Robust Image Classification with Cognitive-Driven Color Priors


Abstract
:1. Introduction
- (1)
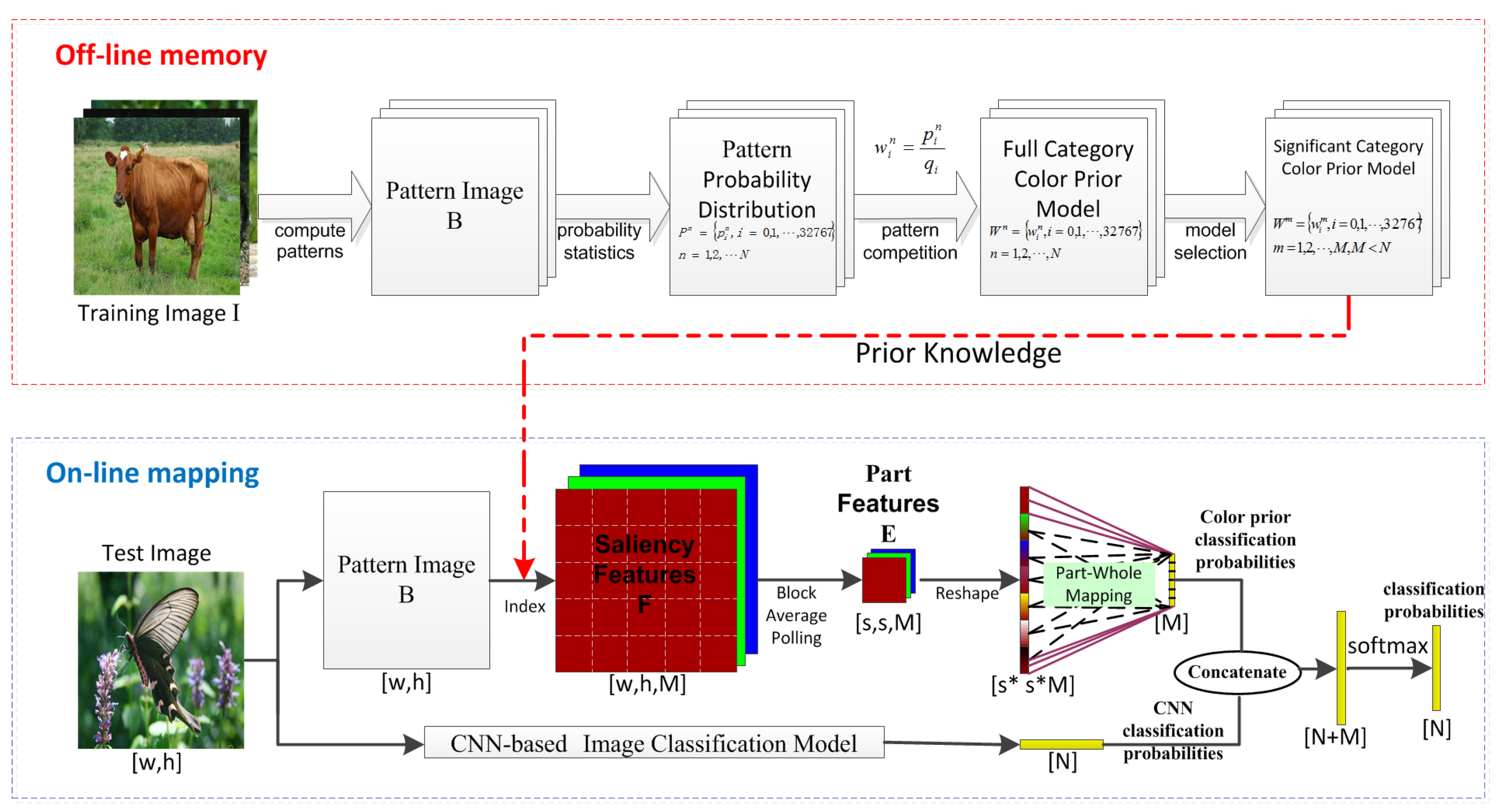
- “Off-line memory” stage: The aim is to establish color prior models of typical category images based on visual attention mechanism and store them. For the convenience of memory and mapping, patterns are used to represent local features of the image, which is essentially a finite one-dimensional discrete number. We use a tuple of {pattern, saliency} to represent the prior model. For a given training image set, the saliency of high frequency patterns is enhanced by accumulating the pattern occurrences of samples within the same category, and the saliency is further enhanced or reduced by competing the relative frequencies between different categories. The tuple of {pattern, saliency} for each category represents the degree of prior correlation between the target pattern and the category, which needs to be calculated once and saved in the table. In order to improve the calculation efficiency in the mapping stage, we only save the color prior model of some selected categories with signifificant color characteristics.
- (2)
- “On-line mapping” stage: Inspired by human conditioned reflex characteristics [12], we obtain the color saliency features of the current image in the form of a lookup table, and fuse them with neural network features to prevent interference from adversarial samples. Based on the established cognitive-driven color prior model, the saliency feature of the test image is obtained by the retrieval method [14], and is regarded as a feature map. Then, block average pooling and part-whole mapping are performed to obtain color-prior-based part features and classification probabilities, respectively. Finally, classification probabilities from color priors and DNN are merged, as if adding a neural network with human-like memory characteristics.
- We propose to use a tuple of {pattern, saliency} to represent the prior model, so that the saliency feature of the test image can be quickly obtained by looking up the table.
- The proposed color prior model comprehensively considers pattern frequencies within the same category and the competition between different categories without training parameters, thus has certain anti-interference ability.
- We fuse color prior model and DNN at the classification probability level, which does not affect the overall structure of the neural network, and can be used in combination with the respective preprocessing modules or adversarial training methods.
2. Related Work
2.1. Image Classification Network
2.2. Adversarial Samples Attack Methods
2.3. Adversarial Samples Defense Methods
3. “Off-Line Memory” Stage
3.1. Prior Model Representation
3.2. Prior Model Estimation
3.3. Prior Model Selection
4. “On-Line Mapping” Stage
4.1. Prior Saliency Feature Generation
4.2. Block Average Pooling
4.3. Part-Whole Mapping
4.4. Fusion with CNN Features
5. Experiments
5.1. Datasets
- ImageNet: This dataset is one of the most famous datasets in the image processing world. Each category contains 1300 training images and 50 test images. The generated adversarial examples are shown in Figure 3.
- CIFAR-10: This dataset contains 60,000 color images with a size of and a total of 10 categories. There are 5000 training images and 1000 test images per category. The generated adversarial examples are shown in Figure 4.
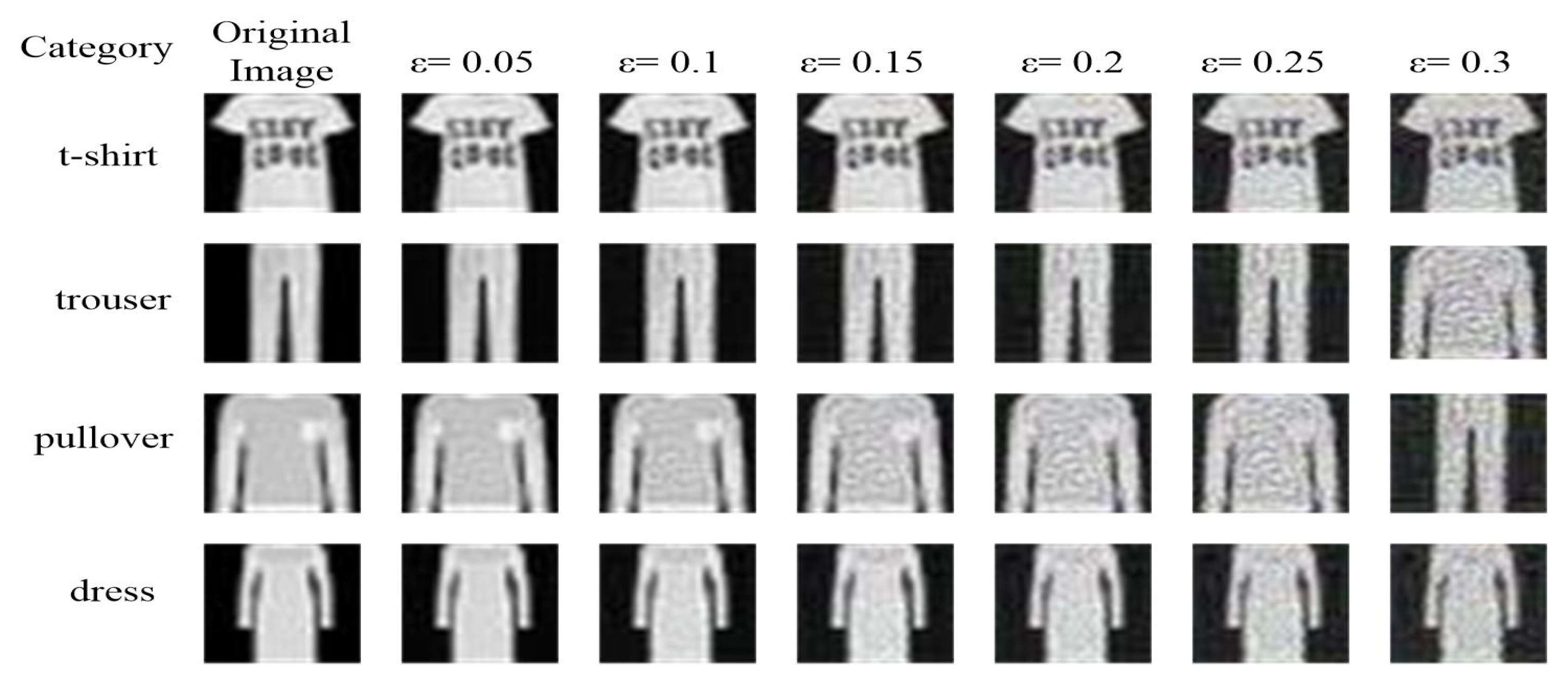
- Fashion-mnist: This dataset is an improved version of Mnist, which covers frontal fashion pictures of a total of 70,000 different products from 10 categories. It contains 60,000 training images and 10,000 test images, each of which is a gray-scale image. The generated adversarial examples are shown in Figure 5.
5.2. Implementation Details
5.3. Ablation Study
- Whether to include a part model: The alternative is to use global average pooling instead of block average pooling.
- Whether to perform prior model selection: The alternative is to use the full-class color prior model instead of the salient class color prior model for online calculation.
- Alternatives to model selection: An alternative way beyond PSR is using the Information Entropy (IE) for model selection. If the PPD contains several significant peaks, it means that the color characteristics of the object class is prominent. Otherwise, if the distribution is disorderly, it means that the color characteristics of the object class is not obvious. This characteristic can be measured by information entropy. We calculate IE of the PPD for each class and chose M object classes with largest IE values for online calculation.
5.4. Comparative Study
- Does the color prior method have a defensive effect on different classification networks.
- Is the color prior method applicable to different datasets.
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Collobert, R.; Weston, J. A unified architecture for natural language processing: Deep neural networks with multitask learning. In Proceedings of the International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; pp. 160–167. [Google Scholar]
- Hinton, G.; Deng, L.; Yu, D.; Dahl, G.E.; Mohamed, A.R.; Jaitly, N.; Senior, A.; Vanhoucke, V.; Nguyen, P.; Sainath, T.N.; et al. Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. IEEE Signal Process. Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Goodfellow, I.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Kurakin, A.; Goodfellow, I.; Bengio, S. Adversarial examples in the physical world. arXiv 2016, arXiv:1607.02533. [Google Scholar]
- Papernot, N.; McDaniel, P.; Goodfellow, I. Transferability in machine learning: From phenomena to black-box attacks using adversarial samples. arXiv 2016, arXiv:1605.07277. [Google Scholar]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv 2013, arXiv:1312.6199. [Google Scholar]
- Papernot, N.; McDaniel, P.; Goodfellow, I.; Jha, S.; Celik, Z.B.; Swami, A. Practical black-box attacks against machine learning. In Proceedings of the Asia Conference on Computer and Communications Security, Abu Dhabi, UAE, 2–6 April 2017; pp. 506–519. [Google Scholar]
- Tramèr, F.; Kurakin, A.; Papernot, N.; Goodfellow, I.; Boneh, D.; McDaniel, P. Ensemble adversarial training: Attacks and defenses. arXiv 2017, arXiv:1705.07204. [Google Scholar]
- Papernot, N.; McDaniel, P. Extending defensive distillation. arXiv 2017, arXiv:1705.05264. [Google Scholar]
- Song, Y.; Kim, T.; Nowozin, S.; Ermon, S.; Kushman, N. Pixeldefend: Leveraging generative models to understand and defend against adversarial examples. arXiv 2017, arXiv:1710.10766. [Google Scholar]
- Borji, A.; Itti, L. State-of-the-art in visual attention modeling. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 185–207. [Google Scholar] [CrossRef]
- Carrasco, M. Visual attention: The past 25 years. Vis. Res. 2011, 51, 1484–1525. [Google Scholar] [CrossRef] [Green Version]
- Shen, Y.; Li, S.; Zhu, C.; Chang, H. A fast top-down visual attention method to accelerate template matching. Comput. Model. New Technol. 2014, 18, 86–93. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. Acm 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef]
- Huang, Y.P.; Vadloori, S.; Chu, H.C.; Kang, Y.C.; Fukushima, Y. Deep Learning Models for Automated Diagnosis of Retinopathy of Prematurity in Preterm Infants. Electronics 2020, 9, 1444. [Google Scholar] [CrossRef]
- Kaabi, R.; Bouchouicha, M.; Mouelhi, A.; Sayadi, M.; Moreau, E. An Efficient Smoke Detection Algorithm Based on Deep Belief Network Classifier Using Energy and Intensity Features. Electronics 2020, 9, 1390. [Google Scholar] [CrossRef]
- Nurmaini, S.; Darmawahyuni, A.; Noviar, A.; Mukti, S.; Tutuko, B. Deep Learning-Based Stacked Denoising and Autoencoder for ECG Heartbeat Classification. Electronics 2020, 9, 135. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Huang, G.; Liu, Z.; Der Maaten, L.V.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Howard, A.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6848–6856. [Google Scholar]
- Wang, R.J.; Li, X.; Ling, C.X. Pelee: A real-time object detection system on mobile devices. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; pp. 1963–1972. [Google Scholar]
- Qin, Z.; Li, Z.; Zhang, Z.; Bao, Y.; Yu, G.; Peng, Y.; Sun, J. ThunderNet: Towards Real-time Generic Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.-F. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Miyato, T.; Maeda, S.; Koyama, M.; Ishii, S. Virtual Adversarial Training: A Regularization Method for Supervised and Semi-Supervised Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 1979–1993. [Google Scholar] [CrossRef] [Green Version]
- Liu, D.C.; Nocedal, J. On the limited memory BFGS method for large scale optimization. Math. Program. 1989, 45, 503–528. [Google Scholar] [CrossRef] [Green Version]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards Deep Learning Models Resistant to Adversarial Attacks. arXiv 2017, arXiv:1706.06083. [Google Scholar]
- Su, J.; Vargas, D.V.; Sakurai, K. One Pixel Attack for Fooling Deep Neural Networks. IEEE Trans. Evol. Comput. 2019, 23, 828–841. [Google Scholar] [CrossRef] [Green Version]
- Chen, P.; Zhang, H.; Sharma, Y.; Yi, J.; Hsieh, C. ZOO: Zeroth Order Optimization Based Black-box Attacks to Deep Neural Networks without Training Substitute Models. In Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security, Dallas, TX, USA, 3 November 2017; pp. 15–26. [Google Scholar]
- Hosseini, H.; Chen, Y.; Kannan, S.; Zhang, B.; Poovendran, R. Blocking Transferability of Adversarial Examples in Black-Box Learning Systems. arXiv 2017, arXiv:1703.04318. [Google Scholar]
- Carlini, N.; Wagner, D. Adversarial Examples Are Not Easily Detected: Bypassing Ten Detection Methods. In Proceedings of the 10th ACM Workshop on Artificial Intelligence and Security, Dallas, TX, USA, 3 November 2017. [Google Scholar]
- Moosavidezfooli, S.; Fawzi, A.; Frossard, P. DeepFool: A Simple and Accurate Method to Fool Deep Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2574–2582. [Google Scholar]
- Hu, W.; Tan, Y. Generating Adversarial Malware Examples for Black-Box Attacks Based on GAN. arXiv 2017, arXiv:1702.05983. [Google Scholar]
- Moosavidezfooli, S.; Fawzi, A.; Fawzi, O.; Frossard, P. Universal Adversarial Perturbations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 June 2017; pp. 86–94. [Google Scholar]
- Zheng, S.; Song, Y.; Leung, T.; Goodfellow, I. Improving the Robustness of Deep Neural Networks via Stability Training. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4480–4488. [Google Scholar]
- Wang, J.; Song, Y.; Leung, T.; Rosenberg, C.; Wang, J.; Philbin, J.; Chen, B.; Wu, Y. Learning Fine-Grained Image Similarity with Deep Ranking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1386–1393. [Google Scholar]
- Gu, S.; Rigazio, L. Towards Deep Neural Network Architectures Robust to Adversarial Examples. arXiv 2014, arXiv:1412.5068. [Google Scholar]
- Yuan, X.; Huang, B.; Wang, Y.; Yang, C.; Gui, W. Deep Learning-Based Feature Representation and Its Application for Soft Sensor Modeling With Variable-Wise Weighted SAE. IEEE Trans. Ind. Inform. 2018, 14, 3235–3243. [Google Scholar] [CrossRef]
- Ross, A.S.; Doshivelez, F. Improving the Adversarial Robustness and Interpretability of Deep Neural Networks by Regularizing their Input Gradients. arXiv 2017, arXiv:1711.09404. [Google Scholar]
- Cisse, M.; Adi, Y.; Neverova, N.; Keshet, J. Houdini: Fooling Deep Structured Prediction Models. arXiv 2017, arXiv:1707.05373. [Google Scholar]
- Papernot, N.; Mcdaniel, P.; Wu, X.; Jha, S.; Swami, A. Distillation as a Defense to Adversarial Perturbations Against Deep Neural Networks. In Proceedings of the 2016 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2016; pp. 582–597. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Akhtar, N.; Liu, J.; Mian, A. Defense Against Universal Adversarial Perturbations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 3389–3398. [Google Scholar]
- Lee, H.; Han, S.; Lee, J. Generative Adversarial Trainer: Defense to Adversarial Perturbations with GAN. arXiv 2017, arXiv:1705.03387. [Google Scholar]
- Krizhevsky, A.; Nair, V.; Hinton, G. Cifar-10 (Canadian Institute for Advanced Research). 2010, 8. Available online: http://www.cs.toronto.edu/kriz/cifar.html (accessed on 8 July 2020).
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-mnist: A novel image dataset for benchmarking machine learning algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]
- Dong, Y.; Liao, F.; Pang, T.; Su, H.; Zhu, J.; Hu, X.; Li, J. Boosting adversarial attacks with momentum. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 9185–9193. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Iandola, F.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| TOP1 Recognition Rate under Different FGSM Interference Amplitudes (%) | |||||||
|---|---|---|---|---|---|---|---|
| = 0 | = 0.5 | = 1 | = 1.5 | = 2 | = 2.5 | = 3 | |
| PeleeNet | 93.0 | 18.4 | 12.3 | 10.1 | 9.7 | 8.8 | 8.2 |
| PeleeNet+ColorPriors | 93.1 | 20.0 | 12.5 | 11.0 | 9.9 | 9.5 | 9.2 |
| Part Model | TOP1 Recognition Rate under Different FGSM Interference Amplitudes (%) | |||||||
|---|---|---|---|---|---|---|---|---|
| = 0 | = 0.5 | = 1 | = 1.5 | = 2 | = 2.5 | = 3 | ||
| PeleeNet+ColorPriors | × | 93.1 | 20.0 | 12.5 | 11.0 | 9.9 | 9.5 | 9.2 |
| √ | 93.1 | 21.5 | 14.2 | 11.8 | 9.8 | 10.2 | 10.1 | |
| Part Model | Model Selection | TOP1 Recognition Rate under Different FGSM Interference Amplitudes (%) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| PSR | IE | = 0 | = 0.5 | = 1 | = 1.5 | = 2 | = 2.5 | = 3 | ||
| PeleeNet+ ColorPriors | √ | × | × | 93.1 | 21.5 | 14.2 | 11.8 | 9.8 | 10.2 | 10.1 |
| √ | √ | × | 93.1 | 21.6 | 14.2 | 11.8 | 10.2 | 9.8 | 9.8 | |
| √ | × | √ | 93.1 | 19.7 | 12.2 | 10.8 | 10.0 | 9.3 | 9.4 | |
| Part Model | Model Selection | TOP1 Recognition Rate under Different FGSM Interference Amplitudes (%) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| PSR | IE | = 0 | = 0.5 | = 1 | = 1.5 | = 2 | = 2.5 | = 3 | ||
| PeleeNet | × | × | × | 93.0 | 18.4 | 12.3 | 10.1 | 9.7 | 8.8 | 8.2 |
| PeleeNet+ ColorPriors | × | × | × | 93.1 | 20.0 | 12.5 | 11.0 | 9.9 | 9.5 | 9.2 |
| √ | × | × | 93.1 | 21.5 | 14.2 | 11.8 | 9.8 | 10.2 | 10.1 | |
| √ | √ | × | 93.1 | 21.6 | 14.2 | 11.8 | 10.2 | 9.8 | 9.8 | |
| √ | × | √ | 93.1 | 19.7 | 12.2 | 10.8 | 10.0 | 9.3 | 9.4 | |
| Color Priorss | TOP1 Recognition Rate under Different FGSM Interference Amplitudes (%) | |||||||
|---|---|---|---|---|---|---|---|---|
| = 0 | = 0.5 | = 1 | = 1.5 | = 2 | = 2.5 | = 3 | ||
| ResNet50 | × | 97.6 | 67.9 | 58.6 | 52.0 | 46.6 | 42.7 | 38.7 |
| √ | 97.7 | 68.4 | 59.9 | 52.4 | 47.8 | 43.5 | 39.4 | |
| VGG16 | × | 95.2 | 33.1 | 22.6 | 18.1 | 16.0 | 14.4 | 13.4 |
| √ | 95.3 | 33.9 | 25.2 | 20.4 | 17.3 | 15.8 | 14.0 | |
| MobileNetV2 | × | 94.3 | 39.8 | 32.3 | 26.5 | 21.2 | 18.7 | 16.4 |
| √ | 94.6 | 41.2 | 34.1 | 27.1 | 22.7 | 20.1 | 18.0 | |
| DenseNet161 | × | 97.7 | 78.3 | 72.0 | 68.2 | 65.0 | 61.8 | 58.8 |
| √ | 98.0 | 78.7 | 73.9 | 68.6 | 65.2 | 61.9 | 59.4 | |
| InceptionV3 | × | 95.4 | 71.1 | 66.7 | 63.5 | 61.0 | 58.7 | 56.0 |
| √ | 95.4 | 71.7 | 67.3 | 64.8 | 61.4 | 59.7 | 56.6 | |
| SqueezeNet | × | 92.5 | 31.4 | 22.4 | 18.4 | 14.9 | 13.0 | 11.5 |
| √ | 92.6 | 33.1 | 24.3 | 18.9 | 16.1 | 14.9 | 12.2 | |
| Color Priorss | TOP1 Recognition Rate under Different FGSM Interference Amplitudes (%) | |||||||
|---|---|---|---|---|---|---|---|---|
| = 0 | = 0.5 | = 1 | = 1.5 | = 2 | = 2.5 | = 3 | ||
| ResNet50 | × | 93.3 | 32.0 | 25.0 | 21.5 | 18.6 | 16.7 | 15.6 |
| √ | 93.3 | 33.2 | 26.3 | 22.3 | 19.3 | 17.4 | 15.9 | |
| VGG16 | × | 94.2 | 41.8 | 38.0 | 34.6 | 31.6 | 29.2 | 26.8 |
| √ | 94.4 | 42.9 | 39.0 | 35.4 | 32.3 | 29.9 | 27.1 | |
| MobileNetV2 | × | 92.6 | 26.4 | 20.8 | 17.8 | 15.8 | 14.4 | 13.6 |
| √ | 92.6 | 27.1 | 21.4 | 18.4 | 16.6 | 15.1 | 14.1 | |
| DenseNet161 | × | 92.7 | 30.3 | 24.3 | 20.7 | 18.3 | 16.9 | 15.7 |
| √ | 93.1 | 31.8 | 25.4 | 21.4 | 19.0 | 17.3 | 16.3 | |
| InceptionV3 | × | 92.7 | 31.1 | 27.0 | 24.4 | 22.1 | 20.8 | 18.8 |
| √ | 92.7 | 32.9 | 27.9 | 25.1 | 23.2 | 21.8 | 19.7 | |
| SqueezeNet | × | 93.9 | 27.9 | 20.9 | 17.4 | 15.3 | 14.0 | 13.2 |
| √ | 93.9 | 31.8 | 25.1 | 20.8 | 18.7 | 17.3 | 16.5 | |
| Color Priorss | TOP1 Recognition Rate under Different FGSM Interference Amplitudes (%) | |||||||
|---|---|---|---|---|---|---|---|---|
| = 0 | = 0.5 | = 1 | = 1.5 | = 2 | = 2.5 | = 3 | ||
| ResNet50 | × | 94.0 | 27.2 | 24.9 | 24.2 | 23.7 | 23.1 | 22.6 |
| √ | 94.0 | 28.9 | 28.1 | 27.3 | 26.5 | 25.9 | 25.2 | |
| VGG16 | × | 93.0 | 45.1 | 42.7 | 40.6 | 38.9 | 37.3 | 35.5 |
| √ | 93.2 | 46.3 | 43.4 | 41.4 | 39.4 | 37.3 | 35.8 | |
| MobileNetV2 | × | 94.6 | 29.0 | 21.9 | 18.6 | 15.6 | 14.3 | 14.2 |
| √ | 95.0 | 30.1 | 22.0 | 20.5 | 17.1 | 16.2 | 14.6 | |
| DenseNet161 | × | 93.8 | 38.7 | 36.5 | 33 | 30.1 | 25.1 | 21.3 |
| √ | 94.0 | 39.9 | 38.0 | 35.3 | 32.1 | 27.5 | 24.7 | |
| InceptionV3 | × | 93.8 | 40.4 | 38.8 | 37.0 | 35.3 | 32.7 | 29.6 |
| √ | 93.9 | 42.4 | 40.6 | 39.4 | 37.7 | 35.3 | 32.3 | |
| SqueezeNet | × | 92.4 | 27.3 | 25.0 | 23.4 | 21.9 | 20.3 | 19.2 |
| √ | 92.6 | 29.8 | 27.5 | 26.0 | 25.2 | 24.3 | 23.1 | |
| Color Priorss | Clean | FGSM | PGD | BIM | DeepFool | |
|---|---|---|---|---|---|---|
| ResNet50 | × | 97.6 | 74.7 | 18.1 | 64.2 | 39.8 |
| √ | 97.7 | 75.9 | 21.3 | 66.7 | 41.2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gu, P.; Zhu, C.; Lan, X.; Wang, J.; Li, S. Robust Image Classification with Cognitive-Driven Color Priors. Electronics 2020, 9, 1837. https://doi.org/10.3390/electronics9111837
Gu P, Zhu C, Lan X, Wang J, Li S. Robust Image Classification with Cognitive-Driven Color Priors. Electronics. 2020; 9(11):1837. https://doi.org/10.3390/electronics9111837
Chicago/Turabian StyleGu, Peng, Chengfei Zhu, Xiaosong Lan, Jie Wang, and Shuxiao Li. 2020. "Robust Image Classification with Cognitive-Driven Color Priors" Electronics 9, no. 11: 1837. https://doi.org/10.3390/electronics9111837
APA StyleGu, P., Zhu, C., Lan, X., Wang, J., & Li, S. (2020). Robust Image Classification with Cognitive-Driven Color Priors. Electronics, 9(11), 1837. https://doi.org/10.3390/electronics9111837