Opponent-Aware Planning with Admissible Privacy Preserving for UGV Security Patrol under Contested Environment


Abstract
:1. Introduction
2. Background and Related Work
2.1. Privacy and Security Assumption
2.2. Privacy-Preserving Planning
2.3. Information Leakage Metric
3. Methodology
3.1. Opponent-Aware Privacy-Preserving Planning
3.2. Information Sharing Restricted Task Planning
- The set of private variables and the number , the domains and the size .
- The set of private actions and the number , the number and values of variables in and .
- The private parts of the public actions in , such as the numbers and values of private variables in and for each action .
3.2.1. Task Plan Generation
3.2.2. Privacy Leakage Analysis
| Algorithm 1: Privacy information leakage analysis based on the MAFS algorithm. |
| Input: , number p, and size d Output: privacy information leakage 1 reconstruct the search tree based on the MAFS algorithm [30]. 2 identify possible parent states. 3 identify possible applied actions. 4 classify actions into five classes (ia, nia, pd, pi, pn). 5 compute privacy information leakage using the Equation (8). 6 return |
3.3. Observability Controlled Path Planning
- is the path planning domain, is a non-empty set of location nodes, is a set of action-related edges, returns the cost of traversing each edge.
- is the start location and is the real goal;
- is a set of candidate goals, where is the real goal
- is a set of m observations that can be emitted as a result of the action taken and the state transition.
- is a many-to-one observation function which maps the taken action and the next state reached to an observation in Ω.
3.3.1. Path Plan Generation
| Algorithm 2: An observability controlled path plan generation algorithm. |
 |
3.3.2. Privacy Leakage Analysis
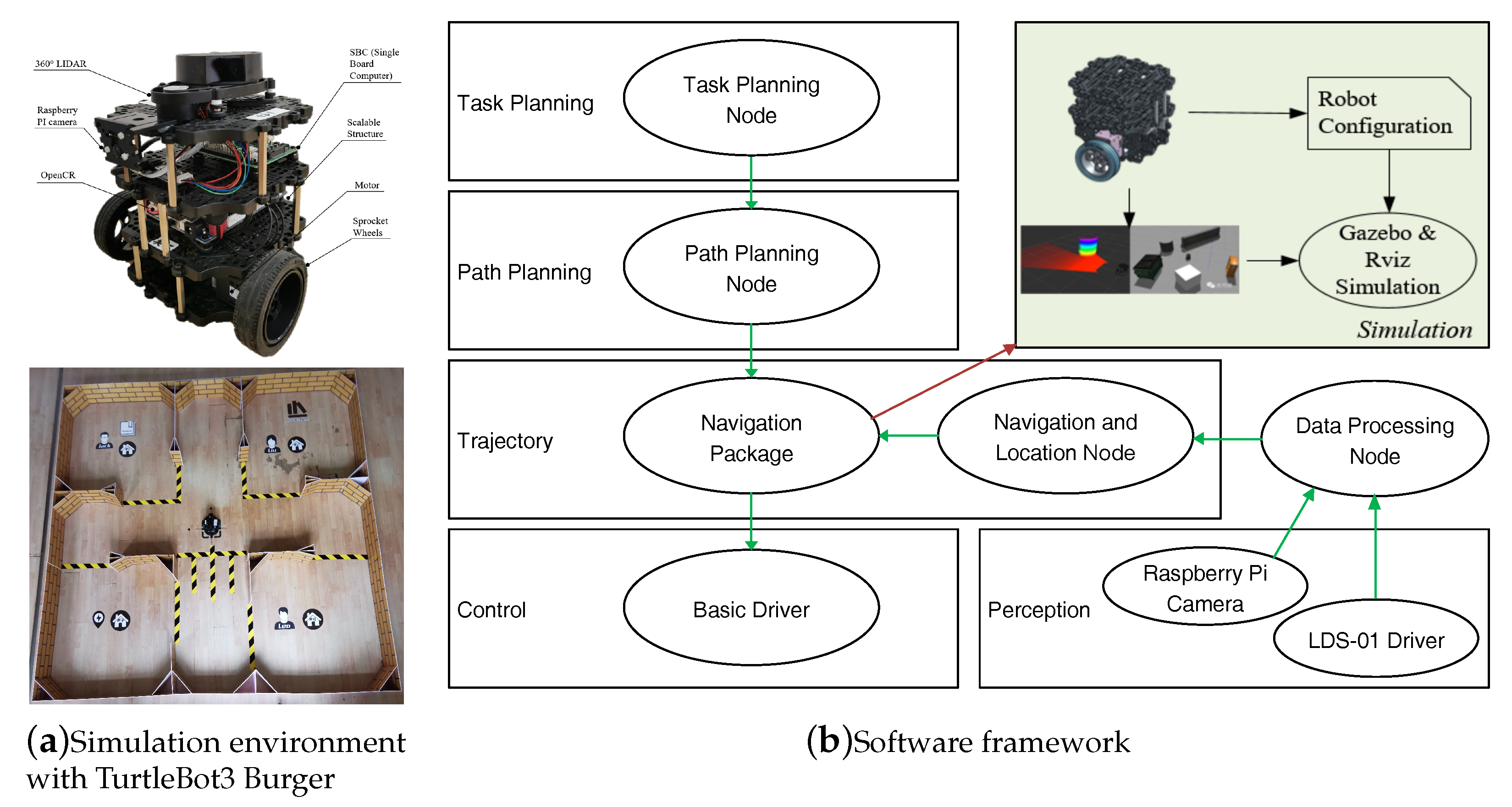
4. Experiments
4.1. Plan Generation and Privacy Leakage Analysis
4.1.1. Task Plan Generation and Privacy Leakage Analysis
4.1.2. Path Plan Generation and Privacy Leakage Analysis
4.2. Indoor Robot Demonstration
5. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| UGV | Unmanned Ground Vehicle |
| MAP | Multi-Agent Planning |
| PIL | Privacy Information Leakage |
| DMAP | Deterministic MAP |
| I-POMDPs | Interactive POMDPs |
| Dec-POMDPs | Decentralized POMDP |
| MPC | Multi-Party Computation |
| DCOP | Distributed Constraint Optimization Problems |
| MAFS | Multi-Agent Forward Search |
| MADLA | Multi-Agent Distributed and Local Asynchronous |
| MILP | Mixed Integer Linear Program |
| PPS | Path Plan Set |
| LOTP | Last Obfuscated Turning Point |
| ROS | Robot Operation System |
Appendix A. Metrics
Appendix A.1. Plan Distance Metrics
References
- Liu, Y.; Liu, Z.; Shi, J.; Wu, G.; Chen, C. Optimization of Base Location and Patrol Routes for Unmanned Aerial Vehicles in Border Intelligence, Surveillance, and Reconnaissance. J. Adv. Transp. 2019, 2019, 9063232. [Google Scholar] [CrossRef] [Green Version]
- Bell, R.A. Unmanned ground vehicles and EO-IR sensors for border patrol. In Optics and Photonics in Global Homeland Security III; International Society for Optics and Photonics: Bellingham, DC, USA, 2007; Volume 6540, p. 65400B. [Google Scholar]
- Dwork, C.; Roth, A. The Algorithmic Foundations of Differential Privacy. Found. Trends Theor. Comput. Sci. 2013, 9, 211–407. [Google Scholar] [CrossRef]
- Wu, F.; Zilberstein, S.; Chen, X. Privacy-Preserving Policy Iteration for Decentralized POMDPs. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Sakuma, J.; Kobayashi, S.; Wright, R.N. Privacy-preserving reinforcement learning. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008. [Google Scholar] [CrossRef] [Green Version]
- Liu, Q.; Ren, X.; Mo, Y. Secure and privacy preserving average consensus. In Proceedings of the 2017 Workshop on Cyber-Physical Systems Security and PrivaCy, Dallas, TX, USA, 3 November 2017. [Google Scholar] [CrossRef]
- Alaeddini, A.; Morgansen, K.; Mesbahi, M. Adaptive communication networks with privacy guarantees. In Proceedings of the American Control Conference, Seattle, WA, USA, 24–26 May 2017. [Google Scholar] [CrossRef] [Green Version]
- Pequito, S.; Kar, S.; Sundaram, S.; Aguiar, A.P. Design of communication networks for distributed computation with privacy guarantees. In Proceedings of the IEEE Conference on Decision and Control, Los Angeles, CA, USA, 15–17 December 2014. [Google Scholar] [CrossRef]
- Brafman, R.I. A privacy preserving algorithm for multi-agent planning and search. In Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI), Buenos Aires, Argentina, 25–31 July 2015. [Google Scholar]
- Štolba, M. Reveal or Hide: Information Sharing in Multi-Agent Planning. Ph.D. Thesis, Czech Technical University in Prague, Prague, Czech Republic, 2017. [Google Scholar]
- Tožička, J. Multi-Agent Planning by Plan Set Intersection. Ph.D. Thesis, Czech Technical University in Prague, Prague, Czech Republic, 2017. [Google Scholar]
- Zhang, S.; Makedon, F. Privacy preserving learning in negotiation. In Proceedings of the Symposium on Applied Computing, Santa Fe, NM, USA, 13–17 March 2005; pp. 821–825. [Google Scholar]
- Shokri, R.; Shmatikov, V. Privacy-preserving deep learning. In Proceedings of the 53rd Annual Allerton Conference on Communication, Control, and Computing, Allerton, IL, USA, 30 September 2015–2 October 2015. [Google Scholar] [CrossRef]
- Léauté, T.; Faltings, B. Protecting privacy through distributed computation in multi-agent decision making. J. Artif. Intell. Res. 2013, 47, 649–695. [Google Scholar] [CrossRef]
- Grinshpoun, T. A Privacy-Preserving Algorithm for Distributed Constraint Optimization. In Proceedings of the 13th International Conference on Autonomous Agents and Multiagent Systems (AAMAS 2014), Paris, France, 5–9 May 2014. [Google Scholar]
- Tassa, T.; Zivan, R.; Grinshpoun, T. Max-sum goes private. In Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI), Buenos Aires, Argentina, 25–31 July 2015. [Google Scholar]
- Štolba, M.; Tožička, J.; Komenda, A. Secure Multi-Agent Planning. In Proceedings of the 1st International Workshop on AI for Privacy and Security - PrAISe ’16, The Hague, The Netherlands, 29–30 August 2016; pp. 1–8. [Google Scholar] [CrossRef]
- Agmon, N.; Kaminka, G.A.; Kraus, S. Multi-Robot Adversarial Patrolling: Facing a Full-Knowledge Opponent. J. Artif. Intell. Res. 2014, 42, 887–916. [Google Scholar]
- Brafman, R.I.; Domshlak, C. From One to Many: Planning for Loosely Coupled Multi-Agent Systems. In Proceedings of the International Conference on Automated Planning and Scheduling (ICAPS), Sydney, Australia, 14–18 September 2008. [Google Scholar]
- Torreño, A.; Onaindia, E.; Sapena, Ó. FMAP: Distributed cooperative multi-agent planning. Appl. Intell. 2014, 41, 606–626. [Google Scholar] [CrossRef] [Green Version]
- Bonisoli, A.; Gerevini, A.E.; Saetti, A.; Serina, I. A privacy-preserving model for the multi-agent propositional planning problem. In Proceedings of the 2nd ICAPS Distributed and Multi-Agent Planning workshop (ICAPS DMAP-2014), Portsmouth, NH, USA, 22 June 2014. [Google Scholar] [CrossRef]
- Decker, K.S.; Lesser, V.R. Generalizing the partial global planning algorithm. Int. J. Intell. Coop. Inf. Syst. 1992, 1, 319–346. [Google Scholar] [CrossRef]
- Borrajo, D. Multi-Agent Planning by Plan Reuse. In Proceedings of the 2013 International Conference on Autonomous Agents and Multi-Agent Systems, St. Paul, MN, USA, 6–10 May 2013. [Google Scholar]
- Maliah, S.; Shani, G.; Stern, R. Stronger Privacy Preserving Projections for Multi-Agent Planning. In Proceedings of the International Conference on Automated Planning and Scheduling (ICAPS), London, UK, 12–17 June 2016. [Google Scholar]
- Komenda, A.; Tožička, J.; Štolba, M. ϵ-strong privacy preserving multi-agent planning. In Lecture Notes in Computer Science; including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics; Springer Science + Business Media: Berlin, Germany, 2018. [Google Scholar] [CrossRef]
- Beimel, A.; Brafman, R.I. Privacy Preserving Multi-Agent Planning with Provable Guarantees. arXiv 2018, arXiv:1810.13354. [Google Scholar]
- Goldreich, O. Foundations of Cryptography; Cambridge University Press: Cambridge, UK, 2010. [Google Scholar] [CrossRef]
- Kulkarni, A.; Klenk, M.; Rane, S.; Soroush, H. Resource Bounded Secure Goal Obfuscation. In Proceedings of the AAAI Fall Symposium on Integrating Planning, Diagnosis and Causal Reasoning, Arlington, VA, USA, 18–20 October 2018. [Google Scholar]
- Chakraborti, T.; Kulkarni, A.; Sreedharan, S.; Smith, D.E.; Kambhampati, S. Explicability? legibility? predictability? transparency? privacy? security? the emerging landscape of interpretable agent behavior. In Proceedings of the International Conference on Automated Planning and Scheduling (ICAPS), Berkeley, CA, USA, 11–15 July 2019. [Google Scholar]
- Nissim, R.; Brafman, R. Distributed heuristic forward search for multi-agent planning. J. Artif. Intell. Res. 2014, 51, 293–332. [Google Scholar] [CrossRef] [Green Version]
- Lindell, Y.; Pinkas, B. Secure Multiparty Computation for Privacy-Preserving Data Mining. J. Priv. Confid. 2018. [Google Scholar] [CrossRef]
- Torreño, A.; Onaindia, E.; Komenda, A.; Štolba, M. Cooperative multi-agent planning: A survey. ACM Comput. Surv. (CSUR) 2018, 50, 84. [Google Scholar] [CrossRef]
- Panella, A.; Gmytrasiewicz, P. Bayesian learning of other agents’ finite controllers for interactive POMDPs. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Oliehoek, F.A.; Amato, C. A Concise Introduction to Decentralized POMDPs; Springer International Publishing: Cham, Switzerland, 2016; Volume 1. [Google Scholar]
- Kulkarni, A.; Srivastava, S.; Kambhampati, S. A unified framework for planning in adversarial and cooperative environments. In Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar]
- Keren, S.; Gal, A.; Karpas, E. Privacy preserving plans in partially observable environments. In Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI), New York, NY, USA, 9–15 July 2016. [Google Scholar]
- Masters, P.; Sardina, S. Deceptive path-planning. In Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI), Melbourne, Australia, 19–25 August 2017. [Google Scholar]
- Masters, P.; Sardina, S. Goal recognition for rational and irrational agents. In Proceedings of the 18th International Conference on Autonomous Agents and MultiAgent Systems, Montreal, QC, Canada, 13–17 May 2019; pp. 440–448. [Google Scholar]
- Root, P.J. Collaborative UAV Path Planning with Deceptive Strategies. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 2005. [Google Scholar]
- Keren, S.; Gal, A.; Karpas, E. Goal Recognition Design for Non-Optimal Agents. In Proceedings of the Twenty-Fourth International Conference on Automated Planning and Scheduling, Portsmouth, NH, USA, 21–26 June 2014. [Google Scholar]
- Strouse, D.; Kleiman-Weiner, M.; Tenenbaum, J.; Botvinick, M.; Schwab, D.J. Learning to share and hide intentions using information regularization. In Advances in Neural Information Processing Systems; The MIT Press: Cambridge, MA, USA, 2018; pp. 10249–10259. [Google Scholar]
- Le Guillarme, N. A Game-Theoretic Planning Framework for Intentional Threat Assessment. Ph.D. Thesis, Thèse de Doctorat, Université de Caen, Caen, France, 2016. [Google Scholar]
- Shen, M.; How, J.P. Active Perception in Adversarial Scenarios using Maximum Entropy Deep Reinforcement Learning. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019. [Google Scholar]
- Štolba, M.; Komenda, A. Relaxation heuristics for multiagent planning. In Proceedings of the Twenty-Fourth International Conference on Automated Planning and Scheduling, Portsmouth, NH, USA, 21–26 June 2014. [Google Scholar]
- Smith, G. On the foundations of quantitative information flow. In Lecture Notes in Computer Science; including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics; Springer Science + Business Media: Berlin, Germany, 2009. [Google Scholar] [CrossRef] [Green Version]
- Rényi, A. On measures of entropy and information. In Proceedings of the Fourth Berkeley Symposium on Mathematical Statistics and Probability, Volume 1: Contributions to the Theory of Statistics; The Regents of the University of California: Los Angeles, CA, USA, 1961. [Google Scholar]
- Štolba, M.; Tožička, J.; Komenda, A. Quantifying privacy leakage in multi-agent planning. ACM Trans. Internet Technol. (TOIT) 2018, 18, 28. [Google Scholar] [CrossRef]
- Štolba, M.; Fišer, D.; Komenda, A. Privacy Leakage of Search-Based Multi-Agent Planning Algorithms. In Proceedings of the International Conference on Automated Planning and Scheduling, Berkeley, CA, USA, 11–15 July 2019; Volume 29, pp. 482–490. [Google Scholar]
- IBM CPLEX. Available online: http://www.ibm.com/us-en/marketplace/ibm-ilog-cplex (accessed on 1 March 2019).
- Masters, P.; Sardina, S. Cost-based goal recognition in navigational domains. J. Artif. Intell. Res. 2019, 64, 197–242. [Google Scholar] [CrossRef] [Green Version]
- TurtleBot3. Available online: https://www.turtlebot.com (accessed on 1 August 2019).
- Srivastava, B.; Nguyen, T.A.; Gerevini, A.; Kambhampati, S.; Do, M.B.; Serina, I. Domain independent approaches for finding diverse plans. In Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI), Hyderabad, India, 6–12 January 2007. [Google Scholar]
- Nguyen, T.A.; Do, M.; Gerevini, A.E.; Serina, I.; Srivastava, B.; Kambhampati, S. Generating diverse plans to handle unknown and partially known user preferences. Artif. Intell. 2012, 190, 1–31. [Google Scholar] [CrossRef] [Green Version]
- Bryce, D. Landmark-based plan distance measures for diverse planning. In Proceedings of the Twenty-Fourth International Conference on Automated Planning and Scheduling, Portsmouth, NH, USA, 21–26 June 2014. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Concepts | Main Contributions |
|---|---|
| Obfuscation | k-ambiguous and d-diverse [35] |
| one candidate goal [36] | |
| secure MAFS [9] | |
| Privacy | privacy leakage [10] |
| plan set intersection [11] | |
| privacy-preserving policy iteration [4] | |
| Security | equidistant states [28] |
| last deceptive point [37,38] | |
| deceptive shortest path [39] | |
| equidistant states [28] | |
| Deception | bounded deception [40] |
| hide intention [41] | |
| Deception [42] | |
| deceptive adversary [43] |
| Variable in | Description | Variable | Values | ||
|---|---|---|---|---|---|
| UGV1 is charged | cg1 | T/F | T | - | |
| UGV2 is charged | cg2 | T/F | T | - | |
| task1 is complete | tc1 | T/F | F | T | |
| task2 is complete | tc2 | T/F | F | T | |
| checkpoint 1 is patrolled | cp1 | T/F | F | - | |
| checkpoint 2 is patrolled | cp2 | T/F | F | - | |
| checkpoint 3 is patrolled | cp3 | T/F | F | - | |
| checkpoint 4 is patrolled | cp4 | T/F | F | - | |
| zone 1 is patrolled | zn1 | T/F | F | T | |
| checkpoint 5 is patrolled | cp5 | T/F | F | - | |
| checkpoint 6 is patrolled | cp6 | T/F | F | - | |
| checkpoint 7 is patrolled | cp7 | T/F | F | - | |
| checkpoint 8 is patrolled | cp8 | T/F | F | - | |
| zone 2 is patrolled | zn2 | T/F | F | T | |
| supply center can provide support | sc | T/F | T | - |
| Action | Description | Label | pre(a) | eff(a) |
|---|---|---|---|---|
| patrol checkpoint 1 | PC1 | {cg1 = T} | {cp1 = T, cg1 = F} | |
| patrol checkpoint 3 | PC3 | {cg1 = T} | {cp3 = T, cg1 = F} | |
| task1 is complete | TC | {cp1 = T, cp3 = T, tc1 = F} | {zn1 = T, tc = T} | |
| recharge | RC | {sc = T, cg1 = F} | {sc = F, cg1 = T} | |
| recharge and resupply | RR | {sc = F, cg1 = F} | {sc = T, cg1 = T} |
| Action | pre(a) | eff(a) |
|---|---|---|
| {cg1 = T} | {cg1 = F} | |
| {tc = F} | {tc = T} | |
| {cg1 = F} | {cg1 = T} |
| Configuration | Checkpoint1 | Checkpoint2 | Checkpoint3 |
|---|---|---|---|
| Line | 13.5 | 14.9 | 13.5 |
| Circular | 20.7 | 10.5 | 10.5 |
| Triangular | 12.3 | 12.2 | 14.7 |
| Items | Configuration |
|---|---|
| Lidar | 360-degree laser Lidar LDS-01 (HLS-LFCD2) |
| SBC | Raspberry PI 3 and Intel Joule 570x |
| Battery | Lithium polymer 11.1V 1800 mAh |
| IMU | Gyroscope 3 Axis, Accelerometer 3 Axis, Magnetometer 3 Axis |
| MCU | OpenCR (32-bit ARM Cortex M7) |
| Motor | DYNAMIXEL(XL430) |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, J.; Zhang, W.; Gao, W.; Liao, Z.; Ji, X.; Gu, X. Opponent-Aware Planning with Admissible Privacy Preserving for UGV Security Patrol under Contested Environment. Electronics 2020, 9, 5. https://doi.org/10.3390/electronics9010005
Luo J, Zhang W, Gao W, Liao Z, Ji X, Gu X. Opponent-Aware Planning with Admissible Privacy Preserving for UGV Security Patrol under Contested Environment. Electronics. 2020; 9(1):5. https://doi.org/10.3390/electronics9010005
Chicago/Turabian StyleLuo, Junren, Wanpeng Zhang, Wei Gao, Zhiyong Liao, Xiang Ji, and Xueqiang Gu. 2020. "Opponent-Aware Planning with Admissible Privacy Preserving for UGV Security Patrol under Contested Environment" Electronics 9, no. 1: 5. https://doi.org/10.3390/electronics9010005
APA StyleLuo, J., Zhang, W., Gao, W., Liao, Z., Ji, X., & Gu, X. (2020). Opponent-Aware Planning with Admissible Privacy Preserving for UGV Security Patrol under Contested Environment. Electronics, 9(1), 5. https://doi.org/10.3390/electronics9010005