Efficient Systolic-Array Redundancy Architecture for Offline/Online Repair

Abstract
:1. Introduction
2. Previous Works
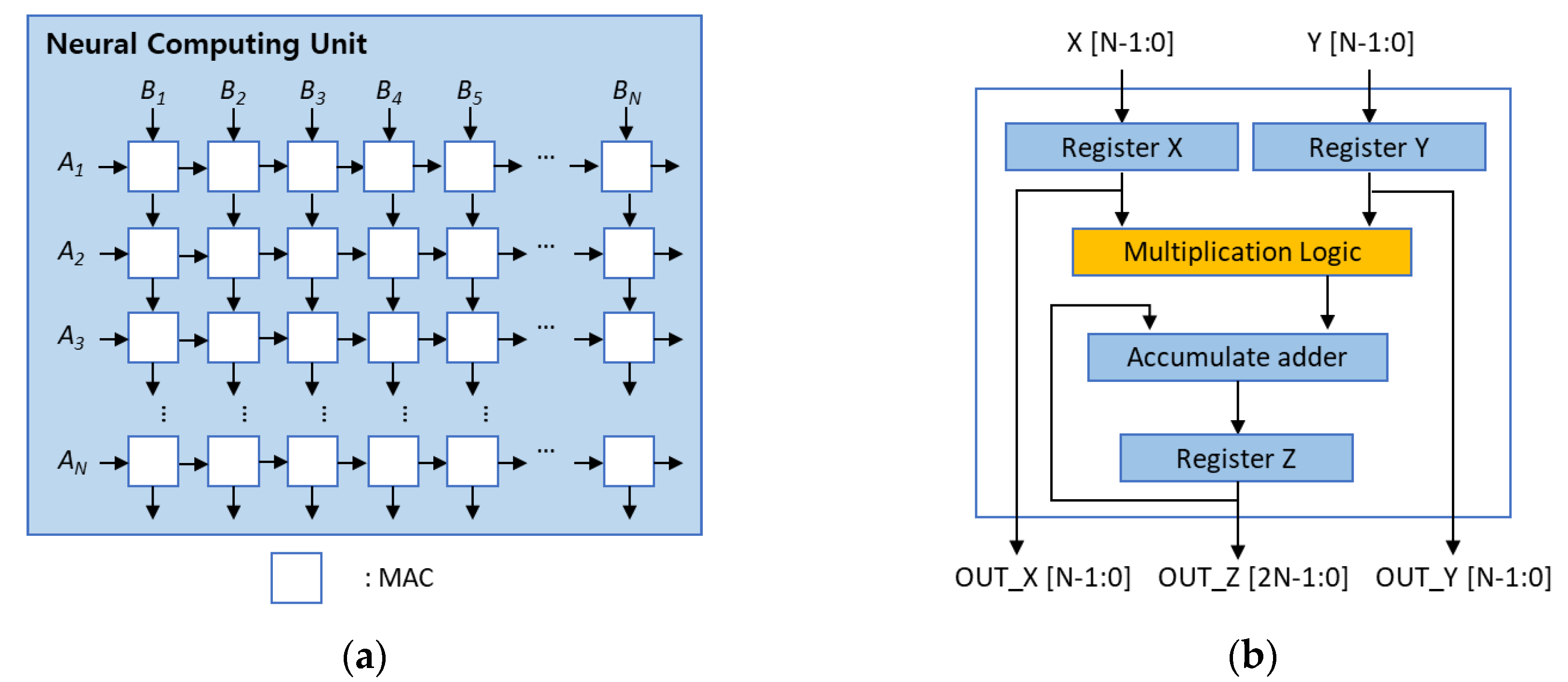
2.1. Systolic-Array Architecture
2.2. Previous Fault Repair Systolic-Array Designs
3. Proposed Redundancy Architecture
3.1. Systolic-Array Redundancy Architecture
3.2. Redundancy Configuration by Partitioning the Entire Array
3.3. One Redundancy per Multiple Rows and Columns
3.4. Repair Strategy for Offline/Online Repair
3.5. Efficient Redundancy Configuration
4. Simulation Results
4.1. Simulation Environment
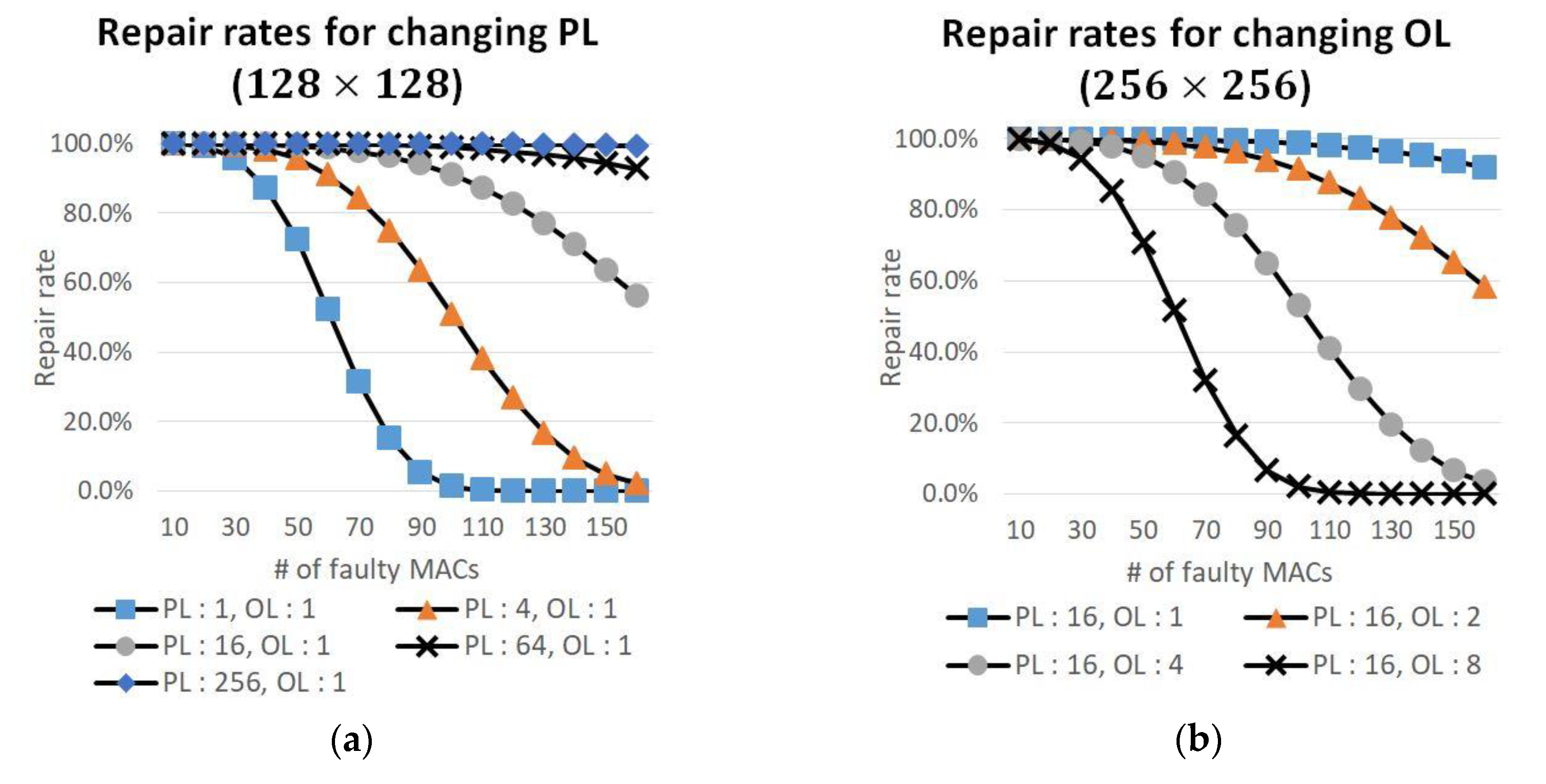
4.2. Repair Rates
4.3. Hardware Overhead
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Stateline, NV, USA, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Fei, L.F. Large-scale video classification with convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 1725–1732. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 8–13 December 2014; pp. 3104–3112. [Google Scholar]
- Ma, Y.; Suda, N.; Cao, Y.; Seo, J.S.; Vrudhula, S. Scalable and modularized rtl compilation of convolutional neural networks onto fpga. In Proceedings of the Field Programmable Logic and Applications (FPL) 26th International Conference, Lausanne, Switzerland, 29 August–2 September 2016; pp. 1–8. [Google Scholar]
- Kung, H.T. Why systolic architectures? IEEE Comput. 1982, 15, 37–46. [Google Scholar] [CrossRef]
- Jouppi, N.P.; Young, C.; Patil, N.; Patterson, D.; Agrawal, G.; Bajwa, R.; Bates, S.; Bhatia, S.; Boden, N.; Borchers, A.; et al. In-datacenter performance analysis of a tensor processing unit. In Proceedings of the 44th Annual International Symposium on Computer Architecture, ISCA ’17, Toronto, ON, Canada, 26 June 2017; pp. 1–12. [Google Scholar]
- Paine, S.W.; Fienup, J.R. Machine learning for improved image-based wavefront sensing. Opt. Lett. 2018, 43, 1235–1238. [Google Scholar] [CrossRef] [PubMed]
- Wu, C.; Ko, J.; Davis, C.C. Lossy wavefront sensing and correction of distorted laser beams. Appl. Opt. 2020, 59, 817–824. [Google Scholar] [CrossRef]
- Liu, S.; Tang, J.; Wang, C.; Wang, Q.; Gaudiot, J.L. A unified cloud platform for autonomous driving. Computer 2017, 50, 42–49. [Google Scholar] [CrossRef]
- Hoang, T.T.; Själander, M.; Edefors, P.L. A High-Speed, Energy-Efficient Two-Cycle Multiply-Accumulate (MAC) Architecture and Its Application to a Double-Throughput MAC Unit. Circuits Syst. I Regul. Pap. IEEE Trans. 2010, 57, 3073–3081. [Google Scholar] [CrossRef]
- Kung, H.T.; Lam, M.S. Fault-tolerance and two-level pipelining in vlsi systolic arrays. Tech. Rep. Carnegie Mellon UNIV 1983. [Google Scholar] [CrossRef]
- Kim, J.H.; Reddy, S.M. On the design of fault-tolerant two-dimensional systolic arrays for yield enhancement. IEEE Trans. Comput. 1989, 38, 515–525. [Google Scholar] [CrossRef]
- Takanami, I.; Horita, T.; Akiba, M.; Terauchi, M.; Kanno, T. A built-in self-repair circuit for restructuring mesh-connected processor arrays by direct spare replacement. In Transactions on Computational Science XXVII, LNCS 9570; Springer: Berlin/Heidelberg, Germany, 2016; pp. 97–119. [Google Scholar]
- Zhang, J.; Gu, T.; Basu, K.; Garg, S. Analyzing and mitigating the impact of permanent faults on a systolic array based neural network accelerator. In Proceedings of the IEEE VLSI Test Symposium, San Francisco, CA, USA, 22–25 April 2018; pp. 1–6. [Google Scholar]
- Lee, C.; Kang, W.; Cho, D.; Kang, S. A new fuse architecture and a new post-share redundancy scheme for yield enhancement in 3-d-stacked memories. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 2014, 33, 786–797. [Google Scholar]
- Synopsys Design Vision, Synopsys, Mountain View, CA, USA. Available online: https://www.synopsys.com/content/dam/synopsys/implementation&signoff/datasheets/design-compiler-nxt-ds.pdf (accessed on 14 February 2020).
- The Synopsys Armenia Educational Department (SAED) 32/28nm Open Cell Library, Synopsys, Mountain View, CA, USA. Available online: https://www.synopsys.com/community/university-program/teaching-resources.html (accessed on 14 February 2020).












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Array Size | 128 × 128 | 256 × 256 | 512 × 512 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| # of Faults | Prev. [12] | PL: 4 OL: 4 | PL: 16 OL: 8 | Prev. [12] | PL: 4 OL: 4 | PL: 16 OL: 8 | Prev. [12] | PL: 4 OL: 4 | PL: 16 OL: 8 |
| 10 | 69.81 | 99.61 | 99.18 | 83.82 | 99.96 | 99.90 | 91.62 | 99.99 | 99.99 |
| 20 | 21.28 | 94.27 | 90.96 | 46.83 | 99.18 | 98.67 | 68.40 | 99.89 | 99.82 |
| 30 | 2.50 | 76.15 | 68.32 | 15.08 | 96.11 | 94.29 | 42.28 | 99.44 | 99.18 |
| 40 | 0.13 | 45.32 | 36.87 | 4.02 | 88.65 | 85.33 | 21.12 | 98.30 | 97.76 |
| 50 | 0.00 | 16.51 | 11.92 | 0.58 | 75.24 | 70.65 | 8.40 | 96.00 | 95.13 |
| 60 | 0.00 | 3.12 | 2.02 | 0.06 | 57.29 | 51.70 | 2.74 | 92.14 | 90.22 |
| 70 | 0.00 | 0.25 | 0.14 | 0.01 | 37.34 | 31.96 | 0.75 | 86.26 | 83.88 |
| 80 | 0.00 | 0.01 | 0.00 | 0.00 | 19.91 | 16.36 | 0.16 | 78.10 | 75.39 |
| 90 | 0.00 | 0.00 | 0.00 | 0.00 | 8.44 | 6.52 | 0.00 | 68.07 | 64.62 |
| 100 | 0.00 | 0.00 | 0.00 | 0.00 | 2.61 | 1.95 | 0.01 | 56.74 | 53.06 |
| 110 | 0.00 | 0.00 | 0.00 | 0.00 | 0.58 | 0.44 | 0.00 | 44.06 | 40.72 |
| 120 | 0.00 | 0.00 | 0.00 | 0.00 | 0.09 | 0.07 | 0.00 | 32.18 | 29.30 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cho, K.; Lee, I.; Lim, H.; Kang, S. Efficient Systolic-Array Redundancy Architecture for Offline/Online Repair. Electronics 2020, 9, 338. https://doi.org/10.3390/electronics9020338
Cho K, Lee I, Lim H, Kang S. Efficient Systolic-Array Redundancy Architecture for Offline/Online Repair. Electronics. 2020; 9(2):338. https://doi.org/10.3390/electronics9020338
Chicago/Turabian StyleCho, Keewon, Ingeol Lee, Hyeonchan Lim, and Sungho Kang. 2020. "Efficient Systolic-Array Redundancy Architecture for Offline/Online Repair" Electronics 9, no. 2: 338. https://doi.org/10.3390/electronics9020338
APA StyleCho, K., Lee, I., Lim, H., & Kang, S. (2020). Efficient Systolic-Array Redundancy Architecture for Offline/Online Repair. Electronics, 9(2), 338. https://doi.org/10.3390/electronics9020338