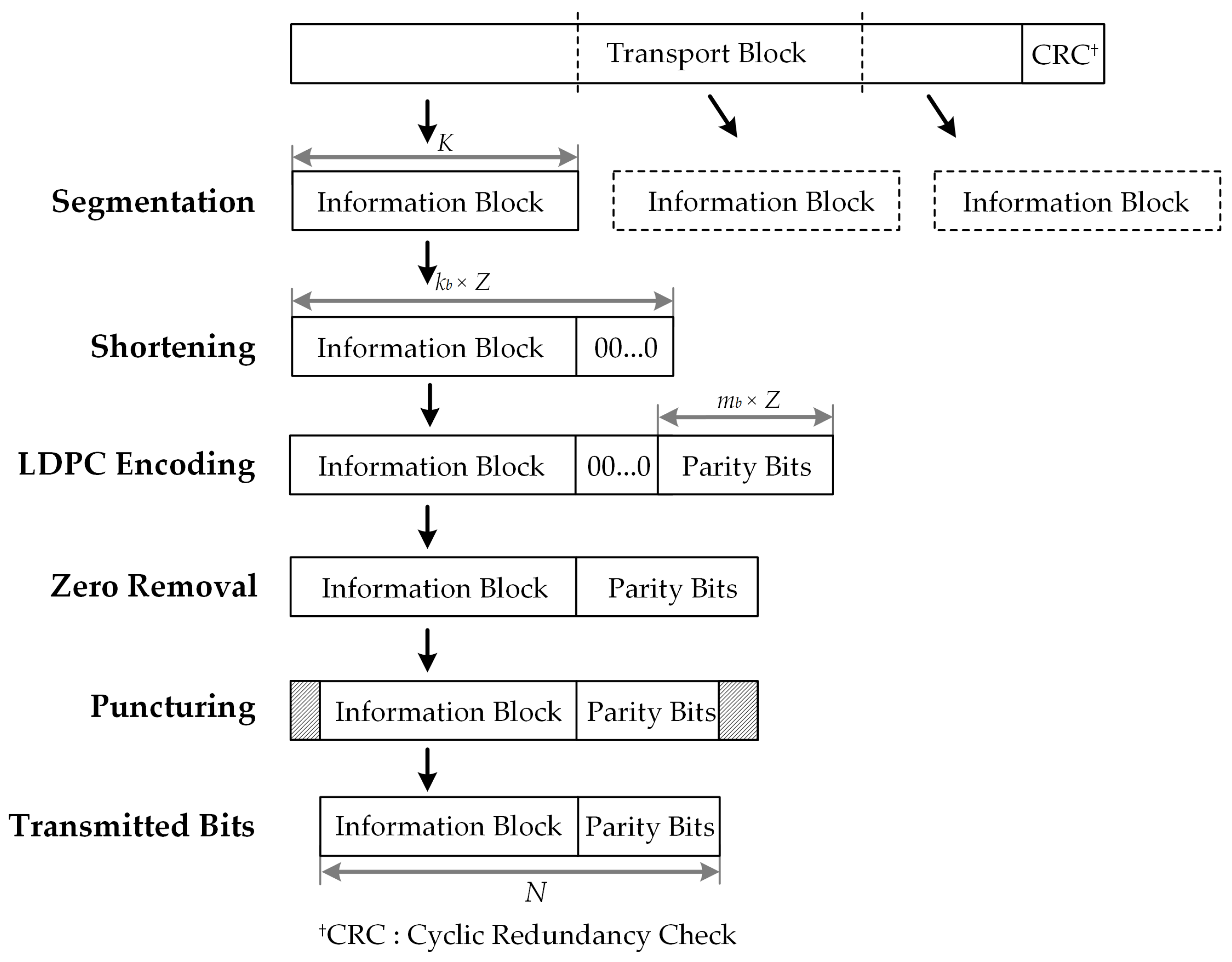
4.1. Proposed QC-LDPC Encoding Algorithm
This section presents an efficient scheme developed in this study for the construction of efficient encoders for 5G NR QC-LDPC codes. The proposed encoding method is based on the special characteristics of 5G NR QC-LDPC codes, which are presented in
Figure 1. The proposed architectures target low-complexity, while ensuring high-throughput. As reported in the literature review, base graphs BG1 and BG2 have similar structures. In this paper, we focus our description on BG1 with a size of
(
= 46, and
= 68), which is the main 5G NR high rate base graph.
Let the codeword
, where
s denotes the systematic portion, which is divided into 22 groups of
Z bits, since the base graph BG1 has
information bit columns. Moreover,
, where each element of
s is a vector of length
Z. The information messages received by the encoder are stored in registers that are organized by
blocks, denoted by
, which correspond to the systematic blocks, where each consists of
Z bits. Given that the encoder was designed to read
Z bits per clock cycle, it requires
cycles to store all the information blocks. Moreover, the parity sequence can be grouped into sets of
Z bits. Suppose that the parity portion of each message
p is split into two sub-components as follows: the first
parity bits
, and the remaining
parity bits
. More precisely, the encoded codeword can be expressed as:
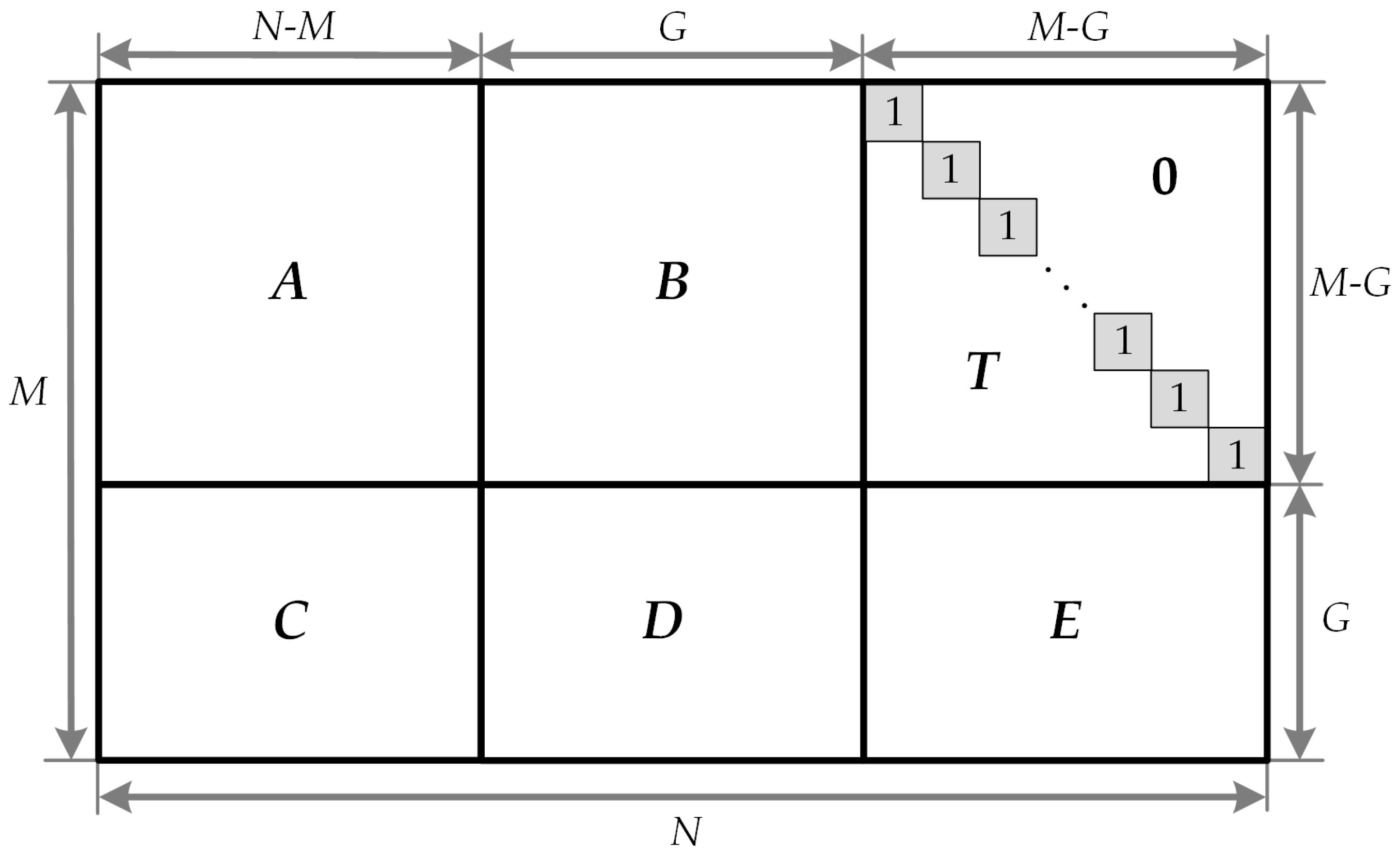
The parity check matrix
H of 5G NR QC-LDPC codes can be partitioned into six matrices and presented in the following form:
where
A is
,
B is
,
is
, and
is
. Moreover,
I is an identity matrix with dimensions of
. The encoding of LDPC codes is carried out using the following defining equation:
Equation (
18) can also be expressed as:
Equation (
19) is then naturally split into two equations, as follows:
The proposed algorithm is performed in two steps. In the initial step, the parity bits in the first portion
are computed by solving Equation (
20). The second step in the encoding process includes the computation of the
parity portions using Equation (
21).
The first step in the encoder implementation is the determination of the
part. Initially, Equation (
20) is re-written in block form as follows:
This can then be expanded into the following set of equations:
where
denotes the
(right) cyclic shifted version of
for
. By adding up all the above equations, the following is obtained:
It should be noted that a straightforward implementation of
can be done with the use of
Z-bit cyclic shifters. Since
is a circular right shift of
with the shift coefficient defined by
, the hardware complexity is trivial. Based on the definition below,
the following can be obtained:
From Equation (
28), each
value is computed by accumulating all the
values. In Modulo 2,
is obtained by carrying out XOR operations on all the elements of
. The
values can be estimated per clock cycle in
cycles. The first block of the parity bits
is then calculated by accumulating all the
values. The remaining parity bits
can be obtained using a method that can be easily derived from Equations (
30)–(
32). This process can be done in two clock cycles since there is dependency between
and
. All the parity bits
in the first parity portion are stored in registers.
In a second step, the
portion can be easily determined based on Equation (
21), where matrices
and
are given by
Upon the application of Equation (
21), the elements of
can be computed using the following equations:
Similarly, represents a circular shift of with the shift coefficient defined by , and represents a circular shift of with the shift coefficient defined by . As soon as and have been obtained, they can be used to determine the value of the corresponding parity bits in the second parity portion . This step can be performed in a single clock cycle. Hence, all the parity bits can be acquired in clock cycles. The encoded codeword is then a combination of the original message s and the two calculated parity portions and .
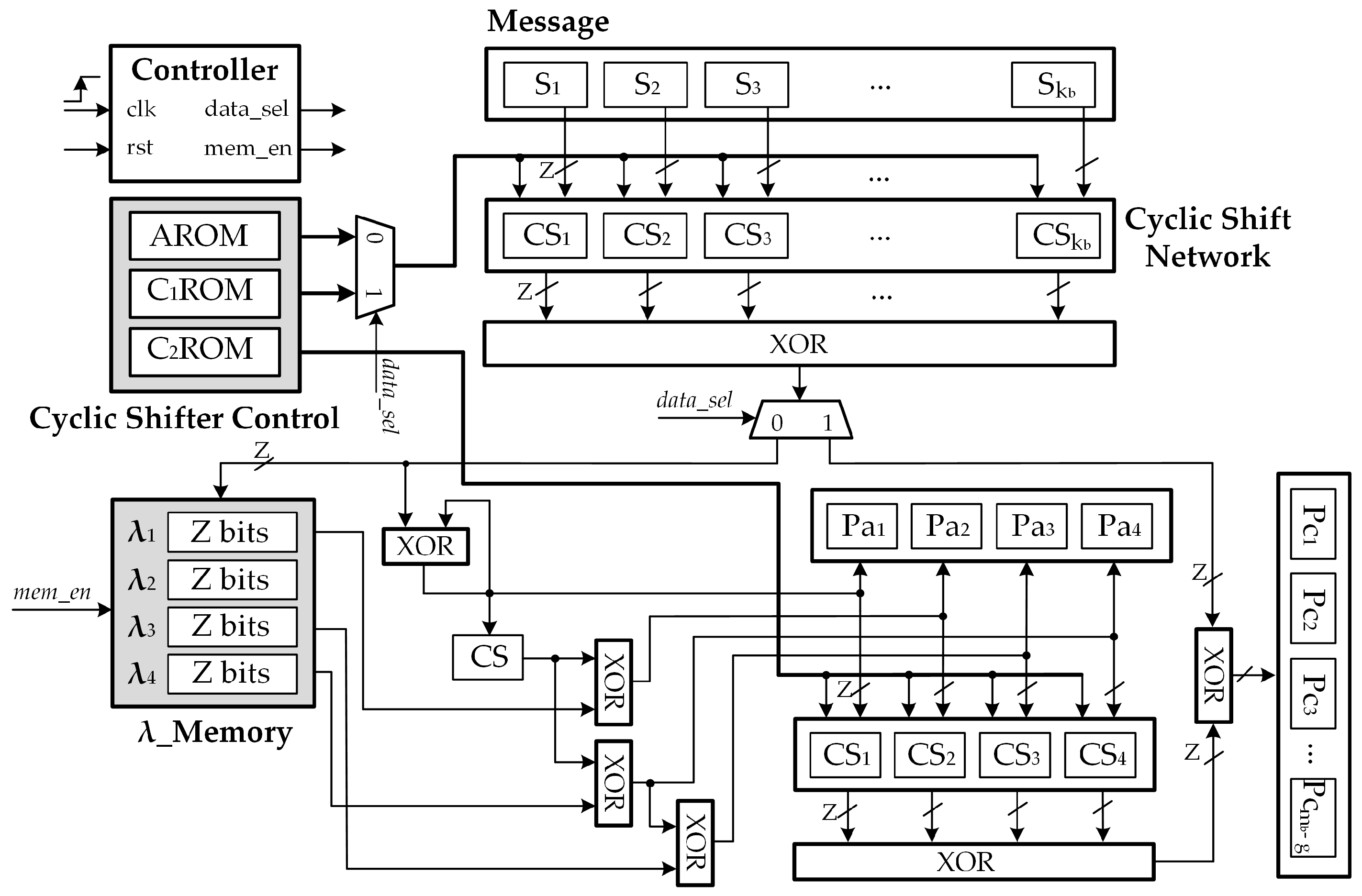
4.2. Proposed QC-LDPC Encoder Architecture
Figure 4 details the overall block diagram for the proposed low complexity 5G NR QC-LDPC code encoder. The hardware architectures were designed to conduct the encoding process through steps defined in Equations (
29)–(
32) and (
34). In the first step, the computation of the parity bits in the first portion
is carried out. From Equation (
28), each
value is computed by accumulating all the cyclic shift results of
. Since the information message
s consists of
blocks of
Z bits, a total of
barrel shifters of size Z, which are denoted by
,
, are required for the circular shift process. The vector addition of all the
components is then carried out by the XOR trees. Each intermediate
value corresponding to Equation (
28) can be estimated per clock cycle and stored in the
to be used later. Thus, the value of
can be obtained in
clock cycles when all
values are obtained and stored in memory. The remaining parity bits of
can be obtained in 2 clock cycles with the use of XOR gates.The objective of the second step is the calculation of the parity bits in the second portion
. According to (
34), the parity blocks
can be achieved by the vector addition of
and
. The value of
is also computed by accumulating all the cyclic shift results of
. In this step, the overall hardware complexity can be further decreased by exploiting the sharing technique. More specifically, the barrel shifters and XOR trees are reused for the computation of
in this step. Control signals are generated by the controller block. The value of
is estimated by accumulating all the cyclic shift results of
. The required number of
Z–bit barrel shifters is
. The main blocks of the proposed architecture can be described as follows.
(1) Input/ Output Buffer: the input buffer, which is implemented as a number of serial input parallel output shift registers, is exploited to store the input systematic bits received by the encoder. The output buffer is used to store the encoded codeword.
(2) Memory Blocks: two memory blocks are utilized, namely, one for the submatrix permutation values, and the others for the accumulated values
that correspond to matrix
A. In
Figure 4, the AROM, C
ROM, and C
ROM correspond to the ROMs that store the coefficients of matrix
A, matrix
, and matrix
, respectively. Under the assumption that
bits represent the required word length to store the permutation information for each submatrix:
,
, and
bits are required to store matrix
A,
, and
, respectively. A significant portion of the hardware complexity of the LDPC encoder consists of the memory required to store the parity check matrix. Unlike the RU method, the proposed algorithm does not require the inverse of the component matrix, which reflects its primary advantage over the RU method. Compared with the Gaussian method, the proposed architecture does not require for block-memories to store the generator matrix
G, which further decreases the number of required components. The
is implemented as a dual port random access memory (RAM) for storing
messages
. Each memory word
consists of
Z bits, corresponding to one accumulated message of matrix
A. Moreover, a total of
bits of
are required for the proposed encoder.
(3) Barrel Shifters: barrel shifters are used to implement the cyclic shift permutations, according to the shift values provided by the cyclic shifter controllers. It should be noted that the number of cyclic shifters is equal to the number of message blocks, and the size of the barrel shifters is equal to submatrix size Z.
(4) XOR Trees: in Modulo 2, the addition implementation is obtained by carrying out an XOR operation on all the elements.
(5) Controller: this block generates control signals, such as to indicate the step being processed; and , to enable write access to the .








{kind=link}
{kind=link}
{kind=link}
{kind=link}