1. Introduction
With the development of mobile communication technology and the commercial use of 5G, mobile operators ensure the normal use of user services in their coverage areas and meet the need for a higher data rate, fast and efficient network services [
1] by deploying a large number of base stations (BSs). The increasing number of BSs will lead to increasing problems. Firstly, in the traditional mobile communication system, each BS is relatively independent and cannot share resources [
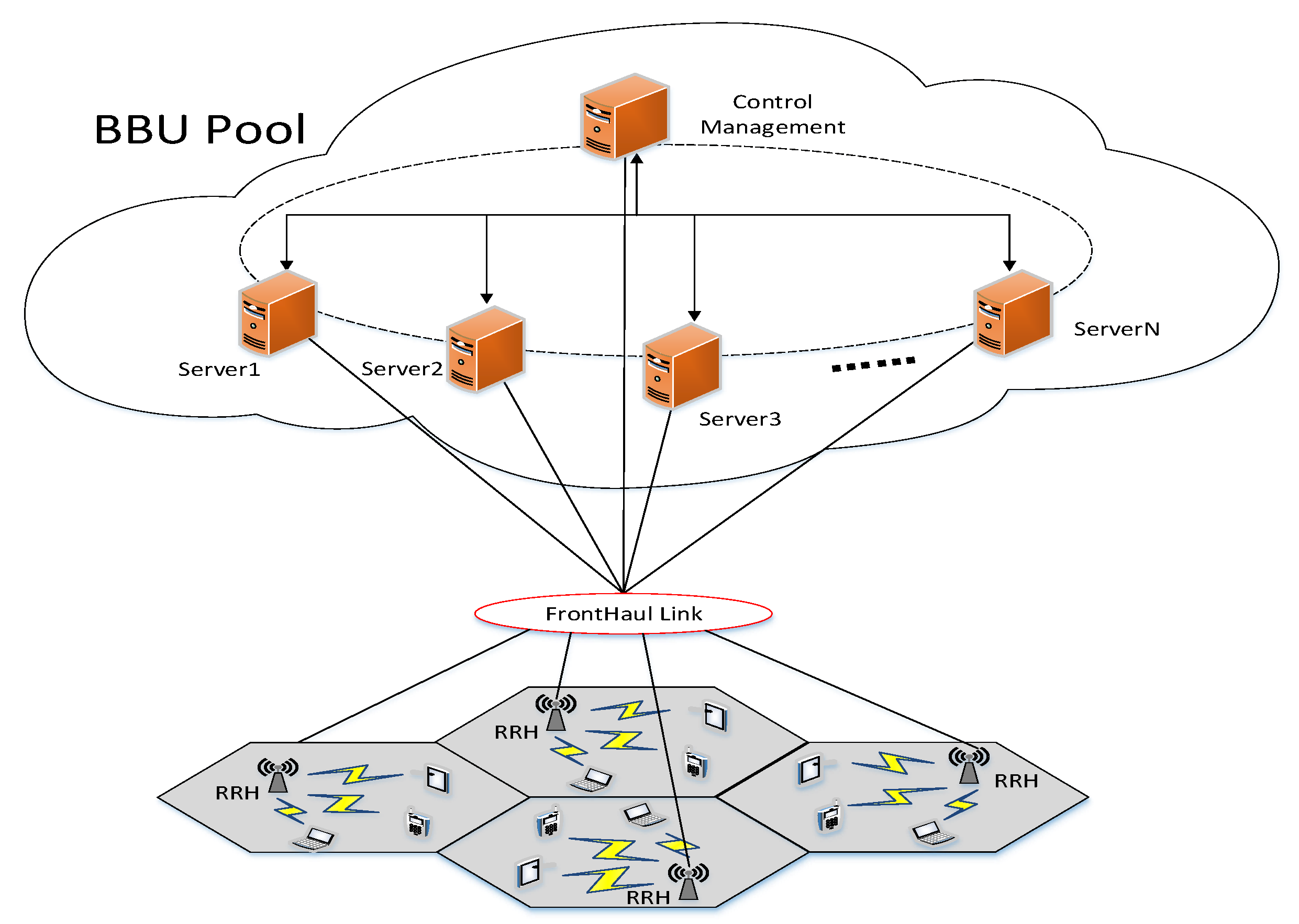
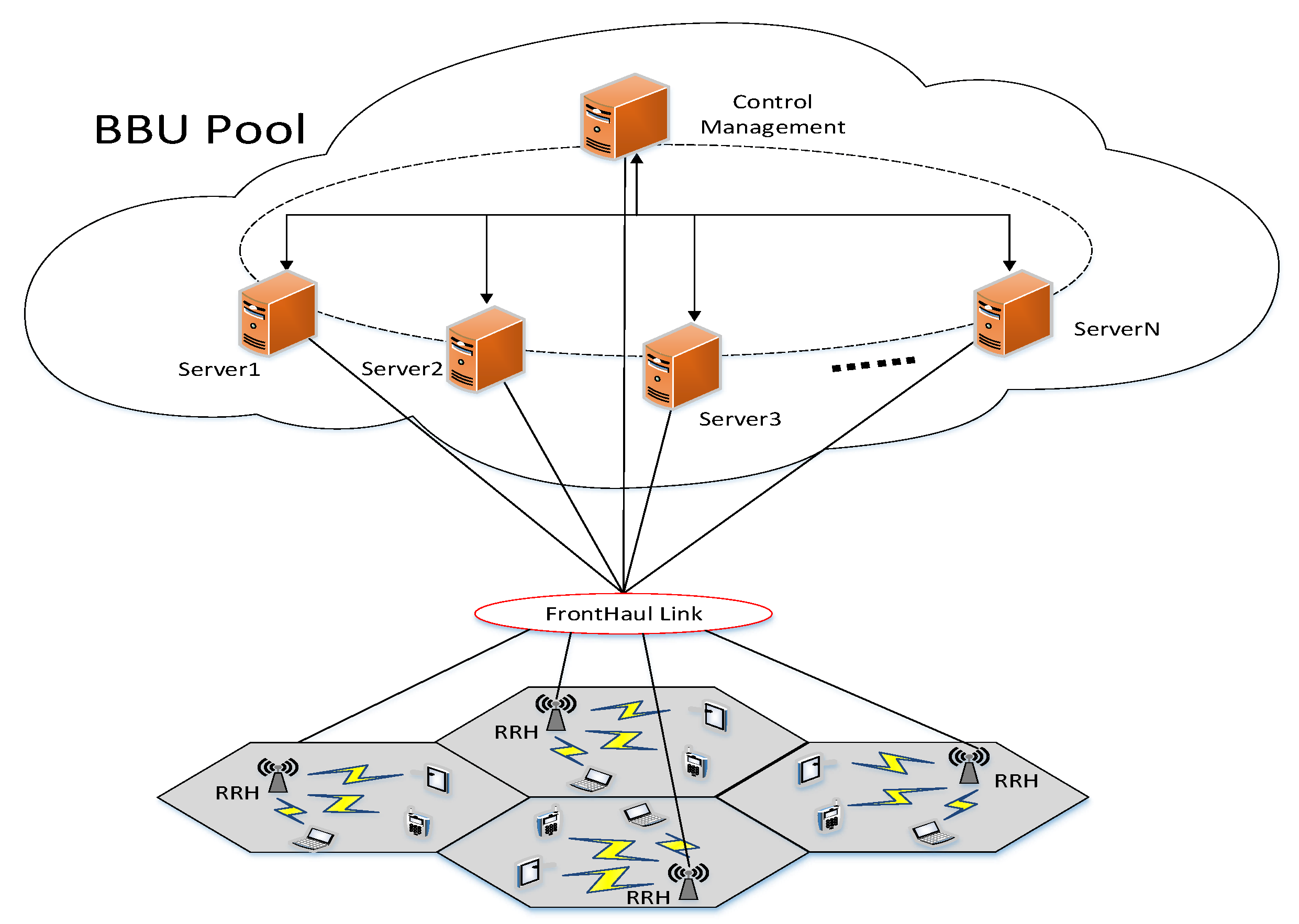
2]. Each BS only undertakes the processing of access user services within its coverage area, so the deployment and maintenance of a large number of BSs require significant construction costs. Secondly, the auxiliary equipment such as air conditioners equipped during the operation of BSs will also cause energy consumption problems. To solve the challenges mentioned above, the concept and architecture of centralized access network are proposed. Cloud-radio access networks (C-RAN) is a promising 5G mobile network architecture [
2], which implements the functional separation of traditional BS into two parts—the baseband unit (BBU) and the remote radio head (RRH). It allows BBUs to be geographically separated from RRHs [
3,
4]. BBU performs baseband signal digital processing together with all upper layer functions. RRH acts as the wireless signal transmission and reception with antennas. Each RRH does not belong to any specific physical BBU and a virtual BS can process the radio signals from /to a particular RRH. C-RAN can reduce capital expenditure (CAPEX) and operating expense (OPEX) of 5G by separating RRH from BBUs based on network functions virtualization (NFV) concepts [
5]. IBM, Huawei and other equipment manufacturers have also put forward a centralized architecture implementation scheme, combined with software defined network (SDN) and NFV, to complete the unified management and allocation of BS computing resources on cloud computing platforms. Applying cloud computing as the computing paradigm of the centralized BBU pool can reduce the power consumption and improve hardware utilization, through resource sharing and virtualization, that is, a server can be further virtualized into many virtual machines (VMs) [
6] running multiple isolated virtual BBU instances.
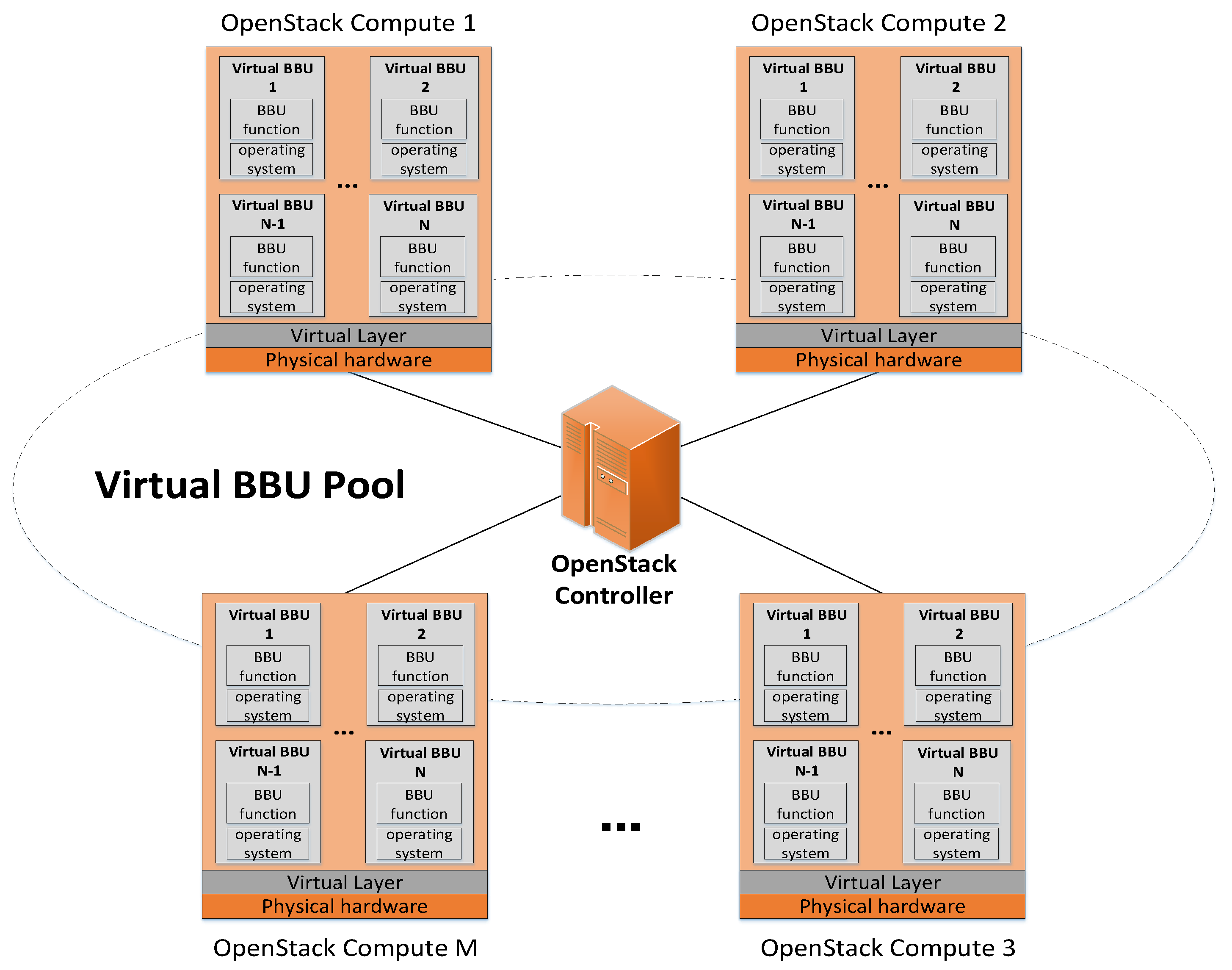
The continuous arrival or end of communication services leads to great differences in the load distribution of different BBUs in the BBU pool. To ensure the normal operation of the user services in the coverage area, the no-load or low-load BBUs must maintain the same running state as the high-load BBUs. On the one hand, the physical servers with these virtualized BBUs may degrade the quality of service because of the too high utilization of resources. On the other hand, the low utilization of resources wastes the physical resources while maintaining the power cost. BBUs are deployed in the server cluster centrally through virtualization to form a BBU pool and realizes the dynamic scheduling of virtual resources according to the utilization of real-time resource, which cannot only share physical resources but also improve the utilization of cluster server processing resources in the BBU pool, improve the overall operation reliability of the pool and reduce the power consumption. Since virtual BBUs are deployed on the VMs, the dynamic migration method of the VMs in the cloud environment can be adopted to improve the resource utilization rate and achieve load balancing.
Load balancing is a migration process of the load from over utilized nodes to underutilized nodes to reduce the wastage of the resources in a cloud environment [
1]. It can be done by VM selection and migration that appropriate VMs are selected either from the overloaded or under-loaded host for migration. Yazir et al. implemented a threshold to determine whether migration is required by monitoring the resource utilization of the server and performs a migration operation once it detects that its resource utilization exceeds the high load threshold [
7]. The authors of References [
8,
9] adopt the algorithm called Minimum Migration Time (MMT), which selects a VM based on the value of the migration time, the less, the better. Reference [
10] selects the VM selection strategy with maximum utilization for migration and VM placement algorithm using the Minimum Power High Available Capacity strategy to find new places of VM has been developed. Reference [
11] calculates total utilization (TU) combined with CPU and memory to choose the smallest TU as destination host. However, if the threshold is exceeded, the migration is triggered immediately and unnecessary migration may be triggered because of an instantaneous peak value, resulting in unnecessary system overhead. Razali et al. in Reference [
12] make the historical data as a training set, establish a prediction model and predict the CPU usage for the next moment. In Reference [
13], a prediction based on fuzzy logic is used to predict future resource utilization. The authors in Reference [
14] use threshold and time sequence prediction technique, which does not perform migration operations immediately when it is detected that server resource utilization exceeds the threshold but continues to observe several cycles to determine whether to initiate migration. This method determines the migration time and avoids invalid migrations, which can save the overall energy consumption of the data center. However, the running communication service is sensitive to the quality of service in the BBU pool. If the virtual BBU does reach the continuous high load state at this time, long observation time of several consecutive cycles may lead to the sharp deterioration of the quality of service of the communication service in the BS.
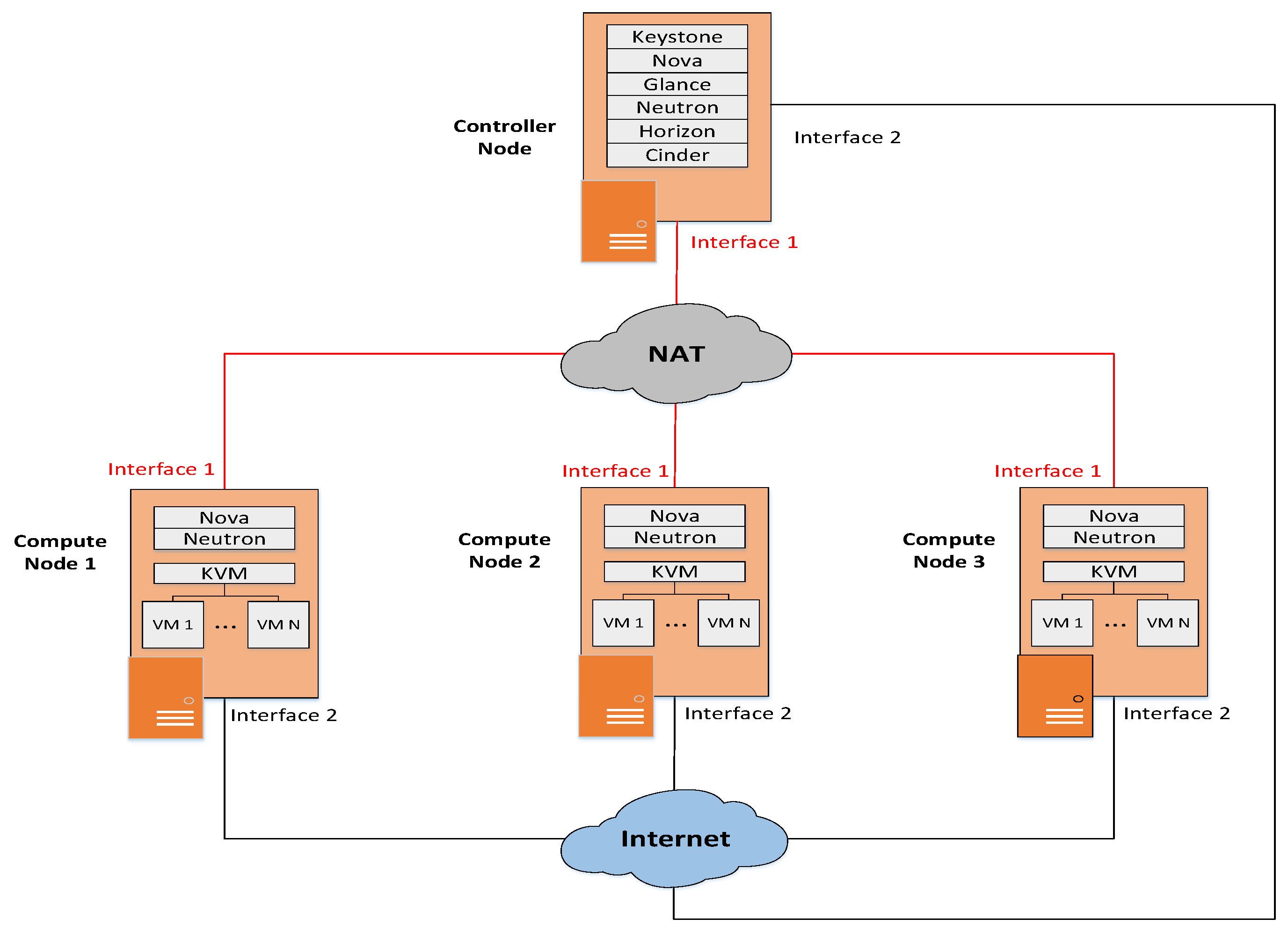
Based on the architecture of a centralized access network, this paper uses virtualization technology on x86 architecture servers to virtualize the functions of traditional BBUs (such as physical layer baseband processing and high-level protocol processing) on VMs, to build a centralized BBU pool and use OpenStack cloud platform for unified control and deployment of virtual resources in the pool. In this scenario, this paper proposes a dual threshold adaptive dynamic migration strategy, which sets the upper and lower threshold for the physical nodes’ resource utilization in the BBU pool and realize adaptive dynamic migration. The main contributions of this paper are summarized as follows:
(1) We virtualize the BBU and build a virtual BBU pool combined with OpenStack cloud architecture. In the OpenStack-based BBU pool, all the processing resources provided by physical servers can be managed and allocated by a unified real-time virtual operating system.
(2) We propose a dual threshold adaptive (DTA) dynamic migration strategy divided into three parts. The first part is the adaptive migration trigger strategy combined with the Kalman filter algorithm, which can avoid a certain instantaneous peak of server resource utilization to trigger unnecessary migration because of too high or too low and effectively determine the time to trigger migration. The second part is selection strategy of VM, based on the number of migrations and the migration time. The last part is selection of target server node, combined with prediction and resource utilization to make a comprehensive judgment.
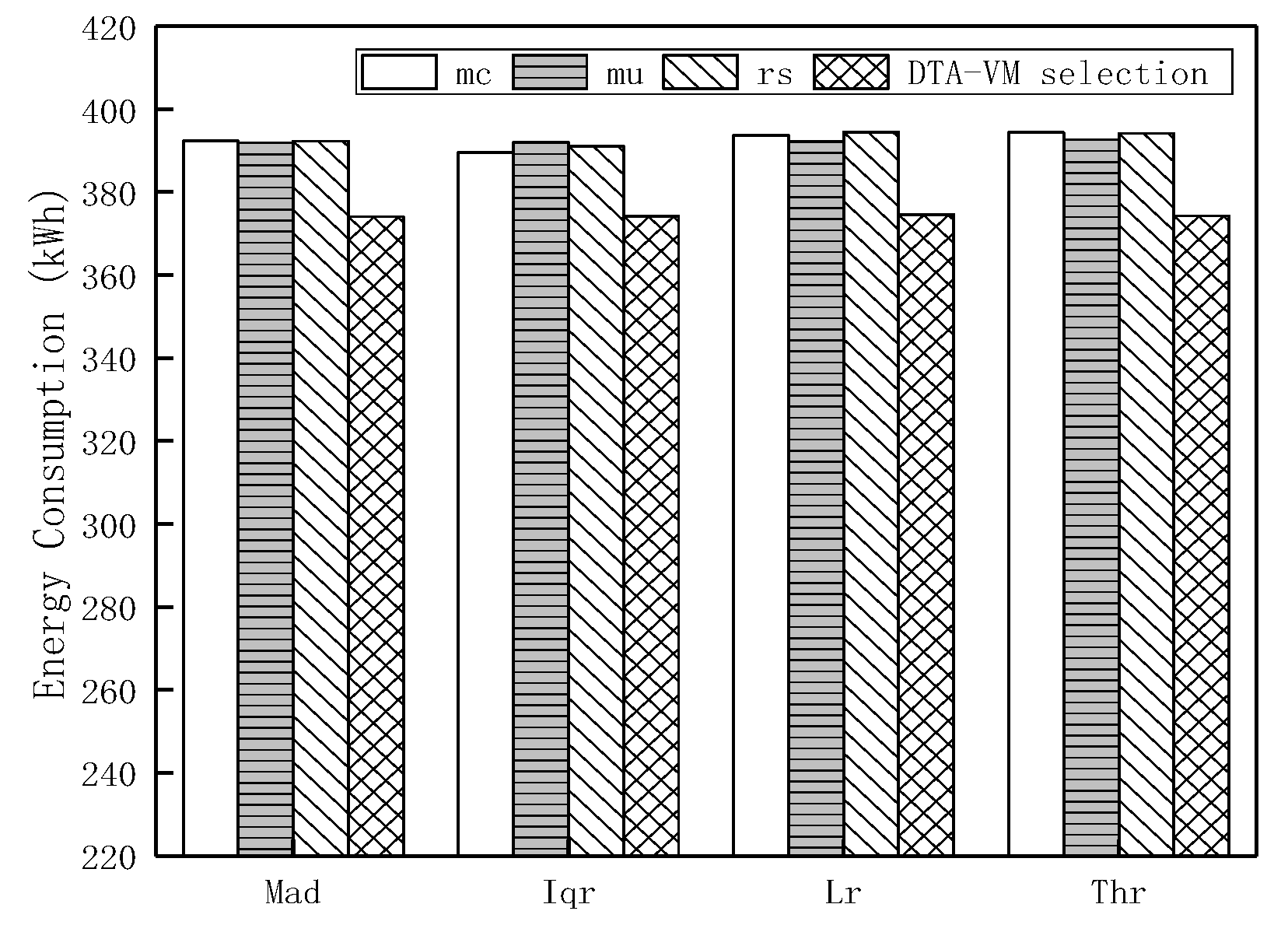
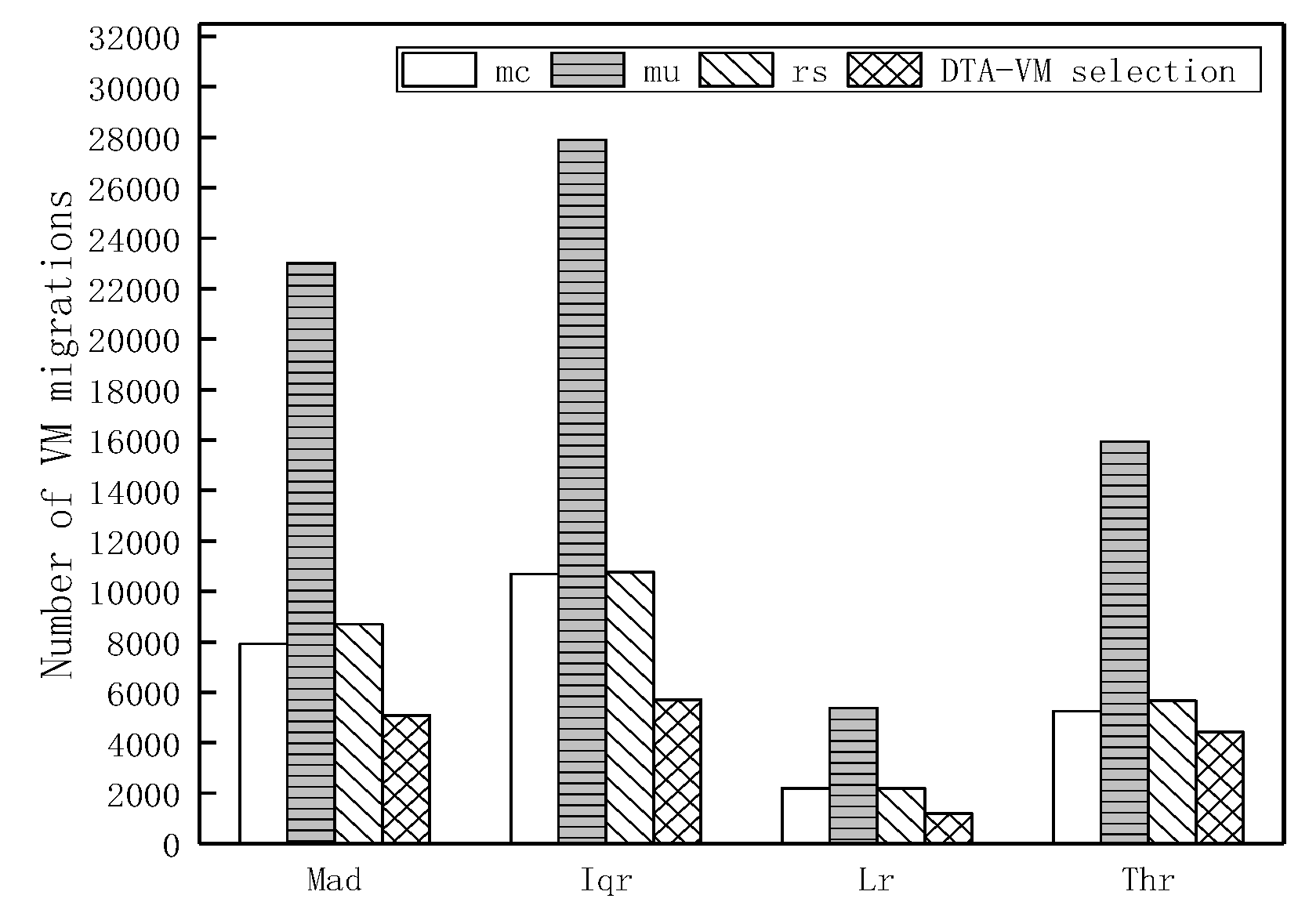
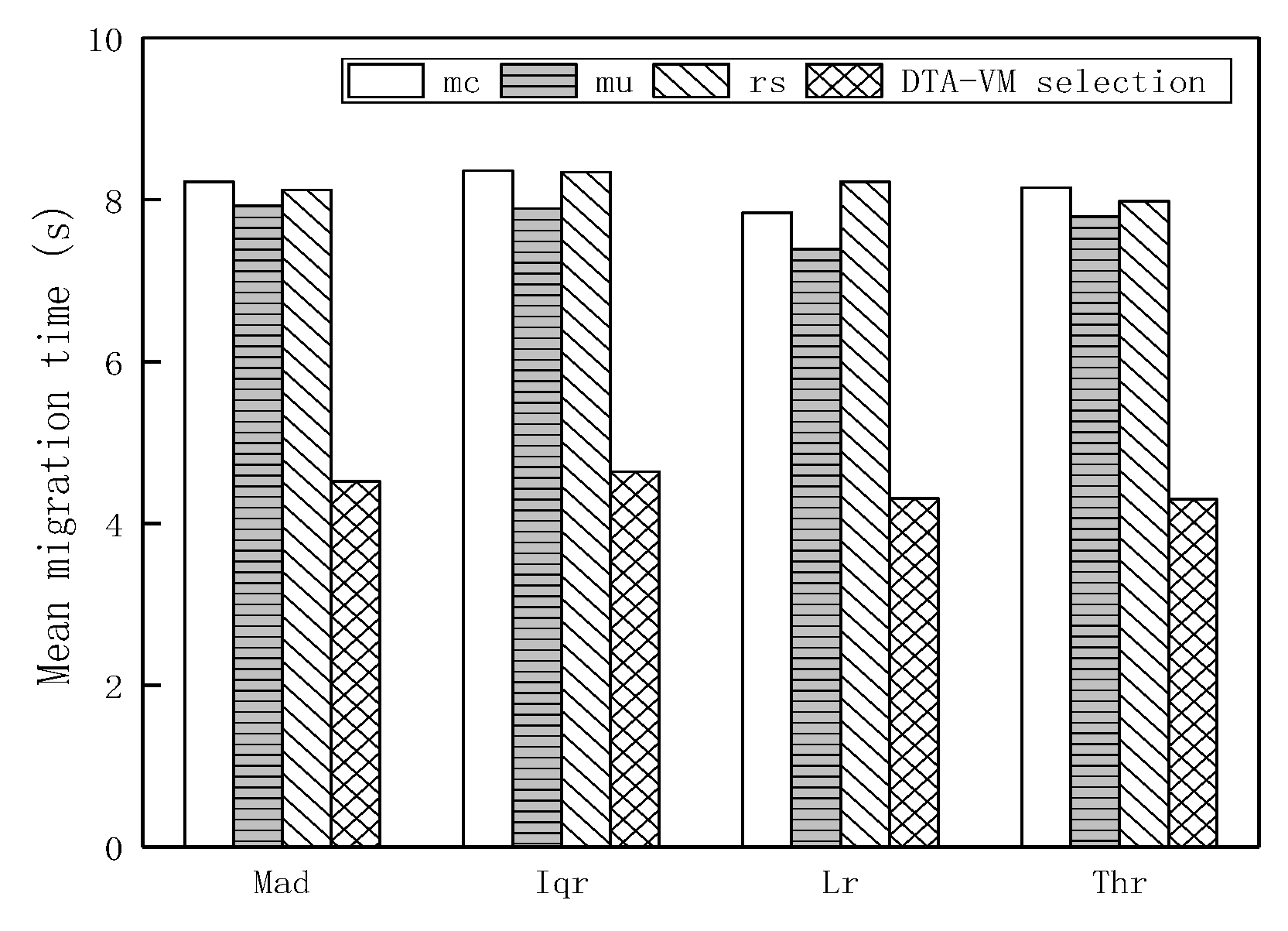
(3) The simulation is carried out first by the CloudSim platform to evaluate the proposed migration strategy, which can improve energy consumption and SLA violation and significantly reduce the total number of migrations and migration time. Then the strategy is implemented on the OpenStack and the results are finally analyzed that this strategy can avoid invalid migration, instead of manual, realize adaptive dynamic migration and achieve the load balancing purpose.
The rest of the paper is organized as follows.
Section 2 presents a system scenario of BBU pool based on OpenStack and introduces related works of migration and parameter definition. In
Section 3, we describe the migration strategy in detail.
Section 4 shows the simulation results on Cloudsim and OpenStack. Then conclusions are drawn in
Section 5.
3. Migration Strategy Description
A dual threshold adaptive (DTA) dynamic migration strategy proposed in this paper is divided into three parts: (1) adaptive trigger migration strategy based on Kalman filter algorithm prediction; (2) the selection of VM to be migrated; and (3), the selection of target physical node. These parts will be discussed in the following sections.
3.1. Adaptive Trigger Migration Strategy based on Kalman Filter Algorithm Prediction
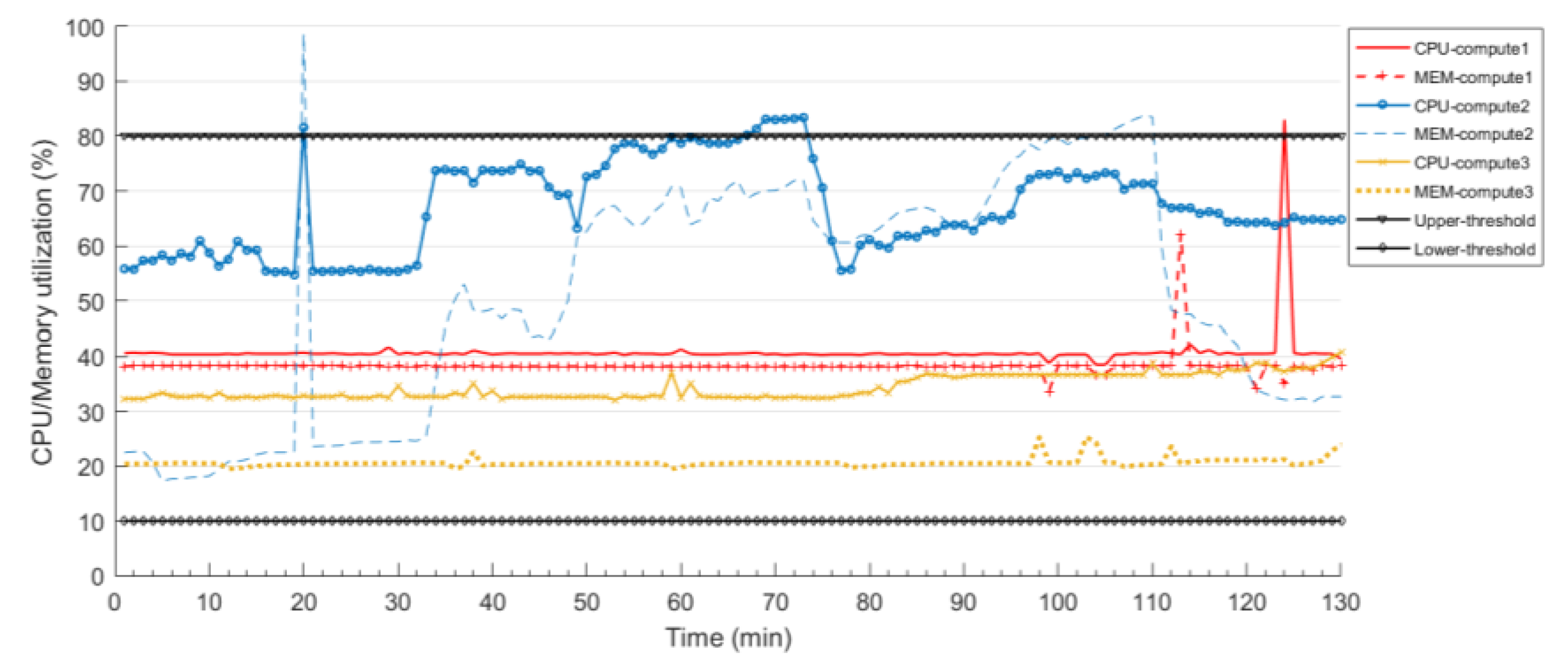
It is necessary to monitor the running state of each physical compute node and set migration conditions for the resource state to determine whether the dynamic migration should be triggered or not. In this paper, the upper threshold is set to alleviate the problem that the physical server increases energy consumption and SLA violations because of the high load, so as to ensure that the resource utilization of the running node in the pool meets the demand on the basis of saving energy consumption. Set a lower threshold and migrate the VM on the compute nodes elsewhere and shut down or sleep the physical server to reduce the energy consumption of the physical cluster, when the server utilization is below the threshold. Because the resource utilization of physical servers is not stable, the CPU or memory utilization at a certain time may cause unnecessary migration due to too high or too low condition, result in a waste of system energy consumption. In this paper, the Kalman filter algorithm is used to predict the resource utilization, which only a small amount of data is needed to get the predicted starting point (the more data will make the result better). It can adjust itself and automatically set the parameters from continuous observation. Because the server resource utilization is instantaneous, the use of prediction technology can effectively prevent the invalid migration of virtual resource. The predicted migration trigger strategy based on the Kalman filter algorithm is used to determine whether the server resource utilization is higher or lower than the threshold.
Kalman filter takes the least mean square error as the best criterion to find a set of recursive estimation models. The basic idea is to use the state space model of signal and noise, to update the estimation of state variables by the estimated value of the previous time and the observed value of the present time and to find the estimated value of the occurrence time. The estimator is considered as a linear system and represents the resource utilization of the server in the migration strategy at the current time.
Firstly, the predicted value
is set as the optimal estimation of the previous state with Equation (6), where
is the last estimated resource utilization.
Then, the estimated value of the current time is calculated by Equation (7). Where
is the observation of the current time.
is the Kalman gain and calculated by the Equation (8) and Equation (9):
where
and
are the variances of system noise and observation noise, respectively.
represents the deviation of the filter and is updated by Equation (10) to continue iteratively filter.
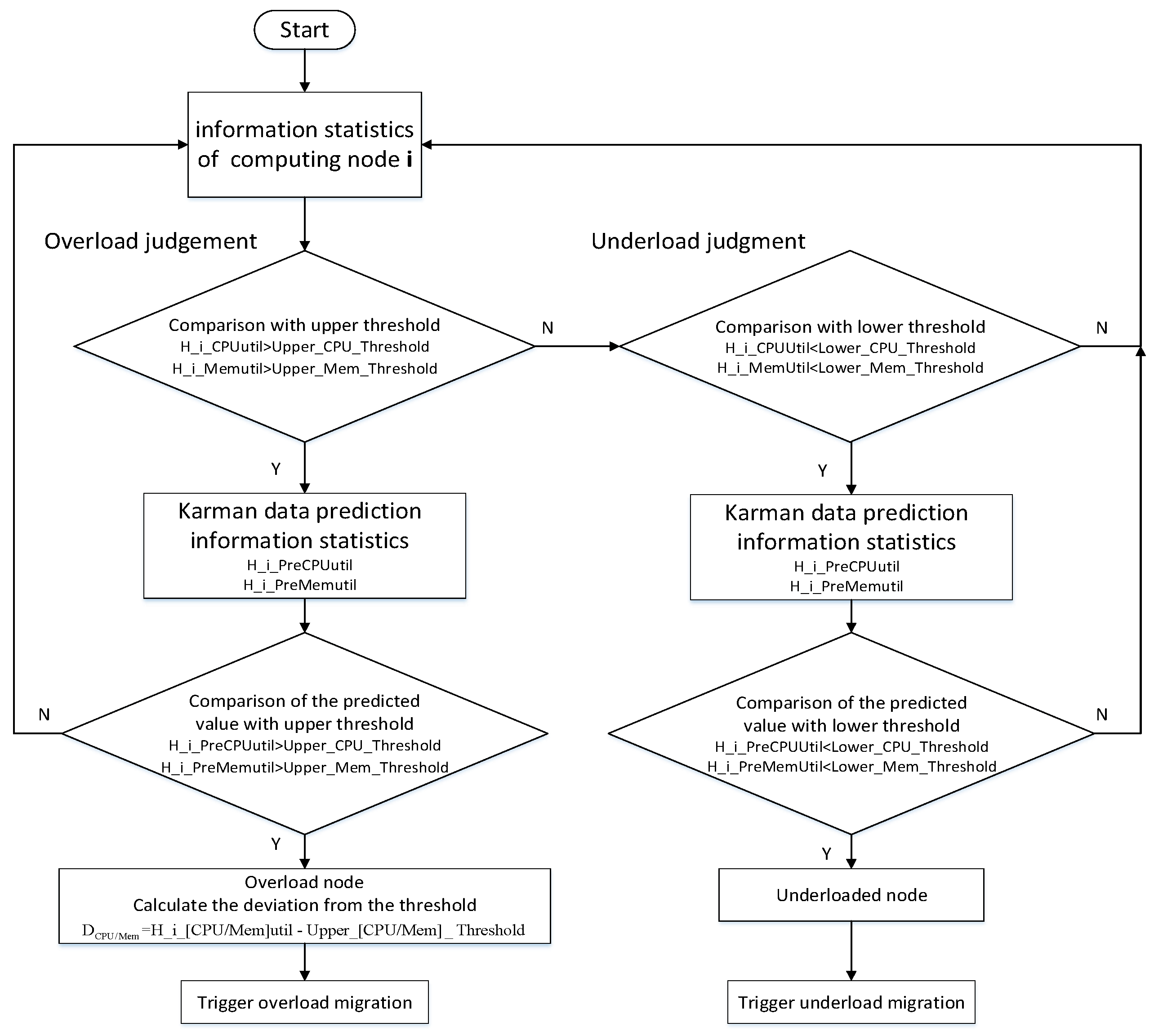
The migration strategy proposed in this paper is to judge the relationship between resource utilization and threshold combined with prediction. A detailed process is shown in
Figure 3 as a trigger flow. In the proposed trigger strategy, the load utilization of each compute node is polled first to monitor and the CPU and memory utilization are used as the trigger migration criteria. Then judge the relationship of utilization and the threshold. If one or more parameters are not within the threshold range, use the prediction model to determine the relationship between the load utilization and the threshold at the next moment. If the predicted value exceeds the upper threshold, the compute node is considered overloaded and calculate
, which is the difference between overload resource utilization and the upper threshold. Otherwise, the strategy enters the underload judgment process with prediction model. If the predicted value is below the lower threshold, the node is identified as the underload node.
To implement a migration strategy, the VM to be migrated is selected from the overload/underload compute node according to the VM selection strategy from
Section 3.2 and then the target server node to be migrated is determined from
Section 3.3 to realize dynamic migrations. The strategy proposed defines the triggering of overload as three cases. (a) type 0: both CPU and memory utilization exceed the upper threshold, (b) type 1: only CPU utilization exceeds the upper threshold and (c) type 2: only memory utilization exceeds the upper threshold. If one or more utilization parameters are below the lower threshold, the dynamic migration is triggered and the underload node is shut down to reduce energy consumption. If all the parameters are within the threshold range, it is considered normal and then enters the next round of judgment process.
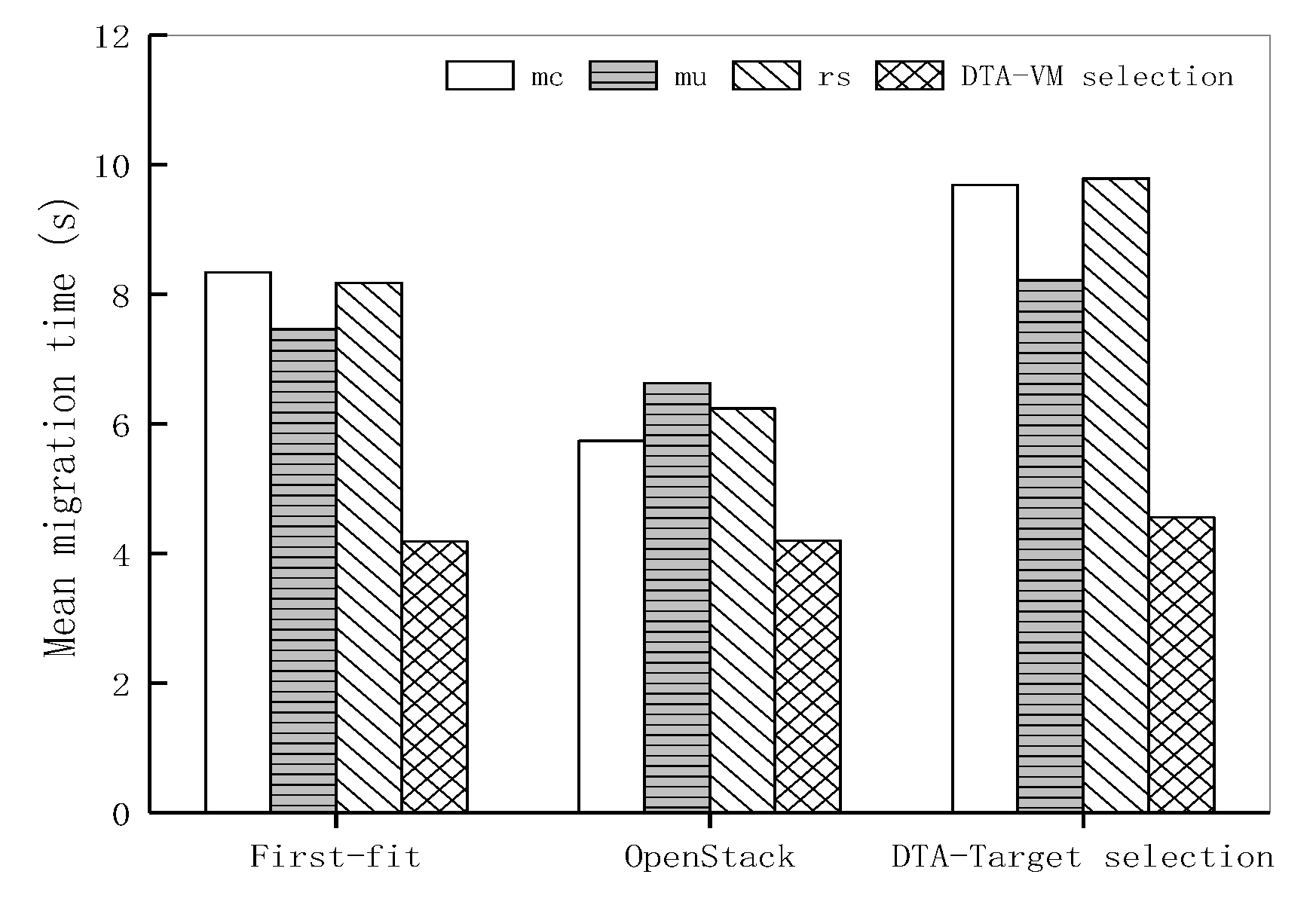
3.2. The Selection of VM to be Migrated (DTA-VM Selection)
Once the overload compute node is detected, the next step is to select VMs to migrate from the node to avoid performance degradation. In this paper, a VM selection strategy (DTA-VM selection) is proposed. Firstly, the VM with the least number of migrations is selected and then, in the selected VM subset, the strategy selects the VM with the minimum migration time. The migration time can be estimated as the number of RAM used by VM divided by the network bandwidth available to the server node. The proposed VM selection strategy shows in Algorithm 1.
and
represent the difference between the utilization of VM’s CPU and memory and D (
). If the difference is greater than or equal to 0, it is indicated that only one VM needs to be migrated to lower the resource utilization rate of the server below the upper threshold and this VM will be stored in the VMlist_count subset. In the subset of VMs that satisfy the minimum migration counts in the VMlist_count, the memory usage of each VM is sorted and the smallest memory is selected as the final VM to be migrated. If the list VMlist_count is empty, the strategy will judge the resource utilization by calculating
from algorithm 1 for each VM on the overloaded host and select the VM, which can alleviate the server load to the greatest extent.
| Algorithm 1 DTA-VM selection strategy |
Input:
Output:
foreach VM in do
type 0:
type 1:
type 2:
if ()
←
else
←,
end if
if
sort by memory
else
sort by
end if
end for
return |
When the compute node triggers migration because of too low load, the VM selection is not needed because all the VMs in the node are then directly migrated and this node will be closed in order to save energy.
3.3. The Selection of Target Physical Node (DTA-Target Selection)
When the Nova_Scheduler module selects the target node in the OpenStack, it selects the node which meets the requirements of VM resources and has the most memory surplus, regardless of other factors. Therefore, the strategy of selecting the target server node proposed in this paper takes into account not only the current CPU and memory usage of the server node but also the resource usage of the target node after the migration of the VM. The target compute node selection strategy is proposed based on Kalman filter prediction, which gives priority to select the nodes in the set within the normal threshold range to reduce the computational workload.
The target node selection strategy shows in Algorithm 2, for each other server node in the cloud-based BBU pool, to avoid unnecessary migration, prediction technology is used to predict the resource utilization of the running nodes that can accept migration in the pool. Only when the predicted values are within the threshold range, the size of the decision value
from algorithm 2 of CPU and memory utilization will be sorted and the sorted server list will be returned. The server node listed first is the most suitable target node. The calculation of the
value is similar to
in the previous section and there are also three cases. The selection of the target node in the case of underload is performed according to type 0.
| Algorithm 2 DTA-Target selection strategy |
Input:
Output:
foreach host in do
if and
for do
,
if then
end if
end for
end if
end for
return |

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}