Jet Features: Hardware-Friendly, Learned Convolutional Kernels for High-Speed Image Classification


Abstract
:1. Introduction
Related Work
2. Jet Features
2.1. Introduction to Jet Features
2.2. Multiscale Local Jets
3. The ECO Features Algorithm
4. The ECO Jet Features Algorithm
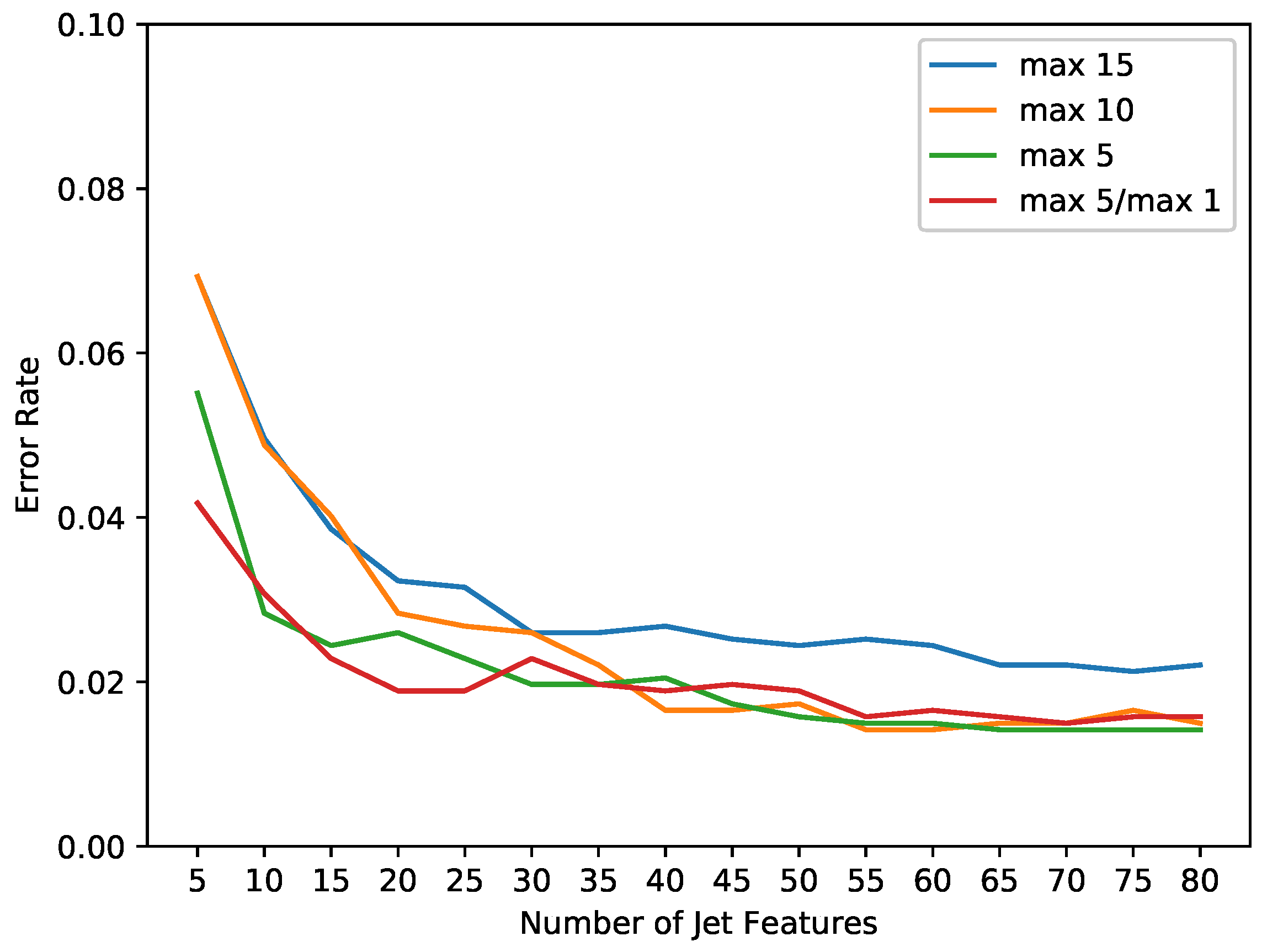
4.1. Jet Feature Selection
4.2. Advantages in Software
4.3. Advantages in Hardware
5. Hardware Architecture
5.1. The Jet Features Unit
5.2. The Random Forest Unit
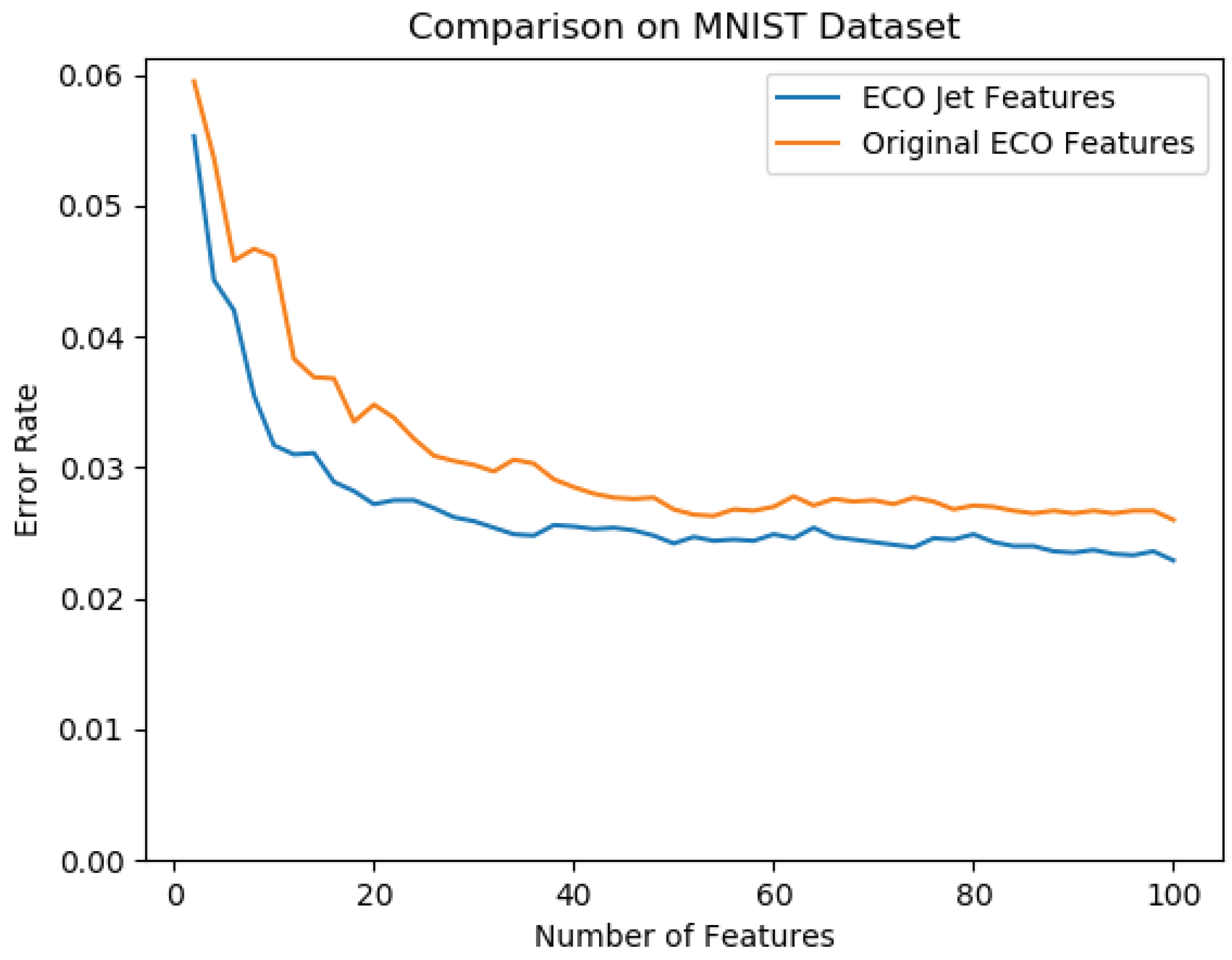
6. Results
6.1. Datasets
6.2. Accuracy on MNIST CIFAR-10
6.3. Accuracy on BYU Fish Dataset
6.4. Software Speed Comparison
6.5. Hardware Implementation Results
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Hubara, I.; Courbariaux, M.; Soudry, D.; El-Yaniv, R.; Bengio, Y. Binarized Neural Networks. In Advances in Neural Information Processing Systems 29; Lee, D.D., Sugiyama, M., Luxburg, U.V., Guyon, I., Garnett, R., Eds.; Curran Associates, Inc.: Dutchess County, NY, USA, 2016; pp. 4107–4115. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Lillywhite, K.; Tippetts, B.; Lee, D.J. Self-tuned Evolution-COnstructed features for general object recognition. Pattern Recognit. 2012, 45, 241–251. [Google Scholar] [CrossRef]
- Lillywhite, K.; Lee, D.J.; Tippetts, B.; Archibald, J. A feature construction method for general object recognition. Pattern Recognit. 2013, 46, 3300–3314. [Google Scholar] [CrossRef]
- Asano, S.; Maruyama, T.; Yamaguchi, Y. Performance comparison of FPGA, GPU and CPU in image processing. In Proceedings of the 2009 International Conference on Field Programmable Logic and Applications, Prague, Czech Republic, 31 August–2 September 2009; pp. 126–131. [Google Scholar] [CrossRef]
- Dawood, A.S.; Visser, S.J.; Williams, J.A. Reconfigurable FPGAS for real time image processing in space. In Proceedings of the 2002 14th International Conference on Digital Signal Processing, DSP 2002 (Cat. No. 02TH8628), Santorini, Greece, 1–3 July 2002; Volume 2, pp. 845–848. [Google Scholar] [CrossRef]
- Fahmy, S.A.; Cheung, P.Y.K.; Luk, W. Novel FPGA-based implementation of median and weighted median filters for image processing. In Proceedings of the International Conference on Field Programmable Logic and Applications, Tampere, Finland, 24–26 August 2005; pp. 142–147. [Google Scholar] [CrossRef]
- Birla, M.K. FPGA Based Reconfigurable Platform for Complex Image Processing. In Proceedings of the 2006 IEEE International Conference on Electro/Information Technology, East Lansing, MI, USA, 7–10 May 2006; pp. 204–209. [Google Scholar] [CrossRef]
- Jin, S.; Cho, J.; Pham, X.D.; Lee, K.M.; Park, S.; Kim, M.; Jeon, J.W. FPGA Design and Implementation of a Real-Time Stereo Vision System. IEEE Trans. Circuits Syst. Vid. Technol. 2010, 20, 15–26. [Google Scholar] [CrossRef]
- Amaricai, A.; Gavriliu, C.; Boncalo, O. An FPGA sliding window-based architecture harris corner detector. In Proceedings of the 2014 24th International Conference on Field Programmable Logic and Applications (FPL), Munich, Germany, 2–4 September 2014; pp. 1–4. [Google Scholar] [CrossRef]
- Qasaimeh, M.; Zambreno, J.; Jones, P.H. A Modified Sliding Window Architecture for Efficient BRAM Resource Utilization. In Proceedings of the 2017 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), Orlando, FL, USA, 29 May–2 June 2017; pp. 106–114. [Google Scholar] [CrossRef]
- Mohammad, K.; Agaian, S. Efficient FPGA implementation of convolution. In Proceedings of the 2009 IEEE International Conference on Systems, Man and Cybernetics, San Antonio, TX, USA, 11–14 October 2009; pp. 3478–3483. [Google Scholar] [CrossRef]
- Chang, C.J.; Huang, Z.Y.; Li, H.Y.; Hu, K.T.; Tseng, W.C. Pipelined operation of image capturing and processing. In Proceedings of the 5th IEEE Conference on Nanotechnology, Nagoya, Japan, 11–15 July 2005; Volume 1, pp. 275–278. [Google Scholar] [CrossRef]
- Courbariaux, M.; Bengio, Y.; David, J.P. Training deep neural networks with low precision multiplications. arXiv 2014, arXiv:1412.7024. [Google Scholar]
- Sun, W.; Zeng, H.; Yang, Y.E.; Prasanna, V. Throughput-Optimized Frequency Domain CNN with Fixed-Point Quantization on FPGA. In Proceedings of the 2018 International Conference on ReConFigurable Computing and FPGAs (ReConFig), Cancun, Mexico, 3–5 December 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Zhou, Y.; Jiang, J. An FPGA-based accelerator implementation for deep convolutional neural networks. In Proceedings of the 2015 4th International Conference on Computer Science and Network Technology (ICCSNT), Harbin, China, 19–20 December 2015; Volume 1, pp. 829–832. [Google Scholar] [CrossRef]
- Zhu, M.; Kuang, Q.; Lin, J.; Luo, Q.; Yang, C.; Liu, M. A Z Structure Convolutional Neural Network Implemented by FPGA in Deep Learning. In Proceedings of the IECON 2018—44th Annual Conference of the IEEE Industrial Electronics Society, Washington, DC, USA, 21–23 October 2018; pp. 2677–2682. [Google Scholar] [CrossRef]
- Farabet, C.; Poulet, C.; Han, J.Y.; LeCun, Y. CNP: An FPGA-based processor for Convolutional Networks. In Proceedings of the 2009 International Conference on Field Programmable Logic and Applications, Prague, Czech Republic, 31 August–2 September 2009; pp. 32–37. [Google Scholar] [CrossRef]
- Zhang, C.; Li, P.; Sun, G.; Guan, Y.; Xiao, B.; Cong, J. Optimizing FPGA-based Accelerator Design for Deep Convolutional Neural Networks. In Proceedings of the 2015 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays (FPGA ’15), Monterey, CA, USA, 22–24 February 2015; ACM: New York, NY, USA, 2015; pp. 161–170. [Google Scholar] [CrossRef]
- Ding, R.; Liu, Z.; Blanton, R.D.S.; Marculescu, D. Quantized deep neural networks for energy efficient hardware-based inference. In Proceedings of the 2018 23rd Asia and South Pacific Design Automation Conference (ASP-DAC), Jeju Island, Korea, 22–25 January 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Natsui, M.; Chiba, T.; Hanyu, T. MTJ-Based Nonvolatile Ternary Logic Gate for Quantized Convolutional Neural Networks. In Proceedings of the 2018 IEEE SOI-3D-Subthreshold Microelectronics Technology Unified Conference (S3S), Burlingame, CA, USA, 15–18 October 2018; pp. 1–2. [Google Scholar] [CrossRef]
- Zhou, S.; Ni, Z.; Zhou, X.; Wen, H.; Wu, Y.; Zou, Y. DoReFa-Net: Training Low Bitwidth Convolutional Neural Networks with Low Bitwidth Gradients. arXiv 2016, arXiv:1606.06160. [Google Scholar]
- Nakahara, H.; Fujii, T.; Sato, S. A fully connected layer elimination for a binarized convolutional neural network on an FPGA. In Proceedings of the 2017 27th International Conference on Field Programmable Logic and Applications (FPL), Gent, Belgium, 4–6 September 2017; pp. 1–4. [Google Scholar] [CrossRef]
- Guo, P.; Ma, H.; Chen, R.; Li, P.; Xie, S.; Wang, D. FBNA: A Fully Binarized Neural Network Accelerator. In Proceedings of the 2018 28th International Conference on Field Programmable Logic and Applications (FPL), Dublin, Ireland, 27–31 August 2018; pp. 51–513. [Google Scholar] [CrossRef]
- Fukuda, Y.; Kawahara, T. Stochastic weights binary neural networks on FPGA. In Proceedings of the 2018 7th International Symposium on Next Generation Electronics (ISNE), Taipei, Taiwan, 7–9 May 2018; pp. 1–3. [Google Scholar] [CrossRef]
- Nurvitadhi, E.; Sheffield, D.; Sim, J.; Mishra, A.; Venkatesh, G.; Marr, D. Accelerating Binarized Neural Networks: Comparison of FPGA, CPU, GPU, and ASIC. In Proceedings of the 2016 International Conference on Field-Programmable Technology (FPT), Xi’an, China, 7–9 December 2016; pp. 77–84. [Google Scholar] [CrossRef]
- Yonekawa, H.; Nakahara, H. On-Chip Memory Based Binarized Convolutional Deep Neural Network Applying Batch Normalization Free Technique on an FPGA. In Proceedings of the 2017 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), Orlando, FL, USA, 29 May–2 June 2017; pp. 98–105. [Google Scholar] [CrossRef]
- Umuroglu, Y.; Fraser, N.J.; Gambardella, G.; Blott, M.; Leong, P.; Jahre, M.; Vissers, K. FINN. In Proceedings of the 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays—FPGA ’17, Monterey, CA, USA, 22–24 February 2017; ACM Press: New York, NY, USA, 2017; pp. 65–74. [Google Scholar] [CrossRef] [Green Version]
- Blott, M.; Preußer, T.B.; Fraser, N.J.; Gambardella, G.; O’brien, K.; Umuroglu, Y.; Leeser, M.; Vissers, K. FINN-R: An End-to-End Deep-Learning Framework for Fast Exploration of Quantized Neural Networks. ACM Trans. Reconfig. Technol. Syst. 2018, 11, 1–23. [Google Scholar] [CrossRef]
- Florack, L.; Ter Haar Romeny, B.; Viergever, M.; Koenderink, J. The Gaussian Scale-space Paradigm and the Multiscale Local Jet. Int. J. Comput. Vis. 1996, 18, 61–75. [Google Scholar] [CrossRef]
- Lillholm, M.; Pedersen, K.S. Jet based feature classification. In Proceedings of the 17th International Conference on Pattern Recognition (ICPR 2004), Cambridge, UK, 23–26 August 2004; Volume 2, pp. 787–790. [Google Scholar]
- Larsen, A.B.L.; Darkner, S.; Dahl, A.L.; Pedersen, K.S. Jet-Based Local Image Descriptors. In Proceedings of the 12th European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Fitzgibbon, A., Lazebnik, S., Perona, P., Sato, Y., Schmid, C., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 638–650. [Google Scholar] [Green Version]
- Manzanera, A. Local Jet Feature Space Framework for Image Processing and Representation. In Proceedings of the 2011 Seventh International Conference on Signal Image Technology Internet-Based Systems, Dijon, France, 28 November–1 December 2011; pp. 261–268. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems (NIPS’12); Curran Associates Inc.: Dutchess County, NY, USA, 2012; Volume 1, pp. 1097–1105. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Zhu, J.; Rosset, S.; Zou, H.; Hastie, T. Multi-class AdaBoost. Stat. Interface 2009, 2, 349–360. [Google Scholar] [CrossRef] [Green Version]
- Freund, Y.; Schapire, R.E. A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef] [Green Version]
- Zhang, M.; Lee, D.J.; Lillywhite, K.; Tippetts, B. Automatic quality and moisture evaluations using Evolution Constructed Features. Comput. Electron. Agric. 2017, 135, 321–327. [Google Scholar] [CrossRef] [Green Version]
- Prost-Boucle, A.; Bourge, A.; Pétrot, F.; Alemdar, H.; Caldwell, N.; Leroy, V. Scalable high-performance architecture for convolutional ternary neural networks on FPGA. In Proceedings of the 2017 27th International Conference on Field Programmable Logic and Applications (FPL), Ghent, Belgium, 4–8 September 2017; pp. 1–7. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Transform | Parameters | Transform | Parameters |
|---|---|---|---|
| Gabor filter | 6 | Sobel operator | 4 |
| Gradient | 1 | Difference of Gaussians | 2 |
| Square root | 0 | Morphological erode | 1 |
| Gaussian blur | 1 | Adaptive thresholding | 3 |
| Histogram | 1 | Hough lines | 2 |
| Hough circles | 2 | Fourier transform | 1 |
| Normalize | 3 | Histogram equalization | 0 |
| Log | 0 | Laplacian Edge | 1 |
| Median blur | 1 | Distance transform | 2 |
| Integral image | 1 | Morphological dilate | 1 |
| Canny edge | 4 | Harris corner strength | 3 |
| Rank transform | 0 | Census transform | 0 |
| Resize | 1 | Pixel statistics | 2 |
| Resource | Number Used | Percent of Available |
|---|---|---|
| Total Slices | 10,868 | 4.9% |
| Total LUTs | 34,552 | 4.9% |
| LUTs as Logic | 31,644 | 4.4% |
| LUTs as Memory | 2908 | 1.0% |
| Flip Flops | 17,132 | 1.2% |
| BRAMs | 0 | 0% |
| DSPs | 0 | 0% |
| Unit | Slices | Total LUTs | LUTs as Logic | LUTs as Memory | Flip Flops | |
|---|---|---|---|---|---|---|
| Jet Features Unit | 7593 | 23,253 | 22,377 | 876 | 11,411 | |
| Random Forests Unit | 3741 | 11,080 | 9080 | 2000 | 5080 | |
| Individual Random Forests | 374 | 1108 | 908 | 200 | 508 | |
| Individual Decision Trees | 73 | 210 | 171 | 40 | 93 | |
| Feature router | 49 | 40 | 40 | 0 | 520 | |
| AdaBoost Tabulation | 61 | 180 | 148 | 32 | 121 | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Simons, T.; Lee, D.-J. Jet Features: Hardware-Friendly, Learned Convolutional Kernels for High-Speed Image Classification. Electronics 2019, 8, 588. https://doi.org/10.3390/electronics8050588
Simons T, Lee D-J. Jet Features: Hardware-Friendly, Learned Convolutional Kernels for High-Speed Image Classification. Electronics. 2019; 8(5):588. https://doi.org/10.3390/electronics8050588
Chicago/Turabian StyleSimons, Taylor, and Dah-Jye Lee. 2019. "Jet Features: Hardware-Friendly, Learned Convolutional Kernels for High-Speed Image Classification" Electronics 8, no. 5: 588. https://doi.org/10.3390/electronics8050588
APA StyleSimons, T., & Lee, D.-J. (2019). Jet Features: Hardware-Friendly, Learned Convolutional Kernels for High-Speed Image Classification. Electronics, 8(5), 588. https://doi.org/10.3390/electronics8050588