1. Introduction
Energy efficiency has become a critical requirement in the design of modern computing systems and system-on-chips, and chip designers are being continually urged to develop energy-efficient design techniques to meet this requirement. Approximate computing can offer remarkable energy savings by trading-off accuracy [
1]. This approach is based on the observation that not all applications require 100% computation accuracy. Specifically, many digital signal processing (DSP) applications are inherently error-resilient [
2,
3,
4]. For example, humans may not recognize sporadic errors in digital image processing, such as lossy discrete cosine transform, since they are usually negligible because of human sensory limitations.
While approximate computing can be performed in all computing layers, ranging from software to circuit level [
5,
6], in this paper, we focus on approximate circuits, particularly an approximate adder. Certainly, an approximate adder is a fundamental arithmetic unit that is frequently used in many error-tolerant applications to decrease the overall energy consumption, and it has drawn much attention from researchers. As a result, numerous approximate adders have been proposed in the literature [
7,
8,
9,
10,
11,
12,
13,
14,
15,
16,
17,
18,
19,
20,
21,
22,
23,
24,
25,
26,
27,
28,
29,
30,
31], which will be reviewed in
Section 2.
In this paper, we propose a novel approximate adder with a hybrid error reduction technique and systematically analyze and extensively compare our proposed adder with other approximate adders in terms of the hardware performance and computation accuracy. The proposed scheme improves the error rate (ER) of the lower-part OR adder (LOA) and error tolerant adder I (ETAI) from 68% to 50%. When the proposed adder is implemented in a 65-nm CMOS technology, its mean error distance (MED) and mean relative error distance (MRED) performances are also enhanced by more than 120% and more than 50%, respectively, compared to those of the ETAI at the cost of extremely low area and power overheads (<10%). Impressively, our adder shows an excellent tradeoff between the hardware cost and the computation accuracy and is clearly superior to the other considered approximate adders. Specifically, the power- and energy-normalized mean error distance (NMED) products of our approximate adder are up to 2.06 and 1.97 times, respectively, better than those of the other considered approximate adders.
The remainder of this paper is organized as follows. In
Section 2, we introduce some of the related works that were recently published in the field of approximate adders. Then, we present the proposed approximate adder by providing illustrative examples in
Section 3. The hardware architecture and error analysis of the adder are given in
Section 3 as well. In
Section 4, the results of hardware implementation together with the systematic analysis and extensive comparison with the other seven approximate adders in terms of the performance and accuracy are presented. In addition, the joint analysis of the approximate adders is provided in
Section 4. Finally, we conclude the work in
Section 5.
2. Related Works
Lu proposed an approximate adder wherein the carry for each sum bit is predicted by the limited number of its less significant bits to improve the overall speed [
7]. Verma et al. reduced the area overheads of Lu’s adder by sharing some components [
8]. These adders are faster than the conventional accurate adders because of the shorter carry propagation chain.
An equal-segment-based approximate adder splits an
n-bit adder into several equally partitioned smaller
k-bit sub-adders that concurrently perform partial additions and partial carry generations using a limited number of input bits. It should be noted that sub-adders can be implemented in any type of conventional accurate adder, such as the ripple carry adder (RCA) and carry lookahead adder (CLA). The adders proposed in [
9,
10] utilize the previous
k input bits only to predict the carry for sub-adders. Kim et al. [
11,
12] proposed an improved carry speculation scheme for sub-adders that leverages 2
k and more input bits to generate carries, which leads to a much better computation accuracy than that of the adders in [
9,
10]. The accuracy-configurable adder proposed by Kahng et al. [
13] includes multiple 2
k-bit sub-adders and makes
k bits overlap to generate approximate outputs.
In addition, approximate 1-bit full adders are utilized to add some least significant bits (LSBs) in a multibit adder. For example, the LOA, as shown in
Figure 1, employs OR gates to approximately add several LSB inputs [
14]. It divides an
n-bit adder into a
k-bit precise adder and an (
n−
k)-bit approximate adder. An AND operation of two (
n−
k−1)th LSB inputs is performed to predict the carry-in signal of the precise adder (i.e.,
Cin), and the precise adder takes the most significant
k bit (MSB) inputs and the carry to generate accurate outputs for the MSBs. The (
n−
k)-bit approximate adder is realized via bit-by-bit OR operations. The adder proposed by Albicoocco et al. [
15], termed the LOAWA (i.e., LOA without AND operation) also uses the OR operation to realize the (
n−
k)-bit approximate adder for the LSBs; however, the main difference with the LOA is the exclusion of the carry prediction scheme to reduce hardware cost at the expense of accuracy. The optimized lower-part constant OR adder (OLOCA) [
16] is almost identical to the LOA. The approximate adder part utilizes the OR function but a few LSB outputs are forced to “1” to reduce hardware cost. In other words, only a few of the upper (
n−
k) LSB outputs are generated by the OR operation, and the remaining lower bits of the LSB outputs are fixed to “1.” The hardware optimized error reduced adder (HOERRA) proposed by Balasubramanian et al. [
31] is another optimized version of the LOA, which is suitable for both field programmable gate array and application specific integrated circuit-based implementations. The approximate adder part of the HOERAA is similar to that of the OLOCA in that the (
n−
k−2) LSB outputs are set to “1.” The remaining two bits of the part leverages OR function, and a 2-to-1 multiplexer is used to produce (
n−
k−1)th LSB output by selecting either an OR operation of two (
n−
k−1)th LSB inputs or an AND operation of two (
n−
k−2)th LSB inputs. The carry-in signal (i.e.,
Cin) serves as the selection input of the multiplexer.
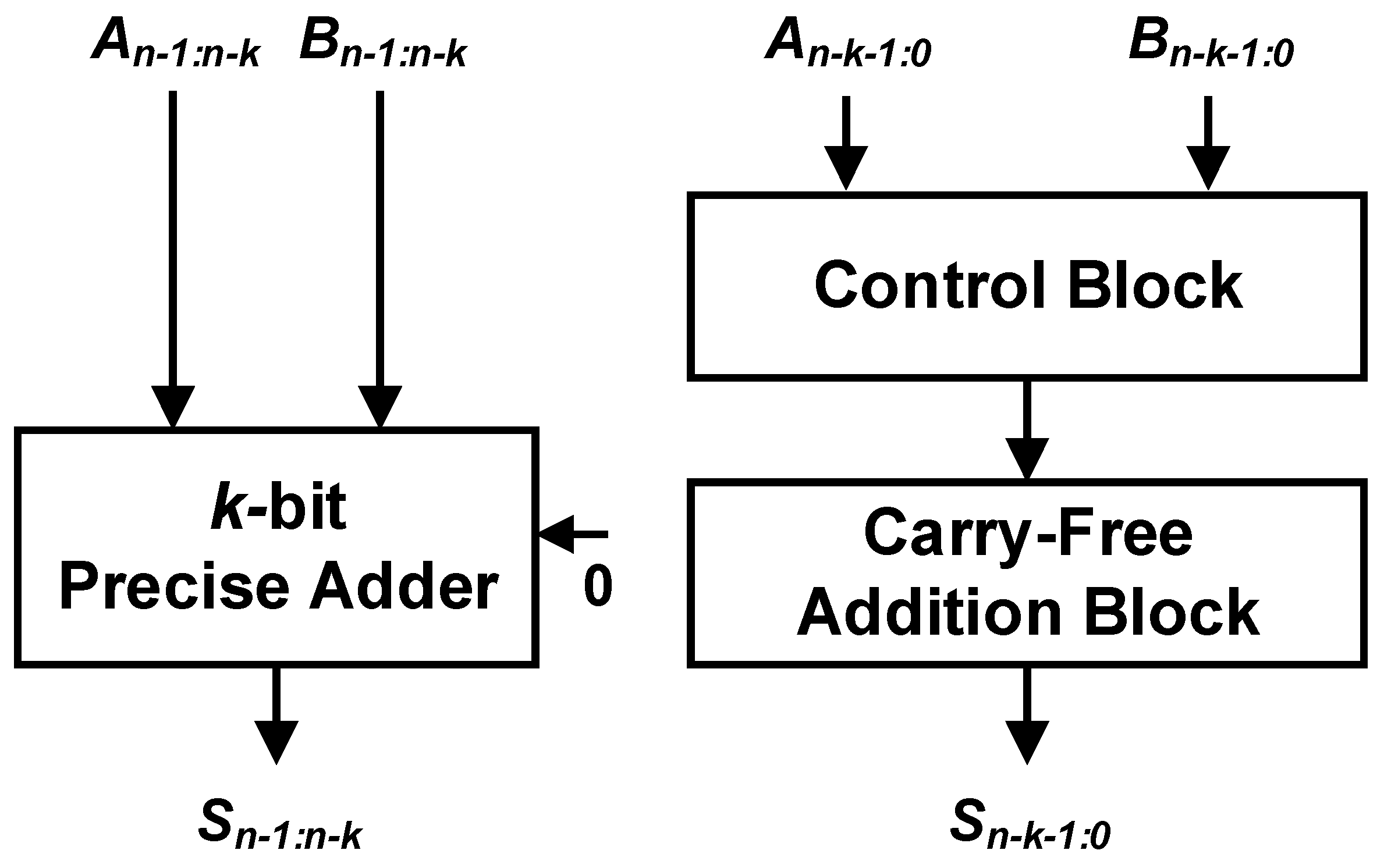
Similar to the LOA, the ETAI uses a
k-bit precise adder and an (
n−
k)-bit approximate adder, the latter of which is realized via its own modified XOR function [
17] and is composed of a control block and a carry-free addition block, as shown in
Figure 2. It is important to note that the ETAI does not include a carry prediction scheme for the precise adder and the carry is set to “0” (i.e.,
Cin = 0), which leads to poor overall computation accuracy compared to that of the LOA. To improve the accuracy, Kim developed the carry predicting ETA (CPETA) and the enhanced CPETA (ECPETA) in [
18] and [
19], respectively, by adding low-cost carry prediction techniques to the original ETAI architecture. Specifically, the CPETA uses the same AND-operation-based carry prediction scheme with the LOA, and the ECPETA utilizes both the (
n−
k−1)th and (
n−
k−2)th LSB inputs with an additional OR gate to predict the carry to improve the accuracy. The LOA, ETAI, and their variants show a good tradeoff between the computation accuracy and the power and area costs thanks to the simplification of the LSB additions.
In addition to design of the approximate adder, the evaluation of its accuracy is also an important task; some error metrics have been introduced for this purpose [
32], such as the MED, MRED, and NMED. These metrics are widely adopted along with power, energy, delay, and area to evaluate and compare the performances of approximate adders [
33].
3. Proposed Approximate Adder
In this section, we present our proposed approximate adder that enhances the computation accuracy of the LOA by application of a novel hybrid error reduction scheme, and the resultant adder is termed a hybrid error reduction LOA (HERLOA). We provide illustrative examples to effectively introduce the proposed adder and use the following notations. Let An−1:0, Bn−1:0, and Sn−1:0 denote, respectively, the two n-bit inputs and one n-bit output of the adder, and let S’n−1:0 denote the n-bit intermediate approximate output prior to error reduction. Additionally, Ai, Bi, Si, and S’i denote the (i)th LSBs of An−1:0, Bn−1:0, Sn−1:0, and S’n−1:0, respectively.
3.1. Operation of the Proposed Adder
Figure 3 shows the operation of the proposed adder with 16-bit inputs. An
n-bit addition requires two different kinds of additions. The precise part is obtained using a
k-bit accurate adder (e.g., RCA or CLA) for
k MSBs, and the approximate part is obtained via OR and XOR operations of the remaining (
n−
k) LSBs, where
k <
n. The example in
Figure 3 splits a 16-bit input into an 8-bit precise part and an 8-bit approximate part. It is worth mentioning that the bit-widths of two parts do not need to be equal. The precise part performs an accurate addition using
k MSB inputs, and the carry-in signal (
Cin) is predicted via an AND operation of two (
n−
k−1)th inputs (i.e.,
Cin =
An−k−1 AND
Bn−k−1). Similar to the LOA, the approximate part leverages the OR function to add the lower order input bits of two operands; however, the main difference with the LOA is that, in the proposed adder, the bit operation of (
n−
k−1)th inputs is replaced with the XOR operation. This results in the formation of a half adder for (
n−
k−1)th LSB inputs and effectively extends the length of accurate addition by one bit, which consequently leads to an overall improvement in accuracy compared to that of the LOA. In other words, the proposed
n-bit adder always generates correct outputs for bit positions from (
n−1) to (
n−
k−1) by replacing the OR gate with the XOR gate at the (
n−
k−1)th LSB position. As a result, under the input shown in
Figure 3, the proposed adder generates the approximate part output of “01011010”, whereas the LOA generates an output of “11011010.” Obviously, the output of the proposed adder is closer to the correct summation of “01101010” than the output of the LOA, and the error distance—which is defined as
, where S
approximate and S
accurate are the approximate and correct outputs, respectively—for the given input decreases from “1110000” (112) to “10000” (16).
3.2. Proposed Hybrid Error Reduction Scheme
The proposed approximate adder performs an error reduction to further decrease the output errors when both (
n−
k−2)th input bits are “1” (i.e.,
An−k−2 = 1 and
Bn−k−2 = 1). Otherwise, it does not perform any error reduction, as shown in the example in
Figure 3. In fact, our adder implements the error reduction logic, but this does not affect the final outputs of the adder in this case. The proposed hybrid error reduction is performed differently depending on the (
n−
k−1)th inputs. In other words, the proposed adder checks the (
n−
k−1)th output bit to determine which of the two error reduction schemes is applicable. If both the inputs are “1” or “0,” the reduction logic corrects the (
n−
k−1)th and (
n−
k−2)th outputs to “1” and “0,” respectively (i.e.,
Sn−k−1:n−k−2 = “10”). Otherwise, it sets all the outputs from
Sn−k−3 to
S0 as “1.”
The example inputs shown in
Figure 4a yield the approximate part output of “01011010” after the normal addition described in
Section 3.1; we term this output the intermediate approximate output. Then, the adder further checks the (
n−
k−1)th output bit because both the (
n−
k−2)th input bits are “1”. An intermediate approximate output
S’n−k−1 of “0” implies that the corresponding input bits are identical because of the XOR operation performed at the (
n−
k−1) bit position, and the final adder outputs at the (
n−
k−1) to (
n−
k−2) bit positions are “1” and “0”, respectively. In short,
Sn−k−1:n−k−2 = “10,” and this is, in fact, the correct summation of outputs at the corresponding positions under the given inputs. This scheme leads to a 2
n−k−2 reduction in the error distance.
On the other hand, if the intermediate approximate output
S’n−k−1 is “1”, as illustrated in
Figure 4b, all the remaining lower order bits are forced to “1,” which results in the approximate output of “11111111.” Under this given input condition, a carry is supposed to be generated in the (
n−
k−2)th LSB and propagate to the precise part through the (
n−
k−1)th LSB. However, as observed in
Figure 4b, the carry does not actually propagate to the precise adder (i.e.
, Cin = 0) because the carry prediction is performed using an AND operation with only the (
n−
k−1)th LSB inputs. This result means that the correct summation will always be larger than the proposed addition in this case. Therefore, forcing all the outputs of the approximate part to “1” brings the approximate output closer to the correct summation. This reduction scheme enables up to a 2
n−k−2 − 1 decrease in the error distance.
3.3. Implementation of the Proposed Adder
Figure 5 shows the hardware implementation of the approximate part of the proposed HERLOA. It should be noted that the precise part is the same as that in
Figure 1, and
Cin is fed to the precise adder. In the approximate addition operation, the XOR and OR gates are used for the (
n−
k−1)th LSB and the other lower order LSBs, respectively, to generate the intermediate approximate outputs
S’
n−k−1:0. Furthermore, the output of the AND operation of the (
n−
k−2)th LSB determines whether or not error reduction should be performed. The intermediate approximate outputs
S’
n−k−1:0 are fed to the INV, AND, OR, and NAND gates to compute the final approximate outputs
Sn−k−1:0. It is important to note that the intermediate approximate outputs will bypass the reduction logic when neither of the (
n−
k−2)th inputs is “1.” The critical path delay of the approximate part,
tapproximate, can be expressed simply as follows:
where
tINV,
tXOR,
tNAND, and
tAND are the delays of an inverter, a two-input XOR gate, a NAND gate, and an AND gate, respectively.
3.4. Error Rate Analysis
An output error occurs when any bit positions from (
n−
k−3) to 0 of both the inputs, A and B, are “1”, which generates a carry for the higher bit position. Moreover, an error occurs when both the (
n−
k−2)th LSB inputs are “1” and the two (
n−
k−1)th LSB inputs are exclusive, as observed in
Figure 4b. Therefore, the ER of the proposed HERLOA with the error reduction scheme under random input patterns is given as follows:
where
n and
k are the sizes of the entire adder and the precise adder, respectively.
4. Experimental Results
The proposed approximate adder with design parameters of
n = 16 and
k = 8 was designed in Verilog HDL and was synthesized using 65-nm CMOS technology and a standard cell library to evaluate the delay, area, power, power-delay product (PDP), and energy-delay product (EDP). The 8-bit RCA was employed as the precise adder. For comparison of our proposed adder with other adders, two conventional accurate adders (RCA and CLA) as well as seven approximate adders (LOA, ETAI, and their variants: LOAWA, OLOCA, HOERAA, CPETA, and ECPETA) were designed and also synthesized using the same technology and library. For fair comparison, identical design parameters, i.e.,
n = 16 and
k = 8, and the RCA structure were used for all the approximate adders. Furthermore, the bit-width of the constant part of the OLOCA and HOERAA were selected to be 6 [
16,
31].
In addition to implementing hardware, we constructed a software simulator to assess the accuracy performance of the approximate adders in terms of the ER, MED, NMED, and MRED. These error metrics are expressed as follows:
where
n is the number of inputs,
EDi is the error distance for the (
i)th item of input data,
Si,accurate is the accurate output for the (
i)th item of input data, and
D is the maximum possible error value of the approximate adder. These error metrics were estimated by using two samples each comprising 10 million (i.e., 10
7) uniformly distributed random input numbers.
4.1. Performance Analysis
Table 1 summarizes the performance of the proposed approximate adder and those of the other eight adders. While the CLA is the fastest, the RCA has the longest delay because of the bit-by-bit carry propagation. This delay of the RCA causes it to consume the largest amount of energy (i.e., the highest PDP) even though its power dissipation is lower than that of the CLA, which consumes the second largest amount of energy. The LOA and its variants (i.e., LOAWA, OLOCA, and HOERAA) are more area-, power-, energy-, and EDP-efficient than the ETAI and its variants (i.e., CPETA and ECPETA) because of the relatively simpler approximation scheme (i.e., OR operation) for the lower half of the input bits in the case of the former category. Specifically, the OLOCA occupies the smallest area, and the LOAWA is the fastest as well as the most power- and energy-efficient among all the approximate adders. The simple AND-operation-based carry prediction in the LOA, OLOCA, HOERAA, CPETA, and our proposed adder results in a longer delay than those of the ETAI and LOAWA, which lack any carry prediction for the precise part. It should be noted that the critical path delay of these adders exists in the precise adder part, including the carry prediction (i.e., the 8-bit RCA with the AND gate). The delay of the HOERAA is insignificantly longer than that of the LOA, OLOCA, CPETA, and the proposed adder even though all these adders have the identical carry prediction scheme. It is because the carry prediction output (i.e., the AND gate output) of the HOERAA is fed into not only the precise adder but also the multiplexer. This causes a higher fan-out of the AND gate and therefore impacts on the delay. The more complicated carry prediction scheme adopted in the ECPETA, which utilizes two MSB inputs from the approximate part, leads to the worst area, delay, and power performances; as a result, this adder consumes the largest amount of energy and has the highest EDP among the seven approximate adders. The proposed HERLOA is comparable to the ETAI in terms of all the hardware performance metrics. It occupies 8% larger area and consumes 9% more power than the LOA while having the same speed. A comparison of our adder with the accurate adders reveals that our adder has up to 2.18, 1.96, 2.19, and 3.31 times greater efficiency in terms of area, delay, power, and energy, respectively.
Our adder shows the best ER performance, whereas the OLOCA shows the worst ER performance: it reaches over 99%, and the HOERAA has almost the same ER with the OLOCA. The ERs of the LOA, LOAWA, and ETAI are the same and the ER of the CPETA is identical to that of the ECPETA. The ETAI variants show better accuracy performance than the LOA and its variants in terms of all the error metrics, i.e., the ER, MED, MRED, and NMED, but consumes more area, power, and energy. The HOERAA shows the best accuracy performance in the metrics except the ER among the LOA and its variants. The MED and NMED of the proposed adder are comparable to those of the ECPETA, and the MRED of the proposed adder is the same as that of the LOA, OLOCA, HOERAA, and CPETA. Importantly, our proposed adder outperforms the other approximate adders in terms of all the accuracy metrics, the exceptions being its higher MED, MRED, and NMED than those of the ECPETA. Specifically, the proposed HERLOA shows 1.31, 2.09, and 2.24 times better MED than the LOA, ETAI, and LOAWA, respectively, and 1.16 times better MRED than the LOAWA and ETAI.
4.2. Accuracy Analysis
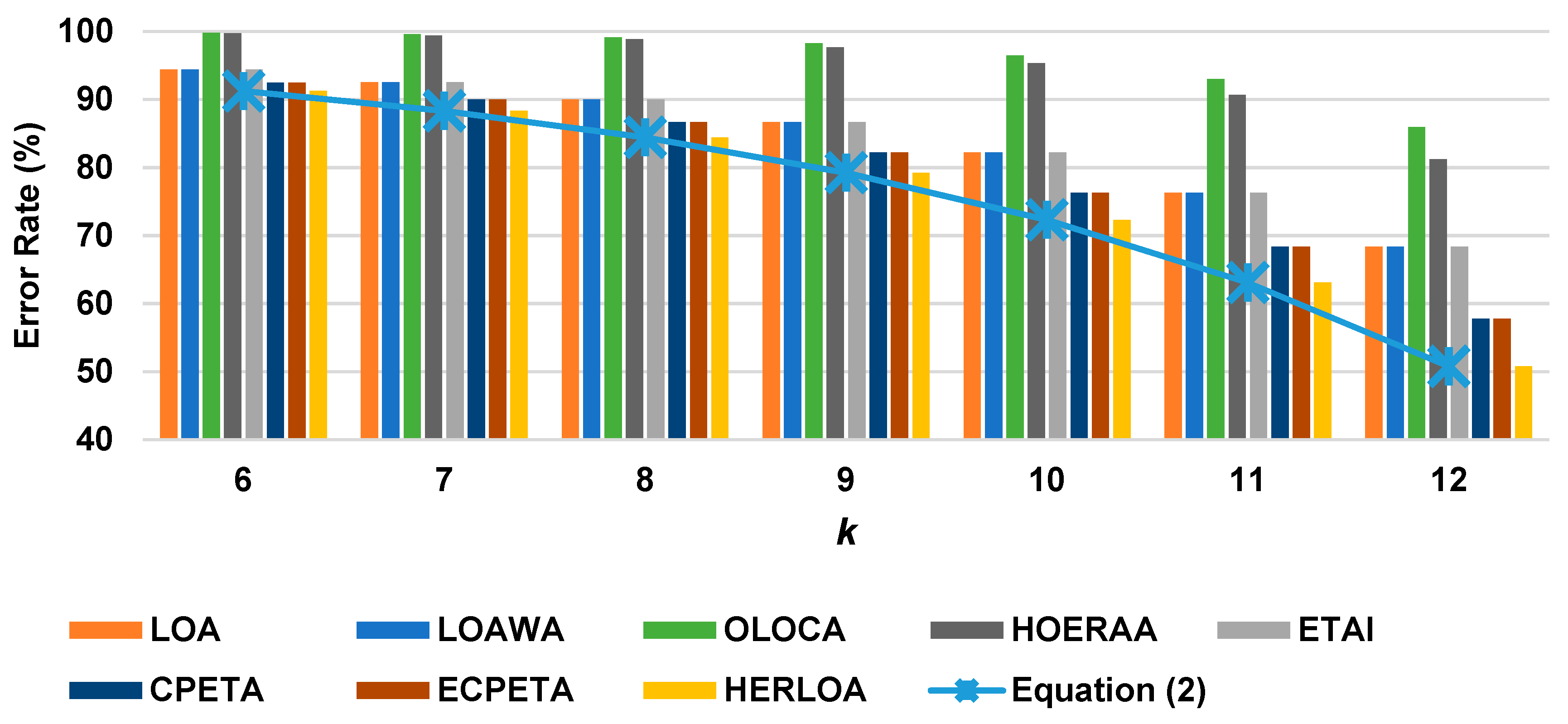
For evaluating the accuracy of the proposed HERLOA in comparison with those of the other seven approximate adders, we varied the design parameter k from 6 to 12 in order to alter the bit-width of the precise part of the 16-bit adders and to extract the value of the ER, MED, MRED, and NMED metrics.
Figure 6 shows the ERs of the approximate adders at various values of
k. Clearly, the ER decreases as the precise adder size
k increases. Regardless of
k, the LOA, LOAWA, and ETAI have an identical ER, as do the CPETA and ECPETA, where the later ER is lower than that of the LOA. The proposed HERLOA has the lowest ER and the OLOCA has the highest ER. The HOERAA shows slightly better ER performance than the OLOCA and has the second highest ER. Specifically, the ERs of the OLOCA and HOERAA reach 85% and 81%, respectively, and that of our HERLOA decreases to 50% thanks to the proposed hybrid error reduction scheme at
k = 12. The LOA and CPETA have ERs of 68% and 57%, respectively, at the same
k. We also plotted the line of Equation (2) in
Figure 6 to determine the accuracy of the ER of our HERLOA as derived by this equation. The line is in very good agreement with the simulated ERs at the various values of
k.
As reported in
Table 1, the proposed adder has the second-best MED performance at
k = 8. To effectively demonstrate the MED of the proposed HERLOA and compare it with those of the other adders, we plotted the improvements in the MED of the proposed adder in comparison with those of the other seven approximate adders at various values of
k in
Figure 7. The MED improvement against all the adders except the ECPETA increases with increasing
k. Although the OLOCA has the highest ER, its MED is similar to that of the LOA. Similarly, the HOERAA shows better MED performance than the LOA, LOAWA, and ETAI in spite of worse ER performance than those adders. Moreover, in terms of the MED, the HOERAA outperforms the OLOCA. The MED of our design is 30–43% better than those of the LOA and OLOCA. Furthermore, at all
k values, the MED improvement of our adder reaches over 100% compared with the LOAWA and ETAI. Unfortunately, the proposed design shows 3–5% less MED performance against the ECPETA. The MED of the proposed design is comparable to those the ETA variants, which include their own carry prediction schemes; the MED difference in this case is ±5% at all
k values.
Table 2 lists the MREDs of the seven approximate adders, including our proposed adder. For all the adders, the MRED decreases as
k increases. The MREDs of the LOA, OLOCA, HOERAA, CPETA, and the proposed HERLOA are almost the same, whereas those of the LOAWA and ETAI are relatively higher and that of the ECPETA is lower. Interestingly, the MREDs of the adders are almost identical when they have the same carry prediction scheme. For example, the LOA, OLOCA, HOERAA, and HERLOA include the AND-operation-based carry prediction scheme and have the same MRED, and the LOAWA and ETAI do not include any carry prediction scheme (i.e.,
Cin = 0) and have identical MREDs. The ECPETA includes the most accurate carry prediction scheme and shows the best MRED performance among all the adders considered in this paper. The MRED difference between the proposed adder and the ETAI/LOAWA remains unchanged as
k increases. Specifically, this MRED difference is are approximately 0.7 over the entire considered range of
k values. Since the MRED decreases as
k increases, the percentage of MRED improvement increases as
k increases. For example, our design achieves MRED reductions of 12.3%, 16.0%, 25.3%, and 51.0%, at
k values of 6, 8, 10, and 12, respectively.
4.3. Joint Analysis of Performance and Accuracy
Power-NMED and energy-NMED products were introduced in [
32] and [
19], respectively, to assess the tradeoff among the power, energy, and accuracy of approximate adders. Here, we can take into account a new metric, the EDP-NMED product, to jointly analyze the tradeoff among energy, delay, and accuracy.
Figure 8 shows the power-NMED, energy-NMED, and EDP-NMED products of the seven approximate adders with
n = 16 and
k = 8. All three products are normalized using corresponding values of the LOA to effectively demonstrate the tradeoffs. Impressively, the proposed HERLOA shows the best tradeoff performance, whereas the ETAI has the largest values of all three products. Specifically, the power-, energy-, and EDP-NMED products of the ETAI are 72%, 65%, and 58%, respectively, larger than those of the LOA. In contrast, all three products of the proposed design are 16% smaller than those of the LOA. The HOERAA, which has slightly less energy- and EDP-NMED products than the proposed adder, also shows a good tradeoff and is comparable to the proposed HERLOA. Although the ECPETA demonstrates the best NMED performance, the additional delay and power consumption of this adder that originate from its carry prediction scheme prevent it from having the best tradeoff metrics. As an example, the EDP-NMED product of the ECPETA is 30% larger than that of the proposed design. Specifically, the power-, energy-, and EDP-NMED products of the proposed approximate adder are, respectively, 2.06, 1.97, and 1.88 times better than those of the ETAI. Clearly, the excellent tradeoff between hardware cost and computation accuracy makes our adder design the most competitive among all the considered approximate adders, which have similar hardware architectures.
5. Conclusions
In this paper, we have developed an accuracy enhanced lower-part OR adder with a hybrid error reduction scheme (termed the HERLOA) to significantly reduce the computation error while maintaining power and energy efficiencies. The proposed HERLOA replaces the OR gate with the XOR gate in the MSB of the approximate part and leverages two MSB inputs of the approximate part to decrease the approximation errors at the cost of a few digital gates. The proposed design is implemented in 65-nm technology to evaluate its performance; it is found to be 3, 2, and 2 times more energy-efficient, area-efficient, and power-efficient, respectively, than the RCA and CLA. In terms of accuracy, the proposed HERLOA outperforms the original LOA and the ETAI. Specifically, at a given design parameter value of k = 12, the ER of our adder decreases to 50%, whereas those of the other adders reach 68%, and at all the considered values of k, the MED improvement of our adder is more than 100% compared with the ETAI and LOAWA. Most importantly, the proposed adder shows an excellent design tradeoff between hardware cost and computation accuracy, as a result of which its power-NMED, energy-NMED, and EDP-NMED products are 2.06, 1.97, and 1.88 times better, respectively, than those of the ETAI. To sum up, our proposed adder outperforms all the approximate adders in a joint analysis of power, energy, EDP, and computation accuracy.
Consequently, the proposed approximate adder with the novel hybrid error reduction scheme is found to be highly power- and energy-efficient while also having good computation accuracy. Therefore, our design is highly suitable for application to inherently error-resilient energy-efficient computing, such as DSP, deep learning, and neuromorphic computing [
2,
3,
4,
34,
35].









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}