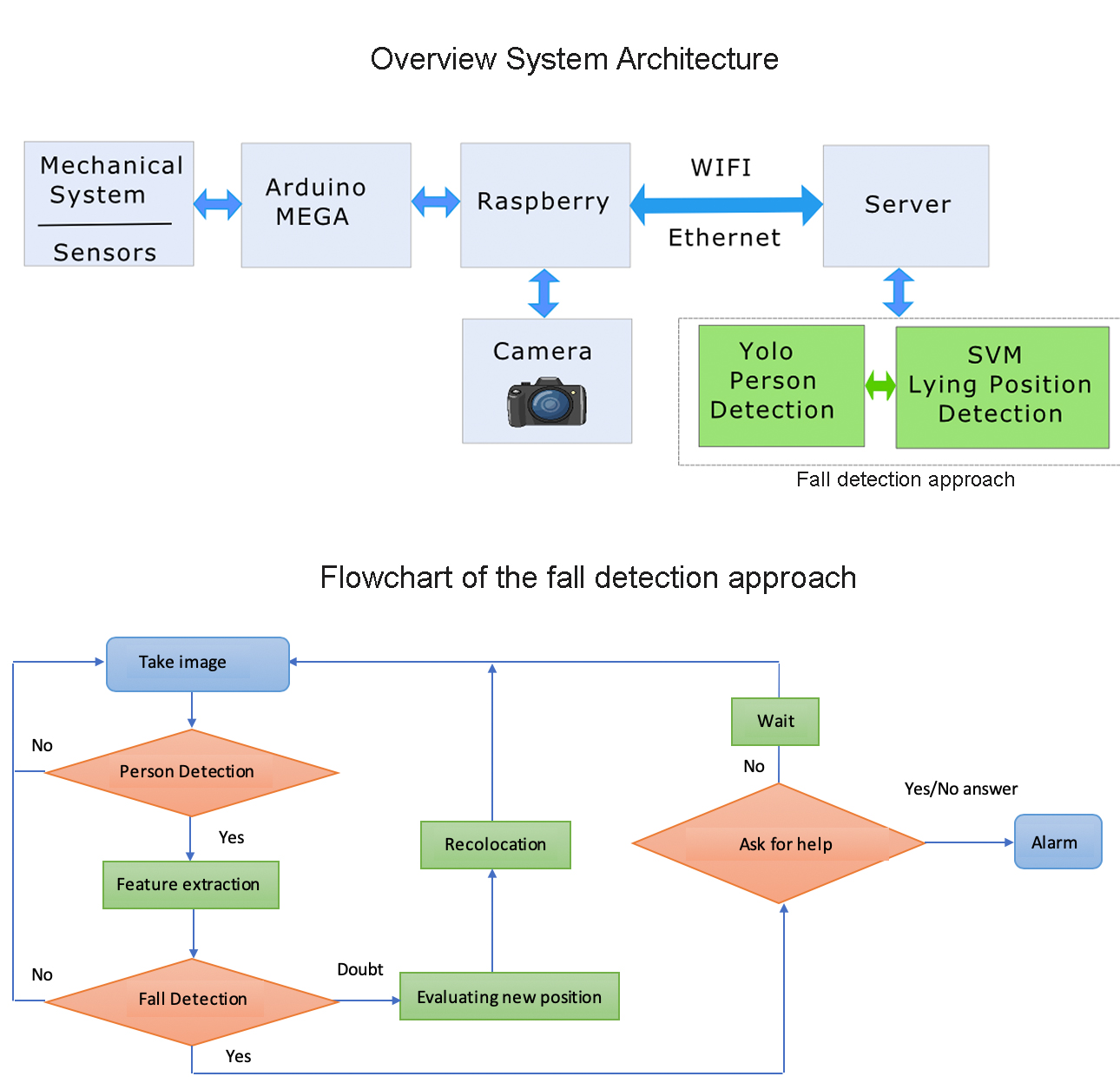
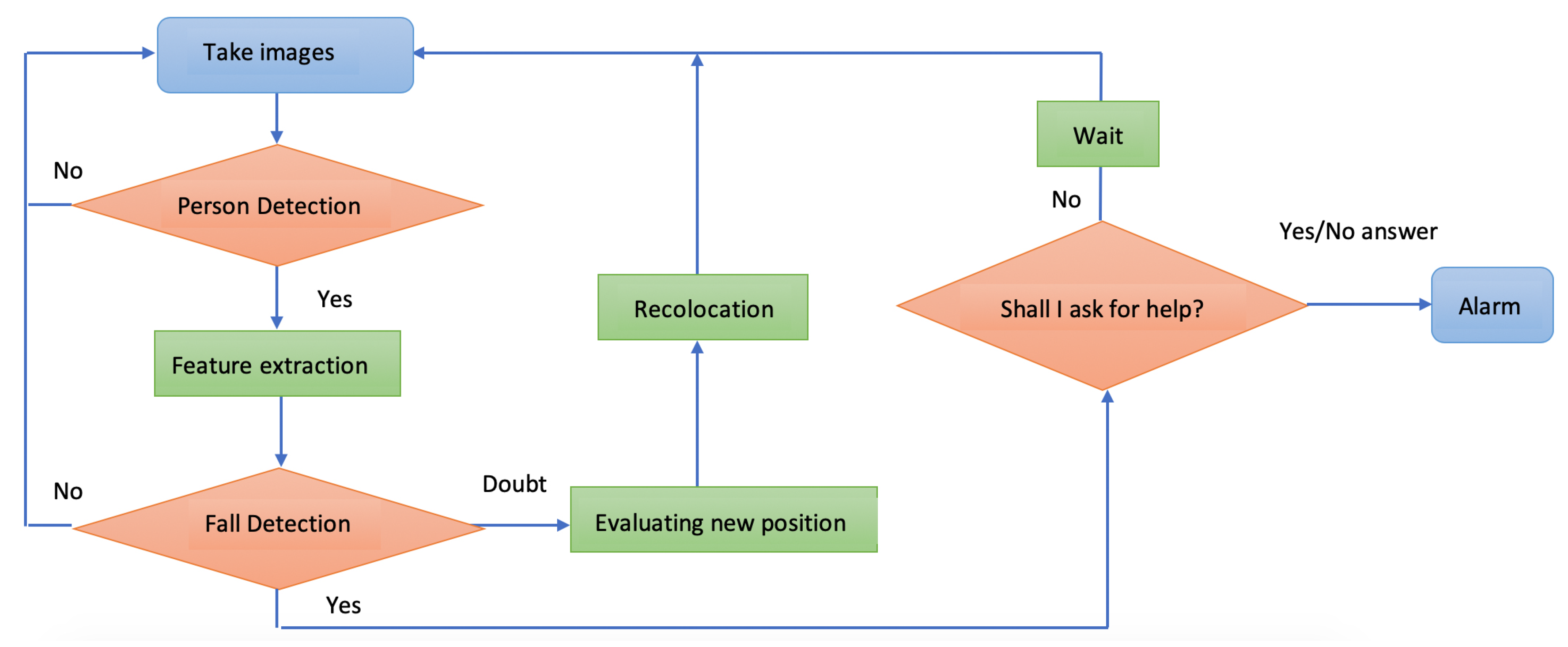
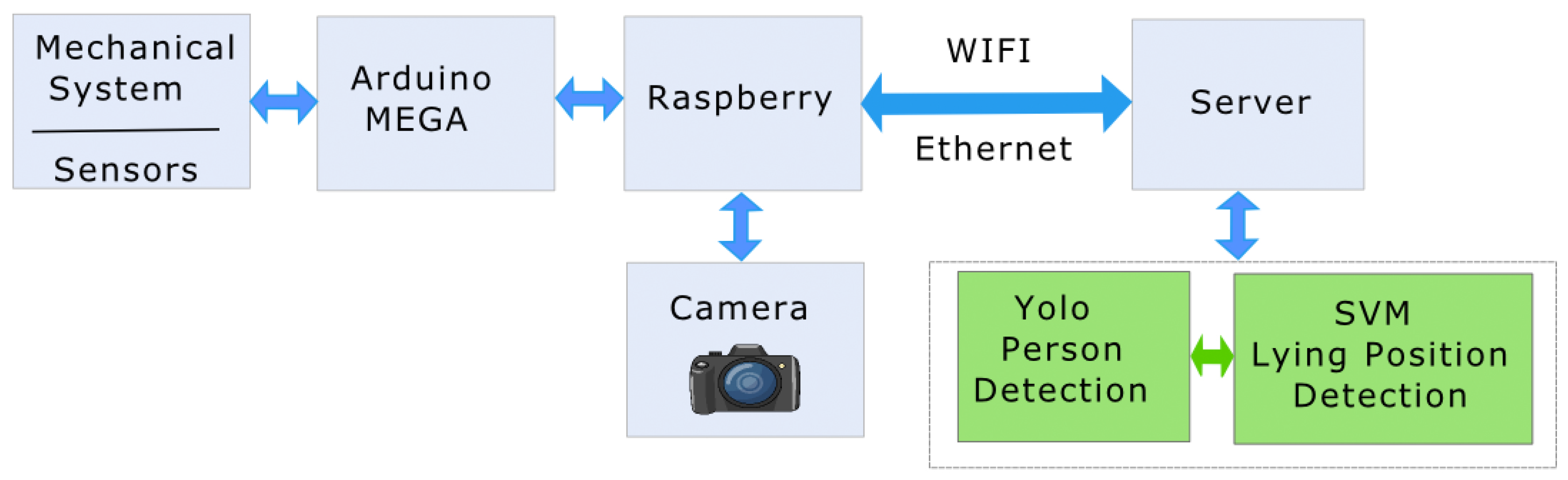
Our approach solves the fall detection problem in an end-to-end solution based on two steps—person detection and fall classification. The person detection algorithm aims to localize all persons in an image. Its output is the enclosing bounding boxes and the confidence scores that reflect how likely it is that the boxes contain a person. Fall classification estimates if the detected person is in a fall or not.
3.2. Deep Learning-Based Person Detection
CNNs are one of the most popular machine-learning algorithm types at present and it has been decisively proven over time that they outperform other algorithms in accuracy and speed for object detection [
28].
Algorithms for object detection using CNN can be broadly categorized into two-stage and single-stage methods. The two-stage algorithm based on classification first generates many proposals or interesting regions from the image (body) and then those regions are classified using the CNN (head). In other words, the network does not check the complete image; instead, it only checks parts of the image with a high probability of containing an object. Region-CNN (R-CNN) proposed by Ross Girshick in 2014 [
29] was the first of this series of algorithms that was later modified and improved, for example, fast R-CNN [
30], faster R-CNN [
31], R-FCN [
32], Mask R-CNN [
33] and Light-Head R-CC [
34]. However, single-stage algorithms based on regression do not use regions to localize the object within the image; the predict bounding boxes and class probabilities at the whole image. The most known examples of this type of algorithm are Single Shot Detector (SSD), proposed by Liu et al. [
35] and ‘you only look once’ (YOLO) proposed by Joesph Redmon et al. in 2016 [
36]. YOLO has been updated to versions YOLOv2, YOLO9000 [
37] and YOLOv3 [
38]. In this paper, we decide to apply real-time object detection system YOLOv3 for person detection, which has proven to be an excellent competitor to other algorithms in terms of speed and accuracy.
The YOLO network takes an image and divides it into S × S grids. Each grid predicts B bounding boxes , and provides a confidence score for each of them , which reflects how likely the box contains an object. Bounding boxes with this parameter above a threshold value are selected and used to locate the object, a person in our case. The bounding box position is the output of this stage for our algorithm.
3.3. Learning-Based Fall/Nonfall Classification
The effectiveness of SVM-based approaches for classification has been widely tested [
39,
40,
41]. The SVM algorithm defines a hyperplane or decision boundary to separate different classes and maximize the margin (maximum distance between data points of the classes). Support vectors are training data points that define the decision boundary [
42]. To find the hyperplane, a constrained minimization problem has to be solved. Optimization techniques such as the Lagrange multiplier method are needed.
In the case of nonlinearly separable data, data points from initial space
are mapped into a higher dimensional space
Q where it is possible to find a hyperplane to separate the points. With this, the classification-decision function becomes
where training data are represented by
,
,
,
b is the bias,
,
are the Lagrange multipliers obtained during the optimization process [
43] and
,
are the support vectors, for which
and
is a kernel function. A Radial Basis Function (RBF) was used as a kernel in this study:
where
is the parameter controlling the width of the Gaussian kernel.
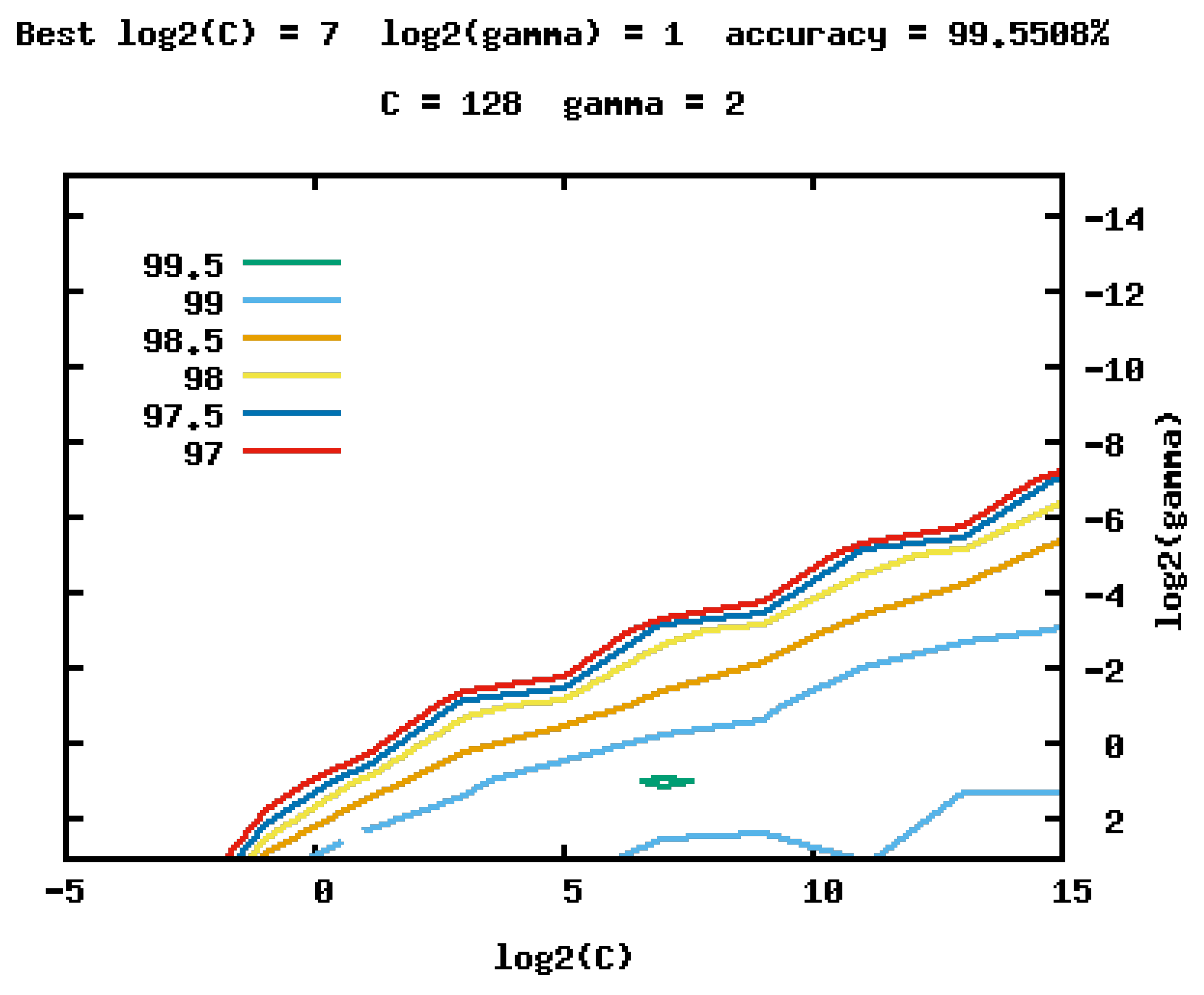
The accuracy of the SVM classifier depends on regularization parameter C and . C is the parameter that controls the penalization associated with the training samples that are misclassified and defines how far the influence of a single training point reaches. So, both parameters must be optimized for every different task in particular, for example, by using cross-validation.
The selection of the right features or input parameters to the SVM plays an important role in having a high-performance classification algorithm. Some features are most widely used in the literature as aspect ratio (AR), change in AR (CAR), fall angle (FA), center speed (CS) or head speed (HS) [
21,
44,
45]. However, after analyzing the parameters that provide the best trade-off performance for goals to achieve in our approach, using the bounding box data of a detected person, we defined the input feature vector for the SVM classifier as
Aspect ratio of bounding box,
:
Normalized bounding box width,
:
Normalized bounding box bottom coordinate,
:
where = , = are the width and height of bounding box , respectively, calculated from the bounding box position provided by YOLOv3 {, , , } and , are the width and height of the overall image. Point is at the top-left corner of the overall image. Parameter defines the distance from the bottom of the image to the lower part of the normalized bounding box. As the values of the and parameters are between 0 and 1, in order to give a similar weight to , we needed to adjust its value as input to the SVM. We analyzed the data and was lower than 10 for all cases, so we normalized by 10 in order to get a feature in [0,1]. Therefore, we considered detection if .
Parameter
is the most significant feature that characterizes the fall. As can be seen from the examples in
Figure 4a,b, a person standing upright has a small
, while this ratio is large in the case of a person lying in a horizontal body orientation position. However, this parameter alone is not enough. There are some cases where the person is in a lying-position but this parameter does not show it; this is the case of lying in a vertical body orientation position, as we show in
Figure 4c.
One of the main goals of the algorithm is the ability to differentiate between fallen people and resting situations.
Figure 5 shows one example of how the optical perspective in the cameras works. The object size in the image (in pixels) depends on the real image size (in mm) and the distance from the camera to the object [
46]:
Objects with the same size at different distances from the camera (object planes) appear with a different size (pixels) in the image plane; the closest one is visible in a larger size (
Figure 5a);
objects with the same size at the same distance to the camera (object planes) appear with the same size (pixels) in the image plane (
Figure 5b). If objects are at different heights in the object plane, the same happens in the image plane.
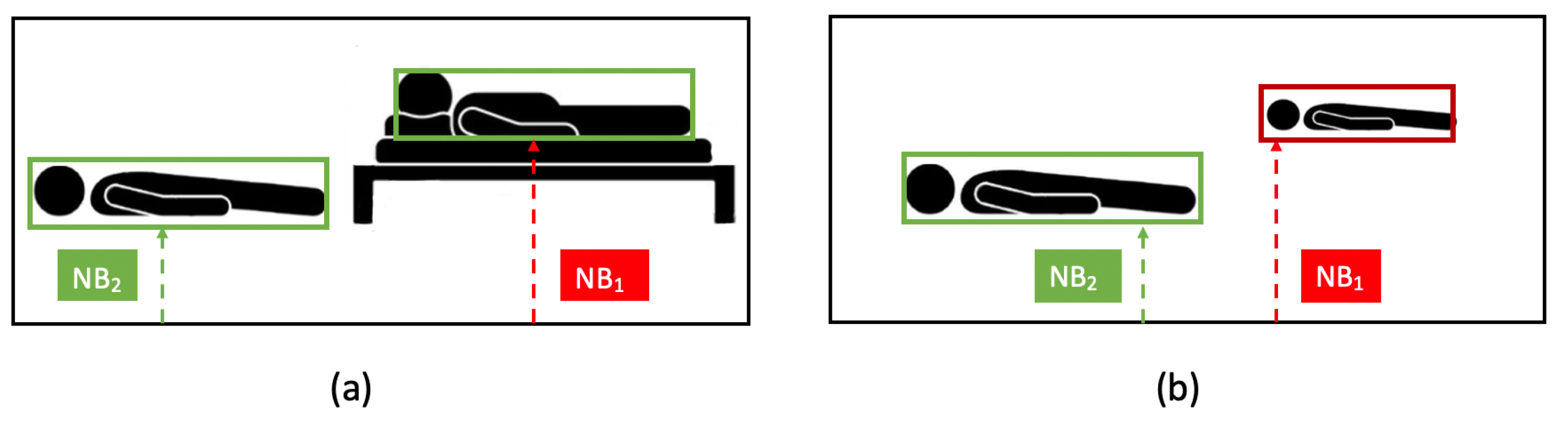
When we compare a fallen person and a resting person at the same distance from the camera, the situation is the one observed in
Figure 5b. The resting person is the person in the higher position. As shown in
Figure 6a, the
and
parameters in both cases were the same (same size of bounding box); however, the
parameter was different
,
. For the same value,
, the bounding box size for a fallen person should be the red one (see
Figure 6b).
Therefore, proposed parameters , and provide needed information for differentiating those situations and, during the training stage, the SVM learns the relation between them in both cases (fall and resting position).
Figure 7 shows the previous explanation with real images. It contains three pairs of images where fallen and resting persons are at the same distance from the camera (1.5, 2 and 3 m away).
Table 1 shows the parameters provided to the SVM in those situations. As can be seen in the table, each pair of images have a similar
parameter (slight differences are due to not being precisely at the same position from the camera). However, parameter
had a larger value in the nonfall situation because the body was in a higher position in the image.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}


