Audio-Based Event Detection at Different SNR Settings Using Two-Dimensional Spectrogram Magnitude Representations

 , , , and
, , , and
Abstract
1. Introduction
2. Proposed Method
2.1. Spectrograms
2.2. Single-Channel Representation
2.3. Multichannel Representation
2.4. Transfer Learning
3. Experimental Setup
3.1. Dataset
3.2. Experimental Procedure
3.2.1. Single-Channel Group of Experiments
3.2.2. Multichannel Group of Experiments
3.2.3. Performance Evaluation and Metrics
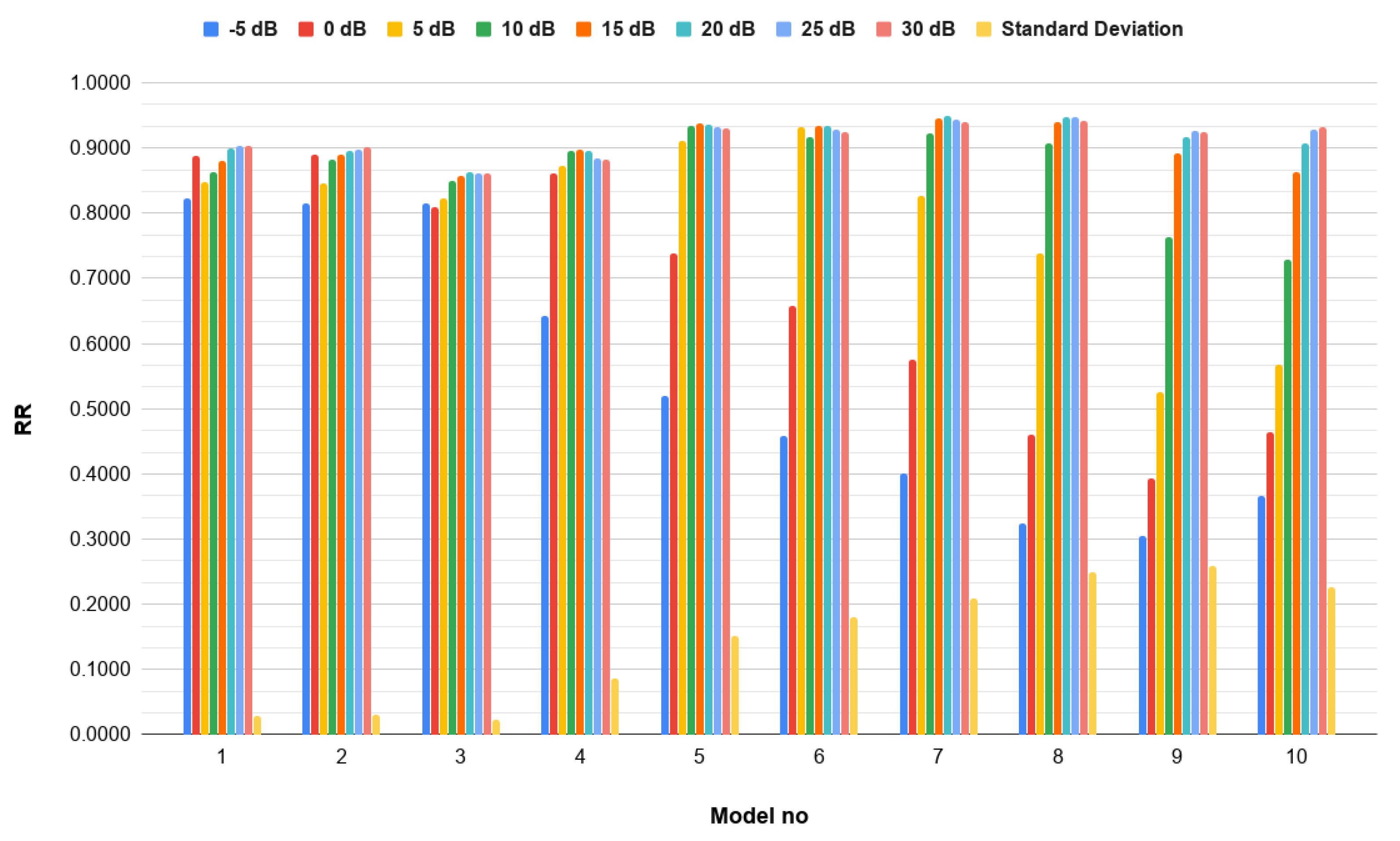
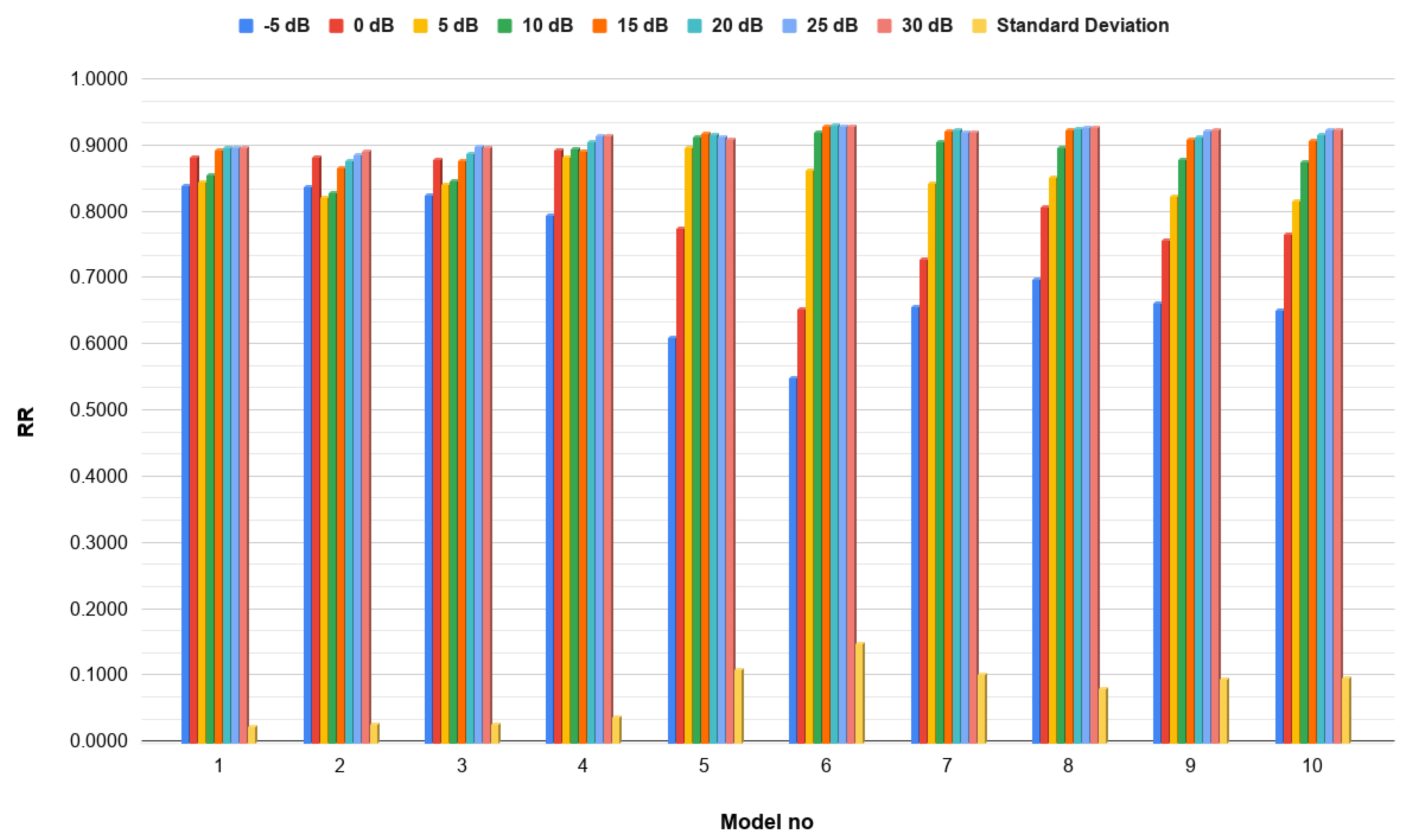
3.3. Results
3.3.1. Single-Channel Spectrograms
3.3.2. Multichannel Spectrograms
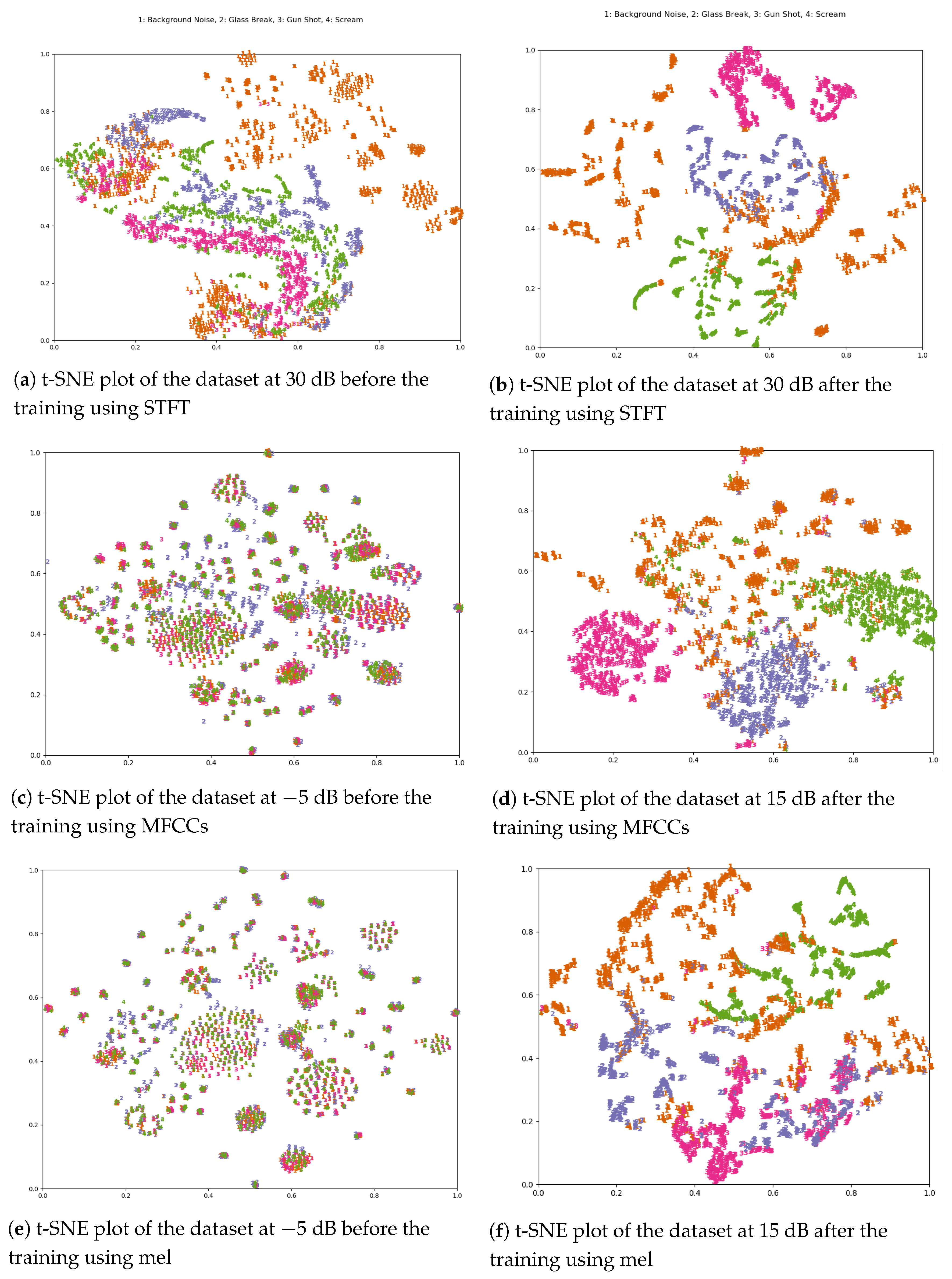
3.4. Experimental Analysis and Discussion
Generalization on Unseen Data
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Räty, T.D. Survey on contemporary remote surveillance systems for public safety. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2010, 40, 493–515. [Google Scholar] [CrossRef]
- Bramberger, M.; Doblander, A.; Maier, A.; Rinner, B.; Schwabach, H. Distributed embedded smart cameras for surveillance applications. Computer 2006, 39, 68–75. [Google Scholar] [CrossRef]
- Elmaghraby, A.S.; Losavio, M.M. Cyber security challenges in Smart Cities: Safety, security and privacy. J. Adv. Res. 2014, 5, 491–497. [Google Scholar] [CrossRef] [PubMed]
- Research, B. Global OR Visualization Systems Market Focus on Systems (OR Camera Systems, OR Display Systems, OR Video Systems, and Surgical Light Sources), Regions (16 Countries), and Competitive Landscape—Analysis and Forecast, 2019–2025. 2019. Available online: businesswire.com/news/home/20190618005416/en/Global-Visualization-Systems-Market-2019-2025-Focus-Camera (accessed on 24 July 2020).
- Salamanis, A.; Kehagias, D.D.; Filelis-Papadopoulos, C.K.; Tzovaras, D.; Gravvanis, G.A. Managing spatial graph dependencies in large volumes of traffic data for travel-time prediction. IEEE Trans. Intell. Transp. Syst. 2015, 17, 1678–1687. [Google Scholar] [CrossRef]
- Bösch, P.M.; Becker, F.; Becker, H.; Axhausen, K.W. Cost-based analysis of autonomous mobility services. Transp. Policy 2018, 64, 76–91. [Google Scholar] [CrossRef]
- Brun, L.; Saggese, A.; Vento, M. Dynamic scene understanding for behavior analysis based on string kernels. IEEE Trans. Circuits Syst. Video Technol. 2014, 24, 1669–1681. [Google Scholar] [CrossRef]
- Valera, M.; Velastin, S.A. Intelligent distributed surveillance systems: A review. IEE Proc.-Vis. Image Signal Process. 2005, 152, 192–204. [Google Scholar] [CrossRef]
- Crocco, M.; Cristani, M.; Trucco, A.; Murino, V. Audio surveillance: A systematic review. ACM Comput. Surv. CSUR 2016, 48, 1–46. [Google Scholar] [CrossRef]
- Foggia, P.; Saggese, A.; Strisciuglio, N.; Vento, M.; Petkov, N. Car crashes detection by audio analysis in crowded roads. In Proceedings of the 2015 12th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Karlsruhe, Germany, 25–28 August 2015; pp. 1–6. [Google Scholar]
- Foggia, P.; Petkov, N.; Saggese, A.; Strisciuglio, N.; Vento, M. Audio surveillance of roads: A system for detecting anomalous sounds. IEEE Trans. Intell. Transp. Syst. 2015, 17, 279–288. [Google Scholar] [CrossRef]
- Lopatka, K.; Kotus, J.; Czyzewski, A. Detection, classification and localization of acoustic events in the presence of background noise for acoustic surveillance of hazardous situations. Multimed. Tools Appl. 2016, 75, 10407–10439. [Google Scholar] [CrossRef]
- Conte, D.; Foggia, P.; Percannella, G.; Saggese, A.; Vento, M. An ensemble of rejecting classifiers for anomaly detection of audio events. In Proceedings of the 2012 IEEE Ninth International Conference on Advanced Video and Signal-Based Surveillance, Beijing, China, 18–21 September 2012; pp. 76–81. [Google Scholar]
- Saggese, A.; Strisciuglio, N.; Vento, M.; Petkov, N. Time-frequency analysis for audio event detection in real scenarios. In Proceedings of the 2016 13th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Colorado Springs, CO, USA, 23–26 August 2016; pp. 438–443. [Google Scholar]
- Besacier, L.; Barnard, E.; Karpov, A.; Schultz, T. Automatic speech recognition for under-resourced languages: A survey. Speech Commun. 2014, 56, 85–100. [Google Scholar] [CrossRef]
- Fu, Z.; Lu, G.; Ting, K.M.; Zhang, D. A survey of audio-based music classification and annotation. IEEE Trans. Multimed. 2010, 13, 303–319. [Google Scholar] [CrossRef]
- Roy, A.; Doss, M.M.; Marcel, S. A fast parts-based approach to speaker verification using boosted slice classifiers. IEEE Trans. Inf. Forensics Secur. 2011, 7, 241–254. [Google Scholar] [CrossRef]
- Vafeiadis, A.; Votis, K.; Giakoumis, D.; Tzovaras, D.; Chen, L.; Hamzaoui, R. Audio content analysis for unobtrusive event detection in smart homes. Eng. Appl. Artif. Intell. 2020, 89, 103226. [Google Scholar] [CrossRef]
- Strisciuglio, N.; Vento, M.; Petkov, N. Learning representations of sound using trainable COPE feature extractors. Pattern Recognit. 2019, 92, 25–36. [Google Scholar] [CrossRef]
- Asadi-Aghbolaghi, M.; Clapes, A.; Bellantonio, M.; Escalante, H.J.; Ponce-López, V.; Baró, X.; Guyon, I.; Kasaei, S.; Escalera, S. A survey on deep learning based approaches for action and gesture recognition in image sequences. In Proceedings of the 2017 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017), Washington, DC, USA, 30 May–3 June 2017; pp. 476–483. [Google Scholar]
- Gao, M.; Jiang, J.; Zou, G.; John, V.; Liu, Z. RGB-D-based object recognition using multimodal convolutional neural networks: A survey. IEEE Access 2019, 7, 43110–43136. [Google Scholar] [CrossRef]
- Sindagi, V.A.; Patel, V.M. A survey of recent advances in cnn-based single image crowd counting and density estimation. Pattern Recognit. Lett. 2018, 107, 3–16. [Google Scholar] [CrossRef]
- Xia, R.; Liu, Y. A multi-task learning framework for emotion recognition using 2D continuous space. IEEE Trans. Affect. Comput. 2015, 8, 3–14. [Google Scholar] [CrossRef]
- Guo, F.; Yang, D.; Chen, X. Using deep belief network to capture temporal information for audio event classification. In Proceedings of the 2015 International Conference on Intelligent Information Hiding and Multimedia Signal Processing (IIH-MSP), Adelaide, Australia, 23–25 September 2015; pp. 421–424. [Google Scholar]
- Wang, C.Y.; Wang, J.C.; Santoso, A.; Chiang, C.C.; Wu, C.H. Sound event recognition using auditory-receptive-field binary pattern and hierarchical-diving deep belief network. IEEE ACM Trans. Audio Speech Lang. Process. 2017, 26, 1336–1351. [Google Scholar] [CrossRef]
- Salamon, J.; Bello, J.P. Deep convolutional neural networks and data augmentation for environmental sound classification. IEEE Signal Process. Lett. 2017, 24, 279–283. [Google Scholar] [CrossRef]
- Zhang, H.; McLoughlin, I.; Song, Y. Robust sound event recognition using convolutional neural networks. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brisbane, Australia, 19–24 April 2015; pp. 559–563. [Google Scholar]
- Takahashi, N.; Gygli, M.; Van Gool, L. Aenet: Learning deep audio features for video analysis. IEEE Trans. Multimed. 2017, 20, 513–524. [Google Scholar] [CrossRef]
- Greco, A.; Saggese, A.; Vento, M.; Vigilante, V. SoReNet: A novel deep network for audio surveillance applications. In Proceedings of the 2019 IEEE International Conference on Systems, Man and Cybernetics (SMC), Bari, Italy, 6–9 October 2019; pp. 546–551. [Google Scholar]
- Greco, A.; Petkov, N.; Saggese, A.; Vento, M. AReN: A Deep Learning Approach for Sound Event Recognition using a Brain inspired Representation. IEEE Trans. Inf. Forensics Secur. 2020, 15, 3610–3624. [Google Scholar] [CrossRef]
- Hertel, L.; Phan, H.; Mertins, A. Comparing time and frequency domain for audio event recognition using deep learning. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 3407–3411. [Google Scholar]
- Mesaros, A.; Heittola, T.; Benetos, E.; Foster, P.; Lagrange, M.; Virtanen, T.; Plumbley, M.D. Detection and classification of acoustic scenes and events: Outcome of the DCASE 2016 challenge. IEEE ACM Trans. Audio Speech Lang. Process. 2017, 26, 379–393. [Google Scholar] [CrossRef]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. arXiv 2015, arXiv:1603.04467. [Google Scholar]
- Oliphant, T.E. A Guide to Numpy; Trelgol Publishing USA: New York, NY, USA, 2006; Volume 1. [Google Scholar]
- McKinney, W. Data Structures for Statistical Computing in Python. In Proceedings of the 9th Python in Science Conference, Austin, TX, USA, 28 June–3 July 2010. [Google Scholar] [CrossRef]
- Hunter, J.D. Matplotlib: A 2D graphics environment. Comput. Sci. Eng. 2007, 9, 90–95. [Google Scholar] [CrossRef]
- Virtanen, P.; Gommers, R.; Oliphant, T.E.; Haberland, M.; Reddy, T.; Cournapeau, D.; Burovski, E.; Peterson, P.; Weckesser, W.; Bright, J.; et al. SciPy 1.0: Fundamental algorithms for scientific computing in Python. Nat. Methods 2020, 17, 261–272. [Google Scholar] [CrossRef]
- McFee, B.; Raffel, C.; Liang, D.; Ellis, D.P.; McVicar, M.; Battenberg, E.; Nieto, O. Librosa: Audio and music signal analysis in python. In Proceedings of the 14th Python in Science Conference, Austin, TX, USA, 6–12 July 2015; Volume 8, pp. 18–25. [Google Scholar]
- Sanner, M.F. Python: A programming language for software integration and development. J. Mol. Graph. Model. 1999, 17, 57–61. [Google Scholar]
- Bradski, G.; Kaehler, A. Learning OpenCV: Computer Vision with the OpenCV Library; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2008. [Google Scholar]
- Kumar, T.; Verma, K. A Theory Based on Conversion of RGB image to Gray image. Int. J. Comput. Appl. 2010, 8, 7–10. [Google Scholar]
- Zinemanas, P.; Cancela, P.; Rocamora, M. End-to-end convolutional neural networks for sound event detection in urban environments. In Proceedings of the 2019 24th Conference of Open Innovations Association (FRUCT), Moscow, Russia, 8–12 April 2019; pp. 533–539. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Foggia, P.; Petkov, N.; Saggese, A.; Strisciuglio, N.; Vento, M. Reliable detection of audio events in highly noisy environments. Pattern Recognit. Lett. 2015, 65, 22–28. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference for Learning Representations (ICLR-15), Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Kullback, S.; Leibler, R.A. On Information and Sufficiency. Ann. Math. Statist. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Salamon, J.; Jacoby, C.; Bello, J.P. A dataset and taxonomy for urban sound research. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 1041–1044. [Google Scholar]
- Davis, N.; Suresh, K. Environmental sound classification using deep convolutional neural networks and data augmentation. In Proceedings of the 2018 IEEE Recent Advances in Intelligent Computational Systems (RAICS), Thiruvananthapuram, India, 6–8 December 2018; pp. 41–45. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Original Training set | Original Test set | |||
|---|---|---|---|---|
| Type | Events | Duration (s) | Events | Duration (s) |
| BN | - | 58,372 | - | 25,037 |
| GB | 4200 | 6025 | 1800 | 2562 |
| G | 4200 | 1884 | 1800 | 744 |
| S | 4200 | 5489 | 1800 | 2445 |
| Extended Training set | Extended Test set | |||
| BN | - | 77,828 | - | 33,382 |
| GB | 5600 | 8033 | 2400 | 3416 |
| G | 5600 | 2512 | 2400 | 991 |
| S | 5600 | 7318 | 2400 | 3261 |
| Train −5 dB/Test −5 dB | Train 0 dB/Test 0 dB | |||||
|---|---|---|---|---|---|---|
| Metrics/ Macro Avg per feature | Precision (%) | Recall (%) | F1-Score (%) | Precision (%) | Recall (%) | F1-Score (%) |
| Macro Average (STFT) | 81.92 | 78.76 | 79.74 | 89.35 | 88.16 | 88.66 |
| Macro Average (mel) | 75.53 | 76.38 | 75.76 | 79.4 | 80.2 | 79.64 |
| Macro Average (MFCC) | 71.04 | 75.69 | 72.7 | 82.85 | 82.3 | 82.36 |
| Train 5 dB/Test 5 dB | Train 10 dB/Test 10 dB | |||||
| Macro Average (STFT) | 87.86 | 89.95 | 88.74 | 91.37 | 90.44 | 90.88 |
| Macro Average (mel) | 86.68 | 85.51 | 85.92 | 87.9 | 88.73 | 88.22 |
| Macro Average (MFCC) | 86.88 | 89.42 | 87.92 | 87.5 | 86.94 | 87.21 |
| Train 15 dB/Test 15 dB | Train 20 dB/Test 20 dB | |||||
| Macro Average (STFT) | 91.25 | 92.6 | 91.89 | 91.97 | 92.75 | 92.34 |
| Macro Average (mel) | 91.28 | 89.3 | 90.19 | 91.71 | 88.76 | 90.07 |
| Macro Average (MFCC) | 88.73 | 88.25 | 88.38 | 90.65 | 89.96 | 90.22 |
| Train 25 dB/Test 25 dB | Train 30 dB/Test 30 dB | |||||
| Macro Average (STFT) | 91.95 | 91.85 | 91.9 | 91.38 | 93.06 | 92.15 |
| Macro Average (mel) | 92.01 | 90.31 | 91.06 | 91.01 | 91.51 | 91.23 |
| Macro Average (MFCC) | 90.96 | 90.35 | 90.65 | 90.43 | 91.17 | 90.78 |
| Train −5 dB/Test 15 dB | Train −5 dB/Test 30 dB | |||||
| Macro Average (STFT) | 72.56 | 65.65 | 62.11 | 73.29 | 65.5 | 63.77 |
| Macro Average (mel) | 70.41 | 63.81 | 61.2 | 70.94 | 68.22 | 66.85 |
| Macro Average (MFCC) | 83.95 | 88.85 | 85.58 | 84.63 | 88.36 | 86.2 |
| Train 15 dB/Test −5 dB | Train 30 dB/Test −5 dB | |||||
| Macro Average (STFT) | 60.96 | 26.86 | 20.56 | 30.65 | 25.82 | 18.26 |
| Macro Average (mel) | 31.13 | 30.58 | 26.32 | 30.6 | 29.45 | 21.62 |
| Macro Average (MFCC) | 49.08 | 37.34 | 37.02 | 53.92 | 33.59 | 31.47 |
| Method Test with SNR > 0 | Representation | RR (%) | Accuracy (%) | MDR (%) | ER (%) | FPR (%) |
|---|---|---|---|---|---|---|
| Present Study | STFT + Mel + MFCC (Stacked) | 92.5 | 95.21 | 7.28 | 0.22 | 2.59 |
| COPE [19] | Gammatonegram | 96 | - | 3.1 | 0.9 | 4.3 |
| AReN [30] | Gammatonegram | 94.65 | - | 4.97 | 0.38 | 0.78 |
| SoundNet [19] | Gammatonegram | 93.33 | - | 9.9 | 1.4 | 1.4 |
| bof [11] | Gammatonegram | 86.7 | - | 9.65 | 1.4 | 3.1 |
| bof [11] | Gammatonegram | 84.8 | - | 12.5 | 2.7 | 2.1 |
| SoreNet [29] | Spectrogram | - | 88.9 | - | - | - |
| AENet [29] | Spectrogram | - | 81.5 | - | - | - |
| AENet [30] | Gammatonegram | 88.73 | - | 8.84 | 2.43 | 2.59 |
| AENet [30] | Spectrogram | 78.82 | - | 16.69 | 4.48 | 5.35 |
| Test with SNR > 0 and SNR ≤ 0 | ||||||
| Present Study | STFT + Mel + MFCC (Stacked) | 90.45 | 93.88 | 8.47 | 0.62 | 3.68 |
| COPE [19] | Gammatonegram | 91.7 | - | 2.61 | 5.68 | 9.2 |
| SoundNet [19] | Gammatonegram | 84.13 | - | 4 | 11.88 | 25.9 |
| bof [11] | Gammatonegram | 59.11 | - | 32.97 | 7.92 | 5.3 |
| bof [11] | Gammatonegram | 56.07 | - | 36.43 | 7.5 | 5.3 |
| Original dataset | ||||
| GB | G | S | MDR | |
| GB | 91.48% | 0.35% | 0% | 8.17% |
| G | 0.11% | 98.46% | 0.02% | 1.41% |
| S | 0.02% | 0.31% | 87.41% | 12.26% |
| Extended dataset | ||||
| GB | G | S | MDR | |
| GB | 94.68% | 0.44% | 0.15% | 4.72% |
| G | 0.1% | 95.4% | 0.43% | 4.07% |
| S | 0.24% | 0.5% | 82.64% | 16.63% |
| Model No | Training SNR (dB) | Testing SNR (dB) |
|---|---|---|
| 1 | ||
| 2 | 30 | |
| 3 | ||
| 4 | 0 | 0 |
| 5 | 5 | 5 |
| 6 | 10 | 10 |
| 7 | 15 | 15 |
| 8 | 20 | 20 |
| 9 | 25 | 25 |
| 10 | 30 | 30 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Papadimitriou, I.; Vafeiadis, A.; Lalas, A.; Votis, K.; Tzovaras, D. Audio-Based Event Detection at Different SNR Settings Using Two-Dimensional Spectrogram Magnitude Representations. Electronics 2020, 9, 1593. https://doi.org/10.3390/electronics9101593
Papadimitriou I, Vafeiadis A, Lalas A, Votis K, Tzovaras D. Audio-Based Event Detection at Different SNR Settings Using Two-Dimensional Spectrogram Magnitude Representations. Electronics. 2020; 9(10):1593. https://doi.org/10.3390/electronics9101593
Chicago/Turabian StylePapadimitriou, Ioannis, Anastasios Vafeiadis, Antonios Lalas, Konstantinos Votis, and Dimitrios Tzovaras. 2020. "Audio-Based Event Detection at Different SNR Settings Using Two-Dimensional Spectrogram Magnitude Representations" Electronics 9, no. 10: 1593. https://doi.org/10.3390/electronics9101593
APA StylePapadimitriou, I., Vafeiadis, A., Lalas, A., Votis, K., & Tzovaras, D. (2020). Audio-Based Event Detection at Different SNR Settings Using Two-Dimensional Spectrogram Magnitude Representations. Electronics, 9(10), 1593. https://doi.org/10.3390/electronics9101593