A Fast Deep Learning Method for Security Vulnerability Study of XOR PUFs

 , and
, and
Abstract
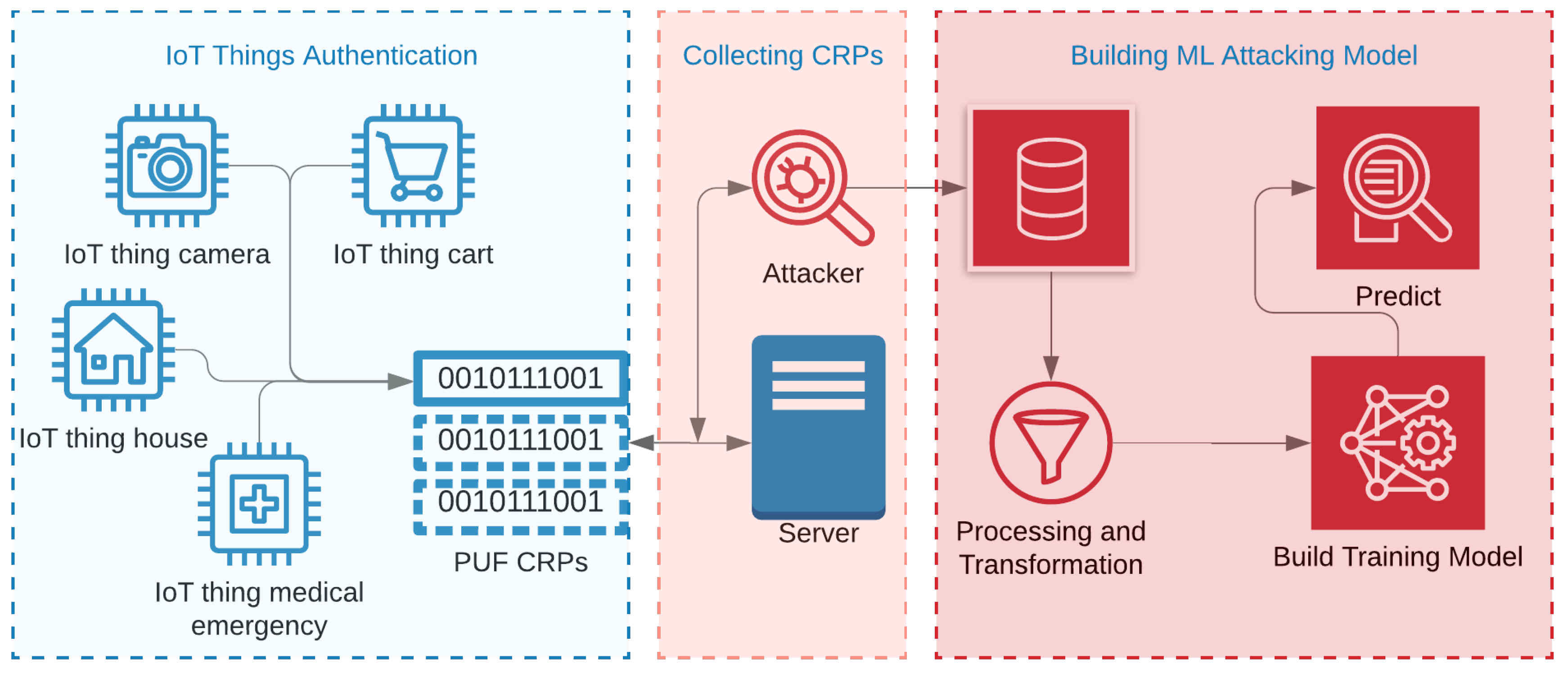
:1. Introduction
2. Preliminaries
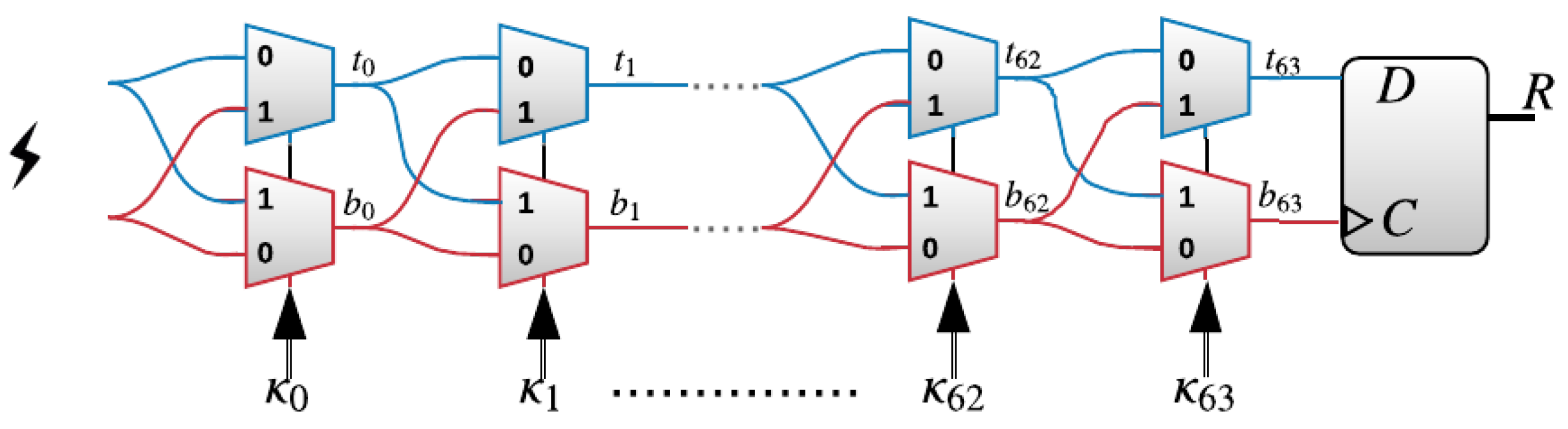
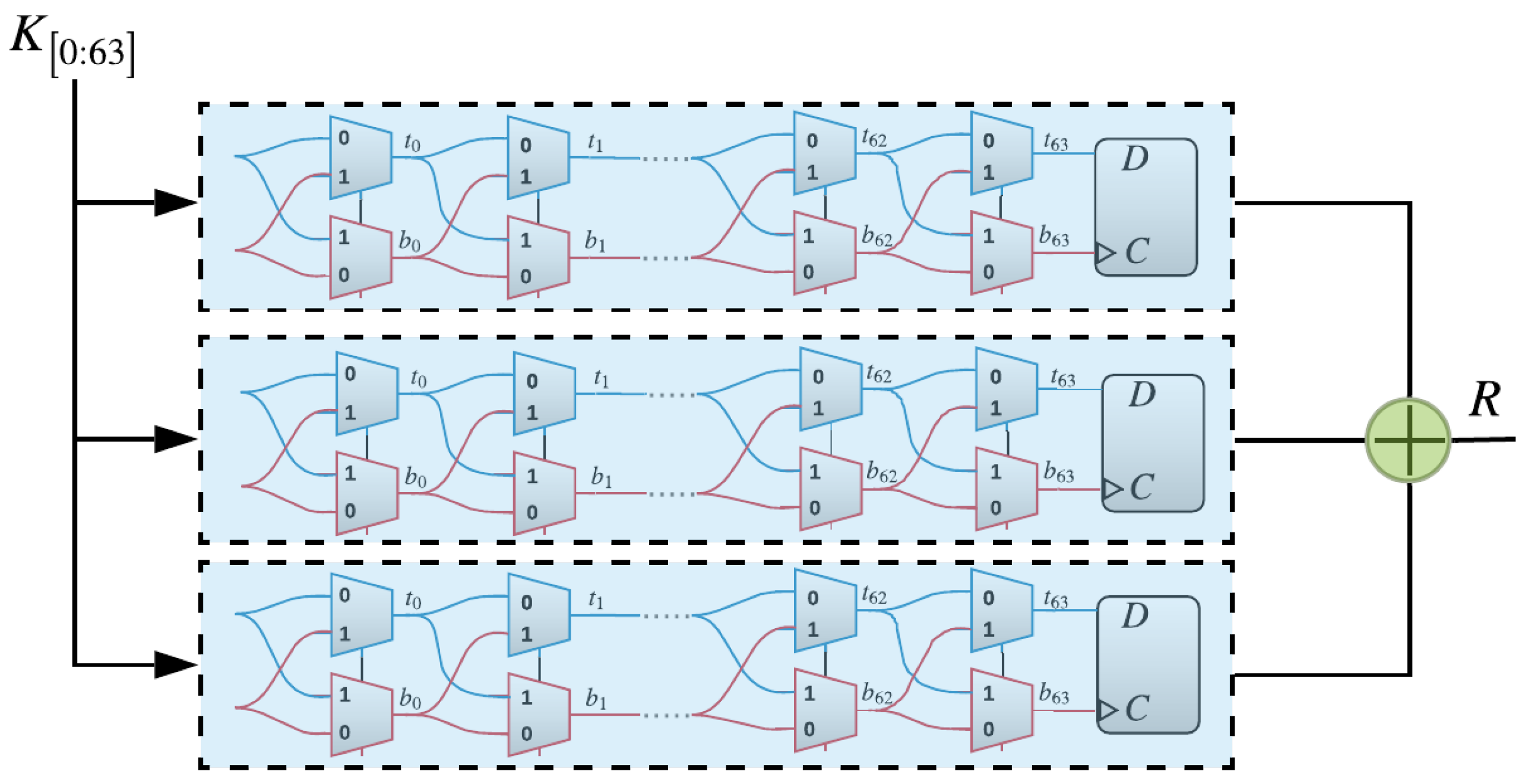
2.1. The XOR Arbiter PUF
2.2. XOR Arbiter PUF Attack Methods
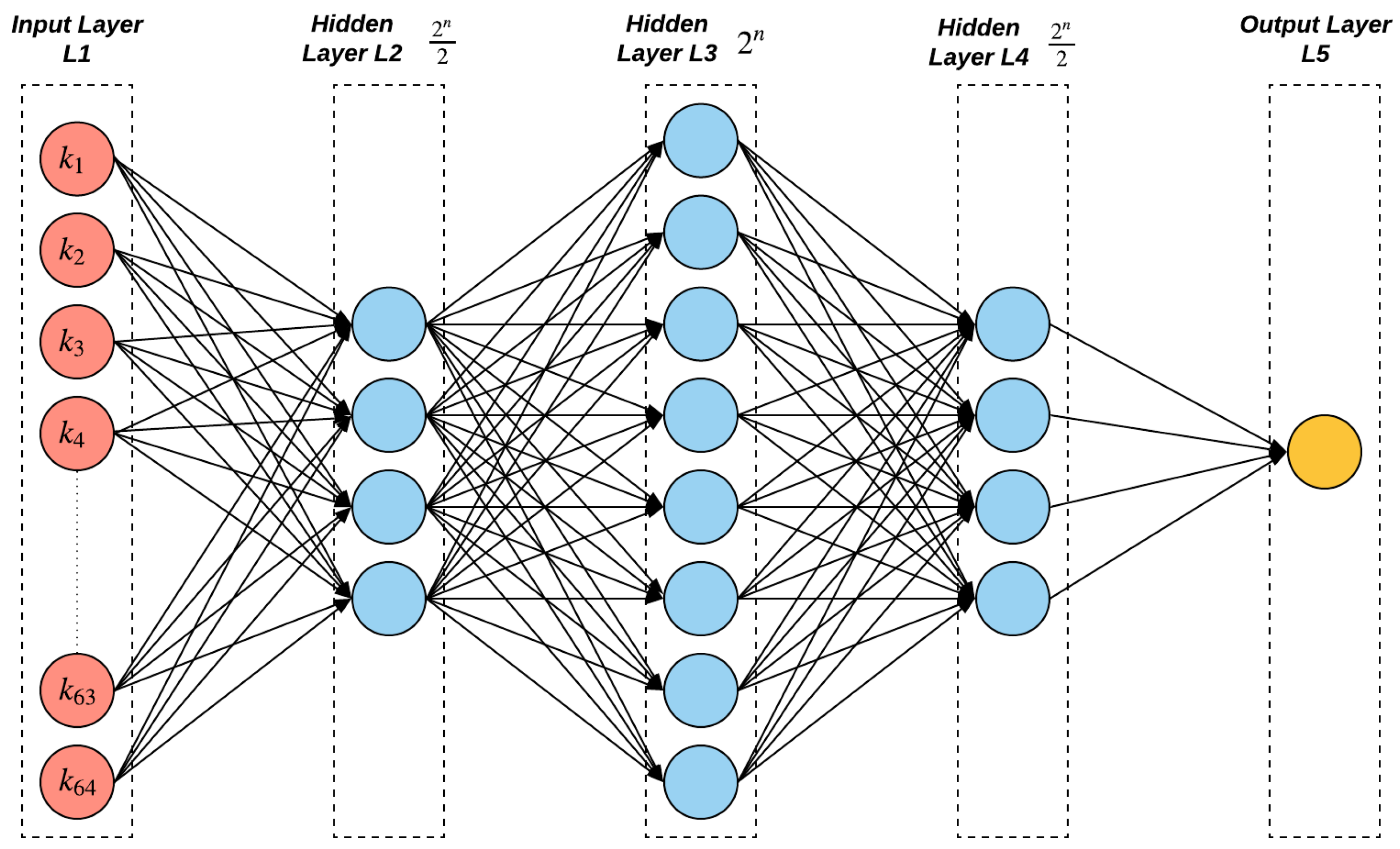
3. The Proposed MLP-Based Architecture Method
4. Experimental Setup
4.1. Simulated CRPs
4.2. Silicon CRPs
4.3. Attacking Model
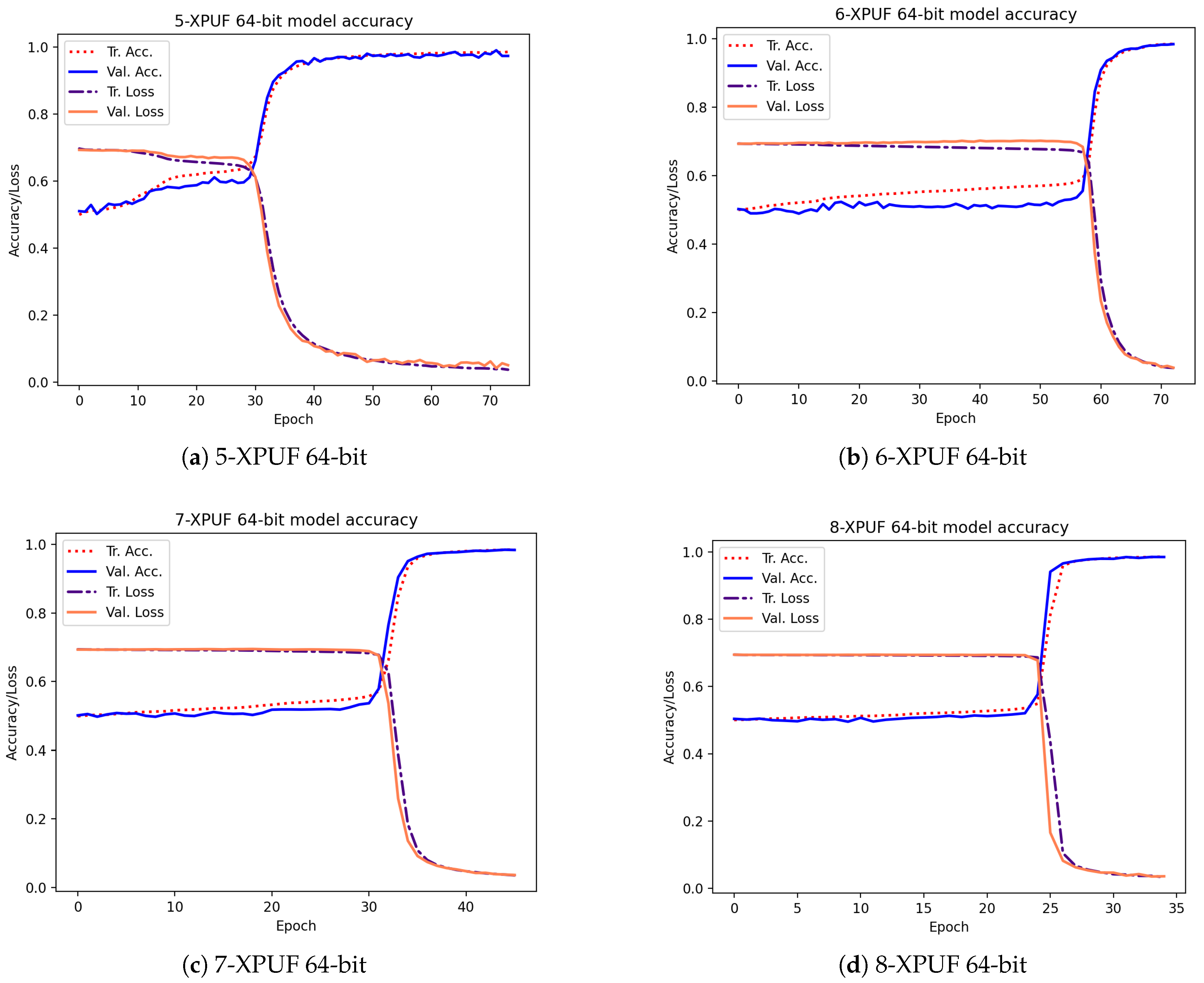
5. Experimental Results and Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| PUF | Physical Unclonable Function |
| CRP | Challenge-Response-Pair |
| XPUF | XOR Arbiter PUFs |
| SVM | Support Vector Machine |
| ML | Machine Learning |
| IoT | Internet of Thing |
| ADM | Additive Delay Model |
| APUF | Arbiter PUF |
| MUX | Multiplexer |
| MLP | Multi-Layered Perceptron |
| DL | Deep Learning |
| ReLU | Rectified Linear Unit |
| tanh | tangent activation function |
| VHDL | VHSIC Hardware Description Language |
References
- van der Meulen, R. Gartner Says 8.4 Billion Connected “Things” Will Be in Use in 2017, up 31 Percent from 2016 Gartner, Newsroom; Press Releases: Brussels, Belgium, 2017. [Google Scholar]
- Yu, M.D.; Hiller, M.; Delvaux, J.; Sowell, R.; Devadas, S.; Verbauwhede, I. A lockdown technique to prevent machine learning on PUFs for lightweight authentication. IEEE Trans. Multi-Scale Comput. Syst. 2016, 2, 146–159. [Google Scholar] [CrossRef] [Green Version]
- Gruss, D.; Maurice, C.; Wagner, K.; Mangard, S. Flush+ Flush: A fast and stealthy cache attack. In International Conference on Detection of Intrusions and Malware, and Vulnerability Assessment; Springer: Berlin/Heidelberg, Germany, 2016; pp. 279–299. [Google Scholar]
- Kömmerling, O.; Kuhn, M.G. Design Principles for Tamper-Resistant Smartcard Processors. Smartcard 1999, 99, 9–20. [Google Scholar]
- Osvik, D.A.; Shamir, A.; Tromer, E. Cache attacks and countermeasures: The case of AES. In Cryptographers’ Track at the RSA Conference; Springer: Berlin/Heidelberg, Germany, 2006; pp. 1–20. [Google Scholar]
- Rührmair, U.; Holcomb, D.E. PUFs at a glance. In Proceedings of the Conference on Design, Automation & Test in Europe, European Design and Automation Association, Grenoble, France, 28 March 2014; p. 347. [Google Scholar]
- Skorobogatov, S.P. Semi-Invasive Attacks: A New Approach to Hardware Security Analysis; Technical Report; Computer Laboratory, University of Cambridge: Cambridge, UK, 2005. [Google Scholar]
- Gassend, B.; Clarke, D.; Van Dijk, M.; Devadas, S. Silicon physical random functions. In Proceedings of the 9th ACM Conference on Computer and Communications Security. ACM, Washington, DC, USA, 18–22 November 2002; pp. 148–160. [Google Scholar]
- Yarom, Y.; Falkner, K. FLUSH+ RELOAD: A high resolution, low noise, L3 cache side-channel attack. In Proceedings of the 23rd {USENIX} Security Symposium ({USENIX} Security 14), San Diego, CA, USA, 20–22 August 2014; pp. 719–732. [Google Scholar]
- Gassend, B.; Clarke, D.; Van Dijk, M.; Devadas, S. Controlled physical random functions. In Proceedings of the 18th IEEE Annual Computer Security Applications Conference, Las Vegas, NV, USA, 9–13 December 2002; pp. 149–160. [Google Scholar]
- Suh, G.E.; Devadas, S. Physical unclonable functions for device authentication and secret key generation. In Proceedings of the 44th ACM/IEEE Design Automation Conference 2007 (DAC’07), San Diego, CA, USA, 4–8 June 2007; pp. 9–14. [Google Scholar]
- Majzoobi, M.; Rostami, M.; Koushanfar, F.; Wallach, D.S.; Devadas, S. Slender PUF protocol: A lightweight, robust, and secure authentication by substring matching. In Proceedings of the 2012 IEEE Symposium on Security and Privacy Workshops, San Francisco, CA, USA, 24–25 May 2012; pp. 33–44. [Google Scholar]
- Lim, D.; Lee, J.W.; Gassend, B.; Suh, G.E.; Van Dijk, M.; Devadas, S. Extracting secret keys from integrated circuits. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2005, 13, 1200–1205. [Google Scholar]
- Majzoobi, M.; Koushanfar, F.; Potkonjak, M. Testing techniques for hardware security. In Proceedings of the 2008 IEEE International Test Conference, Santa Clara, CA, USA, 28–30 October 2008; pp. 1–10. [Google Scholar]
- Rührmair, U.; Sehnke, F.; Sölter, J.; Dror, G.; Devadas, S.; Schmidhuber, J. Modeling attacks on physical unclonable functions. In Proceedings of the 17th ACM Conference on Computer and Communications Security, Chicago, IL, USA, 4–8 October 2010; pp. 237–249. [Google Scholar]
- Majzoobi, M.; Koushanfar, F.; Potkonjak, M. Lightweight secure pufs. In Proceedings of the 2008 IEEE/ACM International Conference on Computer-Aided Design, San Jose, CA, USA, 10–13 November 2008; pp. 670–673. [Google Scholar]
- Santikellur, P.; Bhattacharyay, A.; Chakraborty, R.S. Deep Learning Based Model Building Attacks on Arbiter PUF Compositions. Technical Report, Cryptology ePrint Archive, Report 2019/566. 2019. Available online: https://eprint.iacr.org/2019/566.pdf (accessed on 2 February 2020).
- Nguyen, P.H.; Sahoo, D.P.; Jin, C.; Mahmood, K.; Rührmair, U.; van Dijk, M. The interpose puf: Secure puf design against state-of-the-art machine learning attacks. Iacr Trans. Cryptogr. Hardw. Embed. Syst. 2019, 243–290. [Google Scholar] [CrossRef]
- Aseeri, A.O.; Zhuang, Y.; Alkatheiri, M.S. A Machine Learning-based Security Vulnerability Study on XOR PUFs for Resource-Constraint Internet of Things. In Proceedings of the IEEE International Congress on Internet of Things (ICIOT 2018), San Francisco, CA, USA, 2–7 July 2018. [Google Scholar]
- Tobisch, J.; Becker, G.T. On the scaling of machine learning attacks on PUFs with application to noise bifurcation. In International Workshop on Radio Frequency Identification: Security and Privacy Issues; Springer: Berlin/Heidelberg, Germany, 2015; pp. 17–31. [Google Scholar]
- Zhou, C.; Parhi, K.K.; Kim, C.H. Secure and reliable XOR arbiter PUF design: An experimental study based on 1 trillion challenge response pair measurements. In Proceedings of the 54th Annual Design Automation Conference 2017, Austin, TX, USA, 18–22 June 2017; p. 10. [Google Scholar]
- Herder, C.; Yu, M.D.; Koushanfar, F.; Devadas, S. Physical unclonable functions and applications: A tutorial. Proc. IEEE 2014, 102, 1126–1141. [Google Scholar] [CrossRef]
- Hospodar, G.; Maes, R.; Verbauwhede, I. Machine Learning Attacks on 65nm Arbiter Pufs: Accurate Modeling Poses Strict Bounds on Usability; WIFS: Halifax, NS, Canada, 2012; pp. 37–42.
- Alkatheiri, M.S.; Zhuang, Y. Towards fast and accurate machine learning attacks of feed-forward arbiter PUFs. In Proceedings of the 2017 IEEE Conference on Dependable and Secure Computing, Taipei, Taiwan, 7–10 August 2017; pp. 181–187. [Google Scholar]
- Mursi, K.T.; Zhuang, Y.; Alkatheiri, M.S.; Aseeri, A.O. Extensive Examination of XOR Arbiter PUFs as Security Primitives for Resource-Constrained IoT Devices. In Proceedings of the 2019 17th IEEE International Conference on Privacy, Security and Trust (PST), Fredericton, NB, Canada, 26–28 August 2019; pp. 1–9. [Google Scholar]
- Zhang, J.; Wan, L.; Wu, Q.; Qu, G. DMOS-PUF: Dynamic multi-key-selection obfuscation for strong PUFs against machine learning attacks. arXiv 2018, arXiv:1806.02011. [Google Scholar]
- Alamro, M.A.; Zhuang, Y.; Aseeri, A.O.; Alkatheiri, M.S. Examination of Double Arbiter PUFs on Security against Machine Learning Attacks. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 3165–3171. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Alamro, M.A.; Mursi, K.T.; Zhuang, Y.; Aseeri, A.O.; Alkatheiri, M.S. Robustness and Unpredictability for Double Arbiter PUFs on Silicon Data: Performance Evaluation and Modeling Accuracy. Electronics 2020, 9, 870. [Google Scholar] [CrossRef]
- Zhang, J.L.; Wu, Q.; Ding, Y.P.; Lv, Y.Q.; Zhou, Q.; Xia, Z.H.; Sun, X.M.; Wang, X.W. Techniques for design and implementation of an FPGA-specific physical unclonable function. J. Comput. Sci. Technol. 2016, 31, 124–136. [Google Scholar] [CrossRef]
- Alkatheiri, M.S.; Zhuang, Y.; Korobkov, M.; Sangi, A.R. An experimental study of the state-of-the-art PUFs implemented on FPGAs. In Proceedings of the 2017 IEEE Conference on Dependable and Secure Computing, Taipei, Taiwan, 7 August 2017; pp. 174–180. [Google Scholar]
- Mursi, K.T.; Zhuang, Y. Experimental Study of Component-Differentially-Challenged XOR PUFs as Security Primitives for Internet-of-Things. J. Commun. 2020, 714–721. [Google Scholar]
- Chollet, F. Keras. Available online: https://github.com/fchollet/keras (accessed on 22 September 2020).
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. 2015. Available online: https://www.tensorflow.org/ (accessed on 18 February 2020).
- Maiti, A.; Casarona, J.; McHale, L.; Schaumont, P. A large scale characterization of RO-PUF. In Proceedings of the 2010 IEEE International Symposium on Hardware-Oriented Security and Trust (HOST), Anaheim, CA, USA, 13–14 June 2010; pp. 94–99. [Google Scholar]
- Maiti, A.; Gunreddy, V.; Schaumont, P. A systematic method to evaluate and compare the performance of physical unclonable functions. In Embedded Systems Design with FPGAs; Springer: Berlin/Heidelberg, Germany, 2013; pp. 245–267. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | (2010) [15] | (2012) [23] | (2015) [20] | (2018) [19] | (2019) [17] | Our Method |
|---|---|---|---|---|---|---|
| Library | PyBrain | n/a | PyBrain | sklearn | tf.Keras | tf.Keras |
| Method | LR | MLP | LR | MLP | MLP | MLP |
| CPU Cores | 1 | 1 | 16 | 1 | 1 | 1 |
| Architecture | (, , ) | (, , ) | ||||
| HL actv. func. | Sigmoid | tanh | Sigmoid | ReLU | ReLU | tanh |
| Outp. actv. func. | Linear | Linear | Linear | Sigmoid | Sigmoid | Sigmoid |
| Optimizer | RProp | RProp | RProp | Adam | Adam | Adam |
| Loss function | n/a | n/a | n/a | BCELoss | BCELoss | BCELoss |
| Learning rate | n/a | n/a | n/a | n/a | Adaptive | |
| Initializer | n/a | n/a | n/a | Glorot Uni. | Uniform dist. | Normal dist. |
| CRPs source | synthetic | silicon | synthetic | synthetic | synthetic | synthetic & silicon |
| XOR-Size | Avg. Uniformity for Simulator CRPs | Avg. Uniformity for FPGAs CRPs |
|---|---|---|
| 5-XOR | 50.36% | 49.87% |
| 6-XOR | 50.06% | 49.88% |
| 7-XOR | 50.05% | 50.15% |
| 8-XOR | 50.00% | 49.95% |
| 9-XOR | 49.99% | 49.93% |
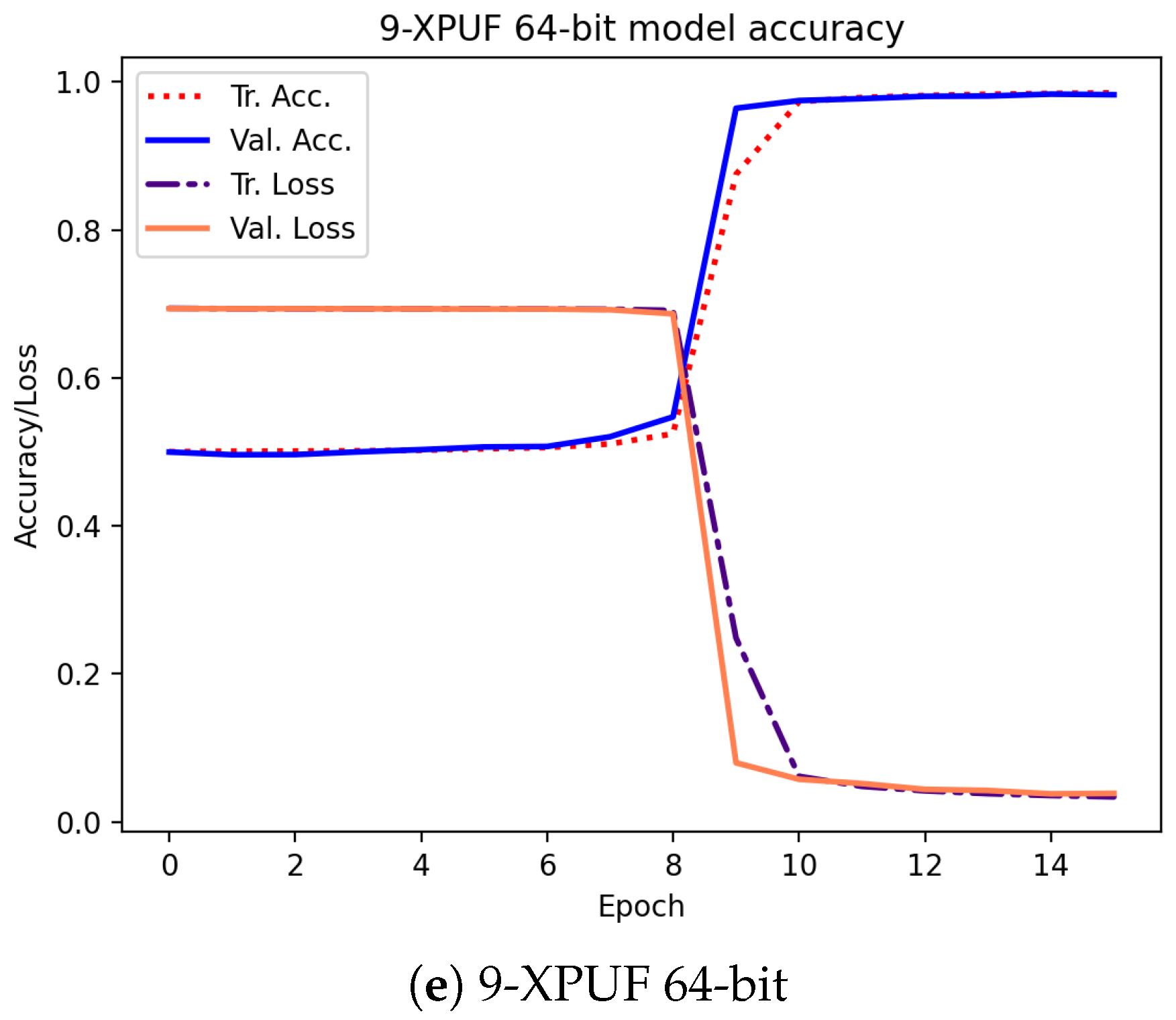
| No. of Stages | XOR Size | Method | Tr. CRPs Size | Best Tst. Acc. | Avg. Tst. Acc. | Tr. Time |
|---|---|---|---|---|---|---|
| 64 Bit | 5-XOR | A | 98% | - | 2.13 min | |
| B | 99% | - | 2.08 h | |||
| C | 98% | 98% | 0.96 min | |||
| D | 98% | - | 10.12 min | |||
| E | 99% | 99% | 0.17 min | |||
| 6-XOR | A | 98% | - | 16.16 min | ||
| B | 99% | - | 31.01 h | |||
| C | 99% | 99% | 7.4 min | |||
| D | 97% | - | 20.52 min | |||
| E | 99% | 98% | 2.04 min | |||
| 7-XOR | A | 98% | - | 14.49 h | ||
| C | 99% | 99% | 11.8 min | |||
| E | 99% | 98% | 0.66 min | |||
| 8-XOR | A | 98% | - | 4.2 days | ||
| C | 99% | 98% | 23.3 min | |||
| E | 99% | 98% | 4.56 min | |||
| 9-XOR | A | 98% | - | 25 days | ||
| E | 99% | 98% | 9.12 min |
| XOR Size | Tr. CRPs Size | Avg. Tst. Acc. | Tr. Time | Batch Size | Exit Loss |
|---|---|---|---|---|---|
| 5-XOR | 96% | 0.38 min | 1000 | 0.072 | |
| 6-XOR | 96% | 0.36 min | 1000 | 0.089 | |
| 7-XOR | 95% | 0.84 min | 10,000 | 0.107 | |
| 8-XOR | 96% | 5.92 min | 10,000 | 0.089 | |
| 9-XOR | 96% | 12.85 min | 10,000 | 0.101 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mursi, K.T.; Thapaliya, B.; Zhuang, Y.; Aseeri, A.O.; Alkatheiri, M.S. A Fast Deep Learning Method for Security Vulnerability Study of XOR PUFs. Electronics 2020, 9, 1715. https://doi.org/10.3390/electronics9101715
Mursi KT, Thapaliya B, Zhuang Y, Aseeri AO, Alkatheiri MS. A Fast Deep Learning Method for Security Vulnerability Study of XOR PUFs. Electronics. 2020; 9(10):1715. https://doi.org/10.3390/electronics9101715
Chicago/Turabian StyleMursi, Khalid T., Bipana Thapaliya, Yu Zhuang, Ahmad O. Aseeri, and Mohammed Saeed Alkatheiri. 2020. "A Fast Deep Learning Method for Security Vulnerability Study of XOR PUFs" Electronics 9, no. 10: 1715. https://doi.org/10.3390/electronics9101715
APA StyleMursi, K. T., Thapaliya, B., Zhuang, Y., Aseeri, A. O., & Alkatheiri, M. S. (2020). A Fast Deep Learning Method for Security Vulnerability Study of XOR PUFs. Electronics, 9(10), 1715. https://doi.org/10.3390/electronics9101715