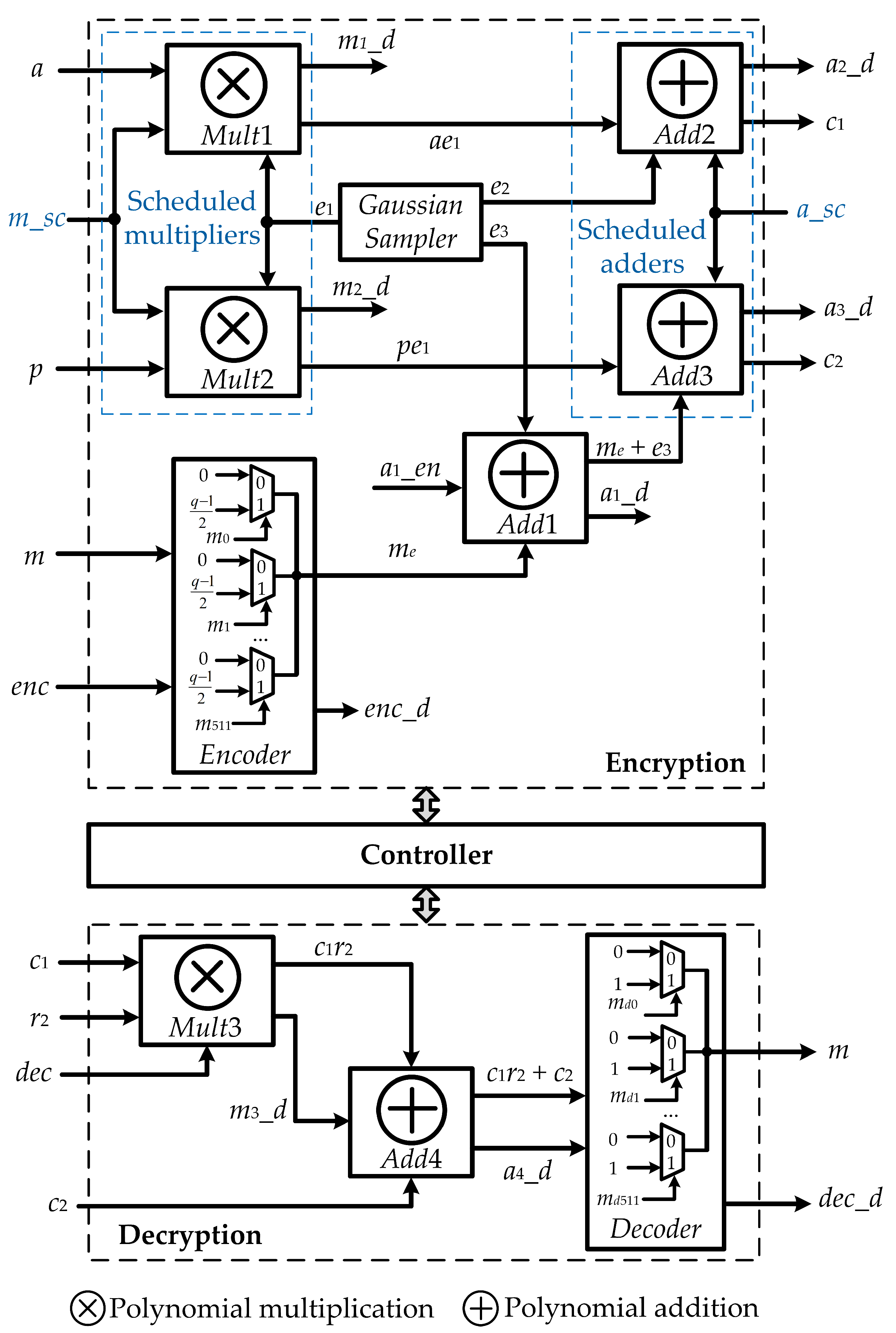
3.1. Proposed Ring-LWE Encryption and Decryption Architectures
3.2. Proposed NTT Multiplier Architecture
4. Simulation Results and Comparison
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Koblitz, N. Elliptic Curve Cryptosystems. Math. Comput. 1987, 48, 203–209. [Google Scholar] [CrossRef]
- Nguyen, T.T.; Lee, H. Efficient Algorithm and Architecture for Elliptic Curve Cryptographic Processor. J. Semicond. Technol. Sci. 2016, 16, 118–125. [Google Scholar] [CrossRef]
- Choi, P.; Lee, M.K.; Kim, J.H.; Kim, D.K. Low-Complexity Elliptic Curve Cryptography Processor Based on Configurable Partial Modular Reduction over NIST Prime Fields. IEEE Trans. Circuits Syst. II 2018, 65, 1703–1707. [Google Scholar] [CrossRef]
- Rivest, R.L.; Shamir, A.; Adleman, L. A Method for Obtaining Digital Signatures and Public-Key Cryptosystems. ACM Commun. 1978, 21, 120–126. [Google Scholar] [CrossRef]
- Shor, P.W. Polynomial-Time Algorithms for Prime Factorization and Discrete Logarithms on a Quantum Computer. SIAM J. Comput. 1997, 26, 1484–1509. [Google Scholar] [CrossRef]
- Liu, Z.; Azarderakhsh, R.; Kim, H.; Seo, H. Efficient Software Implementation of Ring-LWE Encryption on IoT Processors. IEEE Trans. Comput. 2017. [Google Scholar] [CrossRef]
- Rentería-Mejía, C.P.; Velasco-Medina, J. High-Throughput Ring-LWE Cryptoprocessors. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2017, 25, 2332–2345. [Google Scholar] [CrossRef]
- Tan, T.N.; Lee, H. High-Secure Low-Latency Ring-LWE Cryptography Scheme for Biomedical Images Storing and Transmitting. In Proceedings of the 2018 IEEE International Symposium on Circuits and Systems, Florence, Italy, 27–30 May 2018; pp. 1–4. [Google Scholar]
- Chen, D.D.; Mentens, N.; Vercauteren, F.; Roy, S.S.; Cheung, R.C.C.; Pao, D.; Verbauwhede, I. High-Speed Polynomial Multiplication Architecture for Ring-LWE and SHE Cryptosystems. IEEE Trans. Circuits Syst. I 2015, 62, 157–166. [Google Scholar] [CrossRef]
- Tan, T.N.; Lee, H. High-Performance Ring-LWE Cryptography Scheme for Biometric Data Security. IEIE Trans. Smart Process. Comput. 2018, 7, 97–106. [Google Scholar] [CrossRef]
- Tan, T.N.; Lee, H. High-Secure Fingerprint Authentication System using Ring-LWE Cryptography. IEEE Access 2019, 7, 23379–23387. [Google Scholar] [CrossRef]
- Lyubashevsky, V.; Peikert, C.; Regev, O. On Ideal Lattices and Learning with Errors over Rings. J. ACM 2013, 60, 43:1–43:35. [Google Scholar] [CrossRef]
- Pöppelmann, T.; Güneysu, T. Towards Practical Lattice-Based Public-Key Encryption on Reconfigurable Hardware. In Proceedings of the Selected Areas in Cryptography, Burnaby, BC, Canada, 14–16 August 2013; pp. 68–85. [Google Scholar]
- Rentería-Mejía, C.P.; Velasco-Medina, J. Hardware Design of an NTT-Based Polynomial Multiplier. In Proceedings of the 2014 Southern Conference on Programmable Logic (SPL), Buenos Aires, Argentina, 5–7 November 2014; pp. 1–5. [Google Scholar]
- Regev, O. On Lattices, Learning with Errors, Random Linear Codes, and Cryptography. In Proceedings of the ACM Symposium on Theory of Computing, Baltimore, MD, USA, 22–24 May 2005; pp. 84–93. [Google Scholar]
- Roy, S.S.; Vercauteren, F.; Mentens, N.; Chen, D.D.; Verbauwhede, I. Compact Ring-LWE Cryptoprocessor. In Proceedings of the International Workshop on Cryptographic Hardware and Embedded Systems (CHES 2014), Busan, Korea, 23–26 September 2014; pp. 371–391. [Google Scholar]
- Cao, Z.; Wu, X. An Improvement of the Barrett Modular Reduction Algorithm. Int. J. Comput. Math. 2014, 91, 1874–1879. [Google Scholar] [CrossRef]
- Roy, S.S.; Vercauteren, F.; Verbauwhede, I. High Precision Discrete Gaussian Sampling on FPGAs. In Proceedings of the Selected Areas in Cryptography, Burnaby, BC, Canada, 14–16 August 2013; pp. 383–401. [Google Scholar]
- Du, C.; Bai, G. Towards Efficient Discrete Gaussian Sampling for Lattice-Based Cryptography. In Proceedings of the 2015 International Conference on Field Programmable Logic and Applications (FPL), London, UK, 2–4 September 2015; pp. 1–6. [Google Scholar]
- Liu, Z.; Seo, H.; Roy, S.S.; Großschädl, J.; Kim, H.; Verbauwhede, I. Efficient Ring-LWE Encryption on 8-bit AVR Processors. In Proceedings of the Cryptographic Hardware and Embedded Systems (CHES 2015), Saint-Malo, France, 13–16 September 2015; pp. 663–682. [Google Scholar]
- Condo, C.; Gross, W.J. Pseudo-Random Gaussian Distribution Through Optimised LFSR Permutations. Electron. Lett. 2015, 51, 2098–2100. [Google Scholar] [CrossRef]
- Cooley, J.W.; Tukey, J.W. An Algorithm for the Machine Calculation of Complex Fourier Series. Math. Comput. 1965, 19, 297–301. [Google Scholar] [CrossRef]
- Mahdizadeh, H.; Masoumi, M. Novel architecture for efficient FPGA implementation of elliptic curve cryptographic processor over GF(2163). IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2013, 21, 2330–2333. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Proposed Radix-2S | R2S [7] | Proposed Radix-2M | R2M [7] | Proposed Radix-8M | R8M [7] | [13] | [16] | |
|---|---|---|---|---|---|---|---|---|
| Devices | Virtex-7 | Stratix IV | Virtex-7 | Stratix IV | Virtex-7 | Stratix IV | Virtex-6 | Virtex-6 |
| LUTs (enc.) | 23,015 | 28,977 | 29,802 | 31,890 | 61,154 | 62,994 | 5,595 | 1,536 |
| LUTs (dec.) | 6,623 | 6,761 | 7,252 | 7,272 | 25,160 | 27,313 | – | – |
| Slices (enc.) | 13,588 | 29,290 | 18,933 | 31,540 | 42,374 | 56,435 | 4,760 | 953 |
| Slices (dec.) | 6,354 | 7,616 | 7,657 | 8,641 | 23,495 | 32,019 | – | – |
| Cycles (enc.) | 1,832 | 2,207 | 651 | 1,194 | 240 | 391 | 13,769 | 13,300 |
| Cycles (dec.) | 1,754 | 1,145 | 612 | 644 | 224 | 225 | 8,883 | 5,800 |
| Time (enc.) (s) | 4.58 | 9.33 | 1.97 | 5.16 | 0.89 | 1.73 | 54.86 | 47.90 |
| Time (dec.) (s) | 4.35 | 4.59 | 1.82 | 2.78 | 0.71 | 1.04 | 35.39 | 21.00 |
| Thr. (enc.) (Mbps) | 1,565.07 | 824.03 | 3,638.58 | 1,491.26 | 8,053.93 | 4,465.12 | 130.66 | 149.64 |
| Thr. (dec.) (Mbps) | 117.70 | 111.55 | 281.32 | 184.17 | 721.13 | 492.31 | 14.47 | 24.38 |
| Eff. (enc.) (Kbps/LUT) | 68.00 | 28.41 | 122.09 | 46.69 | 131.70 | 70.88 | 23.35 | 97.42 |
| Eff. (dec.) (Kbps/LUT) | 17.77 | 16.50 | 38.79 | 25.33 | 28.66 | 18.02 | 2.29 | 15.87 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nguyen Tan, T.; Lee, H. Efficient-Scheduling Parallel Multiplier-Based Ring-LWE Cryptoprocessors. Electronics 2019, 8, 413. https://doi.org/10.3390/electronics8040413
Nguyen Tan T, Lee H. Efficient-Scheduling Parallel Multiplier-Based Ring-LWE Cryptoprocessors. Electronics. 2019; 8(4):413. https://doi.org/10.3390/electronics8040413
Chicago/Turabian StyleNguyen Tan, Tuy, and Hanho Lee. 2019. "Efficient-Scheduling Parallel Multiplier-Based Ring-LWE Cryptoprocessors" Electronics 8, no. 4: 413. https://doi.org/10.3390/electronics8040413
APA StyleNguyen Tan, T., & Lee, H. (2019). Efficient-Scheduling Parallel Multiplier-Based Ring-LWE Cryptoprocessors. Electronics, 8(4), 413. https://doi.org/10.3390/electronics8040413